

Version Changes
Revised. Amendments from Version 1
The original submission was updated to 1) update references, 2) provide clarification in tool descriptions, 3) Correct numbers in Table 2, 4) Adjust Figure 11 and 12 to ensure readability of labels and 5) ensure all minor typos were removed.
Abstract
In October 2020, 62 scientists from nine nations worked together remotely in the Second Baylor College of Medicine & DNAnexus hackathon, focusing on different related topics on Structural Variation, Pan-genomes, and SARS-CoV-2 related research.
The overarching focus was to assess the current status of the field and identify the remaining challenges. Furthermore, how to combine the strengths of the different interests to drive research and method development forward. Over the four days, eight groups each designed and developed new open-source methods to improve the identification and analysis of variations among species, including humans and SARS-CoV-2. These included improvements in SV calling, genotyping, annotations and filtering. Together with advancements in benchmarking existing methods. Furthermore, groups focused on the diversity of SARS-CoV-2. Daily discussion summary and methods are available publicly at https://github.com/collaborativebioinformatics provides valuable insights for both participants and the research community.
Keywords: Structural variant, CNV, SARS-CoV-2, NextGeneration Sequencing
Introduction
Structural variants (SVs) comprise a number of genomic imbalances including copy number variations (CNVs), insertions (INS), deletions (DELs), inversions (INVs), duplications (DUPs), and inter-chromosomal translocations. 1– 3 SVs have been implicated as clinically significant mutations with proven associations to multiple diseases. 4, 5 Despite next-generation sequencing becoming increasingly common within the field of biomedical research, several practical challenges exist for comprehensively detecting and evaluating SVs particularly in regard to the high false positive or negative rate along with the accuracy of breakpoint prediction. 6, 7 While SV detection with genotyping arrays remains the most commonly used method, the toolbox for SV detection is expanding to incorporate the advancements in third generation sequencing technologies provided by Pacific BioSciences, 8 Oxford Nanopore Technologies, 9, 10 optical mapping and NanoString 11 to name a few. These advancements offer potential for solving previously unresolved structural variants.
In October 2020, 62 scientists from nine nations worked together remotely in the Second Baylor College of Medicine & DNAnexus hackathon, focusing on different related topics on SV, Pan-genomes, and SARS-CoV-2 related research. Consequently, this international structural variation hackathon meeting focused on eight themes: 1.) efficiently genotyping vast quantities of SVs; 2.) mapping CNVs to SV types; 3.) detecting and validating SVs for SARS-CoV-2; 4.) filtering high-confidence SV calls for clinical genomics; 5.) SV read-based phasing for haplotype analysis; 6.) genome graph generation without a reference; 7.) machine learning approaches to predict lab-of-origin of a sample.; and 8.) gene-centric data browsing for SV analysis.
Overall, this manuscript details our tools’ objectives, value-add, implementations, and applications and sets the foundation for further concept development beyond. In this article we present 10 software tools that were the results of this hackathon.
nibSV: efficient genotyping of SVs from short read datasets. Detection of SVs longer than a short-read (<500bp) DNA trace is very challenging as the SV allele becomes split across multiple reads. To this end, long read sequencing technology is preferential for overcoming this challenge however, although long read sequencing has proven more accurate in SV identification, obtaining accurate allele frequencies across a population is important in order to rank and identify potential pathogenic variations.
Thus, it is still important to genotype SV events in pre-existing short read datasets such as those provided by the 1000 genomes project, Topmed, CCDG, etc. Recently, two main approaches, Paragraph 12 and VG, 13 have achieved this with high accuracy even for insertion SV events. However, these methods are computationally expensive particularly when the number of SVs to be genotyped per sample increases. Furthermore, and maybe more crucially, both methods rely on precise breakpoints that do not change in other samples, an assumption that is potentially flawed particularly over repetitive regions. NibbleSV is a software package able to efficiently genotype vast quantities of SVs whilst also using a kmer catalogue of SVs in order to circumvent the need for re-mapping the same dataset to different versions of the same reference genome (e.g. hg19 vs. GRCH38 vs. CHM13), again aiding computational efficiency ( Figure 1).
Figure 1. Overview of the NibbleSV software package workflow.

Overview of NibbleSV workflow that utilises an input reference genome and file containing variant calls to generate a list of genotyped alleles using a kmer based strategy.
CNV2SV: supplement CNV calling in SV detection. Copy number variations (CNVs) are a subset of structural variants (SVs) consisting of duplications and deletions. CNVs constitute an important part of humangenetic diversity but are also known to be involved in the pathogenesis of multiple diseases, including 15% of breast cancers. 14, 15 In clinical NGS applications, CNVs are commonly detected using short-read sequencing. To this end, coverage changes across the reference genome are interpreted by CNV callers as either putative duplication or deletion events. However, short reads grant only limited insight into the larger structural context of the called CNVs. Recent advances in ultra-long read sequencing have enabled projects such as the complete telomere-to-telomerere construction of a haploid human cell line (T2T CHM13). 16 This opens up the opportunity to better understand putative CNVs identified using short reads in the light of the larger, distant or nested structural events as part of which they may arise. To facilitate this, we have developed CNV2SV, a method to automatically link CNV calls to corresponding SVs from a whole-genome alignment. In turn, this may not only aid in improving our understanding of structural changes encompassing large CNVs but also in the resolution of CNVs with complex breakpoints. We demonstrate CNV2SV for a dataset based on the haploid human genome T2T CHM13, using established methods for CNV calling using short reads and SVs called from genome-genome alignment. Agraphical outline of the CNV2SV pipeline is shown in Figure 2.
Figure 2. A graphical overview of the CNV2SV pipeline.

CNV2SV software pipeline that utilises both short and long read data as input to calculate the frequency of copy number variants across complete genomes.
CoronaSV: SV pipeline for SARS-CoV-2. While deletions have been reported in several SARS-CoV-2 genomes at consensus level, 17, 18 the confidence in how these deletions are detected has not yet thoroughly been evaluated. Existing methods for detecting SV at the individual read level often suffer from false positive calls. 19, 20 Additionally, analyses with different variant calling pipelines often result in inconsistent calls. 21, 22 To examine the landscape and extent of SV across SARS-Cov-2 genomes, a method for generating accurate and trustworthy SV calls is needed. With this in mind, we developed the CoronaSV bioinformatics pipeline.
CoronaSV is a SV detection and SV validation pipeline for SARS-CoV-2 that combines an ensemble SV calling approach that relies on both long read and short read sequencing technologies ( Figure 3). Both assembly-based and read based SV detection methods are used by CoronaSV. By combining different sequencing technologies and variant detection approaches, we can identify both a) confident SV call set and b) artifacts that may result from specific technologies + computational approaches.
Figure 3. Illustration of CoronaSV software implementation.

Illustration of the CoronaSV package workflow that takes SARS-CoV-2 short and long read data types along with a SARS-CoV-2 reference genome as input and generates a set of commonly found SVs.
CleanSV: Filtering High-quality SVs. Short-read sequencing is performed within clinical genomics to both inform and directly guide patient care. This has been immensely successful for various Mendelian disorders, where patients now routinely have their genomes sequenced to detect high-quality variants. Indeed, this approach has been utilized within clinical genomics for close to a decade, 23 often to correct misdiagnoses (see 24 for a recent example).
Within precision oncology, short-read sequencing (normally targeted sequencing or whole exome sequencing (WES)) has proved successful not only illuminating the nature of specific cancers, but also guiding novel drug development. Today routine sequencing is used to apply therapies for specific cancer subtypes, and influence the treatment of individual patients. 25, 26 For clinical work, samples from tumors are sequenced for somatic variants in well-studied oncogenes/tumor suppressor genes. Bioinformaticians will then manually investigate the variant calls within IGV in order to validate how accurate they are, and finally send reports summarizing these data to clinicians.
However, SV calling using short-read data is marred by high false positive (FP) call rates, sometimes up to 90% with modern callers. 10, 27, 28 As a result, manual curation for each patient proves oppressively time-consuming for the needs of modern precision care and is prone to human error. Even though aneuploidy has been long studied for its role in tumor progression (see 29 for a recent review), due to algorithmic uncertainties, routine inclusion of high-confidence SVs within clinical reports is often infeasible today.
Therefore, there exists a pressing need within bioinformatics to develop methods to remove false positives from the outputs commonly used SV callers, and benchmark their performance across a variety of assays (including a range of sequencing depths and tumor purities). Individual SV callers rely upon specific strategies to detect SVs, which makes the nature of the false positives algorithm-specific. Having access to a call set with a lower false positive rate would certainly not eliminate the requirements of manual curation, but it would make the problem more tractable.
The goal of this project was to develop a set of publicly available filters tailored for cancer genomics which have been measured to perform reliably across popular SV callers, as the filters must be specific to the SV caller used. Using a large cohort of high-quality normal whole genome sequencing (WGS) samples, we perform systematic false positive filtering. SVs labeled by the algorithm as somatic have evidence as actually being germline, while others are algorithmic artifacts. With such filters, bioinformaticians would have access to a set of high-quality somatic calls to manually curate, which could finally result in more robust clinical reports.
Sniphles: Phasing SVs with parallel programming. Phasing infers the correct cis or trans relationship between different heterozygous variations facilitating accurate haplotype reconstruction. 30 Protocols and programs utilizing molecular phasing (chromosomal separation at the bench before sequencing), pedigree-based phasing (matching parental and offspring genotypes to understand the haplotype), population-based phasing (using genotype data from large cohorts to infer haplotypes), and read-based phasing (mapping sequencing reads with the same variants to construct a haplotype) are all successful approaches to phasing next-generation sequencing data. 31 The long-reads of third generation sequencing have bolstered our ability to phase longer and more comprehensive haplotype blocks. 32 More comprehensive haplotype blocks increase our ability to accurately phase structural variants.
The goal of this project is to develop a wrapper script around the Sniffles SV caller 10 to properly phase SV and augment the ability of Sniffles to accurately call SV ( Figure 5). This result is obtained by using phased reads generated by SNV phasing tools such as WhatsHap or LongShot, 30, 33 and subsequently call SVs on the haploid phase blocks separately using temporary files before finally merging both haplotypes to obtain a single VCF file. As this algorithm processes each phase block separately this is attractive for parallelization. Our wrapper script additionally makes Sniphles compatible with alignments in the CRAM format.
Figure 5.

Illustration of methodology utilized by Sniphles to produce a phased structural variant call set. An overview of the Sniphles pipeline demonstrating how a haplotyped input bam file is used to generate a phased structural variant call set.
Swagg: Structural Variation With Annotated Graph Genomes (Swagg). Most graphical approaches to variant calling only use genome graphs. While this information helps illustrate variation on a genomic level, it does not show variation on the individual protein level. To help leverage the power of graph approaches for SV calling, we introduce a pipeline that delivers both protein and genome graphs.
Swagg is a pipeline that enables the construction of genome graphs from read data ( Figure 6). The input into the pipeline is sequence reads with or without a reference genome(s). Reads can be short reads or preprocessed (basecalled) long reads. These reads are then assembled into longer contigs which are mapped back to the reference genome to highlight discrepancies with the reference genome. These discrepancies can be caused by real mutations or sequencing artifacts and easily identified using SV tools, which output VCF files for each read set. These VCF files are taken together to make the genome graph at the end of the pipeline. The overall pipeline and intertwined modules are shown below. In addition to the pipeline for creating graph genome and graph proteins, we also have a module for simulating reads based on an input reference genome.
Figure 6. Outline of the SWAGG software package workflow.

Illustration of the SWAGG pipeline that utilises both long and short read datasets for the construction of graph genomes.
PanOriginSV: detecting lab-of-origin. The advent of novel synthetic biology methods and organic bench-top synthesis toolkits like CRISPR 34 has enabled rapid developments in genetic engineering. However, this progress has also introduced biosafety concerns surrounding the intentional or unintentional misuse of these tools. In order to increase accountability, the lab-of-origin studies attempt to map a set of plasmids to their lab-of-origin. Subsequently, the Genetic Engineering Attribution Challenge (GEAC) was announced, inviting open source tools from the community that could best predict the lab-of-origin.
Previous methods have employed machine learning or deep learning-based approaches that despite their promise, suffer from sub-optimal accuracy, long training times as well as explainability issues. Recently, a new alignment based tool PlasmidHawk 35 reported higher accuracy than machine learning tools. PlasmidHawk relies on linear pangenome constructs to align query sequences to a pangenome in order to best determine the Top-1 and Top-10 candidate labs. Though PlasmidHawk has a higher accuracy, the runtimes to create the linear plasmid are non-scalable to larger datasets. Another drawback being the linear pangenome doesn’t incorporate SV, which could be important to predict hard-to-classify sequences. To address some of these challenges, we propose a tool PanOriginSV that combines machine learning approaches with graphical pangenome based alignment to predict lab-of-origin ( Figure 7).
Figure 7. Implementation strategy of the PanOriginSV software package.

Pipeline demonstrating the PanOriginSV software package that’s implementation determines that lab-of-origin input sequencing data.
PanOriginSV creates multiple pangenome graphs from similar training sequences using BCALM 36 creating a variation graph that incorporates SV and aligns the sequences back to the graph using GraphAligner. 37 The most similar training sequences for graph construction are clustered using MMSEQ2. 36, 38 After this, top alignments, scores to the pangenome and sequence metadata are considered as features for a downstream machine learning model towards lab-of-origin prediction.
GeneVar: SV Browser. Next-generation sequencing provides the ability to sequence extended genomic regions or a whole-genome relatively cheaply and rapidly, making it a powerful technique to uncover the genetic architecture of diseases. However, significant challenges remain, including interpreting and prioritizing the identified variants and setting up the appropriate analysis pipeline to cover the necessary spectrum of genetic factors, which includes expansions, repeats, insertions/deletions (indels), SV and point mutations. For those outside the immediate field of genetics, a group that includes researchers, hospital staff, general practitioners, and increasingly, patients who have paid to have their genome sequenced privately, the interpretation of findings is particularly challenging. Although various tools are available to predict the pathogenicity of a protein-changing variant, they do not always agree, further compounding the problem. Furthermore, with the increasing availability of next-generation sequencing data, non-specialists, including health care professionals and patients, are obtaining their genomic information without a corresponding ability to analyse and interpret it as the relevance of novel or existing variants in genes is not always apparent. Similarly SV analysis 39, 40 and its interpretation requires care in regard to sample and platform selection, quality control, statistical analysis, results prioritisation, and replication strategy.
Here we present GeneVar, an open access, gene centric data browser for SV analysis ( Figure 8). GeneVar takes as input a gene name or ID and produces a report that informs the user of all SVs overlapping the gene and any non-coding regulatory elements affecting expression of the gene. The tool is intended to have a clinical focus, informing the interpretation of SV pertaining to a gene name provided by the user.
Figure 8. Methodology used by GeneVar for the production of summary report made available through genome browser.

A graphical representation of the pipeline used by GeneVar in order to provide clinicians with a comprehensive summary of SVs associated with a user provided gene name.
SVTeaser: simulated data for SV benchmarking. SV detection tools often have a large number of wrongly detected variations 19, 27 requiring benchmarking to assess method quality before finalizing a workflow. Few tools are currently available to simulate data for SV benchmarking. SVTeaser is a tool for rapid assessment of SV calling fidelity with two main use-cases: 1) genotyping a set of pre-ascertained SVs and 2) benchmarking a new algorithm against pre-existing tools across a range of parameters. Users simply supply SVTeaser with a reference sequence file (.fasta) and, optionally, a set of SVs (.vcf). SVTeaser outputs simulated reads across a range of read lengths and depths and provides a downstream dataframe based analysis framework for evaluating accuracy ( Figure 9). SVTeaser achieves rapid assessment by downsampling the full reference to a subset of numerous 10kb samples to which it adds SVs.
Figure 9. An illustration of the methodology implemented by the SVTeaser software package.

SVTeaser software implementation showing how by using a reference genome a set of SVs can be simulated to benchmark SV calling tools to inform experimental design decisions prior to analyses.
XSVLen: haplotype-resolved assemblies for benchmarking SVs. Since the development of a “gold standard” SV set, sequencing technologies and assembly algorithms have improved to enable nearly complete haplotype-resolved assemblies of human genomes. XSVLen is a framework ( Figure 10) to use haplotype-resolved assemblies for benchmarking SV detection algorithms. Each variant call may be considered an operation to be applied to the reference genome. Our framework for benchmarking SV callsets is to apply SV operations to the reference genome and compare the modified reference against the haplotype-resolved assemblies. This approach allows for SV calls that are different but produce similar sequences due to the repetitive nature of the genome to be scored as valid. In this manner, all variants in a region that is accurately assembled in both haplotypes may be benchmarked using this approach. We demonstrate the effectiveness of this approach by scoring SV calls generated from Oxford Nanopore reads on the HG002 genome 41 using CuteSV 42 and comparing against gold-standard calls by Truvari ( https://github.com/spiralgenetics/truvari). This approach can be extended to use any haplotype-resolved assembly to benchmark SV callsets in additional genomes, enabling benchmarks as a distribution across call sets.
Figure 10. Implementation pipeline of XSVLen software package.

A graphical representation of the XSVLen software pipeline showing the utilisation of haplotype-resolved de novo assembly and a VCF file to benchmarking SV detection algorithms.
Methods
Implementation
nibSV: NibbleSV is a lightweight, scalable and easy to apply method to identify the frequency of SV events across short read data sets. As such, nibSV extracts kmers that are informative if an SV is present or if an SV is absent given the breakpoints of the previous predicted SV. Subsequently, nibSV scans the short read bam or fastq file for the presence of these k-mers and counts their number of occurrences. In the end, nibSV extends the VCF file with tags holding information about the number of times an SV is supported by kmers or not ( Figure 1).
CNV2SV: CNV2SV is a tool for connecting CNVs identified using short-read sequencing to structural variations (SVs) from a whole-genome alignment ( Figure 2). As input, CNV2SV requires two VCF files containing the CNV and SV calls to be linked, respectively, as well as the reference genome sequence for which CNVs were called (.fasta). For each CNV, we identify matching SVs representing putative tandem duplication or translocation events. After validating each putative link through pairwise sequence alignment, the details for each CNV-SV match are saved in a .tsv file along with summary statistics. The output can then be further visualized using a circular plot showing the genomic positions for each discovered link. The results of CNV2SV may be interpreted in order to better understand the structural changes underlying individual CNV calls as well as evaluating and potentially improving the accuracy of break point detection for structural events of different sizes and complexities.
CoronaSV: CoronaSV is a method developed for generating accurate and trustworthy SV calls across SARS-Cov-2 genomes. The tool utilises available SRA data from SARS-CoV-2 isolates that have been sequenced with both Illumina and ONT platforms. CoronaSV utilizes a combination of three different approaches: read-based SV detection with paired-end Illumina reads and ONT long-reads, as well as assembly-based SV detection using both short and long-reads ( Figure 3). All the software packages used by CoronaSV can be installed via the Conda package manager ( https://github.com/conda/conda).
CleanSV: The goal of the hackathon project was to develop filters and QC checks to remove false positive calls from common SV callers. Currently, within clinical genomics, it’s exceptionally difficult to categorize true positives from false positives, thus making accurate diagnoses virtually impossible. The situation is even more complicated within clinical oncology, as researchers need to precisely separate true somatic calls from false positives and (potential) germline calls. In order to aid with precision SV calling, the team wrote a set of scripts to be used with short-read SV callers, allowing researchers to better generate a set of high-quality SVs to further investigate manually ( Figure 4).
Figure 4. An illustration of the approach used by CleanSV to generate and implement filtration of SV calls.

CleanSV pipeline highlighting methods used to generate adequate filters that can be utilised by clinicians to filter false positive and mislabeled SV calls from short-read cancer datasets.
For cancer genomics, groups normally develop in-house filters to improve the precision of SV calling. The scripts developed for this project accept as input GRIDSS, 43 Manta, 44 DELLY, 45 and SvABA 46 calls from short-read WGS data, along with a manually-curated reference set of calls designated as ground truth. The reference set was curated using a paired melanoma and normal lymphoblastoid COLO829 cell lines using four different technologies (Illumina HiSeq, Oxford Nanopore, Pacific Biosciences and 10x Genomics), along with extensive external validation. 47 Using the reference set, we proceeded to investigate the presence and nature of false positives from the initial callsets. (Note that we focused on WGS for this hackathon, but a similar approach could be applied to other assays such as WES.) Samplot 48 visualization of read data allowed manual curation of parameters associated with FP calls, and associations between AnnotSV 48, 49 annotated parameters and FPR helped identify additional FP-associated SV parameters ( Figure 4). Along with the manually-curated reference set, the panel of normal (PON) used for further filtering was generated from a compiled set of high-quality germline calls using 3,782 normal samples freshly-sequenced at a median depth of 38x by the Hartwig Medical Foundation. 50, 51
Sniphles: The main idea is to phase the identified SVs. We use two approaches; the first is to extract the tagged reads from the bam file and use these reads to phase the SVs if not conflicted. The second approach is to split the haplotype bam file based on the haplotype tag, using each split bam file to call SVs separately, this method called (Sniphles). Sniphles utilize information impeded in haplotypes, bam file and reads info support SVs. This method phases structural variants and augments the ability of Sniphles to accurately call SVs ( Figure 5). Sniphles is implemented in Python 3, and it takes a haplotyped bam, and a SV VCF file as input and produces a phased VCF file as output.
Swagg: Structural Variation with Annotated Graph Genomes (SWAGG) is a pipeline to make genome graphs from read data. The input into the pipeline is reads either with or without reference genome(s). Reads can be short-reads or preprocessed (basecalled) long-reads. Reads are assembled into longer contigs, and contigs are mapped back to the reference genome to look for discrepancies with the reference genome. These discrepancies can be either real mutations or sequencing artifacts, and are found using structural variant tools which output VCF files for each read set. These VCF files are taken together to make the genome graph at the end of the pipeline ( Figure 6).
PanOriginSV: This tool is a lab-of-origin prediction tool that combines machine learning approaches with graphical pangenome based alignment to predict lab-of-origin ( Figure 7). PanOriginSV is implemented in Python 3 and uses the scikit-learn package for deploying machine learning models. PanOriginSV also relies on MMseqs2 for clustering, BCALM for graph construction and minigraph for graph alignment. Given a training set of engineered plasmids and their source labs, this software can predict the lab of origin of a test set of plasmids.
GeneVar: The GeneVar tool was developed to help inform the clinical interpretation of structural variants pertaining to a user-provided gene. This software is an open access, gene-centric data browser for SV analysis. GeneVar is a web page application ( Figure 8). After entering the gene name (HGNC, Ensembl gene (ENSG), or transcript (ENST) identifier) in the search box on the homepage, the user is directed to the summary of the gene-specific page. GeneVar is available on GitHub ( https://github.com/collaborativebioinformatics/GeneVar). The repository provides detailed instructions for tool usage and installation. A bash script for automated installation of the required dependencies is also provided.
SVTeaser: SVTeaser is a tool for rapid assessment of SV call fidelity created for geneticists designing experiments to genotype a set of pre-ascertained SVs and bioinformaticians benchmarking a new algorithm against pre-existing tools across a range of parameters ( Figure 9). Users are required to supply SVTeaser with a reference sequence file (.fasta) and, optionally, a set of SVs (.vcf). SVTeaser outputs assorted statistical metrics across a range of read lengths and depths. SVTeaser achieves rapid assessment by downsampling the full reference to a subset of numerous 10kb samples to which it adds SVs.
XSVLen: This software is a framework for benchmarking SV detection algorithms against haplotype-resolved assemblies in which variants are validated by comparing sequence content rather than comparing breakpoints of variants ( Figure 10). XSVLen validates a VCF file with sequence-resolved variants including those produced by cuteSV or Sniffles 10) by creating a test sequence for each variant defined by extracting the region around a variant, and applying the SV operation (insertion or deletion). The test sequences are mapped to the haplotype-resolved assemblies, and high-identity alignments validate calls. All methods are open-source licensed and have been made available on GitHub: https://github.com/collaborativebioinformatics.
Operation
nibSV: nibSV requires a reference genome and VCF file that includes all the SV that should be genotyped ( Figure 1). Next, allele kmers for the reference and alternative are extracted. The extraction process includes each site’s flanking regions. Subsequently, the occurrence of these k-mers in the reference fasta file are counted. This step is necessary to prevent k-mer miscounting between reference vs. alternative allele. To enable scaling of nibSV for large data sets, the results of these two steps are written into a temporary file, which is all that is needed for the actual genotyping step. During the genotyping step, nibSV uses this small temporary file and the bam/cram file of the sample and identifies the presence/absence of the reference and alternative k-mer across the entire sample. This is very fast and requires only minimal resources of memory as the number of k-mers is limited. On completion of nibSV a scanning of the bam/cram file is carried out reporting which SV have been re-identified by adding a tag in the output VCF file of this sample ( Figure 1). The VCF per sample can then be merged to obtain population frequencies. The VCF per sample can then be merged to obtain population frequencies. nibSV requires 4Gb of memory, a single core and around 2GB hard disk space to store its index from e.g. GIAB HG002.
CNV2SV: To link copy number variant calls to matching structural variants, CNV2SV requires three input files: The VCF file containing the CNVs (typically called from short reads), the VCF file with the structural variants (typically called from a genome-genome alignment) as well as the reference sequence(.fasta) that the CNVs were called for. CNVs are then linked to matching SVs in two steps: First, individual CNVs are queried against an interval tree structure containing all SVs from the genome-genome alignment to find adjacent CNV-SV pairs (<1000 bp apart, putative tandem duplication events). For CNVsthat had no match identified in this way, the search is successively extended to the whole genome (putative translocation events). Next, all putative CNV-SV links are evaluated by pairwise sequence alignment using mappy (Python binding for minimap252), with a standard sequence identity threshold of 0.8. The main output comprises detailed information about the discovered links for each CNV. This includes the number of best matched SV, its genomic coordinates and CNV-SV sequence alignment as well as summary statistics useful for evaluating e.g. the quality/resolution of breakpoints identified by the CNV callers. Furthermore, all additionally identified adjacent and distant SVs are reported separately for each CNV. The raw output can be further visualized toshow the CNV-SV links identified across the genome in a circular plot, as well as summary statistics for the linking results. For the results presented in theuse cases section, we applied CNVnator53 and dip call to generate CNV and SV calls for the T2T CHM13 data set and GRCh38, respectively. A quick-start example for the CHM13 and GRCh38 data is available on our GitHub page. In addition, we hosted a detailed description of the output data on the GitHub page. The output data can be further visualized using the additionally provided scripts, which include circular plots to display the positions of each discovered CNV-SV link. System requirements (see GitHub for more information): CNV2SV has been tested to work on a desktop system on the CHM13 data set with an Intel ® i7-6700K Processor (4.00 Ghzquad-core), 32GB RAM (less may be required), 50GB free disk space and running Unix-like operating system (e.g. Ubuntu-based distribution) or Windows subsystem for Linux running Ubuntu. The initial genome-genome alignment (CHM13vs GRCh38) was computed on a cloud-based platform (DNANexus). CNV2SV requires Python (3.8 or newer) and prerequisite Python packages include interval tree, mappy and pyfaidx. For visualization of the discovered CNV-SV links in acircular plot, R and the R package circlize are additionally required. A full list of package dependencies is available on the GitHub page.
System requirements (see GitHub for more information): CNV2SV has been tested to work on a desktop system on the CHM13 data set with an Intel® i7-6700K Processor (4.00Ghz quad-core), 32GB RAM (less may be required), 50GB free disk space and running Unix-like operating system (e.g. Ubuntu-based distribution) or Windows subsystem for Linux running Ubuntu. The initial genome-genome alignment (CHM13 vs GRCh38) was computed on a cloud-based platform (DNANexus). CNV2SV requires Python (3.8 or newer). A full list of package dependencies is available on the GitHub page.
CoronaSV: All software packages used by CoronaSV can be installed via the Conda package manager. Additionally, the CoronaSV workflow is defined using Snakemake. Running the CoronaSV.smk snakemake pipeline handles downloading all specified data and processing of sequencing data to variant calls. Each step of the CoronaSV pipeline ( Figure 3) has a defined conda environment with exact versions of software specified for easy installation. CoronaSV utilizes three approaches that includes 1) read-based SV detection with paired-end Illumina reads, 2) ONT long-reads and 3) assembly-based SV detection. Illumina paired-end short-reads are trimmed using trimmomatic 52 and mapped to the SARS-CoV-2 reference using bwa mem. 53 After mapping, PCR duplicates are removed with Picard MarkDuplicates ( http://broadinstitute.github.io/picard). Structural variants are identified then using Delly, 45 Manta, 44 Lumpy, 54 and Tardis. 55 Nanopore long-reads are filtered using Nanofilt and mapped to SARS-CoV-2 reference using minimap2 with default parameters. SVs are then called using Sniffles, SVIM, and CuteSV. Read quality assessment is carried out by NanoPlot. In order to integrate assembly based methods, de novo SARS-CoV-2 assemblies were generated using Unicycler for short-read sequencing. NucDiff and SVanalyzer tools are used for assembly-to-assembly comparisons. Followup comparative analyses across callsets is implemented by SURVIVOR 56 ( Figure 3).
System requirements: CoronaSV is tested on Linux-based systems with multiple illumina and nanopore sequencing data (see GitHub for full list of the testing data). The RAM usage of CoronaSV depends on the size of input data. Peak RAM usage appears during de novo assembly using Unicycler, and 16 GB of RAM is sufficient for the pipeline to run on 8 CPU cores with additional 50Gb of disk space. CoronaSV requires python (version 3.6 or newer) and snakemake. Required tools and package dependencies can be found on GitHub page.
CleanSV: The methods adopted to construct the CleanSVs filtration protocols are shown in Figure 4. In order to generate the data required to develop adequate filters for the application within clinical ontology, structural variants (SVs) were called on Illumina short reads using novoalign hs37d5 HG002 BAM ( ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/reference/phase2_reference_assembly_sequence/hs37d5.fa.gz) and Illumina short-read HiSeqX Ten hg19 COLO829 BAM ( https://nextcloud.hartwigmedicalfoundation.nl/s/LTiKTd8XxBqwaiC?path=%2FHMFTools-Resources%2FGRIDSS-Purple-Linx-Docke r) using GRIDSS, 43 Delly, 45 and Manta. 44 44 (Note we chose HG00241, the son of the“Ashkenazim Trio”, as it has been extensively characterized to serve as areliable reference in human genomics). The set of curated SVs based on HG002 [Cite: https://www.nature.com/articles/s41587-020-0538-8] was used to determine the false positive (FP) SV calls in the short read dataset. Any SV calls that were found outside of the truthset Tier1 bed regions were then filtered. In the sample COLO829, the SV truthset was used to determine the FP SV calls in the short-read dataset. Calls were inspected through manual curation by Samplot. 57 Generated samplots were annotated with UCSC table browser repeat tracks and converted using vcfanno as well as GC content calculated by BEDOPS file conversion with the function.
We then compiled a set of high-quality germline calls using 3,782 normal samples freshly-sequenced at a median depth of 38x by the Hartwig Medical Foundation. 50, 51 We intiial hypothesized that such a large cohort could be used to both perform systematic FP filtering and possibly detect calls simply incorrectly labeled as somatic. The calls were filtered if a match within 2bp of the breakpoint was found in the PON. System requirements: The scripts to filter SV calls with either VCF or BEDPE format require R version 3.6.0 or higher, which is available for Linux, Mac OS, and Windows. The analyses within were run on R version 4.0.3, with Biocondcutor version 3.12. For running SV callers, it is recommended to use a HPC environment on Linux.
Sniphles: The Sniphles workflow ( Figure 5) requires the following dependencies: Python >= 3.6, Pysam (Version 0.16.0) ( https://github.com/pysam-developers/pysam), Cyvcf2 (Version 0.30.2), 58 Sniffles (Version 1.12), 10, 42 SURVIVOR (Version 1.0.7), 56 Mosdepth (Version 0.2.6), 59 Bcftools (Version 1.9), 60 tabix (Version 1.8). 61 The workflow partitions reads in the bam file into groups based on phase blocks and phase status, which enables parallel analysis of the data. The read coverage at each block and each phase is computed with Mosdepth and used to estimate the parameters for calling SVs by Sniffles. Next, the identified SVs per haplotype are concatenated using bcftools. SVs of two haplotypes are combined using SURVIVOR with option “1000 1 0 0 0 0” to merge SVs within 1 kbp between each other and to allow for different types of variants to be considered on different haplotypes. SVs are then force called with Sniffles using this combined vcf file. Force called SVs from each haplotype are combined with SVs of unphased regions as the final output ( Figure 5). To facilitate workflow testing, Princess ( https://github.com/MeHelmy/princess) was used to align, detect and phase SNVs and SVs from PacBio HiFi reads. The produced Bam from the previous step is the input for Sniphles, where pysam was used for alignment.
Swagg: The minimal system requirements for SWAGG are 8Gb RAM, 1 CPU and 10Gb of storage. Figure 6 demonstrates the implementation and operation of the SWAGG software package. Protein graphs are generated using a multiple sequence alignment of the proteins, then using the tool msa_to_gfa ( https://github.com/fawaz-dabbaghieh/msa_to_gfa) after which this multiple sequence alignment is converted into a graph file in GFA format, with the original sequences embedded as paths in the graph for visualization. This tool is tested with Python 3 and does not require any extra libraries or dependencies. New sequences can be aligned to these graphs using Partial Order Alignment algorithm for example.
PanOriginSV: PanOriginSV has three additional open source dependencies which are MMseqs2 (for clustering), BCALM (pangenome creation) and GraphAligner (for sequence-to-graph alignment). MMseqs2 is the most memory intensive step, and MMseqs2 requires roughly 1 byte per sequence residue. An overview of the pipeline utilised by this tool is highlighted in Figure 7. PanOriginSV performs lab-of-origin prediction in three distinct steps. Firstly, during the training phase PanOriginSV clusters similar sequences using MMseqs2. Further, the most similar clusters having a predefined number of representative lab labels are selected for the pangenome creation. Second, in order to incorporate SV information into the pangenome a graphical pangenome is created using BCALM for each of the clusters identified in the first step. These pangenomes reflect sequence-level structural variation that reveal important differences in highly similar sequences that could belong to different labs thereby reducing the possibility of false positives. The training sequences are then mapped back to their corresponding pangenome graph to obtain important alignment information including but not limited to number of hits and percentage identity of alignment. These are then collated and embedded into a feature vector that is passed on to a machine learning model for prediction.
Thirdly, features from the alignment steps are combined with sequence metadata and input into a random forest classifier that is trained to predict lab-of-origin in a multiclass classification task. Both the top-1 and top-10 predictions are output and compared to previous literature and Genetic Engineering Attribution Challenge (GEAC) benchmarks.
GeneVar: Figure 8 shows the different components of GeneVar, which is a web browser application. The webpage, including data storage, requires only one core with 1 Gb RAM and requires less than 1 Gb of storage. After entering the gene name (HGNC, Ensembl gene (ENSG), or transcript (ENST) identifier) in the search box on the homepage, you will be directed to the gene-specific page containing: 1) Gene-level summary with number of SVs, number of clinical SVs or SVs overlapping clinical SNVs, 2) Links to the gene's page on OMIM, GTEx, gnomAD, 3) A dynamic table with the annotated variants overlapping the gene, 4) A graph with the distribution of the allele frequency for variants matched with gnomAD-SV (50% reciprocal overlap). The profile of the SV to consider, such as type and size range, can be specified on the side bar. Each column in the dynamic table can be "searched" into or reordered dynamically. All data used by the app will be available for download in tab-delimited files. By default, allele frequency is reported based on dbVar 62 and gnomAD genomes and exomes. Furthermore, GeneVar utilises dbVar database and links SV to genes and annotate gene impact, allele frequency, and the overlap with clinically-relevant SVs, SNVs and indels. All data, are available for download in a tab-delimited file. Each variant has been extensively annotated and aggregated in a customizable table. GeneVar is available on GitHub ( https://github.com/collaborativebioinformatics/GeneVar). The repository provides detailed instructions for tool usage.
SVTeaser: SVTeaser generates regions from a user provided reference and adds in a structural variant into each region using one of two methods - 1) a call to SURVIVOR simSV 56 which generates random, simulated SVs by introducing variation (deletions (DEL) and insertions (INS) type of SV breakpoints) in DNA sequences, or 2) automatic spike-in of a known SV from an input SV VCF file. Resultant altered reference sequences are then used for Illumina short-read simulation using ART. 63 Parameters controlling simulated sequencing read-length, insert-size, and depth parameters can be altered. Simulated reads can then be mapped to the original, unaltered reference with any mapper of choice; here, BWA was used. Resultant BAM files can then be used to detect SVs using any mapping-based SV caller of choice; here, Parliament2 64 was used to generate calls with manta, breakseq, 60 cnvnator, and lumpy. The resultant VCFs are then matched to the simulated SVs’ VCFs using Truvari and output is parsed into a pandas dataframe for report generation. SVTeaser requires installation of Python 3.7, Truvari, SURVIVOR, 56 Vcftools and ART read simulator. The components of SVTeaser are shown in Figure 9.
XSVLen: The XSVLen workflow requires Python3, Minimap2, Nextflow, and R >=3.5.0. As demonstrated in Figure 10, XSVLen takes as input a haplotype-resolved de novo assembly, and a VCF file (generated by cuteSV 42 or sniffles 10) of variants including only insertion and deletion calls. For each insertion or deletion call within the vcf file, a modified reference genome is generated. This modified reference will contain a 1.5kb flanking sequence that either has the sequence removed if a deletion call, or the alternate sequence added between the flanking sequences if an insertion call. The resulting ‘query’ sequences are then mapped using minimap2 to both haplotypes. Each aligned query gives rise to a map of aligned bases P={(q 1,t 1), … , (q n,t n)}. To score each variant call, we find two indexes i, j. These index the end of the prefix, and beginning of the suffix in the query. When the call is valid, (P [j][0] - P [i][0]) - (P [j][ 1] - P [j][0]) is equal to 0. To account for differences in alignment, we iteratively search for an (i opt, j opt) combination, with i opt ≤ i and j ≤ j opt that gives the smallest difference. Variants are reported as valid if the difference is less than 10 bases or the intervals defined between P [i opt] and P [j opt] are within 95% length in either haplotype. A summary report is then produced using an R script.
Use Cases
nibSV:
We benchmarked nibSV over the GIAB HG002 SV call set. 65 In summary, this call set was created using multiple long and short read technologies and underwent manual validation across multiple groups to ensure an overall high quality and accuracy. Using an Illumina data set from (2x250 GIAB HG002) we benchmarked true positives (i.e. SV that should be present), false positives (i.e. parental only SV that should not be present in the proband HG002), and false negatives (i.e. SV that should be present in HG002 but were not found). Using only chr 22 from HG002, nibSV with a kmer size of 23 takes around 2-4 minutes on a single thread with a 80gb bam file and the provided VCF file. We assessed our recall at different k-mer sizes which increases with the kmer size. For example, k=21 (2min 3sec) achieves 0.59 recall with a precision of 0.83. Interestingly, for insertions the recall rate increases to 0.86 with a precision of 0.86.
CNV2SV:
Figure 11a shows the best links (based on the alignment identity score) between CNVs identified by CNVnator and duplication SVs inferred from the dipcall alignment of CHM13 and GRCh38. The genomic areas surrounding four selected adjacent duplication events are further highlighted using dot plots, revealing the architecture of the corresponding variation in the context of the genome-genome alignment. In Figure 11b, all CNV-SV links meeting a default alignment identity threshold are shown, further revealing events corresponding to putative copy number increases of greater than two. We further explored the reason why some CNV and SV could not be linked, through statistical analysis of the raw SV calls as shown in Figure 12.
Figure 11. Relationship between the CNV calls and identified SVs across the CHM13 genome.

CNV2SV results using CHM13 in comparison to GRCh38. (A) The diagram connects the genomic location of individual CNV calls on GRCh38 (broad ends) to the location of their linked SV identified in the GRCh38-CHM13 genome-genome alignment (thin ends). The diagram reveals a number of underlying putative translocation events identified for the called CNVs. Adjacent CNV-SV links (putative tandem duplications) are shown as streaks at the respective genomic position. For four select CNV-SV links, the genome-genome alignment for the underlying SV is further shown as a dot plot on the outside of the diagram. Only the best matching SV link (thin end) identified for each CNV call (broad end), as determined by sequence alignment score between both events, is shown here. (B) Similar to A, but displaying all potential CNV-SV links that meet the default alignment identity threshold of 0.8. CNVs with multiple matching duplication SV events identified in the genome-genome alignment can be explained by copy numbers greater than two occuring in distant locations, and alternatively may suggest the involvement of complex genomic rearrangements including transposable elements.
Figure 12. Summary the linkage statistics showing the characteristics of disparities between the CNV calls and SVs.

In terms of linkage statistics, the majority of the CNVs identified have not been linked to a SV event, as indicated by A. One of the main reasons for the unsuccessful linking is the length disparity between the called CNV events and SV events as shown in B. Overall, among linked CNV and SV events, the distribution of three major categories are shown in C: adjacent events, distant events, and events spanning multiple chromosomes. Distant events are called in the case when the linked SV is at least 1Kbp away from the CNV call (either upstream or downstream). Details of the distribution of the adjacent and distant events per CNV call are given in D and E shows that alignment quality is better for adjacent matches when compared to more distant SV matches. While most links for a single CNV event are unanimously distant or adjacent, we observed an event in which a CNV was linked to both an adjacent and a distant SV which occurs on chromosome 7 ( F: adjacent: chr7:100997804 length 8325 and distant: chr7:100994092 length 3249).
CoronaSV: We processed more than 200 SARS-CoV-2 SRA runs with CoronaSV, and Figure 13 shows the high confidence SVs generated with SURVIVOR 56 by taking a majority vote across multiple SV callers. We also looked for shared SVs across multiple samples. There were only a few inversions identified that were consistently and reliably called between samples. The inversions are likely related to the transcriptional landscape of SARS-CoV-2. 66 These inversions are small (less than 1Kb), and five of them were found in ORF1ab and one on ORF M.
Figure 13. An analysis of size and number of identified SARS-CoV-2 SVs.

Histogram showing size of the SVs and the total number of SVs across multiple Nanopore and Illumina datasets. The y-axis of the histogram is log compressed.
CleanSV: We investigated filtering SV calls using both the curated reference set and a high-quality panel of normals (PON). The PON was created using GRIDSS calls from 3,782 normal samples freshly-sequenced at a median depth of 38x by the Hartwig Medical Foundation. 50, 51 Using this PON consisting of GRIDSS calls from 3,792 freshly-sequenced normal WGS samples, we explored how the percentage of calls from short-read SV callers which were incorrectly labeled as true somatic calls, either due to being algorithmic artifacts or germline calls. Our results show the promise of such an approach. ( Figure 14). Note that this is not only a check for false positives: we know a priori that many calls from somatic SV callers are mislabeled as somatic when they’re actually germline. This is a known algorithmic error: SVs are normally first called in the normal sample and labeled as “germline”, and then the resulting SVs called using the tumor sample (separately or jointly with against the normal) are labeled as “somatic”. While such an approach is common for short-read SV callers, this frequently leads to mislabeled results, often for the simple reason that the normal sample is sequenced at a much lower coverage than the tumor sample.
Figure 14. Filtering somatic SV calls using a Panel of Normals.
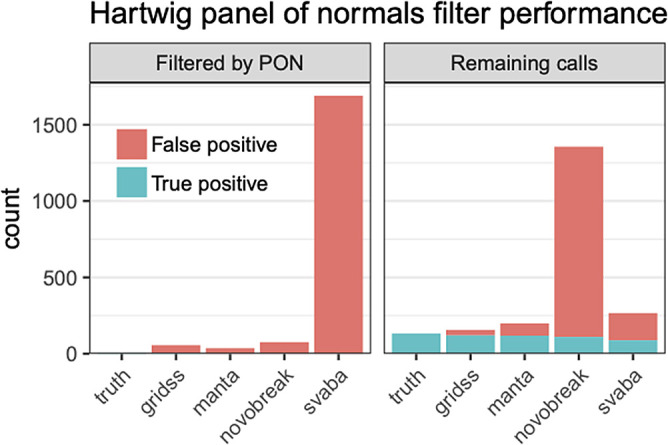
Using a cohort of 3,792 freshly-sequenced WGS normal samples to create a Panel of Normals (PON) from GRIDSS calls and a set of curated calls from sample COLO829 to classify false positives, we discover that a sizeable number of false positives were found within the panel of normals, suggesting that these were miscategorized due to algorithmic errors. PON filtering based on GRIDSS calls is effective for the modern callers such as GRIDSS, Manta and SvABA which (partially) rely upon localized assembly.
In order to release these filters/thresholds to the larger community for general usage, these filters need to be tailored specifically for specific assays. The optimal approach would be to focus on a particular use of SV calling (e.g. therapeutic oncology) with a particular assay of a certain average coverage and tumor purity. We suspect generating filters per SV caller for general use would result in minimal quality control; this is especially true within cancer genomics in terms of calling somatic and germline SVs accurately.
We plan to continue to explore whether the false positives found exhibit distinct features which we could use for future filters to distribute to the community. With these insights, given that clinical genomics still overwhelmingly relies upon short-read sequencing, our goal would be to also apply filters to all variants (e.g. the case of Mendelian diseases).
Sniphles:We used Princess ( https://github.com/MeHelmy/princess) to align, detect and phase SNVs and SVs from PacBio HiFi reads 32x coverage. The resulting haplotyped bam is the input for Sniphles, where pysam ( https://github.com/pysam-developers/pysam) was used for alignment. For each phase block we used the mosdepth 59 to detect coverage. Later, we called SVs using Sniffles 10, 42 with the adequate numbers of reads to support SV. The identified SVs per phase block were sorted and concatenated using bcftools version 1.9, 67 and both the haplotypes were merged using SURVIVOR. Sniphles is a prototype of the idea we introduced in the manuscript and so it is still under development.
Swagg: The main results from the Swagg package includes the development of the graph module and the protein graphical application ( Figure 15). The graph module is able to retrieve basic statistics from a pangenome graph in GFA format from either reference-based (fasta + VCF) or a set of assemblies (fasta), followed by conducting a pairwise comparison of all paths in the graph, and outputting a matrix in TSV format with the path names and corresponding samples in the first position. After creating the pairwise matrix, the module can plot an SV pileup over any path in the graph, counting the number of other paths that contain an SV overlapping each position. In addition to utilizing the pairwise comparisons where hotspots are references to a given sample, this approach also allows for graphs derived from vcf files. The objective from the protein graph mapping application was to show if the variants introduce new amino acids or stop a stop codon. Similarly, a pangenome graph can be constructed from DNA sequences as panproteome graphs can be built from different amino acid sequences of a protein. These graphs can then help visualize the variants between the sequences and show the paths each sequence take through the graph. Another layer of information can be added to the nodes, e.g. does a node represent a conserved or a non-conserved side, does a path divergence in the graph has any significant phenotypic characteristics, relating genome-wide association studies to these proteins graph. 68 Therefore, when aligning a new sequence to the graph, one can check the path the new sequence took in the graph and what information are related to this path. 69 Figure 15 shows an example of an annotated graph of the Nucleocapsid Phosphoprotein in SARS-COV-2.
Figure 15. SARS-COV-2 nucleocapsid protein graph.

Protein graph with paths representing the original sample. This graph here is a directed acyclic graph of an MSA of 26 “N” gene (Nucleocapsid Phosphoprotein) generated from 26 SARS-COV-2. Visualized using gfaviz. 70
PanOriginSV: It became apparent that the quality and representation of the clusters was a main factor in prediction accuracy. To this end, we tested PanOriginSV on a range of clusters of at least 500 sequences and only considered cases where the test sequence had a training representative in the assigned cluster. The CPU time used by PanOriginSV was 10-50x less than the linear model constructed by Plasmidhawk (depending on the cluster). We observed a range of results, with the linear prediction model outperforming PanOriginSV by up to 5% in some clusters and PanOriginSV outperforming the linear model by up to 6% in others ( Table 1). With deeper analysis of the input data, we hope to achieve better clusters and thus better prediction results with the graph model. It is also worth noting that our graph construction method can be improved using more recent pangenome graph construction tools.
Table 1. Summary of PanOriginSV prediction accuracy.
Benchmarking results on large clusters obtained from MMseqs2. For a single cluster, 25% of sequences were held out and used as the testing set. The accuracy of the top predicted lab was consistently higher in PanOriginSV compared to PlasmidHawk, however the accuracy when testing against the top 5 predictions for both tools was comparable.
| Cluster | Train Sequences | Test Sequences | Test accuracy (Linear) | Top 5 test accuracy (Linear) | Test accuracy (Graph) | Top 5 test accuracy (Graph) |
|---|---|---|---|---|---|---|
| J7OEM | 2870 | 714 | 0.96 | 0.99 | 0.97 | 0.99 |
| 3PTDM | 2397 | 571 | 0.82 | 0.93 | 0.81 | 0.93 |
| O3GQU | 1046 | 275 | 0.65 | 0.88 | 0.71 | 0.83 |
| 48073 | 973 | 205 | 0.71 | 0.89 | 0.71 | 0.87 |
| WA905 | 639 | 149 | 0.87 | 0.94 | 0.87 | 0.97 |
| GIGX0 | 604 | 119 | 0.71 | 0.87 | 0.79 | 0.93 |
GeneVar: Databrowser. Upon querying a gene or transcript, the data browser will visualize a rare-variant burden test, allele frequency distribution, and variant level information for known SVs within dbVar. The data browser does not have a login requirement and integrates multiple public resources ( Figure 16). To illustrate whether a particular gene/transcript or exon has been adequately covered to detect variation, the average depth of coverage is graphically represented. An additional panel shows gene expression levels across all general tissues included in GTEx. 71 Report summary. Analysis results are enriched with information from several widely used databases such as ClinVar 72 and gnomAD, 73 as well as graphical visualization utilities integrated in the pipeline as part of GeneVar. Resulting variants are reported in a tab delimited format to favor practical use of worksheet software such as iWork Number, Microsoft Excel or Google Spreadsheets. All information can be downloaded in tabular form.
Figure 16. User interface of GeneVar data browser.

A description of the elementary transcript details for the gene of interest. This includes the Ensembl transcript ID, Ensembl Gene ID, number of exons and genomic coordinates as described in the GRCh38 build.
SVTeaser: SVTeaser was able to simulate SV data on average 14 min per sample when tested on chromosome two. SVTeaser output includes organized VCF results of true positive, false positive, and false negative from evaluated SV callers. Furthermore, performance scores are reported alongside automated plots for quick visual evaluation of SV callers ( Figure 17). SVTeaser is able to simulate sequencing for known deletions and insertions with various coverage, read length, and insert length. This enabled thorough evaluation for understanding the strengths and boundaries of the SV callers in question ( Figure 18).
Figure 17. Summary report output of SVTeaser.

A report generated from benchmarking a real HG002 Manta 30x Illumina sample against GIAB Tier1 SVs. A) Counts of SVs by SVType and their intersection state with GIAB Tier1 benchmark SVs. B) Summary table of benchmarking performance.
C) Proportions of SV intersection states with the benchmark by SV size bin.
Figure 18. A comparison of simulated DELs across SV callers and sequencing coverages.

Count of False Positives, False Negatives, and True Positives from four SV callers (columns) against chromosome 2 deletions through multiple simulated coverages (rows). SV callers: breakseq, lumpy, manta, cnvnator. Coverages: 10x, 20x, 30x.
XSVLen: A diploid assembly of HG002 from Wenger et al74 was used to benchmark variants. The assembly has an N50 of 16.1 and 18.0 Mb per haplotype. Variants were called using 50-fold coverage of ONT reads using CuteSV version v1.0.8. The number of INS and DEL per SV size can be observed in Table 2. The number of INS/DEL overlapping with the haplotype-resolved assemblies are shown in Table 2 as well as a comparison of assembly-based calls and gold-standard Truvari calls.
Table 2. Summary:
Insertion and deletion events are compared according to structural variant size and number and overlaps with the haplotyped assembly used in their performed evaluation. Truvari classification for the overlapping calls are shown as well as TP and FP found in the haplotyped assembly.
| SVType | Insertions | Deletions | ||
|---|---|---|---|---|
| SVLen | <50 | >=50 | <50 | >=50 |
| Number of insertion/deletion calls by cuteSV | 20007 | 14942 | 38331 | 10926 |
| Number of these calls that overlap assembly contigs | 16054 | 12075 | 30494 | 4074 |
| Number of truvari
TP/FP/no-call (NP) |
3351 FP
7200 TP 15974 NP |
368 FP
4348 TP 7359 NP |
1842 FP
18 TP 28634 NP |
117 FP
1137 TP 2820 NP |
| Number of assembly calls
TP/FP/no-call (NP) |
5220 FP
10834 TP |
8979 FP
8502 TP |
23202 FP
7292 TP |
3444 FP
3031 TP |
Conclusion
The results of the 2020 Baylor College of Medicine/DNANexus hackathon described here represent novel work that pushes the field forward for human genome SV detection but also for Covid related research. Both are needed to further current findings about diversity and the complexity of organisms and their genotypes. To further facilitate this progress in a FAIR-compliant manner, 80 people came together from across the world in October 2020 completed 10 groundbreaking prototypes. Hackathons like these not only represent short bursts of prototype development, but are essential to form groups and communities, inspire communication across countries and research institutions, and form novel collaboration networks. As such, this year’s hackathon not only sparked the projects described here, but also highlighted the need for unified databases for SVs and other genomic features hosted on DNAnexus, Anvil, and other platforms as well as larger standards and references (e.g. GIAB, UKBB). This is essential to ensure quality standards for benchmarking and comparability, which will further advance the science and medical research.
Rapidly switching to a completely remote hackathon that enabled increased international participation was made necessary by the COVID-19 pandemic. This allowed for an open science effort across an even more diverse population of individuals and professional backgrounds. That diversity made it possible to complete 10 projects, which spearheaded novel insights in the understanding of structural variants in humans, as well as COVID19 genome structure. More importantly, it led to new synergies among participants, an active online community, and new friendships across borders.
Data availability
Associated code is available at: DOI 10.17605/OSF.IO/ME62X
Data sources utilized:
NibbleSV: Genome in a Bottle, HG002, SV callset ( ftp://ftp-trace.ncbi.nlm.nih.gov/ReferenceSamples/giab/data/AshkenazimTrio/HG002_NA24385_son/PacBio_CCS_15kb/).
CNV2SV: CHM13 ( https://github.com/nanopore-wgs-consortium/CHM13#telomere-to-telomere-consortium) and GRCh38.
CoronaSV: Data sources available on https://github.com/collaborativebioinformatics/coronasv.
CleanSV: hs37d5 HG002 BAM ( ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/reference/phase2_reference_assembly_sequence/hs37d5.fa.gz), hg19 COLO829 BAM ( https://nextcloud.hartwigmedicalfoundation.nl/s/LTiKTd8XxBqwaiC?path=%2FHMFTools-Resources%2FGRIDSS-Purple-Linx-Docker).
SWAGG: Data sources available on https://github.com/collaborativebioinformatics/swagg/blob/main/sample_manifest.tsv.
XSVLen: HG002 haplotyped-resolved assemblies (NCBI assembly with accessions GCA_0047796458.1 (maternal) and GCA_004796285.1 (paternal)), GIAB HG002 truthset ( https://ftp-trace.ncbi.nlm.nih.gov/giab/ftp/data/AshkenazimTrio/analysis/NIST_SVs_Integration_v0.6/HG002_SVs_Tier1_v0.6.vcf.gz).
GeneVar: Data sources available on https://github.com/collaborativebioinformatics/GeneVar.
PanOriginSV: genetic engineering attribution challenge (GEAC).
https://www.drivendata.org/competitions/63/genetic-engineering-attribution/.
SVTeaser: All data utilized was based on simulations
Sniphles: Genome in a Bottle, HG002, SV callset ( ftp://ftp-trace.ncbi.nlm.nih.gov/ReferenceSamples/giab/data/AshkenazimTrio/HG002_NA24385_son/PacBio_CCS_15kb/).
Software availability
NibbleSV
Source code available from: https://github.com/collaborativebioinformatics/nibSV
Archived source code at time of publication:
License: MIT license
CNVSV
Source code available from: https://github.com/collaborativebioinformatics/CNV2SV
Archived source code at time of publication:
License: MIT license
CoronaSV
Source code available from: https://github.com/collaborativebioinformatics/coronasv
Archived source code at time of publication:
License: MIT license
CleanSV
Source code available from: https://github.com/collaborativebioinformatics/CleanSV
Archived source code at time of publication:
License: MIT license
Sniphles
Source code available from: https://github.com/collaborativebioinformatics/Sniphles
Archived source code at time of publication:
License: MIT license
Swagg
Source code available from: https://github.com/collaborativebioinformatics/swagg
Archived source code at time of publication:
License: MIT license
PanOriginSV
Source code available from: https://github.com/collaborativebioinformatics/PanOriginSV
Archived source code at time of publication:
License: MIT license
GeneVar
Source code available from: https://github.com/collaborativebioinformatics/GeneVar
Archived source code at time of publication:
License: MIT license
SVTeaser
Source code available from: https://github.com/collaborativebioinformatics/SVTeaser
Archived source code at time of publication:
License: MIT license
XVSLen
Source code available from: https://github.com/collaborativebioinformatics/The_X_team
Archived source code at time of publication:
License: MIT license
Acknowledgements
The authors like to thank Richard Gibbs, Aaron Wenger and Stephen Rudd for their helpful discussions during the hackathon. In addition, Gerald Wright and Brenton Pyle for helping with advertisement and organising. DNA nexus provided computational resources for the hackathon. The authors would also like to thank Oxford Nanopore Technologies and Pacific Biosciences for sponsored prizes.
Funding Statement
Michael Jochum is supported by NIH/NICHD grant award 1T32HD098068-01A. Wouter De Coster is supported by an FWO junior postdoc grant. Daniel Cameron is supported by NHMRC Ideas Grant 1188098. James Havrilla is supported by R01 GM132713-02S1 for this work. Ann Mc Cartney was supported, in part, by the Intramural Research Program of the National Human Genome Research Institute, National Institutes of Health. Ahmad Al Khleifat is funded by The Motor Neurone Disease Association and NIHR Maudsley Biomedical Research Centre. Timothy Hefferon is supported by the Intramural Research Program of the National Library of Medicine, National Institutes of Health. BK, TT & NS were supported, in part, by a C3.ai Digital Transformation Institute COVID-19 award FS & MH was supported by NIH UM1 HG008898 NIH.
The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
[version 2; peer review: 1 approved
References
- 1.Ho SS, Urban AE, Mills RE: Structural variation in the sequencing era. Nat Rev Genet. 2020 Mar;21(3):171–89. 10.1038/s41576-019-0180-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Feuk L, Carson AR, Scherer SW: Structural variation in the human genome. Nat Rev Genet. 2006 Feb;7(2):85–97. 10.1038/nrg1767 [DOI] [PubMed] [Google Scholar]
- 3.Alkan C, Coe BP, Eichler EE: Genome structural variation discovery and genotyping. Nat Rev Genet. 2011 May;12(5):363–76. 10.1038/nrg2958 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Sanchis-Juan A, Stephens J, French CE, et al. : Complex structural variants in Mendelian disorders: identification and breakpoint resolution using short- and long-read genome sequencing. Genome Med. 2018 Dec 7;10(1):95. 10.1186/s13073-018-0606-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Li Y, Roberts ND, Wala JA, et al. : Patterns of somatic structural variation in human cancer genomes. Nature. 2020 Feb;578(7793):112–21. 10.1038/s41586-019-1913-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Seaby EG, Ennis S: Challenges in the diagnosis and discovery of rare genetic disorders using contemporary sequencing technologies. Brief Funct Genomics. 2020 Jul 29;19(4):243–58. 10.1093/bfgp/elaa009 [DOI] [PubMed] [Google Scholar]
- 7.Jenko Bizjan B, Katsila T, Tesovnik T, et al. : Challenges in identifying large germline structural variants for clinical use by long read sequencing. Comput Struct Biotechnol J. 2020;18:83–92. 10.1016/j.csbj.2019.11.008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Wenger AM, Peluso P, Rowell WJ, et al. : Accurate circular consensus long-read sequencing improves variant detection and assembly of a human genome. Nat Biotechnol. 2019 Oct;37(10):1155–62. 10.1038/s41587-019-0217-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Norris AL, Workman RE, Fan Y, et al. : Nanopore sequencing detects structural variants in cancer. Cancer Biol Ther. 2016 Jan 19;17(3):246–53. 10.1080/15384047.2016.1139236 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Sedlazeck FJ, Rescheneder P, Smolka M, et al. : Accurate detection of complex structural variations using single-molecule sequencing. Nat Methods. 2018 Jun;15(6):461–8. 10.1038/s41592-018-0001-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Tsang H-F, Xue VW, Koh S-P, et al. : NanoString, a novel digital color-coded barcode technology: current and future applications in molecular diagnostics. Expert Rev Mol Diagn. 2017 Jan;17(1):95–103. 10.1080/14737159.2017.1268533 [DOI] [PubMed] [Google Scholar]
- 12.Chen S, Krusche P, Dolzhenko E, et al. : Paragraph: a graph-based structural variant genotyper for short-read sequence data. Genome Biol. 2019 Dec 19;20(1):291. 10.1186/s13059-019-1909-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hickey G, Heller D, Monlong J, et al. : Genotyping structural variants in pangenome graphs using the vg toolkit. Genome Biol. 2020 Feb 12;21(1):35. 10.1186/s13059-020-1941-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Christgen M, van Luttikhuizen JL, Raap M, et al. : Precise ERBB2 copy number assessment in breast cancerby means of molecular inversion probe array analysis. Oncotarget. 2016 Dec 13;7(50):82733–82740. 10.18632/oncotarget.12421 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Boujemaa M, Hamdi Y, Mejri N, et al. : Germline copy number variationsin BRCA1/2 negative families: Role in the molecular etiology of hereditarybreast cancer in Tunisia. PLoS One. 2021 Jan 27;16(1):e0245362. 10.1371/journal.pone.0245362 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Eisenstein M: Closing in on a complete humangenome. Nature. 2021 Feb;590(7847):679–681. 10.1038/d41586-021-00462-9 [DOI] [PubMed] [Google Scholar]
- 17.Islam MR, Hoque MN, Rahman MS, et al. : Genome-wide analysis of SARS-CoV-2 virus strains circulating worldwide implicates heterogeneity. Sci Rep. 2020 Aug 19;10(1):14004. 10.1038/s41598-020-70812-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Young BE, Fong S-W, Chan Y-H, et al. : Effects of a major deletion in the SARS-CoV-2 genome on the severity of infection and the inflammatory response: an observational cohort study. Lancet. 2020 Aug 29;396(10251):603–11. 10.1016/S0140-6736(20)31757-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Cameron DL, Di Stefano L, Papenfuss AT: Comprehensive evaluation and characterisation of short read general-purpose structural variant calling software. Nat Commun. 2019 Jul 19;10(1):3240. 10.1038/s41467-019-11146-4 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.McCrone JT, Lauring AS: Measurements of Intrahost Viral Diversity Are Extremely Sensitive to Systematic Errors in Variant Calling. J Virol. 2016 Aug 1;90(15):6884–95. 10.1128/JVI.00667-16 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Weißbach S, Sys S, Hewel C, et al. : Reliability of genomic variants across different next-generation sequencing platforms and bioinformatic processing pipelines. BMC Genomics. 2021 Jan 19;22(1):62. 10.1186/s12864-020-07362-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Sandmann S, Karimi M, de Graaf AO, et al. : appreci8: a pipeline for precise variant calling integrating 8 tools. Bioinformatics. 2018 Dec 15;34(24):4205–12. 10.1093/bioinformatics/bty518 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Bamshad MJ, Ng SB, Bigham AW, et al. : Exome sequencing as a tool for Mendelian disease gene discovery. Nat Rev Genet. 2011 Sep 27;12(11):745–55. 10.1038/nrg3031 [DOI] [PubMed] [Google Scholar]
- 24.Liu H-Y, Zhou L, Zheng M-Y, et al. : Diagnostic and clinical utility of whole genome sequencing in a cohort of undiagnosed Chinese families with rare diseases. Sci Rep. 2019 Dec 18;9(1):19365. 10.1038/s41598-019-55832-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Murciano-Goroff YR, Taylor BS, Hyman DM, et al. : Toward a More Precise Future for Oncology. Cancer Cell. 2020 Apr 13;37(4):431–42. 10.1016/j.ccell.2020.03.014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Donoghue MTA, Schram AM, Hyman DM, et al. : Discovery through clinical sequencing in oncology. Nature Cancer. 2020 Aug 10;1(8):774–83. 10.1038/s43018-020-0100-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Mahmoud M, Gobet N, Cruz-Dávalos DI, et al. : Structural variant calling: the long and the short of it. Genome Biol. 2019 Nov 20;20(1):246. 10.1186/s13059-019-1828-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Chaisson MJP, Sanders AD, Zhao X, et al. : Multi-platform discovery of haplotype-resolved structural variation in human genomes. Nat Commun. 2019 Apr 16;10(1):1784. 10.1038/s41467-018-08148-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Ben-David U, Amon A: Context is everything: aneuploidy in cancer. Nat Rev Genet. 2020 Jan;21(1):44–62. 10.1038/s41576-019-0171-x [DOI] [PubMed] [Google Scholar]
- 30.Martin M, Patterson M, Garg S, et al. : WhatsHap: fast and accurate read-based phasing. bioRxiv. 2016 [cited 2018 Oct 23]. p.085050. Reference Source
- 31.Majidian S, Sedlazeck FJ: PhaseME: Automatic rapid assessment of phasing quality and phasing improvement. Gigascience. 2020 Jul1;9(7). 10.1093/gigascience/giaa078 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Sedlazeck FJ, Lee H, Darby CA, et al. : Piercing the dark matter: bioinformatics of long-range sequencing and mapping. Nat Rev Genet. 2018 Jun;19(6):329–46. 10.1038/s41576-018-0003-4 [DOI] [PubMed] [Google Scholar]
- 33.Edge P, Bansal V: Longshot enables accurate variant calling in diploid genomes from single-molecule long read sequencing. Nat Commun. 2019 Oct 11;10(1):4660. 10.1038/s41467-019-12493-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Jinek M, Chylinski K, Fonfara I, et al. : A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science. 2012 Aug 17;337(6096):816–21. 10.1126/science.1225829 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wang Q, Liu TR, Leo Elworth RA, et al. : PlasmidHawk: Alignment-based Lab-of-Origin Prediction of Synthetic Plasmids. Cold Spring Harbor Laboratory;2020 [cited 2021 Jan 13]. p.2020.05.22.110270. 10.1038/s41467-021-21180-w [DOI] [Google Scholar]
- 36.Chikhi R, Limasset A, Jackman S, et al. : On the representation of de Bruijn graphs. J Comput Biol. 2015 May;22(5):336–52. 10.1089/cmb.2014.0160 [DOI] [PubMed] [Google Scholar]
- 37.Rautiainen M, Mäkinen V, Marschall T: Bit-parallel sequence-to-graph alignment. Bioinformatics. 2019 Oct 1;35(19):3599–607. 10.1093/bioinformatics/btz162 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Steinegger M, Söding J: MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets. Nat Biotechnol. 2017 Nov;35(11):1026–8. 10.1038/nbt.3988 [DOI] [PubMed] [Google Scholar]
- 39.Ganel L, Abel HJ, FinMetSeq Consortium et al. : SVScore: an impact prediction tool for structural variation. Bioinformatics. 2017 Apr 1;33(7):1083–5. 10.1093/bioinformatics/btw789 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Kumar S, Harmanci A, Vytheeswaran J, et al. : SVFX: a machine learning framework to quantify the pathogenicity of structural variants. Genome Biol. 2020 Nov 9;21(1):1–21. 10.1186/s13059-020-02178-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Zook JM, Catoe D, McDaniel J, et al. : Extensive sequencing of seven human genomes to characterize benchmark reference materials. Sci Data. 2016 Jun 7;3:160025. 10.1038/sdata.2016.25 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Jiang T, Liu Y, Jiang Y, et al. : Long-read-based human genomic structural variation detection with cuteSV. Genome Biol. 2020 Aug 3;21(1):1–24. 10.1186/s13059-020-02107-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Cameron DL, Schröder J, Penington JS, et al. : GRIDSS: sensitive and specific genomic rearrangement detection using positional de Bruijn graph assembly. Genome Res. 2017 Dec;27(12):2050–60. 10.1101/gr.222109.117 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Chen X, Schulz-Trieglaff O, Shaw R, et al. : Manta: rapid detection of structural variants and indels for germline and cancer sequencing applications. Bioinformatics. 2016 Apr 15;32(8):1220–2. 10.1093/bioinformatics/btv710 [DOI] [PubMed] [Google Scholar]
- 45.Rausch T, Zichner T, Schlattl A, et al. : DELLY: structural variant discovery by integrated paired-end and split-read analysis. Bioinformatics. 2012 Sep 15;28(18):i333–9. 10.1093/bioinformatics/bts378 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Wala JA, Bandopadhayay P, Greenwald NF, et al. : SvABA: genome-wide detection of structural variants and indels by local assembly. Genome Res. 2018 Apr;28(4):581–91. 10.1101/gr.221028.117 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Valle-Inclan JE, Besselink NJM, de Bruijn E, et al. : A multi-platform reference for somatic structural variation detection. Cold Spring Harbor Laboratory. 2020 [cited 2021 Feb 2]. p.2020.10.15.340497. Reference Source
- 48.Belyeu JR, Chowdhury M, Brown J, et al. : Samplot: A Platform for Structural Variant Visual Validation and Automated Filtering. Cold Spring Harbor Laboratory. 2020 [cited 2021 Jan 13]. p.2020.09.23.310110. Reference Source [DOI] [PMC free article] [PubMed]
- 49.Geoffroy V, Herenger Y, Kress A, et al. : AnnotSV: an integrated tool for structural variations annotation. Bioinformatics. 2018 Oct 15;34(20):3572–4. 10.1093/bioinformatics/bty304 [DOI] [PubMed] [Google Scholar]
- 50.Priestley P, Baber J, Lolkema MP, et al. : Pan-cancer whole-genome analyses of metastatic solid tumours. Nature. 2019 Oct 23;575(7781):210–6. 10.1038/s41586-019-1689-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Cameron DL, Baber J, Shale C, et al. : GRIDSS2: harnessing the power of phasing and single breakends in somatic structural variant detection. Cold Spring Harbor Laboratory. 2020 [cited 2021 Feb 2]. p.2020.07.09.196527. Reference Source
- 52.Bolger AM, Lohse M, Usadel B: Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics. 2014 Aug 1;30(15):2114–20. 10.1093/bioinformatics/btu170 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Li H: Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. arXiv [q-bio.GN]. 2013. Reference Source
- 54.Layer RM, Chiang C, Quinlan AR, et al. : LUMPY: a probabilistic framework for structural variant discovery. Genome Biol. 2014 Jun 26;15(6):R84. 10.1186/gb-2014-15-6-r84 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Soylev A, Kockan C, Hormozdiari F, et al. : Toolkit for automated and rapid discovery of structural variants. Methods. 2017 Oct 1;129:3–7. 10.1016/j.ymeth.2017.05.030 [DOI] [PubMed] [Google Scholar]
- 56.Jeffares DC, Jolly C, Hoti M, et al. : Transient structural variations have strong effects on quantitative traits and reproductive isolation in fission yeast. Nat Commun. 2017 Jan 24;8:14061. 10.1038/ncomms14061 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Kent WJ, Sugnet CW, Furey TS, et al. : The human genome browser at UCSC. Genome Res. 2002 Jun;12(6):996–1006. Reference Source [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Pedersen BS, Quinlan AR: cyvcf2: fast, flexible variant analysis with Python. Bioinformatics. 2017 Jun 15;33(12):1867–9. 10.1093/bioinformatics/btx057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Pedersen BS, Quinlan AR: Mosdepth: quick coverage calculation for genomes and exomes. Bioinformatics. 2018 Mar 1;34(5):867–8. 10.1093/bioinformatics/btx699 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Hoffman EA, McCulley A, Haarer B, et al. : Break-seq reveals hydroxyurea-induced chromosome fragility as a result of unscheduled conflict between DNA replication and transcription. Genome Res. 2015 Mar;25(3):402–12. 10.1101/gr.180497.114 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Li H: Tabix: fast retrieval of sequence features from generic TAB-delimited files. Bioinformatics. 2011 Mar 1;27(5):718–9. 10.1093/bioinformatics/btq671 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Lappalainen I, Lopez J, Skipper L, et al. : DbVar and DGVa: public archives for genomic structural variation. Nucleic Acids Res. 2013 Jan;41(Database issue):D936–41. 10.1093/nar/gks1213 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Huang W, Li L, Myers JR, et al. : ART: a next-generation sequencing read simulator. Bioinformatics. 2012 Feb 15;28(4):593–4. 10.1093/bioinformatics/btr708 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Zarate S, Carroll A, Mahmoud M, et al. : Parliament2: Accurate structural variant calling at scale. Gigascience. 2020 Dec 21;9(12). 10.1093/gigascience/giaa145 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Zook JM, Hansen NF, Olson ND, et al. : A robust benchmark for detection of germline large deletions and insertions. Nat Biotechnol. 2020 Nov;38(11):1347–55. 10.1038/s41587-020-0538-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Sapoval N: SARS-CoV-2 genomic diversity and the implications for qRT-PCR diagnostics and transmission. Genome Res. 2021;31(4):635–644. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Li H, Handsaker B, Wysoker A, et al. : The Sequence Alignment/Map format and SAMtools. Bioinformatics. 2009 Aug 15;25(16):2078–9. 10.1093/bioinformatics/btp352 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Jaillard M, Lima L, Tournoud M, et al. : A fast and agnostic method for bacterial genome-wide association studies: Bridging the gap between k-mers and genetic events. PLoS Genet. 2018 Nov;14(11):e1007758. 10.1371/journal.pgen.1007758 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Lee C, Grasso C, Sharlow MF: Multiple sequence alignment using partial order graphs. Bioinformatics. 2002 Mar;18(3):452–64. 10.1093/bioinformatics/18.3.452 [DOI] [PubMed] [Google Scholar]
- 70.Gonnella G, Niehus N, Kurtz S: GfaViz: flexible and interactive visualization of GFA sequence graphs. Bioinformatics. 2019 Aug 15;35(16):2853–5. 10.1093/bioinformatics/bty1046 [DOI] [PubMed] [Google Scholar]
- 71.GTEx Consortium: The Genotype-Tissue Expression (GTEx) project. Nat Genet. 2013 Jun;45(6):580–5. 10.1038/ng.2653 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Landrum MJ, Chitipiralla S, Brown GR, et al. : ClinVar: improvements to accessing data. Nucleic Acids Res. 2020 Jan 8;48(D1):D835–44. 10.1093/nar/gkz972 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Karczewski KJ, Francioli LC, Tiao G, et al. : The mutational constraint spectrum quantified from variation in 141,456 humans. Nature. 2020 May;581(7809):434–43. 10.1038/s41586-020-2308-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Chin C-S, Wagner J, Zeng Q, et al. : A diploid assembly-based benchmark for variants in the major histocompatibility complex. Nat Commun. 2020 Sep 22;11(1):4794. 10.1038/s41467-020-18564-9 [DOI] [PMC free article] [PubMed] [Google Scholar]