

Summary
To navigate social environments, people must simultaneously hold representations about their own and others’ abilities. During self-other mergence, people estimate others’ abilities not only on the basis of the others’ past performance, but the estimates are also influenced by their own performance. For example, if we perform well, we overestimate the abilities of those with whom we are co-operating and underestimate competitors. Self-other mergence is associated with specific activity patterns in the dorsomedial prefrontal cortex (dmPFC). Using a combination of non-invasive brain stimulation, functional magnetic resonance imaging, and computational modeling, we show that dmPFC neurostimulation silences these neural signatures of self-other mergence in relation to estimation of others’ abilities. In consequence, self-other mergence behavior increases, and our assessments of our own performance are projected increasingly onto other people. This suggests an inherent tendency to form interdependent social representations and a causal role of the dmPFC in separating self and other representations.
Keywords: social cognition, MRI, frontal cortex, self-other mergence, brain stimulation, performance tracking, reinforcement learning, learning and decision making
Highlights
-
•
During self-other mergence (SOM), people confuse one’s own with another’s performance
-
•
Brain stimulation over dorsomedial prefrontal cortex (dmPFC) alters neural SOM
-
•
Brain stimulation over dmPFC simultaneously alters behavioral SOM
-
•
This suggests a causal role of dmPFC in separating self and other representations
Wittmann et al. find that, after disrupting activity in the dorsomedial prefrontal cortex, humans merge performance estimates concerning other people with performance estimates about themselves. This suggests that representations of self and others are inherently interlinked and that intact dmPFC activity is needed for separating the two.
Introduction
Navigating social environments requires us to interact with other agents that behave similarly to ourselves. Other people’s decisions influence how we decide ourselves (Garvert et al., 2015; Suzuki et al., 2016), and we keep estimates of our own and other people’s performance levels and abilities (Boorman et al., 2013; Wittmann et al., 2016). Ability estimates—impressions of how well we and others perform certain actions—allow us to construct shared representations of ourselves and others when we pursue cooperative goals or compete against each other. As a result, representations of ourselves change dynamically with social context (Wittmann et al., 2018). Here we investigate the causal contribution of the dorsomedial prefrontal cortex (dmPFC) to maintaining an individualized sense of one’s own and others’ abilities. In particular, we show that estimates of our own abilities are merged increasingly with estimates of others’ abilities after causal manipulation of the medial prefrontal cortex.
DmPFC neurons signal others’ trial and error learning in action reversal tasks (Yoshida et al., 2011, 2012) and encode the relative fit of one’s own to other’s actions (Seo et al., 2014). In the human dmPFC, corresponding signals indicate co-occurrence of ability estimates for oneself and others and the specific ways in which they can become merged (Wittmann et al., 2016). During self-other mergence (SOM), people estimate their ability not just as a function of their own performance. Instead, they are also biased by the performance of other people, depending on their contextual relationship with them (cooperation or competition). DmPFC activity is directly linked to context-dependent SOM. This is especially apparent during estimation of other people’s abilities, but it is also apparent, albeit in less direct ways, during estimation of self-ability. For these reasons, here we focus on SOM in relation to estimation of other people’s abilities.
The existence of such signals in the dmPFC and their correlation with SOM can, however, be interpreted in two completely opposite ways. This is partly a consequence of potential ambiguities in interpretation of correlations between variation in behavior and variation in neural activity that occur across participants (Lebreton et al., 2019). As a consequence, such signals might be responsible for causing SOM or, conversely, for ensuring that it does not occur to an even greater degree. These two interpretations suggest fundamentally different perspectives regarding the nature of our sense of self and others during social interaction. According to the first perspective, our default predisposition, in the absence of dmPFC activity, is an atomic, isolated sense of each individual, and dmPFC activity gives rise to interactions in self-other representations. According to the second perspective, our default predisposition is for a contextually embedded and integrated sense of self and other, and separation is only effected by dmPFC activity. Arbitration between these two accounts can be achieved by determining the causal effect of dmPFC disruption: does the dmPFC disrupt or augment SOM? More specifically, in our previous work (Wittmann et al., 2016), dmPFC activity was directly correlated with the degree to which participants merged knowledge of their own performance (self-performance or S-performance) into estimates of others’ abilities (O-ability estimates or O-ability) in a context-dependent manner. According to the first perspective, if the dmPFC enables SOM to occur, then dmPFC disruption should decrease SOM behavior and make O-ability estimates more independent from one’s own performance. Alternatively, according to the second perspective, the dmPFC may be critical for keeping estimates of self and other separate, and higher dmPFC signals might have reflected an increase in activity aimed at preventing SOM from occurring. In this case, disrupting dmPFC activity should increase SOM behavior and make estimates of O-ability more dependent on S-performance.
Here we use a combination of non-invasive brain stimulation, neuroimaging, and computational modeling to assess the effects of causal manipulation of dmPFC activity on SOM in the estimation of other’s abilities. Causal methods in addition to correlational measurements of brain activity, such as those provided by functional magnetic resonance imaging (fMRI), are indispensable for understanding brain function and have recently transformed our understanding of non-social decision-related signals in other brain networks (Ballesta et al., 2020; Knudsen and Wallis, 2020). Nonetheless, their use in social neuroscience is very rare (Hill et al., 2017). Here we show that, related to the estimation of another person, causal manipulation of the dmPFC diminishes neural signatures of SOM in the dmPFC and, in turn, increases behavioral SOM effects. This suggests that self and other ability estimates are inherently interdependent and that the dmPFC serves to keep them separate to ensure a correctly calibrated sense of self.
Results
Measurements of appropriate performance estimation and SOM
We recently developed an experimental paradigm that allows precise measurement of how people form ability estimates (Wittmann et al., 2016). In this situation, people exhibit SOM; their estimates of their own ability are influenced by the performance of others, and, vice versa, their estimates of others’ abilities are influenced by their own performance.
In the paradigm, participants perform arbitrary “minigames” (short reaction-time-based perceptual tasks) in each trial, and explicit performance feedback over many trials enables them to learn about their own abilities and those of two others. Figure 1 shows a simplified timeline of the central features of the task. We used predetermined performance feedback schedules to carefully match performance feedback for self and others and to keep them stable across participants. This ensured that performance learning for self and others was comparable across participants and, therefore, that individual differences in task behavior were interpretable. Subjects were told that the performance feedback reflected their objective performance mapped onto a 15-point performance scale and that the previously established mapping was the same for all players. Therefore, participants received explicit and independent performance feedback for all players. Using not only one but two minigames per session in pseudo-random trial order made it possible to have, on the one hand, slowly drifting performance shifts within a minigame (because abilities are thought to be relatively stable features) but, on the other hand, reduced sequential correlations across trials and ensured a full parametric range of performance feedback, making it possible to perform event-related fMRI analysis. Trial-wise decisions to engage and avoid cooperation/competition with a specified other player ensured that the social context was meaningful and that performance levels of all players were considered carefully by the participants (see STAR Methods and Figures S1–S3 for details regarding the minigames, engage/avoid decisions, and the other two players). Critically, performance ratings at the start of each trial provide a detailed readout of participants’ estimates of their own ability (self-ability estimation: S-ability) and another player’s ability (O-ability estimation). In general, participants perform this task correctly by using what we refer to as appropriate ability estimation—basing S-ability estimates on S-performance and basing O-ability estimates on O-performance. However, at the same time, ability estimates for self and others are intermixed (Figure 1A; Figures S1–S3). SOM is dependent on the social contexts in which trials occur, cooperation or competition, which require participants to entertain different relationships to the other player. During cooperation, high S-performance leads to overestimation of O-ability estimates, whereas in competition, high S-performance decreases estimates of O-ability estimates (Figure 1B). Corresponding SOM effects occur for S-ability estimation. SOM has been linked to activity in the medial prefrontal cortex. The strength of SOM effects correlates with fMRI signal strength in dmPFC area 9, suggesting that the dmPFC coordinates ability estimates for self and other (Wittmann et al., 2016).
Figure 1.

Social performance monitoring and SOM
(A) In each trial of the experiment, participants observed performance feedback for self and other relating to their respective performances in the minigame they had just played (higher yellow bars indicate better performance). Minigames, for example, comprised comparison of two time intervals between cues presented on the screen (see turquoise dots in the panel). Performance ratings made by participants at the start of each trial provided a behavioral readout of S-ability and O-ability estimation (in the example displayed here, the participant manipulates the yellow tick to predict the other player’s performance). This allowed us to test how S- and O-ability estimates were based on recent performance feedback for the appropriate player (appropriate ability estimation; a solid arrow illustrates this for O-ability) and the inappropriate player (self-other mergence [SOM], dotted arrow; in this example, O-ability estimates are based on S-performance). Importantly, trials had a cooperative or competitive context, which is critical for SOM. Note that the task comprised two other players (STAR Methods); only one is shown here for illustration.
(B) Conceptual and mathematical formalization of SOM in the case of SOMint(S→O) (SOMint(O→S) operates analogously). During SOMint(S→O), the estimation of O-ability is not just based on O-performance alone but also on S-performance. If S performed well recently, then O’s performance is overestimated during cooperation but underestimated during competition. This means that the other player is estimated as worse or better in tandem with the current performance level of S. Blue and red slopes illustrate these linear relationships. These positive and negative slopes of the line plot are captured via our regression analysis approach by positive and negative effect sizes (bar graph); the bars summarize the strength and direction of relationships between the observed performances (S- and O-performance) and the resulting ability ratings (S- and O-ability estimates), allowing statistical testing of SOM as the difference between cooperative and competitive context. For the latter, we use the interaction of S-performance with social context. In this way, we quantify the absolute influence of S-performance on S-ability estimates while accounting for the inverted signs of the effects (positive in cooperation, negative in competition).
See also Figures S1–S3.
Neurostimulation protocol
Here we used the same experimental paradigm to causally manipulate SOM by targeting its neural correlates in the dmPFC with 40-s continuous theta burst stimulation (cTBS) (Huang et al., 2005; Polanía et al., 2018) while recording the effect of this causal intervention on behavioral measurements of SOM and simultaneously acquired neural measurements of SOM. cTBS is an offline brain stimulation protocol that decreases cortical excitability of the targeted region for several minutes after application (Huang et al., 2005). cTBS has been used not only to modulate cortical excitability in motor areas but also in brain areas relevant for social cognition (Hill et al., 2017) and metacognition (Miyamoto et al., 2021). A group of participants underwent a shortened version of the experiment in the MRI scanner, preceded by cTBS (cTBS condition). After a temporal delay to guarantee washout of cTBS effects, participants underwent a second session without preceding cTBS (no-cTBS condition; Figure 2A). Session order was counterbalanced across participants (half of the participants performed the no-cTBS session first). Manipulating superficial features of the minigames (Figure S3) allowed us to present the exact same sequence of performance feedback in both sessions. This ensured that any observed SOM differences could only be attributable to the cTBS intervention. In addition to the within-participant control implemented by the two-session design, we used a between-participant control: in parallel, we recruited a same-sized second group of participants who underwent the same procedure, with the only difference being that cTBS was applied over the vertex instead of the dmPFC, a non-active control region where no SOM correlates have been identified previously (Wittmann et al., 2016; Figure 2B). Overall, these procedures resulted in 112 sessions of neural and behavioral data and allowed us to control for application of cTBS per se by testing whether the SOM difference in dmPFC-cTBS and no-cTBS sessions was bigger or smaller than the difference between vertex-cTBS and no-cTBS sessions. We applied the analogous analysis pipeline as previously to the behavioral and neural data (Wittmann et al., 2016) comprising a combination of reinforcement learning modeling (to capture S-performance and O-performance), behavioral regression analysis (to measure SOM effect sizes), and parametric fMRI analysis (to identify neural correlates). An important feature of the task design ensured that SOM is the consequence of the other agent’s performance and not simply due to variation in payoff received in minigames (see Experimental task in the STAR Methods).
Figure 2.

Neurostimulation protocol
(A) We collected fMRI data from each participant twice; once after cTBS stimulation and once in a control session. The order of cTBS and no stimulation blocks was counterbalanced across participants with a 1-h washout period between the sessions.
(B) One group (n = 28) received stimulation of the area of interest, dmPFC area 9, whereas a second group (n = 28) received stimulation of a non-active control region, the vertex. dmPFC stimulation coordinates were chosen based on our previous report of neural correlates of SOM in the dmPFC (Montreal Neurological Institute [MNI] target x/y/z coordinates in millimeters: 2/44/36). cTBS was compared with an order-balanced control condition as shown in (A).
SOM in the baseline data
There was clear evidence of SOM in our experiment when examining data from only no-cTBS sessions collapsed over both groups. As expected, despite small differences in the relative strengths of effects, S-ability was influenced more positively by O-performance in cooperation than in competition (SOMint(O→S), where “int” denotes the interaction term; t(55) = 2.162, p = 0.035; Figure 3A). At the same time, O-ability was similarly influenced more positively by S-performance in cooperation than competition (SOMint(S→O); t(55) = 3.233, p = 0.002; Figure 3B). Therefore, our experiment provided sensitive measurements of behavioral SOM. As previously (Wittmann et al., 2016), we define SOM by reference to the difference between cooperative and competitive trials; i.e., as the interaction of S-performance (O-performance) with the cooperative/competitive context (Figure 3C; Figure S4). This takes into account the fact that the influence of S-performance on O-ability estimates is positive in cooperation but negative in competition; during cooperation, we overestimate others’ abilities at times when we perform very well ourselves, but in competition, we underestimate others’ abilities when we are performing very well currently. Note that SOM is a decision-related rather than learning-related effect (SOM effects reflect the current social context of competition or cooperation between the S and O as opposed to the previous social context that prevailed when S and O last interacted). Moreover, our experimental design was constructed carefully to ensure that trial outcomes and winnings were decorrelated from S- and O-abilities (see Experimental task in the STAR Methods).
Figure 3.

Behavioral SOM in the baseline data
(A and B) SOM is present in the no-cTBS data of the current experiment. Controlling for appropriate ability estimation (Figure 1A), S-ability estimates increase with increasing O-performance during cooperation relative to competition when S-ability estimates decrease with increasing O-performance (SOMint(O→S), where “int” denotes the interaction term; see Figure 1B for an intuitive explanation of the effect sizes). The same difference is apparent when participants estimate O-ability with more positive influence of S-performance in cooperation compared with competition (SOMint(S→O)).
(C) Each SOM effect can be expressed by a single number indexing the difference in effect sizes between contexts (shown here: S-performance × context in O-ability rating; SOMint(S→O)). Positive SOMint(S→O) indicates that O-ability is influenced more positively by S-performance in cooperation compared with competition. The strength of the behavioral SOMint(S→O) effect was, in our previous report, directly related to a neural SOMint(S→O) signal in the dmPFC (Figure S4).
Data are represented as mean ± SEM, and ∗ denotes p < 0.05. See also Figure S4.
The full general linear model (GLM) from which the statistical results in Figures 3A and 3B are derived is shown in Figure 4 and is identical to one used previously by Wittmann et al. (2016). The filled bars in Figure 4 indicate the relevant SOMint effects. The analysis shown in Figure 4 controls for appropriate ability estimation (the effect of S-performance on S-ability estimates and the effect of O-performance on O-ability estimates). Moreover, by including the “context” variable (coded as 1 for cooperation and −1 for competition), it also controls for the fact that people estimate O-ability per se as more positive in cooperation than in competition (t(55) = 16.652, p < 0.001), but the same is not the case for S-ability (t(55) = −0.494, p = 0.624). This may reflect an optimism bias in the estimation of O-ability—estimating O-ability in a way that would lead participants to believe they will maximize cooperative and competitive success. Importantly, by showing these effects in the same GLM as the SOMint effects, we demonstrate that the SOMint effects persist even after controlling for appropriate ability estimation and possible optimism biases. This result highlights the specificity and independence of the SOM effect: ability estimation for each player is affected by the performance of the other player in a manner that is dependent on the social context.
Figure 4.

Full behavioral GLMs used for the baseline data
(A and B) The full GLM used to estimate S-ability (A) and O-ability (B) applied to the no-cTBS data (collapsed over the no-cTBS sessions in the dmPFC and vertex groups). These are the GLMs used to derive the statistical significance for the effects shown in Figure 3. Regressors included S-performance and O-performance, the trial’s social context (cooperate/compete, coded as 1/−1), as well as the relevant interaction terms (see Rating GLM2 for S - with interaction by social context and Rating GLM2 for O - with interaction by social context for details). Filled blue bars highlight SOM interaction (SOMint) effects. SOM regressors were calculated as the interaction of context and the relevant performance history (S-performance × context for O-ability regression [A] and O-performance × context for S-ability regression [B], respectively). Figures 3A and 3B show these effects in GLMs that separate cooperation and competition trials (see Rating-GLM1 for S - binned by social context [cooperate/compete] and Rating-GLM1 for O - binned by social context [cooperate/compete] for details). Significance testing, however, as done previously (Wittmann et al., 2016), was conducted on the SOM effects, indicated by the filled bars.
Data are represented as mean ± SEM, and ∗ denotes p < 0.05.
Disruption of the dmPFC silences neural signatures of SOM
In a previous study (Wittmann et al., 2016), one of the two SOM effects, SOMint(S→O), was directly related to neural activity in the dmPFC (in contrast, dmPFC activity was not directly correlated with SOMint(O→S) but instead with other measures of influence of O-performance on S-ability). Just as the effect of S-performance on O-ability changed depending on social context, the dmPFC carried an S-performance signal that was significantly different in cooperation compared with competition (S-performance × context). We refer to this signal as the neural SOMint(S→O) signal. Strikingly, in our past report, behavioral and neural SOM effects correlated across participants, suggesting that neural activity in the dmPFC is critical for coordinating estimates of self and other abilities (Wittmann et al., 2016). Here we examine whether disturbing neural SOMint(S→O) representations in the dmPFC is possible with cTBS and whether any such changes in neural computations cause measurable changes in behavioral SOMint(S→O). Specifically, the dmPFC might coordinate self/other representations in one of two ways. If dmPFC constructs shared representations between self and other (for instance, to guide joint actions; Tomasello et al., 2005), then dmPFC disruption should decrease behaviorally observed SOMint(S→O), making estimates of O-ability more independent from S-performance. Alternatively, the dmPFC may be critical for keeping estimates of self and other separate, in a manner akin to the way that the lateral orbitofrontal cortex maintains separate representations of choices so that outcomes are attributed correctly to the choices that caused them and not to other choices made close in time (Seo et al., 2014; Walton et al., 2010). In this case, disturbing dmPFC activity should increase behaviorally observed SOMint(S→O), making estimates of O-ability less distinguishable from S-performance.
We directly investigated neural SOMint(S→O) effects in a sphere (16-mm radius) around our dmPFC stimulation coordinates (z > 3.1, p = 0.05 family-wise error [FWE] corrected; Table 1; related effects are shown in Figure S5) as in a recently reported cTBS-fMRI study (Hill et al., 2017). Because the vertex group provided a control for application of cTBS per se, we compared the cTBS effects in the dmPFC group (cTBS − no-cTBS) directly with the vertex group (cTBS − no-cTBS). Strikingly, we found a significant change in neural SOMint(S→O) when applying cTBS to the dmPFC (Figure 5A; SOMint(S→O) in the dmPFC/vertex × cTBS/no-cTBS interaction), indicating a stronger difference in SOMint(S→O) effect sizes in the dmPFC compared with the vertex group. Closer inspection of the causal effect of cTBS on neural SOMint(S→O) revealed that they were mostly driven by a strong reduction of S-performance signals in competitive trials in the dmPFC compared with the vertex group (Figure 5B; S-performance during competition in the dmPFC/vertex × cTBS/no-cTBS interaction). This effect was even strong enough to survive whole-brain correction (z > 3.1, p = 0.05 FWE). A significant reduction in S-performance effect size during competition was also present when examining the dmPFC group in isolation (Figure 5C; dmPFC, cTBS/no-cTBS). This indicates that neural SOMint(S→O) was reduced after cTBS to the dmPFC (Figure 5D; see Figure S6 for corresponding vertex data). One reason why the cTBS effect might have been particularly pronounced during competition is that S-performance was especially strongly represented under this condition in the dmPFC during no-cTBS. The dmPFC might be particularly important in scenarios where representations of self and other must be kept separate, and this is particularly the case during competition. Therefore, cTBS-induced disruption of dmPFC activity weakened neural SOMint(S→O).
Table 1.
MNI peak coordinates of activation clusters
| Contrast | Peak coordinates x/y/z (mm) | z value |
|---|---|---|
| S-performance × context (neural SOMint(S→O)), dmPFC area 9 (cTBS – no-cTBS) > vertex (cTBS – no-cTBS) (GLM1) | 6/46/30 | 3.94 |
| S-performance during competitive trials, dmPFC area 9 (cTBS – no-cTBS) > vertex (cTBS – no-cTBS) (GLM2) | −4/46/24 | −4.27 |
| S-performance during competitive trials, dmPFC area 9 (cTBS – no-cTBS) (GLM2) | 0/44/26 | −3.91 |
All contrasts were calculated in spherical ROIs (16-mm radius) centered on the cTBS stimulation site in the dmPFC (MNI x/y/z coordinates in mm: 2/44/36) prior to thresholding.
Figure 5.

DmPFC-cTBS alters neural and behavioral SOMint(S→O)
(A–C) Neural changes of SOMint(S→O) in a sphere around the stimulation coordinates (pre-threshold masked, z > 3.1, p = 0.05 FWE).
(A) There is a stronger difference in SOMint(S→O) between cTBS and no-cTBS sessions in the dmPFC group compared with the control group (SOMint(S→O): dmPFC [cTBS – no-cTBS] > vertex [cTBS – no-cTBS]); the yellow cluster indicates a more positive difference in SOMint(O→S) effect sizes in the dmPFC group compared with the vertex group.
(B) Closer inspection reveals that this effect is mainly driven by competitive trials in which S-performance is represented more weakly after cTBS stimulation of the dmPFC (left: dmPFC [cTBS – no-cTBS] > vertex [cTBS – no-cTBS]; the blue cluster indicates a more negative difference of S-performance effect sizes in the dmPFC group compared with the vertex group during competition). The effect is negatively signed; i.e., S-performance is represented relatively more weakly during dmPFC cTBS.
(C) Considering only the dmPFC group, S-performance in competition is decreased significantly in the cTBS compared with the no-cTBS condition (dmPFC [cTBS – no-cTBS]; again, the sign of this effect is negative).
(D) To illustrate the directionality of the effects shown in previous panels, (C) illustrates the neural effect sizes from the cluster shown in (B), right side, for S-performance in the dmPFC group. Application of cTBS reduces the difference between S-performance effect sizes in cooperation and competition; i.e., neural SOMint(S→O) is reduced after cTBS application (blue/red indicate cooperation/competition trials).
Data are represented as mean ± SEM. See also Figures S5 and S6.
For transparency, Figure 6 shows unthresholded brain-wide effects for the contrasts presented in Figure 5. No additional significance tests were performed on these whole-brain maps. In addition to the dmPFC region of interest (ROI), additional ROIs relevant for social cognition are highlighted: perigenual anterior cingulate cortex (pgACC), subgenual ACC (sgACC), and posterior temporoparietal junction (pTPJ). These regions are included as visual aids for locating relevant activations. The pTPJ is, apart from the dmPFC, perhaps the main ROI in social cognition research, and activity in this area often co-occurs with signals encoded in the dmPFC. We have taken a pTPJ mask from a recent study identifying subregions within the TPJ according to resting-state functional connectivity (Mars et al., 2012). The pgACC and sgACC were recently identified as carrying social signals (Lockwood and Wittmann, 2018; Lockwood et al., 2016; Will et al., 2017), and these regions are of particular relevance to the current study; social signals were identified in the pgACC in our previous work (Wittmann et al., 2016). We therefore took an ROI centered on the S-performance effect from that previous study (Wittmann et al., 2016). The sgACC is of particular interest in light of a recent combined cTBS-fMRI study that finds that the effect of cTBS on social computations in the TPJ spreads to the dmPFC but also to the sgACC (Hill et al., 2017). This suggests that similar network effects might be observable in our study. Effect sizes in Figures 6B and 6C are also high in the pTPJ. The pTPJ and dmPFC are part of a wider social cognition network, making it plausible that some information is transferred or shared between both areas.
Figure 6.

Brain-wide subthreshold effects related to SOM
Brain-wide effects are shown for the contrasts presented in Figure 5. Colors present uncorrected z-maps thresholded at z > 3.1, z > 2.7, and z > 2.3 (red colors indicate positive effects, and blue colors indicate negative effects). For transparency, further to a dmPFC ROI, additional ROIs relevant for social cognition are highlighted: perigenual ACC (pgACC) (MNI coordinates, x/y/z: 0/40/6), subgenual ACC (sgACC) (MNI coordinates, x/y/z: 9/26/−14; taken from Hill et al., 2017), and posterior temporoparietal junction (pTPJ) (anatomical mask from Mars et al., 2012).
(A) There is a stronger difference in SOMint(S→O) between cTBS and no-cTBS sessions in the dmPFC group compared with the control group (SOMint(S→O): dmPFC [cTBS – no-cTBS] > vertex [cTBS – no-cTBS]). The effect is positively signed.
(B) The SOMint(S→O) effect in the dmPFC is driven mainly by the competitive trials where S-performance is represented more weakly after cTBS stimulation of the dmPFC (left, S-performance during competition: dmPFC [cTBS – no-cTBS] > vertex [cTBS – no-cTBS]). The effect is negatively signed.
(C) Considering only the dmPFC group, S-performance in competition is decreased significantly in the cTBS compared with the no-cTBS condition (S-performance during competition: dmPFC [cTBS – no-cTBS]). As in (B), again, the sign of this effect is negative.
See also Figures S5 and S6.
Disruption of the dmPFC increases behavioral SOM
Finally we assessed whether the effect of cTBS on neural SOMint(S→O) was sufficient to alter behavioral SOMint(S→O). We went back to our behavioral regression, analyzing O-ability ratings using the index of behavioral SOMint(S→O) illustrated in Figures 3C and 4. We performed the same comparison as with the fMRI data, comparing the difference in behavioral effect sizes for cTBS and no-cTBS conditions between the dmPFC and vertex groups. Causal manipulation of behavioral SOM by dmPFC neurostimulation was again evident when we examined behavior. There was a significant interaction between group (dmPFC/vertex) and stimulation (cTBS/no-cTBS) (2-way mixed effects ANOVA, F(1,54) = 6.681, p = 0.012; Figure 7). SOMint(S→O) was increased significantly in the dmPFC group when applying cTBS (paired t test, t(27) = 2.578, p = 0.016), but this was not the case in the vertex control group. Within the dmPFC group, there was no significant correlation of neural (contrast of parameter estimates [COPE] images extracted from the cluster in Figure 5B) and behavioral SOMint(S→O) (Pearson r = −0.205, p = 0.295). This suggests that dmPFC cTBS causally increases SOMint(S→O) in behavior and, hence, decreases the degree to which assessments of others’ abilities are independent of knowledge about one’s own performance. This effect was behaviorally specific (Figure S7). In contrast, mean neural and behavioral signatures of the complementary effect, SOMint(O→S), were not affected by cTBS over the dmPFC. We did find, however, that the dmPFC induced correlated changes in SOMint(O→S) behavior and SOMint(O→S) neural activity; people who showed the greatest reduction in SOMint(O→S) neural activity with dmPFC cTBS showed the greatest increase in SOMint(O→S) behavior (Figure S8).
Figure 7.
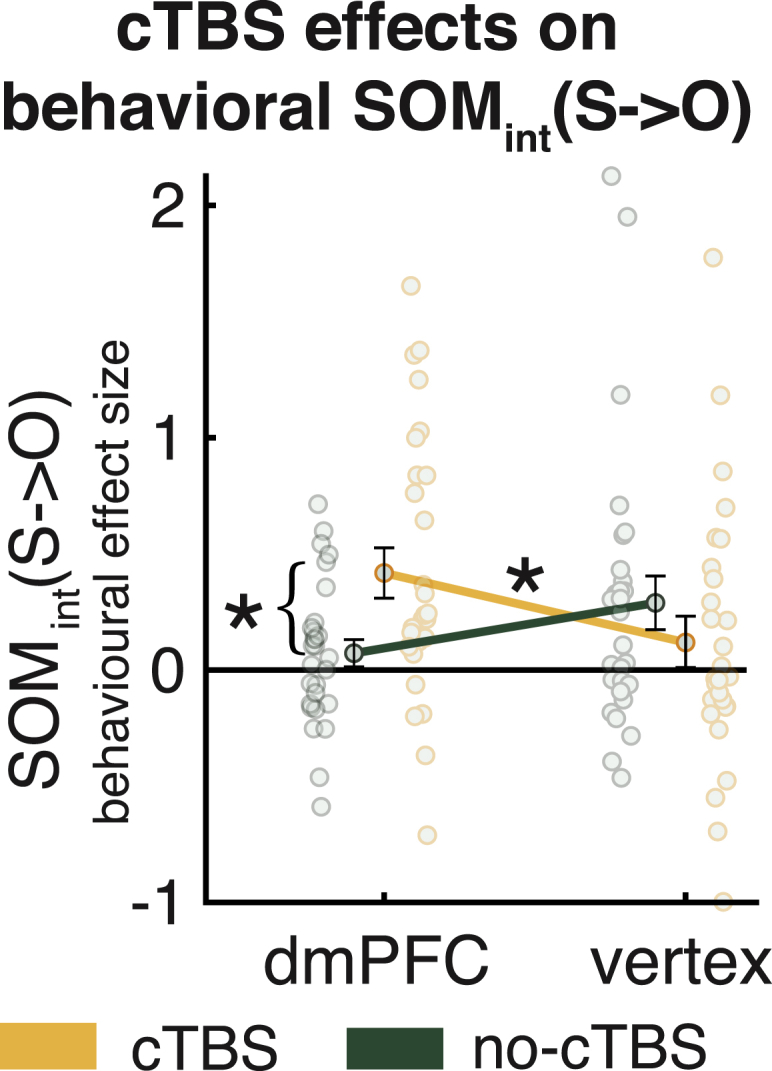
dmPFC cTBS alters behavioral SOMint(S→O)
The neural changes in SOMint(S→O) (Figure 4D) translate into behavioral changes in SOMint(S→O). SOMint(S→O) is increased when applying cTBS to the dmPFC compared with no-cTBS, and this effect is stronger than the effect observed under the vertex control condition (yellow/green indicate cTBS/no-cTBS groups). Data are represented as mean ± SEM, and ∗ denotes p < 0.05. See also Figures S7 and S8.
Discussion
Using non-invasive brain stimulation, fMRI, and computational modeling, we show that disruption of dmPFC causally affects neural signatures of SOM and the expression of SOM in behavior. The dmPFC is a key brain region for social-cognitive function (Ruff and Fehr, 2014; Saxe, 2006; Schurz et al., 2014) and encodes conspecifics’ actions and outcomes in macaque monkeys (Noritake et al., 2018; Yoshida et al., 2012) and in humans (Piva et al., 2019; Sul et al., 2015; Suzuki et al., 2012). Correlative signatures of one’s own and others’ performance in the dmPFC predict the degree to which SOM occurs and people confuse their own ability with the ability of others and vice versa (Wittmann et al., 2016). We show that disruption of the dmPFC weakened these neural signatures of SOM. As a consequence, the degree to which people exhibit behavioral SOM increased; the ability estimated for the other player was influenced more positively by S-performance in cooperation compared with competition. We show the existence of these effects while controlling for a variety of possible confound effects, such as appropriate ability estimation (the influence of O-performance on O-ability estimation and the influence of S-performance on S-ability estimation) and optimism biases afforded by the social context.
Analogously, in the non-social decision-making domain, the brain holds representations not just of individual choices and their values but also representations that reflect their value in aggregate. For example, a region on the boundary between the lateral orbitofrontal cortex and ventrolateral prefrontal cortex, 47/12o, appears to be critical for forming and maintaining representations of specific choice values based on appropriate links between choices and rewards (Howard and Kahnt, 2018; Rudebeck et al., 2017; Walton et al., 2010). In contrast, other signals in the anterior insula and amygdala, respectively, reflect how good the environment is in general—the global reward state (Wittmann et al., 2020)—and less precise estimates of choice value (Chau et al., 2015; Jocham et al., 2016; Klein-Flügge et al., 2019). These brain regions are very different from those usually linked to social cognition, such as the TPJ, the gyrus of the anterior cingulate cortex, or the dmPFC (Apps et al., 2016; Dal Monte et al., 2020; Lockwood et al., 2018; Ruff and Fehr, 2014). However, it may be that different brain networks exhibit a relative specialization for social or non-social information based on their connectivity but that some of the computations performed in them are qualitatively similar (Hunt and Hayden, 2017).
Disruption of the dmPFC decreases neural signatures of SOM and increases the degree to which people merge estimates of their own performance with estimates of other's performance. This suggests a default tendency for representations of the self and of others to interact as a function of social context. Such a predisposition may have served a group-living species well in many situations where an individual’s strength is a function of their allies’ and opponents’ strengths (De Dreu et al., 2016; Schülke et al., 2010; Wittmann et al., 2018) but may produce surprising and even problematic effects when social comparison operates in a wider sphere, as in contemporary society (Allport, 1924; Festinger, 1954; Toma et al., 2010). The neural representation of S-performance in the dmPFC serves to keep estimates of one’s own and others’ abilities separate and is essential for a correctly calibrated sense of self.
STAR★Methods
Key resources table
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
|---|---|---|
| Software and algorithms | ||
| Jasp version 0.11.1 | Jasp | RRID:SCR_015823 |
| Presentation | Neurobehavioral systems | RRID:SCR_002521 |
| MATLAB R2018a | MathWorks | RRID:SCR_001622 |
| FSL | FMRIB, Oxford | RRID:SCR_002823 |
| Brainsight | Rogue Research | RRID:SCR_009539 |
| Spike2 Software | Cambridge Electronic Design Limited | RRID:SCR_000903 |
| Behavioral data and analysis code | https://osf.io | https://accounts.osf.io/login?service=https://osf.io/h7jf8/ |
| Others | ||
| Magstim Rapid2 stimulator (TMS) | Magstim | https://www.magstim.com |
| D440 Isolated EMG amplifier | Digitimer | https://www.digitimer.com/ |
| Hum Bug 50/60 Hz Noise Eliminator | Quest Scientific | https://www.digitimer.com/ |
| CED power1401 | Cambridge Electronic Design Limited | RRID:SCR_017282 |
Resource availability
Lead contact
Further information and requests for resources and reagents should be directed to and will be fulfilled by the Lead Contact, Marco Wittmann (marco.k.wittmann@gmail.com).
Materials availability
This study did not generate new unique reagents.
Data and code availability
We have deposited all choice raw data in an OSF repository. Behavioral results in this paper are derived from these data alone.This repository also comprises the full MATLAB behavioral analysis pipeline including reinforcement learning model, regression analyses and plotting scripts. A README inside the repository explains the details of its use. The access code is: https://accounts.osf.io/login?service=https://osf.io/h7jf8/
Experimental model and subject details
Participants
65 participants participated in the fMRI experiment. Nine of those participants were excluded from the data analysis due to premature cessation of the experimental session (n = 2; no data were available for two participants who terminated the experiment after the pre-experimental procedure described below), technical difficulties with the task program or button box (n = 4), inability to follow the standardized experimental structure (n = 2) or report of the belief that the experiment involves deception (n = 1). The final sample contained 56 participants (age range 18-39 years, 26 female). Two of these 56 participants aborted a scanning session after the majority of the session was completed but prior to its full completion; their data was included in all analyses. Of these 56 participants, 28 were assigned to the dorsomedial prefrontal cortex (dmPFC) group and 28 were assigned to the vertex group. The two groups underwent identical experimental procedures that only differed in the stimulation site where transcranial magnetic stimulation (TMS) was applied. Our sample size is in line with a recent cTBS-fMRI study examining the causal effects of disrupting another node of the social brain network, the temporoparietal junction (Hill et al., 2017).
Subjects received £70 for participating in the fMRI experiment and two preceding behavioral sessions (see below). In addition, they received extra earnings which were allocated according to their task performance (mean = £13.96; std = £2.85; range: £6.23 - £18.18). The ethics committee of the University of Oxford approved the study and all participants provided informed consent (MSD-IDREC-C2-2015-017, MSD-IDREC-C1-2013-133).
Method details
Pre-experimental procedure
Before participating in the fMRI experiment, participants took part in two preparatory sessions on separate days. First, they took part in a “taster session” (∼1.5h), which served to explain TMS as well as the experimental task to the participants, to perform face-to-face TMS safety screenings, and to measure participants’ active motor thresholds. In addition, we also applied a short, 10 s version of the TMS used in the experiment, continuous theta burst stimulation (cTBS) (Huang et al., 2005), at a lower standardized intensity (25% of the machine output) over the approximate location of dmPFC. This was well below the duration and intensity required to yield neural effects and was meant to familiarize participants with the procedure that would be used on the final day in the fMRI experiment. On a subsequent day, participants were invited to a structural magnetic resonance image (MRI) brain scan (30 minutes overall), which was a prerequisite to perform neuronavigated cTBS on the final day during the fMRI experiment.
cTBS stimulation sites
During the fMRI experiment, we stimulated two separate groups of participants in two different target stimulation sites using cTBS. In one of the groups, we aimed to disrupt neural activity in dmPFC where we have previously identified neural correlates of self-other-mergence (SOM) (Wittmann et al., 2016). We used the relevant peak coordinates of effects found in our previous study in Brodmann area 9 (O-performance effects in Figure 3Aii/Table 1 of our previous report (Wittmann et al., 2016); Montreal Neurological institute (Mazziotta et al., 2001) (MNI) x/y/z coordinates in mm: 2/44/36). The stimulation site for the other group, the vertex, served as a non-active control condition and was defined as the intersection of the central sulci from both cortical hemishpheres (Hill et al., 2017) (MNI /x/y/z coordinates in mm: 0/-34/72). The fact that at this location in the brain the distance between brain tissue and skull is very large as well a lack of relevant neural activation found in this location in the previous study (Wittmann et al., 2016) meant that the vertex was an appropriate control stimulation site. Both stimulation sites were defined in standard MNI space and warped to participant specific structural images using FMRIB Software Library’s (FSL) (Jenkinson et al., 2012) non-linear transformations (FNIRT). All participants were blinded as to the site where they were stimulated with cTBS and experimental procedures, including the neuronavigation setup, were identical for all participants. Experimenters were necessarily aware of the stimulation site in order to be able to apply cTBS.
TMS protocols
All TMS stimulation was applied with a Magstim-rapid-2 stimulator (MagStim, Whitland, Carmarthenshire, UK) connected to a 70mm figure-8 coil. We used TMS on two occasions: on the first day during the ‘taster session’ to measure participants’ active motor threshold (Rossini et al., 1994) and during the fMRI experiment on the final day to apply neuronavigated cTBS (Huang et al., 2005). We used the same TMS coil on both occasions.
During the taster session on the first day, we assessed participants’ active motor threshold for the left motor cortex ‘hotspot’, which is the scalp location where TMS evoked the largest MEP amplitude. The active motor threshold was defined as the minimum stimulation intensity sufficient to produce a motor-evoked potential (MEP) in the contralateral small hand muscle, i.e., right first dorsal interosseous (FDI), in at least 50% of trials, when the participants exerted a constant pressure between the index finger and the thumb (20% of maximum force) (Rossini et al., 1994). Electromyographic (EMG) activity in right FDI was recorded with bipolar surface Ag-AgCl electrode montages. Responses were bandpass filtered between 10 and 1000 Hz, with additional 50 Hz notch filtering, sampled at 5000 Hz, and recorded using a CED 1902 amplifier, a CEDmicro1401 Mk.II A/D converter, and PC running Spike2 (Cambridge Electronic Design).
On the day of the fMRI experiment, we performed a standard neuronavigated cTBS protocol (Huang et al., 2005) immediately prior to one of two fMRI sessions that participants performed on the day. The stimulation site was projected onto the high-resolution, T1-weighted MRI brain scan of each participant using frameless stereotactic neuronavigation (Brainsight; Rogue Research). Inion, nasion, right ear and left ear were used for registration of the structural image. The stimulation protocol comprised 600 pulses in bursts of three pulses at 50Hz that are applied every 200 ms following a procedure first described by Huang et al. (2005). When applied over the motor cortex projecting to muscles from the contralateral hand, cTBS reduces motor-evoked potentials recorded from these hand muscles. This reduction in motor output generated from the motor cortex is likely to be caused by reduced efficacy of synaptic transmission lasting approximately half an hour (Huang et al., 2007; Polanía et al., 2018). A TMS coil was held in place tangentially to the skull by an experimenter during stimulation. The total stimulation duration was 40 s. We obtained the cTBS intensity by taking 80% of the output of the TMS machine at each subject’s active motor threshold. So, for example, if a participant’s motor threshold lies at 45% of the TMS machine’s maximal output, the stimulation intensity was 80%∗45% = 36% of the machine’s maximal output. The use of such a low subthreshold intensity (80% active motor threshold) had the advantage of ensuring decreased spread of stimulation away from the targeted site. For dmPFC stimulation, due to the proximity to facial nerves, we tested participants with a maximal cTBS intensity of 45% percent output of the maximal TMS machine (mean = 35.5%, std = 4.3%, range = 27% - 44%). For vertex, we used a stimulation intensity of maximal 51% machine output (mean = 42.2%, std = 6.9%, range = 29% - 51%), which was the highest available output intensity for the TMS machine. Participants for which a stimulation intensity higher than these thresholds were determined after the initial taster session did not go on to participate in the fMRI experiment. Participants rested for 40 s after the end of the stimulation to avoid washout as in previous studies (O’Shea et al., 2007). Afterward, participants went from the stimulation room to the directly adjacent scanning room and started the fMRI session immediately. The scan sequence started approximately 5 minutes after the end of the cTBS application (including the 40 s rest). Participants took approximately half an hour to perform the experimental session in the MRI scanner. Any unnecessary movements were held to a minimum in this process.
fMRI experiment
On the day of the fMRI experiment, participants were again screened for TMS and MRI safety and received a reminder of the task instructions. They performed two experimental sessions in the fMRI scanner (Figure 2). Both sessions lasted approximately 30 minutes and were separated in time by at least one-hour. During a break between the two sessions, participants relaxed and filled in some questionnaires unrelated to the purpose of the TMS manipulation (∼20 minutes). One of the sessions was preceded by the cTBS stimulation. No cTBS manipulation was performed preceding the other session. Importantly, the order of the two sessions was counterbalanced across participants. Prior to both fMRI sessions, participants performed a short ‘starter-session’ on a desktop computer. The experimental task during the starter-session was identical to the fMRI session and served to familiarize participants with the task before entering the scanner and to ensure that in-scanner behavior was maximally informative (see Experimental task section below). The starter-session took 5-7 minutes. One of the two starter-sessions was immediately followed by cTBS (neuronavigation and target localization had been performed before the starter-session). Participants also performed a starter-session before the other fMRI session, but they completed an unrelated questionnaire for 4 minutes between the starter-session and fMRI session to mirror the temporal delay imposed by the cTBS procedure. This means that, for participants that had cTBS in the first session, the mock questionnaire was completed in the second session, whereas for participants who had the cTBS in the second session, the mock questionnaire was completed in the first session. The length of the mock questionnaire matched approximately the duration of the cTBS application. The questionnaires were discarded after the experiment and no analyses were performed on them. In the end, participants were fully debriefed about the experiment.
Experimental task
We used an experimental paradigm established in our previous work (Wittmann et al., 2016) that we summarize in the following. Additional details are described in detail in the section below. Modifications of the paradigm only served to adapt it to the requirements of a paired cTBS-fMRI experiment and are detailed after the summary of the experimental task below in this section.
In the paradigm, participants learned about the approximate performance levels of themselves and two other players over trials. The only way to do this was to track explicit, parametric performance feedback for each player that was provided at the end of the trial. Prior to the performance feedback, participants performed one iteration of a so-called minigame, i.e., a short, reaction-time based task with a continuous performance scale. Participants were instructed to perform as well as possible in these minigames and believed the performance feedback that was subsequently presented reflected how well they themselves and the other players had performed in it. Note that the performance feedback only referred to the immediately preceding run of the minigame; it was not aggregate feedback over a longer time period. Approximate performance levels could only be learned by tracking performance feedback over several trials and using a recency-weighted average score to predict future performance. While participants believed that the performance feedback originated from their true performance in the minigame, it was in fact taken from a pre-determined performance schedule that was adapted from our previous study (Wittmann et al., 2016). However, exceptions from this pre-determined schedule existed and constituted cases of veridical performance feedback; this was an additional measure to assure that performance feedback was believable (see section below). Participants were told that the performance of the other player was pre-recorded on a different day.
Before the performance feedback was provided and the minigame performed, participants made an engage/avoid decision and subsequently rated the expected performance of themselves (S) and one of the two other players (relevant other, O). O was pseudo-randomly determined by the experimenter. The engage/avoid decision was set in either a cooperative or competitive context (experimenter-determined, pseudo-random). It reflected either the decision to engage in or avoid a cooperative relationship with O on the current trial (as opposed to playing individually), or the decision to engage in or avoid a competitive relationship with O on the current trial (as opposed to playing individually). Importantly, trials either offered the cooperative decision or the competitive decision; there was no choice between cooperation and competition. This allowed us to study contextual effects on the ratings that participants made about their own and O’s performance feedback on the current trial. The participant's goal was to predict the performance feedback that they themselves and O would receive at the end of the trial and the payoff scheme incentivized them to do this as accurately as possible. To do this, they had to carefully track the performance history of each player and the ratings provided a detailed readout of participants’ current player-specific performance estimates. Importantly, the experimental design was carefully constructed to ensure that trial outcomes and winnings were decorrelated from both S and O abilities. For example, on trials on which S and O performances were high, the threshold which participants had to surpass to win a trial might also be high. This meant that performance estimates for both players were dissociable from general reward expectation. This should also minimize the impact of any reinforcement-related effects on ability estimations. More detailed description of the paradigm is given the section below. Instructions are explained in detail in Figure S1 and Figure S2 presents a detailed timeline of trial events.
We modified several aspects of the paradigm to adapt it to cTBS-fMRI. First, for both fMRI sessions, we used the identical performance schedule, i.e., the series of trials and the performance feedback given was exactly the same in both sessions. This allowed us to assess participant's neural mechanism of self and other performance learning twice on the same performance schedule with the only difference being the application of cTBS before one session and not the other. However, to avoid any learning effects from one session to the next one, we designed separate minigames for each fMRI session (‘time minigames’ in one session and ‘color minigames’ in the other; Figure S3). This, together with the instructions, created the impression that both sessions measured different aspects of cognitive performance. Participant were told they played with other players during each session. No participant realized that they performed the same schedule twice. The assignment of the time and color minigames to the first or second fMRI session was counterbalanced across participants and orthogonal to the application of cTBS. Second, we shortened the number of trials of the fMRI session to 88 trials per session for participants to be able to complete the session within a time frame over which cTBS effects could be assumed to last (Huang et al., 2005). We also slightly shortened the timings of some trial events to accommodate as many trials as possible in the 30 minutes window (see Figure S2 for timings). Third and finally, we introduced ‘starter-sessions’ to each fMRI session (see fMRI experiment section). These starter-sessions employed the same minigames as the respective fMRI session and their performance schedule naturally preceded the one administered in the fMRI session. However, as our paradigm requires learning over trials, the initial trials of each session cannot provide meaningful readouts of participants’ performance estimates. Participants first need to form initial impressions about each players’ performance levels before these can be assessed. As cTBS effects diminish quickly, the usage of starter-sessions allowed us to shift this behaviorally uninformative time period to a time before cTBS was applied. Starter-sessions preceded the cTBS application. They lasted for 16 trials with no engage/avoid decisions and no ratings performed during the initial four trials. Starter-sessions were similarly performed prior to the other fMRI session with an appropriate break mirroring the time delay cause by cTBS application (see fMRI experiment section). This enabled us to assess the effects of cTBS on self and other performance learning from the very first trial of the fMRI sessions onward.
Details on design, schedule, ability ratings, and performance feedback
In this section, we give some additional details on experimental task details that we also provided when we introduced the paradigm previously (Wittmann et al., 2016). On each trial, participants performed a minigame (short reaction time-based tasks) and received performance feedback for all three players involved. Participants were told that the minigames had been tested on a larger sample of participants and that performance feedback in the minigame reflected individual performance relative to that sample. In the phases before and after the minigames, three scales ranging from 1-15 points were shown with the initials of the three players below. Performance feedback was displayed on these scales in the feedback phase. The initials shown were adjusted to be appropriate for each individual participant. The initials created a social frame for the experiment without using explicitly social cues such as faces.
On each trial, participants also made an engage/avoid decision and rated the expected performance for themselves and a relevant other (O); except the first four trials of the starter-session (see Experimental task). The identity of O (whether it was the player shown to the right or to the left of the participant on the screen) was experimenter-determined and pseudo-random. Each trial took place either in a cooperative or in a competitive social context. In a cooperative trial the engage/avoid decision was between cooperating or refraining from cooperating, while on a competitive trial, the choice was between competing or refraining from competing. If participants took the “avoid” choice, then that meant that they simply either won or lost a small number of points (1.5 points) at the end of the trial. Win or loss occurred with the same probability and hence the “avoid” choice had an expected value of zero on average. Participants were informed about this. However, if participants took the “engage” choice in the cooperative context then they opted to ally themselves with O to see if together they could perform well enough for their average points to exceed a threshold level (which varied from trial to trial and was explicitly cued on the screen). If they did exceed the threshold after engaging, they gained reward points on that trial, but if they fell short of the threshold, they lost points. By contrast, if they took the “engage” decision in the competitive context then the other player became an opponent. The difference between the participant’s and opponent’s performances then had to exceed a threshold (again the threshold was variable). In both cooperation and competition, the reward points earned or lost were proportional to this difference to the threshold (i.e., a win, a loss or neither of the two). In summary, the social context was critical when decisions to engage were made. Reward outcomes for engage/avoid choices were determined by minigame performances of S, O, and a threshold that varied unpredictably from trial to trial:
| (1a) |
| (1b) |
“Feedback” in Equations 1A and 1B refers to performance feedback observed at the end of the trial for S and O and “threshold” abbreviates the height of the cued threshold on the trial. While the likely performance feedback for S and O could be estimated from performance feedback on previous trials, the threshold varied unpredictably from trial to trial and was used to dissociate reward expectation from performance expectation and to make sure that participants did not make their engage/avoid decisions before the beginning of the current trial. Participants found the meaning of the thresholds intuitive when the task was being explained to them and their task behavior confirmed that they had understood the task. See Figure S1 for task instructions.
Participants then also provided an estimate of their ability on each trial by rating the expected performance for themselves (S) and the relevant other (O) for the upcoming trial of the minigame. The order of S and O ratings was randomized across trials. As explained above, although both of the two other players performed the minigame simultaneously, participants were only paired (to compete or cooperate) with one of the other players (the relevant other, O). Therefore, only O, and not the third player, was relevant for a trial’s engage/avoid decision. However, the identity of O switched between trials. On each trial, after the minigame, participants received performance feedback about themselves as well as about the performances of the other two players. See Figure S2 for a detailed trial timeline including timings of all trial events.
The goal of the participants in the experiment was to collect as many rewards (points) as possible, as these were translated into monetary rewards at the end of the experiment. Participants could achieve this by making correct engage/avoid decisions and by predicting performances accurately in the ratings. For all three players, including the participants themselves, performance feedback on every trial was predefined. In other words, the feedback about performance was independent from participants’ actual performance in the minigames (see, however, “false start trials” for a case of veridical performance feedback in the Feedback part of this section below and Figure S2C). This was necessary to control and match performance feedback between participants as well as between participants and the two other players. Importantly, it allowed us to use the identical performance schedule for both fMRI sessions, i.e., the series of trials and the performance feedback given was exactly the same in both sessions. This was crucial to test the effects of cTBS on performance learning of self and other, as it was only the application of cTBS that differed while the experimental schedule was the same.
We designed two ‘time minigames’ and two ‘color minigames’ which were used for the first and second fMRI session. See Figure S3 for details on the minigames including timings. Across participants, we counterbalanced which one was shown in the first session and second session. Importantly, the order of the cTBS application (cTBS was either applied before the first or the second fMRI session) was randomized across participants and orthogonal to the minigame identity. In addition, other task features were counterbalanced across participants and orthogonal to those previous manipulations as well as to each other. These additional features include the mapping between minigame and associated performance feedback schedule for the participant, the association between the other players (left/right) and their performance feedback schedules, and the button mapping between left/right and engage/avoid choice.
The fMRI experimental schedule contained 88 minigame trials. The design was a 2[social context] x 2[partner] x 2[minigame] fully crossed design (11 trials per cell). This meant that a trial could be either cooperative or competitive [social context: cooperation or competition], the O could be either “player” 1 or 2 [O: Other1 or Other2] and, in each trial, participants played one of two minigames [minigame: game1 or game2]. The trial type order was pseudorandom and the same for all participants. The starter-session had 16 trials overall and comprised an approximately similar number of trials per trial type. The first four did not include an engage/avoid decision to allow participants to first learn about the approximate performance levels of each player.
In summary, trials comprised an engage/avoid decision, two ratings (for S and O), a minigame phase, and a feedback phase. Instructions are detailed in Figure S1, trial timelines including timings in Figure S2 and minigame features in Figure S3.
As already mentioned, participants provided S and O ability ratings. For each rating, initially, a tick indicated a value on the performance scale (rating marker) and participants indicated if expected performance (for S or O as appropriate) would surpass or fall below the rating marker (Figure S2B). A positive rating (i.e., performance is expected to be above the rating marker) was made with one button and a negative rating (i.e., performance is expected to be below the rating marker) was made with the other button. As performance feedback was always expressed in integers, the rating makers were always set between two integers (X.5-values) such that either of the two responses was always correct. The rating marker was updated from trial to trial based on the rating choices for the respective player using a staircasing procedure to increase sensitivity of the ratings. A positive rating resulted in an increase of the rating marker’s value by one point in the next trial of the same minigame for the given player; a negative rating resulted in a decrease by one point. Participants received a small payoff for the accuracy of the ratings. To reduce incentives to perform badly on the minigames, negative ratings never yielded payoffs. For positive ratings, participants won or lost 0.25 points depending on whether the subsequent performance feedback received surpassed or fell below the rating marker. Note that the magnitude of the rating payoff was insignificant compared to the payoff for the engage/avoid decision.
Feedback was chunked together in three components which were presented in randomized order. The first component was the performance feedback for S and O, which was presented simultaneously with the information about the accuracy of the participants’ ratings (Figure S2B). The second component was the payoff of the engage/avoid decision. For this, a cue indicating the trial’s choice appeared on the right side of the screen (Figure S2A) together with circles representing coins that were won (yellow circles with a plus sign) or lost (red circles with a minus sign). At the same time, only for engage choices, the performance feedback average (cooperation trials) or performance feedback difference (competition trials) was displayed on the scales on the right side of the screen. The third component was the performance feedback of the other player that was not the O (irrelevant other). The initials of this player were displayed in a different color and the performance was irrelevant for any payoff. Note although the performance feedback for this player was irrelevant to the current trial, it would become relevant in the future when the currently irrelevant other would become the relevant other. The three feedback components appeared in random order to control for sequence effects.
Two types of trials deviated from the described structure. First, the first four trials of the starter-session (which took place outside of the scanner) were “starter trials” (two with one minigame, two with the other). Those trials were for participants to form initial ability estimates about the players. For this reason, in starter trials, there was no option to cooperate or compete and no ability ratings were made. Second, for trials where participants performed very badly in a minigame (“false starts”) the feedback phase was adjusted. The performance thresholds for false start trials are discussed in Figure S3. In false start trials, participants received no performance feedback for themselves, but only for the other players (Figure S2C). The sole payoff for false start trials was a loss of three points independent of participants’ ratings and engage/avoid choice. Participants were instructed about this and asked to avoid producing false start trials. It was explained that extremely bad performances would be detected by the computer running the experiment and discarded as false starts to sort out performance slips that were, for instance, due to inattentiveness and did not reflect a player’s “true” performance. This procedure was used to make the pre-determined feedback in other trials more believable as the feedback in false start trials was actually determined by true minigame performance. Note that participants were also told during the instructions that there would be a special type of false start trial if one of the other players performed very badly. However, this never happened in the experiment. Starter trials and the feedback phase of false start trials were excluded from fMRI analysis.
Quantification and statistical analysis
Reinforcement learning modeling
We used the exact same reinforcement learning (RL) model as in our previous work (Wittmann et al., 2016) (see Details on reinforcement learning model architecture section below). Again, as in our previous work, we submitted the computational variables from our fitted model to a general linear model (GLM) analysis predicting the rating data. The rating GLM was specifically designed to test for self-other-mergence (SOM; e.g., dependence on another player’s performance when estimating one’s own ability or dependence on one’s performance when estimating another player’s ability) as opposed to appropriate ability estimation (e.g., relying on one’s own performance to estimate one’s own ability, relying on the other player’s performance when estimating that other player’s ability). The RL model ensured that we could capture an index of the longer-term average performance levels observed for oneself and the other players – necessary prerequisites for the GLM analysis. The computational variables capturing these longer-term average performance levels were termed S-performance (for oneself) and O-performance (for the relevant other). Importantly the effects we tested for in the subsequent GLM were orthogonal to the RL model fitting because we tested for SOM effects, whereas the RL model only assumed appropriate ability estimation. To avoid bias in the model fitting, for each group (dmPFC and vertex), we fitted both fMRI sessions together for all participants, which resulted in a single set of free parameters per group (one set for the dmPFC and one for the vertex group). The modeling was implemented using MATLAB 2018a.
Details on reinforcement learning model architecture
For every participant, we fitted a standard reinforcement learning model to model the performance estimates assigned to the three players for each trial (Self, S; Other1, O1; Other2, O2). We used two minigame specific performance estimates per player (either for the two color minigames or the two time minigames). The performance estimates summarize the previous performance history of the players and are hence referred to as performance. They reflect the expected performance based on a recency-weighted average of past performance feedback. This resulted in six player and minigame specific performance estimates: performanceS-T1, performanceS-T2, performanceO1-T1, performanceO1-T2, performanceO2-T1, performanceO2-T2. T1/T2 denote the two session-specific minigames. On every trial t, the three performance estimates associated with the current minigame were updated using a prediction error (PE) based learning rule with a learning rate α as a free parameter:
| (1) |
(formula was applied separately for S, O1, O2, given T1 or T2)
The PE itself was calculated based on the specific performance estimate and performance feedback of the player in the current minigame as:
| (2) |
(formula was applied separately for S, O1, O2, given T1 or T2)
In false start trials, the performance estimate for S was not updated and remained unchanged until the next trial of the same minigame. No PEs for S were calculated for false start trials (the other players never displayed false start trials), but PEs were calculated for the other players. For the first trial of the fMRI session for each player for each minigame, the last performance feedback from the starter session in the respective minigame was taken as a starting value for performance.
In each trial in the fMRI session, participants made a decision about cooperating or competing (depending on the current context) with the relevant other (O) and in addition provided ratings of both S and O. Both engage/avoid decisions and ratings were modeled based on performance estimates for S and O, called S-performance and O-performance. S-performance is the performance estimate for Self associated with the minigame of the current trial (performanceS-T1 or performanceS-T2). Similarly, O-performance refers to performanceO1-T1, performanceO1-T2, performanceO2-T1 and performanceO2-T2, depending on which other player was currently selected as the O and which minigame took place. Therefore, S-performance and O-performance represented minigame and player specific performance expectations of the players involved in the current trial’s engage/avoid decision. The same was the case for the PEs associated with S and O.
Participants’ ratings of a player reflected expectations of whether they would perform either better or worse than a level indicated by a rating marker the position of which was adjusted from trial to trial using a staircase procedure explained in the above sections on experimental designs. Expectations expressed in the ratings that exceeded or fell below the rating marker were referred to as positive and negative ratings, respectively. To calculate the probability of a positive rating (p(positiveRating)), we used a softmax function with an inverse temperature β. This was done separately for S and O using S-performance and O-performance, respectively as well as the player specific rating marker:
| (3) |
(this formula was applied separately for S-performance and O-performance given their respective rating markers)
Having calculated the probability of a positive rating on a given trial, the probability of the rating actually observed was derived, again, separately for S and O:
| (4) |
(formula was applied separately for S and O)
Participants also received a small gain or loss at the end of a trial if they had made a positive rating and the expectation indicated by that rating had been accurate (rating bonus of 0.25 points). As explained in the Experimental Procedures, to ensure that there was no temptation to perform poorly in the task no rating bonus was awarded when a negative rating had been given. The expected value of a rating (EVrating) was calculated as
| (5) |
(formula was applied separately for S and O)
Note the formula was chosen such that the bounds of EVrating for positive ratings are 0.25 and −0.25, which are the points that can be lost or won for positive ratings.
In addition to completing a rating for S and O on each trial, participants made a decision to engage in or avoid cooperating/competing. Given the objective payoff scheme of the task (Equations 1A and 1B from the Experimental Design section above), the expected value of engaging in cooperation/competition (EVengage) was calculated in an analogous way:
| (6a) |
| (6b) |
A decision to avoid cooperating/competing led to a gain of 1.5 points and a loss of 1.5 points with equal probability (see previous section on experimental design) and participants had been instructed that the expected value of the decisions to avoid cooperating/competing was zero:
| (7) |
Therefore, EVengage was used as decision variable for the engage/avoid decisions to calculate the probability of engaging in cooperation or competition:
| (8) |
Note that EVavoid is zero in Equation 8, as explained above. The probabilities of the actual choices made were derived from p(engage):
| (9) |
The full reward expectation on each trial (EVchosen) was defined as the sum of the expected values from both ratings and the expected value of the engage/avoid decision (Equations 5 and 7):
| (10) |
The reward prediction error (RPE) was calculated based on all reward outcomes of a trial including both rating reward outcomes and the engage/avoid decision reward outcome (see above Equation 2 for the calculation of player specific prediction errors):
| (11) |
Overall, the free parameter set θ comprised two free parameters: the learning rate α and the inverse temperature β. We fitted these parameters by minimizing the negative log likelihood (nLL) over all trials N from both fMRI sessions from all participants of each group together (dmPFC or vertex), resulting in one set of fitted free parameters per group. For the calculation of nLL, we treated ratings and engage/avoid decisions equally. So the decisions used to fit the model included equal proportions of ratings of S, ratings of the O and engage/avoid choices.
| (12) |
Behavioral data analysis
We analyzed behavioral data using MATLAB 2018a and Jasp version 0.11.1. We analyzed how participants estimated their own and O’s ability by applying a logistic general linear model (GLM) regression to the rating data in which participants predicted the performance outcome for both players based on their observed history of past performance in the minigames. This allowed us to examine if and how TMS changed self-other-mergence. As described in the section Reinforcement learning modeling, we used a reinforcement learning model to capture an index of the longer-term average performance levels observed for oneself and the O. The two key variables from the model feeding into the GLM analyses were S-performance (recency-weighted performance estimate for self) and O-performance (recency-weighted performance estimate for relevant other). The critical effects of interest to measure self-other-mergence were the influence of O-performance on S-ability estimation and the influence of S-performance on O-ability estimation. The key effects of interest were the interactions of S-performance and O-performance with the Context variable (cooperation and competition, coded as 1/-1). Following this definition, SOMint(S→O), for example, quantifies the context-dependent influence of S-performance influence on O-ability estimation. Importantly, by using the interaction term we quantify that influence in complementary ways in cooperation compared to competition, testing for a positive effect of S-performance on O-ability estimation in cooperation and in parallel for a negative effect of S-performance on O-ability in competition. The inclusion of S-performance in the S rating and O-performance in the O rating (the appropriate performances that should be used for ability estimates) only served as control variables in the GLMs. Note that all SOM GLM effects are orthogonal to the fitting done in the RL model, which only assumed appropriate ability estimation. We used the exact identical two GLMs we had used in our previous work with this paradigm (Wittmann et al., 2016). We describe them in detail in the section Behavioral GLM analysis below. After applying the logistic GLMs to each participant independently, based on the resulting beta weights for the SOM-related effects, we calculated a mixed effects ANOVA (group: dmPFC and vertex; condition: cTBS and no-cTBS) and also a paired t test for the dmPFC data alone (Figure 7). This constituted the most critical test of the cTBS effects on self-other-mergence. For demonstrating SOM effects in the baseline no-cTBS data (Figures 3 and 4), we used variance-weighted beta weights (MATLAB’s stats.t object) as index of effect size to de-weight outlying data points as we have done previously (Trudel et al., 2021). The reason for the small trial number was to ensure that the experimental session would finish before cTBS effects subsided. The cTBS-induced changes we report (Figure 7), however, were calculated based on standard beta weights.
Behavioral GLM analysis
We used the exact identical two GLMs we had used in our previous work with this paradigm (Wittmann et al., 2016). As described in the section Reinforcement learning modeling in the STAR Methods, we used a reinforcement learning model to capture an index of the longer-term average performance levels observed for oneself and the O. The two critical variables from the model feeding into the GLM analyses were S-performance (recency-weighted performance estimate for self) and O-performance (recency-weighted performance estimate for relevant other). Note that all SOM GLM effects are orthogonal to the fitting done in the RL model, which only assumed appropriate ability estimation.
We used two rating GLMs that both comprised the same set of regressors of interest, but one of them binned trials into contexts of cooperate and compete trials (the two types of social context), whereas the other one took the interactions of S-performance and O-performance with context. Context was coded as 1 for cooperation and −1 for competition. As in our previous work (Wittmann et al., 2016), these interaction terms were the crucial measures for SOM. They are underlined in the formulas below: the influence of O-performance on the S rating and the influence of S-performance on the O rating. To calculate the interaction terms, we normalized the performance variable and multiplied it with the normalized context variable as we did before. Following the rationale of our previous work (Wittmann et al., 2016), we restricted both rating GLMs to trials in which participants had chosen to engage. Only in those trials, the social context of cooperation or competition is critical (rather than on “avoid” trials when participants simply took the default option of a random payment; see the Experimental task section and Figure S2). Note also that the use of S-performance in the S rating and O-performance in the O rating (the appropriate performances that should be used for ability estimates) only served as control variables in the GLMs. For all GLMs, all regressors (also interaction terms) were normalized (mean of 0 and standard deviation of 1).
First, the binned GLM, rating-GLM-1, was used for visualization only. It was applied separately to cooperate and compete trials:
Rating-GLM1 for S - binned by social context (cooperate/compete):
S-performance, O-performance, ratingmarker-S
Rating-GLM1 for O - binned by social context (cooperate/compete):
O-performance, S-performance, ratingmarker-O
Note that the “ratingmarker” refers to the position of the rating tick against which ability is estimated in the current trial (see the Experimental task section and Figure S2). As output, we used the variance-corrected beta weights (MATLAB’s stats.t object) to account for the relatively low number of trials as we have done before (Trudel et al., 2021). Note that no effects in this GLM were tested for significance. The next GLM, rating-glm-2, used the same regressors, but instead of binning, it employed the interaction terms of performance with social context. These interaction effects were tested for significance of SOMint (“int” denotes “interaction”). A positive interaction effect, for example for S-performance in the O rating, indicated that the effect of S-performance was stronger in cooperation than in competition. Again, the analyses were restricted to engage trials.
Rating GLM2 for S - with interaction by social context
S-performance, O-performance, S-performance x Context, O-performance x Context, Context, ratingmarker-S
(SOMint(O→S) is underlined)
Rating GLM2 for O - with interaction by social context
S-performance, O-performance, S-performance x Context, O-performance x Context, Context, ratingmarker-O
(SOMint(S→O) is underlined)
Imaging data acquisition and preprocessing
Imaging data were acquired with a 3-Tesla Siemens MRI scanner by using a 32-channel head coil. T1 weighted structural images were collected with an echo time (TE) of 4.75msec, a repetition time (TR) of 3secs, an inversion time (TI) of 100msec, 1x1x1mm voxel size and a 256x176x224 grid. Functional images were collected by using a Deichmann echo-planar imaging (EPI) sequence with TE = 30msec, TR = 3sec, 3x3x3mm voxel size, 87° flip angle, 30° slice angle and z-shimming to avoid signal dropout in frontal areas such as medial orbitofrontal areas (Deichmann et al., 2003). Two fieldmap scans (sequence parameters: TE1, 5.19ms; TE2, 7.65ms; TR, 488 s; flip angle, 60 °; voxel size, 3.5 × 5.5 × 3.5 mm) of the B0 field were also acquired and used to assist distortion-correction.
FMRIB’s Software Library (FSL) was used to analyze imaging data (Jenkinson et al., 2012). We pre-processed the data through fieldmap correction, and temporal (3 dB cut-off 100sec) and spatial filtering (Gaussian using full-width half maximum of 5mm) and using FSL’s MCFLIRT to correct for motion. The functional scans were registered to standard MNI space using a two-step process: (1) registration of subjects’ whole- brain EPI to T1 structural image was conducted using BBR with (nonlinear) fieldmap distortion-correction, and (2) registration of the subjects’ T1 structural scan to 1 mm standard space was performed using an affine transformation followed by nonlinear registration. We used FSL’s MELODIC to filter out noise components after visual inspection.
fMRI whole brain analysis
On the first level, we closely adapted the single GLM we had used in our previous work with this paradigm (Wittmann et al., 2016). It uses the identical set of regressors to model self and other ability estimation: S-performance, O-performance, and context as in our previous work. In addition, we constructed a second fMRI GLM that, instead of including the interaction terms (S-performance x context, O-performance x context), bins trials into cooperative and competitive trials to be able to analyze TMS effects separately in the two types of social contexts. These two GLMs operate therefore in a similarly complementary manner as the two behavioral GLMs (see section Behavioral GLM analysis) and are detailed in the First level fMRI analyses section below.
The results of the first level GLM were submitted to a fixed-effects second level analysis. For each participant, irrespective of dmPFC or vertex group, we calculated the difference in activation between the cTBS and the no-cTBS session. These difference maps were then submitted to a third-level analysis. We calculated two-sample unpaired t tests to compare whether the difference in neural activation change due to dmPFC stimulation was indeed stronger than the neural change in the vertex group. In addition, we also examined differences between the cTBS and no-cTBS sessions for the dmPFC group only using one-sample t tests. For statistical analysis of the third-level analysis, we used Flame 1+2 mixed effects analyses (Jenkinson et al., 2012). All results were FWE cluster corrected at p < 0.05 using a cluster-defining threshold of z > 3.1 (p < 0.001) (as recommended in Eklund et al., 2016) within an a priori defined search volume. Following previous studies examining cTBS induced neural changes (Hill et al., 2017), the search volume was a 3-dimensional sphere with 16mm radius. It was centered on our stimulation site in dmPFC, where we previously identified neural correlates of self-other mergence (MNI x/y/z coordinates in mm: 2/44/36).
First-level fMRI analyses
We used two fMRI GLMs for our whole brain analyses. Following the rationale of our behavioral analyses, the two GLMs employ the same set of regressors to model self and other ability estimation but differ in whether they model the social context (cooperation or competition) as an interaction effect or whether trials are binned into cooperative and competitive trials. The first GLM, the interaction GLM, was virtually identical to the one used in our previous work with this paradigm (Wittmann et al., 2016). Both GLMs employ S-performance and O-performance – indices of the longer-term average performance levels observed for oneself and the relevant other, O, derived from our reinforcement learning model (see Reinforcement learning model architecture section above and the Reinforcement learning modeling section). All parametric and binary regressors were normalized (mean of zero, standard deviation of one). The main phase of interest was the decision phase. However, we also modeled the feedback phase to account for variance associated with it and therefore also report feedback-related regressors for completeness.
As in our previous work (Wittmann et al., 2016), fMRI-GLM 1 time-locked the decision phase, as a constant regressor, to the onset of the engage/avoid decision onset. The duration was set to the response time for the engage/avoid decision (Figure S2Aii: phase 1,2 and 3). We added several parametric regressors to the decision phase:
-
•
S-performance
-
•
O-performance
-
•
S-performance x Context,
-
•
O-performance x Context,
-
•
Context (binary regressor; cooperation 1, competition −1)
-
•
Threshold
The two interaction terms were calculated as explained in the Behavioral GLM analysis section above. As in our previous paper (Wittmann et al., 2016), we calculated the Threshold regressor (reflecting the performance that had to be reached to satisfy the cooperative or competitive choice; see Equations 1A and 1B in the Experimental paradigm section above) over all trials by combining the threshold regressors from cooperate and compete conditions and normalizing them separately for each condition. The timing parameters for the parametric regressors were identical with the constant decision phase regressor, except for the Threshold. The threshold onset was delayed by one second, as the threshold was only revealed one second after engage/avoid decision onset and knowledge of the threshold was necessary to make an engage/avoid decision (see phase 2 in Figure S2Ai). The duration of the Threshold regressor was set to the time between its onset and the response button press in the engage/avoid decision
As in our previous report (Wittmann et al., 2016), we used two constant regressors with a duration of zero time-locked to the response of S and O rating to account for the rating events. In addition, we used parametric regressors accompanying these constant regressors accounting for the reward expectations associated with the ratings (EVrating for S and O from Equation 5 in the Reinforcement learning model architecture section above for S rating and O rating, respectively).
The feedback phase was similarly modeled as a constant regressor and parametric modulators. Note that trial feedback was chunked in three components and presented in randomized order (see Experimental Paradigm section above and Figure S2).
-
I)
S and O performance feedback and rating reward outcomes
-
II)
Engage/avoid decision reward outcome
-
III)
Irrelevant other performance feedback
Duration of the constant feedback regressor was 2.5 s, the time window in which the three feedback components initially appeared (phase 2 onset to phase 4 onset in Figure S2Aii). Parametric regressors were modeled as stick functions (i.e., duration of zero) time-locked to the appearance of the relevant feedback component (indicated in brackets in the following). They comprised:
-
•
S-performance (I)
-
•
O-performance (I)
-
•
S-PE (Prediction error for Self) (I)
-
•
O-PE (Prediction error for relevant other) (I)
-
•
Context (I)
-
•
O-PE x Context (I)
-
•
Overall reward payoff from the trial (II)
-
•
Threshold (II)
-
•
Prediction error - irrelevant other (III)
Roman numerals in brackets after the regressors indicate to which feedback component a regressor was time-locked. Feedback phases from false start trials were not modeled.
In addition, the GLM contained three additional regressors of no interest. First, a regressor time-locked to all button presses, modeled as stick functions, to account for movement-related effects. Second, two regressors captured brain signals associated with each minigame, spanning the time period from minigame onset to response button press.
fMRI-GLM-2 modeled the same constant events as the previous GLM. It modeled the decision phase in exactly the same way, but separately for competitive and cooperative trials. It used the same parametric regressors of interest as above, but without the interaction terms:
-
•
S-performance
-
•
O-performance
-
•
Threshold
The Threshold regressor was slightly time-delayed for the same reasons as above.
All remaining regressors modeled events of no interest. We report them for completeness. We again modeled constant regressors with a duration of zero time-locked to the response of S and O rating to account for the rating events, but separately for cooperative and competitive trials.
The feedback phases were also split for cooperative and competitive trials. We modeled the following parametric regressors time-locked to the different feedback phases (Roman numerals in brackets indicate the same phases as above):
-
•
S-performance (I)
-
•
O-performance (I)
-
•
S-PE (Prediction error for Self) (I)
-
•
O-PE (Prediction error for relevant other) (I)
-
•
EVrating for both ratings combined (I)
-
•
reward prediction error for both EVrating combined (I)
-
•
S-pChange (I) [the absolute change in true minigame performance from one trial to the next one; see (Wittmann et al., 2016 for details]
-
•
Threshold (II)
Region of interest (ROI) analyses
We illustrate the neural effects of interest by reading out FSL’s COPE (contrast of parameter estimates) maps for both groups and both stimulation conditions. We extracted the S-performance effects in competitive and cooperative trials from fMRI GLM 2 (see First level fMRI analyses section; Figure 5D; Figure S5) in a mask that was derived from the contrast S-performance in competitive trials (Area 9 (cTBS – no-cTBS); see Figure 5D and Table 1) by thresholding it at z > 3.1.
Acknowledgments
We thank Katharina Angerer, Alberto Lazari, and Olof van der Werf for help with data collection. The study was funded by Wellcome Trust grant WT100973AIA (to M.F.S.R.), a Sir Henry Wellcome fellowship (103184/Z/13/Z to M.C.K-F.), a Bial Foundation grant (44/16 to A.S.), and Wellcome Trust Centre grant 203139/Z/16/Z. Work was carried out in the OHBA TMS lab funded by John Fell/Wellcome Trust Institutional Strategic Support Fund.
Authors contributions
M.K.W., N.T., and M.R.S.R. designed the experiments. M.K.W., N.T., and H.A.T. collected the data. L.V. and M.C.K.-F. supervised the TMS setup. M.C.K.-F., L.V., and A.S. supported data collection. M.K.W. carried out data analyses. M.K.W., N.T., M.C.K.-F., L.V. and M.F.S.R. interpreted the results. M.K.W., N.T., and M.F.S.R. drafted the manuscript, and all authors commented on the manuscript.
Declaration of interests
The authors declare no competing interests.
Published: June 24, 2021
Footnotes
Supplemental information can be found online at https://doi.org/10.1016/j.neuron.2021.05.027.
Supplemental information
References
- Allport F.H. The group fallacy in relation to social science. J. Abnorm. Soc. Psychol. 1924;19:60–73. [Google Scholar]
- Apps M.A., Rushworth M.F., Chang S.W. The Anterior Cingulate Gyrus and Social Cognition: Tracking the Motivation of Others. Neuron. 2016;90:692–707. doi: 10.1016/j.neuron.2016.04.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ballesta S., Shi W., Conen K.E., Padoa-Schioppa C. Values encoded in orbitofrontal cortex are causally related to economic choices. Nature. 2020;588:450–453. doi: 10.1038/s41586-020-2880-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boorman E.D., O’Doherty J.P., Adolphs R., Rangel A. The behavioral and neural mechanisms underlying the tracking of expertise. Neuron. 2013;80:1558–1571. doi: 10.1016/j.neuron.2013.10.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chau B.K., Sallet J., Papageorgiou G.K., Noonan M.P., Bell A.H., Walton M.E., Rushworth M.F. Contrasting Roles for Orbitofrontal Cortex and Amygdala in Credit Assignment and Learning in Macaques. Neuron. 2015;87:1106–1118. doi: 10.1016/j.neuron.2015.08.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dal Monte O., Chu C.C.J., Fagan N.A., Chang S.W.C. Specialized medial prefrontal-amygdala coordination in other-regarding decision preference. Nat. Neurosci. 2020;23:565–574. doi: 10.1038/s41593-020-0593-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Dreu C.K., Gross J., Méder Z., Giffin M., Prochazkova E., Krikeb J., Columbus S. In-group defense, out-group aggression, and coordination failures in intergroup conflict. Proc. Natl. Acad. Sci. USA. 2016;113:10524–10529. doi: 10.1073/pnas.1605115113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deichmann R., Gottfried J.A., Hutton C., Turner R. Optimized EPI for fMRI studies of the orbitofrontal cortex. Neuroimage. 2003;19:430–441. doi: 10.1016/s1053-8119(03)00073-9. [DOI] [PubMed] [Google Scholar]
- Eklund A., Nichols T.E., Knutsson H. Cluster failure: Why fMRI inferences for spatial extent have inflated false-positive rates. Proc. Natl. Acad. Sci. USA. 2016;113:7900–7905. doi: 10.1073/pnas.1602413113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Festinger L. A Theory of Social Comparison Processes. Hum. Relat. 1954;7:117–140. [Google Scholar]
- Garvert M.M., Moutoussis M., Kurth-Nelson Z., Behrens T.E., Dolan R.J. Learning-induced plasticity in medial prefrontal cortex predicts preference malleability. Neuron. 2015;85:418–428. doi: 10.1016/j.neuron.2014.12.033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hill C.A., Suzuki S., Polania R., Moisa M., O’Doherty J.P., Ruff C.C. A causal account of the brain network computations underlying strategic social behavior. Nat. Neurosci. 2017;20:1142–1149. doi: 10.1038/nn.4602. [DOI] [PubMed] [Google Scholar]
- Howard J.D., Kahnt T. Identity prediction errors in the human midbrain update reward-identity expectations in the orbitofrontal cortex. Nat. Commun. 2018;9:1611. doi: 10.1038/s41467-018-04055-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang Y.Z., Edwards M.J., Rounis E., Bhatia K.P., Rothwell J.C. Theta burst stimulation of the human motor cortex. Neuron. 2005;45:201–206. doi: 10.1016/j.neuron.2004.12.033. [DOI] [PubMed] [Google Scholar]
- Huang Y.-Z., Chen R.-S., Rothwell J.C., Wen H.-Y. The after-effect of human theta burst stimulation is NMDA receptor dependent. Clin. Neurophysiol. 2007;118:1028–1032. doi: 10.1016/j.clinph.2007.01.021. [DOI] [PubMed] [Google Scholar]
- Hunt L.T., Hayden B.Y. A distributed, hierarchical and recurrent framework for reward-based choice. Nat. Rev. Neurosci. 2017;18:172–182. doi: 10.1038/nrn.2017.7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jenkinson M., Beckmann C.F., Behrens T.E.J., Woolrich M.W., Smith S.M. FSL. Neuroimage. 2012;62:782–790. doi: 10.1016/j.neuroimage.2011.09.015. [DOI] [PubMed] [Google Scholar]
- Jocham G., Brodersen K.H., Constantinescu A.O., Kahn M.C., Ianni A.M., Walton M.E., Rushworth M.F., Behrens T.E. Reward-Guided Learning with and without Causal Attribution. Neuron. 2016;90:177–190. doi: 10.1016/j.neuron.2016.02.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klein-Flügge M.C., Wittmann M.K., Shpektor A., Jensen D.E.A., Rushworth M.F.S. Multiple associative structures created by reinforcement and incidental statistical learning mechanisms. Nat. Commun. 2019;10:4835. doi: 10.1038/s41467-019-12557-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Knudsen E.B., Wallis J.D. Closed-Loop Theta Stimulation in the Orbitofrontal Cortex Prevents Reward-Based Learning. Neuron. 2020;106:537–547.e4. doi: 10.1016/j.neuron.2020.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lebreton M., Bavard S., Daunizeau J., Palminteri S. Assessing inter-individual differences with task-related functional neuroimaging. Nat. Hum. Behav. 2019;3:897–905. doi: 10.1038/s41562-019-0681-8. [DOI] [PubMed] [Google Scholar]
- Lockwood P.L., Wittmann M.K. Ventral anterior cingulate cortex and social decision-making. Neurosci. Biobehav. Rev. 2018;92:187–191. doi: 10.1016/j.neubiorev.2018.05.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lockwood P.L., Apps M.A., Valton V., Viding E., Roiser J.P. Neurocomputational mechanisms of prosocial learning and links to empathy. Proc. Natl. Acad. Sci. USA. 2016;113:9763–9768. doi: 10.1073/pnas.1603198113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lockwood P.L., Wittmann M.K., Apps M.A.J., Klein-Flügge M.C., Crockett M.J., Humphreys G.W., Rushworth M.F.S. Neural mechanisms for learning self and other ownership. Nat. Commun. 2018;9:4747. doi: 10.1038/s41467-018-07231-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mars R.B., Sallet J., Schüffelgen U., Jbabdi S., Toni I., Rushworth M.F. Connectivity-based subdivisions of the human right “temporoparietal junction area”: evidence for different areas participating in different cortical networks. Cereb. Cortex. 2012;22:1894–1903. doi: 10.1093/cercor/bhr268. [DOI] [PubMed] [Google Scholar]
- Mazziotta J., Toga A., Evans A., Fox P., Lancaster J., Zilles K., Woods R., Paus T., Simpson G., Pike B. A probabilistic atlas and reference system for the human brain: International Consortium for Brain Mapping (ICBM) Philos. Trans. R. Soc. Lond. B Biol. Sci. 2001;356:1293–1322. doi: 10.1098/rstb.2001.0915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miyamoto K., Trudel N., Kamermans K., Lim M.C., Lazari A., Verhagen L., Wittmann M.K., Rushworth M.F.S. Identification and disruption of a neural mechanism for accumulating prospective metacognitive information prior to decision-making. Neuron. 2021;109:1396–1408.e7. doi: 10.1016/j.neuron.2021.02.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Noritake A., Ninomiya T., Isoda M. Social reward monitoring and valuation in the macaque brain. Nat. Neurosci. 2018;21:1452–1462. doi: 10.1038/s41593-018-0229-7. [DOI] [PubMed] [Google Scholar]
- O’Shea J., Johansen-Berg H., Trief D., Göbel S., Rushworth M.F. Functionally specific reorganization in human premotor cortex. Neuron. 2007;54:479–490. doi: 10.1016/j.neuron.2007.04.021. [DOI] [PubMed] [Google Scholar]
- Piva M., Velnoskey K., Jia R., Nair A., Levy I., Chang S.W.C. The dorsomedial prefrontal cortex computes task-invariant relative subjective value for self and other. eLife. 2019;8:e44939. doi: 10.7554/eLife.44939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Polanía R., Nitsche M.A., Ruff C.C. Studying and modifying brain function with non-invasive brain stimulation. Nat. Neurosci. 2018;21:174–187. doi: 10.1038/s41593-017-0054-4. [DOI] [PubMed] [Google Scholar]
- Rossini P.M., Barker A.T., Berardelli A., Caramia M.D., Caruso G., Cracco R.Q., Dimitrijević M.R., Hallett M., Katayama Y., Lücking C.H. Non-invasive electrical and magnetic stimulation of the brain, spinal cord and roots: basic principles and procedures for routine clinical application. Report of an IFCN committee. Electroencephalogr. Clin. Neurophysiol. 1994;91:79–92. doi: 10.1016/0013-4694(94)90029-9. [DOI] [PubMed] [Google Scholar]
- Rudebeck P.H., Saunders R.C., Lundgren D.A., Murray E.A. Specialized Representations of Value in the Orbital and Ventrolateral Prefrontal Cortex: Desirability versus Availability of Outcomes. Neuron. 2017;95:1208–1220.e5. doi: 10.1016/j.neuron.2017.07.042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ruff C.C., Fehr E. The neurobiology of rewards and values in social decision making. Nat. Rev. Neurosci. 2014;15:549–562. doi: 10.1038/nrn3776. [DOI] [PubMed] [Google Scholar]
- Saxe R. Uniquely human social cognition. Curr. Opin. Neurobiol. 2006;16:235–239. doi: 10.1016/j.conb.2006.03.001. [DOI] [PubMed] [Google Scholar]
- Schülke O., Bhagavatula J., Vigilant L., Ostner J. Social bonds enhance reproductive success in male macaques. Curr. Biol. 2010;20:2207–2210. doi: 10.1016/j.cub.2010.10.058. [DOI] [PubMed] [Google Scholar]
- Schurz M., Radua J., Aichhorn M., Richlan F., Perner J. Fractionating theory of mind: a meta-analysis of functional brain imaging studies. Neurosci. Biobehav. Rev. 2014;42:9–34. doi: 10.1016/j.neubiorev.2014.01.009. [DOI] [PubMed] [Google Scholar]
- Seo H., Cai X., Donahue C.H., Lee D. Neural correlates of strategic reasoning during competitive games. Science. 2014;346:340–343. doi: 10.1126/science.1256254. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sul S., Tobler P.N., Hein G., Leiberg S., Jung D., Fehr E., Kim H. Spatial gradient in value representation along the medial prefrontal cortex reflects individual differences in prosociality. Proc. Natl. Acad. Sci. USA. 2015;112:7851–7856. doi: 10.1073/pnas.1423895112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suzuki S., Harasawa N., Ueno K., Gardner J.L., Ichinohe N., Haruno M., Cheng K., Nakahara H. Learning to simulate others’ decisions. Neuron. 2012;74:1125–1137. doi: 10.1016/j.neuron.2012.04.030. [DOI] [PubMed] [Google Scholar]
- Suzuki S., Jensen E.L., Bossaerts P., O’Doherty J.P. Behavioral contagion during learning about another agent’s risk-preferences acts on the neural representation of decision-risk. Proc. Natl. Acad. Sci. USA. 2016;113:3755–3760. doi: 10.1073/pnas.1600092113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Toma C., Yzerbyt V., Corneille O. Anticipated cooperation vs. competition moderates interpersonal projection. J. Exp. Soc. Psychol. 2010;46:375–381. [Google Scholar]
- Tomasello M., Carpenter M., Call J., Behne T., Moll H. Understanding and sharing intentions: the origins of cultural cognition. Behav. Brain Sci. 2005;28:675–691. doi: 10.1017/S0140525X05000129. discussion 691–735. [DOI] [PubMed] [Google Scholar]
- Trudel N., Scholl J., Klein-Flügge M.C., Fouragnan E., Tankelevitch L., Wittmann M.K., Rushworth M.F.S. Polarity of uncertainty representation during exploration and exploitation in ventromedial prefrontal cortex. Nat. Hum. Behav. 2021;5:83–98. doi: 10.1038/s41562-020-0929-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Walton M.E.M., Behrens T.E.J.T., Buckley M.J., Rudebeck P.H., Rushworth M.F.S. Separable learning systems in the macaque brain and the role of orbitofrontal cortex in contingent learning. Neuron. 2010;65:927–939. doi: 10.1016/j.neuron.2010.02.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Will G.J., Rutledge R.B., Moutoussis M., Dolan R.J. Neural and computational processes underlying dynamic changes in self-esteem. eLife. 2017;6:e28098. doi: 10.7554/eLife.28098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wittmann M.K., Kolling N., Faber N.S., Scholl J., Nelissen N., Rushworth M.F. Self-Other Mergence in the Frontal Cortex during Cooperation and Competition. Neuron. 2016;91:482–493. doi: 10.1016/j.neuron.2016.06.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wittmann M.K., Lockwood P.L., Rushworth M.F.S. Neural Mechanisms of Social Cognition in Primates. Annu. Rev. Neurosci. 2018;41:99–118. doi: 10.1146/annurev-neuro-080317-061450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wittmann M.K., Fouragnan E., Folloni D., Klein-Flügge M.C., Chau B.K.H., Khamassi M., Rushworth M.F.S. Global reward state affects learning and activity in raphe nucleus and anterior insula in monkeys. Nat. Commun. 2020;11:3771. doi: 10.1038/s41467-020-17343-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yoshida K., Saito N., Iriki A., Isoda M. Representation of others’ action by neurons in monkey medial frontal cortex. Curr. Biol. 2011;21:249–253. doi: 10.1016/j.cub.2011.01.004. [DOI] [PubMed] [Google Scholar]
- Yoshida K., Saito N., Iriki A., Isoda M. Social error monitoring in macaque frontal cortex. Nat. Neurosci. 2012;15:1307–1312. doi: 10.1038/nn.3180. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
We have deposited all choice raw data in an OSF repository. Behavioral results in this paper are derived from these data alone.This repository also comprises the full MATLAB behavioral analysis pipeline including reinforcement learning model, regression analyses and plotting scripts. A README inside the repository explains the details of its use. The access code is: https://accounts.osf.io/login?service=https://osf.io/h7jf8/