

Abstract
The ability to predict an individual’s menstrual cycle length to a high degree of precision could help female athletes to track their period and tailor their training and nutrition correspondingly. Such individualisation is possible and necessary, given the known inter-individual variation in cycle length. To achieve this, a hybrid predictive model was built using data on 16,524 cycles collected from a sample of 2125 women (mean age 34.38 years, range 18.00–47.10, number of menstrual cycles ranging from 4 to 53). A mixed-effect state-space model was fitted to capture the within-subject temporal correlation, incorporating a Bayesian approach for process forecasting to predict the duration (in days) of the next menstrual cycle. The modelling procedure was split into three steps (1) a time trend component using a random walk with an overdispersion parameter, (2) an autocorrelation component using an autoregressive moving-average model, and (3) a linear predictor to account for covariates (e.g. injury, stomach cramps, training intensity). The inclusion of an overdispersion parameter suggested that of cycles in the sample were overdispersed. The random walk standard deviation for a non-overdispersed cycle is [1.00, 1.09] days while under an overdispersed cycle, the menstrual cycle variance increase in 4.78 [4.57, 5.00] days. To assess the performance and prediction accuracy of the model, each woman’s last observation was used as test data. The root mean square error (RMSE), concordance correlation coefficient and Pearson correlation coefficient (r) between the observed and predicted values were calculated. The model had an RMSE of 1.6412 days, a precision of 0.7361 and overall accuracy of 0.9871. In conclusion, the hybrid model presented here is a helpful approach for predicting menstrual cycle length, which in turn can be used to support female athlete wellness.
Subject terms: Statistical methods, Statistics
Introduction
The availability of mobile apps developed to track the menstrual cycle is growing as they are becoming increasingly popular for contraception purposes, fertility awareness and exercise planning. These apps can be grouped broadly as calendar-based, basal body temperature (BBT), or symptothermal1–3. Calendar apps generally use simple algorithms based on empirical measurements to predict cycle phase length4; BBT apps describe a woman’s menstrual variation through her basal body temperature rise5 and symptothermal apps measure parameters such as cervical mucus changes, bleeding period and so on2.
The mobile app that generated the data used in the study is called FitrWoman. It is a free calendar-based app that enables users to track their menstrual cycle and symptoms, and provides relevant information about wellness, nutrition and exercise, based on the athlete’s predicted menstrual cycle phases and length. The user inputs daily information on 25 symptom variables such as flow, bloating, constipation, injury, illness, irritability and weakness. The target audience is female athletes who wish to track their menstrual cycle to improve their performance and understanding of their individual cycle.
As a woman’s body may respond and adapt differently throughout their cycle, different planning and preparation over the menstrual cycle phases6–8 might be required. McNulty et al.9 observed through meta-analysis that exercise performance might be trivially reduced during the early follicular phase of the menstrual cycle when compared to the other phases.
As few apps are accurate in terms of menstrual cycle length prediction10, the development of an appropriate, exact parametric model for one-step-ahead forecast cycle length is required. Such a model should take into account the between and within-woman variability to identify menstrual cycle patterns and how each symptom could affect cycle length, alongside the implications of significant alterations in cycle length.
According to several studies11–14, the menstrual cycle length can be classified into two groups ‘standard‘ and ‘menstrual dysfunction‘, where a cycle length greater than 35 days is classified as ‘menstrual dysfunction‘ and otherwise as standard. Many statistical models have been proposed in the literature to describe these different groups of menstrual cycles2,15–18. Generally, cycle length related to the ‘standard‘ group can be analysed using classical statistical approaches. In contrast, the mixture of standard and non-standard cycles can be analysed using a mixture distribution accounting for the significant symmetric distribution and the component corresponding to the heavy right tail14,15. To account for the within-individual variability, we focused on the dynamic aspect of menstrual cycles over time, as discussed by Bortot et al. (2010)16, who derived a predictive distribution based on individual repeated measurements using a state-space model formulation. According to these authors16, state-space models under a Bayesian approach have the advantage of incorporating between subject information to compensate for the relatively large number of subjects with a low quantity of repeated measurements and to make predictions for women not included in the sample.
It is well-established that having a regular menstrual cycle is a ’vital sign‘ demonstrating that the body is likely to be in an adaptive state and is tolerating the physical and psychological stressors that are being placed on it19. Significant elongations in cycle length are associated with adverse health and fertility outcomes20–23, therefore gaining a better understanding of the interrelating risk factors for cycle length extension is important.
In this paper, the first objective was to develop an appropriate parametric state-space formulation for the marginal distribution of standard menstrual cycles for female athletes. In addition, symptom variables were included in the model’s linear predictor to evaluate how the individual reported symptoms might affect an athlete’s menstrual cycle duration. The second aim was to develop a one-step-ahead forecasting interval approach, based on a state-space formulation, to describe the experimental and state process while considering both between and within-woman variability.
Results and discussion
Results from the state-space models, state-space mixed-effects models and linear mixed-effects models (LMM), fitted using the available data, are summarised in Table 1. In general, the Bayesian information criteria (BIC) suggests that the random walk models fitted better than the LMM when modelling menstrual cycle length, in agreement with the results reported by Bortot at al. (2010)16 while contradicting the results of2 who report an when fitting a simple linear regression.
Table 1.
Model selection criteria for stages I and II; number of parameters (N. Par.), root mean square error (RMSE), concordance correlation coefficient (CCC), Pearson correlation coefficient (r) between fitted and predicted test data, and Bayesian information criterion (BIC).
| Model | N. Par. | Forecasting | BIC | ||
|---|---|---|---|---|---|
| RMSE | CCC | r | |||
| 3 | 1.6066 | 0.7327 | 0.7537 | 16,886.70 | |
| 4 | 1.5956 | 0.7251 | 0.7546 | 17,920.96 | |
| 4 | 1.6108 | 0.7348 | 0.7533 | 17,694.21 | |
| 5 | 1.5808 | 0.7360 | 0.7603 | 17,695.83 | |
| 5 | 1.6449 | 0.7131 | 0.7283 | 7393.54 | |
| 6 | 1.6332 | 0.7136 | 0.7323 | 8413.30 | |
| 6 | 1.6412 | 0.7266 | 0.7361 | 7381.61 | |
| 7 | 1.6255 | 0.7203 | 0.7363 | 7460.37 | |
| 5 | 1.6274 | 0.7257 | 0.7457 | 17,042.26 | |
| 6 | 1.6640 | 0.7205 | 0.7374 | 17,413.73 | |
| 6 | 1.6810 | 0.7171 | 0.7326 | 17,305.01 | |
| 8 | 1.6832 | 0.7164 | 0.7320 | 17,314.24 | |
The inclusion of to model overdispersed cycle lengths was fundamental to describe menstrual cycle dynamics as evidenced by the BIC criteria where a reduction of compared to , and compared to is evident, as shown in Fig. 1. Additionally, the inclusion of a moving average (MA) parameter was necessary to capture the dynamism of shorter cycles followed by longer cycles and vice-versa. In summary, a random walk with a random variable to capture overdispersion plus a MA(1) model demonstrated the best fit to the data.
To assess model performance, we compared the forecasts of these models using the RMSE of one-step-ahead predictions, CCC and Pearson correlation coefficient evaluated on the test group. Table 1 demonstrates that better forecast predictions were made using a random walk rather than an LMM and that there was little difference between the random walk models in terms of forecasting. As a consequence, the BIC criteria can be used to select the error structure. After selecting the trend and error structures, the next stage of the analysis was the selection of potentially useful explanatory variables. The set of 28 available represented a variety of reported symptoms by the i-th woman, including an interval-based variable representing a woman’s body mass index (Kg/) (Table 2), classified as discussed by Corbel at al. (2004)24. In this analysis, underweight classes I and II were classified as ’severely’ and ’very severely underweight’ while obese classes I, II, and III represented moderately, severely and very severely obese, respectively. The sample of women had a reported BMI of between 14.44 and 54.25, with a mean of 22.85 Kg/; the absolute frequency is shown as a histogram in Fig. 1.
Table 2.
Histogram of BMI and body mass index (BMI) classification.
| Category | BMI | |
|---|---|---|
| From | To | |
| Underweight II | 15 | |
| Underweight I | 16 | |
| Underweight | 18.5 | |
| Normal | 25 | |
| Overweight | 30 | |
| Obese Class I | 35 | |
| Obese Class II | 40 | |
| Obese Class III | ||
Figure 1.
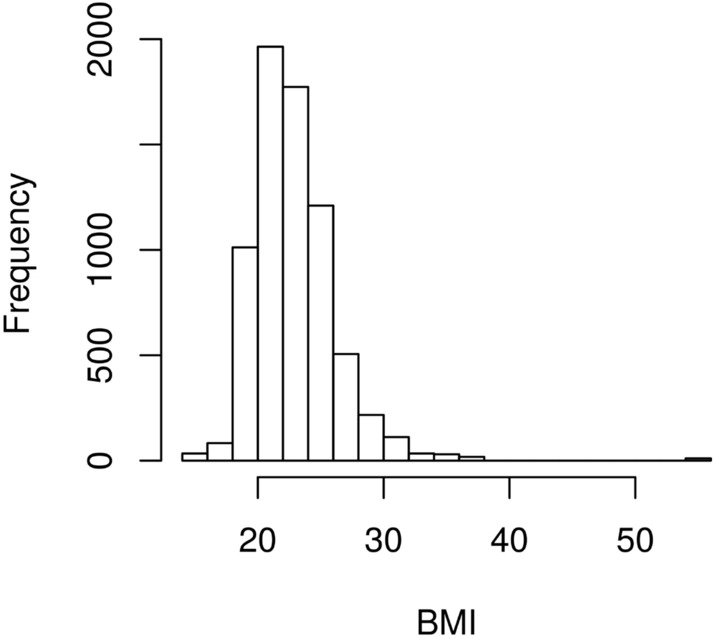
Histogram of Body Mass Index (BMI) classification.
The selected state-space model summary with posterior means and 95% credibility intervals for the population parameters (after predictor selection) is presented in Table 3.As the model parameterisation facilitates the interpretation of the role played by the explanatory variables, our analysis reveals important insights on how some symptoms affect menstrual cycle length.
Table 3.
Posterior means and 95% Bayesian credibility interval for .
| Parameter | Estimate | SE | 95% Credible Interval | |
|---|---|---|---|---|
| Lower | Upper | |||
| 27.4141 | 0.0440 | 27.3283 | 27.4996 | |
| 0.2636 | 0.0142 | 0.2368 | 0.2917 | |
| − 0.0915 | 0.3160 | − 0.1563 | − 0.0320 | |
| (Injury) | 0.2965 | 0.1038 | 0.0554 | 0.4768 |
| (Stomach Cramps) | 0.1682 | 0.0585 | 0.0567 | 0.2835 |
| (Tender Breasts) | − 0.1540 | 0.0457 | − 0.2443 | − 0.0624 |
| (Flow Amount: Heavy) | − 0.0816 | 0.0861 | − 0.2492 | 0.0882 |
| (Flow Amount: Medium) | 0.0290 | 0.0196 | − 0.0094 | 0.0675 |
| (Flow Amount: Light) | − 0.1320 | 0.0560 | − 0.2414 | − 0.0239 |
| (Flow Amount: Spotting) | 0.0589 | 0.0712 | − 0.0792 | 0.2012 |
| (Flow Amount: None) | 0.0093 | 0.0208 | − 0.0314 | 0.0492 |
| 1.0417 | 0.0231 | 0.9971 | 1.0875 | |
| 4.7803 | 0.1096 | 4.5738 | 5.0007 | |
| 1.5407 | 0.0449 | 1.4504 | 1.6259 | |
We found that the overall menstrual cycle length without any reported symptoms was around days, which is in agreement with Guo et al (2006)15 and Bull et al. (2019)2. Additionally, the reporting of injury, stomach cramps and flow amount was associated with increased menstrual cycle length. In contrast, the reporting of tender breasts was associated with decreased cycle length. For example, if a woman reported tender breasts ten times over her cycle, as a consequence, her predicted menstrual cycle length is estimated to reduce, on average, by days.
Self-track symptoms quality depends on both user engagement, app design and unambiguous language to describe the level of a symptom. Consequently, to make it more consistent, filtering the original database based on the scientific literature is a critical way to reduce bias in the covariates used to fit the model, as described by Li et al. (2020)14.
The estimated value of suggests that the probability of a non-standard (overdispersed) menstrual cycle length occurring in this population of interest is 0.2636. Consequently, we can infer that of cycles in the sample are overdispersed. Furthermore, while a non-overdispersed cycle had a standard deviation (SD) of [0.9971, 1.0875], the SD of an overdispersed cycle increases where [4.5738, 5.0007], which represents a 4-fold increment. According to Najmabadi et al. (2020)25, between and within-variability in cycle characteristics should be emphasised as an important health indicator to assess behavioural, metabolic, and environmental factors. Therefore, the inclusion of and play an essential role in the proposed model, as illustrated in Fig. 2. This Figure shows the probability that the proposed model (3) considers an observation as overdispersed where the results clearly demonstrate that is capturing menstrual cycles with overdispersion.
Figure 2.

Example of six women profiles showing the probability that the proposed model considers an observation as overdispersed, where represents the probability of being equal 1 for a given observation.
Using this model, knowledge and understanding can be gleaned as to how symptom variables affect the menstrual cycle, which is essential for individual athletes, coaches and healthcare professionals. Furthermore, these results can improve the forecasting intervals, helping women to know more about their bodies and cycles based on symptoms during a particular phase of their cycles. Further work is needed to translate these findings into recommendations. Although information relating to follicular and luteal phases was not available in the data, a strong linear correlation between menstrual cycle length and follicular phase has been reported26–28. Where the correlation tended to increase with age. To predict ovulation time, further studies, which include both luteal and follicular phases and basal body temperature (BBT), are needed to extend the proposed model2.
Although an ARMA(1,1) model was not needed in this analysis, we have demonstrated that some women have a positive lag-one autocorrelation while others have a negative lag-one autocorrelation. These results contradict the findings of16,29 who report a small general negative autocorrelation for a woman’s profile. In order to better investigate the variability of an autoregressive coefficient, we modified the state-space formulation to accommodate this source of random variation by assuming that , with . However, the normality assumption for was not justified as the normal Q-Q plot suggested a distribution with heavy tails and asymmetry; as a consequence, of points were outside of the 95% simulated envelopes for this random effect (Figure S1).
We also observed that some women had a long cycle followed by a short cycle and vice versa, as observed by Bortot et al. (2010)16. However, we found while with the estimate of the same parameter described by Bortot et al. (2010)16 was . It appears that the sample of female athletes that these analyses are based on had more regular menstrual cycles than a sample of 1,798 women observed from clients of the Catholic Marriage Advisory Council of England and Wales. Although we have a higher number of women in our sample than in16, the time series in their sample were longer (up to 109 measurements) compared with up to 55 measurements in this sample. In order to account for the between-subject variability, we included a random effect in the moving-average coefficient given by , with . However, we observed the same problem as reported when considering the autoregressive coefficient where more than of points were outside of the 95% simulated envelopes, lower asymmetry compared with and heavy tails (Figure S2). Therefore, to avoid bias in individual forecasting predictions, these random effects were dropped from the model. Further work is needed to accommodate individual estimation for the autocorrelation and moving-average coefficients to improve model performance at the individual level.
The analysis workflow was as follows: we initially checked the Bayesian assumptions and the posterior distribution using suitable plots of the Markov Chain Monte Carlo (MCMC) draws from the posterior distribution and Gelman-Rubin diagnostic and autocorrelation plots of all model parameters. Figure 3a shows the iterates of , , , , , and after a burn-in of 10,000 simulated iterations, which indicates convergence of the chains and stationary distributions, as the samples appear to be randomly sampled from the same region of the y-axis rarely venturing outside that area. The autocorrelation and Gelman-Rubin statistics30 were used to assess model convergence. The results suggest that the autocorrelation does not drop dramatically from lag 0 to 50 (Figure S3), indicating a moderate to high autocorrelation among samples. To reduce the impact of this problem, we stipulated a thinning of 50. On the other hand, the Gelman-Rubin statistic based on three chains showed all upper 95% confidence intervals were exactly equal to 1, meaning the chains had converged. Figure 3b shows the posterior densities obtained for estimated parameters derived from 3 Markov chains with 3000 samples per chain, leading to a computational time of around 23 hours executed on Dell Inspiron 17 7000 with 10 Generation Intel i7 processor, 1.80GHz four-processor speed, 16GB random access memory (RAM) plus 20GB of swap space, 64-bit integers, and the platform used is a Linux Mint 19.2 Cinnamon system version 5.2.2-050202-generic. In summary, the posterior distribution has been well characterised by the drawn samples as no unexpected peaks or strange shapes in the posterior density were observed that could signify poor model convergence. As a final assessment, the autocorrelation function, as well as the standardized residual against the athlete’s age, were checked (Fig. 4). No serious discrepancies nor patterns that warrant attention were observed in both graphs.
Figure 3.

(a) Trace plots of Markov chains and (b) Markov chain Monte Carlo (MCMC) draws from the posterior distribution of the parameters , , , , , and based on a sample of length 3000.
Figure 4.

(a) Residual autocorrelation plot, and (b) residual versus age.
Once the assumptions were verified, we evaluated the agreement between the fitted and observed values and forecast intervals. Figure 5 shows the fitted curves for menstrual cycle length of six women, their 95% credible interval, and the one-step-ahead point forecast with 80%, 95% and 99% forecast intervals. We observed that the random walk with overdispersion parameter and MA(1) model performed well in describing the complex dynamics of menstrual cycle length over time. This conclusion is underpinned by CCC’s residual diagnostic and high values and Pearson correlation between fitted and observed values by the woman. These results also show that linear or linear mixed-effects models should not be applied to explain the variability of menstrual cycle length. They generally do not follow the necessary assumptions of linearity–however, a study done in 2019 by Bull et al. (2019)2 appears to use linear models to explain cycle length observed from an extensive database of cycles collected through an app. The authors show an without any discussion as to whether the model assumptions are likely to be fulfilled; a high value does not necessarily imply that a regression model provided an adequate fit to the data31.
Figure 5.

Age versus fitted menstrual cycle length for six women with more than 40 repeated measurements with addition of 95% credible interval (dashed line), 80%, 95%, and 99% forecast intervals for the next cycle, and observed menstrual cycle length as points. The estimated concordance correlation coefficient (CCC), and Pearson correlation coefficient (r) between fitted and observed values are described for each woman. Accuracy () can be obtained using .
The necessity of including in our model to describe cycle length is demonstrated in Fig. 6 where the improvement in the point estimates, credible and forecasting intervals when was and was not included in the model is given.
Figure 6.

Age versus fitted menstrual cycle length for six women with more than 40 repeated measurements with addition of 95% credible interval (dashed line), 80%, 95%, and 99% forecast intervals for their next cycle, and observed menstrual cycle length (points) using the model , when dropping the term from the model. The estimated concordance correlation coefficient (CCC), and Pearson correlation coefficient (r) between fitted and observed values are reported for each woman. Accuracy () can be obtained using .
The results show that the improvement in the Pearson and concordance correlation coefficients when was included in the model was mainly for women who had more overdispersed cycles, resulting in better forecast predictions, and narrower corresponding credible intervals.
Finally, to evaluate the one-step-ahead point forecast prediction we generated prediction using a test set comprised of 1,029 women, each of whom had at least 3 repeated measurements. The results are shown in Fig. 4.
Table 4.
Evaluation of one-step-ahead forecast prediction based on root mean square error (RMSE), concordance correlation (CCC), Pearson correlation (r), and accuracy () coefficients between the predict and observed values of a new group with N women whom have observed cycles.
| N | RMSE | CCC | r | ||||
|---|---|---|---|---|---|---|---|
| Est | Lower | Upper | |||||
| 1029 | 3 | 5.2349 | 0.2213 | 0.1825 | 0.2610 | 0.2953 | 0.7490 |
| 760 | 4 | 5.3515 | 0.2254 | 0.1710 | 0.2784 | 0.2800 | 0.8048 |
| 603 | 5 | 5.4332 | 0.2078 | 0.1374 | 0.2760 | 0.2281 | 0.9108 |
| 434 | 6 | 5.5019 | 0.2102 | 0.1221 | 0.2951 | 0.2182 | 0.9634 |
| 324 | 7 | 5.6496 | 0.2069 | 0.1015 | 0.3078 | 0.2089 | 0.9905 |
| 248 | 8 | 6.3264 | 0.1047 | − 0.0190 | 0.2252 | 0.1055 | 0.9928 |
| 199 | 9 | 6.1774 | 0.0778 | − 0.0602 | 0.2129 | 0.0786 | 0.9901 |
| 160 | 10 | 5.1351 | 0.2632 | 0.1132 | 0.4015 | 0.2633 | 0.9998 |
| 124 | 11 | 5.1964 | 0.1421 | − 0.0335 | 0.3093 | 0.1428 | 0.9954 |
| 99 | 12 | 4.8562 | 0.2713 | 0.0801 | 0.4433 | 0.2726 | 0.9953 |
| 78 | 13 | 4.6067 | 0.1970 | − 0.0185 | 0.3951 | 0.2028 | 0.9716 |
As there are not the same number of repeated measurements for each woman, this makes the forecasting prediction evaluation difficult as the number of women who drop out of the test set increases over time. With this in mind, we found that RMSE values could be two times higher than those presented in Table 1, suggesting that these models are not working well for some women in the test group. The same conclusion is evident when considering the CCC and Pearson correlation coefficients. As the CCC can be written as , where r represents a measure of precision and a measure of accuracy32, we can conclude that our model has high accuracy, with the potential to increase as the number of women with repeated measurements increases. The lower precision reported for the test set suggests that the explanatory variables used in the model may not be enough to explain the variability in the data. Including additional variables such as those that capture information on polycystic ovary presence, daily diet, country of origin,may improve model forecasts in general.
Limitations
The limitation of this study is that it is based on observational data which depends on users logging their information on the app. As a consequence, the models proposed are not intended to elucidate the causal pathway of reported symptoms on cycle length.
Conclusion
State-space models, incorporating a probability as a random effect at the subject level in the random walk component. are a valuable approach for predicting menstrual cycle length. They could be used to support female athlete wellness and optimize performance. For this reason a random walk with an overdispersion parameter and an MA(1) model was selected to describe the complex dynamics of menstrual cycle length over time, which resulted in high values of CCC and Pearson correlation between observed and fitted values. Moreover, the importance of incorporating an overdispersion parameter to capture the variability of non-standard cycles was demonstrated. The data suggested that of cycles are overdispersed. The random walk standard deviation for a non-overdispersed cycle is [0.9971, 1.0875] days which increased to [4.5738, 5.0007] days for non-standard cycles.
We also found that reporting injury, stomach cramps, tender breasts, and flow amount had a significant effect on menstrual cycle length amongst female athletes using the FitrWoman app. Although accurate forecast predictions are reported, improvements in the variables collected and enhancements to the model are still needed, such as considering a random effect for the moving-average coefficient , to improve forecast precision.
Methods
Data characteristics
The sample was comprised of female athletes using the FitrWoman app33 who had given their consent for the use of their data for research purposes. The sample size contains data on 16,524 cycles collected from 2,125 women (Fig. 7a), whose mean (sd) age was 34.38 (7.05) years (range 18 to 47 years); mean (sd) weight 62.75 (9.16) Kg (range 42.18 to 100.23 Kg); mean (sd) height 165.88 (6.89) cm (range 152.4 to 186.0 cm); with several repeated measurements per woman ranging from 4 to 53 cycles. There was approximately 60% of information missing for height and weight where the 95% quantile of the sample distribution, based on 893 women, was between 153.0 and 180.0 cm for height and 48.3 and 86.11 Kg for weight. A bivariate density plot for weight and height given age is shown in Fig. 7b in order to visualise the relationship between anthropometry and age in the sample.
Figure 7.

(a) Individual profiles of 2125 women over time; (b) Bivariate density plot of weight and height given age; (c) Individual profiles for a sample of six women with linear trend superimposed; (d) autocorrelation plot; (e) Proportion of symptoms reported, where the label “Yes” is related with “the event was reported at least one time” and “No” otherwise.
Menstrual cycle length is assumed to be normally distributed as the data represent standard cycles15, where the shortest cycle length record was 18 days and the longest was 43 days. The sample mean and variances are 27.62 and 3.51 days, respectively. As some women contributed more than one sequence to the database, we decided to consider only the first sequence available because we don’t know the reasons that caused this temporary dropout. The inclusion of the following sequences might bias the analysis, as also discussed by Bortot et al. (2010)16.
Figure 7c shows profiles for six women with a blue line representing a fitted mixed-effects linear regression model. It can be observed that the inclusion of a random intercept and slope plays an essential role as each woman’s cycle can be affected by different non-observed explanatory variables. However, the conditional was equal to 0.40, implying that the linear mixed-effects regression is a good approximation for some profiles, but not for all of them, differing from the results presented by Bull et al. (2019)2, who used a simple linear regression model and obtained an . This may have happened because the number of linear profiles observed by Bull et al. (2019)2 is suppressing the non-linear profiles in their sample. It is clear, based on our sample, that each woman’s specific trend must be accounted for in terms of their within-subject temporal dependence and the between subject variability across women.
Figure 7c,d show that for some women a short cycle can be followed by a long cycle and vice-versa, suggesting the need for a moving-average model. Furthermore, Fig. 7d shows that cycle length for some women has a positive autocorrelation. In contrast, others have a negative autocorrelation suggesting the need for an autoregressive moving-average model incorporating individual random effects for the autocorrelation and the moving-average coefficients. Finally, Fig. 7e shows a table containing the reported proportion of reported symptoms, where in most cases symptoms did not happen or were not reported.
As a consequence of possible missing data due to non reporting of symptoms, the effect of symptoms on cycle length may be biased towards the null hypothesis of no association between symptom and cycle length (i.e. a type II error). Despite this possible bias and loss in power, the p values obtained from statistical methods fitted to data subject to random error or misclassification are still valid34–36.
Statistical analysis
Let be a random variable, representing the length of menstrual cycle, where represents the observed cycle length for the i-th woman, for her j-th menstrual cycle where . The main objective is to derive the one-step ahead predictive distribution given by
| 1 |
Consequently, we are interested in evaluating under a parsimonious parametric model, that is,
where is fully specified and is a vector of unknown fixed-effect and variance components parameters. In order to accommodate the within-subject temporal correlation between repeated measures and the between-subject variability a random walk state-space model and mixed-effects state-space model was used, incorporating a Bayesian approach for process forecasting to predict the duration, in days, of the next menstrual cycle. Each prediction is accompanied by a corresponding interval forecast as point prediction is of limited value without an accompanying measure of uncertainty37. We assumed that cycle length are independent and that menstrual cycles tend to decrease over time as a woman ages15,16. In addition, we combined the Bayesian approach and forecasting proceses to include covariates where model validation procedures were used to compare model adequacy.
State space models for cycle length
The state-space formulation is an attractive choice due to its flexibility to work with discrete response variables and temporal dependency amongst observations. At the same time, the mixed-effects model can be used to account for between-subject variability. As the observed event is the difference, in days, between the interval from the first day of one bleeding episode up to and including the day before the next bleeding episode, observed cycle lengths can be modelled as discrete random variables. Let be a continuous random variable, where is a realisation of , which represents the observed cycle length. Furthermore, let be a discrete random variable, where is a realisation of which represents the cycle length in days as a continuous process, that is, . As we have no way to estimate the error term (observation process), we assume that is a good approximation for , where indicates rounding. Thus, the true non-observed continuous cycle length can be generated by the random walk state-space model:
| 2 |
where is the menstrual cycle length for the i-th woman at j-th cycle; is a random walk model that allows an individual trend in the series with assumed to be normally distributed with mean 0 and variance . We assumed an ARMA(1,1) model for , where is the autoregressive parameter; is the moving average parameter; and is assumed to be normally distributed with mean 0 and variance (process error). Furthermore, captures the information provided by additional symptoms predictors () that may have useful roles in understanding and forecasting cycle length, where represents the k-th fixed effect parameter. Finally, is a random effect term used to account for extra-variability (overdispersion) of some menstrual cycle lengths measured on i-th woman at cycle j, which could be classified as outliers. Consequently, under model (2), has probability of being an overdispersed menstrual cycle (non-standard) for the j-th cycle measured on i-th woman, where its additional magnitude is given by (Fig. 8).
Figure 8.
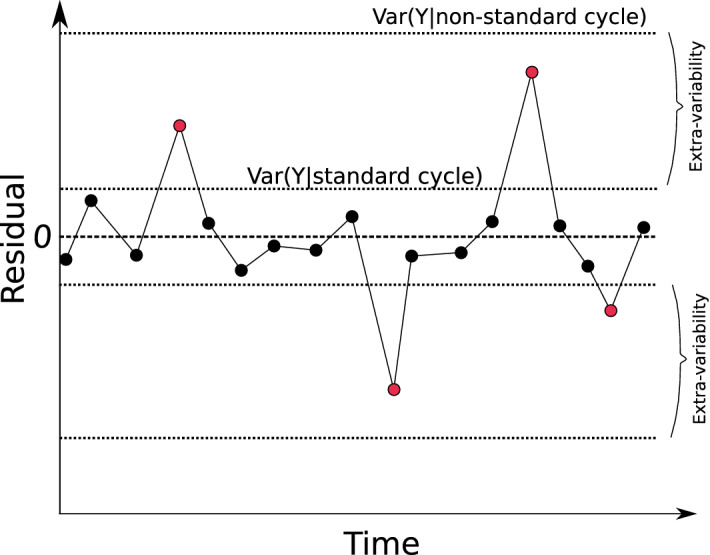
Representation of residuals () over time considering with probability of Y being a standard cycle (non overdispersed) and being a non-standard cycle (overdispersed), with
In this way, can be interpreted as the trend for a standard cycle. In contrast, can be interpreted as the trend for a non-standard cycle, where is an overdispersion parameter at the subject level for measures which induce extra-variability, as discussed in38 when modelling the reported number of cases of COVID-19 where the inclusion of allowed for the flexible modelling approach needed.
The state-space representation of the model (2) using the definition described by Brockwell & Davis (2002)39 is given by
| 3 |
with initial value for the local level model and , with . The linear Gaussian state-space model defined by equation 3 are generated efficiently using the Kalman filter recursions40.
Fitting a separate linear regression for each woman will result in a subject-specific intercept that may account for variability due to non-observed variables likely to affect their first observed menstrual cycle. In contrast, a mixed model incorporating random slopes assumes that each woman has a different menstrual cycle length trend relative to her age. To verify if the random walk model proposed has the necessary flexibility to capture differing trends, it was compared to a linear mixed-effects model16. In that case, , where and are the (marginal) intercept and slope, respectively; and are the random effects for the intercept and slope for the i-th woman at , respectively, where it is assumed that
and represents a woman’s age.
Bayesian implementation and choice of prior distribution
A Bayesian analysis combines information from observed data with prior distribution for the model’s parameters in order to generate a posterior distribution. In this analysis the inverse-gamma is a natural candidate for the prior distributions and are often used for random walk state-space models and variance components of mixed effect models. Such a choice of prior is attractive as it can be considered as non-informative within the conditionally conjugate family, when is set to a low value such as :
A likelihood ratio test was used to test whether the presence of correlations between the random effects in these models played a crucial role. Based on a 95% credible interval for the variance component for the proposed mixed-effects model there was sufficient evidence that the random effects are plausibly mutually independent and a term to capture the correlation structure between the intercept and slope could be removed from the model.
The choice of Prior distribution for fixed effect parameters is given by , with ; , with ; , with ; and we assumed , which is a vague normal density prior. All assumptions were checked to make sure that results were not sensitive to specific choices of prior parameters.
Model selection procedure
The model selection procedure used to compare candidate models involved a balance between forecast accuracy and the Bayesian Information Criterion (BIC). Forecast accuracy was calculated based on RMSE, CCC and Pearson Correlation Coefficient while the BIC was calculated using the following formulation41:
where N is the total number of observations; and p is the number of parameters estimated by the model. The procedure was split into three steps namely the time trend component, the autocorrelation component, and an additional linear predictor as a function of available explanatory variables.
The first step was to account for a possible trend, by identifying the most appropriate error structure for the model, which in our case consisted of a comparison of a random walk model or a linear mixed effect model (Fig. 9). The second step involved the inclusion of temporal dependence among observations, as evident in some women in the sample, where an ARMA model was considered as shown in the Fig. 9. The third and final step involved the inclusion of explanatory variables to account for their (possible) relationship with cycle length. This was achieved using the posterior distribution on the parameter to select all those variables that did not have the null value for their parameter contained in their corresponding 95% credibility interval.
Figure 9.
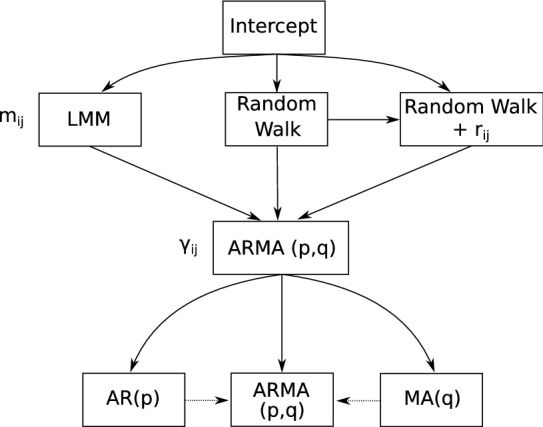
Stages 1 and 2 of the model selection procedure. LMM: linear mixed effect model; : overdispersion parameter at observational level; ARMA(p, q): Autoregressive moving average model of order p and q.
A novel use of train and test set data was used to validate model performance and to estimate the one-step ahead forecasting prediction accuracy as a function of the number of cycles reported. The complete sample of 2125 was used for model validation by treating the last observed cycle length as test data. The procedure is illustrated in Fig. 10 where the last observed cycle length (red dot) is ‘held back’ as test data and the remaining data (blue dots) were used as training data. The forecast performance was calculated using the RMSE and CCC between the observed and predicted cycle lengths and used jointly with the BIC criteria in the model selection process.
Figure 10.

(a) One-step-ahead procedure for evaluation of the forecasting accuracy of training data; (b) time series cross validation for the test data as a function of cycle length. Training and test data are represented by blue and red circles respectively.
Once the model was selected, it was then sequentially tested using i) the complete data as training data and ii) a random sample of 1029 (approximately half the complete data) as test data. As the number of cycles reported varied from 2 to 12, one-step ahead forecasting prediction accuracy was calculated for each of these scenarios by treating the last observed cycle in each scenario as test data. As the number of athletes in the test set decreased with increasing reported cycle lengths, individuals that had fewer observed cycle lengths for the cycle length scenario under consideration were included in the training set to account for this attrition.
The forecast error for an observed value and its forecast was computed as
where the training data are given by and the test data by (i.e. one-step ahead prediction for each woman), see Fig. 10. The forecast accuracy was measured by the root mean square error (RMSE), concordance correlation coefficient32, and the Pearson correlation coefficient between the observed response in the test data and corresponding predicted cycle length value.
Posterior computation
Markov Chain Monte Carlo (MCMC) was used to generate samples from the posterior distribution for the random walk and mixed-effects state-space models using a Gibbs sampler algorithm40, as this approach is widely used to obtain parameter estimates from a posterior distribution. The convergence of the MCMC algorithm was checked by multiple comparisons of MCMC chains with different starting points. The normality assumptions were checked using suitable residual plots and quantile-quantile plots with simulate envelopes42. The one-ahead predictive distribution of was derived through draws from the posterior distribution. Consequently, the -step ahead predictive distribution was obtained by running the Kalman filter sequentially. All analysis were implemented in R including runjags43, coda44, hnp42, and ggplot245 packages.
Ethics approval
This publication has emanated from research supported in part by a research grant from Science Foundation Ireland (SFI) under Grant Number SFI/12/RC/2289, co-funded by the European Regional Development Fund in partnership with Orreco. All methods were carried out in accordance with relevant guidelines and regulation. In particular the data that support this study were made available by ORRECO. Upon first use, all FitrWoman app users provide informed consent by agreeing to their anonymised data being used with third parties for research purposes. However, restrictions apply to the availability of these data used under license for the current study. In order to use the Fitrwoman app each participant must agree to the following conditions: Without prejudice to the foregoing, ORRECO shall have an exclusive, royalty free, perpetual licence to use and retain the User Data and all other information arising from the provision of the Services:- (i) for research purposes, (ii) in order to improve the standard of service provided by ORRECO in the future; (iii) in order to validate ORRECO’s proprietary algorithms or intervention programmes; (iv) to analyse and report anonymously on patterns in User Data by reference to their age, sex, ethnicity, discipline, field, training schedule, performance, results or such other data sets as ORRECO may decide; and (v) in order to develop similar or new services, provided that in each case the identity of the User and any personal data comprised within the User Data shall be kept, removed or anonymised. Anonymised data shall be sent to third party processors to be analysed to uncover patterns and trends and to further sports science research. The FitrWoman app is compliant with the General Data Protection Regulation laws (GDPR 2016/679). All experimental protocols and ethical use of data were approved by the ethics committee of the Insight Centre for Data Analytics, National University of Ireland Galway, Ireland.
Supplementary Information
Acknowledgements
The authors are grateful to The Insight Centre for Data Analytics, National University of Ireland Galway and Orreco, for supporting this research project. We extend our thanks to the Science Foundation Ireland (SFI) under grant number SFI/12/RC/2289, co-funded by the European Regional Development Fund.
Author contributions
T.P.O. and J.N. conceived and implemented the modelling framework and wrote the manuscript with input from all coauthors. G.B., B.M. and C.P. designed the observational study and data collection. All the authors commented and approved the manuscript.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1038/s41598-021-95960-1.
References
- 1.Regidor PA, Kaczmarczyk M, Schiweck E, Goeckenjan-Festag M, Alexander H. Identification and prediction of the fertile window with a new web-based medical device using a vaginal biosensor for measuring the circadian and circamensual core body temperature. Gynecological Endocrinology. 2018;34:256–260. doi: 10.1080/09513590.2017.1390737. [DOI] [PubMed] [Google Scholar]
- 2.Bull JR, Rowland SP, Scherwitzl EB, et al. Real-world menstrual cycle characteristics of more than 600,000 menstrual cycles. npj Digit. Med. 2019;2:83. doi: 10.1038/s41746-019-0152-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Symul L, Wac K, Hillard P, et al. Assessment of menstrual health status and evolution through mobile apps for fertility awareness. npj Digit. Med. 2019;2:64. doi: 10.1038/s41746-019-0139-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ali R, Gürtin ZB, Harper JC. Do fertility tracking apps offer women useful information about their fertile window? Reproductive BioMedicine Online. 2020;00:1–10. doi: 10.1016/j.rbmo.2020.09.005. [DOI] [PubMed] [Google Scholar]
- 5.Scherwitzl EB, Hirschberg AL, Scherwitzl R. Identification and prediction of the fertile window using NaturalCycles. European Journal of Contraception and Reproductive Health Care. 2015;20:403–408. doi: 10.3109/13625187.2014.988210. [DOI] [PubMed] [Google Scholar]
- 6.Schoene RB, Robertson HT, Pierson DJ. Respiratory drives and exercise in menstrual cycles of athletic and nonathletic women. Journal of Applied Physiology Respiratory Environmental and Exercise Physiology. 1981;50:1300–1305. doi: 10.1152/jappl.1981.50.6.1300. [DOI] [PubMed] [Google Scholar]
- 7.Sung E, et al. Effects of follicular versus luteal phase-based strength training in young women. SpringerPlus. 2014;3:668. doi: 10.1186/2193-1801-3-668. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Freemas JA, Baranauskas MN, Constantini K, Constantini N, Greenshields JT, Mickleborough TD, Raglin JS, Schlader ZJ. Exercise Performance Is Impaired during the Midluteal Phase of the Menstrual Cycle. Med Sci Sports Exerc. 2021;53(2):442–452. doi: 10.1249/MSS.0000000000002464. [DOI] [PubMed] [Google Scholar]
- 9.McNulty KL, et al. The Effects of Menstrual Cycle Phase on Exercise Performance in Eumenorrheic Women: A Systematic Review and Meta-Analysis. Sports Medicine. 2020;50:1813–1827. doi: 10.1007/s40279-020-01319-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Duane M, Contreras A, Jensen ET, White A. The performance of fertility awareness-based method apps marketed to avoid pregnancy. Journal of the American Board of Family Medicine. 2016;29:508–511. doi: 10.3122/jabfm.2016.04.160022. [DOI] [PubMed] [Google Scholar]
- 11.Harlow SD, Matanoski GM. The association between weight, physical activity, and stress and variation in the length of the menstrual cycle. American Journal of Epidemiology. 1991;133:38–49. doi: 10.1093/oxfordjournals.aje.a115800. [DOI] [PubMed] [Google Scholar]
- 12.Harlow SD, Zeger SL. An application of longitudinal methods to the analysis of menstrual diary data. Journal of Clinical Epidemiology. 1991;44:1015–1025. doi: 10.1016/0895-4356(91)90003-R. [DOI] [PubMed] [Google Scholar]
- 13.Harlow SD, Lin X, Ho MJ. Analysis of menstrual diary data across the reproductive life span Applicability of the bipartite model approach and the importance of within-woman variance. Journal of Clinical Epidemiology. 2000;53:722–733. doi: 10.1016/S0895-4356(99)00202-4. [DOI] [PubMed] [Google Scholar]
- 14.Li K, et al. Characterizing physiological and symptomatic variation in menstrual cycles using self-tracked mobile-health data. npj Digital Medicine. 2020;3:1–13. doi: 10.1038/s41746-020-0269-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Guo Y, Manatunga AK, Chen S, Marcus M. Modeling menstrual cycle length using a mixture distribution. Biostatistics. 2006;7:100–114. doi: 10.1093/biostatistics/kxi043. [DOI] [PubMed] [Google Scholar]
- 16.Bortot P, Masarotto G, Scarpa B. Sequential predictions of menstrual cycle lengths. Biostatistics. 2010;11:741–755. doi: 10.1093/biostatistics/kxq020. [DOI] [PubMed] [Google Scholar]
- 17.Fukaya K, Kawamori A, Osada Y, Kitazawa M, Ishiguro M. The forecasting of menstruation based on a state-space modeling of basal body temperature time series. Statistics in Medicine. 2017;36:3361–3379. doi: 10.1002/sim.7345. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Lieberman JL, De Souza MJ, Wagstaff DA, Williams NI. Menstrual Disruption with Exercise Is Not Linked to an Energy Availability Threshold. Medicine and Science in Sports and Exercise. 2018;50:551–561. doi: 10.1249/MSS.0000000000001451. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Diaz A, Laufer MR, Breech LL. Menstruation in girls and adolescents: Using the menstrual cycle as a vital sign. Pediatrics. 2006;118:2245–2250. doi: 10.1542/peds.2006-2481. [DOI] [PubMed] [Google Scholar]
- 20.Mumford SL, Steiner AZ, Pollack AZ, Perkins NJ, Filiberto AC, Albert PS, Mattison DR, Wactawski-Wende J, Schisterman EF. The utility of menstrual cycle length as an indicator of cumulative hormonal exposure. J. Clin. Endocrinol. Metab. 2006;97(10):E1871–E1879. doi: 10.1210/jc.2012-1350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Gizzo S, et al. Menstrual cycle length: A surrogate measure of reproductive health capable of improving the accuracy of biochemical/sonographical ovarian reserve test in estimating the reproductive chances of women referred to ART. Reproductive Biology and Endocrinology. 2015;13:1–11. doi: 10.1186/s12958-015-0024-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Mountjoy M, et al. International Olympic Committee (IOC) Consensus statement on relative energy deficiency in sport (red-s): 2018 update. International Journal of Sport Nutrition and Exercise Metabolism. 2018;28:316–331. doi: 10.1123/ijsnem.2018-0136. [DOI] [PubMed] [Google Scholar]
- 23.Melin AK, Heikura IA, Tenforde A, Mountjoy M. Energy availability in athletics: Health, performance, and physique. International Journal of Sport Nutrition and Exercise Metabolism. 2019;29:152–164. doi: 10.1123/ijsnem.2018-0201. [DOI] [PubMed] [Google Scholar]
- 24.Corbel MJ, Tolari F, Yadava VK. Appropriate body-mass index for Asian populations and its implications. The Lancet. 2004;363:157–163. doi: 10.1016/S0140-6736(03)15268-3. [DOI] [PubMed] [Google Scholar]
- 25.Najmabadi S, et al. Menstrual bleeding, cycle length, and follicular and luteal phase lengths in women without known subfertility: A pooled analysis of three cohorts. Paediatric and Perinatal Epidemiology. 2020;34:318–327. doi: 10.1111/ppe.12644. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Treloar AE, Boynton RE, Behn BG, Brown BW. Variation of the human menstrual cycle through reproductive life. Int J Fertil. 1967;12:77–26. [PubMed] [Google Scholar]
- 27.Chiazze L, Brayer FT, Macisco JJ, Parker MP, Duffy BJ. The Length and Variability of the Human Menstrual Cycle. JAMA. 1968;203:377–380. doi: 10.1001/jama.1968.03140060001001. [DOI] [PubMed] [Google Scholar]
- 28.Vollman RF. The menstrual cycle. Major Probl Obstet Gynecol. 1977;7:1–193. [PubMed] [Google Scholar]
- 29.Colombo, B. & Bassi, F. Studi in onore di Giampiero Landenna. Studi in onore di Giampiero Landenna 111–126 (1996).
- 30.Gelman A, Rubin DB. Inference from iterative simulation using multiple sequences. Statistical Science. 1992;7:457–472. [Google Scholar]
- 31.Montgomery D, Peck EA, ViningG G. Introduction to linear regression analysis. 5. London: John Wiley & Sons; 2012. [Google Scholar]
- 32.Lin LI. A Concordance Correlation Coefficient to Evaluate Reproducibility. Biometrics. 1989;45:255–268. doi: 10.2307/2532051. [DOI] [PubMed] [Google Scholar]
- 33.FitrWoman app. https://www.fitrwoman.com/. (2018).
- 34.Stefanski LA. The effects of measurement error on parameter estimation. Biometrika. 1985;72:583–592. doi: 10.1093/biomet/72.3.583. [DOI] [Google Scholar]
- 35.Lagakos WS. Effects of mismodelling and mismeasuring explanatory variables on tests of their association with a response variable. Statistics in Medicine. 1988;7:257–274. doi: 10.1002/sim.4780070126. [DOI] [PubMed] [Google Scholar]
- 36.Buonaccorsi JP, Laake P, Veierod MB. On the effect of misclassification on bias of perfectly measured covariates in regression. Biometrics. 2005;61:831–836. doi: 10.1111/j.1541-0420.2005.00336.x. [DOI] [PubMed] [Google Scholar]
- 37.Christoffersen PF. Evaluating Interval Forecasts. International Economic Review. 1998;39:841–862. doi: 10.2307/2527341. [DOI] [Google Scholar]
- 38.Oliveira TdP, Moral RdA. Global Short-Term Forecasting of Covid-19 Cases. Scientific Reports. 2021;11:1–9. doi: 10.1038/s41598-021-87230-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Brockwell P, Davis R. Introduction to Time Series and Forecasting. 2. New York: Springer-Verlag; 2002. [Google Scholar]
- 40.Carter ACK, Kohn R. On Gibbs Sampling for State Space Models. Biometrika. 1994;81:541–553. doi: 10.1093/biomet/81.3.541. [DOI] [Google Scholar]
- 41.Bengtsson T, Cavanaugh JE. An improved akaike information criterion for state-space model selection. Comput. Stat. Data Anal. 2006;50:2635–2654. doi: 10.1016/j.csda.2005.05.003. [DOI] [Google Scholar]
- 42.Moral RA, Hinde J, Demétrio CG. Half-normal plots and overdispersed models in R: The hnp package. J. Stati. Softw. 2017 doi: 10.18637/jss.v081.i10. [DOI] [Google Scholar]
- 43.Denwood MJ. runjags: An R package providing interface utilities, model templates, parallel computing methods and additional distributions for MCMC models in JAGS. J. Stati. Softw. 2016 doi: 10.18637/jss.v071.i09. [DOI] [Google Scholar]
- 44.Plummer M, Best N, Cowles K, Vines K. CODA: convergence diagnosis and output analysis for MCMC. R News. 2006;6:7–11. [Google Scholar]
- 45.Wickham H. ggplot2: Elegant Graphics for Data Analysis. 2. New York: Springer-Verlag; 2016. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.