

Abstract
Background
The COVID-19 outbreak, an event of global concern, has provided scientists the opportunity to use mathematical modeling to run simulations and test theories about the pandemic.
Objective
The aim of this study was to propose a full-scale individual-based model of the COVID-19 outbreak in Lombardy, Italy, to test various scenarios pertaining to the pandemic and achieve novel performance metrics.
Methods
The model was designed to simulate all 10 million inhabitants of Lombardy person by person via a simple agent-based approach using a commercial computer. In order to obtain performance data, a collision detection model was developed to enable cluster nodes in small cells that can be processed fully in parallel. Within this collision detection model, an epidemic model based mostly on experimental findings about COVID-19 was developed.
Results
The model was used to explain the behavior of the COVID-19 outbreak in Lombardy. Different parameters were used to simulate various scenarios relating to social distancing and lockdown. According to the model, these simple actions were enough to control the virus. The model also explained the decline in cases in the spring and simulated a hypothetical vaccination scenario, confirming, for example, the herd immunity threshold computed in previous works.
Conclusions
The model made it possible to test the impact of people’s daily actions (eg, maintaining social distance) on the epidemic and to investigate interactions among agents within a social network. It also provided insight on the impact of a hypothetical vaccine.
Keywords: epidemiology, computational, model, COVID-19, modeling, outbreak, virus, infectious disease, simulation, impact, vaccine, agent-based model
Introduction
The first case of COVID-19 was detected in China [1], but one of the most serious outbreaks occurred in Italy at the end of January 2020 [2]. This epidemic witnessed a change in risk management: the use of mathematical modeling [3]. As mathematical modeling is complex [4], there are many approaches to solving these problems. One such approach is agent-based modeling [5], which in epidemiology has been used widely in the past. However, due to its computational limitations, approaches based on differential equations like SIR (susceptible-infected-recovered) models have often been preferred [6]. In particular, SIR models are typically mediated by ordinary differential equations (ODEs) [7] and have been used to model general populations worldwide [8,9], as well as the entire Italian population in particular [10]. However, ODE models often require many free parameters to be computed, and they cannot usually be derived directly from experimental data because these parameters are abstract quantities. Hence, the most common approach to ODE models in epidemiology is to fit all the free abstract parameters to experimental time series that will be explained by the model. However, it is difficult to test and quantify alternative scenarios with this approach since the parameters are very abstract.
To solve these problems, the latest advances in computer science and engineering, as well as the COVID-19 outbreak itself, have led to the use of agent-based models for simulating small community epidemic behaviors since in agent-scale simulations. The parameters, all of which involve the individual, are usually experimentally constrained and determined. Previous work by Gharakhanlou and Hooshangi [11] explored the COVID-19 outbreak using an agent-based model of approximately 750,000 inhabitants in the city of Urmia, Iran, with the movement of agents approximated by their location. Similarly, Son et al [12] used a transmission model with a subsampled population of 9000 people living in Daegu, South Korea. There are small-scale models as well, as shown by Cuevas [13]. Also worthy of mention is the model developed by the University of Palermo [14], which was based on the work of Muggeo [15].
The aim of this study was to present a qualitative, full-scale agent-based model with the ability to reproduce the COVID-19 dynamics of Lombardy, Italy, modeling its outbreak and decline in cases, including as much real and open-access data as possible. Lombardy’s population of 10.06 million makes this model very large scale compared to previous works. Secondarily, the study aimed to investigate several alternative scenarios in order to assess their impact at the time. Finally, a social interaction model, used in epidemiological simulations, was employed, per graph theory [16], to study the agents’ interactions as a social network [17]. The results were used to draw several conclusions about the impact of people’s habits during the COVID-19 outbreak.
Methods
The Model Structure
The key objective was to create a 3-layer model (Figure 1). The first layer was an agent-based particle model for Lombardy. Every agent is an inhabitant of the region, making this model a full-scale model of Lombardy. Therefore, we have 10.06 million agents who move according to the random walk theory [18]. The random walk behavior must be intended as an approximation of the actual motion of people during the day; this approximation was introduced to reduce the amount of information required to run the model and is widely used in many fields of science (eg, ideal gas theory) [18]. The large number of agents simulated is part of the novelty of this study because (to the best of the author’s knowledge) it is the first to attempt to simulate such a large population individual by individual for this purpose.
Figure 1.
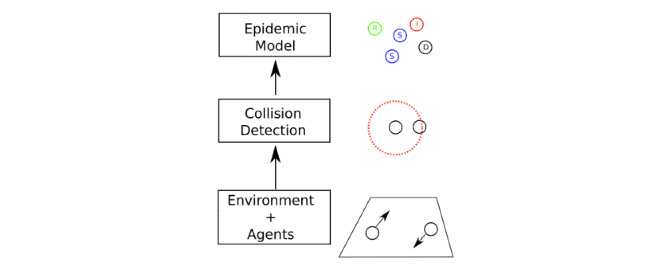
The 3-layer structure of the model. The first layer, environment and agents, represents the motion of the inhabitants. The second layer represents social interaction between people in terms of collision detection. The third layer represents the virus dynamic in terms of epidemic behavior. S: susceptible, I: infected, R: recovered, D: deceased.
A collision detection algorithm was built within the agent-based model to detect whether 2 particles have a distance less than a fixed value. However, the large scale reached by the model required an ad hoc algorithm for this purpose; this challenging problem was solved via a square cells algorithm that permits the code to run in parallel (thereby decreasing the computational complexity of the task).
An epidemic model was built within the collision detection model, that is, a susceptible-infected-recovered-deceased (SIRD) model [19]. The model was filled with many experimental findings on COVID-19, and some fitting parameters were tuned on experimental findings. The whole analysis used as much open-access research as possible; moreover, the entire project was fully open source and is available on GitHub [20].
The model comprised three different layers:
The environment and agents model allows for the use of real data in agent movement, creating the first difference between the proposed model and ODE-based models [6] since this kind of model often only uses a few equations to describe large populations, which makes it difficult to take into account ensemble observations on single agents. On the other hand, the proposed model is suitable for a large number of agents, differentiating from previous contributions in this field [11,12].
The collision detection model, via 2-km–sided square cells, allows the code to run in parallel, making it possible to compute the epidemic spread of a population of 10 million people agent by agent.
The agent-based epidemic model, based on the Markovian process [19], makes it possible to use the experimental probability of infection measured directly from experimental data. This allows the model to be suitable for evaluating alternative scenarios in contrast to ODE-based models [6], which usually must be tuned to fit the time series observed.
The Agents Model
The agents model simulates the behavior of each inhabitant of Lombardy using the approximation of random walks [18]. The displacement of the particles follows the density of inhabitants in Lombardy (ie, publicly available data). Even if more accurate data on people displacement and movement could be used, privacy concerns may not permit the open-source and open-access distribution of this data. Per the random walk approach, every particle moves with a random vector at every step. The model runs at 6 frames per day, which is a good frame rate considering that the scale time for epidemic phenomena is usually months; however, this can be improved as discussed in the Conclusions section. The random walk approach can appear unrealistic, but this hypothesis has been shown to be appropriate to model very large-scale systems (eg, gas thermodynamics [21]). In addition to random walks, a weak velocity field with a dependence of 1/r2 was added, where r is the distance between 2 particles, as in a gravitational field, in order to aggregate the particles. The drift speed of the particles is constant and selected with a Weibull distribution [22] with a scale parameter of 6 and a shape parameter of 1.5. The particles’ speeds were adjusted through a multiplicative constant in order to make the average path length of a particle in a day about 43 km, as suggested in a report by UnipolSai Assicurazioni [23].
The Environment Model
The setting of the simulation is Lombardy, making the environment model a closed 2D box with a boundary shape following Lombardy’s borders. In order to keep the particles inside the region, a bouncing condition was introduced at the border, so that a particle that tries to cross the border bounces backward. This condition is very popular in gas thermodynamics [18]. The initial conditions of the particles in terms of position are distributed following the actual density of the population of Lombardy, extracted from UnipolSai Assicurazioni [23] via image analysis [24]; this is then intended as an approximation of the real data.
Collision Detection
Starting with the assumption that the algorithm has been designed to run on a commercial computer in parallel (the one used in the study has AMD 3900X 12-cores and 64 GB of RAM) and within reasonable time (about 20 minutes of calculation for 14 days of simulation), the collision detection algorithm played a central role in the implementation of the algorithm. In order to find all points with a distance less than a constant in a set of N points, a complexity order of N2 is generally needed. In our model N≈107, the complexity order was 1014, which is a large number.
Next, Lombardy was subdivided into a grid, 20 km in dimension. Collision detection was applied to every cell of the grid, and every cell was assigned to a separate parallel job to run the computation in parallel through the cells. This multiscale processing allowed for the speeding up of the code, reducing the RAM used simultaneously in computation, which made possible a simulation with 10 million particles at the same time. This approach neglects all the connections across the borders of the cells, but this is beyond the aims of this study.
The creation of this algorithm was a challenging aspect of this study. The idea was to use matrix optimization in order to speed up the computation. The territory was subdivided into 20-km–long cells, and the cells in every frame were completely independent, with the supposition that, on average, every cell contains m people. In order to compute the distance between all nodes in the network, we had to compute the order of N2 pairwise distances.
With this scheme, we had to only compute the order of m2 distances for each block multiplied by the number of blocks (which is about N/m) that is an order of Nm. Considering m small in comparison with N, it can be said that the scheme has a complexity near the order of N (for large N and small m). However, determining in which cell a person is located was also challenging because of the large size of the population. For these reasons, a simple grid scheme was used to locate nodes inside the cells. We used the following idea—supposing a segment from 0 km to LC=2 km with Nc=4 cells:
From 0 km to 0.5 km
From 0.5 km to 1 km
From 1 km to 1.5 km
From 1.5 km to 2 km
If, for example, the point p=0.6 km needed to be located, the formula used to calculate this would be idp=ceil(Ncp/Lc). The result is 2, indicating the second cell. Applying this formula for the x-axis and y-axis allows the algorithm to locate people in the cells. Although this algorithm may appear to be simple, it requires few calculations to be computed, which can make a substantial difference when a large number of agents is concerned.
The Epidemic Model
The epidemic model is an SIRD model [3]. Most of the models available up to now are called population models [25]. A population model is a model where every node is modeled by a set of differential equations; it models a subpopulation of a region. The number of people modeled by a single node can range from hundreds to millions. In our model, every node is a single person. The model is not an ODE model, but a stochastic agent-based model. Every node has four states:
Susceptible: a node that has not already contracted the disease. It can be become infected with a probability pI for each contact with an infected node;
Infected: a node that is infected, which can then infect susceptible nodes. After E days, this node will change its state to recovered or to deceased, with a probability pD to die and 1–pD to recover;
Recovered: a node that has recovered from the disease and cannot contract it or infect susceptible nodes anymore;
Deceased: a node that has died and hence cannot infect other nodes.
Validation
The proposed model was compared with a classical SIRD model [26] fitted with a parameter exploration scheme on outbreak data (Figure 2). As seen in Figure 2, the results are comparable in terms of the rooted mean square error of the data: the SIRD model had an error of 150 for the infected, 71 for the recovered, and 18 for the deceased; and the proposed model exhibited an error of 535 for the infected, 58 for the recovered, and 34 for the deceased. This indicates that our model has comparable performance with the SIRD model (outperforming in the recovered), but it is not ODE mediated and is thus suitable for testing alternative scenarios. Moreover, in this paper, since most of the parameters are realistic, the model can be run for a general epidemic upon collecting the few parameters required (which in this case were all open access) and fitting the two parameters left. However, the model can be made more precise by adding additional realistic data, which most of the time are not fully open access; this, however, is out of the scope of this study.
Figure 2.
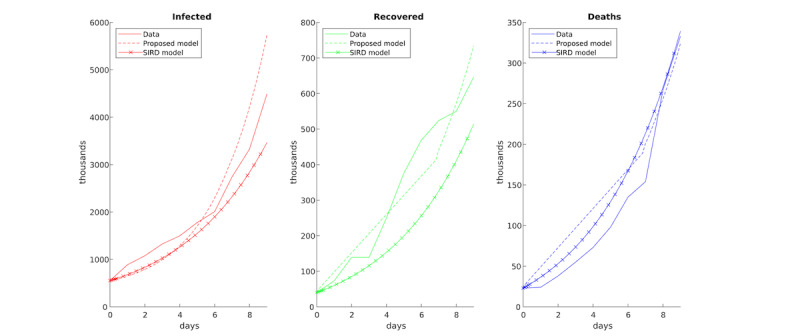
Comparison between data on the outbreak, the proposed model, and a classical susceptible-infected-recovered-deceased (SIRD) model [26].
Results
All simulations are available in .avi format on GitHub [20], as well the MATLAB code, for reproducibility.
The Lombardy Outbreak
The first scenario was the Lombardy outbreak of March 2020 [2]. Our simulation began on February 29, 2020, and terminated on March 14, 2020. The main realistic parameters were pI=1/40,500 (extracted from Bhatia and Klausner [27]) and pD=0.3 (estimated from Worldometer [28], which has also been cited by Dhillon et al [29]).
The fitted parameters have a collision radius of 1 km. This can appear very large compared to the 1-m distance suggested by the World Health Organization [30]; however, when taken into account that there are 6 frames per day, then 1 km is the radius of the interaction of a person who remains in the same place for 4 hours and the duration of the disease (in days) E=7 (the Centers for Disease Control and Prevention suggests E<10 [31]).
The results of the simulations can be seen in Figure 3. The model was able to explain the experimental data until approximately March 9, 2020. On this day, the Decree of the President of the Council of Ministers (DPCM) implemented measures to contain the COVID-19 outbreak [32], which included the beginning of the lockdown in Italy. This discrepancy between the data and the model was the result of the collective effort of the Italian populace to protect itself against SARS-CoV-2. Therefore, the simulation serves to provide a warning about what could have happened.
Figure 3.
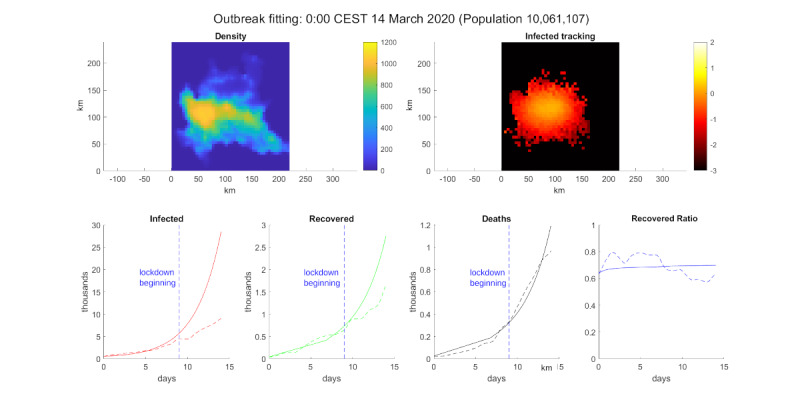
COVID-19 outbreak simulation. Top-left: population density. Top-right: log10 of the infected percentage per cell. Bottom, from left to right: infected number, recovered number, deceased number, and recovered ratio (recovered/deaths). The solid line is the model simulation, the dotted line is extracted data from the Ministry of Health/Civil Protection Department [33] for Lombardy, and the vertical dotted blue line marks the date March 9, 2020 [32].
Impact of People’s Habits
The second scenario was inspired by Chu et al [34], who showed that maintaining a 2-m distance between people halved the risk of contracting COVID-19. Thus, we aimed to simulate this kind of social distancing by halving pI in the model. The results (Figure 4) showed that COVID-19 (in this scenario) was not contagious enough to spread as in the experimental data. This simulation demonstrated the striking role of a simple action like social distancing in fighting COVID-19 and highlighted the difference between a virus under control and a disease of epidemic proportions. This simple fact has already been observed in experimental findings in Germany [35], where a synthetic method was used to estimate the spread of the contagion without the use of masks.
Figure 4.
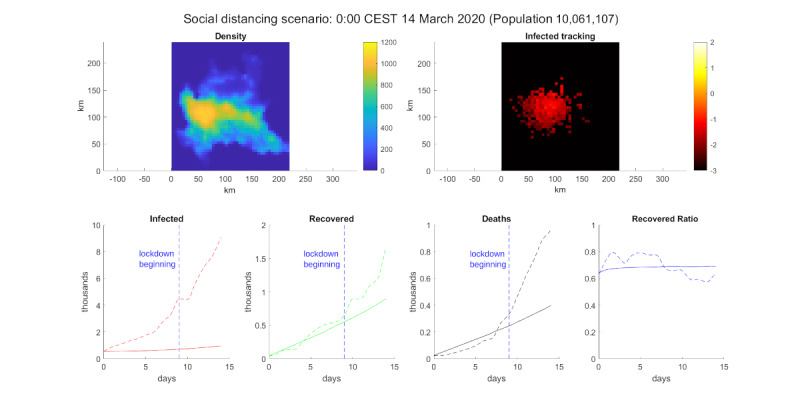
Social distancing simulation. Top-left: population density. Top-right: log10 of the infected percentage per cell. Bottom, from left to right: infected number, recovered number, deceased number, and recovered ratio (recovered/deaths). The solid line is the model simulation, the dotted line is extracted data from the Ministry of Health/Civil Protection Department [33] for Lombardy, and the vertical dotted blue line marks the date March 9, 2020 [32].
We also performed a lockdown simulation, reducing the daily average kilometers traveled by a node from 43 km to 5 km and reducing the interaction distance from 1 km to 100 m. The results of this simulation can be seen in Figure 5. According to the model, these simple actions were enough to control the virus.
Figure 5.
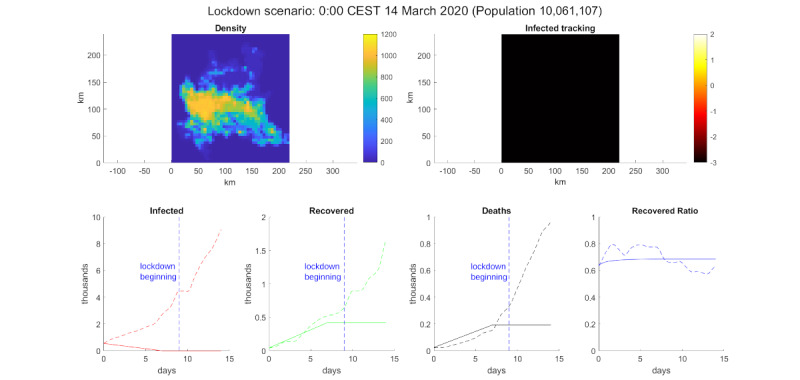
Lockdown simulation. Top-left: population density. Top-right: log10 of the infected percentage per cell. Bottom, from left to right: infected number, recovered number, deceased number, and recovered ratio (recovered/deaths). The solid line is the model simulation, the dotted line is extracted data from the Ministry of Health/Civil Protection Department [33] for Lombardy, and the vertical dotted blue line marks the date March 9, 2020 [32].
Network Topology
The impact of topology in an epidemic model is a popular topic [30,36] in the debate on social networks. Thus, we performed a test: 1000 particles were chosen and then tracked across all simulations to find the total number of connections (ie, contact between particles) made within the whole population. In graph theory, the number of connections of a node is called a degree [16]. This test allowed us to determine the degree distribution and the daily degree distribution (average degree per day) of this small group of people across time. However, only the final result is presented (the full simulation is available on GitHub [20]). The first scenario was the COVID-19 outbreak scenario (Figure 6).
Figure 6.
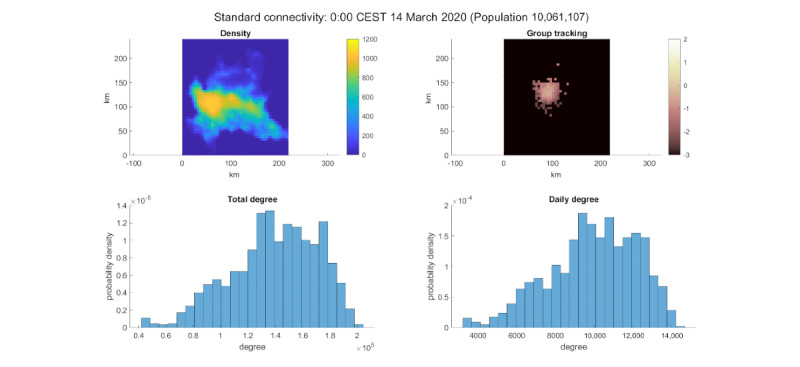
COVID-19 outbreak simulation connectivity. Top-left: population density. Top-right: log10 of the group percentage per cell. Bottom-left: degree distribution of the test group. Bottom-right: daily degree distribution of the test group.
It can be seen that the distribution has an evident left tail (in contrast with the right tail of the Barabási-Albert models [17]). This was probably due to the simulation time of 14 days (in contrast with human social networks, which usually take years to be built). The lockdown scenario was also interesting. In this scenario, we observed a decline in connectivity from thousands of average connections per day to hundreds (Figure 7). This shows the importance of lockdowns in COVID-19 containment.
Figure 7.
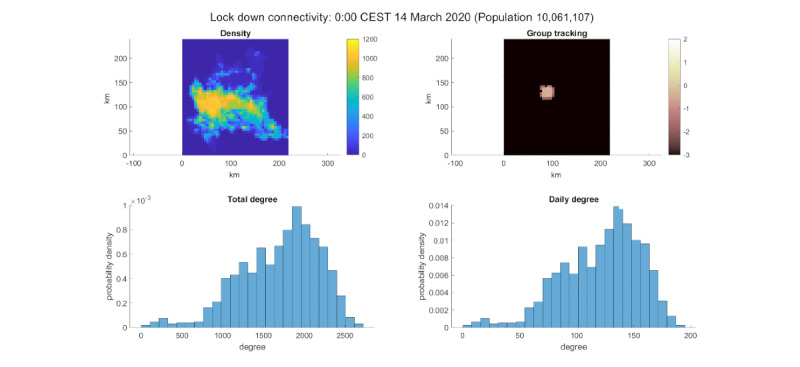
Lockdown simulation connectivity. Top-left: population density. Top-right: log10 of the group percentage per cell. Bottom-left: degree distribution of the test group. Bottom-right: daily degree distribution of the test group.
A Decline-in-Cases Scenario
This scenario took into account the period between May 31, 2020, and June 14, 2020. During this period, Italy concluded its lockdown, and the number of active cases was decreasing. For this simulation, the kilometers per day was set arbitrarily to 15 km because of the lack of additional information on mobility during this period. The probability of contracting the contagion was halved to account for social distancing. The radius of interaction and the duration of the disease were tuned to reproduce the experimental data. The value for the radius of interaction was 300 m and disease duration was 5 weeks (E=35). This value (which is higher in comparison to that of the outbreak) could be influenced by a clinical protocol more accurately and by the queue created by the large number of infected people, which could slow down the tests required to declare recovery. The qualitative fitting can be seen in Figure 8.
Figure 8.
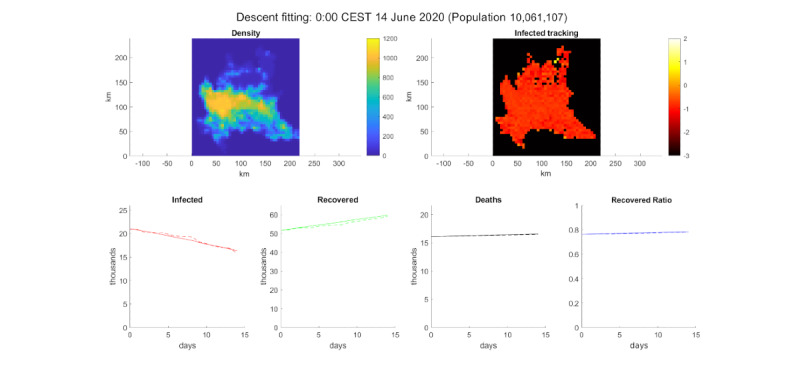
Simulation of a decline in cases. Top-left: population density. Top-right: log10 of the infected percentage per cell. Bottom, from left to right: infected number, recovered number, deceased number, and recovered ratio (recovered/deaths). The solid line is the model simulation and the dotted line is extracted data from the Decree of the President of the Council of Ministers [32] for Lombardy.
The Vaccine Scenario
Using the previous scenario of a decline in cases, we tested the impact of vaccinating 70% of the population, similar to the 62% suggested by Park and Kim [37]. The agent-based models are suitable for testing strategies like vaccination at the individual level. The result of the simulation was a strong decrease in infections, which was unexpected in a simulation of 14 days. The results are shown in Figure 9.
Figure 9.
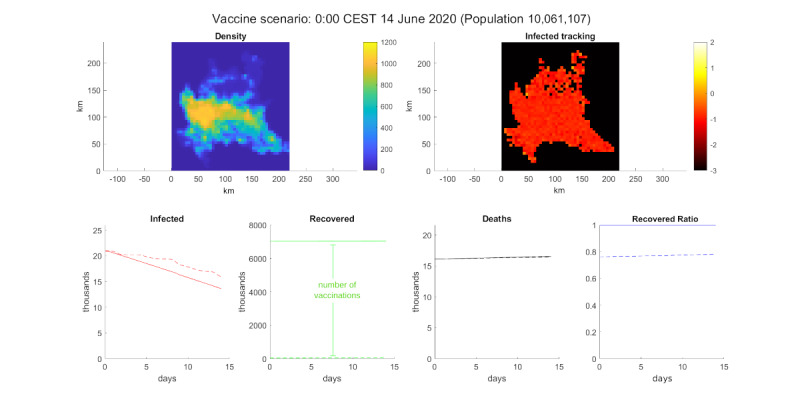
Simulation of vaccination. Top-left: population density. Top-right: log10 of the infected percentage per cell. Bottom, from left to right: infected number, recovered number, deceased number, and recovered ratio.
Discussion
Principal Findings
This model demonstrated the importance of people’s actions in an epidemic setting. Indeed, the behavior of the virus was indicative of our own habits [17]. The agent-based model proposed here has shown great flexibility in simulating alternative scenarios; in contrast, although ODE models [6] are faster than the proposed model, they are not suitable for this task.
Limitations
The model proposed is more computationally expensive than ODE models, which require the calculation of few differential equations to simulate large populations. In general, such algorithms are also faster than agent-based models. The proposed model, however, allows for the interpretation of complex parameters.
Comparison With Prior Work
This study has explained the behavior of the COVID-19 outbreak in Lombardy and has validated the herd immunity threshold obtained with different techniques [37], even if the 62% proposed by Park and Kim [37] is less than the 70% proposed in this study. This contribution also provides a new methodology in social network analysis, where the graph theoretical approach is substituted by agents. It also paves the way to more realistic epidemic models, where hypothetical scenarios can be tested directly on the agents, without any ODE mediation.
Conclusions
This work provides a novel, efficient, and low-demanding (in terms of computational resources) population model. Many features remain to be introduced in the model, like an age-dependent virus model, the ability to introduce an age parameter in the model or a more precise spatial simulation based on big data, and the ability to simulate the habits of the population. In conclusion, future work could be done to increase the number of frames per day, thereby improving the performance of the agents.
Acknowledgments
The author thanks the Department of Mathematics and Informatics of the University of Palermo for its support.
Abbreviations
- DPCM
Decree of the President of the Council of Ministers
- ODE
ordinary differential equation
- SIR
susceptible-infected-recovered
- SIRD
susceptible-infected-recovered-deceased
Footnotes
Conflicts of Interest: None declared.
References
- 1.Wang C, Horby PW, Hayden FG, Gao GF. A novel coronavirus outbreak of global health concern. The Lancet. 2020 Feb;395(10223):470–473. doi: 10.1016/s0140-6736(20)30185-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Coronavirus, primi due casi in Italia «Sono due cinesi in vacanza a Roma» Sono arrivati a Milano il 23 gennaio. Corriere della Sera. 2020. Jan 31, [2021-08-16]. https://www.corriere.it/cronache/20_gennaio_30/coronavirus-italia-corona-9d6dc436-4343-11ea-bdc8-faf1f56f19b7.shtml .
- 3.Giordano G, Blanchini F, Bruno R, Colaneri P, Di Filippo A, Di Matteo A, Colaneri M. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat Med. 2020 Jun 22;26(6):855–860. doi: 10.1038/s41591-020-0883-7. http://europepmc.org/abstract/MED/32322102 .10.1038/s41591-020-0883-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bertozzi AL, Franco E, Mohler G, Short MB, Sledge D. The challenges of modeling and forecasting the spread of COVID-19. Proc Natl Acad Sci U S A. 2020 Jul 21;117(29):16732–16738. doi: 10.1073/pnas.2006520117. http://www.pnas.org/cgi/pmidlookup?view=long&pmid=32616574 .2006520117 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Perez L, Dragicevic S. An agent-based approach for modeling dynamics of contagious disease spread. Int J Health Geogr. 2009;8(1):50. doi: 10.1186/1476-072x-8-50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.McMahon A, Robb NC. Reinfection with SARS-CoV-2: Discrete SIR (Susceptible, Infected, Recovered) Modeling Using Empirical Infection Data. JMIR Public Health Surveill. 2020 Nov 16;6(4):e21168. doi: 10.2196/21168. https://publichealth.jmir.org/2020/4/e21168/ v6i4e21168 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Fernández-Villaverde J, Jones CI. Estimating and Simulating a SIRD Model of COVID-19 for Many Countries, States, and Cities (NBER Working Paper No 27128) National Bureau of Economic Research. 2020 May;:1–58. doi: 10.3386/w27128. http://www.nber.org/papers/w27128 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Shapiro MB, Karim F, Muscioni G, Augustine AS. Adaptive Susceptible-Infectious-Removed Model for Continuous Estimation of the COVID-19 Infection Rate and Reproduction Number in the United States: Modeling Study. J Med Internet Res. 2021 Apr 07;23(4):e24389. doi: 10.2196/24389. https://www.jmir.org/2021/4/e24389/ v23i4e24389 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.He S, Peng Y, Sun K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020 Jun 18;101(3):1–14. doi: 10.1007/s11071-020-05743-y. http://europepmc.org/abstract/MED/32836803 .5743 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Giordano G, Blanchini F, Bruno R, Colaneri P, Di Filippo A, Di Matteo A, Colaneri M. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat Med. 2020 Jun;26(6):855–860. doi: 10.1038/s41591-020-0883-7. http://europepmc.org/abstract/MED/32322102 .10.1038/s41591-020-0883-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Mahdizadeh Gharakhanlou N, Hooshangi N. Spatio-temporal simulation of the novel coronavirus (COVID-19) outbreak using the agent-based modeling approach (case study: Urmia, Iran) Inform Med Unlocked. 2020;20:100403. doi: 10.1016/j.imu.2020.100403. https://linkinghub.elsevier.com/retrieve/pii/S2352-9148(20)30553-0 .S2352-9148(20)30553-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Son W, RISEWIDs Team Individual-based simulation model for COVID-19 transmission in Daegu, Korea. Epidemiol Health. 2020 Jun 15;42:e2020042. doi: 10.4178/epih.e2020042. doi: 10.4178/epih.e2020042. epih.e2020042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Cuevas E. An agent-based model to evaluate the COVID-19 transmission risks in facilities. Comput Biol Med. 2020 Jun;121:103827. doi: 10.1016/j.compbiomed.2020.103827. http://europepmc.org/abstract/MED/32568667 .S0010-4825(20)30192-X [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Covistat19. [2021-09-06]. https://sites.google.com/community.unipa.it/newcovid-19/covistat19 .
- 15.Muggeo VMR. Estimating regression models with unknown break-points. Stat Med. 2003 Oct 15;22(19):3055–71. doi: 10.1002/sim.1545. [DOI] [PubMed] [Google Scholar]
- 16.Giacopelli G, Migliore M, Tegolo D. Graph-theoretical derivation of brain structural connectivity. Applied Mathematics and Computation. 2020 Jul;377:125150. doi: 10.1016/j.amc.2020.125150. [DOI] [Google Scholar]
- 17.Barabasi. Albert R. Emergence of scaling in random networks. Science. 1999 Oct 15;286(5439):509–12. doi: 10.1126/science.286.5439.509. https://www.sciencemag.org/cgi/pmidlookup?view=long&pmid=10521342 .7898 [DOI] [PubMed] [Google Scholar]
- 18.Pearson K. The Problem of the Random Walk. Nature. 1905 Jul 01;72(1865):294–294. doi: 10.1038/072294b0. [DOI] [Google Scholar]
- 19.Shang Y. Mixed SI (R) epidemic dynamics in random graphs with general degree distributions. Applied Mathematics and Computation. 2013 Jan;219(10):5042–5048. doi: 10.1016/j.amc.2012.11.026. [DOI] [Google Scholar]
- 20.Giacopelli G. CTS-Ext. GitHub. 2020. [2021-08-16]. https://github.com/mrjacob241/CTS-Ext .
- 21.Radons G. The thermodynamic formalism of random walks: Relevance for chaotic diffusion and multifractal measures. Physics Reports. 1997 Nov;290(1-2):67–79. doi: 10.1016/s0370-1573(97)00059-8. [DOI] [Google Scholar]
- 22.Papoulis A, Pillai SU. Probability, Random Variables and Stochastic Processes, 4th Edition. New York, NY: McGraw-Hill; 2002. [Google Scholar]
- 23.Osservatorio UnipolSai 2018. UnipolSai Assicurazioni. 2018. Nov, [2021-08-16]. http://www.unipolsai.com/sites/corporate/files/pages_related_documents/cs_osservatorio-unipolsai-2018.pdf .
- 24.Lombardia: settore secondario, terziario, vie di comunicazione e popolazione. blendspace. [2021-08-16]. https://www.tes.com/lessons/RP1R6l5ZB05CMA/
- 25.Zlojutro A, Rey D, Gardner L. A decision-support framework to optimize border control for global outbreak mitigation. Sci Rep. 2019 Feb 18;9(1):2216. doi: 10.1038/s41598-019-38665-w. doi: 10.1038/s41598-019-38665-w. 10.1038/s41598-019-38665-w [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Baldé MAMT. Fitting SIR model to COVID-19 pandemic data and comparative forecasting with machine learning. medRxiv. doi: 10.1101/2020.04.26.20081042. Preprint posted online May 1, 2020. [DOI] [Google Scholar]
- 27.Bhatia R, Klausner J. Estimating individual risks of COVID-19-associated hospitalization and death using publicly available data. medRxiv. Posted online November 17, 2020. doi: 10.1101/2020.06.06.20124446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Italy COVID. Worldometer. [2021-08-16]. https://www.worldometers.info/coronavirus/country/italy/
- 29.Dhillon P, Kundu S, Shekhar C, Ram U, Dwivedi LK, Dwivedi S, Yadav S, Unisa S. Case-Fatality Ratio and Recovery Rate of COVID-19: Scenario of Most Affected Countries and Indian States. IIPS Research on COVID-19. 2020 Apr;:1–19. doi: 10.13140/RG.2.2.25447.68000. https://www.researchgate.net/publication/340950473_Case-Fatality_Ratio_and_Recovery_Rate_of_COVID-19_Scenario_of_Most_Affected_Countries_and_Indian_States . [DOI] [Google Scholar]
- 30.Coronavirus disease (COVID-19) advice for the public. World Health Organization. [2021-08-16]. https://www.who.int/emergencies/diseases/novel-coronavirus-2019/advice-for-public .
- 31.Interim Guidance on Ending Isolation and Precautions for Adults with COVID-19. Centers for Disease Control and Prevention. 2021. Mar 16, [2021-08-16]. https://www.cdc.gov/coronavirus/2019-ncov/hcp/duration-isolation.html .
- 32.Gazzetta Ufficiale. 2020. Mar 9, [2021-08-16]. https://www.gazzettaufficiale.it/eli/gu/2020/03/09/62/sg/pdf .
- 33.COVID-19 Situazione Italia. Ministero della Salute, Dipartimento della Protezione Civile. [2021-08-16]. http://opendatadpc.maps.arcgis.com/apps/opsdashboard/index.html#/b0c68bce2cce478eaac82fe38d4138b1 .
- 34.Chu Dk, Akl Ea, Duda S, Solo K, Yaacoub S, Schünemann Hj, Chu Dk, Akl Ea, El-harakeh A, Bognanni A, Lotfi T, Loeb M, Hajizadeh A, Bak A, Izcovich A, Cuello-Garcia Ca, Chen C, Harris Dj, Borowiack E, Chamseddine F, Schünemann F, Morgano Gp, Muti Schünemann Geu, Chen G, Zhao H, Neumann I, Chan J, Khabsa J, Hneiny L, Harrison L, Smith M, Rizk N, Giorgi Rossi P, AbiHanna P, El-khoury R, Stalteri R, Baldeh T, Piggott T, Zhang Y, Saad Z, Khamis A, Reinap M, Duda S, Solo K, Yaacoub S, Schünemann Hj. Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: a systematic review and meta-analysis. The Lancet. 2020 Jun;395(10242):1973–1987. doi: 10.1016/S0140-6736(20)31142-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Mitze T, Kosfeld R, Rode J, Wälde K. Face Masks Considerably Reduce Covid-19 Cases in Germany. medRxiv. doi: 10.1101/2020.06.21.20128181. Preprint posted online June 29, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Gianluca M. Complex Social Networks are Missing in the Dominant COVID-19 Epidemic Models. Sociologia. 2020 May;:14–49. doi: 10.6092/issn.1971-8853/10839. https://sociologica.unibo.it/article/view/10839/10997 . [DOI] [Google Scholar]
- 37.Park H, Kim SH. A Study on Herd Immunity of COVID-19 in South Korea: Using a Stochastic Economic-Epidemiological Model. Environ Resource Econ. 2020 Jul 13;76(4):665–670. doi: 10.1007/s10640-020-00439-8. [DOI] [PMC free article] [PubMed] [Google Scholar]