

Abstract
In competing event settings, a counterfactual contrast of cause-specific cumulative incidences quantifies the total causal effect of a treatment on the event of interest. However, effects of treatment on the competing event may indirectly contribute to this total effect, complicating its interpretation. We previously proposed the separable effects to define direct and indirect effects of the treatment on the event of interest. This definition was given in a simple setting, where the treatment was decomposed into two components acting along two separate causal pathways. Here we generalize the notion of separable effects, allowing for interpretation, identification and estimation in a wide variety of settings. We propose and discuss a definition of separable effects that is applicable to general time-varying structures, where the separable effects can still be meaningfully interpreted as effects of modified treatments, even when they cannot be regarded as direct and indirect effects. For these settings we derive weaker conditions for identification of separable effects in studies where decomposed, or otherwise modified, treatments are not yet available; in particular, these conditions allow for time-varying common causes of the event of interest, the competing events and loss to follow-up. We also propose semi-parametric weighted estimators that are straightforward to implement. We stress that unlike previous definitions of direct and indirect effects, the separable effects can be subject to empirical scrutiny in future studies.
Supplementary Information
The online version supplementary material available at 10.1007/s10985-021-09530-8.
Keywords: Causal inference, Competing events, Effect decomposition, G-formula, Hazard functions, Separable effects
Introduction
Researchers are often interested in treatment effects on an event of interest that is subject to competing events, that is, events that make it impossible for the event of interest to subsequently occur. For example, when the event of interest is kidney injury, death is a competing event because any individual who dies prior to kidney injury cannot subsequently suffer from kidney injury. Several estimands have already been suggested for causal inference in competing events settings with known shortcomings.
A counterfactual contrast in cause-specific cumulative incidences (risks) quantifies the total effect of the treatment on the event of interest through all causal pathways. Here we intentionally use the term total effect to bridge competing event settings to results from mediation analysis (Stensrud et al. 2020; Robins and Richardson 2010; Robins et al. 2020). When the treatment affects competing events, the total effect also partly includes pathways mediated by these competing events (Robins 1986; Young et al. 2020). For example, a harmful total effect of blood pressure therapy on the risk of kidney injury may be due to a biological side-effect on the kidneys, but could also be fully or partly explained by a protective treatment effect on cardiovascular death. As previously discussed (Robins 1986; Young et al. 2020; Tchetgen Tchetgen 2014), other popular estimands in competing events settings do not resolve this interpretational problem. This includes popular approaches based on cause-specific or subdistribution hazard models, even if formulated in terms of counterfactuals. Hazard based contrasts are broadly problematic as causal contrasts (Martinussen et al. 2020; Robins 1986; Hernán 2010; Stensrud and Hernán 2020), also in competing event settings (Young et al. 2020).
Other estimands that have been considered for causal inference in the face of competing events that do have a causal interpretation include the controlled direct effects (Robins and Greenland 1992; Young et al. 2020) and pure (natural) effects (Robins and Greenland 1992; Pearl 2009). However, these estimands refer to treatment effects under unspecified interventions on the competing events; in the example on blood pressure therapy, we would need to consider an intervention that “eliminates” death from all causes. Such hypothetical interventions are irrelevant in nearly every practical setting. Furthermore, identification of pure (natural) effects relies on counterfactual assumptions across different “worlds” that are untestable, even in principle (Robins and Richardson 2010).
To address these problems, we recently proposed the separable effects for causal inference in competing event settings (Stensrud et al. 2020), inspired by Robins and Richardson’s extended graphical approach to mediation analysis (Robins and Richardson 2010; Didelez 2018; Robins et al. 2020). Given a plausible decomposition of the treatment into different components, we defined these effects as counterfactual contrasts indexed by hypothetical interventions that assign these components different values. The separable effects have clear advantages over existing causal estimands, explicitly quantifying the effects of modified treatments and forcing investigators to sharpen specifications about their causal question of interest, in turn, fostering new ideas and hypotheses about future real-world treatment strategies (Robins and Richardson 2010; Stensrud et al. 2020). The separable effects generally rely on weaker assumptions for identification than the alternative estimands outlined above (Robins and Richardson 2010; Stensrud et al. 2020; Didelez 2018). They do not conceptualize hypothetical interventions that eliminate competing events and avoid cross-world assumptions, which can never be subject to empirical scrutiny. Instead, the separable effects can, at least in principle, be directly identified in a future experiment where the treatment components are assigned different values. However, the interpretation and identification of separable effects given in our initial work (Stensrud et al. 2020) relied fundamentally on the assumption that there exist only pre-treatment common causes of the competing event and event of interest. This assumption, which has implications for both the interpretation and identification of the separable effects, is overly restrictive in many real-world applications thus limiting the applicability of these initial results.
Here, we generalize the early results of Stensrud et al. (2020) to allow more realistic data structures, such that time-varying covariates and common causes of the competing event and event of interest can exist. Our results substantially broaden the theory of separable effects, providing an explicit and transparent approach to reasoning around mechanism in general competing events settings and, in turn, translating this reasoning into a statistical analysis. Specifically, in this paper we formalize conditions that allow particular mechanistic interpretations of separable effects in a range of settings. The strongest of these conditions ensures that the separable effects can be interpreted as the direct effects of the treatment on the event of interest (capturing all treatment effects on the event of interest not via treatment effects on competing events) and the indirect effects of the treatment on the event of interest (capturing all treatment effects on the event of interest only via treatment effects on competing events). However, we show that weaker conditions also allow practically relevant mechanistic interpretations of these effects – e.g. capturing some (but not all) direct effects; that is, some (but not all) treatment effects on the event of interest not via effects on competing events. We formalize conditions for identification of the separable effects in this general setting where baseline and time-varying covariates are measured. Interestingly, the identification formulas are actually identical to formulas contained in Shpitser (2013), although these identification results have different interpretations and require different assumptions. Finally we present semi-parametric weighted estimators of the separable effects under this time-varying data structure.
The manuscript is organized as follows. In Sect. 2, we describe the observed data structure in which the event of interest is subject to competing events and both baseline and time-varying covariates are measured. In Sect. 3, we review the definition of the total effect on an event of interest subject to competing events. In Sect. 4, we define a generalized decomposition assumption that is agnostic to the mechanism by which the treatment exerts effects on the competing event and the event of interest. We also formally define the separable effects. In Sect. 5, we formalize a range of conditions by which the treatment components may exert effects on future outcomes and explain the interpretation of the separable effects in each case. In Sect. 6, we give conditions that allow identification of the separable effects under the observed data structure by a particular g-formula (Robins 1986). We also generalize identification results to allow for censored data. In Sect. 7, we provide two weighted representations of the g-formula for the separable effects and use these representations to motivate weighted estimators, which are supplemented with sensitivity analysis techniques. We also apply these results to a randomized study of the effect of intensive versus standard blood pressure therapy on acute kidney injury. In Sect. 8, we provide a discussion.
Observed data structure
We consider an experiment in which individuals are randomly assigned to one of two treatment arms at baseline (e.g. and denote assignment to standard and intensive blood pressure therapy, respectively). We assume that observations are independent and identically distributed and suppress the i subscript. Let be equally spaced time intervals with interval corresponding to baseline (the interval of randomization) and interval the maximum follow-up of interest at or before the administrative end of follow-up (e.g. 60 months).
For , let and denote indicators of an event of interest (e.g. kidney injury) and a competing event (e.g. death) by interval k, respectively, and a vector of individual time-varying covariates in that interval. Define , i.e. the population is restricted to those alive and at risk of all events prior to randomization. Further, define as a vector of pre-randomization covariates. We denote the history of a random variable by an overbar, e.g. is the history of the event of interest through interval k, and the future of a random variable through by an underline, e.g. . Throughout, we assume a temporal order in each interval . As interval lengths become arbitrarily small, this temporal order assumption is guaranteed because the probability that two events of any type occur within that interval approaches zero (equivalent to the common assumption in survival analysis of no tied event times). When the event of interest is terminal (e.g. death due to prostate cancer), the time-varying event history coincides with the more familiar “competing risks” data structure for T the time to failure from any cause, G a censoring time and J an indicator of cause of failure such that when and otherwise (e.g. if failure from the event of interest and if failure from the competing event). Regardless of whether the event of interest is terminal (we have a “competing risks” data structure) or nonterminal (we have a “semicompeting risks” data structure), defining the observed data structure in terms of time-varying failure status, as opposed to summarized failure times, is essential for understanding identification and interpretation of many causal estimands in survival analysis, including those considered here. Further, it avoids the assumption that there exists a censoring time G for individuals who are observed to fail (e.g. die) during the follow-up.1 Importantly, our results throughout apply regardless of whether the event of interest is terminal or nonterminal.
By definition of a competing event, if an individual experiences this event by interval k without history of the event of interest then ; an individual who experiences the competing event cannot subsequently experience the event of interest, regardless of whether this is terminal or nonterminal, that is, regardless of whether it is also the case that determines . For ease of presentation, we will assume no individual is censored by loss to follow-up (that is, is fully observed for all individuals randomized at baseline) until Sect. 6.3.
The total treatment effect on the event of interest
For any individual in the study population and for , let be the indicator of the event of interest by interval had, possibly contrary to fact, he/she been assigned to . The contrast
| 1 |
is then the cause-specific cumulative incidence function, which we intentionally denote a total effect of treatment A on the risk of the event of interest by interval in this study population. This effect includes treatment effects on the competing event (Young et al. 2020).
We will use causal directed acyclic graphs (DAGs) (Pearl 2009) to represent underlying assumptions on the mechanisms by which random variables in the study of Sect. 2 are generated. A causal DAG must represent all common causes of any variable represented on the DAG. For example, the causal DAG in Fig. 1a represents a generally restrictive assumption on this data generating process for a subset of time points because it depicts no common causes (measured or unmeasured) of event status over time. Throughout we will assume that causal DAGs represent a Finest Fully Randomized Causally Interpreted Structural Tree Graph (FFRCISTG) model, a type of counterfactual causal model that includes the non-parametric structural equation model with independent errors (NPSEM-IE) (Robins 1986; Robins et al. 2020; Robins and Richardson 2010; Pearl 2009; Shpitser et al. 2020) as a submodel, and we assume that statistical independencies in the data are faithful to the DAG (Verma and Pearl 1991).
Fig. 1.

The directed acyclic graph (DAG) in a represents a restrictive data generating assumption on the observed data structure such that there are no common causes of the event of interest and the competing event at any time. The extended DAG in b is an augmented version of the graph in a representing a treatment decomposition satisfying the generalized decomposition assumption. The bold arrows encode deterministic relationships
The total effect of A on in Fig. 1a includes all directed (causal) paths between A and . This includes causal paths that do not capture the treatment’s effect on the competing event (e.g. and ) as well as causal paths that capture this effect (e.g. and ). While the total effect can be straightforward to identify from a study in which A is randomly assigned, its interpretation is complicated when pathways like in Fig. 1a are present (Young et al. 2020; Stensrud et al. 2020). For example, a harmful total effect of intensive versus standard blood pressure therapy on kidney injury, i.e. , may be wholly or partially explained by one of these pathways (e.g. a protective effect of intensive therapy on death).
Generalized decomposition assumption and separable effects
Consider the following assumption:
-
Generalized decomposition assumption
Let , , be the vector of all (direct or indirect) causes of and/or , excluding , and , are these causes in interval j, where V is a cause of W if changing the value of V may result in a change in the value of W. We intentionally distinguish time-varying covariates that are measured in our study, , from ; could e.g. be a subset of . We shall see that the variables in are needed to express the substantive meaning of particular separable effects. We will need to make assumptions about the nature of to reason about whether separable effects can be identified using only what was measured in our study, which will require that is a subset of . There is not surprisingly a link between these interpretation and identification tasks as we formalize in Sect. 6.1. We keep these tasks separate because explicit reasoning about interpretation of separable effects provides value for the design of future studies even if identification in the current study fails given limitations of measurement. This may be the case if causal reasoning about questions and assumptions occurs after the data collection is complete.2 We also assume that an intervention that assigns results in the same outcome as an intervention that assigns , that is,
where for , is the value of had, contrary to fact, he/she been assigned the components and , in place of assignment to a value of the original treatment A.3
Beyond (3), the generalized decomposition assumption makes no mechanistic assumptions on the effects exerted by and . We will consider different examples of treatment decompositions in Sect. 5 where, unlike those considered by Stensrud et al. (2020), the effects exerted by and are not necessarily direct and indirect effects. Furthermore, in Appendix A we consider straightforward further generalizations of our results to settings where and are not a decomposition of A, violating (2), but are still treatments satisfying (3).
For , the contrast
| 4 |
quantifies the causal effect of the component on the risk of the event of interest by under an intervention that assigns (Stensrud et al. 2020; Robins and Richardson 2010; Robins et al. 2020). Similarly
| 5 |
quantifies the causal effect of the component on the risk of the event of interest by under an intervention that assigns .
We will refer to (4) as the separable effect under , and (5) as the separable effect under , . Given the generalized decomposition assumption, the total effect can be expressed as a sum of particular and separable effects, for example,
Isolation conditions and interpretation of separable effects
In this section, we consider conditions, beyond the generalized decomposition assumption, under which we can ascribe a more precise interpretation to the separable effects (4) and (5). The strongest of these assumptions allows interpretation of these effects as the separable direct and indirect effects of Stensrud et al. (2020).
To formally define these additional conditions, we will first review the definition of an extended causal DAG (Robins and Richardson 2010): an extended causal DAG augments the original causal DAG with additional nodes representing components of the treatment, and bold edges representing the deterministic relation between these components and the full treatment in the observed data. For example, the extended causal DAG in Fig. 1b is an augmented version of the causal DAG in Fig. 1a, which generalizes the extended DAG in Figure 3 of Robins and Richardson (2010) to time-dependent mediators and outcomes. The extended causal DAG also encodes assumptions, not represented on the original causal DAG, on the mechanisms by which each treatment component exerts effects on future variables. Arrows from to , (for example in Fig. 1a, b) are unnecessary in our case, where time-varying mediators constitute competing events, but these arrows could have been included without changing any of our results.
Full isolation
Consider an extended causal DAG in which A is decomposed into two components and satisfying the generalized decomposition assumption, and define the following conditions:
| 6 |
| 7 |
When both conditions (6) and (7) hold we will say there is full isolation. This assumption is satisfied in Fig. 1b which assumes there are no common causes of the event of interest and the competing event. It is also satisfied in Fig. 2b which allows the presence of both pre-randomization () and post-randomization () common causes.
Fig. 2.

The causal DAG in a allows a pre-randomization common cause () of and and post-randomization common cause () of and but assumes is not affected by treatment A. b is an extension of a satisfying full isolation
Under the generalized decomposition assumption and full isolation, (4) are the separable direct effects of A on the risk of the event of interest by , which do not capture the treatment’s effect on the competing event: that is, a distinct causal mechanism by which A directly affects the event of interest outside of A’s indirect effects through the competing event. Similarly, (5) are the separable indirect effects of A on this risk, which only capture the treatment’s effect on the competing event. Full isolation coincides with the settings considered by Stensrud et al. (2020), which allowed for the presence of pre-randomization, but not post-randomization, common causes of the event of interest and the competing event.
Returning to our running example, assume that the blood pressure treatment A can be decomposed into a component that binds to receptors in the kidneys, e.g. by relaxing the efferent arterioles which is a well-known biological effect of commonly used blood pressure drugs such as angiotensin-converting-enzyme inhibitors (ACE) and angiotensin II receptor blockers (ARB), and a component that includes the remaining components of the antihypertensive therapy, some of which lead, for example, to reductions in systemic blood pressure.
Then, and are the levels (e.g., doses) of the component under standard and intensive therapy, respectively, and and are defined analogously.
Full isolation would be satisfied in this case if (i) the component only exerts effects on death through its effects on kidney function and (ii) the remaining component only exert effects on kidney function through its effects on survival. In Sect. 5.2, however, we argue that the assumption of full isolation may not be reasonable in this example.
partial isolation
The causal graphs in Figs. 1 and 2 make the restrictive assumption that there are no common causes of the event of interest and competing event that are, themselves, affected by treatment. In our running example, this assumption likely fails: a reduction in blood pressure may increase the risk of kidney injury (the event of interest) due to hypoperfusion of the kidneys (for example, when patients are dehydrated) (Aalen et al. 2019) and also may affect the risk of mortality (the competing event). Further, blood pressure itself clearly may be affected by the blood pressure treatment. The causal DAG in Fig. 3 depicts the more realistic assumption that blood pressure () is both a possible common cause of future kidney injury and mortality and also, itself, affected by treatment A (represented by the dashed arrow connecting A to ).
Fig. 3.
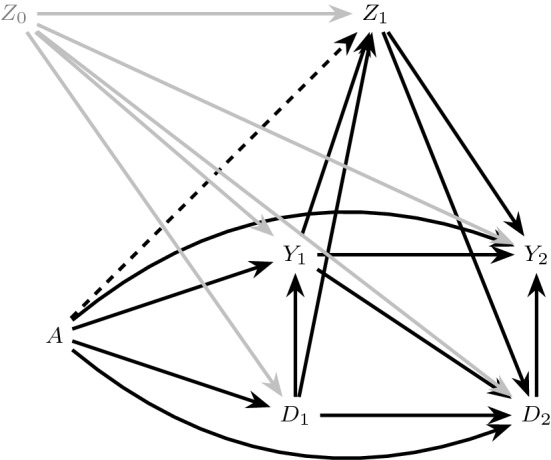
A causal DAG representing the assumption that , a common cause of and , may be affected by treatment A (dashed arrow)
Suppose, however, that the component of the treatment A (that which binds to receptors in the kidneys) has no effect on blood pressure outside of its possible effect on kidney function, such that only the remaining components of treatment, , can directly affect blood pressure. The extended DAG in Fig. 4a, which is one possible extension of the causal DAG in Fig. 3, represents this assumption by the dashed arrow from into and the absence of an arrow from into . In this case, condition (6) holds but (7) does not. When only the condition (6) holds, but (7) fails, we will say there is partial isolation.
Fig. 4.

Extensions of the causal DAG in Fig. 3 illustrating partial isolation. The dashed arrow in a represents the relation in Fig. 3 under partial isolation, and the dashed arrow in b represents partial isolation
Unlike under full isolation, under partial isolation, the separable effects (5) quantify both direct effects of the treatment on the event of interest not through the competing event (e.g. the path in Fig. 4a) and indirect effects through the competing event (e.g. the path in Fig. 4a).2 By contrast, the separable effects only quantify direct effects not through the competing event. However, the separable effects do not capture all direct effects in this case, because some of these pathways may originate from as described above. In the current example, the separable effect evaluated at may be of particular clinical interest, quantifying the effect of assignment to the current intensive therapy containing all components versus a modified intensive therapy that lacks the component possibly affecting the kidneys.
partial isolation
When (7) holds, but (6) fails, we will say there is partial isolation. partial isolation is represented in Fig. 4b, depicting an alternative augmentation of the causal DAG in Fig. 3. Under partial isolation, the separable effects (4) quantify both direct effects of the treatment on the event of interest not through the competing event (e.g. the path in Fig. 4b) and indirect effects through the competing event (e.g. the path in Fig. 4b). By contrast, the separable effects only quantify indirect effects through the competing event. However, the separable effects do not capture all indirect effects in this case, because some of these pathways may originate from as above.
As an example of partial isolation, trials have reported an increase in the risk of new-onset type 2 diabetes among patients assigned to statins (Sattar et al. 2010; Ridker et al. 2012). However, statins also reduce the risk of all-cause mortality, a competing event for type 2 diabetes onset (the event of interest). It is therefore unclear whether a total effect of statin treatment on type 2 diabetes is due a protective treatment effect on mortality, a biologically harmful process leading to type 2 diabetes onset or some combination.
Figure 3 illustrates a possible underlying causal structure for a trial with random assignment to statin therapy relating treatment assignment A, mortality and new-onset type 2 diabetes , . Body weight () is a possible common cause of both mortality and onset of type 2 diabetes which may also be affected by statin treatment. Consider a decomposition of A (represented in Fig. 4b) where may lead to increased risk of diabetes only by reducing mortality risk (e.g. through , where the reduction in mortality risk is likely due to reduced levels of low density lipoprotein in the blood), while a second component exerts unintended effects of statins on diabetes through body weight (e.g. through ). As in the previous example of blood pressure therapy and kidney injury, the separable effect of statin therapy on type 2 diabetes risk evaluated at may be of particular clinical interest, quantifying the effect of assignment to the original statin therapy containing both components versus a modified treatment that removes the component possibly leading to weight gain.
No isolation
If there are direct arrows from and into common causes of and , , as illustrated in Fig. 5, then both (6) and (7) fail. In this case, both the separable effects (4) and the separable effects (5) quantify direct and indirect effects of the treatment on the event of interest, outside of and through, the competing event. When both conditions (6) and (7) fail, we will say there is no isolation.
Fig. 5.

Causal graphs illustrating no isolation. a Violates partition while b satisfies partition
There are two important cases of no isolation that have different implications for the interpretation of separable effects and, as we will see, their identification in a two-arm trial. First, suppose there are direct arrows from and into the same set of common causes of and , as illustrated in Fig. 5a. In this case, the separable effects and the separable effects will capture common downstream pathways (e.g. in Fig. 5a) between the original treatment A and the event of interest .
Alternatively, suppose and may only exert effects on different sets of common causes and of and as illustrated in Fig. 5b; here exerts effects on through one set of causal paths from to , and exerts effects on through a distinct set of causal paths. In this case, the separable effects and the separable effects will capture no common pathways between the original treatment A and the event of interest .
partition
Suppose there exist vectors such that , , and
| 8 |
| 9 |
When both conditions (8) and (9) hold we will say there is a partition.
The assumption of a partition holds trivially under full isolation for any partition of as illustrated in Fig. 2b. However, this assumption will only hold in some cases of partial isolation (e.g. Fig. 4) and no isolation (e.g. Fig. 5b). partition fails under the case of no isolation represented in Fig. 5a, which is the generalization of Robins and Richardson’s (2010) extended graph in Figure 6A to the time dependent case.
partition also fails under the case of partial isolation represented in Fig. 6a and partial isolation represented in Fig. 6b. Under any version of partition, the separable effects and the separable effects will capture no common pathways between the original treatment A and the event of interest .
Fig. 6.

Causal graphs illustrating partial isolation but violation of partition. partial isolation holds in a and partial isolation holds in b
Identification of separable effects
Regardless of the isolation assumptions that impact the interpretation of separable effects, if we had data from a four-arm trial in which and were randomly assigned with no loss to follow-up, we would be guaranteed identification of the separable effects (Stensrud et al. 2020; Robins 2016); that is, we could identify, for ,
| 10 |
by (Hernan and Robins 2018). However, in order to identify (10) for in the absence of a four-arm trial, we must make assumptions that are not guaranteed to hold, even in a two-armed trial such as that described in Sect. 2 with no loss to follow-up. In addition to the generalized decomposition assumption, consider the following assumptions that are expected to hold by design when A is randomly assigned (Hernan and Robins 2018) (recalling that is the measured covariate history in our two-arm trial which may or may not coincide with ):
- Consistency:
Consistency states that if an individual has observed treatment consistent with an intervention that sets , then that individual’s future observed outcomes and time-varying covariates are equal to his/her counterfactual outcomes and time-varying covariates, respectively, under an intervention that sets .12 - Positivity:
Assumption (13) states that, for any possibly observed level of the measured baseline covariates, there exist individuals with and individuals with .13
Fig. 7.

Extended graphs that explicitly depict measured and unmeasured variables. The dismissible component conditions hold in a–d. The dismissible component conditions are violated in e–f
The above assumptions guarantee identification of the total effect (1), a contrast of for different levels of a (Young et al. 2020) but are not sufficient for identification of separable effects, contrasts of for different levels of and which require the following additional assumptions.
-
4.
Dismissible component conditions:
Let G refer to a hypothetical four-arm trial in which both and are randomly assigned, possibly to different values; We add the string “(G)” to indicate the random variables that are defined in this trial. In particular, let and be the outcome of interest and the competing event had we, contrary to fact, randomly assigned and . Furthermore, let and be disjoint vectors such that . We define the following conditions for :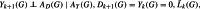
14 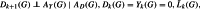
15 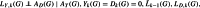
16 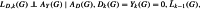
17 It follows directly from the generalized decomposition assumption that, using d-separation rules (Robins and Richardson 2010; Pearl 2009), the dismissible component conditions can be read off of a transformation of the extended causal DAG, representing an augmented version of our original data generating assumption, in which A and the deterministic arrows originating from A are eliminated. These transformations are isomorphic to dynamic Single World Intervention Graphs (SWIGs) (Richardson and Robins 2013; Robins et al. 2020), with interventions on and (we have explicitly drawn such a SWIG in Appendix Fig. 11). See also similar results in Didelez (2018, Figure 2). We denote these graphical transformations as G transformations, describing a four-arm trial where and are randomly assigned.
For example, consider Fig. 8a, a transformation of Fig. 4a, simply assuming . Assumption (14) holds in Fig. 8a by the absence of any unblocked backdoor paths between and conditional on , , , and , and similarly assumption (15) holds due to the absence of any unblocked paths between and conditional on , , and . Analogously, by choosing , (16) and (17) also hold in Fig. 8a.
Consider also the examples in Fig. 7; under G transformations of each graph, all dismissible component conditions hold in Fig. 7a–d, where and in Fig. 7a–c. By contrast, Fig. 7e–f illustrate failure of these conditions under their G transformations. For example, while (15)–(17) hold in Fig. 7e, (14) is violated by the the unblocked collider path , regardless of whether we define and or and . Indeed, here and are recanting districts (Shpitser 2013; Robins et al. 2020), and our identification conditions would hold if we were able to measure either or . Similarly, in Fig. 7f, while (15)–(17) hold when we define and , (14) is violated by the unblocked collider path .
-
5.Strong positivity:
Assumption (18) implies (13) and requires that for any possibly observed level of the measured time-varying covariate history among those surviving all events through each follow-up time, there exist individuals with and individuals with . Even when A is randomized, assumption (18) does not hold by design. However, it can be assessed in the observed data. Given the dismissible component conditions, we need assumption (18) to ensure that all the terms in the identification formula are well-defined (see Sect. 6.2).18
Fig. 11.
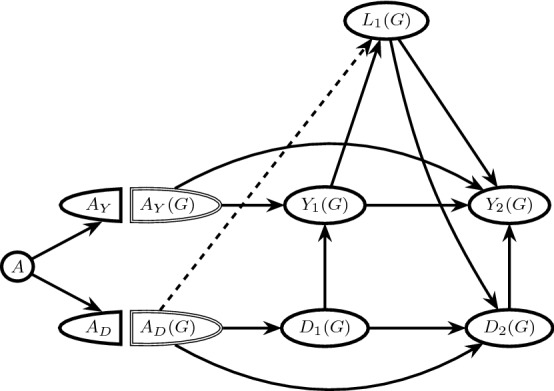
Single World Intervention Graph (SWIG) (Richardson and Robins 2013)
Fig. 8.

The graph in a is a successive transformation of Fig. 4a for that represents a hypothetical trial G in which both and are randomly assigned (We have removed to avoid clutter, but all our arguments are valid in the presence of ). The graph in b is a transformation of Fig. 5b, in which . All dismissible component conditions hold in both graphs
The identification conditions in this section are linked to previous general identification results on identification of path-specific effects (Shpitser 2013; Avin et al. 2005) (who did not consider competing events): there exist (cross-world) path specific effects that may be identified by isomorphic identification formulas as the separable effects (Shpitser 2013).
Relation between isolation and dismissible component conditions
Note that partition is a necessary condition for the dismissible component conditions to hold for any choice of measured covariates and their partition (see proof in Appendix C). However, partition is not sufficient to ensure these conditions as also illustrated by Fig. 7. For example, in Fig. 7e, full isolation holds but, as we noted above, the dismissible component conditions fail due to failure to measure either the common cause or . Similarly, the graph in Fig. 7f satisfies partition, but, as we noted above, the dismissible component conditions fail due to failure to measure the common cause .
In Appendix C we also show that: (i) if the dismissible component conditions hold when we define and for all , then partial isolation holds; (ii) if the dismissible component conditions hold when we define and for all , then partial isolation holds; and (iii) if the dismissible component conditions hold when we choose either of the partitions in (i) and (ii) then full isolation holds and is independent of A at any k, given the measured past.
More generally, our identification conditions will only hold when and are independent of each other given the measured past. When both and are non-empty, our identification results are related to Robins and Richardson’s (2010) identification results for mediation estimands in a non-extended DAG with a recanting witness under cross-world independence assumptions (See Robins and Richardson’s 2010 Figure 2b and Section 4.4).
The g-formula for separable effects
For , let be a realization of the measured time-varying covariates at k, such that and are possible realizations of and , respectively (a chosen partition of under an assumed temporal order ). Provided that exchangeability, consistency, positivity and the 4 dismissible component conditions hold, we can identify by
| 19 |
, where for any vector of random variables A and B, is the conditional density of A given B evaluated at a, b. See Appendix B for proof. We will refer to expression (19) as the g-formula (Robins 1986) for , which is equivalent to identification formulas for path-specific effects with a different interpretation and under different identification assumptions (Shpitser 2013) and interventionist’s mediation effects (Robins et al. 2020).
The g-formula in the presence of censoring
We now relax the assumption of no losses to follow-up, allowing that some individuals are censored at some point during the study. For , let denote censoring by loss to follow-up by interval k, and assume a temporal order in each interval . We remind the reader that the the temporal ordering assumption is analogous to assumptions about ties in continuous time settings, which becomes practically irrelevant when the time intervals are small. Hereby, we will implicitly redefine all counterfactual outcomes in terms of outcomes under an additional intervention that eliminates censoring.
When censoring is present, the isolation conditions defined in Sect. 5 and their implications for interpretation of separable effects are unchanged. However, in this case, additional exchangeability, positivity and consistency assumptions are required for identification of (10) using only the observed data. Given assumptions (28)–(37) in Appendix B, which extend the assumptions of Sect. 6 to allow that censoring is present and dependent on the measured time-varying risk factors , we can identify (10) by
| 20 |
See Appendix B for proof. We say expression (20) is the g-formula for (10) under elimination of censoring. When assumptions (28)–(37) hold replacing , then identification of (10) is achieved by a simplified version of (20), which was given in Stensrud et al. (2020).
Estimation of separable effects and data example
The g-formula (20) has the following alternative representations,
| 21 |
where
and
| 22 |
where is defined as in (21) and
as formally shown in Appendix D.
Here, and are products of conditional discrete cause-specific hazards of the event of interest and the competing event, respectively. The weights and are derived from re-expression of conditional probabilities of and , respectively, see Appendix D.
Representations (21) and (22) motivate weighted estimators of the separable effects, which generalize the weighted estimators given by Stensrud et al. (2020) and are related to inverse odds ratio weights for mediation analysis (Tchetgen Tchetgen 2013). We let denote (20), and is individual i’s values of for a user-chosen partition of .
Define
where is a parametric model for the numerator (and denominator) of indexed by parameter , and is a consistent estimator of (e.g. the MLE). The terms in and are defined analogously, where are consistent estimators of corresponding model parameters , respectively.
Let , and define the estimator of as the solution to the estimating equation with respect to with
and .
Provided that the models indexed by elements in are correctly specified and is a consistent estimator for , then consistency of for follows because (20) and (21) are equal. We describe an implementation algorithm for in Appendix E. In practice, we can use popular regression models for binary outcomes to estimate the weights and . However, when we parameterize the terms in , we must ensure that the statistical models are congenial, which may fail for popular models, such as logistic regressions models. In Appendix D, we have provided an alternative expression of that motivates different weighted estimators based on estimation of the conditional joint densities of . These weighted estimators avoid the problem of incongenial models at the expense of needing to model higher dimensional quantities.
The estimator based on (22) is derived analogously to the estimator based on (21). Suppose
where the terms in , are statistical models for binary outcomes, and where are consistent estimators for , respectively. Similar to , however, we must ensure that congenial models are used to estimate the terms in .
Let , and define the estimator of as the solution to the estimating equation with respect to , where
and . Analogous to the estimator based on (21), provided that the models indexed by elements in are correctly specified and is a consistent estimator for , then consistency of for follows because (20) and (22) are equal.
Simplified estimators under assumptions on
Given a user-chosen partition of such that for , then and the consistency of only requires consistent estimation of the weights and . Thus, if the identification conditions hold and there is no direct effect (arrow) from to , which implies that partial isolation holds (see Lemma 6), we suggest using the estimator , which is motivated by (21), because it does not require any modelling of the covariate distributions ().
Similarly, the partition gives , such that the consistency of only relies on consistent estimation of the weights and . Thus, if the identification conditions hold and there is no direct effect (arrow) from to , which implies partial isolation holds (see Lemma 5), we suggest using the estimator , which is motivated by (22).
Of course, these simplified partitions are only justified if they satisfy the dismissible component conditions. As discussed in Sect. 6.1, identification under these simplified partitions implies partial or full isolation, impacting the interpretation of the separable effects.
Data example: blood pressure therapy and acute kidney injury
As an illustration, we analyzed data from the Systolic Blood Pressure Intervention Trial (SPRINT) (SPRINT Research Group 2015), which randomly assigned individuals to intensive () or standard () blood pressure treatment. We used follow-up data from each month , and restricted our analysis to participants aged older than 75 years at baseline in whom the most deaths (competing events) occurred (Williamson et al. 2016). For simplicity, we further restricted to those patients with complete data on baseline covariates (described below). This resulted in a data set with 1304 and 1297 in the intensive () and standard () blood pressure therapy arms, respectively. During the 30-month follow-up period, 107 and 98 of these patients were lost to follow-up (censored) in some month in the intensive and standard arms, respectively.
In order to adjust for informative censoring by loss to follow-up, we used inverse probability of censoring weighted Aalen-Johansen estimators (Aalen and Johansen 1978; Young et al. 2020) to estimate the total effects of treatment assignment on the cause-specific cumulative incidences at each of kidney injury and mortality. We adjusted for the baseline covariates () smoking status, history of clinical or subclinical cardiovascular disease, clinical of subclinical chronic kidney disease, statin use and gender as well as the time-varying covariates () defined by the most recent measurements of systolic and diastolic blood pressure, scheduled monthly for the first 3 months and every 3 months thereafter. The weight denominators were estimated under the following pooled logistic model for the probability of being censored within each month given the measured past,
| 23 |
| 24 |
where are time-varying intercepts modeled as 3rd degree polynomials. For all analyses, 95% percent confidence intervals were constructed using 500 nonparametric bootstrap samples.
The estimated cumulative incidence of acute kidney injury (the event of interest) under the intensive treatment assignment was consistently higher compared to standard treatment assignment (Fig. 9a, solid lines), in line with a harmful total effect on acute kidney injury. Specifically, the total effect estimate (on the additive scale) of intensive therapy assignment versus standard was 0.01 (95% CI: [0.00, 0.03]) at 30 months of follow-up. This weighted estimator is consistent for the total effect under weaker conditions than those outlined above for separable effects – unlike the separable effects, covariate adjustment here is only necessary due to censoring by loss to follow-up (Young et al. 2020). However, as discussed in Sect. 3, this harmful effect is hard to interpret due to a possible protective effect of intensive treatment assignment on death (the competing event). This concern is not easily ruled out by the data; the cumulative incidence of death under intensive treatment assignment is consistently slightly lower compared to standard treatment assignment over the 30-month follow-up with differences increasing at 25 months, as shown with dashed lines in Fig. 9a. At 30 months, the total effect estimate on mortality was -0.01 (95% CI: ). Effects that quantify mechanism are therefore naturally of interest.
Fig. 9.

a Weighted Aalen-Johansen estimates of the cumulative incidence functions for acute kidney injury (AKI, solid lines) and death (dashed lines) under intensive (, black) and standard (, red) treatment. b Estimates of AKI cumulative incidence based on methods of Sect. 7 under a modified treatment containing only the component (, green). Cumulative incidence estimates under the original intensive (, black) and the standard (, red) of a are overlaid
As discussed in Sect. 5.2, for defined as the component of treatment A that may exert biological effects on the kidneys, e.g. by relaxing the efferent arterioles, and defined as all remaining components of A, partial isolation may be a reasonable assumption given background subject matter knowledge. Under this assumption, the separable effect (4) evaluated at does not capture effects of the treatment on the competing event. It also may be of clinical interest as it quantifies the effect of removing the possibly harmful component from the original treatment A.
Following the recommendations of Sect. 7.1, given our subject-matter driven assumption of partial isolation, the inverse probability weighted estimator described in Sect. 7, based on the representation (22), will rely on considerably fewer parametric model assumptions than the alternative estimator , based on the representation (21). The estimator further avoids the problem of model incongeniality of because we do not need to specify the weights . Therefore, we used to estimate (10) and, in turn, the separable effect (4) evaluated at on acute kidney injury at each under the assumption that the measured baseline and time-varying covariates are sufficient to ensure identification, i.e. to adjust for common causes of the event of interest and the competing event. That is, we assume that the dismissible component conditions (14)–(17) hold under the partitioning . This assumption, at best, approximately holds because contains only intermittent measurements of systolic and diastolic blood pressure.
We estimated under the pooled logistic models
| 25 |
for , where and are time-varying intercepts modeled as 3rd degree polynomials. The inverse probability of censoring weights were estimated under (24).
Figure 9b shows estimates of the counterfactual cumulative incidence for acute kidney injury under assignment to different combinations of and over time. The vertical distance between the black and the green line is a point estimate of the additive separable effect when , and similarly the vertical distance between the red and the green line is the separable effect when . In particular, the estimated separable effect of 0.00 (95% CI: ) at 30 months when , suggests that removing the component from the intensive therapy will not decrease the average risk of kidney injury at 30 months. R code is provided in the supplementary materials.
As a comparison, we estimated the cause-specific hazard ratio under a proportional hazards model conditional on the same baseline covariates () and time-varying covariates (), which was . This estimated association, which is conditional not only on acute kidney injury not having occurred before k, but also on death not having occurred before k and time-varying history of blood pressure measurements, is further from the null than our separable effect estimates. Importantly, this estimand is not guaranteed a causal interpretation even under our identifying conditions of Sect. 6 (Young et al. 2020; Stensrud et al. 2020).
Sensitivity analysis
To illustrate a sensitivity analysis technique for violations of the dismissible component conditions, consider a selection bias function for dismissible component condition (14),
which is identified in a perfectly executed randomized trial in which and are randomly assigned. Analogous sensitivity functions could be defined for dismissible component conditions (15)–(17). If dismissible component condition (14) holds for , we know that . However, if (14) was violated, we would expect that for some values of and . In particular, (14) can be violated in the presence of an unmeasured cause of and , where .
While the following strategy for sensitivity analysis is applicable to any setting in which partition holds, we consider a simpler setting in which (i) partial isolation holds, (ii) dismissible component condition (14) holds for some that contains the measured variable L as a subset, , and (iii) dismissible component conditions (15)–(17) hold. This is coherent with our blood pressure example in Sect. 7.2, and one such setting is described in Fig. 7f where (14) is violated due to failure of measuring . Now, suppose that is known. Then the separable effects can be identified through the modified version of identification formula (22),
| 26 |
where
which is equal to (22) under partial isolation when and for all k and . Formula (26) motivates the estimator , a modified version of from Sect. 7, such that is the solution to the estimating equation with respect to , where
and , where
see Appendix F for proof.
A formal sensitivity analysis can be conducted by repeatedly estimating for each choice of for a set of functions , where is a finite dimensional parameter and describes the setting with no bias, that is, no unmeasured common causes of and or of and , for any j, k such that .
Subject matter knowledge can help us to reason about the sensitivity function . To fix ideas, suppose that the graph in Fig. 7f represents the blood pressure example, where is an unmeasured common cause that increases the blood pressure () and the risk of kidney failure (). Then we would expect to be negative due to selection over time; subjects who do not receive the treatment component that intensively reduces blood pressure () are less likely to be alive with larger values of compared to those who received the component that intensively reduces blood pressure ().
Our sensitivity analysis technique is inspired by Tchetgen Tchetgen (2014). However, unlike Tchetgen Tchetgen (2014), the terms in our sensitivity function are not cross-world quantities that are unobservable in principle, but conditional expectations that can be identified in a future experiment in which and are randomly assigned.
Furthermore, note that our identification results from Sect. 6 also motivate sensitivity analyses of violations of the isolation conditions from Sect. 5. In particular, suppose that an investigator assumed that full isolation was satisfied and, thus, used the simplified identification formula that was given in Stensrud et al. (2020). Then, the assumption of full isolation could be falsified by comparing these estimates to estimates derived from the estimators in Sect. 7, only assuming partition. To do this sensitivity analysis, the investigator needs to measure a set of time-varying covariates .
Discussion
We have provided generalized results for interpretation and identification of separable effects in competing events settings. These results allow the separable effects to be identified and meaningfullly interpreted in much broader settings than those initially considered by Stensrud et al. (2020). Generally these effects clarify the interpretation of total effects when competing events are affected by treatment, provide more information to patients and doctors for current treatment decisions and inform the development of improved treatments with unwanted components removed. In general, our framework provides a basis that allows subject matter experts to formally reason about the mechanisms by which treatments act on time-to-event outcomes and subsequently falsify this reasoning in a future trial.
Even under our generalized conditions, the separable effects may be difficult to identify given currently available data in many studies. However, they can point to shortcomings of the data typically collected in studies of competing events, and may guide the planning for improved data collection in future studies. This is particularly true of randomized trials which have historically relied heavily on the treatment randomization; failing to collect data on baseline and time-varying covariates makes it nearly impossible to adjust for selection bias due to censoring and/or to target estimands other than the total effect of the randomization. Furthermore, we outlined strategies for sensitivity analysis to both the dismissible component conditions and isolation conditions in Appendix F.
We have focused on establishing fundamental results for interpretation and identification of separable effects, as well as suggesting three estimators that are easy to implement. In future work, we aim to derive new estimators from the efficient influence function, which may achieve parametric convergence rates even when machine learning methods are used for model fitting (Robins et al. 1994; Chernozhukov et al. 2018; Robins et al. 2017; Van der Laan and Rose 2018), such that e.g. bias-aware model selection can be performed to minimize bias due to model misspecification (Cui and Tchetgen Tchetgen 2019). We will also extend our results to separable effects of time-varying treatment interventions (Robins et al. 2020) in competing events settings, including per-protocol effects in trials with nonadherence.
Supplementary Information
Below is the link to the electronic supplementary material.
Acknowledgements
This manuscript was prepared using SPRINT POP Research Materials obtained from the NHLBI Biologic Specimen and Data Reppsitory Information Coordinating Center and does not necessarily reflect the opinions or views of the SPRINT POP or the NHLBI.
Appendices
Appendix A: Modified treatment assumption.
Appendix B: Proof of identifiability.
Appendix C partition and the dismissible component conditions.
Appendix D Proof of weighted representation of (20).
Appendix E Estimation algorithms.
Appendix F Proof of sensitivity analysis.
A Modified treatment assumption
To define the generalized decomposition assumption in Sect. 4, we considered a decomposition of treatment A into different components, and , satisfying (2). Yet, a physical decomposition of A into components and is not necessary for the validity of our results on identification and estimation of separable effects in Sects. 6–7. Specifically, the proofs in Appendix B only require condition (3) of the generalized decomposition assumption, which may also hold for treatments and that are not components of A.
In this case, the separable effects can still be meaningfully interpreted as the effects of joint assignment to alternative treatments and in place of assignment to A. The isolation conditions of Sect. 5 still constitute additional mechanistic assumptions on how these alternative treatments operate on the event of interest and the competing event. In the main text we defined a G transformation as a transformation of an extended causal DAG under the assumption of a physical decomposition. More generally, a G transformation can be understood as a (conventional) causal DAG representing data generating assumptions in a trial in which and are randomly assigned. Thus, the G transformation graph differs from the causal DAG describing the observed data in that it depicts assumptions about a study in which the alternative treatments and , rather than the original study treatment A, are assigned, including how these treatments operate on future events. The isolation conditions, which only refer to assumptions about the mechanisms by which the alternative treatments and operate, can thus be evaluated in G transformation graphs, even when and are not assumed a physical decomposition of A. The G transformations are isomorphic to dynamic Single World Intervention Graphs (SWIGs) (Richardson and Robins 2013).
However, when treatments and are not components of A, we require additional assumptions beyond (3) for the separable effects to explain the mechanism by which the original treatment A exerts its effects on for . The following is an alternative assumption to (2) that, when coupled with (3), is sufficient for the separable effects to explain the total effect of the original treatment A on the event of interest when and are not a decomposition of A. For variables, and , consider the following assumption:
| 27 |
where the counterfactuals on the right and left hand side of both equalities in (27) refer to assignment to and no level of and , and assignment to (, ) and no level of A, respectively. A transformed DAG that is consistent with (27) is shown in Fig. 10 where refers to a six arm trial in which subjects are either randomly assigned to A (and no level of and ) or a combination of and (and no level of A).
Fig. 10.
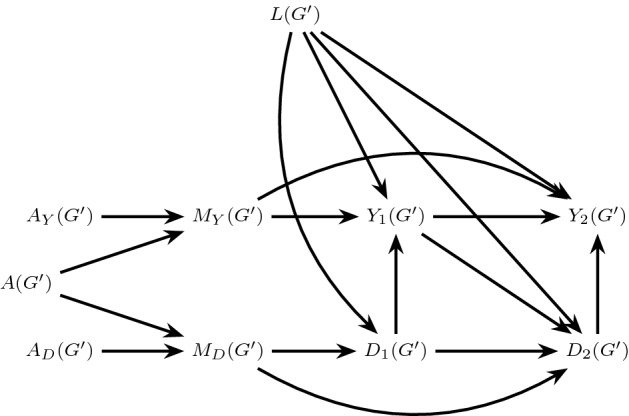
Modified DAG including the additional variables and and their relation to A, and
Note that assumptions (3) and (27) can, in principle, be falsified in a future randomized experiment. For example, by randomly assigning individuals to A or a joint treatment , we can assess whether , for any .
To fix ideas, consider a study of estrogen therapy versus placebo in men with prostate cancer, which was the running example in Stensrud et al. (2020). Estrogen therapy is thought to reduce death due to prostate cancer, because it reduces testosterone levels and thus prevents the cancer cells from growing. However, there is concern that estrogen therapy may also increase mortality due to cardiovascular disease, e.g. through estrogen-induced synthesis of coagulation factors (Turo et al. 2014). Stensrud et al. (2020) used this example to motivate the separable direct and indirect effects under full isolation, and suggested that alternative treatments, such as castration and luteinizing hormone releasing hormone (LHRH) antagonists, can have the same effect as estrogen on testosterone reduction (), but, unlike estrogen, these treatments do not exert effects on the coagulation factors (). Whereas Stensrud et al. (2020) did not formally define the variables and , providing the story that includes these additional variables, satisfying (27), is essential to connect the effect of e.g. (here, assigning testosterone or LHRH antagonists) to the separable direct and indirect effects of estrogen therapy (A) itself.
B Proof of identifiability
Before we provide a proof of identification formula (20), consider the following identifiability conditions that generalize the conditions from Sect. 6 to allow for censoring.
- Exchangeability:
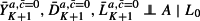
28
Condition (28) holds when and are randomly assigned at baseline, possibly conditional on . Condition (29) requires that losses to follow-up are independent of future counterfactual events, given the measured past; this assumption does not hold by design in a randomised trial, as losses to follow-up are not randomly assigned in practice.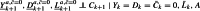
29 - Consistency:
Consistency is satisfied if any individual who has data history consistent with the intervention under a counterfactual scenario, would have an observed outcome that is equal to the counterfactual outcome.33 - Dismissible component conditions:
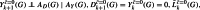
34 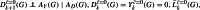
35 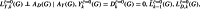
36
The dismissible component conditions are identical to the conditions in Sect. 6, but the superscript is included to emphasize that we consider outcomes in a setting in which loss to follow-up is eliminated even under G.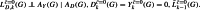
37
Lemma 1
Under a FFRCISTG model, the dismissible component conditions (34)–(37) imply the following equalities for :
| 38 |
| 39 |
| 40 |
| 41 |
| 42 |
Proof
which shows that equality (38) holds, and (39)–(41) can be shown from analogous arguments, where we use conditions (35)–(37) in the second step, respectively, instead of (34).
Lemma 2
Suppose that conditions (28)–(33) hold. Then, for and ,
| 43 |
| 44 |
| 45 |
| 46 |
Proof
Consider first (42),
where we used the fact that all subjects are event-free and uncensored at , laws of probability and (28). Using (29) and positivity,
| 47 |
For , under consistency,
| 48 |
which proves the lemma for .
Further, for , using consistency,
| 49 |
Apply (29) and positivity again,
| 50 |
Using consistency,
| 51 |
Arguing iteratively, we find that
| 52 |
Theorem 1
Suppose conditions (28)–(37) hold. Then, for ,
Proof
If , it is straightforward to use laws of probability to show that the theorem holds. Consider now the case where . In particular, let . Using laws of probability and Lemma 1,
| 53 |
where , and are empty sets. Using Lemma 2, we can substitute the terms in the last equality in (52),
C partition and the dismissible component conditions
Lemma 3
partition fails if and only if any of the following statements are true for some : (i) there is a direct arrow from into , (ii) there is a direct arrow from into , or (iii) there exists a node such that there are direct arrows from both and into W.
Proof
First we directly show that if (i), (ii) or (iii) holds then partition fails. If (i) holds then (8) is violated by the presence of a causal path and therefore partition is violated. If (ii) holds then (9) is violated by the presence of a causal path and therefore partition is violated. Now suppose (iii) is true and define a partition of such that . Then a causal path will exist and (8), and therefore partition, is violated. Alternatively suppose (iii) is true and define a partition of such that, instead, Then a causal path will exist and (9), and therefore partition, is violated.
Next we show by contradiction that if partition fails then (i), (ii) or (iii) must hold. Suppose partition holds and (i), (ii) or (iii) also hold. If (i), (ii) or (iii) hold then one of the following causal paths must be present: , for some ; , for some ; for some ; or for some . The presence of any of these paths violates either (8) or (9) such that partition fails. Thus, we have a contradiction and we are done.
Lemma 4
If partition fails, then at least one of the dismissible component conditions fail.
Proof
Suppose partition fails. Then, by lemma 3, (i), (ii) or (iii) must hold such that at least one of the following paths must be present for , , a cause of and/or , for some : ; ; and ; or and .
If the path is present then the dismissible component condition(15) fails for any choice of . If the path is present then the dismissible component condition (14) fails for any choice of .
Suppose , (W is unmeasured). If the path is present then the dismissible component condition (15) fails for any choice of . If the path is present then the dismissible component condition (14) fails for any choice of .
Suppose for some (W is measured). If the paths and are present then, no matter our choice of , if we choose the dismissible component condition (16) fails and if we choose the dismissible component condition (17) fails. Similarly, if the paths and are present then, no matter our choice of , if we choose the dismissible component condition (16) fails and if we choose the dismissible component condition (17) fails.
Lemma 5
If the dismissible component conditions hold when we define , then partial isolation holds.
Proof
We give a proof by contradiction. Suppose the dismissible component conditions hold under , but partial isolation does not hold. Then, if there is a direct arrow for any , this arrow would violate (15), which is a contradiction. Alternatively, partial isolation can only be violated if there exists a W such that for any . However, if (because ), then (17) is violated, which is a contradiction. If W is unmeasured, then either (15) is violated or (17) is violated, which is a contradiction.
Lemma 6
If the dismissible component conditions hold when we define , then partial isolation holds.
Proof
The proof is analogous to the proof of lemma 5.
Lemma 7
If the dismissible component conditions hold for both the partition and the partition , then full isolation holds.
Proof
It follows immediately from Lemma 5 and Lemma 6, because full isolation holds by definition if both partial isolation and partial isolation holds.
Lemma 8
If the dismissible component conditions hold for both the partition and the partition , then
Proof
We give a proof by contradiction. Suppose that the dismissible component conditions hold for both the partition and the partition , and there is a conditional dependence such that
for at least one . Using the rules of d-separation (Pearl 2009), we will consider the 4 possible ways in which A and can be d-connected, conditional on .
Suppose that the conditional dependence is due to a direct arrow from A into . Then, under the generalized decomposition assumption, either there is a direct arrow from into or a direct arrow from into , and these arrows would, repsectively, violate (16) under the partition and (17) under the partition , which is a contradiction.
Suppose that the conditional dependence is due the unmeasured common cause W of of A and . Then, under the generalized decomposition assumption, either (i) W is a common cause of either and or (ii) W is a common cause of and . However, (i) or (ii) would violate dismissible component condition (16) or (17), which is a contradiction.
Suppose that the conditional dependence is due to an unblocked path due to conditioning on and , that is, by conditioning on a collider or a descendant of a collider. Then, under the generalized decomposition assumption, this path would lead to a conditional dependence between either and or and . Any such path would violate (16) or (17), which is a contradiction of the result in Lemma 7.
Finally, suppose that the conditional dependence is due to a direct arrow from where into A. This would violate our assumption of a temporal order, that is, it would imply that A occurs after , which is a contradiction.
D Proof of weighted representation of (20)
First, using laws of probability we can re-formulate the weights and ,
and
Define
Consider the expression
where we use the definition of expected value in the second equation, the fact that and are binary in the third equation, laws of probability in the fourth and fifth equation.
We use laws of probability to express as
where any variable indexed with a number is defined to be the empty set.
Arguing iteratively for we find that
where we use that in the second equality.
By plugging in the expression for , we get
By plugging in the expression for the weights and we obtain
and the final expression is equal to (20).
E Estimation algorithms
Here we describe an algorithm to estimate the separable effects using estimators based on (21); i.e. the estimator described in Sect. 7. We initially construct our input data set such that each subject has lines, indexed by , and there are measurements of on each line k. For each subject, if , otherwise , where and either , or . Due to the temporal ordering, we do the following: if , then and are set missing. Similarly, if and , then is set missing. Then we do the following to estimate (21) at K:
Using all subject-intervals records, i.e. all lines in the data set, obtain by fitting a parametric model (e.g. pooled logistic regression model) with dependent variable and independent variables a specified function of , and A.
Using all subject-intervals records, obtain by fitting a parametric model (e.g. pooled logistic regression model) with dependent variable and independent variables a specified function of , and A.
Using all subject-intervals records, estimate by fitting a parametric model with dependent variable A and independent variables a specified function of , and A.
Using all subject-intervals records, estimate by fitting a parametric model with dependent variable A and independent variables a specified function of , , and A, ensuring that the models used to fit and are compatible. Notice that this step is redundant if we can define a partition such that , which implies that partial isolation holds.
For subject i, attach a weight to line k with predicted outcome probabilities derived from the parametric models indexed by parameters and to estimate .
- Compute an estimate of from
An estimator based on (22) could be derived analogously, where step (1) we would fit a model with as dependent variable, in step (4) we would fit a model where we replace with , and we finally compute an estimate of from
F Proof of sensitivity analysis
This section includes a proof of the estimating equation for the sensitivity analysis in Sect. 7.3.
Proof
The following equality holds by definition of ,
| 54 |
While (38) of Lemma 1 is violated in our setting where dismissible component condition (14) is violated, note that (39)–(41) of Lemma 1 holds and that Lemma 2 holds regardless of violations of the dismissible component conditions. Thus, following analogous steps as in the proof of Theorem 1, we use (28)–(33), (35)–(37), as well as (54) instead of (34), to obtain the following identification formula for settings where ,
and a weighted representation of this identification formula is analogous to identification formula (22), where is replaced by , which can be shown by an argument that is analogous to the proof in Appendix D.
Funding
Open Access funding provided by EPFL Lausanne.
Footnotes
Many authors use the term “censoring by death” without reference to an estimand. This terminology is appropriate when the estimand is defined with respect to interventions that eliminate competing events, but it is misleading in general. See Young et al. (2020) for details. Here we intentionally avoid the term “censoring by death” because we do not consider such estimands.
The extended graph in Fig. 4a is the generalization of Richardson and Robins’s extended graph in their Figure 6A and the graph in Fig. 4b is the generalization of Richardson and Robins’s graph in their Figure 6B to settings with time dependent confounders, mediators and outcomes.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Aalen O, Johansen S (1978) An empirical transition matrix for non-homogeneous Markov chains based on censored observations. Scand J Stat 141–150
- Aalen O, Stensrud MJ, Didelez V, Daniel R, Røysland K, Strohmaier S (2019) Time-dependent mediators in survival analysis: modeling direct and indirect effects with the additive hazards model. Biom J [DOI] [PubMed]
- Avin C, Shpitser I, Pearl J (2005) Identifiability of path-specific effects
- Chernozhukov V, Chetverikov D, Demirer M, Duflo E, Hansen C, Newey W, Robins J (2018) Double/debiased machine learning for treatment and structural parameters. Econom J 21(1):C1–C68, 01
- Cui Y, Tchetgen Tchetgen EJ (2019) Bias-aware model selection for machine learning of doubly robust functionals. arXiv preprint arXiv:1911.02029
- Didelez V (2018) Defining causal mediation with a longitudinal mediator and a survival outcome. Lifetime Data Anal 1–18 [DOI] [PubMed]
- Hernán MA. The hazards of hazard ratios. Epidemiology (Cambridge, MA) 2010;21(1):13. doi: 10.1097/EDE.0b013e3181c1ea43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hernan MA, Robins JM (2018) Causal inference. CRC Boca Raton, FL
- Martinussen T, Vansteelandt S, Andersen PK. Subtleties in the interpretation of hazard contrasts. Lifetime Data Anal. 2020;26(4):833–855. doi: 10.1007/s10985-020-09501-5. [DOI] [PubMed] [Google Scholar]
- Pearl J. Causality. Cambridge: Cambridge University Press; 2009. [Google Scholar]
- Richardson TS, Robins JM (2013) Single world intervention graphs (swigs): a unification of the counterfactual and graphical approaches to causality. Center for the Statistics and the Social Sciences , University of Washington Series, Working Paper 128(30):2013
- Ridker PM, Pradhan A, MacFadyen JG, Libby P, Glynn RJ. Cardiovascular benefits and diabetes risks of statin therapy in primary prevention: an analysis from the jupiter trial. The Lancet. 2012;380(9841):565–571. doi: 10.1016/S0140-6736(12)61190-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins JM. A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect. Math Model. 1986;7(9–12):1393–1512. doi: 10.1016/0270-0255(86)90088-6. [DOI] [Google Scholar]
- Robins JM (2016) Direct and indirect effects. Presentation at the UK causal inference conference in London
- Robins JM, Greenland S (1992) Identifiability and exchangeability for direct and indirect effects. Epidemiology 143–155 [DOI] [PubMed]
- Robins JM, Richardson TS (2010) Alternative graphical causal models and the identification of direct effects, pp 103–158
- Robins JM, Rotnitzky A, Zhao LP. Estimation of regression coefficients when some regressors are not always observed. J Am Stat Assoc. 1994;89(427):846–866. doi: 10.1080/01621459.1994.10476818. [DOI] [Google Scholar]
- Robins JM, Li L, Rajarshi M, Eric T, van der Vaart A, et al. Minimax estimation of a functional on a structured high-dimensional model. Ann Stat. 2017;45(5):1951–1987. doi: 10.1214/16-AOS1515. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins JM, Richardson TS, Shpitser I (2020) An interventionist approach to mediation analysis. arXiv preprint arXiv:2008.06019
- Sattar N, Preiss D, Murray HM, Welsh P, Buckley BM, de Craen AJM, Seshasai SRK, McMurray JJ, Freeman DJ, Wouter Jukema J, et al. Statins and risk of incident diabetes: a collaborative meta-analysis of randomised statin trials. The Lancet. 2010;375(9716):735–742. doi: 10.1016/S0140-6736(09)61965-6. [DOI] [PubMed] [Google Scholar]
- Shpitser I. Counterfactual graphical models for longitudinal mediation analysis with unobserved confounding. Cogn Sci. 2013;37(6):1011–1035. doi: 10.1111/cogs.12058. [DOI] [PubMed] [Google Scholar]
- Shpitser I, Richardson TS, Robins JM (2020) Multivariate counterfactual systems and causal graphical models. arXiv preprint arXiv:2008.06017
- SPRINT Research Group A randomized trial of intensive versus standard blood-pressure control. N Engl J Med. 2015;373(22):2103–2116. doi: 10.1056/NEJMoa1511939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stensrud MJ, Hernán MA. Why test for proportional hazards? Jama. 2020;323(14):1401–1402. doi: 10.1001/jama.2020.1267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stensrud MJ, Young JG, Didelez V, Robins JM, Hernán MA (2020) Separable effects for causal inference in the presence of competing events. J Am Stat Assoc 1–23
- Tchetgen Tchetgen EJ. Inverse odds ratio-weighted estimation for causal mediation analysis. Stat Med. 2013;32(26):4567–4580. doi: 10.1002/sim.5864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tchetgen Tchetgen EJ. Identification and estimation of survivor average causal effects. Stat Med. 2014;33(21):3601–3628. doi: 10.1002/sim.6181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Turo R, Smolski M, Esler R, Kujawa ML, Bromage SJ, Oakley N, Adeyoju A, Brown SCW, Brough R, Sinclair A, et al. Diethylstilboestrol for the treatment of prostate cancer: past, present and future. Scand J Urol. 2014;48(1):4–14. doi: 10.3109/21681805.2013.861508. [DOI] [PubMed] [Google Scholar]
- Van der Laan MJ, Rose S. Targeted learning in data science. Berlin: Springer; 2018. [Google Scholar]
- Verma T, Pearl J (1991) Equivalence and synthesis of causal models. UCLA, Computer Science Department
- Williamson JD, Supiano MA, Applegate WB, Berlowitz DR, Campbell RC, Chertow GM, Fine LJ, Haley WE, Hawfield AT, Ix JH, et al. Intensive vs standard blood pressure control and cardiovascular disease outcomes in adults aged 75 years: a randomized clinical trial. Jama. 2016;315(24):2673–2682. doi: 10.1001/jama.2016.7050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Young JG, Stensrud MJ, Tchetgen Tchetgen EJ, Hernán MA (2020) A causal framework for classical statistical estimands in failure-time settings with competing events. Stat Med 39(8):1199–1236 [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.