

Abstract
Nonparametric tests do not rely on data belonging to any particular parametric family of probability distributions, which makes them preferable in case of doubt about the underlying population. Although the two‐tailed sign test is likely the most common nonparametric test for location problems, practitioners face serious drawbacks, such as its lack of statistical power and its inapplicability when information regarding data and hypotheses is uncertain or imprecise. In this paper, we generalize the two‐tailed sign test by embedding fuzzy hypotheses caused by uncertainty/imprecision regarding linguistic statements on fractions of underlying quantiles. By achieving this objective, (1) crucial limitations of the common two‐tailed sign test are mitigated/overcome, (2) various further strengths are incorporated into the sign test (e.g., meeting the trade‐off between point‐ and interval‐valued hypotheses, facilitated formulation of fuzzy hypotheses, standardization of membership functions), and (3) shortcomings that often come along with fuzzy hypothesis testing are avoided (e.g., higher complexity, fuzzy test decision, possibilistic interpretation of test results). In addition, we conduct a comprehensive case study using a real data set on the psychosocial status during the COVID‐19 pandemic. The results of the case study clearly indicate that the generalized two‐tailed sign test is preferable to the two‐tailed sign test with point‐ or interval‐valued hypotheses.
Keywords: fuzzy hypotheses, fuzzy statistics, interval‐valued hypotheses, sign test, uncertain knowledge
1. INTRODUCTION
Nonparametric tests are techniques of statistical inference that do not require the underlying distribution to meet specific assumptions, which is why they are also referred to as distribution‐free tests. These tests serve as alternatives to parametric tests that can only be applied when the data comply with certain assumptions and criteria. For instance, the common parametric one‐/two‐sample ‐test and one‐/two‐way analysis of variance (ANOVA) can be substituted by the nonparametric sign test, Mann–Whitney ‐test, Kruskal–Wallis test, and Friedman test, when there is any doubt about the underlying distribution (see, e.g., Grzegorzewski 1 ).
In this paper, we focus on the sign test due to its importance and intuitive way of application when testing for quantiles. Against this backdrop, we highlight some benefits of the classical sign test (see, e.g., Grzegorzewski and Spiewak 2 and Chukhrova and Johannssen 3 ): First, the sign test is versatile in application because it just makes few general assumptions about the underlying distribution. Thus, there are no problems resulting from biased verification of specific assumptions as the sign test is distribution‐free. Second, it tests for robust measures of location, that is, for quantiles. Third, the sign test does not require a large sample size. Fourth, the sign test is also applicable to ordinal data and paired‐sample data such as pre‐ and post‐treatment observations.
However, these advantages are offset by a few disadvantages (see, e.g., Chukhrova and Johannssen 4 ). Besides the well‐known loss of a good performance for small significance levels in combination with very small sample sizes, recent literature especially criticizes its exclusive application to classical problems where data and hypotheses are crisp, and thus a considerable rigidity regarding real‐life scenarios characterized by imprecision or uncertainty. To mitigate and/or to overcome this drawback, some authors have implemented techniques of fuzzy statistics into the classical sign test by utilizing concepts of fuzzy set theory (see for basic concepts the appendix of this paper, and moreover, we refer the interested reader to standard text books like Buckley, 5,6 Klir and Yuan, 7 Kruse and Meyer, 8 Ross, 9 and Zimmermann 10 ). Most of these approaches are introduced to deal appropriately with fuzziness (or its interval‐valued subtype) in data and/or hypotheses formulation (see, e.g., Shafiq et al. 11 ). On the one hand, some authors have considered fuzzy or interval‐valued data caused by the imprecision of observations (see Grzegorzewski, 12 , 13 Grzegorzewski and Spiewak, 2 , 14 Hesamian and Taheri, 15 Hesamian and Chachi, 16 Kahraman et al., 17 Momeni and Sadeghpour‐Gildeh 18 ). On the other hand, a few authors consider the hypotheses as fuzzy or interval‐valued caused by fuzzy quantiles like the fuzzy median (see Grzegorzewski and Spiewak 2 , 14 ) or by imprecision of linguistic statements on quantiles (see Hesamian and Chachi, 16 Hesamian and Taheri, 15 and Momeni and Sadeghpour‐Gildeh 18 ). Recently, Chukhrova and Johannssen 3 have introduced a sign test for quantiles with fuzzy categories and/or fuzzy hypotheses, where fuzziness is caused by imprecision of linguistic statements on fractions of underlying quantiles. In comparison with the above mentioned approaches, the latter approach is characterized by a high degree of
practicability due to the facilitated formulation of fuzzy hypotheses regarding fractions instead of quantiles (e.g., : The population proportion is about ), since the basis of the sign test is the exact binomial test;
generality, that is, specification of crisp and fuzzy areas in hypothesis formulation, consideration of the indifference zone by its gradual fuzzification, and thus flexible implementation of point‐valued, interval‐valued or fuzzy hypotheses (see Chukhrova and Johannssen 19 );
standardization of modeling of membership functions for popular quantiles (such as the median or quartiles) in automated procedures like knowledge extraction from Big Data;
convenience regarding the final (crisp) test decision that is in line with the classical test decision where the null hypothesis is either rejected or not rejected, and the generalized p value allows a common probabilistic interpretation.
However, Chukhrova and Johannssen 3 only consider the one‐tailed case, which is appropriate for testing whether the population proportion deviates from a reference value in one direction (left or right), but not in both directions as the most popular case in practice, the two‐tailed one. Assumed that the direction of interest is unknown, the two‐tailed case is to prefer to its one‐tailed counterpart, as it is easy in application (albeit more complex in derivation) and thus indispensable for new knowledge extraction, especially for given uncertainty/imprecision regarding the quantile of interest.
It is also worth noting that the recent literature is solely focused on comparisons of newly developed, that is, interval‐valued or fuzzy, approaches with the respective classical, mostly point‐valued, approach. However, this is only one side of the coin and there is the lack of an overall comparison regarding all these three closely related approaches. While in the one‐tailed case of the sign test a common point‐valued formulation of the null hypothesis leads to the same test conclusion as the respective interval‐valued alternative, there is a discrepancy between both approaches in the two‐tailed case, and thus a trade‐off with respect to their advantages and disadvantages. In contrast, the fuzzy approach, as a generalization of point‐ and interval‐valued approaches, could balance a disparity regarding precise/imprecise linguistic statements in hypothesis formulation, information value about the underlying distribution and the magnitude of the decision measure (e.g., the p value). Consequently, there is the need for a comparative study on the two‐tailed sign test with point‐ or interval‐valued hypotheses and its generalized version with fuzzy hypotheses.
In this paper, we extend the methodology proposed by Chukhrova and Johannssen 3 , 19 for the two‐tailed case and develop the generalized two‐tailed sign test for quantiles with fuzzy hypotheses caused by uncertainty/imprecision regarding linguistic statements on fractions of underlying quantiles. In addition, we compare the two‐tailed sign test with point‐ or interval‐valued hypotheses to the generalized test and discuss the advantages/disadvantages of all three approaches regarding their complexity, versatility and practicability.
To emphasize the benefits of the proposed generalized two‐tailed sign test for quantiles in comparison with point‐ and interval‐valued approaches, we conduct a comprehensive case study using a real data set on the psychosocial status during the COVID‐19 pandemic. In particular, we perform the two‐tailed sign test with point‐valued, interval‐valued and fuzzy hypotheses, and compare the obtained results in terms of test performance and implications for psychosocial status during the COVID‐19 pandemic. Moreover, we supplement the results of the generalized two‐tailed sign test by considering the respective results obtained in the one‐tailed case.
The paper is organized as follows. Section 2 introduces the two‐tailed sign test with point‐ or interval‐valued hypotheses. In Section 3, the generalized two‐tailed sign test with fuzzy hypotheses is proposed. Section 4 presents an extensive case study based on a real data set with regard to the psychosocial status during the COVID‐19 pandemic. Finally, in Section 5 the paper concludes with an overview of study results.
2. TWO‐TAILED SIGN TEST WITH POINT‐ OR INTERVAL‐VALUED HYPOTHESES
To make statements about an unknown quantile with of an underlying population (with c.d.f. presumed as continuous and strictly increasing in vicinity of ), we apply a common step‐wise test procedure that consists of the following four steps:
-
1
Hypotheses formulation.
-
2
Determination of sample size and level of significance .
-
3
Drawing a random sample and computation of test statistic.
-
4
Decision making by means of the p value.
Thus, in the first step, we formulate two‐tailed preliminary hypotheses and over the real numbers as complementary statements on , say the median, with a hypothesized value :
| (1) |
In Figure 1, and are illustrated graphically. The letters and in and point to the left and right position of the respective interval‐valued subset of in relation to the hypothesized value . Since noncomplementary hypotheses have less relevance for a test of significance, we do not consider them in the following.
Figure 1.

Representation of preliminary hypotheses ,
In addition, both hypotheses can be alternatively reformulated to complementary statements on the fraction of interest with parameter space and a hypothesized fraction value, say 0.5 as in the case of the sign test on the median (see also Figure 2):
Figure 2.
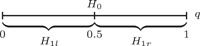
Representation of reformulated hypotheses ,
| (2) |
Consequently, the null hypothesis is simple and the alternative hypothesis is composite as in the case of preliminary hypotheses and .
It should be noted that a simple null hypothesis allows the formulation of statements only regarding one quantile (here, the median). In contrast, a composite would provide the possibility to test on a set of quantiles simultaneously and thus lead to an additional gain of information regarding the population of interest. Moreover, an interval‐valued approach can map both situations with certainty in the formulation of the hypothesized quantile value, that is, as a crisp real number , and also with some uncertainty/imprecision regarding linguistic statements on the fraction of the underlying quantile. For instance, given an uncertainty level of 20% regarding the 50%‐quantile, we can specify the hypotheses like
In the following, we propose to formulate interval‐ instead of point‐valued statements on using two hypothesized fraction values and for and , respectively, that is,
| (3) |
(see also Figure 3).
Figure 3.

Representation of reformulated interval‐valued hypotheses ,
Following the classical test theory, we define subsets of the parameter space as crisp disjoint sets , , (i.e., it holds ) with indicator functions , , (see Table 1, row 1–3). Here, the sets , , correspond to both hypotheses and the indifference zone. The sets and are nonempty, but the set is empty due to the complementary formulation of hypotheses. While the set is formulated as a real interval , the sets and are unions of two disjoint real intervals , and , , respectively, which are located to the left (subscript ) or to the right (subscript ) of the set . It is worth noting that an interval‐valued specification of simplifies to a point‐valued specification for .
Table 1.
Subsets of the parameter space and their indicator functions
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
According to the four‐step test procedure given above, in the second step, the sample size , , and the appropriate significance level , , have to be specified. Although the determination of is up to the practitioner/researcher, it should not be set too small, otherwise problems arise due to increased probabilities of the type II error and situations where can hardly be rejected. For instance, at the 5% level of significance, is necessary before any conclusion can be drawn (see Dixon and Mood 20 ).
In the third step, a random sample of size is to draw from a continuous distribution, where the random variables , , are stochastically independent and the quantile of interest is defined by the constraint . In addition, the continuous variable can be conveniently handled as categorical variable by means of a disjunctive coding 0/1 with respect to the category of interest: “negative signs” () or “positive signs” (). Using indicator function or , the test statistic can then be defined by the number of with or , , depending on the specified success state or . For instance, considering the membership of to as success, the test statistic is binomial‐distributed with probability mass function
This also reveals that the sign test corresponds to an exact binomial test with power function , where and are the critical (rejection) values with , . It also holds
| (4) |
The power function determines probabilities for a correct rejection of () and probabilities for a false rejection of (). It has as a rule an infimum for , that is, , and is monotonically decreasing in the area to the left of and monotonically increasing in the area to the right of . Due to the monotonicity of the power function in its respective domains and , the argument value of the type I error criterion , defined as the supremum of probabilities for false rejection of , is one of the edge elements of the set , that is,
Considering the symmetry of the power function in the case of a symmetrical specification of and regarding the 50%‐point, we obtain
as well as
when holds (exemplary for a point‐valued formulation of ).
Finally, in the fourth step, the p value of the two‐tailed event is to compare with the predetermined ‐level for making a test decision. Applying the general definition of the p value to the binomial test, we obtain
| (5) |
and
| (6) |
for left‐ and right‐tailed events, respectively, and
| (7) |
for a two‐tailed event. Considering the case of (point‐valued ), the above definition of the “one‐tailed” p values reduces to
| (8) |
The null hypothesis is to reject, if the p value for the two‐tailed event is lower than or equal to the given ‐level, otherwise can not be rejected.
3. GENERALIZED TWO‐TAILED SIGN TEST WITH FUZZY HYPOTHESES
As well known, due to the monotonicity of the power function of the two‐tailed sign test in the area of , the type I error generally increases and thus also the p value, by changing from point‐valued to interval‐valued statements in . Further, this increase is the higher, the larger the width () of interval‐valued , caused exemplary by the higher uncertainty/imprecision regarding the 50%‐quantile. To overcome these difficulties, a more promising way of modeling uncertainty/imprecision should be chosen via using fuzzy sets theory, that is, formulation of and via fuzzy sets instead of crisp sets as well as modeling of membership functions , instead of indicator functions.
The most important benefits of fuzzy formulations of hypotheses compared to the interval‐valued approach are as follows:
a gradual (and thus a more appropriate) modeling of uncertainty/imprecision regarding and
in general a reduction of the generalized type I error and the generalized p value
better test results for smaller sample sizes
In the following, we extend the previous two‐tailed test problem to the case of fuzzy hypotheses by utilizing the general approach of Chukhrova and Johannssen. 19 Due to the fact that a fuzzy hypothesis is a generalization of a crisp hypothesis, we derive a generalized two‐tailed sign test following the four‐step procedure introduced in Section 2.
Therefore, in the first step, we consider fuzzy reformulated hypotheses and by embedding fuzzy statements on the fraction of interest. For instance,
The population proportion is about 50% and rather lies between 40% and 60%
The population proportion is not about 50% and rather does not lie between 40% and 60%
In contrast to crisp reformulated hypothesis , fuzzy reformulated null hypothesis
| (9) |
with is proposed to be formulated using
-
1.
all four hypothesized fraction values (e.g., here , , ),
-
2.
fuzzy comparison operators like “fuzzy” lower/larger equal () besides crisp comparison operators like “crisp” lower/larger equal (),
-
3.
gradual fuzzification of the indifference zone around the point‐ (interval‐)valued threshold (e.g., and , given 50%‐threshold).
In Remark 3.1, we comment on points 1–3 regarding the above modeling approach.
Remark 3.1
- 1.
In compliance with the theory proposed in Section 2, we consider in turn an indifference zone , which can now be formulated also as a nonempty set, that is, with , . This formulation is quite natural, especially for given symmetric uncertainty (e.g., ) regarding the 50%‐point. Furthermore, a symmetric modeling of allows for an appropriate representation of the given percentage of the uncertainty level in the support of , for example, given an uncertainty level of 20% one would choose the width of (i.e., the length of the support of ) as , thus it holds , and .
- 2.
Due to the generalization of the crisp set to the fuzzy set , the fuzzy set now consists of a crisp and a fuzzy set, that is, , which are denoted as crisp and fuzzy areas of the null hypothesis. While crisp comparison operators refer to the crisp area of , fuzzy comparison operators provide an indication of the fuzzy area of (see Figure 4). The edge elements of the nonempty supports of , (with ) are thereby based on the hypothesized values , , , .
- 3.
In contrast to the normal crisp area , the fuzzy area , whose support corresponds to the indifference zone, is subnormal. The membership functions and for this area are (strictly) monotonically increasing and decreasing functions.
Figure 4.
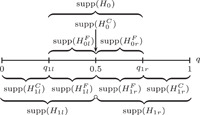
Representation of fuzzy reformulated hypotheses ,
As for the formulation of fuzzy complementary hypothesis (see Figure 4), we propose to model this hypothesis in compliance with the definition of fuzzy in turn under full fuzzification of the indifference zone to the left and right of , that is,
| (10) |
where is the crisp area and is the fuzzy area, whose support corresponds to the indifference zone.
In addition, we recapitulate the general formulation of both fuzzy hypotheses, that is, the definition of fuzzy sets , and (with ), their crisp and fuzzy areas as well as of the corresponding membership functions , , for in Table 2.
Table 2.
Fuzzy subsets of the parameter space and their membership functions
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
||
| Set |
|
|
Due to the fact that the fuzzy sets and are the unions of their crisp and fuzzy areas,
the membership functions and can be defined as follows:
Therefore, these complementary functions (i.e., ) are piecewise monotonically increasing and then monotonically decreasing (regarding ) or vice versa (regarding ). In the case of , hypotheses formulation reduces to crisp complementary hypotheses with , (due to , ).
As for the shape of the membership functions and , we exemplary consider piecewise linear and ‐shaped functions with , and , given in Table 3. Figure 5 illustrates these membership functions and demonstrates the gradual fuzzification of the indifference zone (fuzzy complementary hypotheses). For a sensitivity analysis with regard to the impact of different shapes of membership functions (including piecewise linear and ‐shaped) in the framework of fuzzy hypothesis testing, we refer to Chukhrova and Johannssen. 21
Table 3.
Exemplary shapes of membership functions
| Shape | Left‐tailed events | Right‐tailed events | ||
|---|---|---|---|---|
| linear |
|
|
||
|
|
|
|||
| ‐shaped (polynomial) |
|
|
||
|
|
|
Figure 5.

Fuzzy complementary piecewise linear and polynomial (‐shaped) membership functions [Color figure can be viewed at wileyonlinelibrary.com]
In the second step, the practitioner/researcher determines the sample size , , and the magnitude of the ‐level, . In the third step, the test statistic can be calculated via by using observations obtained from a random sample. Finally, in the fourth step, the user compares the generalized p value for the two‐tailed event with the predetermined ‐level to achieve a crisp test decision. Note that the criteria for decision making are the same as in the case of crisp hypothesis testing.
As for the calculation of the generalized p value, we can use the results obtained in Section 2 solely for the elements from the crisp area of . Therefore, the definition of the p value is first to generalize with respect to the fuzzy area of . In particular, this generalization shall be conducted in compliance with the definition of the generalized type I error criterion,
| (11) |
which is given by the supremum of weighted probabilities for a false rejection of the null hypothesis (see Arnold 22 , 23 ). While the probabilities originate from the power function , the weight function is defined by the difference between the membership of an element to fuzzy and to fuzzy , that is, it holds for all . Definition (11) can also be stated as
against the backdrop that the domain for the supremum of weighted probabilities can logically be restricted to elements of that involve positive weights of the power function. Further, in compliance with the classical sign test, the generalized type I error criterion has a supremum for the elements of the respective support of at or , that is, , where holds for . This is due to (1) the monotonically decreasing (increasing) power function to the left (right) of its minimum,
| (12) |
as well as to (2) the relationship .
Besides the supremum with respect to , has another supremum for (given ). However, it is generally not representable in a closed form caused by the reverse monotonicity of both the power and weight functions, which is why it has to be calculated numerically, and after that, it is to compare with the supremum from the support of the crisp area. Note that we obtain crisp hypotheses and therefore the results presented in Section 2 when the support of the fuzzy area is an empty set.
Using the above results, we define the generalized p value for a left‐tailed, right‐tailed and two‐tailed event as follows:
| (13) |
| (14) |
| (15) |
where (15) corresponds to
by an additional distinction between crisp and fuzzy areas. For , the definition of the generalized p value simplifies to
| (16) |
where (16) holds when choosing .
Considering exemplary the last case (), we propose to interpret the combined test decision, that is, the generalized p value, in turn under separate consideration of crisp and fuzzy areas. In particular, the p value
related to the crisp area of fuzzy leads to a probabilistic p value, which corresponds to the p value of the common test on the median with point‐valued formulated . In contrast, the weighted p value
related to the fuzzy area of fuzzy approximates the (maximum possible) probabilistic p value of the common test on quantiles with interval‐valued (formulated without median) by means of appropriate extent constituted by fuzziness (relaxation) of hypotheses formulation. Thus, the fuzzy test on quantiles is related to both tests (and their decisions) and combines them by means of the generalized p value . As for the rejection of fuzzy (based on ) in favor of fuzzy , we can generally accept fuzzy at the chosen level of significance due to the significant result. Considering the nonrejection of fuzzy (based on ), we fail to reject fuzzy at the chosen level of significance due to the nonsignificant result. Such a crisp decision making corresponds to classical decision making either for point‐valued or interval‐valued .
In addition, we refer to the possibility of obtaining final exploratory results (following a rejection of fuzzy ) by considering the magnitude of the realization of the test statistic :
There is a deviation of the true quantile to the left from the hypothesized quantile , given .
There is a deviation of the true quantile to the right from the hypothesized quantile , given .
It is important to note that such findings are not referred to as test results in the sense of significant conclusions due to a possible type III error, which entails an incorrect decision of direction following a rejected null hypothesis of a two‐tailed test (see Kaiser 24 ).
4. CASE STUDY: PSYCHOSOCIAL STATUS DURING THE COVID‐19 PANDEMIC
In this case study, we intend to investigate the psychosocial status during the COVID‐19 pandemic. For this purpose, we compare the results of the two‐tailed sign test with point‐valued, interval‐valued and fuzzy hypotheses. To complete the statistical analysis, we supplement the results of the generalized two‐tailed sign test by considering the respective results when implementing one‐tailed fuzzy hypotheses introduced by Chukhrova and Johannssen. 3
4.1. The data set
The data set, the COVIDiSTRESS global survey, underlying this case study is taken from Yamada et al. 25 Following COVIDiSTRESS global survey network, 26 this survey is an international collaborative undertaking for data gathering on human experiences, behavior, and attitudes during the COVID‐19 pandemic between March 30 and May 30, 2020. The survey focuses on investigation of eight variables (see Table 4) regarding psychological stress, compliance with behavioral guidelines to slow the spread of coronavirus type 2 as well as trust in governmental institutions and their preventive measures.
Table 4.
Variables of the COVIDiSTRESS global survey
| Variable | Description | Measurement |
|---|---|---|
| PSS‐10 | Perceived stress for the past week | PSS, 10 items, 5‐point Likert scale |
| SPS‐10 | Available social provisions in critical/distressing situations | SPS, 10 items, 6‐point Likert scale |
| SLON‐3 | Short self‐report scale of loneliness for the last week | SLON, 3 items, 5‐point Likert scale |
| BFI‐1 | Big 5—Extraversion | BFI Short, 3 items, 6‐point Likert scale |
| BFI‐2 | Big 5—Neuroticism | BFI Short, 3 items, 6‐point Likert scale |
| BFI‐3 | Big 5—Openness to experience | BFI Short, 3 items, 6‐point Likert scale |
| BFI‐4 | Big 5—Agreeableness | BFI Short, 3 items, 6‐point Likert scale |
| BFI‐5 | Big 5—Conscientiousness | BFI Short, 3 items, 6‐point Likert scale |
Abbreviations: BFI, Big Five Inventory; PSS, Perceived Stress Scale; SLON, Scale of LONeliness; SPS, Social Provisions Scale.
The variables given in Table 4 are explained in more detail in the following:
PSS‐10 is an instrument for assessing perceived stress and includes two subscales: perceived helplessness (six items) and perceived self‐efficacy (four items). Psychological stress is associated with an increased risk of disease (see, e.g., Klein et al. 27 and Bastianon et al. 28 ).
SPS‐10 is an instrument designed to measure the perceived availability of social support and includes five subscales with two items each: emotional support or bonding, social integration, affirmation of worth, material support, and orientation. Perception of social support is one of the best predictors of psychological distress and quality of life (see, e.g., Ibarra‐Rovillard & Kuiper, 29 Caron, 30 Iapichino et al., 31 Steigen & Bergh 32 ).
SLON‐3 is an instrument designed to measure the subjective emotional experience of loneliness and includes three items. SLON‐3 is a subscale of the UCLA loneliness scale that contains 20 items (see, e.g., Hughes et al., 33 ).
BFI‐1–BFI‐5 are five subscales of the Big Five Inventory (see John 34 ) with three items each. The Big Five approach is a psychological concept for assessing personality (see McCrae and John 35 ). Central to this approach is the assumption that personality differences between individuals, expressed in behavioral and experiential terms, are due to the five central personality dimensions of Openness to experience, Conscientiousness, Extraversion, Agreeableness, and Neuroticism (this is why this approach is also called OCEAN model) (see, e.g., Lang et al. 36 ).
It is worth noting that the higher the score on the respective Likert scale (see third column of Table 4), the higher the perceived stress (PSS‐10), the higher the perceived availability of social support (SPS‐10), the higher the subjective emotional experience of loneliness (SLON‐3) or the more distinct the respective psychosocial attribute (BFI‐1–BFI‐5). The respective scores were surveyed for 27 European countries and 15 countries from other continents (North America, South America, Asia, and Australia), the sample size per country varies between 216 (Ireland) and 22,933 (Finland). For each country and each variable, descriptive statistics, such as scale means, have been calculated, see tables 9–16 in Yamada et al. 25
4.2. Design and objective of this case study
In this case study, we examine the psychosocial status during the corona pandemic in European countries measured by means of eight variables of the COVIDiSTRESS global survey. As the psychosocial status may be considerably different for various regions of Europe due to structural factors, cultural circumstances and climatic aspects, it is not appropriate to analyze all the European countries as a collective pool. For this reason, we divide the pool into three subgroups according to European regions: Western, Eastern, and Southern Europe (see Table 5). On the one hand, such a handling reduces the sample size, but on the other hand it allows much more target group‐specific conclusions.
Table 5.
European countries
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Western Europe (WE) | Austria | Belgium | Denmark | Finland | France | Germany | Ireland | Netherlands | Sweden | Switzerland | United Kingdom |
| Eastern Europe (EE) | Bulgaria | Croatia | Czech Republic | Hungary | Lithuania | Poland | Romania | Slovakia | |||
| Southern Europe (SE) | Bosnia and Herzegovina | Greece | Italy | Kosovo | Portugal | Serbia | Spain | Turkey |
The scale means for the eight variables across the European countries are given in Table 6. Since significant upwards or downwards deviations from a benchmark value are associated with significantly stronger or weaker psychosocial effects, it is important to investigate whether there are significant deviations in both directions, that is, to employ a suitable two‐tailed test. Due to the division of the entire data set into three subgroups of interest, we are confronted with rather small sample sizes (8–11 observations per subgroup) and thus the nonparametric sign test is a reasonable choice to test for the median with respect to a single subgroup. As the underlying sample sizes for each country are very large (, on average , for each country), it is appropriate to assume a normal distribution for the observations of the individual countries. Due to the symmetry of the normal distribution, the mean corresponds to the median. Thus, we can use the respective scale means as observed values within the subgroup of interest for testing on the median. As for achieving a corresponding hypothesized median value with respect to the investigated variable, it is reasonable to take the class midpoint of the underlying Likert scale as a benchmark value (see also Table 6).
Table 6.
Mean values of investigated variables for European countries
| PSS‐10 () | SPS‐10 () | SLON‐3 () | BFI‐1 () | BFI‐2 () | BFI‐3 () | BFI‐4 () | BFI‐5 () | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | WE | EE | SE | WE | EE | SE | WE | EE | SE | WE | EE | SE | WE | EE | SE | WE | EE | SE | WE | EE | SE | WE | EE | SE |
| 1 | 2.611 | 2.848 | 2.843 | 5.184 | 4.808 | 4.885 | 2.658 | 2.743 | 2.905 | 4.315 | 4.500 | 4.444 | 3.054 | 3.048 | 3.136 | 4.711 | 4.706 | 4.668 | 4.414 | 4.382 | 4.563 | 4.556 | 4.884 | 4.714 |
| 2 | 2.582 | 2.875 | 2.721 | 4.860 | 5.059 | 5.020 | 2.575 | 2.901 | 2.543 | 3.847 | 4.351 | 4.353 | 3.277 | 3.204 | 3.565 | 4.525 | 4.649 | 4.556 | 4.451 | 4.482 | 4.663 | 4.129 | 4.585 | 4.267 |
| 3 | 2.423 | 2.694 | 2.539 | 5.203 | 4.925 | 4.891 | 2.308 | 2.952 | 2.757 | 4.190 | 3.852 | 4.005 | 2.962 | 3.597 | 3.358 | 4.352 | 4.417 | 4.514 | 4.549 | 4.049 | 4.451 | 4.576 | 3.814 | 4.318 |
| 4 | 2.441 | 2.739 | 2.861 | 5.026 | 4.819 | 4.881 | 2.647 | 2.806 | 2.324 | 4.148 | 4.226 | 4.156 | 3.092 | 3.308 | 3.387 | 4.664 | 4.113 | 4.618 | 4.517 | 4.301 | 4.854 | 4.375 | 4.406 | 4.760 |
| 5 | 2.564 | 2.504 | 2.886 | 4.881 | 4.954 | 5.109 | 2.420 | 2.571 | 2.592 | 3.796 | 3.473 | 4.266 | 3.535 | 3.419 | 3.763 | 4.431 | 4.436 | 4.401 | 4.421 | 4.245 | 4.491 | 4.054 | 4.087 | 4.160 |
| 6 | 2.606 | 2.993 | 2.712 | 5.091 | 5.000 | 5.016 | 2.700 | 3.052 | 2.825 | 4.009 | 3.926 | 4.072 | 3.167 | 3.497 | 3.330 | 4.631 | 4.436 | 4.587 | 4.351 | 4.292 | 4.483 | 4.329 | 4.217 | 4.324 |
| 7 | 2.528 | 2.668 | 2.638 | 5.045 | 4.890 | 4.970 | 2.611 | 2.868 | 2.530 | 3.986 | 4.199 | 4.139 | 3.353 | 3.270 | 3.440 | 4.321 | 4.538 | 4.693 | 4.527 | 4.529 | 4.607 | 4.418 | 4.394 | 4.578 |
| 8 | 2.298 | 2.680 | 3.128 | 5.029 | 4.862 | 4.935 | 2.491 | 2.963 | 2.781 | 4.082 | 4.025 | 4.502 | 2.967 | 3.359 | 3.422 | 4.391 | 4.622 | 4.721 | 4.672 | 4.583 | 4.405 | 4.561 | 4.345 | 4.533 |
| 9 | 2.452 | 5.119 | 2.580 | 4.205 | 2.905 | 4.449 | 4.707 | 4.530 | ||||||||||||||||
| 10 | 2.378 | 5.120 | 2.468 | 4.202 | 2.937 | 4.517 | 4.391 | 4.534 | ||||||||||||||||
| 11 | 2.711 | 4.991 | 2.696 | 3.870 | 3.361 | 4.557 | 4.485 | 4.395 | ||||||||||||||||
4.3. Performing the two‐tailed sign test with point‐valued, interval‐valued and fuzzy hypotheses
In general, the preliminary hypotheses of the two‐tailed sign test are given by (1), where (for PSS‐10, SLON‐3) or (for SPS‐10, BFI‐1–BFI‐5). Considering the conventional two‐tailed sign test on the median with point‐valued hypotheses, we obtain the following reformulated hypotheses (see 2, and also Figure 6 for respective membership functions):
Figure 6.

Membership functions for point‐valued, interval‐valued and fuzzy approaches in the two‐tailed case [Color figure can be viewed at wileyonlinelibrary.com]
As for the case of interval‐valued hypotheses, we have to specify hypothesized fraction values in the first step. For instance, when considering complementary hypotheses in combination with an uncertainty level of 20% (40%) regarding the 50%‐quantile, it holds () and (). The reformulated interval‐valued hypotheses are then defined as follows (see 3, and also Figure 6 for respective membership functions):
Formulating fuzzy hypotheses, we also have to specify . Since we test for the median in the crisp area of , it is suitable to choose symmetric membership functions around 0.5‐value, that is, in the fuzzy areas of , like complementary polynomial (‐shaped) membership functions (see Section 3). The choice of ‐shaped membership functions can be justified as follows (see Chukhrova and Johannssen 3 ):
The slope of the power function is not that steep in the fuzzy area of (due to the symmetry of the binomial distribution for in combination with smaller values of ).
Given rather narrow widths of fuzzy areas of , piecewise linear, convex or concave membership functions entail weight functions that are too steep within the indifference zone. The slope of the weighted power function thus leads to suprema which are not larger as in the crisp area of . In contrast, by employing ‐shaped membership functions, these problems can be avoided, and moreover, a concave‐convex‐shaped function is more appropriate to achieve a “smooth transition” within the fuzzy area around 0.5‐value.
Assuming again an uncertainty level of 20% (40%) regarding the 50%‐quantile, it holds and , ( and ). The reformulated fuzzy hypotheses are then given by (see 9 and 10, and also Figure 6 for respective membership functions):
Example 4.1
((Calculation of the test statistic and p values for PSS‐10 in Eastern Europe)) Since the stress level of people has been shown to have increased during the COVID‐19 pandemic (see, e.g., Statista 37 ), and the variable PSS‐10 measures the extent of the increased perceived stress level due to the pandemic situation, an interesting question arises whether the stress level is slightly or strongly increased. Testing for the extent of the stress level, we investigate if the true median of PSS‐10 is significantly lower or higher than the hypothesized median value , exemplary for Eastern Europe.
As holds for all , the realization of the test statistic is given by . The p value in the point‐valued case is then calculated as follows (see 7 and 8):
The p value when formulating interval‐valued hypotheses, for example, for and , can be obtained via (see 5–7):
The generalized p value in the case of fuzzy hypotheses, for instance when , , , is given by (see 15 and 16):
The (generalized) p value in the case of interval‐valued and fuzzy hypotheses with , can be calculated in an analogous way, and we observe and , respectively.
In addition, Figure 7 shows basic functions of the (generalized) p values (without maximum operator), which depend on the values of the population proportion specified in point‐valued, interval‐valued or fuzzy (with and ) for left‐ and right‐tailed events. Note that the (generalized) p value for a two‐tailed event is the doubled minimum of both respective (generalized) p values for one‐tailed events.
Figure 7.

(Generalized) p values using point‐/interval‐valued and fuzzy approaches for a left‐tailed event (top) and a right‐tailed event (bottom), given , [Color figure can be viewed at wileyonlinelibrary.com]
The complete test results regarding point‐valued, interval‐valued, and fuzzy hypothesis testing for all the variables and European regions can be found in Table 7 that is structured as follows:
Table 7.
Realizations of test statistics, p values for point‐valued, interval‐valued, and fuzzy hypotheses, and levels of expressiveness for statements on the psychosocial status during the COVID‐19 pandemic
| Western Europe (11 countries) | Eastern Europe (8 countries) | Southern Europe (8 countries) | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hypotheses | Point‐valued | Interval‐valued | Fuzzy | Point‐valued | Interval‐valued | Fuzzy | Point‐valued | Interval‐valued | Fuzzy | |||||||||||||||||
| q 1l = 0.4 | q 1l = 0.3 | q 1l = 0.4 | q 1l = 0.3 | q 1l = 0.4 | q 1l = 0.3 | q 1l = 0.4 | q 1l = 0.3 | q 1l = 0.4 | q 1l = 0.3 | q 1l = 0.4 | q 1l = 0.3 | |||||||||||||||
| Variable |
|
q = 0.5 | q 1r = 0.6 | q 1r = 0.7 | q 1r = 0.6 | q 1r = 0.7 |
|
q = 0.5 | q 1r = 0.6 | q 1r = 0.7 | q 1r = 0.6 | q 1r = 0.7 |
|
q = 0.5 | q 1r = 0.6 | q 1r = 0.7 | q 1r = 0.6 | q 1r = 0.7 | ||||||||
| PSS‐10 | 11 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 8 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | 7 | 0.0703 | 0.2128 | 0.5106 | 0.0769 | 0.0953 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 1% | + |
|
|
++ |
|
10% | + |
|
|
++ | ++ | |||||||||
| SPS‐10 | 0 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 1% | + |
|
|
++ |
|
1% | + |
|
|
++ |
|
|||||||||
| SLON‐3 | 11 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 7 | 0.0703 | 0.2128 | 0.5106 | 0.0769 | 0.0953 | 8 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 10% | + |
|
|
++ | ++ | 1% | + |
|
|
++ |
|
|||||||||
| BFI‐1 | 0 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 1 | 0.0703 | 0.2128 | 0.5106 | 0.0769 | 0.0953 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 10% | + |
|
|
++ | ++ | 1% | + |
|
|
++ |
|
|||||||||
| BFI‐2 | 10 | 0.0117 | 0.0605 | 0.2260 | 0.0141 | 0.0211 | 7 | 0.0703 | 0.2128 | 0.5106 | 0.0769 | 0.0953 | 6 | 0.2891 | 0.6308 | 1.0000 | 0.3035 | 0.3428 | ||||||||
| 5% | + |
|
|
++ | ++ | 10% | + |
|
|
++ | ++ | 10% |
|
|
|
|
|
|||||||||
| BFI‐3 | 0 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 1% | + |
|
|
++ |
|
1% | + |
|
|
++ |
|
|||||||||
| BFI‐4 | 0 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 1% | + |
|
|
++ |
|
1% | + |
|
|
++ |
|
|||||||||
| BFI‐5 | 0 | 0.0010 | 0.0073 | 0.0395 | 0.0013 | 0.0022 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | 0 | 0.0078 | 0.0336 | 0.1153 | 0.0090 | 0.0126 | ||||||||
| 1% | + | +++ |
|
++ | ++ | 1% | + |
|
|
++ |
|
1% | + |
|
|
++ |
|
|||||||||
There are three blocks, and each block is associated to a specific European region.
The realization of the test statistic for each of the eight variables is given by the first entry in the first column of each block.
The first entries of columns 2–6 of each block show (generalized) p values for the cases of point‐valued, interval‐valued, and fuzzy hypotheses.
Analyzing the results given in Table 7 leads to the following insights:
The realizations of test statistics mostly have either the largest possible value () or the smallest possible value (). That is, we either observe or for nearly all . As a consequence, the respective p values are mostly lower than 0.01 for or , that is, can be rejected at the 1% significance level. This generally holds for point‐valued hypotheses and mostly for fuzzy hypotheses (except for and , Eastern and Southern Europe), but only in one case for interval‐valued hypotheses ( and , Western Europe). In addition, there are only six cases where the realization of the test statistic differs from or . Here, p values are above 5% (except for point‐valued and fuzzy hypotheses for BFI‐2 in Western Europe) due to the very small underlying sample size.
Considering realizations of the test statistic, we observe the same p value for and , , no matter we have point‐valued, interval‐valued or fuzzy hypotheses (see, for instance, p values for and associated with PSS‐10 and SPS‐10 regarding Western Europe). This fact is due to the axial symmetry of the respective underlying binomial distribution functions and of the respective weight functions. Further, the p values are the highest for interval‐valued hypotheses; and generalized p values for fuzzy hypotheses are higher than respective p values for point‐valued hypotheses (case by case comparison). It is worth noting that the narrower the indifference zone, the lower the generalized p value in the case of fuzzy hypotheses.
When we are able to reject point‐valued, interval‐valued or fuzzy null hypothesis, we can derive the following statement: The true 50%‐, 40%–60%‐ (30%–70%‐) or approximately 40%–60%‐ (30%–70%‐) quantile deviates significantly from the hypothesized quantile (for PSS‐10, SLON‐3) or (for SPS‐10, BFI‐1–BFI‐5).
As for the content‐related interpretation with respect to single variables, we additionally provide general implications for the psychosocial status during the COVID‐19 pandemic:
People's stress level is (slightly) increased in Western and Eastern Europe.
The perceived availability of social support is (strongly) pronounced for all three European regions.
The subjective emotional experience of loneliness is (slightly) increased in Western and Southern Europe.
The personality dimension of extraversion is (strongly) pronounced for Western and Southern Europe.
The personality dimension of neuroticism is (weakly) pronounced for Western Europe.
The personality dimensions of openness to experience, agreeableness, and conscientiousness are (strongly) pronounced for all European regions.
Summarized, the psychosocial status during the COVID‐19 pandemic is similar for the considered European regions, but not the same. We observe similar effects regarding the perceived availability of social support and the personality dimensions of openness to experience, agreeableness, and conscientiousness during the pandemic situation. In contrast, there are deviant effects for the European regions regarding people's stress level, subjective emotional experience of loneliness and the personality dimensions extraversion and neuroticism.
The above statements without tendencies of direction (indicated in parentheses) are valid for all quoted European regions at the 1% significance level, with exceptions for single tests that lead to nonsignificant results (see second entry in each cell of Table 7, denoted by “”). The statements regarding tendencies of direction can be biased by the type III error (which is negligible as the underlying sample sizes of the respective countries are very large). The expressiveness of the above statements varies between performed tests, which is why we consider three levels of expressiveness:
“+” describes a deviation of undefined magnitude from the 50%‐quantile;
“++” describes a considerable deviation from the 50%‐quantile;
“+++” describes a large deviation from the 50%‐quantile.
While the level “+” is applicable to the test on the median, the levels “++” and “+++” are related to the fuzzy and crisp test on quantiles, respectively (see second entry in each cell of Table 7). In addition, Table 7 shows also deviant test results that are significant at common higher significance levels (i.e., 5% or 10%) when the p value of the test on the median exceeds 1%.
Based on the obtained results and with respect to the different kinds of hypotheses, we can summarize the following: Since the generalized p values are throughout considerably lower than the values in the interval‐valued case, the fuzzy test on quantiles is preferable to the common two‐tailed sign test on quantiles. In addition, this test is also beneficial to the common two‐tailed sign test on the median as it provides more information about the underlying distribution at the cost of slightly increased generalized p values.
4.4. Supplementary analysis to the case study by means of one‐tailed fuzzy hypotheses
To complete the statistical analysis of the case study, a comparison with other related approaches (besides the classical point‐ and interval‐valued approaches) would be appropriate. However, a reasonable comparison with existing fuzzy sign tests is not viable since the introduced two‐tailed generalized sign test is a pioneer regarding the formulation of fuzzy hypotheses on fractions instead on quantiles on the one hand (see Grzegorzewski and Spiewak, 2 , 14 Hesamian and Taheri, 15 Hesamian and Chachi, 16 Momeni and Sadeghpour‐Gildeh 18 ) and it is based on crisp instead of fuzzy‐ or interval‐valued data on the other hand (see Grzegorzewski and Spiewak, 2 , 14 Grzegorzewski, 12 , 13 Hesamian and Taheri, 15 Hesamian and Chachi, 16 Kahraman et al., 17 Momeni and Sadeghpour‐Gildeh 18 ). But, there is the possibility to supplement the case study by means of the fuzzy sign test with one‐tailed fuzzy hypotheses introduced by Chukhrova and Johannssen. 3
Following the approach of Chukhrova and Johannssen, 3 first of all, we formulate the respective one‐tailed fuzzy hypotheses in compliance with the reference values , , and in the two‐tailed case, assuming again an overall uncertainty level of 20% (i.e., 10% per test) regarding the 50%‐quantile, that is,
The imprecise linguistic statements in the hypotheses are then
in the left‐tailed case and
in the right‐tailed case. Choosing in turn complementary polynomial membership functions (see Figure 8 and Table 3), we can calculate the respective generalized p values in the next step.
Figure 8.

Membership functions for the fuzzy approach in the left‐tailed and right‐tailed case [Color figure can be viewed at wileyonlinelibrary.com]
Example 4.2
((Calculation of the generalized p values for PSS‐10 in Eastern Europe, one‐tailed case)) Using the category “negative signs,” we obtain the same realization of the test statistic as in the two‐tailed approach (see Example 4.1), that is, ( holds for all with ). The generalized p value in the case of one‐tailed fuzzy hypotheses is then given by (see 13 and 14):
Comparing the results of the one‐tailed case with the respective results of the two‐tailed case leads to the following conclusion: We obtain a significant result () in the two‐tailed case as well as in the one‐tailed case when testing for a significant direction, that is, in the right‐tailed case, while there is no conclusion in the left‐tailed case due to a nonsignificant result. It is worth noting that the generalized p value in the two‐tailed case corresponds to the doubled smallest generalized p value in the one‐tailed case, that is, the significant generalized p value in the two‐tailed case lies between the respective generalized p values in the one‐tailed case (see Figure 7). Analogous conclusions can be applied to overall results of the case study in the framework of respective comparisons between one‐ and two‐tailed cases and are in line with the classical test theory.
Thus, given that the theoretical direction of interest is unknown as in this case study, two‐tailed formulated fuzzy hypotheses are indispensable for new knowledge extraction compared to one‐tailed fuzzy hypotheses. The latter ones are rather appropriate for testing regarding one particular direction of interest.
5. CONCLUSIONS
In this paper, we have presented the generalized two‐tailed sign test for quantiles with fuzzy hypotheses that mitigates/overcomes crucial drawbacks/limitations of the two‐tailed sign test with point‐ or interval‐valued hypotheses. In particular, the following advantages of the proposed generalized two‐tailed sign test arise for practical applications:
-
(1)Advantages compared to a test on a quantile (point‐valued formulation of ):
- Moderate widening of null hypothesis gains in general more information about the underlying distribution.
- Implementing fuzzy sets in hypotheses formulation enables modeling of uncertainty/imprecision in statements to be tested.
- Fuzzy testing provides in general just a slight increase of the generalized type I error and the generalized p value. Thus, the test performance is sufficiently good even for small sample sizes in combination with moderate uncertainty levels.
-
(2)Advantages compared to a test on a set of quantiles (interval‐valued formulation of ):
- Combined consideration of crisp and fuzzy areas of fuzzy gains more information about the underlying distribution.
- Statements in hypotheses are alternatively modeled by implementing fuzzy sets, whose membership functions allow for a gradual and thus a more appropriate modeling of uncertainty/imprecision.
- Fuzzy testing provides in general a considerable reduction of the generalized type I error and the generalized p value. Thus, the test performance regarding small significance levels in combination with very small sample sizes generally increases.
Beyond the above advantages, the generalized two‐tailed sign test enables interpretations of the generalized p value in the common probabilistic way and ensures a crisp test decision, that is, to reject or not to reject . These aspects are not self‐evident, because fuzzy tests often come along with crucial difficulties in practical applications, and therefore lack a sound basis for decision‐making that is most important for the practitioner.
Last but not least, the formulation of fuzzy hypotheses on fractions of underlying quantiles is more intuitive and convenient for the practitioner/researcher. This is due to the fact that we deal with the exact binomial test where the critical region (i.e., the theoretical measure) is defined by means of hypothesized fractions of underlying quantiles, sample size and significance level. As for the test statistic (i.e., the observed measure), we consider it as a crisp quantity, since we do neither deal with uncertainty/imprecision in data nor implement fuzziness in statements on quantiles. Instead, we propose a considerably simplified formulation of uncertainty/imprecision in fractions that enables for standardization in modeling membership functions for the most interesting quantiles such as the median.
To show the benefits of the presented methodology in practical applications, we have performed a comprehensive case study on the psychosocial status during the COVID‐19 pandemic. In particular, we have compared the results of the two‐tailed sign test with point‐valued, interval‐valued, and fuzzy hypotheses. We have found that the fuzzy test on quantiles is preferable to the two‐tailed sign test with interval‐valued hypotheses, because the generalized p values are throughout considerably lower and the gain in additional information is higher. It is also beneficial to the common two‐tailed sign test with point‐valued hypotheses as it provides more information about the underlying distribution at the cost of slightly increased generalized p values. As for implications for the psychosocial status during the COVID‐19 pandemic, we have drawn conclusions regarding people's stress level, perceived availability of social support, subjective emotional experience of loneliness, and five personality dimensions (extraversion, neuroticism, openness to experience, agreeableness, and conscientiousness).
Summarized, since the generalized two‐tailed sign test on quantiles adequately meets the trade‐off between the formulation of point‐ and interval‐valued hypotheses in the framework of the crisp two‐tailed sign test, its generality, versatility, and practicability is improved. It should also be underlined that although the paper is devoted to the two‐tailed sign test, the presented methodology can be transferred to further nonparametric and parametric tests.
CONFLICT OF INTERESTS
The authors declare that there are no conflicts of interests.
ACKNOWLEDGMENTS
The authors gratefully acknowledge the support provided by the German Research Foundation (DFG) in the framework of the research project no. 409030527. The authors are also grateful to the student assistant Marcel Gaweda for his engaged support. Finally, the authors thank both anonymous reviewers for their valuable feedback and suggestions, which were important and helpful to improve the paper.
APPENDIX A. BASIC CONCEPTS OF FUZZY SETS
This Appendix is adapted from Chukhrova and Johannssen 3 (see also Chukhrova and Johannssen 38 , 39 ).
Considering the classical (crisp) set theory, sets are defined as collections of elements , where each either belongs to or does not belong to a crisp set . Thus, a crisp set is described by an indicator function with
While crisp sets allow only for differentiating between membership (1) and nonmembership (0) of single elements to a set , fuzzy sets enable various degrees of membership by generalizing indicator functions to membership functions . A fuzzy set in is then given by a set of ordered pairs
A fuzzy set is referred to as
normal, if there exists an such that ,
subnormal, if for all ,
convex, if for all and ,
where hgt denotes the height of a fuzzy set . The (crisp) set of all fuzzy subsets of is denoted by .
Given two sets with for all , then is a fuzzy subset of (). If there is at least one with , then is a proper fuzzy subset of ().
Since the membership function is the crucial part of fuzzy sets, operations with fuzzy sets are defined by means of their membership functions. In this paper, we make use of basic set‐theoretic operations on fuzzy sets like complement, intersection, and union defined as follows:
As we are generally referring to a nonempty (crisp) universal set , there may be elements of having the degree of membership zero. However, elements with a nonzero degree of membership are mostly of primary interest. This leads us to the support (supp) and the core (ncl) of a fuzzy set :
Chukhrova N, Johannssen A. Generalized two‐tailed hypothesis testing for quantiles applied to the psychosocial status during the COVID‐19 pandemic. Int J Intell Syst. 2021;36:7412‐7442. 10.1002/int.22592
REFERENCES
- 1. Grzegorzewski P. ‐sample median test for vague data. Int J Intell Syst. 2009;24(5):529‐539. [Google Scholar]
- 2. Grzegorzewski P, Spiewak M. The sign test and the signed‐rank test for interval‐valued data. Int J Intell Syst. 2019;34(9):2122‐2150. [Google Scholar]
- 3. Chukhrova N, Johannssen A. Nonparametric fuzzy hypothesis testing for quantiles applied to clinical characteristics of COVID‐19. Int J Intell Syst. 2021;36(6):2922‐2963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Chukhrova N, Johannssen A. Fuzzy hypothesis testing: systematic review and bibliography. Appl Soft Comput. 2021;106(4):107331. [Google Scholar]
- 5. Buckley JJ. Fuzzy Statistics. Springer; 2004. [Google Scholar]
- 6. Buckley JJ. Fuzzy Probability and Statistics. Springer; 2004. [Google Scholar]
- 7. Klir G, Yuan B. Fuzzy Sets and Fuzzy Logic—Theory and Applications. Prentice‐Hall; 1995. [Google Scholar]
- 8. Kruse R, Meyer KD. Statistics with Vague Data. Reidel Publishing Company, 1987.
- 9. Ross TJ. Fuzzy Logic with Engineering Applications. 3rd ed. John Wiley; 2010. [Google Scholar]
- 10. H‐J Zimmermann. Fuzzy Set Theory and Its Applications. 4th ed. Kluwer Academic Publishers; 2001. [Google Scholar]
- 11. Shafiq M, Atif M, Viertl R. Generalized likelihood ratio test and Cox's ‐test based on fuzzy lifetime data. Int J Intell Syst. 2017;32(1):3‐16. [Google Scholar]
- 12. Grzegorzewski P. Statistical inference about the median from vague data. Control Cybernet. 1998;27(3):447‐464. [Google Scholar]
- 13. Grzegorzewski P. Distribution‐free tests for vague data: soft methodology and random information systems. In: Lopez‐Diaz M, Gil MA, Grzegorzewski P, Hryniewicz O, Lawry J, eds. Advances in Intelligent and Soft Computing. Vol 26. Springer; 2004:495‐502. [Google Scholar]
- 14. Grzegorzewski P, Spiewak M. The sign test for interval‐valued data: soft methods for data science. In: Ferraro MB, Giordani P, Vantaggi B, Gagolewski M, Gil MA, Grzegorzew P, Hryniewicz O, eds. Advances in Intelligent Systems and Computing. Vol 456. Springer; 2016:269‐276. [Google Scholar]
- 15. Hesamian G, Taheri SM. Credibility theory oriented sign test for imprecise observations and imprecise hypotheses. In: Kruse R, Berthold M, Moewes C, Gil MA, Grzegorzewski P, Hryniewicz O, eds. Synergies of Soft Computing and Statistics for Intelligent Data Analysis. Advances in Intelligent Systems and Computing. Vol. 190. Springer; 2013:153‐163.
- 16. Hesamian G, Chachi J. Fuzzy sign test for imprecise quantities: a ‐value approach. J Intell Fuzzy Syst. 2014; 27(6): 3159‐3167. [Google Scholar]
- 17. Kahraman C, Bozdag CF, Ruan D, Özok AF. Fuzzy sets approaches to statistical parametric and nonparametric tests. Int J Intell Syst. 2004;19(11):1069‐1078. [Google Scholar]
- 18. Momeni F, Sadeghpour‐Gildeh B. Nonparametric tests for median in fuzzy environment. Int J Fuzzy Syst. 2016;18(1);130‐139. [Google Scholar]
- 19. Chukhrova N, Johannssen A. Fuzzy hypothesis testing for a population proportion based on set‐valued information. Fuzzy Sets Syst. 2020;387:127‐157. [Google Scholar]
- 20. Dixon WJ, Mood AM. The statistical sign test. J Am Stat Assoc. 1946:41(236):557‐566. [DOI] [PubMed] [Google Scholar]
- 21. Chukhrova N, Johannssen A. Generalized one‐tailed hypergeometric test with applications in statistical quality control. J Quality Technol. 2020;52(1):14‐39. [Google Scholar]
- 22. Arnold BF. An approach to fuzzy hypothesis testing. Metrika. 1996;44(1):119‐126. [Google Scholar]
- 23. Arnold BF. Testing fuzzy hypotheses with crisp data. Fuzzy Sets Syst. 1998;94(3):323‐333. [Google Scholar]
- 24. Kaiser HF. Directional statistical decisions. Psychol Rev. 1960;67:160‐167. [DOI] [PubMed] [Google Scholar]
- 25. Yamada Y, Cepulic D‐B, Coll‐Martin T, Debove S, Gautreau G, Han H, Rasmussen J, Tran TP, Travaglino GA, Lieberoth A. COVIDiSTRESS Global Survey Consortium, COVIDiSTRESS Global Survey dataset on psychological and behavioural consequences of the COVID‐19 outbreak. Scientific Data. 2021;8(1):3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. COVIDiSTRESS global survey network . COVIDiSTRESS global survey. 2020. 10.17605/OSF.IO/Z39US [DOI]
- 27. Klein EM, Brähler E, Dreier M, Reinecke L, Müller KW, Schmutzer G, Wölfling K, Beutel ME. The german version of the perceived stress scale–psychometric characteristics in a representative german community sample. BMC Psychiatry. 2016;16:159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Bastianon CD, Klein EM, Tibubos AN, Brähler E, Beutel ME, Petrowski K. Perceived stress scale (PSS‐10) psychometric properties in migrants and native germans. BMC Psychiatry. 2020; 20: 450. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Ibarra‐Rovillard MS, Kuiper NA. Social support and social negativity findings in depression: perceived responsiveness to basic psychological needs. Clin Psychol Review. 2016; 31(3): 342‐352. [DOI] [PubMed] [Google Scholar]
- 30. Caron J. A validation of the Social Provisions Scale: the SPS‐10 items. Santé mentale au Québec. 2013;38(1):297‐318. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Iapichino E, Rucci P, Corbani IE, Apter G, Quartieri Bollani M, Cauli G, Gala C, Bassi M. Development and validation of an abridged version of the Social Provisions Scale (SPS‐10) in Italian. J Psychopathol. 2016;22:157‐163. [Google Scholar]
- 32. Steigen AM, Bergh D. The social provisions scale: Psychometric properties of the SPS‐10 among participants in nature‐based services. Disability Rehabil. 2019;41(14):1690‐1698. [DOI] [PubMed] [Google Scholar]
- 33. Hughes ME, Waite LJ, Hawkley LC, Cacioppo JT. A short scale for measuring loneliness in large surveys: Results from two population‐based studies. Res Aging. 2004;26(6):655‐672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. John OP. The Big Five Inventory. 2008. https://www.ocf.berkeley.edu/johnlab/bfi.php
- 35. McCrae RR, John OP. An introduction to the five‐factor model and its applications. J Personality. 1992;60(2):175‐215. [DOI] [PubMed] [Google Scholar]
- 36. Lang FR, John D, Lüdtke O, Schupp J, Wagner G. Short assessment of the big five: Robust across survey methods except telephone interviewing. Behav Res Methods. 2011:43(2):548‐567. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Statista . Percentage of workers reporting higher, equal or lower levels of stress since the coronavirus outbreak in 2020. 2020. https://www.statista.com/statistics/1169836/covid-stress-level-of-workers-in-select-countries/
- 38. Chukhrova N, Johannssen A. Inspection tables for single acceptance sampling with crisp and fuzzy formulation of quality limits. Int J Qual Reliab Manag. 2018;35(9):1755‐1791. [Google Scholar]
- 39. Chukhrova N, Johannssen A. Randomized vs. non‐randomized hypergeometric hypothesis testing with crisp and fuzzy hypotheses. Statistical Papers. 2020;61(6):2605‐2641. [Google Scholar]