

Abstract
From social networks to biological networks, different types of interactions among the same set of nodes characterize distinct layers, which are termed multilayer networks. Within a multilayer network, some layers, confirmed through different experiments, could be structurally similar and interdependent. In this paper, we propose a maximum a posteriori based method to study and reconstruct the structure of a target layer in a multilayer network. Nodes within the target layer are characterized by vectors, which are employed to compute edge weights. Further, to detect structurally similar layers, we propose a method for comparing networks based on the eigenvector centrality. Using similar layers, we obtain the parameters of the conjugate prior. With this maximum a posteriori algorithm, we can reconstruct the target layer and predict missing links. We test the method on two real multilayer networks, and the results show that the maximum a posteriori estimation is promising in reconstructing the target layer even when a large number of links is missing.
I. INTRODUCTION
Network science has been widely used in different areas, such as information diffusion, infectious disease spread, and gene co-expression analysis. Through network analysis, one can study the relations among nodes, and the robustness of a system [1, 2]. For example, epidemiologists can predict the number of people infected by COVID-19 through epidemic analysis. Then, they can provide advice to policymakers at an early stage to curb the spreading of the disease [3]. By constructing co-expression networks, biologists can discover crucial genes (nodes) by simply choosing genes with high degree centralities, closeness centralities, or eigenvector centralities. In a typical protein network, five to seven layers are considered to represent different types of molecular interactions [4, 5], including proteolysis, genetic interaction, co-expression, etc. Such multilayer networks are obtained through biological experiments, which could be expensive and time-consuming. A layer can be particularly important but also incomplete, with many missing links. A critical research goal is to reconstruct this important layer, called the target layer, without performing the expensive experiments, but by exploiting all information embedded in the other layers. In other words, we can estimate the target layer through existing layers [4, 6–9]. After constructing the target layer, researchers can devote restricted resources to the detection of edges with high probabilities.
Various methods have been proposed to reconstruct networks and predict missing links, and most of them are based on generative models [4, 6, 7, 10–24]. A generative model reconstructs the network topology by fitting a stochastic network model [7, 13, 14, 25], and uses a maximum-likelihood estimation (MLE) algorithm to find the optimal parameters that can describe the network. In [13, 14], the authors presented a degree-correlated stochastic block model to reconstruct a single layer network. Edges are computed through the tensor product of node vectors, and the entries of the node vectors are the degrees of the nodes in each community. Authors in paper [7] extended the single layer stochastic block model to multilayer networks and used it to predict missing links and detect overlapping communities. The authors tried all the layer combinations to find the layers that can improve the maximum likelihood. However, when there are many layers, it is burdensome to try all the layer combinations to find the interdependent layers. The authors validated the algorithm through two real multilayer networks by hiding 20% of links and non-links.
In multilayer networks, there could be structurally similar layers. Therefore, it is possible to take advantage of similar layers to help reconstruct the target layer. We propose comparing the target layer with the remaining layers if the target layer is partially known. In the literature, multiple methods have been proposed to compare networks [26–30]. The authors in [27, 28] present a method called DeltaCon. The DeltaCon method compares the affinity scores of every pair of nodes in two networks. The method is very sensitive to changes in the number of edges, and the removal of edges results in a significant change in the distance. Papers [29, 30] review and compare some network-comparing methods, including vertex/edge overlapping, vertex/edge vector similarity, and the SimHash algorithm. The vertex/edge overlapping method applies the rule that two graphs are similar if they share many vertices and edges. According to the analysis in [29], the drawbacks of this method are that it is not sensitive to changes in high-quality vertices, topology, and properties of networks. The vertex/edge vector similarity method compares the node/edge weight vectors of two networks. The drawback of this method is that it is not sensitive to changes in the topology and other properties of networks. To take advantage of the features of networks, the SimHash algorithm is introduced to compare networks. The PageRank [31] together with edges are used as network features in SimHash algorithm to compare web page networks.
In this paper, we propose a maximum a posteriori (MAP) based-method for target layer reconstruction as well as for link prediction. The MLE algorithm and entropy-related approaches must depend on the known information of the target layer. Consequently, the reconstruction is significantly affected by the available information of the target layer. In the MAP algorithm, the layers that are similar to the target layer will be considered to compute the parameters of the conjugate prior. Experimental results show that the MAP algorithm provides more consistent results than the MLE method. The first contribution of this paper is to discover an incomplete target layer by computing its edges through a dot product of node vectors. The optimal entries of node vectors are obtained by maximizing the posterior probabilities of the stochastic model. In our experiments, we find that the model accuracy can be improved if we increase the dimension of node vectors, but the return is diminishing for large vector dimensions. Another contribution is that we introduce the eigenvector centrality-based SimHash algorithm to detect structurally similar layers (interdependent layers). The eigenvector centralities of nodes are extracted as network features, which allow us to recover the structure of networks, as shown in the experimental results. In this work, we assume that the number of edges between any pair of nodes follows Poisson distribution [7, 13]. Hence, the Gamma distribution will be the conjugate prior for the Poisson distribution [32]. We compute the parameters of the conjugate prior through the adjacency matrices of similar layers, and the contributions of the similar layers are weighted by their similarities. The number of edges between each pair of nodes is calculated as the dot product of the node vectors. In our experiments, we show that similar layers are critical in improving the robustness of link predictions.
The paper is organized as follows. In section two, we first introduce the MAP method on target layer reconstruction. Next, we propose the eigenvector centrality-based SimHash algorithm to find structurally similar layers. Then, we propose the process for identifying parameters of the conjugate prior under different circumstances. In section three, we first evaluate the eigenvector centrality based SimHash algorithm on two real multilayer networks. Then, we evaluate the MAP algorithm-based target layer reconstruction on the two real networks and compare the differences between the MLE algorithm and the MAP algorithm. We conclude the paper in section four.
II. LAYER RECONSTRUCTION IN MULTILAYER NETWORKS
A. Maximum a posteriori based stochastic model
In this section, we define the stochastic model for both directed and undirected multilayer networks. The adjacency matrix of the target layer is denoted by A. The goal of this reconstruction is to estimate A, given a partial knowledge of the target layer and of other layers in the multilayer network. To reconstruct the target layer, a set of parameters is needed to describe the model, which we denote as θ. Based on Bayes’ theorem, the posterior probability of θ is
| (1) |
where P(θ | A) is the posterior probability of θ, P(A | θ) is the likelihood of A under θ, P(θ) is the prior probability of θ and P(A) is the marginal likelihood that contains all the information of the network. Since P(A) is a constant, P(θ | A) is proportional to the product of P(A | θ) and P(θ). Therefore, we have
| (2) |
For any pair of nodes in the network, we use Eij to denote the expected number of links (which could be fractional) between node i and node j. In unweighted networks, the entries of the adjacency matrix are denoted by 0 or 1. Here, since the entries Eij are real numbers, we can interpret network A as a weighted network.
Before we substitute any parameters into expression (2), we make the following assumptions. The links in the target layer are independent and identically distributed. In other words, the number of edges between node i and node j does not affect the relation between node i and node k. Further, we assume the number of links between any pair of nodes is extracted from a Poisson distribution, i.e., . We can rewrite expression (2) after substituting Eij and Aij as
| (3) |
In the MLE algorithm, the prior probability P(Eij) can be neglected since it is a constant. In the MAP algorithm, we need to specify the prior distribution of P(Eij). The conjugate prior distribution for the Poisson distribution is the Gamma distribution
| (4) |
where αij, βij and Γ(αij) are the shape parameter, the scale parameter, and the Gamma function of the Gamma distribution, respectively. In section II C, we introduce a procedure to determine αij and βij through the layers with high similarities. Substituting the conjugate Gamma distribution into expression (3), we have
| (5) |
Note that we have left out constant terms.
The problem now has been simplified to finding the parameters Eij that can maximize the posterior probability. However, an expression for Eij has not been specified. In this work, we compute the links through node vectors. The nodes in the target layer are represented by vectors. The expected number of links Eij can be computed by
| (6) |
where siz and tjz are respectively the zth entry of node i’s vector and node j’s vector. Here, we use s and t to denote source and target nodes. K is the dimension of the vector. Some MLE related works use tensor factorization to decompose the links, and the dimension of the tensor is interpreted as the number of overlapping communities. As a result, there should be an optimal number of communities that can maximize the estimation accuracy. However, this cannot be rigorously achieved and the tensor factorization can be simplified to the dot product according to our analysis in appendix A.
Expression (5) is still intractable after substituting Eij with equation (6). We take the logarithmic form of expression (5), which gives
| (7) |
where L(θ | A) is the log posterior.
To find the maximized posterior for expression (7), we apply the Jensen’s inequality , which gives
| (8) |
The equality is satisfied when
| (9) |
After substituting expression (8) and equation (9) into equation (7), equation (7) can be simplified to
| (10) |
Taking the derivative of equation (10) and equating to zero, we obtain the values of siz and tiz, the optimal node vectors that maximize the posterior probability:
| (11) |
| (12) |
The procedure to obtain the optimized siz and tjz is to assign random initial values for siz and tjz, then update equation (9), (11), and (12) iteratively until equation (7) converges. However, before applying the above iteration, we need to identify αij and βij, which are introduced in section II B and section II C.
B. Similarity and layer comparison
In section II A, we have detailed the procedure to compute the optimal node vectors by maximizing the posterior probability. The parameters αij and βij for the prior distribution are required to perform the posterior probability maximization. We propose to compute αij and βij through the layers of the multilayer network that are similar to the target layer. Keep in mind that there are missing links in the target layer, and the percentage of missing links is not known at all. Therefore, the primary factor for an effective network-comparing method is that the method must not be significantly affected by the percentage of missing links.
Networks can be characterized by multiple types of centralities, such as, degree centrality, eigenvector centrality, closeness centrality. The degree centrality measures the importance of a node by capturing the number of links the node has, while the eigenvector centrality can be regarded as an extension of degree centrality in which node’s importance is also affected by its neighbors’ importance. The closeness centrality of a node is the average length of shortest paths between the node and all other nodes. One or more of the centralities can describe the features of a network. To compare the target layer with the other layers, we can compare the features of the layers. For our purpose, the eigenvector centrality is selected as the network feature, and is used in the SimHash algorithm to compute similarities.
The SimHash algorithm works as follows [29, 30]. The feature of a network can be expressed as a set of token-value pairs {(vi : wi)}, where vi is a node and wi is its measure under the feature, for example its eigenvector centrality. Note that the target layer and the layer to be compared have the same set of tokens. In cryptography, any messages can be encrypted to a unique binary number (digest). Similarly, we can represent each token with a unique binary number with ϕ bits (2ϕ > the number of vi). For each binary number (digest), we map every 1 to wi, and 0 to −wi. Thus, each token is mapped to a weighted digest with ϕ digits. To obtain the weighted digest of the network, we sum up all the weighted digests of the tokens. Note that there is no carry in the summation.
To measure the similarities between the target layer and the other layers, we can compare the digests of the layers. A simple way to compare the digests is to convert the weighted digests to binary digests. The binary digest of a network can be obtained by setting positive digits to 1 and negative digits to 0. The similarity between the target layer m and any other layer r can be measured by
| (13) |
where μm,r is the similarity between layer m and r, is the binary digest of the target layer, and is the binary digest of the layer to be compared, respectively.
An alternative way to obtain the similarities is by computing the Pearson correlation coefficient of the weighted digests.
The estimation results based on the Pearson correlation are shown in appendix B. In this work, we measure the similarity between the target layer and the other layers through the binary-based digests. The influence of the bit number is discussed in appendix C.
C. Identify the parameters of the Gamma distribution prior
Finally, we introduce the procedure to determine the parameters αij and βij of the conjugate prior. We discuss this problem in two cases.
In the first case, we assume the structure of the target layer is partially known, i.e., the entries of the adjacency matrix are partially known. In this case, we apply the layer comparison method introduced above, and the L′ layers with highest similarities are considered to identify the parameters of conjugate priors. The parameters of the Gamma distribution prior are computed as
| (14) |
where m denotes the target layer, μm,r is the similarity between the target layer m and any layer r. is the adjacency matrix of layer r in L′. In equations (11) and (12), since Aij could be zero, if αij is less than one, we obtain a negative sij. Thus, we need to limit the range of αij. If , we set αij = 1, and set βij to to maintain the means of the Gamma distribution prior unchanged. If , we will set αij = 1, and set βij equal to a large number to ensure the MAP algorithm converges.
A special case is the structure of the target layer is not known at all. In this case, the comparison between the target layer and the other layers is not feasible. In this case, an alternative and heuristic way to compute the parameters of conjugate prior can be based on the functionally similar layers. If available, we can use additional published networks and data as a new multilayer network, in which layers are functionally similar. Thereafter, we can apply the proposed MAP algorithm to compute the parameters of conjugate prior through this new multilayer network. The similarities between the target layer and the functionally layers cannot be determined through any network comparison algorithm. Thus, we assume the similarities are all ones. We assign the parameters of the Gamma distribution as
| (15) |
Similarly, if , we will set αij = 1, and set βij to a large number to make the MAP algorithm converge.
In this scenario, we do not have any structural information regarding the target layer. If we set Aij = 0 in equations (11) and (12), this equivalent to assuming zero presences of all the edges in the target layer. To avoid this issue, we take the entries of Aij as the ratio of αij and βij, i.e., Aij = αij/βij. The entries are assigned as the average presences over the other layers.
III. EXPERIMENTAL VALIDATION
In this section, we evaluate the method introduced in section II. First, the SimHash algorithm is applied on two real networks, in which different percentages of links are removed uniformly at random. Second, the effectiveness of the MAP algorithm for the two real multilayer networks is evaluated, and the MAP algorithm is compared to the MLE algorithm.
The first real network we use to evaluate our proposed MAP algorithm is the FAO (Food and Agriculture Organization) trade network [33]. The FAO multilayer network is composed of 364 layers, and each layer represents a product trading among 214 countries. A link is detected between two nodes in a layer if there is trading of the corresponding product between the two countries. We show three layers of the FAO network in Fig. 1 through the KiNG software [34]. Since the layers in the FAO network are not ordered in any particular way, in the experiments, we only perform the evaluation by assuming that the target layer is one of the the first nine layers of the FAO network. Note that all the 363 remaining layers are always used in our experiments for detecting the similar layers.
FIG. 1.
Three layers of the FAO (a) network and HVR (b) network. Nodes in different layers share the same plane coordinates.
The second real network (HVR network) we use to evaluate the proposed MAP algorithm has nine layers and 307 nodes [35], which represent malaria parasite genes. The nine layers correspond to nine highly variable regions on the genes themselves. An edge is detected if two genes share an exact match of significant length in the highly variable region. We show three layers of the HVR network in Fig. 1.
A. Numerical results on layer comparison
The evaluation of the SimHash algorithm is performed on both the FAO network and the HVR network. The binary digest of each layer is obtained through the SimHash algorithm based on the eigenvetor centrality of the nodes. The similarity of any two layers can be computed through equation (13). In Fig. 2, each layer is respectively set as the target layer, and the similarities between the target layer and all the other layers are shown in interquartile ranges (IQR). For the FAO network, we only show the results of the first nine layers as target layers, and each IQR bar contains 363 similarity values. The similarities obtained through the SimHash algorithm are between 0 and 1. A zero similarity means the two layers have totally opposite eigenvector centrality distribution, while for 0.5 similarity the two layers are independent. A similarity approaching one means the two layers are similar. In the FAO network, the similarities are between 0.5 and 1, which indicates there are no layers with totally opposite eigenvector centrality distribution. In the HVR network, most of the layers are independent, since the similarities are all less than 0.8, except layer 7 and layer 9.
FIG. 2.
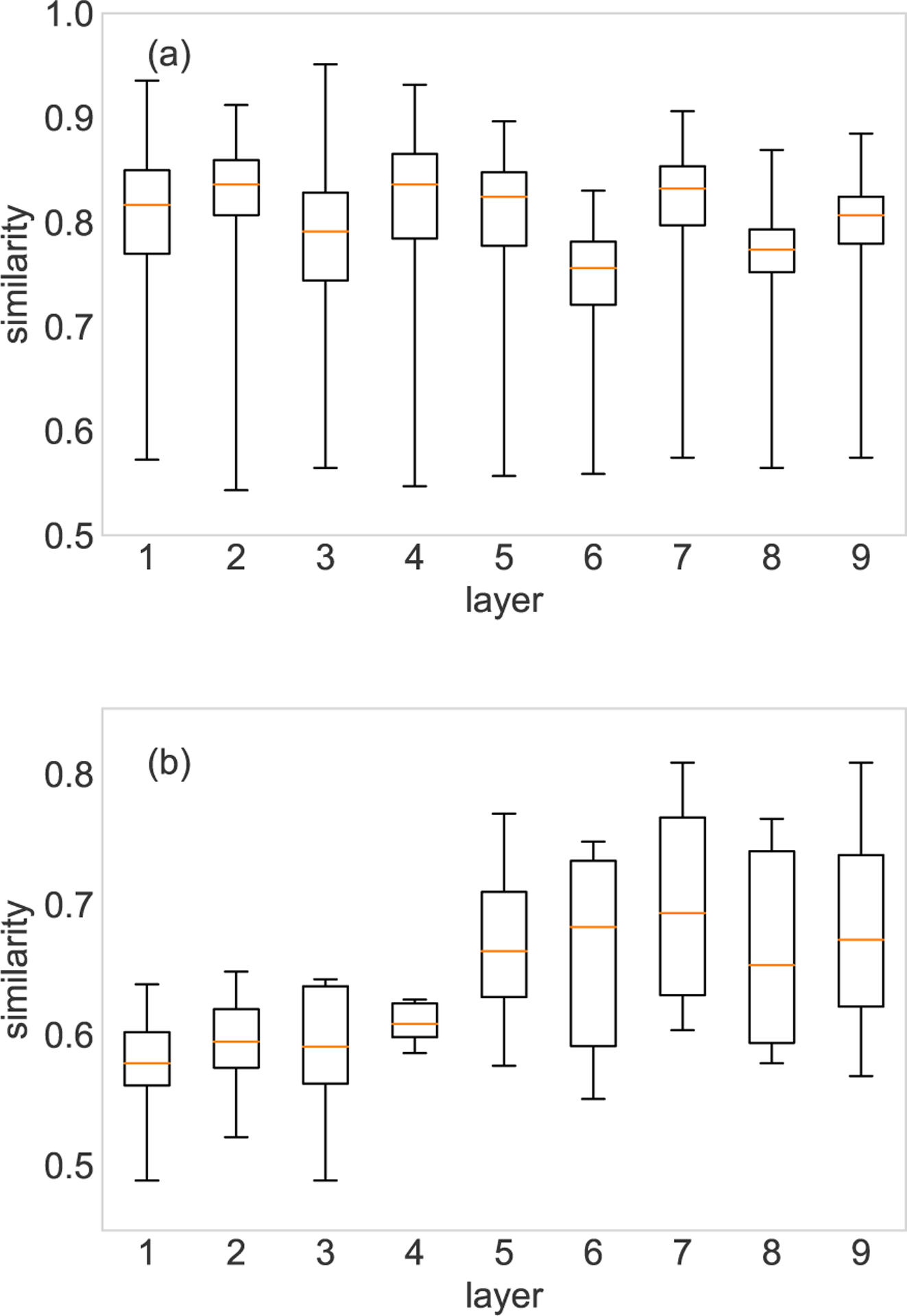
Layer comparison of the FAO network (a) and HVR network (b). (a) shows the similarities between the target layer and all the other 363 layers in the FAO network. (b) shows the similarities between the target layer and the other eight layers in the HVR network. Note that each similarity value is averaged over 10 runs.
The network-comparing method must be able to discover structurally similar layers even if there are missing links in the network. To this end, we uniformly at random remove 20%, 40%, 60% and 80% of edges from the target layer to generate incomplete networks and compare the incomplete networks with the target network. In Fig. 3(a), each layer of the FAO network (first nine layers) and HVR network is set as target network respectively, and we randomly remove 20%, 40%, 60% and 80% of edges from the target layer. The similarities between the incomplete networks with removed edges and the target layer are computed. From the top panels, we observe that the similarities are greater than 0.8 even with 80% of edges randomly removed.
FIG. 3.
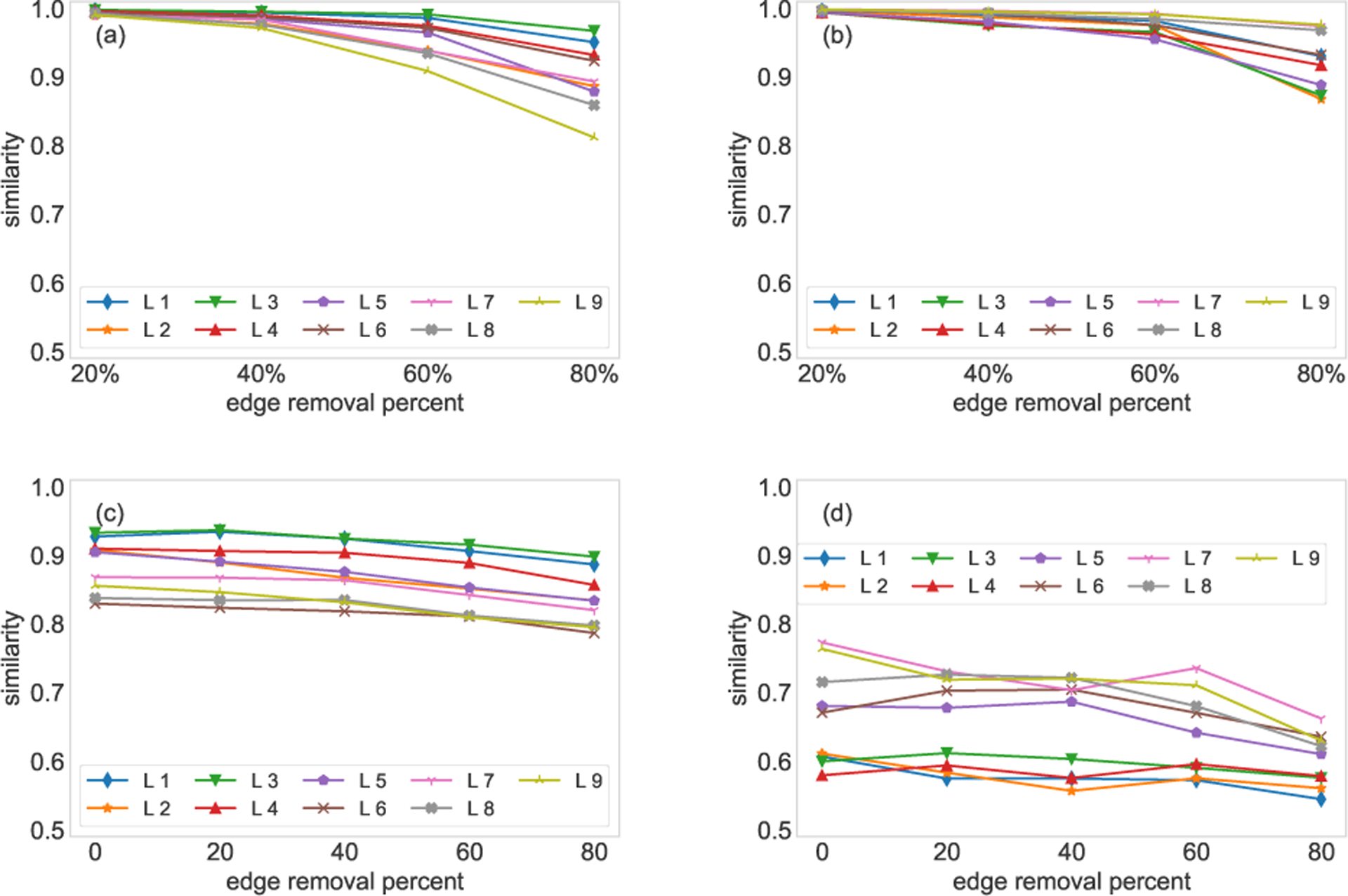
Eigenvector centrality-based SimHash algorithm. Panel (a) shows the comparison between the first nine layers of the FAO network and their incomplete counterparts, where 20%, 40%, 60% and 80% edges are removed uniformly at random from the target layer. Panel (b) shows the same experiment on the HVR network. Panel (c) compares the reduced networks (the first nine layers of the FAO network) with the five most similar layers. The mean of the similarities is shown in the panel. Similarly, 20%, 40%, 60% and 80% edges are removed uniformly at random from the target layer. Panel (d) shows the same experiment on the HVR network. Note that each similarity value is averaged over 10 runs.
There are always differences between the target layer and similar layers. In the second experiment, we show that missing links in the target layers do not affect the similarity significantly between the target layer and its similar layers. For each of the target layers, we choose five most similar layers from all the other layers, we then randomly remove 20%, 40%, 60% and 80% of edges from the target layer to generate incomplete networks. The incomplete networks are compared to the five similar layers, and we can obtain five similarities for different removal percentages. In the bottom panels, we show the average of the five similarities. The results for the first nine layers of the FAO network are shown in Fig. 3(c). We observe that the similarities decrease slightly even when 80% of edges are randomly removed. For the HVR network, where the layers are heterogeneous, though we randomly remove different percentages of links, the similarities are still maintained at low levels.
B. Validation of layer reconstruction and link prediction
The MAP method we have introduced in this work has the goal of layer reconstruction and missing link estimation. The similarity between the target layer and other layers can be obtained through the SimHash algorithm as introduced above. In this part, we show the effectiveness of the MAP algorithm, and compare the differences between the MAP algorithm and the MLE algorithm performance. Other methods such as entropy-based approaches, are equivalent to the MLE algorithm and are discussed in appendix D.
Here, we use the receiver-operator characteristic (ROC) curve and the area under the curve (AUC) to evaluate the effectiveness of our method. The model is perfect when the AUC is approaching one, and 0.5 means the model guesses the edge weights randomly.
a. The dimension of node vectors.
The dimension of node vectors is a critical factor for the MAP algorithm. In experiments, we find that there is no such number of communities [36–40] that can maximize the estimation accuracy. For both the FAO network and HVR network, we remove 40% of edges from the target layer to generate incomplete networks. The five layers with highest SimHash similarities are used to compute the parameters of the conjugate prior. The target layer is reconstructed through both the MLE algorithm and the MAP algorithm. In Fig. 4, we can observe an increased estimation accuracy with respect to the increment of the number of dimensions, though the gain diminishes for dimensions greater than 40. In the following experiments, we use a dimension of 50 which balances running time and estimation accuracy. Apart from the dimension of node vectors, the estimation accuracy is also affected by the number of similar layers. The influence of the number of similar layers on the estimation accuracy is analyzed in appendix E.
FIG. 4.
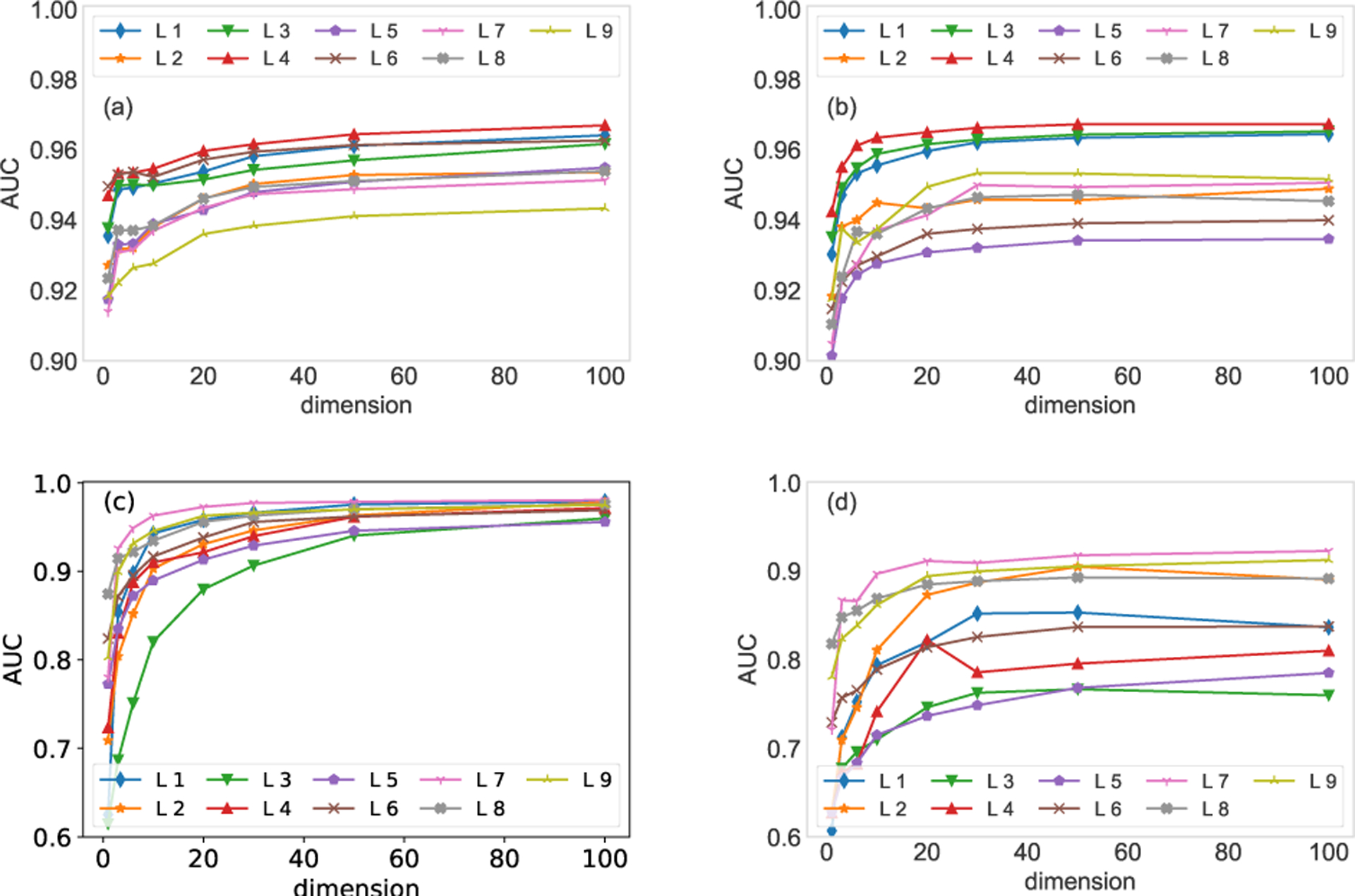
AUC vs. the dimension of node vectors. Panel (a) shows the MLE method on the first nine layers of the FAO network, where each layer is set as the target layer respectively. Panel (b) shows the results of MAP method when the five layers with highest similarities are adopted to compute the parameters of the conjugate prior. Panel (c) shows the results of the MLE method on the HVR network. Panel (d) is the results of MAP method on the HVR network. Note that the results are averaged over 10 runs of cross-validations.
b. Comparison between the MLE algorithm and the MAP algorithm.
Both the MLE algorithm and the MAP algorithm have their own benefits and disadvantages. The major difference between the MAP and MLE methods is that the MAP method can incorporate prior information (other similar layers), while the MLE relies on the available information of the target layer solely. The comparison between the MLE algorithm and the MAP algorithm is performed on both the FAO network (first nine layers) and the HVR network. The two algorithms are implemented on incomplete layers, which are generated by randomly removing 20%, 40%, 60%, 80% and 100% of edges from the two networks. In Fig. 5(a) and Fig. 6(a), we can see that the estimation based on the MLE algorithm is significantly affected by the missing links. However, the robustness of the estimation is greatly improved after we adopt structurally similar layers to reconstruct the target layer, as shown in Fig. 5(b). On the contrary, the estimation accuracy deteriorates if we adopt layers with heterogeneous structures to reconstruct the target layer, which is shown in Fig. 6(b).
FIG. 5.
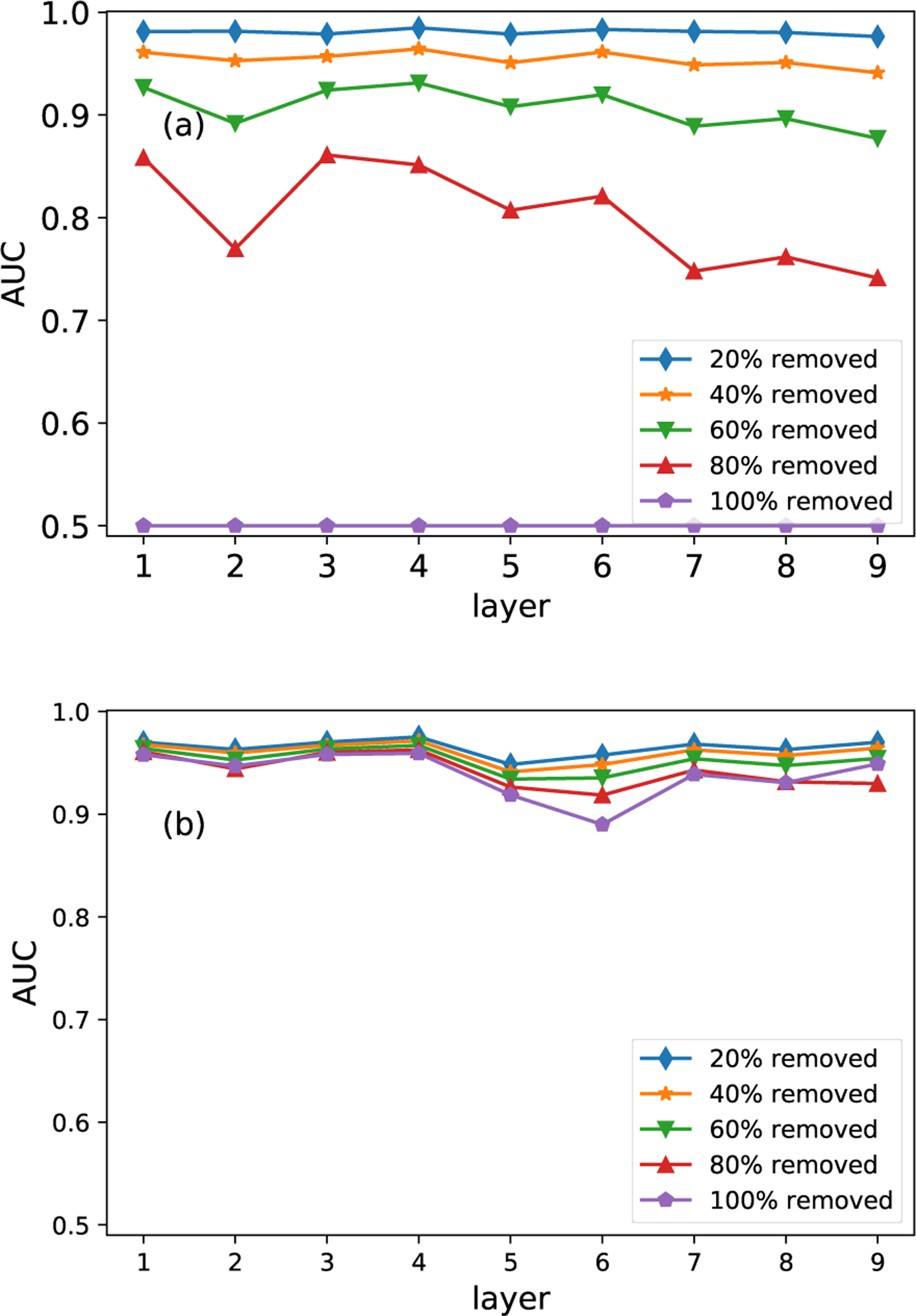
Comparison of the MLE and MAP methods on the FAO network. Panel (a) shows results of the MLE method. Panel (b) shows the results of the MAP method. Results are averaged over 10 runs of cross-validations.
FIG. 6.
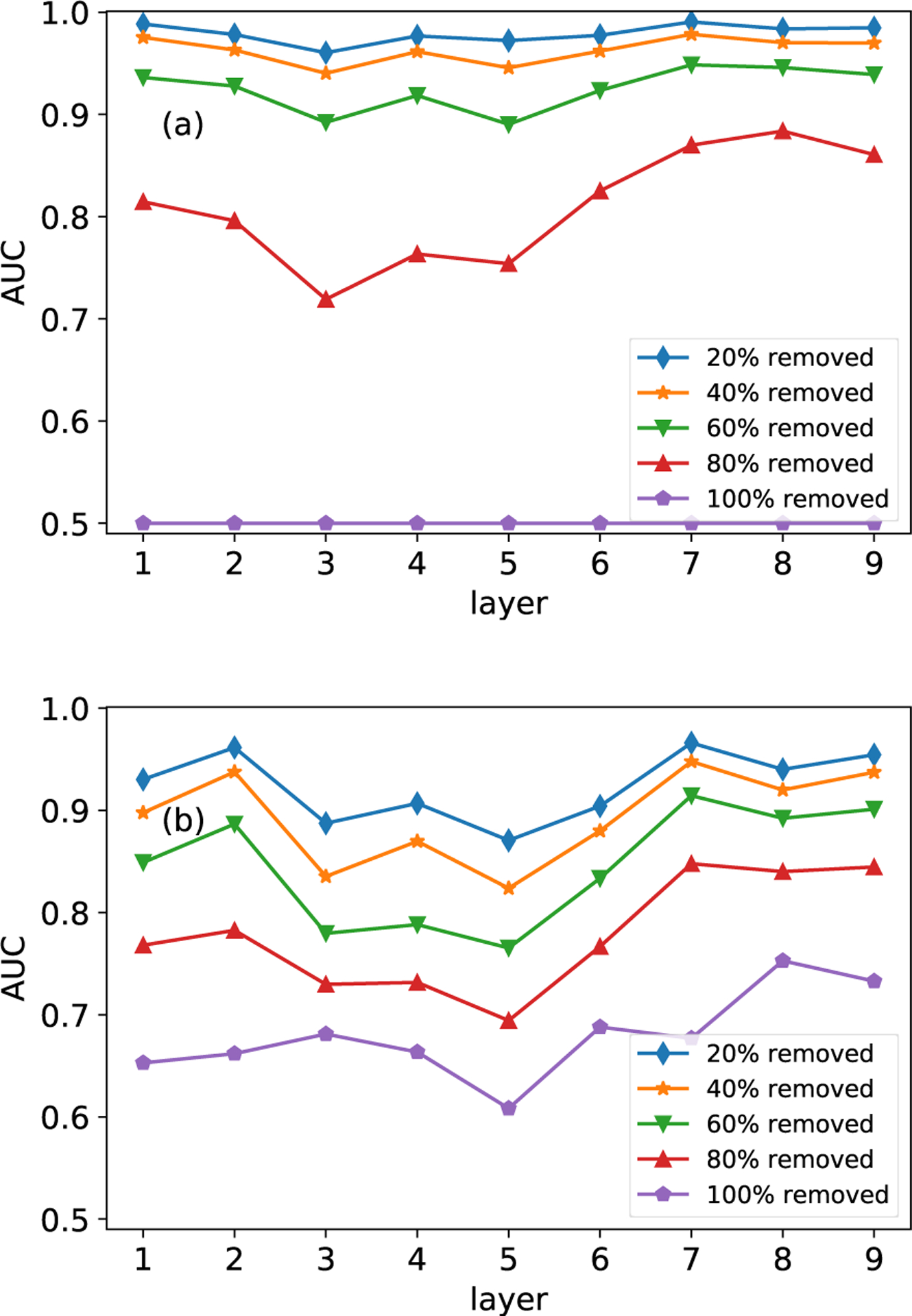
Comparison of the MLE and MAP methods on the HVR network. Panel (a) shows results of the MLE method. Panel (b) shows the results of the MAP method. Results are averaged over 10 runs of cross-validations.
Intuitively, the MLE method reconstructs the target layer through the known information of the target layer itself. As a result, the estimation accuracy is related to the available information, i.e., the percentage of known links. In the MAP algorithm, the estimation is not only affected by the known information of the target layer but also the similar layers. In real applications, if the percent of missing links is less than 20%, it is recommended to use the MLE algorithm, since it provides more accurate results than the MAP algorithm. Conversely, the MAP algorithm is the better choice if researchers are unaware of the percentage of missing links.
IV. CONCLUSION AND FUTURE WORKS
In this paper, we present a novel MAP estimation-based algorithm for target layer reconstruction in multilayer networks. In multilayer networks, some layers are structurally similar; thus, we can take advantage of the similar layers to reconstruct the target layer. In section II, we first derive the maximum a posteriori estimation for target layer reconstruction in multilayer network. Second, the eigenvector centrality-based SimHash algorithm is introduced to detect structurally similar layers. The SimHash algorithm compares network features, thus it is not affected by the missing links. Third, we introduce two scenarios to obtain the parameters of the Gamma conjugate prior. In the first case, where the target layer is partially known, the SimHash algorithm is adopted to detect structurally similar layers. In the second case, where the target layer is not known at all, functionally similar layers is used to compute the parameters of the conjugate prior. In section III, we first show that the eigenvector centrality-based SimHash algorithm is able to return consistent similarity levels for different percentages of missing links. Then, we show that the estimation accuracy can be improved by increasing the number of dimensions of node vectors, and the gain is diminishing for dimensions greater than 40 for the two networks. We find that with a great number of similar layers, we can obtain more consistent estimation results. Finally, the MLE method and MAP method are compared on two real networks. The experimental results suggest that if there are less than 20% of missing links, the MLE method has better performance. However, if the percentage of missing links is 40% or more, the MAP method returns results that are more consistent.
However, there are still some limitations to the MAP method we present. The first limitation is that the missing links in the target layer are required to be removed uniformly at random. The similarities are obtained through network feature comparison, which means the structure of the target layer needs to be maintained. Targeted removal of links will change the structure of the network. The second limitation concerns the unknown relation between the vector dimension and network size. In our numerical experiments, we test multiple dimensions and adopt a dimension of 50, which balances running time and estimation accuracy.
Recent results in [41–44] present some methods to estimate the eigenvector centralities based on nodal data without requiring the network structure. Recall that SimHash algorithm is based on the eigenvector centrality obtained from the target layer. Therefore, estimating eigenvector centrality without constructing network is a good alternative for future work.
The MAP algorithm we present to reconstruct a target layer in a multilayer network shows promising results when we can identify the similarities between the target layer and other layers. The experimental results show that the estimations of our MAP method are less likely to be affected by missing links, which is not known in real applications. Therefore, our MAP method can be used to direct experiments, especially when there is no information about the target layer.
V. ACKNOWLEDGEMENTS
This work has been supported by the National Institutes of Health under Grant No. 1R01AI140760.
Appendix A: tensor factorization
In [7, 13, 14], nodes are factorized by membership vectors. The dimension of membership vectors is interpreted as the number of overlapping communities. In addition, each edge is computed through the tensor product of the membership vectors. The number of communities is obtained by maximizing the likelihood. Vectorization is also used in some natural language processing algorithms [45–49] in which words are embedded as vectors to preserve their relations to contexts. However, the dimension of word vectors does not have any semantic meaning, rather the choice of the vector dimension is first affected by the data set size. According to [46, 49], larger dimensions can improve model accuracy, but the gain diminishes for vectors larger than 200 dimensions. The choice of dimension is also related to the available resources, and it is better to reduce the dimension as long as the choice does not affect the estimation accuracy substantially. In fact, the tensor factorization can be simplified to dot product, we prove this point as follows.
We assume the number of edges between any two nodes is the tensor product of two node vectors and the control matrix, i.e., Eij = Σsiktjlwkl. wkl (k is not equal to l) is the parameter that controls the edges from any source node i (in community k) to any target node j (in community l). Then, we have
| (A1) |
In equation A1, we denote the sum of the first three terms as . Then, we can incorporate wkk into sik, and denote it as . Similarly, . Therefore, we have
| (A2) |
Since nodes between different communities are loosely connected, we have wkl < wkk, and we assume ϵ = wkl/wkk. Then, equation A2 can be written as
| (A3) |
where . For every inter-community edge originating from node i in community k, we can incorporate it into community l by incrementing ϵsik to . Edges can be factorized through the dot product of node vectors. Therefore, the tensor factorization is equivalent to the dot product.
Appendix B: Estimation based on the Pearson correlation
With the SimHash algorithm, the weighted digest of each layer can be obtained. The similarity between any two layers can be measured by computing the Pearson correlation of the weighted digests. In Fig. B.1, we show the estimation results based on the Pearson correlation coefficient. We observe that the estimation is as consistent as the results based on the Hamming distance. Therefore, the correlation can be an alternative for the Hamming distance.
FIG. B.1.
The estimation results based on the Pearson correlation of the weighted digest.
Appendix C: The choice of the number of bits
The choice of ϕ affects the resolution and the consistency of the similarity. If the number of tokens is large, it is recommended to employ large ϕ. In our work, the sizes of the two networks are not too large, so we adopt ϕ = 512 bits. In Fig. C.1, we validate this choice on the FAO network. We set each of the first nine layers of the FAO network as the target network (original network), and randomly remove 20%, 40%, 60% and 80% of edges from the target network to generate incomplete networks. We then compare the incomplete networks with the original network. In the experiments, we adopt ϕ = 16, 64, 256, and 512 digits, respectively. We can observe that the similarities obtained with 256 digits are close to that obtained with 512 digits, while the similarities obtained with 16 and 64 digits vary remarkably.
FIG. C.1.
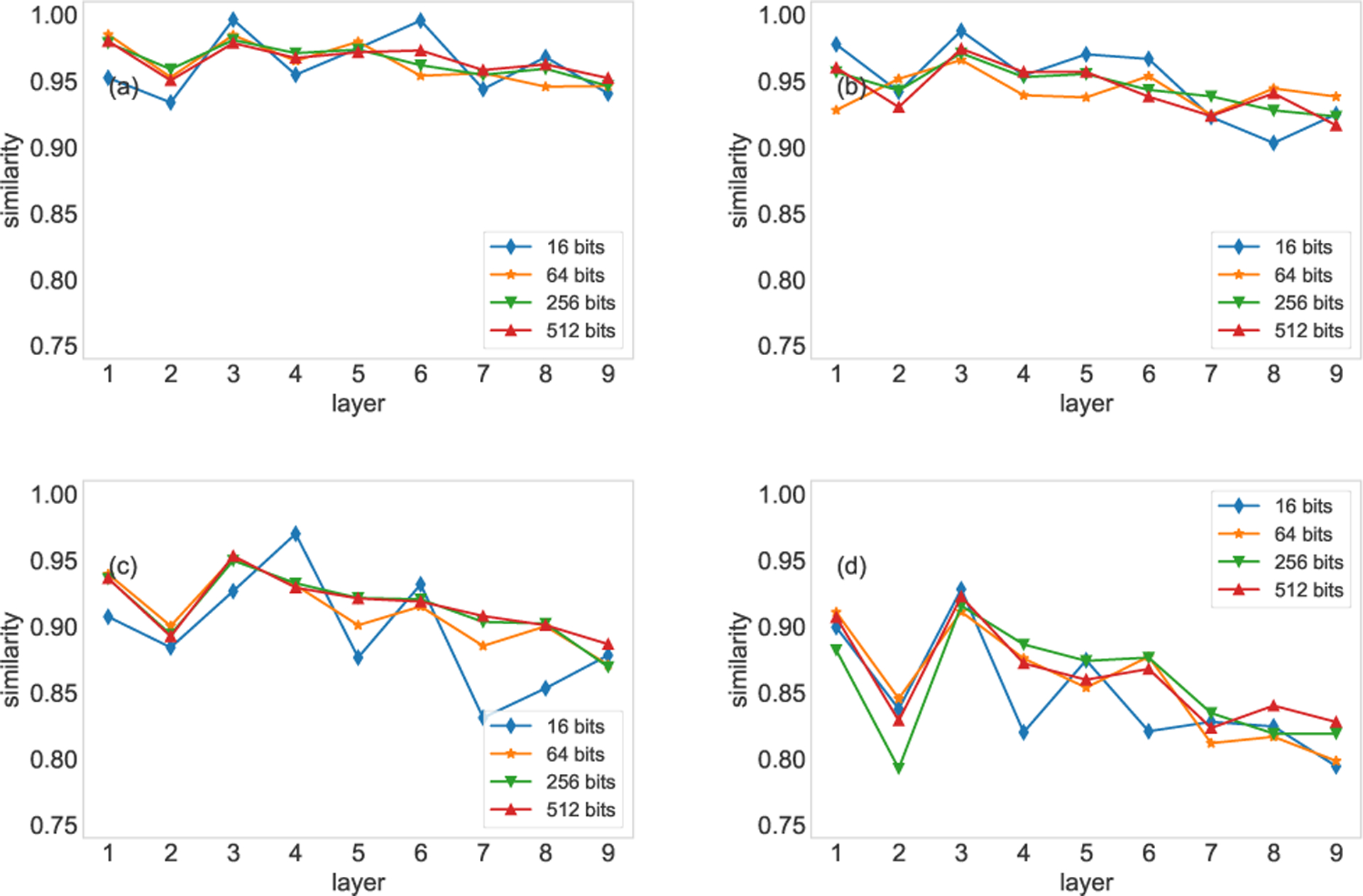
Comparison of varying the number of digits (based on the Hamming distance). The four panels show the results based on 20% (a), 40% (b), 60% (c), and 80% (d) of edges randomly removed.
Appendix D: Comparison between the MLE algorithm and entropy-based approaches
In section III B, we compared the MAP algorithm with the MLE algorithm. In fact, the entropy-based approaches are equivalent to the MLE algorithm. In the following, we prove that the MLE algorithm is equivalent to the entropy-based approaches.
Given a network G, we assume the number of nodes is fixed, and the edge weights are variables. Thus, we can define the entropy of a network in terms of edge weights as
| (D1) |
where U is any edge in the network G, u is the weight of edge U. pU(u) is the precise probability of edge U with weight u. We assume for any edge U, it can take nU values. If the nU values follow uniform distribution, then we have . In this case, the network has the largest entropy, which means the network is totally uncertain. On the other hand, for any edge U, if there is a value us with pU(us) = 1, the entropy of the network will be zero, which indicates all the edge weights in the network are known.
In our problem, the goal is to find a model to reconstruct the target layer, thus, we need a set of parameters to describe the model. If the model is close to the true network, the entropy of the model is minimized. Hence, the problem is transformed to finding the parameters of a model with minimum entropy, i.e., reducing uncertainty.
Equation D1 can be written in expectation form
| (D2) |
Consider the Kullback-Leibler divergence (KL divergence). We assume θ is the parameter set that can describe the model, the probability of edge U with weight u is qU(u; θ). Thus, the relative entropy is
| (D3) |
The second term in the right-hand side is equation D2 and the first term in the right-hand side is the cross entropy, which is
| (D4) |
Recall that our problem is to reconstruct the target layer and equation D2 is the entropy of the target layer. Equation D2 is determined by the data (network) solely. Thus, the problem can be simplified to minimizing the cross entropy, i.e., minimizing equation D4.
Then, we consider the MLE method. The MLE algorithm is to find the parameter set θ that most likely fit a given set of data (network) D. We skip some intermediate steps and use the logarithm form directly as following
| (D5) |
pU(u; θ) is the model with parameter set θ to describe the true data D. We assume that edge U can take nU values and the nU values follow the uniform distribution, then we have . Introducing to equation D5 does not change the results, we have
| (D6) |
Our goal is still to find a set of parameters that can reconstruct the layer. Then, we can generalize this problem by replacing with pU(u), and replacing pU(u; θ) with qU(u; θ). The replacements can be regarded as taking real data (network) into equation D7. We have
| (D7) |
Thus, the MLE algorithm is equivalent to minimizing the cross entropy.
Appendix E: The number of similar layers on the estimation accuracy
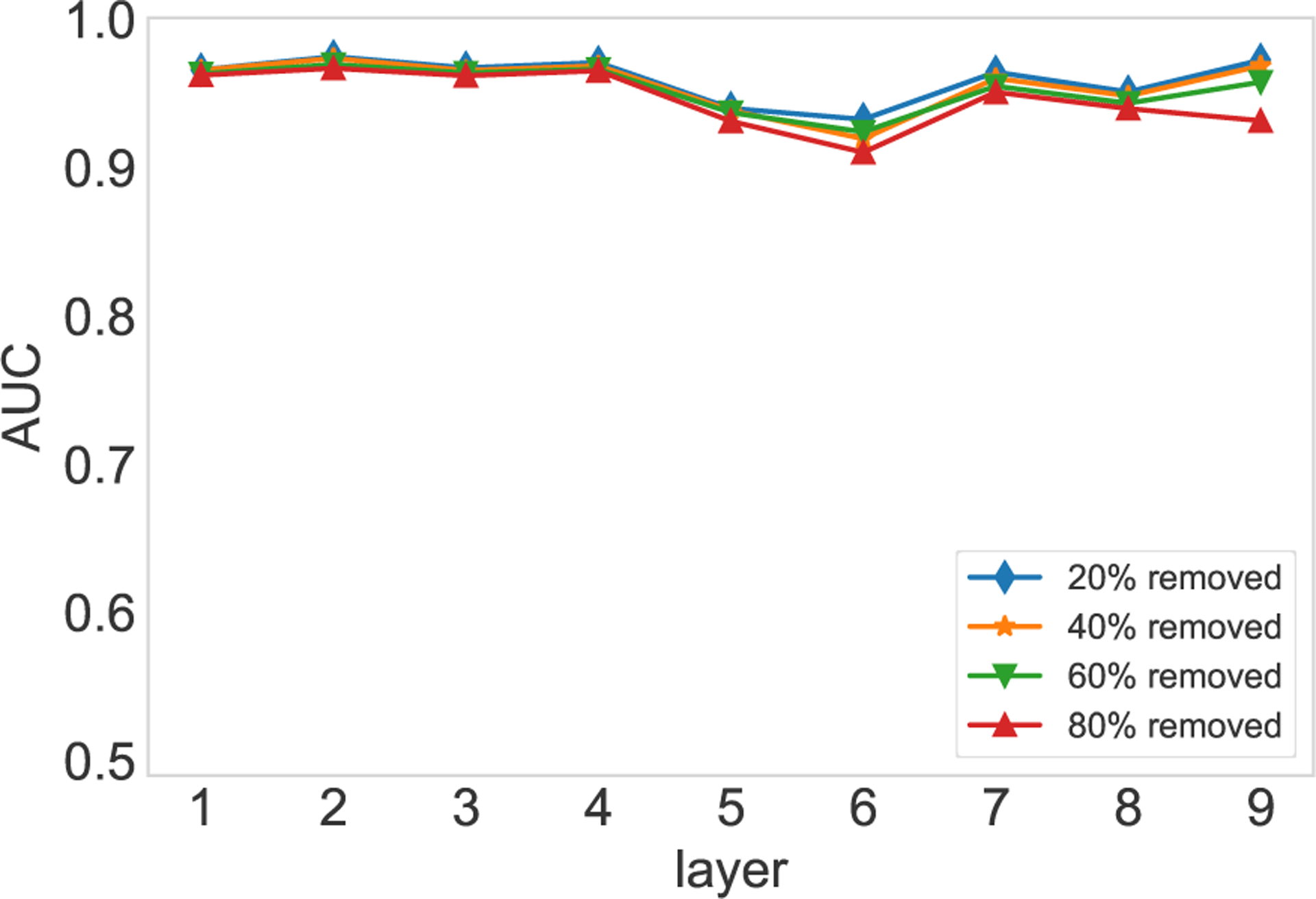
If more similar layers are employed to compute the parameters of the conjugate prior, the influence of similar layers on the reconstruction will be promoted. Consequently, the influence of the known part of the target layer will be down weighted. On the contrary, if we trust the known part of the target layer, we can employ less similar layers to compute the parameters of the conjugate prior. The experimental results are shown in Fig. E.1, top 3, 5, 10, and 20 similar layers are adopted to compute the parameters of the conjugate prior. We observe that the estimation based on 10 and 20 similar layers are robust with respect to the missing links, while the estimation based on three and five similar layers are influenced by the missing links significantly.
FIG. E.1.
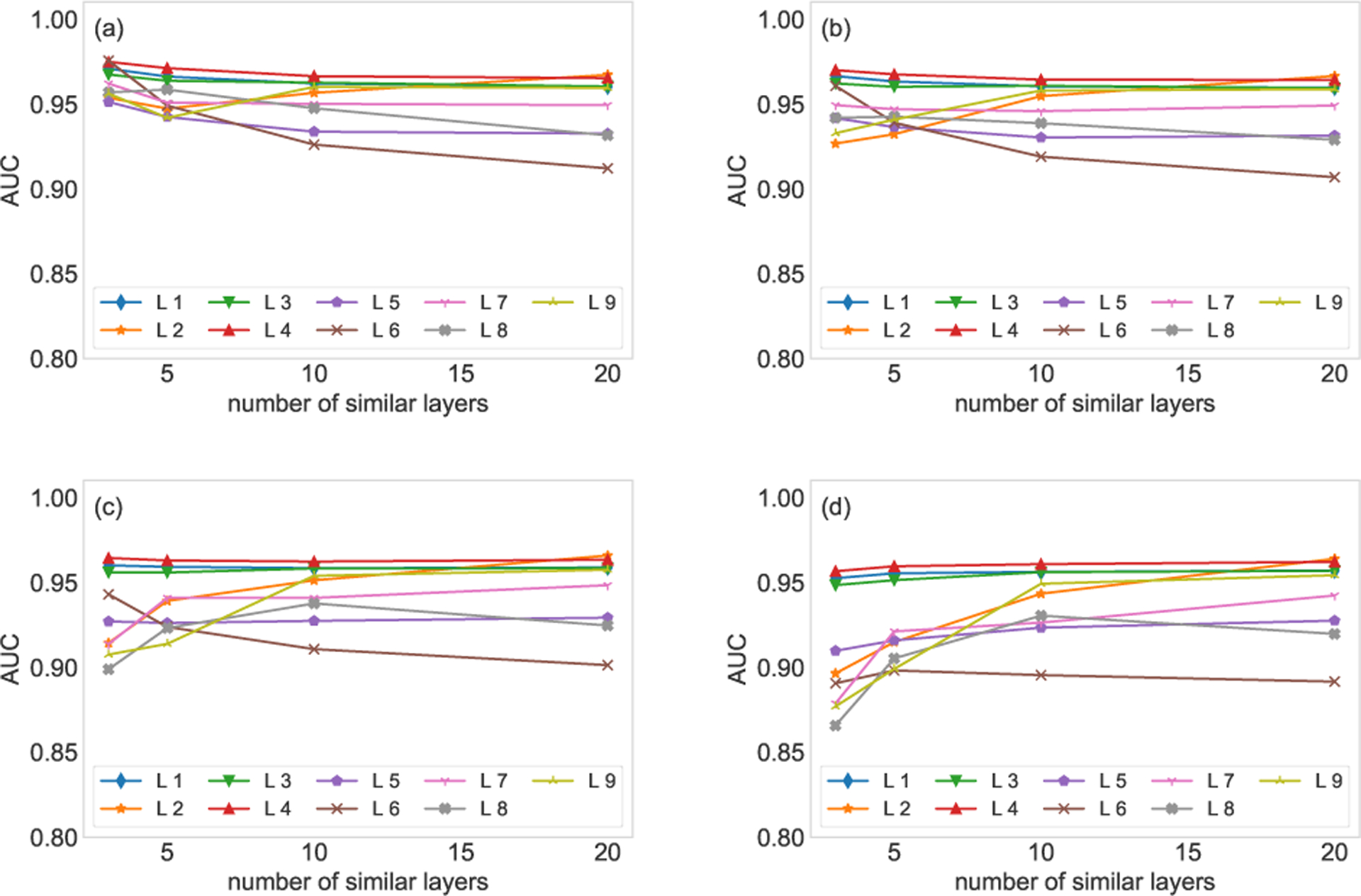
The number of similar layers on the estimation results. 20% (a), 40% (b), 60% (c), and 80% (d) of edges are randomly removed from the target layer. Different numbers of similar layers are used to compute the parameters of the conjugate prior. The experiments are conducted on the first nine layers of the FAO network. Each AUC is averaged over 10 runs of cross-validations.
References
- [1].Yang Q, Gruenbacher D, Heier Stamm JL, Brase GL, DeLoach SA, Amrine DE, and Scoglio C, Physica A. 526, 120856 (2019). [Google Scholar]
- [2].Yang Q, Gruenbacher D, Heier Stamm JL, Brase GL, DeLoach SA, Amrine DE, and Scoglio C, PLoS ONE 15, e0240819 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Gysi DM, Valle ÍD, Zitnik M, Ameli A, Gan X, Varol O, Sanchez H, Baron RM, Ghiassian D, Loscalzo J et al. , arXiv:2004.07229 [Google Scholar]
- [4].Boccaletti S, Bianconi G, Criado R, del Genio CI, Gómez-Gardeñes J, and Romance M, Phys Rep. 544, 1 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Kivela M, Arenas A, Barthelemy M, Gleeson JP, Moreno Y, and Porter MA, J Complex Networks. 2, 203 (2014) [Google Scholar]
- [6].Guimera R and Sales-Pardo M, Proc. Natl. Acad. Sci. U.S.A 106, 22073 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].De Bacco C, Power EA, Larremore DB, and Moore C, Phys. Rev. E 95, 042317 (2017). [DOI] [PubMed] [Google Scholar]
- [8].van Dam S, Vosa U, van der Graaf A, Franke L, and de Magalhaes JP, Briefings in bioinformatics, 19, 575 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Liesecke F, De Craene JO, Besseau S, Courdavault V, Clastre M, Vergès V, Papon N, Giglioli-Guivarc’h N, Glévarec G, Pichon O et al. , Sci rep. 9, 14431 (2019) [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Alfredo B, Alessandro I, and Paola MA, J. R. Soc. Interface 16, 20180844 (2019).30958195 [Google Scholar]
- [11].Han X, Shen Z, Wang WX, and Di Z, Phys. Rev. Lett 114, 028701 (2015). [DOI] [PubMed] [Google Scholar]
- [12].Prasse B and Van Mieghem P, arXiv:1807.08630 [Google Scholar]
- [13].Karrer B and Newman ME, Phys. Rev. E 83, 016107 (2011) [DOI] [PubMed] [Google Scholar]
- [14].Ball B, Karrer B, and Newman ME, Phys. Rev. E 84, 036103 (2011) [DOI] [PubMed] [Google Scholar]
- [15].Newman ME, Nature Phys. 14, 6 (2018). [Google Scholar]
- [16].Peixoto TP, Phys. Rev. Lett 123, 128301 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Peixoto TP, Phys. Rev. X 8, 041011 (2018). [Google Scholar]
- [18].Newman ME and Leicht EA, Proc. Natl. Acad. Sci. USA 104, 9564 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Newman ME, Phys. Rev. E 98, 062321 (2018). [Google Scholar]
- [20].Van Mieghem P and Liu Q, Phys. Rev. E 100, 022317 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Peixoto TP, arXiv:1705.10225 [Google Scholar]
- [22].Parisi F, Caldarelli G, and Squartini T, Appl. Netw. Sci 3, 17 (2018) [Google Scholar]
- [23].Yin L, Zheng H,Bian T, and Deng Y, Physica A. 482, 15 (2017) [Google Scholar]
- [24].Kumar A, Singh SS, Singh K, and Biswas B, Physica A. 553, 1 (2020) [Google Scholar]
- [25].Peixoto TP, Phys. Rev. E 97, 012306 (2018). [DOI] [PubMed] [Google Scholar]
- [26].Costenbader E and Valente TW, Social networks, 25, 4 (2003). [Google Scholar]
- [27].Koutra D, Shah N, Vogelstein JT, Gallagher B, and Faloutsos C, ACM Trans. Knowl. Discov. Data 10, 28 (2016). [Google Scholar]
- [28].Tantardini M, Ieva F, Tajoli L, and Piccardi C, Sci Rep 9, 17557 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Papadimitriou P, Dasdan A, and Garcia-Molina H, J. Internet Serv. Appl 1, 1 (2010). [Google Scholar]
- [30].Charikar M, In Proceedings of the thiry-fourth annual ACM symposium on Theory of computing.(ACM, New York, 2002), pp:380–388. [Google Scholar]
- [31].Page L, Brin S, Motwani R, and Winograd T, Stanford InfoLab. (1999) [Google Scholar]
- [32].Wu MCK, Deniz F, Prenger RJ, and Gallant JL, arXiv:1811.01043 [Google Scholar]
- [33].De Domenico M, Nicosia V, Arenas A, and Latora V, Nature comms. 6, 6864 (2015). [DOI] [PubMed] [Google Scholar]
- [34].Chen VB, Davis IW, and Richardson DC, Protein Sci. 18, 2403 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Larremore DB, Clauset A, and Buckee CO, PLoS Comput Biol. 9, e1003268 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Blondel VD, Guillaume JL, Lambiotte R, and Lefebvre E, J. Stat. Mech P10008 (2008). [Google Scholar]
- [37].Fortunato S and Hric D, Phys. Rep 659, 1 (2016). [Google Scholar]
- [38].Newman MEJ, Phys. Rev. E 74, 036104 (2006). [Google Scholar]
- [39].Girvan M and Newman ME, Proc. Natl. Acad. Sci. USA 99, 7821 (2002). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Clauset A, Moore C, and Newman ME, Nature 453, 98 (2008) [DOI] [PubMed] [Google Scholar]
- [41].Roddenberry TM and Segarra S, 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020 [Google Scholar]
- [42].Roddenberry TM and Segarra S, arXiv:2005.00659 [Google Scholar]
- [43].Ruggeri N and De Bacco C, Appl Netw Sci 5, 81 (2020) [Google Scholar]
- [44].Ruggeri N and De Bacco C, In International Conference on Complex Networks and Their Applications (2019) [Google Scholar]
- [45].Devlin J, Chang M, Lee K, and Toutanova K, ArXiv:1810.04805 [Google Scholar]
- [46].Pennington J, Socher R, and Manning CD, conference on empirical methods in natural language processing (EMNLP). (2014) [Google Scholar]
- [47].Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, and Zettlemoyer L, ArXiv:1802.05365 [Google Scholar]
- [48].Xin R, ArXiv:1411.2738 [Google Scholar]
- [49].Mikolov T, Sutskever I, Chen K, Corrado G, and Dean J, ArXiv:1310.4546 [Google Scholar]