

Abstract
Background
Recent developments in machine learning have shown its potential impact for clinical use such as risk prediction, prognosis, and treatment selection. However, relevant data are often scattered across different stakeholders and their use is regulated, e.g. by GDPR or HIPAA.
As a concrete use-case, hospital Erasmus MC and health insurance company Achmea have data on individuals in the city of Rotterdam, which would in theory enable them to train a regression model in order to identify high-impact lifestyle factors for heart failure. However, privacy and confidentiality concerns make it unfeasible to exchange these data.
Methods
This article describes a solution where vertically-partitioned synthetic data of Achmea and of Erasmus MC are combined using Secure Multi-Party Computation. First, a secure inner join protocol takes place to securely determine the identifiers of the patients that are represented in both datasets. Then, a secure Lasso Regression model is trained on the securely combined data. The involved parties thus obtain the prediction model but no further information on the input data of the other parties.
Results
We implement our secure solution and describe its performance and scalability: we can train a prediction model on two datasets with 5000 records each and a total of 30 features in less than one hour, with a minimal difference from the results of standard (non-secure) methods.
Conclusions
This article shows that it is possible to combine datasets and train a Lasso regression model on this combination in a secure way. Such a solution thus further expands the potential of privacy-preserving data analysis in the medical domain.
Keywords: Secure multi-party computation, Privacy, Machine learning, Lasso regression
Background
Modern machine-learning techniques require large-scale and well-characterized datasets to achieve their full potential. In the medical domain, this requirement translates to a need to store medical patient data, and to combine information from different institutions, the Covid-19 outbreak being an example of a situation where this is deemed crucial [1, 2].
However, the collection, processing and exchange of personal data is a sensitive matter, and the risks coming from privacy violations are especially high for medical data. This has led to legal frameworks that regulate and restrict usage of personal (medical) data, the General Data Protection Regulation1 (GDPR), and the Health Insurance Portability and Accountability Act2 (HIPAA) being two prominent examples. These regulations mandate informed consent from patients in order to use the corresponding medical data; however, asking for consent for machine-learning purposes is often impractical, since it is a time-consuming process, and since contact with patients may have been lost since the moment of data collection.
This conflict between, on the one hand, the need to gather, combine and process large amounts of data for better machine-learning techniques, and on the other hand the need to minimize personal data usage for privacy protection, has lead to the development of several solutions for privacy-preserving data analysis. In particular, a collection of cryptographic techniques known as Secure Multi-Party Computation, or MPC for short, is being applied more and more in the medical domain. Intuitively, the goal of MPC is to allow several parties to compute the output of a certain function or computation, depending on private inputs of each party, without actually disclosing information on their inputs to each other.
In 2018, the Netherlands Organization for Applied Scientific Research (TNO), together with academic medical center Erasmus MC and health insurance company Achmea, started a project within the Horizon 2020 Programme called BigMedilytics3 to develop a secure algorithm to predict the number of hospitalization days for heart failure patients. Although the project does not use real patient data in its current phase, the MPC solution presented in this article is based on the following real-life use-case, which serves as a motivating example for the solution described in this article. In Rotterdam, a group of individuals took part in the “Rotterdam study” [3], a program by the Epidemiology department of Erasmus MC. Erasmus MC has collected data on the lifestyle of these patients, for example their exercising, smoking, and drinking behavior. Achmea, on the other hand, has claims data of its customers (including several participants of the Rotterdam study), which encompass different aspects, such as hospitalization days and healthcare usage outside of the hospital. Recent work has shown that using machine-learning models on medical data has the potential to predict survival of heart-failure patients [4]. The datasets of Achmea and Erasmus MC, once intersected and combined, could be used to train a prediction model that identifies high-impact lifestyle factors for heart failure, and thus, in turn, to recognize high-risk heart-failure patients.
However, privacy concerns mean that Erasmus MC and Achmea cannot simply share their data with each other to allow for a straightforward analysis. TNO has therefore developed and implemented the MPC-based Proof of Concept described in this article, which allows Erasmus MC and Achmea to securely train a prediction model without disclosing any personal medical information.
Before we present the details of our solution, we give an overview of the current landscape of privacy-preserving data analysis techniques, focusing on the medical domain, and on solutions which bear resemblance to ours. We will then discuss how our solution compares to these existing techniques.
Previous and related work
Secure analysis of healthcare data
A straightforward approach for privacy-preserving data analytics consists of data anonymization and pseudonymization. More precisely, in the case of horizontally-partitioned data (i.e. when organizations hold the same type of data on different individuals), organizations may simply remove identifiers such as name, date of birth, or social security numbers, and share the data features with each other; in the case of vertically-partitioned data (i.e. when parties hold the different data on the same individuals), a similar result can be achieved by resorting to an external third party that gets access to all identifiers, replaces them with pseudonyms, and then ensures that the data features from all involved organizations are linked to each other. These methods thus ensure that only feature data are revealed, instead of identifiers. However, feature data can often uniquely identify an individual, especially if other, related data is acquired through public sources, as shown in several studies [5, 6]. Thus in practice, data anonymization and pseudonymization offer little guaranteed on the protection of the identity of individuals involved in collaborative data analysis.
A more sophisticated and popular approach consists of federated learning, where algorithms are trained on decentralized devices or servers, each possessing its own data, by only exchanging intermediate model coefficients with each other. Federated learning promises great potential to facilitate big data for medical application, in particular for international consortia [7].
An example of federated-learning architecture is provided by the Personal Health Train (PHT) [8], which core idea is to keep data at the original sources and to let the analytical tasks “visit” these data sources and perform data analysis tasks locally.
Both federated learning and the PHT work fairly straightforward for horizontally-partitioned data (where institutions hold the same type of data on different individuals), while vertically-partitioned data remains a challenge to be tackled.
Cryptographic solutions such as MPC typically overcome these limitations, but with an inherent overhead in terms of computation time and communication volume compared to non-cryptographic solutions, and typically have a lower technology readiness level. Specific applications in the medical domain cover a wide range, including, for instance, disclosure of case counts, while preserving confidentiality of healthcare providers [9], sharing insights on the effectiveness of HIV treatments, while preserving both privacy of involved patients and confidentiality of practitioners’ treatment choices [10]; privacy-preserving analysis of hospital workflows [11]; secure genome study [12]; and secure distributed logistic regression for medical data [13]. Compliance of MPC techniques with the GDPR has been discussed in [14].
We present in more details MPC solutions with a similar scope as ours in the following sub-section.
Cryptographic techniques for dataset combination and secure regression
A first challenge in secure distributed data analysis lies in the combination of different datasets: namely, different institutions hold, in general, data on different individuals, and a first challenge lies in determining which individuals lie both datasets, and retrieving their relevant features. Various work has been done on “secure set intersection” (also referred to as “private set intersection”) [15–18], where the different involved parties learn which individuals lie in all datasets, but it is guaranteed that no information on individuals outside the intersection will be revealed. To the best of our knowledge, however, no previous work has been published that describes a secure inner join solution, where individuals in the intersection are determined, but not revealed, and where the corresponding feature values are associated to each individual. Notice that a secure inner join is a fundamental step for realistic deployment of a secure data analysis solution, since the identity of individuals in the intersection of datasets is, in general, personal (and thus protected) data.
Concerning securely training a linear regression model on distributed data, a lot of work has been done on a variant of linear regression known as Ridge regression. In linear regression, one aims to find a “coefficient” vector, such that the linear combination of feature values with the coefficients yields roughly the value of another, “target” feature. Such a linear combination cannot, in general, be exactly equal to the target feature: Ridge regression is a relatively straightforward method that aims to find a coefficient vector that minimizes this gap, while also preventing the obtained coefficient models from being biased towards the training features values (and thus poorly predict the target feature for new data). Ridge regression is typically solved in either of two ways: by solving the normal equations, or by minimizing the objective function in a more general fashion, e.g. by application of the Gradient Descent algorithm. The privacy-preserving implementations [19–26] all train a Ridge regression model by solving the normal equations, which is in turn performed through matrix inversion. Privacy is often preserved by using homomorphic encryption techniques [20–23], yet there are also implementations that make of use of secret sharing [19], or of garbled circuits [24].
In contrast to the normal-equations approach, we chose for the secure Gradient Descent approach. The works of [27, 28] all present privacy-preserving Gradient Descent solutions to train Ridge regression models. In [28] and [27] the authors focus on vertically-partitioned data. Finally, the authors of [27] train a linear regression model via a variation of the standard Gradient Descent method, namely conjugate Gradient Descent.
The solution that we present in this article focuses on another linear regression method called Lasso; to the best of our knowledge, no previous work has been published on secure Lasso regression. Lasso is similar to Ridge in that it tries to minimize the gap between the target feature and the linear combination of the other features with the coefficient vector, but it also discards features of little impact on the target feature by pushing the corresponding coefficient to zero. This means that once the model has been (securely) trained, less data are needed to evaluate the model. This is a very desirable property for a healthcare-prediction scenario, and in particular for the identification of high-impact factors for heart failure, as described at the beginning of this section: gathering and using only the data that is strictly necessary to apply the model is important to comply with privacy regulations and their data-minimization requirements. In [4] it is even shown that for the prediction of the survival of heart-failure patients, training a model on two features alone can yield more accurate predictions than those made using all available features.
Our contributions
We present a solution for (1) computing a secure inner join of two datasets and, (2) securely training a Lasso regression model on the obtained (encrypted) data. To the best of our knowledge, both these contributions are novel.
Both components of our solution are essential: the secure inner join ensures that individuals in the overlap of the two datasets can be determined (but not revealed) together with their feature values, and the Lasso regression allows for minimizing the number of features that have an impact on the model, thus meeting the proportionality and data-minimization requirements for subsequent non-encrypted application of the model to identify high-risk patients.
In both components, we assume that a third, “helper” party joins the computation. The helper party does not supply any input and does not learn the input data of the other parties nor the outcome of the model, but its inclusion allows for a very efficient design. Namely, we are able to use efficient techniques such as hashing for the secure inner join, as opposed to the expensive polynomial-evaluation techniques typically required in a two-party setting; for what concerns the secure Lasso regression, we can make use of the MPyC framework, which requires at least three parties to guarantee security.
Our solution is tailored to the heart-failure use-case described above, and involves Achmea and Eramus MC as data parties and healthcare information intermediation company ZorgTTP as helper party. We installed our solution on a test infrastructure of the three involved parties, generated artificial data, and tested the performance in terms of quality of the obtained model and efficiency. Both aspects are fully satisfactory, the secure solution showing a difference in objectives of 0.004 with a standard, non-secure solution (in scikit-learn), and requiring less than one hour to compute the inner join and Lasso coefficients of two datasets, consisting of 5000 records each, and 30 features in total.
Outline
The rest of the article is organized as follows. The "Methods" section is divided into two parts: the first one (section "Description of the desired functionality") illustrates the functionality that we aim to achieve (inner join and Lasso regression), but without taking security and privacy considerations into account. These are discussed in the following section "Description of the secure solution", which shows how our solution securely implements the functionality of section "Description of the desired functionality". The "Results" section discusses what our solution achieves in terms of security (section "Security results"), efficiency (section "Running time"), and quality of the obtained regression model (section "Performance and accuracy results"). We discuss the impact and possible improvements of our work in section "Discussion", and we end with the conclusions in section "Conclusions".
Methods
Description of the desired functionality
We first discuss the details of the functionality that we aim to realize. Privacy and security aspects are not considered here, and will instead be discussed in section "Description of the desired functionality", following the same structure as the current section.
Description of the setting and data formatting
We begin with the general set-up and a description of the format of the input data. In our setting, two data-providing parties are involved: a healthcare insurance company, Achmea (often shortened to AC), and a university hospital, Erasmus MC (which will often be shortened to EMC). We assume that each party owns a dataset where several features of various customers/patients are contained. Each row in the dataset corresponds to a customer or patient, and we refer to it as a record. Specifically, we denote the dataset of Achmea, and its element, as in Table 1, and we denote by its set of identifiers .
Table 1.
AC dataset
| Identifier | Feature | ... | Feature |
|---|---|---|---|
| ... | |||
| ... | |||
The dataset of Erasmus MC, on the other hand, is depicted as in Table 2, and we denote by the set of identifiers .
Table 2.
EMC dataset
| Identifier | Feature | ... | Feature |
|---|---|---|---|
| ... | |||
| ... | |||
Before discussing the properties of identifiers and features, we stress the fact that the research described in this article did not use any actual identifiers or features corresponding to existing individuals. For the running time, accuracy and performance experiments, synthetic data was created or existing public data sets were used. More details can be foud in "Results" section.
It is assumed that identifiers in and in are of the same type; for simplicity, one may think of them as the social security number of a customer/patient. In particular, if and refer to the same person, then . Notice that we are actually interested in the intersection of and , as we want to train a regression algorithm on all features.
For what concerns the features, both and are assumed to be numerical or Boolean. One of the features serves as a target: intuitively, we aim to predict its value as a function of the other feature values. We formalize this intuitive goal in the following sub-sections.
Inner join of the data
In order to find a correlation among different features, a first necessary step is to identify which features belong to the same customer/patient. Namely, not every person of Achmea is necessarily present in the database of Erasmus MC (as not all customers of AC took part in the social and behavioral study of EMC), and vice versa. In mathematical terms, and in the notation defined above, (in general).
Therefore, the two parties need to a) compute (i.e. identify which persons are represented in both databases), b) ensure that and are identified for all i and j such that (i.e. assign to each identifier in the intersection the corresponding features). In Tables 3 and 4, an example of the aimed result of this intersection is shown, inspired by the heart-failure use-case presented in the background section.
Table 3.
Achmea and Erasmus MC example datasets, respectively
| Identifier | Hospitalization days | Identifier | Hours of exercise per week |
|---|---|---|---|
| 000000 | 10 | 000000 | 0 |
| 111111 | 5 | 111111 | 2 |
| 555555 | 8 | 777777 | 1 |
| 777777 | 9 | 999999 | 3 |
Table 4.
Inner Join example
| Identifier | Hospitalization days | Hours of exercise per week |
|---|---|---|
| 000000 | 10 | 0 |
| 111111 | 5 | 2 |
| 777777 | 9 | 1 |
More abstractly, Table 5 would therefore be obtained, using the notation of Tables 1 and 2.
Table 5.
Inner-join dataset
| Identifier | Feature | ... | Feature | Feature | ... | Feature |
|---|---|---|---|---|---|---|
| ... | ... | |||||
| ... | ... | |||||
This type of operation is commonly referred to as Inner Join in the field of database management [29].
The next step is to train a regression algorithm on the data contained in Table 5. We remark that, at this point, the identifier column is no longer necessary, and indeed will play no role in the regression step.
Lasso regression algorithm
Given Table 5, we are now interested in finding a way of expressing a given feature (the number of hospitalization days) as a linear combination of the other features, or as an approximation of such a linear combination. This is accomplished by training a linear regression model on Table 5. In this subsection, we discuss the details of this process.
A linear regression problem can be informally expressed by the following question: for a known matrix , where n is the number of records and m is the number of features, and target vector , can we find a weight vector such that the equality is satisfied? In general the system is over-determined and there exists no solution. Instead, one aims to find , such that some function of the approximation error vector (and possibly some other arguments) is minimized.
The straightforward form of this problem focuses on minimizing the -norm , where ; this is known as (ordinary) least squares linear regression (OLS) [30]. Typically, a so-called regularization term is added to this target value; for instance, Ridge regression [31, 32] uses the -norm of the weight vector, and therefore tries to minimize the value , for a fixed constant . The goal of such a regularization term is to ensure that the weight vector has small values, thereby making the overall model more manageable and reducing the risk of overfitting (i.e. reducing the risk that the model is too tailored to the data and poorly predicts values based on new data).
We choose instead for Lasso (Least Absolute Shrinkage and Selection Operator) [33, 34], which automatically discards features of little impact on the target vector. This is a desirable feature for the use-case described in the Background section, as it is important to focus on factors that have the greatest impact on hospitalization days, in order to minimize data collection for subsequent usage of the obtained model. Furthermore, reducing the number of used features results in a more easily explainable model, thereby increasing the acceptance by end-users. Lasso tries to minimize the following objective function:
| 1 |
where , and where is a user-chosen parameter known as regularization parameter. Note that this method reduces to OLS, if is set to zero. In our set-up we use a proximal gradient descent algorithm to minimize the objective.
Gradient descent approach
Gradient Descent (GD) is a general optimization algorithm that finds a local minimum of an objective function. The algorithm takes repeated steps in the opposite direction of the (approximate) gradient of the objective function at the current point. In that way it moves to the direction of steepest descent. GD is a building block for many different models, including Ridge Regression and Support Vector Machine. The GD algorithm is described in Algorithm 1. We will now describe the parameters and functions in this algorithm.

Stopping criteria. The algorithm can stop for two reasons: either because it has reached the limit of iterations set by , or when the model has been trained “sufficiently”. The latter factor can be quantified by measuring the relative or absolute change in the objective function and comparing this change with a pre-set treshold. Since the secure evaluation of an objective function is computationally intensive, we compare with a treshold the following value, known as update difference:
| 2 |
The model is then said to be sufficiently trained when this value is smaller than a pre-set value known as tolerance.
and In the GD algorithm, we repeatedly calculate the gradient . Because of the -norm in (1), the objective function for Lasso is non-differentiable. We therefore use the technique of proximal gradient descent, that can optimize a function that is not entirely differentiable. We therefore first compute a gradient function over the first part of the objective function in (1),
| 3 |
then approximate the gradient of the second part of (1) by applying a proximal function on . The ith component of is given by the following expression:
| 4 |
Step size . An important parameter when using Gradient Descent is the size of the steps. If the step size is too small, the algorithm will need too many iterations, while if it is too large, the algorithm will never converge. In Algorithm 1, the step size decreases in every iteration, such that the weight vector converges. The initial step-size is typically a user-chosen parameter; however, if it depends on the input data, then it needs to be calculated securely. For example, one could choose , of which we explain the secure calculation in section "Secure lasso regression".
Goodness of fit. To test the performance of Lasso Regression we can use different goodness of fit measures, such as the mean squared error, the mean absolute error or the coefficient of determination . As an example for the secure implementation, we focused on the last measure. provides a measure of how well observed outcomes are replicated by our prediction model, based on the proportion of total variation of outcomes explained by the model. The range of is , where 1 indicates the best fit. We calculate as follows. First, we define the value as the mean of the observed target data , i.e. . We then denote by the vector of the values predicted by the model, and define
This coefficient is important for determining the right regularization parameter . In practice, one will have to run the Lasso regression multiple times with different , to find the optimal model with the highest .
Description of the secure solution
Aim and assumptions
The goal of this section is to show how the functionality described in "Description of the desired functionality" section can be realized in a secure way: this means that while both parties will learn the output of the Lasso regression (i.e. the model coefficients) trained on the inner join of their datasets,4 no other information on the datasets of each party will be disclosed to any other party.
Our secure solution involves a third party, which does not supply any input, and does not receive any output (except from the size of the intersection of the two datasets). For our Proof of Concept, this third-party role is taken by ZorgTTP, a company that offers consultancy and practical solutions on the topic of privacy-preserving data analysis in the healthcare sector. The addition of such a party has two benefits, relating to the two steps of our solution: secure inner join and secure Lasso regression. For the first step, the presence of a third party allows us to design a custom, highly efficient protocol; for the second step, we are able to use the MPyC library [35], that provides useful building blocks but requires at least three parties to guarantee security.
Before discussing the details of our solution, we give a brief introduction to Secure Multi-Party Computation. Notice that we chose to present cryptographic concepts with a focus on intuition, so as not to burden the reader with an unnecessary level of formalism. The reader can refer to [36, 37] for a more formal discussion of general cryptographic concepts (including cryptographic hash functions, homomorphic encryption, and secret sharing), and to [38, 39] for an in-depth discussion of MPC and Secret Sharing.
Introduction to secure multi-party computation
Assume n parties hold private inputs . An MPC protocol is an interactive protocol that allows the parties to compute the value of a function f on their inputs, without revealing any other information to each other on their inputs. Notice that the private inputs are not necessarily just a single element, but could actually consist of an entire dataset. Moreover, not all parties need to supply an input, and not all parties should receive an output; the addition of these “data-less” parties (such as ZorgTTP in our case) allows protocols to achieve better efficiency, or to use techniques which would be insecure with a smaller number of parties.
Secure inner join
As outlined in section "Inner join of the data", in order to realize a protocol that securely implements our desired functionality, the first step to be performed is to compute the so-called inner join of the datasets of Achmea and Erasmus MC. Namely, we need to obtain a database with the identifiers that are present in both the datasets of Achmea (AC) and Erasmus MC (EMC), and with the corresponding features coming from both datasets. Notice that we do not wish to reveal the dataset obtained in this way to any party, as it would still contain highly sensitive personal data (in case of application involving real data). The inner-join database will thus remain secret — yet computing the coefficients of a Lasso regression model on this secret dataset will be possible.
We first give a brief overview of the cryptographic building blocks that are used for this phase, and then present our solution.
Cryptographic Building Blocks. Our solution makes use of three core components: (keyed) cryptographic hash functions, (additively) homomorphic encryption, and 2-out-of-2 secret sharing.
Hash functions. A cryptographic hash function is a deterministic function , that maps any alphanumeric string , to another alphanumeric string , called digest, of fixed length5 Such a function enjoys the property that, given a digest , it is unfeasible to compute a string such that . In our protocol, we compute the hash of values that are concatenated with a random bit-string , thus obtaining . This ensures that a party with no knowledge of is unable to recover from its hash with a brute-force attack; in cryptographic terms, it is a simple form of keyed hashing.
Homomorphic encryption. An (additively) homomorphic encryption scheme is a public-key encryption scheme, thus consisting of a key-generation algorithm , an encryption algorithm and a decryption algorithm . For a keypair of public and secret key generated by , we have that takes as input a message m and some randomness r, and produces as output a ciphertext , with the property that , and that no information whatsoever can be extracted on m or from c and ; in formal terms, the encryption scheme is IND-CCA1 secure. In order to simplify notation, we will often omit the key and randomness when discussing encryption, and write ; moreover, we implicitly assume messages to be numeric values, so that addition and subtraction of messages are well-defined. The scheme is supposed to be additively-homomorphic, which means that there exists special operations on ciphertexts and , such that , and for all messages .
2-out-of-2 secret sharing. This building block can be seen as a form of key-less encryption, distributed among two parties, and works as follows: given a secret (numerical) value s, two elements and called shares are randomly sampled, but subject to the condition that . Then is assigned to a party, and to another party; in this way, each party has individually no knowledge of s (since the share that they have is a random number), but the original secret value s can be reconstructed, when the two parties cooperate and communicate their shares to each other.
The Secure Inner Join Solution. The presence of a third party (ZorgTTP) allows us to design a novel, highly efficient protocol for secure inner join, which we believe to be of independent interest. ZorgTTP is taking care of the communication between the two data holders, but is not allowed to learn any data other than the cardinality of the intersection. The goal is for AC and EMC to obtain a secret-shared version of the features from Table 5. Our secure inner join protocol between AC, EMC, and ZorgTTP uses cryptographic hash functions, and both AC and EMC have an (additively) homomorphic encryption key pair; we used SHA-256 [40] as hash function and the Paillier homomorphic-encryption scheme [41] in our implementation. Both public keys are communicated to the other involved parties, so that everyone can encrypt and perform homomorphic operations on ciphertexts; denote by a value encrypted under the public key of AC, and by a value encrypted under the public key of EMC. The main idea is as follows:
AC and EMC randomly permute the rows of their datasets.
AC and EMC jointly generate a random bit string, not known to ZorgTTP, for the cryptographic hash function.
Using the hash function and the random string, both AC and EMC hide the identifiers from their own databases, and send the obtained hashes to ZorgTTP. AC and EMC then use their own public key to homomorphically encrypt the feature values of their records, and send the resulting ciphertexts to ZorgTTP. For simplicity, we assume here that AC and EMC have only one feature each. More features can be processed by a simple repetition of the steps below; the reader can refer to Table 6 below for a visual representation of the data sent to ZorgTTP, and to “Appendix” section for the details.
ZorgTTP computes how many hashed identifiers from AC also appear among the hashed identifiers of EMC; denote by this value. Due to the properties of cryptographic hash functions, is equal to the number of records in the intersection of the datasets of AC and EMC, and ZorgTTP learns no other information on the identifiers. For simplicity, we assume . In case is larger, the steps below can be repeated, ZorgTTP properly linking the attributes with overlapping hashed identifiers; once again a more detailed description can be found in “Appendix” section. Note that, at this point, ZorgTTP holds the encrypted features of this record, which we denote by and .
Both AC and EMC generate a random value, denoted by s and z respectively.
Both AC and EMC use the public key of the other party to homomorphically encrypt their shares, thus obtaining and , and they then send these ciphertexts to ZorgTTP.
ZorgTTP computes and sends this to EMC. Similarly, ZorgTTP computes and sends to AC. Table 7 below visualized the data obtained and computed by ZorgTTP.
AC and EMC decrypt the received values and obtain and , respectively. Note that we have thus obtained a 2-out-of-2 sharing of and among EMC and AC, since AC still holds s and EMC still holds z. This outcome can be seen in Table 8.
To ensure that the decrypted differences (in step 9) reveal no information on the feature values, the randomly generated shares (in step 6) need to be sufficiently large.
Table 6.
Encrypted data sent to ZorgTTP by AC and EMC, respectively
| Hashed identifier | Encrypted feature | Hashed identifier | Encrypted feature |
|---|---|---|---|
Table 7.
Encrypted data obtained and intersected by ZorgTTP
| Matching identifiers | Feature | Feature | Value AC | Value EMC |
|---|---|---|---|---|
Table 8.
Final tables of secret-shares obtained by AC and EMC, respectively
| -share | -share | -share | -share |
|---|---|---|---|
| s | z |
Secure lasso regression
Once the steps of Paragraph "Secure inner join" section have been performed, we obtain a “2-out-of-2 secret-shared” version of Table 5: namely, Achmea and Erasmus MC each have a table filled with apparently random numbers, but if they were to add up the corresponding numbers, they would obtain exactly Table 5.
Recall that our purpose is to train a linear regression model — specifically, Lasso — on this table. Now letting Achmea and Erasmus MC communicate their datasets to each other in order to reconstruct Table 5, and then train the regression model, is clearly not an option: the information that they would obtain consists of personal data, the exchange of which has to be prevented.
Instead, we present a solution that is able to compute the regression coefficients from the two datasets, without leaking information on their content.
The fundamental building block that allows us to design and implement this solution is Shamir Secret Sharing. We make use of the software platform MPyC [35], which implements this form of secret-sharing, and other useful communication and computation tools. We present the relevant properties and features of MPyC and Shamir Secret Sharing in the next section, and then discuss how these are used in our solution.
Shamir Secret Sharing As mentioned above, the core component of MPyC is Secret Sharing due to Shamir [42]. Shamir Secret Sharing can still be seen as a form of key-less distributed encryption, but the number of involved parties and the privacy and reconstruction guarantees are different. Instead of discussing Shamir Secret Sharing in its full generality, we focus here on the regime of parameters which is relevant for our purposes, called (1, 3)-Secret Sharing.
Given three parties , a (1, 3)-secret-sharing scheme (denoted by SSS for short) consists of two algorithms, namely a sharing and a reconstruction algorithm . is, in general, randomized, and on input a given (secret) value s, it outputs three elements called shares. Typically, any party can use the sharing algorithm to obtain shares of a secret value of their knowledge, and they will then distribute these shares to the parties, with party receiving share . The algorithm tries to invert the process: on input three elements , it outputs a value s or an error message , indicating that the reconstruction failed.
A (1, 3)-SSS enjoys 1-privacy: no information on the secret value s can be extracted from an individual share . On the other hand, two or more shares allow to unequivocally reconstruct s (2-reconstruction), i.e. .6 The in (1, 3)-SSS thus refers to the privacy threshold, while the refers to the total number of parties.
Such a secret-sharing scheme can be used to construct MPC protocols: assume that the three involved parties (Achmea, Erasmus MC, and ZorgTTP) have access to a (1, 3)-SSS. Let us assume that parties wish to perform some computation on a value (held by Achmea) and (held by Erasmus MC). The three parties can then proceed as follows: first, Achmea secret-shares , i.e. computes , such that Achmea, Erasmus MC and ZorgTTP will receive , respectively. Notice that by 1-privacy, no information on is leaked at this point. Erasmus MC then similarly secret-shares , i.e. computes and distributes .
The key property now is that for any operation that the parties wish to perform on the values and , there exists a corresponding operation that can be performed on the shares , resulting in some other sharing , in such a way that no information at all is leaked on , nor . It is important to remark that these operations typically involve all shares and may also require some form of communication among the three parties. While operations such as sum can be straightforwardly be evaluated, multiplications are typically more involved; MPyC makes use of a relatively standard protocol where players locally multiply shares, then re-share the obtained values and apply a Lagrange interpolation function on the received shares [43, 44].
It then becomes possible to evaluate a complex algorithm such as Lasso regression on several features of Achmea and Erasmus MC: parties can secret-share their features, then decompose the Lasso regression into basic operations, and perform the corresponding operations on the shares. Eventually, they will obtain shares of the regression coefficients; due to the 2-reconstruction property, Achmea and Erasmus MC at this point simply need to exchange their shares with each other and to evaluate in order to obtain the coefficients.
A final remark of notable importance is that while sums and multiplications are, per se, sufficient to evaluate any algorithm, MPyC also supports a number of custom sub-protocols to evaluate special operations in a much more efficient way. Notably, efficient systems are implemented to compute the maximum of two values and to evaluate the inner product of two vectors, and there is full support for fixed-point arithmetic operations; we refer to the protocol specifications [35] for the details.
Casting from 2-out-of-2 to Shamir Secret Sharing. Recall that once the steps in section "Secure inner join" have been executed, parties obtain a 2-out-of-2 secret sharing of the table which serves as input for the secure Lasso solution, and not the (1,3) secret sharing that is required for MPyC. The first step to be performed is thus to “cast” this 2-out-of-2 secret sharing to a (1,3)-Shamir sharing.
This is actually a fairly simple step, where only sum operations are required. Indeed, denote by x a 2-out-of-2 share of Achmea and by y the corresponding 2-out-of-2 share of Erasmus MC, which means that , where z is some feature value of an individual record occuring in both datasets. Now Achmea can (1,3)-share x and Erasmus MC can (1,3)-share y, so that Achmea obtains and , Erasmus MC obtains and , and ZorgTTP obtains and . All parties have now have to locally add their shares, resulting in , , and : these are valid (1,3)-shares of that can be used in MPyC.
The Secure Lasso Regression solution. In order to explain our secure Lasso solution, we follow the blueprint of section "Lasso regression algorithm" and show how each step can be securely performed on secret shared data, using the techniques of section "Secure lasso regression".
Secure Gradient Descent. Apart from the stopping criterion, , , step size and goodness of fit , all computations in Algorithm 1 are linear operations, and can thus be calculated on secret-shared data as explained in section "Secure lasso regression". We will now elaborate on these secure calculations.
Secure stopping criteria. As explained in the corresponding paragraph in section "Gradient descent approach", there are two possible stopping criteria: The first one is reaching the maximal number of iterations, and since is a public value, this criterion does not need to be implemented securely: The second criterion demands computing the update difference , and compare this with the tolerance (which is a public constant). For efficiency purposes, we chose not to implement all these steps securely. Instead, for every iteration we reveal the value of the update difference, and compare it with the tolerance in plaintext. To be more precise, recall that the update difference is given by the ratio between and : in order to calculate the update difference, we securely compute both enumerator and denominator and then reveal their values. We believe the information leak of this step to be acceptable, especially given the performance gain that is derived from it by avoiding the expensive secure division step.
- Secureand. In order to securely calculate the gradient of , linear operations are used. We also make use of the custom sub-protocol for vector multiplication, as described in section "Secure lasso regression". In order to compute , we calculate two secret-shared bits, namely , and , where denotes the bit that is equal to 1, if , and to 0, otherwise. We can then securely compute the following linear operation over the shares of :
It is easy to see that this gives the same result as Eq. (4).5 Secure initial step size. Although the operations that we use for computing our choice of the initial step size (inner product and maximum) are computationally expensive, we only need to perform them once. Once again, we make use of the sub-protocols for vector multiplications and maximum from MPyC.
- Secure goodness of fit. Once we have computed the weight vector of the prediction model, we aim to securely compute goodness-of-fit measures. As an example we implemented . Recall that the definition of is given by
With the shares of , and the publicly-known coefficients of , we can calculate the shares of . At this point, by using the secret-shared vector , we can compute the numerator and denominator of , reveal these values, and thus obtain .
Results
In this section we first present the security results of our solution. We then discuss the scalability results of our Proof of Concept, which was not performed on real data but did run on the actual infrastructure between Achmea, Erasmus MC and ZorgTTP. Finally, we describe the performance of our implementation of the Lasso regression and the accuracy of the secure model.
Security results
The security of our solution is guaranteed under the following assumptions. First of all, we assume that any two parties are connected by secure channels; in practice this is done by means of SSL/TLS connections. We assume that parties do follow the instructions of the protocol; in cryptographic lexicon, they are thus assumed to be semi-honest. Privacy is guaranteed, even if parties try to infer extra information from the data they sent and received as part of the protocol, though we assume that no party will collude with any other party and exchange information with them. Finally, we adopt the standard assumption that the involved parties are bounded by polynomial-time computations, and that factoring large integers is feasible under this constraint.
Under the above conditions, the solution we present is provably secure, in the sense that we can mathematically argue that the only information that will be revealed are regression coefficients, and the size of the intersection between the datasets of Achmea and Erasmus MC.
Running time
We implemented our solution in Python. In order to test the efficiency of our implementation, we ran several experiments on three machines, under the control of Achmea, Erasmus MC and ZorgTTP, respectively, and geographically separated.
The experiments include the secure inner-join computation and the protocol to securely train a Lasso regression algorithm as described in section "Description of the secure solution". Notice that we have not evaluated the efficiency of applying the Lasso model to new data, as it would be out-of-scope for this article;7 For the same reason, no test data is extracted from these data artificial datasets.
All three (virtual) machines run a Linux-based operating system, and are equipped with a commercial-grade virtual processor (up to four cores at 2.4GHz) and with 8 to 16 GB of RAM.
The solution was installed as a Docker image on all three machines. Connections within the machines were realized via HTTPs over TCP (for the secure inner join) and via the custom TCP protocol of MPyC. The connections were secured with TLS; certificates were created and installed on the machines to this end.
In order to test the efficiency of our solution, we sampled artificial datasets, using scikit-learn (with the datasets.sample_generator.make_regression functionality, that creates a dataset of real numbers with a rougly linear dependency of the target features). We sampled datasets with an increasing number of records and features, and ran several instances of our solution. The number of records (per dataset) was equal to 5, 100, 500, 1000, 5000 and 10000, while the (total) number of features was equal to 1, 2, 5, 10, 30 and 40. We vertically split the dataset into two datasets, with an (up to one difference) equal number of features and with a complete overlap in record IDs, i.e. the identifiers in the Achmea dataset were identical to those of the Erasmus MC dataset for each iteration.
For datasets with five records, we chose not to run instances with more than two features, as this regime of parameters would be highly unsuitable for a linear regression algorithm. Furthermore, the instance with 10.000 records and 40 features could not be run due to the RAM limitations of the involved machines; we nevertheless believe that the instances we considered are sufficient to analyze the scalability of our solution.
Each instance was run 10 times; all figures presented in this article refer to the median time over these 10 executions.
The total running time (thus encompassing both secure inner join and secure Lasso regression) is showed in in Figs. 1 and 2. Our solution thus takes roughly 3500 s, slightly less than one hour, to process two datasets with 5000 records each and a total of 30 features. Moreover, the running time of our solution scales linearly in the number of records and features.
Fig. 1.
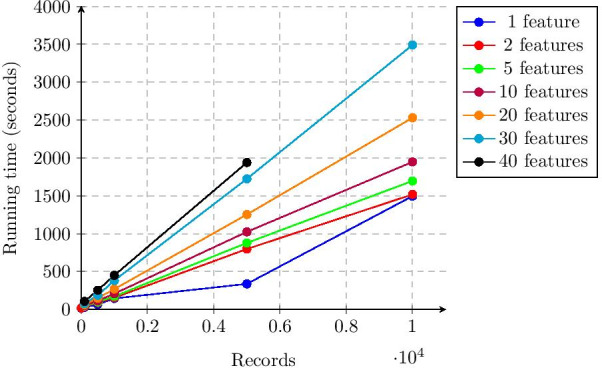
Total running time of the experiments as a function of the number of records (median values)
Fig. 2.
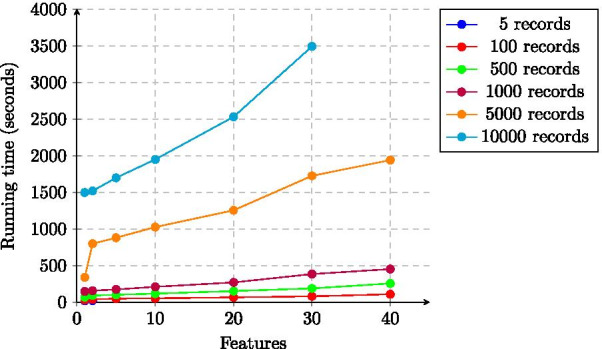
Total running time of the experiments as a function of the number of features (median values)
The running time of our solution is dominated by the Secure Lasso regression, the scalability of which is shown in Figs. 3 and 4. Just as for the total time, the running time of this phase also has a linear dependency on the number of records and of features.
Fig. 3.
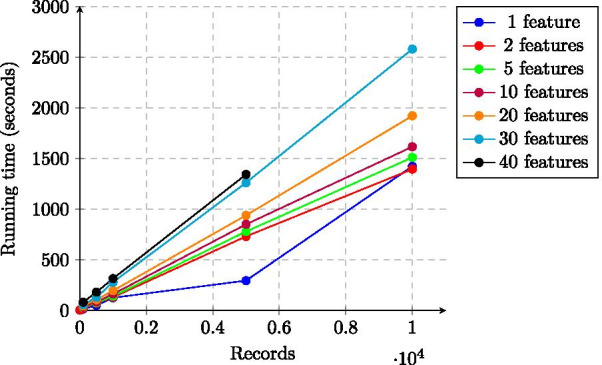
Running time of Lasso regression (training phase) of the experiments as a function of the number of records (median values)
Fig. 4.
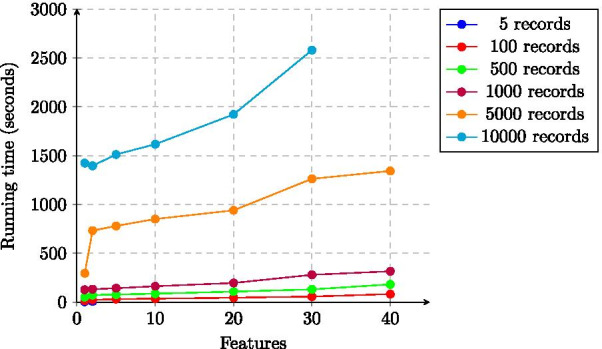
Running time of Lasso regression (training phase) of the experiments as a function of the number of features (median values)
Performance and accuracy results
Data
To test the performance and accuracy of our secure model, we use the “Medical Costs” dataset by Brett Lantz [45]. This public dataset contains 1338 records of patients with 12 features each (including, among others, age, bmi, children, gender, medical costs), of which four are numerical, and eight are Boolean. We centered and scaled the data in advance, such that the feature values are comprised between 0 and 1. We also split into a train and a test set (10% of the data, randomly selected).
Performance of lasso regression
To test the performance of our solution we compare the results of our secure model with the non-secure scikit-learn Lasso model [46]. Note that the secure inner join has no influence on the performance of the Lasso regression. Therefore, as input of our secure model, the data is secret-shared between the three parties. The influence of the calculation on secret-shared values will be discussed in the next paragraph.
We train with our secure model on 11 features of the train set for predicting the (numerical) target feature of medical costs, by varying and tolerance. We found the optimal choice, leading to a good fit (, mean squared error) and enough coefficients set to zero, to be and tolerance . For this choice of parameters, when training our secure model, we need 26 iterations. Applying the trained model on our test set, we achieve an of 0.70, a mean squared error of 0.0086, a mean absolute error of 0.062 and an objective of 0.013. As a validation of the solving method that we used, we compare these results with the (highly optimized) Lasso model of scikit-learn [46], using the same parameters. After the model was trained on the train set, on the test set we find an value of 0.66, a mean squared error of 0.012, a mean absolute error of 0.082 and an objective of 0.0090. Although the goodness-of-fit measures of our secure model are better than the scikit-learn model, it has a larger objective value. In Tables 9 and 10 one can see that in the scikit-learn model, two more coefficients are set to zero, which is one of the aims of Lasso. Therefore, we can conclude that our secure model has a good performance, although the (highly optimized) scikit-learn model performs slightly better.
Table 9.
Comparison plaintext model and Sklearn Lasso: objective, , mean squared error and mean absolute error
| Model | Obj | MSE | MAE | intercept | |
|---|---|---|---|---|---|
| scikit-learn | 0.0090 | 0.66 | 0.012 | 0.082 | 0.39 |
| our secure model | 0.013 | 0.74 | 0.008 | 0.062 | 0.18 |
| Abs. diff. | 0.004 | 0.08 | 0.004 | 0.020 | 0.21 |
Table 10.
Comparison plaintext model and Sklearn Lasso: coefficients
| Model | c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| scikit-learn | 0.08 | 0.01 | 0 | 0 | 0 | − 0.30 | 0 | 0 | 0 | 0 | 0 |
| our secure model | 0.17 | 0.10 | 0.001 | 0 | 0 | − 0.19 | 0.18 | 0 | 0 | 0 | 0 |
| Abs. diff. | 0.09 | 0.09 | 0.001 | 0 | 0 | 0.11 | 0.18 | 0 | 0 | 0 | 0 |
Accuracy of the secure implementation
To compare the performance and accuracy of our secure model, we implemented the Lasso algorithm described in section "Gradient descent approach" in a non-secure way. Although the steps in training both models are the same, a slight difference in outcome is to be expected, due to possible rounding errors of non-integer, secret-shared values. This difference in objective values is less than ; we consider this to be negligible for our research purposes.
Discussion
In light of the results shown in section "Results", we conclude that our solution does provide a viable way of securely training a Lasso regression model on distributed patient data in a privacy-preserving way. In particular, the good quality of the obtained model, together with its satisfying efficiency in a fairly realistic set-up, make our solution a promising tool for privacy-preserving analysis of distributed patient data.
As future work, we have identified two main directions, namely, improvements to the solution and working towards a pilot on real heart-failure risk data.
Improvement to the secure solution
We identify several ways to further improve our solution. First of all, our solution was relatively efficient, the secure solution took less than one hour for the setting with 5000 records and 30 features. This should be fast enough for research purposes. However, while we deem our solution to be fast enough for research purposes, its efficiency might need to be improved when working with very large datasets. Several approaches are possible in order to reduce running time, for instance implementing the solution in another programming language such as C, or making optimal use of parallelisation. Moreover, RAM usage could be reduced by supporting access to advanced database-management systems.
Also, we identified some opportunities to improve the quality of the model. Within this article, we assumed the data to be pre-processed, i.e. scaled and centered; a solution with a higher technology readiness level would need to securely implement this step. Moreover, next to , more goodness-of-fit measures such as mean squared error and mean absolute error could be securely implemented. This would enable parties to perform more quality checks on the model, and to choose a good regularization parameter .
Finally, while we focused on a situation where exactly two parties supply input data, and it would be interesting to extend our solution to more than two data-parties. The secure Lasso regression training poses no issue for such an extension, since MPyC supports a virtually unlimited number of parties, but the secure inner join would need to be re-designed, since it is tailored to the two-party-with-helper setting. A step-by-step approach for this part could probably be realized, i.e. by first performing an inner join of the datasets of two parties and then using the outcome as input for another inner join with the third data party, and so on, but a thorough analysis is required to validate this approach and measure its performance.
Towards prediction of heart-failure risk factors
Given the promising results obtained by our Proof of Concept, a future pilot with real patient data should be started, in order to establish the effectiveness of our solution for prediction of heart-failure risk on combined datasets from Erasmus MC and Achmea. The data needed for such an experiment is already stored at both parties. At Achmea, features express and quantify, notably, the number of days a given customer was admitted to a hospital, and various other aspects such as comorbidities, marital status, and socio-economic status. This information is stored as part of the standard procedures of health insurance companies. At Erasmus MC, on the other hand, features express and quantify social and behavioral aspects such as age, smoking, exercising, and alcohol consumption. This type of data has been collected by the Epidemiology department of Erasmus MC as part of a previous study performed on volunteers in the city of Rotterdam [3], of which a significant part are also ensured at Achmea. In a future pilot, we would aim to predict the number of hospitalization days as a function of the other feature values. Such a pilot would need to address both the technical challenges highlighted above (for instance, Achmea has data on more than five million individuals). But it should also focus on non-technical challenges, such as compliance and legal aspects, and ensure that employees and management are properly involved in the process and get acquainted with the used techniques, which constitutes a time-consuming process.
Conclusions
In this paper, we presented a secure and scalable solution for Lasso regression as a part of the European BigMedilytics project. The solution allows two parties, in this case Erasmus MC and Achmea, to securely compute the inner join of their respective datasets and to train a Lasso regression algorithm on the obtained dataset in a privacy-preserving way, assisted by healthcare information intermediation company ZorgTTP. No party learns any patient data, other than the number of overlapping patients from both datasets, the result of the regression, and some intermediate values of the regression algorithm, which we believe to be fully acceptable.
We implemented our solution on three computing nodes, running at separate machines, and located at different sites, under control of Achmea, Erasmus MC, and ZorgTTP, respectively. The experimental results show that our implementation is reliable, accurate, and fast enough for research purposes. We conclude that our solution is a promising tool for privacy-preserving machine learning tasks on distributed patient data, potentially leading to an improvement of the quality of healthcare, while respecting the privacy of involved patients.
Supplementary information
Additional file 1: Zip archive containing the log files of the scalability experiments. The archive can be opened with any archive manager, and the included log files (with .log extension) can be read with any text editor.
Acknowledgements
The authors wish to thank Tim van der Broek for his useful comments and suggestions to improve this article.
Appendix: Secure inner join protocol
This is a detailed version of the secure inner join protocol, described in “Aim and assumptions” section. Both AC and EMC get a key pair of an additively homomorphic crypto system, which keys are generated in the first step. In the second step a random key r is generated jointly between AC and EMC, without ZorgTTP learning it. This key is used for scrambling the identifiers and encrypting the private data in step 3. They are sent to ZorgTTP in step 4, together with the encrypted attribute values. In step 5 ZorgTTP looks for the matching indices of the scrambled identifiers, and obtains the intersection cardinality. In steps 6 and 7, AC and EMC generate their shares of the inner join table entries, and send them encrypted to ZorgTTP. In step 8, ZorgTTP computes the encrypted remaining shares, so AC and EMC can decrypt them.
Authors' contributions
MBvE contributed to the privacy-preserving Lasso regression solution and to the writing of this manuscript. GS contributed to the cryptographic design and implementation of the solution and to the writing of this manuscript. OvdG formulated requirements and draw conclusion from the perspective of Achmea, and contributed to the writing of this manuscript. AIJ formulated requirements and draw conclusion from the perspective of Erasmus MC, and contributed to the writing of this manuscript. TV contributed to the design of the secure inner join protocol, of the secure gradient descent technique, and to the writing of this manuscript. WK contributed to the use-case definition and to the writing of this manuscript. AS contributed to the design of the secure inner join protocol, to the implementation of the solution, and provided project coordination. TR contributed to the implementation and testing of the solution. PL contributed to the implementation and testing of the solution. BK contributed to the design and implementation of the secure Lasso regression technique. NvdL contributed to the design and implementation of the secure Lasso regression technique. MK-J contributed to the use-case definition and provided project coordination. All authors read and approved the final manuscript.
Funding
The BigMedilytics project has received funding from the European Union’s Horizon 2020 research and innovation program under Grant Agreement No. 780495.
Availability of data and materials
The (artificial) datasets used for the scalability experiments are included in the supplementary material, in the file. The log files measuring the running time of the solution for these inputs datasets are also included, to be found in . Finally, the dataset used to test the accuracy of our solution is a publicly-available dataset [45].
Declarations
Ethics approval and consent to participate
Due to the fact that no personal or medical data was used for the research described in this article (artificial data was instead sampled), approval from an ethics committee was deemed not necessary. For the same reason, consent to participate is not applicable.
Consent for publication
Due to the fact that no personal or medical data was used for the research described in this article (artificial data was instead sampled), consent for publication is not applicable.
Competing interests
The authors declare that they have no competing interests.
Footnotes
To be completely precise, we also reveal the size of the intersection of the two datasets to the involved parties.
Domain and codomain do not need, strictly speaking, to consist of alphanumeric strings, but we restrict to this situation for simplicity.
Formally, each share should be supplied to together with its index i, but we omit this to simplify notation.
In the healthcare-scenario that motivates this article, applying the model could arguably be performed without advanced cryptographic techniques, since the smaller amount of data needed would probably make direct data usage feasible and proportional (under appropriate informed consent). For this reason, we have decided not to focus on the application of the trained Lasso model.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material available at 10.1186/s12911-021-01582-y.
References
- 1.Dwivedi YK, Hughes DL, Coombs C, Constantiou I, Duan Y, Edwards JS, Gupta B, Lal B, Misra S, Prashant P, et al. Impact of covid-19 pandemic on information management research and practice: transforming education, work and life. Int J Inf Manag. 2020;102211.
- 2.Raisaro JL, Marino F, Troncoso-Pastoriza J, Beau-Lejdstrom R, Bellazzi R, Murphy R, Bernstam EV, Wang H, Bucalo M, Chen Y, Gottlieb A, Harmanci A, Kim M, Kim Y, Klann J, Klersy C, Malin BA, Méan M, Prasser F, Scudeller L, Torkamani A, Vaucher J, Puppala M, Wong STC, Frenkel-Morgenstern M, Xu H, Musa BM, Habib AG, Cohen T, Wilcox A, Salihu HM, Sofia H, Jiang X, Hubaux JP. SCOR: a secure international informatics infrastructure to investigate COVID-19. J Am Med Inf Assoc. 2020;27(11):1721–6. doi: 10.1093/jamia/ocaa172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ikram MA, Brusselle GG, Murad SD, van Duijn CM, Franco OH, Goedegebure A, Klaver CC, Nijsten TE, Peeters RP, Stricker BH, et al. The Rotterdam study: 2018 update on objectives, design and main results. Eur J Epidemiol. 2017;32(9):807–850. doi: 10.1007/s10654-017-0321-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Chicco D, Jurman G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med Inform Decis Mak. 2020;20(1):16. doi: 10.1186/s12911-020-1023-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sweeney L. Weaving technology and policy together to maintain confidentiality. J Law Med Ethics. 1997;25(2–3):98–110. doi: 10.1111/j.1748-720X.1997.tb01885.x. [DOI] [PubMed] [Google Scholar]
- 6.Narayanan A, Shmatikov V. Robust de-anonymization of large sparse datasets. In: 2008 IEEE symposium on security and privacy (sp 2008), 2008;111–125 . IEEE.
- 7.Zerka F, Barakat S, Walsh S, Bogowicz M, Leijenaar RT, Jochems A, Miraglio B, Townend D, Lambin P. Systematic review of privacy-preserving distributed machine learning from federated databases in health care. JCO Clin Cancer Inf. 2020;4:184–200. doi: 10.1200/CCI.19.00047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Beyan O, Choudhury A, van Soest J, Kohlbacher O, Zimmermann L, Stenzhorn H, Karim MR, Dumontier M, Decker S, da Silva Santos LOB, Dekker A. Distributed analytics on sensitive medical data: the personal health train. Data Intell. 2020 2(1–2):96–107.
- 9.Emam KE, Hu J, Mercer J, Peyton L, Kantarcioglu M, Malin BA, Buckeridge DL, Samet S, Earle C. A secure protocol for protecting the identity of providers when disclosing data for disease surveillance. J Am Med Inf Assoc. 2011;18(3):212–217. doi: 10.1136/amiajnl-2011-000100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.De Optimale Hiv Behandeling Vinden Met MPC. https://www.tno.nl/nl/tno-insights/artikelen/de-optimale-hiv-behandeling-vinden-met-mpc/. Accessed: 2020-10-26.
- 11.Spini G, van Heesch M, Veugen T, Chatterjea S. Private hospital workflow optimization via secure k-means clustering. J Med Syst. 2020;44(1):8–1812. doi: 10.1007/s10916-019-1473-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Zhang Y, Dai W, Jiang X, Xiong H, Wang S. Foresee: fully outsourced secure genome study based on homomorphic encryption. In: BMC medical informatics and decision making. 2015;15, 5 . Springer. [DOI] [PMC free article] [PubMed]
- 13.Shi H, Jiang C, Dai W, Jiang X, Tang Y, Ohno-Machado L, Wang S. Secure multi-party computation grid logistic regression (SMAC-GLORE) BMC Med Inf Decis Mak. 2016;16(S–3):89. doi: 10.1186/s12911-016-0316-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.van Haaften W, Sangers A, van Engers T, Djafari S. Coping with the general data protection regulation; anonymization through multi-party computation technology. 2020.
- 15.Freedman MJ, Nissim K, Pinkas B. Efficient private matching and set intersection. Eurocrypt Lect Notes Comput Sci. 2004;3027:1–19. doi: 10.1007/978-3-540-24676-3_1. [DOI] [Google Scholar]
- 16.Cristofaro ED, Tsudik G. Practical private set intersection protocols with linear complexity. In: Sion R (ed) Financial cryptography and data security, 14th international conference, FC 2010, Tenerife, Canary Islands, Spain, January 25–28, 2010, Revised selected papers. lecture notes in computer science, 2010; 6052, 143–159. Springer. 10.1007/978-3-642-14577-3_13.
- 17.Pinkas B, Rosulek M, Trieu N, Yanai A. SpOT-light: lightweight private set intersection from sparse OT extension. Cryptology ePrint Archive 2019.
- 18.Pinkas B, Schneider T, Tkachenko O, Yanai A. Efficient circuit-based PSI with linear communication. In: Ishai Y, Rijmen V (eds) Advances in cryptology—EUROCRYPT 2019—38th annual international conference on the theory and applications of cryptographic techniques, Darmstadt, Germany, May 19–23, 2019, proceedings, part III. Lecture notes in computer science. 2019; 11478, 122–153. Springer. 10.1007/978-3-030-17659-4_5.
- 19.Bogdanov D, Kamm L, Laur S, Sokk V. Rmind: a tool for cryptographically secure statistical analysis. IEEE Trans Dependable Secure Comput. 2018;15(3):481–495. doi: 10.1109/TDSC.2016.2587623. [DOI] [Google Scholar]
- 20.Dankar FK, Brien R, Adams C, Matwin S. Secure multi-party linear regression. In: EDBT/ICDT workshops. 2014; 406–414 . Citeseer.
- 21.de Cock M, Dowsley R, Nascimento AC, Newman SC. Fast, privacy preserving linear regression over distributed datasets based on pre-distributed data. In: Proceedings of the 8th ACM workshop on artificial intelligence and security. 2015;3–14 . ACM.
- 22.Hall R, Fienberg SE, Nardi Y. Secure multiple linear regression based on homomorphic encryption. J Off Stat. 2011;27(4):669. [Google Scholar]
- 23.Hu S, Wang Q, Wang J, Chow SSM, Zou Q. Securing fast learning! ridge regression over encrypted big data. In: 2016 IEEE Trustcom/BigDataSE/ISPA. 2016; 19–26 . 10.1109/TrustCom.2016.0041.
- 24.Nikolaenko V, Weinsberg U, Ioannidis S, Joye M, Boneh D, Taft N. Privacy-preserving ridge regression on hundreds of millions of records. In: 2013 IEEE symposium on security and privacy. 2013;334–348. IEEE.
- 25.Chen Y-R, Rezapour A, Tzeng W-G. Privacy-preserving ridge regression on distributed data. Inf Sci. 2018;451–452:34–49. doi: 10.1016/j.ins.2018.03.061. [DOI] [Google Scholar]
- 26.Blom F, Bouman NJ, Schoenmakers B, de Vreede N. Efficient secure ridge regression from randomized gaussian elimination. IACR Cryptol ePrint Arch. 2019;2019:773. [Google Scholar]
- 27.Gascón A, Schoppmann P, Balle B, Raykova M, Doerner J, Zahur S, Evans D. Privacy-preserving distributed linear regression on high-dimensional data. Proc Priv Enhanc Technol. 2017;2017(4):345–364. [Google Scholar]
- 28.Giacomelli I, Jha S, Page CD, Yoon K. Privacy-preserving ridge regression on distributed data. IACR Cryptol ePrint Arch. 2017;2017:707. [Google Scholar]
- 29.Join Clause (SQL). https://en.wikipedia.org/wiki/Join_(SQL)#Inner_join. Accessed: 2020-10-06.
- 30.Schmidt M. Least squares optimization with l1-norm regularization. CS542B Project Report. 2005;504, 195–221.
- 31.Hoerl AE, Kennard RW. Ridge regression: biased estimation for nonorthogonal problems. Technometrics. 1970;12(1):55–67. doi: 10.1080/00401706.1970.10488634. [DOI] [Google Scholar]
- 32.McDonald GC. Ridge regression. Wiley Interdiscip Rev Comput Stat. 2009;1(1):93–100. doi: 10.1002/wics.14. [DOI] [Google Scholar]
- 33.Santosa F, Symes WW. Linear inversion of band-limited reflection seismograms. SIAM J Sci Stat Comput. 1986;7(4):1307–1330. doi: 10.1137/0907087. [DOI] [Google Scholar]
- 34.Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Ser B (Methodol) 1996;58(1):267–288. [Google Scholar]
- 35.Schoenmakers B. MPyC—secure multiparty computation in Python. https://github.com/lschoe/mpyc.
- 36.Katz J, Lindell Y. Introduction to modern cryptography, 2nd edn. CRC Press, 2014. https://www.crcpress.com/Introduction-to-Modern-Cryptography-Second-Edition/Katz-Lindell/p/book/9781466570269.
- 37.Menezes A, van Oorschot PC, Vanstone SA. Handbook of applied cryptography. CRC Press; 1996. 10.1201/9781439821916. http://cacr.uwaterloo.ca/hac/.
- 38.Cramer R, Damgård I, Nielsen JB. Secure multiparty computation and secret sharing. Cambridge University Press; 2015. http://www.cambridge.org/de/academic/subjects/computer-science/cryptography-cryptology-and-coding/secure-multiparty-computation-and-secret-sharing?format=HB&isbn=9781107043053.
- 39.Lindell Y. Secure multiparty computation. Commun ACM. 2021;64(1):86–96. doi: 10.1145/3387108. [DOI] [Google Scholar]
- 40.FIPS P. 180-4. secure hash standard. National Institute of Standards and Technology, 36, 2005.
- 41.Paillier P. Public-key cryptosystems based on composite degree residuosity classes. In: Stern J, editor. Advances in cryptology—UROCRYPT ’99, international conference on the theory and application of cryptographic techniques, Prague, Czech Republic, May 2–6, 1999, proceeding. Lecture notes in computer science, 1999;1592, 223–238. Springer. 10.1007/3-540-48910-X_16.
- 42.Shamir A. How to share a secret. Commun ACM. 1979;22(11):612–613. doi: 10.1145/359168.359176. [DOI] [Google Scholar]
- 43.Ben-Or M, Goldwasser S, Wigderson A. Completeness theorems for non-cryptographic fault-tolerant distributed computation (extended abstract). In: Simon J, editors. Proceedings of the 20th annual ACM symposium on theory of computing, May 2–4, 1988, Chicago, Illinois, USA, 1988;1–10. ACM . 10.1145/62212.62213.
- 44.Gennaro R, Rabin MO, Rabin T. Simplified VSS and fast-track multiparty computations with applications to threshold cryptography. In: Coan BA, Afek Y, editors. Proceedings of the seventeenth Annual ACM symposium on principles of distributed computing, PODC ’98, Puerto Vallarta, Mexico, June 28–July 2, 1998, pp. 101–111. ACM, 1998. 10.1145/277697.277716.
- 45.Medical Costs Dataset, Brett Lantz. https://www.kaggle.com/mirichoi0218/insurance. Accessed: 2020-10-26.
- 46.Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–2830. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 1: Zip archive containing the log files of the scalability experiments. The archive can be opened with any archive manager, and the included log files (with .log extension) can be read with any text editor.
Data Availability Statement
The (artificial) datasets used for the scalability experiments are included in the supplementary material, in the file. The log files measuring the running time of the solution for these inputs datasets are also included, to be found in . Finally, the dataset used to test the accuracy of our solution is a publicly-available dataset [45].