

Abstract
We show that sub-spreading events, i.e. transmission events in which an infection propagates to few or no individuals, can be surprisingly important for defining the lifetime of an infectious disease epidemic and hence its waiting time to elimination or fade-out, measured from the time-point of its last observed case. While limiting super-spreading promotes more effective control when cases are growing, we find that when incidence is waning, curbing sub-spreading is more important for achieving reliable elimination of the epidemic. Controlling super-spreading in this low-transmissibility phase offers diminishing returns over non-selective, population-wide measures. By restricting sub-spreading, we efficiently dampen remaining variations among the reproduction numbers of infectious events, which minimizes the risk of premature and late end-of-epidemic declarations. Because case-ascertainment or reporting rates can be modelled in exactly the same way as control policies, we concurrently show that the under-reporting of sub-spreading events during waning phases will engender overconfident assessments of epidemic elimination. While controlling sub-spreading may not be easily realized, the likely neglecting of these events by surveillance systems could result in unexpectedly risky end-of-epidemic declarations. Super-spreading controls the size of the epidemic peak but sub-spreading mediates the variability of its tail.
Keywords: infectious diseases, heterogeneity, overdispersion, super-spreading, elimination, reproduction numbers
1. Background
Emerging infectious diseases are a major and recurring threat to both global health and economies. The ongoing COVID-19 pandemic has exemplified this, highlighting a need for improved understanding on how interventions might be applied and relaxed to jointly minimize public health risks and socio-economic costs. Key parameters which characterize the impact of interventions on the transmission dynamics of an infectious disease are the time-varying event reproduction number, denoted Rs at time s, with mean μs [1] and the dispersion level, k, of the offspring distribution of the epidemic [2]. The first describes transmission potential by measuring the number of secondary infections per primary case at s. The second defines transmission heterogeneity, i.e. it captures the variation of possible Rs about mean μs. The values of these parameters often inform intervention policy and much debate remains on their implications for both epidemic control and elimination [3–5].
A μs > 1 forewarns of rising incidence (new cases), necessitating the application of controls, while μs < 1 signifies that the epidemic is being controlled, potentially allowing the relaxation of some interventions [1]. Moreover, the risk and effectiveness of policies are modulated by k. If k ≫ 1 then transmission is homogeneous (μs is representative of the realized Rs) and we can apply simple, population-wide controls. Alternatively, if k < 1, then heterogeneity is large (the epidemic offspring distribution is overdispersed). This means that infrequent super-spreading events, in which each primary case causes ≫ μs secondary ones, disproportionately drive overall transmission [2]. The majority of other transmission events, which we refer to as sub-spreading events, lead to fewer than μs or even 0 secondary cases. Heterogeneous epidemics may require more targeted, event-specific policy as population-wide measures can often be ineffectual [2,6].
Many works have examined how k and μs interact to regulate the effectiveness of control measures applied to growing epidemics. When transmission is heterogeneous, the consensus is that interventions aimed at mitigating super-spreading events (e.g. by limiting large gatherings) can minimize both peak epidemic size and resource-usage [2,7,8]. While these insights inform on how to efficiently impose control measures, the converse problem of when to safely release interventions and de-escalate surveillance, for waning epidemics, has been understudied [9,10]. The importance of this problem will only elevate as countries debate the value of elimination-based strategies for handling the ongoing COVID-19 pandemic [3,11]. In this paper, we investigate this relaxation problem in the context of achieving reliable and minimum-risk end-of-epidemic declarations.
The timing of an end-of-epidemic declaration is strategically crucial as it triggers the removal of restrictions or control measures, the re-allocation of resources and the resumption of trade, travel and other economic activities. However, getting this timing right is both non-trivial and consequential. Early declarations (and hence intervention relaxation) can elevate the risk of resurgence or second waves, whereas late ones can cause needless cost. Much is unknown about how the transmission dynamics of an infectious disease dictate the tail of an epidemic. Recent studies suggest that this knowledge gap may have contributed to early declarations for Ebola virus disease (EVD) in West Africa [12] and late ones for MERS-CoV in South Korea [13].
Prime among these unknowns is the influence of heterogeneity and its associated targeted interventions. While some studies have started analysing the interacting roles of μs and k to decipher this influence [12,14], a general framework for rigorously testing hypotheses about how heterogeneity and control choices impact end-of-epidemic declarations is lacking. We extend theory from [2,15] to develop such a framework, which allows us to generate novel and principled insight into how μs and k (and hence possible Rs values) mediate the tail of an epidemic. We take a bottom-up approach, tracing how heterogeneity in transmission, defined by variations in Rs due to k, causes fluctuations in incidence, which then manifest as noise in the probability of epidemic fade-out or elimination.
As this probability defines our confidence in any end-of-epidemic declaration [15], we obtain a measure of the risk of that declaration. This framework leads to several new results. First, we observe that while decreasing k (increasing heterogeneity) reduces the mean waiting time to elimination, measured from the last observed reported case (a standard reference point [16]), it also increases the maximum waiting time. This contextualizes the common assertion that heterogeneity increases the likelihood of epidemic extinction [17], showing that while this may happen on average, the increased uncertainty it brings can actually hamper safe end-of-epidemic declarations.
Second, we find that sub-spreading plays a larger part than super-spreading in setting the uncertainty around the probability of elimination and hence end-of-epidemic declarations. We confirm this by testing three control strategies, which target (i) all transmission events, (ii) super-spreading and (iii) sub-spreading, for a fixed level of control effort ρ (the mean reproduction number is then ρμs). Strikingly, we see that waning epidemics, which feature ρμs < 1, are most reliably eliminated by curbing sub-spreading events. Moreover, we find the benefits of super-spreading control relative to the simpler approach of (i) largely disappear in this epidemic phase.
Because ρ can equally model the mean case reporting or ascertainment rate [18], results from (i)–(iii) also concurrently describe the impact of uniform, size-inverse (super-spreading events are under-ascertained) and size-biased or preferential reporting (sub-spreading is under-ascertained), respectively. Consequently, we uncover that the under-reporting of sub-spreading events, which is likely, can engender overconfident and risky end-of-epidemic declarations. These issues are in addition to known biases caused by under-reporting within the context of epidemic elimination [15]. Robustly assessing the endpoint of an outbreak may therefore require either targeting interventions at sub-spreading events, if possible, or, more likely, increasing contact tracing surveillance to minimize the under-reporting of those events.
One defining characteristic of heterogeneous transmission is an excess of sub-spreading events (zero inflation) [2]. However, these events have received little attention in the literature. Only recently has the importance of sub-spreading been recognized, in related network epidemic models [19]. Our results draw attention to the unexpected influence of sub-spreading, clarifying its impact on epidemic elimination and adding context and detail to the subtleties and uncertainties of controlling and monitoring epidemics with overdispersed transmission. Hopefully, our framework will help inform guidelines for achieving risk-averse and efficient end-of-epidemic declarations and intervention de-escalations in the face of heterogeneity and improve understanding of the complex dynamics driving real epidemics.
2. Methods
2.1. Renewal models with heterogeneous transmission
We consider an outbreak observed daily over the time period (in days) [1, t] with the number of newly infected cases on day s ≤ t as Is. The incidence curve of this epidemic is denoted . We model the time-varying transmission of a communicable disease within a population using a renewal process [20,21]. This process describes how an infection spreads from a primary case to secondary ones at time s using two key variables: the effective reproduction number, Rs, and the generation time distribution, with probability wu at time u. Here Rs is the number of secondary cases at time s every effective case at s − 1 infects, while wu gives the probability that the average time for a primary to secondary transmission is u days [20].
Under this renewal process framework, incident cases observed at time s depend on Rs and past cases (over the period [1, s − 1]) according to the Poisson (Pois) relation on the left side of equation (2.1).
| 2.1 |
Here , which depends on , is known as the total infectiousness. It characterizes how many past effective cases contribute to the next observed case-count at s. The generation time distribution (which we assume to be equal to the serial interval distribution) is central to defining the impact of each past case (via the weights wu) [20].
If we describe an epidemic as consisting of a sequence of spreading or transmission events, with the reproduction number of the spreading event at time s as Rs then standard renewal models assume a fixed Rs [21–23]. This formulation, while useful, does not account for possible heterogeneities in transmission, which are known features of many respiratory diseases such as the SARS and MERS coronaviruses [2]. If we define a distribution over Rs with mean then these models set . Heterogeneous transmission is a mean preserving spread of this condition, i.e. events with fixed mean μs can have different Rs values.
We define super-spreading events as those driven by Rs significantly larger than μs. This characterization differs slightly from the standard in [2], which directly uses numbers of secondary cases. Since the renewal model has long-term memory (i.e. factors in the age of infections via ) using Is would not be as appropriate here. However, because Is behaves like a noisy, scaled version of Rs (by the properties of Poisson mixtures [24]), these two definitions are largely consistent. In this work, we consider the end of the epidemic, which follows the waning phase of the epidemic. This contrasts the development in [2], which focuses on the growth phase. We define sub-spreading events as having Rs notably smaller than μs. This type of event has received appreciably less attention (than super-spreading ones) and is our main topic of study.
If we make the usual assumption that Rs is gamma (Gam) distributed with shape k and scale μsk−1, i.e. the right side of equation (2.1), then we obtain the negative binomial (NB) relation . This is the most common method for incorporating heterogeneity within renewal model frameworks [12,14,25]. As k gets smaller the likelihood of both super- and sub-spreading events increases [2,24]. Special cases are at k → ∞, k = 1 and k → 0 for which Is has a Poisson, geometric and logarithmic distribution respectively with mean [18]. Many of the infectious diseases that feature significant heterogeneity have been found to exhibit k < 1 [2,26]. This NB model can also be used to describe reporting noise and other types of heterogeneity.
2.2. Variation in reproduction numbers and incidence
We explicitly characterize how heterogeneity in transmission can control the incidence of an epidemic and then assess the implications of this observation. Consider any arbitrary distribution over the effective reproduction number at time s, Rs, with mean μs. Using the law of total expectation, we can write with the subscripts clarifying (when needed) about which variable we are taking expectations. Using the renewal model (left expression in equation (2.1)), we obtain the straightforward but general equation (2.2).
| 2.2 |
The above equation shows that for any renewal model there is a direct relationship between mean incidence and μs.
Similarly, we apply the law of total variance to get: [24] (with indicating variance). Expanding this for renewal models we derive equation (2.3), which holds for any Rs distribution.
| 2.3 |
If we substitute the statistics from the standard gamma Rs distribution (right expression in equation (2.1)) we recover the usual variance of the NB incidence distribution, i.e. [12]. The key takeaway from equation (2.3) is that, given the past (summarized by ), the variance of the reproduction numbers linearly controls that of the incidence at any time. Equations (2.2) and (2.3) explain why we can generally map dynamics of Rs onto those of Is.
As a result, we can decipher the influence of super- and sub-spreading events (which are, respectively, linked to the tail and head, i.e. the right and left portions of the Rs distribution) by investigating the level of heterogeneity or variation among reproduction numbers. This is useful because it is hard to reliably estimate secondary cases caused by past primary cases during the waning stages of the epidemic [13].
The impact of control measures [2] or under-reporting [18] (which are often mathematical analogues) can be measured by their signature on the variance-to-mean ratio (VM) of the incidence: . Using equations (2.2) and (2.3), we obtain equation (2.4) connecting the VM ratios of Rs to Is.
| 2.4 |
Thus, once again the statistics of Rs strongly modulate those of Is at any time, for a given . While this result is simple, its ramifications, which are meaningful, have not been explored.
Understanding how properties of the Rs distribution map onto the related Is one, which is a mixed Poisson distribution, provides insights into other epidemic properties. From mixed Poisson theory [24], we deduce that (a) if Rs is unimodal and continuous then Is is also unimodal, (b) the shape of Is will be similar to that of the mixing distribution describing Rs (e.g. when Rs is exponential, Is becomes geometrically distributed) and (c) every mixed Poisson distribution corresponds to a unique mixing distribution, i.e. multiple Rs distributions cannot map to the same Is distribution [24]. Properties (a)–(c) establish that much about super- and sub-spreading events can be learned from Rs. We will exploit these relationships to better understand epidemic elimination and heterogeneity.
2.3. Elimination probabilities and epidemic lifetimes
We define an epidemic to be eliminated (or extinct) [5] at some time s if no future infected (local) cases are observed, i.e. Is+1 = Is+2 = · · · = I∞ = 0 [5,15]. If we initially assume that all future mean reproduction numbers, , are known, then we can construct the probability of elimination given some sample from (see equation (2.1)) as . As we condition on the sample and because incidence is non-negative and Ij does not depend on , we can decompose zs to get equation (2.5).
| 2.5 |
From equation (2.1), (also see [3]) and we obtain equation (2.6), with future computed by incorporating the terms from above as pseudo-data [15,27].
| 2.6 |
Hence, the elimination probability has an uncomplicated log-linear dependence on the sample sequence of reproduction numbers and accordingly depends on all future spreading events. This type of relationship is maintained even if we generalize equation (2.1) to include case observation noise (e.g. due to importation or delays) [22,28]. Methods for inferring zs given these noise sources are currently being developed in [10,15].
While equation (2.5) can be computed at any time, commonly elimination is only considered when zero-case days are observed in sequence [13,16]. Keeping to convention, we will often present results in terms of Δs, which is the time relative to that at which incidence was last non-zero, t0. We compute the relative time at which the epidemic is eliminated with α% confidence, given the transmission event sample , as tα in equation (2.7).
| 2.7 |
The above equation also gives the time that an epidemic, composed of spreading events , can be declared over with at least α% confidence [15,29]. This confidence reflects the remaining variability among possible epidemic trajectories despite conditioning on the fixed future sample and the past observed incidence .
If we think of the epidemic as a process that generates infections then its survival function, which captures the probability of the epidemic propagating at least 1 future case after s, is precisely 1 − zs. The mean lifetime of the epidemic then follows from survival theory (where it is called the mean time to failure) as [30]. Given , we can compute this lifetime exactly, as only depends on future incidence values, which are all 0 for this condition [15]. Hence zs has an influential role in determining the risk of epidemic survival. As end-of-epidemic declaration times depend on zs, this risk has potentially important public health and economic implications.
However, we do not know what sample from will be realized, and must account for this uncertainty, which derives from the heterogeneity in transmission and hence depends on the levels of super- and sub-spreading. Since, practically, an authority would want a single time for declaring an epidemic to be eliminated or over [16], we need some way of summarizing the range of zs curves and hence tα values that could result. We propose two such statistics: the mean and the minimum zs,min. The resulting declaration times are then and tα,max. The mean elimination probability was used in [15], while the worst case (minimum) was proposed in [29].
We derive exactly from equation (2.6) as . This yields equation (2.8) with as the moment generating function according to the distribution of Rj, which we evaluate at [31].
| 2.8 |
This formulation has immediate consequences [20]. First, . Ignoring heterogeneity will therefore on average result in our underestimating the elimination probability and so overestimating when the outbreak is over with α% confidence. This extends earlier works, which used simpler branching process epidemic models to link heterogeneity and extinction [2], to more realistic renewal epidemic descriptions [7].
Second, because has a unique correspondence to the distribution over Rj [31], sub- and super-spreading events have direct roles in shaping the mean elimination probability. For example, given some threshold c, Chernoff’s bound stipulates that , with specifying our spreading event likelihoods. Last, under the gamma distribution in equation (2.1) we can explicitly compute equation (2.8) to obtain equation (2.9) [31].
| 2.9 |
The above equation provides intuition into how the offspring dispersion parameter k controls the mean elimination probability and hence the epidemic lifetime. Applying the product rule, we can show that , proving that as heterogeneity rises, i.e. k gets smaller, (and hence always increases (respectively, decreases).
While the worst case elimination probability, zs,min, does not admit such analytic development and so is computed via simulation, we gain some insight about its behaviour from the variance among the zs curves: . Each term in this product is independent so we decompose this to to get equation (2.10) with taken from equation (2.8).
| 2.10 |
We obtain an explicit form for equation (2.10) by substituting the moment generating functions for gamma distributions as in equation (2.9). It follows that . We generally find that as k falls, variation among zs curves and hence possible tα times increases (see Results). The gap between tα,max and , consequently, widens with heterogeneity.
Understanding how variation in Rs maps to uncertainty in elimination times is the main focus of this work. Specifically, we examine how changes to this variation, due to different control or case ascertainment strategies, express themselves in our ability to reliably adjudge the endpoint of the epidemic. In the Results, we exploit the mathematical framework developed here to investigate how and zs,min, which are two measures of the aggregate risk of an epidemic, depend on super- and sub-spreading events. Based on these, we attempt to derive schemes for reliably eliminating an epidemic, i.e. reducing its lifetime with minimum risk. This moment generating function approach to epidemic elimination or fade-out is novel, as far as we are aware.
3. Results
3.1. Reducing variation among reproduction numbers
In equation (2.4), we showed how VM ratios of the event reproduction numbers, Rs, directly control those of the incidence values, Is. We first verify this relationship on numerous epidemics simulated according to the heterogeneous renewal model of equation (2.1). We consider epidemics characterized by an initial exponential growth followed by drastic control (e.g. a lockdown measure) and compute the VM ratios of both Is and Rs for all times s of the epidemics. Figure 1 shows that as heterogeneity increases (i.e. k falls) the VM of Is and Rs both rise, despite different mean values across the possible epidemics as well as varying total infectiousness .
Figure 1.
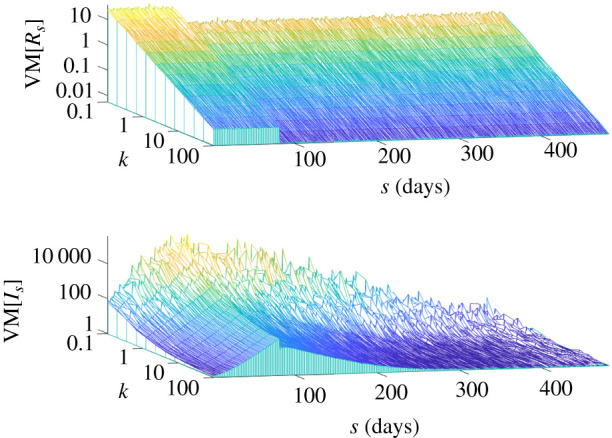
VM ratios of incidence and reproduction numbers. We simulate 2000 epidemics under a reproduction number profile that has fixed mean of 2.5 up to s = 80 and then a step change fall to 0.5 until elimination, using the generation time distribution from [14]. We vary the offspring dispersion parameter k of the renewal model used to generate the epidemics and compute the VM ratios of event reproduction numbers Rs and incidence Is at every time s. In line with equation (2.4), there is a strong correspondence between VM[Rs] and VM[Is] (mediated by the total infectiousness ) and smaller k (larger heterogeneity) inflates both values.
This solidifies the idea of modulating VM[Is] via the control of VM[Rs]. We consider three main strategies ((i)–(iii) below) for implementing control in a heterogeneous epidemic. To simplify notation, we drop the subscript s and constrain all control protocols to reduce the mean reproduction number from μ to ρμ with ρ ≤ 1. Consequently, after control the new distribution describing R satisfies and . These descriptions equally model case reporting or ascertainment schemes, where ρ now defines the sample or reporting fraction instead [18].
-
(i)
Uniform control (constant reporting). Also called population-wide control and introduced in [18], this protocol assumes that all event reproduction numbers are reduced by the constant fraction ρ. This is achieved by rescaling equation (2.1) so that R ∼ Gam(k, ρμk−1) and is the simplest type of control that can be applied. Uniform control admits the analytic VM[R] = ρμk−1, which falls linearly as ρ → 0. It is equivalent to constant (or Bernoulli) reporting with the probability of observing or sampling any type of spreading event set at ρ.
-
(ii)
Super-spreading control (size-inverse reporting). Also called targeted control, and formulated in [7], this strategy disproportionately reduces super-spreading events and is within the class of individual-specific control measures detailed in [2]. It is implemented by upper-truncating the distribution of R at some maximum value b and rescaling so that and . Here b defines the event R we consider to be associated with super-spreading. This is equivalent to size-inverse case ascertainment where super-spreading events are under-sampled. In this analogy b is the right under-reporting point, i.e. we never observe events caused by R > b.
-
(iii)
Sub-spreading control (size-biased or preferential reporting). This is a novel intervention that we introduce. It focuses on removing the sub-spreading events and is the converse of (ii). The gamma distribution of R is lower-truncated at some minimum value a and rescaled so that and . We use a to define sub-spreading events. This scheme is analogous to a size-biased case reporting strategy in which events producing few cases are under-sampled, with a as the left under-reporting point of the R distribution, i.e. we never sample R < a. As (ii) and (iii) do not admit simple VM expressions we investigate them through simulation.
As a → 0 and b → ∞ all three control or reporting measures (and the scale parameter of their respective gamma R distributions) converge. They also converge as k → ∞ since the R distribution becomes degenerate at ρμ under these conditions and there is no heterogeneity. For simplicity, from this point we will usually refer to schemes (i)–(iii) via their control classification, switching to their reporting analogue only later when discussing results. We treat uniform control as a baseline since it ignores the specific form of the R distribution. While preferentially limiting super-spreading is sensible, and has been shown to have superior performance relative to uniform control [2], sub-spreading control has, to our knowledge, not been investigated. This is likely because it seems counterintuitive to focus on events with low transmission potential.
However, we propose sub-spreading control based on the observation that a key source of the extra variability that over-dispersed distributions possess results from the increased probability of observing a zero sample, i.e. zero inflation [32]. In an epidemic with heterogeneous transmission an excess of zero secondary cases would likely result from the sub-spreading event reproduction numbers. Here we investigate, for a fixed mean control effort ρ, whether the excess zeros or the extreme-tail events (i.e. the super-spreading ones) are more critical for shaping VM[I] (later we map VM[I] onto our elimination probabilities). We examine various k and compute the VM ratios for control strategies (i)–(iii) in figure 2 for increasing control effort, i.e. decreasing ρ.
Figure 2.
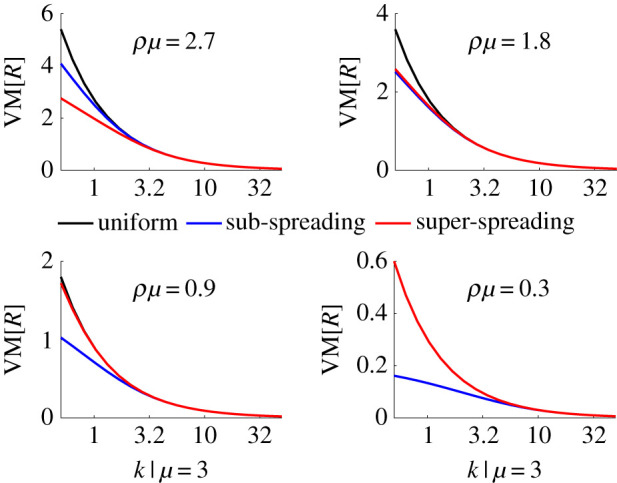
Control strategies and their VM ratios. We compute the VM ratios of the event reproduction number, R, distributions resulting from uniform, super-spreading and sub-spreading control measures for various dispersion parameters k with lower and upper truncations points of a = 1/10 and b = 10, respectively. Before control and after control with smaller ρ indicating increased average control effort. We find that when ρμ is large limiting super-spreading is most effective in reducing VM[R]. However, as ρμ decreases interventions targeting sub-spreading become the most effective at minimizing variability.
Intriguingly, we find that when the controlled mean R, i.e. ρμ, is large, super-spreading control is most effective in reducing the VM ratio of the reproduction numbers. However, as the epidemic is better controlled and so ρμ falls, sub-spreading control becomes the best intervention with respect to the VM ratio. This would make sense if as the mean controlled reproduction number falls the tail (super-spreading) events become increasingly improbable, meaning that most of the variability derives from the sub-spreading events. We confirm this notion in figure 3, which examines the cumulative distribution function F(R) at the extreme values of figure 2.
Figure 3.
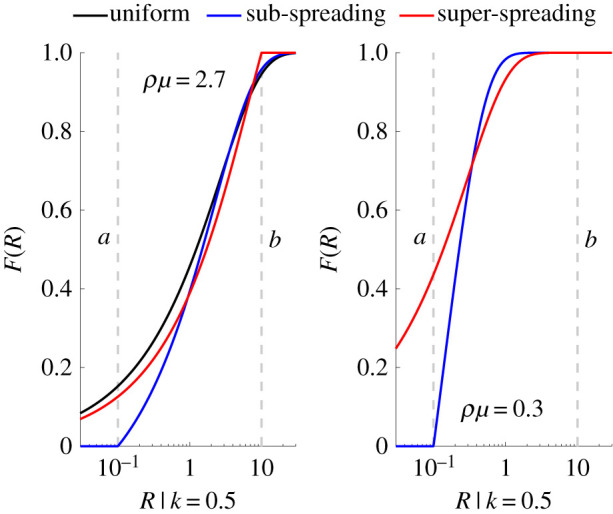
Control strategies shape reproduction number distributions. We plot the cumulative distribution function of the event reproduction number, F(R), for uniform, super-spreading (upper truncation b) and sub-spreading (lower truncation a) control measures under a renewal model with dispersion k = 0.5 at the largest and smallest mean controlled reproduction numbers, ρμ, examined in figure 2. We find that super-spreading control is best (in terms of variance-to-mean ratios) at large ρμ because there is a notable probability of super-spreading events that becomes truncated under this measure, i.e. the resulting F(R) curve rises to 1 first due to R > b events being controlled. However, when ρμ is small this becomes vastly less important (the super-spreading and uniform controls converge) and the F(R) curve under sub-spreading control rises the fastest to 1 (where R < a events are suppressed).
Here we see that, at large ρμ, limiting super-spreading forces F(R) towards 1 at the fastest rate, i.e. the clipping of super-spreading events closes the effective support of the R distribution earlier than the other measures. In this regime, the tail events of the distribution are important. Elimination is not practically possible at such a large reproduction number, but this provides an interesting perspective for comparing to the low ρμ regime. There, because the tail events are strongly improbable, super-spreading and uniform control converge in behaviour. Interestingly, sub-spreading control forces F(R) more quickly to 1 than other measures, by truncating the small reproduction numbers. This may explain its performance in figure 2.
This assessment of the VM ratios and the effective reproduction number support (i.e. how quickly F(R) converges to 1) does not invalidate the results of [2], where a variant of super-spreading control increased VM ratios. We will resolve these apparent contradictions in a later section, highlighting the difference between renewal models and the branching processes used in [2]. We next investigate whether these reductions in VM[R] and VM[I] actually improve our ability to constrain zs and the epidemic lifetime and hence to achieve reliable end-of-epidemic declaration times.
3.2. Reducing variation among elimination times
We examine two data-justified measures of the end of an epidemic: the mean elimination time and the maximum elimination time tα,max. Both have previously been used for assessing end-of-epidemic declarations [13,15]. As is convention, we focus on 95% confidence and set α = 95. Times and tα,max are obtained by finding when the mean and minimum of the zs curves, i.e. and zs,min, generated from possible future epidemic trajectories, first cross 0.95, respectively. We generate possible zs by drawing samples from the distributions of and then computing equation (2.6). All zs curves incorporate the known past incidence (see Methods).
We set to the daily new infections observed over the MERS-CoV epidemic in South Korea in 2015, which was investigated in [29]. We then compute probabilities of zero case-days forward in time as in [15] but for various hypothetical k-values and assess the elimination statistics using the distributions of the control measures (i)–(iii) from above. In appendix A, we perform complementary analyses using the incidence of the SARS 2003 epidemic in Hong Kong from [22] and simulated EVD data from [33], obtaining consistent results.
In figure 4, we present a range of mean and worst case zs curves for various k with blue indicating the smallest k and red the largest. All times are given relative to the last observed non-zero case day. For all control measures, we notice an interesting trend. First, and as expected from equation (2.8), we see that k ranks the mean zs curves, with more heterogeneity (smaller k) leading to a larger . This behaviour is also consistent with [2,30]. Second, we find that this ranking is inverted when we consider the worst case zs,min instead, i.e. epidemics with more heterogeneous transmission have larger worst case extinction or fade-out times.
Figure 4.
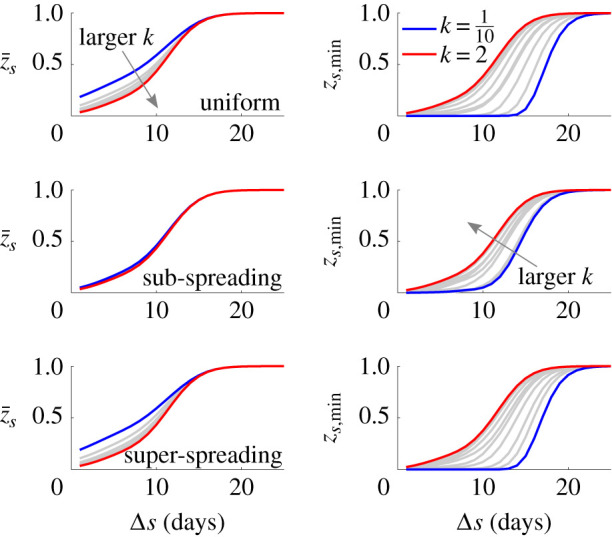
Mean and worst case epidemic elimination probabilities. We compute the mean () and worst case (zs,min) elimination probability curves using the incidence data from the MERS-CoV epidemic in South Korea in 2015 as in [29], i.e. we compute probabilities of sequences of zero future case days based on the available data and samples from the reproduction number distributions of the listed control scenarios (see main text). This procedure is repeated 2000 times to generate elimination curve distributions, from which we extract and zs,min. The curves are for various offspring dispersion parameters, k, rising from 0.1 to 2 under a mean controlled reproduction number of ρμ = 0.5. We find that increasing heterogeneity (smaller k) leads to earlier mean elimination times (the are larger) but later maximum (worst case) elimination times (the zs,min are smaller).
This result is striking. It means that control actions which increase heterogeneity, and have been proposed as the most effective type of interventions [2], may lead to a false sense of confidence in the end of the epidemic. This follows from their larger worst case elimination times. Heterogeneity has the contrasting effect of contracting the mean lifetime of the epidemic but prolonging its maximum lifetime (counted in zero-case days). Since authorities would want a single decision time for safely declaring an epidemic to be over [16] and relaxing interventions (e.g. to re-open trade or travel), this creates a practical, potentially costly and unexpected complication.
However, we observe that non-uniform control measures can help alleviate this problem. The sub-spreading control scheme considerably shrinks the variation among zs curves. This proceeds from the results of the previous section, where we found that, at small mean reproduction numbers (which is realistic when we are near the tail or end of an epidemic), limiting sub-spreading significantly reduces VM[Rs] and hence VM[Is] (see equation (2.4)). We assess this in more detail by examining all the zs curves, which led to the means and minima in figure 4, and the distributions of the 95% declaration times, t95, that result. We provide these in figure 5.
Figure 5.
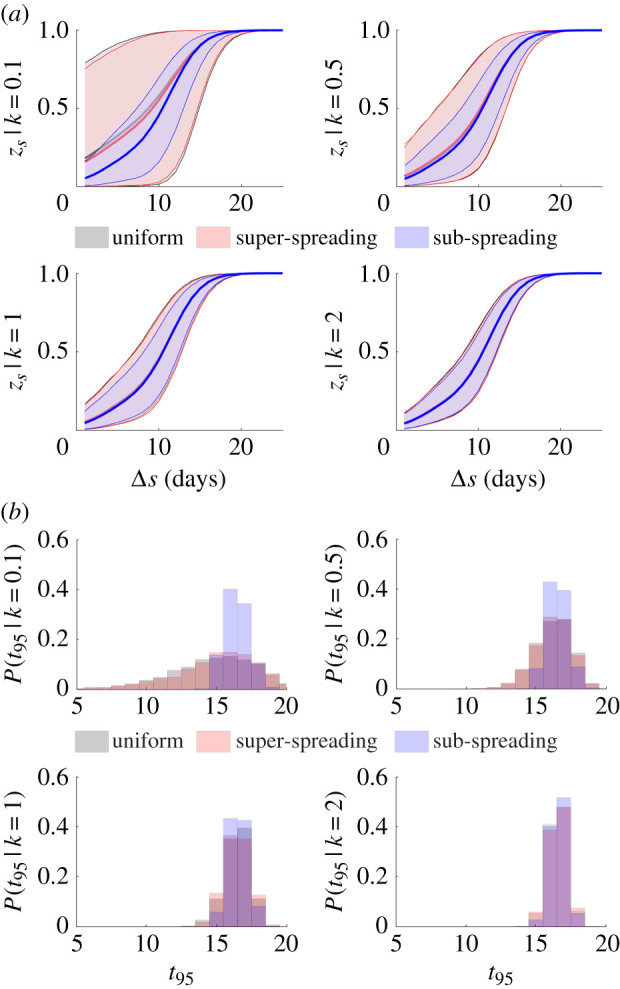
Elimination curves and declaration times for various control strategies. We compute elimination probabilities (zs) of future trajectories of zero case-days starting from the incidence data of the MERS-CoV epidemic in South Korea in 2015 and in line with [29]. Each trajectory is formed by sampling from the future reproduction number, , distributions for uniform, super-spreading and sub-spreading control measures. This procedure is repeated for 2000 possible trajectories. (a) The zs distribution from these trajectories for various offspring dispersion parameters k and (b) the corresponding 95% declaration times (t95). All times are relative to that of the last observed case and we use a mean controlled reproduction number of ρμ = 0.5 at every future time. We find that sub-spreading control is most effective at reducing the variability (or equivalently increasing the reliability) of both zs and t95. We bolster this assertion with additional examples in figure 7.
As k becomes larger the difference among all control measures expectedly shrinks. For epidemics with significant heterogeneity (k < 1), we observe that both uniform and super-spreading control result in large variations in zs (red and grey curves in figure 5a, which mostly overlay each other). This manifests in a notable spread of 95% declaration times (red and grey bars of figure 5b, also overlaid). Sub-spreading control is, however, able to suppress much of this variation yielding more deterministic elimination probabilities and declaration times (blue curves and bars in figure 5) and thus minimizing the possibility of early or late declarations.
We observe consistency in this trend for both EVD and SARS incidence curves in figure 7 of appendix A. We further confirm the ability of sub-spreading control as a means of making heterogeneous incidence curves more deterministic in behaviour by simulating complete epidemic trajectories under each control measure in the bottom panel of figure 6. There we see that the VM ratios of the incidence are indeed minimized by sub-spreading control measures (the mean incidence from all control measures there is approximately the same).
Figure 6.
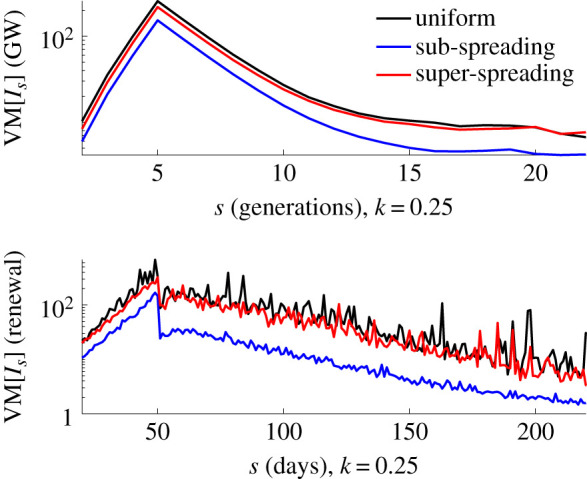
VM ratios for simulated epidemics. Using either a GW branching process [2] (top) or a renewal model [21] (bottom) we simulate 104 trajectories under a step-change in mean effective reproduction number, ρμ, from 2.5 to 0.6, with dispersion k = 0.25. At each time point we draw event reproduction numbers from the uniform, super-spreading and sub-spreading distributions with these means. We consistently find, for waning epidemics, that sub-spreading minimizes VM ratios of the incidence (denoted Is at time s). The mean incidence from all methods is approximately the same.
At this point, we re-interpret these results from the perspective of case ascertainment. The similarity of super-spreading and uniform control means that reporting strategies that sample possible spreading events with a constant probability or inversely to their reproduction numbers have approximately the same effect on elimination waiting times. This likely follows from the vanishingly low probability of super-spreading. However, size-biased sampling, which is not only the analogue to sub-spreading control, but also likely to occur in practice [18], has an important effect. Failing to observe sub-spreading events leads to a strongly overconfident view of elimination. The epidemic tail appears far less variable when those events are excluded, leading to risky end-of-epidemic declarations.
Last, we comment on differences between our renewal model approach and the Galton–Watson (GW) branching process used in [2]. Both models have significant dynamical disparities. Specifically, GW processes are truly only valid early in an epidemic, use a fixed generation time and assume that the number of infected in the next generation only depend on those in the current generation. These characteristics make the GW process unsuitable for the analysis of elimination statistics [7], especially when the generation time distribution is known (a) to be non-degenerate, (b) to have long memory and (c) to determine the epidemic growth rate [12,20,34].
Further, our problem of interest is ill defined for GW processes since, under these models, we always obtain t95 = 1 (time is now defined in generations). This follows as . Our results therefore do not apply to GW processes and should not be expected to correspond with computations of the probability of extinction from [2]. Nevertheless, we make some key comparisons. In [2], increasing heterogeneity elevated the extinction probability of an epidemic by promoting early burn-out. This partially holds true for renewal models, but (a) mostly affects t0 and (b) is not meaningful here as we condition on a significant epidemic having existed.
Since elimination measures only become an important consideration after t0 and for epidemics of notable size [16,29], burn-out due to overdispersion does not benefit our analysis. The extra dynamics beyond t0, which do not exist for GW processes, form our problem of interest. However, the VM ratio behaviour of our control schemes (i)–(iii) is quite general and still works under GW models. In figure 6, we show that the GW process (top panel) conserves the ordering of VM ratios from the renewal model (bottom panel), hence confirming the relative importance of sub-spreading control for achieving reliable elimination.
4. Discussion
Understanding how transmission heterogeneity shapes the dynamics of diverse phases of an emerging epidemic is crucial if we are to safely and efficiently apply or relax interventions during those phases. While much research has focused on super-spreading and the growing phases of epidemics, sub-spreading and the dynamics of waning infectious diseases have been understudied [9,30]. In this paper, we investigated both, by developing a general framework to measure how the variation or heterogeneity (embodied by k) around mean transmission at some time s (summarized by μs, the mean of Rs) engenders risk in the probability of epidemic elimination, zs.
We extended the popular theory of transmission heterogeneity from [2] to precisely describe how variations (via VM ratios) in event reproduction numbers, Rs, manifest in fluctuations of the incidence, Is (figure 1). The resulting proportional relationship meant that the Rs distribution directly modulates the observed Is curve [24]. We then generalized the formulae of [3,15] to derive how these variations propagate uncertainty onto zs. Since end-of-epidemic declarations depend on when zs crosses a confidence threshold, this uncertainty makes adjudging when an epidemic is over complex, risky and potentially costly [13,16].
Using our framework, we found that when epidemics are strongly heterogeneous, i.e. k < 1, the maximum and mean declaration times, relative to that of the last observed case, depend contrastingly on k (figure 4). Although the average time to declaration decreases as k falls, supporting previous work linking heterogeneity to epidemic extinction [14], the concomitant increase in variability means that the safest declaration time actually increases and the risk of early or late declarations can be severely amplified. Variation originating from transmission heterogeneity is therefore not beneficial for achieving safe and reliable end-of-epidemic declarations.
Consequently, we investigated if targeted control can ameliorate this end-of-epidemic volatility. We considered three control schemes (for the same mean level of control ρ), which were non-selective or targeted either super- or sub-spreading (figures 2 and 3). Intriguingly, we found that, because the controlled mean of the event reproduction numbers ρμs is below 1 at pre-elimination settings, curbing super-spreading only marginally improved on non-selective approaches. However, sub-spreading appeared to be the main contributor to end-of-epidemic declaration risk, meaning limiting those events can significantly reduce that risk; forcing the epidemic tail to be more deterministic and increasing the reliability of resulting intervention relaxation policies.
This result, while new and surprising, is supported by current understanding. Overdispersed distributions have two defining characteristics: tall heads and fat tails [24], where head and tail refer to the left and right ends of our Rs distributions. Since ρμs < 1 near elimination and because we only start measuring time once a sequence of days with no cases appear (in accordance with official guidelines [16]) fat tail events are extremely unlikely to affect epidemic dynamics. Consequently, it is the tall head, i.e. the excess of events with Rs ≪ ρμs, which is responsible for sustained overdispersion. Curbing sub-spreading suppresses this remaining source of risk.
We validated these theories on empirical MERS-CoV, SARS and simulated EVD epidemics (where we computed forward probabilities of no future cases based on these given data) and observed significant reductions in end-of-epidemic declaration time spread (figures 5 and 7) when sub-spreading was controlled. The conditions under which these effects were prominent (when k < 0.5) are realistic for these and many other infectious diseases [2,26]. An efficient strategy for controlling and then reliably eliminating an epidemic might therefore re-direct interventions from targeting super-spreading to sub-spreading transmission as infections enter waning phases.
Unfortunately, such selective strategies may be infeasible or difficult to realize. Predicting or simply identifying specific spreading event-types has proven difficult and hampered attempts at targeting super-spreading [8]. As sub-spreading frequently involves zero secondary cases, these events may be significantly harder to investigate. Intensive contact tracing and isolation schemes can help ameliorate some of these issues. Ongoing studies into associations among measurable traits, for example, viral loads or symptom severity, and infectiousness or transmissibility, may also make identifying and curbing specific spreading events easier [35,36]. However, even if these identification problems are overcome, policy resistance can nullify the benefits of targeted strategies [37].
Despite these points, our analysis of spreading events and our framework have several practical implications. First, we showed that the benefits of curbing super-spreading likely diminish with incidence. If targeted control is more costly than population-wide surveillance measures, this can support policy switches as the epidemic wanes. Second, we exposed the inherent risk of control measures that neglect sub-spreading. This knowledge can evidence more risk-averse approaches to end-of-epidemic declarations, in line with works such as [14]. Third, key formulae within our framework (equations (2.2)–(2.8) and (2.10)) are valid for arbitrary reproduction number distributions. Consequently, we can test the influence of other types of heterogeneity (e.g. demographic or spatial effects) on epidemic lifetimes and even incorporate empirical effective reproduction number distributions when available.
An important consequence of our analyses emerges from the mathematical analogue between control and case ascertainment [18]. Uniform, super-spreading and sub-spreading control are equivalent to constant, size-inverse and size-biased reporting. Size-biased reporting protocols are common in practice and generally include any preferential sampling scheme that observes infectious events with likelihoods that grow with the number of secondary cases produced by that event [24,38]. We investigated a specific size-biased scheme, similar to that in [18], where sub-spreading events are unobserved. This leads (by analogy to our sub-spreading control results) to a drastic underestimation of the variance of possible elimination times exhibited by heterogeneous epidemics.
Previously, it was shown that the mean end-of-epidemic declaration time is biased by any type of under-reporting [15]. As a result, practical surveillance schemes, which will almost surely feature some degree of size-biased reporting, are likely to promote simultaneously biased and overconfident end-of-epidemic declarations. These effects emphasize why sustained high-quality epidemic monitoring is crucial for guiding the relaxation of interventions or the reopening of economies during the waning phases of outbreaks. In the absence of such monitoring our results recommend a more cautious approach to designating the end of an outbreak.
While the results we have presented expose the complexities and biases in adjudging epidemic fade-out, there are some limitations to our analyses. We have assumed that the control effort or reporting rate of ρ can be realized with equal ease for both the uniform and selective strategies and that gamma or truncated gamma reproduction number distributions are sensible. These are necessary and standard assumptions for comparing strategies and sensibly summarizing heterogeneity [2,7] but their validity may depend on the disease being considered and the properties (e.g. contact networks) of the area under study. Scale may also matter. For example, across larger regions population-wide measures may more easily achieve a given ρ than more targeted ones.
Moreover, we have not accounted for how interventions (e.g. lockdowns or quarantines) may alter the contact networks and behaviours of individuals and hence the characteristics of serial interval or generation time and offspring distributions (which may vary across epidemic phases) [39]. Such changes could affect the adequacy of the renewal models we have employed or the practical effectiveness of the strategies we have examined. While lack of data precludes improvement here, we note that our framework for investigating epidemic fade-out (a) is sufficiently general to handle empirical (and non-gamma) reproduction number distributions if such knowledge is available, (b) remains valid if up-to-date serial intervals and dispersion parameters are used and (c) applies to the waning phases of the epidemic, after most drastic changes would likely have already settled.
Our framework provides a general toolkit for testing hypotheses about targeted controls or case ascertainment schemes and measuring their influence on end-of-epidemic declaration times. It can also be easily extended to include additional factors such as imported cases or to investigate other types of heterogeneity (e.g. age-based reproduction numbers) [15]. As the current COVID-19 pandemic underscores, much still remains unknown about the relative merits of elimination approaches, e.g. ‘zero COVID’ strategies [11], and the influence of heterogeneity [4,40]. Improved understanding of epidemic dynamics can only aid preparedness and decision-making. We hope that our framework, which exposed unexpected consequences of understudied spreading events [19], can contribute towards this goal and help inform safe intervention relaxation and end-of-epidemic declaration strategies.
Appendix A. Declaration time histograms for SARS and EVD
See figure 7.
Figure 7.
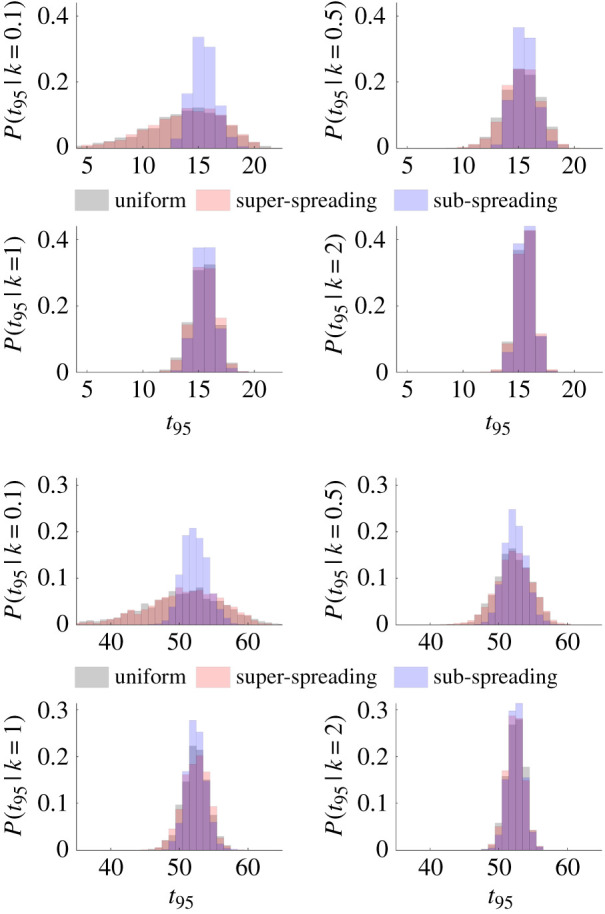
Declaration times for different epidemics. We generate 2000 future trajectories of zero case-days using empirical incidence data of the SARS epidemic in Hong Kong in 2003 (top) [22] and simulated incidence for EVD (bottom) from [33]. We obtain trajectories by sampling from the future reproduction number, , distributions for uniform, super-spreading and sub-spreading control measures and plot corresponding 95% declaration times (t95). The uniform and super-spreading results largely overlap. All times are relative to that of the last observed case and assume a mean controlled reproduction number of ρμ = 0.5. As in the main text, we see that sub-spreading control is most effective at reducing the variability (increasing the reliability) of end-of-epidemic declarations.
Data accessibility
Code to reproduce the analyses in this paper is available at https://github.com/kpzoo/sub-spreading.
Competing interests
I declare I have no competing interests.
Funding
This work is jointly funded under grant no. MR/R015600/1 by the UK Medical Research Council (MRC) and the UK Department for International Development (DFID) under the MRC/DFID Concordat agreement and is also part of the EDCTP2 programme supported by the European Union. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
References
- 1.Nishiura H, Chowell G. 2009The effective reproduction number as a prelude to statistical estimation of time-dependent epidemic trends. In Mathematical and statistical estimation approaches in epidemiology (eds G Chowell, J Hyman, L Bettencourt, C Castillo-Chavez), pp. 103–121. Berlin, Germany: Springer.
- 2.Lloyd-Smith JO, Schreiber SJ, Kopp PE, Getz WM. 2005Superspreading and the effect of individual variation on disease emergence. Nature 438, 355-359. ( 10.1038/nature04153) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Parag K, Cowling B, Donnelly C. 2021Deciphering early-warning signals of the elimination and resurgence potential of SARS-CoV-2 from limited data at multiple scales. medRxiv. ( 10.1101/2020.11.23.20236968) [DOI]
- 4.Susswein Z, Bansal S. 2020Characterizing superspreading of SARS-CoV-2: from mechanism to measurement. medRxiv. ( 10.1101/2020.12.08.20246082) [DOI]
- 5.De Serres G, Gay N, Farrington P. 2000Epidemiology of transmissible diseases after elimination. Am. J. Epidemiol. 151, 1039-1048. ( 10.1093/oxfordjournals.aje.a010145) [DOI] [PubMed] [Google Scholar]
- 6.Woolhouse Met al.1997Heterogeneities in the transmission of infectious agents: implications for the design of control programs. Proc. Natl Acad. Sci. USA 94, 338-342. ( 10.1073/pnas.94.1.338) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Garske T, Rhodes C. 2008The effect of superspreading on epidemic outbreak size distributions. J. Theor. Biol. 253, 228-237. ( 10.1016/j.jtbi.2008.02.038) [DOI] [PubMed] [Google Scholar]
- 8.Frieden T, Lee C. 2020Identifying and interrupting superspreading events— implications for control of severe acute respiratory syndrome Coronavirus 2. Emerg. Infect. Dis. 26, 1059-1066. ( 10.3201/eid2606.200495) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Britton T, House T, Lloyd AL, Mollison D, Riley S, Trapman P. 2015Five challenges for stochastic epidemic models involving global transmission. Epidemics 10, 54-57. ( 10.1016/j.epidem.2014.05.002) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Parag K. 2020Improved estimation of time-varying reproduction numbers at low case incidence and between epidemic waves. medRxiv. ( 10.1101/2020.09.14.20194589) [DOI]
- 11.Baker M, Wilson N, Blakely T. 2020Elimination may be the optimal response strategy for COVID-19 and other emerging pandemic diseases. Br. Med. J. 371, m4907. ( 10.1136/bmj.m4907) [DOI] [PubMed] [Google Scholar]
- 12.Lee H, Nishiura H. 2019Sexual transmission and the probability of an end of the Ebola virus disease epidemic. J. Theor. Biol. 471, 1-12. ( 10.1016/j.jtbi.2019.03.022) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Nishiura H, Miyamatsu Y, Mizumoto K. 2016Objective determination of end of MERS outbreak, South Korea. Emerg. Infect. Dis. 22, 146-148. ( 10.3201/eid2201.151383) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Djaafara BA, Imai N, Hamblion E, Impouma B, Donnelly CA, Cori A. 2021A quantitative framework to define the end of an outbreak: application to Ebola Virus Disease. Am. J. Epidemiol. 190, 642-651. ( 10.1093/aje/kwaa212) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Parag KV, Donnelly CA, Jha R, Thompson RN. 2020An exact method for quantifying the reliability of end-of-epidemic declarations in real time. PLoS Comput. Biol. 16, e1008478. ( 10.1371/journal.pcbi.1008478) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.WHO. 2020 WHO recommended criteria for declaring the end of the Ebola virus disease outbreak. See https://www.who.int/who-documents-detail/who-recommended-criteria-for-declaring-the-end-of-the-ebola-virus-disease-outbreak.
- 17.Lloyd-Smith JO, Cross PC, Briggs CJ, Daugherty M, Getz WM, Latto J, Sanchez MS, Smith AB, Swei A. 2005Should we expect population thresholds for wildlife disease? Trends Ecol. Evol. 20, 511-519. ( 10.1016/j.tree.2005.07.004) [DOI] [PubMed] [Google Scholar]
- 18.Lloyd-Smith J. 2007Maximum likelihood estimation of the negative binomial dispersion parameter for highly overdispersed data, with applications to infectious diseases. PLoS ONE 2, e180. ( 10.1371/journal.pone.0000180) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Lawyer G. 2015Understanding the influence of all nodes in a network. Sci. Rep. 5, 8665. ( 10.1038/srep08665) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Wallinga J, Lipsitch M. 2007How generation intervals shape the relationship between growth rates and reproductive numbers. Proc. R. Soc. B 274, 599-604. ( 10.1098/rspb.2006.3754) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Fraser C, Cummings DA, Klinkenberg D, Burke DS, Ferguson NM. 2011Influenza transmission in households during the 1918 pandemic. Am. J. Epidemiol. 174, 505-514. ( 10.1093/aje/kwr122) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Cori A, Ferguson NM, Fraser C, Cauchemez S. 2013A new framework and software to estimate time-varying reproduction numbers during epidemics. Am. J. Epidemiol. 178, 1505-1512. ( 10.1093/aje/kwt133) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Parag K, Donnelly C. 2020Adaptive estimation for epidemic renewal and phylogenetic skyline models. Syst. Biol. 69, 1163-1179. ( 10.1093/sysbio/syaa035) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Karlis D, Xekalaki E. 2005Mixed poisson distributions. Intern. Statist. Rev. 73, 35-58. ( 10.1111/j.1751-5823.2005.tb00250.x) [DOI] [Google Scholar]
- 25.Churcher TS, Cohen JM, Novotny J, Ntshalintshali N, Kunene S, Cauchemez S. 2014Measuring the path toward malaria elimination. Science 344, 1230-1232. ( 10.1126/science.1251449) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Lau M, Dalziel B, Funk S, McClelland A, Tiffany A, Riley S, Metcalf CJ, Grenfell BT. 2017Spatial and temporal dynamics of superspreading events in the 2014–2015 West Africa Ebola epidemic. Proc. Natl Acad. Sci. USA 114, 2337-2342. ( 10.1073/pnas.1614595114) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Parag K, Donnelly C. 2020Using information theory to optimise epidemic models for real-time prediction and estimation. PLoS Comput. Biol 16, e1007990. ( 10.1371/journal.pcbi.1007990) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Azmon A, Faes C, Hens N. 2014On the estimation of the reproduction number based on misreported epidemic data. Stats. Med. 33, 1176-1192. ( 10.1002/sim.6015) [DOI] [PubMed] [Google Scholar]
- 29.Nishiura H. 2016Methods to determine the end of an infectious disease epidemic: a short review. In Mathematical and statistical modeling for emerging and re-emerging infectious diseases (eds G Chowell, J Hyman), pp. 291–301. Cham, Switzerland: Springer.
- 30.Yan P, Chowell G. 2019Quantitative methods for investigating infectious disease outbreaks. Texts in Applied Mathematics, vol. 70. Cham, Switzerland: Springer. [Google Scholar]
- 31.Wasserman L. 2003All of statistics: a concise course in statistical inference. Berlin, Germany: Springer. [Google Scholar]
- 32.Xekalaki E. 2014On the distribution theory of over-dispersion. J. Stat. Distrib. Appl. 1, 1-22. ( 10.1186/s40488-014-0019-z) [DOI] [Google Scholar]
- 33.Jombart T, Frost S, Nouvellet P, Campbell F, Sudre B. 2019outbreaks: A Collection of Disease Outbreak Data (cited 31 July 2020). See https://github.com/reconhub/outbreaks.
- 34.Parag K, Thompson R, Donnelly C. 2021Are epidemic growth rates more informative than reproduction numbers? medRxiv. ( 10.1101/2021.04.15.21255565) [DOI]
- 35.Edwards Aet al.2021Exhaled aerosol increases with COVID-19 infection, age, and obesity. Proc. Natl Acad. Sci. USA 118, e2021830118. ( 10.1073/pnas.2021830118) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Goyal A, Reeves DB, Cardozo-Ojeda EF, Schiffer JT, Mayer BT. 2021Viral load and contact heterogeneity predict SARS-CoV-2 transmission and super-spreading events. eLife 10, e63537. ( 10.7554/eLife.63537) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Wang Z, Bauch CT, Bhattacharyya S, Manfredi P, Perc M, Perra N, Salathè M, Zhao D. 2016Statistical physics of vaccination. Phys. Rep. 664, 1-113. ( 10.1016/j.physrep.2016.10.006) [DOI] [Google Scholar]
- 38.Zelner J, Masters NB, Broen K, Lofgren E. 2020Preferential observation of large infectious disease outbreaks leads to consistent overestimation of intervention efficacy. medRxiv. ( 10.1101/2020.11.02.20224832) [DOI]
- 39.Ali ST, Wang L, Lau EH, Xu XK, Du Z, Wu Y, Leung GM, Cowling BJ. 2020Serial interval of SARS-CoV-2 was shortened over time by nonpharmaceutical interventions. Science 369, 1106-1109. ( 10.1126/science.abc9004) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Lewis D. 2021Superspreading drives the COVID pandemic—and could help to tame it. Nature 590, 544-546. ( 10.1038/d41586-021-00460-x) [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Code to reproduce the analyses in this paper is available at https://github.com/kpzoo/sub-spreading.