
Figure 5:
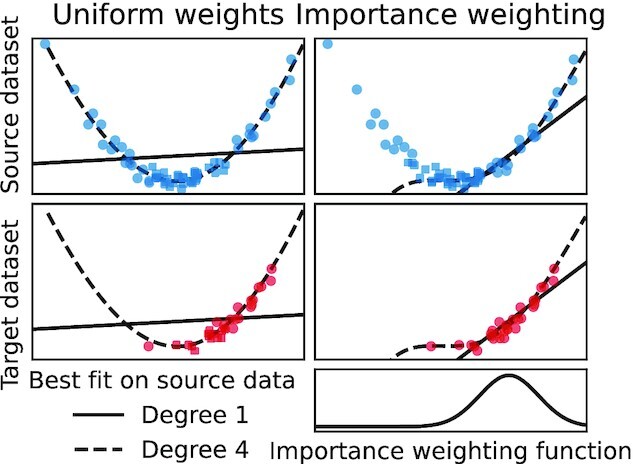
Covariate shift: 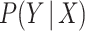 stays the same, but the feature space is sampled differently in the source and target datasets. A powerful learner may generalize well as
stays the same, but the feature space is sampled differently in the source and target datasets. A powerful learner may generalize well as 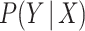 is correctly captured [27]. Thus the polynomial fit of degree 4 performs well on the new dataset. However, an overconstrained learner such as the linear fit can benefit from reweighting training examples to give more importance to the most relevant region of the feature space.
is correctly captured [27]. Thus the polynomial fit of degree 4 performs well on the new dataset. However, an overconstrained learner such as the linear fit can benefit from reweighting training examples to give more importance to the most relevant region of the feature space.