

Abstract
Medical image processing is one of the most important topics in the Internet of Medical Things (IoMT). Recently, deep learning methods have carried out state-of-the-art performances on medical imaging tasks. In this paper, we propose a novel transfer learning framework for medical image classification. Moreover, we apply our method COVID-19 diagnosis with lung Computed Tomography (CT) images. However, well-labeled training data sets cannot be easily accessed due to the disease's novelty and privacy policies. The proposed method has two components: reduced-size Unet Segmentation model and Distant Feature Fusion (DFF) classification model. This study is related to a not well-investigated but important transfer learning problem, termed Distant Domain Transfer Learning (DDTL). In this study, we develop a DDTL model for COVID-19 diagnosis using unlabeled Office-31, Caltech-256, and chest X-ray image data sets as the source data, and a small set of labeled COVID-19 lung CT as the target data. The main contributions of this study are: 1) the proposed method benefits from unlabeled data in distant domains which can be easily accessed, 2) it can effectively handle the distribution shift between the training data and the testing data, 3) it has achieved 96% classification accuracy, which is 13% higher classification accuracy than “non-transfer” algorithms, and 8% higher than existing transfer and distant transfer algorithms.
Keywords: COVID-19 diagnosis, deep learning, distant transfer learning, domain adaptation, machine learning, medical image processing, transfer learning
I. Introduction
Recently, with state-of-art performance, deep learning has dominated the field of image processing [1]–[3]. However, deep learning methods require a massive amount of well-labeled training data, and the majority of deep leaning methods are sensitive to the domain shift [4]. Therefore, transfer learning (TL) has been introduced to deal with the issues [5], [6]. In this paper, we propose a novel medical image classification framework. Moreover, we implement our framework to COVID-19 diagnose with CT images. Generally, medical image data sets are difficult to access due the rarity of diseases and privacy policies. Moreover, it is not feasible to manually collect a massive amount of high-quality labeled lung CT scans associated with of COVID-19. Therefore, it is hard to develop a regular deep lea ring model with insufficient training data. To overcome this obstacle, artificial and synthetic data can be used to expand the volume of the data. However, these methods can lead to a distribution mismatch between the training data and the testing data. Furthermore, transfer learning can handle both problems simultaneously. In theory, transfer learning algorithms aim to develop robust target models by transferring knowledge from other domains and tasks. Previously, [7] proposed an adaptation layer with domain distance measurements to transfer knowledge between deep neural networks. In general, conventional transfer learning algorithms assume that the source domains and the targets share a certain amount of information. However, this assumption does not always hold in many real-world applications, such as medical image processing [8], [9], rare species detection [10] and recommendation systems [11], [12]. Moreover, transferring between two loosely related domains usually causes negative transfer [13], meaning that the knowledge transfer starts hurting the performance on the task in the target domain. For instance, building a dog classification model by directly transferring knowledge from a car classification model would likely to lead to negative transfer due to the weak connection between the two domains. Therefore, it is not always feasible to apply transfer learning to areas where we cannot easily obtain enough source domain data related to the target domain. For instance, COVID-19 diagnosis based on lung CT is a typical example where we cannot easily find related source data for training.
In this paper, we develop a lung CT scan-based COVID-19 classification framework by studying a challenging problem, DDTL, which aims to deal with the shortcomings of traditional machine learning and conventional TL. As shown in Fig. 1, the proposed framework contains two parts: semantic segmentation and DFF. It can perform knowledge transfer between seemingly unrelated domains. Moreover, DDTL [14] is a newly introduced transfer learning method that mainly aims to address the issue of negative transfer caused by loose relations of the source domains and the target domains. Unlike conventional TL methods, the proposed DDTL algorithm benefits from fusing distant features extracted from distant domains. Generally, DDTL is usually involved with situation that the source domain and the target domain have completely tasks. Moreover, the inspiration for DDTL is from the ability of human beings to learn new things by bridging knowledge acquired from several seemingly independent things. For example, a human who knows birds and airplanes can recognize a rocket even without seeing any rockets previously. Importantly, DDTL dramatically extends the use of transfer learning to more areas, and applications where do not always have adequate related source data. In this case, we consider COVID-19 classification as a DDTL problem that can benefit from distant but more accessible domains. Furthermore, we use three open-source image data sets as source domain data sets to develop a robust COVID-19 classification method based on lung CT images.
Fig. 1.

Architecture overview of distant feature fusion model.
Previously, there are few proposed distant transfer algorithms [14], [15], but most of them are task-specific and lack the stability in performance. Inspired by an instance-based method [15] and multi-task learning [16], we build a DDTL algorithm to solve COVID-19 classification tasks by extracting and fusing distant features. There are two main improvements made by our algorithm. Firstly, it does not require any labeled source domain data, and the source domains can be completely different from the target domain. The proposed model only needs a small amount of labeled target domain and can produce very promising classification accuracy on the target domain. Secondly, it only focuses on improving the performance of the target task in the target domain. To the best of our knowledge, it is the first time that DDTL has been applied to medical image classification. Furthermore, we introduce a novel feature selection method (DFF) to discover general features across distant domains and tasks by using convolutional autoencoders with a domain distance measurement. To outline, there are four main contributions made in this study: 1) Propose a new DDTL algorithm for fast and accurate COVID-19 diagnose based on lung CT, 2) Examine existing deep learning models (transfer and non-transfer) on COVID-19 classification problem, 3) The proposed algorithms has achieved the highest accuracy on this task, which has a small set of labeled target data and some unlabeled source data from different domains. Moreover, compared with other transfer learning methods, supervised learning methods, and existing DDTL methods, the proposed DFF model has achieved up to 34% higher classification accuracy and 4) The proposed framework can be easily generalized to other medical image processing problems.
The remainder of this paper is structured as follows: In Section II, we first review the most recent DTTL works. And then, we formulate the problem definition in Section III. Next, we present the details of the proposed algorithm in Section IV. After that, we present experimental results and analysis in Section V. Lastly, we conclude the paper and discuss future directions in Section VI.
II. Related Work
Insufficient training data and domain distribution mismatch have become the two most challenging problems in machine learning. To address these two issues, transfer learning has emerged a lot of attention due to its training efficiency and domain shift robustness. However, transfer learning also suffers from a critical shortcoming, negative transfer [17], which significantly limits the use and performance of transfer learning. In this section, we introduce some related works in three fields: conventional transfer learning, DDTL, and existing ML methods for COVID-19 classification.
A. Conventional Transfer Learning
First of all, TL methods aim to solve the target task by leveraging the common knowledge learned from source tasks in different domains, so it does not need to learn the target task from scratch with a massive amount of data. Furthermore, [18]–[20] expanded the use of transfer learning from traditional machine learning models to deep neural networks. Typically, there are two types of accessible transfer learning: feature-based and instance-based. Both types focus on closing the distribution distance between the source domain and the target domain. In instance-based algorithms, the goal is to discover source instances similar to target instances, so that highly unrelated source samples would be eliminated. Differently, feature-based algorithms aim to map source features and target features into a common feature space where the distribution mismatch is minimized. However, both of them assume that the source domain and the target domain share a fairly strong connection. Unlike conventional transfer learning, our work can transfer knowledge between different domains and tasks that are not closely related.
B. DDTL
Secondly, the setting of DDTL is similar to multi-task learning [21], which also benefits from shared knowledge in multiple close domains. Generally, multi-task learning tends to improve the performance on all tasks. Differently, DDTL only focuses on using the knowledge in other domains to improve the performance of the target task. Moreover, most previous studies of DDTL are instance-based and they tend to take the advantage of massive related source data. Firstly, [14] introduced an instance-based algorithm, transitive transfer learning (TTL). It transfers knowledge between text data in the source domain and the image data in the target domain by using annotated image data as a bridge. However, TTL is highly case-dependent and unstable in performance. Similarly, [15] introduced another instance selection method, Selective Learning Algorithm (SLA). However, this algorithm was mainly designed for binary classification problems. Differently, [22] proposed a feature-based method to deal with scarce satellite image data. It predicts the poverty based on daytime satellite images by transferring knowledge learned from an object classification tasks with the aid of nighttime light intensity information as a bridge. However, this method relies heavily on a massive amount of labeled intermediate training data. Notably, our method benefits from multiple source domains without labeled data, and those source domains can have significant discrepancies. Furthermore, our method can also handle multi-class classification while consistently producing promising results.
C. Machine Learning for COVID-19 Diagnosis
Moreover, to overcome the shortage of COVID-19 testing toolkits, many efforts have been made to search for alternative solutions. Several studies [23]–[25] introduced machine techniques to COVID-19 diagnosis, including but not limited to, convolutional neural networks (CNN), transfer learning, empirical modeling. However, most existing non-transfer models suffer from a common shortcoming that is insufficient well-labeled training data. Transfer leanings methods can carry out fairly decent classifications, but they are still limited by the domain discrepancy between the source data and the target data.
III. Problem Statement
In this DDTL problem, we assume that the data of each target domain is insufficient to train a robust model. And we have a number of unlabeled source domains denoted as 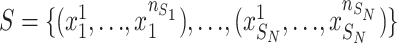 , where
, where 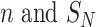 represent the number of samples in each source domain and the number of source domains. Then we denote one or multiple labeled target domains as:
represent the number of samples in each source domain and the number of source domains. Then we denote one or multiple labeled target domains as:
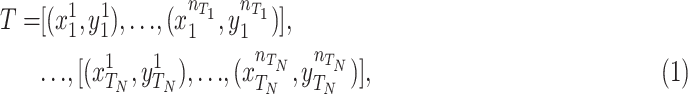 |
where 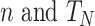 represent the number of samples in each source domain and the number of source domains. Let
represent the number of samples in each source domain and the number of source domains. Let 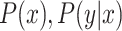 be the marginal and the conditional distributions of a data set. In this DDTL problem, we have the following:
be the marginal and the conditional distributions of a data set. In this DDTL problem, we have the following:
 |
The main objective of the proposed work is to develop a model for the target domain with a minimal amount of labeled data by finding generic features from distant unlabeled source domain data. The motivation behind this study is that data in distant domains is usually seemingly unrelated in the instance-level but related in the feature-level. However, the connection on the feature level from one distant domain can be too weak to be used to train an accurate model. As such, simply using one or two sets of source data is likely to fail in building the target model. Therefore, we leverage from multiple unlabeled distant source domains to obtain enough information for the target task.
IV. Methodology
In this section, we introduce the proposed COVID-19 diagnose framework. Firstly, we present the reduced-size ResNet segmentation model. After that, we introduce the novel DDTL algorithm, DFF.
A. Lung CT Segmentation by Reduced-Size ResUnet
First of all, extracting features from a full size lung CT image with a small training set can be difficult because the model might end up focusing on noise in the useless parts of the images. Therefore, it is important tp pre-process the image by applying semantic segmentation. As shown in Fig. 2, we can remove random noise and preserve the important information in the lung area of a image. Moreover, a small data set for training can lead to a over-fitting for a deep neural network. Therefore, we develop a reduced-size ResNet for this Covid-19 diagnose task.
Fig. 2.

Segmented lung area.
Fisr of all, the proposed reduced-size ResUnet [26] contains two feature extraction parts: four convolutional blocks layers with down-sampling and four deconvolutional layers with up-sampling. Moreover, we reduce the numbers of convolutional layers and deconvolutional layers, and apply dropout layers to prevent over-fitting. Furthermore, we adopt skip-connection to prevent two main problems in the training process: gradient explode and gradient disappear. In this study, we implement a single skip-connection to form convolutional and deconvolutional blocks. By doing this, the convergence time of the model is faster and the training process is more stable.
Commonly, image segmentation tasks require to perform accurate pixel-level classification on the input images. Therefore, it is critical to design a proper loss function based on each task. In this study, the final loss function is composed by a soft-max function over the last feature map combined with the cross-entropy loss. The expressions of the soft-max function and cross-entropy functions are:
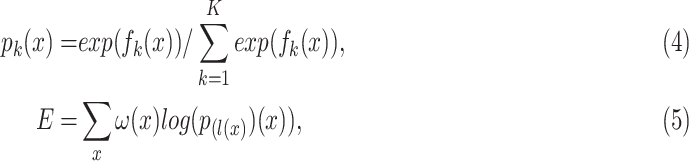 |
where 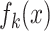 represents the activation map of the
represents the activation map of the 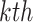 feature at
feature at 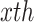 pixel and
pixel and 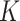 is the total number of classes, and the cross-entropy penalizes at each position the deviation of
is the total number of classes, and the cross-entropy penalizes at each position the deviation of 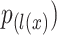 . Furthermore, the segmentation boarder is computed with morphological operations. The weight map is expressed as:
. Furthermore, the segmentation boarder is computed with morphological operations. The weight map is expressed as:
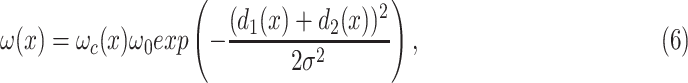 |
where 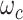 is the weight map to balance the class frequencies,
is the weight map to balance the class frequencies, 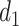 and
and 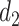 are the distances between a pixel to the closest boarder and the second coolest boarder, and
are the distances between a pixel to the closest boarder and the second coolest boarder, and 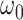 and
and 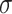 are the initialization values.
are the initialization values.
B. DFF
As shown in Fig. 3, there are three main components in DFF: distant feature extractor, distant feature adaptation, and the target classification. There are three types of losses from three components: reconstruction loss, domain loss, and classification loss.
Fig. 3.

DFF Architecture: there are three main components in DFF, distant feature extractor, distant feature adaptation, and the target classification. There are three types of losses from three components: reconstruction loss, domain loss, and classification loss.
C.
1). Distant Feature Extraction
As one of the inspirations of this study, a convolutional autoencoder pair is used as a feature extractor in DFF. convolutional autoencoders [27] usually benefit unsupervised image processing related problems. Firstly, a convolutional autoencoder is a feed-forward neural network working in an unsupervised manner, which suits this DDTL problem perfectly since there is no labeled data in source domains. Moreover, there are two main components: encoder 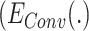 and decoder
and decoder 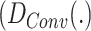 . The standard process of convolutional autoencoder pairs can be demonstrated as:
. The standard process of convolutional autoencoder pairs can be demonstrated as:
 |
where 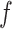 is the extracted features of
is the extracted features of 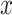 , and
, and 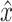 is the reconstructed
is the reconstructed 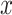 . In addition, the way to tune the parameters of a convolutional autoencoder pair is to minimize the reconstruction error on all the training instances. Conceptually, the output of the encoder can be considered as high-level features of the unlabeled training data. Furthermore, these features are learned in an unsupervised manner, so they are robust if the reconstruction error is lower than a certain threshold.
. In addition, the way to tune the parameters of a convolutional autoencoder pair is to minimize the reconstruction error on all the training instances. Conceptually, the output of the encoder can be considered as high-level features of the unlabeled training data. Furthermore, these features are learned in an unsupervised manner, so they are robust if the reconstruction error is lower than a certain threshold.
In this DDTL problem, as shown in Fig. 3, we use a convolutional autoencoder pair to discover robust feature representation from unlabeled source domain data sets and the labeled target data sets simultaneously. The structure of the auto-encoder pair contains two convolutional layers and two pooling layers in both the encoder and decoder. Up-sampling is applied to the encoder to ensure the quality of the reconstructed images. The process of feature selection has three main steps: feature extraction, instance reconstruction, and reconstruction measurement. First, we feed both the source data and the target data into the encoder to obtain high-level features 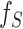 and
and 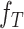 . Then, extracted features are sent into the decoder to get reconstructions,
. Then, extracted features are sent into the decoder to get reconstructions, 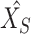 and
and 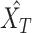 . The equations of the first two steps are expressed as:
. The equations of the first two steps are expressed as:
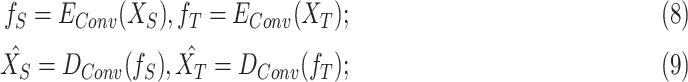 |
where 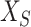 and
and 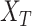 are the source and the target samples, and
are the source and the target samples, and 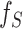 and
and 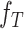 are the source and the target features. Finally, we define the reconstruction errors from both the source domains and the target domains as the loss function of the feature extractor,
are the source and the target features. Finally, we define the reconstruction errors from both the source domains and the target domains as the loss function of the feature extractor, 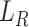 as follow:
as follow:
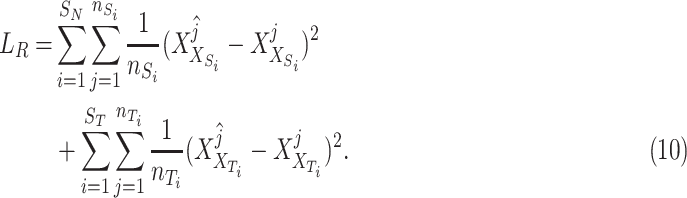 |
where 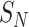 and
and 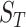 are the numbers of the source domains and the target domains,
are the numbers of the source domains and the target domains, 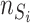 and
and 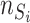 are the numbers of instances in the
are the numbers of instances in the 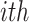 source domain and the target domain.
source domain and the target domain.
D.
2). Distant Feature Adaptation

Commonly, minimizing the reconstruction error 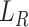 can discover a certain amount of features with the given input. However, there is a large distribution mismatch between the source and the target domains, so minimizing
can discover a certain amount of features with the given input. However, there is a large distribution mismatch between the source and the target domains, so minimizing 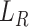 alone cannot extract enough robust and domain-invariant features. Therefore, we need extra side information to close the domain distance. In this research, as shown in Fig. 3, we add a distant feature adaptation layer to the convolutional autoencoder pair to close the domain distance
alone cannot extract enough robust and domain-invariant features. Therefore, we need extra side information to close the domain distance. In this research, as shown in Fig. 3, we add a distant feature adaptation layer to the convolutional autoencoder pair to close the domain distance 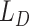 . The maximum mean discrepancy (MMD) [28] is important statistical domain distance estimator. The domain loss is expressed as:
. The maximum mean discrepancy (MMD) [28] is important statistical domain distance estimator. The domain loss is expressed as:
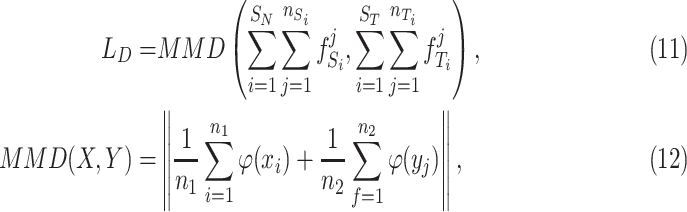 |
where 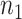 and
and 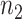 are the numbers of instances of two different domains, and
are the numbers of instances of two different domains, and 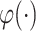 is the kernel that converts two sets of features to a common reproducing kernel Hilbert space (RKHS) where the distance of two domains is maximized.
is the kernel that converts two sets of features to a common reproducing kernel Hilbert space (RKHS) where the distance of two domains is maximized.
E.
3). Target Classifier
Furthermore, with extracted distant features, we add a target classifier 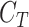 after the encoder. As the motivation of this step, [29] proves that fully-connected layers aim find the best feature combination for each class in the target task. In other words, fully-connected layers do not learn more new features but connect each class to a specific set of features with different weights. In this work, there is only one fully-connected layer followed by the output layer with cross-entropy loss,
after the encoder. As the motivation of this step, [29] proves that fully-connected layers aim find the best feature combination for each class in the target task. In other words, fully-connected layers do not learn more new features but connect each class to a specific set of features with different weights. In this work, there is only one fully-connected layer followed by the output layer with cross-entropy loss, 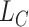 :
:
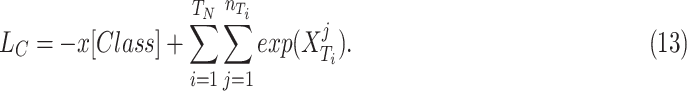 |
where 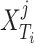 is the
is the 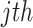 sample in the
sample in the 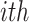 target domain. Finally, by embedding all three losses from 10, 11, and 13, the overall objective function of DFF is formulated as:
target domain. Finally, by embedding all three losses from 10, 11, and 13, the overall objective function of DFF is formulated as:
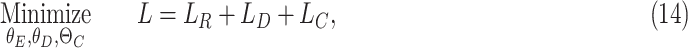 |
where 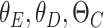 are the parameters of the encoder, decoder, and the classifier, respectively. Moreover,
are the parameters of the encoder, decoder, and the classifier, respectively. Moreover, 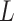 is the final loss constructed by the reconstruction error, domain loss, and classification loss. Finally, all the parameters are optimized by minimizing the objective function in Equation 14.
is the final loss constructed by the reconstruction error, domain loss, and classification loss. Finally, all the parameters are optimized by minimizing the objective function in Equation 14.
F.
4). Algorithm Summary
Lastly, an overview of the proposed work is summarized in Algorithm 1.
V. Experiment and Analysis
In this section, we introduce a number of benchmark models, such as supervised learning models, conventional transfer learning models, and DDTL models. Then we set up a serious of experiments. After that, we demonstrate the experimental results. Finally, we present training details and the analysis of experimental results.
A. Benchmark Models
In this study, as shown in Table I, we choose several transfer models and non-transfer models for comparisons. By comparing results from different methods, we can justify the improvements made by the proposed methods. Firstly, we select three supervised non-transfer baseline models: convolutional neural works (CNN), Alexnet [29], and Resnet [30]. For CNN, the model is constructed with three convolutional layers with 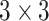 kernels followed by a
kernels followed by a 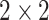 max pooling kernel. Secondly, we also choose three conventional transfer learning models: fine-tuned Alexnet, fine-tuned Resnet, and self-transfer (SelfTran) model [23]. What is more, we choose one instance-based DDTL method: selective learning algorithm (SLA) [15]. Furthermore, all details of each benchmark model are specified in Table I.
max pooling kernel. Secondly, we also choose three conventional transfer learning models: fine-tuned Alexnet, fine-tuned Resnet, and self-transfer (SelfTran) model [23]. What is more, we choose one instance-based DDTL method: selective learning algorithm (SLA) [15]. Furthermore, all details of each benchmark model are specified in Table I.
TABLE I. Model Comparison.
| CNN | Alexnet | Resnet | SelfTran | SLA | DFF | |
|---|---|---|---|---|---|---|
| Transferable | No | Yes | Yes | Yes | Yes | Yes |
| Base Model | Discriminative | Discriminative | Discriminative | Discriminative | Discriminative | Discriminative |
| Loss Type | Entropy | Entropy | Entropy | Entropy | Entropy&MMD | Entropy&MMD |
| Learning Type | Feature-based | Feature-based | Feature-based | Feature-based | Instance-based | Feature-based |
B. Date Sets and Experiment Setups
In this study, as shown in Table II, we totally use six open-source data sets: Caltech-256 [31], Office-31 [32], chest X-Ray for pneumonia detection [33], Lung CT [34], and Covid19-CT [35]. The first, Caltech-256 includes labeled data of 256 different classes. For each class, the number of instances is from 80 to 827. Then, Office-31 has 31 different common office objects, with total 4110 instances collected from three different data sources: “amazon,” “webcam,” and “dslr”. However, Office-31 is an unbalanced data set. Moreover, the chest X-Ray data set contains 5226 well-labeled images. Intuitively, the chest X-Ray images should have the most similarity with lung X-Ray images, so we wonder if directly transfer and fine-tune would carry out better performance than the proposed method. Moreover, Covid19-CT contains 565 labeled lung CT images: 349 positive samples, and 216 negative samples. It is considered as a fairly small data set for training deep learning models. Finally, we use the lung CT data set for the segmentation model. The data set has 367 lung CT images with pixel-level masks.
TABLE II. Data Sets.
| Data Set | Total Classes | Total Samples | Label | Mask |
|---|---|---|---|---|
| Caltech-256 |
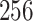
|
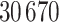
|
|
|
| Office-31 |
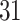
|
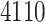
|
|
|
| Chest Xray |
|
|
|
|
| Lung-CT |
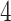
|
|

|
|
| Covid19-CT |
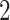
|
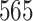
|
|
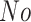
|
Moreover, we run each experiment five times to investigate the performance fluctuation range. Firstly, we produce 4 experiments on CNN and conventional TL models with the Covid19-CT data. And then, we set up a series of experiments on DDTL models with single source domain and multi-source domains to explore the potential of the learning method. As shown in Table V, there are five unlabeled source domains data sets: Caltech-256, Amazon, Amazon, Webcam, Chest X-Ray, and one labeled target data set: Lung CT for Covid-19. What is more, another regular Lung CT contains masks for segmentation. Moreover, the first four source domains are seemingly unrelated to the target domain, but the last source domain is visually related to the target domain.
TABLE V. Accuracies (%) of DDTL Models With Single Source Domain.
| Source Domain | Caltech256 | Amazon | Webcam | Dslr | Chest X-Ray |
|---|---|---|---|---|---|
| SLA (Raw-Image) |
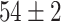
|
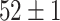
|
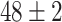
|
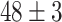
|
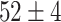
|
| SLA (Segmented-Image) |
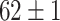
|
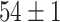
|
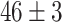
|
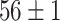
|
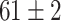
|
| DFF (Raw-Image) |
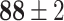
|
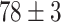
|
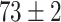
|
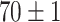
|
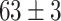
|
| DFF (Segmented-Image) |
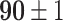
|
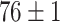
|
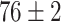
|
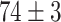
|
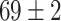
|
| Conventional TL Models | |||||
| Fine-tuned Alexnet (Raw-Image) |
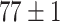
|
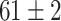
|
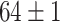
|
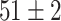
|
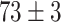
|
| Fine-tuned Alexnet (Segmented-Image) |
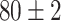
|
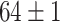
|
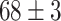
|
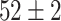
|
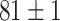
|
| Fine-tuned Resnet (Raw-Image) |
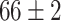
|
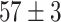
|
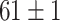
|
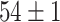
|
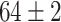
|
| Fine-tuned Resnet (Segmented-Image) |
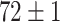
|
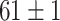
|
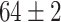
|
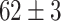
|
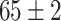
|
Furthermore, unlike previous methods, the proposed method is able to utilize multiple source domains to improve the performance in the target domain. Therefore, as we can tell from Table VI, we choose four primary source domains and use the Chest X-Ray data set as the auxiliary domain. In the following sections, we will present the results and analysis.
TABLE VI. Accuracies (%) of DDTL Models With Multiple Source Domains.
| Primary Source Domain | Caltech256 | Amazon | Webcam | Dslr |
|---|---|---|---|---|
| Auxiliary Source Domain | Chest X-Ray | |||
| SLA (Raw-Image) |
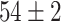
|
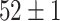
|
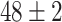
|
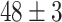
|
| SLA (Segmented-Image) |
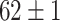
|
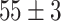
|
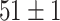
|
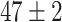
|
| DFF (Raw-Image) |
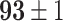
|
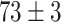
|
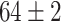
|
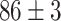
|
| DFF (Segmented-Image) |
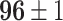
|
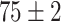
|
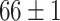
|
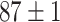
|
TABLE VII. DFF Performance.
| DFF | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Single Source |
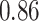
|
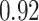
|
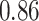
|
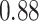
|
| Multi-Source |
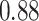
|
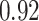
|
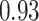
|
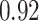
|
| Segmented Multi-Source |
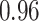
|
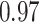
|
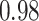
|
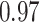
|
C. Performance and Analysis
In this section, we first present the performance of the segmentation model. After that, we give an overview of results of all examined classification methods and present insights on performance differences. Then, we provide training details and analysis of our proposed DDTL algorithm.
D.
1). Segmentation Performance
Firstly, the most informative part of a lung CT is the lung area, and it allows machines to better imitate the behaviors of real specialists. The proposed reduced-size ResUnet is trained from scratch because there is no pre-trained model for this novel architecture. Moreover, the drop-out layers and the skip-connections are applied to prevent over-fitting and non-convergence problems. As we can tell from Fig. 2, the segmented image shows an accurate and clear contour of the lung area, so we can select only the lung area as the input for the DFF model. Furthermore, Fig. 4 shows a better visual results of the segmentation model. The first column presents the original image, the second column shows the ground truth of the lung area, the third column gives the pixel-level classification of the model, and the fourth column illustrates the pixel-level difference between the ground truth and the prediction.
Fig. 4.

Lung CT segmentation.
Moreover, we use two common evaluation metrics for image segmentation tasks to quantify the performance. In the study, we use IoU (intersection over union), Dice (F1 Score), and pixel-level accuracy as the evaluation metrics. The definitions of them are:
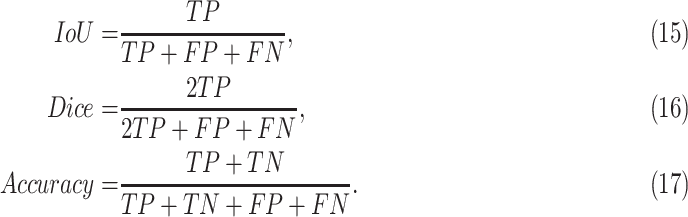 |
Furthermore, for the comparison, we also conduct experiments on the original Unet with the same data set. The details are shown in Table III. Obviously, the reduced-size ResUnet outperforms the original Unet. The possible reasons are: 1) the original Unet cannot effectively prevent the model from learning noise, 2) the skip-connection helps the model to extract deeper features.
TABLE III. Segmentation Performance.
| IoU | Dice | Accuracy | |
|---|---|---|---|
| Reduced-ResUnet |
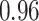
|
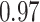
|
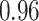
|
| Unet |
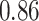
|
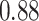
|
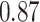
|
E.
2). Classification Performance Overview
As demonstrated in Table IV, the proposed DFF algorithm outperforms the highest test classification accuracy (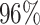 ). And more, the CNN model is only at (
). And more, the CNN model is only at (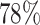 ) classification accuracy. Intuitively, it is caused by insufficient training data. Moreover, the Alexnet and SelfTran output promising accuracies (
) classification accuracy. Intuitively, it is caused by insufficient training data. Moreover, the Alexnet and SelfTran output promising accuracies (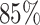 ,
, 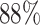 ). In theory, initializing with pre-trained parameters can boost the performance due to the pre-train data set. However, the settings are more or less similar to TL, and the accuracies are still lower than the proposed DDTL method. This performance gap can be caused by large domain discrepancy between two distant domains. The traditional models cannot close the domain distance to avoid the performance degradation. However, there is no evidence of negative transfer in the fine-tuning models. The instance-based DDTL model (SLA) has the worst accuracy (
). In theory, initializing with pre-trained parameters can boost the performance due to the pre-train data set. However, the settings are more or less similar to TL, and the accuracies are still lower than the proposed DDTL method. This performance gap can be caused by large domain discrepancy between two distant domains. The traditional models cannot close the domain distance to avoid the performance degradation. However, there is no evidence of negative transfer in the fine-tuning models. The instance-based DDTL model (SLA) has the worst accuracy (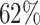 ), which is clearly a negative transfer case. Theoretically, the instance selection by the re-weighting matrix eliminates way too many source domain samples due to a large distribution discrepancy. As such, it cannot extract sufficient information for the knowledge transfer. It can be considered as the same situation as the CNN model with insufficient training data. Furthermore, pre-processing the data with semantic segmentation can improve the performance. Moreover, it proves that preserving the most informative part by eliminating random noise from a small data set can enhance the final classification performance.
), which is clearly a negative transfer case. Theoretically, the instance selection by the re-weighting matrix eliminates way too many source domain samples due to a large distribution discrepancy. As such, it cannot extract sufficient information for the knowledge transfer. It can be considered as the same situation as the CNN model with insufficient training data. Furthermore, pre-processing the data with semantic segmentation can improve the performance. Moreover, it proves that preserving the most informative part by eliminating random noise from a small data set can enhance the final classification performance.
TABLE IV. Top Accuracies (%) of Examined Models.
| CNN | Alexnet | Resnet | SelfTran | SLA | DFF | |
|---|---|---|---|---|---|---|
| Testing Accuracy (Raw-Image) |
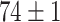
|
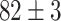
|
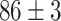
|
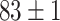
|
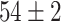
|
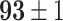
|
| Testing Accuracy (Segmented-Image) |
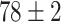
|
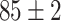
|
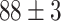
|
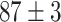
|
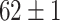
|
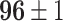
|
Furthermore, we have observed other interesting things. First of all, feature-based algorithms have more promising performances on the COVID-19 classification problem. Differently, the instance-based method completely failed to solve this task. Intuitively, samples in distant domains are seemingly unrelated at the instance level, but they might still share common information at the feature level. Therefore, the instance selection method tend to miss important information with only learning features at the visual-level. Differently, the feature-based models tend to ignore the large discrepancy at the visual-level. Instead, they aim to discover the relationship of two domains at the feature-level. Therefore, it can close the distribution mismatch by extracting domain-confusing features.
Moreover, Table V shows performances of conventional TF models and DDTL models with single source domain. Firstly, the proposed DDTL algorithm achieves the highest classification accuracy (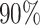 , and SLA method shows negative transfer on all five source domains. It further approves that instance selection process might not be reliable for DDTL problems. However, the advantage of SLA is that it does not require labeled target data, while the proposed method needs labeled target data. In addition, not all source domains are suitable for distant knowledge transfer. The seemingly related domain, chest X-Ray, is actually not the most transfer-friendly for this task. Other data sets that are visually distant from the target domain carry out better results. It approves the theory that seemingly unrelated domains might be statistically connected in the feature-level. We will provide more evidences in later contents.
, and SLA method shows negative transfer on all five source domains. It further approves that instance selection process might not be reliable for DDTL problems. However, the advantage of SLA is that it does not require labeled target data, while the proposed method needs labeled target data. In addition, not all source domains are suitable for distant knowledge transfer. The seemingly related domain, chest X-Ray, is actually not the most transfer-friendly for this task. Other data sets that are visually distant from the target domain carry out better results. It approves the theory that seemingly unrelated domains might be statistically connected in the feature-level. We will provide more evidences in later contents.
The best performance of conventional TL models is (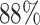 which is better than non-transfer methods. Initializing with pre-trained weights only yields a faster convergence but it does not improve the performance in this case. Accuracies from experiments of Chest X-Ray to Covid19-CT turns out to be worse than other experiment setups even the chest X-Ray is commonly assumed to be the most similar to the target domain. However, as shown in Fig. 6, the domain loss between the Covid19-Xray and chest X-Ray is the greatest in all experiments. It also proves that seemingly related domains might be distant in the feature level, so it is not always reliable to hand-pick source domains in DDTL problems.
which is better than non-transfer methods. Initializing with pre-trained weights only yields a faster convergence but it does not improve the performance in this case. Accuracies from experiments of Chest X-Ray to Covid19-CT turns out to be worse than other experiment setups even the chest X-Ray is commonly assumed to be the most similar to the target domain. However, as shown in Fig. 6, the domain loss between the Covid19-Xray and chest X-Ray is the greatest in all experiments. It also proves that seemingly related domains might be distant in the feature level, so it is not always reliable to hand-pick source domains in DDTL problems.
Fig. 6.

DFF domain losses with single source domain.
Moreover, the enhancement from semantic segmentation is still not good enough to reach the human-level performance. Therefore, unlike most existing DDTL algorithms, we wish to even improve the performance by using multiple source domain. Importantly, in DDTL problems, finding shared information cross different domains is the key to perform a safe knowledge transfer. However, the amount of common information extracted from a single distant domain might not be sufficient. As shown in Table VI, the proposed method achieves (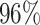 classification accuracy with using Caltech-256 as the primary source domain and Chest X-Ray as the auxiliary source domain. It means that these two data sets have less information overlapping, so the DFF model can extract more useful shared knowledge to transfer to the target domain. Differently, performance degradation appears in others multi-source domain experiments, which means others pairs have shared information that causes over-fitting.
classification accuracy with using Caltech-256 as the primary source domain and Chest X-Ray as the auxiliary source domain. It means that these two data sets have less information overlapping, so the DFF model can extract more useful shared knowledge to transfer to the target domain. Differently, performance degradation appears in others multi-source domain experiments, which means others pairs have shared information that causes over-fitting.
However, one significant weakness of DDTL models is that they are highly dependent on the quantity and versatility of the source domains. As we can tell from Table V, the performances of the proposed model decreases dramatically when the webcam and the dslr data sets of Office-31 are set as the source domains. Theoretically, DDTL models benefit from extracting the common knowledge of the source domain and the target domain, but they cannot complete this type of feature extraction when the source data set is small. There are only 550 and 640 samples in the webcam and the Dslr data sets, which are less than the target samples. Therefore, it is not easy to safely and effectively transfer knowledge between different domains. On the contrary, the Caltech-31 data set has over 33 000 samples from 256 different classes, so it is easier to perform the knowledge transfer.
F.
3). Analysis of DFF
Fig. 5(a)--(d) shows details of the DDF models in single source domain setting and the multi-source domain settings, illustrating four types of losses: total training loss, target classification loss, domain loss, and reconstruction loss. Firstly, The proposed DFF algorithm has achieved the highest test classification accuracy when the Caltech-256 data set is the primary source domain and the chest X-Ray data set is the auxiliary source domain. Overall, it has the most smooth curves and the smallest domain loss. Moreover, with the additional information from the auxiliary source domain, its classification loss and reconstruction loss are dramatically reduced. In other words, the model is able to extract additional features from the auxiliary domain and use it as a bridge to close the distance from the target domain. Moreover, large declines in performance appear in the other experiments with Amazon and Webcam. As mentioned earlier, the performance degradation can be caused by overlapping information in the primary and the secondary source domains. The model is over-fit due to the duplicated knowledge in two source domains. Especially, in the experiment 5(b), the domain loss is increased but the classification loss is not lowered. Furthermore, this proves that seemingly distant instances might share a certain amount of common features. And, such features can be extracted by properly adding a domain loss to the loss function. Moreover, Fig. 6 supports another point: the smaller domain loss means a closer distance between two domains. As we can tell from the figure, the Caltech-256 to Covid19-CT combination has the lowest domain loss, and it also has the best classification accuracy. Furthermore, the domain loss curve of Dslr data set increases during the training. It indicate that the quantity and the versatility of the source data set play an important role in this task. Finally, we quantify the performance of DFF model with four evaluation metrics: accuracy, precision, recall, and F1 score.
Fig. 5.

Training Details of experiments on ADFE with 4 setups: Caltech-256 to Covid19-CT, Office-31-Amazon to Covid19-CT, Office-31-Webcam to Covid19-CT, Office-31-dslr to Covid19-CT. In each sub-figure, up left is total loss, up right is target classification loss, down left is domain distance, and down right is reconstruction error.
VI. Conclusion & Future Work
To draw a conclusion, in this paper, we introduce a novel DDTL framework (DFF) for medical imaging. Moreover, we apply the proposed framework on COVID-19 diagnosis task to justify its proficiency. Moreover, we conduct experiments with another 5 methods with different leaning manners: non-transfer, fine-tuning, DDTL (SLA). To distinguish our work from others, the proposed method can use seemingly unrelated data sets to develop an efficient classification model for COVID-19 diagnose. Unlike previous DDTL models, our method enables knowledge transfer from multiple distant source domains, and it can effectively enhance the performance on the COVID-19 diagnose. Moreover, the proposed method has great potential of expanding the usage of transfer learning on medical image processing by safely transferring the knowledge in distant source domains, which can be completely different from the target domain. Furthermore, this study is related to one of the most challenging problems in transfer learning, negative transfer. To the best of our knowledge, this is the first study that uses distant domain source data for COVID-19 diagnosis and outperforms promising test classification accuracy.
In addition, the framework is designed for general medical imaging tasks. COVID-19 diagnosis is just an example to justify the performance of the proposed work. However, we also apply the framework to pneumonia diagnosis task. It also achieves decent performance (95.1%) test classification accuracy. Intuitively, the reduced-UNet segmentation part is the key to improve the generalization ability of the framework. Is is justified in [26] that the original UNet is effective for medical imaging tasks. Therefore, the framework can be extended to other medical imaging tasks by adjusting the size or the structure of the UNet based on the given data set. It proves that the proposed method has the ability of being adapted to other medical imaging methods. However, without the segmentation part, the proposed framework might also have the potential for regular image processing tasks. We plan to conduct more research in the direction, but it is out of the scope of this study.
Four contributions of this paper are made: 1) it successfully adopts DDTL methods to COVID-19 diagnosis, 2) we introduce a novel feature-based DDTL classification algorithms, 3) the proposed methods achieve state-of-art results on COVID-19 diagnosis task, and 4) proposed methods can be easily expanded to other medical image processing problems.
However, there are several drawbacks of DDTL algorithms: 1) most algorithms tend to be case-specific, 2) source domain selection is too complicated in some cases, 3) distant feature extraction process is computationally expensive.
In the future, there are a number of research directions regarding COVID-19 diagnosis and DDTL problems. Firstly, the explainability of the feature-based DDTL algorithm is a challenging but essential topic. Visualizing the changes on features in deep layers through the training process can not only help us to better understand the domain adaptation in the feature level and decision making process of deep ANN models, but also discover the relationship between two distant domains. Moreover, how to improve the efficiency of feature extraction process is another key to improve the performance. Commonly, generative adversarial networks (GANs) is widely acknowledged as a better feature extraction method. However, how to avoid non-convergence in the training process of adversarial networks is very challenging, and gradient explode and disappear make the training process for adversarial networks extremely difficult. As an inspiration, designing new adversarial loss functions is a possible way of dealing with this problem. Additionally, cross-modality TL, such as from image to audio, can be another potential solution to DDTL problem since semantic information can also exist in different cross-modality domains. Solving this problem can expand the use of transfer learning to an even higher level. Furthermore, for multi-source DDTL algorithms, source domain selection is important to stabilize the performance. Recently, active learning methods attract more and more attention from researchers. Finally, using medical CT images from other diseases as the source domain might or might be able to produce better results because seemingly related domains can also have large discrepancies in the feature level. Moreover, image data sets are usually not easy to access, so it is not always feasible to develop a TL model by using medical image data from other diseases. Therefore, granting access to medical image data sets to the public and generating distribution shift embedded artificial data is a promising future research direction in the field of medical image processing.
Funding Statement
This work was supported by the National Science Foundation under Grant 1956193.
Contributor Information
Shuteng Niu, Email: SHUTENGN@my.erau.edu.
Meryl Liu, Email: meryl.liu@gmail.com.
Yongxin Liu, Email: LIUY11@my.erau.edu.
Jian Wang, Email: WANGJ14@my.erau.edu.
Houbing Song, Email: h.song@ieee.org.
References
- [1].Jeschke S., Brecher C., Song H., and Rawat D., Industrial Internet of Things. Cham, Switzerland: Springer, 2017. [Google Scholar]
- [2].Zhang Y., Sun L., Song H., and Cao X., “Ubiquitous WSN for healthcare: Recent advances and future prospects,” IEEE Internet Things J., vol. 1, no. 4, pp. 311–318, Aug. 2014. [Google Scholar]
- [3].Song H., Srinivasan R., Sookoor T., and Jeschke S., Smart Cities: Foundations, Principles and Applications. Hoboken, NJ, USA: Wiley, 2017. [Google Scholar]
- [4].Dartmann G., Song H., and Schmeink A., Big Data Analytics for Cyber-Physical Systems: Machine Learning for the Internet of Things. Amsterdam, The Netherlands: Elsevier, 2019. [Google Scholar]
- [5].Niu S., Wang J., Liu Y., and Song H., “Transfer learning based data-efficient machine learning enabled classification,” in Proc. IEEE Int. Conf. Cloud Big Data Comput., 2020, pp. 620–626. [Google Scholar]
- [6].Niu S., Hu Y., Wang J., Liu Y., and Song H., “Feature-based distant domain transfer learning,” in Proc. IEEE Int. Conf. Big Data., 2020, pp. 1–8. [Google Scholar]
- [7].Sun B. and Saenko K., “Deep coral: Correlation alignment for deep domain adaptation,” in Proc. Euro. Conf. Comput. Vis., 2016, pp. 443–450. [Google Scholar]
- [8].H.-C. Shin et al. , “Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning,” IEEE Trans. Med. Imag., vol. 35, no. 5, pp. 1285–1298, May 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Cheplygina V., Bruijne M. de, and Pluim J. P., “Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis,” Med. Image Analy., vol. 54, pp. 280–296, 2019. [DOI] [PubMed] [Google Scholar]
- [10].Taroni J. N. et al. , “Multiplier: A transfer learning framework for transcriptomics reveals systemic features of rare disease,” Cell Syst., vol. 8, no. 5, pp. 380–394, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Pan W., Xiang E. W., Liu N. N., and Yang Q., “Transfer learning in collaborative filtering for sparsity reduction,” in Proc. 24th Conf. Artif. Intell., 2010, pp. 230–235. [Google Scholar]
- [12].Pan W., Liu N. N., Xiang E. W., and Yang Q., “Transfer learning to predict missing ratings via heterogeneous user feedbacks,” in Proc. 22nd Int. Joint Conf. Artif. Intell., 2011, pp. 2318–2323. [Google Scholar]
- [13].Pan S. J. and Yang Q., “A survey on transfer learning,” IEEE Trans. Knowledge Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010. [Google Scholar]
- [14].Tan B., Song Y., Zhong E., and Yang Q., “Transitive transfer learning,” in Proc. 21th ACM SIGKDD Int. Conf. Know. Discovery Data Mining, 2015, pp. 1155–1164. [Google Scholar]
- [15].Tan B., Zhang Y., Pan S. J., and Yang Q., “Distant domain transfer learning,” in Proc. 31st Conf. Artif. Intell., 2019, pp. 903–908. [Google Scholar]
- [16].Zhang Z., Luo P., Loy C. C., and Tang X., “Facial landmark detection by deep multi-task learning,” in Proc. Eur. Conf. Comput. Vis., 2014, pp. 94–108. [Google Scholar]
- [17].Ge L., Gao J., Ngo H., Li K., and Zhang A., “On handling negative transfer and imbalanced distributions in multiple source transfer learning,” Stat. Anal. Data Mining: ASA Data Sci. J., vol. 7, no. 4, pp. 254–271, 2014. [Google Scholar]
- [18].Long M., Zhu H., Wang J., and Jordan M. I., “Deep transfer learning with joint adaptation networks,” in Proc. 34th Int. Conf. Mach. Learn.-Volume 70. 2017, pp. 2208–2217. [Google Scholar]
- [19].Niu S., Wang J., Liu Y., and Song H., “Transfer learning based data-efficient machine learning enabled classification,” in Proc. 6th Int. Conf. Cloud Big Data Comput. 2020, pp. 620–626. [Google Scholar]
- [20].Liu Y., Wang J., Niu S., and Song H., “Deep learning enabled reliable identity verification and spoofing detection,” in Proc. Int. Conf. Wireless Algorithms, Syst., Appl. 2020, pp. 333–345. [Google Scholar]
- [21].Zhang W. et al. , “Deep model based transfer and multi-task learning for biological image analysis,” IEEE Trans. Big Data, vol. 6, no. 2, pp. 322–333, Jun. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Xie M., Jean N., Burke M., Lobell D., and Ermon S., “Transfer learning from deep features for remote sensing and poverty mapping,” in Proc. 13th Conf. Artif. Intell., 2016, pp. 3929–3935. [Google Scholar]
- [23].He X. et al. , “Sample-Efficient Deep Learning for Covid-19 Diagnosis Based on Ct Scans,” medrxiv, 2020, doi: 10.1101/2020.04.13.20063941. [DOI] [Google Scholar]
- [24].Chen T., Kornblith S., Norouzi M., and Hinton G., “A simple framework for contrastive learning of visual representations,” in Proc. 37th Int. Conf. Mach. Learn., Jul. 2020, vol. 119, pp. 1597–1607. [Google Scholar]
- [25].Barstugan M., Ozkaya U., and Ozturk S., “Coronavirus (covid-19) classification using ct images by machine learning methods,” 2020, arXiv:2003.09424.
- [26].Ronneberger O., Fischer P., and Brox T., “U-net: Convolutional networks for biomedical image segmentation,” in Proc. Int. Conf. Med. Image Comput. Computer-Assisted Intervention., 2015, pp. 234–241. [Google Scholar]
- [27].Turchenko V., Chalmers E., and Luczak A., “A deep convolutional auto-encoder with pooling-unpooling layers in caffe,” 2017, arXiv:1701.04949.
- [28].Borgwardt K. M., Gretton A., Rasch M. J., H.-P. Kriegel, Schlkopf B., and Smola A. J., “Integrating structured biological data by kernel maximum mean discrepancy,” Bioinformatics, vol. 22, no. 14, pp. e49–e57, 2006. [DOI] [PubMed] [Google Scholar]
- [29].Krizhevsky A., Sutskever I., and Hinton G. E., “Imagenet classification with deep convolutional neural networks,” in Adv. Neural Infor. Process. Syst., 2012, pp. 1097–1105. [Google Scholar]
- [30].He K., Zhang X., Ren S., and Sun J., “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778. [Google Scholar]
- [31].Griffin G., Holub A., and Perona P., “Caltech-256 object category dataset,” California Inst. Technol., Tech. Rep., 2007. [Google Scholar]
- [32].Zhao Y., Ali H., and Vidal R., “Stretching domain adaptation: How far is too far?,” 2017, arXiv:1712.02286. [Google Scholar]
- [33].Kermany D. S. et al. , “Identifying medical diagnoses and treatable diseases by image-based deep learning,” Cell, vol. 172, no. 5, pp. 1122–1131, 2018. [DOI] [PubMed] [Google Scholar]
- [34].Armato S. G. et al. , “The lung image database consortium (lidc) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans,” Med. Phys., vol. 38, no. 2, pp. 915–931, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Zhao J., Zhang Y., He X., and Xie P., “Covid-CT-dataset: A CT scan dataset about covid-19,” 2020, arXiv:2003.13865.