

Abstract
In this study, we analyze the effectiveness of measures aimed at finding and isolating infected individuals to contain epidemics like COVID-19, as the suppression induced over the effective reproduction number. We develop a mathematical model to compute the relative suppression of the effective reproduction number of an epidemic that such measures produce. This outcome is expressed as a function of a small set of parameters that describe the main features of the epidemic and summarize the effectiveness of the isolation measures. In particular, we focus on the impact when a fraction of the population uses a mobile application for epidemic control. Finally, we apply the model to COVID-19, providing several computations as examples, and a link to a public repository to run custom calculations. These computations display in a quantitative manner the importance of recognizing infected individuals from symptoms and contact-tracing information, and isolating them as early as possible. The computations also assess the impact of each variable on the mitigation of the epidemic.
Keywords: Contact tracing, COVID-19, Epidemic models
Introduction
Main concepts and goals
This study aims to develop a probabilistic model to predict the effectiveness of containing an epidemic such as COVID-19 with measures aimed at finding and isolating infected individuals. More precisely, we are interested in modeling such “isolation measures,” by which we mean finding and isolating infected people via their symptoms and contact tracing, to predict the impact of these measures on the effective reproduction number of the epidemic. Special attention is dedicated to the case in which contact tracing is achieved, for a part of the population, through a mobile application.
Studies such as Ferretti et al. (2020) have underlined the role of asymptomatic and presymptomatic transmission in the COVID-19 outbreak, and the consequent importance of using a mobile application for efficient contact tracing. This insight has also led to the development of models to quantitatively assess the impact of a contact tracing app on the epidemic, primarily through agent-based approaches like in Pathogen Dynamics Group (2020).
In this paper, we propose an analytical approach to answer the following questions: How is the effective number of an epidemic impacted when isolation measures are in place versus when they are not, and what are the main factors contributing to the reduction in ? We take the effective reproduction number in the absence of isolation measures, denoted by , as an input of our model, which is thus independent of any underlying epidemic model. Moreover, our approach is parametric in that we concentrate the quantitative description of the isolation measures into relatively few, comprehensible parameters that comprise the input of the model. These parameters include the share of the population using an app, the share of people who self-isolate upon testing positive, and more.
Previous studies concerning the impact on the epidemic of isolating infected individuals include (Müller et al. 2000), which proposes a generative stochastic model of SIR-type, and Fraser et al. (2004), which uses an analytical method more similar to our own. The subject has also been addressed recently in Scarabel et al. (2021) using a deterministic dynamical model.
The starting point of our analysis is the effective reproduction number in the absence of isolation measures,1 that we consider as given. When discussing modeling “isolation measures,” we refer to policies focused on selectively isolating infected individuals after these individuals have been found through contact tracing or because they have displayed symptoms. We do not refer to generalized actions like imposing a lockdown, whose impact on the epidemic is considered already known and encompassed in .
is defined, for any absolute time t, as the expected number of cases generated by a random individual who was infected at time t during their lifetime. This quantity can be written as an integral
where is the infectiousness (also called effective contact rate): is a function describing the expected number of cases generated by an individual infected at time t, per unit of infectious age, that is the period of time (measured in days) elapsed from the time of infection of the individual. So, for example, the number
is the expected number of people infected between 24 and 72 h from the infector’s moment of infection. Note that the normalization is the PDF of the generation time, the time taken by an individual infected at t to infect a different individual.2
In this study, we set up a methodology and a model to analyze changes in the reproduction number when the population is subject to isolation measures, including the support of an app for individuals who have tested positive, and depending on some parameters of simple interpretation. We denote by
the effective reproduction number in presence of isolation measures, and we compute as a function of ,3 other epidemiological data such as the symptom onset distribution, and some parameters describing the isolation measures, such as the probability that an infected, symptomatic individual gets a test, or the probability that a recipient of the infection gets notified when their infector receives a positive test. We only model how isolation measures work and how they affect the epidemic,4 without assuming anything about how the epidemic itself develops. In particular, our model is agnostic of any particular form for and .
The final goal of the model we propose is to understand the most important leverages that may facilitate optimization to better direct efforts of decision-makers, scientists, and developers. Such factors include app efficiencies, timeliness of notifications, app adoption in the population, and others.
The assumptions of the model and outline of the paper
The model developed in Sect. 2 is the translation into mathematical terms of the following assumptions, that describe an idealized schema in which infected individuals acknowledge their illness and take measures to avoid infecting others.
An infected individual who shows symptoms is immediately5 notified that they should take a test (which does not discount the possibility that they acknowledge this necessity independent of an external input). This process does not always necessarily occur, but does so with a probability .
Given a infector–infectee pair, when the infector tests positive after the contagion, the infectee is immediately notified to take a test, with probability .
In either scenario, after an infected individual is notified to take a test, they take a test which will return a positive result after a time from the notification, which is distributed according to a given distribution (possibly reaching to account for the case in which the individual is never tested or never receives the positive outcome).
Immediately upon receiving the positive outcome of the test, an average infected individual will self-isolate with probability . Put differently, the number of individuals they infect from this moment is reduced by a factor compared to the scenario in which they do not take any isolation measures.
The equations derived from these hypotheses produce an algorithm that computes the time evolution of the key quantities. This is summarized in Sect. 2.5.
Note that in our model we are only considering forward contact tracing, i.e., infectees are notified of the positive result of their infectors, but not vice-versa. Doing otherwise would significantly complicate the discussion. This is probably the main limitation of the model, which may thus underestimate the effectiveness of the isolation measures: While backward contact tracing is in general less effective when timeliness in isolating infected individuals is key, it must be noted that its effect may be significant for epidemics for which super-spreaders, i.e. individuals that infect a large number of people, have a major impact on the contagion. Such individuals may be identified more easily thanks to backward tracing. A treatment of backward tracing in the context of a generative model is covered in Müller et al. (2000, §3.1).
Subsequently, in Sect. 3 we consider a more complex model. Instead, we assume that the population is split into two groups, depending on whether or not they use a mobile application for epidemic control. The parameters and are different, depending on whether they refer to individuals who use the app.
Finally, in Sect. 4, we apply these models by computing the suppression of for specific choices of the input parameters, particularly to assess the importance of such parameters. As for the input parameters that describe the epidemic, we use data relative to COVID-19. All these data are taken for a single source (Ferretti et al. 2020). It should be noted that these quantities are still preliminary, have quite large uncertainties, and are not necessarily the most up-to-date. However, we stress that these data are only used as inputs in all our computations, which can be easily reproduced and extended by using the code available in the open repository (Maiorana and Meneghelli 2021). It would be immediate to redo the computations with different inputs, to reflect any new understandings the scientific community should gain on COVID-19. In addition to this, in Sect. 4.2.3 we briefly check the robustness of our results with respect to changes in some epidemic data, namely the share of infected individuals that are asymptomatic, the contribution of those individuals to the reproduction number, and the generation time distribution.
The paper includes an Appendix where the main steps of the mathematical model are proven rigorously, in a framework where the hypotheses can be formulated precisely using the language of probability theory.
Discussion of the results
Summing up, this paper introduces a model of targeted isolation measures—with special attention paid to those based on contact tracing—in the context of an epidemic with given dynamics. It studies the impact of these, measured as the change in the key indicators of the epidemics (first of all, the reproduction number) with respect to the situation without measures. It presents a methodology to turn the assumptions defining the model into mathematical equations, without assuming an underlying model explaining the time evolution of the epidemic. In particular, the formalism developed in the Appendix allows a careful and exact development of the theory, in which all the interdependencies of the involved quantities are clarified. We end up with with a set of equations that express the relevant quantities in terms of those relative to previous times, giving a deterministic time evolution.
These equations (summarized in Sect. 2.5 for the “homogeneous” setting) are quite complex, reflecting the non-triviality of the assumptions about how isolation measures work. This makes it hard to analyze them analytically, for example, to study the asymptotic behaviour of the solutions, as was done in Fraser et al. (2004). On the other hand, our treatment allows us to refrain from making strong and unrealistic independence assumptions about the involved quantities, and leaves us greater freedom in setting up the hypotheses of how contact tracing works (for example, the isolation of contact-traced individuals is not assumed to be certain, nor immediate). And, notably, it allows us to numerically compute, with arbitrary precision, the time evolution of the reproduction number (and, hence, of the epidemic size) starting from the “default” reproduction number , other epidemiological data, and the parameters introduced in Sect. 1.2 describing the isolation measures.
We stress that, despite our extensive use of the language of probability theory, our model of the isolation measures is deterministic: It works as if the full history of the epidemic, with or without isolation measures, is given, and uses some parameters describing the mean efficacy of the isolation measures on the population. It then expresses in terms of and these parameters.
Note also that, in this paper, we always refer to as the case reproduction number. Sometimes, the instantaneous reproduction number is instead used in the literature when monitoring the evolution of an epidemic.6 Our choice is also connected to the way in which we formulate our mitigation hypotheses in Sect. 2 in terms of parameters , , , which we consider depending on absolute infection times rather than notification and isolation times. An alternative formulation following the latter option would add some slightly more cumbersome formulae but otherwise no essential complications of note to the treatment.
A limitation to the model comes from our homogeneous-mixing hypotheses regarding contact tracing and isolation policies: The only heterogeneity taken into account is the separation between individuals who do or do not use an app in Sect. 3. For example, the fact that, in reality, individuals belonging to the same household are more easily traced (in addition to being more easily infected by each other) is not taken into account. Besides the absence of backward contact tracing, mentioned in Sect. 1.2, other limitations may be attributed to the specific form of the hypotheses. However, many changes to the assumptions could be taken into account within the same mathematical framework: Features such as a different delay in testing for symptomatic or contact-traced individuals, or the existence of a targeted quarantine for potential infected individuals (even before they get tested) could be modeled without adding conceptual complications.
By using the model in Sect. 4 to compute the reduction in , we can recognize how isolation measures, particularly app-mediated isolation measures, can play an important role in mitigating epidemics like COVID-19. However, our results show how the impact of such measures is strongly sensitive to parameters describing their efficiency and timeliness: For example, the reduction in quickly becomes insignificant as the time taken to get a positive test result (and then to start isolating) grows past a few days (see Fig. 2).
Fig. 2.
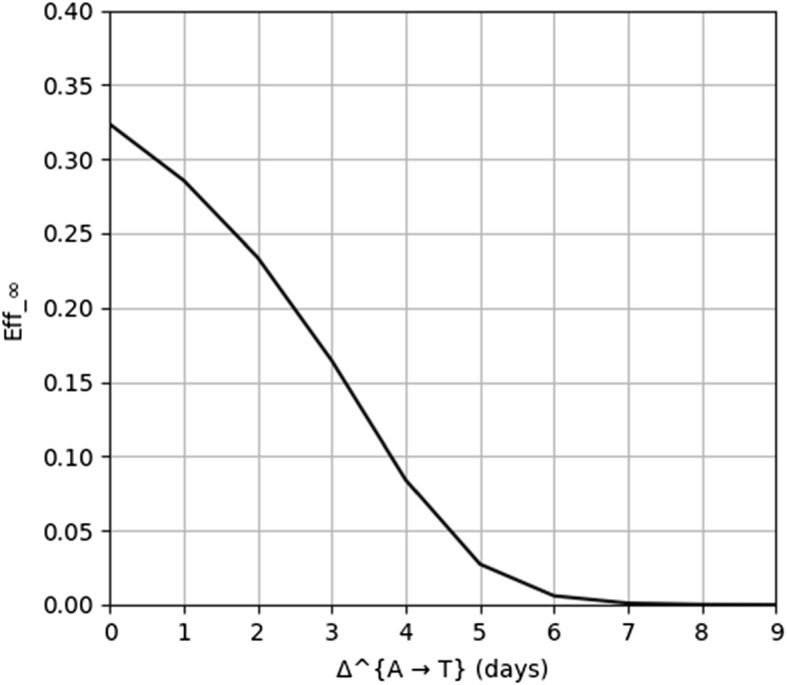
as a function of the time from notification to positive testing
The computations relative to the case in which an app is used show the importance of having an app which is effective at spotting infections, maximizing the fraction of true-positives.7 Past studies like Bendavid et al. (2021) and Li et al. (2020) suggest that “standard” contact tracing measures used by healthcare systems may be less efficient (fewer truly infected individuals are recognized) and slower when compared to an app (usually, several days elapse between symptom onset, the first medical visit, and the test outcome). In the computations, we model this fact by setting different parameters for people using an app and people who don’t, with the latter parameters left to reasonably low values. We analyze how the impact on the epidemics depends on these parameters and the app adoption rate (Fig. 9), showing how these are all key factors in reaching satisfactory epidemic mitigation levels.
Fig. 9.
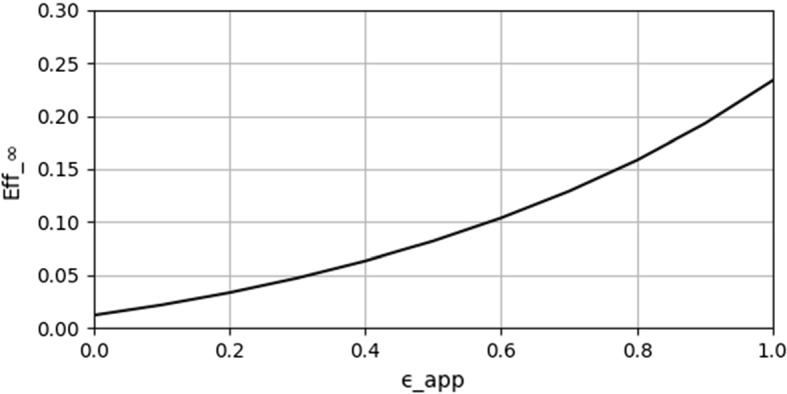
as a function of app adoption
The mathematical model in the homogeneous population setting
In this section, we develop the core mathematical model of the paper. We do so with a simplified scenario in which the same isolation measures apply to the entire population, thus eliminating the need to distinguish between those who do and who do not use an app. Some mathematical derivations require extra care, and their complete proofs have been moved to the Appendix to prevent this section from being loaded with many formulae and a heavier formalism.
Notations and conventions
We consider random variables on the sample space of all infected individuals, describing (absolute) times at which certain events happen: (time of infection), (time of symptom onset), (time of infection notification), (time of positive test). These variables can take as a value to express the cases in which an event never takes place (this is useful when writing relations between them).
As we want to relate these variables to the reproduction number , which measures the average number of people infected by an individual infected at a given time t, it is logical that all these variables refer to the infectious age (that is, the time from the infection) of the average individual infected at t: so we have, for example, the relative time of symptom onset, which is the -valued random variable
We can assume that this variable is independent of the contagion time t. Hence, we denote it by . Analogously, we have the random variables (time of notification for an individual infected at t, measured since t), (time of positive test for an individual infected at t, measured since t).
In this section we need to understand how to describe the random variables , , , and their relation to the reproduction number
based on the assumptions of Sect. 1.2. The finite parts of these random variables are described using improper CDFs, denoted by , , and respectively, whose limit for (representing the probability that each time is less than infinite) may be less than 1. So, for example, denotes the probability that an individual infected at t tests positive within a time from the time of infection. is the probability that the same individual eventually tests positive.
Further auxiliary variables are introduced later on.
The suppression model for
Recall from Sect. 1.2 how we assume that self-isolation works: If an infected individual tests positive, then they immediately self-isolate, resulting in a reduction, on average, of the number of people they subsequently infect by a multiplicative factor , which we assume given, and possibly depending on the time t at which the individual was infected.8
We can then determine a relation between the “default” reproduction number density , its correction as a result of the isolation measures, and the distribution of the relative time at which individuals infected at t receive a positive test result. This relation holds for any t greater or equal to the time at which the isolation measures are enacted.
For simplicity, let’s assume for a moment that receiving a positive test and infecting someone (assuming no isolation measures) at a given infectious age are independent events. By , an individual who was infected at t has already received a test with probability . In such a case, the number of people they infect per unit time is . Alternatively, if the individual has not received a test by (which happens with probability ), they do not self-isolate, and the average number of people they infect per unit time is just . In summary, we have, for any ,
| 1 |
This is analogous to Eq. 6 in Fraser et al. (2004). To illustrate further, suppose that all infected individuals test positive at the same infectious age , i.e. is a Heaviside function with step at : then we have for and for .
However, the above result relies on the assumption of independence between testing positive and the number of people the individual would infect without isolation. In practice, this is not an adequate reflection of what occurs. For example, with COVID-19, it is known that a significant proportion of the infected population is asymptomatic, and less contagious—see e.g. Mizumoto et al. (2020) and Ferretti et al. (2020). Given the lack of symptoms, this population has a lower probability of self-isolating. To overcome this factor, we introduce a new random variable G, which has a finite range that describes the severity of symptoms of an infected individual. It is assumed to be independent of the time of symptom onset, but it is related to the number of infected people and the probability of the individual recognizing their own symptoms. Then, to write a relation between and , we restrict the relevant random variables to each possible value of G: for any we denote by
the probability that an individual infected at time t and with severity g has tested positive by . Similarly, we denote by
the average number of people infected by an individual infected at t and with severity g, and by the analogous quantity in absence of isolation measures. Assuming now that for a given g the number of people infected (without isolation) and the event of being tested are independent, we write our “suppression formula” as
| 2 |
In Sect. A.3 we include a careful derivation of this formula. Note that the relations with the aggregate variables are
where is the probability that an infected individual has symptoms with severity g.9
Also, in Sect. 4 we always take G to assume the values 0 and 1 only, to describe asymptomatic versus symptomatic infected individuals. However, this formalism allows for a greater diversification of , according to the severity of the illness.
We end this subsection with an example of an application of (2) in a simplified scenario. Suppose that G only takes the values 0 and 1, describing asymptomatic and symptomatic infected individuals, and that each constitutes half of the population. Suppose also that , and that asymptomatic individuals are never tested, so that , while symptomatic individuals are tested immediately after infection, so that , where is the Heaviside function. Then, we have and , so that . Had we used Eq. (1) instead, we would have ended up with , which does not take into account the fact that isolating symptomatic individuals has a greater impact on the reduction of than isolating the same proportion of randomly chosen individuals.
First considerations on the variables , , and
The distribution of the time of symptom onset is independent of the isolation policy and is considered as given throughout the paper, although its specific shape is irrelevant in this section.10
The description of is addressed in the next subsection. Here, we only consider its relation with : Having assumed that the time between notification and testing positive is described by a given random variable , which is independent from and for simplicity constant in absolute time, we have
The relation still holds if we restrict it to individuals with a given severity g, and hence
| 3 |
where is the improper CDF of .
Describing
In this subsection, we consider the random variable and study the relations with it that formalize the assumptions of Sect. 1.2, namely:
When an infected individual shows symptoms, they receive an immediate notification to get tested, with probability depending on the severity g of symptoms, and possibly on the infection time t.
Immediately after an infector tests positive, each infectee is notified of the risk, with probability . If the contagion takes place after the positive test, then the infectee is never notified.
We introduce two new random variables relative to individuals infected at a given time t, describing the receiving of a notification for either cause:
- We denote by the time from infection at which an individual infected at t and with severity g is notified because of symptoms. We assume that this happens with probability at the time of the symptom onset, so its improper CDF is simply11
4 We denote by the time from infection at which an individual infected at t receives a notification resulting from the positive test of their infector. Below, we see how to describe this.
The relation between these new variables and is
In terms of improper CDFs, and assuming independence of the two notification times, this gives
| 5 |
Describing requires the introduction of an additional random variable , that gives, for any individual infected at t, the time elapsed between the the infection time of their infector and t. In particular, we need the joint distribution of and the severity G, that can be described in terms of improper CDFs : Let
denote the probability that, given an individual infected at t, their infector has severity g and was infected at a time . Note that these improper CDFs satisfy a normalization condition
and they are completely determined by quantities relative to times preceding t, namely the number of infected people and the infectiousness (more details on how they are computed are deferred to Sect. A.5).
Now, the notification time of an individual infected at t is by hypothesis equal to the testing time of the infector minus the generation time , but only if the notification actually occurs, which happens with probability provided that the contagion took place before . Hence, to get the improper CDF we should first average , translated to the left by , over all possible values of , each weighted by the probability of the generation time being . In doing this we should also treat separately the different severity levels that the infector may have, as these impact the testing time distribution. So should look like a sum
This formula doesn’t take into account that by assumption the notification can only occur after the contagion time, meaning that must be supported on positive numbers. This is considered by replacing the integrand with the probability
Also, in averaging the CDFs we should take into account the fact that the testing time of the infector is not distributed like the testing time of an arbitrary individual: Having infected someone at the infectious age , the infector is more likely than average to be tested after , or to never receive a test. As we will show carefully in the Appendix, to take this into account we need to divide the integrand by the same suppression factor that appears in Eq. (2), evaluated at . We conclude that, for any , we have
| 6 |
This result is proven rigorously in Sect. A.6.
Summary and discrete-time algorithm
In this section, we have translated the hypotheses made in Sect. 1.2 into mathematical equations describing a dynamical system. In doing this, we added a few natural assumptions of independence between the variables under considerations, namely:
the assumption in Sect. 2.2 that the testing time of an individual with given severity is independent from their default infectiousness
the assumption of independence between notification times and and the testing delay
Putting all the equations together, we see that we can compute, at any time t, the suppressed infectiousness in terms of the parameters , , , of the model, the default infectiousness and the other known epidemiological quantities, and the distributions relative to previous times .
To add an initial condition to the dynamical system, we assume that the isolation measures start at a given absolute time , so that for .12 Hence, all individuals infected at will never take a test (even after ) and never self-isolate. As a consequence, the effective reproduction number is for , while it gets reduced according to Eq. (2) for . In particular, individuals infected at can only be notified of the need to take a test through symptoms, so that .
Our set of equations can be approximated with arbitrary precision to a discrete-time algorithm that computes how the epidemic evolves, given the above data.13 This is the algorithm used in the calculations of Sect. 4.
Summing up, for each time , the algorithm works as follows:
Compute the number of individuals infected at t and the improper CDFs , from and for (as detailed in Sect. A.5).
- Compute the distribution of as in Eq. (4):
Compute the distribution of from and the distribution of , for , using Eq. (6). If , just take .
- Compute using the distribution of , via Eq. (2):
The extended model including the use of an app for epidemic suppression
So far, we have operated under the hypothesis that the ability to inform infected people that their source has been infected can be described by a single (possibly time-dependent) parameter . Now, let’s suppose that the population is divided into people who use an app for epidemic control and people who do not. This forces us to complicate the model of Sect. 2 because, when we analyze the distribution of the notification time for people with the app, we need to apply different weights to the cases in which the source of the contagion has the app or does not. We also leave open the possibility that people using the app may have a different probability of requiring a test because of their symptoms.
The generalization of the homogeneous scenario to this case is quite straightforward. In any case, some more mathematical detail has been added in Sect. A.7.
Parameters and random variables in the two-component model
A share of the infected population, perhaps depending on the absolute time t, uses an app that may do the following:
It gives the users clear instructions on how to behave when they have symptoms indicative of the disease, assuming that this can increase the probability that an infected individual asks the health authorities to be tested because of their symptoms.
It notifies the users when they have had contact with an infected individual who also uses the app, assuming that this can increase the probability that an infected individual asks the health authorities to be tested because of contact with an infected person.
We then distinguish into and , describing the probability that an individual infected at t, respectively with or without the app, is notified of the need to be tested given that they have symptoms with severity g. Note that
| 7 |
so that this distinction does not complicate the model, and is made only for adding clarity in the computations.
The increased complexity of this situation lies in the fact that now has to be replaced by two parameters and , describing the probabilities that, given an infector–infectee pair, the positive testing of the infector occurred after the infection caused a notification to be sent to the infectee, respectively in the cases that both the infector and the infectee have the app, and that at least one of them does not have the app. Note that there is no relation between and and the general as simple as Eq. (7).
We also distinguish each random variable between people with the app and people without it. For example, the time of notification due to contact now reads for people with the app and for people without it. The relation between their improper CDFs is
We have analogous formulae for and , while there is no need to make a distinction for .
Likewise, we have to separate into two components and , namely, the average number of people infected by someone infected at t who has or does not have the app, respectively:
Analogous relations hold when restricted to individuals whose illness has a given severity g.
It is reasonable to assume that having or not having the app is independent of symptom severity, so that, for example, the fraction of individuals infected at time t using the app and with severity g is . Also, while of course having an app does impact the testing time distribution and the infectiousness, we can safely suppose that it is independent of the default infectiousness, i.e. the number of people an individual would have infected in the absence of measures. This is why in this scenario the suppression formula (2) simply becomes
| 8 |
for .
The mathematical relations between the random variables
Now, we can write the new relations between the random variables. Eq. (4) is replaced by
The relations (3), (5) immediately extend to each component.
The distributions of and can be computed similarly to as we did in Sect. 2.4 for the homogeneous case. But now, for each of them Eq. (6) needs to be split into two parts, accounting for the cases in which the source of the infection has or doesn’t have the app:
| 9 |
For we get a similar equation with replaced by : In this case, it doesn’t matter whether or not the infector has the app. The equation simplifies to a form analogous to Eq. (6), namely
| 10 |
Again, we refer to the Appendix for a greater mathematical rigor: The last two equations are derived in greater detail in Sect. A.7.
Scenarios and calculations
In this section, we use the models introduced in Sects. 2 and 3 to numerically compute the suppression of due to isolation measures in certain scenarios.
The results reported here, as well as new custom calculations, can be obtained by cloning the public Python repository (Maiorana and Meneghelli 2021).
General considerations
Some inputs of the algorithm developed are parameters or distributions describing the features of the epidemic under consideration. In this section, we focus on COVID-19, and we make the following assumptions, taking all the epidemic data from Ferretti et al. (2020) (Table 1, in particular) for convenience:
- The incubation period is distributed according to a log-normal distribution:
where denotes the CDF of the standard normal distribution. The parameters and used here imply that the mean incubation period is days. - The default infectiousness distribution is assumed to depend on the absolute time t only via a global factor, so that
where (which also represents the default generation time distribution) integrates to 1. It is described by a Weibull distribution with mean 5.00 and variance 3.61:
with , . - We simplify the severity of symptoms by considering only two levels of severity: and , respectively for symptomatic and asymptomatic individuals. We take asymptomatic individuals as 40%, and we assume that they account for 5% of .14 In formulae, this means that the input parameters of our model are
All these assumptions hold throughout the whole section except for Sect. 4.2.3, where we check how the results change using different epidemic data. The other parameters of the model, describing the isolation measures, are selected later.
As Key Performance Indicators (KPIs) describing the effectiveness of the isolation measures, we look at the reduction of compared to the value it would take in the absence of measures. We call effectiveness of the isolation measures the relative reduction in :
| 11 |
Thus, indicates that there is no effect on , while describes a complete suppression of the contagion. We will see in Sect. 4.2.3 that the dependency of on the default reproduction number is very weak.15 As such, attempts to model a realistic profile for have little relevance to our computations, as any choice of leads to almost the same . Thus, in the rest of this section we simply take
Another useful KPI is the probability that an individual infected at a certain time t is eventually found to be positive, namely the limit
In the remainder of this section, we report the results of some selected calculations, considering both the “homogeneous” scenario of Sect. 2 and, in greater detail, the scenario of Sect. 3, in which an app for epidemic control is used. First, we study how the above KPIs evolve in time for certain input parameter choices. Then, we focus on the limits for of these KPIs, i.e., their “stable” values after a sufficient number of iterations, to study how these vary when we change certain input parameters, leaving the others fixed.
Reduction in with homogeneous isolation measures
First, we perform some calculations in the setting of Sect. 2, where the isolation measures are “homogeneous” within the whole population. We recall the parameters that describe this situation, some of which remain fixed in all the calculations:16
| Parameter | Meaning | Value |
|---|---|---|
| Probability that a symptomatic infected individual is notified of the infection because of their symptoms | Not fixed | |
| As above, but for the asymptomatic | 0 | |
| Probability that someone testing positive self-isolates | Not fixed | |
| Time from notification to positive testing | Constant distribution, whose value is not fixed at this moment | |
| Time at which isolation measures begin | 0 |
Note that assuming that is a constant random variable means that we are modeling that all individuals notified of the risk test positive, and take the same time to do so. Although unrealistic, this assumption makes little difference to the results. It is made here for simplicity, although it can be easily changed by using a more realistic , when this datum is available.
Time evolution with isolation due to both symptoms and contact-tracing
We now choose the following parameters, describing an optimistic situation, with reasonable efficiencies in spotting infected individuals:
| Parameter | Value |
|---|---|
| 0.5 | |
| 0.7 | |
| 0.9 | |
| 2 |
The results are shown in Fig. 1. Note that immediately at drops to around 0.92, as half of the symptomatic individuals are notified as soon as they show some symptoms, and they then infect a reduced number of people. Subsequently, continues to decrease due to contact-tracing, quickly approaching its limit value (i.e., 84% of the value it would have had with isolation due to symptoms only).
Fig. 1.
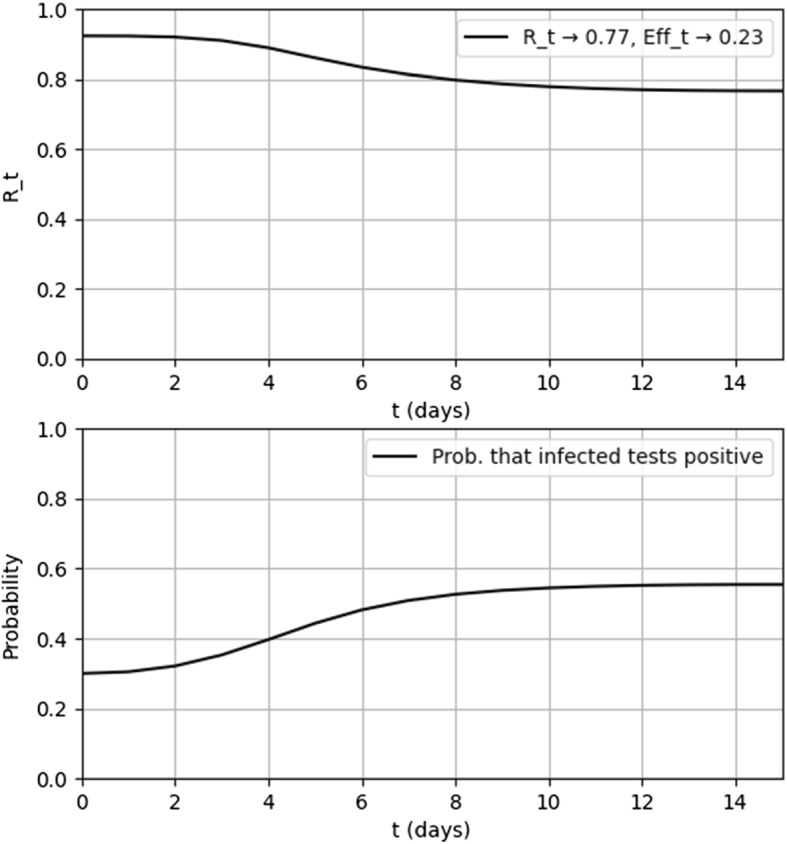
evolution in the homogeneous model, in an optimistic scenario
Dependency on testing timeliness
We now focus on the limit value , investigating its dependency on the time from a notification to the positive result of the test (recall that we are assuming that is a constant random variable).
Like in Sect. 4.2.1, the other parameters are fixed as follows:
| Parameter | Value |
|---|---|
| 0.5 | |
| 0.7 | |
| 0.9 |
The result is plotted in Fig. 2. The effectiveness of the isolation measures improves dramatically with the ability to test (and then isolate) infected individuals as soon as possible after their notification of possible infection.
Dependency on the epidemic data used
In this subsection we briefly explore what happens if we change some of the data describing the epidemic, that were introduced in Sect. 4.1 and used elsewhere in this section. This is done to see how depends on these data. The other parameters, describing the isolation measures, are fixed as usual:
| Parameter | Value |
|---|---|
| 0.5 | |
| 0.7 | |
| 0.9 | |
| 2 |
First, we let the fraction of symptomatic individuals vary, along with their contribution to —let us denote it here by —that is elsewhere taken as . Recall that
The value of for a few choices of and is plotted in Fig. 3, where it is apparent how the result is robust with respect to changes in these input data. Note that if we fix and let vary, then the two components of (and hence those of ) are linearly rescaled, meaning that also changes linearly.
Fig. 3.

for some values of and
Second, we fix and as usual, and we modify instead the density of the default generation time, by replacing it with
for . Note that this implies that the expected value of the default generation time (denoted here by ) is multiplied by f:
Figure 4 depicts the relation between and , as f varies. As expected, the isolation measures become more effective as the time taken by the infection to be transmitted increases.
Fig. 4.

for some rescalings of the distribution of
Finally, Fig. 5 shows how changes slightly as we change the value of (for ).
Fig. 5.
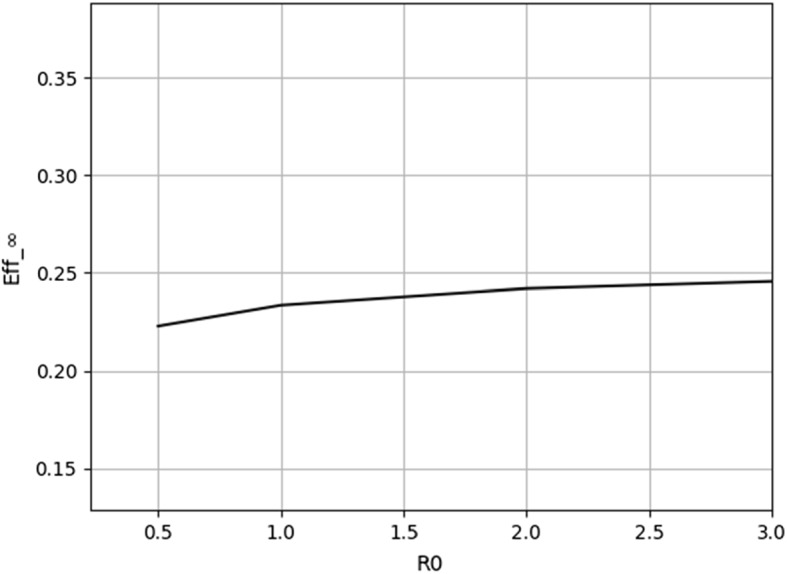
for some values of , for
Reduction in in the case of app usage
Now, we focus on applying the model of Sect. 3 to study how is reduced when a fraction of the population uses an app for epidemic control.
In this case, we summarize the input parameters in the following table, fixing some of them to the given values for the rest of the section (unless explicitly mentioned).
| Parameter | Meaning | Value |
|---|---|---|
| Probability that a symptomatic infected individual using the app is notified of the infection because of their symptoms | Not fixed | |
| As above, but for individuals without the app | 0.2 | |
| , | As with the two parameters above, but for asymptomatic individuals | 0, 0 |
| Probability that an infected individual with the app is notified of the infection because of their source having tested positive | Not fixed | |
| Probability that an infected individual without the app is notified of the infection because of their source having tested positive | 0.2 | |
| Probability that someone testing positive self-isolates | Not fixed | |
| , | Time from notification to positive testing for people with and without the app, respectively | Constant distributions, whose values are not fixed at this moment |
| Fraction of the population adopting the app at time t | Not fixed | |
| Time at which isolation measures begin | 0 |
Time evolution in an optimistic scenario
We start with an optimistic scenario, where the app is effective at recognizing infected individuals from symptoms and contact-tracing information. The internal predictive models that estimate the probability of an individual being infected have high efficiencies (a situation likely bound to the possibility of training the predictive models on real data, in practice). The app is adopted by a large fraction (60%) of the population, and is trusted, so that most of the people notified take a test and self-isolate. The app also helps a notified individual to get tested more quickly.17
| Parameter | Value |
|---|---|
| 0.8 | |
| 0.8 | |
| 0.9 | |
| 0.6 | |
| 2 | |
| 4 |
As we start from , we reach a limit value of for an effectiveness of 0.16. Note also that , while . The time evolution of , along with the other main quantities of interest, is shown in Fig. 6.
Fig. 6.

KPIs evolution in the optimistic scenario
Time evolution in a pessimistic scenario
We now run an analogous computation in a “pessimistic” scenario. The app can only recognize infected individuals from contact-tracing information, and not from symptoms ( consequently defaults to the no-app value). In addition, we assume a low efficiency , perhaps due to poor predictive models. Also, only 70% of those testing positive self-isolate.
| Parameter | Value |
|---|---|
| 0.2 | |
| 0.5 | |
| 0.7 | |
| 0.6 | |
| 2 | |
| 4 |
Even with a high app adoption rate (60% of the population), the effectiveness drops dramatically. We get and . Most notably, the app does not change things much with respect to “standard” isolation measures: and .
Time evolution in the case of gradual adoption of the app
Now, we study the evolution of in a scenario whereby the fraction of people using the app is not constant, but increasing in a linear fashion until it reaches 60% in 30 days:
The other parameters are chosen as in the optimistic scenario of Sect. 4.3.1:
| Parameter | Value |
|---|---|
| 0.8 | |
| 0.8 | |
| 0.9 | |
| 2 | |
| 4 |
As shown in Fig. 7, decreases until stabilizing again to the same value obtained in Sect. 4.3.1, although it takes more time to do so. The limit values of the KPIs are not changed by a gradual adoption of the app, compared with a prompt adoption.
Fig. 7.

KPIs evolution in case of gradual adoption of the app
Dependency of effectiveness on the efficiencies and
We now focus on the study of how the limit values of the KPIs change when we vary certain parameters, starting with the app efficiencies and . In Fig. 8, we plot as a function of these two parameters, while the others are fixed to the following values:
| Parameter | Value |
|---|---|
| 0.9 | |
| 0.6 | |
| 2 | |
| 4 |
Fig. 8.
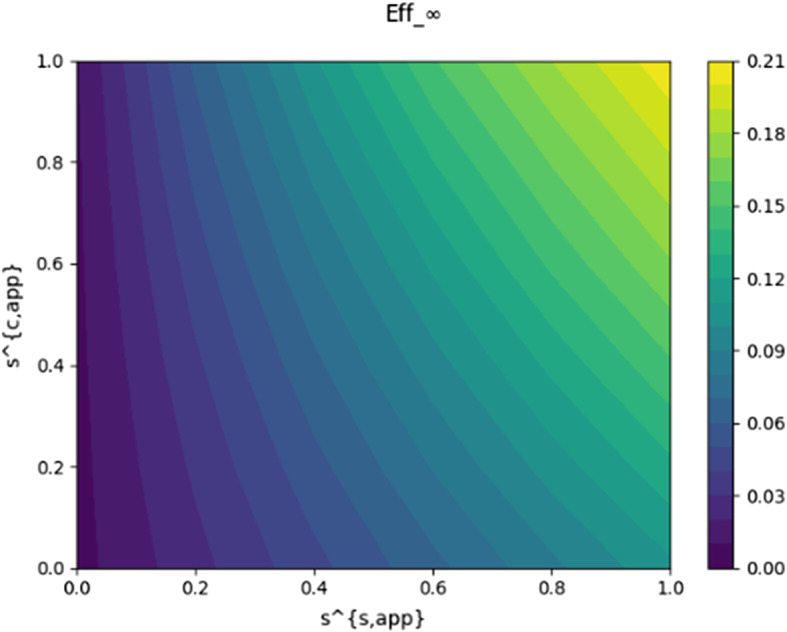
as a function of the efficiencies and
Dependency on the app adoption
In Fig. 9, we can observe the dependency of the effectiveness on the share of the population using the app. The remaining parameters are fixed to these values:
| Parameter | Value |
|---|---|
| 0.5 | |
| 0.7 | |
| 0.9 | |
| 2 | |
| 4 |
Acknowledgements
We thank our colleagues Christy Keenan and Luca Ferrari for carefully proofing the manuscript and providing significant stylistic improvements. We are also grateful to Giorgio Guzzetta and the anonymous referees for several useful comments and suggestions about this study and its publication.
A Appendix: formalism and detailed derivations of mathematical results
The goal of this Appendix is to introduce a mathematical framework in which the hypotheses of our model can be formulated precisely and their consequences proven rigorously. In particular, we will derive the formula (2) describing the suppression of due to the testing and isolation policies, and the time evolution equation (6). Some more details about the two-component scenario of Sect. 3 are added.
A.1 Modeling a deterministic epidemics with a probability space
In this subsection, we define the fundamental components of our framework. denotes the set of all the individuals infected during the epidemic. It is endowed with two functions. First,
associates to each individual the absolute time of their infection. Note that we take 0 as the initial time of the epidemics. partitions into a foliation
We also write
for the set of individuals infected at a positive time.
Second, for any individual we denote by their infector. This defines a map
It is natural to assume that, for all ,
Fig. 10.

Schematic representation of , , and . Dots represent individuals
As is the case in the rest of the paper, we will consider other quantities referring to infected individuals and study the mathematical relations between them, with special attention to their average properties over all individuals infected at a given time t. Hence, we will study functions defined over , and to talk about their averages over each set we will introduce a probability measure P on . Since is finite and we want to weight all individuals equally, P is the uniform discrete probability measure:
where denotes the cardinality of a set . Relevant quantities then become random variables, and we are interested in studying their distributions. This always reduces to solving certain counting problems, and introducing P is largely a way to conveniently write formulas using the language of probability theory. Let us stress that our methodology does not involve any simulation of random processes: The history of the epidemic is completely determined by the triple , and our study of its evolution consists of writing deterministic relations that express random variables restricted to a time slice in terms of random variables restricted to slices , for times .
The probability measure P “disintegrates” along , giving a uniform probability measure on each . Also, for any random variable we will denote by
its restriction to . We will be mostly interested in studying the distributions of such restrictions of random variables. In considering quantities like the expected value
of , we will always make the relevant probability measure explicit to avoid confusion.
A.2 Infector–infectee pairs, generation time and the reproduction number
Let us introduce some additional notation, for future convenience: First, we define the set
of infector–infectee pairs. This is the graph of the map , which thus determines a bijection . We also consider two functions describing the generation time: a function , given by
and a function given by
Consider, for all , the random variable such that is the number of people infected by at ’s infectious age (that is, at the absolute time ):
Also, for , we denote by the random variable that counts all individuals infected within the infectious age :
In particular, is the total number of people infected by . The average values of these variables are key indicators of the speed of propagation of the epidemics. In particular, restricting to an absolute time t, we let
be the effective reproduction number at t. Note that averaging on all infected individuals simply gives . We also consider the average values of , for finite :
Notice that is an improper CDF supported on , and because of the finiteness of , it is a sum of finitely many step functions. It represents the cumulative infectiousness of individuals infected at t, and tends to for .
For practical reasons, it is common to tacitly consider a continuum limit in which each tends to infinity and all random variables become continuous. is then approximated by a smooth function, whose derivative is denoted by (as is the case in the rest of the paper):
However, in this Appendix we always work in the discrete setting discussed so far, and then we consider the continuum limit only to get formulas for , for consistency with the standard terminology and notation. Using the formalism of measure theory, or simply writing the relations between random variables in terms of their CDFs, allows us to treat both the discrete scenario and the continuum limit in a unified notation.
A.3 The suppression formula
Here, we discuss in greater mathematical detail the content of Sect. 2.2. In particular, we will derive the suppression formula (Eq. 2) relating the reproduction number and the distribution of the random variable describing the infectious age (possibly infinite) at which each individual is tested positive.
To do this, we introduce two additional random variables which are analogues to and , but which instead count the number of individuals that each would have infected without isolation measures. Similarly, we denote by
and the analogues of , and in the absence of isolation measures.
Recall that we assumed the average number of people infected by each individual is reduced by a factor (possibly depending on the infection time ) at times greater or equal than the testing time . This is encoded by the following relation between the expected values of and conditioned by : For all , we postulate that
| 12 |
where is 1 when and 0 otherwise. Now we would like to remove the conditioning on from the expected values of to get an expression in terms of known quantities only. If, for simplicity, we supposed that and are independent, then Eq. (12) would reduce to . But, as discussed in Sect. 2.2, this is not a realistic hypothesis. Instead, we only assume that and are independent when restricted to individuals having the same severity of illness, which we describe through a random variable
In other words, we take and to be conditionally independent with respect to G.18 We assume now that the suppression formula applies equally to individuals of all degrees of severity:
| 13 |
having introduced
and the obvious notation for restrictions of random variables to and for the uniform probability measure on it. The assumption of conditional independence implies
| 14 |
Summing over we find
having denoted the improper CDF of by , as usual.
Finally, to average over all , we simply notice that
where .19 On the other hand, summing over gives a relation between and :
Then, we can sum up the content of this subsection as follows:
Proposition 1
Take . Assuming the suppression hypothesis (13) and the conditional independence of and with respect to G, we have
| 15 |
where . Moreover,
Note that taking the continuum limit of Eq. (15) we retrieve Eq. (2):
We conclude this subsection by noting, for future convenience, that we can rewrite the suppression hypothesis without referring to :
| 16 |
A.4 Random variables technology
Given a random variable , it is natural to consider the composition
The main use case of this is when X represents the time at which some event related to an individual happens. For example, the infectious age at which they get tested. In this case, is the probability that, given an individual infected at t, their infector is tested at the infector’s infectious age .
In fact, we are often more interested in a slightly different distribution, namely that of the random variable defined by
When , then is now the probability that, given an individual infected at t, their source is tested at the individual’s infectious age .
The next Proposition relates the distributions of , , and :
Proposition 2
Take . For all , we have
Proof
We prove both formulas at once by defining as
for , so that and .
Notice that we can also break down the right hand side of the formulae of Prop. 2 by the values of G. In particular, the second equation can be rewritten as
| 17 |
A.5 Remarks on generation time and numbers of infected individuals
In this subsection, we study the distribution of the generation time. First, we do this considering it as a function of infector–infectee pairs, and in particular taking its restriction to the set
As usual, on we put the uniform probability measure, denoted by . In this way, we find the intuitive fact that the distribution of restricted to is just the normalization of the infectiousness:
Proposition 3
The CDF of the random variable is given by
Proof
The limit gives
and the claim immediately follows.
Next, we focus on the generation time as a function of the infectee. Its probability distribution is given by the formula
which follows from the definitions. Summing the left-hand side over all gives 1, from which we find how to compute in terms of quantities relative to previous times:
The last two formulae are easily proven, and the first is an immediate consequence of the next Proposition, which describes the joint probability distribution of and :
Proposition 4
This is the probability that the infector of someone infected at t was infected at and had severity g.
Proof
This formula for the joint probability measure will be used in the next subsection, where we will often use it in integrals. Given that in this paper we always consider G to have a given discrete range, while becomes continuous in the continuum limit, we will preferably write these integrals with respect to the improper CDFs
| 18 |
A.6 Time evolution
As we saw in Sect. 2.3, the key step to determining the time evolution of the system is writing the distribution of the notification time in terms of that of the testing time , for . Our assumption is that any infected individual is notified precisely at the testing time of their infector with a certain probability , provided that such testing time follows the infection time of (otherwise, is never notified). Referring these instants to the infectee’s infectious age, we get that is equal to
with probability in case it is a positive number, and in the remaining cases. This can be written synthetically as
| 19 |
where and are the improper CDFs of and , respectively.
Thus, our goal reduces to computing the distribution of , the (possibly negative) time elapsed from the infectee’s contagion to the infector’s testing. Applying Eq. (17) to and using the suppression formula (16) we get, for any ,
Notice that in the last line we used the improper CDFs introduced in Eq. (18).
Let us try to interpret this formula. The probability distribution of is obtained by averaging the distributions of for all and all g, each shifted by to the left to account for the switch from the infector’s to the infectee’s infectious age. This averaging is done by integrating over all and g with respect to the joint distribution of the generation time and the infector’s severity . But a correction factor (the fraction) appears in the integral, as the fact that the infector infects at relative time and has severity g conditions the distribution of , by shifting it toward values greater than . Indeed, the correction factor is greater than 1 for and less than 1 otherwise. This means that, compared to a hypothetical case in which the testing time and the infectiousness are independent (which happens when is constantly zero), the probability is higher after the contagion time (i.e., when ) and lower before.
It follows now that the improper CDF of reads
We only have to replace this equation in (19) to get the time evolution formula:
Proposition 5
Assuming the suppression hypothesis (13), the conditional independence of and with respect to G, and the notification hypothesis (19), we have
for and otherwise.
A.7 Modifications in the case of use of a contact tracing app
The inhomogeneity in the population due to the use of a contact tracing app by a part of it can be partly addressed in an analogous way to the inhomogeneity due to different degrees of severity of the illness. Namely, we introduce a new random variable
whose value determines whether or not an individual has the app. We assume that whether or not an individual has the app is independent of both their severity and their infectiousness in the absence of measures. In other words, A is independent of G and , for all . On the other hand, the infectiousness (in presence of measures) and the testing time of an individual will be different depending on whether or not they use the app.
A further partitions : we write
and so on. The content of Sect. A.3 fully applies to this scenario, but we want now to have formulae conditioned on A. As A and are independent, the previous formulae simply become
and
| 20 |
The suppression formula for can be broken down to
where .
The time evolution equation has to be treated differently, as the receipt of the notification depends on whether both the infector and the infectee use the app.
Let denote the probability that, given an individual , the infector is tested at a time and we have .
According to our assumptions, given an infection occurred at t, the probability that the infector notifies the infectee when they test positive (provided that this happens after the infection) is in the case that both individuals have the app, and is otherwise. Therefore, the contact tracing hypothesis (19) is now replaced by the following expressions for the CDFs of the time of the notification received by an individual with or without the app, respectively:
| 21 |
Now, the improper CDFs can be computed just as before, simply treating the conditioning on as we treated the conditioning on :
| 22 |
where we defined as follows, proceeding like in Sect. A.5 to compute the joint distribution of , , and :
| 23 |
It is worth noting that comparing this equation with (18) we get
| 24 |
Replacing the suppression formula (20) in (22) and summing over , we end up with
for . Plugging this into (21) gives us in terms of and for , that is the time evolution equation for the scenario with app usage. For , this is Eq. (9), while for it simplifies to Eq. (10), since when the infectee doesn’t have the app it is irrelevant whether or not the infector has the app. This is evident from the last line of Eq. (21), which in fact could also have been used, together with the expression for derived in Sect. A.6, to get Eq. (10). Using Eq. (24), it can be checked immediately that the two approaches give the same result.
Author Contributions
M.M. and M.R. conceived the study and its main ideas; A.M. developed the mathematical model; A.M. and M.M. developed the Python repository with the calculations and wrote the manuscript.
Declarations
Conflict of Interest
This work was supported by the authors’ employer, Bending Spoons S.p.A, which was involved in the development of the contact tracing app adopted by the Italian Government.
Footnotes
must not be confused with the basic reproduction number .
This is better explained in Sect. A.5.
We stress that the time evolution of , describing how the epidemics would have evolved without the measures we are modeling, is taken as known—our goal is to study the relative impact of the measures. In particular, we do not take into account possible second-order effects on , such as general changes in the behavior of the population, that may come as a consequence of the measures and their impact.
Recall that our model simultaneously includes the effect of isolating infected individuals recognized either through their symptoms or through contact tracing. However, as becomes apparent in the examples of Sect. 4, we will immediately be able to single out the additional impact of contact tracing only, for example.
This and the following assumption of immediate notification simplify the treatment to the extent that they avoid adding further distributions modeling some delays. In fact, they are not essential hypotheses, and such real-world delays could be also taken into account in the current setting, by including them in the distribution of the time between notification and test, introduced below.
This typically involves modeling the generation time distribution as constant in time, which is an assumption we do not make. See Cori et al. (2013) for a detailed account of this matter.
To be trusted by its users, the app should also aim at reducing the fraction of false-positives. This is something that our study does not consider.
Equivalently, this hypothesis could be viewed as the assumption that an individual who tests positive either self-isolates completely, without infecting anyone else from that moment, or, alternatively, does nothing, with the first circumstance happening with probability .
Note that, according to our convention, is the weighted average of its components . Often, in the literature (e.g. in Ferretti et al. 2020) a different convention is used, according to which the components sum to . To switch to the latter convention, each should be divided by the respective probability .
In Sect. 4 we take to be a log-normal distribution, following the literature.
For simplicity, we use a unique distribution for all degrees of severity. For asymptomatic individuals, would be equal to 0.
Note that this doesn’t prevent us from modeling isolation measures gradually put into place, which can be done simply by taking these parameters to be continuous in t.
In this discrete setting, all the integrals appearing in the equations reduce to finite sums. In fact, our approach in the Appendix is to derive the same equations starting from a discrete probabilistic model.
Note that this does not include pre-symptomatic transmission, which is taken into account within the group .
This dependency is due to higher order effects: A higher means that the distribution of is more concentrated on small values, and hence the most recent testing time distributions have a greater weight in the time-evolution equation (6).
In all the examples these parameters are constant in time. Hence we remove the subscript t from them.
Remember that in this work, the joint distribution of and G is assumed known, and we want to study how our assumptions on the isolation measures determine the distribution of , and hence .
Note that, for simplicity, in the rest of the paper we took the distribution of G independent of absolute time, and wrote .
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Andrea Maiorana, Email: anm@bendingspoons.com.
Marco Meneghelli, Email: mm@bendingspoons.com.
Mario Resnati, Email: mr@bendingspoons.com.
References
- Bendavid E, Mulaney B, Sood N, Shah S, Bromley-Dulfano R, Lai C, Weissberg Z, Saavedra-Walker R, Tedrow J, Bogan A, Kupiec T, Eichner D, Gupta R, Ioannidis JPA, Bhattacharya J (2021) COVID-19 antibody seroprevalence in Santa Clara County, California. Int J Epidemiol. 10.1093/ije/dyab010 [DOI] [PMC free article] [PubMed]
- Cori A, Ferguson NM, Fraser C, Cauchemez S. A new framework and software to estimate time-varying reproduction numbers during epidemics. Am J Epidemiol. 2013;178(9):1505–1512. doi: 10.1093/aje/kwt133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferretti L, Wymant C, Kendall M, Zhao L, Nurtay A, Abeler-Dörner L, Parker M, Bonsall D, Fraser C. Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science. 2020 doi: 10.1126/science.abb6936. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fraser C, Riley S, Anderson RM, Ferguson NM. Factors that make an infectious disease outbreak controllable. Proc Natl Acad Sci. 2004;101(16):6146–6151. doi: 10.1073/pnas.0307506101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Q, Guan X, Wu P, Wang X, Zhou L, Tong Y, Ren R, Leung KS, Lau EH, Wong JY, et al. Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia. N Engl J Med. 2020 doi: 10.1056/NEJMoa2001316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maiorana A, Meneghelli M (2021) Epidemics suppression model. https://github.com/BendingSpoons/epidemic-suppression-model
- Mizumoto K, Kagaya K, Zarebski A, Chowell G. Estimating the asymptomatic proportion of coronavirus disease 2019 (COVID-19) cases on board the Diamond Princess cruise ship, Yokohama, Japan, 2020. Eurosurveillance. 2020;25(10):2000180. doi: 10.2807/1560-7917.ES.2020.25.10.2000180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Müller J, Kretzschmar M, Dietz K. Contact tracing in stochastic and deterministic epidemic models. Math Biosci. 2000;164(1):39–64. doi: 10.1016/S0025-5564(99)00061-9. [DOI] [PubMed] [Google Scholar]
- Pathogen Dynamics Group OU Big Data Institute (2020) https://github.com/BDI-pathogens/OpenABM-Covid19
- Scarabel F, Pellis L, Ogden NH, Wu J (2021) A renewal equation model to assess roles and limitations of contact tracing for disease outbreak control. R Soc Open Sci 8:202091. 10.1098/rsos.202091 [DOI] [PMC free article] [PubMed]