

Abstract
Various self-cleaving ribozymes appearing in nature catalyze the sequence-specific intramolecular cleavage of RNA and can be engineered to catalyze cleavage of appropriate substrates in an intermolecular fashion, thus acting as true catalysts. The mechanisms of the small, self-cleaving ribozymes have been extensively studied and reviewed previously. Self-cleaving ribozymes can possess high catalytic activity and high substrate specificity; however, substrate specificity is also engineerable within the constraints of the ribozyme structure. While these ribozymes share a common fundamental catalytic mechanism, each ribozyme family has a unique overall architecture and active site organization, indicating that several distinct structures yield this chemical activity. The multitude of catalytic structures, combined with some flexibility in substrate specificity within each family, suggests that such catalytic RNAs, taken together, could access a wide variety of substrates. Here, we give an overview of 10 classes of self-cleaving ribozymes and capture what is understood about their substrate specificity and synthetic applications. Evolution of these ribozymes in an RNA world might be characterized by the emergence of a new ribozyme family followed by rapid adaptation or diversification for specific substrates.
Self-cleaving ribozymes have become important tools of synthetic biology. Here we summarize the substrate specificity and applications of the main classes of these ribozymes.
Introduction
Functional ribonucleic acid (RNA) is a molecule of special interest due to its dual ability to store information and catalyze chemical reactions. Ribozymes are a class of RNAs that typically catalyze self-referential activities (e.g., self-cleavage, self-splicing, ligation, template-directed polymerization) and are the foundation of a branch of synthetic biology aimed at creating a simple cell with primitive metabolism.1 Self-cleaving ribozymes are some of the most well-studied ribozymes and are often used as model RNAs for testing new methods or reaction conditions. These have been discovered as naturally occurring transcripts (e.g., as viral/viroid replication intermediates), through in vitro selection from a pool of random or genomic sequences, or, increasingly, through bioinformatic searches. There are now more than eleven characterized families of small, self-cleaving ribozymes. Here, we review what is known about the sequence specificity of the naturally-occurring families of these ribozymes, and indicate how some of the ribozymes could have synthetic biology applications.
Ribozyme specificity is an important consideration for possible applications, such as mRNA inactivation. In particular, high sequence specificity of the ribozymes for their substrates, i.e., the ability to distinguish between target and closely related alternative sequences, is desirable for such applications. Conversely, substrate promiscuity is the basis for the potential evolvability of ribozymes to process new substrates. It has been previously suggested that early ribozymes might have been characterized by low activity and low specificity, allowing diversifying evolution toward multiple functions in parallel.2–4 Substrate specificity (or promiscuity) would therefore be a critical aspect influencing the ability of an RNA world to expand in complexity during early evolution.
The families of small self-cleaving ribozymes include the hepatitis delta virus (HDV)-like, glucosamine-6-phosphate synthase (glmS), hatchet, hammerhead, hairpin, twister, twister sister, pistol, Neurospora Varkud satellite (VS); in addition to recently discovered mammalian SINE and hovlinc ribozymes. In general, these ribozymes act in cis (i.e., on the same strand), and therefore execute a single catalytic turnover. It is usually possible to engineer the RNA into separate catalytic and substrate strands such that the catalytic strand acts in trans. In those cases, the ribozyme can often perform multiple turnovers.
Although the different ribozymes have distinct primary, secondary, and tertiary structures, as well as self-scission sites, they accelerate the same transesterification reaction. The chemical mechanism of the cleavage reaction is achieved through general acid–base catalysis (Fig. 1). The ribozymes need to be correctly folded to bring functional nucleotides to the vicinity of the cleavage site and adopt a conformation that positions the cleavage site in the required in-line geometry. In most cases, the ribozymes use nucleobases from their structure or exogenous cofactors as the general base or acid. The general base deprotonates the 2′-hydroxyl group, thus enhancing nucleophilicity of the oxygen, which attacks the adjacent phosphorous. As a result, a trigonal bipyramidal transition state (or intermediate, if stabilized) is formed. Protonation of the 5′-oxygen in the pentavalent phosphorane by a general acid leads to departure of the leaving group and formation of the characteristic products: a 2′,3′-cyclic phosphate and a free 5′-OH group.4 Mechanisms of these ribozymes have been extensively reviewed recently and are not covered in depth here.5–8 In this review, we provide a brief introduction to the mechanism of each ribozyme in order to contextualize the accompanying description of substrate specificity. We also discuss how gaining more insight into these ribozymes can allow for synthetic biology applications to be realized, such as engineering of aptazymes to control gene expression through cleavage of the 5′ and 3′ untranslated regions (UTRs) of mRNAs.
Fig. 1. Mechanism of RNA self-scission and ligation by general acid–base catalysis.

Hepatitis delta virus (HDV)-like ribozymes
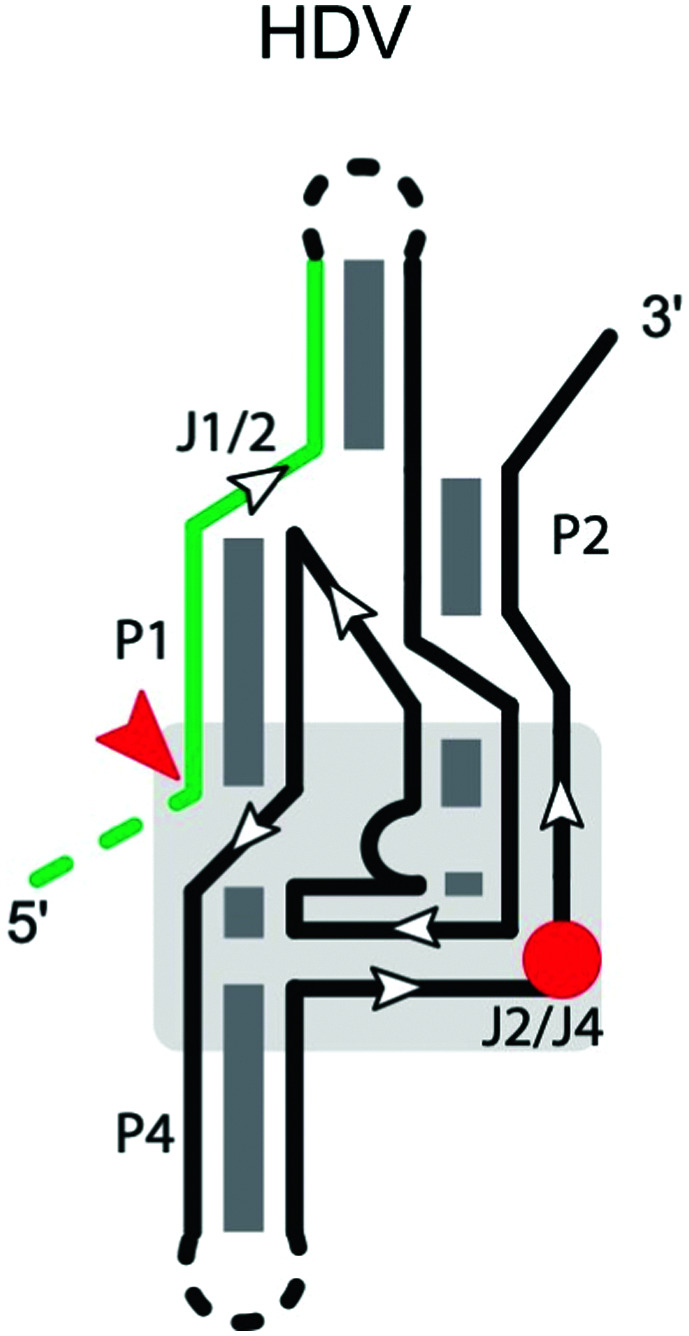
HDV is an RNA satellite of the hepatitis B virus (HBV) that relies on host cellular machinery for rolling-circle replication of its circular, single-stranded, 1700-nucleotide (nt) RNA genome.13 This family of ribozymes is widespread in genomes of eukaryotes, including mammals,14–16 with several examples mapping to bacterial genomes.17,18 The cis-acting HDV ribozyme consists of five helical regions (P1 through P4 and P 1.1), which form two coaxial stacks: P1 and P1.1 stack on P4 while P2 stacks on P3 (Table 1).19–21 In the trans-acting ribozyme, the substrate is typically derived from the 5′ strand of P1 and the remainder of the sequence forms the ribozyme.
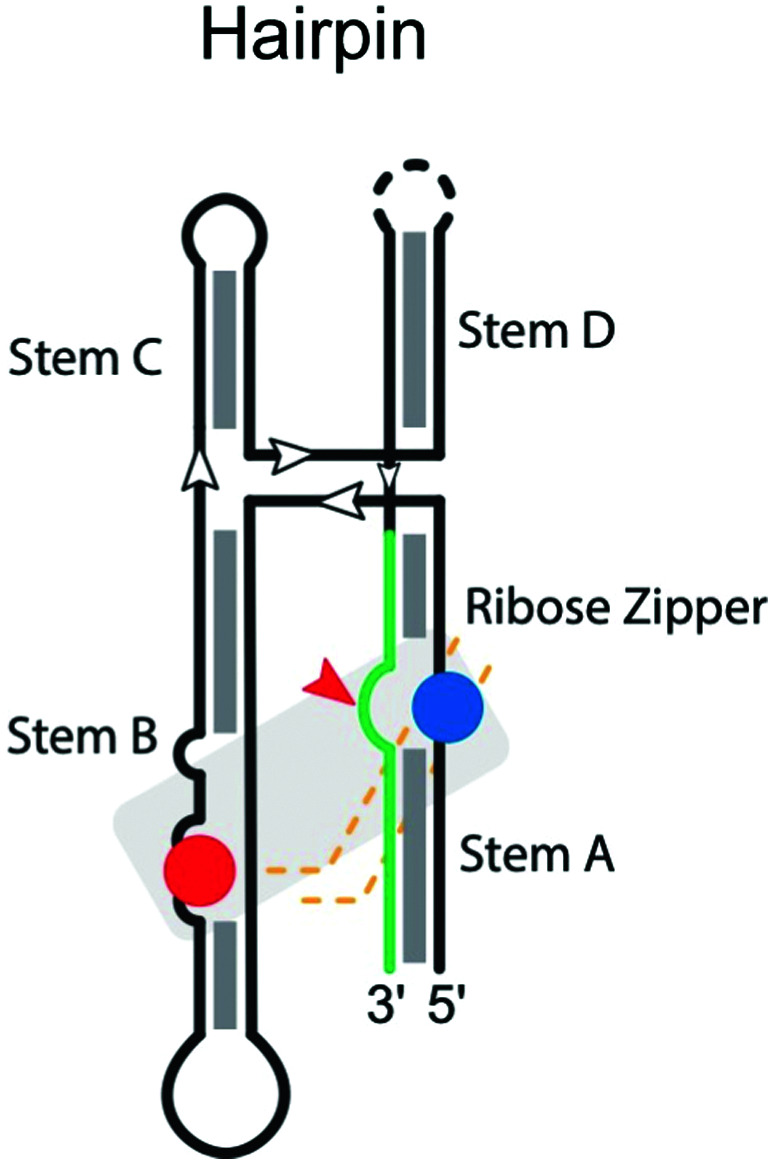
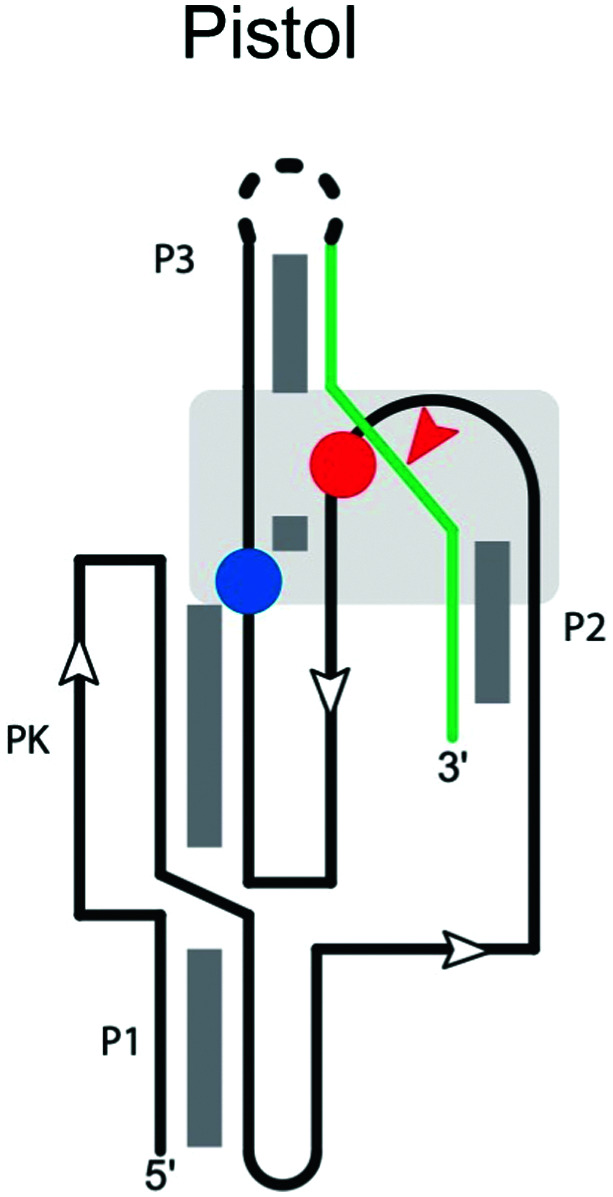
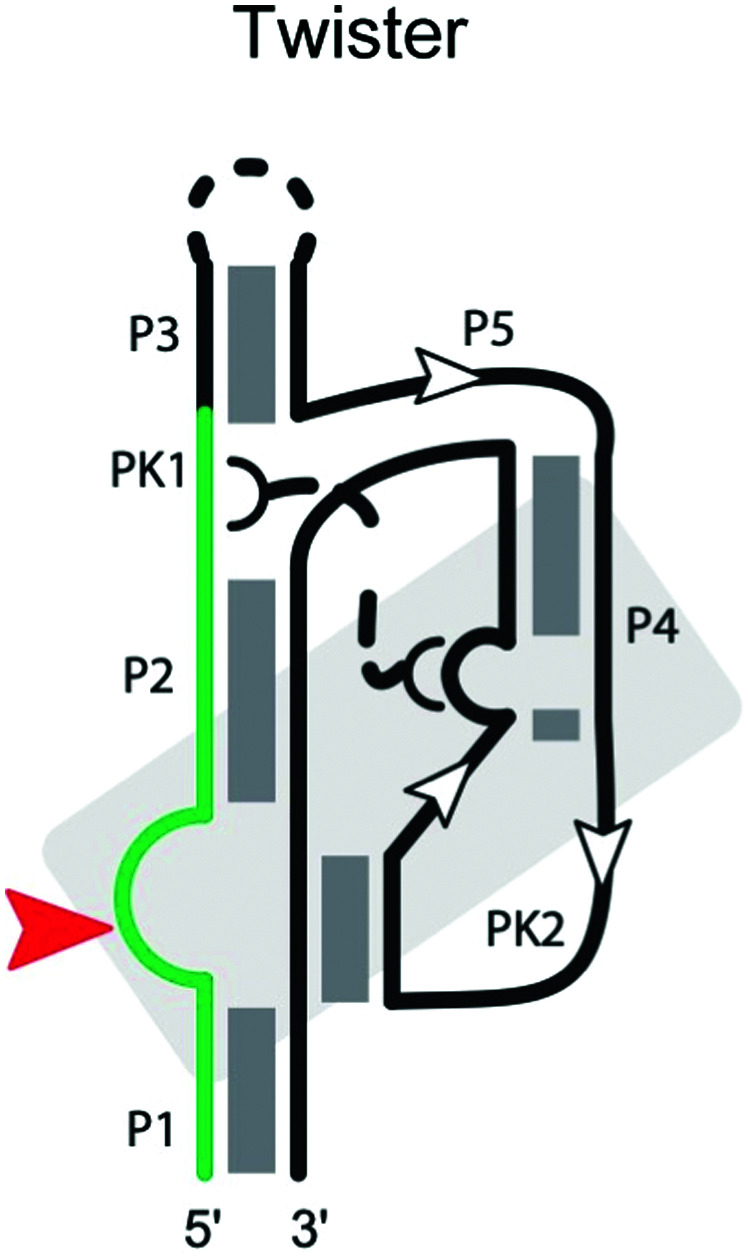
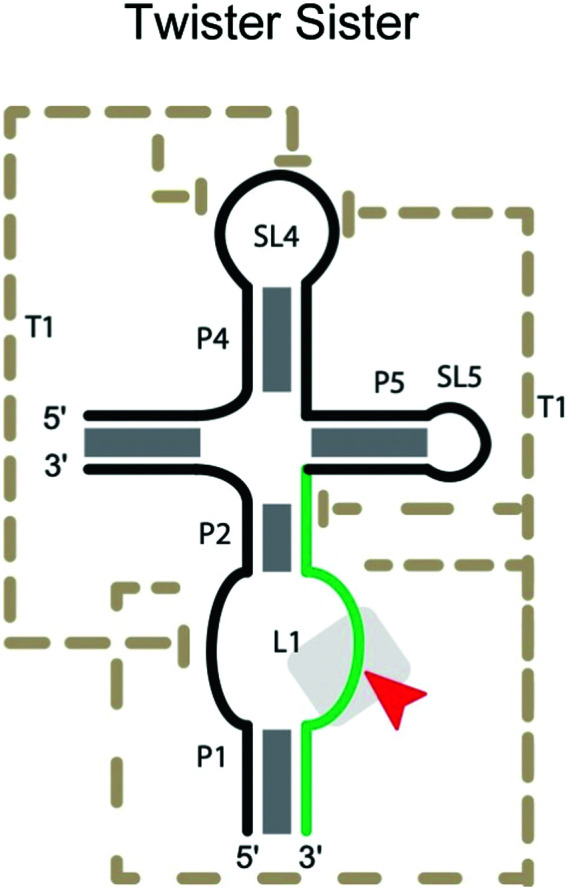
Ribozymes with peripheral sites of self-cleavage. The substrate strand is labeled in green and the ribozyme strand is in black. The red arrowheads indicate the sites of cleavage, and the light gray boxes designate the regions of the catalytic core of each represented ribozyme. The dark gray blocks in-between the strands show base-paired regions. The red and blue circles indicate the residue location of the general acid and base, respectively. The white arrows indicate the direction of the strands, while the black dashed circles indicate regions where the ribozyme can be disrupted to become a trans ribozyme.
| 2° Structure | Active site | Substrate strand requirement |
|---|---|---|
|
Cleavage site: peripheral | Upstream: single nucleotide |
| General acid: C75 in J2/4 | Downstream: at least 6 base pairs, starting with a G + 1 | |
| General base: hydrated divalent metal ion | ||
| Ligation: no | ||
| Ref. 9 and 10 | ||
|
Cleavage site: peripheral | Upstream: single nucleotide |
| General acid: GlcN6P | Downstream: base pairing | |
| General base: G40 in P2.1 | ||
| Ligation: no | ||
| Ref. 11 | ||
|
Cleavage site: peripheral | Upstream: single nucleotide |
| General acid: G30 or Mg2+-H2O coordinated G30 located in base pair and stacks on P2 | Downstream: base pairing | |
| General base: potentially G31 located in base pair and stacks underneath P3 | Notes: G30 and G31 mutations poorly tolerated. | |
| Ligation: no | ||
| Ref. 12 | ||
A hydroxide from the hydration shell of a divalent metal ion, such as Mg2+ or Ca2+, and C75, which maps to the beginning of the J4/2 strand, serve as the general base and general acid, respectively. The crystal structure of the self-cleaved ribozyme suggested that the N3 of C75 can hydrogen bond with the leaving group,19 donating a proton to the 5′-oxyanion of G1.22 Although Mg2+ is not absolutely required for the reaction, changing the pH from 6 to 8 either enhances or reduces the reaction rate, in the presence or absence of Mg2+, respectively,23 consistent with a hydrated Mg2+ acting as the general base when present, accepting the proton from the 2′-OH nucleophile. The nucleophile appears to exist in the protonated form in the ground state, but becomes negatively charged at the beginning of the reaction.24 This appears to be supported by the active site Mg2+ ion.25 The pKa of the general acid C75 is shifted to facilitate protonation of the leaving group.26,27 In the HDV and HDV-like ribozymes (i.e., other non-HDV, self-cleaving ribozymes with structural and biochemical similarities to the HDV ribozyme28), self-scission is supported by a number of divalent cations.29
Two forms of a trans-acting HDV ribozyme have been generated from the cis-acting ribozyme sequences. In the first form, the ribozyme was interrupted in the loop of P4, yielding a large piece containing the substrate strand and a relatively small strand containing the catalytic cytosine. The two pieces interact via P4 and P2 to cleave the 5′-fragment of P1.26,30,31 Because the active site is split between the two parts, the construct is useful for mechanistic studies of the ribozyme, but not for applications involving cleaving target RNAs in trans.
In the second form, the 5′ segment of P1 is separated from P2 in J1/2, forming the substrate strand, which associates by base pairing in P1 to the larger catalytic domain.32 In this situation, a circularly permuted trans-acting ribozyme can be generated by closing the end of P2 with a short loop.33 Interchanging 1–4 nucleotide pairs between the substrate strand and the catalytic strand maintains cleavage activity.34–37 The peripheral terminus of the stem formed by the substrate and ribozyme strands appears to be more tolerant of a distortion of the P1 stem caused by mismatches compared to internal positions. Nucleotides in the middle of the substrate strand are of critical importance to substrate recognition and cleavage activity, with the wobble pair (G–U) at the cleavage site being essential. Simultaneous alteration of two nucleotides in the middle of the P1 stem eliminates cleavage activity in both trans- and cis-acting HDV ribozymes, possibly by disrupting formation of the metal-ion binding site.38 The trans-acting ribozyme can cleave a substrate with a minimum of six nucleotides adjacent to the cleavage site in the 3′ direction. Substrates with a single mismatch show low cleavage rates, likely due to the poor binding between the substrate and the ribozyme.
The 5′ region of the cleavage site (positions upstream of site −1) also affects substrate specificity.39 A systematic study of mutations at positions −1 to −4 of the substrate40,41 revealed that cleavage is somewhat sensitive to these positions. The consensus cleavable substrate from −1 to −4 was found to be −1HRHY−4 (H = U, C, or A; R = A or G; Y = C or U). For position −1, the order of reactivity was A > C > U, with G being a poorly-cleavable substrate, while for position −2, the order was A > G ≫ U, with C being a low-cleavage substrate. The reactivity of the nucleotide at position −2 also depended on the base at position −1. Positions −1 to −4 appear to be important for formation of the P1.1 pseudoknot, which is essential for cleavage activity.42,43 Base-pairing between the single-stranded 5′ end of the substrate and the J1/4 junction of the ribozyme inhibits folding of the P1.1 stem, causing a significant decrease of cleavage. Thus, some substrate sequences may inhibit activity by causing misfolding of the ribozyme-substrate complex.
Longer substrates have also been studied, illustrating a trade-off between substrate affinity and sequence specificity, which are improved by additional base-pairing interactions formed in the J1/2 region. However, longer base-paired products result in very slow off-rates, greatly decreasing turnover.44 Overall, at least 6 nucleotides are invariant to make an active HDV-like ribozyme, but only one of these (G1) resides in the substrate strand. The multitude of natural HDV-like ribozymes provides a good starting point for designing ribozymes with variable sequence specificity and size, particularly for trans-cleavage.28 The substrate helix (P1) must be at least 6 bp long,29 but can be extended to an arbitrarily long substrate through interactions in a P1.2 helix.29,45
Glucosamine-6-phosphate synthase (glmS) ribozyme
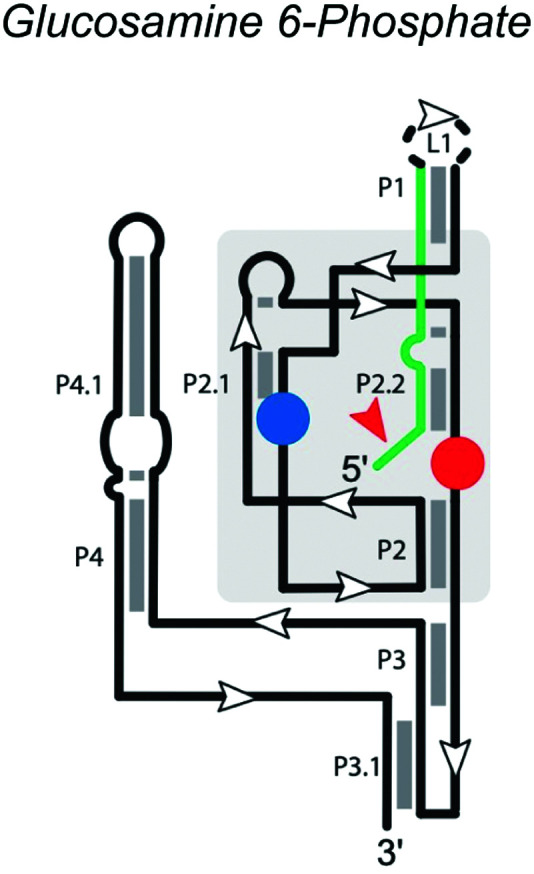
The glmS ribozyme, found in many Gram-positive bacteria, regulates the expression of the glmS gene, which encodes glutamine-fructose-6-phosphate transaminase.46 It is a conserved motif located in the 5′ untranslated region of the glmS gene and the only self-cleaving ribozyme family known to use the metabolite glucosamine 6-phosphate (GlcN6P) as a cofactor for catalysis. The secondary structure (Table 1) of the glmS ribozyme contains three near-parallel coaxial stacks, with P1 stacking on P3.1, P4 stacking on P4.1, and P2.1. The core structure of the glmS ribozyme is a double pseudoknot involving both P2.1 and P2.2. P1 and P2 contain the necessary conserved base-pairs for the catalytic center, located in the pseudoknots of P2.1 and P2.2. P2.2 forms part of the binding site for the GlcN6P cofactor and also serves as the substrate strand. Folding of P2.2 enables the ribozyme to adopt the active conformation.47 Although P3 and P4 are not necessary for catalytic activity, they provide structural stability and enhance cleavage ability,46,48 especially at low Mg2+ concentrations.49
Unlike many riboswitches, ligand binding of the glmS ribozyme does not cause a major conformational change.50 GlcN6P is buried in the binding pocket with its sugar ring stacked on the substrate-strand G1 nucleobase and its phosphate, forming a hydrogen bond with N1 of G1 and coordinating a Mg2+ ion. The GlcN6P cofactor appears to have multiple roles, including protonation of the 5′-O leaving group, alignment of the active site, activation of the 2′-O nucleophile through disruption of an inhibitory interaction, and charge stabilization of the nonbridging oxygen atoms during the reaction.50–52 The glmS ribozyme thus utilizes an overdetermined set of competing hydrogen bond donors in the active site to ensure potent activation and regulation by the cofactor GlcN6P. In the active site, G40 of the Thermoanaerobacter tengcongesis glmS ribozyme (shown in Table 1) or guanosine G33 of the B. anthracis glmS ribozyme acts as the general base by hydrogen bonding with the A-1 2′-OH nucleophile.50,53,54
Replacement of the C2-amine of GlcN6P by a hydroxyl group in Glc6P incurs a ∼104-fold reduction of activity, similar to the activity without GlcN6P,46,55 although the importance of GlcN6P varies somewhat in this family of ribozymes.55 Interestingly, G33 modulates the pKa of both the phosphate and the amine of GlcN6P.56 In some cases, a different amine may functionally substitute for GlcN6P, but the rate enhancement of GlcN6P is approximately 5 orders of magnitude higher than that by Tris at the same concentration (10 mM). Similar results were observed when using glucosamine or serinol to replace GlcN6P. On the other hand, glucose, ethanol, methylamine and ammonium ions cannot activate the self-cleavage reaction, suggesting that adjacent amine and hydroxyl groups are necessary to support the activity of the glmS ribozyme.55
A trans-acting core version of the B. cereus glmS ribozyme has been created by removing the closing loop of helix P1.57 Compared with the cis-acting full-length glmS ribozyme, the apparent GlcN6P and Mg2+ affinity of the trans-acting ribozyme was ∼24-fold and ∼10-fold weaker, respectively. Nevertheless, like the cis-acting glmS ribozyme, this trans-acting variant shows a very slow cleavage rate in the absence of GlcN6P and is activated by ∼5000-fold with 10 mM GlcN6P. Addition of comparable amounts of GlcN, a ligand analog lacking the 6-phosphate moiety, activates the trans-acting glmS weakly (by ∼30-fold), and Glc6P, lacking the 2-amino group, does not significantly activate the ribozyme. The trans-acting glmS ribozyme is fully folded in solution before binding GlcN6P, supporting a direct role of this cofactor in the catalytic mechanism rather than folding. The cleavage site is located at the 5′ end of the ribozyme, with only one nucleotide required upstream of the cut site. Downstream, only base-pairing is required within the P2.2 and P1 regions.
Hatchet ribozyme
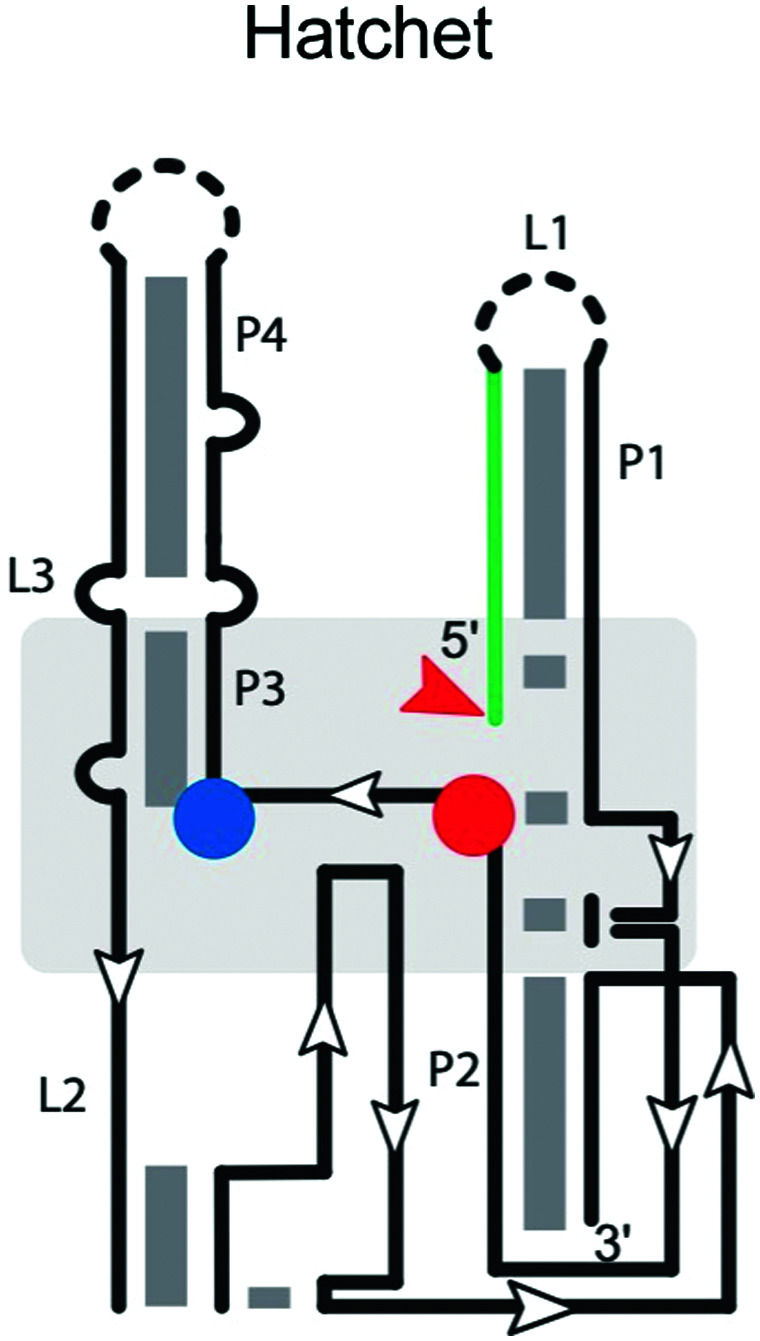
Many ribozymes have been found by bioinformatic searches for conserved RNA structures.5 This applies to the GlmS, pistol, twister, twister sister, and hatchet ribozymes. The hatchet ribozyme58 has a secondary structure comprising four stems (P1, P2, P3 and P4), with the first two linked by three highly conserved residues and the latter three bridged by two internal loops (L2 and L3) (Table 1).59 Loop L2 harbors most of the highly conserved residues. The crystal structure of the product state59 shows a compact pseudo-symmetrical RNA, with each ‘half’ stabilized by long-range interactions involving highly conserved nucleotides in close proximity to the scissile phosphate. The cleavage site of the hatchet ribozyme is located at the 5′ end of stem P1—a distal location like that in the HDV-like ribozyme. Modeling of C(−1) into the active site pocket suggested that N7 of G31 may act as the general base to deprotonate the 2′-OH of C(−1) for nucleophilic attack.59 A hatchet variant with 7-deazaguanosine in position 31 is completely inactivated. Additionally, Mg2+ is essential for self-cleavage,17 and important for ribozyme folding,60 but not necessarily for active site chemistry. Further work on these ribozymes will be necessary to reveal key determinants of substrate specificity.
The hammerhead ribozyme
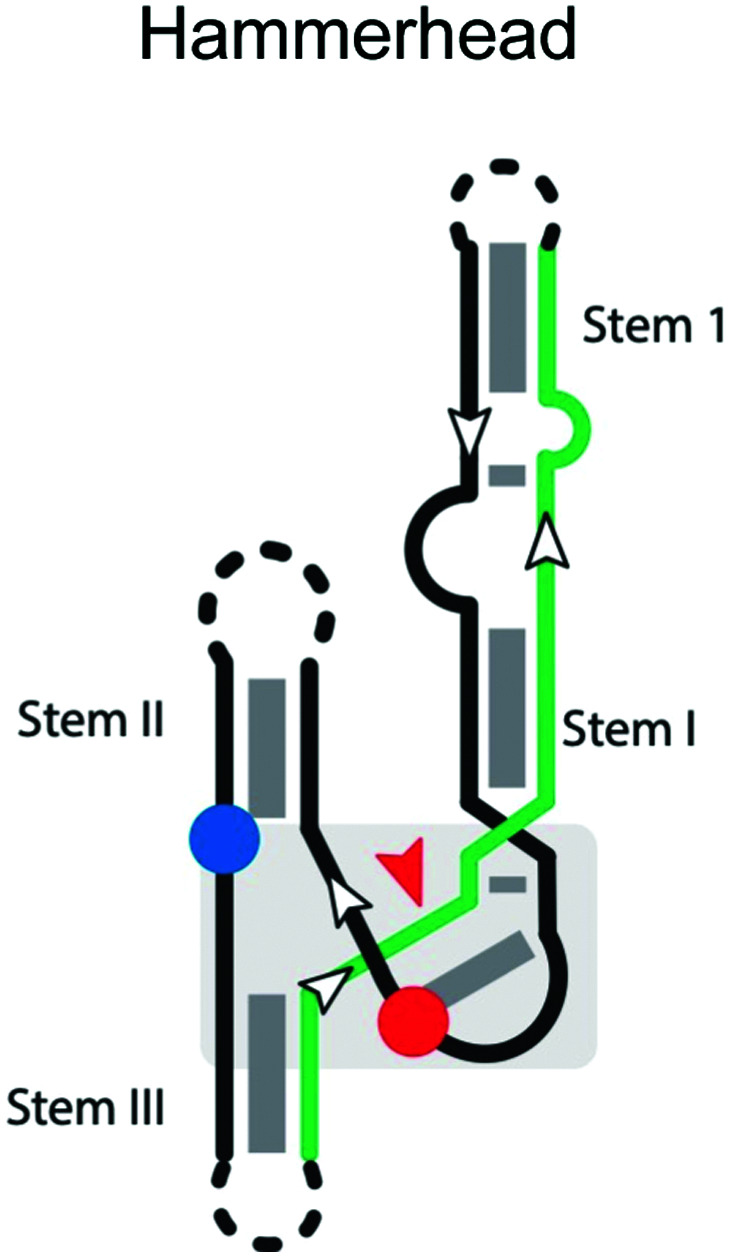
The hammerhead ribozymes are a widespread class of self-cleaving RNAs that were originally found in plant viroids and satellites, catalyzing specific cleavage reactions during processing of rolling-circle transcripts.68 The cis-acting hammerhead ribozyme consists of a universally conserved junction sequence and three helices (stem I, II and III;69Table 2).69 The general base that activates the nucleophile is the N1 of G12 from stem II, which forms an H-bond to the nucleophilic 2′-OH of C17.70,71 Additional studies indicate that a divalent metal cation activates G12 and helps organize the active site.69 G8 is stabilized in place by Watson–Crick base-pairing to C3.72 However, a more recent study indicates that a Mn2+-bound water, rather than the 2′-OH of G8, serves as the general acid in the cleavage reaction.73
Ribozymes with internal sites of self-cleavage. See legend of Fig. 1 for labeling.
| 2° Structure | Active site | Substrate strand requirement |
|---|---|---|
|
Cleavage site: internal | Upstream: stem III base pairing |
| General acid: invariant G8 in ribozyme strand of loop within catalytic core | Downstream: stem I base pairing | |
| General base: invariant G12 in between stem II & stem III | Notes: cleavage is between CN | |
| Ligation: yes | *All terminal loops can be manipulated into a trans version | |
| Ref. 61 | ||
|
Cleavage site: internal | Upstream: base pairing within stem A and D |
| General acid: A38 in stem B | Downstream: base pairing following G + 1 in stem A | |
| General base: G8 in stem A | Notes: H-bond substitutions for G + 1 destroy activity. A38 cannot be mutated | |
| Ligation: yes | ||
| Ref. 62 | ||
|
Cleavage site: internal | Upstream: base pairing |
| General acid: A32 on the ribozyme strand between P2 and pseudoknot (PK) | Downstream: base pairing | |
| General base: G40 located on the ribozyme strand between pseudoknot (PK) and P3 | ||
| Ligation: yes63 | ||
| Ref. 64 | ||
|
Cleavage site: internal | Upstream: base pairing |
| General acid: A10? or A1?65 | Downstream: base pairing, starting with A | |
| General base: A63? G62?66 G3365 | Notes: core of twister is stabilized by stacking and two pseudoknots | |
| Ligation: ? | ||
| Ref. 66 | ||
|
Cleavage site: internal | Upstream: base pairing |
| General acid: ? | Downstream: base pairing | |
| General base: ? | Notes: mutation of A63 and G5 cannot be mutated | |
| Ligation: ? | ||
| Ref. 60 and 67 | ||
G12 and G8 are critical residues that should be preserved in the catalytic strand, as well as for proper folding and positioning of the scissile phosphate in the required in-line geometry of the catalytic core. Mutation of G12 to any other nucleobases or substitution of G12 by analogs perturbing the pKa of N1 were found to significantly decrease the reaction rate.74,75 The 2′-OH of G8 is similarly essential,76,77 and mutation of G8 to C decreases the reaction rate by 105-fold.72,75 Interestingly, the reaction rate of the G8C mutant can be partially restored by the compensatory mutation C3G,72 suggesting some flexibility in the identity of these important residues.
A major determinant of sequence specificity is the stable base-pairing of the substrate strand to the catalytic strand. The sequence specificity of the hammerhead ribozyme was reported to be NUH,78 where N is any nucleotide, and H is any nucleotide except G. Eckstein and coworkers re-investigated the sequence specificity of the hammerhead ribozyme reaction and rewrote the NUH rule to be NHH.79,80 In the trans-acting hammerhead ribozyme, cleavage specificity is largely determined by the different binding affinities between the matched and mismatched substrates,81 which is influenced by the length and base composition of the helices formed upon ribozyme-substrate binding. Therefore, for high specificity, these helices should have the minimum length necessary to ensure binding, because overly long recognition helices reduce the specificity of cleavage and the bound form can have a substantial lifetime even with a suboptimal match. Adding more nucleotides to the recognition sequence ultimately reduces substrate specificity,82 because the cleavage rate of both matched and mismatched substrate is still much faster than the substrate dissociation rate. Thus, optimal substrate specificity can be achieved by increasing the substrate dissociation rate (reducing the binding affinity) to be close to the cleavage rate. The position of mismatches is also important, with mismatches in the innermost base pairs of stem I and III having the greatest effect on cleavage rate, and distal mismatches having less effect.83 Overall, while the influence of bases involved in catalysis may be more difficult to predict, sequence specificity caused by substrate association can be understood in this framework and is therefore amenable to engineering.
The hairpin ribozyme
Like the hammerhead ribozyme, the hairpin ribozyme is found in RNA satellites of plant viruses like the tobacco ringspot,68 chicory yellow mottle,84 and arabis mosaic virus.85 The hairpin ribozyme performs a reversible self-cleavage reaction in processing multimeric RNA during rolling-circle replication of the viral genome. There are four helical stems anchoring a four-way junction in the secondary structure of the hairpin ribozyme. The catalytic center involves a complex ribose zipper formed by A10 and G11 and A24 and C25 (Table 2).86 Residues G8 and A38 on the ribozyme strand, located within stems B and A, respectively, serve as the general base and general acid, respectively.87,88 The microscopic pKa of the N1 imino group of A38 matches the macroscopic pKa measured for the cleavage reaction for the most active, four-way helical junction, form of the ribozyme, consistent with its proposed role as general acid.89 Interestingly, crowded environments also pose a critical influence on the catalysis of the hairpin ribozyme, stabilizing the active ‘docked’ conformation and the transition state, leading to increased catalytic activity.90
Hairpin ribozyme mutants were extensively studied using in vitro selection to screen for active variants,91,92 identifying key catalytic residues in both loops (positions 8–10 and 21–25). These studies demonstrated a very strong preference for G at the +1 position, but the base identity at positions −1, +2, and +3 was less constrained. Accordingly, the consensus sequence at the cleavage site was defined as N*GUY.93 However, later studies demonstrated that also G*GUN, G*GGR, and U*GUA substrates were cleaved, although with about five-fold lower activity.94 To improve activity on poorly processed substrates, hairpin ribozyme variants were engineered for G*GUA95 and A*GCU sites,96 thus further extending substrate specificity. These two latter studies clearly demonstrated that, as implicated before,97 compensatory base changes of the ribozyme strand can rescue nucleobase substitutions in the substrate, thus recovering not only cleavage but also ligation activity. For example, mutation of C + 3 to A in the substrate can be tolerated by substitution of A7 by U in the ribozyme strand, compensating for the lost interaction between wild-type C + 3 and A7.95 Similarly, mutation of U + 2 to C in the substrate is compensated by replacement of A8 with G in the ribozyme strand.96 Thus, substrate specificity can be expanded by appropriate engineering of the hairpin ribozyme.
Pistol ribozyme
The secondary structure of the pistol ribozyme is composed of one pseudoknot and three helical stems (P1, P2 and P3; Table 2), which are connected by three loops (loops 1, 2 and 3), with the P1 stem and pseudoknot forming a stacked structure.98 In the trans construct,99 stems P1 and P2 each comprise five Watson–Crick base pairs, and stem P2 contains an additional U–U base pair between U29 on the ribozyme and U1 on the substrate strand. The U–U base pair has two potential roles, helping to adjust the orientation of the scissile phosphate for the cleavage reaction and/or stabilizing U1 after the cleavage reaction. Three highly conserved adenosine residues in loop 1 form an A-minor interaction with stem P1 and orient stem P2 in the active site. Loops 2 and 3 flank the pseudoknot and form the active site. The scissile phosphate on the substrate strand is located on a sharp turn between stems P2 and P3.
The N1 of G40 appears to act as the general base, activating the 2′-OH nucleophile to initiate cleavage.99 To do this, the N1 of G40 needs to be deprotonated by ionization or tautomerization. A32 is also in proximity to the active site and it has been suggested to act as the general acid by neutralizing the charge of the 5′-O during the reaction. Instead, because disruption of the inner-sphere coordination of the active-site Mg2+ cation to N7 of G33 significantly reduces the cleavage rate, it has been proposed that the hydrated Mg2+ acts as a general acid. A crystal structure of the ribozyme100 suggested that this cation plays a major role in catalysis. A second Mg2+ stabilizing the 2′,3′-cyclic phosphate in the product complex further supports the cleavage process.101
The ribozyme displays full activity with an A32G mutation, consistent with interactions with the ribose ring being more critical than the base. Overall, while data on specificity are limited, residues affecting positions 32 and 40, and the U–U wobble base pair in stem P2, are expected to influence substrate specificity.
Twister ribozyme
The twister ribozyme is a small catalytic RNA motif, present in many species of bacteria and eukaryotes.102 It comprises five stems (P1, P2, P3, P4 and P5; Table 2) and internal loops stabilized by two pseudoknots.66,102–106 Cleavage of the twister ribozyme is folding-dependent. In particular, the central pseudoknot displays reversible opening and closing dynamics at physiological Mg2+ concentration, and proper orientation of the substrate is required to achieve the cleavage-competent conformation.107 A Mg2+ ion in the env22 twister ribozyme appears to coordinate the non-bridging phosphate oxygen at the U–A cleavage site,103,106 potentially stabilizing the transition state into an intermediate. Consistent with these influences, ribozyme activity strongly depends on the environmental conditions including pH, Mg2+ concentration and temperature.102,103,105
A highly conserved guanine at the cleavage site appears to be critical for the ribozyme activity. In the env22 twister ribozyme structure,103 as well as the env9 and O. sativa twister ribozyme structures,66,105 the guanine is thought to act as the general base, whereas an adenine at the cleavage site is suggested to play the role of a general acid.106 The locations of other key residues, such as the conserved U at the cleavage site, differ among the ribozyme structures, possibly reflecting conformational changes in the transition state of the twister ribozyme.
At least ten strongly conserved nucleotides are located at the active site,66 which contains the scissile phosphate between a conserved A and U adjoining stem P1. Mutants at these conserved positions display largely reduced activity. Although the twister ribozyme has not yet been as closely examined as other self-cleaving ribozymes, we expect the substrate specificity of the twister ribozyme to be largely determined by base-pairing between the ribozyme strand and the substrate strand, as well as the conserved nucleotides and tertiary interactions in the cleavage center, including interactions with the Mg2+ ion.
Twister sister ribozyme
The twister sister ribozymes are another family discovered through bioinformatics, and have similar sequence and secondary structure to the twister ribozymes.17 However, they lack the double pseudoknot interaction found in the twister ribozymes. In the pre-catalytic structure of the four-way version (Table 2),67 Mg2+ cations mediate long-range interactions, which bring 11 conserved, but spatially separated loop nucleotides close to the core of the ribozyme. C62 and A63, which flank the cleavage site on the internal loop between stems P1 and P2, are splayed apart, unlike in the stack found in the three-way junctional version. Instead, the scissile phosphate is anchored in place by a network of hydrogen bonding, including the N1H of G5, the inner sphere water of a hydrated Mg2+ and a non-bridging phosphate oxygen.67
Mutation of G5 and A63 can completely inactivate the four-way junction ribozyme. The unusual number of coordinated Mg2+ ions suggests that, in addition to mutations affecting the active site and base-pairing between ribozyme and substrate strands, mutations disturbing the binding of Mg2+ influence catalytic efficiency. A caveat of the current understanding is that the structural information is derived from complexes that may be far from the catalytically active conformation. Understanding the substrate specificity of this ribozyme is less developed compared to the ribozymes discussed earlier.
Neurospora Varkud satellite (VS) ribozyme
The Varkud satellite (VS) RNA is a transcript found in some strains of Neurospora.112 It is the largest nucleolytic ribozyme known (∼150 nucleotides) and functions in replication of the single-stranded RNA satellite. Its secondary structure contains seven helices (1–7) (Table 3) forming three three-way junctions: 2-3-6, 3-4-5, and 1-7-2.109 The cleavage site of the VS ribozyme is in the inner loop of stem 1.113 Therefore, part of stem I acts as the substrate strand in the cis-acting VS ribozyme. The sequence in the junction domain is critically important for the coaxial stacking of stems.113 The catalytic center of the ribozyme is located within stem 6 and 1. A stable kissing loop interaction is formed between the GUC in stem loop 1 and the GAC in stem loop 5, docking the loops together114 to form the active site and bring the cleavage site into the catalytic center. Additionally, the kissing loop interaction leads to an intramolecular secondary structure rearrangement in stem 1, which is important for the activity of the VS ribozyme,114 but requires surmounting a major thermodynamic barrier.115 A756 and G638 are adjacent to the scissile phosphate,116 and are believed to play the role of general acid and general base, respectively.42,101 The crystal structure of the VS ribozyme from Neurospora intermedia indicates that the ribozyme actually exists as an intertwined dimer formed by the exchange of substrate helices,109 creating two active sites in trans around cleavage site nucleotides G620 and A621. The proposed general base G638 forms a cross-strand stack with G620, which contains the 2′-O nucleophile. The imino group of G638 is within hydrogen-bonding distance of the scissile phosphate, suggesting that G638 stabilizes the in-line conformation and facilitates catalysis directly via hydrogen bonding or proton transfer. In addition, Mg2+ in the active site appears to interact critically with the scissile phosphate and also activates G638.117
VS and hovlinc ribozymes. See legend of Fig. 1 for labeling.
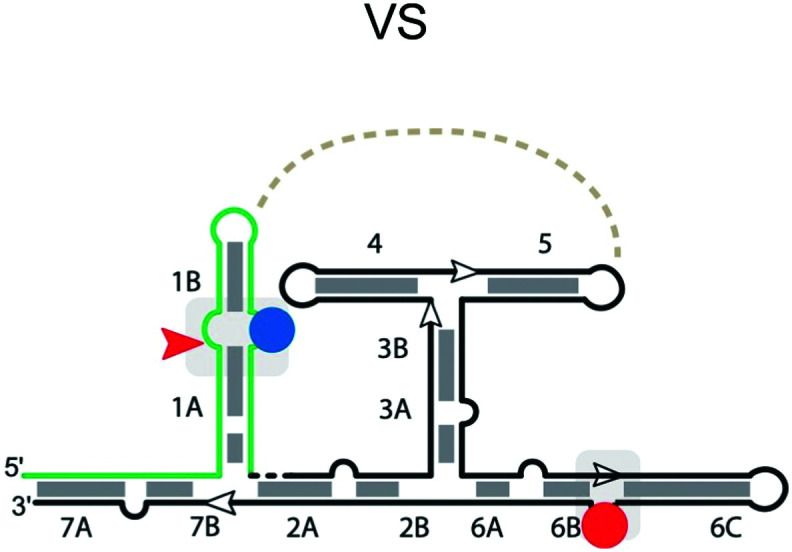
|
Cleavage site: internal | Upstream: base pairing, ending with a loop |
| General acid: A756 located in loop between stem 6B and 6C | Downstream: base pairing | |
| General base: G638 located in loop between stem 1A & stem 1B | Notes: active sites are assembled by interactions between internal loops found within two separate helices (G638 & A756 loops) | |
| Ligation: yes108 | ||
| Ref. 109 and 110 | ||

|
Cleavage site: internal | Upstream: base pairing |
| General acid: unknown | Downstream: residues involved in Pseudoknot | |
| General base: Unknown | Notes: disruption of base pairing in S4 helix and pseudoknot abolishes cleavage activity. | |
| Ligation: unknown | ||
| Ref. 111 | ||
Formation of the kissing loop and the preservation of the function of A756 and G638 are important considerations for substrate specificity of the cis-acting VS ribozyme. Mutation of A756 to G or G638 to A causes a significant decrease (103–104-fold) in the rate of cleavage.42,118 Introducing low pKa analogs, such as purine or 8-aza-adenosine at A756 interferes with ribozyme activity, but activity can be rescued by adjusting the pH.119 This is consistent with the protonated form at A756 being important, e.g., for donating a proton to the leaving group or stabilizing the transition state.
A trans-acting VS ribozyme containing 144 nucleotides (helices 2–6) can be created by disconnecting the stem-loop of 1 from the rest of the RNA.110 A minimal substrate requires one base upstream of the cleavage site and 19 bases downstream of the cleavage site to form a stable stem-loop hairpin. These interactions are supplemented by tertiary contacts between the ribozyme and substrate, such as the GUC/GAC kissing-loop interaction.120 The ribozyme appears to be amenable to extensive engineering for substrate specificity. For example, activity can be maintained while varying the number of base pairs in stem 1, as long as a compensating number of base pairs are added to stem 5.121 Also, the 1/5 kissing-loop interaction can be replaced by other kissing-loop interactions while maintaining efficient substrate cleavage.122 These features illustrate how substrate specificity depends on the unusual structure of this ribozyme.
Hovlinc ribozyme
A new type of self-cleaving ribozyme (Hovlinc) has recently emerged through an experimental genome-wide search aimed at uncovering naturally-occurring ribozymes in humans.111,123 While there is limited information about this ribozyme's mechanism of cleavage, RNA structure analysis suggests that the catalytic core consists of two stem-loops with two pseudoknots (Table 3). The ribozyme exhibited a dependence on Mg2+ and pH and showed the highest activity in Mn2+ with the reactivity changing depending on the cation present (Mn2+ > Mg2+ > Ca2+). Given that the ribozyme appears to have emerged relatively recently and that its activity is linearly dependent on pH and divalent metal ions, it is likely that the ribozyme acts primarily through positioning of the scissile phosphate for a near-optimal geometry for scission and through coordination of a hydrated metal ion.124 Thus, its active site may be simpler than active sites of other ribozymes. Additional studies will be required to further understand the structure and the mechanism of cleavage of this ribozyme.
Utilization and considerations for using self-cleaving ribozymes for synthetic biology applications
Deeper understanding and exploration of self-cleaving ribozymes brought a newer field of interest to the spotlight. Aptazymes are a class of RNAs that have the unique capability to contain the specificity of an aptamer domain, while also encompassing the catalytic potential of a ribozyme. Aptazymes form an emerging field of study in the RNA world because of their exploitation to control gene expression by utilizing a ligand dependent switch that ultimately leads to inducing cleavage and degradation of their own mRNAs.46,125 However, while much effort has been put into understanding the design aspects of creating aptazymes,126,127 no naturally occurring aptazymes have been discovered (with the exception of potential allosteric regulation of a bacterial HDV-like ribozyme by GlcN6P).18 Some of the ribozymes described above have been extensively studied in order to engineer and design aptazymes for dynamic control of gene expression.127,128 Throughout studies in constructing synthetic aptazymes for that purpose, only four classes of self-cleaving ribozymes (HDV, hammerhead, pistol and twister) have been shown to produce working aptazymes.128–131
Researchers have been taking advantage of either the 5′ or 3′ untranslated regions (UTR) within mRNA to control gene expression. In bacteria, this has been shown by either repression due to rho-independent transcriptional termination or by translation initiation by occluding the Shine–Dalgarno sequence.132,133 It has also been suggested that RNAs bearing 5′-OH groups have been able to avoid degradation by RNaseE because they are poorer substrates compared to 5′ phosphorylated RNAs.134,135 This idea has been used in designing aptazymes for the purposes of stabilizing downstream transcripts upon cleavage by ligand-dependent ribozymes.136
While most of the literature for bacterial UTRs has focused on the 5′ region, in eukaryotic systems more information about manipulating the 3′ region is coming to light.8,137 Several eukaryotic examples have suggested downregulation of mRNA expression in the 3′ UTR, one being the theophylline-binding aptamer with a hammerhead ribozyme. In the presence of theophylline, the aptamer changes conformation and activates the hammerhead to self-cleave, preventing expression of β-lactamase, leading to decreased antibiotic resistance138 (Fig. 2B). In another approach, an aptazyme was engineered by replacing the P4–L4 stem-loop of an HDV ribozyme with an aptamer for guanine, which, upon binding, stabilizes the catalytically competent form of the ribozyme, and result in down-regulation of EGFP. The aptazyme was placed in the 3′ UTR of the mRNA, and in response to guanine, causes HDV to cleave its 5′ end from the transcript130 (Fig. 2A). Another group constructed an artificial library containing pistol-based aptazymes and utilized a deep sequencing approach to analyze over 16 000 aptazyme mutants. The guanine aptamer was fused in tandem vs the conventional placement within a ribozyme, which opens up a new potential aptazyme architecture and consideration for engineering aptazymes137,138 (Fig. 2C). While this method was viable, a new, rapid identification method was developed for high throughput screening for conditionally cleaved ribozymes in cellular systems through barcode amplification. This not only uncovered tet-hammerhead and guanine-HDV on and off switches, but also a tet-twister based aptazyme.139
Fig. 2. Aptazyme-based cleavage for mRNA degradation. The yellow regions indicate the aptamer domain, while the black areas indicate the associated ribozyme. The gray boxes indicate base-pairing and the red arrows are the sites of cleavage for each ribozyme. (A) HDV-based, (B) hammerhead-based, and (C) pistol-based aptazymes. (D) Aptazymes inserted in the 3′ untranslated regions of mRNA and cleaving after binding their respective ligands. (E) Cleavage of the ribozyme portion of the aptazyme leads to degradation of the mRNA.

Overall, there is much that needs to be understood about the mechanisms and applications for utilizing self-cleaving ribozymes and aptazymes. This includes the requirements for designing aptazymes, which contain not only the aptamer domain and ribozyme selected, but also the communication module between the aptamer and ribozyme domains.140 These modules play an important role, as it has been shown that connector stability can impact the activity of the ribozyme. Multiple groups have mutagenized and in vitro selected a library of potential aptazymes, which were subsequently analyzed for the best combination of the communication module, ribozyme, and aptamer to allow for increased cleavage under their desired conditions.130,141–143 Other concerns include the consideration that too much ribozyme could lead to high levels of background cleavage, or an excessively stable aptamer domain may not give a sufficient ligand-dependent response when looking at a response range for downregulation of gene expression. Utilizing all the discussed properties of these catalytic RNAs can allow for other applications in controlling gene expression.
Conclusion
The discovery of ribozymes is considered as one of the strongest pieces of evidence for the RNA World theory, which states that early life forms relied primarily on RNA for genetic information storage and biochemical function (including catalysis), without major participation in cellular processes by DNA or proteins. The specificity of ribozymes for their substrates is a key factor in the behavior of a collective of RNAs. Highly specific ribozymes may be desirable in some cases (e.g., self-aminoacylating ribozymes that would be precursors to the tRNA/synthetase system), but highly promiscuous ribozymes might be desired in other cases (e.g., an RNA polymerase ‘copying’ ribozyme). In addition, network-level behaviors can emerge from the peculiarities of substrate specificities (e.g., as mediated by internal guide sequences144). The important conceptual role of ribozyme specificity was highlighted by Levy and Ellington,145 who surmised that, absent other mechanisms of compartmentalization, cooperating ribozymes in the RNA World would need to recognize each other through sequence ‘tags’ to avoid parasitization by non-catalytic RNAs. Such target-specific polymerases have been recently demonstrated.146
In this review, we have discussed substrate specificity of small nucleolytic ribozymes, which is closely tied to their mechanism and structure. In general, substrate specificity is influenced strongly by base-pairing interactions with the substrate strand, and at least in some cases, can be rationally engineered with knowledge of base-pair stabilities. We have also indicated key structural features that affect substrate recognition, as well as requirements for the activity of the ribozymes. Mapping out the key nucleotides involved in the self-cleaving mechanism and structural requirements that assemble the catalytically competent conformations (kissing loops, ribose zippers, tertiary interactions, etc.) will allow more efficient engineering of new ribozyme variants and facilitate further analysis of trans-cleaving versions of these ribozymes. Substrate nucleotides that affect the catalytic mechanism (e.g., Mg2+ binding, proper folding) add to the sequence-specificity of the ribozyme. Ribozymes in which sequence specificity of the substrate strand has been extensively investigated reveal that the base-pairing between the substrate and ribozyme strands plays an important role. Typically, central residues are conserved while mutations are tolerated at more distal sites, and specificity is maximized when the correct substrate binds strongly, but not strongly enough that mismatches would be tolerated (except when such redundancy is desired).
It is noteworthy that the site of cleavage for most of these ribozymes occurs between two base-paired regions (Table 2). Cleavage then results in products which each have lower affinity for the ribozyme than the substrate. While this is advantageous for multiple-turnover reactions, sequence requirements on both sides of the cleavage site constrain potential substrates and applications. On the other hand, some ribozymes (e.g., HDV, hatchet; Table 1) cleave peripherally of the specified substrate sequence, and the products thus have similar affinity to the ribozyme as the substrates. Although this decreases substrate turnover, the placement of most sequence determinants on one side of the cleavage site is a useful property when designing constructs to synthesize RNAs with a defined 3′ end.
The increasing number of these ribozyme motifs discovered demonstrates that, with respect to the small endonucleolytic ribozymes, the same biochemical goal can be reached with a variety of RNA folds. A given ribozyme can be adapted to different substrates, as long as those contain essential sequence elements required for catalysis. If these requirements are not fulfilled, another ribozyme having different requirements for its substrate sequence may be able to process the substrate in question. For example, HDV ribozymes have been widely used to process guide RNAs in CRISPR-based gene editing applications. However, there are guide sequences that may base-pair with critical segments of the HDV ribozyme, leading to poor self-scission. In such cases one of the many other examples of the HDV-like ribozymes can be used, or the processing can be achieved by the hatchet or the metabolite-dependent GlmS ribozyme, which also cleave peripherally (Table 1), allowing the ribozyme to be wholly independent of the guide RNA sequence and structure. Similarly, an RNA world may have had the potential to process numerous substrates while simultaneously maintaining sequence-specific catalysis. Understanding the determinants of specificity in these ribozymes and others may aid synthetic biology efforts to re-create an RNA World.
Conflicts of interest
There are no conflicts to declare.
Supplementary Material
Acknowledgments
Funding was provided by the Simons Foundation Collaboration on the Origins of Life [290356FY18], the NIH New Innovator Program [DP2GM123457], and NSF [1935087] to I. A. C. and by NSF-CBET 1804220 and NASA 20-EXO20-0110 to A. L.
Notes and references
- Pressman A. Blanco C. Chen I. A. Curr. Biol. 2015;25:R953–R963. doi: 10.1016/j.cub.2015.06.016. [DOI] [PubMed] [Google Scholar]
- Khersonsky O. Tawfik D. S. Annu. Rev. Biochem. 2010;79:471–505. doi: 10.1146/annurev-biochem-030409-143718. [DOI] [PubMed] [Google Scholar]
- Jensen R. A. Annu. Rev. Microbiol. 1976;30:409–425. doi: 10.1146/annurev.mi.30.100176.002205. [DOI] [PubMed] [Google Scholar]
- Janzen E. Blanco C. Peng H. Kenchel J. Chen I. A. Chem. Rev. 2020;120:4879–4897. doi: 10.1021/acs.chemrev.9b00620. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weinberg C. E. Weinberg Z. Hammann C. Nucleic Acids Res. 2019;47:9480–9494. doi: 10.1093/nar/gkz737. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lilley D. F1000Research. 2019;8:1462. doi: 10.12688/f1000research.19324.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seith D. D. Bingaman J. L. Veenis A. J. Button A. C. Bevilacqua P. C. ACS Catal. 2018;8:314–327. doi: 10.1021/acscatal.7b02976. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ren A. Micura R. Patel D. J. Curr. Opin. Chem. Biol. 2017;41:71–83. doi: 10.1016/j.cbpa.2017.09.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reymond C. Beaudoin J.-D. Perreault J.-P. Cell. Mol. Life Sci. 2009;66:3937. doi: 10.1007/s00018-009-0124-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Riccitelli N. and Lupták A., in Progress in Molecular Biology and Translational Science, ed. G. A. Soukup, Academic Press, 2013, vol. 120, pp. 123–171 [DOI] [PubMed] [Google Scholar]
- Ferré-D'Amaré A. R. Q. Rev. Biophys. 2010;43:423–447. doi: 10.1017/S0033583510000144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zheng L. Falschlunger C. Huang K. Mairhofer E. Yuan S. Wang J. Patel D. J. Micura R. Ren A. Proc. Natl. Acad. Sci. U. S. A. 2019;116:10783–10791. doi: 10.1073/pnas.1902413116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor J. M. Intervirology. 1999;42:173–178. doi: 10.1159/000024977. [DOI] [PubMed] [Google Scholar]
- Salehi-Ashtiani K. Lupták A. Litovchick A. Szostak J. W. Science. 2006;313:1788–1792. doi: 10.1126/science.1129308. [DOI] [PubMed] [Google Scholar]
- Webb C.-H. T. Riccitelli N. J. Ruminski D. J. Lupták A. Science. 2009;326:953. doi: 10.1126/science.1178084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ruminski D. J. Webb C.-H. T. Riccitelli N. J. Lupták A. J. Biol. Chem. 2011;286:41286–41295. doi: 10.1074/jbc.M111.297283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weinberg Z. Kim P. B. Chen T. H. Li S. Harris K. A. Lünse C. E. Breaker R. R. Nat. Chem. Biol. 2015;11:606–610. doi: 10.1038/nchembio.1846. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Passalacqua L. F. M. Jimenez R. M. Fong J. Y. Lupták A. Biochemistry. 2017;56:6006–6014. doi: 10.1021/acs.biochem.7b00879. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferré-D'Amaré A. R. Zhou K. Doudna J. A. Nature. 1998;395:567–574. doi: 10.1038/26912. [DOI] [PubMed] [Google Scholar]
- Ke A. Zhou K. Ding F. Cate J. H. D. Doudna J. A. Nature. 2004;429:201–205. doi: 10.1038/nature02522. [DOI] [PubMed] [Google Scholar]
- Chen J. Ganguly A. Miswan Z. Hammes-Schiffer S. Bevilacqua P. C. Golden B. L. Biochemistry. 2013;52:557–567. doi: 10.1021/bi3013092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Das S. R. Piccirilli J. A. Nat. Chem. Biol. 2005;1:45–52. doi: 10.1038/nchembio703. [DOI] [PubMed] [Google Scholar]
- Nakano S. Chadalavada D. M. Bevilacqua P. C. Science. 2000;287:1493–1497. doi: 10.1126/science.287.5457.1493. [DOI] [PubMed] [Google Scholar]
- Lu J. Koo S. C. Weissman B. P. Harris M. E. Li N.-S. Piccirilli J. A. Biochemistry. 2018;57:3465–3472. doi: 10.1021/acs.biochem.8b00031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Y. Eldho N. V. Dayie T. K. Carey P. R. Biochemistry. 2010;49:3427–3435. doi: 10.1021/bi902117w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lupták A. Ferré-D'Amaré A. R. Zhou K. Zilm K. W. Doudna J. A. J. Am. Chem. Soc. 2001;123:8447–8452. doi: 10.1021/ja016091x. [DOI] [PubMed] [Google Scholar]
- Gong B. Chen J.-H. Chase E. Chadalavada D. M. Yajima R. Golden B. L. Bevilacqua P. C. Carey P. R. J. Am. Chem. Soc. 2007;129:13335–13342. doi: 10.1021/ja0743893. [DOI] [PubMed] [Google Scholar]
- Webb C.-H. T. Lupták A. RNA Biol. 2011;8:719–727. doi: 10.4161/rna.8.5.16226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Riccitelli N. J. Delwart E. Lupták A. Biochemistry. 2014;53:1616–1626. doi: 10.1021/bi401717w. [DOI] [PubMed] [Google Scholar]
- Perrotta A. T. Been M. D. Nucleic Acids Res. 1993;21:3959–3965. doi: 10.1093/nar/21.17.3959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Branch A. D. Robertson H. D. Proc. Natl. Acad. Sci. U. S. A. 1991;88:10163–10167. doi: 10.1073/pnas.88.22.10163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perrotta A. T. Been M. D. Biochemistry. 1992;31:16–21. doi: 10.1021/bi00116a004. [DOI] [PubMed] [Google Scholar]
- Puttaraju M. Perrotta A. T. Been M. D. Nucleic Acids Res. 1993;21:4253–4258. doi: 10.1093/nar/21.18.4253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Been M. D. Perrotta A. T. Rosenstein S. P. Biochemistry. 1992;31:11843–11852. doi: 10.1021/bi00162a024. [DOI] [PubMed] [Google Scholar]
- Wu H. N. Wang Y. J. Hung C. F. Lee H. J. Lai M. M. C. J. Mol. Biol. 1992;223:233–245. doi: 10.1016/0022-2836(92)90728-3. [DOI] [PubMed] [Google Scholar]
- Kumar P. K. Suh Y. A. Taira K. Nishikawa S. FASEB J. 1993;7:124–129. doi: 10.1096/fasebj.7.1.8422958. [DOI] [PubMed] [Google Scholar]
- Perrotta A. T. Been M. D. Nature. 1991;350:434–436. doi: 10.1038/350434a0. [DOI] [PubMed] [Google Scholar]
- Ananvoranich S. Perreault J. P. J. Biol. Chem. 1998;273:13182–13188. doi: 10.1074/jbc.273.21.13182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roy G. Ananvoranich S. Perreault J. P. Nucleic Acids Res. 1999;27:942–948. doi: 10.1093/nar/27.4.942. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deschenes P. Lafontaine D. A. Charland S. Perreault J. P. Antisense Nucleic Acid Drug Dev. 2000;10:53–61. doi: 10.1089/oli.1.2000.10.53. [DOI] [PubMed] [Google Scholar]
- Deschênes P. Ouellet J. Perreault J. Perreault J. P. Nucleic Acids Res. 2003;31:2087–2096. doi: 10.1093/nar/gkg307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson T. J. McLeod A. C. Lilley D. M. J. EMBO J. 2007;26:2489–2500. doi: 10.1038/sj.emboj.7601698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ruminski D. J. Webb C.-H. T. Riccitelli N. J. Lupták A. J. Biol. Chem. 2011;286:41286–41295. doi: 10.1074/jbc.M111.297283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Webb C.-H. T. Lupták A. Biochemistry. 2018;57:1440–1450. doi: 10.1021/acs.biochem.7b00789. [DOI] [PubMed] [Google Scholar]
- Webb C.-H. T. Nguyen D. Myszka M. Lupták A. Sci. Rep. 2016;6:28179. doi: 10.1038/srep28179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Winkler W. C. Nahvi A. Roth A. Collins J. A. Breaker R. R. Nature. 2004;428:281–286. doi: 10.1038/nature02362. [DOI] [PubMed] [Google Scholar]
- Savinov A. Block S. M. Proc. Natl. Acad. Sci. U. S. A. 2018;115:11976–11981. doi: 10.1073/pnas.1812122115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roth A. Nahvi A. Lee M. Jona I. Breaker R. R. RNA. 2006;12:607–619. doi: 10.1261/rna.2266506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hull C. M. Anmangandla A. Bevilacqua P. C. ACS Chem. Biol. 2016;11:1118–1127. doi: 10.1021/acschembio.6b00081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klein D. J. Ferré-D'Amaré A. R. Science. 2006;313:1752–1756. doi: 10.1126/science.1129666. [DOI] [PubMed] [Google Scholar]
- Bingaman J. L. Zhang S. Stevens D. R. Yennawar N. H. Hammes-Schiffer S. Bevilacqua P. C. Nat. Chem. Biol. 2017;13:439–445. doi: 10.1038/nchembio.2300. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bingaman J. L. Gonzalez I. Y. Wang B. Bevilacqua P. C. Biochemistry. 2017;56:4313–4317. doi: 10.1021/acs.biochem.7b00662. [DOI] [PubMed] [Google Scholar]
- Cochrane J. C. Lipchock S. V. Strobel S. A. Chem. Biol. 2007;14:97–105. doi: 10.1016/j.chembiol.2006.12.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davis J. H. Dunican B. F. Strobel S. A. Biochemistry. 2011;50:7236–7242. doi: 10.1021/bi200471c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCarthy T. J. Plog M. A. Floy S. A. Jansen J. A. Soukup J. K. Soukup G. A. Chem. Biol. 2005;12:1221–1226. doi: 10.1016/j.chembiol.2005.09.006. [DOI] [PubMed] [Google Scholar]
- Gong B. Klein D. J. Ferré-D’Amaré A. R. Carey P. R. J. Am. Chem. Soc. 2011;133:14188–14191. doi: 10.1021/ja205185g. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tinsley R. A. Furchak J. R. W. Walter N. G. RNA. 2007;13:468–477. doi: 10.1261/rna.341807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li S. Lünse C. E. Harris K. A. Breaker R. R. RNA. 2015;21:1845–1851. doi: 10.1261/rna.052522.115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zheng L. Falschlunger C. Huang K. Mairhofer E. Yuan S. Wang J. Patel D. J. Micura R. Ren A. Proc. Natl. Acad. Sci. U. S. A. 2019;116:10783–10791. doi: 10.1073/pnas.1902413116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gasser C. Gebetsberger J. Gebetsberger M. Micura R. Nucleic Acids Res. 2018;46:6983–6995. doi: 10.1093/nar/gky555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Przybilski R. Hammann C. ChemBioChem. 2006;7:1641–1644. doi: 10.1002/cbic.200600312. [DOI] [PubMed] [Google Scholar]
- Rupert P. B. Ferré-D'Amaré A. R. Nature. 2001;410:780–786. doi: 10.1038/35071009. [DOI] [PubMed] [Google Scholar]
- Lihanova Y. Weinberg C. E. RNA Biol. 2021:1–9. doi: 10.1080/15476286.2021.1874706. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson T. J. Liu Y. Li N.-S. Dai Q. Piccirilli J. A. Lilley D. M. J. J. Am. Chem. Soc. 2019;141:7865–7875. doi: 10.1021/jacs.9b02141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gaines C. S. York D. M. J. Am. Chem. Soc. 2016;138:3058–3065. doi: 10.1021/jacs.5b12061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eiler D. Wang J. Steitz T. A. Proc. Natl. Acad. Sci. U. S. A. 2014;111:13028–13033. doi: 10.1073/pnas.1414571111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zheng L. Mairhofer E. Teplova M. Zhang Y. Ma J. Patel D. J. Micura R. Ren A. Nat. Commun. 2017;8:1180. doi: 10.1038/s41467-017-01276-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Prody G. A. Bakos J. T. Buzayan J. M. Schneider I. R. Bruening G. Science. 1986;231:1577–1580. doi: 10.1126/science.231.4745.1577. [DOI] [PubMed] [Google Scholar]
- Mir A. Chen J. Robinson K. Lendy E. Goodman J. Neau D. Golden B. L. Biochemistry. 2015;54:6369–6381. doi: 10.1021/acs.biochem.5b00824. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson M. Schultz E. P. Martick M. Scott W. G. J. Mol. Biol. 2013;425:3790–3798. doi: 10.1016/j.jmb.2013.05.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chi Y.-I. Martick M. Lares M. Kim R. Scott W. G. Kim S.-H. PLoS Biol. 2008;6:e234. doi: 10.1371/journal.pbio.0060234. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martick M. Scott W. G. Cell. 2006;126:309–320. doi: 10.1016/j.cell.2006.06.036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mir A. Golden B. L. Biochemistry. 2016;55:633–636. doi: 10.1021/acs.biochem.5b01139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han J. Burke J. M. Biochemistry. 2005;44:7864–7870. doi: 10.1021/bi047941z. [DOI] [PubMed] [Google Scholar]
- Ruffner D. E. Stormo G. D. Uhlenbeck O. C. Biochemistry. 1990;29:10695–10702. doi: 10.1021/bi00499a018. [DOI] [PubMed] [Google Scholar]
- Williams D. M. Pieken W. A. Eckstein F. Proc. Natl. Acad. Sci. U. S. A. 1992;89:918–921. doi: 10.1073/pnas.89.3.918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fu D. J. McLaughlin L. W. Proc. Natl. Acad. Sci. U. S. A. 1992;89:3985–3989. doi: 10.1073/pnas.89.9.3985. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Birikh K. R. Heaton P. A. Eckstein F. Eur. J. Biochem. 1997;245:1–16. doi: 10.1111/j.1432-1033.1997.t01-3-00001.x. [DOI] [PubMed] [Google Scholar]
- Kore A. R. Vaish N. K. Kutzke U. Eckstein F. Nucleic Acids Res. 1998;26:4116–4120. doi: 10.1093/nar/26.18.4116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ludwig J. Blaschke M. Sproat B. S. Nucleic Acids Res. 1998;26:2279–2285. doi: 10.1093/nar/26.10.2279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crooke S. T. and Lebleu B., Antisense research and applications, CRC Press, Boca Raton, 1993 [Google Scholar]
- Herschlag D. Proc. Natl. Acad. Sci. U. S. A. 1991;88:6921–6925. doi: 10.1073/pnas.88.16.6921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Werner M. Uhlenbeck O. C. Nucleic Acids Res. 1995;23:2092–2096. doi: 10.1093/nar/23.12.2092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rubino L. Tousignant M. E. Steger G. Kaper J. M. J. Gen. Virol. 1990;71:1897–1903. doi: 10.1099/0022-1317-71-9-1897. [DOI] [PubMed] [Google Scholar]
- Kaper J. M. Tousignant M. E. Steger G. Biochem. Biophys. Res. Commun. 1988;154:318–325. doi: 10.1016/0006-291X(88)90687-0. [DOI] [PubMed] [Google Scholar]
- Hamm M. L. Piccirilli J. A. Karpeisky A. Beigelman L. Ross B. S. Manoharan M. Gait M. J. Biochemistry. 2000;39:6410–6421. doi: 10.1021/bi992974d. [DOI] [PubMed] [Google Scholar]
- Rupert P. B. Massey A. P. Sigurdsson S. T. Ferré-D'Amaré A. R. Science. 2002;298:1421–1424. doi: 10.1126/science.1076093. [DOI] [PubMed] [Google Scholar]
- Kath-Schorr S. Wilson T. J. Li N.-S. Lu J. Piccirilli J. A. Lilley D. M. J. J. Am. Chem. Soc. 2012;134:16717–16724. doi: 10.1021/ja3067429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberman J. A. Guo M. Jenkins J. L. Krucinska J. Chen Y. Carey P. R. Wedekind J. E. J. Am. Chem. Soc. 2012;134:16933–16936. doi: 10.1021/ja3070528. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Paudel B. P. Rueda D. J. Am. Chem. Soc. 2014;136:16700–16703. doi: 10.1021/ja5073146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berzal-Herranz A. Joseph S. Burke J. M. Genes Dev. 1992;6:129–134. doi: 10.1101/gad.6.1.129. [DOI] [PubMed] [Google Scholar]
- Berzal-Herranz A. Joseph S. Chowrira B. M. Butcher S. E. Burke J. M. EMBO J. 1993;12:2567–2573. doi: 10.1002/j.1460-2075.1993.tb05912.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joseph S. Berzal-Herranz A. Chowrira B. M. Butcher S. E. Burke J. M. Genes Dev. 1993;7:130–138. doi: 10.1101/gad.7.1.130. [DOI] [PubMed] [Google Scholar]
- Pérez-Ruiz M. Barroso-delJesus A. Berzal-Herranz A. J. Biol. Chem. 1999;274:29376–29380. doi: 10.1074/jbc.274.41.29376. [DOI] [PubMed] [Google Scholar]
- Drude I. Strahl A. Galla D. Müller O. Müller S. FEBS J. 2011;278:622–633. doi: 10.1111/j.1742-4658.2010.07983.x. [DOI] [PubMed] [Google Scholar]
- Balke D. Zieten I. Strahl A. Müller O. Müller S. ChemMedChem. 2014;9:2128–2137. doi: 10.1002/cmdc.201402166. [DOI] [PubMed] [Google Scholar]
- Pinard R. Lambert D. Walter N. G. Heckman J. E. Major F. Burke J. M. Biochemistry. 1999;38:16035–16039. doi: 10.1021/bi992024s. [DOI] [PubMed] [Google Scholar]
- Ren A. Vušurović N. Gebetsberger J. Gao P. Juen M. Kreutz C. Micura R. Patel D. J. Nat. Chem. Biol. 2016;12:702–708. doi: 10.1038/nchembio.2125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nguyen L. A. Wang J. Steitz T. A. Proc. Natl. Acad. Sci. U. S. A. 2017;114:1021–1026. doi: 10.1073/pnas.1611191114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Teplova M. Falschlunger C. Krasheninina O. Egger M. Ren A. Patel D. J. Micura R. Angew. Chem., Int. Ed. 2020;59:2837–2843. doi: 10.1002/anie.201912522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson T. J. Li N.-S. Lu J. Frederiksen J. K. Piccirilli J. A. Lilley D. M. J. Proc. Natl. Acad. Sci. U. S. A. 2010;107:11751–11756. doi: 10.1073/pnas.1004255107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roth A. Weinberg Z. Chen A. G. Y. Kim P. B. Ames T. D. Breaker R. R. Nat. Chem. Biol. 2014;10:56–60. doi: 10.1038/nchembio.1386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ren A. Košutić M. Rajashankar K. R. Frener M. Santner T. Westhof E. Micura R. Patel D. J. Nat. Commun. 2014;5:5534. doi: 10.1038/ncomms6534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weinberg Z. Wang J. X. Bogue J. Yang J. Corbino K. Moy R. H. Breaker R. R. Genome Biol. 2010;11:R31. doi: 10.1186/gb-2010-11-3-r31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu Y. Wilson T. J. McPhee S. A. Lilley D. M. J. Nat. Chem. Biol. 2014;10:739–744. doi: 10.1038/nchembio.1587. [DOI] [PubMed] [Google Scholar]
- Košutić M. Neuner S. Ren A. Flür S. Wunderlich C. Mairhofer E. Vušurović N. Seikowski J. Breuker K. Höbartner C. Patel D. J. Kreutz C. Micura R. Angew. Chem., Int. Ed. 2015;54:15128–15133. doi: 10.1002/anie.201506601. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vušurović N. Altman R. B. Terry D. S. Micura R. Blanchard S. C. J. Am. Chem. Soc. 2017;139:8186–8193. doi: 10.1021/jacs.7b01549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jones F. D. Ryder S. P. Strobel S. A. Nucleic Acids Res. 2001;29:5115–5120. doi: 10.1093/nar/29.24.5115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suslov N. B. DasGupta S. Huang H. Fuller J. R. Lilley D. M. J. Rice P. A. Piccirilli J. A. Nat. Chem. Biol. 2015;11:840–846. doi: 10.1038/nchembio.1929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guo H. C. Collins R. A. EMBO J. 1995;14:368–376. doi: 10.1002/j.1460-2075.1995.tb07011.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Y. Qi F. Gao F. Cao H. Xu D. Salehi-Ashtiani K. Kapranov P. Nat. Chem. Biol. 2021;17:601–607. doi: 10.1038/s41589-021-00763-0. [DOI] [PubMed] [Google Scholar]
- Collins R. A. Biochem. Soc. Trans. 2002;30:1122–1126. doi: 10.1042/bst0301122. [DOI] [PubMed] [Google Scholar]
- Lafontaine D. A. Norman D. G. Lilley D. M. J. EMBO J. 2001;20:1415–1424. doi: 10.1093/emboj/20.6.1415. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andersen A. A. Collins R. A. Mol. Cell. 2000;5:469–478. doi: 10.1016/S1097-2765(00)80441-4. [DOI] [PubMed] [Google Scholar]
- Bouchard P. Legault P. RNA. 2014;20:1451–1464. doi: 10.1261/rna.046144.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lipfert J. Ouellet J. Norman D. G. Doniach S. Lilley D. M. J. Structure. 2008;16:1357–1367. doi: 10.1016/j.str.2008.07.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ganguly A. Weissman B. P. Giese T. J. Li N.-S. Hoshika S. Rao S. Benner S. A. Piccirilli J. A. York D. M. Nat. Chem. 2020;12:193–201. doi: 10.1038/s41557-019-0391-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lafontaine D. A. Norman D. G. Lilley D. M. J. EMBO J. 2002;21:2461–2471. doi: 10.1093/emboj/21.10.2461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jones F. D. Strobel S. A. Biochemistry. 2003;42:4265–4276. doi: 10.1021/bi020707t. [DOI] [PubMed] [Google Scholar]
- Rastogi T. Beattie T. L. Olive J. E. Collins R. A. EMBO J. 1996;15:2820–2825. doi: 10.1002/j.1460-2075.1996.tb00642.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lacroix-Labonté J. Girard N. Lemieux S. Legault P. Nucleic Acids Res. 2011;40:2284–2293. doi: 10.1093/nar/gkr1018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lacroix-Labonté J. Girard N. Dagenais P. Legault P. Nucleic Acids Res. 2016;44:6924–6934. doi: 10.1093/nar/gkw401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen C. C. Lupták A. Nat. Chem. Biol. 2021;17:507–508. doi: 10.1038/s41589-021-00778-7. [DOI] [PubMed] [Google Scholar]
- Li Y. Breaker R. R. J. Am. Chem. Soc. 1999;121:5364–5372. doi: 10.1021/ja990592p. [DOI] [Google Scholar]
- Ogawa A. Maeda M. ChemBioChem. 2008;9:206–209. doi: 10.1002/cbic.200700478. [DOI] [PubMed] [Google Scholar]
- Tang J. Breaker R. R. Chem. Biol. 1997;4:453–459. doi: 10.1016/S1074-5521(97)90197-6. [DOI] [PubMed] [Google Scholar]
- Zhong G. Wang H. Bailey C. C. Gao G. Farzan M. eLife. 2016;5:e18858. doi: 10.7554/eLife.18858. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yokobayashi Y. Curr. Opin. Chem. Biol. 2019;52:72–78. doi: 10.1016/j.cbpa.2019.05.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kobori S. Takahashi K. Yokobayashi Y. ACS Synth. Biol. 2017;6:1283–1288. doi: 10.1021/acssynbio.7b00057. [DOI] [PubMed] [Google Scholar]
- Nomura Y. Zhou L. Miu A. Yokobayashi Y. ACS Synth. Biol. 2013;2:684–689. doi: 10.1021/sb400037a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng H. Zhang Y. Wang H. Sun N. Liu M. Chen H. Pei R. Mol. BioSyst. 2016;12:3370–3376. doi: 10.1039/C6MB00540C. [DOI] [PubMed] [Google Scholar]
- Hammann C. Westhof E. Genome Biol. 2007;8:210. doi: 10.1186/gb-2007-8-4-210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breaker R. R. Mol. Cell. 2011;43:867–879. doi: 10.1016/j.molcel.2011.08.024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deana A. Celesnik H. Belasco J. G. Nature. 2008;451:355–358. doi: 10.1038/nature06475. [DOI] [PubMed] [Google Scholar]
- Celesnik H. Deana A. Belasco J. G. Mol. Cell. 2007;27:79–90. doi: 10.1016/j.molcel.2007.05.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carothers J. M. Goler J. A. Juminaga D. Keasling J. D. Science. 2011;36498:1716–1719. doi: 10.1126/science.1212209. [DOI] [PubMed] [Google Scholar]
- Felletti M. Bieber A. Hartig J. S. RNA Biol. 2017;14:1522–1533. doi: 10.1080/15476286.2016.1240141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Feng X. Liu L. Duan X. Wang S. Chem. Commun. 2011;47:173–175. doi: 10.1039/C0CC00980F. [DOI] [PubMed] [Google Scholar]
- Strobel B. Spöring M. Klein H. Blazevic D. Rust W. Sayols S. Hartig J. S. Kreuz S. Nat. Commun. 2020;11:714. doi: 10.1038/s41467-020-14491-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X. Ellington A. PLoS Comput. Biol. 2009;5:e1000620. doi: 10.1371/journal.pcbi.1000620. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wieland M. Hartig J. S. Angew. Chem., Int. Ed. 2008;47:2604–2607. doi: 10.1002/anie.200703700. [DOI] [PubMed] [Google Scholar]
- Wittmann A. Suess B. Mol. BioSyst. 2011;7:2419–2427. doi: 10.1039/C1MB05070B. [DOI] [PubMed] [Google Scholar]
- Klauser B. Rehm C. Summerer D. Hartig J. S. Methods Enzymol. 2015;550:301–320. doi: 10.1016/bs.mie.2014.10.037. [DOI] [PubMed] [Google Scholar]
- Vaidya N. Manapat M. L. Chen I. A. Xulvi-Brunet R. Hayden E. J. Lehman N. Nature. 2012;491:72–77. doi: 10.1038/nature11549. [DOI] [PubMed] [Google Scholar]
- Levy M. Ellington A. D. Nat. Struct. Biol. 2001;8:580–582. doi: 10.1038/89601. [DOI] [PubMed] [Google Scholar]
- Cojocaru R. Unrau P. J. Science. 2021;371:1225–1232. doi: 10.1126/science.abd9191. [DOI] [PubMed] [Google Scholar]