

Abstract
Determining the composition of bacterial communities beyond the level of a genus or species is challenging because of the considerable overlap between genomes representing close relatives. Here, we present the mSWEEP pipeline for identifying and estimating the relative sequence abundances of bacterial lineages from plate sweeps of enrichment cultures. mSWEEP leverages biologically grouped sequence assembly databases, applying probabilistic modelling, and provides controls for false positive results. Using sequencing data from major pathogens, we demonstrate significant improvements in lineage quantification and detection accuracy. Our pipeline facilitates investigating cultures comprising mixtures of bacteria, and opens up a new field of plate sweep metagenomics.
Keywords: plate sweeps, bacterial strain identification, microbial communities, metagenomics, probabilistic modeling
Introduction
High-throughput sequencing technologies have enabled researchers to study bacterial populations in unprecedented detail using whole-genome sequencing of pure individual bacterial colonies. Sequencing of individual isolates has provided insights into antimicrobial resistance and the complex ecology of the spread of antimicrobial resistant variants globally. The application of community profiling metagenomics, in which the 16S rRNA gene is sequenced from complex multi-species samples, can provide information about the composition and dynamics of highly diverse bacterial populations. However, the resolution of this approach is limited due to insufficient nucleotide variation 1 and profiling beyond the level of genus/species is generally not possible. Whole-genome shotgun metagenomics delivers a much higher resolution than 16s rRNA sequencing 2 but widespread application is hindered by the cost associated with sequencing a sample to a sufficient depth to capture the diverse set of organisms and strain-level variation that may be present in the sample 3 .
Current methods for taxonomic profiling of bacteria from sequencing data 4 typically perform well only up to the species-level 5 or focus on analysing predetermined single nucleotide variants (SNVs) and/or marker genes to capture the variation contained in a mixed colony of closely related strains 6– 8 . Sequencing isolated colonies offers means to ignore this variation but only focusing on pure colonies is insufficient for many potential applications 9, 10 . Furthermore, whilst the SNV-based approach has been successful in studies of the history of the human population, focusing solely on SNVs inadequately captures the greater variability and different modalities of variation in bacterial genomes. Conversely, solely gene-based approaches can capture some of this while potentially losing finer detail. Therefore, we aimed to strike a balance between these two approaches by making use of a complete genome reference database.
Here, we have developed the mSWEEP pipeline, which is designed to make efficient use of large collections of reference genomes that are available for numerous important human pathogens and other culturable bacterial species. mSWEEP combines clustering of the reference genomes into biologically relevant groups, fast pseudoalignment of reads to the references, fast and accurate probabilistic inference of the cluster abundances and a method for controlling false positive detections. Similar methods taking advantage of pseudoalignment either with 11, 12 or without 13 the application of probabilistic modelling have been developed but we show that our combination of clustering with large reference collections vastly increases the accuracy of obtained estimates.
Although applicable to any scenario where reference genomes for the sequenced bacteria are available, mSWEEP specifically enables a new kind of high-resolution analysis in plate sweep metagenomics, where a mixture of colonies is harvested from an enrichment culture by sweeping the whole plate in contrast to isolating a single colony. Plate sweep experiments fall between whole-genome sequencing of single colonies and culture-independent metagenomics by analysing the entire complexity of a community from a specific growth medium. Since the potential species are restricted in advance by the growth medium, plate sweeps offer a cost-effective way to obtain high-depth sequencing data from only the target organisms of interest and reduce potential sources for bias when comparing enrichment cultures from different timepoints. As illustrated in our experiments, this setting is ideal for analysing samples representing populations of pathogenic bacteria, where the infecting species of primary interest have generally been previously encountered and sequenced frequently. By leveraging on existing high-resolution genomic pictures of pathogen populations, mSWEEP provides means to address a range of novel biological questions related to within-host variation, transmission and the effect of ecological factors on the microbial diversity present in samples.
Results
Lineage identification
Abundance estimation with mSWEEP is performed in two phases: reference preparation, performed once for a given reference collection, and analysis of samples ( Figure 1). Reference preparation consists of defining a reference sequence database and grouping the sequences according to biological criteria such as sequence type (ST), clonal complexes (CC), or by using a clustering algorithm for bacterial genomes. Grouping related reference sequences is essential in enabling identification of the taxonomic origin of each read 11 and enables abundance estimation when the sequencing reads originate from a sequence having no exact match in the reference database but which is represented by sequences from closely related organisms within the same group (typically bacterial lineage). Consequently, accuracy of the abundance estimates provided by mSWEEP is reliant on an extensive reference database and a biologically meaningful grouping.
Figure 1. Flowchart of the mSWEEP pipeline describing a typical workflow for relative abundance estimation.
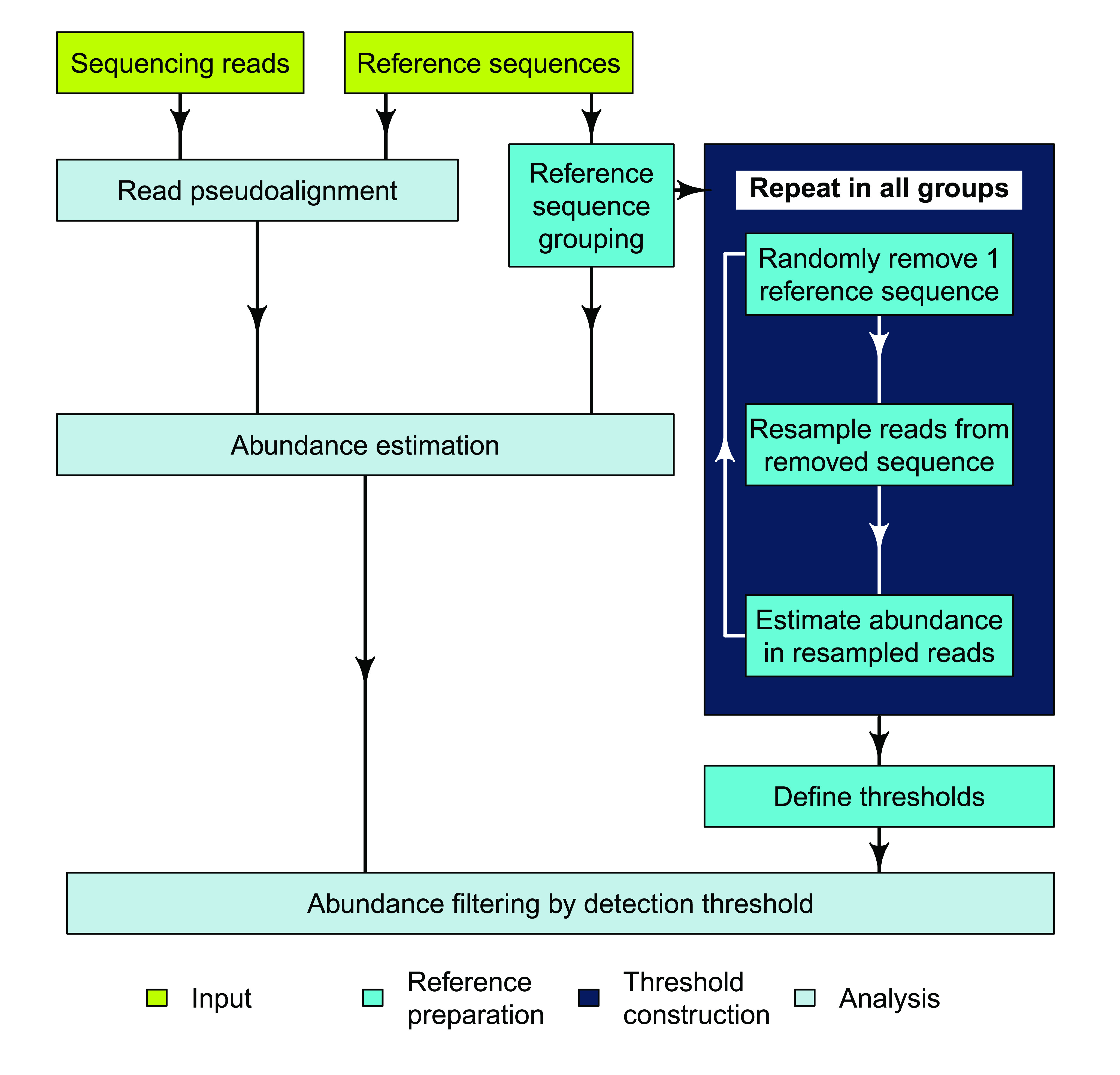
The input part refers to the input data, reference preparation to the operations that need to be performed once per set of reference sequences, and analysis contains the steps run for every sample.
We constructed detection thresholds for the groups during the reference preparation from the reads used to assemble the reference sequences ( Figure 1). We performed repeated in silico experiments in each reference group, where we randomly chose one reference sequence from the group, removed it from the reference set, resampled from the sequencing reads used to assemble the removed sequence, and estimated abundances from the resampled reads with mSWEEP. This process was repeated within the group for a predetermined number of iterations, and then repeated in all other groups within the reference set. The detection threshold for a given group was determined by first examining abundance estimates for the given group from the repeated experiments where a different group was the true source (meaning estimates for the given group should ideally be zero), and determining from those estimates a source-specific cutoff point where only a preset number of estimates exceed the cutoff. After determining the source-specific cutoffs in all other groups, the detection threshold of the given group is obtained by taking the maximum of the source-specific cutoffs. This approach provides a statistical confidence score for estimates exceeding the detection thresholds with the confidence determined by the number of estimates from the resampled reads allowed to exceed the source-specific cutoffs.
The first phase of analysis is pseudoaligning 14 sequencing reads to the reference sequences. Pseudoalignment produces binary compatibility vectors indicating which reference sequences a read pseudoaligns to. Based on the pseudoalignment count to each reference group, we defined the likelihood of a read originating from each of the groups. We assumed that 1) if multiple groups have the same total number of reference sequences, the group with a higher fraction of pseudoalignments is more likely the source for the read, and 2) the likelihood of the read to originate from a group is not dependant on the number of reference sequences in the group. Basing the likelihood on the pseudoalignment counts defines an extension of a probabilistic model that has previously been applied in RNA-sequencing 15, 16 and to bacterial data 11 . The extended model utilizes multiple reference sequences from each group as opposed to the previous attempts that rely on selecting a single, best-representative sequence from each of the groups 11 . Our model obtained the relative abundances of the reference groups by considering the generating process for a sample as a pooling of sequencing reads originating from the reference groups according to some unknown proportions, corresponding to a statistical mixture model. We fit the model and inferred the mixing proportions using variational inference 16 .
Assigning single-colony isolates to lineage
We compared the performance of the mSWEEP pipeline (using kallisto 14 version 0.45 for pseudoalignment and mSWEEP software version 1.1.0 for abundance estimation) against two existing methods capable of identification beyond the species-level based on leveraging reference sequence collections: metakallisto 13 (version 0.45) and the BIB pipeline 11 (commit hash 2999540). We additionally attempted to compare mSWEEP with ditasic 12 (commit hash 90fee24b), but the comparison proved infeasible due to ditasic's quadratic scaling in the number of reference sequences — based on running the indexing step in ditasic for one day, indexing the reference data would have taken roughly 90 days and over 30 terabytes of disk space. The main differences between the chosen methods are that metakallisto attempts to identify individual strains based on all available sequences, BIB uses grouped reference sequences with a single representative sequence from each group to assign abundances to the groups, and mSWEEP identifies the presence of lineages by using grouped reference sequences with all the available sequence representatives.
As the reference data, we used bacterial sequence assemblies from four studies 17– 20 augmented by single representative sequences from 27 species; a total of 3815 reference sequences. We grouped the sequences in either clonal complexes based on multilocus sequence typing 21 , lineages identified with the BAPS clustering algorithm 22 , or on the species-level. We removed 504 sequences from all groups represented by more than one sequence to create a dataset where the true group is known but the true sequence is not available to the method pipelines being compared ( Table 1). In addition to the test data described in Table 1, we referred to a study sequencing 77 K. pneumoniae, K. variicola, and K. quasipneumonae isolates from Thailand 23 to assess the accuracy of all methods when the reference sequences and the test samples were not obtained from the same source.
Table 1. Reference data used to perform the analyses and to evaluate the performance of mSWEEP, metakallisto, and BIB.
Clonal complexes are defined as either single-locus variants from the central sequence type ( Campylobacter jejuni, Campylobacter coli) or double-locus variants ( Klebsiella pneumoniae and Escherichia coli). The Staphylococcus epidermidis lineages were identified in the original study with the BAPS clustering algorithm.
| Grouping | Species | Sequences | Test
sequences |
Groups | Test groups |
|---|---|---|---|---|---|
| Clonal complex | Campylobacter coli | 120 | 27 | 1 | 1 |
| Campylobacter jejuni | 462 | 73 | 13 | 11 | |
| Escherichia coli | 1509 | 188 | 132 | 54 | |
| Klebsiella pneumoniae | 1351 | 129 | 79 | 39 | |
| Species | Klebsiella quasipneumoniae | 9 | 3 | 1 | 1 |
| Klebsiella variicola | 12 | 3 | 1 | 1 | |
| Staphylococcus aureus | 181 | 1 | |||
| Lineage | Staphylococcus epidermidis | 143 | 81 | 3 | 3 |
| Species | Multiple species with single sequences | 28 | 28 | ||
| total | 3815 | 504 | 259 | 110 |
mSWEEP significantly outperformed BIB and metakallisto in cases measuring accuracy of abundance estimates in the true group ( Figure 2; p < 10 -9, in all comparisons, Wilcoxon signed-rank test; median error in all estimates for mSWEEP was 0.00003, for BIB 0.23, and for metakallisto 0.54). When measured by highest estimates in the incorrect groups, mSWEEP outperformed the other two methods in all cases except the S. epidermidis 11-group clustering and the K. pneumoniae out-of-reference samples ( Figure 2; p < 0.0012, Wilcoxon signed-rank test; median error in all estimates for mSWEEP was 0.000002, for BIB 0.05, and for metakallisto 0.01). In these two latter cases, mSWEEP and metakallisto performed similarly ( Figure 2; p > 0.10 when testing for the difference in accuracy in either direction, Wilcoxon signed-rank test). Since metakallisto attempts to identify strains rather than lineages, the observed behaviour is likely a result of the majority of the abundance estimates being spread across strains belonging to the true lineage.
Figure 2. Error of abundance estimates in single-colony isolates (lower is better).
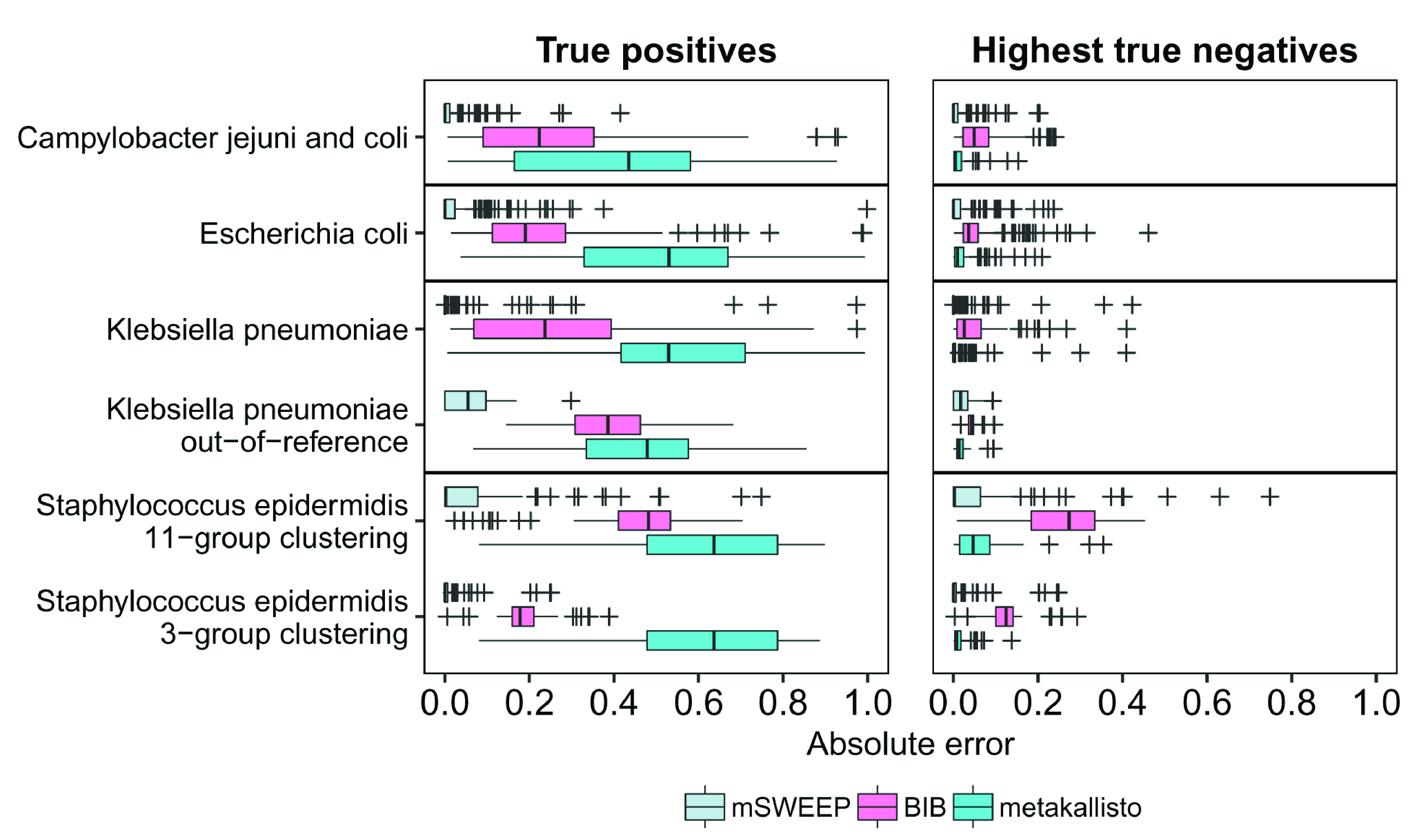
True positives refer to the relative abundance estimates in the true lineage (mSWEEP and BIB) or the highest estimate for a strain within the true lineage (metakallisto). Highest true negatives refer to the highest estimate in the incorrect lineages. The absolute error is the difference from an abundance of one (True positives) or from zero (Highest true negatives).
We additionally compared mSWEEP and BIB by measuring accuracy in classification based on assigning the samples to the lineage with the highest abundance estimate. With this criterion, both methods correctly identified the true clonal complex in all 100 C. jejuni and C. coli isolates, and in all 81 S. epidermidis isolates when using the 3-cluster grouping. In the 11-cluster S. epidermidis grouping, mSWEEP correctly identified the true lineage in 78 and BIB in 80 samples. In the 188 E. coli and 129 K. pneumoniae isolates, mSWEEP identified the lineage correctly in 187 and 126 samples, while BIB correctly identified 184 and 117. The K. pneumoniae and E. coli isolates that were misidentified by mSWEEP likely contain a sequence type that is missing from the reference, or are mixtures of K. pneumoniae and E. coli lineages (Extended Data Figures S1a and S1b 24 ). Out of the last 61 out-of-reference K. pneumoniae samples, mSWEEP identified the true origin in all 61 isolates and BIB in 53.
The least accurate estimates for all methods (measured by the true positives and highest true negatives) were obtained for the 81 S. epidermidis isolates when using the second level of the hierarchical BAPS clustering with 11 groups ( Figure 2), where none of the three methods reached the level of accuracy observed in the other cases. These inaccuracies are explained by the comparably small reference for the S. epidermidis population ( Table 1), which does not exhibit a clear cluster structure (Extended Data Figure S2a 24 ) beyond the coarsest BAPS clustering into three groups. The lack of structure causes the abundance estimates to spread across the new groups defined within each of the three top-level clusters (Extended Data Figure S1c 24 ).
We examined the grouping of the reference sequences by producing t-SNE 25 plots of 31-mer distances estimated with mash 26 (version 2.0) between the reference sequences including the test isolates ( Figure 3; Extended Data Figures S2a-c 24 ). The C. jejuni and C. coli reference conforms to the clonal complex grouping while the S. epidermidis population only conforms to the coarsest 3-group BAPS clustering. The t-SNE plots correctly place the assemblies into the true groups but the method does not preserve the distances between the points or the clusters 25 and is on its own unsuited to analysing mixed isolate data.
Figure 3. C. jejuni and C. coli reference 31-mer embedding.

t-SNE embedding of the 31-mer distances between the reference isolates shows that the reference population conforms relatively well to the clonal complex grouping. The test cases, indicated by circles, are all correctly identified by mSWEEP and t-SNE also places them within or near the true source group.
Processing the 504 single-colony isolates with mSWEEP took an average of 23 minutes and 50 seconds per sample, metakallisto an average of 24 minutes and 42 seconds, and BIB an average of 143 minutes and 46 seconds per sample using the same reference data. mSWEEP used a maximum of 79.5 GB RAM (maximum of 24.6 GB counting only the abundance estimation step), metakallisto 108.1 GB, and BIB 31.5 GB. Resource usage was obtained by running each sample separately with a total of eight processor cores available. Reads were pseudoaligned with kallisto 14 (version 0.45) against the test reference of 3311 sequences (obtained from the 3815 reference sequences in Table 1 by removing the 504 single-colony isolates) in 259 groups (mSWEEP and metakallisto), or aligned with bowtie2 27 (version 2.3.5.1) against a reference consisting of randomly selected representative sequences from each of the 259 groups (BIB).
Quantifying synthetic mixtures of single-colony reads
We investigated the performance of mSWEEP in quantifying samples containing multiple lineages of bacteria from the same species by synthetically mixing reads from the single-colony samples. Each mixture sample was set to contain a total of one million reads from three single-colony samples from three lineages, with randomly assigned proportions from the set (0.20, 0.30, 0.50). We used a balanced incomplete block design to ensure that all lineages appear in at least 13 mixture samples, and each single-colony isolate appears at least once, producing 161 C. jejuni and C. coli, 477 E. coli, 584 K. pneumoniae, and 100 S. epidermidis synthetic mixture samples in total.
Compared to abundance estimates from the single-colony samples, estimates obtained from the synthetic mixture samples show that the presence of sequencing reads from multiple lineages in a synthetic mixture results in an error distribution resembling the one observed in the single-colony samples ( Figure 4; Extended Data Figure S3 28 ). Estimates from the synthetic S. epidermidis mixture samples using the 11-group split produce an error distribution that differs from the single-colony error distribution more than that observed with the other groupings.
Figure 4. False positives in single-colony samples versus synthetic mixtures.

Abundance estimates from synthetic mixtures of three lineages do not result in higher number of false positive estimates when compared to estimates from the single-colony samples, as measured by the largest estimate for a lineage that does not contribute any sequencing reads. The only exception is the S. epidermidis 11-cluster case which is not accurately identified in neither the synthetic mixtures nor the single-colony samples.
Comparing the empirical distributions of the errors from the synthetic mixtures and the single-colony isolates (Extended Data Figures S3 and S4 24 ) shows that for estimates exceeding a threshold of 0.016, the accuracy of estimates from the mixture samples stochastically dominates the accuracy observed in the single-colony samples, except in the S. epidermidis 11-cluster case where stochastic dominance is observed only above a threshold of 0.17. Stochastic dominance establishes a partial ordering between two random variables and, in this case, implies that estimates from the mixture samples are more accurate (in a probabilistic sense) than estimates from the single-colony samples when the estimates are large enough. In the S. epidermidis 11-cluster case we do not establish the mixture estimates as more accurate since the distribution (Extended Data Figure S3 24 ) and the observed threshold differ considerably from the other cases.
The results indicate that above this relatively low background noise level of 0.016, quantifying mixture samples is not expected to produce more false positive results than would be obtained from single-colony samples. This justifies simplifying the problem of determining the detection thresholds accompanying mSWEEP, which provide a threshold for reliable detection of the reference groups in mixture samples, to determining the thresholds based on the single-colony isolates. Due to the requirement that the abundance estimates must be large enough for this assumption to hold, we incorporate the threshold observed in comparing the estimates into the detection thresholds by using it as the minimum threshold regardless of the results from the resampling procedure.
Results from plate sweeps
We applied the mSWEEP pipeline to three datasets containing multiple lineages of the same species: 116 samples from C. coli and C. jejuni, 96 paired samples from E. coli, and 179 samples from K. pneumoniae. The E. coli samples were obtained from MacConkey plate sweeps from a cohort study of 48 Vietnamese children during a diarrhoeal episode (48 samples), and when healthy (48 samples), purposefully expecting multiple lineages in each sweep. Conversely, the C. coli/ C. jejuni and K. pneumoniae datasets were presumed pure cultures but flagged during downstream analysis as mixed. In all three experiments, we applied the detection threshold procedure (described in more detail in the Methods section) to filter the resulting abundance estimates. We used two thresholds, corresponding to confidence scores of 0.99 and 0.90, from now on referred to as filtering by 0.99 or 0.90 confidence thresholds.
Population structure of commensal Escherichia coli from Vietnamese children
The most abundant sequence type complex identified in over half the samples (diarrhoeal and control samples) was CC10 ( Figure 5; Extended Data Table S1 29 ). Notably, 95% of the samples (46/48 Diarrheal and 45/48 Healthy) harboured multiple antimicrobial resistance genes (identified using the ARIBA software 30 ) that belonged to three or more classes of drugs (Extended Data Figure S5 31 ), which we defined as multi-drug resistance 32 . One sample was found to contain the plasmid associated resistance gene MCR-1, which confers resistance to colistin, a last line antimicrobial drug 33 . We found no significant difference in the antimicrobial resistance gene profile between the healthy and diarrhoeal samples (Two tailed, Fisher's exact test p=0.5). Extended Data Table S2 34 details how many samples harboured antimicrobial resistance genes in each antimicrobial drug class; the full antimicrobial resistance gene data can be found in Extended Data Table S3 28 .
Figure 5. Difference in Escherichia coli clonal complex (CC) and sequence type (ST) lineage abundances during and after diarrhoea.

The plot displays the differences in unfiltered relative abundance estimates before and after treatment in 20 most common (defined by the sum of relative abundances; blue denotes increase, red decrease) E. coli reference lineages or other species across all 47 paired samples represented in the columns.
We additionally examined differences between the community composition in the healthy and diarrhoeal samples based on both the distribution of the relative abundance estimates (alpha diversity), and changes in the identified strains (beta diversity). The alpha diversity, measured by Shannon entropy (Extended Data Figure S6 24 ), showed no significant differences between the two paired samples (p > 0.90, Wilcoxon signed-rank test; median Shannon entropy in the diarrhoeal samples was 0.60, and in the healthy samples 0.59). However, we found significant shifts in lineage composition (see Figure 5) when comparing the beta diversity, measured by Bray-Curtis dissimilarity, between the two samples (p < 0.005, multivariate-ANOVA). Tests were performed on relative abundance estimates filtered by both 0.99 and 0.90 confidence thresholds.
Co-occurrence patterns in Campylobacter lineages
The network diagram ( Figure 6a) shows ST-clonal complex (CC) (nodes) of the isolate genomes with the thickness of edges representing the number of times that isolates from these CCs are found together in a single plate sweep sample, and the size of the node the total number of observations. The overall amount of co-occurrence between CCs ( Figure 6b) provides basic information about the frequency that CCs are found together in natural populations. C. jejuni CCs 45, 661, 607, 353, 48, and C. coli CC828 are all found in samples with 4 or more other CCs and there is evidence that isolates from some CC’s cohabit with other species including Campylobacter lari and Bacillus subtilis. While the sample set in this study was deliberately selected to include mixed isolate samples, quantifying the co-occurrence of species and lineages can provide information about different ecologies or lineage interactions, particularly when CCs are known to have varied sources, such as different hosts.
Figure 6. C. jejuni and C. coli clonal complex (CC) coexistence in 116 samples.
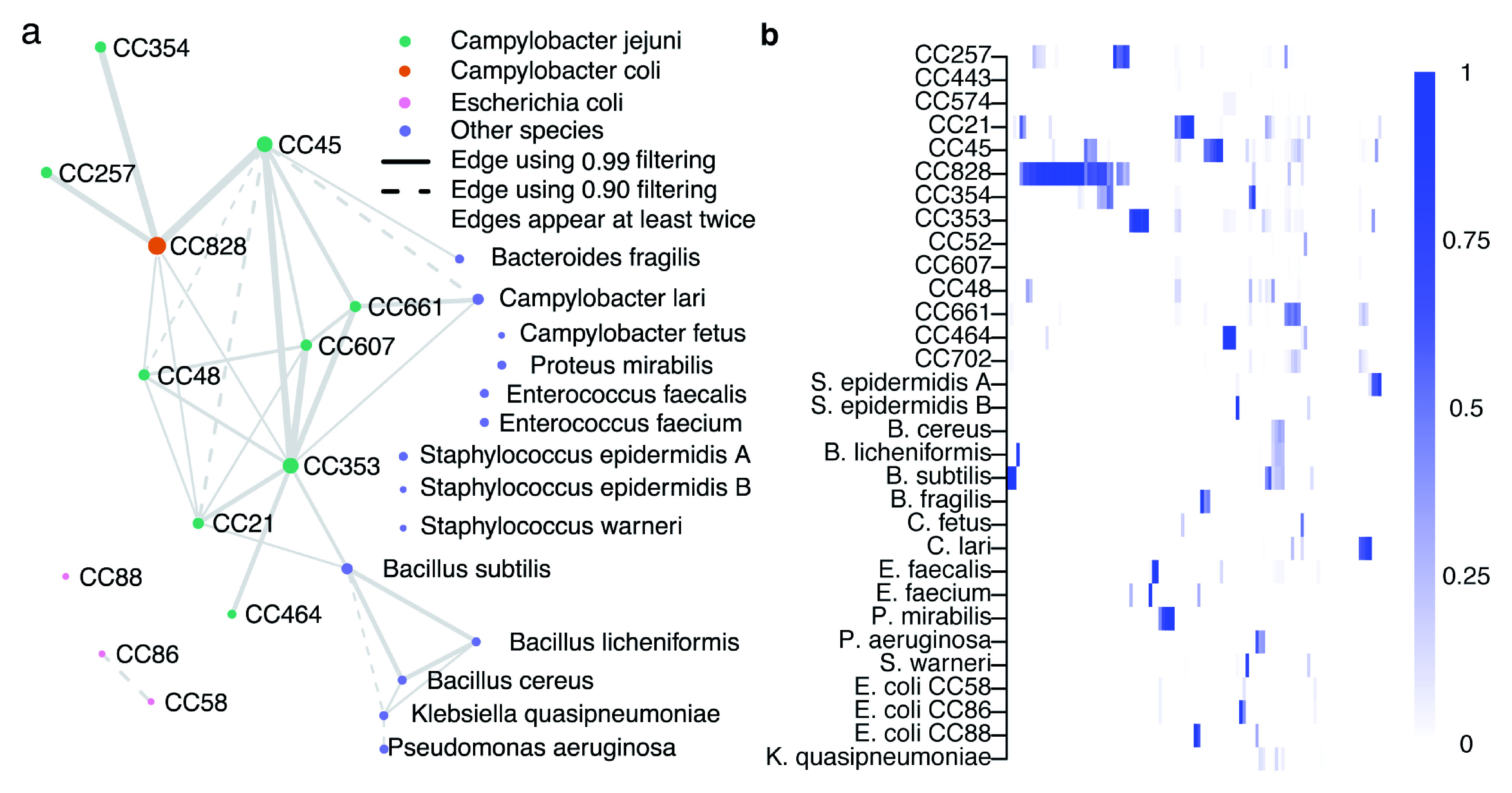
The coexistence network in panel a was constructed from relative abundance estimates filtered by detection thresholds constructed using a confidence score of either 0.90 (dashed edges) or 0.99 (solid edges). An edge between two groups represents coexistence in at least two samples with the chosen threshold. Edge size is proportional to the number of times the joined nodes were observed together, and node size to the total times the group was detected. Panel b visualizes the unfiltered relative abundance estimates in the same reference groups (rows) as in panel a, across 116 samples (columns).
There is some preliminary evidence that common clinical lineages CC45 and CC21 are rarely found together in a single sample (plate sweep) while other lineages, such as the chicken associated CC353, are frequently isolated from samples containing multiple strains. From an evolutionary perspective, it is unlikely that closely related strains can stably occupy identical niches because competition would be expected to lead one to prevail. The results demonstrate co-occurrence of strains within individual host animals and multi-strain infections in humans and provide information about the complex ecology of co-occurring interacting species that leads to the observed community structure in a given sample.
Multi-drug resistant Klebsiella pneumoniae coexist with other lineages
The coexistence network ( Figure 7) and the sample-lineage heatmap (Extended Data Figure S7 24 ) for the 179 human clinical samples of K. pneumoniae demonstrates common co-occurrence of K. pneumoniae with a wide variety of E. coli lineages, as well as occasional co-occurrence with Acinetobacter baumanii and other species. Both E. coli and A. baumanii grow on the media used for culture of K. pneumoniae. Clonal complexes of K. pneumoniae centered on sequence types associated with high levels of multi-drug resistance (e.g. ST258, ST147 and ST101) were frequently observed co-existing with a variety of other K. pneumoniae lineages as well as with each other, and with other important Gram-negative pathogens. Developing a deeper understanding of these community structures and interactions will be critical for monitoring horizontal transfer of antimicrobial resistance genes between taxa.
Figure 7. K. pneumoniae lineage coexistence in 179 mixture samples.
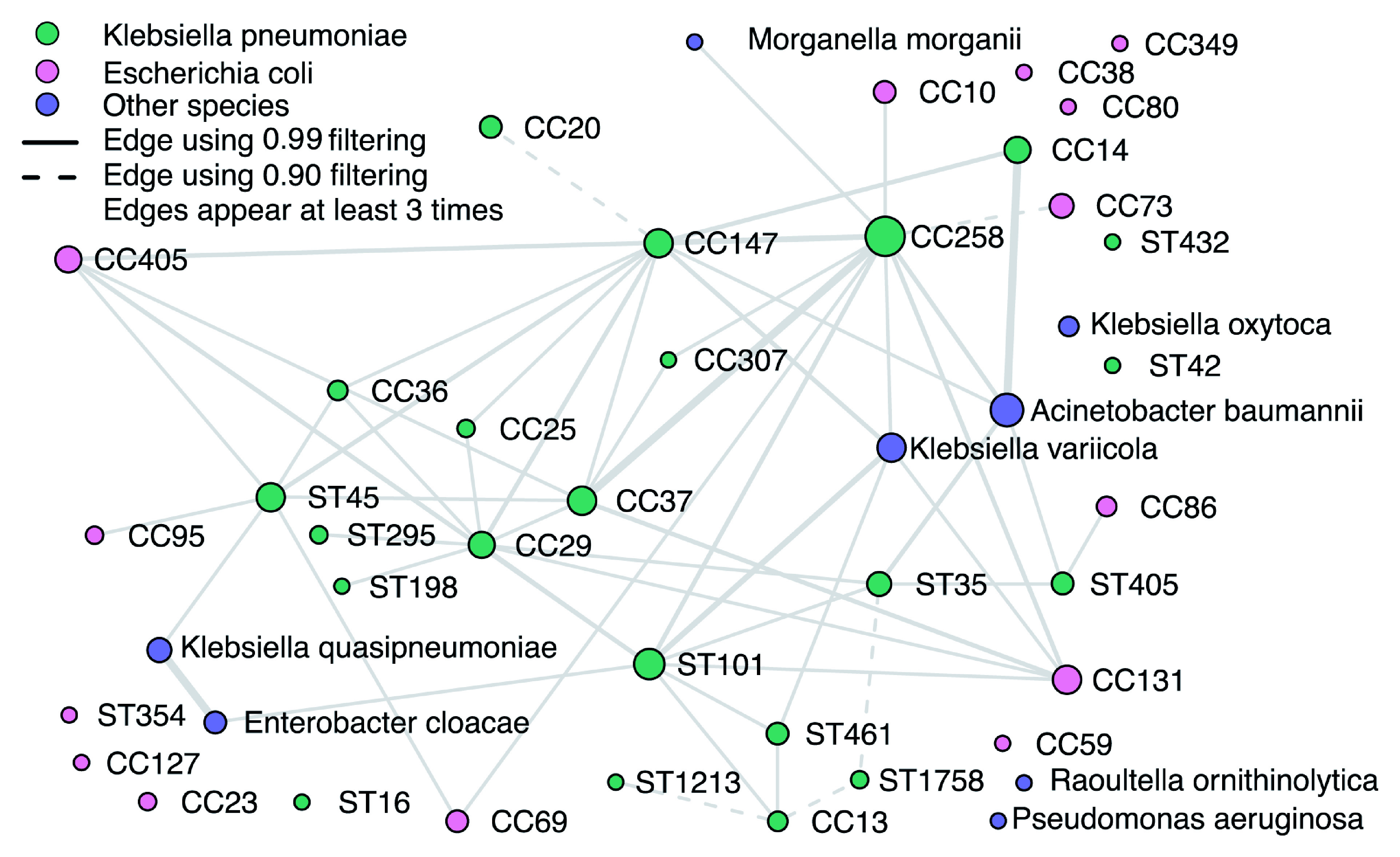
The coexistence network was constructed from relative abundance estimates remaining after filtering by the detection thresholds. Visible edges denote coexistence in at least three samples. Dashed edges represent coexistence when using detection thresholds corresponding to the 0.90 confidence score, and solid edges using the 0.99 detection threshold. Node sizes are proportional to the number of times the lineage was observed; edge sizes to the number of times coexistence was established.
Discussion
Metagenomics using high-throughput sequencing has become a common approach when investigating the bacterial composition of different environments or changes introduced by intervention, such as in the human gut microbiome. In most epidemiological applications, the relevant target organisms are culturable using established media which offers a clear advantage to obtaining high sequencing depths in a cost-effective manner. We developed the mSWEEP pipeline to enable high-resolution inference of the lineages present in plate sweeps of enrichment cultures. mSWEEP can be used to infer the detailed population structure of a single species, or the diverse populations of bacteria typically encountered in clinical and public health settings where standard culturing media is routinely used to isolate epidemiologically relevant organisms. This pipeline also estimates the relative abundance of lineages and reliability cut-offs. mSWEEP was designed to have a minimal execution time using the latest advances in RNA-seq analysis and its maximum memory footprint is determined by the pseudoalignment algorithm. We demonstrated significant improvements in accuracy over the previous state-of-the-art method in our experiments.
mSWEEP provides considerable power for improving our understanding of infection by recovering a true representation of bacteria in a complex sample. For example, genotyping studies have shown that C. jejuni and C. coli colonizing the primary host (birds and mammals) form clusters of related isolates that are host-associated 35 , which can be used to identify the reservoir for human infection 36 . However, multiple organisms can be isolated from the same sources 37, 38 . The co-occurrence of different organisms could be a snapshot in time of a wider process of lineage succession 39 in which the resident microbiota might resist new colonizations or be displaced by recently acquired bacteria 40, 41 . Further, we suggest we may be able to infer complex interactions between organisms that occupy different microniches 42 and are not in direct competition 43, 44 by analysing their co-occurrence. Therefore, this approach provides a means to investigate the nature of polymicrobial infections to improve our understanding of the spread of a specific organism between hosts and transmission to humans in addition to enabling characterization of physical and temporal variation in the distribution of lineages among multi-strain samples.
Because of limitations in the initial culture and DNA isolation processes, we can only infer relative (not absolute) abundances and spike-in methods 45 must be used if an estimate of the absolute abundances is desired. However, only inferring relative abundances is not a significant limitation as the absolute abundances of target organisms are also subject to large biological and technical variation 46 . Memory requirements for large reference collections or simultaneous analysis of multiple samples necessitate a dedicated computer cluster to run the analysis pipeline, but even for very large reference collections the resource usage is still at the level available at most bioinformatics centres. Alternatively, the reference sequences can be modified to include only the directly relevant species, which makes mSWEEP widely applicable to biologists; or traditional alignment algorithms employed to trade decreased memory usage for increased runtime. As with any method intended to identify sequence variation, the target species need to be relatively well known to allow building of sufficiently informative reference databases. Similarly, to allow for sensible and easily interpretable inferences, the biological clustering of the reference database should be based on well-established biological entities, such as multi-locus sequence types (STs) or clonal complexes (CCs) which are frequently employed as labels of lineages. As a by-product, mSWEEP can also be used to estimate the quality of the reference collection and to discard contaminated or mis-identified genomes.
Strain identification from metagenomic data has been recently suggested by the StrainPhlAn method 47 . mSWEEP, and similar methods, are complementary to StrainPhlAn as these methods analyse similar data but from different directions. mSWEEP assigns strains present in the sample to biologically established genetically separated lineages and estimates the relative abundance of these, whereas StrainPhlAn infers SNPs and phylogenetic relations within the whole sample. Given the flexibility and generality of the mSWEEP approach, we anticipate this pipeline will pave the way for numerous novel applications of plate sweep metagenomics in many fields of microbiology.
Conclusions
mSWEEP represents a novel means to quantify the composition of bacterial communities beyond the resolution offered by bacterial identification methods based on 16S ribosomal RNA gene sequencing or whole-genome shotgun metagenomics. We have demonstrated significant improvements in accuracy over similar methods, and novel co-existence analyses using plate sweeps of enrichment cultures of the human pathogens Campylobacter jejuni, Campylobacter coli, Escherichia coli, Klebsiella pneumoniae and Staphylococcus epidermidis. We expect that mSWEEP will find use in similar studies of bacterial pathogens, where high-resolution inference is required, ample reference collections for the species of interest are available, and the plate sweep metagenomic approach can be applied in-depth at a fraction of the current cost of single-colony sequencing.
Methods
Reference construction
The reference sequences ( Table 1, Extended Data Table S4 48 ) are the genomic assemblies of a number of strains or species that represent the organisms of interest in a sample. We used a collection of assemblies from four studies 17– 20 augmented with the genomes of a representative strain from 27 species that were identified in the real mixture data by MetaPhlAn 49 .
Grouping the reference sequences
We used multilocus sequence typing (MLST) of the C. coli, C. jejuni, E. coli and K. pneumoniae reference sequences to group them into clonal complexes defined by the allelic profile of a central sequence type, and all other sequence types that vary in at most a single MLST locus ( C. coli and C. jejuni) or in at most two loci ( E. coli and K. pneumoniae). The K. pneumoniae reference contained sequences belonging to K. variicola, K. quasipneumoniae, and K. quasivariicola which we assigned to three groups defined by the three species. We similarly treated the 181 S. aureus contained in the S. epidermidis study as a single group, and split the 143 S. epidermidis sequences using the first and second levels of the hierarchical clustering produced by the hierBAPS 22 software (version 6.0). The complete grouping is provided in Extended Data Table S4 48 .
Pseudoalignment
We used kallisto 14 (version 0.45) with default settings to perform pseudoalignment. Pseudoalignment produces binary compatibility vectors which indicate whether the read pseudoaligns to a reference sequence or not. In our model, we sum the pseudoalignment counts within each reference group and thus consider the observations of the reads r n = ( r n,1, ... , r n,k ), n = 1, ... , N as containing only the information about the number of pseudoalignments r n,k within each of the K groups.
Abundance estimation model
We assume that the reads r n are conditionally independent given the mixing proportions of the groups θ = ( θ 1, ..., θ K ), and augment the model with the latent indicator variables I = I 1, ..., I N which denote the true source group of each read. The joint distribution of the collection of reads R = r 1, ..., r N , the indicator variables I = I 1, ..., I N for the source group, and the mixing proportions of the groups θ = ( θ 1, ..., θ K ) is defined as
The formulation in Equation (1) corresponds to a standard mixture model with observations r n , categorically distributed latent variables I n , event probability parameters θ, and the likelihood p( r n | I n = k) of observing the full pseudoalignment count vector r n given that the group k is the true source.
Likelihood
The likelihood p( r n | I n = k) needs to be defined carefully in order to satisfy the goals of invariance to group identity and size, and monotonicity with increasing pseudoalignment counts within a group. Given the vector r n , whose components r n,k denote the pseudoalignment count in group k, we define the likelihood p( r n | I n = k) of observing the whole vector r n assuming that k is the true group in three parts
with
where B( a, b) is the beta function and M k is the number of reference sequences in the group k. Equation (2) and Equation (3) zero inflate the model by an amount roughly corresponding to the error rate in both the sequencing data and the reference sequences. The denominator Z( r n ) in Equation (4) and Equation (5) arises from deriving the normalizing constant for normalizing f( r n,k, k) over r n . The derivation follows from using the identity to express each f( r n,k, k), k = {1, ..., K : M k > 1} as a product of the probability mass function of a beta-binomial distribution with parameters ( α k + M k , β k ), and the term which leads to the form f( r n,k, k) has in Equation (5). Then, Z( r n ) is obtained by considering normalizing over the full vector f( r n ) = ( f( r n,1, 1), ..., f( r n,k, k), ..., f( r n,K, K)), where k = {1,..., K : M k > 1}.
The formulation of f( r n,k, k) in Equation (4) and Equation (5) intuitively arises when the probability mass function of a beta-binomial random variable with hyperparameters ( α k , β k ) is multiplied by the factor This factor is the inverse of the value of the probability mass function when the observed value is equal to the total number of sequences M k in the group, meaning in our context a read which is compatible with all reference sequences in a group. Formulating the likelihood in this manner ( Equation (4) and Equation (5)) causes groups where all sequences in the group are compatible with the read to have equal likelihoods. Compared to a model assuming independence between the groups, this formulation reduces the effect of the likelihoods being flattened in groups with large numbers of assigned reference sequences when compared to small groups, which is necessary to compare groups that differ greatly in size.
Reads with identical pseudoalignment count vectors r n have the same likelihood and can be assigned into equivalence classes defined by the count of compatible sequences in each group. This enables a computational optimization where the likelihoods need only be calculated for the observed equivalence classes and then multiplied by the total number of times each equivalence class was observed.
Model hyperparameters
Instead of using the parametrization ( α k , β k ) in Equation (5), we use a reparameterization where
The first parameter π k corresponds to the mean of the beta distribution that has been compounded with a binomial distribution to obtain the beta-binomial-derived component in Equation (5), and the second parameter φ k represents a measure of variation in the success probability of each observation 50 .
We constrain the mean success rate π k in Equation (6) to π k ∊ (0.5, 1), which produces beta-binomial distributions with an increasing probability mass function 51 in the number of compatible sequences r n,k , which leads to the definition in Equation (5) having the same property. Increasing probability mass functions fulfil our requirement for the likelihood that of two equally sized groups with different number of compatible reference sequences, the one with more compatible sequences is always a better candidate for being the true source. The values of the parameters ( π k , φ k ) are set to to capture the variance in the alignment count distributions and perform well across the set of experiments presented.
Inference
We perform inference over the mixing proportions θ of the different groups using fast collapsed variational inference 52 . The method collapses the mixing proportions θ and uses natural gradients to optimise an approximation to the posterior distribution over the indicator variables I n , assuming the distribution factorises over θ and I n . The same variational Bayesian method was also used in BitSeqVB 16 to obtain transcript expression levels and has been applied to estimate mixing proportions in bacterial sequencing data in BIB 11 using a different likelihood. The prior distribution on the mixing proportions θ is set to Dirichlet ( α, ..., α) with α = 1. The same prior was also used by BIB. Since reads originating from the same equivalence class have the same likelihood, variational inference will yield identical posterior inferences for them. This allows us to perform the inference on the smaller number of equivalence classes rather than all reads, leading to faster inference.
Detection thresholds
Detection thresholds define a means to quantify reliable identification of the reference groups through constructing a minimum relative abundance threshold on the groups. Abundance estimates that fall under the threshold are considered unreliable and set to zero. To obtain the detection thresholds ( Figure 1), we generate 100 samples from each reference group within a species by resampling one million sequencing reads from a randomly chosen reference sequence for that group, roughly matching the number of reads in our study samples, from the reads used to assemble the chosen sequence. Only reads corresponding to one sequence are used in each new sample. Reads included in the new samples are sampled with replacement with each read having the same probability of being included. The sequences used for resampling were chosen at random such that the number of reference sequences from each group corresponds to the square root of the total size of the group. Each group is represented at least once, except for groups which contain only one reference sequence where we apply the maximum detection threshold observed for other groups of the same species. Similarly, species that are represented in the reference by a single group were not resampled from, and the detection threshold was instead fixed at 0.05. After resampling, the new samples are put through pseudoalignment and mSWEEP abundance estimation without including the sequences used in resampling as pseudoalignment reference sequences.
In defining the detection thresholds, the relative abundance estimates obtained from the resampled sequencing reads are represented by where n = 1, ..., N (in our examples we chose N = 100) indicates the new samples resampled from the reference group i = 1, ..., K. The third index j = 1, ..., K denotes the reference group that the abundance estimate was obtained for. We first define source-specific thresholds q i,j that give a threshold on the reference groups j assuming that the true group i in the sample is known. The source-specific threshold q i,j on group j ≠ i is defined by ordering the relative abundance estimates for the cluster j, in an ascending order in n, and determining the cutoff point q i,j where m,m ∊ {1, ..., N}, relative abundance estimates fall below the cutoff. Using the source-specific thresholds q i,j , we define the detection threshold q i on group i as q i = max{ max{ j : q i,j }, ∈}, where ∈ is the constant minimum threshold for a specific grouping of the sequences within a species that is observed when comparing the empirical cumulative distribution functions in Extended Data Figure S5. We recommend that ∈ be determined for new species by a synthetic mixing procedure similar to what was used to compare the accuracy of mixture estimates to their single-colony counterparts in Figure 4.
Based on the selected value of m, we define a statistical confidence score for the abundance estimates exceeding the detection threshold q i as
which corresponds roughly to the fraction of resampled samples that exceed the threshold corresponding to the value of m. Using a value of m closer to the number of samples N in constructing the detection thresholds result in stricter thresholds and thus more confidence in the abundance estimates exceeding the threshold. Results reported in our experiments include thresholds constructed with m = 100 and m = 90, corresponding to confidence scores ( Equation 7) of approximately 0.99 and 0.90, respectively.
Implementation
The mSWEEP software provides a C++ implementation of the abundance estimation part of the pipeline described in this manuscript. After pseudoaligning the sequencing reads, mSWEEP can be called from the command line to construct the abundance estimation model and infer the relative abundances of the reference lineages as described above in the Abundance estimation model, Likelihood, Model hyperparameters, and Inference sections. The mSWEEP pipeline consists of running both the pseudoalignment and the mSWEEP abundance estimation software.
Operation
Precompiled binaries and the source code for the mSWEEP software are available in GitHub. Compiling mSWEEP from source requires a compiler with full support for the C++11 standard (for example clang version 3.3 or later, or GCC version 4.8.1 or later) and the build process utility CMake (version 2.8.12 or later). The mSWEEP software itself does not have additional external dependencies. Prospective users of the mSWEEP pipeline will also need to install kallisto 14 for pseudoalignment, and possibly construct a set of scripts tailored to their reference data should they wish to take advantage of the detection threshold approach. The GitHub repository includes usage information, a general pipeline for abundance estimation with mSWEEP, and a toy dataset for an example workflow.
A typical workflow with mSWEEP begins by indexing the set of reference sequences (reference.fasta below) for pseudoalignment (here using kallisto version 0.45)
kallisto -i kallisto_index reference.fasta
The reference sequences need to be indexed only once and the same index can be used multiple times.
Analysing sequencing data (below the paired-end reads in two files: reads_1.fastq.gz and reads_2.fastq.gz) is done by first using kallisto to pseudoalign the reads
kallisto pseudo -i kallisto_index -o pseudoalignments reads_1.fastq.gz reads_2.fastq.gz
and then running the mSWEEP software (here using version 1.1.0) to produce the relative_abundances.txt file containing the relative abundance estimates.
mSWEEP -f pseudoalignments -i lineages.txt -o relative_abundances.txt
The lineages.txt file defines the reference lineages, with each line in the file containing the name of the lineage the corresponding sequence in the reference.fasta file has been assigned to. Entries in the lineages.txt file must be in the same order as the sequences are in the reference.fasta file.
E. coli plate sweeps from Vietnamese children
In Ho Chi Minh City, 750 children were recruited into a diarrhoeal cohort study and followed for 2 years. Stool samples were collected at routine sampling points and when the children had an episode of diarrhoea. All stool samples were cultured to identify pathogens and onto MacConkey plates to isolate E. coli and other Enterobacteriaceae. The MacConkey plates were scraped and stored in 20% glycerol at -80 °C. The frozen plate sweeps from 48 diarrhoea episodes, paired with 48 asymptomatic samples (96 in total), were revived on MacConkey media; plates were scraped and total genomic DNA was extracted using the Wizard genomic DNA purification kit (Promega, USA). The extracted DNA was sequenced using the Illumina HiSeq platform using the method described elsewhere 53 . Antimicrobial resistance genes were detected using the ARIBA software 27 . The raw sequence data can be found in the ENA under the accession numbers detailed in Extended Data Table S5.
Ethics approval and consent to participate
Ethical approval was required for the cohort study contributing the E. coli organisms. Approvals were provided by the Oxford University Tropical Research Ethics Committee (OxTREC approval 1058–13) as well as from the local partners (Institutional Review Board at the Hospital for Tropical Diseases and Hung Vuong Hospital). Written informed consent was obtained from the parent or guardian of all children for participation in the study.
Data availability
Underlying data
Figshare: mSWEEP_reference_v1-0-0.tgz, https://doi.org/10.6084/m9.figshare.8222636.v2 54 . This project contains the reference sequences and the grouping used in producing the results.
Data are available under the terms of the Creative Commons Zero "No rights reserved" data waiver (CC0 1.0 Public domain dedication).
Accession numbers for the reference data can be found in Extended Data Table S4 48 . Accession numbers for the 96 Vietnamese E. coli plate sweeps are available in Extended Data Table S5 31 . Accession numbers for the K. pneumoniae mixture samples and 39 Campylobacter mixture samples are available in Extended Data Table S6 57 . The remaining 77 Campylobacter mixture samples have been submitted to Figshare:
-
-
campylobacter_mixtures_1.tgz, https://doi.org/10.6084/m9.figshare.6445136.v1 55 .
-
-
campylobacter_mixtures_2.tgz, https://doi.org/10.6084/m9.figshare.6445190.v1 56 .
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
Extended data
All extended data files have been submitted to Figshare under the mSWEEP project ( https://figshare.com/projects/mSWEEP/64172).
Figshare: Extended Data Figures S1–S7. Additional figures supporting claims in the manuscript, https://doi.org/10.6084/m9.figshare.11379648.v1 24 .
Figshare: Extended Data Table S1. Table of the most common clonal complexes and sequence types identified in the Vietnamese E. coli samples, https://doi.org/10.6084/m9.figshare.11379705.v1 29 .
Figshare: Extended Data Table S2. Antimicrobial classes found in the Vietnamese E. coli samples; separated by diarrheal and healthy samples, https://doi.org/10.6084/m9.figshare.11379753.v1 34 .
Figshare: Extended Data Table S3. Full antimicrobial resistance gene data in the Vietnamese E. coli samples, as identified by ARIBA, https://doi.org/10.6084/m9.figshare.11379756.v1 28 .
Figshare: Extended Data Table S4. Description, accession numbers, and source studies for the reference sequence data used with mSWEEP, https://doi.org/10.6084/m9.figshare.11379762.v1 48 .
Figshare: Extended Data Table S5. Accession numbers, status, and names of the Vietnamese E. coli samples, https://doi.org/10.6084/m9.figshare.11379771.v1 31 .
Figshare: Extended Data Table S6. Accession numbers for the Klebsiella and Campylobacter mixture samples available in public repositories, https://doi.org/10.6084/m9.figshare.11379777.v1 57 .
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
Software availability
Source code and precompiled binaries (generic Linux and macOS) for the mSWEEP software: https://github.com/PROBIC/mSWEEP
Archived source code as at time of publication: https://doi.org/10.5281/zenodo.3585009 58
License: MIT
Acknowledgements
A previous version of this work is available from: https://doi.org/10.1101/332544.
Funding Statement
This work was supported by the Academy of Finland (grants no. 259440 and 310261; to TM and AH) as well as the Flagship programme (Finnish Center for Artificial Intelligence FCAI; to JC and AH). TK, JC, DA and EJF are supported by the JPI-AMR consortium SpARK (MR/R00241X/1). JC was funded by the ERC (grant no. 742158). TK was funded by the Norwegian Research Council JPIAMR (grant no. 144501). SB is a Sir Henry Dale Fellow, jointly funded by the Wellcome Trust and the Royal Society [100087]. Sequencing of the Vietnamese E. coli samples was supported by the Wellcome Trust [098051]. Computational resources were provided by the 'Finnish Grid and Cloud Infrastructure' (persistent identifier urn:nbn:fi:research-infras-2016072533).
The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
[version 1; peer review: 1 approved, 1 approved with reservations]
References
- 1. Ellegaard KM, Engel P: Beyond 16S rRNA Community Profiling: Intra-Species Diversity in the Gut Microbiota. Front Microbiol. 2016;7:1475. 10.3389/fmicb.2016.01475 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Quince C, Walker AW, Simpson JT, et al. : Shotgun metagenomics, from sampling to analysis. Nat Biotechnol. 2017;35(9):833–844. 10.1038/nbt.3935 [DOI] [PubMed] [Google Scholar]
- 3. Yang X, Noyes NR, Doster E, et al. : Use of Metagenomic Shotgun Sequencing Technology To Detect Foodborne Pathogens within the Microbiome of the Beef Production Chain. Appl Environ Microbiol. 2016;82(8):2433–2443. 10.1128/AEM.00078-16 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Ye SH, Siddle KJ, Park DJ, et al. : Benchmarking Metagenomics Tools for Taxonomic Classification. Cell. 2019;178(4):779–794. 10.1016/j.cell.2019.07.010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Sczyrba A, Hofmann P, Belmann P, et al. : Critical Assessment of Metagenome Interpretation-a benchmark of metagenomics software. Nat Methods. 2017;14(11):1063–1071. 10.1038/nmeth.4458 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Greenblum S, Carr R, Borenstein E: Extensive strain-level copy-number variation across human gut microbiome species. Cell. 2015;160(4):583–594. 10.1016/j.cell.2014.12.038 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Joseph SJ, Li B, Ghonasgi T, et al. : Direct amplification, sequencing and profiling of Chlamydia trachomatis strains in single and mixed infection clinical samples. PLoS One. 2014;9(6):e99290. 10.1371/journal.pone.0099290 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Nayfach S, Rodriguez-Mueller B, Garud N, et al. : An integrated metagenomics pipeline for strain profiling reveals novel patterns of bacterial transmission and biogeography. Genome Res. 2016;26(11):1612–1625. 10.1101/gr.201863.115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Paterson GK, Harrison EM, Murray GGR, et al. : Capturing the cloud of diversity reveals complexity and heterogeneity of MRSA carriage, infection and transmission. Nat Commun. 2015;6:6560. 10.1038/ncomms7560 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Worby CJ, Lipsitch M, Hanage WP: Within-host bacterial diversity hinders accurate reconstruction of transmission networks from genomic distance data. PLoS Comput Biol. 2014;10(3):e1003549. 10.1371/journal.pcbi.1003549 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Sankar A, Malone B, Bayliss SC, et al. : Bayesian identification of bacterial strains from sequencing data. Microb Genom. 2016;2(8):e000075. 10.1099/mgen.0.000075 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Fischer M, Strauch B, Renard BY: Abundance estimation and differential testing on strain level in metagenomics data. Bioinformatics. 2017;33(14):i124–i132. 10.1093/bioinformatics/btx237 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Schaeffer L, Pimentel H, Bray N, et al. : Pseudoalignment for metagenomic read assignment. Bioinformatics. 2017;33(14):2082–2088. 10.1093/bioinformatics/btx106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Bray NL, Pimentel H, Melsted P, et al. : Near-optimal probabilistic RNA-seq quantification. Nat Biotechnol. 2016;34(5):525–527. 10.1038/nbt.3519 [DOI] [PubMed] [Google Scholar]
- 15. Glaus P, Honkela A, Rattray M: Identifying differentially expressed transcripts from RNA-seq data with biological variation. Bioinformatics. 2012;28(13):1721–1728. 10.1093/bioinformatics/bts260 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Hensman J, Papastamoulis P, Glaus P, et al. : Fast and accurate approximate inference of transcript expression from RNA-seq data. Bioinformatics. 2015;31(24):3881–3889. 10.1093/bioinformatics/btv483 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Kallonen T, Brodrick HJ, Harris SR, et al. : Systematic longitudinal survey of invasive Escherichia coli in England demonstrates a stable population structure only transiently disturbed by the emergence of ST131. Genome Res. 2017;27(8):1437–1449. 10.1101/gr.216606.116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Long SW, Olsen RJ, Eagar TN, et al. : Population Genomic Analysis of 1,777 Extended-Spectrum Beta-Lactamase-Producing Klebsiella pneumoniae Isolates, Houston, Texas: Unexpected Abundance of Clonal Group 307. mBio. 2017;8(3):pii: e00489-17. 10.1128/mBio.00489-17 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Meric G, Miragaia M, de Been M, et al. : Ecological Overlap and Horizontal Gene Transfer in Staphylococcus aureus and Staphylococcus epidermidis. Genome Biol Evol. 2015;7(5):1313–1328. 10.1093/gbe/evv066 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Yahara K, Meric G, Taylor AJ, et al. : Genome-wide association of functional traits linked with Campylobacter jejuni survival from farm to fork. Environ Microbiol. 2017;19(1):361–380. 10.1111/1462-2920.13628 [DOI] [PubMed] [Google Scholar]
- 21. Maiden MC, Bygraves JA, Feil E, et al. : Multilocus sequence typing: a portable approach to the identification of clones within populations of pathogenic microorganisms. Proc Natl Acad Sci U S A. 1998;95(6):3140–3145. 10.1073/pnas.95.6.3140 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Cheng L, Connor TR, Sirén J, et al. : Hierarchical and spatially explicit clustering of DNA sequences with BAPS software. Mol Biol Evol. 2013;30(5):1224–1228. 10.1093/molbev/mst028 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Runcharoen C, Moradigaravand D, Blane B, et al. : Whole genome sequencing reveals high-resolution epidemiological links between clinical and environmental Klebsiella pneumoniae. Genome Med. 2017;9(1):6. 10.1186/s13073-017-0397-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Mäklin T, Kallonen T, David S, et al. : Extended Data Figures S1-S7. figshare. Figure.2019. 10.6084/m9.figshare.11379648.v2 [DOI]
- 25. Maaten Lvd, Hinton G: Visualizing data using t-SNE. J Mach Learn Res. 2008;9:2579–2605. Reference Source [Google Scholar]
- 26. Ondov BD, Treangen TJ, Melsted P, et al. : Mash: fast genome and metagenome distance estimation using MinHash. Genome Biol. 2016;17(1):132. 10.1186/s13059-016-0997-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Langmead B, Salzberg SL: Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012;9(4):357–359. 10.1038/nmeth.1923 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S3. figshare. Dataset.2019. 10.6084/m9.figshare.11379756.v2 [DOI]
- 29. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S1. figshare. Dataset.2019. 10.6084/m9.figshare.11379705.v2 [DOI]
- 30. Hunt M, Mather AE, Sánchez-Busó L, et al. : ARIBA: rapid antimicrobial resistance genotyping directly from sequencing reads. Microb Genom. 2017;3(10):e000131. 10.1099/mgen.0.000131 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S5. figshare. Dataset.2019. 10.6084/m9.figshare.11379771.v2 [DOI]
- 32. Magiorakos AP, Srinivasan A, Carey RB, et al. : Multidrug-resistant, extensively drug-resistant and pandrug-resistant bacteria: an international expert proposal for interim standard definitions for acquired resistance. Clin Microbiol Infect. 2012;18(3):268–281. 10.1111/j.1469-0691.2011.03570.x [DOI] [PubMed] [Google Scholar]
- 33. Liu YY, Wang Y, Walsh TR, et al. : Emergence of plasmid-mediated colistin resistance mechanism MCR-1 in animals and human beings in China: a microbiological and molecular biological study. Lancet Infect Dis. 2016;16(2):161–168. 10.1016/S1473-3099(15)00424-7 [DOI] [PubMed] [Google Scholar]
- 34. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S2. figshare. Dataset.2019. 10.6084/m9.figshare.11379753.v2 [DOI]
- 35. Sheppard SK, Colles FM, McCarthy ND, et al. : Niche segregation and genetic structure of Campylobacter jejuni populations from wild and agricultural host species. Mol Ecol. 2011;20(16):3484–3490. 10.1111/j.1365-294X.2011.05179.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Sheppard SK, Dallas JF, Strachan NJ, et al. : Campylobacter genotyping to determine the source of human infection. Clin Infect Dis. 2009;48(8):1072–1078. 10.1086/597402 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Colles FM, McCarthy ND, Layton R, et al. : The prevalence of Campylobacter amongst a free-range broiler breeder flock was primarily affected by flock age. PLoS One. 2011;6(12):e22825. 10.1371/journal.pone.0022825 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Sproston EL, Ogden ID, MacRae M, et al. : Temporal variation and host association in the Campylobacter population in a longitudinal ruminant farm study. Appl Environ Microbiol. 2011;77(18):6579–6586. 10.1128/AEM.00428-11 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Lu J, Idris U, Harmon B, et al. : Diversity and succession of the intestinal bacterial community of the maturing broiler chicken. Appl Environ Microbiol. 2003;69(11):6816–6824. 10.1128/aem.69.11.6816-6824.2003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Buffie CG, Pamer EG: Microbiota-mediated colonization resistance against intestinal pathogens. Nat Rev Immunol. 2013;13(11):790–801. 10.1038/nri3535 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Nowrouzian FL, Wold AE, Adlerberth I: Escherichia coli strains belonging to phylogenetic group B2 have superior capacity to persist in the intestinal microflora of infants. J Infect Dis. 2005;191(7):1078–1083. 10.1086/427996 [DOI] [PubMed] [Google Scholar]
- 42. Hayashi H, Takahashi R, Nishi T, et al. : Molecular analysis of jejunal, ileal, caecal and recto-sigmoidal human colonic microbiota using 16S rRNA gene libraries and terminal restriction fragment length polymorphism. J Med Microbiol. 2005;54(Pt 11):1093–1101. 10.1099/jmm.0.45935-0 [DOI] [PubMed] [Google Scholar]
- 43. Johns BE, Purdy KJ, Tucker NP, et al. : Phenotypic and Genotypic Characteristics of Small Colony Variants and Their Role in Chronic Infection. Microbiol Insights. 2015;8:15–23. 10.4137/MBI.S25800 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. von Bronk B, Schaffer SA, Götz A, et al. : Effects of stochasticity and division of labor in toxin production on two-strain bacterial competition in Escherichia coli. PLoS Biol. 2017;15(5):e2001457. 10.1371/journal.pbio.2001457 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Stämmler F, Gläsner J, Hiergeist A, et al. : Adjusting microbiome profiles for differences in microbial load by spike-in bacteria. Microbiome. 2016;4(1):28. 10.1186/s40168-016-0175-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Costea PI, Zeller G, Sunagawa S, et al. : Towards standards for human fecal sample processing in metagenomic studies. Nat Biotechnol. 2017;35(11):1069–1076. 10.1038/nbt.3960 [DOI] [PubMed] [Google Scholar]
- 47. Truong DT, Tett A, Pasolli E, et al. : Microbial strain-level population structure and genetic diversity from metagenomes. Genome Res. 2017;27(4):626–638. 10.1101/gr.216242.116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S4. figshare. Dataset.2019. 10.6084/m9.figshare.11379762.v2 [DOI]
- 49. Segata N, Waldron L, Ballarini A, et al. : Metagenomic microbial community profiling using unique clade-specific marker genes. Nat Methods. 2012;9(8):811–814. 10.1038/nmeth.2066 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Griffiths DA: Maximum likelihood estimation for the beta-binomial distribution and an application to the household distribution of the total number of cases of a disease. Biometrics. 1973;29(4):637–648. 10.2307/2529131 [DOI] [PubMed] [Google Scholar]
- 51. Berg S: Condorcet's jury theorem, dependency among jurors. Social Choice and Welfare. 1993;10:87–95. 10.1007/BF00187435 [DOI] [Google Scholar]
- 52. Hensman J, Rattray M, Lawrence ND: Fast Variational Inference in the Conjugate Exponential Family. In Advances in Neural Information Processing Systems25.2012. Reference Source [Google Scholar]
- 53. Quail MA, Otto TD, Gu Y, et al. : Optimal enzymes for amplifying sequencing libraries. Nat Methods. 2011;9(1):10–11. 10.1038/nmeth.1814 [DOI] [PubMed] [Google Scholar]
- 54. Mäklin T, Kallonen T, David S, et al. : mSWEEP_reference_v1-0-0.tgz. figshare. Dataset.2019. 10.6084/m9.figshare.8222636.v2 [DOI]
- 55. Mäklin T, Kallonen T, David S, et al. : campylobacter_mixtures_1.tgz. figshare. Dataset. 2018. 10.6084/m9.figshare.6445136 [DOI]
- 56. Mäklin T, Kallonen T, David S, et al. : campylobacter_mixtures_2.tgz. figshare. Dataset.2018. 10.6084/m9.figshare.6445190 [DOI]
- 57. Mäklin T, Kallonen T, David S, et al. : Extended Data Table S6. figshare. Dataset.2019. 10.6084/m9.figshare.11379777.v2 [DOI]
- 58. Mäklin T, Honkela A: PROBIC/mSWEEP: v1.1.0 (17 December 2018). (Version v1.1.0) Zenodo. 2019. 10.5281/zenodo.3585009 [DOI] [Google Scholar]