

Abstract
Investigators increasingly need high quality face photographs that they can use in service of their scholarly pursuits—whether serving as experimental stimuli or to benchmark face recognition algorithms. Up to now, an index of known face databases, their features, and how to access them has not been available. This absence has had at least two negative repercussions: First, without alternatives, some researchers may have used face databases that are widely known but not optimal for their research. Second, a reliance on databases comprised only of young white faces will lead to science that isn’t representative of all the people whose tax contributions, in many cases, make that research possible. The “Face Image Meta-Database” (fIMDb) provides researchers with the tools to find the face images best suited to their research, with filters to locate databases with people of a varied racial and ethnic backgrounds and ages. Problems of representation in face databases are not restricted to race and ethnicity or age – there is a dearth of databases with faces that have visible differences (e.g., scars, port wine stains, and cleft lip and palate). A well-characterized database is needed to support programmatic research into perceivers’ attitudes, behaviors, and neural responses to anomalous faces. The “ChatLab Facial Anomaly Database” (CFAD) was constructed to fill this gap, with photographs of faces with visible differences of various types, etiologies, sizes, locations, and that depict individuals from various ethnic backgrounds and age groups. Both the fIMDb and CFAD are available from: https://cliffordworkman.com/resources/.
Keywords: faces, photographs, stimuli, perception, visible difference, stigma
1. Introduction
Over the past two decades, the number of scientific papers referring to “face photographs” (or images, pictures, or variants thereof) has risen sharply, increasing from under 800 papers in 2000 to well over 3,500 per year since 2016 and representing a net contribution to the literature of nearly 50 thousand papers (Fig. 1). Albeit indirect, these metrics reveal increasing demand by investigators for high quality face photographs they can use in service of their scholarly pursuits—whether serving as experimental stimuli, or to benchmark face recognition algorithms. In tandem with increased demand by investigators, the past twenty years has also witnessed a proliferation of face databases freely available for academic use—we count at least 381 databases of static face images from 127 different sources. Up to now, however, an index of known face databases, their features, and how to access them has not been available. Consequently, to find face databases, investigators have relied on word of mouth (e.g., peer recommendations in forums like ResearchGate) and/or their familiarity with published research using face photographs. Researchers interested in facial displays of affect, for instance, would likely encounter the “Radboud Faces Database” (RaFD), which has been cited over 1,900 times according to Google scholar (Langner et al., 2010), or the “FACES” database, which has been cited over 800 times (Ebner et al., 2010).
Figure 1 |. Growing demand by researchers for databases of face photographs.
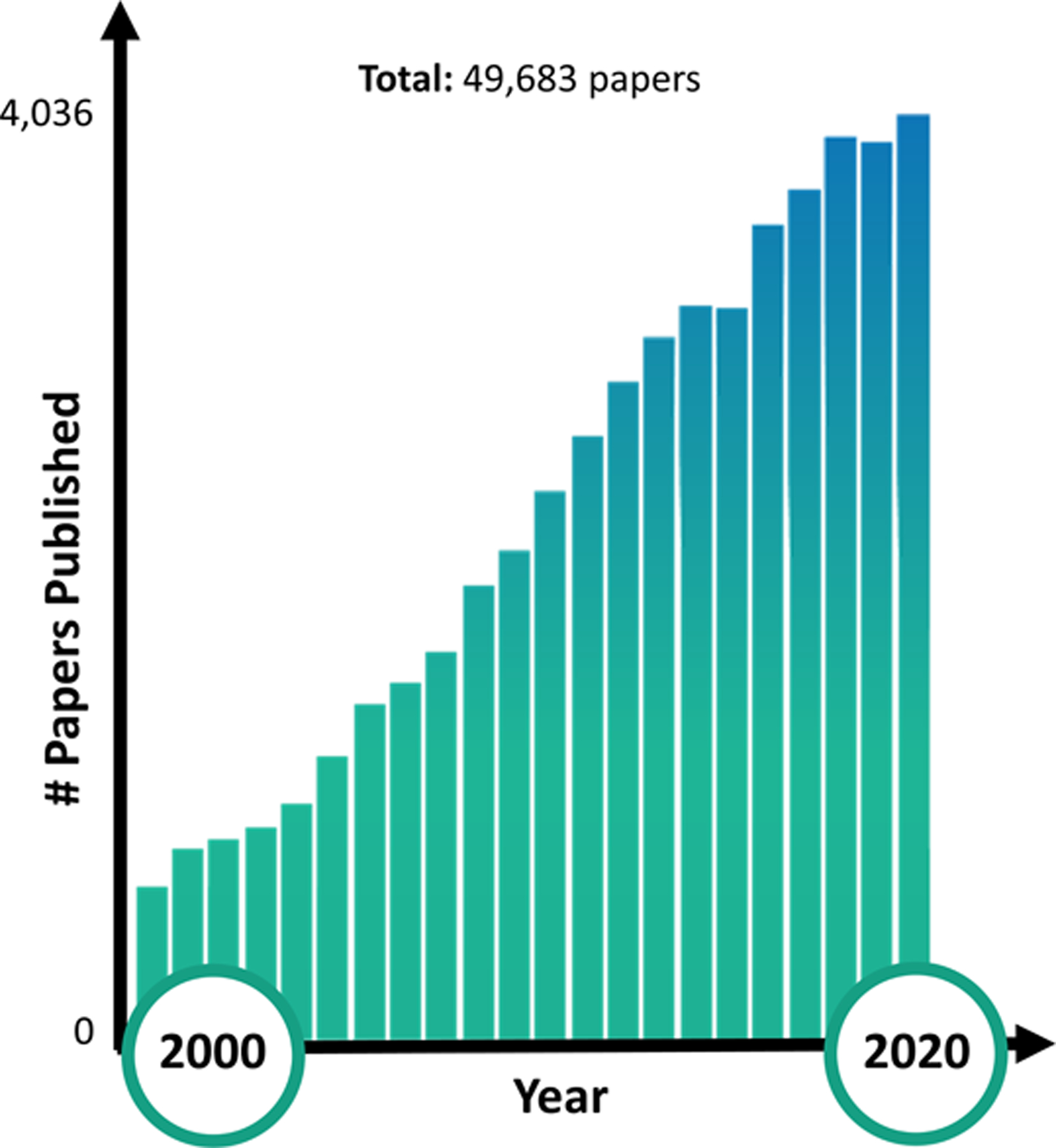
Since 2000, the number of scientific papers referring to “face photographs” (or a variant thereof) has increased from under 800 papers to well over 3,500 per year since 2016. This growing body of literature represents a net scientific contribution of around 50 thousand papers.
The lack of an available mechanism linking researchers to available face databases has had at least two negative repercussions: First, without knowing about alternatives, some researchers are likely to have used face databases that are widely known but not optimal for their research. Recent evidence, for instance, indicates that the facial expressions in the RaFD are not perceived as genuine (Dawel et al., 2017). Researchers interested in responses to genuine facial affect, or in training algorithms to distinguish between real facial emotions, may prefer an alternative to the RaFD but might not know what alternatives exist. One alternative might be the FACES database, although it should give researchers pause that it is comprised entirely of white faces (of note, though, the RaFD and FACES databases are two of only a handful that include multiple age groups; Ebner et al., 2010). This leads to the second negative repercussion: using face databases comprised only of young white faces will lead to scientific claims that are not representative of the diverse people whose tax contributions, in many cases, make that research possible.
A central “meta-database” of face databases can facilitate greater representation in faces used in research, the importance of which is receiving increasing attention (Henrich et al., 2010; Obermeyer et al., 2019). It is striking that, compared to the FACES database’s over 800 citations, the (admittedly newer) “Multi-Racial Mega-Resolution Database of Facial Stimuli” has received only 72 (Strohminger et al., 2016). The “Face Image Meta-Database” (fIMDb) provides researchers with tools to find the face databases best suited to their research, with filters to locate databases with people of a varied racial and ethnic backgrounds and ages. The fIMDb was devised with cognitive scientists in mind—for instance, researchers seeking to characterize social face perception along dimensions like dominance and trustworthiness (Oosterhof and Todorov, 2008; Sutherland et al., 2018; Walker and Vetter, 2016). The fIMDb is, however, also a valuable resource for research in computer vision (e.g., Kushwaha et al., 2018), face recognition (e.g., Yang et al., 2016), facial pose estimation (e.g., Gao et al., 2008) and expression recognition (e.g., Mollahosseini et al., 2019), and eye detection (e.g., Phillips et al., 1998), among others.
Problems of representation in face databases are not restricted to race and ethnicity or age – there is a dearth of databases with faces that have visible anomalies (e.g., scars, port wine stains, and cleft lip and palate). We refer to visible facial differences as “anomalies” to avoid the negative connotations associated with the term “disfigurement” (Changing Faces, 2019). People with visible facial differences are subjected to an “anomalous-is-bad” stereotype: they are judged to have worse characters before compared to after surgical intervention (Jamrozik et al., 2019; Workman et al., 2021), they are subjected to implicit and explicit biases (Changing Faces, 2017; Hartung et al., 2019; Workman et al., 2021), they may receive less prosociality from the people most able to help (Workman et al., 2021), and their faces elicit neural activation in perceivers that is suggestive of dehumanization (Hartung et al., 2019; Workman et al., 2021).
The social penalties associated with having facial anomalies are poorly understood—this may owe, in part, to the limited availability of stimuli depicting anomalous faces. A well-characterized database is needed to support programmatic research into perceivers’ attitudes, behaviors, and neural responses to anomalous faces. The “ChatLab Facial Anomaly Database” (CFAD) was constructed to fill this gap, with photographs of facial anomalies of different types, etiologies, sizes, locations, and that depict individuals from various ethnic backgrounds and age groups. Both the fIMDb and CFAD are available from: https://cliffordworkman.com/resources/.
2. Material and methods
2.1. Face Image Meta-Database (fIMDb)
2.1.1. Face Image Database Identification:
We identified 14 extant meta-databases of face photographs that were consulted when first constructing the fIMDb. The face images captured in these meta-databases were recorded for potential inclusion into the fIMDb. Each of the meta-databases is given in Table 1, along with permalinks to archived versions of the corresponding websites. Permalinks are necessary because several meta-databases have gone offline—or are at least frequently unavailable—since the initial construction of the fIMDb (e.g., LISA Face Database). This underscores the need for a central repository that is routinely updated to ensure broken links are repaired in a timely fashion. (The first author notes that, since its release, several researchers have reached out to ensure changes to the web addresses corresponding to their stimulus sets are reflected in the fIMDb. This communication suggests there is community-level interest in maintaining such a resource.)
Table 1 |.
Meta-databases consulted when constructing the fIMDb.
Besides existing meta-databases, we also searched academic forums like ResearchGate for conversations about face stimuli (five examples of such discussions are provided in Table 1 – they are also real-world examples of the challenges researchers face in identifying the face databases best suited to their scholarly work). Additional stimulus sets were also identified through web searches and word of mouth. The inclusion criteria were at least one set of static images of faces neutral in expression. Although we included as many eligible face databases into the fIMDb as possible, we anticipate including additional databases as awareness of the fIMDb grows.
2.1.2. User Interface:
A graphical depiction of the fIMDb user interface is provided in Figure 2. Users interested in accessing the fIMDb can bookmark: https://cliffordworkman.com/resources/. From here, users can access the most up-to-date link to the fIMDb. After clicking this link, users are greeted with a splash page. Clicking the “fIMDb Search Tools” button expands and contracts a search menu with options users can set to refine their searches using the features most relevant to their research. Users can customize their searches using the following criteria: the source of a given face database (fIMDb search setting: SOURCE), acronyms associated with the sources or databases (ACRONYM), a link to the website corresponding to each source or database (LINK), categories of available face stimuli (i.e., posed, spontaneous, or “wild”; CATEGORIES), numbers of available categories (N CATEGORIES), numbers of different sets (i.e., different facial expressions; SETS), miscellaneous notes about the stimuli (NOTES), the citation that should be used for each database (REFERENCE), the total number of images provided by a given source (N IMGs), total number of different faces (SUBS; and at least approximations of numbers of female [F] and male [M] faces), the number of distinct camera angles captured by the photographs (N VIEWPTS), the number of distinct sets of faces with neutral expressions (NEU), the number of distinct sets of faces with non-neutral expressions (NonNEU), whether there are restrictions in who may access a given database (RESTRICTIONS), whether or not a given database represents more than one ethnic or racial group (GRT1 ETH), whether a given database represents more than one age group (GRT1 AGE), and whether the database includes meta-data (e.g., average attractiveness ratings, facial landmarking; METADATA). Hovering over each of the search criteria reveals tooltips with additional information that users may find helpful.
Figure 2 |. Searching the fIMDb.
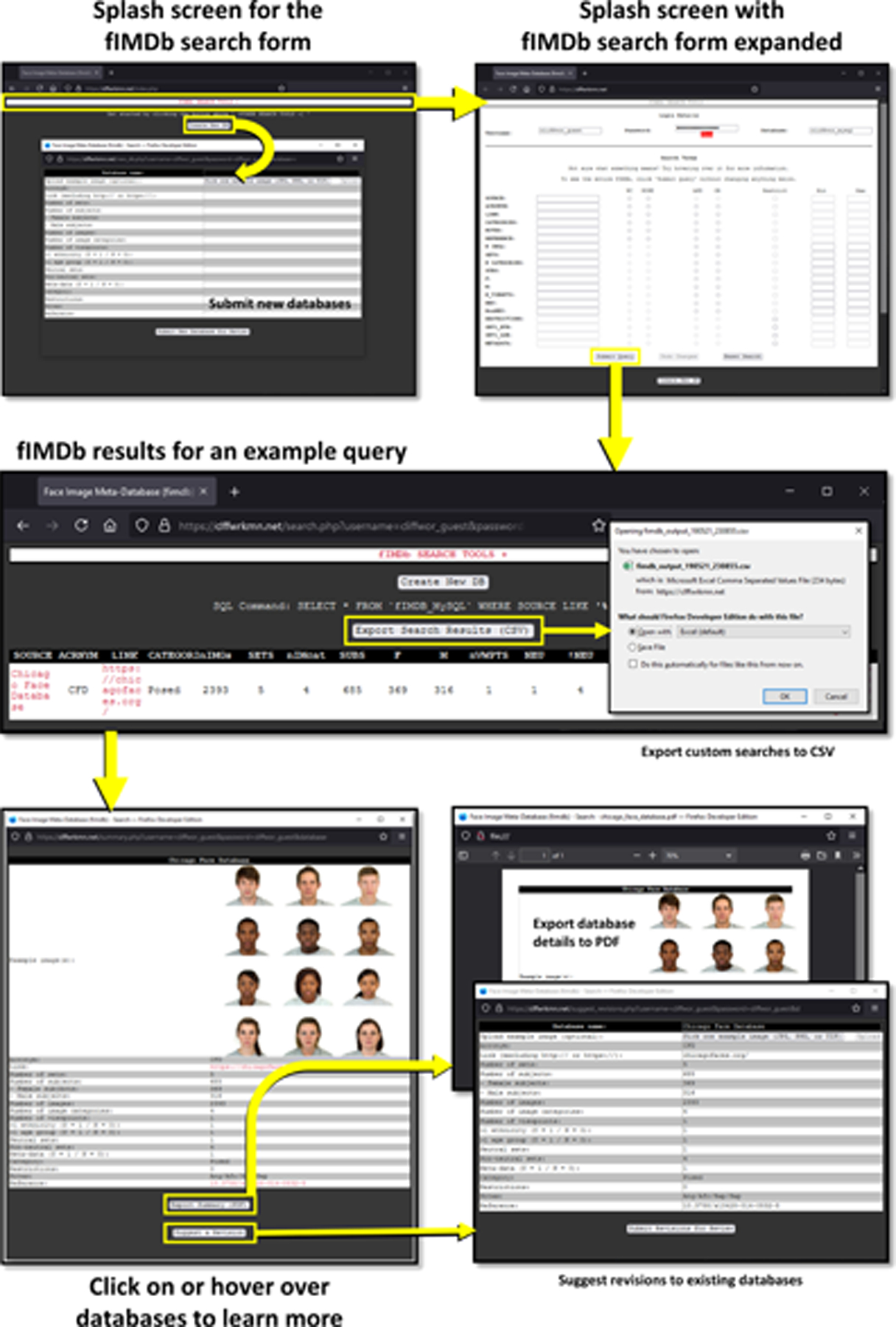
Clicking the “fIMDb Search Tools” button expands and contracts a search menu with options users can set to refine their searches using the features most relevant to their research. Users can export the fIMDb filtered according to their search criteria to a CSV file by clicking the “Export Search Results (CSV)” button. Beneath this button, the filtered fIMDb is displayed. Hovering over the names of face databases under “SOURCE” creates a small preview window with information about each database. Clicking each name opens a new window with a preview image of the stimuli and any available information about the corresponding database. These previews can be exported to PDF for later viewing by clicking the “Export Summary (PDF)” button at the bottom of each summary window. Beneath this, “Suggest a Revision” can be used to suggest modifications to existing databases. New databases can be submitted by clicking the “Create New DB” button. fIMDb, Face Image Meta-Database.
Once the user has specified their fIMDb search criteria—e.g., entered a string of text under “ACRONYM”, selected whether or not to exclude stimuli with access restrictions, or set minima and/or maxima for variables like numbers of images—users can choose whether to treat strings of text as “wildcards” and whether to link elements of their searches with “AND” or “OR” operators. Submitting the search form without specifying any search criteria displays the fIMDb in its entirety. Just as before, clicking the “fIMDb Search Tools” button will expand and contract the search menu. Search settings are carried onto the resulting page, such that users can continue refining their queries, reset changes to the search form since the last search, or start new searches entirely. Once the fIMDb is satisfactorily filtered using the search criteria, users can export the filtered fIMDb to a CSV file by clicking the “Export Search Results (CSV)” button. Beneath this button, the filtered fIMDb is displayed. Users can sort the results of their search by clicking the column headers (one click to sort in ascending order, two clicks for descending). Hovering over the names of face databases under “SOURCE” creates a small preview window with information about each database. Clicking each name opens a new window with a preview image of the stimuli and any available information about the corresponding database. These previews can be exported to PDF for later viewing by clicking the “Export Summary (PDF)” button at the bottom of each summary window.
The fIMDb includes the infrastructure for accepting user submissions of new databases and of suggested revisions to existing databases. To submit a new database, users must click the “Create New DB” button on the fIMDb splash page or search results. New databases can be submitted by clicking the “Submit New Database for Review” button. To revise an existing database, users must first locate the database in the fIMDb and then click the corresponding source name (e.g., ChatLab Facial Anomaly Database). In the window that opens, users should scroll to the bottom and click the “Suggest a Revision” button. After making any desired changes, users should click the “Submit Revisions for Review” button. To prevent malicious actors from harming the fIMDb database, new and revised entries are first submitted to an online database that is separate from the fIMDb. Submissions to this independent database are then subjected to moderation by CIW, which typically occurs within 48 hours of submission.
2.1.3. Characteristics:
The fIMDb includes data on (or approximations for) 127 sources of stimuli regarding: number of unique photosets, number of individuals photographed and their sexes, total number of images, total number of viewpoints, whether meta-data (e.g., average ratings) are available, and whether the photos feature models of multiple ethnicities and/or from multiple age groups. Estimates for some of these values are provided in Table 2.
Table 2 |.
Characteristics of the Face Image Meta-Database (fIMDb).
| Total number of indexed images: | 4,080,183 |
| Unique stimulus sets: | 381 |
| Unique faces: | 497,356 |
| Unique F faces: | 25,221 (~57%; approximate) |
| Unique M faces: | 18,824 (~43%; approximate) |
| Viewpoints, median: | 1 |
| Includes multiple ethnicities: | 74.04% |
| Includes multiple ages: | 67.62% |
| Non-neutral stimuli, median: | 3 |
| Sources with meta-data: | 70.41% |
2.2. ChatLab Facial Anomaly Database (CFAD)
2.2.1. Face Stimulus Selection:
Images were identified by reviewing craniofacial and dental surgery atlases (e.g., Baker, 2011; Kaminer et al., 2002; Niamtu, 2011; Rodriguez et al., 2018; Samii & Gerganov, 2013), the research literature on craniofacial reconstruction (e.g., Jowett & Hadlock, 2015), and plastic surgery outcome compilations (e.g., https://www.realself.com/). Authors on research papers that used photos of facial differences were also contacted to request these stimuli for inclusion in the CFAD (i.e., Zebrowitz et al., 2003). Google images searches using keywords (e.g., “disfigured”, “neurofibroma”, and “port-wine stain”) were used to identify additional photographs eligible for inclusion. Any available demographic information (e.g., sex, age or estimates thereof) was recorded along with the source of each image.
2.2.2. Pre-Processing
All of the photographs of faces included in the CFAD were subjected to the following pre-processing steps, which have been described previously (Workman et al., 2021): First, the face photographs were normalized to inter-pupillary distance with algorithms from the OpenCV computer vision library (https://opencv.org/) together with facial landmarks from the dlib machine learning toolkit (https://dlib.net/). Second, images were resized and cropped with the IrfanView software package (https://irfanview.com/; width: 345px; height: 407px). Third, the backgrounds were removed from each of the images using the remove.bg machine learning algorithm (https://remove.bg/) and replaced with black in the GIMP 2 software package (https://gimp.org/). Fourth, the resulting images were processed with the SHINE toolbox in MATLAB (Willenbockel et al., 2010). First, images were converted to grayscale in GIMP2. Then, the SHINE toolbox was used to luminance correct the grayscaled images (i.e., using several approaches to both histogram and intensity normalization; see the CFAD codebook in Figure 3).
Figure 3 |. Searching the CFAD.
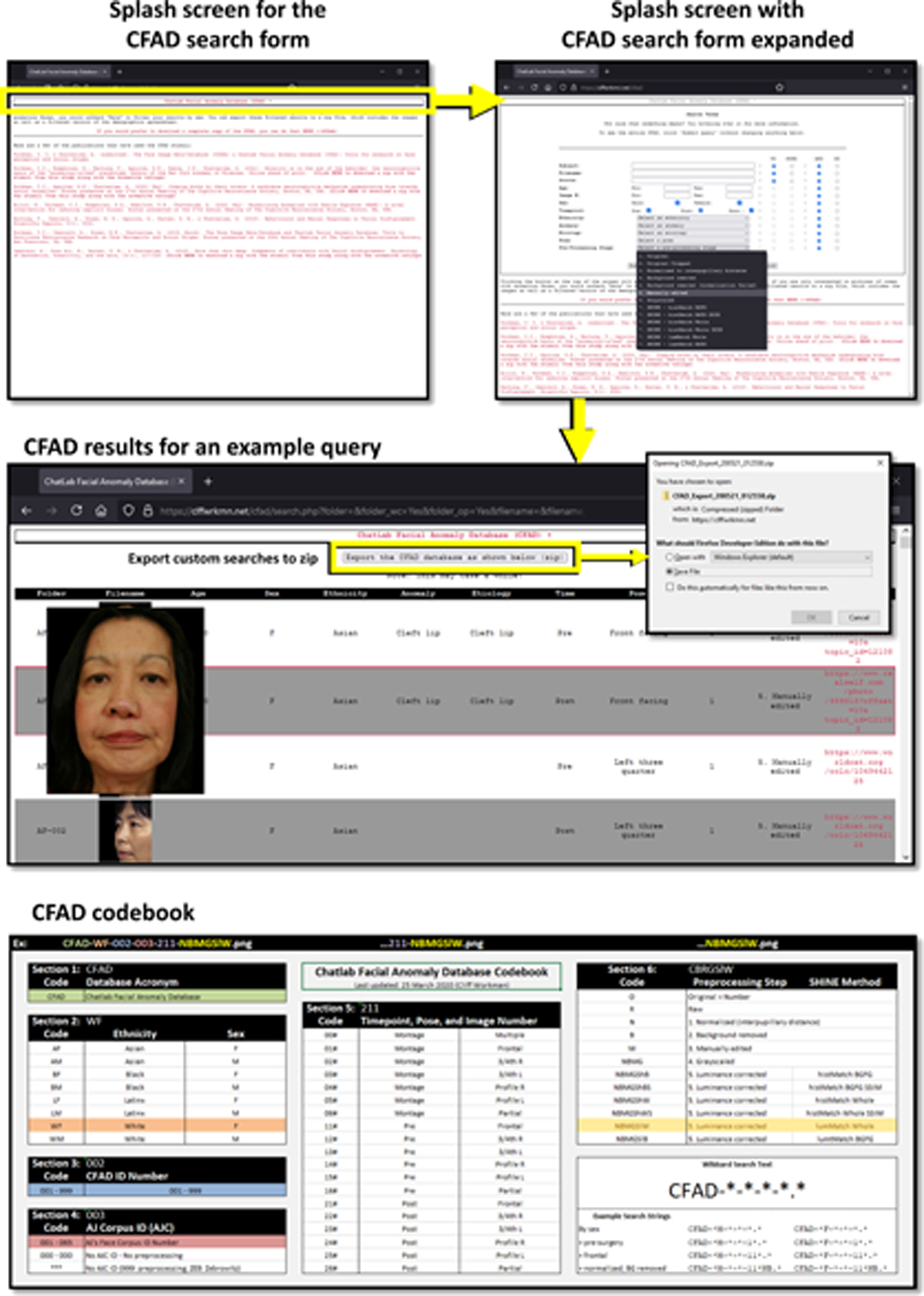
Clicking the “ChatLab Facial Anomaly Database (CFAD)” button expands and contracts a search menu with options users can set to filter the available CFAD stimuli. Users can export the filtered CFAD to a zip file by clicking the “Export the CFAD database as shown below (zip)” button. Beneath this button, the filtered CFAD is displayed. Hovering over individual images from the CFAD “zooms in” so that users can examine them more closely. The zip document to which the CFAD is exported contains the file “CFAD_Codebook.xlsx”, which can be used to infer multiple properties about each image based solely on filename.
2.2.3. Normative Ratings:
Normative ratings for subsets of CFAD stimuli were acquired in two previous studies (Jamrozik et al., 2019; Workman et al., 2021; Table 3). Average face ratings from these previous studies and are included with the CFAD. Although the methods used in these studies were reported in their respective manuscripts, brief summaries are provided below for completeness. Both studies were approved by the Institutional Review Board at the University of Pennsylvania and all participants gave informed consent prior to starting any study procedures (Protocol 806447). Participants from both studies received monetary compensation for their time.
Table 3 |.
Characteristics of the normed stimuli from the ChatLab Facial Anomaly Database (CFAD).
| Workman et al., 2021 | M | SD | Min | Max | |||
|---|---|---|---|---|---|---|---|
| Age | 50.07 | 16.39 | 18 | 76 | |||
| Attractive | 1.85 | 0.32 | 1.40 | 2.65 | |||
| Trustworthy | 2.72 | 0.35 | 2.04 | 3.39 | |||
| Content | 2.36 | 0.41 | 1.71 | 3.31 | |||
| Dominant | 2.93 | 0.57 | 2.10 | 4.11 | |||
| Anxious | 3.42 | 0.35 | 2.71 | 4.08 | |||
| SAM Dominance | 4.71 | 0.39 | 3.87 | 5.37 | |||
| SAM Happiness | 3.32 | 0.54 | 2.46 | 4.55 | |||
| SAM Arousal | 4.69 | 0.51 | 3.58 | 5.85 | |||
| Race / Ethnicity (N) | |||||||
| White | 22 | ||||||
| Asian | 0 | ||||||
| Black | 2 | ||||||
| Hispanic / Latinx | 6 | ||||||
| Facial Anomaly (N) | |||||||
| Scar | 15 | ||||||
| Cancer | 11 | ||||||
| Paralysis | 3 | ||||||
| Swelling | 1 | ||||||
| Jamrozik et al., 2019 | M | SD | Min | Max | |||
| Age | 38.46 | 12.78 | 20 | 61 | |||
| Pre-operative ratings | M | SD | Min | Max | |||
| Attractive | 2.37 | 0.46 | 1.77 | 3.84 | |||
| Trustworthy | 3.08 | 0.38 | 2.17 | 3.68 | |||
| Content | 2.72 | 0.49 | 1.91 | 3.46 | |||
| Dominant | 2.70 | 0.38 | 2.00 | 3.53 | |||
| Anxious | 3.26 | 0.28 | 2.77 | 3.72 | |||
| SAM Dominance | 4.66 | 0.42 | 3.03 | 5.30 | |||
| SAM Happiness | 3.79 | 0.70 | 2.45 | 5.07 | |||
| SAM Arousal | 3.99 | 0.42 | 3.03 | 4.73 | |||
| Post-operative ratings | M | SD | Min | Max | |||
| Attractive | 2.91 | 0.72 | 2.04 | 4.44 | |||
| Trustworthy | 3.33 | 0.43 | 2.63 | 4.18 | |||
| Content | 3.14 | 0.69 | 1.95 | 4.46 | |||
| Dominant | 2.97 | 0.38 | 1.99 | 3.72 | |||
| Anxious | 2.90 | 0.46 | 2.06 | 3.66 | |||
| SAM Dominance | 5.07 | 0.60 | 2.99 | 5.96 | |||
| SAM Happiness | 4.97 | 0.98 | 3.42 | 7.31 | |||
| SAM Arousal | 3.47 | 0.36 | 2.85 | 4.52 | |||
| Race / Ethnicity (N) | |||||||
| White | 20 | ||||||
| Asian | 3 | ||||||
| Black | 0 | ||||||
| Hispanic or Latinx | 3 | ||||||
| Facial Anomaly (N) | |||||||
| Scar | 7 | ||||||
| Cleft lip | 1 | ||||||
| Atrophy | 1 | ||||||
| Pigmentation | 4 | ||||||
| Swelling | 2 | ||||||
| Paralysis | 7 | ||||||
| Cancer | 4 | ||||||
SAM, Self-Assessment Manikin.
2.2.3.1. Ratings from Jamrozik et al. (2019):
2.2.3.1.1. Participants.
A sample of N = 145 participants (63 female, average age = 35.39) was recruited through Amazon’s Mechanical Turk (MTurk; Buhrmester et al., 2018) to complete an online survey hosted through Qualtrics—data from an additional 14 participants were excluded for failing attention checks. This sample size provided approximately 80% statistical power.
2.2.3.1.2. Experimental Procedures.
Participants saw a random subset of 26 out of 52 possible face images (13 of faces before and 13 after surgery to limit the visual salience of facial anomalies). Ratings were provided for three 9-point Self-Assessment Manikin (SAM) visual scales: unhappy to happy, low to high emotional arousal, and low to high control. Ratings were provided for 30 5-point semantic differential scales—of these, 10 were about personality (extraverted to introverted; outgoing to reserved; careful to careless; reliable to unreliable; emotionally stable to unstable; anxious to peaceful; warm to cold; supportive to critical; creative to uncreative; and open to not open to new experiences), 12 were about internal attributes (content to bitter; angry to calm; optimistic to pessimistic; energetic to sluggish; happy to unhappy; competent to incompetent; intelligent to unintelligent; hardworking to lazy; sensitive to insensitive; nice to mean; honest to dishonest; and uptight to easy-going), and 8 were about social attributes (confident to insecure; connected to lonely; dominant to submissive; interesting to uninteresting; likeable to unlikeable; popular to unpopular; trustworthy to untrustworthy; and attractive to unattractive).
Before getting started, participants were shown instructions. They were told they would first rate each photograph on “how the face made [them] feel.” Then, they were told they would rate their impressions of each person depicted in the photographs. Participants completed a practice trial before starting the face rating task. In the practice trial and throughout the task, photographs appeared for 2.5 each before participants were redirected to a separate page to give their ratings. Each participant provided (26 faces × 33 dimensions) 858 ratings in total.
2.2.3.2. Ratings from Workman et al. (2021):
2.2.3.2.1. Participants.
A sample of N = 403 participants (168 female, average age = 35.69) was recruited from MTurk to complete a survey in Qualtrics—data from an additional 48 participants were excluded for failed attention checks, poor quality self-reported by participants, and/or for not reporting sex and/or sexual orientation (this was required for planned analyses reported in Workman et al., 2021). The raw data from Jamrozik et al. (2019) were used to calculate effect sizes that were then entered into power analyses, which suggested a sample of this size would provide around 80% power. A sample of this size was also expected to provide adequate reliability (Cronbach’s α > 0.8; DeBruine & Jones, 2018).
2.2.3.2.2. Experimental Procedures.
Workman et al. (2021) used a truncated version of the survey from Jamrozik et al. (2019), with only eight scales for emotional reactions to (SAM happiness, SAM emotional arousal, SAM dominance) and perceptions of (anxious, content, dominant, trustworthy, attractive) the people in the photographs. These dimensions covered all four significant principal components (sociability [content], dominance [dominant], emotional stability [anxious], and objectification [SAM dominance]) described in Jamrozik et al. (2019). The experimental procedures were otherwise identical to those above. Participants provided (50 faces × 8 dimensions) 400 ratings in total. They saw both anomalous (30 possible images) and typical faces (without a known history of visible difference; 150 possible images). Ratings of the 150 typical faces, which were acquired for images selected from the Chicago Face Database (Ma et al., 2015), are not included with the CFAD but are available upon request.
2.2.4. User Interface:
A graphical overview of the CFAD user interface is given in Figure 3 (users are advised to bookmark: https://cliffordworkman.com/resources/). After clicking the link to the CFAD, users are greeted with a splash page. Clicking the “ChatLab Facial Anomaly Database (CFAD)” button expands and contracts a search menu with options users can set to filter the available CFAD stimuli. The following search criteria can be modified: CFAD subject ID / folder name inside the CFAD zip file (CFAD search setting: Folder), the names of each CFAD image (displayed as images in search results; Filename), the ages (Age), sexes (Sex), and ethnicities (Ethnicity) of the people whose photographs were included in the CFAD, the types of anomaly that were or are present on each face (e.g., acute facial palsy; Anomaly), the etiology of each anomaly (e.g., paralysis; Etiology), the timepoint of each image (pre- or post-operative; Time), the available viewpoints (e.g., front facing, left and right profile, left and right three quarter; Pose), the numbers of the images in cases where multiple alternatives are available (Img), the pre-processing step to which each image was subjected (Preproc), links to the sources for each of the images (Source), In some cases, it was necessary to approximate e.g. ages from ranges provided in the source material.
Once the user has specified their CFAD search criteria—e.g., entered a string of text under “Subject”, selected which timepoints to include, or set minima and/or maxima for variables like age—users can choose whether to treat strings of text as “wildcards” and whether to link elements of their searches with “AND” or “OR” operators. Submitting the search form without specifying any search criteria displays the CFAD in its entirety (a link to the complete CFAD is available on the splash page). Search settings are carried onto the resulting page, such that users can continue refining their queries, reset changes to the search form since the last search, or start new searches entirely. Once the CFAD is satisfactorily filtered using the search criteria, users can export the filtered CFAD to a zip file by clicking the “Export the CFAD database as shown below (zip)” button. Beneath this button, the filtered CFAD is displayed. Users can sort the results of their search by clicking the column headers. Hovering over individual images from the CFAD “zooms in” so that users can examine them more closely.
The zip document to which the CFAD is exported contains the following items: First, the CSV file “CFAD_Database_YYMMDD_HHMMSS.csv” is the filtered version of the CFAD table that appears after users submit their searches. Second, the file “CFAD_Codebook.xlsx” contains a codebook that can be used to infer multiple properties about each image based solely on filename (see Figure 3). Third, the file “Workman-et-al_2019_CNS-Meeting.pdf” is a PDF of the poster that initially described the fIMDb and CFAD (Workman et al., 2019). Finally, the directory “CFAD” is comprised of sub-folders corresponding to each person whose photographs were ultimately included in the filtered CFAD. The PNG images comprising the filtered CFAD are stored inside these subdirectories.
2.2.5. Characteristics:
The CFAD contains 3,613 images of 163 unique individuals before and, whenever available, after corrective surgical intervention (see Table 3 for descriptions of the subsets of these stimuli reported in Jamrozik et al., 2019 & Workman et al., 2021).
3. Results
Although it is difficult to estimate the impact of the fIMDb and CFAD, several indicators are available (Figure 4). The “Resources” page that links researchers to the fIMDb and CFAD was created for the explicit purpose of hosting these resources—consequently, traffic to this page reflects traffic to these resources. Since the release of the fIMDb in October 2018 up to May 1st, 2021, this page has been accessed 12,878 times, with increased traffic after releases of the current fIMDb and CFAD versions and after an advertising push (i.e., the first author engaged in discussions on ResearchGate about face stimuli, such as the examples from Table 1). Second, the website “clffwrkmn.net”, which was created to host the fIMDb and CFAD, also tracks incoming web traffic—since its creation in July 2019 up to May 1st, 2021, the host website has received 10,366 unique visitors.
Figure 4 |. Estimating the impact of the fIMDb and CFAD.
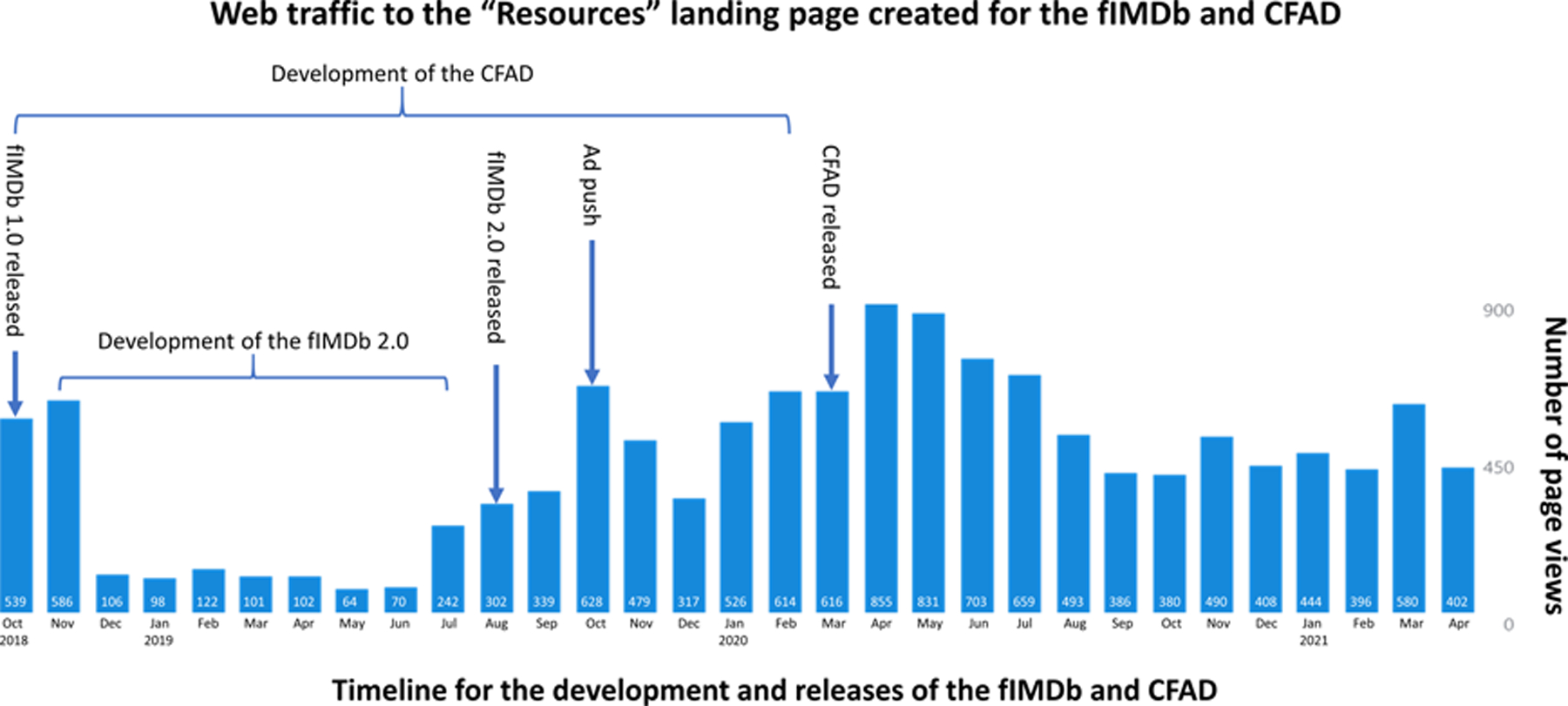
The “Resources” page that links researchers to the fIMDb and CFAD was created for the explicit purpose of hosting these resources—consequently, traffic to this page reflects traffic interested in accessing the fIMDb and/or CFAD. Since the initial release of the fIMDb, the “Resources” page has been accessed over 12,000 times, with traffic increasing after releases of the current version of the fIMDb and of the CFAD, and after an advertising push. CFAD, ChatLab Facial Anomaly Database; fIMDb, Face Image Meta-Database.
4. Discussion
The objectives of this work were twofold: First, to construct an index of known face databases, their features, and information about how to access them that investigators can use to find high quality face photographs for their scholarly pursuits: the “Face Image Meta-Database” (fIMDb). Second, to contribute to the fIMDb a well-characterized database of faces with and without visible differences that can support programmatic research into perceivers’ attitudes, behaviors, and neural responses to facial anomalies: the “ChatLab Facial Anomaly Database” (CFAD).
Regarding future directions, for the CFAD, we are currently using the InterFace software package to place landmarks across 82 fiducial points on each of the pre-processed face photographs comprising the CFAD (Kramer et al., 2017). Once available, these landmarks can be used to calculate facial characteristics hypothesized to bear on evolutionary fitness, such as symmetry and/or sexually dimorphic traits (e.g., cheekbone prominence and ratios of face width to height). We are also continuing the search for face databases that are not yet present in the fIMDb.
Despite their utility, the fIMDb and CFAD are not without limitations. Users of the fIMDb cannot, for instance, download face databases directly from the meta-database. Many of the linked face databases require signed agreements before access can be granted. Users are given the most direct known link to access each database, but the purpose of the fIMDb is to efficiently signpost researchers to face databases—not to provide direct access. With respect to the CFAD, normative ratings were acquired along several dimensions simultaneously, increasing the risk of carryover effects. Also, since faces were only visible to raters for a few seconds, their ratings may have been anchored in memory instead of perception. Despite these limitations, it is worth noting that the ratings reported by Workman et al. (2021) generally replicated the pattern of effects reported by Jamrozik et al. (2019), despite contrasting different sets of faces. Dominance ratings did not differ between anomalous and typical faces in Workman et al. (2021), however, suggesting the results are not attributable to a general inversion of the “halo effect.”
Several pieces of evidence indicate our continued commitment to the maintenance and development of both the fIMDb and CFAD (Figure 4). The fIMDb was originally released as a spreadsheet, without the characteristics describing each individual database. Since then, the fIMDb has not only grown in terms of total numbers of databases but is more informationally rich and is supported by many features intended to facilitate research with face stimuli. Since its initial description in a 2019 poster (Workman et al., 2019), the fIMDb has grown from 88 sources for images to 127 sources, increasing the total number of indexed images by over 1.4 million (an increase of about 158%). We also note the large increase in both CFAD subjects (from 49 to 163—an increase of about 332%) and images (from 492 to 3,623—an increase of about 736%) when comparing the original description of the CFAD in the same 2019 poster (Workman et al., 2019) to that given here.
4.1. Conclusions
The fIMDb provides researchers with the tools to find the face images best suited to their research, and the CFAD provides a much-needed database of faces with anomalies of different types, etiologies, sizes, locations, and that depict individuals from various ethnic backgrounds and age groups. Researchers interested in using the fIMDb and/or CFAD in their research can access them from: https://cliffordworkman.com/resources/.
Acknowledgments:
Conceptualization, CIW & AC; Methodology, CIW; Data curation, CIW; Software, CIW; Writing-Original Draft, CIW; Writing-Review & Editing, CIW & AC; Funding Acquisition, CIW & AC; Supervision, AC. Research reported in this publication was supported by the Penn Center for Human Appearance (awarded to AC) and the National Institute of Dental & Craniofacial Research of the National Institutes of Health (F32DE029407 awarded to CIW). The content is solely the responsibility of the authors and does not necessarily represent the official views of the Penn Center for Human Appearance or of the National Institutes of Health. The authors have no competing interests to declare.
References
- Baker SR, 2011. Principles of Nasal Reconstruction. Springer; New York, New York, NY. 10.1007/978-0-387-89028-9 [DOI] [Google Scholar]
- Buhrmester MD, Talaifar S, Gosling SD, 2018. An Evaluation of Amazon’s Mechanical Turk, Its Rapid Rise, and Its Effective Use. Perspect. Psychol. Sci 13, 149–154. 10.1177/1745691617706516 [DOI] [PubMed] [Google Scholar]
- Changing Faces, 2019. My Visible Difference. London, UK. [Google Scholar]
- Changing Faces, 2017. Public Attitudes to Disfigurement in 2017. London, UK. [Google Scholar]
- Dawel A, Wright L, Irons J, Dumbleton R, Palermo R, O’Kearney R, McKone E, 2017. Perceived emotion genuineness: normative ratings for popular facial expression stimuli and the development of perceived-as-genuine and perceived-as-fake sets. Behav. Res. Methods 49, 1539–1562. 10.3758/s13428-016-0813-2 [DOI] [PubMed] [Google Scholar]
- DeBruine L, Jones BC, 2018. Determining the number of raters for reliable mean ratings. 10.17605/OSF.IO/X7FUS [DOI]
- Ebner NC, Riediger M, Lindenberger U, 2010. FACES—A database of facial expressions in young, middle-aged, and older women and men: Development and validation. Behav. Res. Methods 42, 351–362. 10.3758/BRM.42.1.351 [DOI] [PubMed] [Google Scholar]
- Gao W, Cao B, Shan S, Chen X, Zhou D, Zhang X, Zhao D, 2008. The CAS-PEAL Large-Scale Chinese Face Database and Baseline Evaluations. IEEE Trans. Syst. Man, Cybern. - Part A Syst. Humans 38, 149–161. 10.1109/TSMCA.2007.909557 [DOI] [Google Scholar]
- Hartung F, Jamrozik A, Rosen ME, Aguirre G, Sarwer DB, Chatterjee A, 2019. Behavioural and Neural Responses to Facial Disfigurement. Sci. Rep 9, 8021. 10.1038/s41598-019-44408-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henrich J, Heine SJ, Norenzayan A, 2010. The weirdest people in the world? Behav. Brain Sci 33, 61–83. 10.1017/S0140525X0999152X [DOI] [PubMed] [Google Scholar]
- Jamrozik A, Oraa Ali M, Sarwer DB, Chatterjee A, 2019. More than skin deep: Judgments of individuals with facial disfigurement. Psychol. Aesthetics, Creat. Arts 13, 117–129. 10.1037/aca0000147 [DOI] [Google Scholar]
- Jowett N, Hadlock TA, 2015. A Contemporary Approach to Facial Reanimation. JAMA Facial Plast. Surg 17, 293–300. 10.1001/jamafacial.2015.0399 [DOI] [PubMed] [Google Scholar]
- Kaminer MS, Arndt KA, Dover JS, 2002. Atlas of Cosmetic Surgery. Elsevier. [DOI] [PubMed] [Google Scholar]
- Kramer RSS, Jenkins R, Burton AM, 2017. InterFace: A software package for face image warping, averaging, and principal components analysis. Behav. Res. Methods 49, 2002–2011. 10.3758/s13428-016-0837-7 [DOI] [PubMed] [Google Scholar]
- Kushwaha V, Singh M, Singh R, Vatsa M, Ratha N, Chellappa R, 2018. Disguised Faces in the Wild, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, pp. 1–18. 10.1109/CVPRW.2018.00008 [DOI] [Google Scholar]
- Langner O, Dotsch R, Bijlstra G, Wigboldus DHJ, Hawk ST, van Knippenberg A, 2010. Presentation and validation of the Radboud Faces Database. Cogn. Emot 24, 1377–1388. 10.1080/02699930903485076 [DOI] [Google Scholar]
- Ma DS, Correll J, Wittenbrink B, 2015. The Chicago face database: A free stimulus set of faces and norming data. Behav. Res. Methods 47, 1122–1135. 10.3758/s13428-014-0532-5 [DOI] [PubMed] [Google Scholar]
- Mollahosseini A, Hasani B, Mahoor MH, 2019. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput 10, 18–31. 10.1109/TAFFC.2017.2740923 [DOI] [Google Scholar]
- Niamtu J, 2011. Cosmetic Facial Surgery, 1st ed. Elsevier. [Google Scholar]
- Obermeyer Z, Powers B, Vogeli C, Mullainathan S, 2019. Dissecting racial bias in an algorithm used to manage the health of populations. Science (80-.) 366, 447–453. 10.1126/science.aax2342 [DOI] [PubMed] [Google Scholar]
- Oosterhof NN, Todorov A, 2008. The functional basis of face evaluation. Proc. Natl. Acad. Sci 105, 11087–11092. 10.1073/pnas.0805664105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Phillips PJ, Wechsler H, Huang J, Rauss PJ, 1998. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput 16, 295–306. 10.1016/S0262-8856(97)00070-X [DOI] [Google Scholar]
- Rodriguez ED, Losee JE, Neligan PC, 2018. Plastic Surgery, 4th ed. Elsevier. [Google Scholar]
- Samii M, Gerganov V, 2013. Surgery of Cerebellopontine Lesions. Springer Berlin Heidelberg, Berlin, Heidelberg. 10.1007/978-3-642-35422-9 [DOI] [Google Scholar]
- Strohminger N, Gray K, Chituc V, Heffner J, Schein C, Heagins TB, 2016. The MR2: A multi-racial, mega-resolution database of facial stimuli. Behav. Res. Methods 48, 1197–1204. 10.3758/s13428-015-0641-9 [DOI] [PubMed] [Google Scholar]
- Sutherland CAM, Liu X, Zhang L, Chu Y, Oldmeadow JA, Young AW, 2018. Facial First Impressions Across Culture: Data-Driven Modeling of Chinese and British Perceivers’ Unconstrained Facial Impressions. Personal. Soc. Psychol. Bull 44, 521–537. 10.1177/0146167217744194 [DOI] [PubMed] [Google Scholar]
- Walker M, Vetter T, 2016. Changing the personality of a face: Perceived Big Two and Big Five personality factors modeled in real photographs. J. Pers. Soc. Psychol 110, 609–624. 10.1037/pspp0000064 [DOI] [PubMed] [Google Scholar]
- Willenbockel V, Sadr J, Fiset D, Horne GO, Gosselin F, Tanaka JW, 2010. Controlling low-level image properties: The SHINE toolbox. Behav. Res. Methods 42, 671–684. 10.3758/BRM.42.3.671 [DOI] [PubMed] [Google Scholar]
- Workman CI, Jamrozik A, Rosen ME, Chatterjee A, 2019. The Face Image Meta-Database and Chatlab Facial Anomaly Database: Tools to Facilitate Neuroscience Research on Face Perception and Social Stigma, in: 26th Annual Meeting of Cogntivie Neuroscience Society. San Francisco, CA, USA. [Google Scholar]
- Workman CI, Humphries S, Hartung F, Aguirre GK, Kable JW, Chatterjee A, 2021. Morality is in the eye of the beholder: the neurocognitive basis of the “anomalous‐is‐bad” stereotype. Ann. N. Y. Acad. Sci. nyas 14575. 10.1111/nyas.14575 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang S, Luo P, Loy CC, Tang X, 2016. WIDER FACE: A Face Detection Benchmark, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 5525–5533. 10.1109/CVPR.2016.596 [DOI] [Google Scholar]
- Zebrowitz LA, Fellous J-M, Mignault A, Andreoletti C, 2003. Trait Impressions as Overgeneralized Responses to Adaptively Significant Facial Qualities: Evidence from Connectionist Modeling. Personal. Soc. Psychol. Rev 7, 194–215. 10.1207/S15327957PSPR0703_01 [DOI] [PubMed] [Google Scholar]