

Abstract
In this work, the SIR epidemiological model is reformulated so to highlight the important effective reproduction number, as well as to account for the generation time, the inverse of the incidence rate, and the infectious period (or removal period), the inverse of the removal rate. The aim is to check whether the relationships the model poses among the various observables are actually found in the data. The study case of the second through the third wave of the Covid-19 pandemic in Italy is taken. Given its scale invariance, initially the model is tested with reference to the curve of swab-confirmed infectious individuals only. It is found to match the data, if the curve of the removed (that is healed or deceased) individuals is assumed underestimated by a factor of about 3 together with other related curves. Contextually, the generation time and the removal period, as well as the effective reproduction number, are obtained fitting the SIR equations to the data; the outcomes prove to be in good agreement with those of other works. Then, using knowledge of the proportion of Covid-19 transmissions likely occurring from individuals who didn’t develop symptoms, thus mainly undetected, an estimate of the real numbers of the epidemic is obtained, looking also in good agreement with results from other, completely different works. The line of this work is new, and the procedures, computationally really inexpensive, can be applied to any other national or regional case besides Italy’s study case here.
Introduction
The SIR model [1–6], developed by Kermack and McKendrick [1] in 1927, is the well-known very simple model of infectious diseases that considers three-compartments, recalled here to state terminology and notations:
The compartment S of susceptible individuals;
The compartment I of the infectious (or currently positive) individuals, who have been infected and are capable of infecting susceptible individuals during the infectious period;
The compartment R of the removed individuals, who recovered from the disease or died from the disease, the former assumed to remain immune afterwards.
Births and non-epidemic-related deaths are neglected.
The cardinality of each of the compartments is indicated with the corresponding non bold letters, while N denotes the involved total population at an initial time :
| 1 |
The disease incidence rate is defined so that gives the number of new infections per unit time [5]; the removal rate is defined so that gives the rate at which infectious individuals “deactivate” (heal or die). Typically, is taken constant over time, which is not the general case, due to possible mutations of the decease carrier or social measures to counter the spread of the infection; also, to simplify mathematics, the generation time is neglected, that is the infector-infected pairing time lapse; as well as the removal period , which is the average time between infection and recovery or death, despite the important relation
| 2 |
Within the removal period , a typical infectious individual is expected to cause new infections, so defining a function of time that, normalized, is called effective reproduction number (see, for instance, [7]), namely:
| 3 |
So, the SIR equations as used here become:
| 4a |
| 4b |
| 4c |
Of course, they imply that the sum is conserved, so that at any time t.
Outlines of the work
The purpose of this work is to check whether the relations established in Eq. 4 are actually found in the data or, at least, whether “corrections”, accounting for incomplete data or systematic errors, may or should be introduced, with the implication that consequently the relationships are satisfied. Crucial is the fact that the model is scale-invariant, thus allowing to conveniently choose as a reference one sub-compartmental curve whose real data can be considered reliable, such as the swab-confirmed infectious individuals curve. This choice is done indeed here: swab-confirmed infectious are mostly individuals who have developed symptoms and are actually found to cover a nearly constant fraction of all the infectious people, given the circumstances that symptomatic and asymptomatic individuals roughly are, respectively, fractions of the age groups of over sixty and younger people ([8–11]).
The case of the second through the third pandemic wave of Covid-19 in Italy is studied. First, it will be shown that the relation established through Eq. 4c holds true if R(t) is scaled by a factor that is obtained, together with the removal period , by a least-square procedure of matching over data. Arguments will be given for how a scaling-up over the official data should be due indeed.
Once , and thus , is obtained, the effective reproduction number is evaluated through Eq. 4b , reliably, despite using the swab-confirmed infection cases only, for that equation is scale-invariant on its own.
The transition to real numbers is finally done, correcting the swab-confirmed infectious cases for the proportion factor of transmissions that likely occur from asymptomatic subjects. The results are compared with those obtained at the MRC Centre for Global Infectious Disease Analysis, Imperial College London (ICL, [12]), where a completely independent approach is used.
The data set
The data set is from Italy’s Department of Protezione Civile [13], lasting from 1 June 2020 to 31 May 2021. Since every weekend there was a postponement in cases recording to a few days later, according to common practice the data are smoothed via a multi-day moving average; the choice is 9 days, to systematically include a couple of days after each weekend.
The swab-confirmed infectious towards the daily removed
Verifying that the relationship given by Eq. 4c is indeed found in the data is not so trivial. For example, there is evidence that the monthly deaths from Covid-19 in 2020, as given by Italy’s Department of Protezione Civile, are largely underestimated: this is shown by an ISTAT study on the monthly excess of deaths in 2020, compared to the corresponding averages over the previous five years (see [14] and [15]). ISTAT is Italy’s Istituto Nazionale di Statistica. The matter is illustrated in Fig. 1. In addition to this, it is to be expected that R(t) does not include most of the cases that had an asymptomatic or mild course. Also, asymptomatic infected people are probably not reported among the infectious, whereas by far most of the reported infectious are those who had swabs confirmation, whose number will be called . Let’s indicate with the curve of the actually registered healed and deaths: it is found that its derivative, the daily variation, shifted forward in time, is indeed proportional to . To methodically verify Eq. 4b, the correction factor is introduced so as to give maximum generality to a least-square search over the positive definite form
| 5 |
with varying and the removal period . It is worth remarking the notation , intended to emphasize that any correction on , possibly required by the SIR model at this stage, is relative to the swab-confirmed infectious population only. The sum is over the days of the pandemic period considered, with the choice of weighing equally all daily data. In principle two functions of the kind 5 should be used, one for deaths and one for recoveries; however, deaths are well known to be only at most some 4–5 of the whole removed compartment, so that a probably negligible error is made by simplifying as in Eq. 5 because of the huge statistical and systematic uncertainties in the data. The minimization is performed using a C++ object of the class Minimizer of the CERN package ROOT, typically used by high energy physicist in their data analysis ([16, 17]): its statistical methodology is described in [18]. Since the surface defined from the data through Eq. 5 is rather rough, the minimization algorithm is run 150,000 times to maximize the chance of hitting an optimal minimum: the initial values of and are drawn at random in the intervals and respectively. Execution on raw and smoothed data takes about one minute time altogether. The final issue for and and their uncertainties and are taken as the mean and the standard deviation of the distributions of the respective outcomes at each iterated minimization, weighted with the normalized inverse of the .
Fig. 1.
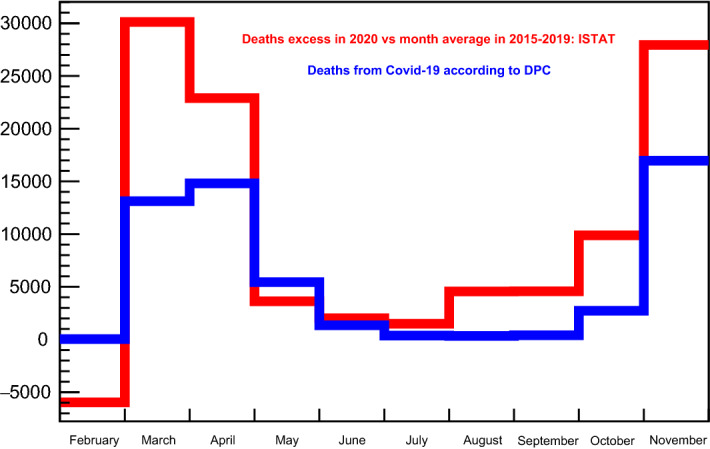
Monthly deaths from Covid-19 in Italy during 2020, according Italy’s Department of Protezione Civile (blue histogram); monthly excess of deaths the same year compared to the averages over the previous five years, according Italy’s ISTAT (Istituto Nazionale di Statistica)
The results are shown on the first and the second lines of Table 1, for the raw and the smoothed data respectively.
Table 1.
k-factor and
| Ndf | red. | ||||
|---|---|---|---|---|---|
| Likelihood on raw data | 93185 | 360 | 266 | ||
| Likelihood on smoothed | 32823 | 360 | 91 | ||
| Gaussian fit | 1.15 | 32 | 0.04 | ||
| Skew sigm. derivative | 2.48 | 66 | 0.04 |
Since the value of the removal period is critical in determining , it is sought from the data in two further independent ways, as explained in the next two subsections.
The removal period from a Gaussian fit
At any new “wave” of epidemic, the rise in number of the infectious individuals follows with good approximation a sigmoidal shape, i.e. it is roughly exponential at the very beginning, up to an inflection point, after which it bends towards a plateau; consequently, its daily variation (the time derivative) exhibits a maximum at the inflection point, around which it is approximately Gaussian. If Eq. 4c correctly described the data, an analogous shape should be had in the second derivative of the removal curve. Very remarkably, this is in fact the case, as shown in Fig. 2 , where fitting Gaussians are plotted over the first derivative of the infectious curve and the second derivative of the removal curve: the distance in time between the vertexes of the two Gaussians gives a new independent measurement of the removal period , reported in the third line of Table 1 with associated uncertainty and fit . The uncertainty is the sum in quadrature of the uncertainty on the position in time of the vertexes of the two fitting Gaussians; the , with its reduced, is their worse. The fit algorithm is from the already mentioned ROOT package (CERN, [19]).
Fig. 2.
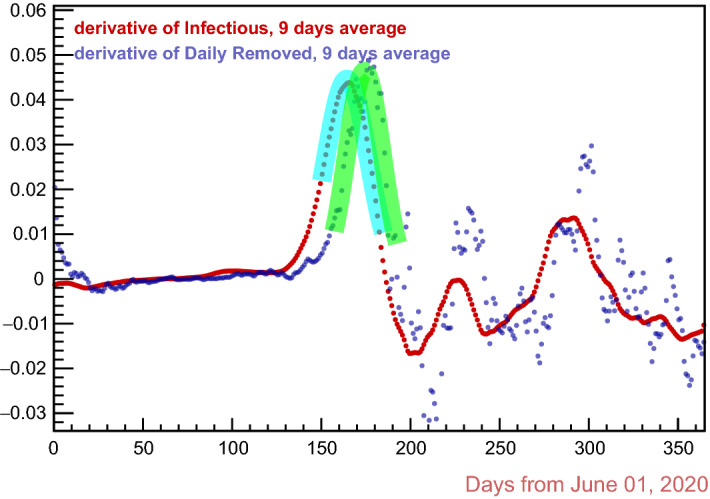
The two fitting Gaussian functions in cyan and green
The removal period from the “asymmetric sigmoid derivative” fit
Given the almost sigmoidal initial growth of an epidemic wave, as already mentioned in the last subsection, an alternative fit function turns to be an asymmetric modification of the derivative of a sigmoid, which will be called skew sigmoid derivative, namely:
| 6 |
This function has absolute maximum in , with . It is plotted in Fig. 3 for , and , and various values of the skewness parameter : for one has the derivative of a very sigmoid. The fits of the skew sigmoid derivative to the first derivative of the swab-confirmed infectious curve and to the second derivative of the removal curve, respectively, are shown in Fig. 4: again, the distance in time between the vertexes of the fitting functions gives a new measurement of the removal period , reported in the fourth line of Table 1.
Fig. 3.
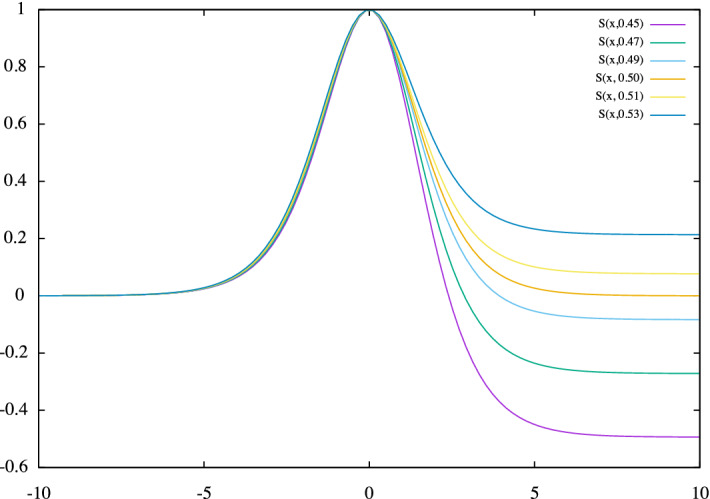
The skew sigmoid derivative for , , ;
Fig. 4.
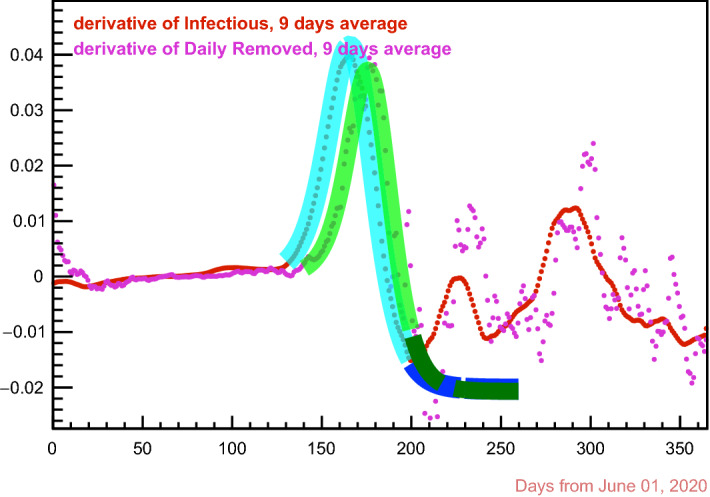
The two fitting “asymmetric sigmoid derivative” functions in cyan and green
The removal curve corrected relatively to the swab-confirmed infectious only
From Table 1 the removal period is assumed to be days, bearing in mind that the data have just one day resolution; also, comparing the on the first and second lines of the table, the correction factor is taken equal to . So, we have the curve of the removed individuals, corrected relatively to the swab-confirmed infectious only, given by:
| 7 |
Figure 5 does illustrate this: the cyan error bars are generated by the propagation of three times the uncertainty over .
Fig. 5.
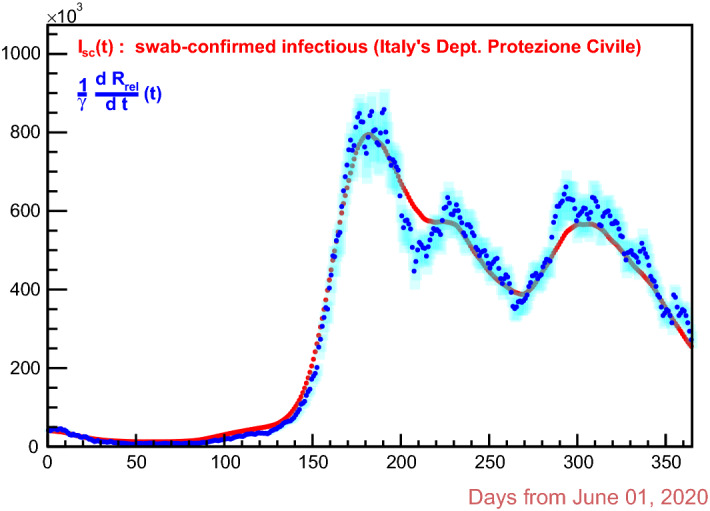
Relation 7 in the data. The derivative of (blue marks) is time-shifted by the removal period . The cyan error bars are given by propagation from three times uncertainty over
Getting the generation time and the effective reproduction number
There are several algorithms to estimate the effective reproduction number from the data: a simplified one is given in [20], where also an extensive bibliography on the subject can be found. The simplest yet effective estimate that very directly interprets the meaning of the function (see, for instance, [21]) is given by
| 8 |
As far as the SIR model is concerned, from Eq. 4b one has
| 9 |
So, the derivative is implemented by the symmetric difference quotient, to have the cancellation of the first-order error in the numerical discretization.
While only the generation time appears in Eq. 8, both and the removal period are present in Eq. 9; consequently, the validity test of the SIR model through the effective reproduction number it manages to provide, is to be considered quite stringent.
In the previous section, the removal period was obtained from the data using the SIR model; the question is how to get the generation time as well.
In our conventions, I(t) denotes the total of all the infectious people, swab-confirmed or not. If is a day when I(t) presents a maximum, then correspondingly, but days earlier, i.e. at day , the effective reproduction number should be equal to 1, because an increase in the number of the people becoming infectious requires and a decrease requires . Of course, every variation of has impact on I(t) with a delay of days, so also for , assuming this to be proportional to I(t) . With fixed at days, as set out in the previous section, let’s say a day when, for any given choice of , is equal to 1: in general, checking over the data, it doesn’t happen that the nearest next day , on which has a maximum, is such that , as it should; indeed it happens only for a specific choice of , namely, for the case being studied, with , an integer value just in view of the one-day resolution of the data. A convenient double check is done on the maximum of falling on 2 December 2020 (see Fig. 5). Very remarkable is the fact that the height of the peaks of does depend on the value one wants to give to , the same way as the days when is equal to 1 do: so, all of these things are bounded by the SIR model, a fact that must be considered truly important in evaluating the validity of the model.
The estimate days is in total agreement with the average days given for Italy in Ref. [22]: this is a success of Eq. 9 that strengthens the agreement, within the uncertainties, of the resulting with that from other algorithms, as those reported in Ref. [20] , with references therein. Figure 6 shows this SIR generated , together with the one from Eq. 8; for either, error bars corresponding to a days uncertainty on both and are also shown.
Fig. 6.
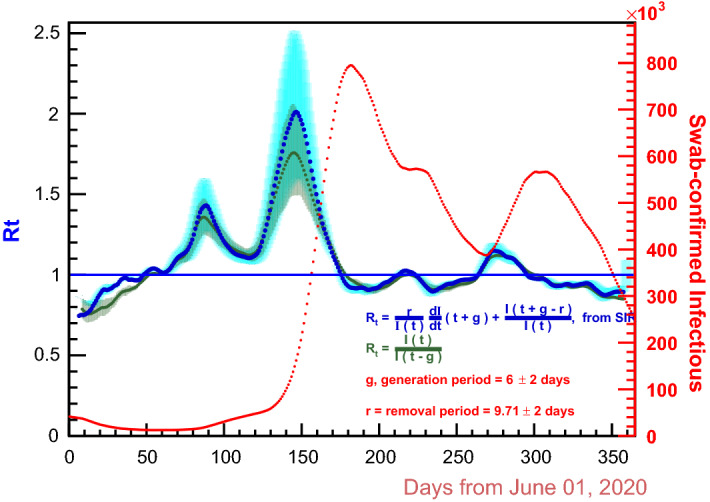
according to the SIR model, compared with the used simplest formula, Eq. 8. In cyan are the error bars for Eq. 9; the other are in black. ;
The “corrected” cumulative and daily-new infections relatively to the swab-confirmed infectious people
To avoid confusion, it is worth remarking that infections at day t is meant as the cumulative number of infections up to and including that day, while the number of infectious people at some day t refers to those people who were infected possibly earlier and are still able to transmit infection at that day. Thus, the (daily new) infections curve is different from the infectious curve.
Since N in Eq. 1 is conserved, Eq. 4a can be written as
| 10 |
expressing the daily new infections, gross of removed people (while the infectious numbers are net of removals). Indeed,
| 11 |
is nothing but the total cases of infections at time t .
For what has been done so far, Eq. 10 must be replaced by
| 12a |
| 12b |
giving the corrected cumulative number of infections relatively to the swab-confirmed infectious people only. Figure 7 illustrates Eq. 12.
Fig. 7.
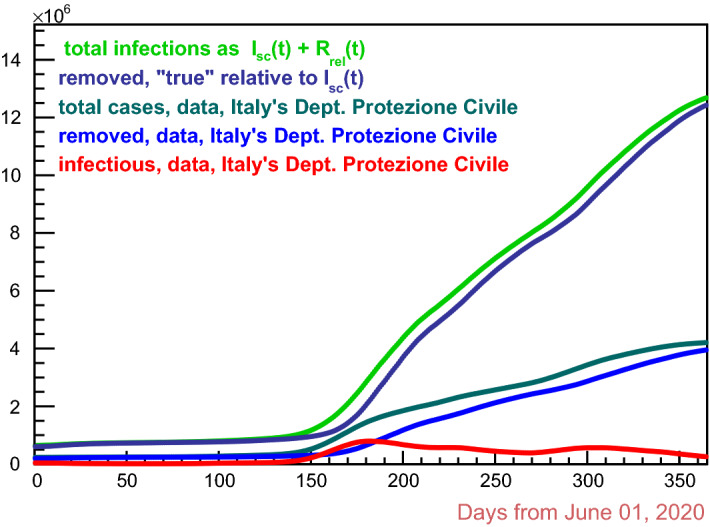
Italy, Covid-19 second through the third waves: estimates of removal (dark blue curve) and total (green curve) cases as from correction relative to the swab-confirmed infectious (red) curve. Also shown data in dark green (total cases) and blue (removals)
Infections from asymptomatic and symptomatic infectious people: estimate of the “real” numbers
There are several studies on the relevance of SARS-CoV-2 transmission from asymptomatic people, like [8, 23–25] and references therein. Quite recent and complete is ref. [25], where a decision analytical model is used to assess the proportion of SARS-CoV-2 transmissions in the community likely occurring from subjects who did not develop any symptom. In that work data from a meta-analysis were used to set the generation time at a median of 5 days and infectious period at 10 days, in good agreement, respectively, with the 6 and 10 days stated in the present work. The reported conclusion is that, across a range of plausible scenarios, a of infection transmission occurs from persons without symptoms: no clear uncertainty is given, but the statement that the figure should be at least , suggests an uncertainty of . Also it is stated that the infected individuals who never develop symptoms are as infectious as those who do develop symptoms.
Let’s call the percentage fraction of the asymptomatic infectious subjects over all the infectious people and their relative infectiousness, that is the percentage fraction of the infectiousness of those who had developed symptoms: then, according to the best available figures, it would be and , the latter with a trial, very conservative, uncertainty of .
Denoting by the number of the asymptomatic infectious individuals and recalling that indicates the number of the swab-confirmed infectious subjects, it should be
whence
| 13a |
| 13b |
| 13c |
Then, in view of Eq. 11, Eq. 10 becomes
| 14 |
with the “real” cumulative number of infections at day t, while its derivative represents the “real” daily new infections.
Figure 8 shows the daily new infections curve, compared with the Imperial College’s (ICL) model estimate, as published in [12]. The model in question is a stochastic SEIR variant that adopts multiple infectious states, which in turn reflect different COVID-19 severities. It uses an estimate of the infectious fatality rate (IFR), assuming that the number of confirmed deaths from Covid-19 is equal to the real Covid-19 deaths number; it also uses an estimate of the effective reproduction number, based on the changes of the virus transmission rate caused by the average mobility trends.
Fig. 8.
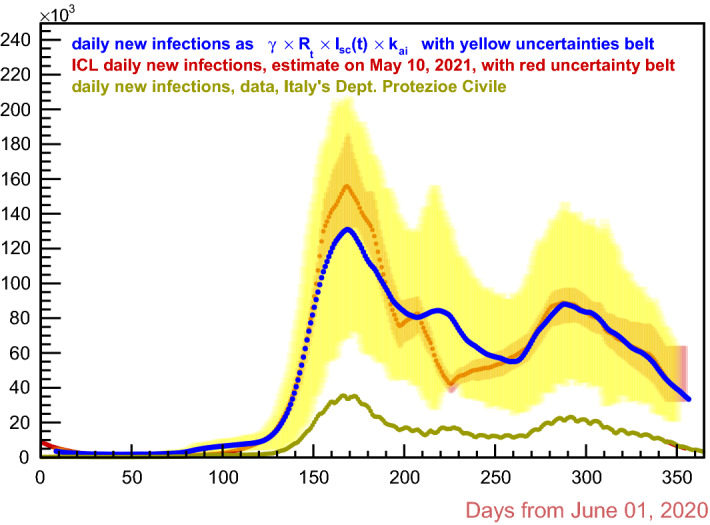
Italy, Covid-19 second through the third waves. Estimates of daily new infections in this work are in blue and uncertainty belt in yellow; ICL is in dark red
So, the ICL model’s approach is totally different from the one followed in the present work; nevertheless the respective “real” daily new infections estimates appear to be in quite good agreement, except on a time interval around 1 January 2021 (day 220 in plots of this paper), where the ICL curve shows a deep local minimum instead of a local maximum as in the data of Italy’s Department of Protezione Civile. The uncertainty belt of the ICL estimates is surprisingly narrow. In Fig. 9 the present work’s estimates of the “real” total cases of infections are shown, together with the estimated “real” daily new infections, the latter with their own scale on the right; also, the data as from Italy’s Department of Protezione Civile are plotted.
Fig. 9.
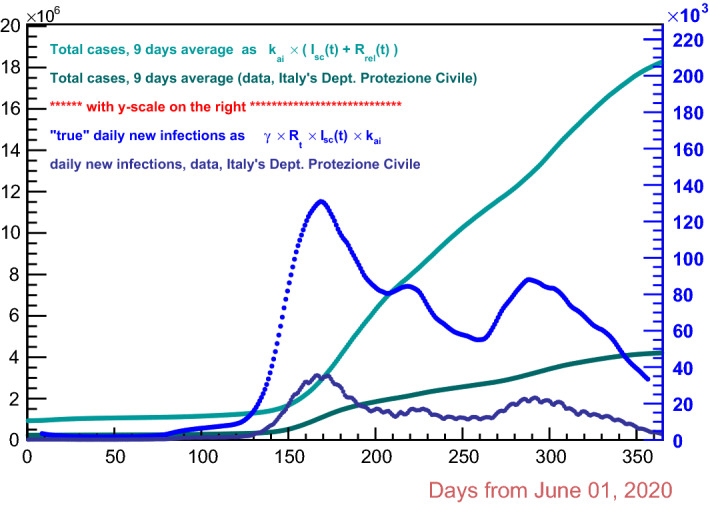
This work estimates of the “real” total cases (light green) and correspondent data form Italy’s Department of Protezione Civile (dark green) with scale on the left; this work “real” daily new infections (blue) and corresponding official data (dark blue) with scale on the right
Incidentally, the ripple visible in Figs. 8 and 9 on the data from Italy’s Department of Civil Protection has the typical 7-day periodicity that arises from the weekend reduced data recording.
Conclusions
Taking as case study the second to the third waves of SARS-CoV-2 in Italy, the SIR model is confronted with data, after reformulating its equations by the explicit introduction of the important effective reproduction number , as well as the generation time and the infectious period, usually, erroneously, neglected. The relationships it sets among the main observables are actually found in the data, in particular between the curve of the swab-confirmed infectious individuals and the curve of the removed (healed or deceased) subjects. Indeed, taking advantage of its scale invariance and choosing the curve of the swab-confirmed infectious people as a reference, the model suggests a correction on the number of removed individuals for just a factor which would take into account: (a) infected people who have not developed relevant symptoms and, therefore, were not detected; (b) deaths erroneously not attributed to Covid-19. Generation time, infectious period and effective reproduction number have been sought from the data through the model. At the very end, the curve of the swab-confirmed infectious individuals has been completed for the proportion of infection transmissions likely occurred from individuals with no symptoms, using figures published in important works ([8, 23–25]). Thus, an estimate of the real numbers of the pandemic in Italy is obtained for the considered period of time. All the results are in good agreement with those of other studies, in particular of the ICL group ([12]), whose approach is totally different from the present. The vision on and use of the SIR model of this work are new; the C++ code, computationally really inexpensive and available under request to the author, can be applied to any other national or regional case besides Italy’s study case here.
Funding
Open access funding provided by Universitá degli Studi di Trento within the CRUI-CARE Agreement.
Data Availability Statement
This manuscript has associated data in a data repository. [Authors comment: Original data are those from Italy’s Department of “Protezione Civile”, available at a public repository according to reference [13] in the paper. The resulting estimation data, as shown in the paper, are available from the author under request to him.]
References
- 1.Kermack WO, McKendrick AG. Contribution to the mathematical theory of epidemics. Proc. R. Soc. A. 1927;115:700–721. doi: 10.1098/rspa.1927.0118. [DOI] [Google Scholar]
- 2.Murray J. Mathematical Biology. Berlin: Springer-Verlag; 1993. [Google Scholar]
- 3.Daley D, Gani J. Epidemic Modelling. Cambridge: Cambridge University Press; 1999. [Google Scholar]
- 4.Brauer F. Mathematical epidemiology: past, present, and future. Infect. Dis. Model. 2017;2:113–127. doi: 10.1016/j.idm.2017.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Martcheva M. An introduction to mathematical epidemiology. New York: Springer; 2015. [Google Scholar]
- 6.Brauer F, Castillo-Chavez C, Feng Z. Mathematical Models in Epidemiology. New York: Springer; 2019. [Google Scholar]
- 7.Hethcote HW. The mathematics of infectious diseases. SIAM Rev. 2000;42(4):599–653. doi: 10.1137/S0036144500371907. [DOI] [Google Scholar]
- 8.Snider B, Patel B, McBean E. Asymptomatic cases, the hidden challenge in predicting COVID-19 caseload increases. Infect. Dis. Rep. 2021;13:340–347. doi: 10.3390/idr13020033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Poletti P, Tirani M, Cereda D, et al. Association of age with likelihood of developing symptoms and critical disease among close contacts exposed to patients with confirmed SARS-CoV-2 infection in Italy. JAMA Netw Open. 2021;4(3):e211085. doi: 10.1001/jamanetworkopen.2021.1085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Unim B, Palmieri L, Lo Noce C, Brusaferro S, Onder G. Prevalence of COVID-19-related symptoms by age group. Aging Clin. Exp. Res. 2021;33(4):1145–1147. doi: 10.1007/s40520-021-01809-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Monod M, Blenkinsop A, Xi X, et al. Age groups that sustain resurging COVID-19 epidemics in the United States. Science. 2021 doi: 10.1126/science.abe8372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.https://ourworldindata.org/covid-models#imperial-college-london-icl
- 13.https://github.com/pcm-dpc/COVID-19
- 14.https://public.tableau.com/profile/istat.istituto.nazionale.di.statistica
- 15.Bonifazi G, Lista L, Menasce D, Mezzetto M, Oliva A, Pedrini D, Spighi R, Zoccoli A. A statistical analysis of death rates in Italy for the years 2015–2020 and a comparison with the casualties reported from the COVID-19 pandemic. Infect. Dis. Rep. 2021;13(2):285–301. doi: 10.3390/idr13020030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.https://root.cern/root/htmldoc/guides/users-guide/ROOTUsersGuide.html
- 17.https://root.cern.ch/doc/v614/classROOT_1_1Math_1_1Minimizer.html
- 18.Jacoboni, Eadie CWT, Dryard D, James FE, Roos M, Sadoulet B. Statistical methods in experimental physics. Nuov Cim. A. 1977;40:235. doi: 10.1007/BF02776791. [DOI] [Google Scholar]
- 19.https://root.cern.ch/root/html534/guides/users-guide/FittingHistograms.html
- 20.Bonifazi G, Lista L, Menasce D, Mezzetto M, Pedrini D, Spighi R, Zoccoli A. A simplified estimate of the effective reproduction number Rt using its relation with the doubling time and application to Italian COVID-19 data. Eur. Phys. J. Plus. 2021;136(4):386. doi: 10.1140/epjp/s13360-021-01339-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Robert Koch Institut, “Erläuterung der Schätzung der zeitlich variierenden Reproduktionszahl” https://www.rki.de/DE/Content/InfAZ/N/Neuartigesc_oronavirus/Projekte_RKI,R-Wert-Erlaeuterung.pdf (2020)
- 22.D. Cereda et al., The early phase of the COVID-19 outbreak in Lombardy, Italy. arXiv:2003.09320 (2020)
- 23.Oran DP, Topol EJ. Prevalence of Asymptomatic SARS-CoV-2 InfectionFREE. Ann. Intern. Med. 2021 doi: 10.7326/M20-3012. [DOI] [PubMed] [Google Scholar]
- 24.Alene M, Yismaw L, Assemie MA, Ketema DB, Mengist B, Kassie B, Birhan TY. Magnitude of asymptomatic COVID-19 cases throughout the course of infection: A systematic review and meta-analysis. PLoS ONE. 2021;16(3):e0249090. doi: 10.1371/journal.pone.0249090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Johansson MA, Quandelacy TM, Kada S, et al. SARS-CoV-2 transmission from people without COVID-19 symptoms. JAMA Netw. Open. 2021;4(1):e2035057. doi: 10.1001/jamanetworkopen.2020.35057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.J.A.P. Heesterbeek, A brief history of and a recipe for its calculation. 10.1023/A:1016599411804
- 27.Edelstein-Keshet L. Mathematical Models in Biology. Philadelphia: Society for Industrial and Applied Mathematics; 1988. [Google Scholar]
- 28.https://opendatadpc.maps.arcgis.com/apps/dashboards/b0c68bce2cce478eaac82fe38d4138b1
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
This manuscript has associated data in a data repository. [Authors comment: Original data are those from Italy’s Department of “Protezione Civile”, available at a public repository according to reference [13] in the paper. The resulting estimation data, as shown in the paper, are available from the author under request to him.]