

Abstract
Active mechanisms that regulate cochlear gain are hypothesized to influence speech-in-noise perception. However, evidence of a relationship between the amount of cochlear gain reduction and speech-in-noise recognition is mixed. Findings may conflict across studies because different signal-to-noise ratios (SNRs) were used to evaluate speech-in-noise recognition. Also, there is evidence that ipsilateral elicitation of cochlear gain reduction may be stronger than contralateral elicitation, yet, most studies have investigated the contralateral descending pathway. The hypothesis that the relationship between ipsilateral cochlear gain reduction and speech-in-noise recognition depends on the SNR was tested. A forward masking technique was used to quantify the ipsilateral cochlear gain reduction in 24 young adult listeners with normal hearing. Speech-in-noise recognition was measured with the PRESTO-R sentence test using speech-shaped noise presented at −3, 0, and +3 dB SNR. Interestingly, greater cochlear gain reduction was associated with lower speech-in-noise recognition, and the strength of this correlation increased as the SNR became more adverse. These findings support the hypothesis that the SNR influences the relationship between ipsilateral cochlear gain reduction and speech-in-noise recognition. Future studies investigating the relationship between cochlear gain reduction and speech-in-noise recognition should consider the SNR and both descending pathways.
I. INTRODUCTION
The descending pathway of the peripheral auditory system is known to modify the response characteristics of the cochlea to optimize the coding of sound in the ascending pathway (Dean et al., 2005). One example is the medial olivocochlear reflex (MOCR), which adjusts the gain of the cochlea in response to sounds. The MOCR is a bilateral reflex that decreases the cochlear gain provided by the outer hair cells via efferent pathways between the brainstem and cochlea (for review, see Guinan, 2018; Lopez-Poveda, 2018). This gain reduction is frequency-specific to the place of the eliciting sound in the cochlea (Cooper and Guinan, 2006). Relative to other cochlear mechanical responses, the MOCR is sluggish with onset and offset delays of approximately 25 ms (James et al., 2005; Backus and Guinan, 2006).
The MOCR has been hypothesized to serve several functions. Physiological evidence from guinea pig and mouse models indicates that strong MOCR activation is protective against hearing damage resulting from noise exposure (Maison and Liberman, 2000; Taranda et al., 2009). Emerging evidence also indicates that the MOCR plays a role in auditory attention and learning in humans as well as mice (de Boer and Thornton, 2007, 2008; Terreros et al., 2016). Finally, there is substantial evidence that the MOCR improves auditory perception in noise. This function of the MOCR is supported by physiological data showing that the dynamic range of neural coding in noise improves when the medial olivocochlear (MOC) fibers are stimulated with electric pulses (Nieder and Nieder, 1970; Winslow and Sachs, 1987) or contralateral noise (Kawase et al., 1993). Supporting this hypothesis, deficits in localization (May et al., 2004) and vowel discrimination (Dewson, 1968; Hienz et al., 1998) in background noise have been shown in animal models with MOC lesions.
In addition to animal studies, evidence that the MOCR affects perception in noise has been documented in people who have undergone vestibular neurectomy surgery. Following surgery, these people are presumed to have lesioned MOC neurons because efferent fibers travel with the vestibular nerve. Therefore, any perceptual effects of the MOCR should be disrupted. First, overshoot—a psychophysical measure related to cochlear gain—is reduced in these patients (Zeng et al., 2000). Second, stimulation with contralateral noise improved speech-in-noise performance in the nonsurgical ears with intact MOC fibers but not in the surgical ears with lesioned MOC fibers (Giraud et al., 1997). This supports the hypothesis that the MOCR enhances speech-in-noise recognition. However, evidence to the contrary comes from testing vestibular neurectomy patients on a battery of psychoacoustic tasks, including but not limited to tone detection in noise, overshoot, frequency selectivity, and detection of expected or unexpected tones in noise (Scharf et al., 1994, 1997; but see Chays et al., 2003). These studies showed limited functional deficits post-surgery compared to pre-surgery. One exception to these general findings was an improvement in the detection of unexpected tones post-surgery, which was interpreted as evidence of a possible role of the MOCR for selective attention.
To the extent that the MOCR is important for speech-in-noise perception, it follows that individual differences in reflex strength may be related to speech-in-noise recognition. To investigate this, studies have examined the relationship between cochlear gain reduction and speech-in-noise recognition. In many of these experiments, cochlear gain reduction was quantified using evoked otoacoustic emissions (OAEs), a noninvasive, physiological measure associated with cochlear gain. The typical OAE paradigm uses noise in the contralateral ear to activate the contralateral MOCR pathway and thereby reduces the level of emissions in the test ear (Collet et al., 1990). Alternatively, cochlear gain reduction has been quantified using ipsilateral psychoacoustic measures (DeRoy Milvae et al., 2015). The ipsilateral descending pathway is of particular interest because findings from animal models (e.g., Maison et al., 2003) indicate that it may be stronger than the contralateral descending pathway.
Forward masking with a short-duration, off-frequency masker is one psychoacoustic measure that has been used to investigate the effects of cochlear gain reduction (e.g., Jennings and Strickland, 2012; Yasin et al., 2014) and the strength of ipsilateral gain reduction across individuals (e.g., Krull and Strickland, 2008; Roverud and Strickland, 2010; DeRoy Milvae et al., 2015; DeRoy Milvae and Strickland, 2018). To estimate ipsilateral cochlear gain reduction, forward-masked tone-detection thresholds are compared with and without a precursor—a preceding sound with energy at the signal frequency. Because the masker is off-frequency from the signal, it is processed linearly at the signal place. Therefore, any reduction in gain elicited by the precursor should affect the signal but not the masker, which allows one to infer a change in cochlear gain based on the shift in signal threshold between conditions. In addition, because the masker duration is short in this paradigm, there is little-to-no possible MOC activity induced in the condition without a precursor. Thus, owing to the time course of the MOCR, the forward masking provided by the masker is assumed to be unrelated to cochlear gain reduction. A similar estimate of cochlear gain reduction can also be measured with the masker removed from the paradigm, supporting this interpretation (DeRoy Milvae and Strickland, 2018). Furthermore, the magnitude of the threshold shift with a precursor is consistent with the magnitude of cochlear gain reduction (Jennings et al., 2009; Roverud and Strickland, 2014). Additional evidence supports a contribution of gain reduction to masked threshold shifts with a precursor. First, as the precursor is separated in time from the masker and signal (Roverud and Strickland, 2010) and as the precursor duration is increased (Roverud and Strickland, 2014), there are non-monotonicities in the signal threshold that are more consistent with the timecourse of cochlear gain reduction than with temporal integration. Second, precursors are known to broaden psychophysical estimates of frequency selectivity (Jennings et al., 2009; Jennings and Strickland, 2012), which is an effect that is consistent with a reduction in gain.
We hypothesize that the signal-to-noise ratio (SNR) is an important factor that influences the observed relationship between individual gain reduction strength and speech-in-noise recognition. First, it stands to reason that because the outer hair cells provide more gain to low-level sounds than to high-level sounds that cochlear gain reduction will affect the perception of lower-level sounds to a greater extent than higher-level sounds. It then follows that MOCR activation may improve the SNR of the internal representation of speech when it is more intense than the noise (turning down the noise more than the speech over time) and decrease the SNR of the internal representation of speech when it is less intense than the noise. Figure 1 shows a schematic of this hypothesized relationship between gain reduction and long-term SNR. Gain reduction should have the greatest effect on the lower-level segments in a speech-in-noise signal. When the overall SNR is negative, the lower-level segments will more often be comprised of speech-in-noise, whereas the higher-level segments will more often be comprised of noise only; therefore, the output SNR will decrease when the MOCR is activated. When the overall SNR is positive, the probabilities are reversed and the output SNR will increase when the MOCR is activated. This idea is supported by research with hearing technology that demonstrates how amplitude compression systems can change the overall output SNR (Souza et al., 2006; Naylor and Johannesson, 2009; Alexander and Masterson, 2015; Watkins et al., 2018). When these changes reduce the SNR, performance can decline (Stone and Moore, 2003). However, this is likely a simplistic view of antimasking due to the MOCR (for more detailed explanations and models, see Messing et al., 2009; Chintanpalli et al., 2012) because the temporal variations in frequency and level present in speech may make it a poorer elicitor of the MOCR than a continuous noise signal (Liberman and Guinan, 1998).
FIG. 1.

Schematics of the hypothesized relationship between the SNR and gain reduction. The left panels show the cochlear input-output function with full gain (gray solid lines) and gain reduction (black dotted lines). Gain reduction reduces the output level of the lower-level input: speech-in-noise at a negative SNR (A) and noise in the dips of the speech at a positive SNR (B). The right panels show the overall output SNR for these scenarios. Compared to full gain (gray bars), output SNR is hypothesized to decrease with gain reduction (black bars) for a negative SNR (A) and increase with gain reduction for a positive SNR (B).
Most of the studies that have investigated the relationship between cochlear gain reduction strength and speech-in-noise recognition have used contralateral suppression of transient-evoked otoacoustic emissions (TEOAEs) to quantify the amount of gain reduction. As shown by the summary in Table I, the results from these studies are mixed. Some studies found that larger gain reduction estimates are related to better performance on speech-in-noise tests (Giraud et al., 1997; Kumar and Vanaja, 2004; Yilmaz et al., 2007; de Boer and Thornton, 2008; Abdala et al., 2014; Mishra and Lutman, 2014; Bidelman and Bhagat, 2015; Maruthy et al., 2017; Mertes et al., 2019). Other studies found the opposite relationship (de Boer et al., 2012; DeRoy Milvae et al., 2015) or no relationship (Harkrider and Smith, 2005; Mukari and Mamat, 2008; Wagner et al., 2008; Stuart and Butler, 2012; Mishra and Lutman, 2014; Mertes et al., 2018; Mertes et al., 2019). It appears from this body of research that a relationship between MOCR activation and speech-in-noise recognition is possible, but there is no clear consensus on what situations might benefit from MOCR activation. The studies differ in the SNRs tested, speech materials used, types of noises used, monaural or binaural nature of the speech perception measures, ages of the participants, and measures of cochlear gain reduction. This makes it difficult to elucidate the nature of the relationship between individual reflex strength and speech-in-noise recognition.
TABLE I.
A variety of speech-in-noise tests, SNRs, levels, and gain reduction measures have been used in studies examining the relationship between speech understanding in noise and cochlear gain reduction. Studies shown in bold concluded that better speech-in-noise recognition was related to higher estimates of gain reduction. BBN, broadband noise; SSN, speech-shaped noise; CV, consonant-vowel; CVC, consonant-vowel-consonant; VCV, vowel-consonant-vowel; TEOAEs, transient-evoked otoacostic emissions; DPOAEs, distortion product otoacoustic emissions.
| Study | Speech-in-noise test | Speech-in-noise test SNR | Speech-in-noise test level | Gain reduction measure |
|---|---|---|---|---|
| Giraud et al. (1997) | Monaural word recognition in ipsilateral and bilateral BBN | −20–25 dB in 5 dB steps | 10 dB SL target | TEOAEs |
| Kumar and Vanaja (2004) | Monaural word recognition in quiet, ipsilateral BBN, contralateral BBN, and bilateral BBN | 10–20 dB in 5 dB steps | 50 dB HL target | TEOAEs |
| Harkrider and Smith (2005) | Monaural word recognition in ipsilateral multitalker babble | 0 dB | 55 dB HL target | TEOAEs |
| Yilmaz et al. (2007) | Monaural word recognition in ipsilateral BBN | 10 dB | 40 dB SL target | TEOAEs |
| Mukari and Mamat (2008) | Monaural sentence recognition in ipsilateral, contralateral, and front SSN | −10–2 dBa | 65 dB SPL SSN | DPOAEs |
| Wagner et al. (2008) | Binaural sentence recognition in front SSN | −8 to −5 dBa | 65 dB SPL SSN | DPOAEs |
| de Boer and Thornton (2008) | Monaural CV syllable discrimination in ipsilateral or bilateral BBN | 10 dB | 40 dB SL BBN | TEOAEs |
| de Boer et al. (2012) | Monaural CV syllable discrimination in ipsilateral BBN | 10 dB | 40 dB SL BBN | TEOAEs |
| Stuart and Butler (2012) | Monaural and binaural sentence recognition in quiet, ipsilateral BBN, and bilateral BBN | −10–15 dBa | 50 dB SL BBN | TEOAEs |
| Abdala et al. (2014) | Monaural CVC and VCV syllable discrimination in ipsilateral BBN | −21–12 dB in 3 dB steps | 30 dB SL target (never < 60 dB SPL) | DPOAEs |
| Mishra and Lutman (2014) | Monaural word recognition in ipsilateral and bilateral SSN | −8 to −2 dB a | 60 dB SPL target | TEOAEs |
| Bidelman and Bhagat (2015) | Monaural sentence recognition in ipsilateral multitalker babble | 0–25 dB in 5 dB steps a | 70 dB SPL target | TEOAEs |
| DeRoy Milvae et al. (2015) | Monaural sentence recognition in ipsilateral multitalker babble | 0–25 dB in 5 dB stepsa | 70 dB SPL target | Psychoacoustic |
| Maruthy et al. (2017) | Monaural sentence recognition in ipsilateral multitalker babble | −10–20 dB in 5 dB steps a | 40 dB HL target | TEOAEs |
| Mertes et al. (2018) b | Monaural word and sentence recognition in ipsilateral SSN | −9 to −3 dB in 3 dB steps | 70 dBC target | TEOAEs |
| Mertes et al. (2019) | Monaural word recognition in ipsilateral and bilateral SSN | −12–0 dB in 3 dB steps a | 50 dBA target | TEOAEs |
A speech reception threshold (SRT) measure was used in the analysis.
Slope of the psychometric function was related to estimated gain reduction.
Mertes et al. (2018) recently examined the relationship between contralateral suppression of TEOAEs and speech-in-noise recognition at two SNRs and for two types of speech materials (words and sentences). They did not find a significant relationship between cochlear gain reduction and percent-correct scores for either type of speech material across the individual SNRs, but they did find a significant relationship between the slope of the psychometric function for speech-in-noise recognition and contralateral suppression of TEOAEs. They interpreted this result as indicating that individuals with stronger gain reduction have greater improvement in speech-in-noise perception as SNR increases. A later experiment that investigated a larger range of negative SNRs found no significant relationship between the slopes of the psychometric function and contralateral suppression (Mertes et al., 2019). These contradictory results may be related to differences between the participants across the two studies with younger adults participating in the second study. However, both studies suggest that performance at an individual SNR and cochlear gain reduction are unrelated. This finding may have been limited by the range of SNRs explored, which were all negative; perhaps more ecological SNRs are necessary to measure a benefit.
The present study builds on previous research by including ipsilateral, forward masking measures of cochlear gain reduction and measuring speech-in-noise recognition at negative, zero, and positive SNRs for monaural noise conditions. With our approach, we examined the effect of the SNR on the relationship between these measures and matched the efferent pathway that is most likely activated during the gain reduction and speech-in-noise tests. It was hypothesized that stronger cochlear gain reduction would be associated with speech understanding benefits at positive SNRs and detriments at negative SNRs.
II. METHODS
A. Participants
Twenty-four participants completed this experiment. Five of these participants (P1, P6, P7, P8, and P24) also completed a previously published experiment (DeRoy Milvae and Strickland, 2018; as P2, P4, P5, P3, and P6, respectively), therefore, psychoacoustic gain reduction estimates at 2 kHz for these participants are shared between the two experiments. Participants' ages ranged from 18 years old to 25 years old (median age of 20 years old), 71% of them were female (17 of 24), and 92% of them were right-handed (22 of 24). All participants were native speakers of English and required to have audiometric thresholds ≤15 dB hearing level (HL) from 0.25 to 8 kHz (the one exception was P13, who had a threshold of 20 dB HL at 1 kHz in the left ear). To control for potential middle-ear muscle confounds, all participants were also required to have ipsilateral and contralateral acoustic reflex thresholds (measured with clinical immittance equipment) for a broadband noise stimulus >60 dB SPL. The average measures for the left ipsilateral [M = 83 dB SPL, standard deviation (SD) = 8 dB], right ipsilateral (M = 82 dB SPL, SD = 6 dB), left contralateral (M = 95 dB SPL, SD = 7 dB; no response for one participant excluded from mean), and right contralateral (M = 97 dB SPL, SD = 5 dB; no response for 3 participants excluded from mean) acoustic reflex thresholds were typically well above this cutoff. Finally, all participants had present distortion product otoacoustic emissions (DPOAEs) from 1.5 to 10 kHz (minimum criteria of −6 dB SPL distortion product, 6 dB SNR, 9 of 12 frequencies present). This research protocol was approved by the Institutional Review Board at Purdue University and all participants provided informed consent.
B. Psychoacoustic measure of cochlear gain reduction
1. Stimuli
Ipsilateral cochlear gain reduction was estimated psychoacoustically at 2 kHz. This frequency was chosen because the spectrum around 2 kHz is known to contribute the most to speech perception (Fletcher and Galt, 1950) and a previous experiment found a significant relationship between speech-in-noise recognition and forward masking gain reduction at 2 kHz but not at 4 kHz (DeRoy Milvae et al., 2015).
Stimuli consisted of an 8-ms, 2-kHz signal; a 20-ms, 1.2-kHz masker; and a 50-ms pink noise precursor band limited from 0.25 to 8 kHz. The durations included cos2 ramps at onset and offset: 4-ms ramps for the signal and 5-ms ramps for the masker and precursor. The masker level for the gain reduction estimate was chosen for each participant as the level that elevated the signal threshold by approximately 5 dB. The pink noise precursor was fixed at an overall level of 60 dB SPL. Differences in the signal threshold across masking conditions were measured to estimate the cochlear gain reduction as described below.
2. Procedure
Measurements were made in a double-walled, sound-treated booth. Stimuli were selected and presented with custom matlab (2012a, MathWorks, Natick, MA) software (Bidelman et al., 2015). Sounds were produced by a Lynx TWO-B sound card (Lynx Studio Technology, Inc., Costa Mesa, CA), passed through a headphone buffer (TDT HB6, Tucker-Davis Technologies, Alachua, FL), and presented to ER-2 insert earphones (Etymotic Research, Inc., Elk Grove Village, IL). From 0.25 to 8 kHz, these insert earphones are designed to have a flat frequency response at the tympanic membrane for an average adult ear canal. Both insert earphones were worn but all stimuli were presented to the right ear. High-pass noise (2.4–10 kHz) was presented in an effort to limit off-frequency listening for all masked conditions (Nelson et al., 2001). The onset of the high-pass noise was 50 ms prior to the first stimulus and the offset was 50 ms after the final stimulus. The level of the high-pass noise was 50 dB below the signal level.
The signal threshold was measured with a three-interval forced-choice paradigm. Participants were instructed to identify the interval that was different (contained the signal) by pressing a key or clicking a button on the screen. Visual feedback indicated whether the given response was correct. A two-down, one-up tracking rule was used to estimate the signal level necessary for 70.7% correct on the psychometric function (Levitt, 1971). The final eight reversals were averaged to determine the signal threshold.
The growth of masking (GOM) functions (Oxenham and Plack, 1997; Plack and Oxenham, 1998) were first measured to estimate the cochlear input-output function at 2 kHz. The masker immediately preceded the signal with a fixed range of masker levels (30 and 60–85 dB SPL), and the signal level was adaptively varied to determine the signal threshold. These functions were measured to determine an appropriate masker level for the gain reduction estimate. The masker level associated with a signal threshold of approximately 5 dB SL on the lower leg of the cochlear input-output function was chosen because gain reduction has the largest effect (largest shift to the right) on the lower leg of the cochlear input-output function (Krull and Strickland, 2008; Roverud and Strickland, 2010).
Participants completed three one-hour training sessions at the start of the experiment (GOM measured with a 2-kHz, 8-ms signal) that were excluded from experimental data, and testing continued for four additional test sessions. The first three test sessions (completed after the training sessions) included measurement of two signal thresholds in quiet, followed by two signal thresholds for each masking level of the GOM function. When the SD of the final eight reversals was above 5 dB, indicating an unreliable adaptive track, the track was discarded and an additional track was measured to obtain the threshold. This resulted in six total thresholds for each masker level over the three test sessions. These thresholds were averaged and the masker level that raised the signal threshold closest to 5 dB above the quiet threshold was chosen for the gain reduction estimate. In the fourth test session, the precursor measurements were obtained for the gain reduction estimates. Signal threshold for the “masker-present” and “masker-absent” conditions was measured when the precursor was immediately followed by the masker at the chosen masker level and when the 20-ms masker was replaced by silence, respectively. The masker-present gain reduction estimate was the difference between the masked signal thresholds with and without a precursor, and the masker-absent gain reduction estimate was the difference between the signal threshold in quiet with and without a precursor. Training and test data for the precursor conditions were collected in this session; the training data were omitted from the analysis. Three training thresholds were measured for each precursor condition (masker-absent and -present), followed by data collection for six thresholds per condition for analysis with the same procedure for discarding unreliable tracks and replacing those with new tracks as done for the GOM measures. This same procedure was used by DeRoy Milvae and Strickland (2018); therefore, the 2-kHz data for the five participants who also participated in this experiment were not remeasured.
It was assumed that participants listened for the signal at the signal frequency place in the cochlea (Moore, 1986). It was also assumed that the masker was low enough in frequency to be processed linearly at the signal frequency place (Cooper and Guinan, 2006). With these assumptions, the gain reduction due to the presence of a precursor should not affect the gain of the off-frequency masker at the signal frequency place.
C. Speech-in-noise recognition
1. Stimuli
The PRESTO-R test (Plotkowski and Alexander, 2016), a revised version of the PRESTO (Gilbert et al., 2013), was used to test speech recognition. List equivalency was demonstrated for this revised version with monaural presentation at −3 dB SNR with speech-shaped noise. The PRESTO-R is a high-variability sentence test made up of TIMIT (Texas Instruments and Massachusetts Institute of Technology) sentences. Lists G and K were included as practice lists. Lists F, I, T, C, E, and O were used as test lists in this experiment. Each list included nine different female and nine different male talkers with varying regional American accents. Keywords (76 per list of 18 sentences) were scored to obtain a percent-correct score.
Speech-in-noise recognition was measured with ipsilateral noise. Sentences were fixed at 60 dB SPL, a comfortable, conversational level, and noise levels were chosen appropriately for −3, 0, and +3 dB SNR conditions. Speech-shaped noise was generated in matlab software (MathWorks, Natick, MA) by bandpass filtering broadband noise and spectrally shaping the noise to approximate the 1/3-octave band levels from the international long-term average speech spectrum (Byrne et al., 1994). The delay between the onset of the noise and the onset of the speech was 250 ms, and the noise offset was of the same duration. During this onset and offset, the noise was ramped on and off with 250-ms cos2 ramps.
2. Procedure
Participants listened to the sentences in a double-walled, sound-treated booth and typed their responses. Custom matlab software (MathWorks, Natick, MA) was used to present the stimuli. The stimuli were presented using the same audio setup that was used for the psychoacoustic measures.
Sentences were played to participants' right ears. Participants advanced through the sentences by clicking a button with the mouse. Sentences could not be replayed and no feedback was given regarding the accuracy, but participants could see how many sentences remained in the experiment.
Participants first completed a practice list of 18 sentences; however, they were not aware that these sentences would not be scored. In the practice list, the first six sentences were presented at +3 dB SNR, the next six sentences were presented at 0 dB SNR, and the final six sentences were presented at −3 dB SNR. This was done so that participants were introduced to the stimuli with progressively increasing difficulty. After the practice list, sentences from three test lists were combined and then presented in a randomized order that was the same across participants. The same sentence order was used so that any contextual cues across sentences due to lexical and syntactic priming were always the same (e.g., Traxler et al., 2014). For example, if the presentation of a word like “flowers” in one sentence facilitated recognition of the word “vase” in the following sentence, due to the lexical relationship, fixing the sentence order allowed all of the participants the opportunity to benefit from such priming effects rather than allowing them to vary with random sentence presentation order. For each participant, the three lists were assigned different SNRs. In this way, the difficulty level from sentence to sentence varied in an effort to keep the participants interested and challenged throughout the experiment. Half of the participants were tested with practice list G and test lists F, I, and T, and the other half of the participants were tested with practice list K and test lists C, E, and O. There were 12 possible SNR assignments (6 combinations of lists and SNRs × 2 sets of lists). Because there were 24 participants, each SNR assignment and test list combination was given to 2 participants to counterbalance. Participants completed this experiment in approximately 30 min. After the session, sentences were reviewed with the participants to clarify typographical errors. Each participant also completed speech-in-noise testing with bilateral noise for the remaining lists in an additional 30 min of testing following the same procedures. These data can be found in the Appendix.
Scoring was independently completed offline by two scorers. Differences in scoring occurred rarely and were discussed and changed to an agreed-upon score. Each keyword was scored as correct or incorrect. Spelling errors were not penalized as long as the intended word was clear to the scorers.
III. RESULTS
A. Psychoacoustic measure of cochlear gain reduction
Two gain reduction estimates were made to determine if similar gain reduction estimates would be obtained from the two estimates with a larger sample size than that of a previous experiment (DeRoy Milvae and Strickland, 2018). In Fig. 2, the GOM functions are shown for each participant as open circles and squares. The difference between the open and filled squares is the masker-present gain reduction estimate, and the difference between the open and filled triangles is the masker-absent gain reduction estimate. A one-way repeated-measures analysis of variance (ANOVA) was completed to test if the gain reduction estimates measured with the two methods were significantly different. The gain reduction estimate measured when the masker was present (M = 9.02, SD = 3.19) was not significantly different from the gain reduction estimate measured when the masker was absent [M = 9.76, SD = 3.23, F(1,23) = 2.53, p = 0.125, = 0.099]. It was concluded that at 2 kHz, the masker-absent condition generates a similar gain reduction estimate as the masker-present condition. This result is consistent with the previous observation that omission of the masker leads to a similar shift in the signal threshold as is seen with a masker present (Roverud and Strickland, 2010, Fig. 2). The masker-present estimate, a more traditional estimate of cochlear gain reduction, was used in the analysis in Sec. III C.
FIG. 2.
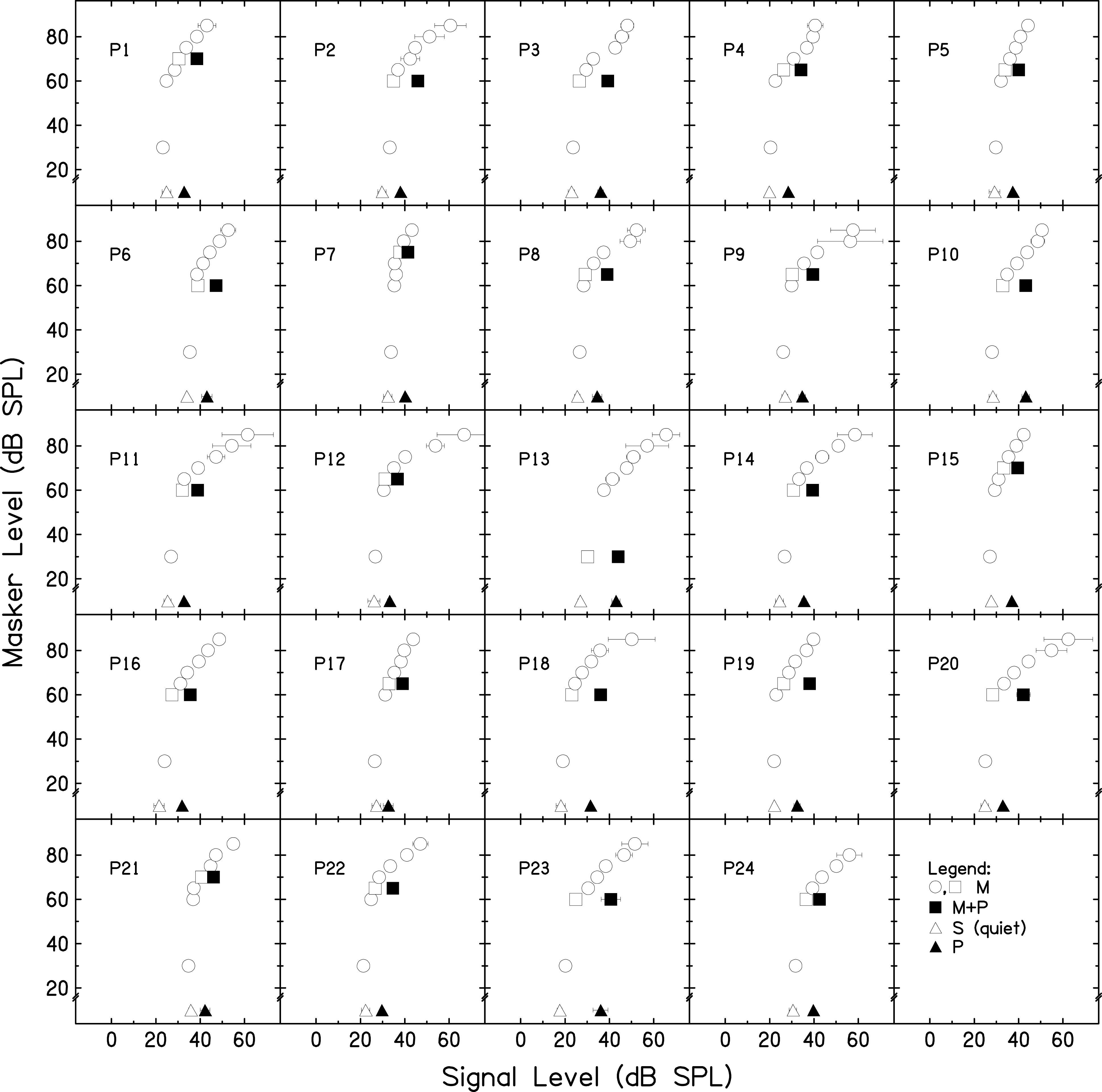
GOM and gain reduction estimates measured with a 2-kHz, 8-ms signal: individual data. Open circles and squares depict the GOM of a 2-kHz, 8-ms tone when masked by a 1.2-kHz, 20-ms masker tone. The quiet threshold is represented by open triangles. The threshold for the same tone preceded by a 50-ms pink noise precursor and a 20-ms silent gap is represented by the filled triangles. The threshold for the tone preceded by both a precursor and masker is represented by the filled squares. The difference between the square symbols is the masker-present gain reduction estimate, and the difference between the triangle symbols is the masker-absent gain reduction estimate. Error bars represent one SD.
B. Speech-in-noise recognition
The PRESTO-R speech-in-noise test was scored and the percent-correct scores were converted to rationalized arcsine units (RAU) for comparison (Studebaker, 1985). Average scores at +3 (M = 90.67, SD = 6.25), 0 (M = 80.32, SD = 7.96), and −3 (M = 63.05, SD = 6.07) dB SNR showed decreasing performance as the SNR became more adverse.
A one-way repeated-measures ANOVA was completed with speech-in-noise recognition as the dependent variable and the factor of SNR (-3, 0, and +3 dB). SNR (F[2,46] = 159.73, p <0.001, = 0.874) was statistically significant. Post hoc tests using a Bonferroni correction revealed that the speech-in-noise recognition at all three SNRs was significantly different from the other two SNRs (p < 0.001 for all comparisons).
C. Relationship between the psychoacoustic measure of cochlear gain reduction and speech-in-noise recognition
Linear regressions were calculated to examine the relationship between the psychoacoustic measure of cochlear gain reduction and speech-in-noise recognition at each SNR (see Fig. 3). A Holm-Bonferroni correction was used to adjust the p-values to account for multiple comparisons. At +3 dB SNR, the relationship was not significant (F[1,22] = 0.45, p = 0.507, R2 = 0.020). At 0 dB SNR, the relationship was significant (F[1,22] = 5.88, p = 0.048, R2 = 0.211). The predicted speech-in-noise recognition in RAU was equal to 90.67 − 1.15 (gain reduction estimate in dB). At −3 dB SNR, the relationship was also significant (F[1,22] = 13.58, p = 0.003, R2 = 0.382). The predicted speech-in-noise recognition in RAU was equal to 73.66 − 1.18 (gain reduction estimate in dB).
FIG. 3.

The relationship between psychoacoustic gain reduction estimates and speech recognition by SNR is shown. The light gray triangles represent individual data at +3 dB SNR, the medium gray circles represent individual data at 0 dB SNR, and the black squares represent individual data at −3 dB SNR. R2 is larger with a decreasing SNR.
An additional analysis was included to examine the relationship between the psychoacoustic gain reduction measure and the slope of the growth in speech-in-noise recognition with increasing SNR, performed in recent experiments examining SNR as a factor (Mertes et al., 2018, 2019). To account for the variability in the measure of the slope, a linear mixed-effects model (LMM) approach was used to test if these slopes were significant. The dependent variable was the speech recognition score (RAU). Fixed effects included the SNR (a categorical variable; −3, 0, and +3 dB) and masker-present gain reduction estimate (a continuous variable) and their interaction. A significant interaction would indicate a significant relationship between speech understanding improvement with a higher SNR and gain reduction estimate. The reference level chosen for the SNR in the model was 0 dB. Model testing was completed using R 4.0.3 (R Core Team, 2020) and the “buildmer” version 1.5 (Voeten, 2020) and “lme4” version 1.1–26 (Bates et al., 2015) packages. From the maximal model (Barr et al., 2013), the buildmer function ordered effects in the model using the likelihood-ratio test (LRT) statistic and then used a backward-elimination approach to model testing, based on the significance of changes in the log-likelihood to find a model that converged and provided the best fit to the data (Matuschek et al., 2017; Voeten, 2020). Random intercepts and slopes were included for the fixed effects by participant in the maximal model. The Satterthwaite approximation (Luke, 2017) was used for the p-values. The best-fitting model is summarized in Table II. The interaction between the SNR and gain reduction estimate was not included in this best-fitting model, indicating that it was not significant (LRT p > 0.05). To confirm the finding in Sec. III B that speech recognition scores were significantly different with a varied SNR, the reference level of the SNR variable was systematically changed in the model of best fit, allowing pairwise examination of the three levels of the variable. All SNRs were significantly different from each other (p < 0.001).
TABLE II.
Linear mixed-effects model (LMM) summary describing the effects of the SNR and masker-present gain reduction estimate on speech recognition (RAU). The interaction between the SNR and masker-present gain reduction estimate was a nonsignificant factor and was removed from the model during model testing. Significant fixed effects are shown in bold with a Satterthwaite approximation used to generate p-values.
| Speech recognition (RAU) | ||||
|---|---|---|---|---|
| Fixed effects | Estimate | SE | t | p |
| Intercept | 88.14 | 2.94 | 29.94 | <0.001 |
| SNR (−3 > 0) | −17.27 | 1.56 | −11.06 | <0.001 |
| SNR (+3 > 0) | 10.35 | 1.56 | 6.63 | <0.001 |
| Masker-present gain reduction estimate | −0.87 | 0.29 | −2.96 | 0.007 |
| Random effects | Variance | SD |
|---|---|---|
| By-participant intercepts | 10.39 | 3.22 |
| Residual | 29.26 | 5.41 |
IV. DISCUSSION
This experiment investigated the relationship between a psychoacoustic measure of cochlear gain reduction and speech-in-noise recognition. Ipsilateral gain reduction, as estimated psychoacoustically, was negatively associated with speech-in-noise recognition at SNRs ≤ 0 dB; there was no relationship at a higher SNR. This supports our overarching hypothesis that the functional benefit from gain reduction for ipsilateral elicitation depends on the SNR.
We specifically hypothesized that gain reduction would be beneficial at positive SNRs because the noise would be affected by the gain reduction more than the speech over time, and detrimental at negative SNRs because the speech would be affected by the gain reduction more than the noise over time. Consequently, it was hypothesized that the regression between gain reduction and speech recognition would be positive at positive SNRs and negative at negative SNRs. As expected, there was a negative relationship between the gain reduction and speech-in-noise recognition at −3 dB SNR. Contrary to our hypotheses, participants in the present experiment who had larger gain reduction also had poorer performance on the speech-in-noise test at 0 dB SNR, and there was no significant relationship at +3 dB SNR. There are several possible interpretations of these findings.
One possible explanation is simply that gain reduction is disadvantageous for speech-in-noise perception. However, physiological studies show a decompression of neural rate-level functions following efferent activation by the MOCR, which is believed to provide an antimasking effect when listening in noise (Winslow and Sachs, 1987; Kawase et al., 1993). There is also significant evidence that damage to the MOCR results in poorer auditory performance in noise (Giraud et al., 1995, 1997; Hienz et al., 1998; Zeng et al., 2000; May et al., 2004). Finally, positive correlations have been observed by the majority of studies that measured a significant correlation between OAE measures of gain reduction and speech-in-noise recognition (Kumar and Vanaja, 2004; de Boer and Thornton, 2008; Mishra and Lutman, 2014; Bidelman and Bhagat, 2015), although a significant negative correlation has been observed as well (de Boer et al., 2012). For the simpler task of tone detection, stronger contralateral suppression of OAEs has been associated with poorer tone detection in a repeating tone complex with unpredictable frequency components (Garinis et al., 2011). Detection of the tone in the tone complex occurred at a negative SNR, consistent with the present finding of a negative correlation between performance in noise at a negative SNR and gain reduction strength. Due to this conflicting evidence, the explanation of the present result is likely more complex than a disadvantageous effect of cochlear gain reduction for speech-in-noise understanding.
Another possible explanation is that ceiling effects in the current study limited the ability to see the expected positive relationship at the positive SNR. Kumar and Vanaja (2004) found a significant correlation between the improvement in speech perception with contralateral noise and TEOAE suppression at ipsilateral SNRs of +10 and +15 dB. The difficulty of the speech materials likely contributed to their ability to test at such high SNRs without encountering ceiling effects. The participants were also Indian children tested on an English speech-in-noise test, which may have contributed to low scores at high SNRs if English was not a native language. However, ceiling effects do not explain the significant negative relationship at 0 dB SNR in this experiment. In the situation in which the speech and noise are at the same level, no relationship between gain reduction and performance was expected because they could be equally subject to gain reduction. However, speech and noise have inherent differences that may explain this negative relationship at a matched overall level. While the noise maintains a relatively steady level throughout the duration of the stimulus, speech has more peaks and valleys in level over time. If the noise leads to strong gain reduction across the speech range of frequencies, it is possible that the dips in speech are affected by the gain reduction to a degree that affects performance, leading to the observed relationship.
It is of note that in typical communication situations, SNR is positive (Smeds et al., 2015). Since positive SNRs are the ones typically encountered, it is important to expand our knowledge of how the auditory system copes with signal degradation at these SNRs. In fact, several of the studies devoid of ceiling effects at positive SNRs found positive relationships between cochlear gain reduction strength and speech-in-noise recognition (Kumar and Vanaja, 2004; de Boer and Thornton, 2008; Bidelman and Bhagat, 2015), but others found the opposite relationship (de Boer et al., 2012; DeRoy Milvae et al., 2015). The temporal characteristics of the noise and difficulty of the speech-in-noise test could explain these conflicting findings. However, no clear patterns emerge. In fact, studies with very similar speech-in-noise tests using broadband noise (de Boer and Thornton, 2008; de Boer et al., 2012) or identical speech-in-noise tests using multitalker babble (Bidelman and Bhagat, 2015; DeRoy Milvae et al., 2015) found opposite relationships between the cochlear gain reduction strength and speech-in-noise recognition (positive and negative correlations).
Other factors may also play roles in the conflicting findings across studies. The overall level of the speech-in-noise test may be important because gain reduction impacts sound levels near or below the compression point. To observe larger effects of the gain reduction, the peaks and dips in the stimuli must span the linear and compressive regions of the input-output function (see Fig. 1). This is very likely to occur for conversational speech levels (Cox and Moore, 1988; Byrne et al., 1994), and indeed acoustic analysis of the PRESTO-R sentences at an overall level of 60 dB SPL showed that at 2 kHz, the peaks were approximately 50 dB SPL and the dips were approximately 20 dB SPL. We were able to observe a significant relationship in the present study at the two lowest SNRs and relationships have been observed at conversational levels (see Table I), suggesting that conversational speech levels are sensitive to gain reduction effects. The strength of gain reduction at a fixed level could also vary across individuals, depending on their cochlear input-output functions (e.g., see Fig. 2). Perhaps selecting individual levels for the speech-in-noise testing in reference to the individual's cochlear input-output function, as done for the gain reduction measure, would result in stronger relationships between the two measures. Effects of the overall level could be explored in future experiments. Another factor that could be important is the participant population tested. Most studies explored the relationship between speech-in-noise recognition and cochlear gain reduction in young adults with normal hearing, but some tested children (Kumar and Vanaja, 2004), a range of children to older adults (Yilmaz et al., 2007; Abdala et al., 2014), or older adult groups (Mukari and Mamat, 2008; Maruthy et al., 2017; Mertes et al., 2018). No clear pattern emerges in these studies, but changes in cochlear gain reduction across the lifespan may affect the relationship with speech-in-noise recognition and could contribute to variability in the measures.
Another possible explanation of the present study results is that the observed relationship between ipsilateral gain reduction and speech-in-noise recognition reflects the influence of a factor not measured directly in this experiment. For example, participant motivation and engagement may be a factor because a more attentive participant who performs well on the speech-in-noise test may also have lower masked thresholds in the psychoacoustic task, thereby leading to a smaller gain reduction estimate. In addition, as the speech-in-noise recognition was a raw measure rather than a change from a baseline without gain reduction (as in the psychoacoustic measure), it is possible that people with high performance did not need the benefit of gain reduction, and people with lower speech recognition would have performed more poorly without gain reduction. This could be explored in future experiments by setting the level of the speech-in-noise test for each individual based on the measured cochlear input-output functions to maximize the opportunity for benefit from gain reduction.
Limitations of this study should be considered. The gain reduction estimate was obtained at a single frequency for this measure, and it is not known if the relationships observed hold for other frequency regions. In addition, the gain reduction estimate at 2 kHz relies on the assumption that an off-frequency masker is processed linearly at the signal place and, as such, is not affected by the gain reduction elicited by the precursor. This assumption was based on basilar membrane displacement data measured near the base of the cochlea, showing that efferent stimulation does not affect the gain of basilar membrane displacement from an off-frequency tone (Cooper and Guinan, 2006). However, cochlear tuning broadens toward the apex (Cooper and Rhode, 1997), potentially calling this assumption into question. Furthermore, developments in the field of cochlear mechanics have revealed that the motion of the reticular lamina is greater than that of the basilar membrane (Ren et al., 2016) and the cochlear apex of guinea pigs (below 2 kHz) is compressive for frequencies below the center frequency with a low-pass filter response (Recio-Spinoso and Oghalai, 2017). In mice with higher-frequency hearing overall, it appears that the cochlear amplifier impacts the peak of the reticular lamina response (Dewey et al., 2019) as previously observed for the basilar membrane (Fisher et al., 2012). Further study is needed to determine if this off-frequency nonlinearity of reticular lamina motion extends to the 2-kHz region in humans and how efferent activity affects cochlear mechanics in this region. The potential impact of a masker processed nonlinearly at the signal place in this measurement is an underestimate of cochlear gain reduction. However, our previous data suggest that even at 1 kHz, there is a difference in the gain provided to on- and off-frequency maskers, differentially affected by the preceding sound (DeRoy Milvae and Strickland, 2018).
Additionally, middle-ear muscle contractions cannot be ruled out entirely as thresholds were measured with clinical immittance equipment and likely were higher than the thresholds measured with more sensitive approaches (Feeney and Keefe, 2001; Feeney et al., 2017). On average, clinical thresholds are 12 dB higher than those measured with wideband acoustic immittance (Feeney et al., 2017), meaning that the thresholds in this group were, on average, well above the level of the speech-in-noise stimuli. However, it is possible that for some listeners and at the peaks in the stimuli, middle-ear muscle contraction could have affected the results.
The results could have also been affected by top-down influences on cochlear gain reduction. Perrot et al. (2006) measured a reduction in OAEs following stimulation of the auditory cortex with electrodes placed during surgery of epileptic patients. This suggests that pathways exist in the human auditory system from the cortex to the auditory periphery, making it possible for higher-level processing to modulate the MOCR. In addition, there is evidence that the MOCR is under some attentional control. Maison et al. (2001) measured OAEs at two test frequencies and found that participants had a larger suppression of OAEs at one of the frequencies when they were instructed to detect tones at that frequency in the background noise of the suppressor. De Boer and Thornton (2007) found smaller suppression of OAEs in an active auditory task detecting tones in the click train. This evidence suggests that directed attention to an auditory task in the measurement ear can reduce the effect observed in that ear. Attention was directed toward the measurement ear for both the psychoacoustic and speech-in-noise tests in this experiment and, thus, any modulation of the effect related to ear attention was not likely a factor in the relationship between measures.
The results of this study provide evidence that the functional benefits of ipsilateral cochlear gain reduction depend on the SNR. Future research is needed to further explore the importance of the spectro-temporal composition of the speech and noise to a functional benefit from cochlear gain reduction, as well as the role that attention and top-down control may play in cochlear gain reduction and functional benefits.
ACKNOWLEDGMENTS
The authors would like to thank Hayley Morris for assistance in sentence scoring. Funding support was received from the National Institute On Deafness and Other Communication Disorders of the National Institutes of Health under Award Nos. R01-DC008327 (E.A.S.), T32-DC000030 (trainee K.D.M.), and T32-DC000046 (trainee K.D.M.). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. Additional support was also received from the Purdue Research Foundation and the Robert L. Ringel Research Fund Scholarship.
APPENDIX: SPEECH-IN-NOISE RECOGNITION IN BILATERAL NOISE
Additional speech-in-noise recognition data with bilateral noise were collected with the data presented in this paper for the same 24 participants. These data were collected to examine the relationship between improvement in speech-in-noise performance with bilateral elicitation of cochlear gain reduction and a physiologic measure of cochlear gain reduction that was unable to be collected successfully, but are presented here to demonstrate the improvement observed. The contralateral noise was uncorrelated with the ipsilateral noise and generated by scrambling the phase of the ipsilateral noise, ramping this scrambled noise, and scaling to match the level of the ipsilateral noise. The target speech was presented to the right ear only in this bilateral noise condition. This condition was tested in a separate block from the ipsilateral noise block presented in this paper with the block order counterbalanced across participants. Practice list G and test lists F, I, and T were used in the first block and practice list K and test lists C, E, and O were used in the second block. All procedures for the bilateral noise block were the same as in the ipsilateral noise block. For one participant (P2), one of the sentences did not play (-3 dB SNR bilateral noise condition). The score for this participant in this condition was computed over 17 sentences instead of the 18 sentences in the full list. One participant (P18) completed the two blocks on two separate days rather than within the same one-hour session.
Results from the bilateral noise condition showed improvement in speech recognition on average with the additional noise. Speech recognition with bilateral noise was highest in the +3 dB SNR condition (M = 93.33 RAU, SD = 8.44 RAU) with decreased speech recognition in the 0 dB SNR condition (M = 83.52 RAU, SD = 6.12 RAU) and lowest speech recognition in the −3 dB SNR condition (M = 67.19 RAU, SD = 6.79 RAU). The entire speech-in-noise dataset is shown in Fig. 4. A two-way repeated-measures ANOVA was completed on the entire speech-in-noise dataset with the speech-in-noise performance as the dependent variable and factors of the SNR (−3, 0, and +3 dB) and noise laterality (ipsilateral and bilateral noise). The SNR (F[2,46] = 287.77, p < 0.001, = 0.926) and noise laterality (F[1,23] = 16.16, p = 0.001, = 0.413) were statistically significant, but the interaction between them was not significant (F[2,46] = 0.28, p = 0.756, = 0.012). Post hoc tests using a Bonferroni correction revealed that the speech-in-noise performance at all three SNRs was significantly different from the other two SNRs (p < 0.001 for all comparisons). Speech recognition was significantly better when the noise was presented bilaterally compared to when it was presented ipsilaterally (p = 0.001).
FIG. 4.

Individual speech recognition (RAU) for the PRESTO-R sentences in ipsilateral noise compared to bilateral noise. The light gray triangles represent individual data at +3 dB SNR, the medium gray circles represent individual data at 0 dB SNR, and the black squares represent individual data at −3 dB SNR. The dotted line represents matched performance on both measures with improvement in the bilateral noise condition plotted above this line.
The improvement in speech recognition with bilateral noise may be related to additional MOC stimulation. However, it may have been modulated by factors other than cochlear gain reduction. Although the noise presented to the two ears was uncorrelated in an effort to limit masking level differences, it is possible that given the simultaneous onset, amplitude rise and fall, and similar frequency spectrum that the noises may still have been grouped as an auditory object and this allowed some release from masking and perceived difference in location from the speech (Bregman, 1990; Hartmann and Constan, 2002). Another factor that may have influenced the results is middle-ear muscle contractions. Although an attempt was made to avoid confounds related to middle-ear muscle contractions by requiring ipsilateral and contralateral acoustic reflex thresholds above 60 dB SPL, there is evidence that binaural stimulation results in a lower threshold (Simmons, 1965). It cannot be ruled out that the binaural noise evoked middle-ear muscle contractions and influenced the results.
References
- 1.Abdala, C., Dhar, S., Ahmadi, M., and Luo, P. (2014). “ Aging of the medial olivocochlear reflex and associations with speech perception,” J. Acoust. Soc. Am. 135, 754–765. 10.1121/1.4861841 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Alexander, J. M., and Masterson, K. (2015). “ Effects of WDRC release time and number of channels on output SNR and speech recognition,” Ear Hear. 36, e35–e49. 10.1097/AUD.0000000000000115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Backus, B. C., and Guinan, J. J. (2006). “ Time-course of the human medial olivocochlear reflex,” J. Acoust. Soc. Am. 119, 2889–2904. 10.1121/1.2169918 [DOI] [PubMed] [Google Scholar]
- 4.Barr, D. J., Levy, R., Scheepers, C., and Tily, H. J. (2013). “ Random effects structure for confirmatory hypothesis testing: Keep it maximal,” J. Mem. Lang. 68, 255–278. 10.1016/j.jml.2012.11.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Bates, D., Mächler, M., Bolker, B. M., and Walker, S. C. (2015). “ Fitting linear mixed-effects models using lme4,” J. Stat. Softw. 67, 1–48. 10.18637/jss.v067.i01 [DOI] [Google Scholar]
- 6.Bidelman, G. M., and Bhagat, S. P. (2015). “ Right-ear advantage drives the link between olivocochlear efferent ‘antimasking’ and speech-in-noise listening benefits,” Neuroreport 26, 483–487. 10.1097/WNR.0000000000000376 [DOI] [PubMed] [Google Scholar]
- 7.Bidelman, G. M., Jennings, S. G., and Strickland, E. A. (2015). “ PsyAcoustX: A flexible MATLAB® package for psychoacoustics research,” Front. Psychol. 6, 1498. 10.3389/fpsyg.2015.01498 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Bregman, A. S. (1990). Auditory Scene Analysis: The Perceptual Organization of Sound ( MIT Press, Cambridge, MA). [Google Scholar]
- 9.Byrne, D., Dillon, H., Tran, K., Arlinger, S., Wilbraham, K., Cox, R., Hagerman, B., Hetu, R., Kei, J., Lui, C., Kiessling, J., Kotby, M. N., Nasser, N. H. A., El Kholy, W. A. H., Nakanishi, Y., Oyer, H., Powell, R., Stephens, D., Meredith, R., Sirimanna, T., Tavartkiladze, G., Frolenkov, G. I., Westerman, S., and Ludvigsen, C. (1994). “ An international comparison of long-term average speech spectra,” J. Acoust. Soc. Am. 96, 2108–2120. 10.1121/1.410152 [DOI] [Google Scholar]
- 10.Chays, A., Maison, S., Robaglia-Schlupp, A., Cau, P., Broder, L., and Magnan, J. (2003). “ Are we sectioning the cochlear efferent system during vestibular neurotomy?,” Rev. Laryngol. Otol. Rhinol. 124, 53–58. [PubMed] [Google Scholar]
- 11.Chintanpalli, A., Jennings, S. G., Heinz, M. G., and Strickland, E. A. (2012). “ Modeling the anti-masking effects of the olivocochlear reflex in auditory nerve responses to tones in sustained noise,” J. Assoc. Res. Otolaryngol. 13, 219–235. 10.1007/s10162-011-0310-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Collet, L., Kemp, D. T., Veuillet, E., Duclaux, R., Moulin, A., and Morgon, A. (1990). “ Effect of contralateral auditory stimuli on active cochlear micro-mechanical properties in human subjects,” Hear. Res. 43, 251–261. 10.1016/0378-5955(90)90232-E [DOI] [PubMed] [Google Scholar]
- 13.Cooper, N. P., and Guinan, J. J. (2006). “ Efferent-mediated control of basilar membrane motion,” J. Physiol. 576, 49–54. 10.1113/jphysiol.2006.114991 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Cooper, N. P., and Rhode, W. S. (1997). “ Mechanical responses to two-tone distortion products in the apical and basal turns of the mammalian cochlea,” J. Neurophysiol. 78, 261–270. 10.1152/jn.1997.78.1.261 [DOI] [PubMed] [Google Scholar]
- 15.Cox, R. M., and Moore, J. N. (1988). “ Composite speech spectrum for hearing aid gain prescriptions,” J. Speech Hear. Res. 31, 102–107. 10.1044/jshr.3101.102 [DOI] [PubMed] [Google Scholar]
- 16.Dean, I., Harper, N. S., and McAlpine, D. (2005). “ Neural population coding of sound level adapts to stimulus statistics,” Nat. Neurosci. 8, 1684–1689. 10.1038/nn1541 [DOI] [PubMed] [Google Scholar]
- 17.de Boer, J., and Thornton, A. R. D. (2007). “ Effect of subject task on contralateral suppression of click evoked otoacoustic emissions,” Hear. Res. 233, 117–123. 10.1016/j.heares.2007.08.002 [DOI] [PubMed] [Google Scholar]
- 18.de Boer, J., and Thornton, A. R. D. (2008). “ Neural correlates of perceptual learning in the auditory brainstem: Efferent activity predicts and reflects improvement at a speech-in-noise discrimination task,” J. Neurosci. 28, 4929–4937. 10.1523/JNEUROSCI.0902-08.2008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.de Boer, J., Thornton, A. R. D., and Krumbholz, K. (2012). “ What is the role of the medial olivocochlear system in speech-in-noise processing?,” J. Neurophysiol. 107, 1301–1312. 10.1152/jn.00222.2011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.DeRoy Milvae, K., Alexander, J. M., and Strickland, E. A. (2015). “ Is cochlear gain reduction related to speech-in-babble performance?,” Proc. Int. Symp. Audit. Audiol. Res. 5, 43–50, see https://proceedings.isaar.eu/index.php/isaarproc/article/view/2015-05. [Google Scholar]
- 21.DeRoy Milvae, K., and Strickland, E. A. (2018). “ Psychoacoustic measurements of ipsilateral cochlear gain reduction as a function of signal frequency,” J. Acoust. Soc. Am. 143, 3114–3125. 10.1121/1.5038254 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Dewey, J. B., Applegate, B. E., and Oghalai, J. S. (2019). “ Amplification and suppression of traveling waves along the mouse organ of corti: Evidence for spatial variation in the longitudinal coupling of outer hair cell-generated forces,” J. Neurosci. 39, 1805–1816. 10.1523/JNEUROSCI.2608-18.2019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Dewson, J. H. (1968). “ Efferent olivocochlear bundle: Some relationships to stimulus discrimination in noise,” J. Neurophysiol. 31, 122–130. 10.1152/jn.1968.31.1.122 [DOI] [PubMed] [Google Scholar]
- 24.Feeney, M. P., and Keefe, D. H. (2001). “ Estimating the acoustic reflex threshold from wideband measures of reflectance, admittance, and power,” Ear Hear. 22, 316–332. 10.1097/00003446-200108000-00006 [DOI] [PubMed] [Google Scholar]
- 25.Feeney, M. P., Keefe, D. H., Hunter, L. L., Fitzpatrick, D. F., Garinis, A. C., Putterman, D. B., and McMillan, G. P. (2017). “ Normative wideband reflectance, equivalent admittance at the tympanic membrane, and acoustic stapedius reflex threshold in adults,” Ear Hear. 38, e142–e160. 10.1097/AUD.0000000000000399 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Fisher, J. A. N., Nin, F., Reichenbach, T., Uthaiah, R. C., and Hudspeth, A. J. (2012). “ The spatial pattern of cochlear amplification,” Neuron 76, 989–997. 10.1016/j.neuron.2012.09.031 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Fletcher, H., and Galt, R. H. (1950). “ The perception of speech and its relation to telephony,” J. Acoust. Soc. Am. 22, 89–151. 10.1121/1.1906605 [DOI] [Google Scholar]
- 28.Garinis, A., Werner, L., and Abdala, C. (2011). “ The relationship between MOC reflex and masked threshold,” Hear. Res. 282, 128–137. 10.1016/j.heares.2011.08.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Gilbert, J. L., Tamati, T. N., and Pisoni, D. B. (2013). “ Development, reliability, and validity of PRESTO: A new high-variability sentence recognition test,” J. Am. Acad. Audiol. 24, 26–36. 10.3766/jaaa.24.1.4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Giraud, A. L., Collet, L., Chéry-Croze, S., Magnan, J., and Chays, A. (1995). “ Evidence of a medial olivocochlear involvement in contralateral suppression of otoacoustic emissions in humans,” Brain Res. 705, 15–23. 10.1016/0006-8993(95)01091-2 [DOI] [PubMed] [Google Scholar]
- 31.Giraud, A. L., Garnier, S., Micheyl, C., Lina, G., Chays, A., and Chéry-Croze, S. (1997). “ Auditory efferents involved in speech-in-noise intelligibility,” Neuroreport 8, 1779–1783. 10.1097/00001756-199705060-00042 [DOI] [PubMed] [Google Scholar]
- 32.Guinan, J. J. (2018). “ Olivocochlear efferents: Their action, effects, measurement and uses, and the impact of the new conception of cochlear mechanical responses,” Hear. Res. 362, 38–47. 10.1016/j.heares.2017.12.012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Harkrider, A. W., and Smith, S. B. (2005). “ Acceptable noise level, phoneme recognition in noise, and measures of auditory efferent activity,” J. Am. Acad. Audiol. 16, 530–545. 10.3766/jaaa.16.8.2 [DOI] [PubMed] [Google Scholar]
- 34.Hartmann, W. M., and Constan, Z. A. (2002). “ Interaural level differences and the level-meter model,” J. Acoust. Soc. Am. 112, 1037–1045. 10.1121/1.1500759 [DOI] [PubMed] [Google Scholar]
- 35.Hienz, R. D., Stiles, P., and May, B. J. (1998). “ Effects of bilateral olivocochlear lesions on vowel formant discrimination in cats,” Hear. Res. 116, 10–20. 10.1016/S0378-5955(97)00197-4 [DOI] [PubMed] [Google Scholar]
- 36.James, A. L., Harrison, R. V., Pienkowski, M., Dajani, H. R., and Mount, R. J. (2005). “ Dynamics of real time DPOAE contralateral suppression in chinchillas and humans,” Int. J. Audiol. 44, 118–129. 10.1080/14992020400029996 [DOI] [PubMed] [Google Scholar]
- 37.Jennings, S. G., and Strickland, E. A. (2012). “ Evaluating the effects of olivocochlear feedback on psychophysical measures of frequency selectivity,” J. Acoust. Soc. Am. 132, 2483–2496. 10.1121/1.4742723 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Jennings, S. G., Strickland, E. A., and Heinz, M. G. (2009). “ Precursor effects on behavioral estimates of frequency selectivity and gain in forward masking,” J. Acoust. Soc. Am. 125, 2172–2181. 10.1121/1.3081383 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Kawase, T., Delgutte, B., and Liberman, M. C. (1993). “ Antimasking effects of the olivocochlear reflex. II. Enhancement of auditory-nerve response to masked tones,” J. Neurophysiol. 70, 2533–2549. 10.1152/jn.1993.70.6.2533 [DOI] [PubMed] [Google Scholar]
- 40.Krull, V., and Strickland, E. A. (2008). “ The effect of a precursor on growth of forward masking,” J. Acoust. Soc. Am. 123, 4352–4357. 10.1121/1.2912440 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Kumar, U. A., and Vanaja, C. S. (2004). “ Functioning of olivocochlear bundle and speech perception in noise,” Ear Hear. 25, 142–146. 10.1097/01.AUD.0000120363.56591.E6 [DOI] [PubMed] [Google Scholar]
- 42.Levitt, H. (1971). “ Transformed up-down methods in psychoacoustics,” J. Acoust. Soc. Am. 49, 467–477. 10.1121/1.1912375 [DOI] [PubMed] [Google Scholar]
- 43.Liberman, M. C., and Guinan, J. J. (1998). “ Feedback control of the auditory periphery: Anti-masking effects of middle ear muscles vs. olivocochlear efferents,” J. Commun. Disord. 31, 471–483. 10.1016/S0021-9924(98)00019-7 [DOI] [PubMed] [Google Scholar]
- 44.Lopez-Poveda, E. A. (2018). “ Olivocochlear efferents in animals and humans: From anatomy to clinical relevance,” Front. Neurol. 9, 197. 10.3389/fneur.2018.00197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Luke, S. G. (2017). “ Evaluating significance in linear mixed-effects models in R,” Behav. Res. Methods 49, 1494–1502. 10.3758/s13428-016-0809-y [DOI] [PubMed] [Google Scholar]
- 46.Maison, S. F., Adams, J. C., and Liberman, M. C. (2003). “ Olivocochlear innervation in the mouse: Immunocytochemical maps, crossed versus uncrossed contributions, and transmitter colocalization,” J. Comp. Neurol. 455, 406–416. 10.1002/cne.10490 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Maison, S. F., and Liberman, M. C. (2000). “ Predicting vulnerability to acoustic injury with a noninvasive assay of olivocochlear reflex strength,” J. Neurosci. 20, 4701–4707. 10.1523/JNEUROSCI.20-12-04701.2000 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Maison, S., Micheyl, C., and Collet, L. (2001). “ Influence of focused auditory attention on cochlear activity in humans,” Psychophysiology 38, 35–40. 10.1111/1469-8986.3810035 [DOI] [PubMed] [Google Scholar]
- 49.Maruthy, S., Kumar, U. A., and Gnanateja, G. N. (2017). “ Functional interplay between the putative measures of rostral and caudal efferent regulation of speech perception in noise,” J. Assoc. Res. Otolaryngol. 18, 635–648. 10.1007/s10162-017-0623-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., and Bates, D. (2017). “ Balancing type I error and power in linear mixed models,” J. Mem. Lang. 94, 305–315. 10.1016/j.jml.2017.01.001 [DOI] [Google Scholar]
- 51.May, B. J., Budelis, J., and Niparko, J. K. (2004). “ Behavioral studies of the olivocochlear efferent system: Learning to listen in noise,” Arch. Otolaryngol. Head Neck Surg. 130, 660–664. 10.1001/archotol.130.5.660 [DOI] [PubMed] [Google Scholar]
- 52.Mertes, I. B., Johnson, K. M., and Dinger, Z. A. (2019). “ Olivocochlear efferent contributions to speech-in-noise recognition across signal-to-noise ratios,” J. Acoust. Soc. Am. 145, 1529–1540. 10.1121/1.5094766 [DOI] [PubMed] [Google Scholar]
- 53.Mertes, I. B., Wilbanks, E. C., and Leek, M. R. (2018). “ Olivocochlear efferent activity is associated with the slope of the psychometric function of speech recognition in noise,” Ear Hear. 39, 583–593. 10.1097/AUD.0000000000000514 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Messing, D. P., Delhorne, L., Bruckert, E., Braida, L. D., and Ghitza, O. (2009). “ A non-linear efferent-inspired model of the auditory system; matching human confusions in stationary noise,” Speech Commun. 51, 668–683. 10.1016/j.specom.2009.02.002 [DOI] [Google Scholar]
- 55.Mishra, S. K., and Lutman, M. E. (2014). “ Top-down influences of the medial olivocochlear efferent system in speech perception in noise,” PLoS One 9, e85756. 10.1371/journal.pone.0085756 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Moore, B. C. J. (1986). “ Parallels between frequency selectivity measured psychophysically and in cochlear mechanics,” Scand. Audiol. Suppl. 25, 139–152. [PubMed] [Google Scholar]
- 57.Mukari, S. Z.-M. S., and Mamat, W. H. W. (2008). “ Medial olivocochlear functioning and speech perception in noise in older adults,” Audiol. Neurotol. 13, 328–334. 10.1159/000128978 [DOI] [PubMed] [Google Scholar]
- 58.Naylor, G., and Johannesson, R. B. (2009). “ Long-term signal-to-noise ratio at the input and output of amplitude-compression systems,” J. Am. Acad. Audiol. 20, 161–171. 10.3766/jaaa.20.3.2 [DOI] [PubMed] [Google Scholar]
- 59.Nelson, D. A., Schroder, A. C., and Wojtczak, M. (2001). “ A new procedure for measuring peripheral compression in normal-hearing and hearing-impaired listeners,” J. Acoust. Soc. Am. 110, 2045–2064. 10.1121/1.1404439 [DOI] [PubMed] [Google Scholar]
- 60.Nieder, P., and Nieder, I. (1970). “ Stimulation of efferent olivocochlear bundle causes release from low level masking,” Nature 227, 184–185. 10.1038/227184a0 [DOI] [PubMed] [Google Scholar]
- 61.Oxenham, A. J., and Plack, C. J. (1997). “ A behavioral measure of basilar-membrane nonlinearity in listeners with normal and impaired hearing,” J. Acoust. Soc. Am. 101, 3666–3675. 10.1121/1.418327 [DOI] [PubMed] [Google Scholar]
- 62.Perrot, X., Ryvlin, P., Isnard, J., Guénot, M., Catenoix, H., Fischer, C., Mauguière, F., and Collet, L. (2006). “ Evidence for corticofugal modulation of peripheral auditory activity in humans,” Cereb. Cortex 16, 941–948. 10.1093/cercor/bhj035 [DOI] [PubMed] [Google Scholar]
- 63.Plack, C. J., and Oxenham, A. J. (1998). “ Basilar-membrane nonlinearity and the growth of forward masking,” J. Acoust. Soc. Am. 103, 1598–1608. 10.1121/1.421294 [DOI] [PubMed] [Google Scholar]
- 64.Plotkowski, A. R., and Alexander, J. M. (2016). “ A sequential sentence paradigm using revised PRESTO sentence lists,” J. Am. Acad. Audiol. 27, 647–660. 10.3766/jaaa.15074 [DOI] [PubMed] [Google Scholar]
- 65.R Core Team (2020). “R: A language and environment for statistical computing,” R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (Last viewed March 30, 2021).
- 66.Recio-Spinoso, A., and Oghalai, J. S. (2017). “ Mechanical tuning and amplification within the apex of the guinea pig cochlea,” J. Physiol. 595, 4549–4561. 10.1113/JP273881 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Ren, T., He, W., and Kemp, D. (2016). “ Reticular lamina and basilar membrane vibrations in living mouse cochleae,” Proc. Natl. Acad. Sci. U.S.A. 113, 9910–9915. 10.1073/pnas.1607428113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Roverud, E., and Strickland, E. A. (2010). “ The time course of cochlear gain reduction measured using a more efficient psychophysical technique,” J. Acoust. Soc. Am. 128, 1203–1214. 10.1121/1.3473695 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Roverud, E., and Strickland, E. A. (2014). “ Accounting for nonmonotonic precursor duration effects with gain reduction in the temporal window model,” J. Acoust. Soc. Am. 135, 1321–1334. 10.1121/1.4864783 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Scharf, B., Magnan, J., and Chays, A. (1997). “ On the role of the olivocochlear bundle in hearing: 16 case studies,” Hear. Res. 103, 101–122. 10.1016/S0378-5955(96)00168-2 [DOI] [PubMed] [Google Scholar]
- 71.Scharf, B., Magnan, J., Collet, L., Ulmer, E., and Chays, A. (1994). “ On the role of the olivocochlear bundle in hearing: A case study,” Hear. Res. 75, 11–26. 10.1016/0378-5955(94)90051-5 [DOI] [PubMed] [Google Scholar]
- 72.Simmons, F. B. (1965). “ Binaural summation of the acoustic reflex,” J. Acoust. Soc. Am. 37, 834–836. 10.1121/1.1909453 [DOI] [PubMed] [Google Scholar]
- 73.Smeds, K., Wolters, F., and Rung, M. (2015). “ Estimation of signal-to-noise ratios in realistic sound scenarios,” J. Am. Acad. Audiol. 26, 183–196. 10.3766/jaaa.26.2.7 [DOI] [PubMed] [Google Scholar]
- 74.Souza, P. E., Jenstad, L. M., and Boike, K. T. (2006). “ Measuring the acoustic effects of compression amplification on speech in noise,” J. Acoust. Soc. Am. 119, 41–44. 10.1121/1.2108861 [DOI] [PubMed] [Google Scholar]
- 75.Stone, M. A., and Moore, B. C. J. (2003). “ Effect of the speed of a single-channel dynamic range compressor on intelligibility in a competing speech task,” J. Acoust. Soc. Am. 114, 1023–1034. 10.1121/1.1592160 [DOI] [PubMed] [Google Scholar]
- 76.Stuart, A., and Butler, A. K. (2012). “ Contralateral suppression of transient otoacoustic emissions and sentence recognition in noise in young adults,” J. Am. Acad. Audiol. 23, 686–696. 10.3766/jaaa.23.9.3 [DOI] [PubMed] [Google Scholar]
- 77.Studebaker, G. A. (1985). “ A ‘rationalized’ arcsine transform,” J. Speech Lang. Hear. Res. 28, 455–462. 10.1044/jshr.2803.455 [DOI] [PubMed] [Google Scholar]
- 78.Taranda, J., Maison, S. F., Ballestero, J. A., Katz, E., Savino, J., Vetter, D. E., Boulter, J., Liberman, M. C., Fuchs, P. A., and Elgoyhen, A. B. (2009). “ A point mutation in the hair cell nicotinic cholinergic receptor prolongs cochlear inhibition and enhances noise protection,” PLoS Biol. 7, e1000018. 10.1371/journal.pbio.1000018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Terreros, G., Jorratt, P., Aedo, C., Elgoyhen, A. B., and Delano, P. H. (2016). “ Selective attention to visual stimuli using auditory distractors is altered in alpha-9 nicotinic receptor subunit knock-out mice,” J. Neurosci. 36, 7198–7209. 10.1523/JNEUROSCI.4031-15.2016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Traxler, M. J., Tooley, K. M., and Pickering, M. J. (2014). “ Syntactic priming during sentence comprehension: Evidence for the lexical boost,” J. Exp. Psychol. Learn. Mem. Cogn. 40, 905–918. 10.1037/a0036377 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Voeten, C. C. (2020). “ Buildmer: Stepwise elimination and term reordering for mixed-effects regression,” R Package version 1.5, available at https://cran.r-project.org/package=buildmer (Last viewed March 30, 2021).
- 82.Wagner, W., Frey, K., Heppelmann, G., Plontke, S. K., and Zenner, H.-P. (2008). “ Speech-in-noise intelligibility does not correlate with efferent olivocochlear reflex in humans with normal hearing,” Acta Otolaryngol. 128, 53–60. 10.1080/00016480701361954 [DOI] [PubMed] [Google Scholar]
- 83.Watkins, G. D., Swanson, B. A., and Suaning, G. J. (2018). “ An evaluation of output signal to noise ratio as a predictor of cochlear implant speech intelligibility,” Ear Hear. 39, 958–968. 10.1097/AUD.0000000000000556 [DOI] [PubMed] [Google Scholar]
- 84.Winslow, R. L., and Sachs, M. B. (1987). “ Effect of electrical stimulation of the crossed olivocochlear bundle on auditory nerve response to tones in noise,” J. Neurophysiol. 57, 1002–1021. 10.1152/jn.1987.57.4.1002 [DOI] [PubMed] [Google Scholar]
- 85.Yasin, I., Drga, V., and Plack, C. J. (2014). “ Effect of human auditory efferent feedback on cochlear gain and compression,” J. Neurosci. 34, 15319–15326. 10.1523/JNEUROSCI.1043-14.2014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Yilmaz, S. T., Sennaroǧlu, G., Sennaroǧlu, L., and Köse, S. K. (2007). “ Effect of age on speech recognition in noise and on contralateral transient evoked otoacoustic emission suppression,” J. Laryngol. Otol. 121, 1029–1034. 10.1017/S0022215107006883 [DOI] [PubMed] [Google Scholar]
- 87.Zeng, F.-G., Martino, K. M., Linthicum, F. H., and Soli, S. D. (2000). “ Auditory perception in vestibular neurectomy subjects,” Hear. Res. 142, 102–112. 10.1016/S0378-5955(00)00011-3 [DOI] [PubMed] [Google Scholar]