

Abstract
In mixed multi-view data, multiple sets of diverse features are measured on the same set of samples. By integrating all available data sources, we seek to discover common group structure among the samples that may be hidden in individualistic cluster analyses of a single data view. While several techniques for such integrative clustering have been explored, we propose and develop a convex formalization that enjoys strong empirical performance and inherits the mathematical properties of increasingly popular convex clustering methods. Specifically, our Integrative Generalized Convex Clustering Optimization (iGecco) method employs different convex distances, losses, or divergences for each of the different data views with a joint convex fusion penalty that leads to common groups. Additionally, integrating mixed multi-view data is often challenging when each data source is high-dimensional. To perform feature selection in such scenarios, we develop an adaptive shifted group-lasso penalty that selects features by shrinking them towards their loss-specific centers. Our so-called iGecco+ approach selects features from each data view that are best for determining the groups, often leading to improved integrative clustering. To solve our problem, we develop a new type of generalized multi-block ADMM algorithm using sub-problem approximations that more efficiently fits our model for big data sets. Through a series of numerical experiments and real data examples on text mining and genomics, we show that iGecco+ achieves superior empirical performance for high-dimensional mixed multi-view data.
Keywords: Integrative clustering, convex clustering, feature selection, convex optimization, sparse clustering, GLM deviance, Bregman divergences
1. Introduction
As the volume and complexity of data grows, statistical data integration has gained increasing attention as it can lead to discoveries which are not evident in analyses of a single data set. We study a specific data-integration problem where we seek to leverage common samples measured across multiple diverse sets of features that are of different types (e.g., continuous, count-valued, categorical, skewed continuous and etc.). This type of data is often called mixed, multi-view data (Hall and Llinas, 1997; Acar et al., 2011; Lock et al., 2013; Tang and Allen, 2018; Baker et al., 2019). While many techniques have been developed to analyze each individual data type separately, there are currently few methods that can directly analyze mixed multi-view data jointly. Yet, such data is common in many areas such as electronic health records, integrative genomics, multi-modal imaging, remote sensing, national security, online advertising, and environmental studies. For example in genomics, scientists often study gene regulation by exploring only gene expression data, but other data types, such as short RNA expression and DNA methylation, are all part of the same gene regulatory system. Joint analysis of such data can give scientists a more holistic view of the problem they study. But, this presents a major challenge as each individual data type is high-dimensional (i.e., a larger number of features than samples) with many uninformative features. Further, each data view can be of a different data type: expression of genes or short RNAs measured via sequencing is typically count-valued or zero-inflated plus skewed continuous data whereas DNA methylation data is typically proportion-valued. In this paper, we seek to leverage multiple sources of mixed data to better cluster the common samples as well as select relevant features that distinguish the inherent group structure.
We propose a convex formulation which integrates mixed types of data with different data-specific losses, clusters common samples with a joint fusion penalty and selects informative features that separate groups. Due to the convex formulation, our methods enjoy strong mathematical and empirical properties. We make several methodological contributions. First, we consider employing different types of losses for better handling non-Gaussian data with Generalized Convex Clustering Optimization (Gecco), which replaces Euclidean distances in convex clustering with more general convex losses. We show that for different losses, Gecco’s fusion penalty forms different types of centroids which we call loss-specific centers. To integrate mixed multi-view data and perform clustering, we incorporate different convex distances, losses, or divergences for each of the different data views with a joint convex fusion penalty that leads to common groups; this gives rise to Integrative Generalized Convex Clustering (iGecco). Further, when dealing with high-dimensional data, practitioners seek interpretability by identifying important features which can separate the groups. To facilitate feature selection in Gecco and iGecco, we develop an adaptive shifted group-lasso penalty that selects features by shrinking them towards their loss-specific centers, leading to Gecco+ and iGecco+ which performs clustering and variable selection simultaneously. To solve our problems in a computationally efficient manner, we develop a new general multi-block ADMM algorithm using sub-problem approximations, and make an optimization contribution by proving that this new class of algorithms converge to the global solution.
1.1. Related Literature
Our goal is to develop a unified, convex formulation of integrative clustering with feature selection based on increasingly popular convex clustering methods. Pelckmans et al. (2005); Lindsten et al. (2011); Hocking et al. (2011) proposed convex clustering which uses a fusion penalty to achieve agglomerative clustering like hierarchical clustering. This convex formulation guarantees a global optimal solution, enjoys strong statistical and mathematical theoretical properties, and often demonstrates superior empirical performance to competing approaches. Specifically, in literature, Pelckmans et al. (2005); Chi et al. (2017) showed it yields stable solutions to small perturbations on the data or tuning parameters; Radchenko and Mukherjee (2017) established clustering consistency by proving the clustering tree produced by convex clustering consistently estimates the clustering tree produced by the population procedure for the penalty case; Tan and Witten (2015) established its link to hierarchical clustering as well as prediction consistency (finite sample bound for the prediction error); the perfect recovery properties of convex clustering with uniform weights have been proved by Zhu et al. (2014) for the two-clusters case and Panahi et al. (2017) for the general k-clusters case while Sun et al. (2021) proved results for general weighted convex clustering model; and many others have studied other appealing theoretical properties (Wu et al., 2016; Chi and Steinerberger, 2019). Despite these advantages, convex clustering has not yet gained widespread popularity due to its intensive computation. Recently, some proposed fast and efficient algorithms to solve convex clustering and estimate its regularization paths (Chi and Lange, 2015; Weylandt et al., 2020). Meanwhile, convex clustering has been extended to biclustering (Chi et al., 2017) and many other applications (Chi et al., 2018; Choi et al., 2019).
One potential drawback to convex clustering however, is that thus far, it has only been well-studied employing Euclidean distances between data points and their corresponding cluster centers. As is well known, the Euclidean metric suffers from poor performance with data that is highly non-Gaussian such as binary, count-valued, skewed data, or with data that has outliers. To alleviate the impact of outliers, Wang et al. (2016) studied robust convex clustering, Sui et al. (2018) investigated convex clustering with metric learning and Wu et al. (2016) mentioned replacing -norm with -norm loss function as extensions. Despite these, however, no one has conducted a general investigation of convex clustering for non-Gaussian data, let alone studied data integration on mixed data, to the best of our knowledge. But, many others have proposed clustering methods for non-Gaussian data in other contexts. One approach is to perform standard clustering procedures on transformed data (Anders and Huber, 2010; Bullard et al., 2010; Marioni et al., 2008; Robinson and Oshlack, 2010). But, choosing an appropriate transformation that retains the original cluster signal is a challenging problem. Another popular approach is to use hierarchical clustering with specified distance metrics for non-Gaussian data (Choi et al., 2010; Fowlkes and Mallows, 1983). Closely related to this, Banerjee et al. (2005) studied different clustering algorithms utilizing a large class of loss functions via Bregman divergences. Yet, the proposed methods are all extensions of existing clustering approaches and hence inherit both good and bad properties of those approaches. There has also been work on model-based clustering, which assumes that data are generated by a finite mixture model; for example Banfield and Raftery (1993); Si et al. (2013) proposed such a model for the Poisson and negative binomial distributions. Still these methods have a non-convex formulation and local solutions like all model-based clustering methods. We propose to adopt the method similar to Banerjee et al. (2005) and study convex clustering using different loss functions; hence our method inherits the desirable properties of convex clustering and handles non-Gaussian data as well. More importantly, there is currently no literature on data integration using convex clustering and we achieve this by integrating different types of general convex losses with a joint fusion penalty.
Integrative clustering, however, has been well-studied in the literature. The most popular approach is to use latent variables to capture the inherent structure of multiple types of data. This achieves a joint dimension reduction and then clustering is performed on the joint latent variables (Shen et al., 2009, 2012, 2013; Mo et al., 2013, 2017; Meng et al., 2015). Similar in nature to the latent variables approach, matrix factorization methods assume that the data has an intrinsic low-dimensional representation, with the dimension often corresponding to the number of clusters (Lock et al., 2013; Hellton and Thoresen, 2016; Zhang et al., 2012; Chalise and Fridley, 2017; Zhang et al., 2011; Yang and Michailidis, 2015). There are a few major drawbacks of latent variable or dimension reduction approaches, however. First it is often hard to directly interpret latent factors or low-dimensional projections. Second, many of these approaches are based on non-convex formulations yielding local solutions. And third, choosing the rank of factors or projections is known to be very challenging in practice and will often impact resulting clustering solutions. Another approach to integrative clustering is clustering of clusters (COC) which performs cluster analysis on every single data set and then integrates the primary clustering results into final group assignments using consensus clustering (Hoadley et al., 2014; Lock and Dunson, 2013; Kirk et al., 2012; Savage et al., 2013; Wang et al., 2014). This, however, has several potential limitations as each individual data set might not have enough signal to discern joint clusters or the individual cluster assignments are too disparate to reach a meaningful consensus. Finally, others have proposed to use distance-based clustering for mixed types of data by first defining an appropriate distance metric for mixed data (for example, the Gower distance by Gower, 1971) and then applying an existing distance-based clustering algorithm such as hierarchical clustering (Ahmad and Dey, 2007; Ji et al., 2012). Consequently, this method inherits both good and bad properties of distance-based clustering approaches. Notice that all of these approaches are either two-step approaches or are algorithmic or non-convex problems that yield local solutions. In practice, such approaches often lead to unreliable and unstable results.
Clustering is known to perform poorly for high-dimensional data as most techniques are highly sensitive to uninformative features. One common approach is to reduce the dimensionality of the data via PCA, NMF, or t-SNE before clustering (Ghosh and Chinnaiyan, 2002; Bernardo et al., 2003; Tamayo et al., 2007). A major limitation of such approaches is that the resulting clusters are not directly interpretable in terms of feature importance. To address this, several have proposed sparse clustering for high-dimensional data. This performs clustering and feature selection simultaneously by iteratively applying clustering techniques to subsets of features selected via regularization (Witten and Tibshirani, 2010; Sun et al., 2012; Chang et al., 2014). The approach, however, is non-convex and is highly susceptible to poor local solutions. Others have proposed penalized model-based clustering that selects features (Raftery and Dean, 2006; Wang and Zhu, 2008; Pan and Shen, 2007). Still, these methods inherit several advantages and disadvantages of model-based clustering approaches. Moreover, sparse integrative clustering is relatively under-studied. Shen et al. (2013); Mo et al. (2013) extended iCluster using a penalized latent variable approach to jointly model multiple omics data types. They induced sparsity on the latent variable coefficients via regularization. As feature selection is performed on the latent variables, however, this is less interpretable in terms of selecting features directly responsible for distinguishing clusters. Recently, and most closely related to our own work, Wang et al. (2018) proposed sparse convex clustering which adds a group-lasso penalty term on the cluster centers to shrink them towards zero, thus selecting relevant features. This penalty, however, is only appropriate for Euclidean distances when the data is centered; otherwise, the penalty term shrinks towards the incorrect cluster centers. For feature selection using different distances and losses, we propose an adaptive shifted group-lasso penalty that will select features by shrinking them towards their appropriate centroid.
2. Integrative Generalized Convex Clustering with Feature Selection
In this section, we introduce our new methods, beginning with the Gecco and iGecco and then show how to achieve feature selection via regularization. We also discuss some practical considerations for applying our methods and develop an adaptive version of our approaches.
2.1. Generalized Convex Clustering Optimization (Gecco)
In many applications, we seek to cluster data that is non-Gaussian. In the literature, most do this using different distance metrics other than Euclidean distances (Choi et al., 2010; Fowlkes and Mallows, 1983; de Souza and De Carvalho, 2004). Some use losses based on exponential family or deviances closely related to Bregman divergences (Banerjee et al., 2005).
To account for different types of losses for non-Gaussian data, we propose to replace the Euclidean distances in convex clustering with more general convex losses; this gives rise to Generalized Convex Clustering Optimization (Gecco):
Here, our data X is an n × p matrix consisting of n observations and p features; U is an n × p centroid matrix with the ith row, , the cluster centroid attached to point The general loss refers to a general loss metric that measures dissimilarity between the data point and assigned centroids . We choose one loss type as ℓ that is appropriate based on the data type of X. For example, we use ℓ1 loss in the presence of outliers. is the ℓq-norm of a vector and usually is considered (Hocking et al., 2011). Here we prefer using the ℓ2-norm in the fusion penalty (q = 2) as it encourages the entire rows of similar observations to be fused together simultaneously and is also rotation-invariant; but one could use ℓ1 or ℓ∞-norm as well. γ is a positive tuning constant and wij is a nonnegative weight. When γ equals zero, each data point occupies a unique cluster. As γ increases, the fusion penalty encourages some of the rows of the cluster center U to be exactly fused, forming clusters. When γ becomes sufficiently large, all centroids eventually coalesce to a single cluster centroid, which we define as the loss-specific center associated with . Hence γ regulates both the cluster assignment and number of clusters, providing a family of clustering solutions. The weight wij should be specified by the user in advance and is not a tuning parameter; we discuss choices of weights for various convex losses in Section 2.5.
Going beyond Euclidean distances, we propose to employ convex distance metrics as well as deviances associated with exponential family distributions and Bregman divergences, which are always convex. Interestingly, we show that each of these possible loss functions shrinks the cluster centers, U, to different loss-specific centers, instead of the mean-based centroid as in convex clustering with Euclidean distances. For example, one may want to use least absolute deviations (ℓ1-norm or Manhattan distances) for skewed data or for data with outliers; with this loss, we show that all observations fuse to the median when γ is sufficiently large. We emphasize loss-specific centers here as they will be important in feature selection in the next section. For completeness, we list common distances and deviance-based losses, as well as their loss-specific centers respectively in Table 1. (See Appendix F for all calculations associated with loss-specific centers, and we provide a formal proof when studying the properties of our approaches in Section 2.4.)
Table 1:
Different losses and their loss-specific centers. We provide all calculations associated with loss-specific centers in Appendix F. Note the Gecco problem with Hamming or Canberra distances is not convex. Though we discuss general convex losses in this paper, we list these non-convex losses for reference. For multinomial log-likelihood and multinomial deviance, we change Gecco formulation slightly to accommodate three indices; we provide a detailed formulation in Appendix E.
| Data Type | Loss Type | Loss Function | Loss-specific Center |
|---|---|---|---|
| Continuous | Euclidean (ℓ2) | ||
| Skewed continuous | Manhattan (ℓ1) Minkowski (ℓq) Mahalanobis (weighted ℓ2) Chebychev (ℓ∞) Canberra (weighted ℓ1) |
|
median(x) no closed form no closed form no closed form no closed form |
| Binary | Bernoulli log-likelihood Binomial deviance Hinge loss KL divergence Hamming (ℓ0) |
|
logit() mode(x) no closed form mode (x) |
| Count | Poisson log-likelihood Poisson deviance Negative binomial log-likelihood Negative binomial deviance Manhattan (ℓ1) Canberra (weighted ℓ1) |
|
log() log() median(x) no closed form |
| Categorical | Multinomial log-likelihood Multinomial deviance |
|
mlogit() |
2.2. Integrative Generalized Convex Clustering (iGecco)
In data integration problems, we observe data from multiple sources and would like to get a holistic understanding of the problem by analyzing all the data simultaneously. In our framework, we integrate mixed multi-view data and perform clustering by employing different convex losses for each of the different data views with a joint convex fusion penalty that leads to common groups. Hence we propose Integrative Generalized Convex Clustering (iGecco) which can be formulated as follows:
Here, we have K data sources. The kth data view X(k) is an n × pk matrix consisting of n observations and pk features; U(k) is also an n × pk matrix and the ith row, , is the cluster center associated with the point . And, is the loss function associated with the kth data view. Still, we choose one loss type as that is appropriate based on the data type of each view. Each loss function is weighted by , which is fixed by the user in advance. We have found that setting to be inversely proportional to the null deviance evaluated at the loss-specific center, i.e., , performs well in practice. The null deviance, refers to the loss function evaluated at where each jth column of denotes the loss-specific center . We employ this loss function weighting scheme to ensure equal scaling across data sets of different types. Recall that in generalized linear model (GLM), the likelihood-ratio test statistic, or the difference between the log-likelihoods, , follows a -distribution. Here is our iGecco estimate while is the loss-specific center (cluster centroid when there is only one cluster). Therefore, the ratio of the two quantities, i.e., should be the same scale for each data view k. Finally, notice that we employ a joint convex fusion penalty on all of the U(k)’s; this incorporates information from each of the data sources and enforces the same group structure amongst the shared observations. Similar to convex clustering, our joint convex fusion penalty encourages the differences in the rows of concatenated centroids to be shrunk towards zero, inducing a clustering behavior. Specifically, it forces the group structure of the ith row of U(k) to be the same for all k data views. Note the joint convex fusion penalty can be also written as . We say that subject i and i′ belong to the same cluster if , for all k. Hence, due to this joint convex fusion penalty, the common group structure property always holds. We study our methods further and prove some properties in Section 2.4.
2.3. Feature Selection: Gecco+ and iGecco+
In high dimensions, it is important to perform feature selection both for clustering purity and interpretability. Recently, Wang et al. (2018) proposed sparse convex clustering by imposing a group-lasso-type penalty on the cluster centers which achieves feature selection by shrinking noise features towards zero. This penalty, however, is only appropriate for Euclidean distances when the data is centered; otherwise, the penalty term shrinks towards the incorrect cluster centers. For example, the median is the cluster center with the ℓ1 or Manhattan distances. Thus, to select features in this scenario, we need to shrink them towards the median, and we should enforce “sparsity” with respect to the median and not the origin. To address this, we propose adding a shifted group-lasso-type penalty which forces cluster center U·j to shrink towards the appropriate loss-specific center for each feature. Both the cluster fusion penalty and this new shifted-group-lasso-type feature selection penalty will shrink towards the same loss-specific center.
To facilitate feature selection with the adaptive shifted group-lasso penalty for one data type, our Generalized Convex Clustering Optimization with Feature Selection (Gecco+) is formulated as follows:
Again, U is an n × p matrix and is the loss-specific center for the jth feature introduced in Table 1. The tuning parameter α controls the number of informative features and the feature weight is a user input which plays an important role to adaptively penalize the features. (We discuss choices of in Section 2.5.2 when we introduce the adaptive version of our method.) When α is small, all features are selected and contribute to defining the cluster centers. When α grows sufficiently large, all features coalesce at the same value, the loss-specific center , and hence no features are selected and contribute towards determining the clusters. Another way of interpreting this is that the fusion penalty exactly fuses some of the rows of the cluster center U, hence determining groups of rows. On the other hand, the shifted group-lasso penalty shrinks whole columns of U towards their loss-specific centers, thereby essentially removing the effect of uninformative features. Selected features are then columns of U that are not shrunken to their loss-specific centers, . These selected features, then, exhibit differences across the clusters determined by the fusion penalty. Clearly, sparse convex clustering of Wang et al. (2018) is a special case of Gecco+ using Euclidean distances with centered data. Our approach using both a row and column penalty is also reminiscent of convex biclustering (Chi et al., 2017) which uses fusion penalties on both the rows and columns to achieve checker-board-like biclusters.
Building upon integrative generalized convex clustering in Section 2.2 and our proposed feature selection penalty above, our Integrative Generalized Convex Clustering Optimization with Feature Selection (iGecco+) is formulated as follows:
| (1) |
Again, is an matrix and is the loss-specific center for the jth feature for kth data view. By construction, iGecco+ directly clusters mixed multi-view data and selects features from each data view simultaneously. Similarly, adaptive choice of gives rise to adaptive iGecco+ which will be discussed in Section 2.5.2. Detailed discussions on practical choices of tuning parameters and weights can be also found in Section 2.5.
2.4. Properties
In this section, we develop some properties of our methods, highlighting several advantages of our convex formulation. Corresponding proofs can be found in Section A of the Appendix.
Define the objective function in (1) as where . Then due to convexity, we have the following properties. First, any minimizer achieves a global solution.
Proposition 1 (Global solution) If ℓk is convex for all k, then any minimizer of , , is a global minimizer. If is strictly convex for all k, then is unique.
Our method is continuous with respect to data, tuning parameters and input parameters.
Proposition 2 (Continuity with respect to data, tuning and input parameters) The global minimizer of iGecco+ exists and depends continuously on the data, X, tuning parameters γ and α, the weight matrix w, the loss weight πk, and the feature weight .
When tuning parameters are sufficiently large, all U’s coalesce to the loss-specific centers.
Proposition 3 (Loss-specific center) Define where each jth column of equals the loss-specific center . Suppose each observation corresponds to a node in a graph with an edge between nodes i and j whenever . If this graph is fully connected, then is minimized by the loss-specific center when γ is sufficiently large or α is sufficiently large.
Remark. As Gecco, Gecco+ and iGecco are special cases of iGecco+, it is easy to show that all of our properties hold for these methods as well.
These properties illustrate some important advantages of our convex clustering approaches. Specifically, many other widely used clustering methods are known to suffer from poor local solutions, but any minimizer of our problem will achieve a global solution. Additionally, we show that iGecco+ is continuous with respect to the data, tuning parameters, and other input parameters. Together, these two properties are very important in practice and illustrate that the global solution of our method remains stable to small perturbations in the data and input parameters. Stability is a desirable property in practice as one would question the validity of a clustering result that can change dramatically with small changes to the data or parameters. Importantly, most popular clustering methods such as k-means, hierarchical clustering, model-based clustering, or low-rank based clustering, do not enjoy these same stability properties.
Finally in Proposition 3, we verify that when the tuning parameters are sufficiently large, full fusion of all observations to the loss-specific centers is achieved. Hence, our methods indeed behave as intended, achieving joint clustering of observations. We illustrate this property in Figure 1 where we apply Gecco+ to the authors data set (described fully in Section 4). Here, we illustrate how our solution, , changes as a function of γ and α. This so-called “cluster solution path” begins with each observation as its own cluster center when γ is small and stops when all observations are fused to the loss-specific center when γ is sufficiently large. In between, we see that observations are fusing together as γ increases. Similarly, when α is small, all features are selected and as α increases, some of the features get fused to their loss-specific center.
Figure 1:
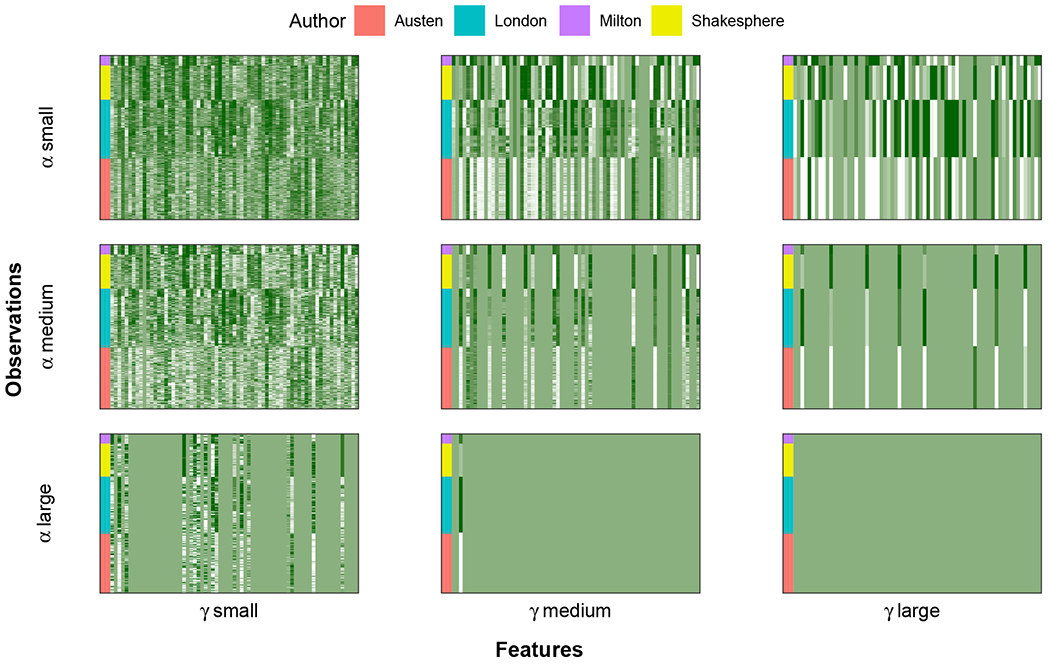
Regularization path of Gecco+ solutions for authors data. From left to right, we increase the parameter for fusion penalty γ. From top to bottom, we increase the parameter for feature penalty α. The interpretation of regularization path is discussed in more detail in Section 2.4.
2.5. Practical Considerations and Adaptive iGecco+
In this section, we discuss some practical considerations for applying our method to real data. In the iGecco+ problem, , w and are user-specific fixed inputs while γ and α are tuning parameters; γ controls the number of clusters while α controls the number of features selected. We discuss choosing user-specific inputs such as weights as well as how to select tuning parameters. In doing so, we introduce an adaptive version of our method as well.
2.5.1. Choice of Weights and Tuning Parameters
In practice, a good choice of fusion weights wij has been shown to enhance both computational efficiency and clustering quality of convex clustering (Chi and Lange, 2015). It has been empirically demonstrated that using weights inversely proportional to the distances yields superior clustering performance; this approach is widely adopted in practice. Further, setting many of the weights to zero helps reduce computation cost. Considering these two, the most common weights choice for convex clustering is to use K-nearest-neighbors method with a Gaussian kernel. Specifically, the weight between the sample pair (i, j) is set as , where equals 1 if observation j is among observation i’s κ nearest neighbors or vice versa, and 0 otherwise. However, this choice of weights based on Euclidean distances may not work well for non-Gaussian data in Gecco(+) or for mixed data in iGecco(+). To account for different data types and better measure the similarity between observations, we still adopt K-nearest-neighbors method with an exponential kernel, but further extend this by employing appropriate distance metrics for specific data types in the exponential kernel. In particular, for weights in Gecco and Gecco+, we suggest using the same distance functions or deviances in the loss function of Gecco and Gecco+. For weights in iGecco and iGecco+, the challenge is that we need to employ a distance metric which measures mixed types of data. In this case, the Gower distance, which is a distance metric used to measure the dissimilarity of two observations measured in different data types (Gower, 1971), can address our problem. To be specific, the Gower distance between observation i and i′ overall is defined as where refers to the Gower distance between observation i and i′ for feature j in data view k and is the range of feature j in data view k. In the literature, Gower distance has been commonly used as distance metrics for clustering mixed types of data (Wangchamhan et al., 2017; Hummel et al., 2017; Akay and Yüksel, 2018) and shown to yield superior performance than other distance metrics (Ali and Massmoudi, 2013; dos Santos and Zárate, 2015).
Alternatively, we also propose and explore using stochastic neighbor embedding weights based on symmetrized conditional probabilities (Maaten and Hinton, 2008). These have been shown to yield superior performance in high-dimensions and if there are potential outliers. Specifically, the symmetrized conditional probabilities are defined as , where We propose to use the weights where still equals 1 if observation j is among observation i’s κ nearest neighbors or vice versa, and 0 otherwise. Again, we suggest using distance metrics appropriate for specific data types or the Gower distance for mixed data. In empirical studies, we experimented with both weight choices and found that stochastic neighbor embedding weights tend to work better in high-dimensional settings and if there are outliers. Hence, we recommend these and employed them in our empirical investigations in Section 4 and 5.
Estimating the number of clusters in a data set is always challenging. Going beyond, we have two tuning parameters in our iGecco+ problem; γ controls the number of clusters while α controls the number of features selected. Current literature for tuning parameter selection for convex clustering mainly focuses on stability selection (Wang, 2010; Fang and Wang, 2012), hold-out validation (Chi et al., 2017) and information criterion (Tan and Witten, 2015). We first adopt the stability selection based approach for tuning parameter selection and follow closely the approach described in the work of Wang (2010); Fang and Wang (2012). We choose stability selection based approach because i) its selection consistency has been established and ii) Wang et al. (2018) adopted similar approach for tuning parameter selection and demonstrated strong empirical performance. However, stability selection is often computationally intensive in practice. To address this, we further explore information criterion based approaches like the Bayesian information criterion (BIC). We explain full details of both approaches in Appendix J and demonstrate empirical results when the number of clusters and features are not fixed but estimated based on the data.
2.5.2. Adaptive Gecco+ and iGecco+ to Weight Features
Finally, we consider how to specify the feature weights, used in the shifted group-lasso penalty. While employing these weights are not strictly necessary, we have found, as did Wang et al. (2018), that like the fusion weights, well-specified can both improve performance and speed up computation. But unlike the fusion weights where we can use the pairwise distances, we don’t have prior information on which features may be relevant in clustering. Thus, we propose to use an adaptive scheme that first fits the iGecco+ with no feature weights and uses this initial estimate to define feature importance for use in weights. This is similar to many adaptive approaches in the literature (Zou, 2006; Wang et al., 2018).
Our adaptive iGecco+ approach is given in Algorithm 1; this applies to adaptive Gecco+ as a special case as well. We assume that the number of clusters (or a range of the number of clusters) is known a priori. We begin by fitting iGecco+ with α = 1 and uniform feature weights . We then find the γ which gives the desired number of clusters, yielding the initial estimate, . (We provide alternative adaptive iGecco+ Algorithm 17 when the number of clusters is not known in Appendix J.) Next, similar to the adaptive approaches by Zou (2006); Wang et al. (2018), we use this initial estimate to adaptively weight features by proposing the following weights: . (To avoid numerical issues, we add ϵ = 0.01 to the denominator.) These weights place a large penalty on noise features as is close to zero in this case. Note, compared with sparse convex clustering where the authors defined feature weights by solving a convex clustering problem with feature penalty α = 0, we propose to fit iGecco+ with feature penalty α = 1 first and then update the feature weights adaptively. We find this weighting scheme works well in practice as it shrinks noise features more and hence penalizes more on those features. Such with-penalty initialization for adaptive weights has also been proposed in literature (Zhou et al., 2009; Fan et al., 2009; van de Geer et al., 2011). We also notice that noise features impact the distances used in the fusion weights as well. Hence, we suggest updating the distances adaptively by using the selected features to better measure the similarities between observations. To this end, we propose a new scheme to compute weighted Gower distances. First, we scale the features within each data view so that informative features in different data views contribute equally and on the same scale. Then, we employ the inverse of , i.e., the null deviance, to weight the distances from different data types, resulting in an aggregated and weighted Gower distance, as further detailed in Algorithm 1. Note that if the clustering signal from one particular data type is weak and there are few informative features for this data type, then our weighting scheme will down-weight this entire data type in the weighted Gower distance. In practice, our adaptive iGecco+ scheme works well as evidenced in our empirical investigations in the next sections.
Algorithm 1.
Adaptive iGecco+
| 1. Fit iGecco+ with , and a sequence of γ. |
| 2. Find γ which gives desired number of clusters; Get the estimate . |
| 3. Update the feature weights and fusion weights , where |
| 4. Fit adaptive iGecco+ with , and a sequence of γ and α; Find optimal γ and α which give desired number of clusters and features. |
Note that Algorithm 1 for adaptive iGecco+ assumes desired number of clusters and features. (Panahi et al. (2017); Sun et al. (2021) proved that perfect recovery can be guaranteed for the general case of q-clusters for convex clustering. To yield exact q desired number of clusters, Weylandt et al. (2020) suggested back-tracking in practice.) We provide the alternative adaptive iGecco+ (Algorithm 17) in Appendix J when the number of clusters or features are not known a priori but estimated from the data.
3. iGecco+ Algorithm
In this section, we introduce our algorithm to solve iGecco+, which can be easily extended to Gecco, Gecco+ and iGecco. We first propose a simple, but rather slow ADMM algorithm as a baseline approach. To save computation cost, we further develop a new multi-block ADMM-type procedure using inexact one-step approximation of the sub-problems. Our algorithm is novel from optimization perspective as we extend the multi-block ADMM to a higher number of blocks and combine it with the literature related to inexact-solve ADMM with sub-problem approximations, which often results in major computational savings.
3.1. Full ADMM to Solve iGecco+ (Naive Algorithm)
Given the shifted group-lasso and fusion penalties along with general losses, developing an optimization routine for iGecco+ method is less straight-forward than convex clustering or sparse convex clustering. In this section, we propose a simple ADMM algorithm to solve iGecco+ as a baseline algorithm and point out its drawbacks.
The most common approach to solve problems with more than two non-smooth functions is via multi-block ADMM (Lin et al., 2015; Deng et al., 2017), which decomposes the original problem into several smaller sub-problems and solves them in parallel at each iteration. Chen et al. (2016) established a sufficient condition for the convergence of three-block ADMM. We develop a multi-block ADMM approach to fit our problem for certain types of losses and prove its convergence.
We first recast iGecco+ problem (1) as the equivalent constrained optimization problem:
Recently, Weylandt et al. (2020) derived the ADMM for convex clustering in matrix form and we adopt similar approach. We index a centroid pair by with , define the set of edges over the non-zero weights , and introduce a new variable where to account for the difference between the two centroids. Hence is a matrix containing the pairwise differences between connected rows of and the constraint is equivalent to for all k; is the directed difference matrix corresponding to the non-zero fusion weights. We give general-form multi-block ADMM (Algorithm 2) to solve iGecco+. Here is the proximal mapping of function h. Also, the superscript in in Algorithm 2 refers to the kth data view; we omit iteration counter indices in all iGecco+ algorithm for notation purposes and use the most recent values of the updates. The dual variable is denoted by .
Algorithm 2.
General multi-block algorithm for iGecco+
| while not converged do |
| for all do |
| end for |
| end while |
Notice that, in Algorithm 2, there is no closed-form analytical solution for the U(k) sub-problem for general losses. Typically, at each iteration of Algorithm 2, we need to apply an inner optimization routine, which requires a nested iterative solver, to solve the U(k) sub-problem until full convergence. In the next section, we seek to speed up this algorithm by using U(k) sub-problem approximations. But, first we propose two different approaches to fully solve the U(k) sub-problem based on specific loss types and then use these to develop a one-step update to solve the sub-problem approximately with guaranteed convergence. For the V sub-problem, one can easily show that it has a closed-form analytical solution for each iteration, as given in Algorithm 2.
3.2. iGecco+ Algorithm
We have introduced Algorithm 2, a simple baseline ADMM approach to solve iGecco+. In this section, we consider different ways to solve the U(k) sub-problem in Algorithm 2. First, based on specific loss types (differentiable or non-differentiable), we propose two different algorithms to solve the U(k) sub-problem to full convergence. These approaches, however, are rather slow for general losses as there is no closed-form solution which requires another nested iterative solver. To address this and in connection with current literature on variants of ADMM with sub-problem approximations, we propose iGecco+ algorithm, a multi-block ADMM algorithm which solves the sub-problems approximately by taking a single one-step update. We prove convergence of this general class of algorithms, a novel result in the optimization literature.
3.2.1. Differentiable Case
When the loss ℓk is differentiable, we consider solving the U(k) sub-problem with proximal gradient descent, which is often used when the objective function can be decomposed into a differentiable and a non-differentiable function. While there are many other possible optimization routines to solve the U(k) sub-problem, we choose proximal gradient descent as there is existing literature proving convergence of ADMM algorithms with approximately solved sub-problems using proximal gradient descent (Liu et al., 2013; Lu et al., 2016). We will discuss in detail how to approximately solve the sub-problem by taking a one-step approximation in Section 3.2.3. Based upon this, we propose Algorithm 3, which solves the U(k) sub-problem by running full iterative proximal gradient descent to convergence. Here .
Algorithm 3.
U(k) sub-problem for differentiable loss ℓk (proximal gradient):
| while not converged do |
| end while |
In Algorithm 3 and typically in general (proximal gradient) descent algorithms, we need to choose an appropriate step size sk to ensure convergence. Usually we employ a fixed step size by computing the Lipschitz constant as in the squared error loss case; but in our method, it is hard to compute the Lipschitz constant for most of our general losses. Instead, we suggest using backtracking line search procedure proposed by Beck and Teboulle (2009); Parikh et al. (2014), which is a common way to determine step size with guaranteed convergence in optimization. Further, we find decomposing the U(k) sub-problem to pk separate sub-problems brings several advantages such as i) better convergence property (than updating U(k)’s all together) due to adaptive step size for each sub-problem and ii) less computation cost by solving each in parallel. Hence, in this case, we propose to use proximal gradient for each separate sub-problem. To achieve this, we assume that the loss is elementwise, which is satisfied by every deviance-based loss. Last, as mentioned, there are many other possible ways to solve the U(k) sub-problem than proximal gradient, such as ADMM. We find that when the loss function is squared Euclidean distances or the loss function has a Hessian matrix that can be upper bounded by a fixed matrix, using ADMM approach saves more computation. We provide all implementation details discussed above in Section C of the Appendix.
3.2.2. Non-differentiable Case
When the loss ℓk is non-differentiable, we can no longer adopt the proximal gradient method to solve the U(k) sub-problem as the objective is now a sum of more than one separable non-smooth function. To address this, as mentioned, we can use multi-block ADMM; in this case, we introduce new blocks for the non-smooth functions and hence develop a full three-block ADMM approach to fit our problem.
To augment the non-differentiable term, we assume that our loss function can be written as where fk is convex but non-differentiable and gk is affine. This condition is satisfied by all distance-based losses with ; for example, for Manhattan distances, we have , and . The benefit of doing this is that now the U(k) sub-problem has a closed-form solution. Particularly, we can rewrite the U(k) sub-problem as:
where is an n × pk matrix with the jth column equal to scalar .
It is clear that we can use multi-block ADMM to solve the problem above and each primal variable has a simple update with a closed-form solution. We propose Algorithm 4, a full, iterative multi-block ADMM, to solve the U(k) sub-problem when the loss is a non-differentiable distance-based function. Algorithm 4 applies to iGecco+ with various distances such as Manhattan, Minkowski and Chebychev distances and details are given in Section D of the Appendix.
Algorithm 4.
U(k) sub-problem for non-differentiable distance-based loss ℓk (multi-block ADMM):
| Precompute: Difference matrix . |
| while not converged do |
| end while |
3.2.3. iGecco+ Algorithm: Fast ADMM with Inexact One-step Approximation to the Sub-problem
Notice that for both Algorithm 3 and 4, we need to run them iteratively to full convergence in order to solve the U(k) sub-problem in Algorithm 2 for each iteration, which is dramatically slow in practice. To address this, in literature, many have proposed variants of ADMM with guaranteed convergence that find an inexact, one-step, approximate solution to the sub-problem (without fully solving it); these include the generalized ADMM (Deng and Yin, 2016), proximal ADMM (Shefi and Teboulle, 2014; Banert et al., 2016) and proximal linearized ADMM (Liu et al., 2013; Lu et al., 2016). Thus, we propose to solve the U(k) sub-problem approximately by taking a single one-step update of the algorithm (Algorithm 3 or 4) for both types of losses and prove convergence. For the differentiable loss case, we propose to apply the proximal linearized ADMM approach while for the non-differentiable case, we show that taking a one-step update of Algorithm 4, along with V and Λ update in Algorithm 2, is equivalent to applying a four-block ADMM to the original iGecco+ problem and we provide a sufficient condition for the convergence of four-block ADMM. Our algorithm, to the best of our knowledge, is the first to incorporate higher-order multi-block ADMM and inexact ADMM with a one-step update to solve sub-problems for general loss functions.
When the loss is differentiable, as mentioned in Algorithm 3, one can use full iterative proximal gradient to solve the sub-problem, which however, is computationally burdensome. To avoid this, many proposed variants of ADMM which find approximate solutions to the sub-problems. Specifically, closely related to our problem here, Liu et al. (2013); Lu et al. (2016) proposed proximal linearized ADMM which solves the sub-problems efficiently by linearizing the differentiable part and then applying proximal gradient due to the non-differentiable part. We find their approach fits into our problem and hence develop a proximal linearized 2-block ADMM to solve iGecco+ when the loss ℓk is differentiable and gradient is Lipschitz continuous. It can be shown that applying proximal linearized 2-block ADMM to Algorithm 2 is equivalent to taking a one-step update of Algorithm 3 along with V and Λ update in Algorithm 2. In this way, we avoid running full iterative proximal gradient updates to convergence for the U(k) sub-problem as in Algorithm 3 and hence save computation cost.
When the loss is non-differentiable, we still seek to take an one-step update to solve the U(k) sub-problem. We achieve this by noticing that taking a one-step update of Algorithm 4 along with V and Λ update in Algorithm 2 is equivalent to applying multi-block ADMM to the original iGecco+ problem recast as follows (for non-differentiable distance-based loss):
Typically, general higher-order multi-block ADMM algorithms do not always converge, even for convex functions (Chen et al., 2016). We prove convergence of our algorithm and establish a novel convergence result by casting the iGecco+ with non-differentiable losses as a four-block ADMM, proposing a sufficient condition for convergence of higher-order multi-block ADMMs, and finally showing that our problem satisfies this condition. (Details are given in the proof of Theorem 4 in Appendix B.) Therefore, taking a one-step update of Algorithm 4 converges for iGecco+ with non-differentiable losses.
So far, we have proposed inexact-solve one-step update approach for both differentiable loss and non-differentiable loss case. For mixed type of losses, we combine these two algorithms and this gives Algorithm 5, a multi-block ADMM algorithm with inexact one-step approximation to the U(k) sub-problem to solve iGecco+. We also establish the following convergence result.
Algorithm 5.
iGecco+ algorithm
| while not converged do |
| for all do |
| Update : |
| if ℓk is differentiable then |
| Take a one-step update of Algorithm 3 |
| else if ℓk is non-differentiable then |
| Take a one-step update of Algorithm 4 |
| end if |
| end for |
| for all k |
| end while |
Theorem 4 (iGecco+ convergence) Consider the iGecco+ problem (1) with fixed inputs πk, w and ζj. If ℓk is convex for all k, Algorithm 5 converges to a global solution. In addition, if each ℓk is strictly convex, it converges to the unique global solution.
Remark. Our corresponding Theorem 4 establishes a novel convergence result as it is the first to show the convergence of four-block or higher ADMM using approximate sub-problems for both differentiable and non-differentiable losses.
It is easy to see that Algorithm 5 can be applied to solve other Gecco-related methods as special cases. When K = 1, Algorithm 5 gives the algorithm to solve Gecco+. When α = 0, Algorithm 5 gives the algorithm to solve iGecco+. When K = 1 and α = 0, Algorithm 5 gives the algorithm to solve Gecco.
To conclude this section, we compare the convergence results of using both full ADMM and inexact ADMM with one-step update in the sub-problem to solve Gecco+ (n = 120 and p = 210) in Figure 2. The left plots show the number of iterations needed to yield optimization convergence while the right plots show computation time. We see that Algorithm 5 (one-step update to solve the sub-problem) saves much more computational time than Algorithm 2 (full updates to solve the sub-problem). It should be pointed out that though Algorithm 5 takes more iterations to converge due to inexact approximation for each iteration, we still reduce computation time dramatically as the computation time per iteration is much less than the full-solve approach.
Figure 2:
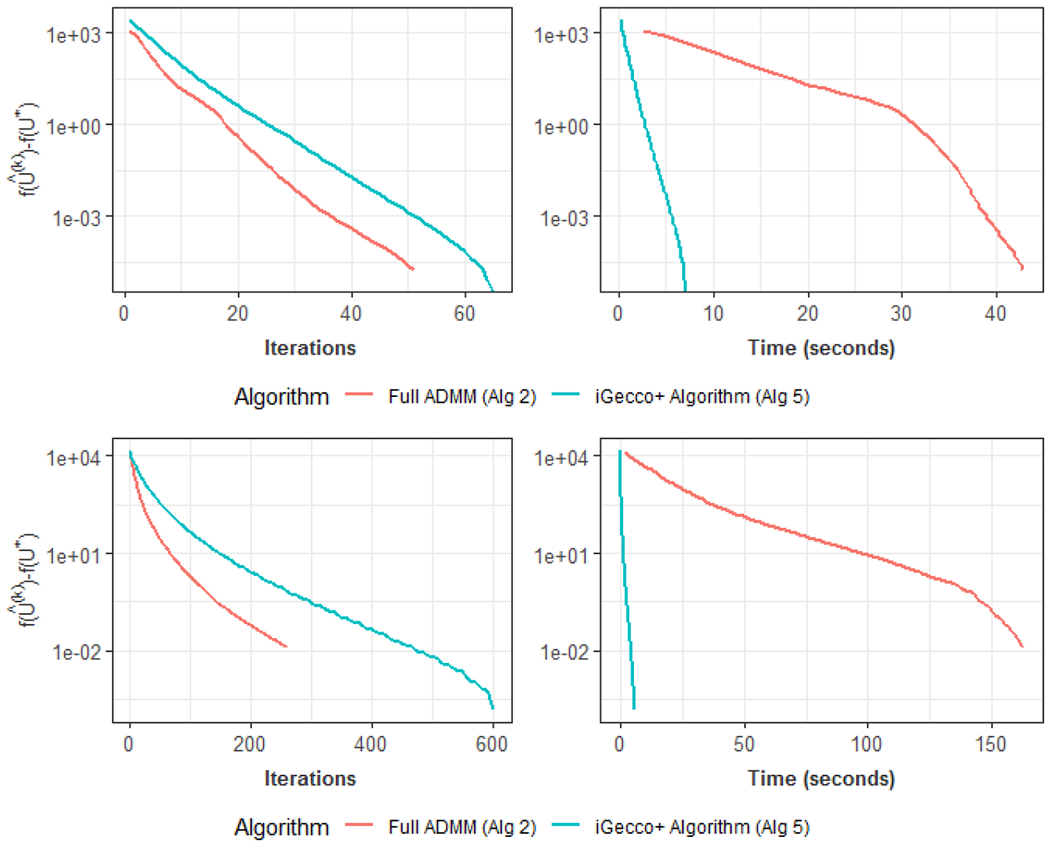
Comparisons of full ADMM and one-step ADMM to solve Gecco+ with Poisson log-likelihood (top panel, differentiable loss) and Gecco+ with Manhattan distances (bottom panel, non-differentiable loss). Left plots show the number of iterations needed to converge while right plots show computation time. Algorithm with one-step update to solve the sub-problem saves much more computational time.
4. Simulation Studies
In this section, we first evaluate the performance of Gecco+ against existing methods on non-Gaussian data. Next we compare iGecco+ with other methods on mixed multi-view data.
4.1. Non-Gaussian Data
In this subsection, we evaluate the performance of Gecco and (adaptive) Gecco+ by comparing it with k-means, hierarchical clustering and sparse convex clustering. For simplicity, we have the following naming convention for all methods: loss type name + Gecco(+). For example, Poisson Deviance Gecco+ refers to Generalized Convex Clustering with Feature Selection using Poisson deviance. Sparse CC refers to sparse convex clustering using Euclidean distances where each feature is centered first. We measure the accuracy of clustering results using adjusted Rand index (Hubert and Arabie, 1985). The adjusted Rand index is the corrected-for-chance version of the Rand index, which is used to measure the agreement between the estimated clustering assignment and the true group label. A larger adjusted Rand index implies a better clustering result. For all methods we consider, we assume oracle number of clusters for fair comparisons.
Each simulated data set is comprised of n = 120 observations with 3 clusters. Each cluster has an equal number of observations. Only the first 10 features are informative while the rest are noise. We consider the following simulation scenarios.
-
S1: Spherical data with outliers
The first 10 informative features in each group are generated from a Gaussian distribution with different μk’s for each class. Specifically, the first 10 features are generated from N(μk, I10) where , , . The outliers in each class are generated from a Gaussian distribution with the same mean centroid μk but with higher variance, i.e., N(μk, 25 · I10). The remaining noise features are generated from N(0,1).
In the first setting (S1A), number of noise features ranges in 25, 50, 75, ⋯ up to 225 with the proportion of number of outliers fixed ( = 5%). We also consider the setting when the variance of noise features increases with number of features fixed p = 200 and number of outliers fixed (S1B) and high-dimensional setting where p ranges from 250, 500, 750 to 1000 (S1C).
-
S2: Non-spherical data with three half moons
Here we consider the standard simulated data of three interlocking half moons as suggested by Chi and Lange (2015) and Wang et al. (2018). The first 10 features are informative in which each pair makes up two-dimensional three interlocking half moons. We randomly select 5% of the observations in each group and make them outliers. The remaining noise features are generated from N(0,1). The number of noise features ranges from 25, 50, 75, ⋯ up to 225. In both S1 and S2, we compare Manhattan Gecco+ with other existing methods.
-
S3: Count-valued data
The first 10 informative features in each group are generated from a Poisson distribution with different μk’s (i = 1, 2, 3) for each class. Specifically, μ1 = 1 · 110, μ2 = 4 · 110, μ3 = 7 · 110. The remaining noise features are generated from a Poisson distribution with the same μ’s which are randomly generated integers from 1 to 10. The number of noise features ranges from 25, 50, 75, ⋯ up to 225.
We summarize simulation results in Figure 3. We find that for spherical data with outliers, adaptive Manhattan Gecco+ performs the best in high dimensions. Manhattan Gecco performs well in low dimensions but poorly as the number of noisy features increases. Manhattan Gecco+ performs well as the dimension increases, but adaptive Manhattan Gecco+ outperforms the former as it adaptively penalizes the features, meaning that noisy features quickly get zeroed out in the clustering path and that only the informative features perform important roles in clustering. We see that, without adaptive methods, we do not achieve the full benefit of performing feature selection. As we perform adaptive Gecco+, we show vast improvement in clustering purity as the number of noise features grows where regular Gecco performs poorly. Sparse convex clustering performs the worst as it tends to pick outliers as singleton clusters. In the presence of outliers, Manhattan Gecco+ performs much better than sparse convex clustering as we choose a loss function that is more robust to outliers. Interestingly, k-means performs better than sparse convex clustering. This is mainly because sparse convex clustering calculates pairwise distance in the weights, placing outliers in singleton clusters more likely than k-means which calculates within-cluster variances (where outliers could be closer to the cluster centroids than to other data points). Our simulation results also show that adaptive Manhattan Gecco+ works well for non-spherical data by selecting the correct features. For count data, all three adaptive Gecco+ methods perform better than k-means, hierarchical clustering and sparse convex clustering. We should point out that there are several linkage options for hierarchical clustering. For visualization purposes, we only show the linkage with the best and worst performance instead of all the linkages. Also we use the appropriate data-specific distance metrics in hierarchical clustering. For k-means, we use k-means++ (Arthur and Vassilvitskii, 2006) for initialization.
Figure 3:
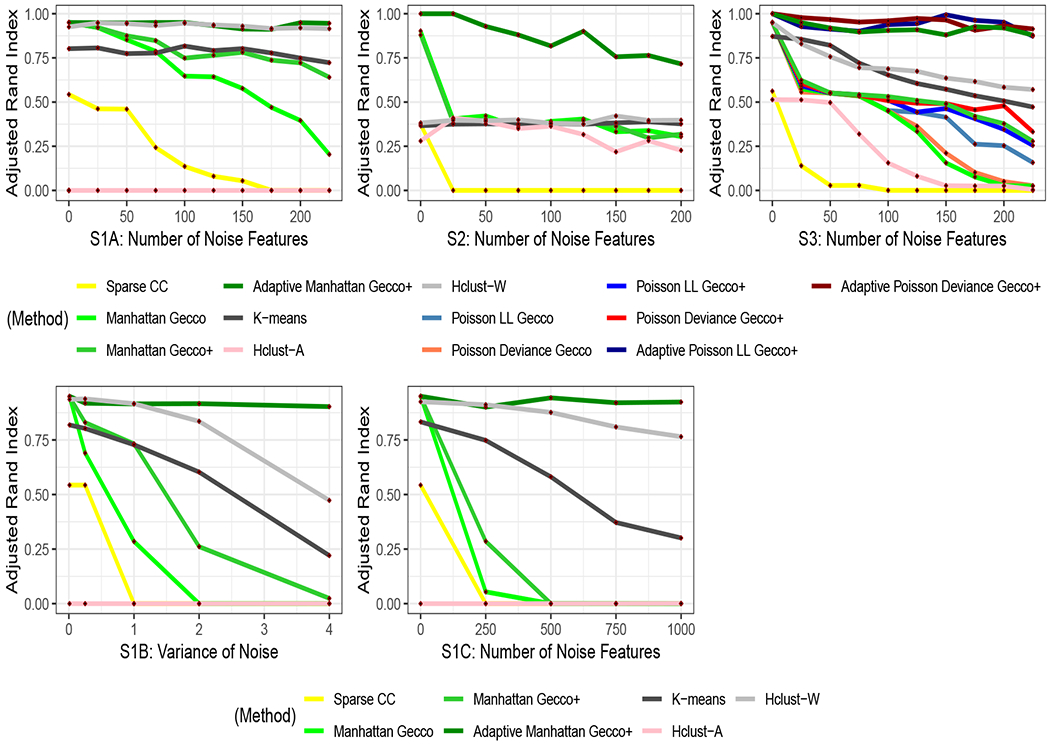
Simulation results of non-Gaussian data: (S1A) We increase number of noise features for spherical data with outliers; (S2) We increase number of noise features for non-spherical data with outliers; (S3) We increase number of noise features for count-valued data; (S1B) We increase noise level for spherical data with outliers; (S1C) We further increase number of noise features for spherical data with outliers in high dimensions. The adaptive Gecco+ outperforms existing methods in high dimensions.
Table 2 shows the variable selection accuracy of sparse convex clustering and adaptive Gecco+ in terms of F1 score. In all scenarios, we fix p = 225. We see that adaptive Gecco+ selects the correct features, whereas sparse convex clustering performs poorly.
Table 2:
Comparisons of F1 score for adaptive Gecco+ and sparse convex clustering
| Method | Scenario 1 (A) | Scenario 2 | Scenario 3 |
|---|---|---|---|
| Sparse Convex Clustering | 0.37 (3.1e-2) | 0.25 (2.4e-2) | 0.14 (7.2e-3) |
| Adaptive Gecco+ | 0.97 (1.9e-2) | 0.99 (1.0e-2) | 0.81 (8.0e-2) |
4.2. Multi-View Data
In this subsection, we evaluate the performance of iGecco and (adaptive) iGecco+ on mixed multi-view data by comparing it with hierarchical clustering, iClusterPlus (Mo et al., 2013) and Bayesian Consensus Clustering (Lock and Dunson, 2013). Again, we measure the accuracy of clustering results using the adjusted Rand index (Hubert and Arabie, 1985).
As before, each simulated data set is comprised of n = 120 observations with 3 clusters. Each cluster has an equal number of observations. Only the first 10 features are informative while the rest are noise. We have three data views consisting of continuous data, count-valued data and binary/proportion-valued data. We investigate different scenarios with different dimensions for each data view and consider the following simulation scenarios:
S1: Spherical data with p1 = p2 = p3 = 10
S2: Three half-moon data with p1 = p2 = p3 = 10
S3: Spherical data with p1 = 200, p2 = 100, p3 = 50
S4: Spherical data with p1 = 50, p2 = 200, p3 = 100
S5: Three half-moon data with p1 = 200, p2 = 100, p3 = 50
S6: Three half-moon data with p1 = 50, p2 = 200, p3 = 100
We employ a similar simulation setup as in Section 4.1 to generate each data view. The difference is that here for informative features, we increase the within-cluster variance for Gaussian data and decrease difference of cluster mean centroids μk’s for binary and count data so that there is overlap between different clusters. Specifically, for spherical cases, Gaussian data is generated from N(μk, 3 · I10); count data is generated from Poisson with different μk’s (μ1 = 2, μ2 = 4, μ3 = 6, etc); binary data is generated from Bernoulli with different μk’s (μ1 = 0.5, μ2 = 0.2, μ3 = 0.8, etc). For half-moon cases, continuous data is simulated with larger noise and the count and proportion-valued data is generated via a copula transform. In this manner, we have created a challenging simulation scenario where accurate clustering results cannot be achieved by considering only a single data view.
Again, for fair comparisons across methods, we assume oracle number of clusters. When applying iGecco(+) methods, we employ Euclidean distances for continuous data, Manhattan distances for count-valued data and Bernoulli log-likelihood for binary or proportion-valued data. We use the latter two losses as they perform well compared with counterpart losses in Gecco+ and demonstrate faster computation speed.
Simulation results in Table 3 and Table 4 show that our methods perform better than existing methods. In low dimensions, iGecco performs comparably with iCluster and Bayesian Consensus Clustering for spherical data. For non-spherical data, iGecco performs much better. For high dimensions, iGecco+ performs better than iGecco while adaptive iGecco+ performs the best as it achieves the full benefit of feature selection. We also applied k-means to the simulated data. The results of k-means are close to (or in some cases worse than) hierarchical clustering with the best-performing linkage; hence we only show the results of hierarchical clustering here for comparison.
Table 3:
Comparisons of adjusted Rand index for mixed multi-view data
| Method | Scenario 1 | Scenario 2 |
|---|---|---|
|
| ||
| Hclust: X1 | 0.35 (2.9e-2) | 0.53 (2.3e-2) |
| Hclust: X2 | 0.53 (4.6e-2) | 0.65 (1.8e-2) |
| Hclust: X3 | 0.52 (2.2e-2) | 0.70 (2.4e-2) |
| Hclust: [X1X2X3] - Euclidean | 0.68 (4.7e-2) | 0.63 (3.3e-2) |
| Hclust: [X1X2X3] - Gower | 0.86 (1.5e-2) | 0.83 (7.3e-2) |
| iCluster+ with λ = 0 | 0.90 (1.6e-2) | 0.71 (1.6e-2) |
| Bayesian Consensus Clustering | 0.95 (1.2e-2) | 0.63 (1.1e-2) |
| iGecco | 0.93 (5.0e-3) | 0.98 (2.2e-2) |
Table 4:
Comparisons of adjusted Rand index for high-dimensional mixed multi-view data
| Method | Scenario 3 | Scenario 4 | Scenario 5 | Scenario 6 |
|---|---|---|---|---|
|
| ||||
| Hclust: X1 | 0.42 (2.3e-2) | 0.56 (2.5e-2) | 0.43 (2.5e-2) | 0.51 (2.7e-2) |
| Hclust: X2 | 0.23 (2.8e-2) | 0.29 (3.4e-2) | 0.51 (2.6e-2) | 0.49 (2.1e-2) |
| Hclust: X3 | 0.25 (3.1e-2) | 0.27 (3.1e-2) | 0.55 (2.6e-2) | 0.48 (1.9e-2) |
| Hclust: [X1X2X3] - Euclidean | 0.40 (3.7e-2) | 0.57 (3.3e-2) | 0.55 (2.5e-2) | 0.52 (2.1e-2) |
| Hclust: [X1X2X3] - Gower | 0.68 (3.4e-2) | 0.58 (6.3e-2) | 0.58 (3.2e-2) | 0.58 (3.0e-2) |
| iCluster+ | 0.57 (6.5e-2) | 0.77 (2.7e-2) | 0.61 (2.4e-2) | 0.62 (1.6e-2) |
| Bayesian Consensus Clustering | 0.35 (1.1e-1) | 0.64 (1.0e-1) | 0.59 (1.2e-2) | 0.63 (6.6e-3) |
| iGecco | 0.00 (6.7e-4) | 0.06 (5.0e-2) | 0.39 (4.5e-2) | 0.23 (6.9e-2) |
| iGecco+ | 0.12 (3.3e-2) | 0.16 (7.1e-2) | 0.44 (3.6e-2) | 0.39 (3.8e-2) |
| Adaptive iGecco+ | 0.97 (7.8e-3) | 0.99 (7.5e-3) | 1.00 (0.0e-0) | 1.00 (0.0e-0) |
Also we show the variable selection results in Table 5 and compare our method to that of iClusterPlus. For fair comparisons, we assume oracle number of features. For our method, we choose α that gives oracle number of features; for iClusterPlus, we select top features based on Lasso coefficient estimates. Our adaptive iGecco+ outperforms iClusterPlus for all scenarios.
Table 5:
Comparisons of F1 score for adaptive iGecco+ and iClusterPlus
| Overall | Gaussian | Count | Binary | |||||
|---|---|---|---|---|---|---|---|---|
| iCluster+ | A iGecco+ | iCluster+ | A iGecco+ | iCluster+ | A iGecco+ | iCluster+ | A iGecco+ | |
| S3 | 0.81 (3.1e-2) | 0.94 (1.7e-2) | 0.84 (5.7e-2) | 0.99 (6.3e-3) | 0.73 (3.3e-2) | 0.88 (3.5e-2) | 0.85 (1.5e-2) | 0.93 (2.1e-2) |
| S4 | 0.95 (9.9e-3) | 0.98 (1.3e-2) | 0.99 (6.7e-3) | 0.99 (7.3e-3) | 0.92 (1.3e-2) | 0.97 (1.8e-2) | 0.94 (1.9e-2) | 0.97 (1.8e-2) |
| S5 | 0.94 (3.5e-2) | 1.00 (0.0e-0) | 0.95 (3.3e-2) | 1.00 (0.0e-0) | 0.91 (4.2e-2) | 1.00 (0.0e-0) | 0.95 (3.3e-2) | 1.00 (0.0e-0) |
| S6 | 0.92 (3.3e-2) | 1.00 (3.3e-3) | 0.97 (2.1e-2) | 1.00 (0.0e-0) | 0.84 (4.5e-2) | 0.99 (1.0e-2) | 0.95 (3.3e-2) | 1.00 (0.0e-0) |
Note in this section, we assume that the oracle number of clusters and features are known a priori for fair comparisons. Results when the number of clusters and features are not fixed but estimated based on the data using tuning parameter selection, are given in Appendix J.3.
5. Real Data Examples
In this section, we apply our methods to various real data sets and evaluate our methods against existing ones. We first evaluate the performance of Gecco+ for several real data sets and investigate the features selected by various Gecco+ methods.
5.1. Authors Data
The authors data set consists of word counts from n = 841 chapters written by four famous English-language authors (Austen, London, Shakespeare, and Milton). Each class contains an unbalanced number of observations with 69 features. The features are common “stop words” like “a”, “be” and “the” which are typically removed before text mining analysis. We use Gecco+ not only to cluster book chapters and compare the clustering assignments with true labels of authors, but also to identify which key words help distinguish the authors. We choose tuning parameters using BIC based approach; results for stability selection based approach are given in Table 15, Appendix J.3.
In Table 6, we compare Gecco+ with existing methods in terms of clustering quality. For hierarchical clustering, we only show the linkage with the best performance (in this whole section). Our method outperforms k-means and the best hierarchical clustering method. Secondly, we look at the word texts selected by Gecco+. As shown in Table 7, Jane Austen tended to use the word “her” more frequently than the other authors; this is expected as the subjects of her novels are typically females. The word “was” seems to separate Shakespeare and Jack London well. Shakespeare preferred to use present tense more while Jack London preferred to use past tense more. To summarize, our Gecco+ not only has superior clustering performance but also selects interpretable features.
Table 6:
Adjusted Rand index of different methods for authors data set
| Method | Adjusted Rand Index |
|---|---|
|
| |
| K-means | 0.74 |
| Hierarchical Clustering | 0.73 |
| Sparse Convex Clustering | 0.50 |
| Manhattan Gecco+ | 0.96 |
| Poisson LL Gecco+ | 0.96 |
| Poisson Deviance Gecco+ | 0.96 |
Table 7:
Features selected by different Gecco+ methods for authors data set
| Method | Features |
|---|---|
| Manhattan Gecco+ | “be” ,“had” ,“her”, “the” ,“to”, “was” |
| Poisson LL Gecco+ | “an” , “her” , “our”, “your” |
| Poisson Deviance Gecco+ | “an”, “be” , “had”, “her”, “is”, “my” , “the”, “was” |
5.2. TCGA Breast Cancer Data
The TCGA data set consists of log-transformed Level III RPKM gene expression levels for 445 breast-cancer patients with 353 features from The Cancer Genome Atlas Network (The Cancer Genome Atlas Network, 2012). Five PAM50 breast cancer subtypes are included, i.e., Basal-like, Luminal A, Luminal B, HER2-enriched, and Normal-like. Only 353 genes out of 50,000 with somatic mutations from COSMIC (Forbes et al., 2010) are retained. The data is Level III TCGA BRCA RNA-Sequencing gene expression data that have already been pre-processed according to the following steps: i) reads normalized by RPKM, and ii) corrected for overdispersion by a log-transformation. We remove 7 patients, who belong to the normal-like group and the number of subjects n becomes 438. We also combine Luminal A with Luminal B as they are often considered one aggregate group (Choi et al., 2014).
From Table 8, our method outperforms k-means and the best hierarchical clustering method. Next, we look at the genes selected by Gecco+ in Table 9. FOXA1 is known to be a key gene that characterizes luminal subtypes in DNA microarray analyses (Badve et al., 2007). GATA binding protein 3 (GATA3) is a transcriptional activator highly expressed by the luminal epithelial cells in the breast (Mehra et al., 2005). ERBB2 is known to be associated with HER2 subtype and has been well studied in breast cancer (Harari and Yarden, 2000). Hence our Gecco+ not only outperforms existing methods but also selects genes which are relevant to biology and have been implicated in previous scientific studies.
Table 8:
Adjusted Rand index of different methods for TCGA data set
| Method | Adjusted Rand Index |
|---|---|
|
| |
| K-means | 0.40 |
| Hierarchical Clustering | 0.37 |
| Sparse Convex Clustering | 0.01 |
| Manhattan Gecco+ | 0.76 |
| Poisson LL Gecco+ | 0.72 |
| Poisson Deviance Gecco+ | 0.72 |
Table 9:
Features selected by different Gecco+ methods for TCGA data set
| Method | Features |
|---|---|
| Manhattan Gecco+ | “BCL2” , “ERBB2” ,“GATA3” “HMGA1”, “IL6ST” |
| Poisson LL Gecco+ | “ERBB2” “FOXA1” “GATA3” |
| Poisson Deviance Gecco+ | “ERBB2” , “FOXA1”, “GATA3” “RET”, “SLC34A2” |
Next we evaluate the performance of iGecco+ for mixed multi-view data sets and investigate the features selected by iGecco+.
5.3. Multi-omics Data
One promising application for integrative clustering for multi-view data lies in integrative cancer genomics. Biologists seek to integrate data from multiple platforms of high-throughput genomic data to gain a more thorough understanding of disease mechanisms and detect cancer subtypes. In this case study, we seek to integrate four different types of genomic data to study how epigenetics and short RNAs influence the gene regulatory system in breast cancer.
We use the data set from The Cancer Genome Atlas Network (2012). Lock and Dunson (2013) analyzed this data set using integrative methods and we follow the same data pre-processing procedure: i) filter out genes in expression data whose standard deviation is less than 1.5, ii) take square root of methylation data, and iii) take log of miRNA data. We end up with a data set of 348 tumor samples including:
RNAseq gene expression (GE) data for 645 genes,
DNA methylation (ME) data for 574 probes,
miRNA expression (miRNA) data for 423 miRNAs,
Reverse phase protein array (RPPA) data for 171 proteins.
The data set contains samples used on each platform with associated subtype calls from each technology platform as well as integrated cluster labels from biologists. We use the integrated labels from biologists as true label to compare different methods. Also we merged the subtypes 3 and 4 in the integrated labels as those two subtypes correspond to Luminal A and Luminal B respectively from the predicted label given by gene expression data (PAM50 mRNA).
Figure 6 in Appendix H gives the distribution of data from different platforms. For our iGecco+ methods, we use Euclidean distances for gene expression data and protein data as the distributions of these two data sets appear Gaussian; binomial deviances for methylation data as the value is between [0, 1]; Manhattan distances for miRNA data as the data is highly-skewed.
We compare our adaptive iGecco+ with other existing methods. From Table 10, we see that our method outperforms all the existing methods.
Table 10:
Adjusted Rand index of different methods for multi-omics TCGA data set
| Method | Adjusted Rand Index |
|---|---|
|
| |
| Hclust: X1 GE | 0.51 |
| Hclust: X2 Meth | 0.39 |
| Hclust: X3 miRNA | 0.21 |
| Hclust: X4 Protein | 0.24 |
| Hclust: [X1X2X3X4] - Euclidean | 0.51 |
| Hclust: [X1X2X3X4] - Gower | 0.40 |
| iCluster+ | 0.36 |
| Bayesian Consensus Clustering | 0.35 |
| Adaptive iGecco+ | 0.71 |
We also investigate the features selected by adaptive iGecco+, shown in Table 11, and find that our method is validated as most are known in the breast cancer literature. For example, FOXA1 is known to segregate the luminal subtypes from the others (Badve et al., 2007), and AGR3 is a known biomarker for breast cancer prognosis and early breast cancer detection from blood (Garczyk et al., 2015). Several well-known miRNAs were selected including MIR-135b, which is upregulated in breast cancer and promotes cell growth (Hua et al., 2016) as well as MIR-190 which suppresses breast cancer metastasis (Yu et al., 2018). Several known proteins were also selected including ERalpha, which is overexpressed in early stages of breast cancer (Hayashi et al., 2003) and GATA3 which plays an integral role in breast luminal cell differentiation and breast cancer progression (Cimino-Mathews et al., 2013).
Table 11:
Features selected by adaptive iGecco+ methods for multi-omics TCGA data set
| Data view | Features |
|---|---|
| Gene Expression | “AGR3”, “FOXA1”, “AGR2”, “ROPN1”, “ROPN1B”, “ESR1”, “C1orf64”, “ART3”,“FSIP1” |
| miRNA | “hsa-mir-135b”, “hsa-mir-190b”, “hsa-mir-577”, “hsa-mir-934” |
| Methylation | “cg08047457”, “cg08097882”, “cg00117172”, “cg12265829” |
| Protein | “ER.alpha”, “GATA3”, “AR”, “CyclimE1” |
We also visualize the resulting clusters from adaptive iGecco+. Figure 4 shows the cluster heatmap of multi-omics TCGA data with row orders determined by cluster assignments from iGecco+ and left bar corresponding to the integrated cluster labels from biologists. We see that there is a clear separation between groups and adaptive iGecco+ identifies meaningful subtypes. The black bars at the bottom of each data view correspond to the selected features in Table 11.
Figure 4:
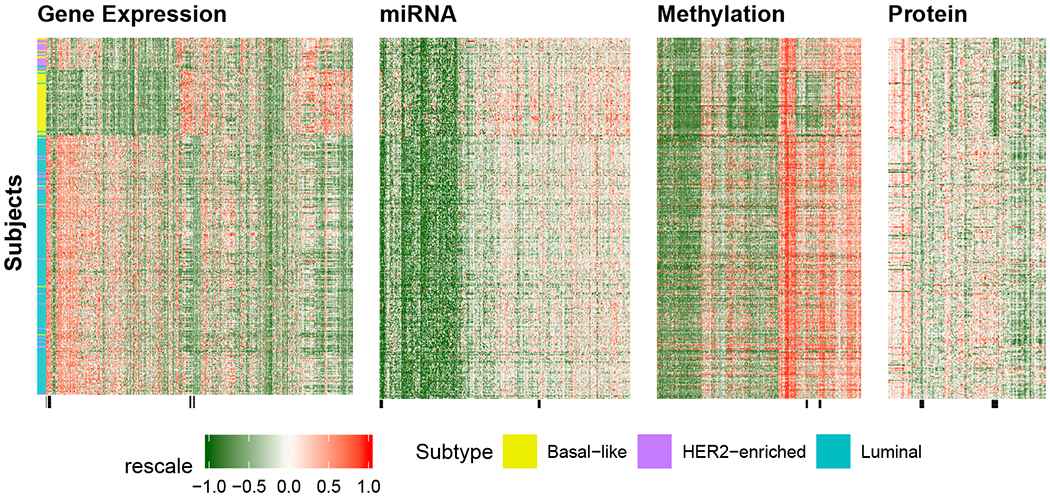
Cluster heatmap of multi-omics TCGA data with row orders determined by cluster assignments from iGecco+. The left bar refers to the integrated cluster labels from biologists. The black bars at the bottom of each data view correspond to the selected features. Our adaptive iGecco+ identifies meaningful subtypes.
6. Discussion
In this paper, we develop a convex formulation of integrative clustering for high-dimensional mixed multi-view data. We propose a unified, elegant methodological solution to two critical issues for clustering and data integration: i) dealing with mixed types of data and ii) selecting sparse, interpretable features in high-dimensional settings. Specifically, we show that clustering for mixed, multi-view data can be achieved using different data-specific convex losses with a joint fusion penalty. We also introduce a shifted group-lasso penalty that shrinks noise features to their loss-specific centers, hence selecting features that play important roles in separating groups. In addition, we make an optimization contribution by proposing and proving the convergence of a new general multi-block ADMM algorithm with sub-problem approximations that efficiently solves our problem. Empirical studies show that iGecco+ outperforms existing clustering methods and selects sparse, interpretable features in separating clusters.
This paper focuses on the methodological development for integrative clustering and feature selection, but there are many possible avenues for future research related to this work. For example, we expect in future work to be able to show that our methods inherit the strong statistical and theoretical properties of other convex clustering approaches such as clustering consistency and prediction consistency. An important problem in practice is choosing which loss function is appropriate for a given data set. While this is beyond the scope of this paper, an interesting direction for future research would be to learn the appropriate convex loss function in a data-driven manner. Additionally, many have shown block missing structure is common in mixed data (Yu et al., 2019; Xiang et al., 2013). A potentially interesting direction for future work would be to develop an extension of iGecco+ that can appropriately handle block-missing multi-view data. Moreover, Weylandt et al. (2020) developed a fast algorithm to compute the entire convex clustering solution path and used this to visualize the results via a dendrogram and pathwise plot. In future work, we expect that algorithmic regularization path approaches can also be applied to our method to be able to represent our solution as a dendrogram and employ other dynamic visualizations. Finally, while we develop an efficient multi-block ADMM algorithm, there may be further room to speed up computation of iGecco+, potentially by using distributed optimization approaches.
In this paper, we demonstrate that our method can be applied to integrative genomics, yet it can be applied to other fields such as multi-modal imaging, national security, online advertising, and environmental studies where practitioners aim to find meaningful clusters and features at the same time. In conclusion, we introduce a principled, unified approach to a challenging problem that demonstrates strong empirical performance and opens many directions for future research.
Our method is implemented in MATLAB and available at https://github.com/DataSlingers/iGecco.
Acknowledgments
The authors would like to thank Michael Weylandt and Tianyi Yao for helpful discussions. Additionally, we would like to thank the anonymous reviewers and action editor for constructive comments and suggestions on this work. GA and MW also acknowledge support from NSF DMS-1554821, NSF NeuroNex-1707400, NSF DMS-1264058, and NIH 1R01GM140468.
Appendix A. Proof of Propositions
Proposition 1 and 2 are direct extensions from Proposition 2.1 of Chi and Lange (2015). Notice they proved the solution path depends continuously on the tuning parameter γ and the weight matrix w. It follows that the argument can be also applied to tuning parameter α, the loss weight πk, and feature weight . Also it is obvious that the loss is continuous with respect to the data, X.
We show in detail how to prove Proposition 3 in the following. First we rewrite the objective as:
By definition, loss-specific cluster center is . Since ℓk is convex, it is equivalent to u such that . Hence, .
We use the similar proof approach of Chi and Lange (2015). A point X furnishes a global minimum of the convex function if and only if all forward directional derivatives at X are nonnegative. Here represents a direction in the space of possible concatenated centroids, where . We calculate the directional derivatives:
Note . The generalized Cauchy-Schwartz inequality therefore implies:
Hence, we have:
Take γ sufficiently large such that:
When all , one can take any γ that exceeds
In general set
For any pair i and i′ there exists a path along which the weights are positive. It follows that
We have
Hence the forward directional derivative test is satisfied for any .
On the other hand, for fixed γ, the generalized Cauchy-Schwartz inequality implies:
Hence, we have:
Take α sufficiently large so that
When all , one can take any α that exceeds
In general, set . It is easy to check the forward directional derivative test is satisfied. ■
Appendix B. Proof of Theorem 4
Recall the iGecco+ problem is:
We can recast the original iGecco+ problem as the equivalent constrained problem:
| (2) |
where ℓk refers to the differentiable losses and ℓk′ refers to the non-differentiable losses. We use multi-block ADMM algorithm (Algorithm 6) to solve the problem above.
To prove convergence of Algorithm 5, we first show that multi-block ADMM Algorithm 6 converges to a global minimum. Then we show that we can proximal-linearize the sub-problems in the primal updates of Algorithm 6 with proved convergence and this is equivalent to Algorithm 5. Without loss of generality, we assume we have one differentiable loss and one non-differentiable distance-based loss .
Algorithm 6.
Multi-block ADMM to solve iGecco+
| while not converged do |
| for all do |
| end for |
| for all k and k′ |
| end while |
To prove convergence of Algorithm 6, we first propose a sufficient condition for the convergence of four-block ADMM and prove it holds true. This is an extension of the convergence results in Section 2 of the work by Chen et al. (2016). Suppose the convex optimization problem with linear constraints we want to minimize is
| (3) |
The multi-block ADMM has the following form. Note here, the superscript in refers to the (k + 1)th iteration in the ADMM updates. We have:
| (4) |
where
We establish Lemma 5, a sufficient condition for convergence of four-block ADMM:
Lemma 5 (Sufficient Condition for Convergence of Four-block ADMM) A sufficient condition ensuring the convergence of (4) to a global solution of (3) is: , , .
We prove Lemma 5 at the end of this section. Note that Lemma 5 is stated in vector form and therefore we need to transform the constraints in the original iGecco+ problem (2) from matrix form to vector form in order to apply Lemma 5. Note that . Hence we can write the constraints in (2) as:
where , , , , , , is a column vector consisting of all and is repeated n times in b.
Next we show that the constraints in (2) for our problem satisfy the condition in Lemma 5 and hence the multi-block ADMM Algorithm 6 converges.
By construction, , and . It is easy to verify that: , , . Hence our setup satisfies the sufficient condition in Lemma 5 and the multi-block ADMM Algorithm 6 converges.
Next, we see that each primal update in Algorithm 5 is equivalent to the primal update by applying proximal linearized ADMM to the sub-problems in Algorithm 6. (We will show this in detail in Theorem 6.) It is easy to show that these updates with closed-form solutions are special cases of proximal-linearizing the sub-problems. Meanwhile, Lu et al. (2016); Liu et al. (2013) showed the convergence of proximal linearized multi-block ADMM. Hence Algorithm 5 converges to a global minimum if ℓk is convex for all k and has Lipschitz gradient when it is differentiable. Further, if each ℓk is strictly convex, it converges to the unique global solution. ■
Proof of Lemma 5:
According to the first-order optimality conditions of the minimization problems in (4), we have:
Since , , , we have:
which is also the first-order optimality condition of the scheme:
| (5) |
Clearly, (5) is a specific application of the original two-block ADMM to (3) by regarding (x2, x3, x4) as one variable, [A2, A3, A4] as one matrix and θ2(x2) + θ3(x3) + θ4(x4) as one function. ■
Appendix C. Gecco+ for Differentiable Losses
In this section, we propose algorithms to solve Gecco+ when the loss ℓ is differentiable and gradient is Lipschitz continuous. In this case, we develop a fast two-block ADMM algorithm without fully solving the U sub-problem. Our result is closely related to the proximal linearized ADMM literature (Liu et al., 2013; Lu et al., 2016). Also solving the sub-problem approximately is closely connected with the generalized ADMM literature (Deng and Yin, 2016).
In the following sections, we discuss algorithms to solve Gecco+ instead of iGecco+ for notation purposes as we would like to include iteration counter indices in the algorithm for illustrating backtracking; but we can easily extend the algorithm to solve iGecco+. To begin with, we clarify different notations in Gecco+ and iGecco+: the superscript in U(k) in iGecco+ refers to the kth data view while U(k) in Gecco+ refers to the kth iteration counter in the ADMM updates. We omit iteration counter indices in all iGecco+ algorithm for notation purposes and use the most recent values of the updates.
C.1. Two-block ADMM in Matrix Form
Suppose the loss is differentiable. Similar to the formulation in convex clustering, we can recast the Gecco+ problem as the equivalent constrained problem:
Like in convex clustering (Chi and Lange, 2015; Weylandt et al., 2020), we index a centroid pair by with , define the set of edges over the non-zero weights , and introduce a new variable to account for the difference between the two centroids. Hence V is a matrix containing the pairwise differences between connected rows of U. Also D is the directed difference matrix corresponding to the non-zero fusion weights defined in the work of Weylandt et al. (2020).
We can show that the augmented Lagrangian in scaled form is equal to:
where the dual variable is denoted by Λ.
To update U, we need to solve the following sub-problem:
Let . The sub-problem becomes:
where is the jth column of . For each ADMM iterate, we have:
This can be solved by running iterative proximal gradient to full convergence:
which is equivalent to:
Here U(k,m) refers to the mth inner iteration counter in the U sub-problem out of the kth outer iteration counter of the ADMM update. It is straightforward that this is computationally expensive. To address this, we propose to solve the U sub-problem approximately using just a one-step proximal gradient update and prove convergence in the next section. This approach is based on proximal linearized ADMM (Liu et al., 2013; Lu et al., 2016), which solves the sub-problems efficiently by linearizing the differentiable part and then applying proximal gradient due to the non-differentiable part. To ensure convergence, the algorithm requires that gradient should be Lipschitz continuous. The V and Λ updates are just the same as in regular convex clustering.
We adopt such an approach and develop the proximal linearized 2-block ADMM (Algorithm 7) to solve Gecco+ when the loss is differentiable and gradient is Lipschitz continuous.
Algorithm 7.
Proximal linearized 2-block ADMM when the loss is differentiable and gradient is Lipschitz continuous — matrix form
| while not converged do |
| end while |
Further, if the U sub-problem can be decomposed to p separate U.j sub-problems where the augmented Lagrangian for each now is a sum of a differentiable loss, a quadratic term and a sparse group-lasso penalty, we propose to use proximal gradient descent for each separate U.j sub-problem. In this way, we yield adaptive step size for each U.j sub-problem and hence our algorithm enjoys better convergence property than updating U’s all together. (In the latter case, the step size becomes fairly small as we are moving all U to some magnitude in the direction of negative gradient.) To achieve this, we assume that the loss is elementwise, which means we can write the loss function as a sum of p terms. (The loss can be written as where q(·) is the element-wise version of the loss while ℓ(·) is the vector-wise version of the loss.) We see that every deviance-based loss satisfies this assumption. Moreover, by decomposing to p sub-problems, we can solve each in parallel which saves computation cost. We describe in detail how to solve each U.j sub-problem in the next subsection.
C.2. Two-block ADMM in Vector Form in Parallel
Suppose the U sub-problem can be decomposed to p separate U.j sub-problems mentioned above. The augmented Lagrangian now becomes:
In this way we can perform block-wise minimization. Now minimizing the augmented Lagrangian over U is equivalent to minimizing over each :
Let . The problem above becomes:
Similarly, this can be solved by running iterative proximal gradient to full convergence. However, as mentioned above, we propose to solve the U sub-problem approximately by taking just a one-step proximal gradient update and prove convergence. Still this approach is based on proximal linearized ADMM (Liu et al., 2013; Lu et al., 2016), which solves the sub-problems efficiently by linearizing the differentiable part and then applying proximal gradient due to the non-differentiable part. To ensure convergence, the algorithm requires that gradient should be Lipschitz continuous.
We propose Algorithm 8 to solve Gecco+ when ℓ is differentiable and gradient is Lipschitz continuous in vector form. Note the U-update in Algorithm 8 is a just a vectorized version of that in Algorithm 7 if we use fixed step size sk for each feature j. We use the vector form update here since it enjoys better convergence property mentioned above and we use this form to prove convergence. Next we prove the convergence of Algorithm 8.
Algorithm 8.
Proximal linearized 2-block ADMM when the loss is differentiable and gradient is Lipschitz continuous — vector form in parallel
| Input: |
| Initialize: |
| Precompute: Difference matrix |
| while not converged do |
| for j = 1 to p do |
| end for |
| end while |
| Output: U(k). |
C.3. Proof of Convergence
Theorem 6 If ℓ is convex and differrentiable and ∇ℓ is Lipschitz continuous, then Algorithm 8 converges to a global solution. Further, if ℓ is strictly convex, it converges to the unique global solution.
Proof: We will show that the U-update in Algorithm 8 is equivalent to linearizing the U sub-problem and then applying a proximal operator, which is proximal linearized ADMM.
Note that each U.j sub-problem is:
For simplicity of notation, we replace U.j with uj in the following:
Rearranging terms, we have:
According to the proximal linearized ADMM with parallel splitting algorithm (see Algorithm 3 of Liu et al. (2013) and Equation (14) of Lu et al. (2016)), we can linearize the first two terms and add a quadratic term in the objective:
Rearranging terms and removing irrelevant terms, we have:
where .
Let . We have:
Recall the definition of proximal operator:
Therefore, the update is just a proximal gradient descent update:
Now we plug back and get the , i.e., update:
which is equivalent to the U.j update in Algorithm 8.
The V and Λ update is just the same as the one in convex clustering. Hence Algorithm 8 is equivalent to the form of proximal linearized ADMM by Liu et al. (2013); Lu et al. (2016) and hence converges to a global solution as long as ∇ℓ is Lipschitz continuous. Note that Algorithm 7 is equivalent to Algorithm 8 with a fixed step size sk. (We can choose sk to be the minimum step size sk over all features.) Therefore, Algorithm 7 also converges to a global solution as long as ∇ℓ is Lipschitz continuous. Further, if ℓ is strictly convex, the optimization problem has unique minimum and hence Algorithm 7 and 8 converges to the global solution. ■
Note:
In Liu et al. (2013); Lu et al. (2016), the algorithm requires that ∇ℓ is Lipschitz continuous to guarantee convergence. We know that ∇ℓ being Lipschitz continuous is equivalent to ℓ being strongly smooth. It is easy to show that the Hessian of log-likelihood of exponential family and GLM deviance is upper bounded since in (generalized) convex clustering, the value of U is bounded as it moves along the regularization path from X to the loss-specific center; also to avoid numerical issues, we add trivial constraint that uij > 0 when zero is not defined in the log-likelihood/deviance. Hence the condition for convergence of proximal linearized ADMM is satisfied.
To obtain a reasonable step size sk, we need to compute the Lipschitz constant. However, it is non-trivial to calculate the Lipschitz constant for most of our general losses. Instead, we suggest using backtracking line search procedure proposed by Beck and Teboulle (2009); Parikh et al. (2014), which is a common way to determine step size with guaranteed convergence in optimization. Empirical studies show that choosing step size with backtracking in our framework also ensures convergence. The details for backtracking procedure are discussed below.
For proximal linearized ADMM, Liu et al. (2013); Lu et al. (2016) established convergence rate of O(1/K). An interesting future direction might be establishing the linear convergence rate of proximal linearized ADMM when the objective is strongly convex.
C.4. Backtracking Criterion
In this section we discuss how to choose the step size sk in Algorithm 8. As mentioned, usually we employ a fixed step size by computing the Lipschitz constant as in the squared error loss case; but in our method, it is hard to compute the Lipschitz constant for most of our general losses. Instead, we propose using backtracking line search procedure proposed by Beck and Teboulle (2009); Parikh et al. (2014), which is a common way to determine step size with guaranteed convergence in optimization.
Recall the objective function we want to minimize in the U sub-problem is:
where .
Define:
We adopt the backtracking line search procedure proposed by Beck and Teboulle (2009); Parikh et al. (2014). At each iteration, while
shrink t = βt.
We still adopt the one-step approximation and hence suggest taking a one-step proximal update with backtracking to solve the U sub-problem. To summarize, we propose Algorithm 9, which uses proximal linearized 2-block ADMM with backtracking when the loss is differentiable and gradient is Lipschitz continuous.
C.5. Alternative Algorithm for Differentiable Losses
It should be pointed out that there are many other methods to solve the U sub-problem when the loss ℓ is differentiable. We choose to use proximal gradient descent algorithm as there is existing literature on approximately solving the sub-problem using proximal gradient under ADMM with proved convergence (Liu et al., 2013; Lu et al., 2016). But there are many other optimization techniques to solve the U sub-problem such as ADMM.
In this subsection, we show how to apply ADMM to solve the U sub-problem and specify under which conditions this method is more favorable. Recall to update U, we need to solve the following sub-problem:
We use ADMM to solve this minimization problem and can now recast the problem above as the equivalent constrained problem:
Algorithm 9.
Proximal linearized 2-block ADMM with backtracking when the loss is differentiable and gradient is Lipschitz continuous
| Input: |
| Initialize: U(0), V(0), Λ(0), t |
| Precompute: Difference matrix D, |
| while not converged do |
| for j = 1 to p do |
| t = 1 |
| while |
| t = βt |
| end while |
| end for |
| end while |
| Output: U(k). |
The augmented Lagrangian in scaled form is:
where the dual variable for V is denoted by Λ; the dual variable for R is denoted by N.
The U.j sub-problem in the inner nested ADMM is:
Now, we are minimizing a sum of a differentiable loss ℓ and two quadratic terms which are all smooth. Still the U.j sub-problem does not have a closed-form solution for general convex losses and we need to run an iterative descent algorithm (such as gradient descent, Newton method) to full convergence to solve the problem. Similarly, to reduce computation cost, we take a one-step update by applying linearized ADMM (Lin et al., 2011) to the U.j
Algorithm 10.
Full-step multi-block algorithm for Gecco+ with Bernoulli log-likelihood ℓk:
| Precompute: Difference matrix . |
| while not converged do |
| while not converged do |
| end while |
| end while |
sub-problem. The U.j update in the inner ADMM now becomes:
In this case, empirical studies show that taking a one-step Newton update is favored than a one-step gradient descent update as the former enjoys better convergence properties and generally avoids backtracking. However, inverting a Hessian matrix is computationally burdensome at each iteration when n is large. Exceptions are for Euclidean distances case where there is a closed-form solution for the U.j update and for Bernoulli log-likelihood case where the Hessian of the loss can be upper bounded by a fixed matrix. In the latter case, we propose to pre-compute the inverse of that fixed matrix instead of inverting a Hessian matrix at each iteration. To illustrate this, we write out the U.j sub-problem of Gecco+ with Bernoulli log-likelihood:
The Hessian is which can be upper bounded by . We propose to replace the Hessian with this fixed matrix in Newton method and use its inverse. This is closely related to the approximate Hessian literature (Krishnapuram et al., 2005; Simon et al., 2013). In this way, we just pre-compute this inverse matrix instead of inverting the Hessian matrix at each iteration, which dramatically saves computation. We give Algorithm 10 to solve Gecco+ for Bernoulli log-likelihood with a one-step update to solve the U sub-problem. Empirical studies show that this is faster than taking the inner nested proximal gradient approach as we generally don’t need to perform the backtracking step.
Yet, Algorithm 10 is slow as we need to run iterative inner nested ADMM updates to full convergence. To address this, as mentioned, we can take a one-step update of the inner nested iterative ADMM algorithm. To see this, we can recast the original Gecco+ problem as:
We apply multi-block ADMM to solve this optimization problem and hence get Algorithm 11. As discussed above, we take a one-step update to solve the U sub-problem with linearized ADMM and use the inverse of fixed approximate Hessian matrix, M1.
Algorithm 11.
One-step inexact multi-block algorithm for Gecco+ with Bernoulli log-likelihood ℓk:
| Precompute: Difference matrix . |
| while not converged do |
| end while |
Similarly, we adopt this approach to solve Gecco+ with Euclidean distances (sparse convex clustering). We first recast the original problem as:
Still, we use multi-block ADMM to solve this optimization problem and hence get Algorithm 12. Note that U sub-problem now has a closed-form solution. Typically, we do not have an approximate Hessian matrix or a closed-form solution to the sub-problem for general losses and we have to use one-step gradient descent with backtracking to solve the U sub-problem. Empirical study shows that this approach converges slower than Algorithm 9 which uses one-step proximal gradient descent with backtracking.
Appendix D. Gecco+ for Non-Differentiable Losses
In this section, we propose an algorithm to solve Gecco+ when the loss ℓ is non-differentiable. In this case, we develop a multi-block ADMM algorithm to solve Gecco+ and prove its algorithmic convergence.
Algorithm 12.
One-step inexact multi-block algorithm for Gecco+ with Euclidean distances ℓk:
| Precompute: Difference matrix . |
| while not converged do |
| end while |
D.1. Gecco+ Algorithm for Non-Differentiable Losses
Suppose the non-differentiable loss ℓ can be expressed as ℓ(X, U) = f(g(X, U)) where f is convex but non-differentiable and g is affine. This expression is reasonable as it satisfies the affine composition of a convex function. For example, for the least absolute loss, and . We specify the affine function g as we want to augment the non-differentiable term in the loss function ℓ.
We can rewrite the problem as:
We can now recast the problem above as the equivalent constrained problem:
where is an n × p matrix with the jth column equal to scalar .
The augmented Lagrangian in scaled form is:
where the dual variable for V is denoted by Λ; the dual variable for Z is denoted by Ψ; the dual variable for R is denoted by N.
Since we assume g to be affine, i.e., g(X, U) = AX + BU + C, the augmented Lagrangian in scaled form can be written as:
It can be shown that the U sub-problem has a closed-form solution.
Note that, hinge loss is also non-differentiable and we can write g(X, U) = 1 − U ο X where 1 is a matrix of all one and “ο” is the Hadamard product. In this case, the U sub-problem does not have a closed-form solution and we will discuss how to solve this problem in the next section.
For distance-based losses, the loss function can always be written as: ℓ(X, U) = f(X − U), which means g(X, U) = X − U. Then the augmented Lagrangian in scaled form can be simplified as:
Now the U sub-problem has a closed-form solution:
This gives us Algorithm 13 to solve Gecco+ for non-differentiable distance-based loss.
Algorithm 13.
Multi-block ADMM for non-differentiable distance-based loss
| Precompute: Difference matrix . |
| while not converged do |
| end while |
Algorithm 13 can be used to solve Gecco+ problem with various distances such as Manhattan, Minkowski and Chebychev distances by applying the corresponding proximal operator in the Z-update. For example, for Gecco+ with Manhattan distances, the Z-update is just applying element-wise soft-thresholding operator. For Gecco+ with Chebychev distances, the proximal operator in the Z-update can be computed separately across the rows of its argument and reduces to applying row-wise proximal operator of the infinity-norm. For Gecco+ with Minkowski distances, we similarly apply row-wise proximal operator of the ℓq-norm.
Next we prove the convergence of Algorithm 13.
D.2. Proof of Convergence for Algorithm 13
Theorem 7 If ℓ is convex, Algorithm 13 converges to a global minimum.
Proof: Note we have provided a sufficient condition for the convergence of four-block ADMM in Lemma 5. Next we show that the constraint set in our problem satisfies the condition in Lemma 5 and hence the multi-block ADMM Algorithm 13 converges. Recall our problem is:
Note that Lemma 5 is stated in vector form. Hence we transform the constraints above from matrix form to vector form. Note that . Hence we can write the constraints as:
where , , , , , , is a column vector consisting of all and is repeated n times in b.
By construction, , , and . It is easy to verify that: , , . Hence our setup satisfies the sufficient condition in Lemma 5 and the multi-block ADMM Algorithm 13 converges. ■
D.3. Special Case: Gecco+ with Hinge Losses
As mentioned, we cannot directly apply Algorithm 13 to solve Gecco+ with hinge losses as the function g(X, U) in this case is not the same as the one in distance-based losses. Recall Gecco+ with hinge losses is:
Like before, we can rewrite the problem as:
We can now recast the problem above as the equivalent constrained problem:
Here, f(Z) = max(0, Z). With a slight abuse of notation, we refer f to applying element-wise maximum to all entries in the matrix. We set g(X, U) = 1 − U ο X where 1 is a matrix of all one and “ο” is the Hadamard product. is an n × p matrix with the jth column equal to scalar .
The augmented Lagrangian in scaled form is:
The U sub-problem now becomes:
The first-order optimality condition is:
which can be written as:
To solve U from the above equation, one way is to first find the SVD of the leading coefficient:
From this decomposition we create two sets of diagonal matrices:
The Hadamard product can now be replaced by a sum
where .
Now we can solve this equation via vectorization:
where B+ denotes the pseudo-inverse of B, and Mat() is the inverse of the vec() operation.
Here we have to compute the pseudo-inverse of a matrix which is computationally expensive in practice. To avoid this, we adopt generalized ADMM approach proposed by Deng and Yin (2016) where the U sub-problem is augmented by a positive semi-definite quadratic operator. In our case, our modified U sub-problem becomes:
The first-order optimality condition now becomes:
We have:
where H = (DTD + I + 1). Hence we have analytical update:
It is easy to see that the V, Z and R updates all have closed-form solutions.
Appendix E. Multinomial Gecco+
In this section, we briefly demonstrate how Gecco+ with multinomial losses is formulated, which is slightly different from the original Gecco+ problems. Suppose we observe categorical data as follows (K = 3):
We can get the indicator matrix X(k) for each class k as:
Then we concatenate X(1), X(2), X(3) and get . This is equivalent to the dummy coding of the categorical matrix after some row/column shuffle:
It is obvious that measuring the difference of two observations by comparing rows of is better than simply comparing the Euclidean distances of rows of original data matrix X. Also parameterizing in is beneficial for computing the multinomial log-likelihood or deviance. Hence we concatenate all columns of X(k) as input data. Similarly, we concatenate all columns of the corresponding U(k) and then fuse in a row-wise way.
E.1. Gecco with Multinomial Log-likelihood
Gecco with multinomial log-likelihood can be formulated as:
where refers to the elements of indicator matrix discussed previously and .
E.2. Gecco+ with Multinomial Log-likelihood
Gecco+ with multinomial log-likelihood can be formulated as:
where , and is the loss-specific center for j variable in kth class.
Appendix F. Loss-specific Center Calculation
In this section, we show how to calculate the loss-specific center in Table 1.
F.1. Continuous Data
For continuous data, we consider Gecco with Euclidean distances.
F.1.1. Euclidean Distance
When total fusion occurs, , . Let . The problem above becomes:
Taking derivative, we get:
F.2. Count Data
For count-valued data, we consider Gecco with Poisson log-likelihood/deviance, negative binomial log-likelihood/deviance and Manhattan distances.
F.2.1. Poisson log-likelihood
When total fusion occurs, , . Let u be the fusion vector and . The problem above becomes:
Taking derivative, we get:
F.2.2. Poisson Deviance
Let u be the fusion vector and u = (u1, ⋯ , up). The problem above becomes:
Taking derivative, we get:
F.2.3. Negative Binomial log-likelihood
When total fusion occurs, , . Let u be the fusion vector and . The problem above becomes:
Taking derivative, we get:
F.2.4. Negative Binomial Deviance
The formulation above is equivalent to:
Let u be the fusion vector and . The problem above becomes:
Taking derivative, we get:
F.2.5. Manhattan Distance
When total fusion occurs, , . Let . We have:
For each j, we have:
We know that the optimal uj is just the median of xij for each j.
F.3. Binary Data
For binary data, we consider Gecco with Bernoulli log-likelihood, binomial deviance and hinge loss.
F.3.1. Bernoulli log-likelihood
When total fusion occurs, , . Let u be the fusion vector and . The problem above becomes:
Taking derivative, we get:
F.3.2. Binomial Deviance
Let u be the fusion vector and . The problem above becomes:
Taking derivative, we get:
F.3.3. Hinge Loss
Let u be the fusion vector and . The problem above becomes:
For each feature j, the problem becomes:
Note in hinge loss, . Suppose we have n1 observations for class “1” and n2 observations for class “−1”. The problem now becomes:
Define . We have:
Clearly, if n2 > n1 (more “−1”), h(t) is minimized by t = −1; if n1 > n2 (more “1”), h(t) is minimized by t = 1; if n1 = n2, h(t) is minimized by any t between [−1, 1]. Therefore, uj should be the mode of all observations for feature j:
F.4. Categorical Data
For categorical data, we consider Gecco with multinomial log-likelihood and deviance.
F.4.1. Multinomial log-likelihood
When total fusion occurs, , . Let u be the fusion vector and . The problem above becomes:
Taking derivative with respect to , we get:
F.4.2. Multinomial Deviance
When total fusion occurs, , . Let u be the fusion vector and . The problem above becomes:
We can write the constraint in Lagrangian form:
Taking derivative with respect to , we get:
We have:
Therefore,
Appendix G. Visualization of Gecco+ for Authors Data
Figure 5 illustrates selected features and cluster assignment for authors data set with one combination of α and γ. We select meaningful features and achieve satisfactory clustering results. We have already discussed the results and interpretation in detail in Section 5.1.
Figure 5:
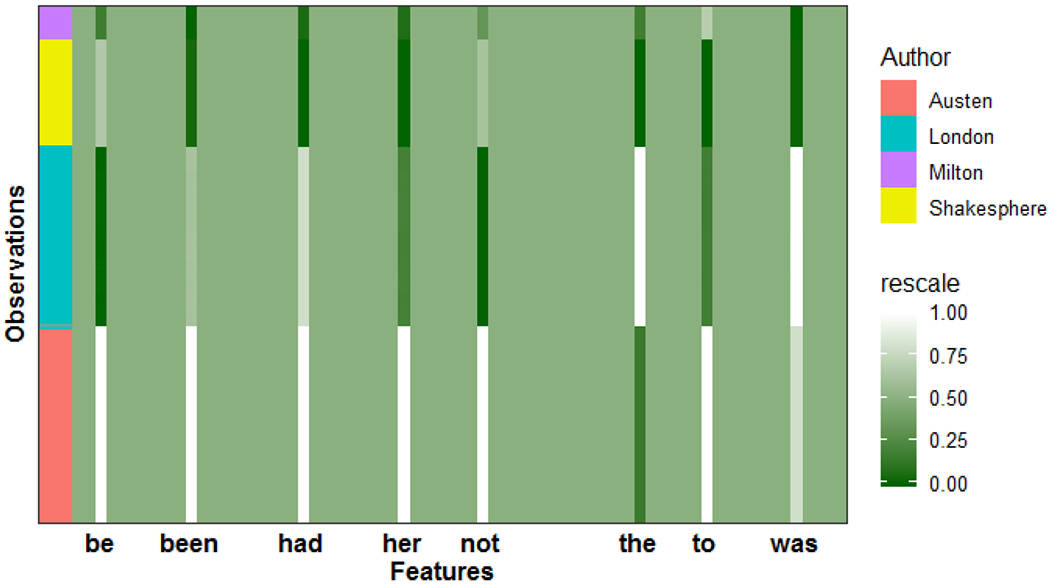
Cluster heatmap of Gecco+ solution for authors data set with α = 15 and γ = 105. The left bar refers to the true author label. We highlight selected features at the bottom. Gecco+ selects informative features that separate groups.
Appendix H. Multi-omics Data
In this section, we show the distribution of data from different platforms in Section 5.3. We see that both gene expression data and protein data appear Gaussian; methylation data is between [0, 1]; miRNA data is highly-skewed.
Figure 6:
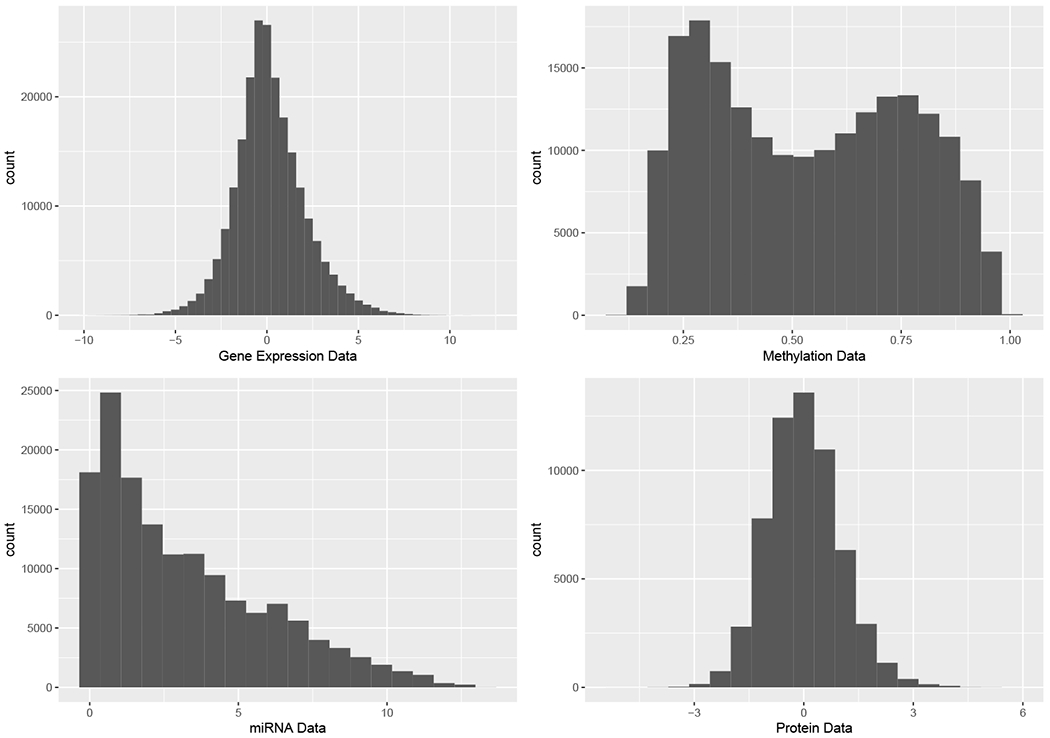
Histograms of data from different platforms for multi-omics TCGA data set. Both gene expression data and protein data appear Gaussian; methylation data is proportion-valued; miRNA data is highly-skewed.
Appendix I. Null Deviance
In this appendix, we list the null deviance D for some common losses used in iGecco. Recall in the iGecco formulation, πk, which are set inversely proportional to the null deviance evaluated at the loss-specific center, are scaling factors to ensure that the losses are measured at the same scale in the objective function.
By definition, the null deviance D evaluated at the loss-specific center, refers to where each jth column of is the loss-specific center for that column/feature. Table 12 shows the null deviance D for some common losses.
Table 12:
Null deviance for common losses used in iGecco
| Loss Function | Null Deviance D |
|---|---|
|
| |
| Euclidean distance | |
| Manhattan distance | |
| Bernoulli log-likelihood | |
| Binomial deviance | |
Here refers to the mean for the jth column/feature while median(xj) refers to the median for the jth column. Simple calculation shows that the Bernoulli log-likelihood is equivalent to binomial deviance by noting .
Appendix J. Choice of Tuning Parameters
In this appendix, we propose two different approaches to select tuning parameters γ and α in the iGecco+ problem; γ controls the number of clusters while α controls the number of features selected. We first consider stability selection based approach, which has been shown to enjoy nice statistical properties such as selection consistency (Wang, 2010; Fang and Wang, 2012) and been adopted in practice with strong empirical performance (Wang et al., 2018). Next, to reduce computation, we consider information criterion based approaches. Finally, we demonstrate empirical results when the number of clusters and features are not fixed but estimated based on the data.
J.1. Stability Selection Based Approach
We first adopt the stability selection based approach for tuning parameter selection and follow closely the approach described in the work of Wang (2010); Fang and Wang (2012). We choose the stability selection based approach because i) its selection consistency has been established and ii) Wang et al. (2018) adopted similar approach for tuning parameter selection and demonstrated strong empirical performance. The rationale behind stability selection is that a good clustering algorithm with optimal tuning parameter should produce clusterings that do not vary much with respect to a small perturbation to the training samples.
By Wang (2010); Fang and Wang (2012), a clustering ψ(x) is defined as a mapping where q is the given number of clusters. Here, we use q as the number of clusters since we have already used k to represent the kth data view X(k). A clustering algorithm Ψ(·; q) with a given number of clusters q ≥ 2 yields a clustering mapping ψ(x) when applied to a sample. Here, we choose the number of clusters q, which is equivalent to choosing optimal γ since we can yield the cluster assignment and corresponding q for each γ. To account for the tuning parameter α for feature selection, we further denote the clustering algorithm as Ψ(·; q, α). Then, in our case, for any given pair of q and α, two clustering results can be obtained from two sets of bootstrapped samples. Then the clustering distance d, defined by Fang and Wang (2012), can be computed to measure the dissimilarity between two clustering results. We repeat the procedure multiple times and the optimal tuning parameter pair is the one that minimizes the average clustering instability. This gives Algorithm 14, which uses stability selection to choose tuning parameters.
Algorithm 14.
Choice of number of clusters q and feature penalty γ in Gecco+/iGecco+ using stability selection
| 1. Generate B independent bootstrap sample-pairs , . | |
| 2. Construct and based on , . | |
| 3. For each pair, and , calculate their clustering distance defined by Fang and Wang (2012). Then the clustering instability can be estimated by | |
| 4. Finally, the optimal number of clusters q and feature penalty α can be estimated by |
J.2. Information Criterion Based Approach
While choosing number of clusters based on stability selection has been shown to enjoy nice properties such as selection consistency (Wang, 2010), such methods are always computationally burdensome. To address this, on the other hand, information criterion based approach has been proposed for tuning parameter selection in convex clustering (Tan and Witten, 2015). We adopt the similar approach and propose the Bayesian information criterion (BIC) based approach to choose optimal number of clusters and features; this gives Algorithm 15.
Algorithm 15.
Choice of number of clusters q and feature penalty α in Gecco+/iGecco+ using BIC
| Initialize: , , . | |
| 1. Fit iGecco+ with a sequence of γ and fixed . Choose the number of clusters using BIC. | |
| 2. Fit iGecco+ with a sequence of α and fixed number of clusters . Choose number of features s using BIC. Get corresponding , active set and total number of selected features . | |
| 3. Repeat Step 1 and 2 until and stabilize. |
Here, the submatrix corresponds to the subset of features (columns) of X(k) that are in the active set selected by iGecco+. The quantity refers to πk calculated on the set of selected features , i.e., .
In summary, in step 1, we choose number of clusters only based on the selected features; in step 2, we choose number of features with the optimal number of clusters estimated from the previous step. Note in step 1, is a function of number of clusters q while in step 2, is a function of whether the feature is selected. Specifically, in step 1, since all features in are selected, correspond to the cluster centroids for each cluster and change with respect to the number of clusters. In step 2, by iGecco+, if the jth feature in the kth data view is selected, still correspond to the cluster centroids which are different for observations across different clusters; if the jth feature is not selected, corresponds to the same constant, i.e., loss-specific center for that feature.
The criterion to minimize is inspired by the BIC approach for convex clustering proposed by Tan and Witten (2015). Notice that we use different criterion in step 1 and 2 to choose number of clusters and features respectively. When choosing the number of clusters, we use the same loss function as in iGecco since all the features are selected. When choosing the number of features, for the presence of noise features, we find that the weighted loss function with respect to each feature in step 2 works better, as the criterion in step 1 downweights the contribution of signal features by adding informative terms along with the noise terms in the denominator. (When a feature is not selected, equals ; when a feature is selected, is less than ; if we use the unweighted criterion in step 1, the noise terms will dominate this criterion given a large number of noise features.) The degrees of freedom for choosing number of clusters in step 1 is q while in step 2, the degrees of freedom is since we need to estimate number of cluster centroids for each selected feature.
Stability selection is known to be more stable in terms of choosing number of clusters, with selection consistency theoretically established in literature. Meanwhile, BIC works better in choosing number of features in practice and saves much more computation compared with stability selection. Hence, to take full advantage of both approaches, we propose a sequential tuning parameter selection procedure, outlined in Algorithm 16. We demonstrate the clustering and variable selection accuracy results in Appendix J.3 using the proposed two tuning parameter selection approaches.
Algorithm 16.
Choice of number of clusters q and feature penalty α in Gecco+/iGecco+ using stability selection + BIC
| 1. Choose the number of clusters using Algorithm 14 with α = 1 (stability selection). |
| 2. Fit iGecco+ with a sequence of α and fixed number of clusters . Choose α using BIC based on Step 2 of Algorithm 15. |
Based on the algorithms above for tuning parameter selection and the adaptive iGecco+ Algorithm 1 (with oracle number of clusters and features) to choose the feature weights, we propose Algorithm 17, the alternative adaptive iGecco+ when the number of clusters or features are not known a priori. Notice that in step 2, we do not perform tuning parameter selection for number of clusters q, as we are only interested in some type of adaptive feature selection to weigh the features.
Algorithm 17.
Adaptive iGecco+ when the number of clusters or features are not known a priori
| 1. Fit iGecco+ with α = 1, and a sequence of γ. |
| 2. Find γ which gives non-trivial number of clusters, say q = 2; Get the estimate . |
| 3. Update the feature weights and fusion weights , where . |
| Fit adaptive iGecco+ with , and a sequence of γ and α; Find optimal γ and α using the tuning parameter selection procedure in Algorithm 15 or 16. |
J.3. Empirical Results in Simulation and Real Data Example
In this section, we demonstrate the empirical results when the number of clusters and features are not fixed but estimated based on the data. Specifically, we apply the two tuning parameter selection schemes proposed above: i) BIC based approach (Algorithm 17 + 15) and ii) stability selection + BIC based approach (Algorithm 17 + 16). We show the results of the tables in Section 4 and 5 when the number of clusters and features are estimated and not fixed to be the oracle. For simulation studies, we show the results of iGecco and iGecco+; Gecco and Gecco+ are special cases of these two. Moreover, we apply the proposed two tuning parameter selection approaches to the three real data examples in Section 5.
For iGecco, the stability selection based approach simplifies to choosing the number of clusters q in Algorithm 14; the BIC based approach refers to using the criterion in step 1 of Algorithm 15 to choose the number of clusters.
For iGecco+, we show the overall F1-score and number of selected features across all three data views. Recall that each data view has 10 true features and hence there are 30 true features in total. Also, the optimal number of clusters is q = 3. We compare the results with iClusterPlus when the number of clusters and features are not fixed. Note we only include estimated number of clusters for iClusterPlus as there is no tuning parameter for the number of selected features. (The authors mentioned feature selection could be achieved by selecting the top features based on Lasso coefficient estimates.)
Table 13 and 14 show the results of Table 3, 4 and 5 in Section 4.2 when the number of clusters (and features in iGecco+) is not fixed but estimated based on the data. Table 13 and 14 suggest that our proposed BIC based approach selects the correct number of clusters and features most of the time. On the other hand, information criterion based approaches save much more computation than stability selection. Hence, we recommend the BIC based approach for choosing tuning parameters which demonstrates strong empirical performance and saves computation. Yet, one might have their own justified choice of approach or information criterion to select tuning parameters.
Table 13:
Adjusted Rand index and estimated number of clusters of iGecco and iCluster for mixed multi-view data of Table 3 in Section 4.2 when the number of clusters is not fixed but estimated based on the data.
| S1 | S2 | |||
|---|---|---|---|---|
| ARI | # of Clusters | ARI | # of Clusters | |
| iGecco with BIC | 0.93 (5.2e-3) | 3.10 (1.0e-1) | 0.98 (2.2e-2) | 3.00 (0.0e-0) |
| iGecco with Stability Selection | 0.92 (8.1e-3) | 3.20 (2.0e-1) | 0.89 (4.1e-2) | 4.00 (3.9e-1) |
| iCluster+ with λ = 0 | 0.92 (4.1e-2) | 3.20 (2.0e-1) | 0.67 (1.9e-2) | 3.40 (1.6e-1) |
Table 14:
Adjusted Rand index, F1 score, along with estimated number of clusters and features of adaptive iGecco+ and iClusterPlus for high-dimensional mixed multi-view data of Table 4 and 5 in Section 4.2 when the number of clusters and features are not fixed but estimated based on the data. We only include estimated number of clusters for iClusterPlus as there is no tuning parameter for the number of selected features.
| S3 | S4 | S5 | S6 | |||||
|---|---|---|---|---|---|---|---|---|
| ARI | # of Clusters | ARI | # of Clusters | ARI | # of Clusters | ARI | # of Clusters | |
| Algorithm 17 + 15 (BIC) | 0.97 (7.8e-3) | 3.00 (0.0e-0) | 0.97 (1.3e-2) | 3.10 (1.0e-1) | 1.00 (0.0e-0) | 3.00 (0.0e-0) | 1.00 (0.0e-0) | 3.00 (0.0e-0) |
| Algorithm 17 + 16 (SS+BIC) | 0.93 (4.1e-2) | 2.90 (1.0e-1) | 0.89 (5.5e-2) | 2.80 (1.3e-1) | 0.99 (1.2e-2) | 3.10 (1.0e-1) | 0.82 (8.1e-2) | 4.90 (9.1e-1) |
| iCluster+ | 0.53 (8.1e-2) | 2.70 (3.0e-1) | 0.72 (5.3e-2) | 3.50 (3.1e-1) | 0.63 (2.4e-2) | 3.50 (2.2e-1) | 0.60 (1.4e-2) | 3.30 (1.5e-1) |
|
| ||||||||
| S3 | S4 | S5 | S6 | |||||
| F1-score | # of Features | F1-score | # of Features | F1-score | # of Features | F1-score | # of Features | |
|
| ||||||||
| Algorithm 17 + 15 (BIC) | 0.93 (1.1e-2) | 30.00 (1.1e-0) | 0.95 (1.9e-2) | 31.60 (7.2e-1) | 0.99 (6.3e-3) | 30.50 (4.0e-1) | 0.99 (6.5e-3) | 30.90 (4.1e-1) |
| Algorithm 17 + 16 (SS+BIC) | 0.93 (1.2e-2) | 29.60 (1.2e-0) | 0.96 (1.5e-2) | 29.40 (6.5e-1) | 0.99 (6.3e-3) | 30.50 (4.0e-1) | 0.99 (6.0e-3) | 30.10 (3.8e-1) |
Also, we apply the proposed two tuning parameter selection approaches to the real data examples in Section 5. Table 15 shows the estimated number of clusters. Again, the BIC based approach selects the correct number of clusters for all three cases.
Table 15:
Adjusted Rand index, along with estimated number of clusters using adaptive (i)Gecco+ for real data of Table 6, 8 and 10 in Section 5 when the number of clusters and features are not fixed but estimated based on the data. For the first two data set, we show the results of Manhattan Gecco+.
| Authors Data | TCGA Data | Multi-omics Data | ||||
|---|---|---|---|---|---|---|
| ARI | # of Clusters | ARI | # of Clusters | ARI | # of Clusters | |
| Algorithm 17 + 15 (BIC) | 0.96 | 4.00 | 0.76 | 3.00 | 0.71 | 3.00 |
| Algorithm 17 + 16 (SS+BIC) | 0.96 | 4.00 | 0.59 | 2.00 | 0.52 | 2.00 |
Appendix K. Stable to Perturbations of Data
In this appendix, we demonstrate that clustering assignments of iGecco+ are stable to perturbations in the data as shown in Proposition 2 of Section 2.4.
To show this, we include a simulation study similar to the one by Chi et al. (2017). We first apply adaptive iGecco+ on the original data to obtain baseline clustering. Then we add i.i.d. noise to each data view to create a perturbed data set on which we apply the same iGecco+ method. Specifically, for Gaussian data view, we add i.i.d. N(0, σ2) noise where σ = 0.5, 1.0, 1.5; for count data view, we add i.i.d. Poisson noise; for binary data view, we randomly shuffle a small proportion of the entries. We compute the adjusted Rand index between the baseline clustering and the one obtained on the perturbed data. We adopt the same approach for other existing methods. Table 16 shows the average adjusted Rand index of 10 replicates. For all values of σ, we see that iGecco+ tends to produce the most stable results.
Table 16:
Stability and reproducibility of adaptive iGecco+ on simulated data. Adaptive iGecco+ and other existing methods are applied to the simulated data to obtain baseline clusterings. We then perturb the data by adding i.i.d. noise. Specifically, for Gaussian data view, we add i.i.d. N(0, σ2) noise where σ = 0.5, 1.0, 1.5; for count data view, we add i.i.d. Poisson noise; for binary data view, we randomly shuffle a small proportion of the entries. We compute the adjusted Rand index (ARI) between the baseline clustering and the one obtained on the perturbed data.
| σ | A iGecco+ | Hclust: Euclidean | Hclust: Gower | iCluster+ | BCC |
|---|---|---|---|---|---|
| 0.5 | 1.00 (0.0e-0) | 0.85 (5.1e-2) | 0.90 (1.4e-2) | 0.69 (2.6e-2) | 0.92 (1.6e-2) |
| 1.0 | 1.00 (0.0e-0) | 0.69 (8.3e-2) | 0.89 (1.8e-2) | 0.71 (3.0e-2) | 0.90 (1.7e-2) |
| 1.5 | 0.95 (3.4e-2) | 0.66 (2.8e-2) | 0.86 (2.0e-2) | 0.70 (2.9e-2) | 0.90 (2.0e-2) |
Appendix L. Noisy Data Sources
In this appendix, we show the performance of iGecco+ when a purely noisy data view is observed.
Often in real data, not all the data views observed contain clustering information, i.e., one or more data views might be pure noise. Our iGecco+ is able to filter out noisy data views by adaptively shrinking all the (noise) features in these data sets towards the loss-specific centers. We include a simulation study to demonstrate the performance of iGecco+ in the presence of some purely noisy data sets. Similar to the base simulation, each simulated data set consists of n = 120 observations with 3 clusters. Each cluster has an equal number of observations. Only the first data view contains clustering signal with the first 30 features being informative while the rest features being noisy; the rest two data views are pure noise.
Table 17 shows that iGecco+ still performs well in the presence of noise data sources by adaptively shrinking noise features.
Table 17:
Adjusted Rand index of different methods in the presence of noisy data sources
| Method | Adjusted Rand Index |
|---|---|
|
| |
| Hclust: [X1X2X3] - Euclidean | 0.40 (4.9e-2) |
| Hclust: [X1X2X3] - Gower | 0.33 (4.8e-2) |
| iCluster+ | 0.88 (5.8e-2) |
| Bayesian Consensus Clustering | 0.00 (2.8e-4) |
| Adaptive iGecco+ | 0.99 (5.6e-3) |
Appendix M. Computation Time
In this section, we provide some computation run time results of iGecco(+) with different sample sizes and dimensions. We include results for both run times per iteration of the ADMM algorithm in Table 18 as well as the full training time for tuning parameter selection in Table 19. All timing results are run on a Dell XPS 15 with a 2.4 GHz Intel i5 processor and 8 GB of 2666 MHz DDR4 memory.
For training, we use BIC based approach to select tuning parameters for both iGecco and iGecco+ as it works well in practice and saves computation. It takes more time to train iGecco+ than iGecco as iGecco+ needs to select two tuning parameters (the number of clusters and features). Yet, our BIC based approach selects optimal tuning parameters in a reasonable amount of time. Note, for sample size n = 120 and feature size p1 = 200, p2 = 100, p3 = 50, it takes iClusterPlus hours for tuning parameter selection (using tune.iClusterPlus function in R).
Table 18:
Run time results per iteration of iGecco(+) with different sample sizes and dimensions; the first three experiments use iGecco while the rest use iGecco+
| Sample Size n | p 1 | p 2 | p 3 | Computation Time (in seconds) | |
|---|---|---|---|---|---|
|
iGecco |
120 | 10 | 10 | 10 | 0.0018 |
| 300 | 10 | 10 | 10 | 0.0044 | |
| 120 | 30 | 30 | 30 | 0.0038 | |
|
| |||||
|
iGecco+ |
120 | 200 | 100 | 50 | 0.0041 |
| 300 | 200 | 100 | 50 | 0.0105 | |
| 120 | 300 | 200 | 100 | 0.0055 | |
| 120 | 400 | 200 | 100 | 0.0061 | |
Table 19:
Training run time results of iGecco(+) with different sample sizes and dimensions; the first three experiments use iGecco with BIC to choose number of clusters while the rest use adaptive iGecco+ with BIC to choose number of clusters and features.
| Sample Size n | p 1 | p 2 | p 3 | Computation Time (in seconds) | |
|---|---|---|---|---|---|
|
iGecco |
120 | 10 | 10 | 10 | 0.89 |
| 300 | 10 | 10 | 10 | 2.58 | |
| 120 | 30 | 30 | 30 | 2.55 | |
|
| |||||
|
iGecco+ |
120 | 200 | 100 | 50 | 63.72 |
| 300 | 200 | 100 | 50 | 117.94 | |
| 120 | 300 | 200 | 100 | 90.77 | |
| 120 | 400 | 200 | 100 | 104.04 | |
Contributor Information
Minjie Wang, Department of Statistics, Rice University, Houston, TX 77005, USA.
Genevera I. Allen, Departments of Electrical and Computer Engineering, Statistics, and Computer Science, Rice University, Houston, TX 77005, USA; Jan and Dan Duncan Neurological Research Institute, Baylor College of Medicine, Houston, TX 77030, USA
References
- Acar Evrim, Kolda Tamara G, and Dunlavy Daniel M. All-at-once optimization for coupled matrix and tensor factorizations. ArXiv Pre-Print 1105.3422, 2011. https://arxiv.org/abs/1105.3422. [Google Scholar]
- Ahmad Amir and Dey Lipika. A k-mean clustering algorithm for mixed numeric and categorical data. Data & Knowledge Engineering, 63(2):503–527, 2007. doi: 10.1016/j.datak.2007.03.016. [DOI] [Google Scholar]
- Akay Özlem and Yüksel Güzin. Clustering the mixed panel dataset using Gower’s distance and k-prototypes algorithms. Communications in Statistics-Simulation and Computation, 47(10):3031–3041, 2018. doi: 10.1080/03610918.2017.1367806. [DOI] [Google Scholar]
- Ali Bilel Ben and Massmoudi Youssef. K-means clustering based on gower similarity coefficient: A comparative study. In 2013 5th International Conference on Modeling, Simulation and Applied Optimization (ICMSAO), pages 1–5. IEEE, 2013. doi: 10.1109/ICMSAO.2013.6552669. [DOI] [Google Scholar]
- Anders Simon and Huber Wolfgang. Differential expression analysis for sequence count data. Genome Biology, 11(10):R106, 2010. doi: 10.1186/gb-2010-11-10-r106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arthur David and Vassilvitskii Sergei. k-means++: The advantages of careful seeding. Technical report, Stanford, 2006. [Google Scholar]
- Badve Sunil, Turbin Dmitry, Thorat Mangesh A, Morimiya Akira, Nielsen Torsten O, Perou Charles M, Dunn Sandi, Huntsman David G, and Nakshatri Harikrishna. FOXA1 expression in breast cancer—correlation with luminal subtype A and survival. Clinical Cancer Research, 13(15):4415–4421, 2007. doi: 10.1158/1078-0432.CCR-07-0122. [DOI] [PubMed] [Google Scholar]
- Baker Yulia, Tang Tiffany M, and Allen Genevera I. Feature selection for data integration with mixed multi-view data. ArXiv Pre-Print 1903.11232, 2019. https://arxiv.org/abs/1903.11232. [Google Scholar]
- Banerjee Arindam, Merugu Srujana, Dhillon Inderjit S, and Ghosh Joydeep. Clustering with Bregman divergences. Journal of Machine Learning Research, 6(Oct):1705–1749, 2005. http://www.jmlr.org/papers/v6/banerjee05b.html. [Google Scholar]
- Banert Sebastian, Bot Radu Ioan, and Csetnek Ernö Robert. Fixing and extending some recent results on the ADMM algorithm. ArXiv Pre-Print 1612.05057, 2016. https://arxiv.org/abs/1612.05057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Banfield Jeffrey D and Raftery Adrian E. Model-based Gaussian and non-Gaussian clustering. Biometrics, pages 803–821, 1993. doi: 10.2307/2532201. [DOI] [Google Scholar]
- Beck Amir and Teboulle Marc. Gradient-based algorithms with applications to signal recovery. Convex Optimization in Signal Processing and Communications, pages 42–88, 2009. doi: 10.1017/CB09780511804458.003. [DOI] [Google Scholar]
- Bernardo JM, Bayarri MJ, Berger JO, Dawid AP, Heckerman D, Smith AFM, and West M. Bayesian clustering with variable and transformation selections. In Bayesian Statistics 7: Proceedings of the Seventh Valencia International Meeting, volume 249. Oxford University Press, USA, 2003. [Google Scholar]
- Bullard James H, Purdom Elizabeth, Hansen Kasper D, and Dudoit Sandrine. Evaluation of statistical methods for normalization and differential expression in mRNA-Seq experiments. BMC Bioinformatics, 11(1):94, 2010. doi: 10.1186/1471-2105-11-94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chalise Prabhakar and Fridley Brooke L. Integrative clustering of multi-level ‘omic data based on non-negative matrix factorization algorithm. PLoS ONE, 12(5):e0176278, 2017. doi: 10.1371/journal.pone.0176278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang Xiangyu, Wang Yu, Li Rongjian, and Xu Zongben. Sparse K-means with ℓ∞/ℓ0 penalty for high-dimensional data clustering. ArXiv Pre-Print 1403.7890, 2014. https://arxiv.org/abs/1403.7890. [Google Scholar]
- Chen Caihua, He Bingsheng, Ye Yinyu, and Yuan Xiaoming. The direct extension of ADMM for multi-block convex minimization problems is not necessarily convergent. Mathematical Programming, Series A, 155(1-2):57–79, 2016. doi: 10.1007/s10107-014-0826-5. [DOI] [Google Scholar]
- Chi Eric C. and Lange Kenneth. Splitting methods for convex clustering. Journal of Computational and Graphical Statistics, 24(4):994–1013, 2015. doi: 10.1080/10618600.2014.948181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chi Eric C and Steinerberger Stefan. Recovering trees with convex clustering. SIAM Journal on Mathematics of Data Science, 1(3):383–407, 2019. doi: 10.1137/18M121099X. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chi Eric C., Allen Genevera I., and Baraniuk Richard G.. Convex biclustering. Biometrics, 73(1):10–19, 2017. doi: 10.1111/biom.12540. [DOI] [PubMed] [Google Scholar]
- Chi Eric C, Gaines Brian R, Sun Will Wei, Zhou Hua, and Yang Jian. Provable convex co-clustering of tensors. ArXiv Pre-Print 1803.06518, 2018. https://arxiv.org/abs/1803.06518. [PMC free article] [PubMed] [Google Scholar]
- Choi Hosik, Poythress JC, Park Cheolwoo, Jeon Jong-June, and Park Changyi. Regularized boxplot via convex clustering. Journal of Statistical Computation and Simulation, 89(7): 1227–1247, 2019. doi: 10.1080/00949655.2019.1576045. [DOI] [Google Scholar]
- Choi Seung-Seok, Cha Sung-Hyuk, and Tappert Charles C. A survey of binary similarity and distance measures. Journal of Systemics, Cybernetics and Informatics, 8(1):43–48, 2010. [Google Scholar]
- Choi Woonyoung, Porten Sima, Kim Seungchan, Willis Daniel, Plimack Elizabeth R, Hoffman-Censits Jean, Roth Beat, Cheng Tiewei, Tran Mai, Lee I-Ling, et al. Identification of distinct basal and luminal subtypes of muscle-invasive bladder cancer with different sensitivities to frontline chemotherapy. Cancer Cell, 25(2):152–165, 2014. doi: 10.1016/j.ccr.2014.01.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cimino-Mathews Ashley, Subhawong Andrea P, Illei Peter B, Sharma Rajni, Halushka Marc K, Vang Russell, Fetting John H, Park Ben Ho, and Argani Pedram. GATA3 expression in breast carcinoma: utility in triple-negative, sarcomatoid, and metastatic carcinomas. Human Pathology, 44(7):1341–1349, 2013. doi: 10.1016/j.humpath.2012.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Souza Renata M.C.R. and De Carvalho Francisco de A.T.. Clustering of interval data based on city-block distances. Pattern Recognition Letters, 25(3):353–365, 2004. doi: 10.1016/j.patrec.2003.10.016. [DOI] [Google Scholar]
- Deng Wei and Yin Wotao. On the global and linear convergence of the generalized alternating direction method of multipliers. Journal of Scientific Computing, 66(3):889–916, 2016. doi: 10.1007/s10915-015-0048-x. [DOI] [Google Scholar]
- Deng Wei, Lai Ming-Jun, Peng Zhimin, and Yin Wotao. Parallel multi-block ADMM with o(1/k) convergence. Journal of Scientific Computing, 71(2):712–736, 2017. doi: 10.1007/s10915-016-0318-2. [DOI] [Google Scholar]
- dos Santos Tiago R.L. and Zárate Luis E.. Categorical data clustering: What similarity measure to recommend? Expert Systems with Applications, 42(3):1247–1260, 2015. doi: 10.1016/j.eswa.2014.09.012. [DOI] [Google Scholar]
- Fan Jianqing, Feng Yang, and Wu Yichao. Network exploration via the adaptive lasso and scad penalties. The annals of applied statistics, 3(2):521, 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fang Yixin and Wang Junhui. Selection of the number of clusters via the bootstrap method. Computational Statistics & Data Analysis, 56(3):468–477, 2012. doi: 10.1016/j.csda.2011.09.003. [DOI] [Google Scholar]
- Forbes Simon A, Bindal Nidhi, Bamford Sally, Cole Charlotte, Kok Chai Yin, Beare David, Jia Mingming, Shepherd Rebecca, Leung Kenric, Menzies Andrew, et al. COSMIC: mining complete cancer genomes in the Catalogue of Somatic Mutations in Cancer. Nucleic Acids Research, 39(suppl_1):D945–D950, 2010. doi: 10.1093/nar/gkq929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fowlkes Edward B and Mallows Colin L. A method for comparing two hierarchical clusterings. Journal of the American Statistical Association, 78(383):553–569, 1983. doi: 10.2307/2288117. [DOI] [Google Scholar]
- Garczyk Stefan, von Stillfried Saskia, Antonopoulos Wiebke, Hartmann Arndt, Schrauder Michael G, Fasching Peter A, Anzeneder Tobias, Tannapfel Andrea, Ergönenc Yavuz, Knüchel Ruth, et al. AGR3 in breast cancer: Prognostic impact and suitable serum-based biomarker for early cancer detection. PLoS ONE, 10(4):e0122106, 2015. doi: 10.1371/journal.pone.0122106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghosh Debashis and Chinnaiyan Arul M. Mixture modelling of gene expression data from microarray experiments. Bioinformatics, 18(2):275–286, 2002. doi: 10.1093/bioinformatics/18.2.275. [DOI] [PubMed] [Google Scholar]
- Gower John C. A general coefficient of similarity and some of its properties. Biometrics, pages 857–871, 1971. doi: 10.2307/2528823. [DOI] [Google Scholar]
- Hall David L and Llinas James. An introduction to multisensor data fusion. Proceedings of the IEEE, 85(1):6–23, 1997. doi: 10.1109/5.554205. [DOI] [Google Scholar]
- Harari Daniel and Yarden Yosef. Molecular mechanisms underlying ErbB2/HER2 action in breast cancer. Oncogene, 19(53):6102, 2000. doi: 10.1038/sj.onc.1203973. [DOI] [PubMed] [Google Scholar]
- Hayashi SI, Eguchi H, Tanimoto K, Yoshida T, Omoto Y, Inoue A, Yoshida N, and Yamaguchi Y. The expression and function of estrogen receptor alpha and beta in human breast cancer and its clinical application. Endocrine-Related Cancer, 10(2):193–202, 2003. doi: 10.1677/erc.0.0100193. [DOI] [PubMed] [Google Scholar]
- Hellton Kristoffer H and Thoresen Magne. Integrative clustering of high-dimensional data with joint and individual clusters. Biostatistics, 17(3):537–548, 2016. doi: 10.1093/biostatistics/kxw005. [DOI] [PubMed] [Google Scholar]
- Hoadley Katherine A, Yau Christina, Wolf Denise M, Cherniack Andrew D, Tamborero David, Ng Sam, Leiserson Max DM, Niu Beifang, McLellan Michael D, Uzunangelov Vladislav, et al. Multiplatform analysis of 12 cancer types reveals molecular classification within and across tissues of origin. Cell, 158(4):929–944, 2014. doi: 10.1016/j.cell.2014.06.049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hocking Toby Dylan, Joulin Armand, Bach Francis, and Vert Jean-Philippe. Clusterpath: An algorithm for clustering using convex fusion penalties. In Getoor Lise and Scheffer Tobias, editors, ICML 2011: Proceedings of the 28th International Conference on Machine Learning, pages 745–752. ACM, 2011. ISBN 978-1-4503-0619-5. http://www.icml-2011.org/papers/419_icmlpaper.pdf. [Google Scholar]
- Hua Kaiyao, Jin Jiali, Zhao Junyong, Song Jialu, Song Hongming, Li Dengfeng, Maskey Niraj, Zhao Bingkun, Wu Chenyang, Xu Hui, et al. miR-135b, upregulated in breast cancer, promotes cell growth and disrupts the cell cycle by regulating LATS2. International Journal of Oncology, 48(5):1997–2006, 2016. doi: 10.3892/ijo.2016.3405. [DOI] [PubMed] [Google Scholar]
- Hubert Lawrence and Arabie Phipps. Comparing partitions. Journal of Classification, 2(1): 193–218, 1985. doi: 10.1007/BF01908075. [DOI] [Google Scholar]
- Hummel Manuela, Edelmann Dominic, and Kopp-Schneider Annette. Clustering of samples and variables with mixed-type data. PloS ONE, 12(11):e0188274, 2017. doi: 10.1371/journal.pone.0188274. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ji Jinchao, Pang Wei, Zhou Chunguang, Han Xiao, and Wang Zhe. A fuzzy k-prototype clustering algorithm for mixed numeric and categorical data. Knowledge-Based Systems, 30:129–135, 2012. doi: 10.1016/j.knosys.2012.01.006. [DOI] [Google Scholar]
- Kirk Paul, Griffin Jim E, Savage Richard S, Ghahramani Zoubin, and Wild David L. Bayesian correlated clustering to integrate multiple datasets. Bioinformatics, 28(24):3290–3297, 2012. doi: 10.1093/bioinformatics/bts595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krishnapuram Balaji, Carin Lawrence, Figueiredo Mario AT, and Hartemink Alexander J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(6):957–968, 2005. doi: 10.1109/TPAMI.2005.127. [DOI] [PubMed] [Google Scholar]
- Lin Tianyi, Ma Shiqian, and Zhang Shuzhong. On the global linear convergence of the ADMM with multiblock variables. SIAM Journal on Optimization, 25(3):1478–1497, 2015. doi: 10.1137/140971178. [DOI] [Google Scholar]
- Lin Zhouchen, Liu Risheng, and Su Zhixun. Linearized alternating direction method with adaptive penalty for low-rank representation. In Advances in neural information processing systems, pages 612–620, 2011. [Google Scholar]
- Lindsten Fredrik, Ohlsson Henrik, and Ljung Lennart. Just relax and come clustering!: A convexification of k-means clustering. Linköping University Electronic Press, 2011. [Google Scholar]
- Liu Risheng, Lin Zhouchen, and Su Zhixun. Linearized alternating direction method with parallel splitting and adaptive penalty for separable convex programs in machine learning. In Asian Conference on Machine Learning, pages 116–132, 2013. doi: 10.1007/s10994-014-5469-5. [DOI] [Google Scholar]
- Lock Eric F and Dunson David B. Bayesian consensus clustering. Bioinformatics, 29(20): 2610–2616, 2013. doi: 10.1093/bioinformatics/btt425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lock Eric F, Hoadley Katherine A, Marron James Stephen, and Nobel Andrew B. Joint and individual variation explained (JIVE) for integrated analysis of multiple data types. The Annals of Applied Statistics, 7(1):523, 2013. doi: 10.1214/12-AOAS597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu Canyi, Li Huan, Lin Zhouchen, and Yan Shuicheng. Fast proximal linearized alternating direction method of multiplier with parallel splitting. In AAAI, pages 739–745, 2016. https://arxiv.org/abs/1511.05133. [Google Scholar]
- van der Maaten Laurens and Hinton Geoffrey. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008. http://www.jmlr.org/papers/v9/vandermaaten08a.html. [Google Scholar]
- Marioni John C, Mason Christopher E, Mane Shrikant M, Stephens Matthew, and Gilad Yoav. RNA-seq: an assessment of technical reproducibility and comparison with gene expression arrays. Genome Research, 2008. doi: 10.1101/gr.079558.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mehra Rohit, Varambally Sooryanarayana, Ding Lei, Shen Ronglai, Sabel Michael S, Ghosh Debashis, Chinnaiyan Arul M, and Kleer Celina G. Identification of GATA3 as a breast cancer prognostic marker by global gene expression meta-analysis. Cancer Research, 65 (24):11259–11264, 2005. doi: 10.1158/0008-5472.CAN-05-2495. [DOI] [PubMed] [Google Scholar]
- Meng Chen, Helm Dominic, Frejno Martin, and Kuster Bernhard. moCluster: Identifying joint patterns across multiple omics data sets. Journal of Proteome Research, 15(3): 755–765, 2015. doi: 10.1021/acs.jproteome.5b00824. [DOI] [PubMed] [Google Scholar]
- Mo Qianxing, Wang Sijian, Seshan Venkatraman E, Olshen Adam B, Schultz Nikolaus, Sander Chris, Scott Powers R, Ladanyi Marc, and Shen Ronglai. Pattern discovery and cancer gene identification in integrated cancer genomic data. Proceedings of the National Academy of Sciences, 110(11):4245–4250, 2013. doi: 10.1073/pnas.1208949110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mo Qianxing, Shen Ronglai, Guo Cui, Vannucci Marina, Chan Keith S, and Hilsenbeck Susan G. A fully Bayesian latent variable model for integrative clustering analysis of multi-type omics data. Biostatistics, 19(1):71–86, 2017. doi: 10.1093/biostatistics/kxx017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pan Wei and Shen Xiaotong. Penalized model-based clustering with application to variable selection. Journal of Machine Learning Research, 8(May):1145–1164, 2007. http://www.jmlr.org/papers/v8/pan07a.html. [Google Scholar]
- Panahi Ashkan, Dubhashi Devdatt, Johansson Fredrik D, and Bhattacharyya Chiranjib. Clustering by sum of norms: Stochastic incremental algorithm, convergence and cluster recovery. In International conference on machine learning, pages 2769–2777. PMLR, 2017. [Google Scholar]
- Parikh Neal, Boyd Stephen, et al. Proximal algorithms. Foundations and Trends® in Optimization, 1(3):127–239, 2014. doi: 10.1561/2400000003. [DOI] [Google Scholar]
- Pelckmans Kristiaan, de Brabanter Joseph, Suykens Johan, and de Moor Bart. Convex clustering shrinkage. In PASCAL Workshop on Statistics and Optimization of Clustering, 2005. [Google Scholar]
- Radchenko Peter and Mukherjee Gourab. Convex clustering via ℓ1 fusion penalization. Journal of the Royal Statistical Society, Series B: Statistical Methodology, 79(5):1527–1546, 2017. doi: 10.1111/rssb.12226. [DOI] [Google Scholar]
- Raftery Adrian E and Dean Nema. Variable selection for model-based clustering. Journal of the American Statistical Association, 101(473):168–178, 2006. doi: 10.1198/016214506000000113. [DOI] [Google Scholar]
- Robinson Mark D and Oshlack Alicia. A scaling normalization method for differential expression analysis of RNA-seq data. Genome Biology, 11(3):R25, 2010. doi: 10.1186/gb-2010-11-3-r25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Savage Richard S, Ghahramani Zoubin, Griffin Jim E, Kirk Paul, and Wild David L. Identifying cancer subtypes in glioblastoma by combining genomic, transcriptomic and epigenomic data. ArXiv Pre-Print 1304.3577, 2013. https://arxiv.org/abs/1304.3577. [Google Scholar]
- Shefi Ron and Teboulle Marc. Rate of convergence analysis of decomposition methods based on the proximal method of multipliers for convex minimization. SIAM Journal on Optimization, 24(1):269–297, 2014. doi: 10.1137/130910774. [DOI] [Google Scholar]
- Shen Ronglai, Olshen Adam B, and Ladanyi Marc. Integrative clustering of multiple genomic data types using a joint latent variable model with application to breast and lung cancer subtype analysis. Bioinformatics, 25(22):2906–2912, 2009. doi: 10.1093/bioinformatics/btp543. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen Ronglai, Mo Qianxing, Schultz Nikolaus, Seshan Venkatraman E, Olshen Adam B, Huse Jason, Ladanyi Marc, and Sander Chris. Integrative subtype discovery in glioblastoma using iCluster. PloS ONE, 7(4):e35236, 2012. doi: 10.1371/journal.pone.0035236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shen Ronglai, Wang Sijian, and Mo Qianxing. Sparse integrative clustering of multiple omics data sets. The Annals of Applied Statistics, 7(1):269, 2013. doi: 10.1214/12-AOAS578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Si Yaqing, Liu Peng, Li Pinghua, and Brutnell Thomas P. Model-based clustering for RNA-seq data. Bioinformatics, 30(2):197–205, 2013. doi: 10.1093/bioinformatics/btt632. [DOI] [PubMed] [Google Scholar]
- Simon Noah, Friedman Jerome, and Hastie Trevor. A blockwise descent algorithm for group-penalized multiresponse and multinomial regression. ArXiv Pre-Print 1311.6529, 2013. https://arxiv.org/abs/1311.6529. [Google Scholar]
- Sui Xiaopeng, Xu Li, Qian Xiaoning, and Liu Tie. Convex clustering with metric learning. Pattern Recognition, 81:575–584, 2018. doi: 10.1016/j.patcog.2018.04.019. [DOI] [Google Scholar]
- Sun Defeng, Toh Kim-Chuan, and Yuan Yancheng. Convex clustering: model, theoretical guarantee and efficient algorithm. Journal of Machine Learning Research, 22(9):1–32, 2021. [Google Scholar]
- Sun Wei, Wang Junhui, and Fang Yixin. Regularized k-means clustering of high-dimensional data and its asymptotic consistency. Electronic Journal of Statistics, 6:148–167, 2012. doi: 10.1214/12-EJS668. [DOI] [Google Scholar]
- Tamayo Pablo, Scanfeld Daniel, Ebert Benjamin L, Gillette Michael A, Roberts Charles WM, and Mesirov Jill P. Metagene projection for cross-platform, cross-species characterization of global transcriptional states. Proceedings of the National Academy of Sciences, 104(14): 5959–5964, 2007. doi: 10.1073/pnas.0701068104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tan Kean Ming and Witten Daniela. Statistical properties of convex clustering. Electronic Journal of Statistics, 9(2):2324–2347, 2015. doi: 10.1214/15-EJS1074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tang Tiffany M and Allen Genevera I. Integrated principal components analysis. ArXiv Pre-Print 1810.00832, 2018. https://arxiv.org/abs/1810.00832. [Google Scholar]
- The Cancer Genome Atlas Network. Comprehensive molecular portraits of human breast tumours. Nature, 490(7418):61–70, 2012. doi: 10.1038/nature11412. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Geer Sara, Bühlmann Peter, Zhou Shuheng, et al. The adaptive and the thresholded lasso for potentially misspecified models (and a lower bound for the lasso). Electronic Journal of Statistics, 5:688–749, 2011. [Google Scholar]
- Wang Binhuan, Zhang Yilong, Sun Will Wei, and Fang Yixin. Sparse convex clustering. Journal of Computational and Graphical Statistics, 27(2):393–403, 2018. doi: 10.1080/10618600.2017.1377081. [DOI] [Google Scholar]
- Wang Bo, Mezlini Aziz M, Demir Feyyaz, Fiume Marc, Tu Zhuowen, Brudno Michael, Haibe-Kains Benjamin, and Goldenberg Anna. Similarity network fusion for aggregating data types on a genomic scale. Nature Methods, 11(3):333, 2014. doi: 10.1038/nmeth.2810. [DOI] [PubMed] [Google Scholar]
- Wang Junhui. Consistent selection of the number of clusters via crossvalidation. Biometrika, 97(4):893–904, 2010. doi: 10.1093/biomet/asq061. [DOI] [Google Scholar]
- Wang Qi, Gong Pinghua, Chang Shiyu, Huang Thomas S, and Zhou Jiayu. Robust convex clustering analysis. In Data Mining (ICDM), 2016 IEEE 16th International Conference on, pages 1263–1268. IEEE, 2016. doi: 10.1109/ICDM.2016.0170. [DOI] [Google Scholar]
- Wang Sijian and Zhu Ji. Variable selection for model-based high-dimensional clustering and its application to microarray data. Biometrics, 64(2):440–448, 2008. doi: 10.1111/j.1541-0420.2007.00922.x. [DOI] [PubMed] [Google Scholar]
- Wangchamhan Tanachapong, Chiewchanwattana Sirapat, and Sunat Khamron. Efficient algorithms based on the k-means and Chaotic League Championship Algorithm for numeric, categorical, and mixed-type data clustering. Expert Systems with Applications, 90:146–167, 2017. doi: 10.1016/j.eswa.2017.08.004. [DOI] [Google Scholar]
- Weylandt Michael, Nagorski John, and Allen Genevera I. Dynamic visualization and fast computation for convex clustering via algorithmic regularization. Journal of Computational and Graphical Statistics, 29(1):87–96, 2020. doi: 10.1080/10618600.2019.1629943. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Witten Daniela M and Tibshirani Robert. A framework for feature selection in clustering. Journal of the American Statistical Association, 105(490):713–726, 2010. doi: 10.1198/jasa.2010.tm09415. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu Chong, Kwon Sunghoon, Shen Xiaotong, and Pan Wei. A new algorithm and theory for penalized regression-based clustering. The Journal of Machine Learning Research, 17(1): 6479–6503, 2016. [PMC free article] [PubMed] [Google Scholar]
- Xiang Shuo, Yuan Lei, Fan Wei, Wang Yalin, Thompson Paul M, and Ye Jieping. Multi-source learning with block-wise missing data for Alzheimer’s disease prediction. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 185–193. ACM, 2013. doi: 10.1145/2487575.2487594. [DOI] [Google Scholar]
- Yang Zi and Michailidis George. A non-negative matrix factorization method for detecting modules in heterogeneous omics multi-modal data. Bioinformatics, 32(1):1–8, 2015. doi: 10.1093/bioinformatics/btv544. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu Guan, Li Quefeng, Shen Dinggang, and Liu Yufeng. Optimal sparse linear prediction for block-missing multi-modality data without imputation. Journal of the American Statistical Association, (just-accepted):1–35, 2019. doi: 10.1080/01621459.2019.1632079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yu Yue, Luo Wei, Yang Zheng-Jun, Chi Jiang-Rui, Li Yun-Rui, Ding Yu, Ge Jie, Wang Xin, and Cao Xu-Chen. miR-190 suppresses breast cancer metastasis by regulation of TGF-β-induced epithelial–mesenchymal transition. Molecular Cancer, 17(1):70, 2018. doi: 10.1186/s12943-018-0818-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Shihua, Li Qingjiao, Liu Juan, and Zhou Xianghong Jasmine. A novel computational framework for simultaneous integration of multiple types of genomic data to identify microRNA-gene regulatory modules. Bioinformatics, 27(13):i401–i409, 2011. doi: 10.1093/bioinformatics/btr206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Shihua, Liu Chun-Chi, Li Wenyuan, Shen Hui, Laird Peter W, and Zhou Xianghong Jasmine. Discovery of multi-dimensional modules by integrative analysis of cancer genomic data. Nucleic Acids Research, 40(19):9379–9391, 2012. doi: 10.1093/nar/gks725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou Shuheng, van de Geer Sara, and Bühlmann Peter. Adaptive lasso for high dimensional regression and gaussian graphical modeling. arXiv preprint arXiv:0903.2515, 2009. [Google Scholar]
- Zhu Changbo, Xu Huan, Leng Chenlei, and Yan Shuicheng. Convex optimization procedure for clustering: Theoretical revisit. In Advances in Neural Information Processing Systems, pages 1619–1627, 2014. https://papers.nips.cc/paper/5307-convex-optimization-procedure-for-clustering-theoretical-revisit. [Google Scholar]
- Zou Hui. The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101(476):1418–1429, 2006. doi: 10.1198/016214506000000735. [DOI] [Google Scholar]