

Abstract
The contact structure of a population plays an important role in transmission of infection. Many ‘structured models’ capture aspects of the contact pattern through an underlying network or a mixing matrix. An important observation in unstructured models of a disease that confers immunity is that once a fraction has been infected, the residual susceptible population can no longer sustain an epidemic. A recent observation of some structured models is that this threshold can be crossed with a smaller fraction of infected individuals, because the disease acts like a targeted vaccine, preferentially immunising higher-risk individuals who play a greater role in transmission. Therefore, a limited ‘first wave’ may leave behind a residual population that cannot support a second wave once interventions are lifted. In this paper, we set out to investigate this more systematically. While networks offer a flexible framework to model contact patterns explicitly, they suffer from several shortcomings: (i) high-fidelity network models require a large amount of data which can be difficult to harvest, and (ii) very few, if any, theoretical contact network models offer the flexibility to tune different contact network properties within the same framework. Therefore, we opt to systematically analyse a number of well-known mean-field models. These are computationally efficient and provide good flexibility in varying contact network properties such as heterogeneity in the number contacts, clustering and household structure or differentiating between local and global contacts. In particular, we consider the question of herd immunity under several scenarios. When modelling interventions as changes in transmission rates, we confirm that in networks with significant degree heterogeneity, the first wave of the epidemic confers herd immunity with significantly fewer infections than equivalent models with less or no degree heterogeneity. However, if modelling the intervention as a change in the contact network, then this effect may become much more subtle. Indeed, modifying the structure disproportionately can shield highly connected nodes from becoming infected during the first wave and therefore make the second wave more substantial. We strengthen this finding by using an age-structured compartmental model parameterised with real data and comparing lockdown periods implemented either as a global scaling of the mixing matrix or age-specific structural changes. Overall, we find that results regarding (disease-induced) herd immunity levels are strongly dependent on the model, the duration of the lockdown and how the lockdown is implemented in the model.
Introduction
The recent emergence of SARS-CoV-2 and the associated disease COVID-19 has had worldwide impact. Many cities have had large outbreaks and brought them under control through major interventions. Once those interventions are lifted, in the absence of effective vaccination, a homogeneous model of infection spread would predict that as long as less than of the population was infected, there is always a threat of resurgence.
Despite large epidemics, cities such as New York remain well below the threshold expected to be required to achieve herd immunity (Stadlbauer et al. 2020).
To avoid the significant economic and health costs associated with continued interventions, it is natural to consider the so-called herd immunity strategy. This strategy allows infection to spread with restrictions in place so that the outbreak finishes and interventions are lifted when the herd immunity threshold is reached. Typically in an uncontrolled epidemic, the herd immunity threshold is reached at the peak of the epidemic, and many additional infections occur as the outbreak slowly wanes. The additional infections are sometimes referred to as the overshoot (Handel et al. Mar 2007). By calibrating the intervention so that there are no (or almost no) infections when the herd immunity threshold is reached, interventions can be removed with minimal overshoot (Di Lauro et al. 2021; Morris et al. 2021).
The severity of the epidemic in many places whose seroprevalence is still very low has led many to suggest that the herd immunity strategy is not tenable. However, recent papers (Britton et al. 2020; Gabriela et al. 2020) suggest that immunity acquired through infection may be distributed through the population in such a way as to achieve herd immunity at a lower fraction affected than a homogeneous model would predict. This is because the initial wave of infections preferentially affects those most at risk. Thus, it acts like a targeted vaccination, removing the people who are most likely to transmit infection from the susceptible pool. Generally, the time course of a real epidemic involves the following stages: (i) short period of unconstrained transmission, (ii) significant control or lockdown and (iii) relaxation of control measures. Typically, during lockdown some spread persists and one pertinent question is whether relaxing the lockdown will lead to a second wave. In Britton et al. (2020), this question was explored by looking at prevalence at the end of lockdown in scenarios where lifting the lockdown did not lead to resurgence. For the purposes of this paper, we refer to this fraction as the disease-induced herd immunity (DIHI). This means that if DIHI is higher in one scenario compared to another, then in the former a higher prevalence is required than in the latter to achieve herd immunity through the disease.
These papers make some simplifying assumptions about population structure that may not hold. In particular, they do not consider the fact that existing interventions tend to affect some contacts more than others. For example, the transmission rates of household contacts are not significantly reduced (and in fact may increase) during interventions focused on reducing movement. Moreover, many of the highest risk positions in the disease network are in fact roles (health care workers, delivery drivers, teachers, etc.) that would need to be maintained in most forms of a lockdown, meaning that some community links may be increased even as others are limited, and the changes are distributed heterogeneously through the population.
While using networks to explicitly model contact patterns is an attractive approach, it entails several drawbacks. If one aims to accurately reproduce real contact networks, then the amount of data needed may be considerable. Furthermore, data at enough granularity or quality may simply not be available, or only partly accessible. Even in the best case scenario, there may be aspects of the contact network (e.g. temporal and weighted nature of the links, meso-scale structures) that would remain subject to approximation, inference or parametrisation based on some empirical evidence. This would open the door to further scrutiny regarding model validity and would make the model and its conclusions situation-specific. On the other hand, it is equally challenging to design theoretical network models where several key network properties (e.g. degree heterogeneity, assortativity, clustering, household structure) can be varied and tuned as desired within the same model. Hence, we aim to achieve a compromise by using mean-field models of epidemic transmission on networks which are computationally efficient (compared to simulating epidemics on explicit networks) and allow us to analyse systematically how different network properties impact the DIHI threshold. Such mean-field models include the pairwise, edge-based-compartmental (Miller et al. 2012), percolation (Miller 2016; Moore and Newman 2000) and message-passing (Bianconi et al. 2021) models. Most of these models focus on some average quantity, such as expected number of nodes/edges of different types or the probability that a typical node is still susceptible at a given time, followed by some form of closure that curtails the dependence on higher moments.
A significant part of the mathematical analysis of epidemic models on networks (from regular and Erdős–Rényi to scale-free networks such as the Barabási–Albert preferential attachment model) involves the use of mean-field models (Kiss et al. 2017). In fact many elegant analytical/explicit results regarding the impact of network properties (e.g. degree heterogeneity, assortativity and clustering) on the epidemic threshold, final epidemic size or endemic equilibrium, optimal vaccination strategies (Porter and Gleeson 2016; Pastor-Satorras et al. 2015; Chen and Sun 2014; Holme and Litvak 2017) have been derived from the analysis of mean-field models. Even more surprisingly, perhaps, certain mean-field SIR models are exact in the limit of large configuration model networks (Miller and Volz 2013; Miller and Kiss 2014). Many such models are mathematically tractable and provide important intuition about how an epidemic spreads and which properties of the contact network affect this spread.
In this paper, we use four different mean-field models (Kiss et al. 2017): (a) degree-based heterogeneous mean field, (b) clustered and unclustered heterogeneous pairwise, (c) a new edge-based-compartmental model that allows us to distinguish between household/local contacts and community/global contacts and (d) an age-structured compartmental model parameterised with realistic age structure and contact matrices. The first can only account for degree heterogeneity, while the second and third add an extra layer to account for local structure such as clustering and households. The fourth model is based on realistic mixing matrices and implicitly accounts for various degrees of heterogeneity in mixing.
The primary aim is to investigate how changes in properties of the contact network impact DIHI. More importantly perhaps, we challenge the way lockdown has been implemented in many models, namely by a simple reduction in or the transmission rate, while keeping the contact network or mixing matrix the same. We build a new edge-based-compartmental model able to distinguish between household and community transmissions and use this to implement lockdown by either intervening on both types of connections or only on the community-based ones. In the same spirit, we use an age-structured compartmental model in which we implement lockdown either as a simple scaling of the entire mixing matrix or, more realistically, a set of age-specific structural changes.
The paper is structured as follows. In Sect. 2, we describe all models including the underlying network types and relevant model and epidemic parameters. Section 3 contains the results for the network models, while Sect. 3.4 provides the results for the age-structured model. Finally, in Sect. 4 we discuss the implications of our findings. Additional technical details are given in Appendix.
Methods
We consider a set of mean-field models that capture different types of small-scale structure in the contact network. This helps reveal the mechanisms underlying qualitatively different outcomes.
The first two models are able to account for heterogeneous degree distributions, without and with clustering. This is followed by a new edge-based-compartmental model with household structure, i.e. with the ability to distinguish between household and community contacts. All of these will use the susceptible-infected-and-infectious-recovered (SIR) epidemic model. Finally, we consider an age-structured SEIRD model based on realistic age-structure and mixing matrices. One key input into mean-field models is the choice of initial conditions. For example, by specifying the number of susceptible nodes with degree k at time we effectively specify the degree distribution of contacts. Since we wish to map out the impact of degree heterogeneity, we choose a flexible degree distribution with good control of the mean and variance, i.e. the negative binomial. We loosely order the models by their relative complexity, corresponding to gradually incorporating more features of the underlying population contact structure. While the last model is not explicitly network-based, it uses realistic mixing matrices over an age-structured model based on the UK data. One can consider this an extrapolation from (or an approximation of) an explicit network model where individual-level interactions are averaged out over groups of interest from an epidemiological viewpoint.
Contact Structure and Epidemic Model
We consider a SIR/SEIRD epidemic spreading in a closed population of size (loosely the population size of the UK) with a well-defined contact structure. For illustrative purposes, we assume that the probability of an individual having k contacts follows a negative binomial distribution
| 1 |
The reason for this choice is that we want to map out how heterogeneities in the contact structure impact on the value of the disease induce herd immunity. To illustrate this point, we consider three different scenarios for the degree distribution of the population. In all cases, we fix and we use the remaining free parameter to tune the variance. To avoid individuals with degree 0, the degree distribution is shifted by a constant m, thus making the effective average degree . For normal-like and scale-free-like distributions, we take , and for the delta-like distribution, we take (see Table 1).
Table 1.
The three degree distributions considered. The delta-like distribution is shifted by 9, as its mean would be 1 otherwise. The reason for this choice is the fact that in negative binomials the variance cannot be lower than the mean. Normal-like and scale-free-like distributions instead are shifted by one, so that the minimum degree is 1. The resulting degree distributions are shown in Fig. 1
| Name | n | p | |||
|---|---|---|---|---|---|
| Delta-like | 1 | 0.99 | 10 | 1 | 0.016 |
| Normal-like | 3.86 | 0.3 | 10 | 30 | 0.016 |
| Scale-free-like | 1.07 | 0.107 | 10 | 300 | 0.016 |
The parameters chosen are reported in Table 1 and represent degree distributions of increasing variance, see Fig. 1, moving from almost no variance (delta-like degree distribution) to a degree distribution with a longer tail, akin to a scale-free network. These are going to serve as initial conditions in mean-field models which are constructed based on compartments such as the expected number of nodes of degree k that can be either susceptible, infected or recovered. The infection is driven by a per-link transmission rate and a recovery rate .
Fig. 1.

The three degree distributions described in Table 1
Degree-Based Mean-Field Model
In the degree-based mean-field model [also called heterogeneous mean field (Pastor-Satorras et al. 2015)], we denote by the expected number of susceptibles with degree k at time t, similarly for and . We define , similarly [I] and [R]. The closure is made at the level of individuals, meaning that the infection pressure across a link is simply averaged across the entire spectrum of infected nodes. The resulting ODEs are
| 2 |
where is the number of nodes with degree . This system keeps track of degree and heterogeneity, but mixing between nodes of different degrees happens at random but proportionally to degree (Pastor-Satorras et al. 2015; Kiss et al. 2017), with clustering (the tendency of nodes to form connected triples) playing no role.
The degree-based mean-field model can be derived under the assumption that individuals with degree k re-select their partners very rapidly, so at every moment, the status of a node is independent of the status of its current partners. Networks with this property are also known as ‘annealed networks’, in which links evolve (while maintaining the degree distribution) fast compared to the dynamics on the network. In reality, many edges are long-lasting, and so correlations build up: a randomly selected infected node is more likely to connect to another infected node than a randomly selected susceptible node. More complex models are needed to correct this.
Heterogeneous Pairwise without and with Clustering
An improvement in terms of retaining more of the contact network features is to consider heterogeneous pairwise models. In this case, we keep track of pairs which are responsible for driving the infection: for example, is the expected number of links connecting a node of degree k in state A to a node of degree in state B (House and Keeling 2011; Kiss et al. 2017), likewise for triples of the form . The closure is done at the level of pairs (i.e. triples are approximated by singles and pairs), and hence, an approximation for the triples is needed. These are given by
| 3 |
where is the global clustering coefficient in the network. For the un-clustered case, we simply set . The resulting ODEs are,
| 4 |
where triples are closed using Eq. (3). The system can be significantly simplified for the case. When , the closures become more complicated and present further challenges when implemented numerically (see notes in Appendix 1).
The number of equations in the heterogeneous pairwise model grows very large if the network has degrees of many different types (e.g. because there is an equation for for every k, pair). Generalising this to more complex structures can become unwieldy. Edge-based compartmental models provide an alternative and are discussed next.
Edge-Based Compartmental Model with Household Structure and Community Transmission
It is important to consider models which explicitly distinguish between links that happen within the households and those that happen elsewhere, as lockdowns act mostly on inter-household contacts. To consider household structures, we take advantage of the edge-based compartmental modelling (EBCM) framework (Miller 2011; Miller et al. 2012), adapting the framework in Volz et al. (2011) to build a model that (i) has a more realistic contact structure with households and (ii) can distinguish between within household and community transmission, see Fig. 2. This model keeps the number of equations tractable.
Fig. 2.
Caricature of the network model with households of size four and community stubs due to be connected up following the configuration model
We assume that individuals are divided into households of size 4. Within households, there is complete mixing. In addition, each individual has a number of contacts outside the household, which allow for community transmission. The equations for this model are given in Appendix 1.
Age-Structured Compartmental Model
We use a version of the SEIRD compartmental model by Enrique et al. (2015) adapted to remove any built-in control measures (originally modelled as a Hill repression function modulating the number of daily contacts in response to control measures) and to include age-structured interactions in the population. The model is as follows:
| 5 |
where , and are age-independent parameters denoting infectivity, rate at which exposed individuals become infected (inverse of incubation period) and rate at which infected individuals recover or die (inverse of disease duration), respectively. (Note that in this model corresponds to in the above models.) The are age-dependent mortality probabilities and control the fraction of those infected individuals who die. Susceptible individuals become exposed proportionally to a force of infection defined as the product of the contagion matrix with the prevalence by age. The contagion matrix is simply the product of the intrinsic infectivity of the epidemic and the daily contacts of individuals in age group i with individuals from age group j, . Finally, n is the number of age groups considered and is the count of individuals in age group i.
Epidemic Parameters
Ling et al. (2020) reported that the median time from symptoms onset to first negative RT-PCR in oropharyngeal swabs of convalescent patients was around 10 days, and further evidence Wei et al. (Apr 2020) suggested that pre-symptomatic infection could happen days before the first symptoms appear. Accordingly, we set (i.e. an average of two weeks before recovery). Before setting , we summarise the expression for for the various models that we consider. For the heterogeneous degree-based mean-field model (Kiss et al. 2017), we have
| 6 |
For the heterogeneous pairwise model, we use
| 7 |
For the edge-based model, we set the in-household infection parameter to be times bigger than the inter-households infection parameter .
The basic reproduction number of the edge-based and the age-structured models are given by the leading eigenvalues of the following two next-generation matrices (Diekmann et al. June 2010). First, for the edge-based compartmental model, based on Pellis et al. (2012), we have
| 8 |
where
| 9 |
with and D the distribution of the excess degree [i.e. the distribution of the left-over edges attached to a node reached by following one random edge, see (Newman 2018)] and degree distribution of the network, respectively. , , and are the expected number of infected in generation 0, 1, 2 and 3 in a household of size 4. These values can be found in Britton et al. (2019) on page 222/223, with .
Finally, the for the age-structured compartmental model is given by the largest eigenvalue of:
where is the intrinsic infectivity, is the rate at which infected individuals either recover or die, is the size of the population in age group i, and is the number of age groups in the model. is the age-mixing matrix, and the normalisation factor comes from the fact that at , there are only susceptible individuals in the population of each age group and therefore in the partial derivative with respect to I of the r.h.s of the second equation in system (5).
Results
The Impact on DIHI
Most of our scenarios are concerned with determining the impact of model and demographic heterogeneities on the DIHI levels. In well-mixed homogeneous populations, each individual contributes equally to spreading, and therefore, DIHI is a well-defined quantity, independent of whom has been infected during the first wave. In models with degree heterogeneities, nodes with higher degree contribute to the spreading of the disease much more than nodes with fewer links. This means that depending on whom has been infected, we can observe different levels of DIHI. This effect, however, does not show in our results since the DIHI is based on the infections accumulated during the first wave as determined by our equations.
It is well known that in the simple compartmental model herd immunity at time is achieved as long as at least of the susceptible individuals are removed or immunised. In line with Britton et al. (2020), our general setup is that an initial epidemic spreading freely for a short time is intervened upon by implementing a lockdown period of fixed duration. Afterwards, all parameters immediately return to their pre-lockdown values. In the most basic case, this is done by keeping the network or the mixing matrix the same and multiplying the transmission rate by a constant . Crucially, however, we also explore the implications of how the lockdown is modelled; that is, we investigate the difference between reducing the transmission rate while keeping the network the same and changing the contact network, the latter being more in tune with what happens in reality. In the age-structured model, we compare a reduction of all entries in the mixing matrix with a number of scenarios involving school closure and work distancing.
For the edge-based compartmental model, we focus on final epidemic size but still under the assumption of a lockdown period. This is because we want to compare how the two different strategies affect the eventual outcome of the epidemic, rather than how the optimal varies between the two strategies, a comparison that would be difficult to interpret.
There is an extremely strong relation between the speed or rate of spread of the uncontrolled epidemic and the timing and length of the lockdown. In fact this can be visualised in terms of the ‘flattening of the curve’ argument. A reduction of the transmission rate during lockdown leads to a flattening of the epidemic curve with a reduced peak and an extended duration which ideally should fit within the control period. This means that if the epidemic grows quickly and the lockdown period is short, two outcomes are possible. First, a fast growing epidemic with a short lockdown period needs to be met with a significant reduction in the transmission rate, i.e. small values of . This will lead to a reduced epidemic which does not have enough time to unfold, and the lifting of lockdown is followed by a full-blown epidemic. Second, if the reduction is not strong enough (i.e. larger values of ), then a significant epidemic will occur during the lockdown itself with no further peak after lifting control Di Lauro et al. (2021), see also Fig. 3.
Fig. 3.
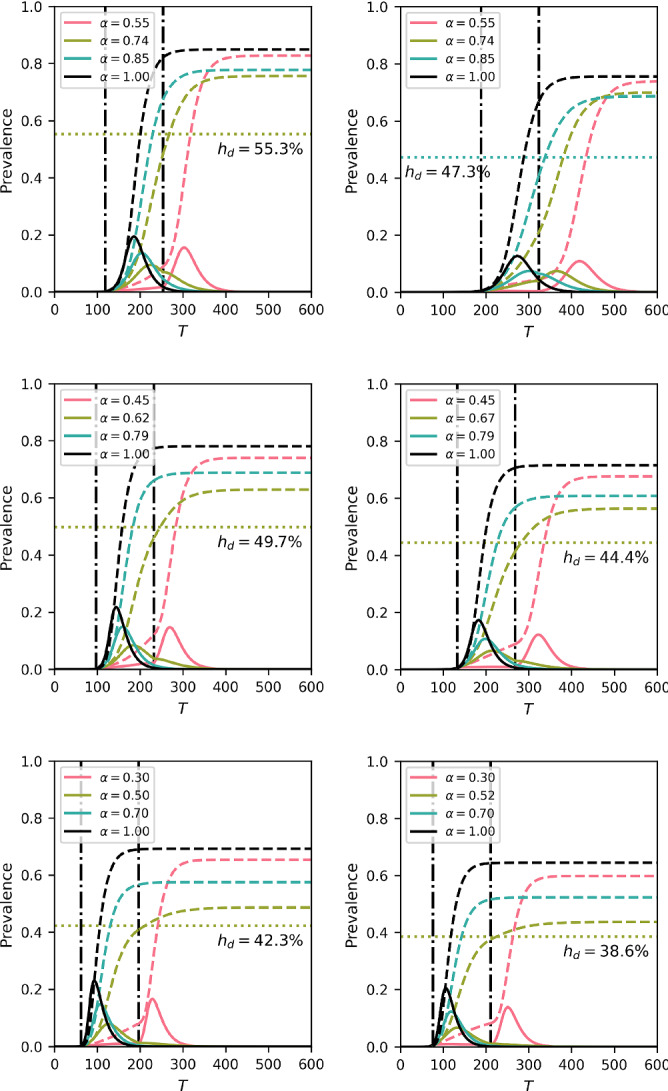
Optimal (see legend) and DIHI (denoted as in figure legends and axis labels) in delta-like (first row), normal-like (second row) and scale-free-like (third row) networks using the heterogeneous mean-field (first column) and heterogeneous pairwise model with (second column). Continuous curves indicate [I], while dashed curves indicate [R]. The two vertical curves represent the beginning and the end of the lockdown. Duration of lockdown is 130 days. Finally, the horizontal line and the corresponding percentage reported are the cumulative prevalence at the end of lockdown for the best strategy that does not allow for a second wave
Contact Heterogeneity and Clustering
The main focus here is to investigate the impact of degree-heterogeneity and clustering on herd immunity induced by a first wave of the epidemic. In populations with heterogeneous contact patterns, one can preferentially target high-risk individuals and this will reduce the number needed to achieve DIHI. Such heterogeneity can be exploited in many ways: for example, targeted immunisations (Albert et al. 2000) and acquaintance immunisation (Cohen et al. 2003). Equally, the epidemic itself typically finds the high-risk groups first and thus ‘removes’ important individuals or risk groups. In line with (Britton et al. 2020; Gabriela et al. 2020), we exploit this fact and consider different levels of degree-heterogeneity and different mean-field models to explore what happens in the wake of the lockdown period when some level of spreading is possible.
In each scenario considered, we seeded nodes with degree with infected individuals, the rest of the population being fully susceptible. We let the epidemic run until the cumulative number of infected people reached of the population. Then, a one-shot intervention lasting exactly days kicked in. During lockdown, control measures made (by acting on ). Afterwards, lockdown was lifted and immediately returned to its pre-lockdown value. For the edge-based-compartmental and age-structured models, lockdown also involved preferential interventions on community or household links and modulation of the mixing matrix, respectively.
Figure 3 shows results from the degree-based mean field model (left column) and heterogeneous pairwise model without clustering (right column) for networks with increasing levels of degree heterogeneity (from top to bottom). In each case, we find the optimal (a simple down scaling of the transmission rate without change to the network) and report the number of infections required to achieve DIHI (i.e. total of infected and recovered nodes at the end of lockdown such that the epidemic after lockdown is subcritical). Several observations can be made. First, a higher value of DIHI also means a higher value of the cumulative incidence, but the two quantities are different. Secondly, for both models, aggressive control (value of ) leads to a second wave. Equally, if the control is too weak (high value of ), the epidemic will still run its course during the first wave with some reduction in the final size. Hence, there is an optimal value of for which the final epidemic size is smallest and the epidemic post-lockdown is subcritical.
Both models clearly show that the value of DIHI decreases with the variance of the degree distribution. Despite displaying the same overall trends, the two models are quantitatively different. In a like-for-like comparison, the degree-based heterogeneous mean-field model leads to larger overall epidemics. This is to be expected since this model does not keep track of the links explicitly and thus over estimates what would happen in a true simulation on an explicit network (Kiss et al. 2017). The pairwise model, however, accounts for links and correlations and leads to epidemics that are typically less potent. Furthermore, the heterogeneous pairwise model leads to smaller values of DIHI showing that the accuracy with which the network structure is accounted for matters. This demonstrates that model choice is important as the precise levels of DIHI matter in a real-world scenario.
The effect of clustering is illustrated in Fig. 4. Typically, clustering lengthens the duration of the epidemic and lowers the peak when compared to the unclustered case [see also (Volz et al. 2011)]. The final epidemic size is also smaller. This means that there is a small amount of leeway for implementing control and that the control effort can be smaller compared to the unclustered case. It is worth noting that the final epidemic size is also smallest at the optimal value [(see also (Britton et al. 2020)].
Fig. 4.

(left) Difference between control acting on un-clustered networks (continuous lines) and clustered networks (dashed lines), with clustering coefficient , corresponding to the second point on the x-axis of the right panel. Vertical lines are at the beginning (continuous) and end (dashed) of control. Blue curve is optimal control for , red for . (right) Impact of variance in degree distribution on DIHI , for different pairwise models with different values of . Average degree is , and . Control duration is 100 days from the moment (Color figure online)
Finally, opting for the more accurate heterogeneous pairwise model, the level of DIHI is plotted for increasing values of variance and for different clustering levels, see Fig. 4. It is clear that higher variance can drive DIHI levels to as low as . Clustering in the heterogeneous pairwise model leads to even smaller values of the DIHI, although increasing variance in the degree negates the effect of clustering and the DIHI levels are very similar to those observed with and . This highlights the non-trivial interactions between network properties where clustering has biggest impact in sparse networks and where high levels of degree heterogeneity can negate the effect of clustering.
All Versus Community Control Only
Although the previous models do account for some important contact network features, they are not ideal to capture structure such as households. Being able to capture households explicitly and having the flexibility to differentiate between household and community transmission are important because many of the interventions available to us (e.g. closing schools and workplaces) affect community transmission differently from household transmission. Thus, a distinctive feature of most lockdown measures is a change in network structure, rather than a global reduction in transmission rate.
Although our model is not an exact reflection of true population structure, it allows us to investigate whether an intervention that disproportionately affects between-household transmission can be appropriately captured by a model that treats the intervention as reducing all transmission rates.
For a given start time and intervention strength, if the duration of the intervention is long enough, the number of infections becomes very small and the eventual rebound has the same shape, regardless of duration. The optimal intervention strength leaves the population sitting at the DIHI threshold when the epidemic dies out. When the intervention is lifted, no rebound occurs. Thus, the outcomes of the optimal intervention are the same if the duration is long enough. In Fig. 5 and at the top right in both panels of Fig. 6, we notice that if the intervention is long enough, the optimal final size becomes independent of duration. To see this for earlier start times requires longer durations.
Fig. 5.

Control scenarios based on the EBCM model with intervention scaling factor of starting at (dashed vertical line), and lasting for different durations (continuous vertical lines). (left) Intervention on the whole network, (right) intervention on the community structure. Parameters of the epidemic and community network are
Fig. 6.

Final epidemic sizes based on the EBCM as a function of the beginning of lockdown and its duration, with two different strategies: intervention on the whole network (left) or intervention on the community links only (right). Each value is the minimum final epidemic size that can be obtained for varying . Parameters of the epidemic and community network are: , ,
Our argument to explain why this happens is as follows: suppose that for a given , we find the smallest time such that DIHI is achieved. Prolonging the intervention for longer than said time will result in the number of actively infectious people reducing even further by end of lockdown but not change the downward trend of the epidemic, which will eventually die out.
Comparison of the top right of both panels in Fig. 6 shows that the optimal community intervention allows more infections than the optimal global intervention.
The intuition behind this is based on the observation that epidemics typically exploit ‘heterogeneities’ in the population. For networks, this means that high-degree nodes typically become infected early on in the epidemic. This is the main reason why a first epidemic wave in a network with very heterogeneous degree infects the highly connected nodes. In a scale-free-like network, the number of such nodes is small (e.g. 20% of the nodes responsible for 80% of infection). If the epidemic progresses with strong interventions in place, it cannot spread far beyond these high-degree nodes. Once it dies out, the residual network is highly fragmented and made up of much lower degree nodes.
In this household model, community links drive degree heterogeneity. Household links alone lead to a regular network. Hence, when we effectively cut most community links, heterogeneity in degree is significantly reduced for the duration of control. This means that many high-degree nodes that would normally be infected during the first wave will now not get infected. The infection is unable to target the highest degree nodes. When control is lifted, the high-degree nodes reactivate their links, allowing the epidemic to rebound.
However, when controlling both link types equally, degree heterogeneity is preserved and the infection again preferentially targets the high-degree nodes. A weaker control targeted to all edges rather than just community edges may allow an initial wave of similar size, but it will preferentially target the high-degree nodes. So this type of control acts as a very effective way of finding highly connected nodes. This then means that at the end of lockdown, it is more likely that the most ‘dangerous’ nodes be removed, and with that, a smaller chance of a second wave.
Consider two epidemics with the same intervention start time, providing the optimal strategy for either the global or the community case. We would expect that the average community degree of those who have been infected in the global case would be higher than in the community case. Thus, on average, the individuals immunised by infection in the community case will be less important to disease transmission and thus more of them must be immunised to achieve the DIHI threshold. This is important because households may be able to sustain the epidemic for extended amounts of time and therefore change the outcome in DIHI levels.
Scaling Versus Modulating the Mixing Matrix Model
In this section, we further explore the notion that modulating the effective of the epidemic through modifying the structure of the mixing matrix (in this case, the age-structure mixing matrix) can affect the system differently from achieving it through simply scaling each element of the mixing matrix. To do so, we began by considering three scenarios described by Prem et al. (2017), namely school closure, school closure and social distancing, and work distancing. In a baseline, no-intervention case, the matrix of daily contacts was set to be the sum of 4 components: school contacts, work contacts, home contacts and other contacts. In what follows, we use the corresponding matrices of age-banded daily contacts in the UK produced by the POLYMOD study (Prem et al. 2017). Briefly, school closure is realised by zeroing the school component of the mixing matrix; school closure and social distancing involved zeroing school contacts as well as reducing by half the number contacts at other locations between school-going individuals (first four age groups); and work distancing is implemented by halving the contacts made at the workplace. For each of these interventions, we compared the behaviour of the system when re-scaling the matrix of total contacts so that its during the intervention was the same as the of the modified mixing matrix during the intervention (namely 2.114, 2.106 and 2.179 for scenarios 1 to 3, respectively).
Age-banded population counts (18 5-year bands) were taken from the Office for National Statistics (licensed under the Open Government Licence), pooling all age groups above 85. Mortality rates were taken from the modelling of Robert et al. (2019), assuming that the rates in ten-year age bands are the same as across two five-year age bands. These rates were calculated based on cases in China in the initial outbreak and from the closed population on the Diamond Princess cruise ship. It is possible that these rates may prove to be overestimates compared to populations that do not experience overwhelming levels of hospitalisation, but they are not likely to be impacted by the interventions considered here.
To determine the evolution of the epidemic in this baseline case, we first scaled the contact matrices so that the system’s was 2.5 (to maintain consistency with previous sections). In all cases, we used the same start date () and duration (150 days) for the intervention. These parameters were arbitrarily chosen among the sets of possible parameters resulting in a sub-critical epidemic post-intervention.
Figure 7 confirms that all interventions (coloured lines) result in a reduction in the number of infected individuals. However, whether this intervention is realised through modulating the contact matrix (solid lines) or through uniform scaling (dashed lines) results in substantially different outcomes ( differences for scenarios 1 and 2, in scenario 3), even though the scaling factors used in the control interventions (dashed lines) are very similar from one scenario to the other. This is clear evidence that the structure of the contacts modulates the effects of the intervention.
Fig. 7.

Comparison of the effect of three different control measures in the age-structured compartmental model. The three measures, school closure, school closure and social distancing, work distancing (coloured continuous lines, from left to right), act on the structure of the matrix (see text). For reference, the dashed lines result from an intervention reducing infectivity but yielding the same effective during the intervention. Epidemic values are . Vertical dashed lines indicate beginning and end of control
Figure 8 provides a visual intuition as to why the work distancing scenario is closest to simply scaling the matrix. As pointed out by Mossong et al. (2008), assortative mixing dominates in 3 of the components (home, school, other). Thus, school closure primarily affects diagonal elements of the mixing matrix (and primarily for the first 4 age groups). Intervention 2 does involve halving (some of) the contacts in the other component, and some of those terms diffuse away from the diagonal; however, these contribute little to the overall mixing matrix. In contrast, the work component is the only component to feature what Mossong et al. (2008) describe as a wide contact plateau. Because this plateau accounts for more than half of the total number of contacts within the corresponding 8 age bands, intervention 3 (social distancing) is most akin to scaling the entire matrix.
Fig. 8.

The four components of the POLYMOD age mixing matrix (after subtraction of the diagonal)
To further clarify how the structure of the contacts modulates the effects of the intervention, we carried out simulations in which two confounding factors were removed, namely heterogeneity in the number of individuals in the different age bands and in the frequency of contacts by age. Whereas the former plays a key role in the calculation of the effective (see Sect. 2.6), the latter weights the impact of the intervention. For example, zeroing school contacts which only account for of the total number of contacts will be negligible compared to zeroing other contacts that account for . Therefore, in what follows, all age groups were set to have the same number of individuals (1/18-th of the total population) and all contact components were scaled to have the same sum of elements (arbitrarily, the sum of the original number of other contacts). We then systematically analysed the effect of three different interventions in which one component (school, work or other) was systematically scaled down by a factor taking values between 1.0 (no intervention) and 0.0 in steps of 0.1.
Figure 9 shows the effect of the most severe form of intervention (the zeroing of the relevant component) and clearly demonstrates that once confounding factors are removed, changes in the mixing matrix lead to different outcomes in terms of whether such an intervention is more or less effective than simply scaling the matrix to achieve the same effective . Here, zeroing the school component is less effective than scaling the overall matrix (despite an overall scaling factor of 0.61). Instead, zeroing either the work or other component is more effective than scaling the overall matrix (despite larger scaling factors, 0.87 and 0.88, respectively). It should be noted that while zeroing the work and other components leads to similar results in terms of total prevalence, there are differences in prevalence by age which could have significant implications when age-structured mortality rates are considered.
Fig. 9.

Impact of zeroing school (left), work (middle) and other (right) components when each age group has the same number of individuals and each component contributes the same number of contacts. For each, left panel shows the total prevalence of infected individuals in the population using the intervention (red) and the control (scaling of the entire contact matrix to achieve the same effective , in black). The right panel shows the prevalence of infected in three pooled age groups chosen to reflect the target of each intervention
Discussion
We explored the impact of different types of small-scale structures of contact networks on disease-induced herd immunity. We did so by using well-established and widely used mean-field models of epidemics on networks. This choice was motivated by the following considerations. First, constructing high-fidelity contact networks requires detailed and extensive data, which may not be available or only partially so. Even if extensive data were available, models of high fidelity remain subject to further improvements and would be scenario-specific with results that could be difficult to generalise. Second, we do not know of any theoretical network models that are flexible enough to independently tune degree-heterogeneity, assortativity, clustering and household structure in a large population. It is worth noting that, in a more realistic scenario in which simulations on explicit networks are considered, the precise definition of disease-induced herd immunity is problematic, as we would have to deal with stochastic processes in which distinguishing between sub- or super-critical epidemics is far from trivial. Finally, mean-field models are computationally efficient compared to simulations and allow to investigate the impact of various network properties on DIHI in a qualitative manner, even if the choice of mean-field model depends on which contact network property we wish to study.
In order of increasing complexity, the models used in this paper are: the degree-based heterogeneous mean-field, heterogeneous pairwise (without and with clustering) and an edge-based compartmental model which explicitly includes household structure and can distinguish between household and community transmission. While these cannot be used as such to inform policy, they still provide important insights into model selection and key features that need to be captured, or can be exploited, to identify the best possible control measures. In addition, we also tested our findings against a more realistic age-structured model with real mixing matrices. We stress that we did not set out to identify the ‘best’ or most ‘accurate’ model but rather we used well-established and computationally efficient models of epidemic on networks to systematically investigate the impact of various small-scale structures in the contact network on DIHI levels.
We have shown that increased degree heterogeneity (i.e. higher variance in the degree distribution) leads to DIHI levels that are much smaller than the basic compartmental model, . This is line with the findings of Britton et al. (2020), Gabriela et al. (2020). Moreover, we quantified the extent to which the DIHI induced by the first wave depends on the variance in the degree distribution. We have shown that herd immunity in clustered networks is even lower because epidemics on clustered networks last longer and have lower peaks, allowing more flexibility regarding the start and intensity of control.
Perhaps, the most important question that we addressed regards how lockdown/control is implemented in different models. Many models assume that during lockdown the contact network or mixing matrix is not changing but rather the transmission rate is scaled (Britton et al. 2020; Di Lauro et al. 2021; Gabriela et al. 2020; Morris et al. 2021). We do not believe that this is appropriate because during lockdown the underlying contact structure changes. Our results with the edge-based compartmental and age-structured models have shown that these two approaches differ in outcome. Perhaps, the assumption of a non-changing contact structure during lockdown is more likely to be made in mean-field models. In models at higher than mean-field resolution (e.g. agent-based), it is much easier to explicitly modify the contact network.
Using simple models, we have therefore illustrated that small-scale structures, such as households, have an impact on the value of the DIHI threshold. Models where this is incorporated, and where it is possible to distinguish between local (within household) and community links (between households), have shown that interventions make the contact structure more homogeneous (e.g. when community links are cut or transmission across these is reduced), and the immunity induced by the disease spread will no longer effectively target the most active individuals. In an extreme case, it will require more infections to achieve herd immunity than through random vaccination (Ferrari et al. 2006). Indeed, when transmission across community links is reduced, the first wave leaves behind clusters of either susceptibles (i.e. households who avoided infection) or clusters of recovered individuals (i.e. households who became infected). This unusual correlation means that the residual network of susceptible nodes has more contacts, compared to the scenario where the same fraction of currently recovered individuals were vaccinated randomly. This means that when control finishes, there is still a significant amount of heterogeneity in contacts that can lead to a significant second wave. The exact difference in DIHI levels between a model that accounts for small-scale structure and one that does not, will depend on the precise parameterisation. However, we expect that one would get slightly more optimistic estimates for DIHI levels (i.e. lower values, meaning fewer infected individuals needed in order to avoid a super-critical epidemic at the end of the lockdown) when such features of the contact networks are ignored.
Another important observation resulting from our work is that it is extremely difficult to make general statements by extrapolating from findings based on simple models. Most models in fact ignore meso-scale structures (e.g. degree heterogeneity does well for local or microstructure, while mixing matrices do well for macro-scale mixing) and their absence may exacerbate the impact of an intervention (either positively or negatively) leading to erroneous conclusions. In the present paper, we saw that when intervention could not act on the global network of contacts, DIHI levels varied substantially, although heterogeneities still played a major role in reducing them.
Finally, it is worth noting that in all models we considered, when lockdown ended (and if DIHI was not reached), epidemics went on to grow exponentially. However, in many real-life scenarios, a prolonged phase of sub-critical spreading (i.e. slow decay) has been observed before the exponential growing phase returned. There is a number of reasons why this behaviour is not observed in our models: (i) deterministic models fail to capture fluctuations that dominate when the number of infected people is small, which might have a major impact on resurgence; (ii) during lockdown, the contact structure changes drastically and abruptly, but when lockdown is lifted, there is a delay/inertia in going back to pre-lockdown status, such lag having important implications on resurgence; and (iii) after lockdown, some social distancing measures remain along with social awareness reducing exposure to the disease. Understanding and modelling these effects are an interesting challenge to address in future work.
In complementing our study of network-based mean-field models, we used a model with no explicit contact structure, where instead contact structure was alluded to via age-related mixing patterns. In the present situation with COVID-19, such models are appealing because they explain some of the structure of the population and provide a rationale for establishing a lockdown. Moreover, with higher mortality rates among older people, age-structured models are of interest in their own right. There is some tension between which model is most apt for describing population experience of the infection, the control measures effected and the outcomes for the population. The ideal solution may lie between some of the options presented here.
However, age-structured models cannot say much that is explicit about the structure of contacts within the population. While we have discussed ways in which lockdowns can be implemented in such models, the formulation is arguably less intuitive than in the network case. How to bridge the gap is an interesting question. An age-related network might be one labelled with age classes, with analysis focused on understanding the positions in the network occupied by individuals of a given age. This could be coupled to household models of network formation, one with variable sizes and smaller households more likely to feature older individuals. Once the general structure of such networks is known, adapting the models here would be simple enough. These considerations are beyond the presentation here but would be a fruitful avenue for future discussions, particular if additional lockdowns are required.
Acknowledgements
F. Di Lauro, L. Berthouze and I.Z. Kiss acknowledge support from the Leverhulme Trust for the Research Project Grant RPG-2017-370. J.C Miller acknowledges start-up funding from La Trobe University.
5 Appendix
5.1 Pairwise Equations
We can account for clustering in the pairwise model, by introducing a clustering factor . The equations are similar to (4), but when closures are implemented we have to consider both open and closed triples.
In the case of open triples, the equations for the closures are the same as in (4), scaled by to account for clustering, i.e.
| 10 |
where the superscript indicates open triples. For closed triples, we first study . This quantity represents triples in which the first node is in state A, the middle node is in state S with degree k, and the third node is in state I with degree m. The triple is closed; therefore, the third node is connected to the first one. This introduces correlations when we write the triple in terms of pairs for the closure, which we indicate with .
| 11 |
The correlation can be written in terms of the ratio between realised pairs and possible pairs in a well-mixed population:
| 12 |
Hence, the closure is
| 13 |
In a similar manner, we can write the expression for . The resulting system is therefore
| 14 |
where
Edge-Based Compartmental Model
We consider a network with 4N nodes partitioned into households of size 4. Apart from the within household community, each node has a number of links to nodes outside the household, according to the degree distribution . The within household per-contact-transmission is denoted by , while the community transmission by . The resulting system is given below,
| 15 |
| 16 |
| 17 |
| 18 |
| 19 |
| 20 |
| 21 |
| 22 |
| 23 |
| 24 |
| 25 |
| 26 |
| 27 |
| 28 |
| 29 |
| 30 |
| 31 |
with the following initial conditions:
| 32 |
| 33 |
| 34 |
| 35 |
| 36 |
| 37 |
| 38 |
| 39 |
with all other variables set to zero at time .
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Albert R, Jeong H, Barabási A-L. Error and attack tolerance of complex networks. Nature. 2000;406(6794):378–382. doi: 10.1038/35019019. [DOI] [PubMed] [Google Scholar]
- Álvarez E, Donado-Campos J, Morilla F (2015) New coronavirus outbreak. Lessons learned from the severe acute respiratory syndrome epidemic. Epidemiol Infect 143(13):2882–2893 [DOI] [PMC free article] [PubMed]
- Bianconi G, Sun H, Rapisardi G, Arenas A (2021) A message-passing approach to epidemic tracing and mitigation with apps. Phys Rev Res 3(1):L012014
- Britton T, Ball F, Trapman P (2020) A mathematical model reveals the influence of population heterogeneity on herd immunity to SARS–CoV–2. Science 371(6529):574–575 [DOI] [PMC free article] [PubMed]
- Britton T, Pardoux E, Ball F, Laredo C, Sirl D, Tran VC. Stochastic epidemic models with inference. Berlin: Springer; 2019. [Google Scholar]
- Chen L, Sun J (2014) Optimal vaccination and treatment of an epidemic network model. Phys Lett Sect A General Atom Solid State Phys 378(41):3028–3036
- Cohen R, Havlin S, Ben-Avraham D. Efficient immunization strategies for computer networks and populations. Phys Rev Lett. 2003;91(24):247901. doi: 10.1103/PhysRevLett.91.247901. [DOI] [PubMed] [Google Scholar]
- Di Lauro F, Kiss IZ, Miller, JC (2021) Optimal timing of one-shot inter-ventions for epidemic control. PLOS Comput Biol 17(3):e1008763 [DOI] [PMC free article] [PubMed]
- Diekmann O, Heesterbeek JAP, Roberts MG. The construction of next-generation matrices for compartmental epidemic models. J R Soc Interface. 2010;7(47):873–885. doi: 10.1098/rsif.2009.0386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferrari MJ, Bansal S, Meyers LA, Bjørnstad ON. Network frailty and the geometry of herd immunity. Proc R Soc B Biol Sci. 2006;273(1602):2743–2748. doi: 10.1098/rspb.2006.3636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gabriela M, Gomes M, Aguas R, Corder RM, King JG, Langwig KE, Souto-Maior C, Carneiro J, Ferreira MU,Penha-Goncalves C (2020) Individual variation in susceptibility or exposure to sars-cov-2 lowers the herd immunity threshold. medRxiv, 2020 [DOI] [PMC free article] [PubMed]
- Handel A, Longini IM, Jr, Antia R. What is the best control strategy for multiple infectious disease outbreaks? Proc R Soc B Biol Sci. 2007;274(1611):833–837. doi: 10.1098/rspb.2006.0015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holme P, Litvak N (2017) Cost-efficient vaccination protocols for network epidemiology. PLoS Comput Biol 13(9) [DOI] [PMC free article] [PubMed]
- House T, Keeling MJ. Insights from unifying modern approximations to infections on networks. J R Soc Interface. 2011;8(54):67–73. doi: 10.1098/rsif.2010.0179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kiss IZ, Miller JC, Simon PL (2017) Mathematics of Epidemics on Networks: from exact to approximate models. Springer, Berlin
- Ling Y, Shui BX, Lin Yi X, Tian D, Zhu ZQ, Dai FH, Fan W, Song ZG, Huang W, Chen J, Bi JH, Wang S, Mao EQ, Zhu L, Zhang WH, Hong ZL (eds) (2020) vol 133. Persistence and clearance of viral RNA in 2019 novel coronavirus disease rehabilitation patients. Chinese Med J, 133(9):1039-1043, 2020 [DOI] [PMC free article] [PubMed]
- Miller JC. A note on a paper by Erik Volz: SIR dynamics in random networks. J Math Biol. 2011;62(3):349–358. doi: 10.1007/s00285-010-0337-9. [DOI] [PubMed] [Google Scholar]
- Miller JC. Equivalence of several generalized percolation models on networks. Phys Rev E. 2016;94:032313. doi: 10.1103/PhysRevE.94.032313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller JC, Kiss IZ. Epidemic spread in networks: existing methods and current challenges. Math Modell Nat Phenom. 2014;9(02):4–42. doi: 10.1051/mmnp/20149202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller JC, Slim AC, Volz EM. Edge-based compartmental modelling for infectious disease spread. J R Soc Interface. 2012;9(70):890–906. doi: 10.1098/rsif.2011.0403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller JC, Volz EM. Model hierarchies in edge-based compartmental modeling for infectious disease spread. J Math Biol. 2013;67(4):869–899. doi: 10.1007/s00285-012-0572-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore C, Newman MEJ. Epidemics and percolation in small-world networks. Phys Rev E. 2000;61(5):5678. doi: 10.1103/PhysRevE.61.5678. [DOI] [PubMed] [Google Scholar]
- Morris DH, Rossine FW, Plotkin JB, Levin SA (2021) Optimal, near-optimal, and robust epidemic control. Commun Phys 4(1)
- Mossong J, Hens N, Jit M, Beutels P, Auranen K, Mikolajczyk R, Massari M, Salmaso S, Gianpaolo ST, Wallinga J, Heijne J, Sadkowska-Todys M, Rosinska M, John EW. Social contacts and mixing patterns relevant to the spread of infectious diseases. PLOS Med. 2008;5(3):e74. doi: 10.1371/journal.pmed.0050074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Newman M. Networks. Cambridge: Oxford University Press; 2018. [Google Scholar]
- Pastor-Satorras R, Castellano C, Van Mieghem P, Vespignani A. Epidemic processes in complex networks. Rev Mod Phys. 2015;87(3):925. doi: 10.1103/RevModPhys.87.925. [DOI] [Google Scholar]
- Pellis L, Ball F, Trapman P (2012) Reproduction numbers for epidemic models with households and other social structures. I: definition and calculation of . Math Biosci 235(1):85–97 [DOI] [PMC free article] [PubMed]
- Porter M, Gleeson J (2016) Dynamical systems on networks, vol 4. Frontiers in applied dynamical systems: reviews and tutorials. Springer, Cham
- Prem K, Cook AR, Jit M. Projecting social contact matrices in 152 countries using contact surveys and demographic data. PLOS Comput Biol. 2017;13(9):e1005697. doi: 10.1371/journal.pcbi.1005697. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stadlbauer D, Tan J, Jiang K, Hernandez M, Fabre S, Amanat F, Teo C, Arunkumar GA, McMahon M, Jhang J et al (2020) Repeated cross-sectional sero-monitoring of SARS-CoV-2 in New York City. Nature 590(7844):146–150 [DOI] [PubMed]
- Verity R, Okell LC, Dorigatti I, Winskill P, Whittaker C, Imai N, Cuomo-Dannenburg G, Thompson H, Walker PGT, Fu H, Dighe A, Jamie TG, Marc B, Sangeeta B, Adhiratha B, Anne C, Zulma C, Rich F, Katy G, Will G, Arran H, Wes H, Daniel L, Gemma N-G, Steven R, van Sabine E, Erik V, Haowei W, Yuanrong W, Xiaoyue X, Christl A, Azra CG, Neil MF. Estimates of the severity of coronavirus disease 2019: a model-based analysis. Lancet Inf Diseases. 2020;20(6):669–677. doi: 10.1016/S1473-3099(20)30243-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Volz EM, Miller JC, Galvani A, Meyers LA (2011) Effects of heterogeneous and clustered contact patterns on infectious disease dynamics. PLoS Comput Biol, 7(6):e1002042, 06 [DOI] [PMC free article] [PubMed]
- Wei WE, Li Z, Chiew CJ, Yong SE, Toh MP, Lee VJ. Presymptomatic transmission of SARS-CoV-2-Singapore, January 23-March 16. Morbid Mortal Weekly Rep. 2020;69(14):411–415. doi: 10.15585/mmwr.mm6914e1. [DOI] [PMC free article] [PubMed] [Google Scholar]