

Abstract
Purpose:
In current clinical practice, noisy and artifact-ridden weekly cone-beam computed tomography (CBCT) images are only used for patient setup during radiotherapy. Treatment planning is done once at the beginning of the treatment using high-quality planning CT (pCT) images and manual contours for organs-at-risk (OARs) structures. If the quality of the weekly CBCT images can be improved while simultaneously segmenting OAR structures, this can provide critical information for adapting radiotherapy mid-treatment as well as for deriving biomarkers for treatment response.
Methods:
Using a novel physics-based data augmentation strategy, we synthesize a large dataset of perfectly/inherently registered planning CT and synthetic-CBCT pairs for locally advanced lung cancer patient cohort, which are then used in a multitask 3D deep learning framework to simultaneously segment and translate real weekly CBCT images to high-quality planning CT-like images.
Results:
We compared the synthetic CT and OAR segmentations generated by the model to real planning CT and manual OAR segmentations and showed promising results. The real week 1 (baseline) CBCT images which had an average MAE of 162.77 HU compared to pCT images are translated to synthetic CT images that exhibit a drastically improved average MAE of 29.31 HU and average structural similarity of 92% with the pCT images. The average DICE scores of the 3D organs-at-risk segmentations are: lungs 0.96, heart 0.88, spinal cord 0.83 and esophagus 0.66.
Conclusions:
We demonstrate an approach to translate artifact-ridden CBCT images to high quality synthetic CT images while simultaneously generating good quality segmentation masks for different organs-at-risk. This approach could allow clinicians to adjust treatment plans using only the routine low-quality CBCT images, potentially improving patient outcomes. Our code, data, and pre-trained models will be made available via our physics-based data augmentation library, Physics-ArX, at https://github.com/nadeemlab/Physics-ArX.
Keywords: 3D CBCT-to-CT translation, organs-at-risk segmentation
1. Introduction
In image-guided radiotherapy [1, 2] for lung cancer treatment, weekly cone-beam computed tomography (CBCT) images are primarily used for patient setup. At the start of treatment, high quality planning computed tomography (pCT) images are acquired for treatment planning purposes. Tumors and major organs-at-risk (OARs) are manually delineated by a trained radiation oncologist using the pCT images. During the treatment phase, weekly/daily low-quality CBCT images are acquired for patient setup and qualitative visual assessment of tumor and critical OARs. A variety of scattering and noise artifacts [3] render CBCT images unsuitable for quantitative analysis (e.g., it is much harder to manually delineate OARs in CBCT images due to low soft tissue contrast).
Several attempts have been made to quantify CBCT images in radiotherapy (RT) using both model-based methods [4, 5, 6] as well as the more recent deep learning based methods [7, 8]. CBCT imaging suffers from several types of artifacts and these methods focus on the correction of only a particular type of artifacts such as either beam hardening [9, 10], scattering [5], metal artifacts [6], or cupping [11]. Instead of trying to fix particular noise artifacts in CBCT images, a more recent line of research using deep learning methods attempts to directly generate higher-quality synthetic CT (sCT) from CBCT images. One particular approach is to use cycle-consistent generative adversarial networks [12] (CycleGAN) to generate sCT from CBCT images [13, 14]. CycleGANs and other unsupervised image-to-image translation methods using unpaired CT and CBCT images can easily produce randomized outputs or in other words, hallucinate anatomy [15].
A supervised learning based method, sCTU-net [16], used a 2D Unet [17] architecture to translate CBCT to sCT images. In addition to 2D slices of weekly CBCT images, it also feeds the corresponding pCT slice to the network and uses a combination of mean absolute error and structural similarity index loss to train the network. It utilizes hand-crafted loss function which makes it difficult to enhance this method for a multitask setting of simultaneous CBCT-to-CT translation and OARs segmentation. This is due to the fact that addition of a loss term for segmentation may cause destructive gradient interference during back-propagation. Another recent approach [18] combined the architecture of a GAN designed to deblur images [19] with the CycleGAN architecture [12] to translate chest CBCT images to synthetic CT images. The authors showed better results compared to CycleGAN alone [20] as well as to a residual encoder-decoder convolution neural network (RED-CNN) [21], designed to reduce noise in low-dose CT images. Another method designed for segmenting prostate CBCT images [22] trained a CycleGAN model using aligned CBCT and MRI pairs to translate prostate CBCT images to synthetic MRI (sMRI) images. Afterwards it used two different Unet models to extract features from the CBCT and sMRI images respectively, combined the features using attention gates and finally predicted multi-organ prostate segmentations using a CNN network. A recent paper [23] studied generalizability issues in deep learning based models in applying a model trained on a particular dataset to another different dataset. The authors investigated how a model trained for one machine and one anatomical site works on other machines and other anatomical sites for the task of CBCT to CT translation. The paper also explored solutions for the generalizability issues using the transfer learning approach.
In this paper, we use a supervised image-to-image translation method based on conditional generative adversarial networks [24] (cGANs), to translate CBCT to sCT images while also performing OAR segmentation driven by a novel physics-based artifact/noise-induction [25] data augmentation pipeline. A particular single-task 2D implementation of cGANs called pix2pix [26] is a generic image translation approach which obviates the need for hand-engineered loss functions and unlike CycleGANs does not produce randomized outputs. The physics-based data augmentation technique creates multiple perfectly paired/registered pseudo-CBCTs (psCBCTs) corresponding to a single planning CT. Combined with geometric data augmentation techniques, this non-deep learning strategy allows us to generate several perfectly registered pCT/CBCT/OARs pairs from a single pCT. This makes it possible for us to train a multi-task 3D cGAN based model inspired by pix2pix for the joint task of CBCT to sCT translation and OARs segmentation without the risk of over-fitting. To further improve our results, we used our psCBCT generation technique on an open source dataset used in American Association of Physicists in Medicine (AAPM) thoracic auto-segmentation grand challenge [27]. We converted the AAPM planning CT and OAR segmentation dataset consisting of 60 cases to an augmented psCBCT dataset using artifacts extracted from one of our internal CBCT images and used it to further augment our training data that resulted in better segmentation and translation performance.
2. Materials and Method
2.1. Input Data
We use a novel physics-based artifact induction technique to generate a large dataset of perfectly-paired/registered pseudo CBCTs (psCBCTs) and corresponding planning CTs (pCTs)/organs-at-risk (OARs) segmentations. A variety of CBCT artifacts are extracted from real week 1 (baseline) CBCTs and mapped to corresponding pCTs to generate psCBCTs. The generated psCBCTs have similar artifacts distribution as the clinical CBCT images and include all the physics-based aspects of diagnostic imaging i.e. scatter, noise, beam hardening, and motion. This data augmentation technique creates multiple paired/registered psCBCTs corresponding to a single planning CT. Figure 1 shows our entire workflow for generating multiple perfectly paired psCBCT variations from a single pair of deformably registered week1 CBCT and pCT pair.
Figure 1.

Entire workflow of generating different variations of perfectly paired pseudo CBCT variations from single deformable registered planning CT and week1 CBCT pair. The generated data is used to train a multitask 3D model to generate synthetic CT and OAR segmentations. The trained model is tested on real weekly CBCT data.
2.1.1. Image Dataset
We used the data from a study which included 95 locally advanced non-small cell lung cancer patients treated via intensity-modulated RT and concurrent chemotherapy. All patients had high-quality planning CT and 5/6 weekly CBCTs; all CTs were 3D scans acquired under free-breathing conditions. The pCT and wCBCT resolutions were 1.17 × 1.17 × 3.0 mm3 and 0.98 × 0.98 × 3.0 mm3 respectively. OARs including, esophagus, spinal cord, heart and lungs were delineated by an experienced radiation oncologist according to anatomical atlases of organs-at-risk [28]. This data formed the basis for generating synthetic artifact-induced psCBCTs which in turn was used to train our multitask cGAN model.
2.1.2. Pseudo-CBCT Dataset
To facilitate extraction of CBCT artifacts, week1 baseline CBCTs were deformably registered to their pCTs using a BSpline regularized diffeomorphic image registration [29] technique. Since the pCT and baseline week1 CBCT images are acquired on the same day or have few days’ difference, the registration artifact mapping accuracy is least susceptible to uncertainties. After image registration, scatter/noise artifacts were extracted from the week1 CBCT using power-law adaptive histogram equalization (PL-AHE) [30] that contained the highest to the smoothest frequency components. Different combinations of the parameters of PL-AHE method were used to extract artifacts covering a large range of frequency components. The extracted CBCT artifacts were added to the corresponding pCT and intensities were scaled to [0, 1]. Then, 2D x-ray projections were generated from the artifact-induced pCTs using the 3D texture memory linear interpolation of the integrated sinograms. The projections with added gaussian noise were reconstructed using iterative Ordered-Subset Simultaneous Algebraic Reconstruction Technique (OSSART) [31], to generate psCBCTs. Finally, we also used geometric data augmentations including, scale (1.2)/shear (8 degree), and scale (0.8)/rotate (5 degree). Using this combination of physics-based artifact induction and geometric data augmentations, we can convert a single pCT/week1 CBCT pair into 17 perfectly registered pCT/psCBCT/OAR pairs. Figure 2 shows an example of five different psCBCT variations generated from a single deformably registered week 1 CBCT and pCT pair.
Figure 2.

Example result of the physics-based psCBCT generation process. Left two columns show several slices of deformably registered pCT and real week 1 CBCT images. The next 5 columns show the corresponding slices of five different variations of psCBCT images generated by transferring artifacts/noise from week 1 CBCT to pCT and reconstructing using OS-SART technique. The five different variations correspond to different parameters in the power-law adaptive histogram equalization (PL-AHE) technique. The OAR masks manually segmented on pCT images are perfectly paired to all different psCBCT variations as well.
2.2. Deep Learning Setup
In this paper, we use the general purpose framework of Image-to-Image translation with Conditional Adversarial Networks (pix2pix) for the joint task of CBCT-to-CT translation and OARs segmentation.
2.2.1. Conditional Generative Adversarial Networks (cGANs)
Conditional GANs (cGANs) generate an output conditioned on an input. In cGANs, both the generator and discriminator models are conditioned on ground truth labels or images. More formally, GANs learn a mapping, G : z → y, where z is a random noise vector and y is the output. Conditional GANs, on the other hand, learn a mapping, G : {x, z} → y, where x is an observed image. So, cGANs learn the mapping conditioned on the input. The generator G is trained to produce real looking outputs which cannot be distinguished, from real images, by an adversarially trained discriminator network D. This process can be captured by the following loss function:
| (1) |
where the generator network G tries to minimize this objective against the adversarial network D that tries to maximize it, i.e.
| (2) |
Along with this cGAN loss, an L1 loss is also used on the generator. The generator is tasked to not only fool the discriminator but also produce outputs that are near the input in an L1 sense.
| (3) |
The final combined objective function is given as:
| (4) |
where λ is a tunable hyperparameter to balance the two loss components. We customize the cGAN framework to translate input 3D psCBCT images to artifact-free 3D synthetic-CT images along with the corresponding OARs segmentation. In our case, the generator takes a 3D psCBCT image (X : 1283) as input and outputs a two channel 3D image (Ŷ : 1283, 2) where the channels are composed of sCT and segmented OARs for a given input. Ideally, this output, Ŷ, would be indistinguishable from the ground truth (Y : 1283, 2), which is the real planning CT and OAR pair concatenated in the channel axis. We want the anatomy in sCT and OARs to correspond to a particular input (psCBCT). This is why we use cGANs which generate new output sample conditioned on the input instead of a random noise vector. Since the output is dependent on a particular input, the input psCBCT image is concatenated once with the corresponding ground truth pCT and OAR contours creating the real sample (R : 1283, 3) and once with the generated sCT and OAR contours to create the fake sample (F : 1283, 3). The real and fake samples are input to the discriminator model which predicts how real each input appears (D(R) and D(F)). The weights of the generator and discriminator models are then updated using back-propagation based on the loss functions LG and LD such that the generator produces outputs that match the ground truth inputs leading to the discriminator failing to distinguish between real and fake samples. Instead of the typical loss function for LG and LD, we use a more robust least-squares (LSGAN) [32] variation:
| (5) |
| (6) |
2.2.2. Generator/Discriminator Architecture
The generator network follows a common encoder-decoder style architecture which is composed of a series of layers which progressively downsample the input (encoder), until a bottleneck layer, where the process is reversed (decoder). Additionally, Unet-like skip connections are added between corresponding layers of encoder and decoder. This is done to share low-level information between the encoder and decoder counterparts.
The generator (Fig. 3 bottom) uses combinations of Convolution-BatchNorm-ReLU and Convolution-BatchNorm-Dropout-ReLU layers with some exceptions. Batchnorm is not used in the first layer of encoder and all ReLU units in the encoder are leaky with slope of 0.2 while the decoder uses regular ReLU units. Whenever dropout is present, a dropout rate of 50% is used. All the convolutions in the encoder and deconvolutions (transposed convolutions) in decoder are 4×4×4 3D spatial filters with a stride of 2 in all 3 directions. The convolutions downsample by 2 in the encoder and deconvolutions upsample by 2 in the decoder. Note that, this eliminates the need for separate downsampling or upsampling layers and allows the model to learn up/down sampling functions. The last layer in the decoder maps its input to a two channel output (1283, 2) followed by a Tanh non-linearity.
Figure 3.
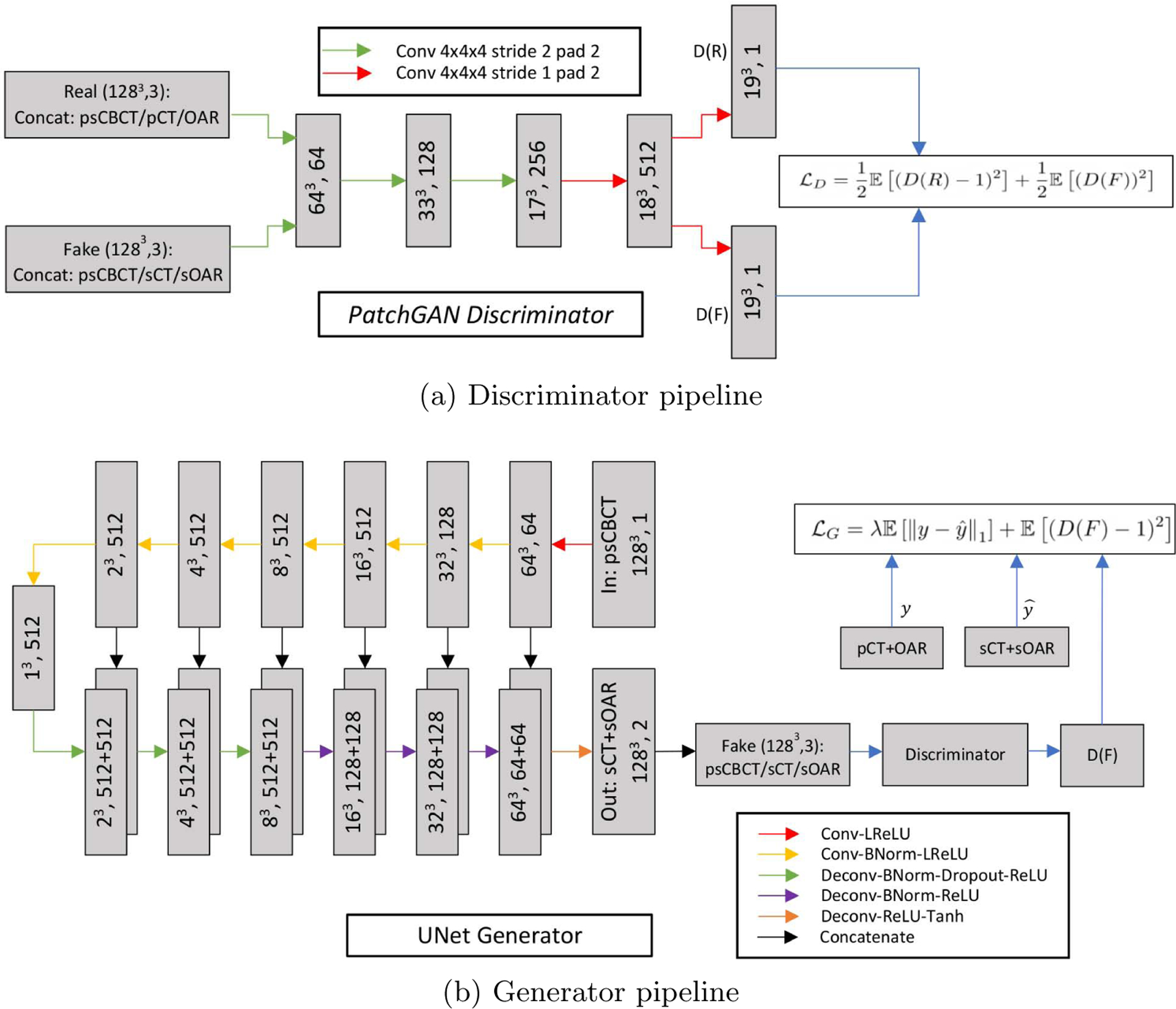
(a) 70×70×70 patchGAN Discriminator architecture and (b) Unet-like Generator architecture.
A discriminator network (Fig. 3 top) termed PatchGAN [33] is used that only penalizes structure at the scale of patches. It is run convolutionally across the input image and tries to classify if each 70×70×70 input image patch1 (3D) is real or fake. All the patch responses are averaged to provide the final output of discriminator D. The input to the discriminator can be either the real or fake images. The real input is obtained by concatenating the input psCBCT with CT and OAR images along the channel axis while the fake input is obtained by concatenating the input psCBCT with the translated sCT/sOAR pair output by the generator network. The discriminator’s job is to tell apart the real or fake inputs. All ReLUs in the discriminator are leaky, with slope 0.2 and similar to the generator network, batch norm is not applied to the first convolution layer.
2.2.3. Input Preprocessing
The input psCBCT and CT images are in the range [−1000, 3095]. In deep learning methods, for faster convergence and numerical stability, input images are generally converted to the range [0, 1]. The generator applies a Tanh function (range [−1, 1]) to produce its final output. Hence, we apply the following mapping to all our input CT/CBCT images to convert them to [−1, 1] range:
| (7) |
We combine the binary RT structure labels for different organs into a single multi-label image with labels: Background = 0, Lungs = 1, Heart = 2, Spinal cord = 3 and Esophagus = 4. We then apply the following transformation to make the multi-label image to have [−1, 1] range:
| (8) |
We deformably register week 1 CBCT (target) to its full FOV pCT (reference) to make sure corresponding OAR structures are well aligned. Then we crop the pCT according to the overlapped FOV. Finally, the images are resized to an isotropic dimension of 128 × 128 × 128. The dataset is split into 80 training and 15 testing images. The training set is further divided into 60 training and 20 validation images leading to a 60/20/15(train/valid/test) split. We test various settings on this 60/20 split and after all optimization and thorough experimentation, we train our final models on the 80 images (training + validation), and report the results on the week1 CBCT images in the remaining testing split of 15 images. We use our data augmentation pipeline (physics-based artifact induction + geometric augmentations) to convert the 80 training images into 1360 3D training images. To further improve our results, we later converted the 60 AAPM pCT/OAR cases to 732 psCBCT datasets and added to our training set. Since the streak/scatter artifacts are random, we experimentally chose a CBCT case from our internal dataset and added its different types of extracted artifacts to each AAPM CT cases. The artifact images were first deformably registered to each case to align them into the same coordinate system (same origin, voxel size, dimension, etc). Then we simply perform a pixelwise addition of the CTs and artifact-only images in the overlapped area (numeric conversion [casting] is done to make sure they have same pixel type). Then, the resulting artifact-induced CT intensities are rescaled to [0,1]. Eventually x-ray projections were generated from the intensity rescaled artifact-induced CTs and reconstructed using OS-SART technique to produce synthetic-CBCTs for the entire AAPM dataset.
2.2.4. Settings
In our experiments, used to report the final results, we use Stochastic Gradient Descent (SGD), with a batch size of 1, and Adam optimizer [34] with an initial learning rate of 0.0002, and momentum parameters β1 = 0.5, β2 = 0.999. We train the network for total of 100 epochs. We use a constant learning rate of 0.0002 for the first 50 epochs and then let the learning rate linearly decay to 0 for the final 50 epochs. We use λ = 100, as a balancing factor between cGAN and L1 losses.
A common problem in using GAN based methods, especially for image segmentation (discrete label generation) tasks, is that the discriminator can differentiate between real and fake outputs very easily. This leads to severe instability in training the networks. We use a combination of several strategies [35, 36] to overcome this issue. We use label smoothing whereby instead of using 0/1 to represent fake/real samples, we use random numbers between 0 to 0.3 for fake labels and between 0.7 to 1.2 for real labels. We also use the strategy of confusing the discriminator by randomly exchanging the real and fake images before passing to the discriminator. During the optimization phase, we exchange real and fake images with a probability of 10%. Finally, we inject noise to the input of the discriminator by adding zero mean gaussian noise to the real/fake images before feeding to the discriminator. This noise is annealed linearly over the course of training, starting with a variance of 0.2 it goes linearly down to 0 at the final epoch of training. This leads to stabilization of the training process with better gradient back-propagation.
2.2.5. Model implementation and training
We created the implementations of the multi-task 3D Unet-like generator, patchGAN discriminator, L1 and cGAN loss functions, GAN stabilizing techniques and all other related training/testing scripts in pytorch and we conducted all our experiments on a Nvidia RTX 2080 Ti GPU with 11 GB VRAM.
3. Results
3.1. Qualitative results
Figure 4 shows planning CT, registered week 1 CBCT and our synthetic CT output along with the corresponding OARs for one of the test images. The week 1 CBCT translation to synthetic CT brings the intensity-value histogram closer to planning CT images, showing that the trained model has learnt to remove the CBCT scatter/noise artifacts. We can however also note that, the generated sCT image has somewhat less contrast than the real CT image. We believe this is due to smoothing effect of the L1 loss. We can also see the slight smoothing effect of the translation process in the planning CT/synthetic CT histogram: real CT has two distinct peaks which are somewhat averaged into a single peak in the translated CT. Finally, we show an example 5 of synthetic CTs and OARs generated for real week 1 to week 6 CBCT images.
Figure 4.
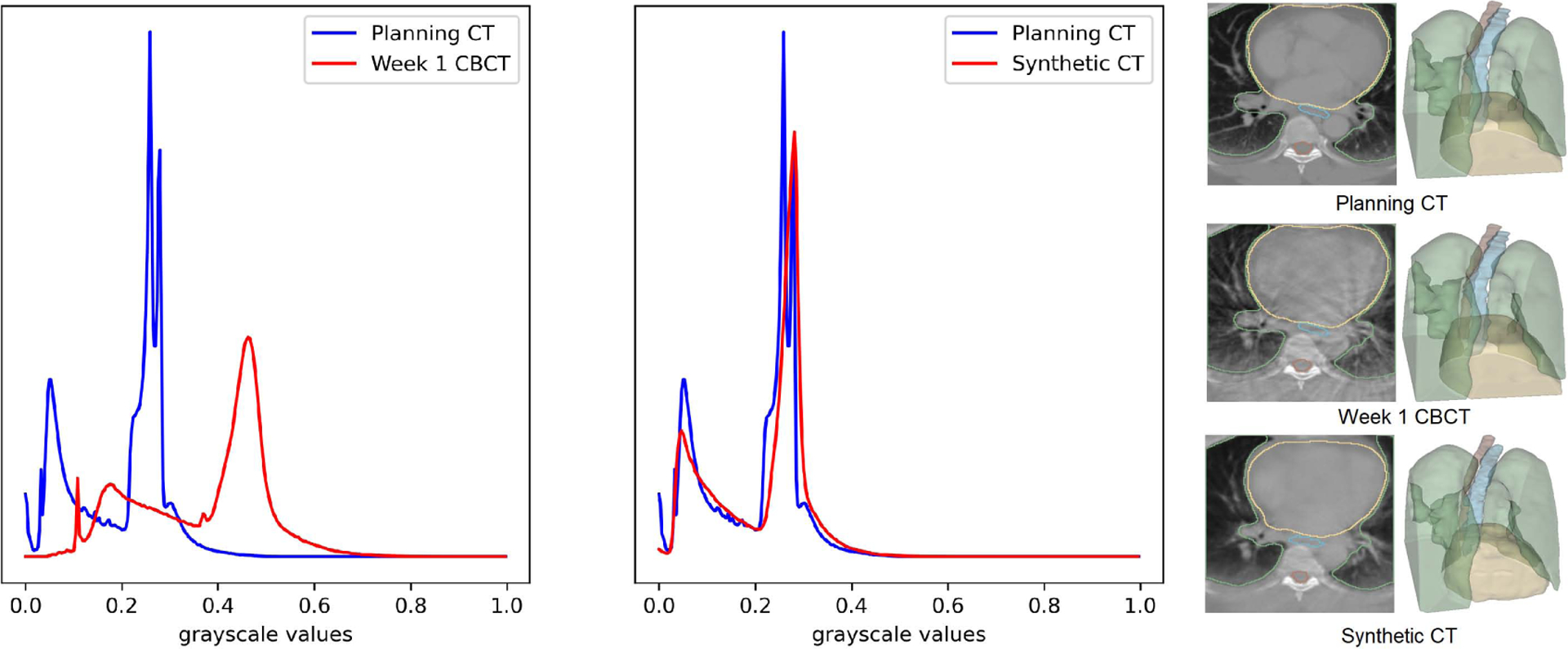
Planning CT, week 1 CBCT, the generated synthetic CTs and the corresponding OARs. The histogram of the synthetic CT is clearly aligned with planning CT compared to Week 1 CBCT.
3.2. Quantitative results
We used mean structural similarity index measure (MSSIM), mean absolute error (MAE), root mean square error (RMSE) and peak signal-to-noise ratio (PSNR) criteria to measure the similarity of the generated sCT (from real week 1 CBCT) with pCT images; MAE and RMSE is reported in CT Hounsfield Units (HU). The metrics are reported in Table 1. As shown, the addition of publicly available AAPM data augmented with our physics-based technique to our training improved the results for both translation and segmentation tasks. Without GAN stabilizing techniques poor results are obtained for both the tasks.
Table 1:
Evaluation criteria for comparing quality of generated sCT with the real CT compared to the input real week 1 CBCT. Mean absolute error and RMSE are given in CT Hounsfield Units (HU) with respect to pCT values. msk and aapm refers to our internal data and the physics-augmented AAPM challenge data. eso1 refers to experiments where esophagus was labeled 1 and eso4 to the experiment where the labels were flipped and esophagus was labeled 4. The stabilized version with GAN stabilization techniques added to the optimization phase produces better results compared to the unstabilized version.
| Modality/Settings | MSSIM | MAE (HU) | PSNR (dB) | RMSE (HU) |
|---|---|---|---|---|
| mean ± std | mean ± std | mean ± std | mean ± std | |
| w1CBCT | 0.73 ± 0.07 | 162.77 ± 53.91 | 22.24 ± 2.40 | 328.18 ± 84.65 |
| sCT (msk+aapm+stabilized+eso4) | 0.92 ± 0.01 | 29.31 ± 12.64 | 34.69 ± 2.41 | 78.62 ± 24.22 |
| sCT (msk+aapm+unstabilized+eso4) | 0.88 ± 0.02 | 39.19 ± 19.95 | 32.89 ± 3.08 | 99.15 ± 38.32 |
| sCT (msk+stabilized+eso4) | 0.91 ± 0.02 | 40.06 ± 22.72 | 32.93 ± 3.39 | 100.03 ± 41.57 |
| sCT (msk+aapm+stabilized+eso1) | 0.90 ± 0.02 | 43.57 ± 22.72 | 32.80 ± 3.79 | 102.84 ± 42.93 |
To measure the accuracy of the generated organs-at-risk segmentations, we computed DICE coefficient, mean surface distance (MSD) and 95% Hausdorff distance (HD95), shown in Table 2. The heart, lungs, and spinal cord segmentation results are close to the state-of-the-art [27]. Esophagus is the most challenging of the OAR structures given the thin tubular structure. Addition of the physics-augmented AAPM data helped improve segmentation of esophagus with the DICE increasing from 0.63 to 0.66. A key element in improving the segmentation results, particularly for spinal cord and esophagus turned out to be the numerical labels used for different anatomies. In one experiment, we used the labels 1,2,3,4 (eso1) for esophagus, spinal cord, heart and lungs respectively, and in another we flipped the order to 4,3,2,1 (eso4). The order with higher label values for esophagus and spinal cord substantially increased their respective segmentation scores. Using eso4 label order resulted in average DICE of 0.66 and 0.84 for esophagus and spinal cord respectively, up from 0.56 and 0.58 respectively for the eso1 label order. This increase primarily comes from the fact that L1 loss is used in the generator. In general, a mismatch in the actual and generated values for the anatomy with higher label value will result in higher L1 loss value and in turn greater gradient back-propagation. Lungs and heart structures occupy much larger volume compared to esophagus and spinal cord which are thinner tubular structures. Hence, there is natural class imbalance in the L1 loss function. Ideally, a loss function which produces identical loss magnitude regardless of the label of the structure would be more desirable. In the context of L1 loss in our framework this could be achieved by using one hot encoding of the structures instead of assigning numerical labels to the different structures. With one hot encoding reweighting of the loss magnitude could be possible using the inverse of real volume to deal with the class imbalance issue.The one-hot encoding scheme failed to produce results owing to the inherent unstability in training GAN models. In our case, it becomes trivially easy for the discriminator to distinguish the real and fake structures especially the smaller ones (esophagus and spinal cord). By combining the structures into a single multilabel image combined with the training stabilization techniques we were able to overcome this difficulty. With this strategy, once the training had stabilized we dealt with class imbalance issue of relative loss weighting between different structures by modifying the structure labeling order. In future work, we will focus our efforts on developing a loss function which is naturally suited to both the tasks of general image-to-image translation (CBCT-to-CT) and segmentations while simultaneously incorporating features to help mitigate the class imbalance issue of segmentation.
Table 2:
Evaluation criteria for comparing quality of generated segmentation masks for organs-at-risk compared to manual segmentations for real week1 CBCT input images. Setting anatomy labels for esophagus, spinal cord, heart and lungs as 4, 3, 2, 1 respectively (instead of 1, 2, 3, 4 respectively) helps to substantially improve the segmentation results for esophagus and spinal cord without any noticeable degradation in heart and lungs results. The stabilized version has GAN stabilization techniques added in the optimization phase and produces better results compared to the unstabilized version.
| Settings | Anatomy | DICE | MSD (mm) | HD95 (mm) |
|---|---|---|---|---|
| mean ± std | mean ± std | mean ± std | ||
| msk+aapm+stabilized+eso4 | Lungs | 0.96 ± 0.01 | 0.96 ± 0.20 | 3.44 ± 0.93 |
| Heart | 0.88 ± 0.08 | 2.28 ± 0.94 | 8.07 ± 4.80 | |
| Spinal Cord | 0.83 ± 0.03 | 1.12 ± 0.32 | 3.45 ± 3.39 | |
| Esophagus | 0.66 ± 0.06 | 2.22 ± 0.40 | 6.50 ± 1.91 | |
| msk+aapm+unstabilized+eso4 | Lungs | 0.95 ± 0.01 | 1.38 ± 0.55 | 6.34 ± 4.83 |
| Heart | 0.81 ± 0.09 | 4.24 ± 1.32 | 19.08 ± 7.19 | |
| Spinal Cord | 0.80 ± 0.03 | 1.25 ± 0.39 | 3.81 ± 3.97 | |
| Esophagus | 0.58 ± 0.11 | 4.01 ± 2.96 | 17.83 ± 20.73 | |
| msk+stabilized+eso4 | Lungs | 0.95 ± 0.01 | 1.01 ± 0.21 | 3.71 ± 1.08 |
| Heart | 0.88 ± 0.10 | 2.13 ± 0.82 | 7.38 ± 3.27 | |
| Spinal Cord | 0.82 ± 0.03 | 1.16 ± 0.36 | 3.61 ± 3.68 | |
| Esophagus | 0.63 ± 0.06 | 2.51 ± 0.45 | 8.27 ± 4.08 | |
| msk+aapm+stabilized+eso1 | Lungs | 0.96 ± 0.01 | 1.03 ± 0.24 | 3.73 ± 1.08 |
| Heart | 0.87 ± 0.08 | 2.31 ± 0.78 | 7.43 ± 2.21 | |
| Spinal Cord | 0.78 ± 0.04 | 1.32 ± 0.36 | 3.81 ± 2.87 | |
| Esophagus | 0.56 ± 0.12 | 3.61 ± 2.26 | 15.22 ± 15.76 |
4. Discussion
Weekly/daily CBCT images are currently used for patient setup only during image-guided radiotherapy. In this paper, we presented an approach to help quantify CBCT images by converting them to high-quality synthetic CT images while simultaneously generating segmentation masks for organs-at-risk including lungs, heart, spinal cord and esophagus. While our approach produces high quality results, nevertheless there are some drawbacks worth mentioning. One of issues relates to the use of L1 loss in the generator network which causes blurred results. This results in lower contrast in the generated sCT compared to pCT. A large proportion of the residual errors in the sCT images are concentrated on or near the edges of different anatomical regions, as shown in figure 6. We tried to fix this issue by using combination of linear or nearest neighbor upsampling and convolution instead of transposed convolutions in the generator decoder. This modification indeed increased the contrast in the sCT images, however, it led to a significant decrease in the segmentation results of the smaller anatomies, namely, esophagus and spinal cord. In the future, we will look for more principled ways to overcome this problem including alternative loss functions.
Figure 6.

Planning CT, w1CBCT and sCT slices for two patient cases along with residual images between w1CBCT/pCT (MAE 216.19 HU) and sCT/pCT (MAE 31.47 HU). Histograms of residual images show that the sCT image residual errors are concentrated around 0 HU largely contained within ± 100 HU whereas w1CBCT images show extremely large differences compared to pCT.
Finally, all our results, including CBCT to CT translation, lungs, heart and spinal cord segmentation, except esophagus segmentation, are close to the state-of-the-art results for these individual tasks using different approaches and models. For further improvements, we will focus our efforts to develop ways to improve the esophagus segmentation to state-of-the-art levels as well. In that direction, our previous work [25] used a modified 3D Unet architecture with the physics-based data augmentation approach to achieve state-of-the-art segmentation results on esophagus. To improve our segmentation results, we will change our current generator architecture in line with the modified 3D Unet. Furthermore, with the addition of the publicly available AAPM training data, we saw improved results across tasks with our model i.e. both decreased MAE on sCT images and increased DICE scores on OAR segmentation. In the future, we plan to use physics-augmented 422 non-small cell lung cancer patients data from publicly available The Cancer Imaging Archive (TCIA) [37] to help improve results across tasks. Another major enhancement in future work will be to add an additional task of radiation dose inference along with the current tasks of simultaneous sCT generation and OAR segmentation.
5. Conclusion
In this paper we presented an approach to help quantify noisy artifact-ridden CBCT images by converting them to high quality synthetic CT images while simultaneously segmenting organs-at-risk including lungs, heart, spinal cord and esophagus. This approach can allow clinicians to use weekly/daily CBCT images for adapting radiotherapy mid-course, given the anatomical changes, to potentially improve patient outcomes.
Figure 5.

Synthetic CTs (middle) and OAR segmentations (bottom) generated for real weekly CBCTs (top).
Acknowledgments
This project was supported by MSK Cancer Center Support Grant/Core Grant (P30 CA008748). This work was funded in part by National Institutes of Health (NIH) grant R01 HL143350.
Appendix
We use the following definitions and formulae for the evaluation criteria of synthetic CT generation task and organs-at-risk segmentation:
- MSSIM: It is an objective measure to characterize the perceived quality of an image compared to a reference image. It considers the idea that spatially close pixels have strong inter-dependencies. The following expression is used in the computation of MSSIM:
where x, y are two images, μ is the mean of an image, σ is the standard deviation, σxy is covariance between two images, C1, C2 are constants with C1 = 0.012 and C2 = 0.032. In our implementation we use a sliding window approach to compute local SSIM and take average to report mean SSIM (MSSIM).(9) - MAE: Mean absolute error computes the average of absolute errors of all corresponding pixels in the two images. A lower MAE indicates improved quality and is calculated using the following expression:
where I1 and I2 are two images with N number of total pixels.(10) RMSE: It is commonly used to measure the difference between observed values and those predicted by a model. A lower RMSE indicates better match between two images and is calculated using the following expression:
- PSNR: PSNR is typically used to measure the quality of results produced by noise reduction methods. Increasing PSNR indicates better quality match between reference and target images. It is calculated as follows:
where Ir is one of I1 or I2 to be used as reference image. In our case we will use the pCT as reference and compare the generated synthetic CT against it.(11) - DICE: The DICE coefficient is routinely used in medical imaging applications to measure the quality of segmentations. It measures the overlap between a reference and algorithmically generated binary segmentation using the following formula:
(12) - MSD: Mean surface distance (MSD) between a surface S from an automatic method and a reference surface Sref is defined as:
where is the average of distances from every voxel in S to its closest voxel in Sref and is calculated similarly but is directed from Sref to S.(13) HD95: The Hausdorff distance (HD) between a surface S from an automatic method and a reference surface Sref is defined as the maximum of distances from every voxel in S to its closest voxel in Sref. The 95 percentile Hausdorff distance (HD95) is the voxel in S with distance to its closest voxel in Sref greater or equal to 95% of other voxels in S. It is a directed measure and the undirected version is defined as the average of directed HD95 from S to Sref and vice versa. HD95 distance is more robust to outliers than simple HD.
Receptive field calculation of PatchGAN discriminator
The receptive field is calculated between the output of a layer and its input. For example, we could ask how many features in the layer right before the final output layer of the discriminator affect the output at any of the 1×1×1 locations in the output layer? The answer is given by the relationship: Rl−1 = Kl + Sl * (Rl − 1) where Rl is the receptive field, Sl is the stride and Kl is the kernel size at layer l (https://distill.pub/2019/computing-receptive-fields/). For the discriminator architecture shown in Figure 3(a), the layers may be numbered from l = 0 at the input to l = 5 at the output. We may then apply the above relationship recursively to map the receptive field of a 1×1×1 location in the output to the input image. The kernel size and strides are provided in the figure for each layer. If the kernel sizes and strides are different in different dimensions then the relation can be used separately for each dimension. In our case all kernels and strides are symmetric in all three dimensions. As an example, for the output layer, S5 = 1, K5 = 4 and R5 = 1 (we are looking at 1×1×1 location in the output). The calculations for all the layers are as follows:
R4 = 4 + 1 * (1 − 1) = 4
R3 = 4 + 1 * (4 − 1) = 7
R2 = 4 + 2 * (7 − 1) = 16
R1 = 4 + 2 * (16 − 1) = 34
R0 = 4 + 2 * (34 − 1) = 70
Hence, a 1×1×1 location in the output of the discriminator is dependent on a 70×70×70 patch of the input image (receptive field).
Footnotes
Financial Disclosures
The authors have no conflicts to disclose.
Code and Data Availability
The code and the trained models will be made available via our physics-based data augmentation library, Physics-ArX, at https://github.com/nadeemlab/Physics-ArX. Physics-augmented AAPM data used for training our model will be made available via https://zenodo.org/record/5002882#.YM_ukXVKiZQ. Internal processed/de-identified data can be made available via reasonable request.
Receptive field calculation shown in appendix.
References
- [1].Boda-Heggemann J, Lohr F, Wenz F, Flentje M, and Guckenberger M, kV Cone-Beam CT-Based IGRT, Strahlentherapie und Onkologie 187, 284–291 (2011). [DOI] [PubMed] [Google Scholar]
- [2].Elsayad K, Kriz J, Reinartz G, Scobioala S, Ernst I, Haverkamp U, and Eich HT, Cone-beam CT-guided radiotherapy in the management of lung cancer, Strahlentherapie und Onkologie 192, 83–91 (2016). [DOI] [PubMed] [Google Scholar]
- [3].Schulze R, Heil U, Gross D, Bruellmann D, Dranischnikow E, Schwanecke U, and Schoemer E, Artefacts in CBCT: a review, Dentomaxillofacial Radiology 40, 265–273 (2011), PMID: 21697151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Zhu L, Xie Y, Wang J, and Xing L, Scatter correction for cone-beam CT in radiation therapy, Medical physics 36, 2258–2268 (2009), 19610315[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Xu Y, Bai T, Yan H, Ouyang L, Pompos A, Wang J, Zhou L, Jiang SB, and Jia X, A practical cone-beam CT scatter correction method with optimized Monte Carlo simulations for image-guided radiation therapy, Physics in medicine and biology 60, 3567–3587 (2015), 25860299[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Wu M, Keil A, Constantin D, Star-Lack J, Zhu L, and Fahrig R, Metal artifact correction for x-ray computed tomography using kV and selective MV imaging, Medical physics 41, 121910–121910 (2014), 25471970[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Zhang Y and Yu H, Convolutional Neural Network Based Metal Artifact Reduction in X-Ray Computed Tomography, IEEE Transactions on Medical Imaging 37, 1370–1381 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Xu S, Prinsen P, Wiegert J, and Manjeshwar R, Deep residual learning in CT physics: scatter correction for spectral CT, 2018.
- [9].Li Y, Garrett J, and Chen G-H, Reduction of Beam Hardening Artifacts in Cone-Beam CT Imaging via SMART-RECON Algorithm, Proceedings of SPIE–the International Society for Optical Engineering 9783, 97830W (2016), 29200592[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Zhao W, Fu G-T, Sun C-L, Wang Y-F, Wei C-F, Cao D-Q, Que J-M, Tang X, Shi R-J,Wei L, and Yu Z-Q, Beam hardening correction for a cone-beam CT system and its effect on spatial resolution, Chinese Physics C 35, 978–985 (2011). [Google Scholar]
- [11].Xie S, Zhuang W, and Li H, An energy minimization method for the correction of cupping artifacts in cone-beam CT, Journal of applied clinical medical physics 17, 307–319 (2016), 27455478[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Zhu J-Y, Park T, Isola P, and Efros AA, Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, in Computer Vision (ICCV), 2017 IEEE International Conference on, 2017. [Google Scholar]
- [13].Liang X, Chen L, Nguyen D, Zhou Z, Gu X, Yang M, Wang J, and Jiang S, Generating synthesized computed tomography (CT) from cone-beam computed tomography (CBCT) using CycleGAN for adaptive radiation therapy, Physics in Medicine & Biology 64, 125002 (2019). [DOI] [PubMed] [Google Scholar]
- [14].Kurz C, Maspero M, Savenije MHF, Landry G, Kamp F, Pinto M, Li M, Parodi K, Belka C, and van den Berg CAT, CBCT correction using a cycle-consistent generative adversarial network and unpaired training to enable photon and proton dose calculation, Physics in Medicine & Biology 64, 225004 (2019). [DOI] [PubMed] [Google Scholar]
- [15].Cohen JP, Luck M, and Honari S, Distribution matching losses can hallucinate features in medical image translation, in International conference on medical image computing and computer-assisted intervention, pages 529–536, Springer, 2018. [Google Scholar]
- [16].Chen L, Liang X, Shen C, Jiang S, and Wang J, Synthetic CT generation from CBCT images via deep learning, Medical Physics 47, 1115–1125 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Ronneberger O, Fischer P, and Brox T, U-Net: Convolutional Networks for Biomedical Image Segmentation, 2015.
- [18].Tien H-J, Yang H-C, Shueng P-W, and Chen J-C, Cone-beam CT image quality improvement using Cycle-Deblur consistent adversarial networks (Cycle-Deblur GAN) for chest CT imaging in breast cancer patients, Scientific Reports 11, 1133 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Kupyn O, Budzan V, Mykhailych M, Mishkin D, and Matas J, DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8183–8192, 2018. [Google Scholar]
- [20].Kida S, Kaji S, Nawa K, Imae T, Nakamoto T, Ozaki S, Ohta T, Nozawa Y, and Nakagawa K, Visual enhancement of Conebeam CT by use of CycleGAN, Medical Physics 47 (2019). [DOI] [PubMed] [Google Scholar]
- [21].Chen H, Zhang Y, Kalra MK, Lin F, Chen Y, Liao P, Zhou J, and Wang G, Low-Dose CT With a Residual Encoder-Decoder Convolutional Neural Network, IEEE Transactions on Medical Imaging 36, 2524–2535 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Fu Y, Lei Y, Wang T, Tian S, Patel P, Jani AB, Curran WJ, Liu T, and Yang X, Daily cone-beam CT multi-organ segmentation for prostate adaptive radiotherapy, in Medical Imaging 2021: Image Processing, edited by Igum I and Landman BA, volume 11596, pages 543–548, International Society for Optics and Photonics, SPIE, 2021. [Google Scholar]
- [23].Liang X, Nguyen D, and Jiang SB, Generalizability issues with deep learning models in medicine and their potential solutions: illustrated with cone-beam computed tomography (CBCT) to computed tomography (CT) image conversion, Machine Learning: Science and Technology 2, 015007 (2020). [Google Scholar]
- [24].Mirza M and Osindero S, Conditional Generative Adversarial Nets, 2014.
- [25].Alam SR, Li T, Zhang P, Zhang S-Y, and Nadeem S, Generalizable cone beam CT esophagus segmentation using physics-based data augmentation, Physics in Medicine & Biology 66, 065008 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Isola P, Zhu J-Y, Zhou T, and Efros AA, Image-to-Image Translation with Conditional Adversarial Networks, CVPR (2017). [Google Scholar]
- [27].Yang J, Veeraraghavan H, Armato III SG, Farahani K, Kirby JS, Kalpathy-Kramer J, van Elmpt W, Dekker A, Han X, Feng X, Aljabar P, Oliveira B, van der Heyden B, Zamdborg L,Lam D, Gooding M, and Sharp GC, Autosegmentation for thoracic radiation treatment planning: A grand challenge at AAPM 2017, Medical Physics 45, 4568–4581 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Kong F-MS, Ritter T, Quint DJ, Senan S, Gaspar LE, Komaki RU, Hurkmans CW,Timmerman R, Bezjak A, Bradley JD, Movsas B, Marsh L, Okunieff P, Choy H, and Curran WJ Jr., Consideration of dose limits for organs at risk of thoracic radiotherapy: atlas for lung, proximal bronchial tree, esophagus, spinal cord, ribs, and brachial plexus, International journal of radiation oncology, biology, physics 81, 1442–1457 (2011), 20934273[pmid]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Tustison N and Avants B, Explicit B-spline regularization in diffeomorphic image registration, Frontiers in Neuroinformatics 7, 39 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Stark JA, Adaptive image contrast enhancement using generalizations of histogram equalization, IEEE Transactions on Image Processing 9, 889–896 (2000). [DOI] [PubMed] [Google Scholar]
- [31].Wang G and Jiang M, Ordered-subset simultaneous algebraic reconstruction techniques (OSSART), Journal of X-ray Science and Technology 12, 169–177 (2004). [Google Scholar]
- [32].Mao X, Li Q, Xie H, Lau RYK, Wang Z, and Smolley SP, Least Squares Generative Adversarial Networks, in 2017 IEEE International Conference on Computer Vision (ICCV), pages 2813–2821, 2017. [Google Scholar]
- [33].Li C and Wand M, Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks, in Computer Vision - ECCV 2016 – 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part III, edited by Leibe B, Matas J, Sebe N, and Welling M, volume 9907 of Lecture Notes in Computer Science, pages 702–716, Springer, 2016. [Google Scholar]
- [34].Kingma DP and Ba J, Adam: A Method for Stochastic Optimization, in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings, edited by Bengio Y and LeCun Y, 2015. [Google Scholar]
- [35].Arjovsky M, Chintala S, and Bottou L, Wasserstein GAN, 2017.
- [36].Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, and Chen X, Improved Techniques for Training GANs, 2016.
- [37].Aerts HJWL, Wee L, Rios Velazquez E, Leijenaar RTH, Parmar C, Grossmann P, and Lambin P, Data From NSCLC-Radiomics [Data set], The Cancer Imaging Archive (2019). [Google Scholar]