

Abstract
In this paper, we propose a deep learning model to forecast the range of increase in COVID-19 infected cases in future days and we present a novel method to compute equidimensional representations of multivariate time series and multivariate spatial time series data. Using this novel method, the proposed model can both take in a large number of heterogeneous features, such as census data, intra-county mobility, inter-county mobility, social distancing data, past growth of infection, among others, and learn complex interactions between these features. Using data collected from various sources, we estimate the range of increase in infected cases seven days into the future for all U.S. counties. In addition, we use the model to identify the most influential features for prediction of the growth of infection. We also analyze pairs of features and estimate the amount of observed second-order interaction between them. Experiments show that the proposed model obtains satisfactory predictive performance and fairly interpretable feature analysis results; hence, the proposed model could complement the standard epidemiological models for national-level surveillance of pandemics, such as COVID-19. The results and findings obtained from the deep learning model could potentially inform policymakers and researchers in devising effective mitigation and response strategies. To fast-track further development and experimentation, the code used to implement the proposed model has been made fully open source.
Keywords: COVID-19, deep learning, interpretable machine learning, feature interactions, pandemic surveillance, disease spread modeling, policy making
I. Introduction
COVID-19 has had an unprecedented social and economic impact worldwide. With more than 13 million infected cases and more than half a million deaths as of mid-July, the pandemic is still accelerating globally without showing any signs of nearing an end. In dealing with COVID-19 and future pandemics, it is imperative to design reliable intervention strategies and to implement effective mitigation efforts. The design of such strategies hinges on effective surveillance of the spatiotemporal evolution of disease. Hence, a reliable and relatively interpretable method of forecasting the spread of the virus could significantly improve the predictive surveillance capability and help in designing policies for disease containment.
Facing this need, prior research has proposed and tested various statistical, epidemiological and machine learning-based forecasting models for COVID-19 [1]–[8] based on features such as number of existing infections, deaths and recoveries. Other forecasting models proposed for other epidemics [9]–[11] rely on features like human mobility and within-season and between-season observations. Although these models show potential for predicting the initial outbreak and growth trajectories, their capability in capturing various temporally dynamic and spatially variant features affecting disease spread is limited [12]. For example, mathematical models such as susceptible-infectious-recovery (SIR) models only account for a small subset of relevant features identified to be responsible for the spread of the virus, as shown below.
Existing studies [13] have shown that the spread of disease is dependent on many factors; thus, reliable forecasting models must capture all major factors that might influence the spread of infection. Specifically, a multitude of factors including, but not limited to, human mobility [14], social distancing guidelines [15], [16], weather [17], population density [18], and demographics [19] affect the spread of COVID-19. In other fields of study where prediction also depends upon a large number of features, researchers often find that identifying interactions between input features is essential to yielding satisfactory results [20], [21]. Although, to the best of our knowledge, no literature has yet been published that identifies specific feature interactions for the spread of COVID-19, we hypothesize that it is quite likely that many features upon which the spread is dependent interact in complex ways. Hence, an exhaustive examination of the relevant features and their possible interactions is essential for an effective prediction model of disease spread.
Advances in deep learning can enable contemporary models to use a large number of features and to account for possible interactions. Several deep learning models [22]–[24] used for online ad click predictions are particularly known for using multiple heterogeneous features as input and learning interactions among them; however, since many features used for epidemic forecasting are in the form of multivariate time series and multivariate spatial time series, an effective method to compute representations of such features that accounts for both the temporal and spatial structure of data is essential before using them as input to the aforementioned models. Perhaps, due to the challenges associated with building such representations for heterogeneous input features, existing deep learning models for epidemic forecasting rely upon more conventional recurrent architectures that do not explicitly account for feature interactions and consider only few input features [2], [6], [25].
To complement existing epidemiological models, we propose a deep learning model based on the high-level framework of DeepFM [22] that takes in multiple features, accounts for interactions between them and forecasts growth in the number of infected cases in all U.S. counties. For effective processing of the many input features, the model includes a novel method to compute equidimensional representations (also called embeddings) of heterogeneous features such as multivariate time series, multivariate spatial time series, and multidimensional time-independent variables. Furthermore, we perform feature importance evaluations to identify the most influential features for predicting the growth of infected cases. Also, since the proposed model accounts for possible interactions among input features, we perform an analysis to estimate the relative amount of second-order interaction between pairs of input features. The results show that the model obtains satisfactory performance. In addition, the highly interpretable feature importance results can also help policymakers develop control strategies in response to the rapidly evolving pandemic situation. To fast-track future research and experimentation with new features or models, we have also made our code fully open source.
II. Related Work
A. Standard Disease-Spread Models
To estimate the growth of infected populations, epidemiologists and mathematical modelers have developed multiple statistical and mathematical models to simulate the spread of disease in terms of susceptible, infected, recovered, and deceased populations. These models include the susceptible-infectious-recovery (SIR) model and its derived models, such as the susceptible-exposed-infectious-recovery (SEIR) model [26], [27]. Through contact activities of people, these standard models attempt to capture the community spread of disease [28]. While these models provide useful insights regarding the initial outbreak and growth trajectories, they have limitations in terms of the number of influencing factors and complex relationships captured. For example, existing models can include only a limited number of features (primarily infection rate) to forecast the spread of infection; however, research has shown that disease spread is related to a large number of factors (such as socio-demographic factors, mobility, population density, and visits to points of interest), which possibly interact in complex ways. Data-driven models can be adopted to capture various dynamic features and their interactions to complement the standard disease-spread models.
Existing studies also reveal that population flow drives the spatiotemporal distribution of COVID-19 cases [29], and travel ban was projected to be successful in slowing the epidemic spread. This has been demonstrated in the context of COVID-19 in China [30]. To complement existing mathematical disease spread models, the global epidemic and mobility model [10] was developed to incorporate the movement of people (which may hasten transmission of the disease across different areas) and predict the spread of disease. This model focuses mainly on cross- and within-community transmission of the disease through the analysis of global human mobility; however, as shown in recent literature, the spread of the disease is affected not only by human contact, but is also related to multiple additional factors, such as population density, human shopping activities, and directives of local government [14]–[16], [31]. Existing models have a limited capability to capture the effects of these factors; hence, developing a model that can take various relevant factors into account, predict the spread of disease, and attribute importance to each factor could be informative for pandemic surveillance and associated policy making.
B. Deep Learning Models
Deep learning [33] is a sub-field of machine learning with the goal of studying deep artificial neural networks (i.e. networks with many layers) and how they can be used for knowledge discovery and enhanced predictive intelligence. Recent advances in deep learning [34], [35] have significantly improved the state of the art in computer vision, natural language processing, and many other fields. Based on such advances, researchers have identified that deep learning-based predictive models could be effective in aiding decision making in response to COVID-19 [36]–[38]. In the following, we discuss some related work on using deep learning to forecast the spread of the virus.
Huang et al. [5] proposed a convolutional neural network to forecast the spread of the virus using six input features related to the number of confirmed, recovered, and deceased people. Their model predicts the spread one day ahead using data from last five days. Although their work shows that deep learning can be effective in forecasting the pandemic, the model cannot be directly deployed in practice because it predicts only one day of future scenario and considers only a limited number features affecting the spread of disease.
Chimmula and Zhang [6] proposed a long short-term memory (LSTM) model [39] to forecast the spread of the virus based on past number of confirmed, deceased, and recovered cases. Similarly, Tian et al. [25] also used an LSTM model to forecast the spread based on similar features but normalized by population. The authors also compared their results with a Hidden Markov Model and a Hierarchial Bayes Model, but concluded that LSTM exhibits the best performance of the three, demonstrating the potential impact deep learning can have on pandemic forecasting.
Tian et al. [40] also proposed a custom model to forecast cumulative confirmed cases and deaths by combining the LSTM [39] and GRU [35] cells. Their model used past numbers of confirmed cases and deaths as input and five other time-independent features. They reported their model performance only in terms of relative error, so it is difficult to judge the effectiveness of their model in absolute terms. Further, the authors did not clarify why some features, such as violent crime rate, were used in the model and how these features could contribute to prediction of infections and deaths by COVID-19.
In another study, Huang et. al. [1] proposed a novel deep learning model using convolutional and bidirectional GRU layers to forecast the virus in European countries. The study used the proposed architecture to process spatial and temporal features separately and obtained good performance. However, the study only considered a limited number of features and captured only the past trends of confirmed, recovered and deceased populations even though past research [13] has shown that the spread of the virus depends on several features related to population attributes, activities, and mobility as mentioned above.
Further, an important and perhaps similar work is the DeepCOVID model [41]. The associated researchers have developed a deep learning-based forecasting model using “syndromic, clinical, demographic, mobility, and point-of-care data” to forecast mortality and hospitalization in the United States. However, information such as model accuracy, model architecture, and feature importance about this work has not yet been made public.
To the best of our knowledge, the proposed DeepCOVIDNet model is among the first significant deep learning models for COVID-19 forecasting to be completely open-source. Moreover, a notable distinction of our work is that we perform feature analysis to understand which features are important in forecasting the growth of the virus, an analysis not performed in prior studies. Further, we also account for possible interactions among our many input features and identify pairs of features with relatively higher amount of second-order interaction between them, which again has not been done by other models.
III. Input Feature Groups
To have a comprehensive understanding of the situation and characteristics of counties, it is important to examine several features for each county. To this end, we extensively surveyed the literature and identified certain “influencing factors” that might affect the spread of infection. We then identified specific feature groups that corresponded with the set of influencing factors identified earlier. A feature group is simply a set of similar features grouped together to facilitate further processing. A brief description of all feature groups is presented in Table 1. In this section, we describe the process of feature collection, organization, and inclusion in the proposed model in detail.
TABLE 1. Short Description of Input Feature Groups. Refer Appendix for Full Details.
| Feature Group Name | Brief Description | Type |
|---|---|---|
| Census features | Population distribution with age/sex, race, poverty/employment status, etc | Constant |
| Vulnerability features | Population density and other features to determine vulnerability of a county to COVID-19 (refer appendix A) | Constant |
| Past rise in infected cases | Daily rise in cumulative cases in past days | Time-Dependent |
| Reproduction Number | Estimate of number of other people infected by one person | Time-Dependent |
| Venables distance [32] | A measure of the concentration of population activities in a county (refer appendix A) | Time-Dependent |
| Social distancing metrics | Amount of adherence to social distancing guidelines | Time-Dependent |
| Visitation patterns | Intra-county mobility to certain types of places (grocery stores, amusement parks, etc) | Time-Dependent |
| Cross-county mobility and infections | Incoming traffic from one county to another and cumulative infected cases in source county | Cross-County Time-Dependent |
A. Feature Collection
Since there is no universally accepted set of input features to use in the task of COVID-19 forecasting, it is important to comprehensively review the literature and identify influencing factors that play a major role in explaining the spread of the virus. Our extensive analysis of the literature helped us identify four such factors that may influence the spread of COVID-19 both spatially and temporally. These “influencing factors” include population attributes (such as population density, age/race-based population distribution, etc.), population activities (such as visits to certain types of points of interest, adherence to social distancing guidelines, etc.), mobility (movement from more infected places to less infected ones), and disease spread attributes (such as reproduction number, growth of infections in past, etc.). The feature groups used in correspondence with each influencing factor are shown in Table 2. A more complete discussion of all feature groups is provided in appendix. In the following, we provide evidence to show the importance of each influencing factor in predicting the growth of the virus.
TABLE 2. The Feature Groups Used in Correspondence With Each Influencing Factor.
| Influencing Factor | Feature Groups Contained |
|---|---|
| Population attributes |
|
| Population activities |
|
| Mobility |
|
| Disease Spread Attributes |
|
Features related to population attributes, such as population size and density, are important in predicting the growth of infection as shown by research studies discussed below. Rocklöv and Sjödin [18] demonstrated that the spread of the virus in a geography is directly proportional to its population density. Dyer [42] and Kirby [43] showed that the impact of the pandemic has been disproportionately higher in black and other minority communities. Dowd et al. [19] illustrated how population age distribution and inter-generational contacts (possibly captured by household type and size) affect the impact of the virus in a community. Together, these studies provide a strong rationale for using features that capture population attributes of counties by showing that these unchangeable population characteristics contribute significantly in understanding the spread/impact of the virus. As shown in Table 2, to account for population attributes, we use census features, population density, and some other engineered features built by the Surgo Foundation to assess vulnerability of each county due to COVID-19 (refer appendix).
Multiple research studies have found that population activities are important in predicting the growth of future cases. Benzell et al. [44] identified risks associated with visits to venues at which people would be placed in proximity and showed that particularly high risk was associated with visits to restaurants, grocery stores, fast food establishments, cafes, and gyms. Also, Lai et al. [45] found that there is high risk of small disease outbreaks within residential facilities for elderly, indicating that examining the number of visits to such facilities could be helpful in forecasting the growth of infection. Moreover, since research has shown that COVID-19 is communicated via airborne particles, especially indoors, visits to hospitals, especially by healthcare workers, could be risky [46], [47], and therefore are important to consider when determining the growth of infection. Further, Gao et al. [48] showed that adherence to social distancing orders helps to reduce the spread of infection. Cohen and Kupferschmidt [49] and Sen-Crowe et al. [50] also acknowledged the importance of social distancing in slowing the spread of the virus. Further, Béland et al. [51] demonstrated that workers in certain occupations in which they are more likely to work in proximity are more affected by the virus, indicating that the percentage of people working full- or part-time could influence infection spread. These studies, together, show the importance of capturing population activities as input features. As shown in Table 2, we use points of interest (POI) visitation patterns, Venables distance [32], and social distancing metrics to capture these activities. As explained in appendix, visitation patterns capture the number of visits to important types of POIs, Venables distance captures the agglomeration of population activities in a county, and social distancing metrics show adherence to stay-at-home orders. Together, these three feature groups show the extent to which people are likely to come in close contact and potentially facilitate the spread of infection.
Further, the dynamics of urban mobility are also important in predicting the spatial spread of the virus. Kraemer et al. [14] showed that human mobility played a major role in explaining the initial spatial distribution of infections in China. They showed that more than 50% of initial cases identified outside Wuhan could be traced back to travel from Wuhan. Sirkeci et al. [52] also confirmed that human mobility from more infected places to less infected places is a significant factor in predicting the spatial spread of the virus. Other studies [29], [53] also concurred regarding the role played by mobility in the spread of the virus. Therefore, we use data of incoming traffic from other counties to capture mobility in the proposed model as shown in Table 2. We further augment the mobility information by including the number of infections in source counties because travel statistics alone are not sufficient to inform the model about counties from which travel could be more dangerous due to the high prevalence of infection.
Finally, disease spread attributes, such as the growth of cases in the past few days and reproduction number, are also important factors in determining the spread of virus in the future. As mentioned in Section II, several existing models [5], [6], [25] obtain satisfactory results in forecasting future cases by using features similar to the growth of cases in past days. Further, epidemiology-based studies [54]–[56] have reported that estimating the reproduction number can be essential to understanding the behavior of virus spread, thereby making it an important input feature to consider. Based on these studies, we include both the growth of cases in past days and reproduction number (estimated by the method proposed by Fan et al [54]) as input features to the model.
B. Feature Organization
As discussed above, we combine similar features into a feature group to better process and organize data. We define three types of feature groups based on their spatial and temporal characteristics as described below: constant, time-dependent, and cross-county time-dependent feature groups. The exact feature groups used in the model are shown in Table 1 and are fully explained in the appendix.
1). Constant Feature Groups
Constant feature groups contain features that do not vary significantly over the analysis period. For example, the set of census features for a county (such as population size and population density) are considered constant features because their values do not change significantly within a few months.
2). Time-Dependent Feature Groups
This group contains features whose values change over time. For example, the number of people who visit grocery stores on a particular day in a given county is a time-dependent feature since its value changes depending on the particular day. A time-dependent feature group is basically a multivariate time series.
3). Cross-County Time-Dependent Feature Groups
In cross-county time-dependent feature groups, features capture a time-dependent interaction between two counties. For example, the number of people traveling from one county to another on a particular day is a cross county time dependent feature. A cross-county time-dependent feature group is basically a multivariate spatial time series.
IV. DeepCOVIDNet
We have designed a novel deep learning model, DeepCOVIDNet, to estimate the range of increase in the number of infected cases on a particular day given multiple constant, time-dependent, and cross-county time-dependent feature groups as input. The “projection interval” of the model is 7 days, which means the model can forecast the range of increase in cases for 7 days into the future.
The model comprises of two modules: the embedding module and the DeepFM module. The embedding module takes as input various heterogeneous feature groups and outputs an equidimensional embedding corresponding to each feature group. These embeddings are then passed to the DeepFM module which computes second- and higher-order interactions between them. Finally, we use a shallow, fully connected network which takes as input the computed interactions and the sum of feature embeddings (to improve gradient flow) and outputs 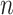 probabilities corresponding to
probabilities corresponding to 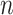 binary classification tasks, as explained in Section V. We transform the
binary classification tasks, as explained in Section V. We transform the 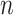 probabilities to get the probability distribution of the current rise in cases to lie within
probabilities to get the probability distribution of the current rise in cases to lie within 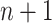 ordered ranges. We expect the rise in cases to lie within the range with the greatest probability. Fig. 1 shows a schematic representation of the process described above.
ordered ranges. We expect the rise in cases to lie within the range with the greatest probability. Fig. 1 shows a schematic representation of the process described above.
FIGURE 1.
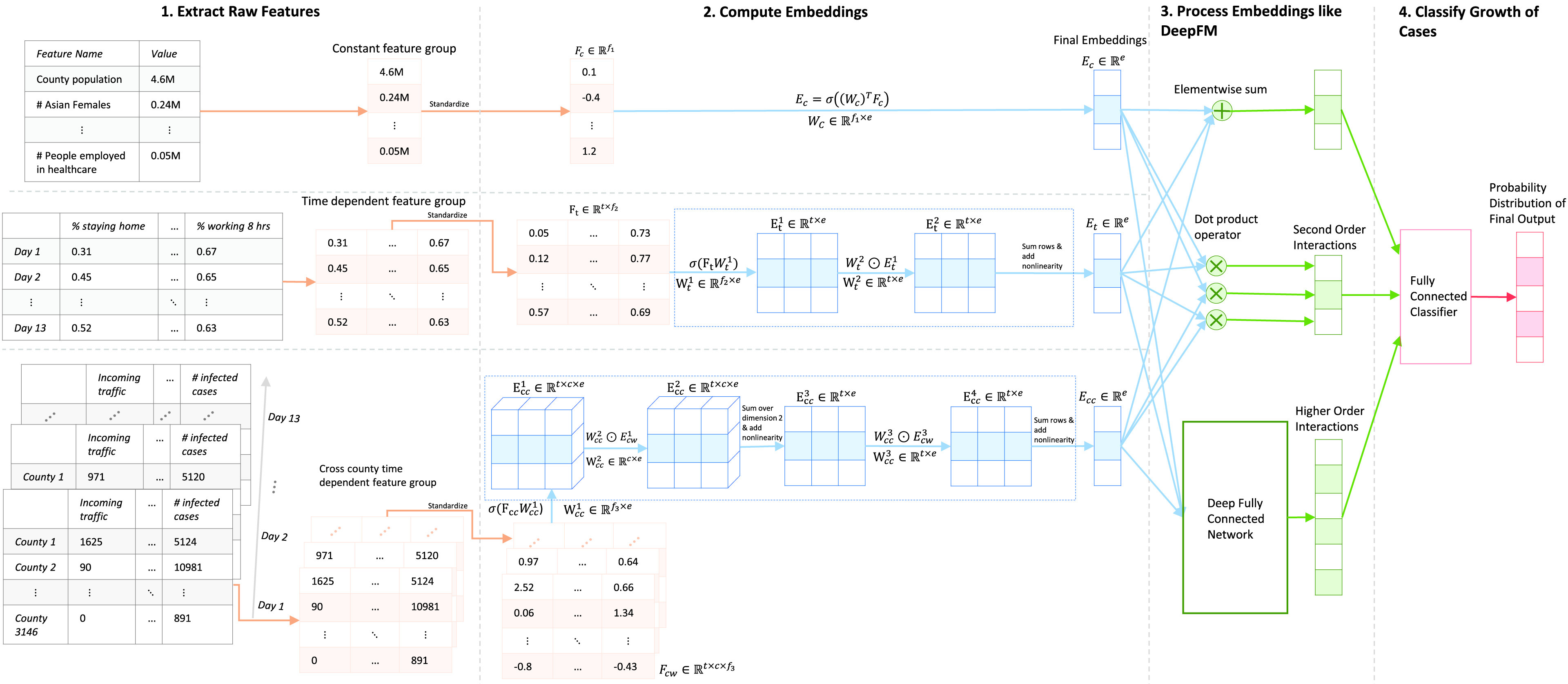
A schematic representation of the entire pipeline of the DeepCOVIDNet model which takes as input raw features and outputs a probability distribution to predict the range of the rise in infected cases in a given county on a given date in the future. 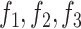 correspond to number of features,
correspond to number of features, 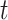 refers to the number of time steps (experimentally set to 13),
refers to the number of time steps (experimentally set to 13), 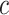 refers to the number of counties (set to 3146),
refers to the number of counties (set to 3146), 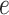 refers to the dimension of each embedding, and
refers to the dimension of each embedding, and 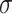 refers to any non-linearity. More explanation related to the tensor shapes is presented in Section IV-A.
refers to any non-linearity. More explanation related to the tensor shapes is presented in Section IV-A.
A. Embedding Module
The novel embedding module used in this study produces embeddings of the same dimension for all feature groups using a generalizable process, which is described in detail below for each feature group type. The fundamental idea behind extracting embeddings from various feature groups is to utilize all available structure in the data. For example, for time-dependent features, we would like the model to be able to treat the same features on different dates more similarly than different features on different dates. We accomplish this goal by sharing parameters, which is a successful technique used to design novel models and arguably is at the heart of the success of both recurrent and convolutional neural networks.
1). Constant Feature Embeddings
Since constant feature groups do not have a time dimension, the shape of a group of constant features is simply 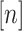 , where
, where 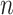 is the number of features in the group. As shown in Fig. 1, the embeddings of constant features are calculated simply by using a fully connected layer that converts the input tensor of shape
is the number of features in the group. As shown in Fig. 1, the embeddings of constant features are calculated simply by using a fully connected layer that converts the input tensor of shape 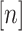 to a tensor of shape
to a tensor of shape 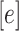 where
where 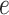 is the embedding dimension.
is the embedding dimension.
2). Time-Dependent Feature Embeddings
Since the time dimension of time-dependent feature groups needs to be taken into account, the shape of a time-dependent feature group is 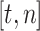 , where
, where 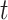 represents the time steps, and
represents the time steps, and 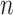 represents the number of features for each time step. From the
represents the number of features for each time step. From the 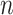 input features, our method computes a holistic feature score by performing a weighted summation of the
input features, our method computes a holistic feature score by performing a weighted summation of the 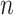 original features for every time step. This holistic score can be thought of as a new time-dependent feature, engineered by the model as per its needs. Next, a weighted summation is conducted over all time steps to learn the influence of different time steps on the final output. As shown in equation 1, when the embedding size is
original features for every time step. This holistic score can be thought of as a new time-dependent feature, engineered by the model as per its needs. Next, a weighted summation is conducted over all time steps to learn the influence of different time steps on the final output. As shown in equation 1, when the embedding size is 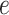 , the model has a chance to engineer
, the model has a chance to engineer 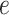 new time-dependent features and understand how each new feature behaves over time.
new time-dependent features and understand how each new feature behaves over time.
In a formal formulation, let 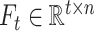 be a time-dependent feature matrix of shape
be a time-dependent feature matrix of shape 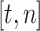 . Let
. Let 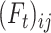 represent the
represent the 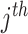 feature at the
feature at the 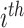 time step. Let the output embedding be
time step. Let the output embedding be 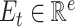 and
and 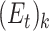 represent the
represent the 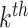 element in the embedding. Then, we calculate
element in the embedding. Then, we calculate 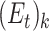 in the following way:
in the following way:
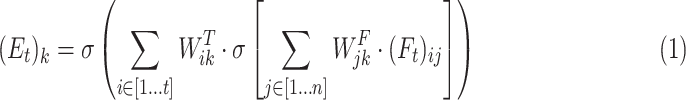 |
where 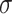 is any activation function and
is any activation function and 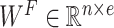 and
and 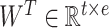 are learnable parameters in the network.
are learnable parameters in the network.
In part 2 of Fig. 1, we show exactly how equation 1 is implemented in a vectorizable method.
3). Cross-County Time-Dependent Feature Embeddings
Since each feature value of a cross-county time-dependent feature group is associated with all counties and all time steps, the shape of a cross-county time-dependent feature group is 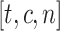 , where
, where 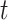 represents the total time steps,
represents the total time steps, 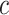 represents the total number of counties in the U.S. and
represents the total number of counties in the U.S. and 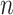 represents the number of features.
represents the number of features.
As shown in Fig. 1, let 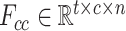 represent the raw features so that
represent the raw features so that 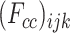 is the
is the 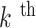 feature of the
feature of the 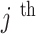 county at the
county at the 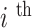 time step. Further, if we let
time step. Further, if we let 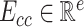 represent the final embedding of this feature group and
represent the final embedding of this feature group and 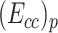 represent the
represent the 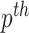 element of
element of 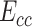 , then we compute
, then we compute 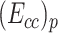 using an extension of equation 1 in the following way:
using an extension of equation 1 in the following way:
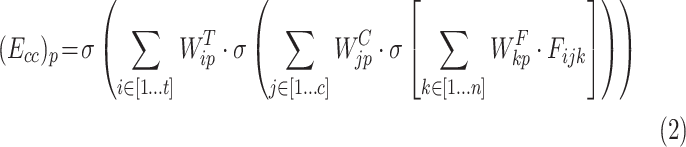 |
where 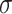 is any activation function,
is any activation function, 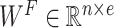 ,
, 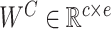 and
and 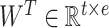 are learnable parameters in the network.
are learnable parameters in the network.
Note that equation 2 is an extension of equation 1 over the county dimension. As in the previous case, the innermost summation computes a holistic feature score for every county and time step using the same weights/parameters. Next, an overall score for each time step is computed by a weighted sum of all holistic feature scores for all counties. Finally, a weighted combination of all time steps is computed.
B. DeepFM Module
We hypothesize that there exist several interactions between different feature groups. An interaction between two features exists when their values together convey some information that cannot be extracted by considering their values individually. For example, there could be an interaction between the percentage of population staying indoors in a county and the total number of infected cases in the county. A higher incidence of new cases is expected if few people remain indoors and there are already a high number of infected cases. However, the model may not be able to predict the number of new cases as effectively if only one of the two feature values is given. Hence, it is important for the model to identify and learn many such interactions that could exist among different features. In this section, we provide an overview of how the model computes second- and higher-order interactions among input features using the DeepFM [22] framework (with slight modifications).
The embeddings of all features obtained from the embeddings module described above serve as input to the DeepFM model. Note that all raw features groups are of different sizes, but their embeddings have the same dimensions and are easy to further process by the DeepFM module, as shown in Fig. 1.
In the model, the dot products between a pair of embeddings represent second-order interactions between the corresponding two feature groups. To identify higher-order interactions, we concatenate all embeddings and process them through a self-normalizing neural network [57]. The network comprises of a sequence of dense layers with the same output dimensions, followed by the SELU (Scaled Exponential Linear Units) non-linearity and the alpha dropout layer [57]. We treat the number of dense layers and the dimension of their output as hyperparameters in the model, which are tuned by using Bayesian optimization as explained in Section V. The final architecture to compute higher order interactions, as chosen by Bayesian optimization, is shown in Fig. 2.
FIGURE 2.

The architecture of the network that takes in the concatenated feature embeddings and computes higher order interactions. “FC 468” denotes a fully connected layer with 468 output neurons.
V. Implementation Details
A. Loss Function
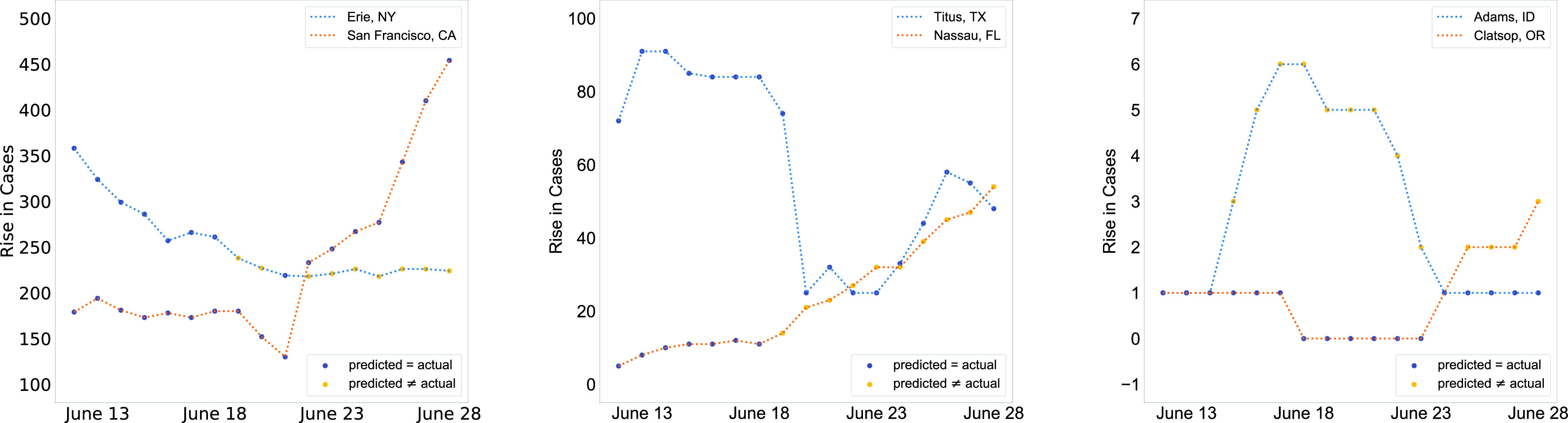
The proposed model predicts a range between which the rise in the number of infected cases is expected to lie. In this section, we describe how the model is trained with this output. Let 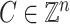 represent a list containing boundaries of ranges used for prediction in the model. Therefore, if the model predicts class
represent a list containing boundaries of ranges used for prediction in the model. Therefore, if the model predicts class 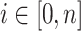 , the rise in cases is expected to be within the interval
, the rise in cases is expected to be within the interval 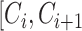 ) under the assumptions that
) under the assumptions that 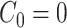 and
and 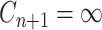 . Naturally,
. Naturally, 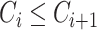 for all
for all 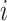 .
.
Since 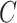 is sorted and ordered, we can treat the output of the model as an ordinal variable and perform ordinal regression using the method described by Frank et al.
[58]. According to the method,
is sorted and ordered, we can treat the output of the model as an ordinal variable and perform ordinal regression using the method described by Frank et al.
[58]. According to the method, 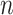 binary classifiers need to be trained such that classifier
binary classifiers need to be trained such that classifier 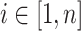 outputs the probability
outputs the probability 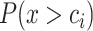 , where
, where 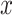 is the rise in number of cases and
is the rise in number of cases and 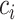 is a constant. After
is a constant. After 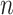 probabilities are obtained from these
probabilities are obtained from these 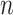 classifiers, we can easily find
classifiers, we can easily find 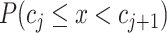 for all
for all 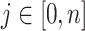 . Finally, the rise in cases is expected to lie in the interval
. Finally, the rise in cases is expected to lie in the interval 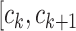 ) for some
) for some 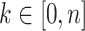 so that
so that 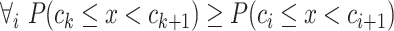 . Frank et al.
[58] suggest that the model should be trained by using only binary cross entropy loss on the
. Frank et al.
[58] suggest that the model should be trained by using only binary cross entropy loss on the 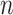 binary classifiers. However, this could seem non-ideal because the final goal is to predict the interval
binary classifiers. However, this could seem non-ideal because the final goal is to predict the interval 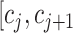 ) rather than to predict
) rather than to predict 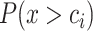 for all
for all 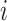 . Therefore, for the proposed model, a multi-class cross-entropy loss on
. Therefore, for the proposed model, a multi-class cross-entropy loss on 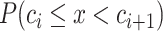 for all
for all 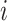 is added in addition to the binary cross-entropy loss on all binary classifiers. The conducted experiments show that the results are slightly better when this new loss term is added.
is added in addition to the binary cross-entropy loss on all binary classifiers. The conducted experiments show that the results are slightly better when this new loss term is added.
B. Class Ranges for Outputs
As described above, the proposed method predicts a range within which the increase in the number of cases would lie. It is important to discuss how range boundaries (i.e., list 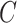 ) are actually chosen. Basically, we start by finding the rise in the number of cases in every county from April 5 through June 28 during the same projection interval of the model. We then find the 33rd, 67th and the 90th percentile of the rise in cases during those dates. In raw numbers, this turns out to be 1, 13, and 93. So the output classes correspond to the following ranges: 0 to 1 (negligible increase), 2 to 13 (moderately low increase), 14 to 93 (moderately high increase), and 94 and above (significantly high increase). These numbers denote the rise in cases in every county during one week. For more clarity, Fig. 3 shows the histogram of weekly rise in cases of all counties from April 5 through June 28 with the class boundaries marked in different colors.
) are actually chosen. Basically, we start by finding the rise in the number of cases in every county from April 5 through June 28 during the same projection interval of the model. We then find the 33rd, 67th and the 90th percentile of the rise in cases during those dates. In raw numbers, this turns out to be 1, 13, and 93. So the output classes correspond to the following ranges: 0 to 1 (negligible increase), 2 to 13 (moderately low increase), 14 to 93 (moderately high increase), and 94 and above (significantly high increase). These numbers denote the rise in cases in every county during one week. For more clarity, Fig. 3 shows the histogram of weekly rise in cases of all counties from April 5 through June 28 with the class boundaries marked in different colors.
FIGURE 3.

A histogram to show the distribution of the weekly rise in infected cases across the U.S. from April 5 through June 28 — the x-axis shows a value for the weekly rise in cases and the y-axis shows the frequency of occurrences of that value in the dataset. The colored shaded regions correspond to different classes representing a range of the weekly rise in cases as explained in Section V. As shown, all instances in which the weekly rise in cases is above 103 have been merged into the last bin. Note that the logarithmic scale is used on both axis.
It should be noted that due to the distribution of the labels, a naive model which predicts the same class always would at most get 33% accuracy. This should also help contextualize our results. We achieved about 64% accuracy on the testing data (June 12 through June 28), which is about two times better than a naive model. In light of this and the feature analysis results presented in Section VI-B, we can be confident that the model has learned useful information. It is also important to note that these class boundaries can easily be changed to make the model predictions finer or coarser as per different use cases.
C. Train and Test Splits
The total data used was from April 5 through June 28. 68% of this data was used for the training set, 12% for validation and 20% for the testing set. Equivalently, data from April 5 through June 1 was used for training, June 2 through June 11 for validation, and June 12 through June 28 for testing. Although data since January 21 was available, we used data only from April 5 onward because of the lack of widespread testing availability before then. Since the model was trained on labels derived from the results of COVID-19 testing data, it was essential to use data that was relatively accurate and did not underestimate the number of infections due to lack of testing [12].
D. Amount of Past Data Used
As explained in Section III, the values of many input feature groups used in the model change with time (time-dependent or cross-county time-dependent feature groups). For all such features, we used 13 days of past data. We experimentally found that increasing the number of past days to 21 and 28 had insignificant effect on the model accuracy. Therefore, for reasons related to computational efficiency, we chose to use 13 days of past data.
So, to be clear, when predicting the range of increase in infected cases on, for example, June 21, we use input data from June 1 to June 13. Features from June 14 through 20 are not given as input because that represents the interval for which the model is predicting the rise in cases.
E. Hyperparameter Tuning
We used Bayesian optimization for 30 iterations with expected improvement as the acquisition function to choose hyperparameters for the model [59].
F. Training Method
As shown in Fig. 4, the model’s testing results become less accurate as it is tested on dates further in time from the dates on which it was trained. Since the dates of the training, validation, and testing set are in ascending order, we hypothesized that training on the validation set as well should improve testing performance, since more recent dates will be used in training. In light of this belief, the model is trained in two steps.
FIGURE 4.

The plot of accuracy vs time on the testing set - the results show that the accuracy keeps decreases as the model tries to project further in the future.
First, we keep the original training and validation sets intact and use Bayesian optimization as described above to perform hyperparameter tuning. We then choose the model with the best performance on the validation set and note the corresponding hyperparameters and the number of epochs needed to train this model using backpropagation. Second, we combine the training and validation sets to make a larger set and train the model on it with the hyperparameters chosen in the first step and for the same number of epochs. The model obtained in the second step is the final model. Note that the first step has two purposes: (1) choosing best hyperparameters, and (2) helping decide a stopping point for the second step to avoid/reduce overfitting.
G. Feature Analysis
For the model to be informative for policy making, it should be explainable. To this end, we adopted a simple and popular method to evaluate feature importance [60]. We first evaluated the accuracy of the model on a small section of the training set. Next, we looped through every feature in every feature group, randomized its value, and reevaluated the model’s accuracy on the same section of the training set. We assigned higher importance to those features which when randomized cause greater decrease in the model accuracy.
A similar analysis was performed to determine feature values at which time steps are the most important in determining the final output. To perform this analysis, we randomized all features on a given time step, and then assigned greater importance to those time steps which when randomized cause greater decrease in performance.
It is important to note that the method used to evaluate importance at both the time step and feature level shows only relative importance and must be interpreted as such.
H. Feature Interaction Analysis
As described in Section IV, the DeepCOVIDNet model explicitly computes second-order interactions between input feature groups. Due to this explicit representation of second-order interactions, it is possible to identify pairs of features between which high amount of interaction is observed. To perform this analysis, we evaluated the network on a section of the training set and tracked the magnitude of activations in the vector representing the second-order interactions of input features. We concluded that the observed interaction among two feature groups is high when the average magnitude of their second-order interaction is also high. This implicit assumption that neurons are activated highly when they capture a pattern to which they are responding to is common in deep learning and is used in other interpretation techniques, such as activation maximization [61].
VI. Results
A. Predictive Performance
In this section, we discuss the performance of the proposed model on the test set. As discussed above, the test set contains 17 days of data from June 12 through June 28. The average accuracy of the model on these 17 days is 63.7% when using four output classes to categorize the growth in the number of new cases for each county (i.e. negligible increase, moderately low increase, moderately high increase, and significantly high increase).
Further, as shown in Fig. 4, the performance of the model, which is trained from April 5 through June 11, decreases as we evaluate on dates further from June 11. The same trend of the model performance decreasing over time can also be observed in Fig. 5 and Fig. 6. It should be noted that research [13] has shown that predictive performance of many other forecasting models also declines with time. This could be due to two possible reasons. One, the COVID-19 situation is highly dynamic and the behavior of people and the adaptive strategies they use change frequently. For example, mask use in the United States has increased over time, especially after the Centers for Disease Control and Prevention (CDC) advised it [62]. So if the model were trained on data before mask use became prevalent, it would learn trends that will not hold true after masks become more widespread. Two, the testing capacity of the United States continues to ramp up with time. As testing becomes more accessible, the trends a model may have learned earlier may not hold, as more people would be tested, resulting in more infected cases being found.
FIGURE 5.
Results showing the absolute difference in predicted class and the actual class for all counties (since classes are ordered). Therefore, the value of 0 means the model’s prediction was correct, 1 means it was one class away from ground truth, and so on. The accuracy of the model on the given date is shown above each subfigure. (The few counties not shown in these plots either have no infected cases or did not have sufficient data.)
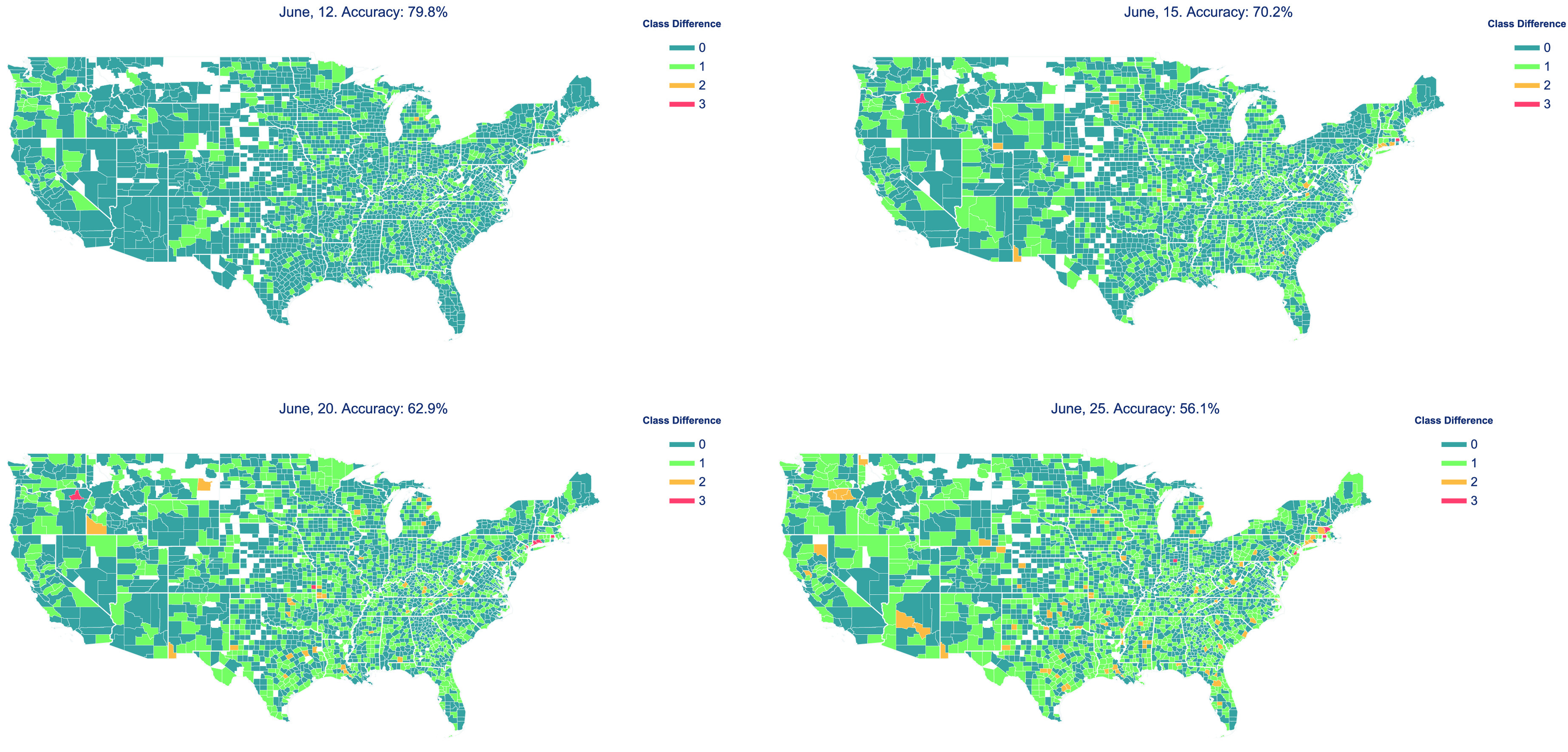
FIGURE 6.
Example results for the model predictions over time for three types of counties: counties with high growth, counties with medium growth, and counties with low growth of cases.
Therefore, during deployment, a good strategy is to let the model forecast only 7 days beyond the end of dates used in training, as new features are released about every 7 days. To project further into the future, the model must be retrained on the most recent training data available to ensure that the knowledge it learns holds for the dates it is asked to forecast on. Therefore, since the model will only forecast 7 days into the future in practice, it is important to know its “use case accuracy” or “7-day accuracy,” which is the model’s accuracy from June 12 through June 18 (7 days of test data). The model’s “use case accuracy” is much higher at 70.8%. Note that since other deep learning models [2], [5], [6], [25], [40] use different types of input features, different output formats (by treating COVID-19 forecasting as a regression problem instead of an ordinal classification one like in this paper), and test their models on different set of dates and spatial locations, it is difficult to directly compare DeepCOVIDNet’s performance with them. However, to contextualize performance better, note that the proposed model performs about two times better than a naive model that predicts the same class always as explained in Section V.
Fig. 5 shows the predictive performance of the model in all U.S. counties on a series of dates. The figure shows that the majority of the predicted results are consistent with or one class away from the actual growth in the number of cases. The predicted growth for only a few counties are more than two or three classes away from the actual situation. This shows that the model generally performs well in predicting growth in spread of infection in a county. Even when the model’s predictions are incorrect, they are usually just one category away from being correct. Further, as discussed above, the figure also shows that the accuracy of the model decreases for dates further away from those used in the training set.
Fig. 6 shows the model predictions over time for different counties based on the growth of infected cases in them. We see the same general trend as in Fig. 5 that the model makes more inaccurate predictions as we go further in the future.
B. Feature Importance Evaluation
In the next step, we evaluated the importance of different county features in terms of their contribution to the prediction of the number of new cases in each county. Fig. 7 shows some of the most salient features identified by the model using the method described in Section V. As shown in Fig. 7, the most important feature is the past increase in infected cases in the current county. This implies that the past trend of the growth of infection in a county is a strong determinant of future growth. Moreover, the second and third most important features are the cumulative infected cases in all counties and the number of people from other counties visiting the county under study. As explained in appendix, these are both cross-county time-dependent features. Together, these features could imply that the phenomenon of people traveling from more infected counties to other counties is associated with the growth of infected cases in the destination county. In other words, the results show that inter-county travel risk could be high for the destination county, consistent with previous studies about the risks of travel [63], [64]. Other important features, such as the median home dwell time, percentage of people working full- or part-time, percentage of people staying home, and number of people traveling to work for less than 5 minutes all show that the model has learned the importance of staying home and social distancing in general, which is again consistent with the reported findings in previous studies [65]. In addition, the model also shows that various manually engineered features are effective and indicative of the growth of infected cases. For example, COVID-19 Vulnerability Index (CCVI) score, socioeconomic vulnerability, epidemiological vulnerability, and healthcare system factors are engineered features designed by the Surgo Foundation [66] to identify communities that are at a greater risk of infection, and our results show that all these features are important. Note that other features, such as estimated reproduction number (equal to the number of other infections caused by one infected person) and population density, also make the list of important features.
FIGURE 7.

Feature importance results (the greater the decrease in accuracy, the more important the feature).
Fig. 8 shows the results of the time-step analysis so we know features of which of the past days are most influential in predicting the final output. As discussed earlier, all time-dependent and cross-county time-dependent features use 13 days of past data. Since the projection interval of the model is 7 days, the most recent day used for input features is 7 days before the prediction date (also called projected date). As shown by Fig. 8, the most recent days are the most important in predicting the growth of cases.
FIGURE 8.

Time step analysis. This analysis shows how important features of each of the past days are in predicting the final output. The results indicate that the feature values related to the most recent days are most important in predicting the growth of cases 7 days in the future. Refer VI-B for more details.
C. Feature Interactions
Fig. 9 shows second-order interactions between all feature groups computed by the method described in Section V. The values in the cells represent the mean activations of the second-order interactions of corresponding feature groups. As discussed in Section V, higher values represent higher observed interactions. An important observation from the figure is that almost all feature groups have notable interaction with census features. This result indicates that all other county-level features must be interpreted in the context of the population attributes of that county. For example, two counties with different population attributes may require varying amounts of adherence to social distancing orders to produce the same dampening effect in the growth of disease spread. Note also that Fig. 7, which shows important features identified by the model, does not include many census features, indicating that census features alone do not contribute much to prediction of the growth in future cases.
FIGURE 9.

The observed second-order interactions between input feature groups. Higher value in a cell represents higher amount of interaction among the corresponding feature groups. Refer to VI-C for more details.
Also, the results show that many feature groups have relatively high interaction with cross-county mobility and infections. For example, a relatively high interaction exists between cross-county mobility & infections and social distancing metrics. This result indicates that travellers from other counties have a different kind of impact in destination counties which have higher adherence to social distancing than they do in destination counties with lower adherence levels. This analysis validates our initial hypothesis that interactions among the many input feature groups are likely to exist and aid in predicting the rise in future number of cases in counties.
VII. Limitations and Future Work
Although a novel and effective deep learning based COVID-19 forecasting model has been proposed in this paper, there are a few limitations of the proposed method as described in this section.
Although the model explicitly accounts for second order interactions between feature groups, there is currently no suitable method to interpret these interactions at the individual feature level. In other words, although we may be able to show with our current analysis that there is high interaction between census features and social distancing features, we cannot determine which exact census features interact with which exact social distancing features. Also, since the current model is based on the DeepFM [22] framework, higher order interactions are only captured implicitly, and therefore, cannot be easily interpreted. However, any interpretable information about both individual feature interactions and higher order interactions could be very useful for researchers and policymakers to better understand the spread of the virus. In the future, the design of the DeepFM framework can be modified to capture feature interactions more explicitly based on recent deep learning advances [67], [68] with similar goals.
In addition, although the model achieves satisfying accuracy, there is still room for improvement. One potential method to improve the accuracy can be to add new features to the model since the model is capable of taking in arbitrary number of heterogeneous features. As mentioned in section VI-B, many features identified to be important in forecasting the spread of the virus have been manually engineered. Hence, researchers could engineer more temporal and spatiotemporal features important in predicting the spread of the virus, which can later be included in models like DeepCOVIDNet to increase their performance.
VIII. Discussion and Concluding Remarks
In this paper, we propose a novel deep learning model to examine heterogeneous county-level features and to predict growth of infected cases in the future. The proposed method can extract embeddings from multivariate time series and multivariate spatial time series data in a novel way by utilizing both the temporal and spatial (if available) structure of the data. This process of extracting embeddings could be employed by other deep learning research to process similar type of data. Further, unlike existing models [2]–[6], [8], the proposed model takes in a large number of input features and learns interactions between them. The application of the model has been demonstrated in predicting the growth in the number of new cases in U.S. counties during the COVID-19 pandemic. The model has acceptable performance in prediction and provides highly interpretable feature analysis results that can help policymakers cope with spread.
The proposed forecasting model can be effectively used for predictive pandemic surveillance by both governments and industries. For example, hospitals in each U.S. county can use the model to estimate the growth in the number of cases and determine their needs of future supplies and resources based on the projected number of infections. Similarly, schools and offices can make better plans for future weeks to be prepared in the best way. In addition, policymakers can use this model to deploy proactive measures instead of taking a reactive approach to dampen the spread of the virus and possibly save lives.
The findings of feature importance evaluations can further help researchers decide which features to include in their forecasting models. The results also open up new avenues for other researchers to do a detailed statistical analysis on how the most important features identified by our model exactly contribute to the growth of infected cases. Further, the proposed model can also be used to test the effectiveness of various hand engineered features in predicting the growth of the virus. For example, our results have shown that several manually engineered features like COVID-19 Vulnerability Index (CCVI) is effective in predicting the spread of the virus. Similarly, newly developed features created by other researchers can be added to our model and the feature analysis results can be relied upon to show relative importance of those features. Lastly, due to the high interpretability of our feature importance results, policymakers can design effective control strategies to prevent the growth of infection based on controlling the important factors identified by this study.
Similarly, the results of identifying pairs of features with high second-order interactions show that interactions among the many input features exist and are important to explicitly account for by future researchers in their forecasting models. Further, this analysis also opens up opportunities for data scientists and statisticians to explain more clearly the reasons for such interactions and their possible implications to epidemiologists studying the spread of COVID-19.
In addition, we believe that data-driven models like the DeepCOVIDNet mark the advent of an era of extensively using deep learning for pandemic forecasting, which can complement existing epidemiology models. Already, there is an increasing interest in using recurrent networks to forecast the spread of COVID-19 [40], [69], [70]. To the best of our knowledge, the proposed model is among the earliest non-recurrent and non-conventional deep learning models used for pandemic prediction, which should encourage other researchers to develop more creative models. Finally, this work also presents one of the first attempts to make the results of a deep learning based COVID-19 forecasting model interpretable to policymakers and the public.
Acknowledgment
The authors would like to acknowledge the support from Mapbox [75] and Safegraph [71]–[73] in providing data. Any opinions, findings, conclusions and/or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation, Amazon Web Services, and Microsoft.
Biographies

Ankit Ramchandani received the B.S. degree in computer science from Texas A&M University, College Station, TX, USA, in 2020. He is currently pursuing the master’s degree in machine learning with Carnegie Mellon University, Pittsburgh, PA, USA. He is also a Research Assistant with the Urban Resilience.AI Lab, Zachry Department of Civil and Environmental Engineering, Texas A&M University. During his time at Texas A&M, he has researched in autonomous driving using machine learning and interned in an applied machine learning team at Facebook.

Chao Fan received the M.Sc. degree in civil engineering from the University of California at Davis, CA, USA, in 2017. He is currently pursuing the Ph.D. degree with the Zachry Department of Civil and Environmental Engineering, Texas A&M University, College Station, TX, USA. He joined the Urban Resilience.AI Lab, in Fall 2017. His research interests include cutting-edge interdisciplinary research with the interface of engineering, science, and policy, and integrated and resilience studies in disaster management using social media and data analytics methods. He received the Ph.D. Fellowship and the Best Paper Nomination at The HAWAII International Conference on System Sciences.

Ali Mostafavi received the M.Sc. degree in industrial administration degree from the Krannert School of Management and the Ph.D. degree in civil engineering from Purdue University, West Lafayette, IN, USA, in 2013. He is currently an Associate Professor with the Zachry Department of Civil and Environmental Engineering, Texas A&M University, College Station, TX, USA. He is also the Director of the Urban Resilience.AI Lab. His researches focus on creating transformative solutions for addressing the grand challenges pertaining to the nexus of humans, disasters, and infrastructure systems.
Appendix. Feature Descriptions
In this section, we provide detailed descriptions of the feature groups used in the model and some general statistical information of some features. As shown in Section III, the feature groups of the model are categorized based on four influencing factors. In this section, we provide the definition and detailed calculation of all feature groups based on their influencing factors followed by some general statistical information.
A. Population Attributes
As mentioned in Table 2, we use the following features to capture population attributes:
-
1)
Census Features: We use a subset of 2100 sociodemographic features compiled by SafeGraph [71]. These features include population level information about age/sex, race, ethnicity, commuting information, household/family type, school enrollment, language spoken at home, poverty status, income, employment status and occupation. This data was originally collected by the American Community Survey in 2016.
-
2)Vulnerability Features: In this group, we add population density and other features built by the Surgo Foundation [66] to identify counties that are more vulnerable to the spread of the virus. Specifically, the foundation has created seven features, six of which assess vulnerability of a county across different areas and one assesses overall vulnerability to COVID-19 as described in the following. All features are bounded between 0 and 1, where 0 means least vulnerability and 1 means greatest vulnerability. It is important to note that these features are defined in a relative context, meaning that the value 1 is associated with the most vulnerable county. Due to this reason, the “feature values” actually represent vulnerability rankings of all counties. Each of the seven features shown below is developed by combining multiple other features as described below.
-
a)Socioeconomic Vulnerability. This feature is developed based on population below poverty line, unemployed population, per-capita income, and population without high school diploma and represents the socioeconomic vulnerability of a county.
-
b)Household Composition & Disability. This feature is developed based on the distribution of population older than 65, population younger than 17, population with a disability, and single parent households. It is a measure of vulnerability of households and the population at large.
-
c)Minority Status & Language. As the name suggests, this feature is developed based on minority population and number of people who speak “less than well” English.
-
d)Housing Type & Transportation. This feature is developed by using the estimate of mobile homes, households with more people than rooms, households with no available vehicle, housing with structures with 10 or more units, and persons living in institutionalized group quarters. This feature helps identify communities with poor housing or transportation situation.
-
e)Epidemiological Vulnerability This feature identifies communities with greater risk of negative impact during disease epidemics. It is built by using 11 other features capturing the number of people with cardiovascular issues, respiratory conditions, weak immune systems, obesity, diabetes, and high vulnerability to influenza and pneumonia. The feature also considers population density of the county.
-
f)Healthcare System Factors. This feature tries to measure the capacity, strength (measured by county spending on health and research quality) and preparedness of the health care system in a county using 8 different features.
-
g)COVID-19 Vulnerability Index (CCVI). Finally, the above 6 features are combined with equal weighting to create the COVID-19 vulnerability index, which is intended to identify communities “with a limited ability to mitigate, treat, and delay the transmission of” the virus.
-
a)
B. Population Activities
We use the mobility data collected by SafeGraph to capture population activities. The SafeGraph Patterns [72] and SafeGraph Social Distancing Metrics [73] are adopted in our use case. The former includes information related to the number of visits to certain points of interest, and the latter provides data to show adherence to stay-at-home guidelines.
-
1)
Visitation Patterns: SafeGraph Patterns data has information about the number of people that visit different types of points of interest (i.e. grocery stores, health facilities, etc) on a given day. We consider visits to the following types of places in our model: amusement parks and arcades, colleges/universities/professional schools, living facilities for elderly, department stores, hospitals, merchandise stores/supercenters, grocery stores, and restaurants/eating places. As discussed in III-A, visits to grocery stores, restaurants/other eating places, living facilities for elderly, and hospitals could be particularly helpful in forecasting the growth of cases since these places could facilitate virus transmission [44]–[47].
-
2)
Social Distancing Metrics: We use SafeGraph social distancing metrics to compute/extract the percentage of people staying home, percentage of people working full- or part-time, median distance travelled from home and the median amount of time spent at home for each county and each day. As discussed in III-A, adherence to stay-at-home guidelines and the number of people working outside are both important in determining the spread of the virus [48]–[51].
-
3)Venables Distance: Venables distance captures the concentration of population activities in a county. Venables distance,
 , is defined formally as [32]:
, is defined formally as [32]:
where
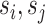 represents the population activity intensity in cell
represents the population activity intensity in cell 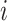 and
and 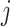 respectively and
respectively and 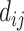 represents the distance between the two cells. In our analysis, we define a cell to be a 4 km2 area. We compute
represents the distance between the two cells. In our analysis, we define a cell to be a 4 km2 area. We compute 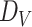 for each day and county by basically using the daily average values for
for each day and county by basically using the daily average values for 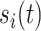 and
and 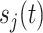 . Louail et al.
[32] describe more details about this equation. We use Mapbox digital trace telmetry data, which basically uses aggregated cell phone data to estimate population activity in small spatial regions of each county, to extract values of
. Louail et al.
[32] describe more details about this equation. We use Mapbox digital trace telmetry data, which basically uses aggregated cell phone data to estimate population activity in small spatial regions of each county, to extract values of 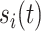 and
and 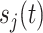 for cells.
for cells.
C. Mobility
To capture mobility across regions, we employed inter-county travel data from SafeGraph as described below.
-
1)
Cross County Mobility & Infections: The SafeGraph data [72] include the census blocks where the travelers visiting a certain point of interest come from. With this information, we can estimate the total number of travelers from one county to another. We further augment the mobility data by also adding the cumulative number of infections in source counties, so the model can realize that visitors from a more infected county could be more dangerous than visitors from a less infected county.
D. Disease Spread Attributes
-
1)
Past Rise in Infected Cases: We consider the weekly rise in the number of confirmed cases in past days as a feature to represent the past pandemic situation in a county. This data is obtained from the New York Times GitHub repository [74]. Since the proposed model predicts the growth of cases a week in the future, the weekly rise in cases for the past few days as an input feature can inform the model about the recent trend of the variable that it has to predict.
-
2)Reproduction Number: The basic reproduction number is also used, which is an estimate of how fast the number of cases are expected to increase by. Formally, it is the estimated number of other cases caused by one infected person. Fan et al. [54] describe the exact method of estimating reproduction number by using a simple epidemic model. They assume that an infected person infects another
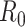 people after time
people after time 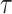 . Therefore, if the number of infected people at time step 0 are
. Therefore, if the number of infected people at time step 0 are 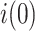 , then at time step
, then at time step 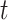 , the number will grow to
, the number will grow to 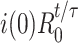 . Simple algebraic manipulations show that:
. Simple algebraic manipulations show that:
Fan et al. [54] set
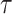 to 5.1 days and provide justifications for this choice in their work. As Table 1 shows, we use reproduction number as a time dependent feature in the model. Therefore, for this analysis, we estimate the daily reproduction number based on 10 days of past data. In other words, to estimate
to 5.1 days and provide justifications for this choice in their work. As Table 1 shows, we use reproduction number as a time dependent feature in the model. Therefore, for this analysis, we estimate the daily reproduction number based on 10 days of past data. In other words, to estimate 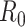 at day
at day 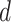 , we use the following formula:
, we use the following formula:
E. General Statistical Information
Table 3 shows general statistical information about some individual features to help contextualize their values in a better way.
TABLE 3. Summary Statistics for Some Features Collected From April 5 Through June 28.
| Feature Name | Feature Group | Mean | SD | 25th percentile | 75th percentile |
|---|---|---|---|---|---|
| County Population | Census Features | 101646.4 | 325631.00 | 11033 | 67905 |
| County Population Density (per sq. mi.) | Vulnerability Features | 270.81 | 1805.79 | 16.86 | 117.31 |
| Past Rise in Infected Cases | Past Rise in Infected Cases | 59.07 | 320.31 | 1 | 22 |
| Percentage People Staying Fully Home | Social Distancing Metrics | 30.00% | 6.97% | 25.75% | 35.18% |
| Median Home Dwell Time (min.) | Social Distancing Metrics | 663.09 | 155.38 | 579.50 | 758.35 |
| Median Distance Traveled From Home (mi.) | Social Distancing Metrics | 4.42 | 24.19 | 2.77 | 8.77 |
| Total Visits to Points of Interests | Visitation Patterns | 6468.75 | 18759.48 | 484 | 4679 |
Data and Code Availability
The data that support this study are available from SafeGraph, Mapbox, and The New York Times GitHub repository containing information about the past number of cases. Restrictions apply to the availability of some of these data, which were used under license for the current study. Due to the same reason, the raw data used in the study cannot be released publicly and interested users should directly contact the original providers to access data. However, the full code used to implement the proposed DeepCOVIDNet model is available on Github: https://github.com/urban-resilience-lab/covid-county-prediction. Any future updates such as model architectural changes, inclusion of new input features based on new research, and results on more recent dates will be posted on GitHub.
Funding Statement
This work was supported in part by the National Science Foundation under Grant SES-2026814 (RAPID), in part by the National Academies’ Gulf Research Program Early-Career Research Fellowship, in part by the Amazon Web Services (AWS) Machine Learning Award, and in part by the Microsoft AI for Health COVID-19 Grant for cloud computing resources.
References
- [1].Huang C.-J., Shen Y., Kuo P.-H., and Chen Y.-H., “Novel spatiotemporal feature extraction parallel deep neural network for forecasting confirmed cases of coronavirus Disease 2019,” medRxiv, May 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.04.30.20086538v1 [DOI] [PMC free article] [PubMed]
- [2].Tomar A. and Gupta N., “Prediction for the spread of COVID-19 in india and effectiveness of preventive measures,” Sci. Total Environ., vol. 728, Aug. 2020, Art. no.138762, doi: 10.1016/j.scitotenv.2020.138762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Perc M., Miksić N. G., Slavinec M., and Stožer A., “Forecasting COVID-19,” Frontiers Phys., vol. 8, p. 127, Apr. 2020, doi: 10.3389/fphy.2020.00127. [DOI] [Google Scholar]
- [4].Anastassopoulou C., Russo L., Tsakris A., and Siettos C., “Data-based analysis, modelling and forecasting of the COVID-19 outbreak,” PLoS ONE, vol. 15, no. , Mar. 2020, Art. no. e0230405. [Online]. Available: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.02304%05 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Huang C.-J., Chen Y.-H., Ma Y., and Kuo P.-H., “Multiple-input deep convolutional neural network model for COVID-19 forecasting in China,” medRxiv, Mar. 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.03.23.20041608v1
- [6].Chimmula V. K. R. and Zhang L., “Time series forecasting of COVID-19 transmission in canada using LSTM networks,” Chaos, Solitons Fractals, vol. 135, Jun. 2020, Art. no. 109864. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0960077920302642 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Rustam F., Reshi A. A., Mehmood A., Ullah S., On B.-W., Aslam W., and Choi G. S., “COVID-19 future forecasting using supervised machine learning models,” IEEE Access, vol. 8, pp. 101489–101499, May 2020, doi: 10.1109/ACCESS.2020.2997311. [DOI] [Google Scholar]
- [8].Punn N. S., Sonbhadra S. K., and Agarwal S., “COVID-19 epidemic analysis using machine learning and deep learning algorithms,” medRxiv, Jun. 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.04.08.20057679v2
- [9].Siriyasatien P., Chadsuthi S., Jampachaisri K., and Kesorn K., “Dengue epidemics prediction: A survey of the State-of-the-Art based on data science processes,” IEEE Access, vol. 6, pp. 53757–53795, Sep. 2018. [Online]. Available: https://ieeexplore.ieee.org/document/8468168 [Google Scholar]
- [10].Balcan D., Colizza V., Goncalves B., Hu H., Ramasco J. J., and Vespignani A., “Multiscale mobility networks and the spatial spreading of infectious diseases,” Proc. Nat. Acad. Sci. USA, vol. 106, no. 51, pp. 21484–21489, Dec. 2009, doi: 10.1073/pnas.0906910106. [Online]. Available: https://www.pnas.org/content/106/51/21484 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Wang L., Chen J., and Marathe M., “DEFSI: Deep learning based epidemic forecasting with synthetic information,” in Proc. AAAI Conf. AI, vol. 33, Jul. 2019, pp. 9607–9612, doi: 10.1609/aaai.v33i01.33019607. [DOI] [Google Scholar]
- [12].Jewell N. P., Lewnard J. A., and Jewell B. L., “Predictive mathematical models of the COVID-19 pandemic: Underlying principles and value of projections,” Jama, vol. 323, no. 19, pp. 1893–1894, Apr. 2020. [Online]. Available: https://jamanetwork.com/journals/jama/fullarticle/2764824 [DOI] [PubMed] [Google Scholar]
- [13].Holmdahl I. and Buckee C., “Wrong but useful—What covid-19 epidemiologic models can and cannot tell us,” New England J. Med., vol. 383, no. 4, pp. 303–305, Jul. 2020, doi: 10.1056/NEJMp2016822. [DOI] [PubMed] [Google Scholar]
- [14].Kraemer M. U. G., Yang C.-H., Gutierrez B., Wu C.-H., Klein B., Pigott D. M., du Plessis L., Faria N. R., Li R., Hanage W. P., Brownstein J. S., Layan M., Vespignani A., Tian H., Dye C., Pybus O. G., and Scarpino S. V., “The effect of human mobility and control measures on the COVID-19 epidemic in China,” Science, vol. 368, no. 6490, pp. 493–497, May 2020. [Online]. Available: https://science.sciencemag.org/content/368/6490/493 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Jia J., Ding J., Liu S., Liao G., Li J., Duan B., Wang G., and Zhang R., “Modeling the control of COVID-19: Impact of policy interventions and meteorological factors,” Electr. J. Diff. Eq., vol. 2020, no. 23, pp. 1–24, 2020. [Online]. Available: https://ejde.math.txstate.edu/Volumes/2020/23/jia.pdf [Google Scholar]
- [16].Jarvis C. I., Van Zandvoort K., Gimma A., Prem K., Klepac P., Rubin G. J., and Edmunds W. J., “Quantifying the impact of physical distance measures on the transmission of COVID-19 in the UK,” BMC Med., vol. 18, pp. 1–10, May 2020, doi: 10.25561/77581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Qiu Y., Chen X., and Shi W., “Impacts of social and economic factors on the transmission of coronavirus disease 2019 (COVID-19) in China,” J. Population Econ., vol. 33, no. 4, pp. 1127–1172, Oct. 2020, doi: 10.1007/s00148-020-00778-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Rocklöv J. and Sjödin H., “High population densities catalyse the spread of COVID-19,” J. Travel Med., vol. 27, no. 3, Mar. 2020, doi: 10.1093/jtm/taaa038. [Online]. Available: https://academic.oup.com/jtm/article/27/3/taaa038/5807719 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Dowd J. B., Andriano L., Brazel D. M., Rotondi V., Block P., Ding X., Liu Y., and Mills M. C., “Demographic science aids in understanding the spread and fatality rates of COVID-19,” Proc. Nat. Acad. Sci. USA, vol. 117, no. 18, pp. 9696–9698, Apr. 2020, doi: 10.1073/pnas.2004911117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Song W., Shi C., Xiao Z., Duan Z., Xu Y., Zhang M., and Tang J., “AutoInt: Automatic feature interaction learning via self-attentive neural networks,” in Proc. 28th ACM Int. Conf. Inf. Knowl. Manage., Nov. 2019, pp. 1161–1170, doi: 10.1145/3357384.3357925. [DOI] [Google Scholar]
- [21].Gao J.. (2014). Machine Learning Applications for Data Center Optimization. Google. Mountain View, CA, USA. [Online]. Available: https://static.googleusercontent.com/media/research.google.com/en//pubs%/archive/42542.pdf [Google Scholar]
- [22].Guo H., Tang R., Ye Y., Li Z., and He X., “DeepFM: A factorization-machine based neural network for CTR prediction,” in Proc. 26th Int. Joint Conf. Artif. Intell. (IJCAI), Melbourne, VIC, Australia, Aug. 2017, pp. 1725–1731, doi: 10.5555/3172077.3172127. [DOI] [Google Scholar]
- [23].Cheng H.-T., Ispir M., Anil R., Haque Z., Hong L., Jain V., Liu X., Shah H., Koc L., Harmsen J., Shaked T., Chandra T., Aradhye H., Anderson G., Corrado G., and Chai W., “Wide & deep learning for recommender systems,” in Proc. 1st Workshop Deep Learn. Recommender Syst. DLRS, 2016, pp. 7–10, doi: 10.1145/2988450.2988454. [DOI] [Google Scholar]
- [24].Wang R., Fu B., Fu G., and Wang M., “Deep & cross network for ad click predictions,” in Proc. ADKDD ZZZ ADKDD, 2017, pp. 1–7, doi: 10.1145/3124749.3124754. [DOI] [Google Scholar]
- [25].Tian Y., Luthra I., and Zhang X., “Forecasting COVID-19 cases using machine learning models,” medRxiv, Jul. 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.07.02.20145474v1
- [26].McCluskey C. C., “Complete global stability for an SIR epidemic model with delay—Distributed or discrete,” Nonlinear Anal., Real World Appl., vol. 11, no. 1, pp. 55–59, Feb. 2010, doi: 10.1016/j.nonrwa.2008.10.014. [DOI] [Google Scholar]
- [27].Fan C., Jiang X., and Mostafavi A., “A network percolation-based contagion model of flood propagation and recession in urban road networks,” 2020, arXiv:2004.03552. [Online]. Available: http://arxiv.org/abs/2004.03552 [DOI] [PMC free article] [PubMed]
- [28].Liu Q.-H., Ajelli M., Aleta A., Merler S., Moreno Y., and Vespignani A., “Measurability of the epidemic reproduction number in data-driven contact networks,” Proc. Nat. Acad. Sci. USA, vol. 115, no. 50, pp. 12680–12685, Dec. 2018, doi: 10.1073/pnas.1811115115. [Online]. Available: http://www.pnas.org/content/115/50/12680.abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Jia J. S., Lu X., Yuan Y., Xu G., Jia J., and Christakis N. A., “Population flow drives spatio-temporal distribution of COVID-19 in China,” Nature, vol. 582, no. 7812, pp. 389–394, Jun. 2020, doi: 10.1038/s41586-020-2284-y. [DOI] [PubMed] [Google Scholar]
- [30].Chinazzi M., Davis J. T., Ajelli M., Gioannini C., Litvinova M., Merler S., Piontti A. Y. P., Mu K., Rossi L., Sun K., Viboud C., Xiong X., Yu H., Halloran M. E., Longini I. M., and Vespignani A., “The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak,” Science, vol. 368, no. 6489, pp. 395–400, Apr. 2020, doi: 10.1126/science.aba9757. [Online]. Available: http://science.sciencemag.org/content/368/6489/395.abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Engle S., Stromme J., and Zhou A., “Staying at home: Mobility effects of COVID-19,” in Proc. SSRN, Apr. 2020. [Online]. Available: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3565703 [Google Scholar]
- [32].Louail T., Lenormand M., Cantu Ros O. G., Picornell M., Herranz R., Frias-Martinez E., Ramasco J. J., and Barthelemy M., “From mobile phone data to the spatial structure of cities,” Sci. Rep., vol. 4, no. 1, p. 5276, Jun. 2014, doi: 10.1038/srep05276. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].LeCun Y., Bengio Y., and Hinton G., “Deep learning,” Nature, vol. 521, pp. 436–444, May 2015. [Online]. Available: https://www.nature.com/articles/nature14539 [DOI] [PubMed] [Google Scholar]
- [34].Krizhevsky A., Sutskever I., and Hinton G. E., “Imagenet classification with deep convolutional neural networks,” in Proc. Adv. Neural Info. Proc. Sys., 2012, pp. 1097–1105. [Online]. Available: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-con%volutional-neural-networks [Google Scholar]
- [35].Chung J., Gulcehre C., Cho K., and Bengio Y., “Empirical evaluation of gated recurrent neural networks on sequence modeling,” in Proc. NIPS Workshop Deep Learn., Dec. 2014, pp. 1–9. [Online]. Available: https://arxiv.org/abs/1412.3555 [Google Scholar]
- [36].Hussain A. A., Bouachir O., Al-Turjman F., and Aloqaily M., “AI techniques for COVID-19,” IEEE Access, vol. 8, pp. 128776–128795, 2020. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9136710/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Pham Q.-V., Nguyen D. C., Huynh-The T., Hwang W.-J., and Pathirana P. N., “Artificial intelligence (AI) and big data for coronavirus (COVID-19) pandemic: A survey on the state-of-the-arts,” IEEE Access, vol. 8, pp. 130820–130839, Jul. 2020, doi: 10.1109/ACCESS.2020.3009328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Boccaletti S., Ditto W., Mindlin G., and Atangana A., “Modeling and forecasting of epidemic spreading: The case of covid-19 and beyond,” Chaos, Solitons Fractals, vol. 135, Jun. 2020, Art. no.109794, doi: 10.1016/j.chaos.2020.109794. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Hochreiter S. and Schmidhuber J., “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, Nov. 1997, doi: 10.1162/neco.1997.9.8.1735. [DOI] [PubMed] [Google Scholar]
- [40].Tian T., Jiang Y., Zhang Y., Li Z., Wang X., and Zhang H., “COVID-Net: A deep learning based and interpretable predication model for the county-wise trajectories of COVID-19 in the United States,” medRxiv, May 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.05.26.20113787v1
- [41].Prakash A., Rodriguez A., Cui J., Xie J., Tabassum A., and Adhikari B.. DeepCOVID: For COVID-19 US Mortality and Hospitalization Forecasting. Accessed: Jul. 26, 2020. [Online]. Available: https://deepcovid.github.io/index.html [Google Scholar]
- [42].Dyer O., “COVID-19: Black people and other minorities are hardest hit in US,” BMJ, vol. 369, Apr. 2020, Art. no. m1483. [Online]. Available: https://www.bmj.com/content/369/bmj.m1483, doi: 10.1136/bmj.m1483. [DOI] [PubMed] [Google Scholar]
- [43].Kirby T., “Evidence mounts on the disproportionate effect of COVID-19 on ethnic minorities,” Lanc. Resp. Med., vol. 8, no. 6, pp. 547–548, May 2020, doi: 10.1016/S2213-2600(20)30228-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Benzell S. G., Collis A., and Nicolaides C., “Rationing social contact during the COVID-19 pandemic: Transmission risk and social benefits of US locations,” Proc. Nat. Acad. Sci. USA, vol. 117, no. 26, pp. 14642–14644, Jun. 2020, doi: 10.1073/pnas.2008025117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Lai C.-C., Wang J.-H., Ko W.-C., Yen M.-Y., Lu M.-C., Lee C.-M., and Hsueh P.-R., “COVID-19 in long-term care facilities: An upcoming threat that cannot be ignored,” J. Microb., Immun., Infec., vol. 53, no. 3, p. 444, Apr. 2020, doi: 10.1016/j.jmii.2020.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [46].Bahl P., Doolan C., de Silva C., Chughtai A. A., Bourouiba L., and MacIntyre C. R., “Airborne or droplet precautions for health workers treating coronavirus disease 2019?” J. Infectious Diseases, Apr. 2020. [Online]. Available: [Online]. Available: https://academic.oup.com/jid/advance-article/doi/10.1093/infdis/jiaa189/5820886, doi: 10.1093/infdis/jiaa189. [DOI] [PMC free article] [PubMed]
- [47].Morawska L.et al. , “How can airborne transmission of COVID-19 indoors be minimised?” Environ. Int., vol. 142, Sep. 2020, Art. no.105832, doi: 10.1016/j.envint.2020.105832. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [48].Gao S., Rao J., Kang Y., Liang Y., Kruse J., Doepfer D., Sethi A. K., Reyes J. F. M., Patz J., and Yandell B. S., “Mobile phone location data reveal the effect and geographic variation of social distancing on the spread of the COVID-19 epidemic,” 2020, arXiv:2004.11430. [Online]. Available: http://arxiv.org/abs/2004.11430
- [49].Cohen J. and Kupferschmidt K., “Countries test tactics in ‘war’ against COVID-19,” Science, vol. 367, no. 6484, p. 1287, Mar. 2020. [Online]. Available: https://science.sciencemag.org/content/367/6484/1287 [DOI] [PubMed] [Google Scholar]
- [50].Sen-Crowe B., McKenney M., and Elkbuli A., “Social distancing during the COVID-19 pandemic: Staying home save lives,” Amer. J. Emergency Med., vol. 38, no. 7, pp. 1519–1520, Jul. 2020, doi: 10.1016/j.ajem.2020.03.063. [Online]. Available: https://www.ajemjournal.com/article/S0735-6757(20)30221-7/fulltext [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Béland L.-P., Brodeur A., and Wright T.. (2020). The Short-Term Economic Consequences of COVID-19: Exposure to Disease, Remote Work and Government Response. [Online]. Available: https://ideas.repec.org/p/zbw/glodps/524.html [DOI] [PMC free article] [PubMed] [Google Scholar]
- [52].Sirkeci I. and Yucesahin M. M., “Coronavirus and migration: Analysis of human mobility and the spread of covid-19,” Migration Lett., vol. 17, no. 2, pp. 379–398, Apr. 2020. [Online]. Available: https://journals.tplondon.com/ml/article/view/935 [Google Scholar]
- [53].Gatto M., Bertuzzo E., Mari L., Miccoli S., Carraro L., Casagrandi R., and Rinaldo A., “Spread and dynamics of the COVID-19 epidemic in italy: Effects of emergency containment measures,” Proc. Nat. Acad. Sci. USA, vol. 117, no. 19, pp. 10484–10491, Apr. 2020, doi: 10.1073/pnas.2004978117. [Online]. Available: https://www.pnas.org/content/117/19/10484 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [54].Fan C., Lee S., Yang Y., Oztekin B., Li Q., and Mostafavi A., “Effects of population co-location reduction on cross-county transmission risk of COVID-19 in the united states,” 2020, arXiv:2006.01054. [Online]. Available: http://arxiv.org/abs/2006.01054 [DOI] [PMC free article] [PubMed]
- [55].Liu Y., Gayle A. A., Wilder-Smith A., and Rocklöv J., “The reproductive number of COVID-19 is higher compared to SARS coronavirus,” J. Travel Med., vol. 27, no. 2, Feb. 2020, Art. no. taaa021, doi: 10.1093/jtm/taaa021. [Online]. Available: https://academic.oup.com/jtm/article/27/2/taaa021/5735319 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [56].Dietz K., “The estimation of the basic reproduction number for infectious diseases,” Stat. Methods Med. Res., vol. 2, no. 1, pp. 23–41, Mar. 1993. [DOI] [PubMed] [Google Scholar]
- [57].Klambauer G., Unterthiner T., Mayr A., and Hochreiter S., “Self-normalizing neural networks,” in Proc. Adv. Neural Info. Proc. Sys., Dec. 2017, pp. 971–980. [Online]. Available: https://papers.nips.cc/paper/6698-self-normalizing-neural-networks.pdf [Google Scholar]
- [58].Frank E. and Hall M., “A simple approach to ordinal classification,” in Proc. Eur. Conf. Mach. Learn., Aug. 2001, pp. 145–156. [Online]. Available: https://link.springer.com/chapter/10.1007/3-540-44795-4_13 [Google Scholar]
- [59].Snoek J., Larochelle H., and Adams R. P., “Practical Bayesian optimization of machine learning algorithms,” in Proc. 25th Int. Conf. Neural Inf. Process. Syst., Lake Tahoe, NV, USA, vol. 2, Dec. 2012, pp. 2951–2959. [Online]. Available: https://dl.acm.org/doi/10.5555/2999325.2999464 [Google Scholar]
- [60].Samek W., Wiegand T., and Müller K.-R., “Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models,” 2017, arXiv:1708.08296. [Online]. Available: http://arxiv.org/abs/1708.08296
- [61].Erhan D., Bengio Y., Courville A., and Vincent P., “Visualizing higher-layer features of a deep network,” Univ. Montr. Montreal, QC, Canada, Tech. Rep. Jan. 2009. [Online]. Available: http://www.iro.umontreal.ca/~lisa/publications2/index.php/publications/%show/247 [Google Scholar]
- [62].Goldberg M. H., Gustafson A., Maibach E. W., Ballew M. T., Bergquist P., Kotcher J. E., Marlon J. R., Rosenthal S. A., and Leiserowitz A., “Mask-wearing increased after a government recommendation: A natural experiment in the U.S. during the COVID-19 pandemic,” Frontiers Commun., vol. 5, p. 44, Jun. 2020, doi: 10.3389/fcomm.2020.00044. [DOI] [Google Scholar]
- [63].Rodríguez-Morales A. J., MacGregor K., Kanagarajah S., Patel D., and Schlagenhauf P., “Going global—Travel and the 2019 novel coronavirus,” Travel Med. Infectious Disease, vol. 33, Jan. 2020, Art. no.101578, doi: 10.1016/j.tmaid.2020.101578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [64].Lai S., Bogoch I. I., Ruktanonchai N. W., Watts A., Lu X., Yang W., Yu H., Khan K., and Tatem A. J., “Assessing spread risk of Wuhan novel coronavirus within and beyond China, january-april 2020: A travel network-based modelling study,” medRxiv, Mar. 2020. [Online]. Available: https://www.medrxiv.org/content/10.1101/2020.02.04.20020479v2
- [65].Ferguson N., Laydon D., Nedjati-Gilani G., Imai N., Ainslie K., Baguelin M., Bhatia S., Boonyasiri A., Cucunubá Z., Cuomo-Dannenburg G., and Dighe A., “Report 9: Impact of non-pharmaceutical interventions (NPIs) to reduce COVID19 mortality and healthcare demand,” Imperial College London, vol. 10, Mar. 2020, Art. no. 77482. [Online]. Available: https://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid%-19/report-9-impact-of-npis-on-covid-19/ [Google Scholar]
- [66].Foundation S.. The COVID-19 Community Vulnerability Index (CCVI). Accessed: Jul. 26, 2020. [Online]. Available: https://precisionforcovid.org/ccvi [Google Scholar]
- [67].Lian J., Zhou X., Zhang F., Chen Z., Xie X., and Sun G., “XDeepFM: Combining explicit and implicit feature interactions for recommender systems,” in Proc. 24th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, Jul. 2018, pp. 1754–1763. [Online]. Available: https://dl.acm.org/doi/pdf/10.1145/3219819.3220023 [Google Scholar]
- [68].Liu B., Xue N., Guo H., Tang R., Zafeiriou S., He X., and Li Z., “AutoGroup: Automatic feature grouping for modelling explicit high-order feature interactions in CTR prediction,” in Proc. 43rd Intl. ACM SIGIR Conf. Res. Dev. Info. Retr., Jul. 2020, pp. 199–208, doi: 10.1145/3397271.3401082. [DOI] [Google Scholar]
- [69].Ayyoubzadeh S. M., Ayyoubzadeh S. M., Zahedi H., Ahmadi M., and Niakan Kalhori S. R, “Predicting COVID-19 incidence through analysis of Google trends data in iran: Data mining and deep learning pilot study,” JMIR Public Health Surveill., vol. 6, no. 2, Apr. 2020, Art. no. e18828, doi: 10.2196/18828. [Online]. Available: https://publichealth.jmir.org/2020/2/e18828/ [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Yang Z.et al. , “Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions,” J. Thor. Dis., vol. 12, no. 3, p. 165, 2020. http://www.jtd.amegroups.com/article/view/36385/html [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].SafeGraph. Census Block Group Data. Accessed: Jul. 26, 2020. [Online]. Available: https://docs.safegraph.com/docs/open-census-data
- [72].SafeGraph. Places Schema. Accessed: Jul. 26, 2020. [Online]. Available: https://docs.safegraph.com/docs/places-schema#section-patterns
- [73].SafeGraph. Social Distancing Metrics. Accessed: Jul. 26, 2020. [Online]. Available: https://docs.safegraph.com/docs/social-distancing-metrics
- [74].Smith M., Yourish K., Almukhtar S., Collins K., Ivory D., and Harmon A.. Data From The New York Times, Based on Reports From State and Local Health Agencies. Accessed: Jul. 26, 2020. [Online]. Available: https://github.com/nytimes/covid-19-data
- [75].Mapbox. Data Products. Accessed: Jul. 26, 2020. [Online]. Available: https://www.mapbox.com/data-products/
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support this study are available from SafeGraph, Mapbox, and The New York Times GitHub repository containing information about the past number of cases. Restrictions apply to the availability of some of these data, which were used under license for the current study. Due to the same reason, the raw data used in the study cannot be released publicly and interested users should directly contact the original providers to access data. However, the full code used to implement the proposed DeepCOVIDNet model is available on Github: https://github.com/urban-resilience-lab/covid-county-prediction. Any future updates such as model architectural changes, inclusion of new input features based on new research, and results on more recent dates will be posted on GitHub.