

Social reinforcement and norm learning interact with social media design to amplify moral outrage in online social networks.
Abstract
Moral outrage shapes fundamental aspects of social life and is now widespread in online social networks. Here, we show how social learning processes amplify online moral outrage expressions over time. In two preregistered observational studies on Twitter (7331 users and 12.7 million total tweets) and two preregistered behavioral experiments (N = 240), we find that positive social feedback for outrage expressions increases the likelihood of future outrage expressions, consistent with principles of reinforcement learning. In addition, users conform their outrage expressions to the expressive norms of their social networks, suggesting norm learning also guides online outrage expressions. Norm learning overshadows reinforcement learning when normative information is readily observable: in ideologically extreme networks, where outrage expression is more common, users are less sensitive to social feedback when deciding whether to express outrage. Our findings highlight how platform design interacts with human learning mechanisms to affect moral discourse in digital public spaces.
INTRODUCTION
Moral outrage is a powerful emotion with important consequences for society (1–3): It motivates punishment of moral transgressions (4), promotes social cooperation (5), and catalyzes collective action for social change (6). At the same time, moral outrage has recently been blamed for a host of social ills, including the rise of political polarization (7, 8), the chilling of public speech (9), the spreading of disinformation (10), and the erosion of democracy (11). Some have speculated that social media can exacerbate these problems by amplifying moral outrage (11). However, evidence to support such claims remains scarce. Our current understanding of moral outrage is largely based on studies examining its function in small group settings (2, 12), which impose constraints on behavior that are very different from those imposed by online environments (13, 14). There is therefore a pressing need to understand the nature of moral outrage as it unfolds in online social networks.
Foundational research shows that people experience moral outrage when they perceive that a moral norm has been violated (2, 15–17), and express outrage when they believe that it will prevent future violations (5, 18) or promote social justice more broadly (6). At the same time, however, outrage expressions may be sensitive to factors that have less to do with individual moral convictions, particularly in the context of social media. More specifically, we suggest that online outrage expressions are shaped by two distinct forms of learning. First, people may change their outrage expressions over time through reinforcement learning, altering expressive behaviors in response to positive or negative social feedback (13, 19, 20). Second, people may adjust their outrage expressions through norm learning, matching their expressions to what they infer is normative among their peers through observation (21–25). Social media platforms have specific design features that can affect both forms of learning: They deliver highly salient, quantifiable social feedback (in the form of “likes” and “shares”), a central component of reinforcement learning, and they enable users to self-organize into homophilic social networks with their own local norms of expression displayed in newsfeeds (26, 27), which should guide norm learning.
Supporting these hypotheses, recent work demonstrates that social media users post more frequently after receiving positive social feedback (28), consistent with a reinforcement learning account. These observations lead to a straightforward prediction that social media users’ current moral outrage expressions should be positively predicted by the social feedback (likes and shares) they received when they expressed moral outrage in the past. Furthermore, because moral and emotional expressions like outrage receive especially high levels of social feedback (29–31), moral outrage expressions may be especially likely to increase over time via social reinforcement learning. Finding evidence for this would contradict the idea that social media platforms provide neutral channels for social expressions and do not alter those expressions.
However, reinforcement learning alone is unlikely to fully explain the dynamics of online moral outrage expression. Social media users interact with others in large social networks, each with its own norms of expression (27). Every time a user logs onto a platform, their newsfeed immediately provides a snapshot of the communication norms currently present in their network (26). This information is likely to guide norm learning, where users adjust their behavior by following what others do, rather than responding to reinforcement (21–23, 32–35). Crucially, reinforcement learning and norm learning processes might interact with one another: When individuals can directly observe which actions are most valuable, they rely less on reinforcement learning (22, 36). Thus, moral outrage expressions might be guided more by norm learning than reinforcement learning when normative information is readily observable in a network.
We tested our hypotheses across two preregistered observational studies of Twitter users and two preregistered behavioral experiments in a simulated Twitter environment. Collectively, this work demonstrates that social media users’ moral outrage expressions are sensitive to both direct social feedback and network-level norms of expression. These findings illustrate how the interaction of human psychology and digital platform design can affect moral behavior in the digital age (26, 34, 37, 38).
RESULTS
Studies 1 and 2
Measuring moral outrage
To test our hypotheses, we developed a method for measuring moral outrage expressions at scale in social media text, focusing on Twitter as our data source. This platform is appropriate for testing our hypotheses because of the occurrence of several high-profile, rapid swells of outrage on this platform (39) and the fact that many important public figures use it to communicate with their audiences, frequently expressing and provoking outrage both online and offline. We used supervised machine learning to develop a Digital Outrage Classifier (DOC; Materials and Methods) that can classify tweets as containing moral outrage or not. To train DOC, we collected a set of 26,000 tweets from a variety of episodes that sparked widespread public outrage (see Materials and Methods and Table 1) and used theoretical insights from social psychology to annotate those tweets according to whether they expressed moral outrage. The key definition of moral outrage included the following three components (1–3): A person can be viewed as expressing moral outrage if (i) they have feelings in response to a perceived violation of their personal morals; (ii) their feelings are composed of emotions such as anger, disgust, and contempt; and (iii) the feelings are associated with specific reactions including blaming people/events/things, holding them responsible, or wanting to punish them. The full instructions including examples given to participants and distinctions between moral outrage and other related concepts (e.g., “pure trolling”) can be viewed in section S1.2.
Table 1. Characteristics of all training datasets.
DOC was first trained on 16,000 tweets collected during the Brett Kavanaugh confirmation hearings. We then tested generalizability and retrained on the combination of Kavanaugh and all other topics (26,000 total tweets).
| Topic | Description | Tweet date range |
Political ideology
of users |
Tweets containing
outrage |
N |
| Kavanaugh | During the confirmation process for the Supreme Court, nominee Brett Kavanaugh was accused of sexually assaulting Dr. Christine Blasey Ford. Both parties testified to the Senate Judiciary Committee, and Kavanaugh was ultimately confirmed. |
15 September to 18 October 2018 |
Mixed | 52.00% | 16,000 |
| Covington | White high school students wearing “Make America Great Again” hats were filmed appearing to harass a Native American man in Washington, D.C. After the video went viral, subsequent footage suggested that the interaction was more complicated. Several media outlets issued retractions. |
22 January to 1 February 2019 |
Mixed | 26.36% | 2,500 |
| United | A United Airlines passenger was forcibly removed from an overbooked plane. Footage of the event showed the passenger being injured. The video went viral and elicited backlash against the airline. |
10–14 April 2017 | Mixed | 20.08% | 2,500 |
| Smollett | In January 2019, actor Jussie Smollett claimed to have been the victim of a violent hate crime perpetrated by supporters of President Trump. Investigating officers later alleged in February that Smollett had staged the attack. |
22–26 February 2019 | Conservative | 23.00% | 2,500 |
| Transgender ban | The Trump administration’s ban on transgender individuals serving in the military was upheld by the U.S. Supreme Court, reversing the 2016 decision by President Obama to open the military to transgender service members. |
22–25 January 2019 | Liberal | 52.60% | 2,500 |
To enhance the generalizability of our classifier, our annotated dataset contained episodes that spanned diverse topics, ideologies, and time points. Table 2 provides examples of classifications made by DOC. Extensive evaluation demonstrated that DOC classified moral outrage in tweets with reliability comparable to expert human annotators (see Materials and Methods). DOC is freely available for academic researchers via a Python package at the following link: https://github.com/CrockettLab/outrage_classifier.
Table 2. Example outrage and non-outrage tweets as classified by the DOC.
The table shows example tweets from five political topics appearing in our training set that were classified as containing outrage versus not containing outrage by DOC. To protect Twitter user privacy from reverse text searches, for figure display purposes only, some words from each original tweet have been edited while maintaining salient features of the message.
| Topic | Text | Classification |
| Kavanaugh | @SenGillibrand you are a DISGRACE. Shut your lying mouth. There is no evidence of assault | Outrage |
| Kavanaugh | @JeffFlake thank you for stepping up. Don’t let them do a poor job in the investigation | Non-outrage |
| Covington | I cannot with the “Stand with Covington” gofundme? WTF? People are giving these brats money? Unbelievable! | Outrage |
| Covington | There are good people on both sides of the #Covington debate. Let’s all slow down | Non-outrage |
| United | I’m in total disgust and madness because of what #united did. Totally Unacceptable. | Outrage |
| United | Here’s the latest ad from @united. #united #advertising https://... | Non-outrage |
| Smollett | Hey @JussieSmolett you are a worthless piece of shit. A greedy, corrupt liar. | Outrage |
| Smollett | We need some more @JussieSmolett memes. Where are they? | Non-outrage |
| Transgender ban | This is a disgusting display of hatred and oppression. #FUCKYOUTRUMP and your criminal cabinet! | Outrage |
| Transgender ban | Hillary Clinton said some thoughtful words about the ban: https://... | Non-outrage |
Our measurement of moral outrage is based on a theoretical assumption that it is a specific subcategory of the broader category of negative sentiment, which, in addition to moral outrage, includes other negative emotion expressions such as fear and sadness (2, 40). In other words, we expected that expressions of negative sentiment are necessary but not sufficient for positive classifications by DOC. We examined this expectation by testing DOC’s discriminant validity against a negative sentiment classifier (NSC) trained on the widely used Sentiment140 dataset (41). We predicted that DOC’s and the NSC’s classifications would be correlated but would also have many cases of nonoverlap. To test this prediction, we analyzed our 26,000-tweet dataset used to train DOC (described in Table 1) to compare moral outrage classifications by DOC and negative sentiment classifications by the NSC. As expected, we found a weak correlation between the two classifiers’ outputs using Kendall’s rank correlation test (τ = 0.11, P < 0.001). Thus, we demonstrate discriminant validity: DOC’s classifications and the NSC’s classifications are correlated, but not identical. See section S1.7 for more details.
Reinforcement learning hypothesis
Our first hypothesis was that positive social feedback for previous outrage expressions should predict subsequent outrage expressions. To test this, we used Twitter’s standard and premium application programming interfaces (APIs) to collect the full tweet histories of 3669 “politically engaged” users who tweeted at least once about the Brett Kavanaugh confirmation hearings in October 2018 (study 1). We choose this population because we expected these users’ tweet histories to contain a sufficient amount of outrage to examine reinforcement learning effects. To test how results generalized to less politically engaged users, we also collected the same number of users (3669 tweet histories) who tweeted at least once about the United Airlines passenger mistreatment incident (study 2). Across both studies, we collected 7331 users and 12.7 million total tweets. See Materials and Methods and Fig. 1 for further details about data collection and validation of characteristics of the two samples. Data collection and analysis parameters were preregistered at https://osf.io/dsj6a (study 1) and https://osf.io/nte3y (study 2).
Fig. 1. Distributions of ideological extremity of user networks and levels of outrage expression.
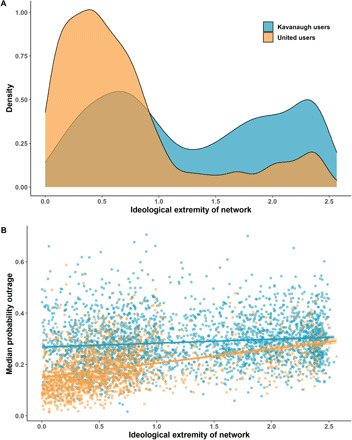
(A) Density plots of the ideological extremity of user networks for the Kavanaugh dataset (study 1) and United dataset (study 2). The x axis represents a continuous estimate of the mean ideological extremity of a user’s network; greater values represent greater extremity. (B) Each user’s median probability of expressing outrage in their tweets as a function of the ideological extremity of their network.
In each dataset, we ran time-lagged regression models to examine the association between the previous day’s social feedback for outrage expressions and a given day’s amount of outrage expression. We used generalized estimating equations (GEEs) with robust SEs (42) to estimate population-level effects treating tweets nested within users. Daily amounts of outrage tweets were modeled using a negative binomial distribution (43). Our main model estimated the effect of a previous day’s outrage-specific feedback on the current day’s outrage expression while statistically adjusting for the following variables: daily tweeting frequency, the users’ number of followers, the presence of uniform resource locators (URLs) or media in each tweet, the past week’s amount of outrage expressions and outrage-specific feedback (to account for autocorrelation effects between past and present outrage expressions and the feedback those receive), and feedback that was not specific to outrage (to account for the fact that people tend to tweet everything more when they receive more feedback, and to demonstrate specificity in the effect of outrage-specific feedback on subsequent outrage expression). These model parameters were preregistered for both study 1 and study 2 (see Materials and Methods). We also show that results reported below are robust to models that treat time as a fixed and random factor, which measure how the population-average effect of social feedback changes over time, and account for variation in day-specific events (“exogenous shocks”) that could affect outrage expression, respectively (see section S2.0).
Supporting our hypotheses, we found that daily outrage expression was significantly and positively associated with the amount of social feedback received for the previous day’s outrage expression [study 1: b = 0.03, P < 0.001, 95% confidence interval (CI) = [0.03, 0.03]; study 2: b = 0.02, P < 0.001, 95% CI = [0.02, 0.03]]. For our model, this effect size translates to an expected 2 to 3% increase in outrage expression on the following day of tweeting if a user received a 100% increase in feedback for expressing outrage on a given day. For instance, a user who averaged 5 likes/shares per tweet, and then received 10 likes/shares when they expressed outrage, would be expected to increase their outrage expression on the next day by 2 to 3%. While this effect size is small, it can easily scale on social media over time, become notable at scale at the network level, or for users who maintain a larger followership and could experience much higher than 100% increases in social feedback for tweeting outrage content (e.g., political leaders). For other model specifications to test the robustness of the effect, see section S2.0.
A classical finding in the reinforcement learning literature is that reinforcement effects on behavior tend to diminish over time as the relationships between actions and outcomes are learned (44, 45). Accordingly, we next considered the possibility that our model is underestimating the magnitude of the effect of social reinforcement on outrage expression because we are studying users who already have a long history of tweeting and receiving feedback (a minimum of 1 month up to many years of tweeting). Users with longer reinforcement histories may be less sensitive to recent feedback after larger earlier adjustments of their behavior. To test this possibility, we ran a model where the length of users’ learning histories (i.e., the more days they had tweeted and received feedback) was allowed to interact with the recent effects of social reinforcement. This model demonstrated a significant negative interaction between previous social feedback and days tweeted when predicting current outrage expression, indicating that the longer a users’ reinforcement history, the smaller the effect of recent social feedback on outrage expression (study 1: b = −0.02, P < 0.001, 95% CI = [−0.02, −0.01]; study 2: b = −0.02, P < 0.001, 95% CI = [−0.03, −0.01]).
Our observation that outrage expression on a given day increases in tandem with social feedback for the previous day’s outrage expression is broadly consistent with the principles of reinforcement learning (19). However, reinforcement learning theory also suggests a more specific hypothesis: Increases in current outrage expression should be related to previous outrage-specific social feedback that is higher or lower than expected, i.e., that generates a prediction error (46). To test this hypothesis, we created positive and negative prediction error variables by computing positive and negative differences between the mean of the previous 7 days’ outrage-specific social feedback and the previous day’s outrage-specific social feedback (see section S2.3 for more details). This analysis revealed a significant, positive relationship between positive prediction errors from previous tweeting and current outrage expression in both studies. In this case, greater positive prediction errors on the previous day were associated with greater outrage expression on a given day (study 1: b = 0.01, P ≤ 0.001, 95% CI = [0.01, 0.02]; study 2: b = 0.02, P ≤ 0.001, 95% CI = [0.02, 0.03]). Meanwhile, negative prediction errors were negatively associated with outrage expression on the next day in study 1 (b = −0.03, P ≤ 0.001, 95% CI = [−0.03, −0.02]). However, this effect was not replicated in study 2, as there was no reliable association between negative prediction error and subsequent outrage expression (b = 0.05, P = 0.325, 95% CI = [−0.04, 0.15]).
Above, we found that DOC shows discriminant validity against classifications of the broader category of negative sentiment. We also explored whether we observe similar effects of social reinforcement on negative sentiment expressions as we do for moral outrage expressions. Toward this end, we reran our main model, replacing the outrage expression variable with a negative sentiment expression variable, as determined by the NSC described above. In this case, we conducted a conservative test by tuning the NSC so that its classifications of negative sentiment matched the distribution of negative sentiment extremity in tweets classified as outrage by DOC (see section S2.4). Thus, any differences observed cannot be explained by differences in sentiment extremity but rather are from differences in the specificity of moral outrage relative to the broader category of negative sentiment. The dependent variable was a given day’s negative sentiment expression, and the main predictor variable was the lagged negative sentiment–specific social feedback (see section S2.4). These models showed inconsistent results across datasets: In politically engaged users, we observed a significant positive effect of social reinforcement on subsequent negative sentiment expressions, albeit with a smaller effect size than was observed for moral outrage expressions in the same users (study 1: b = 0.01, P < 0.001, 95% CI = [0.01, 0.01]). For less politically engaged users, however, the effect of social reinforcement on subsequent negative sentiment expressions was null (study 2: b = −0.00, P = 0.338, 95% CI = [−0.01, 0.00]). These findings provide preliminary evidence that outrage expressions are more readily predicted by previous social feedback than expressions of negative sentiment more broadly.
Norm learning hypothesis
Next, we tested a hypothesis that norm learning processes affect online outrage expressions. We approached this question in two steps. First, we reasoned that, in the context of the political topics we study here, outrage expressions should be more prevalent in social networks populated by more ideologically extreme users. This logic is based on evidence that ideological extremity predicts outrage expression (30, 47, 48). More specifically, we predicted that individual users who are embedded within more ideologically extreme networks should be more likely to express outrage, over and above their own political ideology. In other words, if norm learning guides outrage expression, then individual users should be more likely to express outrage when they are surrounded by others expressing outrage, even accounting for their personal ideology.
To test this, we gathered data about the social network composition of the users in our datasets (“egos”), including the full list of users who follow each ego (“followers”) and the full list of users followed by each ego (“friends”). This yielded a total of 6.28 million friends and followers for egos in the Kavanaugh dataset and a total of 21 million friends and followers for egos in the United dataset. We used these data to estimate the ideological extremity of each ego in our dataset (49), as well as all of each ego’s friends and followers, yielding estimates of each ego’s network-level ideological extremity (see Fig. 1).
As expected, we observed higher network extremity in our politically engaged users (Kavanaugh dataset, study 1) than in our less politically engaged users (United dataset, study 2; Fig. 1). However, there was substantial variation in network extremity in both datasets. We exploited this variability to test whether egos were more likely to express outrage in networks with more ideologically extreme members, statistically adjusting for users’ own ideological extremity. We confirmed that this was the case (study 1: b = 0.13, P < 0.001, 95% CI = [0.10, 0.15]; study 2: b = 0.31, P < 0.001, 95% CI = [0.26, 0.36]; Fig. 1). As can be seen in Fig. 1, network extremity affects outrage expression both between and within datasets: Users in the Kavanaugh dataset, who, on average, are embedded in more extreme networks than users in the United dataset, show higher levels of outrage expression than users in the United dataset. In addition, within each dataset, users embedded within more extreme networks show higher levels of outrage expression.
Testing the difference between moral outrage expression and the broader category of negative sentiment, we found that users embedded within more ideologically extreme networks also expressed significantly more negative sentiment for study 1 (b = 0.03, P < 0.001, 95% CI = [0.01, 0.04]) but not for study 2 (b = −0.01, P = 0.679, 95% CI = [−0.06, 0.04]). Furthermore, the effect of network extremity in study 1 showed a substantially weaker relationship with negative sentiment than with moral outrage (with the size of the negative sentiment effect being less than half the size of the moral outrage effect). This finding suggests that moral outrage expressions are more closely related to a social network’s ideological extremity than voicing negative emotions more broadly. This is expected from a functionalist perspective of emotion expression, because moral outrage is more specifically tied to the domain of political ideology than the broader category of negative sentiment (40).
Second, we built on previous work demonstrating that individuals rely less on reinforcement learning to guide behavior when they are directly instructed which actions are valuable (22). One key prediction from recent theories of social learning is that information about social norms may be “internalized” by learners (21), making them less responsive to local feedback from peers. Simply put, if a user can glean the appropriateness of outrage expression in their network by observing their newsfeed, then they have less of a need to rely on reinforcement learning. This suggests that egos embedded in more ideologically extreme networks will be less sensitive to peer feedback in adjusting their outrage expressions.
To test this, we added ego- and network-level ideological extremity as predictors to our time-lagged regression models examining social reinforcement of outrage, allowing both ego extremity and network extremity to interact with the social feedback effect. This analysis revealed that network extremity significantly moderated the impact of social feedback on outrage expression such that users embedded within more extreme networks showed weaker effects of social feedback on outrage expression (study 1: b = −0.02, P = 0.004, 95% CI = [−0.03, −0.01]; study 2: b = −0.05, P < 0.001, 95% CI = [−0.08, −0.02]) (see Fig. 2). Meanwhile, ego extremity did not moderate the impact of social feedback on outrage expression (study 1: b = 0.01, P = 0.167, 95% CI = [0.00, 0.03]; study 2: b = −0.02, P = 0.147, 95% CI = [−0.04, 0.01]). These results suggest that network-level norms of outrage expression moderate reinforcement learning over and above individual variation in ideology. More broadly, this finding supports the idea that, to understand variation in users’ outrage expression, it is important to consider both reinforcement learning and the frequency of outrage present in a network that users can observe to learn norms in their network. Users who infer that outrage is normative from its frequency in their network have less of a need to exclusively rely on reinforcement learning from social feedback to guide their outrage expressions. For negative sentiment expression, we found inconsistent results for the interaction of sentiment-specific feedback and network ideological extremity (study 1: b = −0.01, P = 0.060, 95% CI = [−0.02, 0.00]; study 2: b = −0.04, P = 0.018, 95% CI = [−0.08, −0.01]).
Fig. 2. Network-level ideological extremity moderates the effect of social feedback on outrage expressions.
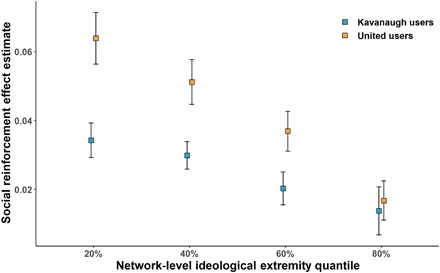
Each point displays the effect size estimate of previous social feedback, predicting current outrage expression. Error bars were calculated on the basis of SEs of the estimate. The x axis represents quantile breaks from 20 to 80%. The blue color represents the Kavanaugh dataset users (study 1), and the orange color represents the United dataset users (study 2).
In summary, studies 1 and 2 demonstrated three key findings: (i) Outrage expression on Twitter can be explained, in part, by variation in social feedback that people receive via the platform; (ii) users are more likely to express outrage in more ideologically extreme social networks; and (iii) in more ideologically extreme social networks, users’ outrage expression behavior is less sensitive to social feedback. These findings support our hypothesis that outrage expression on social media is shaped by both reinforcement learning and norm learning.
However, our observational approach in studies 1 and 2 has several limitations. First, we cannot draw causal inferences about how social feedback or network-level norms shape outrage expressions, which limits the claims we can make about reinforcement learning and norm learning processes. Relatedly, we cannot rule out the possibility that social network composition might be endogenous to individuals’ outrage expression. In other words, the effects we documented might also reflect the possibility that users who express more outrage may be more likely to follow more ideologically extreme users. This would suggest a different causal story than users learning to express outrage based on norms established by more extreme users. There is a high likelihood that both processes occur in tandem and feed into one another, as the joint influence of learning and self-selection into networks or social media platforms has been examined in recent work (34, 50). Last, while we demonstrated a relationship between network-level ideological extremity and individual outrage expressions, it was computationally intractable to measure levels of outrage expression in the full tweet histories of >27 million users, which meant that we could not directly measure network-level norms of outrage expression. We addressed these limitations with behavioral experiments in studies 3 and 4.
Study 3
Study 3 directly manipulated social feedback and network-level norms of outrage expression in a simulated Twitter environment. The study was preregistered at https://osf.io/rh2jk. Participants (N = 120) were randomly assigned to either an “outrage norm” or a “neutral norm” condition, where they could scroll through a “newsfeed” containing 12 tweets from their “new” social network (Fig. 3, “Scrolling stage”). Stimuli consisted of real tweets sampled from four contentious political topics, and outrage tweets were those classified as containing outrage expression by DOC (see Materials and Methods). In the outrage norm condition, 75% of the tweets contained outrage expressions and 25% contained neutral expressions. The outrage tweets displayed more likes and shares than the neutral tweets, in line with actual Twitter data (29, 30). In the neutral norm condition, all tweets contained neutral expressions and displayed likes and shares in line with the 25% of neutral tweets displayed in the outrage norm condition. Participants were instructed to try and learn the content preferences of their new network (see appendix SE for full instructions).
Fig. 3. Depiction of social media learning task (studies 3 and 4).
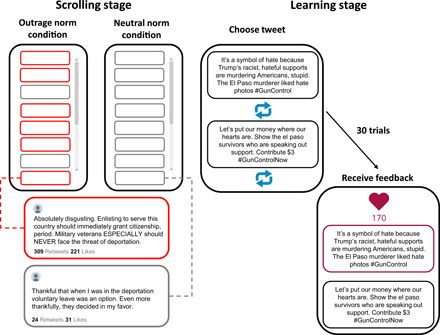
Participants first viewed what types of expressions were normative in their network by scrolling through 12 tweets. Next, they participated in a learning task where their goal was to maximize feedback.
Participants then completed 30 trials of a learning task (Fig. 3, “Learning stage”), where they were incentivized to maximize social feedback (likes) from their network that were ostensibly provided by previous participants. On each trial, participants chose between two political tweets to “post” to the network (one outrage, one neutral) and subsequently received feedback. Choosing an outrage tweet yielded greater social feedback on average. Our task design therefore allowed us to test the causal impact of social reinforcement on subsequent outrage expressions. Because the learning task was identical for participants in both the outrage norm and neutral norm conditions, we were also able to test the causal impact of norm information on subsequent reinforcement learning. We operationalized norm learning as a tendency to select the normative stimulus on the first trial of the learning task (outrage tweet in the outrage norm condition; neutral tweet in the neutral norm condition). We operationalized reinforcement learning as a tendency to increase selection of the positively reinforced stimulus over time (outrage tweets in both norm conditions).
Results confirmed that both reinforcement learning and norm learning shape outrage expression. As evidence of norm learning, on the first trial, participants in the outrage norm condition were significantly more likely to select an outrage tweet than a neutral tweet [odds ratio (OR) = 4.94, P < 0.001, 95% CI = [3.10, 7.89]], and participants in the neutral norm condition were significantly more likely to select a neutral tweet than an outrage tweet (OR = 1.73, P < 0.001, 95% CI = [1.11, 2.69]). In addition, we found evidence for reinforcement learning across both norm conditions (OR = 1.10, P < 0.001, 95% CI = [1.08, 1.12]). That is, participants learned to select more outrage tweets over time as a result of the trial-wise social feedback (see Fig. 4A). Simple effects revealed that participants in both the outrage norm condition (OR = 1.04, P < 0.001, 95% CI = [1.03, 1.08]) and the neutral norm condition (OR = 1.10, P < 0.001, 95% CI = [1.08, 1.12]) learned from social feedback to express more outrage over the course of the experiment.
Fig. 4. Reinforcement learning and norm learning shape outrage expressions in a simulated social media environment.
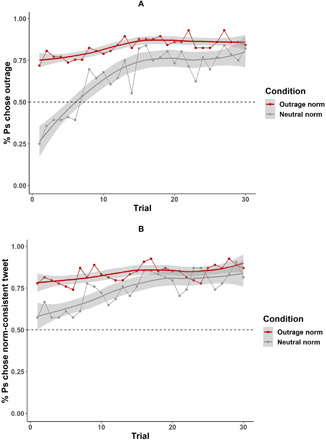
The y axis represents the percentage of participants (Ps) on each trial that selected outrage tweets to post. The x axis represents the trial number. The red line represents participants in the outrage norm condition while the grey line represents participants in the neutral norm condition. Error bands represent the standard errors produced by fitting with a GAM function in R 3.6.1. The dotted line represents a 50% selection rate for participants in a given trial. Panel (A) displays results for Study 1, Panel (B) displays results for Study 2.
However, the reinforcement learning effect was significantly smaller in the outrage norm condition than the neutral norm condition, as indicated by a significant negative interaction between the reinforcement learning effect and norm condition (OR = 0.95, P < 0.001, 95% CI = [0.92, 0.97]; see Fig. 4A). This suggests that participants in the outrage norm condition relied on social feedback less to guide their outrage expressions, consistent with the findings of studies 1 and 2.
Study 4
Study 4 (N = 120) replicated and extended study 3 by testing whether the relative reliance on norm learning versus reinforcement learning is similar for outrage expressions compared to neutral expressions. The study was preregistered at https://osf.io/9he4n/. We used the same paradigm as in study 3, with one critical difference: In the learning stage, participants received greater social feedback, on average, for the norm-congruent expression. That is, participants in the outrage norm condition received more positive feedback for selecting outrage tweets, while participants in the neutral norm condition received more positive feedback for selecting neutral tweets. This design allowed us to directly compare participants’ reliance on norm learning versus reinforcement learning, for outrage expressions versus neutral expressions. As in study 3, we operationalized norm learning as a tendency to select the normative stimulus on the first trial of the learning task (outrage tweet in the outrage norm condition; neutral tweet in the neutral norm condition). We operationalized reinforcement learning as a tendency to increase selection of the positively reinforced stimulus over time (outrage tweets in the outrage norm condition; neutral tweets in the neutral norm condition).
We again find evidence for norm learning: On the first trial, participants in the outrage norm condition were more likely to select an outrage tweet than a neutral tweet (OR = 5.38, P < 0.001, 95% CI = [3.48, 8.31]), while participants in the neutral norm condition were more likely to select a neutral tweet than an outrage tweet (OR = 1.54, P < 0.001, 95% CI = [1.03, 2.28]). We also find evidence for reinforcement learning: Social feedback affected participants’ posting of outrage expressions (OR = 1.03, P < 0.001, 95% CI = [1.01, 1.05]) and neutral expressions (OR = 1.06, P < 0.001, 95% CI = [1.05, 1.08]). Last, we found that the reinforcement learning effect was smaller in the outrage norm condition compared to the neutral norm condition, as indicated by a significant interaction between the reinforcement learning effect and norm condition (OR = 0.97, P < 0.001, 95% CI = [0.95, 0.99]) (see Fig. 4). In other words, participants in the outrage norm condition relied less on social feedback to guide their outrage expression compared to participants in the neutral norm condition.
DISCUSSION
Across two observational studies analyzing the tweet histories of 7331 total users (12.7 million total tweets) and with two behavioral experiments (total N = 240), we investigated how reinforcement learning and norm learning shape moral outrage expressions on social media. Our findings revealed three key discoveries about moral outrage in the digital age. First, social feedback specific to moral outrage expression significantly predicts future outrage expressions, suggesting that reinforcement learning shapes users’ online outrage expressions. Second, moral outrage expressions are sensitive to expressive norms in users’ social networks, over and above users’ own preferences, suggesting that norm learning processes guide moral expressions online. Third, network-level norms of expression moderate the social reinforcement of outrage: In networks that are more ideologically extreme, where outrage expression is more common, users are less sensitive to social feedback when deciding whether to express outrage. These findings underscore the importance of considering the interaction between human psychological tendencies and new affordances created by the specific design of social media platforms (26, 37, 38) to explain moral behavior in the digital age. This perspective dovetails with recent work in human-computer interaction research, suggesting that consequential moral and political social media phenomena (e.g., the spread of disinformation) are best understood as a combination of top-down, orchestrated influence from powerful actors and bottom-up, participatory action from unwitting users (34, 51).
At first blush, documenting the role of reinforcement learning in online outrage expressions may seem trivial. Of course, we should expect that a fundamental principle of human behavior, extensively observed in offline settings, will similarly describe behavior in online settings (28). However, reinforcement learning of moral behaviors online, combined with the design of social media platforms, may have especially important social implications. Social media newsfeed algorithms can directly affect how much social feedback a given post receives by determining how many other users are exposed to that post. Because we show here that social feedback affects users’ outrage expressions over time, this suggests that newsfeed algorithms can influence users’ moral behaviors by exploiting their natural tendencies for reinforcement learning. In this way, reinforcement learning on social media differs from reinforcement learning in other environments because crucial inputs to the learning process are shaped by corporate interests (26, 52). Even if platform designers do not intend to amplify moral outrage, design choices aimed at satisfying other goals such as profit maximization via user engagement can indirectly affect moral behavior because outrage-provoking content draws high engagement (29–31). Given that moral outrage plays a critical role in collective action and social change (40, 53), our data suggest that platform designers have the ability to influence the success or failure of social and political movements, as well as informational campaigns designed to influence users’ moral and political attitudes (34, 51). Future research is required to understand whether users are aware of this and whether making such knowledge salient can affect their online behavior.
Our findings also highlight other aspects of reinforcement learning that may be unique to the context of online social networks. First, we find consistent effects of positive prediction errors on reinforcement learning but inconsistent effects of negative prediction errors. This may be due to the fact that social media platform design makes positive feedback (likes and shares) highly salient, while negative feedback (the absence of likes and shares) is less salient. This design feature could make it much more difficult to learn from negative than positive feedback in online environments. Second, because users can self-organize into homophilic networks with easily observable communicative norms (54), following those norms might sometimes supersede reinforcement learning. We observe that, in ideologically extreme networks where outrage expressions are more common, individual users are less sensitive to the social feedback they do receive, perhaps because the social feedback is redundant with information they gleaned from observation or because they have internalized network-level norms of expression (21). Crucially, our experimental data suggest that the context of social media makes the interaction of network norms and reinforcement learning especially likely to affect learning of expressions that convey reputational information to one’s social group, like moral outrage (55). Future work may investigate how other properties of social networks affect the balance between norm learning and reinforcement learning.
It is important to note that all of our conclusions concern the expression of moral outrage in social media text, and not the emotion itself, which we were unable to measure directly. Although in theory the experience and expression of moral outrage should be highly correlated, one intriguing possibility is that the design of social media platforms decouples expressions of outrage from experiencing the emotion itself (13, 26). Such decoupling has implications for accounts of “outrage fatigue”—the notion that experiencing outrage is exhausting and thus diminishes over time. If expression becomes decoupled from experience, then outrage online may appear immune to fatigue even when experiencing it is not. Determining the extent to which expressions of emotion online represent actual emotional experiences is critical because if the social media environment decouples outrage expressions from experience, then this could result in a form of pluralistic ignorance (56), whereby people falsely believe that their peers are more outraged than they actually are (26).
This possibility is especially relevant in the context of political discourse (57, 58), which has become increasingly polarized in recent years (59). Our findings may shed light on the rise of affective polarization—intense, negative emotions felt toward political outgroups (8, 60) that have erupted into violent clashes in the United States (61) and have been linked with inaccurate meta-perceptions of intergroup bias (58, 62). In the current studies, we show that users conform to the expressive norms of their social network, expressing more outrage when they are embedded in ideologically extreme networks where outrage expressions are more widespread, even accounting for their personal ideology. Such norm learning processes, combined with social reinforcement learning, might encourage more moderate users to become less moderate over time, as they are repeatedly reinforced by their peers for expressing outrage. Further studies that measure polarization longitudinally alongside social reinforcement and norm learning of outrage expressions will be required to test this prediction.
Our studies have several limitations. First, we note that all the users in our observational analyses were identified by having tweeted at least once during an episode of public outrage (although not all users necessarily expressed outrage during these episodes). This approach allowed us to ensure that we collected a sample with a measurable signal of moral outrage, but it remains unclear whether these findings generalize to a broader population, other social media platforms, or outside the U.S. political context. Relatedly, Twitter users are not representative of the general population (63). However, they do comprise a high proportion of journalists and public figures who have an outsized influence on public affairs and the narratives surrounding them. Furthermore, our observational studies were unable to establish causal relationships between feedback, norms, and outrage expression. We therefore chose to replicate the findings and demonstrate the causal relationship in tightly controlled experiments using mock social media environments (studies 3 and 4). Although it would be scientifically interesting in future research to manipulate social feedback given to Twitter users, we caution that experimentally inducing changes in moral and political behavior in real online social networks raises a number of ethical concerns, especially considering that most Twitter users are unaware that their public data can be used for scientific study (64, 65). An alternative possibility for future research is to recruit social media users who consent to participating in experiments where they are randomly assigned to conditions in which their social feedback experience is potentially modified.
There are also several limitations with our method for classification of moral outrage in social media text (DOC). As with all machine learning methods, DOC is not 100% accurate, although we achieve performance on par with existing sentiment analysis methods that aim to classify more broad affective phenomena such as whether an expression is “positive” versus “negative” (66). For this reason, within-sample estimates in changes of outrage over time might be more accurate than any single point estimate for the purposes of generalizing out of sample. Furthermore, we note that we observed modest overlap between DOC’s classifications of moral outrage and broader classifications of negative sentiment using existing classifiers (67), although social learning effects were stronger and more consistent for moral outrage expressions than negative sentiment. Although moral outrage is interesting to study because of its specific functional ties to morality and politics and the consequences it can bring about for individuals and organizations, more research is required to understand the extent to which our findings regarding moral outrage extend to other emotional expressions that are similarly tied to ideological extremity in politics such as fear (68). We also note that DOC is trained specifically on moral and political discourse in Twitter text and therefore may have limited generalizability when applied to other social media platforms or other topics. As with all text classifiers, it is essential that researchers perform validity tests when applying DOC to a new sample before drawing conclusions from its results. Last, we note that DOC was trained on the basis of consensus judgments of tweets from trained annotators, which is useful for detecting broad linguistic features of outrage across individuals. However, specific social networks and even individuals may have diverse ways of expressing outrage, which suggests that future research should test whether incorporating individual- or group-level contextual features can lead to greater accuracy in moral outrage classification (69).
Broadly, our results imply that social media platform design has the potential to amplify or diminish moral outrage expressions over time. Ultimately, whether it is “good” or “bad” to amplify moral outrage is a question that is beyond the scope of empirical studies, although leaders, policy-makers, and social movements might assess whether online outrage achieves group-specific goals effectively (6, 70). While our studies were not designed to assess the effectiveness of online outrage, we note that significant asymmetries have been documented along ideological and demographic lines, including the political right gaining far more political power from outrage in the media than the left (71), men gaining more status from anger than women (72), and anger mobilizing white people more than black people in politics (73). These asymmetries might be exacerbated by social media platform design, in light of the growing impact of online discourse on political events and awareness (74, 75). Future work is required to determine how online amplification of moral outrage might also spill over into offline social interactions, consumer decisions, and civic engagement.
MATERIALS AND METHODS
Studies 1 and 2
Measuring moral outrage expressions in social media text
For our social media studies, we developed DOC using supervised machine learning. We trained DOC on a total of 26,000 tweets labeled as containing an expression of outrage or not, collected during a variety of episodes that sparked widespread public outrage (see Table 1 for sources of training data and section S1.0 for details of classifier development). Extensive evaluation demonstrated that DOC classified moral outrage expressions with accuracy and reliability comparable to extensively trained (“expert”) human annotators (see section S1.4 for details and Table 2 for examples of tweets classified as containing moral outrage expression by DOC). DOC is available for academic researchers via a Python package at the following link: https://github.com/CrockettLab/outrage_classifier.
To develop DOC, we leveraged the Global Vectors for Word Representation (76) to encode tweets into vector space and then input these word embeddings into a deep gated recurrent unit (GRU) (77) neural network architecture (for tests of alternative models, see section S1.0). The GRU model was trained on an initial dataset of 16,000 tweets collected during a contentious political episode in American politics: the confirmation hearings of Supreme Court nominee Brett Kavanaugh (section S1.1). Crucially, this episode sparked outrage from both liberals and conservatives, which made it ideal for training a classifier to detect aspects of outrage expressions that are not specific to a particular political ideology. We collected these tweets by gathering data on public mentions of politicians who were embroiled in controversy over statements about the confirmation hearings (see section S1.1). We then trained “crowdsourced” annotators to identify moral outrage expressions in these tweets based on social psychological theory (see appendix SA for full training instructions). Each tweet in the dataset was rated as containing outrage or not by an ideologically heterogeneous group of 10 annotators (5 liberals and 5 conservatives). Annotators demonstrated excellent reliability in applying our criteria for identifying moral outrage expressions as assessed by an intraclass correlation: ICC(3,10) = 0.82, 95% CI = [0.82, 0.83]. Importantly, we found that when holding the number of annotators constant at 5, politically heterogenous groups [ICC(3,5) = 0.69)] showed similar reliability as politically homogenous groups [mean ICC(3,5) = 0.70], justifying the combined use of liberal and conservative annotators to determine outrage ratings (for more details, see section S1.2).
We then collected a secondary set of various political topics and had them labeled by expert human annotators (N = 10,000) to enhance the domain generalizability of DOC. We selected these topics to represent diverse moral transgressions that violated both liberal and conservative values, as well as a nonpolitical moral transgression (see Table 2 and section S1.5). To test DOC’s performance, we trained and tested on the 26,000-tweet labeled dataset using fivefold cross-validation and found that our GRU model achieved an accuracy of 75% and F-1 score of 0.71 in classification of moral outrage (see section S1.0 for more details). DOC applied outrage labels similarly to the expert annotators in a sample of 500 tweets: The reliability applying outrage labels for the group of eight expert annotators [ICC(2,8) = 0.88, 95% CI = [0.86, 0.89]] was statistically indistinguishable from the mean reliability of all possible groups comprising seven expert annotators and DOC [ICC(2,8) = 0.87, 95% CI = [0.86, 0.89]]. In short, DOC classified moral outrage in a manner consistent with expert human annotators.
As moral outrage is a specific type of negative sentiment, we expected outrage expression and negative sentiment to be correlated but not identical. Supporting this prediction, DOC showed discriminant validity comparing its classifications to the classifications of a model trained to identify the broader category of negative sentiment. When examining the classifications made by the two models in the 26,000-tweet labeled dataset, we observed a weak correlation (τ = 0.11, P < 0.001). Descriptively, we observed that outrage and negative sentiment classifications showed agreement in only 29% of cases. See section S1.7 and table S15 for more details and examples of tweets containing negative sentiment but not moral outrage expression.
Hypothesis testing
To test our research questions regarding the social learning of outrage expressions, we first used metadata from our training dataset to select a group of Twitter users who were identifiable as authors of tweets in the Kavanaugh dataset and who maintained public profiles for at least 3 months after the original data collection (3669 users). We connected to Twitter’s standard and premium APIs and collected these users’ full tweet histories, yielding 6.1 million tweets available for analysis (see section S2.0 for more details). We used the same method to collect a second group of less politically engaged users, who were identified as authors of tweets in the United Airlines dataset (3669 Twitter users with 6.6 million tweets available for analysis). Because tweets in the United dataset did not concern a politically partisan issue, we expected that users identified from this dataset would be less ideologically extreme than the Kavanaugh users. Estimating the ideology of users in both the Kavanaugh and United datasets confirmed this (see section S2.2). This analysis strategy enabled us to test to what extent our findings generalize across different levels of political engagement and ideological extremity.
To test the association between outrage and previously received social feedback, we used GEEs (42) with robust SEs (observations, or tweets, were clustered by user) to estimate the population-level association between moral outrage expression and the amount of social feedback received on the previous day, with data aggregated at the level of days. We modeled the sum of outrage expression as a negative binomial distribution with a log link function and an independent correlation structure using PROC GENMOD in SAS 9.4. Decisions for modeling the outcome variable and correlation structure were based on the fact that the outcome variable was overdispersed count data and also on quasi-likelihood under independence model criterion (QIC) model fit statistics (78) available in PROC GENMOD. To replicate the analyses in R 3.6.1 in a computationally efficient manner, we used the “bam” function in the package “mgcv” v1.8. SAS and R scripts used for data organization and model estimation described in this section are available at https://osf.io/9he4n/. Model specifications and variable formations listed below were preregistered at https://osf.io/dsj6a (study 1) and https://osf.io/nte3y (study 2).
The model predicting outrage expression from previous social feedback included as predictors the sum of feedback received when outrage was expressed for seven lagged days, previous outrage tweeting for seven lagged days, previous sums of non-outrage feedback for seven lagged days, user-level tweet history total, number of tweets containing URLs per day, number of tweets containing media per day, and the user follower count. Results were robust to various model specifications including a model that included one previous day of outrage feedback, previous tweeting, and feedback for non-outrage tweets (i.e., including only one lag for each variable). Results were also robust when modeling the main lagged predictor variable as the difference between feedback received for outrage tweets versus non-outrage tweets (i.e., what is the effect of receiving more feedback for outrage expression compared to other tweets a user sent?). Section S2.0 presents full model details and tabulated results.
We created positive and negative prediction error variables by computing the difference between the previous day’s outrage-specific social feedback and the feedback from 7 days previous to the first lag. For example, if a user received an average of five likes/shares across days t-2 to t-8, and on day t-1 they received eight likes and shares, that observation would be recorded as a +3 for the positive prediction error variable and a 0 for the negative prediction error variable. If on day t-1 they received three likes and shares, then the observation would be recorded as a −2 for the negative prediction variable and a 0 for the positive prediction error variable. Further details are presented in section S2.3.
To test norm learning hypotheses in the Kavanaugh and United Airlines datasets, we defined the social network of each “ego” (a user in a dataset) as all friends and followers of the ego, and estimated the political ideology of each user in the ego’s network (49). We defined ideological extremity as the absolute value of the mean political ideology of all users in an ego’s social network (thus, higher values represent more extreme users; see section S2.0 for more details). To test how network ideological extremity moderated the social reinforcement effects, we regressed daily outrage expression on the two-way interaction of the previous day’s outrage-specific feedback and each ego’s network ideological extremity while also adjusting for daily tweet frequency and covariates included in above models. Section S2.0 presents full model details and tabulated results.
Study 3
Participants
We recruited 120 participants via the Prolific participant recruitment platform. We report how we determined our sample size, all data exclusions (if any), all manipulations, and all measures in the study in our preregistration at https://osf.io/rh2jk. Participants were all liberal, as our Twitter stimuli express left-leaning opinions about contentious political topics.
Procedure
Participants were recruited to participate in a simulated Twitter environment and told they were a new member of an ostensible network of platform users. They were explicitly instructed to learn the content preferences of their new network (for full instructions, see section S3.0). Participants were randomly assigned to either an outrage norm or neutral norm condition. Both conditions consisted of two stages: a scrolling stage and a learning stage (Fig. 3). In the scrolling stage, participants passively viewed 12 tweets that were sent from their new network by scrolling through a simulated Twitter newsfeed. Each tweet commented on one of four contentious political topics: (i) the first impeachment of Donald Trump as U.S. president, (ii) Medicare for All, (iii) U.S. immigration policy, and (iv) the “extinction rebellion” climate change movement. Each tweet discussed one of these issues from a liberal perspective. Three tweets from each of the topics were selected and combined to make the 12 tweets participants viewed.
The tweet stimuli were collected from publicly available tweets (no usernames were displayed for the tweet stimuli), and outrage expression was determined using DOC. In the outrage norm condition, 75% of the tweets that participants saw contained an expression of outrage, while the remaining 25% did not. None of the tweets seen by participants in the neutral norm condition contained outrage. Whether a tweet contained outrage or not was determined by using DOC to classify the tweets and then checking for validity of classification.
In addition to manipulating the prevalence of outrage in each condition, the amount of positive social feedback (i.e., likes) displayed under each tweet was also varied. In the outrage norm condition, tweets that contained expressions of outrage displayed an amount of likes randomly drawn from a “high reward distribution” (M = 250, SD = 50). Non-outrage tweets in this condition were assigned a number of likes sampled from a much lower distribution (M = 25, SD = 6). In the neutral norm condition, a random selection of 75% of the tweets in the neutral condition had high feedback and 25% had low feedback, as determined by the same distributions in the outrage norm condition.
After completing the scrolling stage, participants completed a learning stage where their goal was to maximize the social feedback they received for “retweeting” content (i.e., reposting a tweet to their network). Participants were incentivized to maximize their feedback via potential bonus payment related to total likes accumulated during the experiment. Social feedback was operationalized as Twitter likes, also known as “favorites,” which were ostensibly awarded by participants who previously completed the task and who shared the views of the network. On each of 30 trials, participants were presented with two new tweets discussing the same political topics that were used in the scrolling stage. As before, these tweets were classified for outrage expression using DOC. Thus, while both tweets in a pair discussed the same topic, one tweet contained outrage while the other did not. The position of the tweets when presented (left or right side of the screen) was randomized. Participants responded on each trial by clicking a “retweet button” that corresponded to the member of the pair of tweets they wished to share. Once they clicked the retweet button, participants were immediately presented with the feedback awarded to the selected tweet.
The social feedback awarded on each trial was drawn from either of two predetermined “reward trajectories” with the trajectory used determined by the participants’ retweet choice. For example, if a participant chose to retweet the outraged content in the nth trail, then the feedback they were awarded corresponded to the nth integer in an array of values. Of these values, 80% were randomly drawn from the high reward distribution used in the scroll task. The remaining 20% of reward values were sampled from the low distribution. These reward contingencies were the same for all participants, irrespective of the norm condition they were assigned in the scrolling task. The 80/20 split was used to add noise to the feedback and thus make it more difficult for participants to quickly infer the underlying reward structure.
Data analysis
We modeled participants’ binary tweet choices over trials using a generalized linear mixed model with the “lme4” package in R 3.6.1. Norm condition, trial number, and their interaction were entered as fixed effects, and we entered a random intercept for participants. Results were robust to modeling stimulus as a random factor (see section S3.0) (79).
Study 4
Participants
We recruited 120 participants via the Prolific participant recruitment platform. We report how we determined our sample size, all data exclusions (if any), all manipulations, and all measures in the study in our preregistration at https://osf.io/jc9tq. Participants were all liberal, as our Twitter stimuli express left-leaning opinions about contentious political topics.
Procedure
As in study 3, participants completed a simulated Twitter task with a scrolling stage and a learning stage (Fig. 3). The scrolling stage was identical to that in study 3. The learning stage was similar to that in study 3, with one exception: Participants in the neutral norm condition received more likes for selecting neutral tweets, while participants in the outrage norm condition received more likes for selecting outrage tweets. This design allowed us to directly compare learning rates in environments where outrage versus neutral tweets receive more positive feedback.
Data analysis
We modeled participants’ binary tweet choices over trials using a generalized linear mixed model with the lme4 package in R 3.6.1. Norm condition, trial number, and their interaction were entered as fixed effects, and we entered a random intercept for participants. Results were robust to modeling stimulus as a random factor (see section S3.0) (79).
Acknowledgments
We thank members of the Yale Crockett Lab for valuable feedback throughout the project. We thank K. Hu and M. Torres for assistance with fine-tuning of our outrage classifier. We thank A. Gerber and N. Christakis for providing helpful feedback on the paper. We thank the following students who contributed to annotating tweets: M. Brown, J. Burton, V. Copeland, V. Fung, A. Goolsbee, S. Hollander, B. Kijsriopas, N. Lipsey, S. Rice, I. Robinson, J. Wylie, L. Yuan, A. Zheng, and M. Zhou. Funding: This project was supported by the National Science Foundation (award no. 1808868), the Democracy Fund (award no. R-201809-03031), and a Social Media and Democracy Research Grant from the Social Science Research Council. Ethics statement: All research was conducted in accordance with the Yale University Institutional Review Board (IRB nos. 200026899 and 2000022385). For studies 1 and 2, data collection was ruled “exempt” due to our use of public tweets to be aggregated into summary statistics when posted online. A public tweet is a message that the user consents to be publicly available rather than only to a collection of approved followers. The main potential risk of our research is that the users whose data we analyzed could be identified. To prevent this risk and ensure user privacy, data made available for other researchers are in summary form only, without the original text of tweets. This prevents anyone either accidentally or intentionally making public identifiable information of users if the data are reanalyzed. Furthermore, as stated in table captions, all example tweets have been modified to prevent reverse text searches. In other words, people reading the paper cannot put the example text into Google and find the user who posted the message. The broad benefit of this research is the production of knowledge that helps our society understand how the interaction of human psychology and platform design can shape moral and political behaviors in the digital age. Over time, this knowledge can help inform scientific theory, policy-makers, and the general public. Author contributions: W.J.B. and M.J.C. designed research; W.J.B., K.M., and T.N.D. performed research; W.J.B., K.M., and M.J.C. planned analyses; W.J.B. analyzed data; W.J.B., K.M., and M.J.C. wrote the paper; and all authors contributed to revisions. Competing interests: The authors declare that they have no competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. All deidentified data, analysis scripts, and preregistered data collection and analysis plans are available at https://osf.io/9he4n/.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/7/33/eabe5641/DC1
REFERENCES AND NOTES
- 1.H. Gintis, S. Bowles, R. Boyd, E. Fehr, Moral Sentiments and Material Interests: The Foundations of Cooperation in Economic Life (MIT Press, 2005). [Google Scholar]
- 2.Salerno J. M., Peter-Hagene L. C., The interactive effect of anger and disgust on moral outrage and judgments. Psychol. Sci. 24, 2069–2078 (2013). [DOI] [PubMed] [Google Scholar]
- 3.Tetlock P. E., Kristel O. V., Elson S. B., Green M. C., Lerner J. S., The psychology of the unthinkable: Taboo trade-offs, forbidden base rates, and heretical counterfactuals. J. Pers. Soc. Psychol. 78, 853–870 (2000). [DOI] [PubMed] [Google Scholar]
- 4.Fehr E., Fischbacher U., Third-party punishment and social norms. Evol. Hum. Behav. 25, 63–87 (2004). [Google Scholar]
- 5.Simpson B., Willer R., Harrell A., The enforcement of moral boundaries promotes cooperation and prosocial behavior in groups. Sci. Rep. 7, 42844 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Spring V., Cameron D., Cikara M., The upside of outrage. Trends Cogn. Sci. 22, 1067–1069 (2018). [DOI] [PubMed] [Google Scholar]
- 7.D. G. Young, Irony and Outrage: The Polarized Landscape of Rage, Fear, and Laughter in the United States (Oxford Univ. Press, 2019). [Google Scholar]
- 8.Finkel E. J., Bail C. A., Cikara M., Ditto P. H., Iyengar S., Klar S., Mason L., McGrath M. C., Nyhan B., Rand D. G., Skitka L. J., Tucker J. A., Van Bavel J. J., Wang C. S., Druckman J. N., Political sectarianism in America: A poisonous cocktail of othering, aversion, and moralization poses a threat to democracy. Science 370, 533–536 (2020). [DOI] [PubMed] [Google Scholar]
- 9.Shepard J., Culver K. B., Culture Wars on Campus: Academic freedom, the first amendment and partisan outrage in polarized times. San Diego Law Rev. 55, 87–158 (2018). [Google Scholar]
- 10.M. Lynch, “Do we really understand ‘fake news’?,” New York Times, 23 September 2019; www.nytimes.com/2019/09/23/opinion/fake-news.html.
- 11.J. Haidt, T. Rose-Stockwell, “The dark psychology of social networks,” The Atlantic, December 2019; www.theatlantic.com/magazine/archive/2019/12/social-media-democracy/600763/.
- 12.H. Gintis, in Moral Sentiments and Material Interests: The Foundations of Cooperation in Economic Life (MIT Press, 2005), vol. 6. [Google Scholar]
- 13.Crockett M. J., Moral outrage in the digital age. Nat. Hum. Behav. 1, 769–771 (2017). [DOI] [PubMed] [Google Scholar]
- 14.Lieberman A., Schroeder J., Two social lives: How differences between online and offline interaction influence social outcomes. Curr. Opin. Psychol. 31, 16–21 (2020). [DOI] [PubMed] [Google Scholar]
- 15.M. L. Hoffman, Empathy and Moral Development (Cambridge Univ. Press, 2000). [Google Scholar]
- 16.Montada L., Schneider A., Justice and emotional reactions to the disadvantaged. Soc. Justice Res. 3, 313–344 (1989). [Google Scholar]
- 17.J. Haidt, in Handbook of Affective Sciences, R. J. Davidson, K. R. Scherer, H. H. Goldsmith, Eds. (Oxford Univ. Press, 2003), pp. 572–595. [Google Scholar]
- 18.Darley J. M., Morality in the Law: The psychological foundations of citizens’ desires to punish transgressions. Annu. Rev. Law Soc. Sci. 5, 1–23 (2009). [Google Scholar]
- 19.Gläscher J., Daw N., Dayan P., O’Doherty J. P., States versus rewards: Dissociable neural prediction error signals underlying model-based and model-free reinforcement learning. Neuron 66, 585–595 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Glimcher P. W., Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis. Proc. Natl. Acad. Sci. U.S.A. 108, 15647–15654 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ho M. K., MacGlashan J., Littman M. L., Cushman F., Social is special: A normative framework for teaching with and learning from evaluative feedback. Cognition 167, 91–106 (2017). [DOI] [PubMed] [Google Scholar]
- 22.Li J., Delgado M. R., Phelps E. A., How instructed knowledge modulates the neural systems of reward learning. Proc. Natl. Acad. Sci. U.S.A. 108, 55–60 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Cialdini R. B., Kallgren C. A., Reno R. R., A focus theory of normative conduct: A theoretical refinement and reevaluation of the role of norms in human behavior. Adv. Exp. Soc. Psychol. 24, 201–234 (1991). [Google Scholar]
- 24.Vélez N., Gwon H., Learning from other minds: An optimistic critique of reinforcement learning models of social learning. Curr. Opin. Behav. Sci. 38, 110–115 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.B. T. R. Savarimuthu, R. Arulanandam, M. Purvis, in Lecture Notes in Computer Science (Springer, 2011), pp. 36–50. [Google Scholar]
- 26.Brady W. J., Crockett M. J., Van Bavel J. J., The MAD model of moral contagion: The role of motivation, attention and design in the spread of moralized content online. Perspect. Psychol. Sci. 15, 978–1010 (2020). [DOI] [PubMed] [Google Scholar]
- 27.Dehghani M., Johnson K., Hoover J., Sagi E., Garten J., Parmar N. J., Vaisey S., Iliev R., Graham J., Purity homophily in social networks. J. Exp. Psychol. Gen. 145, 366–375 (2016). [DOI] [PubMed] [Google Scholar]
- 28.B. Lindström, M. Bellander, A. Chang, P. Tobeler, D. M. Amodio, A computational reinforcement learning account of social media engagement. PsyArXiv Preprints (2019).
- 29.Brady W. J., Wills J. A., Jost J. T., Tucker J. A., Van Bavel J. J., Emotion shapes the diffusion of moralized content in social networks. Proc. Natl. Acad. Sci. U.S.A. 114, 7313–7318 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Brady W. J., Wills J. A., Burkart D., Jost J. T., Van Bavel J. J., An ideological asymmetry in the diffusion of moralized content on social media among political leaders. J. Exp. Psychol. Gen. 148, 1802–1813 (2019). [DOI] [PubMed] [Google Scholar]
- 31.Valenzuela S., Piña M., Ramírez J., Behavioral effects of framing on social media users: How conflict, economic, human interest, and morality frames drive news sharing. J. Commun. 67, 803–826 (2017). [Google Scholar]
- 32.R. B. Cialdini, M. R. Trost, Social influence: Social norms, conformity and compliance, in The Handbook of Social Psychology, D. T. Gilbert, S. T. Fiske, G. Lindzey, Eds. (McGraw-Hill, 1998), vol. 2, pp. 151–192. [Google Scholar]
- 33.Chapman H. A., Kim D. A., Susskind J. M., Anderson A. K., In bad taste: Evidence for the oral origins of moral disgust. Science 323, 1222–1226 (2009). [DOI] [PubMed] [Google Scholar]
- 34.Starbird K., Arif A., Wilson T., Disinformation as collaborative work: Surfacing the participatory nature of strategic information operations. Proc. ACM Hum. Comput. Interact. 3, 1–26 (2019).34322658 [Google Scholar]
- 35.Y. Nagar, What do you think?: The structuring of an online community as a collective-sensemaking process, in Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (ACM, 2012), pp. 393–402. [Google Scholar]
- 36.Atlas L. Y., How instructions shape aversive learning: Higher order knowledge, reversal learning, and the role of the amygdala. Curr. Opin. Behav. Sci. 26, 121–129 (2019). [Google Scholar]
- 37.Evans S. K., Pearce K. E., Vitak J., Treem J. W., Explicating affordances: A conceptual framework for understanding affordances in communication research. J. Comput. Mediat. Commun. 22, 35–52 (2017). [Google Scholar]
- 38.Bayer J. B., Triệu P., Ellison N. B., Social media elements, ecologies, and effects. Annu. Rev. Psychol. 71, 471–497 (2020). [DOI] [PubMed] [Google Scholar]
- 39.J. Ronson, So You’ve Been Publicly Shamed (Riverhead Books, 2016). [Google Scholar]
- 40.Hutcherson C., Gross J., The moral emotions: A social–functionalist account of anger, disgust, and contempt. J. Pers. Soc. Psychol. 100, 719–737 (2011). [DOI] [PubMed] [Google Scholar]
- 41.A. Go, R. Bhayani, Huang, Sentiment140—A Twitter Sentiment Analysis Tool; http://help.sentiment140.com/home.
- 42.J. W. Hardin, J. M. Hilbe, Generalized estimating equations (Chapman & Hall/CRC, Boca Raton, FL, 2003), vol. 2. [Google Scholar]
- 43.Hilbe J. M., Negative binomial regression. Public Adm. Rev. 70, 1–6 (2011). [Google Scholar]
- 44.Dickinson A., Actions and habits: The development of behavioural autonomy. Philos. Trans. R. Soc. B Biol. Sci. 308, 67–78 (1985). [Google Scholar]
- 45.Grusec J. E., Goodnow J. J., Impact of parental discipline methods on the child’s internalization of values: A reconceptualization of current points of view. Dev. Psychol. 30, 4–19 (1994). [Google Scholar]
- 46.Pessiglione M., Seymour B., Flandin G., Dolan R. J., Frith C. D., Dopamine-dependent prediction errors underpin reward-seeking behaviour in humans. Nature 442, 1042–1045 (2006). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Marcus G. E., Valentino N. A., Vasilopoulos P., Foucault M., Applying the theory of affective intelligence to support for authoritarian policies and parties. Polit. Psychol. 40, 109–139 (2019). [Google Scholar]
- 48.Partisan conflict and congressional outreach (Pew Research Center, 2017); www.people-press.org/2017/02/23/partisan-conflict-and-congressional-outreach/.
- 49.Barberá P., Birds of the same feather tweet together: Bayesian ideal point estimation using twitter data. Polit. Anal. 23, 76–91 (2015). [Google Scholar]
- 50.Munger K., Phillips J., A supply and demand framework for YouTube politics. Int. J. Press Polit. (2019). [Google Scholar]
- 51.Arif A., Stewart L. G., Starbird K., Acting the part: Examining information operations within #BlackLivesMatter discourse. Proc. ACM Hum. Comput. Interact. 2, 1–27 (2018). [Google Scholar]
- 52.Goldenberg A., Gross J. J., Digital emotion contagion. Trends Cogn. Sci. 24, 316–328 (2020). [DOI] [PubMed] [Google Scholar]
- 53.Reifen Tagar M., Federico C. M., Halperin E., The positive effect of negative emotions in protracted conflict: The case of anger. J. Exp. Soc. Psychol. 47, 157–164 (2011). [Google Scholar]
- 54.Yardi S., Boyd D., Dynamic debates: An analysis of group polarization over time on twitter. Bull. Sci. Technol. Soc. 30, 316–327 (2010). [Google Scholar]
- 55.Jordan J. J., Rand D. G., Signaling when no one is watching: A reputation heuristics account of outrage and punishment in one- shot anonymous interactions. J. Pers. Soc. Psychol. 118, 57–88 (2020). [DOI] [PubMed] [Google Scholar]
- 56.Prentice D. A., Miller D. T., Pluralistic ignorance and alcohol use on campus: Some consequences of misperceiving the social norm. J. Pers. Soc. Psychol. 64, 243–256 (1993). [DOI] [PubMed] [Google Scholar]
- 57.Hwang H., Kim Y., Huh C. U., Seeing is believing: Effects of uncivil online debate on political polarization and expectations of deliberation. J. Broadcast. Electron. Media 58, 621–633 (2014). [Google Scholar]
- 58.Lees J., Cikara M., Inaccurate group meta-perceptions drive negative out-group attributions in competitive contexts. Nat. Hum. Behav. 4, 279–286 (2020). [DOI] [PubMed] [Google Scholar]
- 59.N. McCarty, K. Poole, H. Rosenthal, Polarized America: The Dance of Ideology and Unequal Riches (MIT Press, ed. 2, 2016). [Google Scholar]
- 60.Rogowski J. C., Sutherland J. L., How ideology fuels affective polarization. Polit. Behav. 38, 485–508 (2016). [Google Scholar]
- 61.S. Stolberg, B. Rosenthal, “Man charged after white nationalist rally in Charlottesville in deadly violence,” New York Times, 12 August 2017; www.nytimes.com/2017/08/12/us/charlottesville-protest-white-nationalist.html.
- 62.Moore-Berg S. L., Ankori-Karlinsky L.-O., Hameiri B., Bruneau E., Exaggerated meta-perceptions predict intergroup hostility between American political partisans. Proc. Natl. Acad. Sci. U.S.A. 117, 14864–14872 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.M. Duggan, J. Brenner, The demographics of social media users—2012 (Pew Research Center, (2012); www.pewresearch.org/internet/2013/02/14/the-demographics-of-social-media-users-2012/.
- 64.Fiesler C., Proferes N., “Participant” perceptions of Twitter research ethics. Soc. Media Soc. 4, (2018). [Google Scholar]
- 65.Hallinan B., Brubaker J. R., Fiesler C., Unexpected expectations: Public reaction to the Facebook emotional contagion study. New Media Soc. 22, 1076–1094 (2020). [Google Scholar]
- 66.J. Barnes, R. Klinger, S. Schulte im Walde, in Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (Association for Computational Linguistics, 2017), pp. 2–12. [Google Scholar]
- 67.Silge J., Robinson D., tidytext: Text mining and analysis using tidy data principles in R. J. Open Source Softw. 1, 37 (2016). [Google Scholar]
- 68.van Prooijen J.-W., Krouwel A. P. M., Boiten M., Eendebak L., Fear among the extremes: How political ideology predicts negative emotions and outgroup derogation. Pers. Soc. Psychol. Bull. 41, 485–497 (2015). [DOI] [PubMed] [Google Scholar]
- 69.Garten J., Kennedy B., Sagae K., Dehghani M., Measuring the importance of context when modeling language comprehension. Behav. Res. 51, 480–492 (2019). [DOI] [PubMed] [Google Scholar]
- 70.Brady W. J., Crockett M. J., How effective is online outrage? Trends Cogn. Sci. 23, 79–80 (2019). [DOI] [PubMed] [Google Scholar]
- 71.J. Hacker, P. Pierson, Let Them Eat Tweets: How the Right Rules in an Age of Extreme Inequality (Liveright, 2020). [Google Scholar]
- 72.Brescoll V. L., Uhlmann E. L., Can an angry woman get ahead? Status conferral, gender, and expression of emotion in the workplace: Research article. Psychol. Sci. 19, 268–275 (2008). [DOI] [PubMed] [Google Scholar]
- 73.D. L. Phoenix, The Anger Gap: How Race Shapes Emotion in Politics (Cambridge Univ. Press, 2019). [Google Scholar]
- 74.Jost J. T., Barberá P., Bonneau R., Langer M., Metzger M., Nagler J., Sterling J., Tucker J. A., How social media facilitates political protest: Information, motivation, and social networks. Polit. Psychol. 39, 85–118 (2018). [Google Scholar]
- 75.Freelon D., Marwick A., Kreiss D., False equivalencies: Online activism from left to right. Science 369, 1197–1201 (2020). [DOI] [PubMed] [Google Scholar]
- 76.J. Pennington, R. Socher, C. Manning, GloVe: Global vectors for word representation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Association for Computational Linguistics, 2014). [Google Scholar]
- 77.K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv:1406.1078 [cs.CL] (3 June 2014).
- 78.Pan W., Akaike’s information criterion in generalized estimating equations. Biometrics 57, 120–125 (2001). [DOI] [PubMed] [Google Scholar]
- 79.Judd C. M., Westfall J., Kenny D. A., Treating stimuli as a random factor in social psychology: A new and comprehensive solution to a pervasive but largely ignored problem. J. Pers. Soc. Psychol. 103, 54–69 (2012). [DOI] [PubMed] [Google Scholar]
- 80.S. Tatum, “Brett Kavanaugh’s nomination: A timeline,” CNN (2018).
- 81.J. Roesslein, Tweepy: Twitter for Python! (2020); https://github.com/tweepy/tweepy.
- 82.E. Summers, twarc: Archive tweets from the command line; https://github.com/docnow/twarc.
- 83.Kearney M. W., rtweet: Collecting and analyzing Twitter data. J. Open Source Softw. 4, 1829 (2019). [Google Scholar]
- 84.Shrout P. E., Fleiss J. L., Intraclass correlations: Uses in assessing rater reliability. Psychol. Bull. 86, 420–428 (1979). [DOI] [PubMed] [Google Scholar]
- 85.Chawla N. V., Bowyer K. W., Hall L. O., Kegelmeyer W. P., SMOTE: Synthetic minority over-sampling technique nitesh. J. Artif. Intell. Res. 16, 321–357 (2002). [Google Scholar]
- 86.N. Anand, D. Goyal, T. Kumar, Analyzing and preprocessing the Twitter data for opinion mining, in Proceedings of International Conference on Recent Advancement on Computer and Communication (Springer, Singapore, 2018), pp. 213–221. [Google Scholar]
- 87.H. Saif, M. Fernández, Y. He, H. Alani, On stopwords, filtering and data sparsity for sentiment analysis of Twitter, in Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014 ( European Language Resources Association, 2014), pp. 810–817. [Google Scholar]
- 88.Porter M. F., An algorithm for suffix stripping. Program 14, 130–137 (1980). [Google Scholar]
- 89.Miller G. A., WordNet: A lexical database for english. Commun. ACM 38, 39–41 (1995). [Google Scholar]
- 90.J. Li, X. Chen, E. Hovy, D. Jurafsky, in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Association for Computational Linguistics, 2016), pp. 681–691. [Google Scholar]
- 91.U. Michelucci, Applied Deep Learning: A Case-Based Approach to Understanding Deep Neural Networks (Apress, 2018). [Google Scholar]
- 92.T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality, in Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2, NIPS’13 (Curran Associates Inc., 2013), pp. 3111–3119. [Google Scholar]
- 93.Hochreiter S., Schmidhuber J., Long short-term memory. Neural Comput. 9, 1735–1780 (1997). [DOI] [PubMed] [Google Scholar]
- 94.P. Zhou, Z. Qi, S. Zheng, J. Xu, H. Bao, B. Xu, Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling, in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (The COLING 2016 Organizing Committee, 2016), pp. 3485–3495. [Google Scholar]
- 95.K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using RNN encoder-decoder for statistical machine translation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (Association for Computational Linguistics, 2014), pp. 1724–1734. [Google Scholar]
- 96.J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, in NIPS 2014 Workshop on Deep Learning (2014).
- 97.J. D. Kelleher, B. MacNamee, A. D’Arcy, Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies (MIT Press, 2015). [Google Scholar]
- 98.S. Moreira, J. Filgueiras, B. Martins, F. Couto, M. J. Silva, REACTION: A naive machine learning approach for sentiment classification, in Second Joint Conference on Lexical and Computational Semantics (*{SEM}), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (Association for Computational Linguistics, 2013), pp. 490–494. [Google Scholar]
- 99.Warriner A. B., Kuperman V., Brysbaert M., Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 45, 1191–1207 (2013). [DOI] [PubMed] [Google Scholar]
- 100.A. Go, R. Bhayani, L. Huang, “Twitter sentiment classification using distant supervision” (CS224N Project Report, 2009), vol. 150.
- 101.L. F. Barrett, J. A. Russell, The Psychological Construction of Emotion (The Guilford Press, 2014). [Google Scholar]
- 102.Tausczik Y. R., Pennebaker J. W., The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 29, 24–54 (2009). [Google Scholar]
- 103.L.-P. Jing, H.-K. Huang, H.-B. Shi, Improved feature selection approach TFIDF in text mining, in Proceedings International Conference on Machine Learning and Cybernetics (IEEE, 2002), vol. 2, pp. 944–946. [Google Scholar]
- 104.A. Liptak, “Supreme Court revives transgender ban for military service,” New York Times, 22 January 2019.
- 105.S. Deb, “Accused of faking own assault, Jussie Smollett arrested on felony charge,” New York Times, 20 February 2019.
- 106.P. Libbey, “Sentiments on social media evolve with Jussie Smollett news,” New York Times, 21 February 2019.
- 107.S. Mervosh, “Viral video shows boys in ‘Make America Great Again’ hats surrounding Native Elder,” New York Times, 19 January 2019; www.nytimes.com/2019/01/19/us/covington-catholic-high-school-nathan-phillips.html.
- 108.H. Yan, C. Zdanowicz, E. Grinberg, “Backlash erupts after United passenger gets yanked off overbooked flight,” CNN, 10 April 2018.
- 109.J. Moffitt, twitterdev/search-tweets-python (@TwitterDev (2021); https://github.com/twitterdev/search-tweets-python.
- 110.A. Tornes, Introducing Twitter premium APIs (2017); https://blog.twitter.com/developer/en_us/topics/tools/2017/introducing-twitter-premium-apis.html.
- 111.Weiss G. M., Provost F., Learning when training data are costly: The effect of class distribution on tree induction. J. Artif. Intell. Res. 19, 315–354 (2003). [Google Scholar]
- 112.S. Lei, H. Zhang, K. Wang, Z. Su, How training data affect the accuracy and robustness of neural networks for image classification, in International Conference on Learning Representations (2019). [Google Scholar]
- 113.R. Therrien, S. Doyle, Role of training data variability on classifier performance and generalizability, in Proc. SPIE (2018), vol. 10581.
- 114.W. J. Brady, J. J. Van Bavel, Social identity shapes antecedents and functional outcomes of moral emotion expression in online networks. OSF Preprints (2021).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/7/33/eabe5641/DC1