

Abstract
A significant research problem of recent interest is the localization of targets like vessels, surgical needles, and tumors in photoacoustic (PA) images. To achieve accurate localization, a high photoacoustic signal-to-noise ratio (SNR) is required. However, this is not guaranteed for deep targets, as optical scattering causes an exponential decay in optical fluence with respect to tissue depth. To address this, we develop a novel deep learning method designed to explicitly exhibit robustness to noise present in photoacoustic radio-frequency (RF) data. More precisely, we describe and evaluate a deep neural network architecture consisting of a shared encoder and two parallel decoders. One decoder extracts the target coordinates from the input RF data while the other boosts the SNR and estimates clean RF data. The joint optimization of the shared encoder and dual decoders lends significant noise robustness to the features extracted by the encoder, which in turn enables the network to contain detailed information about deep targets that may be obscured by noise. Additional custom layers and newly proposed regularizers in the training loss function (designed based on observed RF data signal and noise behavior) serve to increase the SNR in the cleaned RF output and improve model performance. To account for depth-dependent strong optical scattering, our network was trained with simulated photoacoustic datasets of targets embedded at different depths inside tissue media of different scattering levels. The network trained on this novel dataset accurately locates targets in experimental PA data that is clinically relevant with respect to the localization of vessels, needles, or brachytherapy seeds. We verify the merits of the proposed architecture by outperforming the state of the art on both simulated and experimental datasets.
Keywords: Deep Learning, Neural Networks, Photoacoustic Imaging, Optical Scattering, Target Localization
I. Introduction
Photoacoustic (PA) imaging is a promising method for the non-invasive visualization of optical contrasts in deep tissue. PA images (PAI) are typically reconstructed from measurements of acoustic waves generated by the thermoelastic expansion of light-absorbing molecules (e.g. hemoglobin) in the imaged tissue [1], [2]. Thermoelastic expansion of biological tissue occurs as a result of transient heating and expansion caused by the absorption of optical energy. Ultrasound transducers, capable of measuring high-frequency changes in pressure, capture the acoustic waves in the form of radio-frequency (RF) data. This data is typically reconstructed with a beamforming algorithm to produce a PA image representative of initial pressure distribution that is proportional to optical absorption in the tissue [3]–[5]. Given knowledge about the relative optical absorption of different tissue constituents, these images enable mapping of vascular structure and other tissue molecular contents. Moreover, the distribution of specific molecules and contrast agents (e.g. indocyanine green) can be determined, and blood oxygen saturation can be imaged [6]–[9]. Despite these benefits, PAI suffers from low signal-to-noise ratios (SNR) when imaging deep tissue targets. This is mainly due to an unknown non-linear attenuation in optical fluence as a function of tissue depth. Figure 1 provides a visualization of this effect in PA experimental RF data captured from three 0.5 mm diameter pencil lead targets, placed at different depths, in an optically scattering medium.
Fig. 1:
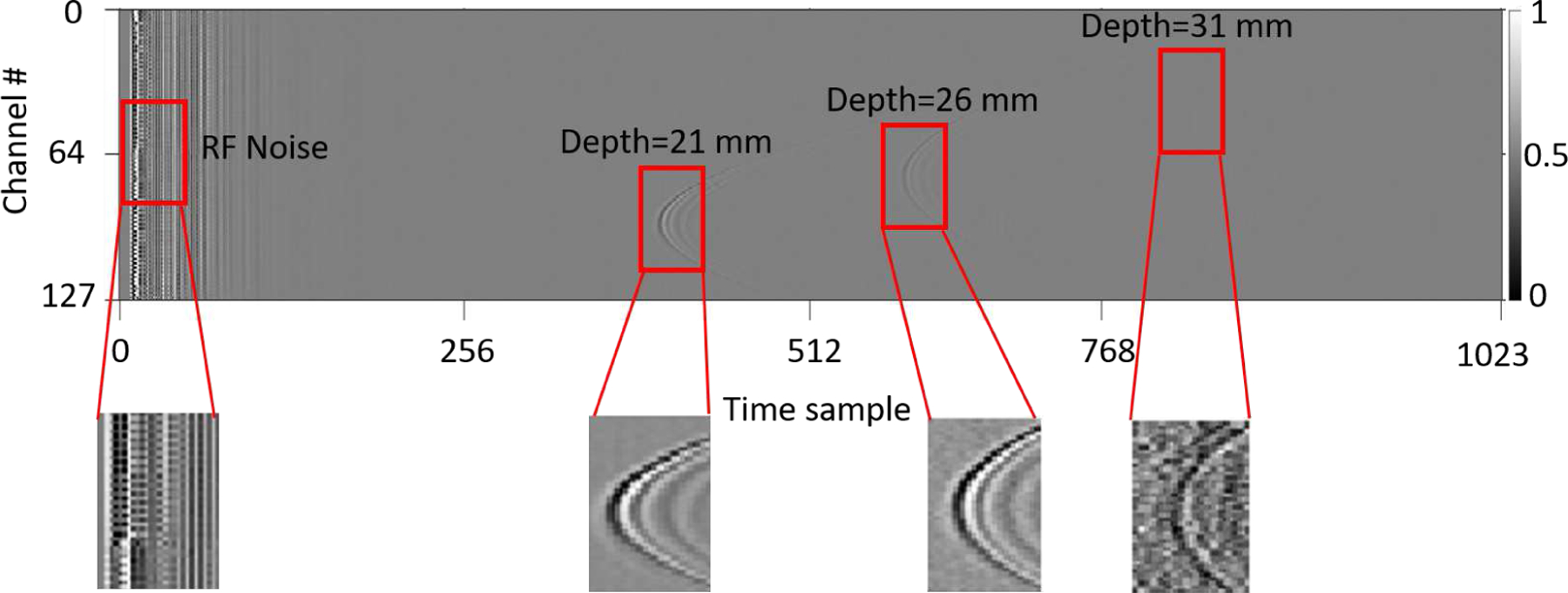
Experimental photoacoustic RF data shows the depth dependent signal strength from three 0.5 mm diameter pencil lead targets, placed at 21 mm, 26 mm and 31 mm depths inside an optically scattering medium along with the RF noise.
Deep learning has recently been shown to perform well in a variety of problem domains encompassing image processing [10]–[12], natural language processing [13], [14], and other applications [15]–[17]. Specifically, Convolutional Neural Networks (CNN’s) have supplanted state of the art for image classification and segmentation with the ability to extract fine and coarse features from various types of images [18]–[24]. The most recent studies involving deep learning in the field of PAI benefit from CNNs as well. In the first significant effort towards PA target localization, Reiter et al. in [25] map PA RF data to numerical coordinates using VGG16 [20] followed by fully connected layers. Extending Reiter et al.’s work, the authors in [26] use faster R-CNN [23] to propose regions for the targets as well as classify them as sources or artifacts. This work considers multiple point targets under different (simulated) noise levels; however, it doesn’t consider the non-uniform and depth dependent optical fluence distribution inside tissue medium and associated with above-mentioned challenges. The encoder-decoder structures like U-Net [18] are ideal for reconstruction tasks where the details in different fields of view are needed to be extracted by the encoder step by step through downsampling the input image. Moreover, the skip connections help the upsampling layers in the decoder generate the output with knowledge gained by layers in the encoder from lower fields of view. Many past works benefited from this for sinogram super-resolution [27], [28], and low CT denoising [29]–[31]. Of similar interest to denoising works, Lu et al. [32] propose a model based on generative adversarial network (GAN) for recovering high-quality optoacoustic images from limited-view images. Davoudi et al. [33] also make use of a U-Net based model to remove artifacts from optoacoustic artifactual inputs. To address the non-uniform optical fluence distribution, Johnstonbaugh et al. [34], [35] proposed a structure based on U-Net with residual modules which downsamples the input data while extracting coarse detail. It subsequently upsamples the resulting low dimensional feature maps to construct a high-resolution heatmap and estimate PA target coordinates inside a deep tissue scattering medium. The network training of Johnstonbaugh et al. [34], [35] incorporates depth-dependent optical scattering but does not account for variable scattering levels of the tissue medium. Crucially, existing deep learning solutions for PAI target localization employ representative training RF image samples that are noisy but do not explicitly develop noise robustness by exploiting problem characteristics1.
Recognizing that noise is a significant challenge in PAI, our work makes the following contributions:
Novel Problem-Inspired Network Architecture: We propose a custom architecture in which we extract noise-robust features from the input noisy images. Our proposal is a structure with a shared encoder and two parallel decoders. The first decoder is in charge of generating denoised images and therefore helping the encoder extract features that have vastly enhanced noise robustness. The second decoder localizes the targets in the input image using the features provided by the shared encoder. We, therefore, refer to our proposal as the Simultaneous Denoising and Localization Network (SDL). Our experimental results verify that our proposed simultaneous strategy as opposed to a sequential or cascaded strategy (of denoising followed by localization) has state-of-the-art performance and efficiency. An architecture of two-cascaded networks would be heavily parameterized, cumbersome to train and yields slower inference in the test phase. For the same number of network parameters, we find (experimentally) that our SDL, in fact, leads to more accurate localization. Moreover, our network also outperforms state of the art in terms of the denoising fidelity metrics.
New Regularized Training Loss Function: While existing deep learning approaches in PAI [26], [34], [35] use a loss comprised of the differences between ground truth and network estimated target coordinates, we embellish our loss with new regularization terms that enhance noise robustness. First, because we perform denoising: a new fidelity prior/regularizer is used that optimizes the network parameters to minimize departures from the ground truth noiseless images used in training. Second, to incorporate the knowledge from the domain of photoacoustic imaging, we introduce processing on the estimated clean image via wavefront/noise filters to effectively help the network to focus on enhancing geometric attributes that help localize better while mitigating RF noise. These filters are designed based on the behavior of the noise and signal in the data and influence the network parameter optimization via new domain-specific regularization terms introduced in the training loss function.
A Practically Representative Simulated Dataset and Experimental Insights: To comprehensively evaluate the effect of scattering level and the number of the targets, we generate a new dataset which is highly diverse with respect to the number of targets, their locations, and the background tissue scattering level. Our numerical evaluation shows greater localization accuracy and higher noise robustness than state of the art on both simulated and experimental data. We also investigate the effect of the number of training images (for the first time in the field of PA target localization) and show that as the number of training samples is reduced, the proposed SDL gracefully degrades in performance vs. competing methods, owing to the regularizers in SDL.
II. Methods: Simultaneous Denoising and Localization Network
A. Joint Denoising-Localization Autoencoder
1). Encoder:
We use an autoencoder structure. Autoencoders have shown good performance, where features are extracted from images at various scales [35], [38]–[41]. The encoder downsamples the input while constructing a low dimensional feature map, extracting low resolution, high field-of-view features. If we denote the input image by x, the encoder trainable parameters by θenc, and the new representation of the input image in the lower dimensional feature space by z: f(x, θenc) = z. The low dimensional feature map z is passed to upsampling modules in each of the two decoders.
2). Localization Decoder:
The localization decoder (Dec-L) upsamples the low dimensional input to the final size defined for the output heatmap. The heatmap represents the probability distribution of a target being located at any depth and lateral position. Finer features extracted in the initial layers of the encoder may be used (through skip connections) to refine the high-resolution heatmap. In terms of Dec-L parameters (θDec−L) and the feature map input (z), the heatmap (h) can be represented as follows: g1(z, θDec−L) = h. The numerical coordinates of PA targets are extracted using the Differentiable Spatial to Numerical Transform (DSNT) [42].
3). Denoising Decoder:
So far, we have developed a typical autoencoder structure where no additional information from the noise present in the images is used. To do so, we use the features extracted by the encoder to estimate the clean RF input. In other words, we train a parallel decoder designed to output the high SNR version of the RF input: , where θDec−D and denote denoising decoder parameters and the cleaned RF data, respectively. The joint optimization of the shared encoder and dual decoders (denoising and localization) lends significant noise robustness to the features extracted by the encoder, enabling them to contain detailed information about deep targets obscured by noise.
B. Feature Extraction and Optimization of the Network
1). Parallel Branches and Joint Optimization:
As mentioned above, there are two paths in the network: 1) Input → Heatmap and Numerical Coordinates and 2) Input → Cleaned RF Data. The parameters in a neural network architecture must be optimized according to a loss function defined over the network outputs and desired ground truth via (typically) stochastic gradient descent [43] and backpropagation [44]. Our primary goal is to predict PA target coordinates as accurately as possible. Thus, the loss term defined on the output of the localization decoder is:
| (1) |
where C and are both normalized Cartesian coordinates corresponding to the lateral and axial position of the target and the output of the network. (for example, C = (−1,−1) and C = (1,1) are the coordinates of the targets lying on the top left of the heatmap and bottom right of the heatmap, respectively.) The operation denotes the ℓ2 norm. The second term imposes an additional constraint on the heatmap , forcing it to follow a spherical Gaussian distribution (hGaussian) by the measure of Jenson-Shannon divergence [42].
We also intend to generate a high SNR version of the input RF data, evaluated with respect to ground truth clean images included in the training set. This is enforced by a fidelity prior/regularization term given by:
| (2) |
where xclean is the ground truth high-SNR PA RF data. Eq. (2) is used as a regularizer in the final training loss function – see Eq. (6). The joint optimization of the denoising decoder (Dec-D in Fig. 2) with the shared encoder and localization decoder (Dec-L) in effect enhances target localization (i.e. the output of Dec-L). This is due to the fact that the encoder parameters (and hence resulting features) are optimized to simultaneously recover a clean PA image and accurately estimate target locations, which are tasks that benefit each other.
Fig. 2:
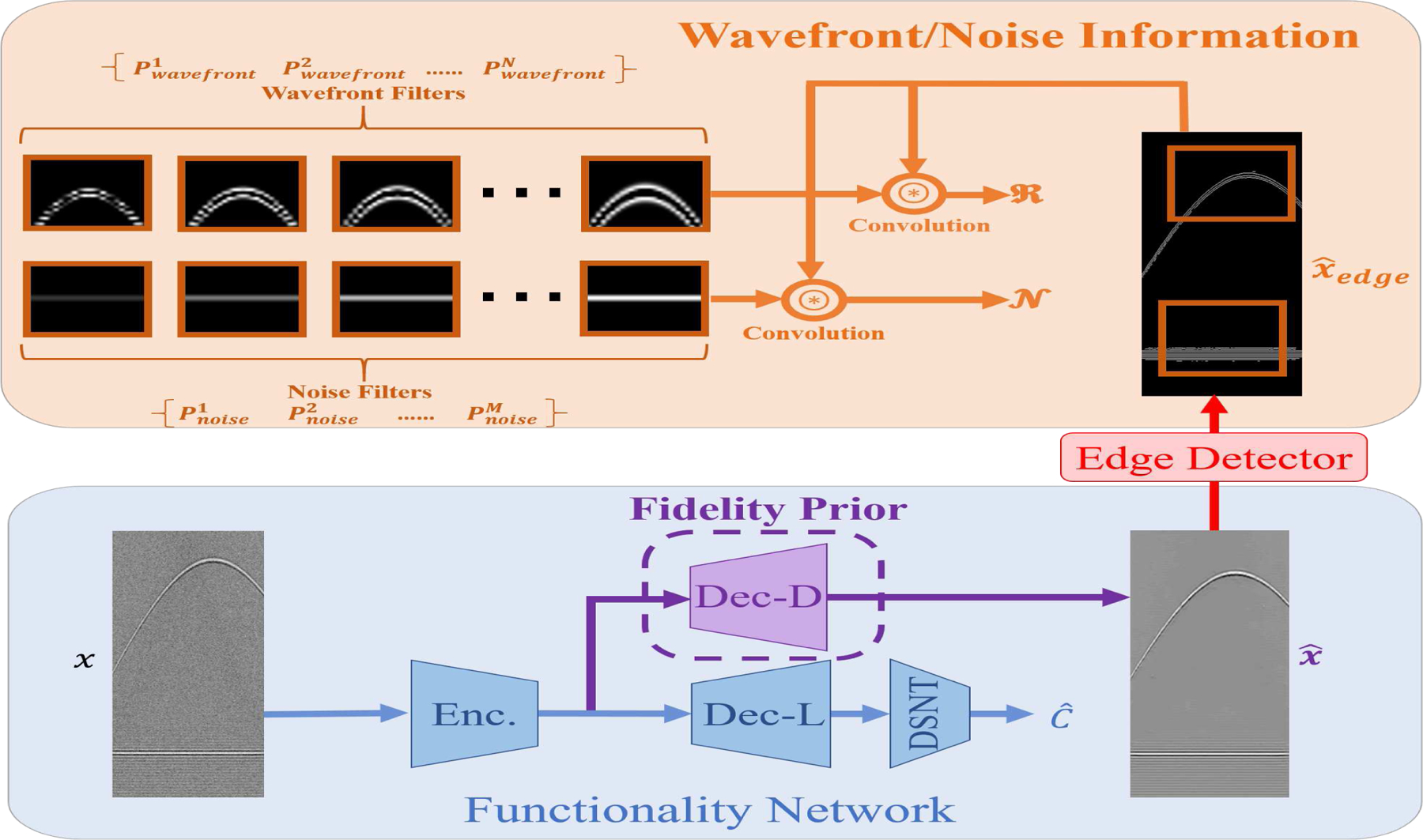
The overall scheme of proposed SDL architecture. The Functionality Network consists of the main branches (encoder, denoising decoder, localization decoder, and differentiable spatial to numerical transform layer (DSNT)) to generate the coordinates and the denoised PA RF image. Note that the Dec-D branch essentially acts as a prior on the encoded features, which is enforced in the training via the regularizer in Eq. (2). The Wavefront/Noise Information part calculates two terms needed for the regularizers in Eq. (3) and Eq. (4). This is accomplished by extracting edges from the denoised image and subsequently convolving them with noise and wavefront filters. The goal is to minimize the strength of the noise while matching the wavefront behavior to its counterpart in the ground truth noiseless image. Finally note that once trained, target localization involves processing the PA input image via the shared encoder and localization decoder (Dec-L).
Justification of the SDL Network Architecture in Fig. 2:
The main benefit of a shared encoder-dual decoder architecture is that the denoising decoder acts as a prior and ensures that the encoded features are noise-robust. The use of these noise-robust features then leads to superior results in target localization over networks that just use noisy images and ground truth coordinates for training.
An alternative option for using the knowledge of the noiseless images could be using a cascade of two networks in which the output of the denoising decoder (Dec-D) is first obtained and then fed into another deep network for target localization. We contend, however, that our proposed simultaneous strategy, as opposed to a sequential or cascaded strategy, has the upper hand both in performance and efficiency. An architecture of two-cascaded networks would be heavily parameterized and cumbersome to train. For the same number of network parameters, we find (experimentally) that our SDL strategy, in fact, leads to more accurate localization. Second, the cascade of denoising and localization networks would be considerably slower than the proposed SDL for processing input PA image data. It is worth emphasizing that our proposed architectural enhancements in Fig. 2 only influence the training stage. Once trained, only the shared encoder and Dec-L are used to arrive at target coordinates, which means that SDL incurs no additional computational burden over existing state-of-the-art methods.
2). Custom Regularizer and Wavefront/Noise Filters:
Fitting the denoising decoder output over the ground truth noiseless images can be achieved using the loss in Eq. (2). However, this criterion may not lead to completely accurate outputs because, as we can see in Fig. 3, the RF data is mostly free of signal, and the l2 norm in Eq. (2) is a global measure that does not pose special emphasis on signal-containing regions in the data. This leads to gradients and updates that put significant weight on cleaning signal-free areas in the RF input. Moreover, even in the ground truth noiseless images, RF noise usually appears at the beginning or the end of data (Fig. 3 a,b and Fig. 1), which we intend to mitigate. To achieve these objectives, we define new representation filters as depicted in Fig. 2. These filters fall into one of two groups: 1) Wavefront filters: which are generated using the idea of Scale and Curvature Invariant Ridge Detectors (SCIRD) [45] to extract the wavefronts (curves/signals) and 2) Noise filters: which are crafted manually according to the behavior of RF noise in the images2. The corresponding features are extracted by correlating these filters with the edges in the denoising network’s cleaned RF outputs:
| (3) |
| (4) |
Here, Pwavefront and Pnoise denote wavefront and noise filters, respectively. represents the extracted edges in the cleaned output (extracted using simple edge filters) and is the convolution operation. The filters are defined based on the shape of the RF noise and signals in the images (see Fig. 2). Thus, we have a new regularizer term defined as:
| (5) |
where is the wavefront in the ground truth clean image. Thus, we impose a more restrictive constraint over the cleaned data by forcing it to follow the patterns in the ground truth, and at the same time remove the RF noise.
Fig. 3:

Depiction of how wavefront/noise filters are inspired. (a) Presence and intensity of signal wavefront and RF noise in PA noisy data. Expected clean outputs of the network (b) without wavefront and noise filter training, and (c) with wavefront and noise filter training. The goal is to suppress RF noise signals, while enhancing the strength of the PA signal wavefront.
The loss function to be minimized for the whole network is the sum of the central loss term in Eq. (1), the fidelity prior/regularizer in Eq. (2), and regularization term involving wavefront and noise filters in Eq. (5):
| (6) |
where λ1, λ2 and γ are regularizer constants for Jenson-Shannon divergence, the fidelity, and wavefront/noise loss, respectively. Note that the regularization constants are experimentally determined by cross-validation [46]. N and M denote the number of wavefront and noise filters, respectively.
C. New Practically Representative Simulated Dataset
For the success of any deep learning application in the medical imaging domain, the problem of obtaining large training datasets must be addressed. Conventionally, the researchers in PAI community have used various types of simulations to obtain the training data. Allman et al. [26] have used the K-wave simulation tool to obtain the photoacoustic raw data, considering a uniform optical fluence along the tissue depth. These simulations are helpful while considering the illumination source always present near the target, which is true for endoscopic applications. However, for deep tissue non-invasive imaging conditions, heterogeneous optical fluence distribution must be considered. To address the problem of PA signal attenuation due to scattering, Agrawal et al. [47] recently introduced a hybrid simulation platform where depth-dependent fluence attenuation is considered while obtaining the photoacoustic raw data. Johnstanbaugh et al. [34] used this simulation platform to obtain a large training dataset of single target photoacoustic images with the scattering of background tissue fixed to 10 cm−1, in contrast to realistic PAI scenarios where the scattering noise levels might vary up to 20 cm−1. In the work presented here, we have addressed these shortcomings by using the same simulation platform [47] to produce a dataset that includes multiple point targets placed at different depths inside a deep tissue medium with three different , and 20 cm−1. As shown in Fig. 4, this hybrid simulation platform uses the NIRFAST toolbox to solve for the optical fluence distribution inside the tissue medium [48], [49]. At each point in the digital phantom, the calculated optical fluence is multiplied by the optical absorption coefficient at that point to yield the initial pressure distribution. The K-Wave function kspaceFirstOrder2D [50] takes the initial pressure distribution as input and simulates the propagation and detection of the resulting photoacoustic waves. The platform outputs time vs. pressure measurements detected with a 256-element ultrasound transducer array.
Fig. 4:
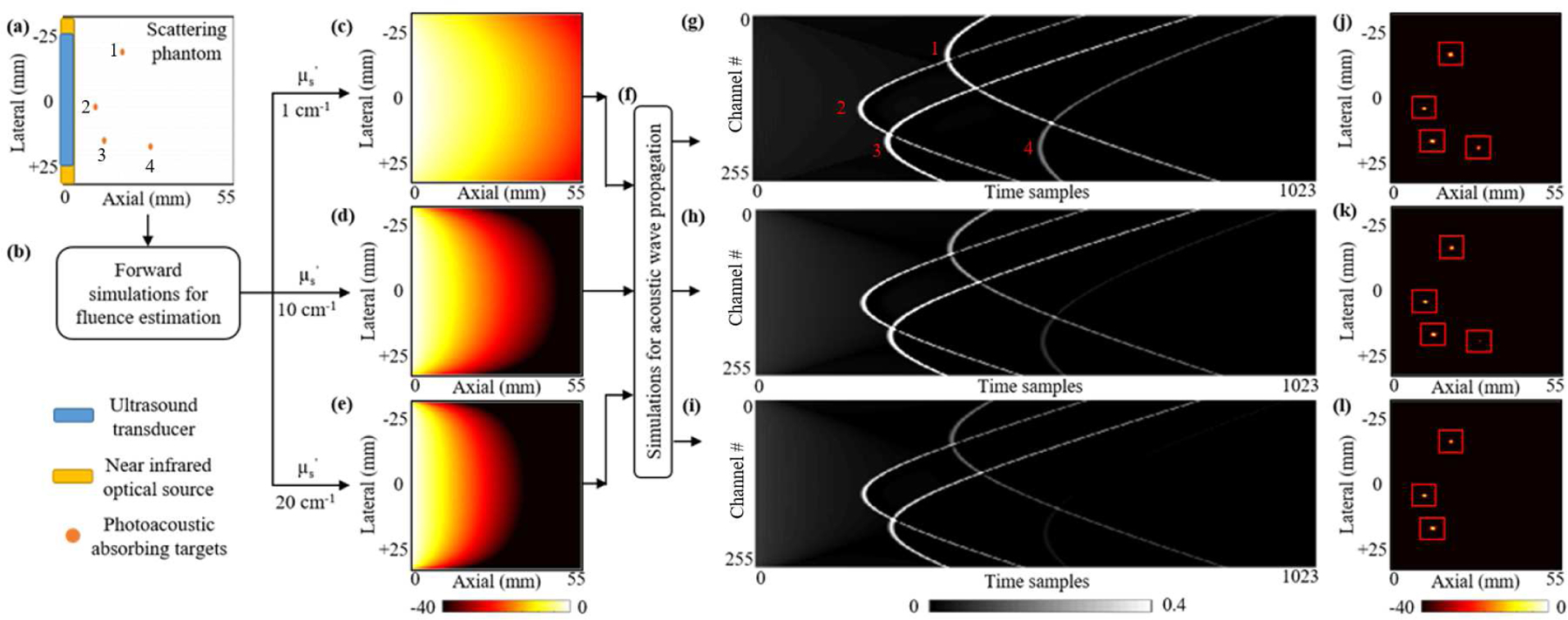
The schematic of our simulated dataset generation platform with different optical scattering levels and numbers of targets. (a) A schematic view of the 55×55 mm digital tissue phantom. A 51.2 mm wide 256-element ultrasound transducer array (blue stripe) and a 54 mm wide optical source (yellow stripe) are placed along the left edge of the phantom. Orange circles are 0.3 mm diameter vascular targets. (b) Simulated diffused light propagation via the NIRFAST toolbox solves optical fluence distributions for three different tissue mediums with reduced optical scattering coefficients of (c) 1 cm−1; (d) 10 cm−1; and (e) 20 cm−1. (f) The photoacoustic wave propagation resulting from the optical fluence-induced initial pressure is simulated via the K-Wave toolbox. (g, h, i) The time sampled photoacoustic signals detected by the 256-element transducer array for each scattering level and (j, k, l) their corresponding beamformed images.
Using this platform, simulated PA signal measurements were generated for 8000 digital (in silico) tissue phantoms. The digital phantom consists of a 276ˆˆc3ˆˆ97276 two-dimensional grid with 0.2 mm node spacing (Fig. 4a). This grid represents a 55 mm×55 mm sized soft tissue. For each phantom, an integer from 1 to 4 was randomly selected. This number of blood targets was placed at random positions within the 10 mm to 50 mm depth range of the homogeneous tissue medium. The lateral positions of the vascular targets were constrained to a range of 10 mm on either side of the center of the transducer array. After the targets were placed, PA signal propagation was simulated with three different background scattering levels, (, 10 cm−1, and 20 cm−1) (Figs. 4g, h, i).
1). Optical Fluence Calculation:
The first step in generating a photoacoustic signal is the photoexcitation of optically absorbing molecules. Acoustic wave propagation follows thermoelastic expansion of such molecules, and the initial pressure is modeled as proportional to the local optical fluence (Eq. (8)). We adopt the diffusion approximation model of light propagation [48] in our digital scattering phantoms (Fig. 4b):
| (7) |
where φ(r,ω) is the fluence rate at position r and modulation frequency ω, µa and µs are the absorption and reduced scattering coefficients, the diffusion coefficient κ = 1/3(µa+µs), q0(r, ω) is an isotropic optical source term, and cm(r) is the speed of light at position r in the tissue.
2). Initial Pressure Calculation and Propagation:
The initial pressure distribution in the phantom is calculated by multiplication of the optical fluence at each point with the corresponding optical absorption (Fig. 4f):
| (8) |
where φ(r) and µa(r,λ) are the optical influence at position r and optical absorption coefficient at position r and excitation wavelength λ, respectively. Γ is the Grüneisen parameter, which we model as equal to one unit for simplicity. p0 is the initial pressure at tissue position r. The value of the optical absorption coefficient of oxygenated human blood is modeled with an optical absorption coefficient of µa = 0.425 mm−1 at 800 nm [51]. The initial pressure distribution is input to the k-Wave function kspaceFirstOrder2D, which simulates the propagation of acoustic waves in the tissue medium (Fig. 4d). The acoustic propagation is solved for using the following set of equations [51]:
| (9) |
Where p is the acoustic pressure, u is the particle velocity, ρ0 is the ambient density in the tissue, ρ is the acoustic density, c is the tissue speed of sound.
III. Experimental Results
A. Network Implementation
Reproducibility:
Our implementation code for different training/test scenarios, data files for wavefront/noise filters, training, and test dataset, and the exact package numbers can be found at: https://github.com/yazdaniamir38/SDL-network-for-PA-target-localization.
Our network is implemented using Python and deep learning packages of Pytorch [52] and all of the training and testing experiments were conducted on an NVIDIA Titan X GPU (12GB). We trained our model for 100 epochs with batch size 4 using RMSprop [53] optimizer with an initial learning rate of 0.0001. We used a learning rate scheduler with a decrease factor of 0.1 and a patience factor of 10 epochs. To find the optimum values for hyperparameters including regularizing constants, we performed cross-validation by keeping a portion of training data as the validation set (2000 samples) and training the network for a couple of epochs to see how fast and stably the error decreases. The values we found by cross-validation for λ1, λ2, and γ are 1, 0.5, and 10−4 respectively. The simultaneous presence of multiple regularization terms may prevent the training loss of the network from converging. So we initially train the model without the term. After about 60 epochs when the model converges to a suboptimal point, we activate the terms corresponding to to further refine the network parameters. We extract windows of size 45×40 pixels centered on the wavefront in noiseless samples as in Eq. (5). To approximately estimate the location of the wavefront in the image, we make use of the ground truth coordinates and project them to pixel coordinates. The encoder and localization decoder architecture (see Fig. 6 for details) follow the residual U-Net based structure of [34], [35] with changes in the number of the output channels of the last convolutional layer according to the number of targets to be detected. As we will further explain in different setups, the network can be used for localizing either single targets or a variable number of targets. The denoising decoder jointly with the shared encoder also follow the residual U-Net architecture (with a different number of layers) and consist of the following:
Fig. 6:
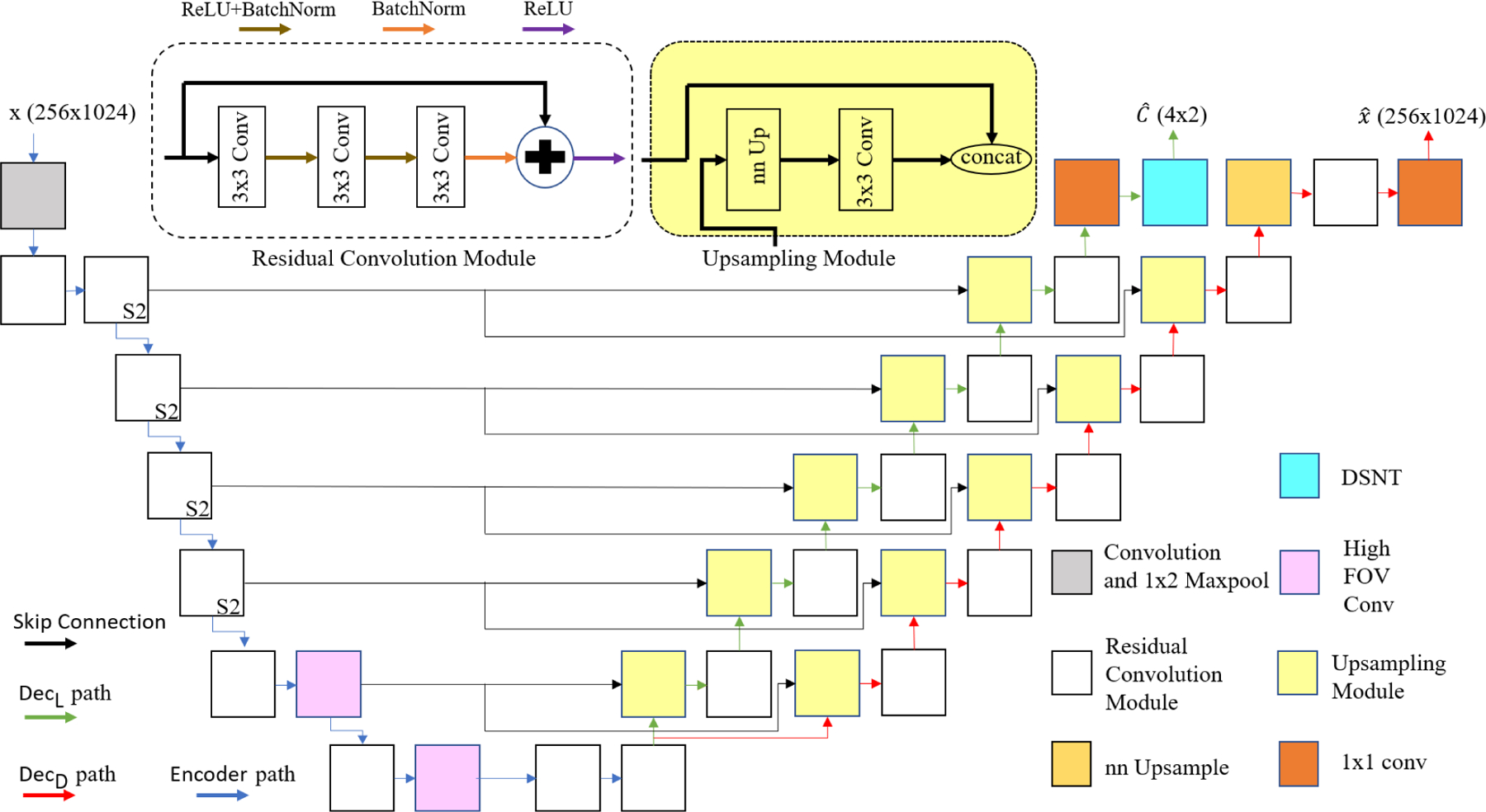
The architecture of the U-Net based network used for the encoder and decoders. Different colored boxes represent the following specific modules: Convolution and 1×2 Maxpool, residual convolution module (S2 on the right corner of some modules indicates that they downsample the input features with stride 2), nn Upsample which is based on the nearest neighboring algorithm, DSNT layer, Upsampling module, 1×1 conv, and high field-of-view convolution module with 5×5 kernels and strides 1 and 3. They are termed the high field-of-view modules because the size of kernels (5×5) is comparable to the size of feature maps (16×32) which is useful for detecting the dependencies between far apart pixels in the input image.
1). Residual Convolutional Modules:
These modules consist of three convolutional blocks with a 3×3 kernels where each is followed by a batch normalization layer and a ReLU activation function. The output of the last batch normalization layer of each module is added to the input of the same module and passed to a ReLU activation function. The stride in the first block is 2 to downsample the input. The purpose of these modules is to encode features at various scales. Downsampling enables larger-scale features to be captured with 3×3 convolutions via hierarchical feature extraction. Fig. 6 depicts these modules with white boxes and S2 on the right corner of the boxed denotes that the input features are downsampled with stride 2.
2). Upsampling Modules:
These modules increase the resolution of the low dimensional features to the desired size of the output. There is a nearest neighbor upsampling block, with a factor of 2, to upsample the input followed by a convolutional block with 3×3 kernel. The output of the convolutional block is concatenated with the corresponding skip connections from the encoder and passed to a residual module. In Fig. 6, these modules are shown in yellow and fed with two inputs.
Since the output of the denoising decoder (cleaned output) is larger than the output of the localization decoder (heatmap), the denoising decoder has one extra module. [35] uses the Nyquist convolutional layer to downsample the image; however, in the presence of the noise, better performance is observed, when the input image is not downsampled. In total, the encoder, the localization decoder, and the denoising decoder have 7, 6, and 7 layers, respectively. Table I shows the details of each layer in the encoder and the decoders with respect to input/output size and Fig. 6 shows the model architecture.
TABLE I:
The details for the layers of the encoder (Enc), Localization decoder (Dec − L), and Denoising decoder (Dec−D). The size of the PA input is 256*1024. The definition of encoder in our work is slightly different with [35]’s as we consider layer 7 belonging to the encoder and its output is considered as the shared input for decoders. Each layer for decoders consists of a residual and upsampling module except for the last layer which is a simple convolutional layer and all of these layers benefit from the skip connections of their corresponding layer in the encoder.
| Layers | Number of Kernels/feature maps | Size of output feature maps | Layers | Number of Kernels/feature maps | Size of output feature maps | Layers | Number of Kernels/feature maps | Size of output feature maps |
|---|---|---|---|---|---|---|---|---|
| Layer1Enc | 16 | 256*1024 | Layer8Dec−L | 256 | 16*32 | Layer8DecD | 256 | 16*32 |
| Layer2Enc | 16 | 256*512 | Layer9Dec−L | 128 | 32*64 | Layer9Dec−D | 128 | 32*64 |
| Layer3Enc | 32 | 128*256 | Layer10Dec−L | 64 | 64*128 | Layer10Dec−D | 64 | 64*128 |
| Layer4Enc | 64 | 64*128 | Layer11Dec−L | 32 | 128*256 | Layer11Dec−D | 32 | 128*256 |
| Layer5Enc | 128 | 32*64 | Layer12Dec−L | 16 | 256*512 | Layer12Dec−D | 16 | 256*512 |
| Layer6Enc | 256 | 16*32 | Layer13Dec−L | 1 | 256*512 | Layer13Dec−D | 8 | 512*1024 |
| Layer7Enc | 256 | 8*16 | Layer14Dec−D | 1 | 256*1024 |
B. Experimental Setup
The performance of the proposed network is compared with the state of the art by considering different experimental setups. Furthermore, we designed new scenarios to evaluate the network in more challenging conditions and find the boundary to which our network can still show good performance. Our different scenarios include i) comparing the performance of our network over the datasets employed in [26] and ii) [35] for a similar application, iii) performance on our own practically representative simulated dataset and experimental phantoms with multiple targets, including inside chicken breast tissue. Unless otherwise stated, for the proposed SDL – the number of wavefront filters N = 10 and the number of noise filters was set to M = 20. These numbers were determined by cross-validation for the best overall results.
C. Comparisons with State of the Art
1). Experiments on Allman et al.’s Dataset: Up to Two Targets:
To perform a fair comparison with the work of [26], we use their released simulated dataset3. This dataset contains 16,000 and 4,000 images for training and testing, respectively, with at most two targets (source and artifact). The labels provided for the targets are the bounding box coordinates, whose centers are used as labels for SDL. We compare the networks in 3 different scenarios: 1) noiseless images, 2) noisy images when the signal to noise ratio (SNR) is −3dB, and 3) when the SNR is −9dB. Zero mean Gaussian noise with a certain standard deviation is added to obtain the desired noise levels and the noiseless images are used as ground truth for our denoising decoder. Of note, since in this dataset scattering noise level is not considered, the signal intensity in different depths is almost fixed. Table II compares the results for both networks. Table II confirms that SDL reduces the error significantly over [26], particularly for the −3 dB case. Some of the test samples along with their corresponding cleaned outputs and heatmaps from our network are shown in Fig. 7. It may be observed that SDL predictions have higher precision, since the network generates a very small concentrated point versus a bounding box.
TABLE II:
Comparing the results in the same manner, [26] reported the results over their simulated test set. T is the inference time reported per image sample.
| Architecture | percentage of total Error≤0.5 mm | T(sec) | ||
|---|---|---|---|---|
| Noiseless | SNR= −3dB | SNR= −9dB | ||
| [26] | 93.73 | 96.51 | 95.63 | 0.068 |
| SDL | 99.71 | 99.47 | 96.65 | 0.058 |
Fig. 7:

Performance of our SDL network on [26]’s photoacoustic dataset. (a) A noiseless sample. (b,c) Its −3 dB noisy version and its reconstructed output from our network, respectively. (d,e) −9 dB noisy version and its reconstructed output, respectively. (f,g) Output heatmaps generated by the network for −3 dB and −9 dB inputs, respectively.
2). Experiments on Johnstonbaugh et al.’s Dataset: Single Target with Tissue Optical Scattering:
The dataset used by Johnstonbaugh et al. [35] is much more realistic with regard to scattering noise level, but only considers the single target localization within a deep tissue medium of fixed background scattering value. This dataset contains 16,240 and 4,060 samples for training and test, respectively. Since we are using their proposed autoencoder structure as a base for our encoder and denoising decoder, we have the same performance in the case without additive Gaussian noise. To obtain the objective SNR (−9 dB), the average signal intensity in depth 40 mm is calculated and the variance of the noise is defined according to that. The numerical results for both networks are compared in Table III where lateral, axial, and Euclidean error are calculated as follows:
| (10) |
where x and denote the ground truth and network’s output for axial coordinate, respectively. y and are the ground truth and network’s output for lateral coordinate, respectively. These results indicate that injecting PA domain knowledge about RF and scattering dependent noise - as SDL exploits – improves the results specifically for the targets that lie deeper (than 40 mm) in the scattering noise.
TABLE III:
Performance over [35]’s dataset with respect to depth. We can see the significant improvement over deep targets which is due to the effect of denoising part as deeper targets suffer from optical scattering more.
Johnstonbaugh et al. [35] also test the network on experimental samples with different scattering levels and in the case of 20 cm−1 noise level, as shown in Fig. 8, their network fails (as well as the network proposed in [26]). The output of our network (after it’s trained with their modified dataset and tested on these samples) can be seen in Fig. 8, where SDL can still predict even with the extreme level of scattering.
Fig. 8:
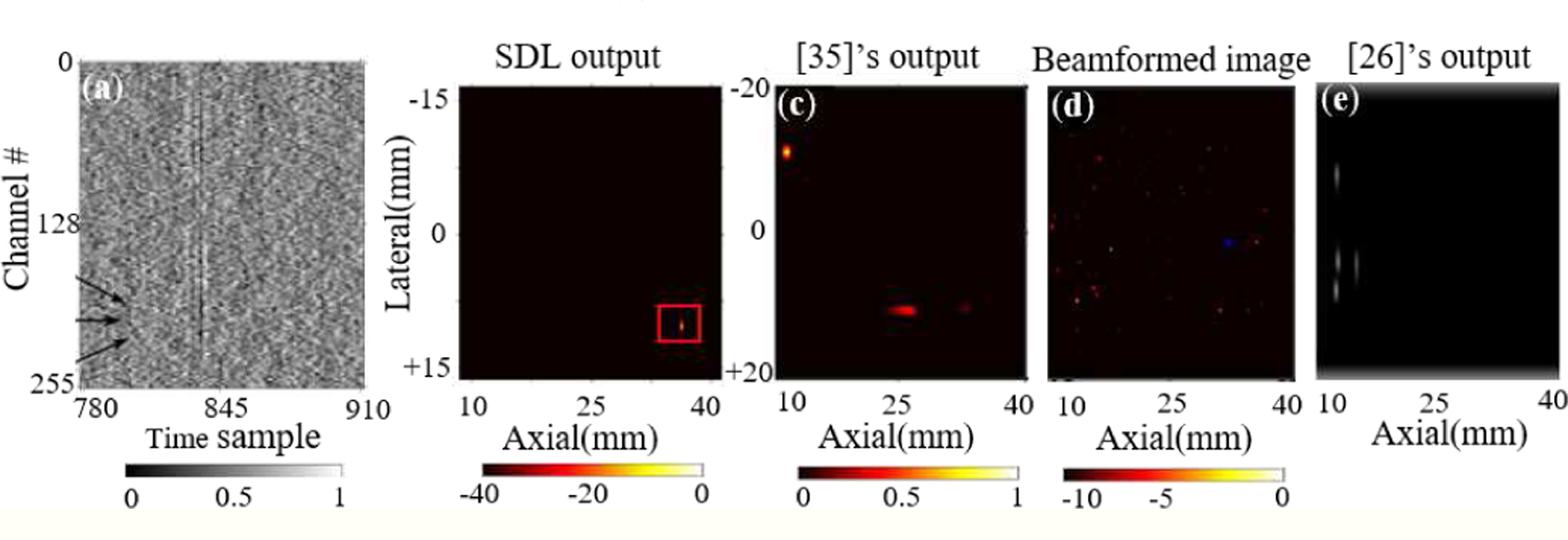
Comparison between SDL, [26], [35]’s performance, and traditional beamforming. (a) Experimental RF data with 20 cm−1 scattering noise taken from [35], (b) the prediction from SDL, (c) [35]’s output, (d) beamformed image, and (e) [26]’s output (bounding box centers are shown).
Effect of training sample size:
To observe the effect of priors and carefully devised architectures, it’s common in state-of-the-art methods [54]–[56] to evaluate the performance of the models when the training set is limited. This is important from a practical point of view as in most of real world cases the number of annotated samples is limited. Therefore networks should be able to maintain their performance with the least degradation possible compared to when training samples are not limited. The models should also show robustness when the train/test splits change. To investigate this, we chose 5 different randomly chosen train/test splits with a training size of 8,120 and a test size of 4,060 using the original dataset with SNR=−9dB (used in [35]). We trained SDL and the model in [35] 5 times on different training sets and tested them on the corresponding test set. Fig. 9 conveys two key messages: 1) the average error for SDL even when training is halved is still quite good and much better than what [35] achieves with half the data; 2) the significantly lower variance of the error for SDL vs. [35] for the 5 train/test splits shows that SDL is much more robust to selection bias, i.e. SDL performance is less sensitive to the exact choice of training samples - an important practical benefit, which is provided by the priors/regularizers used with SDL.
Fig. 9:
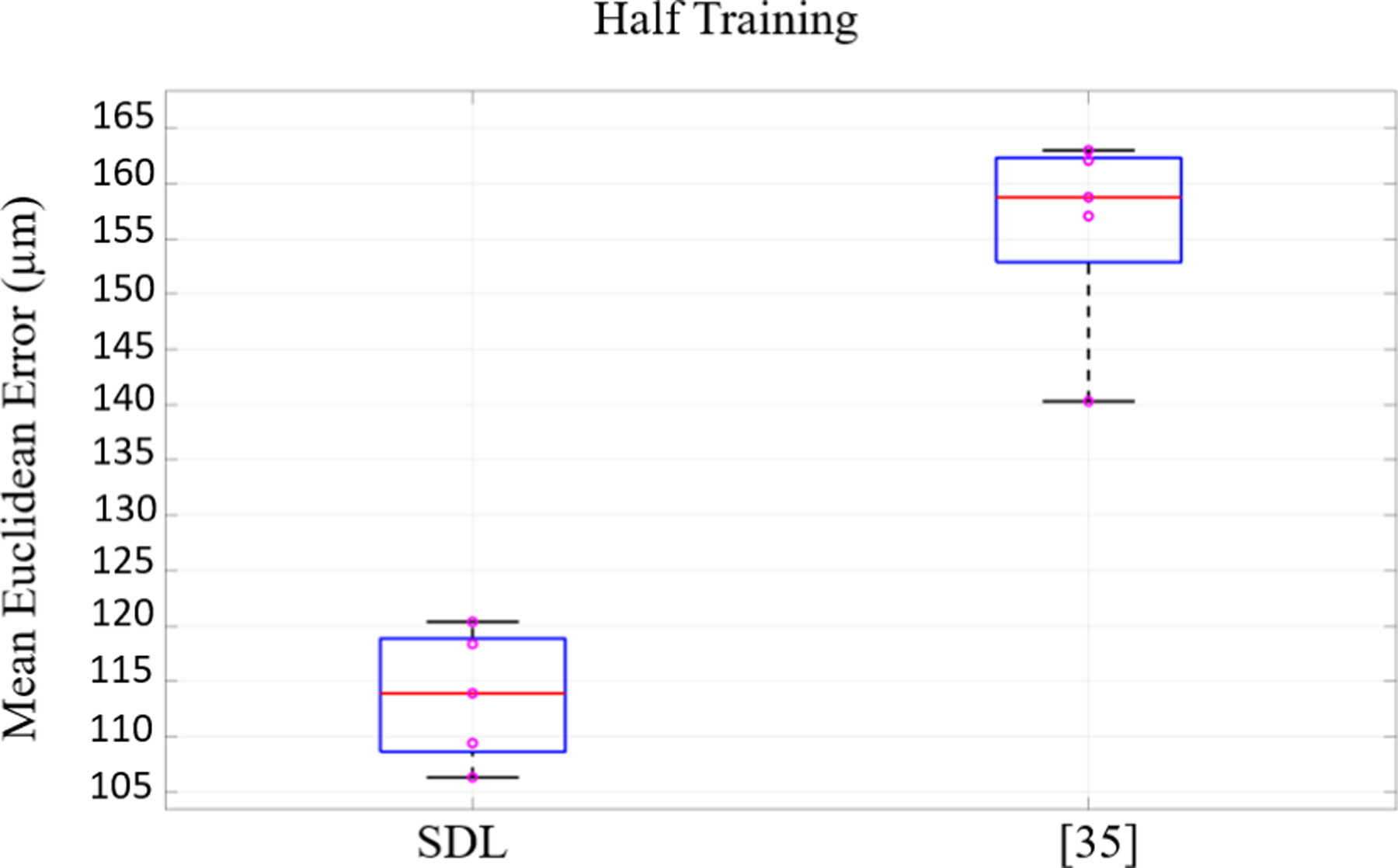
The performance results of the models for 5 different training/test splits when the training size reduces to half (8,120 samples). Our lower mean and variance shows the reliability of the network in limited training regime.
D. Experiments on Challenging Simulated and Real Data
We use the dataset in Section II-C for evaluating the capability of the network with respect to the noise level. To do so, we trained the network 2 times, over 2 different training sets of size 8,000, where the scattering noise level in each set was different (10 cm−1 and 20 cm−1). The samples with 1 cm−1 noise level were used as ground truth for the denoising decoder. Each trained model was tested on a test set with the size of 2000 and corresponding scattering level. In addition to separate noise level experiments, we also trained the SDL network over a large training set obtained by varying the scattering noise level (1 cm−1, 10 cm−1, and 20 cm−1) and tested it over the combined test set – these are labeled as mixed in Table IV. Table IV shows the results with respect to depth and distinct noise levels. Results in Table IV reveal that as expected, the average errors for SDL are generally higher for the higher scattering noise level. We should mention that average localization errors for the mixed case in Table IV appear lower because the training set is a combined set of all the training samples with different scattering coefficients and hence it’s richer; moreover, the test includes the 1 cm−1 case, which is practically noiseless.
TABLE IV:
The performance of three networks: SDL, the network without filters, and single decoder for different noise levels with models’ training time (T1) and inference time (T2). Note that T2 is reported per image sample. The benefits of wavefront/noise filters when the training set is limited are clearly apparent with best results indicated in bold.
| µ’s | Architecture | Depth<35 mm | Depth≥35 mm | T1(hr) | T2(sec) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Ax(µm) | Lat(µm) | Euc(µm) | Ax(µm) | Lat(µm) | Euc(µm) | ||||
| 10 cm−1 | single decoder | 15.67 | 13.30 | 23.22 | 14.66 | 10.59 | 20.51 | 8.29 | 0.049 |
| w/o wavefront/noise filters | 3.48 | 4.35 | 6.74 | 3.18 | 2.28 | 4.37 | 37.44 | 0.051 | |
| SDL | 2.13 | 1.78 | 3.10 | 2.16 | 1.75 | 3.07 | 55.30 | 0.053 | |
|
| |||||||||
| 20 cm−1 | single decoder | 20.32 | 18.49 | 30.56 | 19.47 | 18.93 | 29.88 | 8.25 | 0.057 |
| w/o wavefront/noise filters | 5.99 | 4.22 | 7.91 | 4.05 | 2.53 | 5.27 | 37.52 | 0.046 | |
| SDL | 3.62 | 3.18 | 5.15 | 1.99 | 1.84 | 3.05 | 55.7 | 0.050 | |
|
| |||||||||
| mixed | single decoder | 4.54 | 4,76 | 8.22 | 4.71 | 4.24 | 7.70 | 15.65 | 0.063 |
| w/o wavefront/noise filters | 1.24 | 0.68 | 1.57 | 1.20 | 0.80 | 1.59 | 50.76 | 0.068 | |
| SDL | 0.98 | 0.39 | 1.17 | 1.02 | 0.42 | 1.22 | 94.86 | 0.065 | |
Ablation Study:
To lend greater insight into SDL components, Table IV performs an ablation study by reporting results for two SDL variants: one without wavefront/noise filters (and hence also without the regularizer) and another single encoder-decoder configuration that does not employ the denoising decoder. The gains of SDL, over its counterparts that are stripped of regularization, are readily apparent in Table IV showing the benefit of each regularizer in Eq. (6). While the networks in state of the art were trained and designed for different experimental setups as investigated in Section III-C, the single encoder-decoder results in Table IV essentially can be thought to represent the performance of [26], [35] because they are without the architectural enhancements and regularizers that SDL employs. Fig. 4i shows a test sample with a scattering level of 20 cm−1 and Fig. 5 shows its corresponding cleaned output and heatmap predicted by the SDL network (trained over varying scattering levels), which effectively localizes multiple targets while beamforming in Fig. 4i does not detect all 4 targets.
Fig. 5:
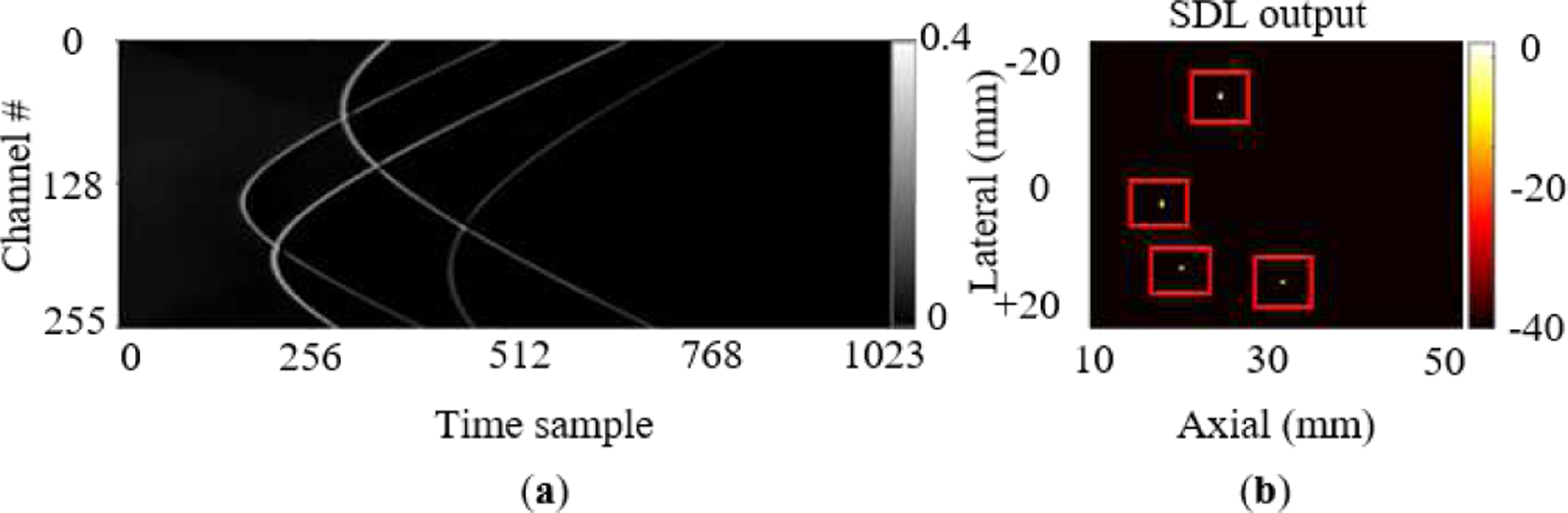
(a) Denoised output and (b) the corresponding heatmap of 4 photoacoustic targets used in Fig. 4i (as it will be explained in section III.D) Note that SDL successfully detects all 4 targets, whereas one is missed by conventional beamforming approaches in Fig. 4i.
Cascaded vs. parallel denoising:
To emphasize the benefits of our denoising approach over a cascaded strategy (denoising followed by localization), we compare SDL with a network consisting of a denoiser followed by a localization network. We make use of the denoising network proposed by Awasthi et al. [27] which is based on a hybrid U-Net [18] and represents state-of-the-art denoising for PA imaging applications. For the localization part, we incorporate the same encoder-decoder structure as the encoder and localization decoder in SDL. Both networks are trained over our combined training set (with all scattering noise levels) and tested on a set which is the combination of our test sets for scattering noise levels of 10 cm−1 and 20 cm−1 (Training size of 24,000 and test size of 4,000). Table V shows the localization results and Table VI shows the denoising performance of the networks in terms of peak signal to noise ratio (PSNR) and structural similarity index measure (SSIM) [57]. While the inference time is significantly less for SDL, it outperforms the cascaded network with respect to both localization and denoising. We can visually verify the quality of denoised outputs produced by SDL in Fig. 10c compared to the output of the denoising network proposed in [27] - Fig. 10d. We contend that SDL outperforms state of the art because, in our proposal, localization helps denoising (and vice-versa) via the shared encoder in Fig. 2.
TABLE V:
The localization results of the two models, SDL and the cascaded network for the combined 10 cm−1 and 20 cm−1 test set. T is the inference time reported per image sample.
| Architecture | Depth<35 mm | Depth≥35 mm | T(sec) | ||||
|---|---|---|---|---|---|---|---|
| Axial(µm) | Lateral(µm) | Euclidean(µm) | Axial(µm) | Lateral(µm) | Euclidean(µm) | ||
| cascaded network | 7.33 | 5.08 | 10.20 | 8.96 | 5.82 | 12.28 | 0.097 |
| SDL | 0.91 | 0.38 | 1.09 | 0.96 | 0.40 | 1.15 | 0.059 |
TABLE VI:
The denoising results of the two models, SDL and the cascaded network for the combined 10 cm−1 and 20 cm−1 test sets. SSIM is an image quality measure normalized to (0,1).
| Architecture | PSNR(dB) | SSIM |
|---|---|---|
| cascaded network | 39.00 | 0.9929 |
| SDL | 42.36 | 0.9945 |
Fig. 10:
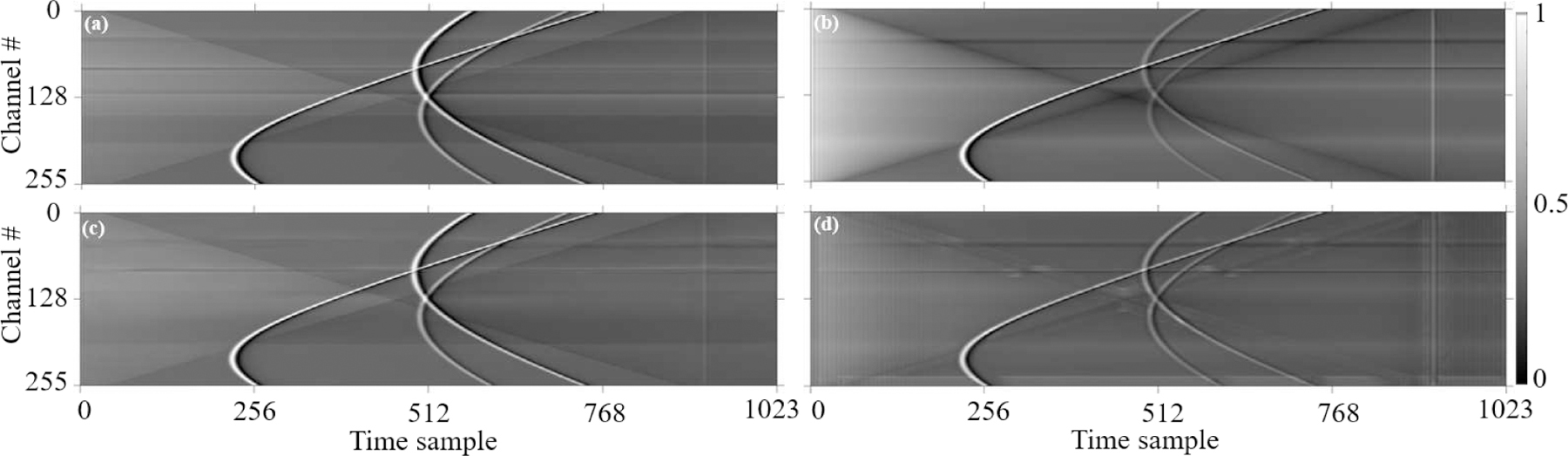
The denoising performance of SDL and the cascaded network on a test sample: (a) noiseless ground truth, (b) noisy input, (c) SDL denoised output, and (d) the cascaded network denoised output.
Impact of the number of the elements:
To investigate the reliability of the network when the number of elements (transducers) decreases, we design a new experimental scenario with a dataset that is generated with the same setup as our practically representative simulated dataset except that the number of transducers decreases from 256 to 128. In this experiment, we generate 24,000 samples with optical scattering coefficients of 1, 10, and 20 cm−1 ( of the whole dataset each) with random number of targets (1–4). We used a set of size 18,000 for training and the 6,000 remaining samples for test. We train two models in this experiment: SDL and a variation of [35]’s network for detecting multiple targets (referred to as the single decoder model). We evaluate the performance of each model on the test set. Table VII shows the results. As can be expected, when the number of elements decreases, a slight degradation is observed in the performance of both networks (SDL and single decoder). This is because the information that the network can grasp decreases with the reduced number of elements, viz. the model now has a downsampled lateral view of the wavefront. Note however in Table VII, the relative benefits of SDL still remain.
TABLE VII:
The performance results of the two models, SDL and single decoder for 128-element transducer dataset. The margin between the two model performances is almost the same as 256 elements dataset (mixed scattering noise level).
| Architecture | Depth<35 mm | Depth≥35 mm | ||||
|---|---|---|---|---|---|---|
| Axial(µm) | Lateral(µm) | Euclidean(µm) | Axial(µm) | Lateral(µm) | Euclidean(µm) | |
| single decoder | 6.73 | 5.18 | 9.40 | 6.94 | 5.58 | 9.91 |
| SDL | 1.96 | 2.53 | 3.49 | 2.05 | 2.51 | 3.51 |
The performances of the SDL network and [26] are evaluated with experimental PA data from two phantoms, intralipid optical scattering and a chicken breast tissue phantom, consisting of 0.5 mm pencil lead targets placed at different depths. Since the size of the experimental samples is different from the training data, the training data is resized and the samples with targets deeper than 35 mm are removed to mimic the experimental RF data and the network is trained over the modified dataset. The experimental samples and corresponding heatmaps are shown in Fig. 11, 12. Corresponding beamformed image for each sample shows the accuracy level of SDL in these highly challenging scenarios. Remarkably, SDL detects all three targets accurately in Fig. 11e vs. two targets detected by the beamformed output in Fig. 11g and the third target detected by [26] with lower accuracy. The SDL’s superiority is more clear for the chicken tissue data in Fig. 12 where both beamformed image and [26] fail in detecting the 4th target.
Fig. 11:

(a) The experimental setup to measure photoacoustic signals from light-absorbing pencil lead targets submerged inside an optically scattering intralipid solution. (b) Experimental photoacoustic data for two different experiments and their corresponding (d,e) heatmap outputs from the network, (f,g) respective beamformed images, and (h,i) [26]’s outputs (centers of bounding boxes are shown).
Fig. 12:
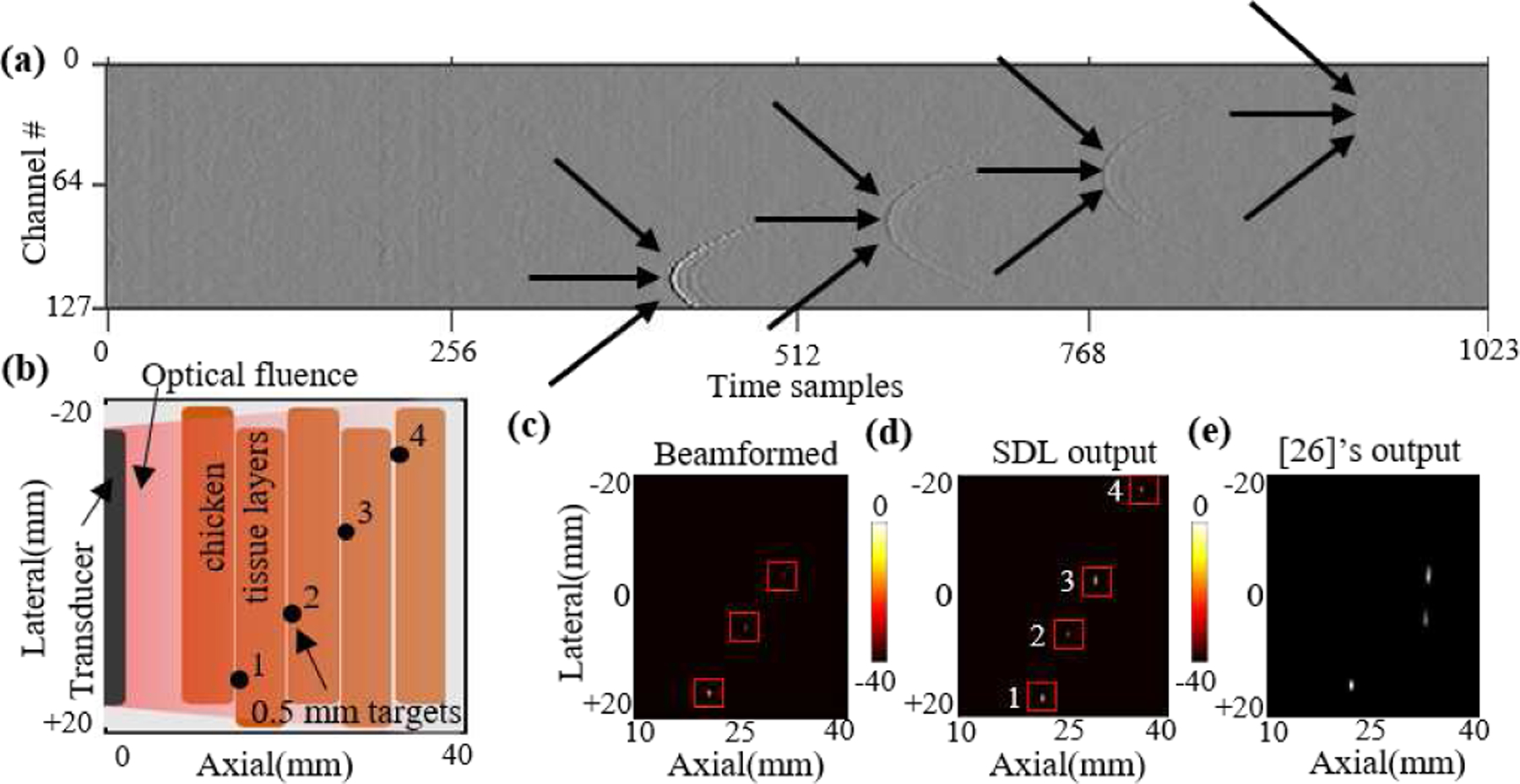
(a) Photoacoustic sample, (b) the chicken tissue experimental setup used for capturing this sample, (c) the beamformed image, (d) SDL’s output heatmap, and (e) [23]’s output (centers of the bounding boxes are shown).
IV. Discussions and Conclusion
Design of custom denoising filters that affect the output coordinates by the autoencoder is achieved by sharing the low dimensional output of the encoder between the localization decoder and our novel denoising decoder. Experimental results indicate this method works by influencing the parameters of the encoder as the denoising decoder is not used in the test phase. Although the intuitive approach for training the localization decoder is to define the mean square error between predicted and ground truth target coordinates as the loss function (Eq. (2)), this approach is naive as it does not make use of any domain knowledge specific to the problem. We take advantage of our understanding of how noise and signal appear in the photoacoustic RF data by devising Noise and Wavefront filters and formulating custom regularizers to augment the loss function. Of note, how the network is trained is a matter of interest as well. Finding the optimal value for each of the regularization constants in the loss is not trivial and convergence of the training loss of the network with many regularization terms is not guaranteed. We experimented with different training routines and found that the best outcome was achieved by neglecting the wavefront and noise terms for the first few training epochs, allowing the network to converge to a sub-optimal point, and then engaging the noise and wavefront terms to drive the network toward a more optimal point.
The experiments on the datasets of [26] and [35] prove the capability of our network in dealing with simulated additive noise in addition to signal attenuation due to optical scattering. This is due to the fact that our designed robustness to noise (using the Dec-D branch in Fig. 2) is data adaptive and does not make any statistical assumptions on the nature of the noise. According to our results on the dataset of [26] (Table II), the percentage of test samples for which our network has a total error (mean Euclidean error) of less than 0.5 mm shows very slight degradation as the SNR decreases to −3dB, and this degradation becomes more noticeable as the noise level increases. This may be explained by considering the fact that the labels used for training the network are the bounding box centers provided by [26], and the data used for training the network is the resized version of the original data. On the other hand, there is a surprising trend in the results of [26], which is the unpredictable improvement when noise is added. Note that we exactly reproduced the results of [26] from their work, while training and testing on the same samples (as the authors of [26] kindly make their dataset available). [35]’s dataset, on the other hand, is more realistic with respect to the effect of optical scattering in photoacoustic imaging. However, it only considers single target data. Comparing the performance of the network in [35] with proposed SDL (Table III), two observations can be made: 1) the overall performance is improved with respect to different criteria (lateral, axial, and Euclidean error) and 2) results for targets deeper than 40 mm indicate higher gains via SDL in both lateral and axial error. This deep region is where optical scattering plays a dominant role, as the weakened optical fluence results in photoacoustic signals that barely peak above the noise floor in the data. For real-world experimentally captured data with an optical scattering coefficient of 20 cm−1, Fig. 8 confirms a highly valuable benefit of SDL over state of the art in handling significant levels of scattering noise practically. We attribute this success to the explicit attention to noise robustness in the design of SDL via custom-designed regularizers. Overall, the proposed architecture shows flexibility with respect to noise level/type and number of targets, which suggests its potential significance for PA imaging applications including cancer detection and treatment [58]–[60], and treatment of vascular diseases such as deep vein thrombosis [61] and blood vessel morphology [62]. One practical constraint in the application of deep learning methods for many medical imaging problems is that representative labeled training data is often not abundant, unlike analogous detection and classification problems in consumer imaging; PAI shares this challenge. The incorporation of problem specific domain knowledge via regularization terms/architectural innovations, as have been performed in this work, can be useful in addressing the challenge of limited training. Our investigation in Fig. 7 demonstrates that SDL can outperform state of the art while using half the training data.
In conclusion, this work reveals the importance of taking into account the optical scattering noise for photoacoustic target localization problems. Deep learning frameworks have been used before for this problem with promising success, but those architectures did not explicitly build or enhance noise robustness. Existing deep learning approaches for PAI also rely significantly on the quantity and quality of training data available. Our proposal addresses these challenges by exploiting the characteristics of PA images towards a noise-robust approach. Specifically, a shared encoder-dual decoder architecture is designed for simultaneous denoising and localization. Custom-designed regularizers inspired by the shape of the noise and the signal in the PA images help fit the reconstructed data to the ground truth noiseless data more effectively. These regularizers also help enhance performance when training data samples are limited. Finally, we design a new dataset that introduces significant diversity with respect to the scattering noise levels and the number of the targets. Experiments performed on the practically representative simulated dataset, as well as existing simulated and experimental datasets from the state of the art, demonstrates the capability of our proposed deep network in detecting targets with higher accuracy. Our method is also shown to successfully operate in scenarios where existing trained networks do not produce meaningful outputs. While our proposed methodology benefits from custom priors to effectively improve the signal strength, one can design the wavefront and noise filters using a generative model such as GANs to potentially achieve even better prior inspired regularization in Eq (6). GAN-inspired learned filters may hence enhance both denoising and localization and form a viable future research direction. Moreover, our model is designed for the detection of up to 4 targets in photoacoustic data, which could be a limit for the cases when the number of targets is more. However, we can modify the output layer of the network to detect a higher number of targets. A versatile detection of an arbitrary number of targets is a future research direction. Also, a broad direction for all machine learning efforts in PA imaging is the detection of non-point targets.
V. Acknowledgement
The authors would like to thank Isaac Gerg for proofreading the paper and helping increase the comprehensibility of the manuscript.
We gratefully acknowledge the funding for this research from NIH-NIBIB R00EB017729–05 (SRK), R21EB030370–01 (SRK), and Leighton Reiss Graduate Fellowship (SA)
Footnotes
There are other deep learning based works for denoising the PA images leading to improvement in imaging frame rates of PAI [36], [37].
RF noise may be removed using pre-processing steps on the PA image as well, but that process may not be perfect and in certain scenarios may, in fact, degrade or distort the signal too. Our proposed regularization will invariably help to enhance signal (wavefront) strength with respect to noise, albeit the extent of benefit may be dependent on the particular PA image data.
Contributor Information
Amirsaeed Yazdani, Electrical Engineering Department at Pennsylvania State University, State College, PA 16802, USA.
Sumit Agrawal, Biomedical Engineering Department at Pennsylvania State University, State College, PA 16802, USA.
Kerrick Johnstonbaugh, Biomedical Engineering Department at Pennsylvania State University, State College, PA 16802, USA.
Sri-Rajasekhar Kothapalli, Biomedical Engineering Department at Pennsylvania State University, State College, PA 16802, USA.
Vishal Monga, Electrical Engineering Department at Pennsylvania State University, State College, PA 16802, USA.
References
- [1].Ntziachristos et al. , “Looking and listening to light: The evolution of whole-body photonic imaging,” Nature Biotechnology, vol. 23, pp. 313–20, 04 2005. [DOI] [PubMed] [Google Scholar]
- [2].Beard P., “Review biomedical photoacoustic imaging,” Interface focus, vol. 1, pp. 602–31, 08 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Kothapalli et al. , “Simultaneous transrectal ultrasound and photoacoustic human prostate imaging,” Science Translational Medicine, 2019. [DOI] [PubMed]
- [4].Karaman M, Li Pai-Chi, and O’Donnell M., “Synthetic aperture imaging for small scale systems,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, vol. 42, no. 3, pp. 429–442, 1995. [DOI] [PubMed] [Google Scholar]
- [5].Jaeger M. et al. , “Fourier reconstruction in optoacoustic imaging using truncated regularized inverse k -space interpolation,” Inverse Problems, vol. 23, no. 6, pp. S51–S63, November 2007. [Google Scholar]
- [6].Baik JW et al. , “Super wide-field photoacoustic microscopy of animals and humans in vivo,” IEEE Transactions on Medical Imaging, vol. 39, no. 4, pp. 975–984, 2020. [DOI] [PubMed] [Google Scholar]
- [7].Knieling et al. , “Multispectral optoacoustic tomography for assessment of crohn’s disease activity,” N Engl J Med, 03 2017. [DOI] [PubMed] [Google Scholar]
- [8].Lin et al. , “Single-breath-hold photoacoustic computed tomography of the breast,” Nature Communications, vol. 9, 12 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Nandy et al. , “Evaluation of ovarian cancer: Initial application of coregistered photoacoustic tomography and us,” Radiology, vol. 289, p. 180666, 09 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Rasti R, Rabbani H, Mehridehnavi A, and Hajizadeh F., “Macular oct classification using a multi-scale convolutional neural network ensemble,” IEEE Transactions on Medical Imaging, 2018. [DOI] [PubMed]
- [11].Yazdani A. et al. , “Domain-enriched deep network for micro-CT image segmentation,” in 2019 53rd Asilomar Conference on Signals, Systems, and Computers, 2019, pp. 1867–1871. [Google Scholar]
- [12].Stephens NB et al. , “Machine learning in anthropology: A regularized deep network for osteological micro-CT image segmentation,” American Journal of Physical Anthropology, vol. In press., no. S69, 2020.
- [13].Lotfidereshgi R and Gournay P., “Speech prediction using an adaptive recurrent neural network with application to packet loss concealment,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5394–5398. [Google Scholar]
- [14].Wang R, Li Z, Cao J, Chen T, and Wang L., “Convolutional recurrent neural networks for text classification,” in 2019 International Joint Conference on Neural Networks (IJCNN), 2019, pp. 1–6. [Google Scholar]
- [15].Tabar M. et al. , “Ameliorating farmer suicides by predicting crop price trends using a deep learning approach,” in ECAI 2020 International Workshop on Artificial Intelligence for a Fair, Just and Equitable World (AI4EQ), 2020. [Google Scholar]
- [16].Shokouhi P, Girkar VS, Sepehrinezhad A, Shreedharan S, Riviere J, Marone C, and Kifer D., “Deep learning of the precursory signatures in active source seismic data for improved prediction of laboratory earthquake.” AGU, 2020.
- [17].Khajeh Talkhoncheh M, Shahrokhi M, and Askari MR, “Observer-based adaptive neural network controller for uncertain nonlinear systems with unknown control directions subject to input time delay and saturation,” Information Sciences, vol. 418–419, pp. 717–737, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0020025517308757 [Google Scholar]
- [18].Ronneberger O, Fischer P, and Brox T, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. [Google Scholar]
- [19].Krizhevsky A, Sutskever I, and Hinton GE, “Imagenet classification with deep convolutional neural networks,” Commun. ACM, 2017.
- [20].Simonyan K and Zisserman A., “Very deep convolutional networks for large-scale image recognition,” CoRR, vol. abs/1409.1556, 2015.
- [21].Szegedy C. et al. , “Going deeper with convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. [Google Scholar]
- [22].He K, Zhang X, Ren S, and Sun J., “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778. [Google Scholar]
- [23].Ren S, He K, Girshick R, and Sun J., “Faster r-cnn: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. [DOI] [PubMed]
- [24].Yazdani A. et al. , “Multi-class micro-CT image segmentation using sparse regularized deep networks,” in forthcoming 2020 54th Asilomar Conference on Signals, Systems, and Computers, 2020. [Google Scholar]
- [25].Reiter A and Bell MAL, “A machine learning approach to identifying point source locations in photoacoustic data,” in Photons Plus Ultrasound: Imaging and Sensing. SPIE; 2017. [Google Scholar]
- [26].Allman D, Reiter A, and Bell MAL, “Photoacoustic source detection and reflection artifact removal enabled by deep learning,” IEEE Transactions on Medical Imaging, vol. 37, no. 6, pp. 1464–1477, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Awasthi N, Jain G, Kalva SK, Pramanik M, and Yalavarthy PK, “Deep neural network-based sinogram super-resolution and bandwidth enhancement for limited-data photoacoustic tomography,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, vol. 67, no. 12, pp. 2660–2673, 2020. [DOI] [PubMed] [Google Scholar]
- [28].Sharma A and Pramanik M., “Convolutional neural network for resolution enhancement and noise reduction in acoustic resolution photoacoustic microscopy,” Biomedical Optics Express, vol. 11, p. 6826, 12 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Heinrich MP, Stille M, and Buzug TM, “Residual u-net convolutional neural network architecture for low-dose ct denoising,” Current Directions in Biomedical Engineering, vol. 4, no. 1, pp. 297–300, 01 Sep. 2018. [Online]. Available: https://www.degruyter.com/view/journals/cdbme/4/1/article-p297.xml [Google Scholar]
- [30].Yuan H, Jia J, and Zhu Z., “SIPID: A deep learning framework for sinogram interpolation and image denoising in low-dose CT reconstruction,” in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), 2018, pp. 1521–1524. [Google Scholar]
- [31].Lee H, Lee J, Kim H, Cho B, and Cho S., “Deep-neural-network-based sinogram synthesis for sparse-view CT image reconstruction,” IEEE Transactions on Radiation and Plasma Medical Sciences, vol. 3, no. 2, pp. 109–119, 2019. [Google Scholar]
- [32].Lu T, Chen T, Gao F, Sun B, Ntziachristos V, and li J., “Lvgan : A deep learning approach for limitedview optoacoustic imaging based on hybrid datasets,” Journal of Biophotonics, vol. 14, 11 2020. [DOI] [PubMed] [Google Scholar]
- [33].Davoudi N, Den-Ben X, and Razansky D., “Deep learning optoacoustic tomography with sparse data,” Nature Machine Intelligence, vol. 1, pp. 1–8, 10 2019. [Google Scholar]
- [34].Johnstonbaugh K et al. , “Novel deep learning architecture for optical fluence dependent photoacoustic target localization,” in Photons Plus Ultrasound: Imaging and Sensing 2019. SPIE. [Google Scholar]
- [35].Johnstonbaugh K. et al. , “A deep learning approach to photoacoustic wavefront localization in deep-tissue medium,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, pp. 1–1, 2020. [DOI] [PMC free article] [PubMed]
- [36].Anas et al. , “Enabling fast and high quality led photoacoustic imaging: A recurrent neural networks based approach,” Biomedical Optics Express, vol. 9, p. 3852, 08 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].others H., “Deep learning improves contrast in low-fluence photoacoustic imaging,” Biomedical Optics Express, vol. 11, 05 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Zabalza et al. , “Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging,” Neurocomputing, vol. 185, 12 15. [Google Scholar]
- [39].Fan et al. , “Low-level structure feature extraction for image processing via stacked sparse denoising autoencoder,” Neurocomputing, 2017.
- [40].Grhl et al. , “Reconstruction of initial pressure from limited view photoacoustic images using deep learning,” in Photons Plus Ultrasound: Imaging and Sensing, 02 2018, p. 98. [Google Scholar]
- [41].Antholzer S, Haltmeier M, Nuster R, and Schwab J., “Photoacoustic image reconstruction via deep learning,” in BiOS, 2018.
- [42].Nibali A. et al. , “Numerical coordinate regression with convolutional neural networks,” CoRR, vol. abs/1801.07372, 2018.
- [43].Lecun Y, Bottou L, Bengio Y, and Haffner P., “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, 1998.
- [44].Werbos PJ, The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting. Wiley-Interscience, 1994. [Google Scholar]
- [45].Annunziata and others., “Scale and curvature invariant ridge detector for tortuous and fragmented structures,” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015.
- [46].Monga V, Handbook of Convex Optimization Methods in Imaging Science. Springer International Publishing, Cham, 2018. [Google Scholar]
- [47].Agrawal S. et al. , “Modeling combined ultrasound and photoacoustic imaging: Simulations aiding device development and deep learning,” bioRxiv, 2020. [DOI] [PMC free article] [PubMed]
- [48].Dehghani et al. , “Near infrared optical tomography using nirfast: Algorithm for numerical model and image reconstruction,” Communications in Numerical Methods in Engineering, vol. 25, pp. 711–732, 06 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Jermyn et al. , “Fast segmentation and high-quality three-dimensional volume mesh creation from medical images for diffuse optical tomography,” Journal of biomedical optics, vol. 18, p. 86007, 08 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [50].Treeby BE and Cox BT, “k-Wave: MATLAB toolbox for the simulation and reconstruction of photoacoustic wave fields,” Journal of Biomedical Optics, vol. 15, no. 2, pp. 1–12, 2010. [DOI] [PubMed] [Google Scholar]
- [51].Jacques SL, “Optical properties of biological tissues: a review,” Physics in Medicine and Biology, vol. 58, no. 11, pp. R37–R61, 2013. [DOI] [PubMed] [Google Scholar]
- [52].Paszke et al. , “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32, Wallach H, Larochelle H, Beygelzimer A, d’Alche-Buc F, Fox E, and Garnett R, Eds., 2019, pp. 8026–8037. [Google Scholar]
- [53].Hinton G, “Neural networks for machine learning- lecture 6a - overview of mini-batch gradient descent.” 2012.
- [54].Bahrami K, Shi F, Zong X, Shin HW, An H, and Shen D., “Reconstruction of 7T-like images from 3T MRI,” IEEE Transactions on Medical Imaging, vol. 35, no. 9, pp. 2085–2097, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [55].Bahrami K, Shi F, Rekik I, and Shen D, “Convolutional neural network for reconstruction of 7T-like images from 3T MRI using appearance and anatomical features,” vol. 10008 LNCS, 2016. [Google Scholar]
- [56].Cherukuri V, Guo T, Schiff SJ, and Monga V., “Deep MR brain image super-resolution using spatio-structural priors,” IEEE Transactions on Image Processing, vol. 29, p. 13681383, 2020. [Online]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [57].Wang Zhou, Bovik AC, Sheikh HR, and Simoncelli EP, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004. [DOI] [PubMed] [Google Scholar]
- [58].Mehrmohammadi et al. , “Photoacoustic imaging for cancer detection and staging,” Current molecular imaging, vol. 2, pp. 89–105, 03 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [59].Mallidi S. et al. , “Photoacoustic imaging in cancer detection, diagnosis, and treatment guidance,” Trends in Biotechnology, vol. 29, no. 5, pp. 213–221, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [60].Bell L. et al. , “In vivo visualization of prostate brachytherapy seeds with photoacoustic imaging,” Journal of biomedical optics, 2014. [DOI] [PMC free article] [PubMed]
- [61].Juratli et al. , “Noninvasive label-free detection of circulating white and red blood clots in deep vessels with a focused photoacoustic probe,” Biomedical Optics Express, vol. 9, p. 5667, 11 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [62].Matsumoto et al. , “Label-free photoacoustic imaging of human palmar vessels: A structural morphological analysis,” Scientific Reports, 2018. [DOI] [PMC free article] [PubMed]