

Abstract
The quality of importance distribution is vital to adaptive importance sampling, especially in high dimensional sampling spaces where the target distributions are sparse and hard to approximate. This requires that the proposal distributions are expressive and easily adaptable. Because of the need for weight calculation, point evaluation of the proposal distributions is also needed. The Gaussian process has been proven to be a highly expressive non-parametric model for conditional density estimation whose training process is also straightforward. In this paper, we introduce a class of adaptive importance sampling methods where the proposal distribution is constructed in a way that Gaussian processes are combined autoregressively. By numerical experiments of sampling from a high dimensional target distribution, we demonstrate that the method is accurate and efficient compared to existing methods.
Index Terms—: adaptive importance sampling, generative model, Gaussian Process, population Monte Carlo
1. INTRODUCTION
Adaptive importance sampling (AIS) is a class of powerful estimation methods that iteratively optimize the proposal distribution along with drawing weighted samples. There are many different variations of AIS; however the performance of all these methods is very sensitive to the quality of the chosen proposal distribution [18]. Traditionally, fixed parametric distributions, such as Gaussian mixtures, are used as proposal distributions [2, 16]. However, in high dimensional samples spaces, the target distributions are usually hard to be captured by these fixed-form distributions.
With the development of machine learning, several kinds of compound data generating methods have proven to be highly expressive, such as neural generative models [6, 14] and Gaussian process latent variable machines [20]. These methods succeed in capturing details of high dimensional data distributions. However, to use data generating methods as proposal distributions for AIS, point evaluations of the generative models are required to calculate the weights of the drawn samples. However, many data generating models cannot evaluate the probability analytically. For example, in [22], a variational autoencoder (VAE) model is used as a proposal distribution, where the probability is evaluated by Monte Carlo approximations.
There are two kinds of compound distributions that can evaluate probability of samples analytically. One is latent variable machines that use bidirectional transformations [5, 11, 15, 21]. The other kind of distributions, which are called autoregressive distributions, are the ones that can be factorized by the chain rule of conditional distributions. In [13], it was shown that these two types of models are equivalent under certain conditions. In this paper, we work within the autoregressive framework.
Kernel density estimation is a commonly used non-parametric density estimation method, and it is usually invoked in low dimension sample spaces. In terms of estimation of conditional distributions, there are several methods such as [9, 10]. Gaussian processes allow for a powerful non-parametric conditional density estimation, where the models of the data are conditional Gaussian distributions.
In this paper, we introduce a class of AIS methods that use autoregressive distributions whose components are non-parametric distributions, including kernel density estimation and Gaussian processes, as proposal distributions. We provide two examples of this class of methods, and they are based on AIS and adaptive multiple importance sampling (AMIS). By numerical experiments, we show that when the dimension of the target distribution is high, the proposed methods outperform the state-of-the-art AMIS methods and Gaussian mixture distributions.
The problem is defined in Section 2. In Section 3, we briefly review AIS, autoregressive distributions, and Gaussian processes. We propose our method in Section 4 and present results of numerical experiments in Section 5. In Section 6, we discuss the results and provide concluding remarks.
2. PROBLEM DEFINITION
Our goal is to draw samples from a given non-normalized target distribution π(x). We assume that we can only evaluate π(x) point-wisely. We also assume that the integral of π(·) is not tractable and that as a result, the partition function is not available. This is a common situation in Bayesian estimation when we want to draw samples from a posterior distribution: the partition function of a high-dimensional posterior distribution is usually not available.
When x is high dimensional, the target distribution is sparse, and the sampling process is very challenging. We address the problem of sampling from target distributions of this type.
3. BACKGROUND
3.1. Adaptive importance sampling and its variations
We operate in settings when we do not have much information about the target distribution π(x), and thus, handcrafting a proposal distribution q(x) for importance sampling (IS) is challenging [8]. AIS is a class of iterative importance sampling that optimizes the proposal distribution over iterations of IS [12]. We will use the subscript t to denote the iteration index. We start from some initialization of the proposal distribution q1(x), and in each importance iteration t, we use the accumulated weighted samples (,), to optimize an updated proposal distribution qt+1(x). This step is called “adaptation.” There are many ways of adaptation, depending on the form of the proposal distribution. Proceeding with iterations, we improve the proposal distribution, and thereby the quality of the drawn samples and the various statistics obtained from them.
Variations of AIS methods [2], such as AMIS [4] are usually different because of the adopted form of the proposal distribution, the process of adaptation, and how the results from previous iterations are used. Many of these methods use Gaussian or Gaussian mixture distributions as proposal distributions [3, 4]. The accuracy of these methods degrades fast with the increase of the dimension of the sample space. Therefore, an expressive proposal distribution that can approximate the target distribution better in higher dimensions is needed.
3.2. Autoregressive distributions
Autoregressive distributions are joint distributions that can be factorized based on the conditional distribution expansion rule,
| (1) |
where D is the number of dimensions of the sample space. Samples of this distribution can be drawn by ancestral sampling [1]. Evaluation of the log-probability of a sample can be achieved by separately computing the factors corresponding to each dimension, and the sum of the evaluations is the log-probability of that sample. When optimizing the autoregressive distribution, each factor of the proposal distribution can be optimized separately in parallel.
3.3. Gaussian processes
The Gaussian process regression [23] is a non-parametric Bayesian model for estimation of functions from noisy data. They rely on conditional Gaussian distributions, where their covariances are regulated by “kernels” that measure similarities among data.
Suppose that training input and output data are given by (x(1:N), y(1:N)), where N is the number of training data. The predictive distribution of y* conditioned on x* is modeled by
| (2) |
where
and
where θ and σ2 are hyperparameters of the GP model, and kθ(·, ·) is the kernel function of the GP. In the proposed method, we use the radial basis function (RBF) kernel.
However, it is hard for the GP to work with large datasets because the inverse of the covariance matrix requires O(N3) complexity. There are many methods that aim to reduce the computational complexity of Gaussian process regression [17]. In our work, we utilize a python package GPy [7] that uses the deterministic training conditional (DTC) approximation [19] to reduce the computational complexity to O(n3) where n is the number of inducing input, and n is much smaller than the data size N.
4. THE PROPOSED METHOD
4.1. AIS with non-parametric proposals
In the proposed AIS method, the proposal distribution has the autoregressive form (1). Because the proposal distribution is non-parametric, in the initialization step, we need to provide some initialization of the underlying data . Here we can use random data drawn from a non-informative distribution, such as a standard Gaussian distribution,
| (3) |
where N is the number of drawn samples, and ID denotes the D-by-D identical matrix.
The distribution of the first dimension q1,t(x1,t) can be modeled by kernel density approximation, which is non-parametric. Kernel density estimation is usually not challenging in low dimensional spaces. As we are using it for just one dimension, it will be suitable for modeling the distribution of the first dimension,
| (4) |
where bt is the bandwidth of the smoothing kernel at iteration t.
The conditional distributions are modeled by Gaussian processes according to (2), with (, ) as underlying input and output training data, or
| (5) |
When sampling from a distribution, we first draw samples from the kernel density approximation and then we generate samples from the conditional distributions sequentially, i.e.,
| (6) |
where means discrete uniform distribution that samples integers from 1 to N.
The non-normalized sample weights are calculated by
| (7) |
where the log-pdf evaluation of the proposal distribution is
| (8) |
and denotes the log-pdf of a Gaussian distribution.
The proposal distribution is non-parametric, and therefore adaptations can be achieved by replacing the underlying data set of the proposal distribution with resampled data from the accumulated weighted samples. Note that the number of resampled samples N does not have to be the same as the number of samples drawn from the proposal distribution M. The resampling process can be performed as follows:
| (9) |
where , and L is the maximum number of iterations that is kept. The earlier iterations are considered as burn-in. The symbols denote a categorical distribution from which we draw x according to the weights w.
In addition to replacing the underlying data, we can also update the hyperparameters based on the resampled samples for better performance. The bandwidth of the kernel density estimation, the hyperparameters of the Gaussian process kernel, the white noise of the Gaussian process, and the inducing points can be updated by the type-II maximum likelihood as follows:
| (10) |
The inducing inputs are optimized by DTC using the GPy [7] package. The proposed AIS method is summarized by Algorithm 1, which we refer to as autoregressive GP AIS (AGP-AIS).

4.2. AMIS with non-parametric proposals
Our non-parametric proposal distribution can be used in different variations of AIS. For example, it can be applied in the AMIS structure if we change the weighting process of AIS (7) to the following:
| (11) |
where qi is the exponent of (8). Note that in each iteration t, we need to re-weight the history samples from iteration s to t. The proposed AMIS method is summarized by Algorithm 2 AGP-AMIS.

5. NUMERICAL EXPERIMENTS
The target distribution for all the experiments is a banana-shaped distribution [4], which is defined by
| (12) |
where Σ = diag(σ2, 1, …, 1). In our experiments, we set the parameters to b = 0.03 and σ = 10.
We ran experiments with the proposed AGP-AIS and AGP-AMIS methods. For comparison purposes, we also tested AMIS that uses a Gaussian mixture distribution with 10 components as a proposal distribution.
Even though we only utilize point evaluation of the target distribution, it is actually possible to generate samples from the target distributions directly by first drawing z(1:M) from a standard Gaussian distribution, and then twist its first two dimensions to acquire x(1:M), that is to follow these steps:
| (13) |
and then, for m = 1 : M
| (14) |
In the experiment, the ideal samples are directly drawn from the target distribution for benchmark performance comparisons.
The performance is measured in two ways. First, as suggested in [4], we measure the difference between the following statistics and their theoretical values:
| (15) |
| (16) |
| (17) |
Second, we focus on the first two dimensions of the samples. Because we know the ideal samples can be acquired transforming the standard Gaussian distribution samples, we can apply the inverse transformation of (14) on samples from the proposed methods and measure the Gaussianity of the inverse transformed samples , where T−1(·) is defined by
| (18) |
The performance is measured by the maximum difference between the sample cumulative distribution function (CDF) and the standard Gaussian CDF, which can be further used in the Kolmogorov–Smirnov Gaussianity test.
We did two sets of experiments. In the first experiment, we used M =1E5 and N =1E3 in all the compared sampling methods. We performed 10 simulations of the methods for target distributions with different dimensions D =5, 10, 15, 20. In this example, we see that the performance decays quickly for GM-AMIS when the number of dimensions increases, while the AGP-based methods remain with very high accuracy.
In the second experiment, we used the same dimension of the target distribution, D =10, and the same number of resampled samples for proposal adaptation N =1E3 for all the tested methods but drew different numbers of samples M =1E3, 1E4, 1E5 from the proposal distribution. In this example, we see that to achieve similar performance, GM-AMIS needs to draw many more samples than the AGP methods.
Because the target distribution becomes sparser in high dimensions, the Gaussian process-based distribution, which is more expressive, can estimate the target distribution better. The method is non-parametric, and it makes full use of the weighted samples. Thus, it needs less samples than the Gaussian mixture-based methods.
6. CONCLUSIONS AND DISCUSSIONS
In this paper, we proposed a class of adaptive importance sampling methods that use auto-regressive generative models and Gaussian processes for obtaining proposal distributions. Our numerical experiments suggest that the methods are efficient in the number of samples, more accurate, and less sensitive in dimensions than existing methods.
Fig. 1:
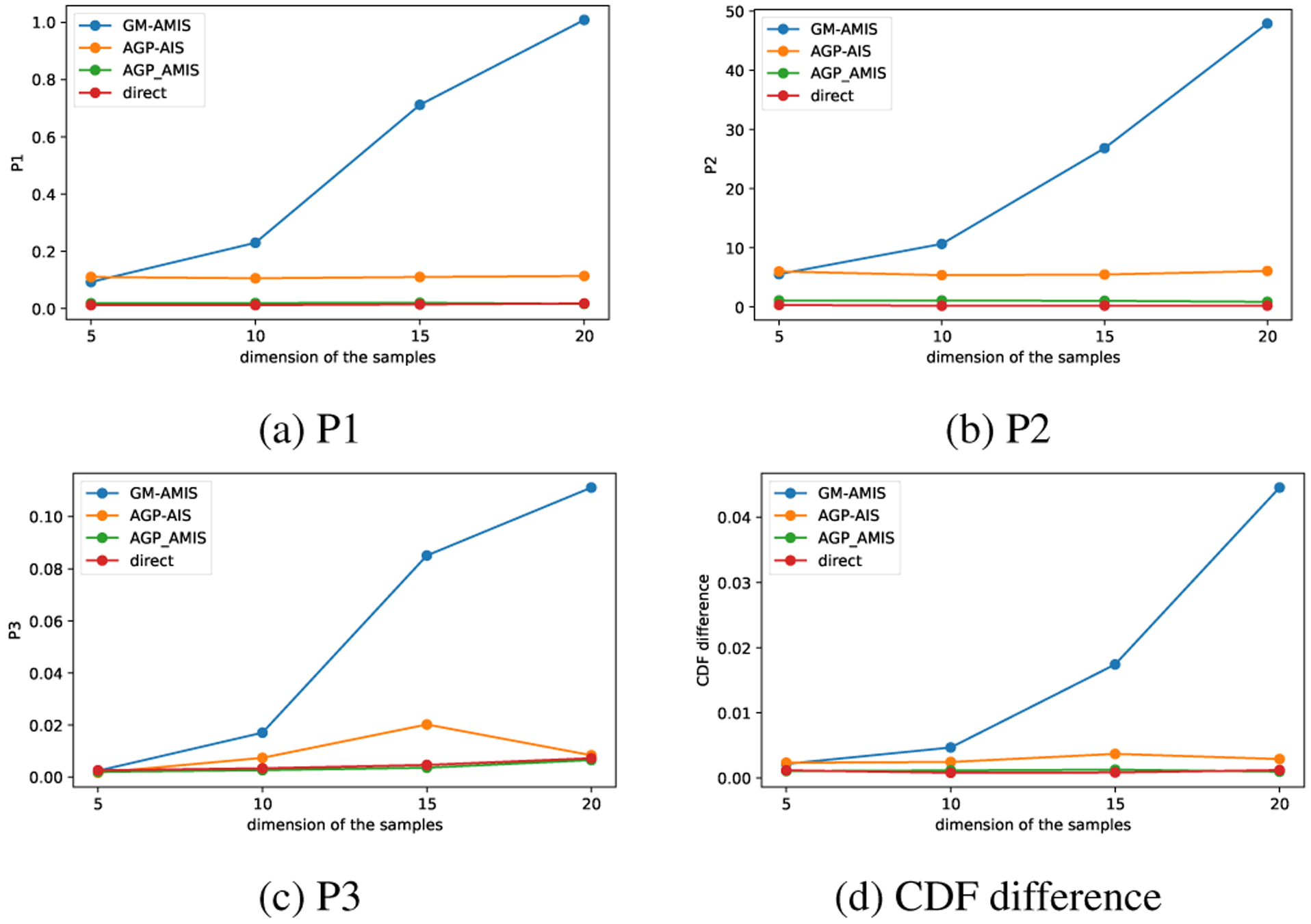
Performance of the methods as a function of the dimension of x. The definitions of P1, P2, and P3 are given by (15)–(17).
Fig. 2:
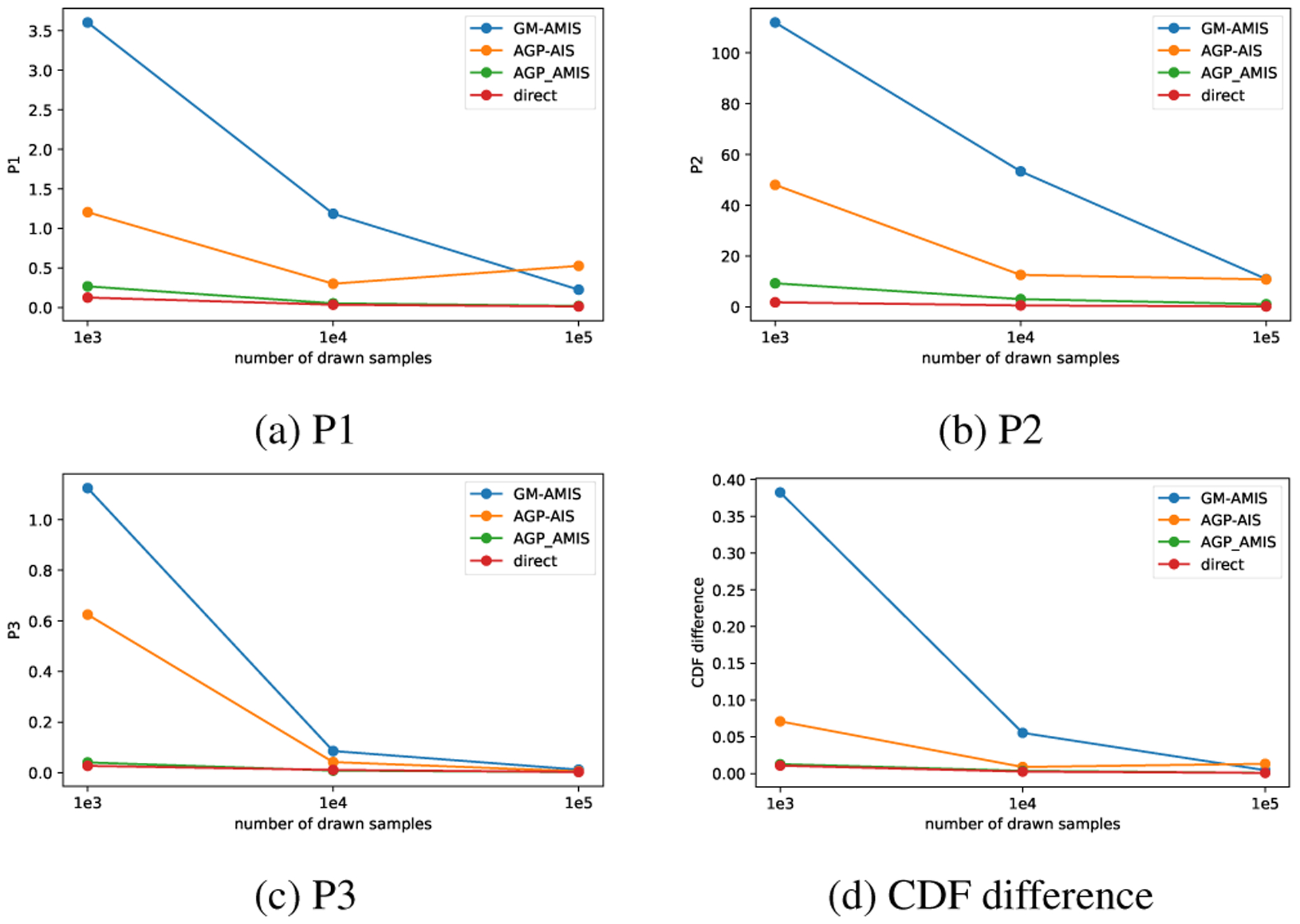
The performance of the methods as functions of the number of drawn samples. The definitions of P1, P2, and P3 are given by (15)–(17).
Fig. 3:
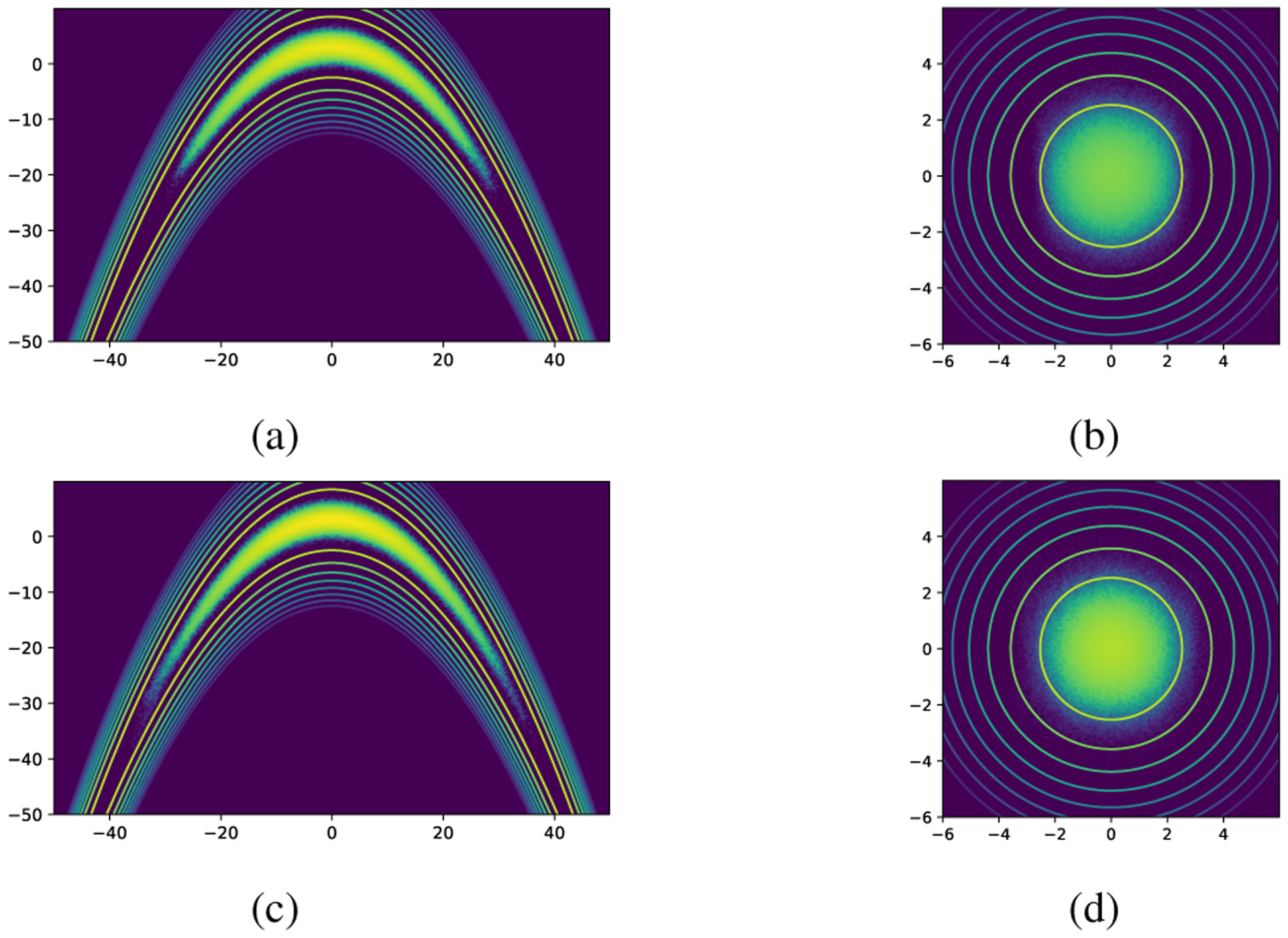
(a) and (c) are log-histograms of the samples acquired from one realization of the proposed methods with 1E5 samples drawn from a 20-dimensional banana-shaped distribution, where (a) is obtained by AGP-AIS and (c) is obtained by AGP-AMIS. The lines are contours of the log target distribution. (b) and (d) are transformed samples from (a) and (c) correspondingly. The lines are contours of the log standard normal distribution.
Acknowledgments
This work was supported by NIH under Award RO1HD097188-01 and the Growing Convergence Research Program of NSF under Award 2021002.
7. REFERENCES
- [1].Bishop CM. Pattern Recognition and Machine Learning. springer, 2006. [Google Scholar]
- [2].Bugallo MF, Elvira V, Martino L, Luengo D, Miguez J, and Djuric PM. Adaptive importance sampling: The past, the present, and the future. IEEE Signal Processing Magazine, 34(4):60–79, 2017. [Google Scholar]
- [3].Cappé O, Guillin A, Marin J-M, and Robert CP. Population Monte Carlo. Journal of Computational and Graphical Statistics, 13(4):907–929, 2004. [Google Scholar]
- [4].Cornuet J-M, Marin J-M, Mira A, and Robert CP. Adaptive multiple importance sampling. Scandinavian Journal of Statistics, 39(4):798–812, 2012. [Google Scholar]
- [5].Germain M, Gregor K, Murray I, and Larochelle H. Made: Masked autoencoder for distribution estimation. In International Conference on Machine Learning, pages 881–889, 2015. [Google Scholar]
- [6].Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, and Bengio Y. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014. [Google Scholar]
- [7].GPy. GPy: A gaussian process framework in python. url: http://github.com/SheffieldML/GPy,since2012.
- [8].Hammersley JM and Morton KW. Poor man’s monte carlo. Journal of the Royal Statistical Society: Series B (Methodological), 16(1):23–38, 1954. [Google Scholar]
- [9].Hansen BE. Autoregressive conditional density estimation. International Economic Review, pages 705–730, 1994. [Google Scholar]
- [10].Hansen BE. Nonparametric conditional density estimation. url: https://www.ssc.wisc.edu/bhansen/papers/ncde.pdf, 2004.
- [11].Huang C-W, Krueger D, Lacoste A, and Courville A. Neural autoregressive flows. arXiv preprint arXiv:1804.00779, 2018. [Google Scholar]
- [12].Karamchandani A, Bjerager P, and Cornell C. Adaptive importance sampling. In Structural Safety and Reliability, pages 855–862. ASCE, 1989. [Google Scholar]
- [13].Kingma DP, Salimans T, Jozefowicz R, Chen X, Sutskever I, and Welling M. Improved variational inference with inverse autoregressive flow. In Advances in neural information processing systems, pages 4743–4751, 2016. [Google Scholar]
- [14].Kingma DP and Welling M. Auto-encoding variational Bayes. arXiv preprint arXiv:1312.6114, 2013. [Google Scholar]
- [15].Larochelle H and Murray I. The neural autoregressive distribution estimator. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 29–37, 2011. [Google Scholar]
- [16].Liu JS. Monte Carlo Strategies in Scientific Computing. Springer Science & Business Media, 2008. [Google Scholar]
- [17].Quiñonero-Candela J and Rasmussen CE. A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research, 6(Dec):1939–1959, 2005. [Google Scholar]
- [18].Ripley BD. Stochastic Simulation, volume 316. John Wiley & Sons, 2009. [Google Scholar]
- [19].Schwaighofer A and Tresp V. Transductive and inductive methods for approximate Gaussian process regression. In Advances in Neural Information Processing Systems, pages 977–984, 2003. [Google Scholar]
- [20].Titsias M and Lawrence ND. Bayesian Gaussian process latent variable model. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 844–851, 2010. [Google Scholar]
- [21].Uria B, Murray I, and Larochelle H. Rnade: The real-valued neural autoregressive density-estimator. In Advances in Neural Information Processing Systems, pages 2175–2183, 2013. [Google Scholar]
- [22].Wang H, Bugallo MF, and Djurić PM. Adaptive importance sampling supported by a variational auto-encoder. In 2019 IEEE 8th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pages 619–623. IEEE, 2019. [Google Scholar]
- [23].Williams CK and Rasmussen CE. Gaussian processes for regression. In Advances in neural information processing systems, pages 514–520, 1996. [Google Scholar]