

Abstract
Overlap in meta-reviews results from the use of multiple identical primary studies in similar reviews. It is an important area for research synthesists because overlap indicates the degree to which reviews address the same or different literatures of primary research. Current guidelines to address overlap suggest that assessing and documenting the degree of overlap in primary studies, calculated via the Corrected Covered Area (CCA) is a promising method. Yet, the CCA is a simple percentage of overlap and current guidelines do not detail ways that reviewers can use the CCA as a diagnostic tool while also comprehensively incorporating these findings into their conclusions. Furthermore, we maintain that meta-review teams must address non-independence via overlap more thoroughly than by simply estimating and reporting the CCA. Instead, we recommend and elaborate five steps to take when examining overlap, illustrating these steps through the use of an empirical example of primary study overlap in a recently conducted meta-review. This work helps to show that overlap of primary studies included in a meta-review is not necessarily a bias but often can be a benefit. We also highlight further areas of caution in this task and potential for the development of new tools to address non-independence issues.
Keywords: Citation Matrix, Corrected Covered Area, Meta-review, Overlap, Overview
Introduction
As primary research as well as systematic reviews and meta-analyses grow exponentially each year, the need to systematically synthesize the evidence base by conducting a meta-review has grown as well (also known as an overview or review of reviews; as argued elsewhere,1 the term “meta-review” has the advantage of being relatively precise as the term literally means “review of reviews”; in contrast, “overview” could refer to a large number of possibilities).2,3 Meta-reviews can serve several purposes, including to compare and contrast the findings from systematic reviews and to provide a summary of the evidence and the quality of the evidence across these reviews.1,4,5 Along with the rapid growth of meta-reviews, there are numerous methodological tools and considerations, many of which are still in the early phases of development or for which there are no established guidelines.6-8 Overlap of the primary-level studies in meta-reviews is one such area for consideration, and an important one for evidence synthesis methodologists because it concerns the potential for non-independence in the primary studies across similar reviews. The extent to which systematic reviews in a particular domain include the same studies varies widely, depending on many factors.1,9 On the one hand, if reviews address similar questions with similar methods and integrate largely the same primary-level studies’ results, then their review conclusions should not differ. On the other hand, to the extent that different reviews summarize different primary studies, or use different methods, then it is understandable that their conclusions will differ. In a meta-review, both instances – review conclusion similarity and review conclusion discrepancy – occur and it is typically the task of the meta-reviewer to identify why reviews agree or disagree on important findings. To do so, meta-reviewers must first understand to what degree the underlying reviews sampled the same primary studies by examining how much study overlap occurs across included reviews.
Several efforts to address overlap have been suggested,6,7 including removing some reviews (to reduce or totally remove overlap) or by assessing and documenting the degree of overlap (which can be calculated via the Corrected Covered Area, CCA).10 These suggestions do not, however, detail ways that reviewers should address overlap for subgroups of outcomes in a meta-review, nor do they address how overlap assessment can be an important diagnostic tool at a meta-reviewer’s disposal, one which enables further inferences about the underlying body of research. Furthermore, we recommend that meta-review teams do more with the issue of non-independence via overlap than simply estimating and reporting the CCA. Specifically, this article aims to provide concrete guidance on these issues by outlining five steps to take in overlap assessment and discussing potential challenges reviewers will encounter. We also provide an empirical example of primary study overlap resulting from a recently conducted meta-review.11 In providing this guidance, we are focusing on the case of meta-reviews that sample systematic reviews that include meta-analyses, although many of our conclusions may be generalized as well to other forms of meta-reviews. Our discussion of meta-reviews primarily focuses on a narrative approach to reviewing, and as such, it should be distinguished from current statistical approaches to pool data drawn from prior meta-analyses. One, first-order meta-analysis pools individual studies’ effect sizes; the second pools estimates drawn from meta-analyses of individual study effects, respectively.12 In these cases, overlap would be a disadvantage for the reason we have stated in the text, because it over-weights the over-sampled studies (unless somehow controlled statistically).
Meta-Reviews in the Context of Research Evidence
Meta-reviews are the product of a systematic synthesis of the available reviews on a given phenomenon; consequently, they can represent thousands of primary studies and hundreds of thousands of observations, perhaps even millions. If conducted rigorously and in a timely manner, then they deserve their spot at the peak of the evidence pyramid,13 providing a cumulative and systematic synthesis of all empirical literature on a particular topic that will inform research, practice, and policy. With the potential to have this much influence, it is paramount that the evidence is appropriately synthesized and presented.
Non-independence of observations in classical meta-analysis is a problem because this approach assumes each observation enters the analysis only once.14 Ignoring non-independence in the synthesis literature is akin to asking a subset of primary study participants to complete a survey multiple times (X) and keeping all of those responses in the analysis. Their responses would be represented X more than other participants and their inclusion may bias the results. (Alternatively, if the sampling strategy was flawed and missed an important segment of the population, the results might again be biased). Obviously, given the attention to reducing selection bias and ensuring generalizability of samples, this error would be problematic in the representativeness of the results. Fortunately, new techniques are emerging to solve this problem, such as robust variance estimators, multi-level modeling, and structural equation modeling.15-18
Non-independence in meta-reviews—which is labeled overlap—refers to the extent to which the primary studies in the reviews are the same or different. Yet, as we expand below, in meta-reviews, overlap among the primary-level studies sampled is typically an advantage because it simplifies the work of the meta-reviewers: Now, any differences in the conclusions reached likely stems from the methods used to summarize the evidence. In such cases, one review might have focused on a different outcome variable than another did. Or, it might have used more refined statistical modeling strategies. When overlap is lower, it can stem from many reasons: A review may have included the last several years of new studies and thus differs from earlier reviews. A review may have used different selection criteria. A review might not have optimally selected from literature databases. And so on.
Recommendations for dealing with overlap in a meta-review—which may have costs or benefits, as we elaborate below—have been proposed.6,10,19,20 These recommendations vary based on the degree of overlap and how feasible it is to obtain additional information about the primary studies in question. One initial simple solution is to consider a priori selection choices such as by (1) only including the most recent instance of a review (in the case of a review topic with many updates by the same authors); (2) assessing which review is most comprehensive among similar reviews and selecting the most comprehensive one, omitting the others; or (3) conducting quality assessments and selecting the highest quality review, omitting the others. (Note that in these instances where some reviews are removed, we recommend reporting all reviews that met the inclusion criteria and identifying those as removed due to the issue of overlap and for the reasons given above, if applicable). However, in very diverse meta-reviews that cover a broader body of literature, these three options may not be feasible as the overlap may be fairly minimal, with only some identical studies shared across reviews, or for particular outcomes. As a result, one further development has been the suggestion to generate a citation matrix and calculate the Corrected Covered Area (CCA), a metric that provides a percentage of overlap of the primary studies.
The current guidelines for generating the CCA involve first creating a citation matrix of all primary studies (rows) included for each review (columns), where primary studies in particular reviews are indicated with a check mark; duplicate rows (i.e., identical primary studies) are removed so that all the instances of that primary study appearing across reviews are noted in a single line. The first occurrence of a primary publication in a particular review is considered the “index case”. Next, calculate CCA:10
where N is the total number of included publications (including double counting) in evidence synthesis (this is the sum of the ticked boxes in the citation matrix); r is the number of rows (number of index publications); and c is the number of columns (number of reviews). CCA is a proportion that can be represented as a percentage, as we do in the remainder of this article. The top of Figure 1 graphically shows CCA among three hypothetical reviews of a phenomenon; the bottom portion of Figure 1 shows that CCA can be examined as well as in subsets (such as by comparing the overlap between only two reviews).
Figure 1.

Example matrix and CCA formula to examine overlap for subsets of outcomes (“1” implies a checkmark, that is the study is included; and “0” implies that the study is not included in the review in question).
Pieper and colleagues10 suggest guidelines for interpreting CCA values such that lower than five indicates slight overlap and values greater than or equal to 15 indicate high overlap. In presenting this information, the authors caution that reviewers may still have erroneous understandings of overlap if there are the same studies across reviews, but they are used for different outcomes; as well, this single value may underestimate rather than overestimate overlap. In Figure 1’s examples, overall overlap for the three reviews is high, but it widely varies when comparing two individual reviews (from 0-33%). Thus, simply determining the degree of overlap by the CCA in a meta-review is not enough. That is, overlap within meta-reviews of very broad scope is likely to be minimal because the underlying studies are likely very different.10 Yet, while the overall CCA may be low, there still could be substantial overlap for similar outcomes, for different types of research designs, and so on. A single CCA value across all the primary study references would conceal such sub-clusters.
Guidance for Using the Citation Matrix and CCA as Diagnostic Tools
Given the lack of guidance on how to address overlap systematically in a meta-review, we developed a decision tree with a series of five primary steps to examine and incorporate overlap information into the results and implications (Figure 2).
Figure 2.
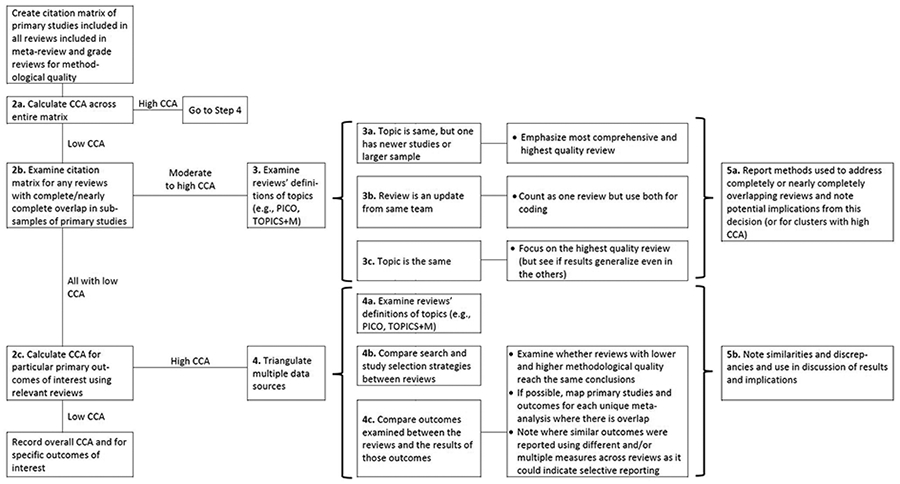
Decision tree of steps to take in assessing primary study overlap in a meta-review and using the CCA (Corrected Covered Area) index and other factors as diagnostics for further examination. See text for further detail.
1. Step 1. The first step is to create the citation matrix following Pieper and colleagues10 instructions (for an example, see Figure 1).
2. Step 2. First (2a) calculate the CCA across the entire matrix; (2b) then, examine the matrix for any reviews with completely/nearly completely overlap of primary studies; and (2c), finally, calculate CCA for particular primary outcomes of interest by limiting the matrix (or creating a series of smaller matrices) to the reviews that just focused on these similar outcomes. We anticipate that, at minimum, all meta-review teams would conduct steps 2a and 2b; Step 2c may become unnecessary if the scope of the meta-review is very narrow and most of the overlap is due to review authors conducting updates of their own reviews or if there are many reviews on the same exact topic and with the same scope.
For each component of Step 2, the process that follows will vary depending on the CCA value generated. In Step 2a, if the CCA across the entire matrix is high, then the review team should move to Step 4, which involves triangulating data from multiple sources to examine reasons for the high overlap. The first source of relevant data is generated by comparing the inclusion criteria using the most relevant acronym for the literature included in the synthesis (e.g., CIMO,21 SPIDER,22 PECO,23 PICO,24 or TOPICS+M25) between the overlapping reviews to examine their similarity; reviews with very similar inclusion criteria are likely to have sampled from the same pool of primary studies, while those with different criteria are likely to have less overlap. One exception to this scenario is where the reviews have similar criteria but different quality of search processes, a further assumption that can be examined in Step 4. An additional source of relevant data involves mapping out all the outcomes that are examined by the overlapping reviews and examining whether the reviews come to similar or different conclusions about those outcomes. If possible, review teams may also be able to map the exact primary studies used to generate pooled effects in unique meta-analyses, although this may be limited by review reporting quality. If review teams are able to complete this mapping exercise, they will pinpoint exact areas for disagreement (e.g., missing studies from a relevant meta-analysis or differing effect size calculations).
Returning to Step 2a, if the CCA is low, then reviewers should move to Step 2b, which involves examining the overall matrix for any reviews with complete/nearly complete overlap of primary studies. Complete overlap could happen if two reviews include the exact same primary studies (i.e., if reviews on the same topic were published in different journals in the same year). Complete overlap also occurs when one review encompasses all the primary studies in another review. That is, if a review is updated for new studies but retains all the studies from the previous version or if a large review is broken into smaller subsets of data for additional analyses and publication. If there are no such cases, then the review team can move to Step 2c.
The final part of Step 2, 2c, involves narrowing down the overall citation matrix to one (or more) smaller matrices of reviews that address particular outcome domains of interest in the meta-review. For each of these subsets of domains, only the reviews that examined those particular domains should be included, and the CCA should be recalculated for each smaller matrix. If the CCA is low for any of these, then the review team can simply report the overall CCA and the CCA for each of these domains of interest. If the CCA is high for any of these matrices, then the review team should move to Step 4.
3. Step 3. This step is reserved for instances of complete/nearly complete overlap between individual reviews and guidance varies depending on the reason for the overlap. We have identified three primary reasons, although there may be more unique cases. In the first instance, the review topic is the same, but one review has newer studies and/or a larger sample; review teams could choose the newest one or the most comprehensive one for their meta-review. In the second instance, if the review is an update by the same (or very similar) author team, then these two reviews may be considered the same review and both manuscripts used for coding methodological features. If the only difference is in the number of studies included, then review teams will likely want to focus on the outcomes from the updated (newer review) as these may present the most up-to-date standard of evidence. In the third instance, the review topic is the same (or very similar) and the review team has already completed the quality assessment of the included reviews; review teams could then focus on the results generated in the highest quality, most comprehensive review.
4. Step 4. This step is reserved for meta-reviews with an overall low CCA score and for which there may be clusters of interest (e.g., by primary outcomes of interest). It involves triangulating data sources in a similar fashion to Step 3. The meta-review team would compare and contrast: (in 4a) the reviews’ definitions of topics (e.g., CIMO,21 SPIDER,22 PECO,23 PICO,24 or TOPICS+M25); (in 4b) search and study selection strategies; and (in 4c), outcomes examined and what results appeared.
5. Step 5. Finally, Step 5, involves transparent reporting of process and findings. This step includes (a) attention to reporting methods used to address complete/nearly complete overlap of reviews and potential implications from this decision as well as (b) similarities and discrepancies between overlapping reviews in findings from their results and implications. Figure 2 illustrates that the types of conclusions will differ depending both on whether there is high or low overlap as well as whether the included reviews agree or disagree on their conclusions. When CCA is high, or there are sub-samples with high CCA (i.e., at Steps 2b or 2c), then conclusions are more straightforward: The reviews with the highest quality and comprehensiveness are probably the ones to emphasize, especially in cases of divergent results. If overlap is low, the meta-review team must do additional sleuth work to determine what can be learned from the reviews in their sample. Ideally, as with other steps in a systematic meta-review, the process of examining and using overlap and the CCA should have been specified during the protocol phase of the project. Although some of these steps may not be necessary (or their necessity unknown during the protocol stage), plans to handle completely overlapping reviews (noted in Step 3) should be considered ahead of time as this decision could influence the order of review processes.
Empirical Illustration
As an illustration, we draw from our team’s recent broad meta-review that included any recent systematic reviews with meta-analysis (2006-2017) that focused on psychosocial interventions addressing health behaviors linked to chronic diseases and that also quantitatively examined self-regulation mechanisms.11 We did not limit the intervention type or health behavior type provided the review met the other criteria. CCA across all included reviews was 0.0029 (<1%). On the one hand, this low number might suggest to readers that overlap was not an issue for this meta-review. Although the meta-review focused on psychosocial interventions, the examined behaviors were diverse (e.g., smoking prevention, diet, physical activity, medication adherence, etc.). Indeed, our meta-review documented that the explicitly stated TOPICS+M elements25 varied widely from review to review. There is little reason to expect a great deal of overlap across primary research reviewed in at least one meta-analysis because so few of the included meta-analyses had the same scope or focus.
Consider what might happen, on the other hand, if the meta-review was reporting outcomes within a more focused health behavior domain, for example, cardiovascular disease (CVD) prevention and treatment. In our empirical example, when we focus on the seven meta-analyses in the domain of CVD prevention and treatment,26-32 the CCA remains fairly minimal (i.e., still less than 2%). Yet, within three of these reviews that focused on CVD, overlap was much higher (12%); they shared the same seven primary studies, and, two of these three reviews shared an additional six studies (the total unique k included across the three reviews was 98). Thus, we concluded that overlap of primary studies among these three reviews warranted further investigation for similar outcomes of interest.
To conduct a more detailed analysis, we first collected the outcomes of interest that these three reviews28,30,31 reported and grouped them according to similar domains/measures in Table 1. As is evident there, the two outcomes with both overlap and discrepant findings were for the effect of self-monitoring on diastolic blood pressure (DBP) and systolic blood pressure (SBP) outcomes; although other meta-analyses in these reviews focused on self-monitoring and blood pressure, these were operationalized in different ways that did not produce overlap/discrepancies (e.g., the dichotomous outcome of whether blood pressure targets were met or proportions of those with successful blood pressure control). Of note for the meta-review team, these other non-overlapping outcomes are not relevant to further investigations of overlap, yet, they can assist in identifying areas of potential bias in the literature. That is, if all reviews focused on similar outcomes, in this case blood pressure, yet there is variation in the way this outcome is reported, it could be a sign that selective reporting and/or publication bias are present in the literature, a problem that has been documented in synthesis literature for certain disciplines.33 It could be that outcomes were only significant when presented using a particular measure so either (a) primary studies only reported that measure or reported that measure in addition to the other, more commonly used (but non-positive) measures or (b) review authors only selected that outcome-measure combination to report or (c) in some instances, both happened. Thus, in addition to findings about the effectiveness of self-monitoring for blood pressure control, the meta-review team has additional information about potential selection bias in this area of literature.
Table 1.
Empirical example for illustration: Outcome characteristics for each review (I = 3), organized by outcome type and measure and reported using detail provided by review authors.
| Study | Outcome type |
Outcome measure | k | Synthesis model |
Effect size |
Pooled effect [95% CI] |
Heterogeneity | Intervention effective? |
|---|---|---|---|---|---|---|---|---|
| Fletcher et al. (2015) | Medication adherence | Antihypertensive medication, measured in multiple ways | 13 | RE | SMD | 0.21 [0.08, 0.34] | Q= 20.88, p= 0.05; τ2=0.02; I2 = 43% | Yes |
| Fletcher et al. (2015) | DBP | Self-monitoring of DBP - 6 months | 11 | RE | WMD | −2.02 [−2.93, −1.11] | Q= 5.07, p=0.89; τ2= 0; I2= 0% | Yes |
| Bray et al. (2010) | DBP | Office DBP - range of follow-up time points | 23 | RE | WMD | −1.45 [−1.95, −0.94] | I2= 42.1%, p<0.01 | Yes |
| Glynn et al. (2010) | DPB | DBP - studies have a range of follow-up time points, some information on follow-up points for each study is missing | 14 | FE | WMD | −1.8 [−2.4, −1.21] | χ2 = 20.71, p= 0.08; I2 =37% | Yes |
| Bray et al. (2010) | DBP | Mean day-time ambulatory DBP | 3 | RE | WMD | −0.79 [−2.35, 0.771 | I2<0.05%, p= 0.96 | No |
| Bray et al. (2010) | SBP | Office SBP - range of follow-up time points | 21 | RE | WMD | −3.82 [−5.61, −2.03] | I2=71.9%, p< 0.001 | Yes |
| Glynn et al. (2010) | SBP | SBP - studies have a range of follow-up time points, some information on follow-up is missing | 12 | FE | WMD | −2.5 [−3.7, −1.3] | χ2 = 26.79, p= 0.005; I2 =59% | Yes |
| Fletcher et al. (2015) | SBP | Self-monitoring of SBP - 6 months | 9 | RE | WMD | −4.07 [−6.71, −1.43] | Q = 24.29, p= 0.002; τ2 = 9.46; I2 = 67% | Yes |
| Bray et al. (2010) | SBP | Change in mean day-time ambulatory SBP | 3 | RE | WMD | −2.04 [−4.35, 0.271 | I2<0.05%, p=0.89 | No |
| Bray et al. (2010) | BP control | Change in proportion of people with office-measured BP controlled below target between TX and CT | 12 | RE | RR | 1.09 [1.02, 1.16) | I2=73.6, p<0.01 | Yes |
| Glynn et al. (2010) | BP control | Individual study definitions of BP control | 6 | FE | OR | 0.97 [0.81, 1.16] | χ2=10.95, p = 0.05; I2 = 54% | No |
Note. BP = Blood pressure. DBP = Diastolic blood pressure. OR = Odds ratio. RR = Risk ratio. SBP = Systolic blood pressure. SMD = Standardized mean difference. WMD = Weighted mean difference.
We next focused on describing each review’s inclusion criteria using the TOPICS+M25 elements to assess whether there were key differences in inclusion criteria, which might warrant some differences between included studies. As can be noted from Table 2, the inclusion criteria were very similar across all three reviews, although the review by Glynn and colleagues (2010) was more specific than the other two. Based on the above assessments, we next collated the list of the primary studies used in each of these separate reviews and their individual meta-analyses to map by which outcome reviews had overlapping studies (or not). For our purposes, we are focusing on the SBP outcomes only in this article, but the results for the DBP analysis were parallel.
Table 2.
Empirical example for illustration: Inclusion criteria for each of three included reviews according to TOPICS+M.
| Timing | Outcome(s) | Population | Intervention | Comparator | Study design | Moderators | |
|---|---|---|---|---|---|---|---|
| Bray et al., 2010 | NR | BP outcome measure taken independently of the self-measurement (either systolic or diastolic office pressure or ambulatory monitoring (mean day-time ambulatory pressure)) | NR | Intervention included self-measurement of BP without medical professional input, if usual care did not include patient self-monitoring | NR | RCTs; non-randomized designs were excluded. No additional quality criteria in terms of methodology or study size were applied |
NR |
| Fletcher et al., 2015 | NR | Medication adherence and/or lifestyle factor outcomes were available | Participants had hypertension, were receiving care in ambulatory/outpati ent settings | Intervention group includes home BP monitoring. Trials will be eligible if HBPM is a sole intervention or is used as an adjunct to other interventions (i.e., tele-monitoring, education) | Control/usual care group does not include home monitoring: Control group may use HBPM to measure BP at trial end, but not exceed 1 week. |
RCTs and quasi-RCTs | NR |
| Glynn et al., 2010 | NR | (1) Mean SBP and/or mean DBP; (2) control of blood pressure (BP threshold that determines “control” being prespecified or defined by each trial’s investigators); (3) proportion of patients followed-up at clinic | Adult patients (18+ years) with essential hypertension (treated or not currently treated with blood pressure lowering drugs) in a primary care, outpatient or community setting |
Included: Interventions aimed at improving BP control or clinic attendance: (1) self-monitoring; (2) educational directed to the patient; (3) educational directed to the health professional; (4) health professional (nurse or pharmacist) led care; (5) organisational to improve the care delivery; (6) appointment reminder systems. Excluded: interventions not intended to increase BP control by organisational means (e.g., drug trials and trials of non-pharmacological treatment) |
Contemporaneous control group of no intervention or usual care | RCTs of interventions to evaluate different models of care to improve BP control or patient follow-up care | NR |
Note. BP = blood pressure. DBP = Diastolic blood pressure. NR = not reported. RCT=Randomized controlled design. SBP = Systolic blood pressure.
These three reviews differ markedly on a few dimensions. First, based on the inclusion criteria of all studies and when these reviewers were published, one of the primary studies (Rogers 2001) should have appeared in all three reviews rather than just the Glynn and colleagues (2010) review. Similarly, the most recent review by Fletcher and colleagues (2015) did not include many of the studies that the other earlier reviews had incorporated: Given that there was no time inclusion criterion and that the Fletcher review had the most flexible inclusion criteria, this leaves serious doubts about their search and screening process. Bray and colleagues (2010) and Glynn and colleagues (2010) published their review in the same year and appeared to use many of the same search strategies. Some of the primary studies that were eligible for the Bray review were noted as screened but ineligible for the Glynn review; yet eight others were not identified at all by the Glynn review (unless these were excluded during title/abstract screening). As a result, some of the differences in included studies suggest inadequate processes at the earlier stages of the review. As our team had already used the AMSTAR 2 tool to assess review quality,34 we could also compare these findings with the quality ratings. Based on our original assessment, the Glynn review received a full “yes” according to the AMSTAR 2 tool while the other two reviews received partial “yes” responses (Fletcher for not reporting consulting experts in the field for additional studies and Bray for not having a comprehensive search for gray literature, including not contacting experts or searching trial registries). Thus, our deeper assessment into overlap highlights not only additional search-related methods issues that the AMSTAR 2 does not identify, but also illustrates how a simple checklist for items may misidentify reviews as subpar even if their results were comprehensive, despite not meeting every checkbox; these nuances should also be narratively reported in the meta-review of these manuscripts.
Focusing now on the metric of the effect, despite the weighted mean difference (WMD) being one of the more straightforward effect size calculations, for many of the included outcomes, these three reviews document different estimates of the WMD and/or its 95% confidence interval for the same primary study. For some of these estimates, the appropriate data for effect size calculations were missing, so the review authors had to make adjustments. Yet, only Bray and colleagues (2010) provided supplemental information listing how effect sizes or standard errors were estimated when there were missing source statistics. Some of the studies with discrepant effect size data were not identified as those missing either an r value and/or the change standard deviation; thus, it is unclear how differences between the review calculations arose.
The final major difference is in the model approach review authors used; Glynn and colleagues (2010) synthesized effects with fixed effect assumptions, while the other two reviews assumed random effects. The level of heterogeneity present in the analyses suggested that use of random effects assumptions would be more appropriate and that further analyses via meta-regression could have been attempted to better understand the effectiveness of these interventions, if the investigators had ideas for potential moderators.
Given the differences in the included studies, effect size estimation, and modeling approaches, it is not surprising that the overall pooled estimates differ somewhat. Reassuringly, all reviews essentially reached the same conclusion for the effect on both SBP and DBP, despite having different ranges; specifically, they concluded that the interventions lowered blood pressure. A meta-review team could use this additional information, beyond the simple CCA value, to discuss more comprehensively the state of the evidence as well as identify some key flaws in the methods process. The synthesis team could also identify for future synthesis authors (or conduct themselves as part of a separate endeavor)6 a meta-analysis of the included studies to assess what the overall true effect should have been if all relevant studies were collected and synthesized appropriately. Furthermore, the differences between the primary studies included in each review is a clear empirical example of how poorly constructed and implemented searches can result in real differences in one’s view of the cumulated literature.
Discussion
Overlap in meta-reviews is a methodological issue that, if ignored or improperly handled, can lead to false assumptions about the evidence presented. As a result, some meta-review methodologists have examined whether and how author teams have addressed this issue with fairly disappointing results, indicating authors are not taking this issue seriously enough.8,10,35 Thus, authors have proposed to develop a citation matrix and calculate the CCA. Although the CCA value is useful to gauge the extent of overlap of primary studies in a meta-review, it is clear that meta-review teams must push their analysis further. To address this issue systematically, we strongly recommend that authors triangulate the available data by using the systematic process outlined in the decision tree in this article (Figure 2). These steps involve using the CCA as an initial diagnostic tool, while also moving beyond that initial numeric value to provide more nuanced and elaborate conclusions about both the phenomenon in question and the quality of the underlying evidence base. Overlap of primary studies in the included reviews in the sample of a given meta-review should generally not be a problem if appropriately addressed, and in fact, can guide the meta-review team to clearer inferences about the phenomenon at hand.
Both high and low overlap can provide useful information. For example, in cases of high overlap, such as in our illustration, examining whether reviews came to the same conclusions, and potential reasons for different conclusions can be highly informative. In this illustration, the high (but not complete) overlap and slightly different numerical results led us to further examine and then question some of the review methods the review authors used; that is, although these three reviews may have seemed to follow similar systematic and rigorous search processes, we found potential limitations in two of the three reviews’ search and selection process, which further informs our assessment of review quality. Additionally, in cases when reviews reported either (a) dropping studies due to lack of reported effect size data or (b) a more diverse set of outcome measures for the same type of outcome, we can begin to pinpoint areas of potential publication bias or selective reporting in the literature. Although we continue to recommend the use of a standardized tool for assessing the quality of systematic reviews and meta-analyses such as AMSTAR34,36,37 or ROBIS,38 we urge meta-review teams to go beyond these checklists and incorporate additional data, such as the issues we have highlighted here, to make more accurate inferences about the state of the underlying literature. In cases of low overlap throughout the meta-review, reviewers could have sampled different studies due to differing topic definitions (e.g., SPIDER,22 TOPICS+M25), inclusion criteria, and/or search strategies; if the scope of the meta-review was very broad, then this result would be in line with the review scope, but if the scope of the meta-review was very narrow, then the authors may need to conduct further qualitative assessments to understand and describe why there is such low overlap.
Of note, one issue that remains a limitation of this approach is for reviews that are poorly reported and this may be especially salient when meta-reviews are interested in collating results of similar moderator analyses. For example, although systematic reviews often report study citations included in a particular meta-analysis (e.g., via the forest plot), further analyses of subsets of the data may be relegated to a table, and it is often less clear which studies were included in these additional analyses. Furthermore, systematic reviews often identify multiple reports for a single study—although the review authors have a variety of ways of linking these studies, it may not always be apparent when collecting their primary study citations during a meta-review which references are linked to a single primary study. Alternatively, among reviews that had a more extensive search and included gray literature compared to similar reviews that did not, it may appear as though there is less overlap if the meta-review team cannot accurately identify which primary study citations should be linked across reviews. Both instances lead to a potential under-assessment of the CCA (i.e., via including additional unique rows for manuscripts from the same primary studies that should in fact not be considered unique). Currently, further mapping of these primary studies might be quite burdensome for meta-review authors, so we suggest acknowledging this possibility as much as possible during the review process and urging primary synthesis authors to engage in more transparent reporting processes.
In closing, we advocate for a more nuanced use of the citation matrix and CCA. We also maintain the hope that research synthesists will move these ideas forward by (1) conducting and reporting more nuanced assessments of these issues in their own reviews and (2) developing further metrics and tools to assist in this process.
Table 3.
Empirical example statistics for illustration: Meta-analyses for systolic blood pressure outcomes across three reviews.
|
Glynn et al., 2010
|
Bray et al., 2010
|
Fletcher et al., 2015
|
|||
|---|---|---|---|---|---|
| Citation | WMD (95% CI) | Citation | WMD (95% CI) | Citation | WMD (95% CI) |
| Artinian (2001) | −26.00 (−40.38, −11.62) | Artinian (2001)bc | −25.60 (−41.78, −9.42) | Missing | |
| Bailey (1998)* | 5.00 (−4.72, 14.72) | Bailey (1999) bc | 5.00 (−6.07, 16.07) | Missing | |
| NI a | Baque (2005) | −0.14 (−2.05, 1.77) | Missing | ||
| EXCL - no usual care | Binstock (1988) | −18.00 (−27.13, −8.87) | Missing | ||
| NA | NA | Bove (2013) | 30 (−9.58, 0.98) | ||
| EXCL - study design issues | Broege (2001) | −2.00 (−16.33, 12.33) | Missing | ||
| Carnaham (1975) | −7.50 (−14.18, −0.82) | Carnaham (1975) bc | −7.50 (−14.28, −0.72) | Missing | |
| NA | NA | de Souza (2012) | −8.40 (−30.60, 13.80) | ||
| NA | NA | Fikri-benbrahim (2013) | −4.70 (−8.17, − 1.23) | ||
| Freidman (1996) | −0.40 (−3.88, 3.08) | Freidman (1996) bc | −0.90 (−4.98, 3.18) | Missing | |
| NI | Green a (2008) | −3.40 (−5.91, −0.89) | Missing | ||
| NI | Green b (2008) | −9.30 (−11.80, −6.80) | Missing | ||
| NA | NA | Green (2014) | −2.50 (−8.14, 3.14) | ||
| Halme (2005) | −3.20 (−7.25, 0.85) | Halme (2005) | −3.10 (−7.93, 1.73) | Missing | |
| NA | NA | Hosseininasab (2014) | 1.00 (−0.84, 2.84) | ||
| NA | NA | Magid (2011) | −6.00 (−10.35, −1.65) | ||
| NI | Marquez-Contreras (2006) | −4.60 (−9.01, −0.19) | Marquez-Contreras (2006) | −4.50 (−8.91, −0.09) | |
| McManus (2005) | −2.30 (−5.39, 0.79) | McManus (2005) c | −2.30 (−5.47, 0.87) | Missing | |
| Mehos (2000) | −10.10 (−19.82, −0.38) | Mehos (2000) | −10.10 (−20.61, 0.41) | Missing | |
| Midanik (1991) | −2.00 (−7.38, 3.38) | Midanik (1991) | −2.60 (−7.26, 2.06) | Missing | |
| NI | Mulhauser (1993) | −5.00 (−10.45, 0.45) | Missing | ||
| NI | Parati (2009) | −0.20 (−3.84, 3.44) | Missing | ||
| Rogers (2001) | −4.80 (−9.80, 0.20) | Missing | Missing | ||
| Rudd (2004) | −8.50 (−14.29, −2.71) | Rudd (2004) bc | −8.50 (−14.16, −2.84) | Rudd (2004) | −8.50 (−14.42, −2.58) |
| Soghikan (1992) | −3.30 (−6.39, −0.21) | Soghikan (1992) | −3.30 (−6.77, 0.17) | Missing | |
| NA | NA | Stewart (2014) | −5.40 (−10.65, −0.15) | ||
| NI | Verberk (2007) | 0.50 (−3.65, 4.65) | Missing | ||
| Vetter (2000) | −0.50 (−2.77, 1.77) | Vetter (2000) bc | −0.50 (−3.07, 2.07) | Missing | |
| NI | Zillich (2005) | −4.40 (−10.52, 1.72) | Missing | ||
| Overall Pooled Effect | −2.53 (−3.73, −1.34) | Overall Pooled Effect | −3.82 (−5.61, −2.03) | Overall Pooled Effect | −4.07 (−6.71, −1.43) |
Note. Rows are organized alphabetically by primary study included in each analysis. If a primary study is missing from a particular review, then EXCL = excluded; NA = not applicable because study published after review published; NI = not identified, only available when review authors reported excluded studies at full text level; otherwise, this information was “Missing.” Effect sizes and/or 95% CIs for the same outcome/trial that differ between meta-analyses appear in boldface.
WMD = Weighted mean difference effect size.
Appeared in “eligible for review” section but the only instance was in "Table 1. Quality of included randomized trials" and it did not appear in any meta-analyses.
missing r – calculated.
missing change SD – calculated
Highlights.
Overlap in meta-reviews results from multiple identical primary studies in similar reviews
The Corrected Covered Area (CCA) is a promising method to examine overlap
Current guidelines do not detail how reviewers can use the CCA as a diagnostic tool
This article elaborates five steps to take when examining overlap
We illustrate the recommended steps through an empirical example of primary study overlap in a recently conducted meta-review
We discuss further areas of caution and potential for the development of new tools to address non-independence issues
Acknowledgments
This work was supported by the National Institutes of Health (NIH) Science of Behavior Change Common Fund Program through an award administered by the National Institute on Aging (U.S. PHS grant 5U24AG052175). The views presented here are solely the responsibility of the authors and do not necessarily represent the official views of the NIH.
Footnotes
Data Sharing
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
References
- 1.Hennessy EA, Johnson BT, Keenan C. Best practice guidelines and essential methodological steps to conduct rigorous and systematic meta-reviews. Applied psychology.Health and well-being. 2019. doi: 10.1111/aphw.12169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.John PAI. Meta-research: Why research on research matters. PLoS Biology. 2018;16(3):e2005468. doi: 10.1371/journal.pbio.2005468. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pieper D, Buechter R, Jerinic P, Eikermann M. Overviews of reviews often have limited rigor: A systematic review. J Clin Epidemiol. 2012;65(12):1267–1273. doi: 10.1016/j.jclinepi.2012.06.015. [DOI] [PubMed] [Google Scholar]
- 4.Ioannidis JP. The mass production of redundant, misleading, and conflicted systematic reviews and meta-analyses. Milbank Q. 2016;94(3):485–514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Page MJ, Altman DG, Mckenzie JE, et al. Flaws in the application and interpretation of statistical analyses in systematic reviews of therapeutic interventions were common: A cross-sectional analysis. J Clin Epidemiol. 2018;95:7–18. doi: 10.1016/j.jclinepi.2017.11.022. [DOI] [PubMed] [Google Scholar]
- 6.Cooper H, Koenka AC. The overview of reviews: Unique challenges and opportunities when research syntheses are the principal elements of new integrative scholarship. Am Psychol. 2012;67(6):446–462. doi: 10.1037/a0027119. [DOI] [PubMed] [Google Scholar]
- 7.Ballard M, Montgomery P. Risk of bias in overviews of reviews: A scoping review of methodological guidance and four-item checklist. Research Synthesis Methods. 2017;8(1):92–108. doi: 10.1002/jrsm.1229. [DOI] [PubMed] [Google Scholar]
- 8.Lunny C, Brennan SE, Reid J, McDonald S, McKenzie JE. Overviews of reviews incompletely report methods for handling overlapping, discordant and problematic data. Journal of Clinical Epidemiology. 2019:In Press. [DOI] [PubMed] [Google Scholar]
- 9.Siontis C K., Ioannidis JPA. Replication, duplication, and waste in a quarter million systematic reviews and meta-analyses. Circulation: Cardiovascular Quality and Outcomes. 2018;11(12):e005212–e005212. doi: 10.1161/CIRCOUTCOMES.118.005212. [DOI] [PubMed] [Google Scholar]
- 10.Pieper D, Antoine S, Mathes T, Neugebauer EAM, Eikermann M. Systematic review finds overlapping reviews were not mentioned in every other overview. J Clin Epidemiol. 2014;67(4):368–375. doi: 10.1016/j.jclinepi.2013.11.007. [DOI] [PubMed] [Google Scholar]
- 11.Hennessy EA, Johnson BT, Acabchuk RL, McCloskey K, Stewart-James J. Mechanisms of health behaviour change: A systematic meta-review of meta-analyses, 2006-2017. Health Psychology Review. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Schmidt F, Oh I. Methods for second order meta-analysis and illustrative applications. Organ Behav Hum Decis Process. 2013;121(2):204. doi: 10.1016/j.obhdp.2013.03.002. [DOI] [Google Scholar]
- 13.Biondi-Zoccai G, ed. Umbrella reviews: Evidence synthesis with meta-reviews of reviews and meta-epidemiologic studies. 1st ed. Switzerland: Springer; 2016. Biondi-Zoccai G., ed. [Google Scholar]
- 14.Riley R. Multivariate meta-analysis: The effect of ignoring within-study correlation. Journal of the Royal Statistical Society.Series A, Statistics in Society. 2009;172(4):789. doi: 10.1111/j.1467-985X.2008.00593.x. [DOI] [Google Scholar]
- 15.Hedges LV, Tipton E, Johnson MC. Robust variance estimation in meta-regression with dependent effect size estimates. Research synthesis methods. 2010;1(1):39–65. [DOI] [PubMed] [Google Scholar]
- 16.Tanner-Smith EE, Tipton E. Robust variance estimation with dependent effect sizes: Practical considerations including a software tutorial in stata and SPSS. Research Synthesis Methods. 2014;5(1):13–30. [DOI] [PubMed] [Google Scholar]
- 17.Cheung MW, Hong RY. Applications of meta-analytic structural equation modelling in health psychology: Examples, issues, and recommendations. Health Psychology Review. 2017;11(3):265–279. [DOI] [PubMed] [Google Scholar]
- 18.Cheung MW. Modeling dependent effect sizes with three-level meta-analyses: A structural equation modeling approach. Psychological Methods. 2014;19(2):211–229. [DOI] [PubMed] [Google Scholar]
- 19.Pollock M, Fernandes RM, Newton AS, Scott SD, Hartling L. The impact of different inclusion decisions on the comprehensiveness and complexity of overviews of reviews of healthcare interventions. Systematic Reviews. 2019;8(1):1–14. doi: 10.1186/s13643-018-0914-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Pollock M, Fernandes RM, Newton AS, Scott SD, Hartling L. A decision tool to help researchers make decisions about including systematic reviews in overviews of reviews of healthcare interventions. Systematic Reviews. 2019;8(1):1–8. doi: 10.1186/s13643-018-0768-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Denyer D, Tranfield D, Van Aken JE. Developing design propositions through research synthesis. Organization Studies. 2008;29(3):393–413. [Google Scholar]
- 22.Cooke A, Smith D, Booth A. Beyond PICO: The SPIDER tool for qualitative evidence synthesis. Qual Health Res. 2012;22(10):1435–1443. doi: 10.1177/1049732312452938. [DOI] [PubMed] [Google Scholar]
- 23.European Food SA. Application of systematic review methodology to food and feed safety assessments to support decision making. Efsa guidance for those carrying out systematic reviews. European Food Safety Authority Journal. 2010;8(6):1–89. doi: 10.2903/j.efsa.2010.1637. [DOI] [Google Scholar]
- 24.Haynes RB. Forming research questions. J Clin Epidemiol. 2006;59(9):881–886. doi: S0895-4356(06)00233-2 [pii]. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Johnson BT, Hennessy EA. Systematic reviews and meta-analyses in the health sciences: Best practice methods for research syntheses. Social Science & Medicine. 2019;233:237–251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Samdal GB, Eide GE, Barth T, Williams G, Meland E. Effective behaviour change techniques for physical activity and healthy eating in overweight and obese adults; systematic review and meta-regression analyses. International Journal of Behavioral Nutrition and Physical Activity. 2017;14(1). doi: 10.1186/s12966-017-0494-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Goodwin L, Ostuzzi G, Khan N, Matthew HH, Rona Moss-Morris. Can we identify the active ingredients of behaviour change interventions for coronary heart disease patients? A systematic review and meta-analysis. PLoS ONE. 2016;11(4):e0153271. doi: 10.1371/journal.pone.0153271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Fletcher BR, Hartmann-Boyce J, Hinton L, McManus RJ. The effect of self-monitoring of blood pressure on medication adherence and lifestyle factors: A systematic review and meta-analysis. American Journal of Hypertension. 2015;28(10):1209–1221. doi: 10.1093/ajh/hpv008. [DOI] [PubMed] [Google Scholar]
- 29.Janssen V, De Gucht V, Dusseldorp E, Maes S. Lifestyle modification programmes for patients with coronary heart disease: A systematic review and meta-analysis of randomized controlled trials. European Journal of Preventive Cardiology. 2013;20(4):620. doi: 10.1177/2047487312462824. [DOI] [PubMed] [Google Scholar]
- 30.Glynn LG, Murphy AW, Smith SM, Schroeder K, Fahey T. Self-monitoring and other non-pharmacological interventions to improve the management of hypertension in primary care: A systematic review. The British Journal of General Practice. 2010;60(581):e476. doi: 10.3399/bjgp10X544113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Bray EP, Holder R, Mant J, McManus RJ. Does self-monitoring reduce blood pressure? meta-analysis with meta-regression of randomized controlled trials. Annals of Medicine. 2010;Vol.42; 42(5; 5):371; 371–386; 386. doi: 10.3109/07853890.2010.489567. [DOI] [PubMed] [Google Scholar]
- 32.Chase DJ, Bogener LJ, Ruppar MT, Conn SV. The effectiveness of medication adherence interventions among patients with coronary artery disease: A meta-analysis. J Cardiovasc Nurs. 2016;31(4):357–366. doi: 10.1097/JCN.0000000000000259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Page MJ, McKenzie JE, Forbes A. Many scenarios exist for selective inclusion and reporting of results in randomized trials and systematic reviews. J Clin Epidemiol. 2013;66(5):524–537. doi: 10.1016/j.jclinepi.2012.10.010 [doi]. [DOI] [PubMed] [Google Scholar]
- 34.Shea BJ, Reeves BC, Wells G, et al. AMSTAR 2: A critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ. 2017;358:j4008. doi: 10.1136/bmj.j4008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Polanin JR, Maynard BR, Dell NA. Overviews in education research: A systematic review and analysis. Review of Educational Research. 2017;87(1):172–203. doi: 10.3102/0034654316631117. [DOI] [Google Scholar]
- 36.Shea BJ, Grimshaw JM, Wells GA, et al. Development of AMSTAR: A measurement tool to assess the methodological quality of systematic reviews. BMC Med Res Methodol. 2007;7:10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Shea BJ, Hamel C, Wells GA, et al. AMSTAR is a reliable and valid measurement tool to assess the methodological quality of systematic reviews. Journal of clinical epidemiology. 2009;62(10):1013. [DOI] [PubMed] [Google Scholar]
- 38.Whiting P, Savovic J, Higgins JP, et al. ROBIS: A new tool to assess risk of bias in systematic reviews was developed. J Clin Epidemiol. 2016;69:225–234. doi: 10.1016/j.jclinepi.2015.06.005. [DOI] [PMC free article] [PubMed] [Google Scholar]