

Abstract
We present a mixed-effects location scale model (MELSM) for examining the daily dynamics of affect in dyads. The MELSM includes person and time-varying variables to predict the location, or individual means, and the scale, or within-person variances. It also incorporates a submodel to account for between-person variances. The dyadic specification can accommodate individual and partner effects in both the location and the scale components, and allows random effects for all location and scale parameters. All covariances among the random effects, within and across the location and the scale are also estimated. These covariances offer new insights into the interplay of individual mean structures, intra-individual variability, and the influence of partner effects on such factors. To illustrate the model, we use data from 274 couples who provided daily ratings on their positive and negative emotions toward their relationship – up to 90 consecutive days. The model is fit using Hamiltonian Monte Carlo methods, and includes subsets of predictors in order to demonstrate the flexibility of this approach. We conclude with a discussion on the usefulness and the limitations of the MELSM for dyadic research.
Keywords: Mixed-effects location scale model, dyadic interaction, intra-individual variability, longitudinal data analysis
Introduction
Modeling interactions between two individuals requires methods that are able to capture the dynamics of such interactions, as they unfold over time, and separate these interactions from dynamics that take place within each individual. A number of models have been developed to examine these dynamics (e.g., Kenny, 1996; Raudenbush, Brennan, & Barnett, 1995). We argue that, although some of these methods have very desirable features, an important shortcoming is the fact that all the unexplained variance goes into the residual component. In this paper, we propose a mixed-effects location scale model (MELSM). This model allows partitioning this unexplained variance, which consists of within-person variance over time, and explain it as a function of covariates. The MELSM is particularly well suited to examine the changes (or fluctuations) in a given process for each individual in a dyad, together with the interrelations between both individuals.
Intra-individual variability designs
A key methodological question in investigations of social interactions concerns the study design for yielding information about within- and between-person dynamics. One such design, suited to identify dynamics with a high temporal resolution, is based on intra-individual variability (IIV). In this design, individuals are measured across multiple variables and multiple occasions with short intervals, such as weekly, daily or hourly measurements, allowing researchers to study processes, as they unfold over time (e.g., Ferrer & Rast, 2017). Depending on particular features, these studies go by names such as Ecological Momentary Assessments (EMA; Shiffman, Stone, & Hufford, 2008) or experience sampling and daily diary studies (Bolger, Davis, & Rafaeli, 2003). These intensive measurements may be combined across multiple waves spanning years to obtain intensive measurement bursts allowing for the investigation of within- and between-person dynamics that span across different time scales (Nesselroade, 1991b; Sliwinski, 2008). Generally, short time intervals among measurement occasions in intra-individual variability designs are well suited to capture behavioral fluctuations or variation within persons and/or partners.
The focus on these designs is largely on day-to-day variability, which is typically referred to as within-person or intra-individual variability. The main assumption of IIV is that such variability does not merely reflect measurement error, but that it conveys systematic information that is potentially important and that would go otherwise unaccounted for (Cattell, Cattell, & Rhymer, 1947; Eizenman, Nesselroade, Featherman, & Rowe, 1997; Fiske & Rice, 1955; Horn, 1972; Hultsch, Hertzog, Small, McDonald-Miszczak, & Dixon, 1992; Nesselroade & Salthouse, 2004; Woodrow, 1932). IIV is commonly used to describe the amount of reversible, short-term behavioral fluctuations that are observed over time (Ram & Gerstorf, 2009). Fluctuations can also occur across situations and are often interpreted as carrying information about short-term adaptive processes, regulative mechanisms and the system’s vulnerability (Baltes, Reese, & Nesselroade, 1977; Nesselroade, 1991a; Röcke & Brose, 2013).
Most importantly, it is assumed that IIV reflects another quality of behavioral outcomes such as consistency or precision in responses, compared to individual levels, that are thought to provide information on average effects. Hence, with the availability of intensive data, the focus of the interaction among individuals can be widened to include dynamics of within-person variability in the sense that not only average effects may be influenced by the partner but also variability in one’s behavior may be related to, and interact with, a partner’s traits.
Models for dyadic interactions
There have been important advances in the development of methodology suited to model dynamics in social interactions, including dyads. Some of these models include, for example, the Actor-Partner Interdependence Model (Kenny, 1996) or the “Two-Intercept” multilevel model (Raudenbush et al., 1995), which incorporates individual and partner effects over time. While there are many ways to model data from intensive repeated designs, multilevel, or mixed-effects, modeling techniques are probably the most common choice, perhaps due to the fact that they take into account clustering in the data (repeated measures nested within individuals, nested within dyads) and partition the variance accordingly. Specifically, in research on dyads, multilevel models have been successfully used to distinguish among actor, partner, and interaction effects (Campbell & Kashy, 2002; Kenny, Kashy, & Cook, 2006), investigate the quality of marital roles in married couples (Raudenbush et al., 1995), characterize the interrelations of affect between romantic partners (Butner, Diamond, & Hicks, 2007), model daily intimacy and disclosure in married couples (Bolger & Laurenceau, 2013; Laurenceau, Troy, & Carver, 2005), and capture emotional contagion between couple members undergoing a stressful event (Thompson & Bolger, 1999).
Besides multilevel models, a number of other methods have been developed and implemented as well. One of such models is, for example, the dynamic factor analysis (DFA; Browne & Nesselroade, 2005; Molenaar, 1985), which combines factor analysis with time series and allows the identification of the factorial structure of the data as well as its time-related signature (Ferrer & Nesselroade, 2003; Ferrer & Zhang, 2009). Another method that has been applied to intensive measurement data is differential equation models (DEM) which are useful for modeling continuous data. In dyadic interactions, DEM have been used to develop theoretical models (Felmlee, 2006; Felmlee & Greenberg, 1999) but they have also proven useful for modeling empirical data on the emotional interaction between spouses and subsequent break-up (Gottman, 2002), daily intimacy and disclosure in married couples (Boker & Laurenceau, 2006), and the dynamics of emotional experiences between individuals in close relationships (Chow, Ferrer, & Nesselroade, 2007; Ferrer, Gonzales, & Steele, 2013; Ferrer & Steele, 2014; Ferrer, Steele, & Hsieh, 2012; Steele, Ferrer, & Nesselroade, 2014).
Another class of models that are well suited to capture the dynamics of change in the variance components are generalized autoregressive conditional heteroscedasticity (GARCH) models (Bollerslev, 1986). These models are popular in the econometric literature and are used to predict the mean and variance (volatility) in a time-series, conditional on past information. The typical GARCH model assumes that the current variance is the sum of an average variance, the lagged (e.g., t − 1, with t = 1, …T) variance, and the lagged error variance. The multivariate extension (MGARCH; Engle, 2002) includes a time-varying covariance matrix Ht that includes the covariances among the GARCH parameters for each time series. The covariance is allowed to change across time which makes the estimation of the Ht matrix challenging (Laurent, Rombouts, & Violante, 2012; Tse & Tsui, 2002). While MGARCH models have proven to be useful in economics settings with only few simultaneous time-series, their application in psychological research with multiple individual time-series remains limited. The research in psychology typically involves multiple individuals and, thus, each individual time series would have to enter the MGARCH covariance matrix. The dimension of H would expand to N × N × T, making it extremely difficult to estimate in the context of most psychological applications, even for small N (de Almeida, Hotta, & Ruiz, 2018).
In this paper, we focus on mixed-effects models because of their desirable features for extracting information about variability. Specifically, mixed-effects models partition the overall variance into between- and within-person variance. The within-person component represents the residual variance that remains unexplained at the individual level while controlling for all predictors at the person level. In research on IIV, this “unexplained” part is the very focus of interest, the target of exploration in further modeling steps (e.g., Hultsch, Strauss, Hunter, & MacDonald, 2008). To date, probably the most common index of IIV is the intra-individual standard deviation (iSD; see e.g., Ram & Gerstorf, 2009), which can be computed from the residuals of a mixed effects model or individual models, or from observed scores. As such, the investigation of IIV is often treated as a two-stage approach: In the first stage, IIV is extracted to compute some form of person-specific variability index, such as the iSD. In the second stage, the IIV index is then used in a model either as a predictor or as the outcome. While this approach has been widely adopted to extract within-person information, it is not without controversy. IIV indices can lead to estimates that are highly correlated with other within-person moments, such as the intra-individual mean, especially when Gaussian normality is violated (Mestdagh et al., n.d.; Rast, Hofer, & Sparks, 2012; Wang, Hamaker, & Bergeman, 2012). Moreover, IIV indices or estimates tend to be unreliable especially when the number of measurement occasions is small (Estabrook, Grimm, & Bowles, 2012; Wang & Grimm, 2012).
The model that we present here to examine IIV in dyads is the mixed-effects location scale model (MELSM; Hedeker, Mermelstein, & Demirtas, 2008), an extension of the standard multilevel model. This model is particularly well suited to examine changes (or fluctuations) in a given process for individuals in dyadic relationships. The model expands the focus from the “classic” actor-partner interrelation on location effects (individual means) to include dyadic interactions on the IIV, the scale effects. As outlined earlier, the investigation of IIV and dynamics in partner relationships is strongly tied to the design, which must entail some form of intensive repeated measurements.
A distinguishing feature of the MELSM with respect to multi-stage models, is that the MELSM does not rely on multiple steps but rather estimates intraindividual means (iM) and iSD’s simultaneously in one model. By estimating these two components simultaneously, we are able to account for possible correlations that arise among iM’s and iSD’s, which ensures that we can make valid inferences about our parameter estimates (Verbeke & Davidian, 2009). The MELSM jointly models location and scale random effects by keeping them in one covariance matrix – as with any covariance matrix, its individual values are conditional on the other values. Multi-stage approaches, on the other hand, do not jointly model the covariances among its location and scale parameters. This makes the covariances oblivious to the correlations among its parameters. As a result, they only provide unbiased estimates for the rare case when location and scale are indeed completely uncorrelated (for a simulation, see e.g., Leckie, French, Charlton, Browne, & Langford, 2014). Moreover, the MELSM includes explanatory components for the between- and within-person variance, which circumvents the need for multiple modeling steps to capture IIV (see also Leckie et al., 2014; Rast et al., 2012). That is, while standard mixed-effect models relegate all the unexplained variance into the residual term, the MELSM allows partitioning the within-person variance over time and modeling it as a function of time-varying as well as person-level covariates. This is a particularly important feature because such within-person variance can be examined in relation to variables external to the system. For example, a researcher interested in, say, emotion in romantic couples, will want to use variables related to emotion to predict the stability or volatility in emotions. But, in addition, there might be variables external to the modeled system (e.g., work, daily stressors, weather) that could potentially explain part of the emotional ups and downs that are not accounted for by the main components of the model (Ferrer & Rast, 2017).
The aim of this paper is to extend the MELSM to accommodate data from two individuals who are part of a dyadic system (e.g., romantic couple, teacher-student). The remainder of the manuscript is organized as follows. First, we formally describe the general MELSM for dyads (or other dyadic system). Second, we provide an example involving empirical data from daily fluctuations in emotion from romantic couples. Third, we discuss the findings in the context of dyadic interactions and list shortcomings and possible extensions of the MELSM model.
A mixed-effects location scale model (MELSM) for dyads
The mixed effects location scale model (MELSM) put forward by Hedeker et al. (2008), combines earlier work on variance heterogeneity (Aitkin, 1987) and models for random scale effects (Cleveland, Denby, & Liu, 2002). Here, we briefly recast the model and then we expand it to accommodate cases with dyadic interactions involving partner and individual predictors. The starting point is the standard linear mixed effects model with repeated measurement on occasions j (j = 1, 2, …, ni occasions) that may be specified as
| (1) |
where yi is the ni × 1 response vector for observations in person i. Xi is the ni × k design matrix for the fixed effects for observations in person i. β captures the fixed effects and its dimension is k × 1. The random effects are in the ni × q matrix Zi for observations in person i where bi is the according q × 1 vector with the random effects coefficients. These effects characterize a person’s mean response or location. ϵi is a vector of errors specific to person i. The general assumption in standard mixed effects models is that random effects are bi ~ N(0, Φ). Where Φ is a q × q covariance matrix for the random effects with the variances and the covariances σbb′ (for q ≠ q′). The errors ϵi are also assumed to be normally distributed with a mean of 0 and covariance of where Ψi is a ni × ni matrix which can take different structures. In these models the between-person variance is captured by and the within-person variance is represented in .
Within-person variance
In this standard form, the error variance is a fixed entity. In order to allow it to differ at the individual level, we add the subscript i to the within-person variance term (cf. Hoffman, 2007; Myles, Price, Hunter, Day, & Duffy, 2003) but we also allow it to differ among j-time points to obtain . Changes in the within-person variance are explained by time-varying covariates in the ni × m matrix Wi for the fixed effects and Vi, with dimension ni × p (and m ≥ p) for the random effects (Rast et al., 2012). Hence, with the inclusion of time-varying covariates the within-person variance not only varies across persons but also across time given the model:
| (2) |
φi then is the ni × 1 vector that contains all error variances for individuals i and for each measurement occasion j. η is comparable to the regression weights β in Equation (1). That is, for an intercept and slope term, η0 defines the average within-person variance and η1 weights the influence of the predictor on the variance. The individual departures from the fixed effects that are captured in the random effects ti are normally distributed with ti ~ N(0, Θ), where Θ is a covariance matrix dimension p × p that contains the random effects of the scale. Note that Wi and Vi may, or may not, be the same as Xi and Zi. In fact, the model that we will discuss here contains different predictors for the location and the scale. Given that Equation (2) is for variances, we need to ascertain that the estimates are positive real values. This can be obtained, for example, via the exponential function (e.g., Hedeker et al., 2008; Rast et al., 2012). Note that by doing so, we assume that is log-normally distributed.
Between-person variance
The MELSM also introduces a submodel for the between-person variance. It is important to note here that we now have random effects bi from the location of the model (the means structure) and random effects ti from the scale of the model (the within-person variance structure). All these random effects are assumed to come from a Gaussian Normal distribution with mean zero. Hence, we can stack both bi and ti vectors, resulting in ui ~ N(0, Σi). This also means that Σi contains the variances and covariances of both, the location and scale. In order to define a variance model for Σi, we can decompose , where τi is a diagonal matrix for person i in which the diagonal elements are the random-effect standard deviations and Ω is the correlation matrix that contains the correlations among all random effects. That is, Ω is of dimension (q + p) × (q + p) and contains the correlations among the random effects of the location, the correlations among the random effects of the scale, and the correlations among the random effects of the location and the scale. Given this definition, Ω remains constant across conditions. We can now define a model for the random effects, which, in SD metric, can be defined as
| (3) |
where, for example, ι0 is an intercept and ι1 is a slope parameter. gi is the design matrix that contains between-person predictors. This means that the random-effects variance is not constant but may change due to person- or group-specific characteristics (e.g., Leckie et al., 2014).
Hence, having specified all elements, we can define the full MELSM as
with the random effects for both the location and the scale coming from the same multivariate distribution
Dyadic effects
In order to account for the interrelationship of the dyad members, we introduce dummy variables to address each of the two partners of the couple (cf. Ferrer & Rast, 2017; Raudenbush et al., 1995). In particular, we introduce a dyad-specific level k at both the location and scale part. The mean structure from Equation (1) can be expanded to
| (4) |
where, k = 1, …, m represents the number of units in the level (two in our case). Hence, in this specification for dyads, we define m = 2 dummy variables, one for each partner, where dk = 1 if a given measure is yk and dk = 0 otherwise. Considering a given value in , then dk = 1 if k = k* and dk = 0 if k ≠ k*. The elements in dk are mutually exclusive and ensure that the model is estimated either for one or the other partner in the dyad. The same approach can be used for the scale part, so Equation (2) can be rewritten as
| (5) |
In order to model within-dyad dependencies, the design matrices X and W typically contain variables that are thought to influence the other partner’s outcome. For example, the same-day positive affect of partner A might influence partner’s B positive affect for that same day – and vice versa.
Again, the within-person variances are estimated for both partners and are mutually exclusive. This approach does not preclude one from obtaining covariances among random effects of both partners, as they are still drawn from a common multivariate distribution. This enables one to model the correlations among the individuals in the dyads, within and across the location and the scale part of the model. This constitutes a unique feature of the MELSM for dyads.
Estimation
Mixed-effects location scale models can be estimated via maximum-likelihood methods in standard software (Ferrer & Rast, 2017; Hedeker, Mermelstein, Berbaum, & Campbell, 2009; Leckie et al., 2014), using specific software such as MIXREGLS (Hedeker & Nordgren, 2013), or Bayesian estimation procedures (Kapur, Li, Blood, & Hedeker, 2015; Rast et al., 2012). To minimize estimation issues when relying on maximum-likelihood techniques, we take advantage of a Bayesian framework that performs better with covariance matrices (such as Σ) that are prone to high collinearity and multidimensionality (cf. Rast et al., 2012; Rast & MacDonald, 2014). No-U-turn sampling (NUTS), an extension of the Hamiltonian Monte Carlo (HMC) Sampler, is particularly well suited to handle these situations (Hoffman & Gelman, 2014). This method is implemented in Stan (Stan Development Team, 2016b) and it has the added advantage, compared to Gibbs-sampling that the priors do not need to be conjugate to the likelihood of parameters.
Illustrative example
Subjects and procedure
The data for this empirical example come from 274 heterosexual couples that were recruited as part of a study of dyadic interactions (Ferrer et al., 2012; Ferrer & Widaman, 2008). Participants included couples involved in a romantic relationship who completed a daily questionnaire about their affect for up to 90 consecutive days. They ranged in age from 17 to 74 years (M = 25.08, SD = 10.39) and reported having been in the relationship from 1 month to 54 years (M = 3.26 years, SD = 6.06).
Materials and design
To obtain daily measures of affect, we used the Relationship-Specific Affect scale (RSA; Ferrer et al., 2012), a set of 18 Likert-scale items (ranging from 1 to 5) that tapped into positive and negative emotions specific to one’s relationship. In this example, positive affect (PA) serves as the dependent variable and negative affect (NA) as a predictor for within-person variance. In addition, we use a measure of relationship satisfaction based on six items from the Perceived Relationship Quality Component Inventory (Fletcher, Simpson, & Thomas, 2000). These items were rated on a 7-point Likert scale ranging from 1 (not at all) to 7 (extremely) and were completed by the participants at the beginning of the study.
Statistical analyses
We tested a sequence of increasingly more complex models, starting from an empty linear mixed effects model to the final mixed effects location scale model with all predictors.1 Here, we describe the final model that was used to obtain the parameter estimates reported in the results section. In order to make the structure of the model more visible, we rewrite Equations (4) and (5) following multilevel notation.
Location model
The location submodel of positive affect RSA (PA) for each person i at day j is given at level 1 as:
| (6) |
The predictors in level 1 of the location are each person’s own PA rating of the previous day (PALag1) as well as the partner’s PA rating (PAPartner) at the same day. Both level 1 predictors PALag1 and PAPartner are person-mean centered.
The person effects are defined at level 2 separately for both partners. For females
and for males
At level 2, we introduce the moderator Rel.satki (individual relationship satisfaction), which was measured at the beginning of the study. This variable was centered at its grand-mean (M = 6.2). is the person-mean that was obtained when centering the corresponding level 1 variable PAPartner,ij and it captures between-person differences in individual levels of partner affect. The person-mean for the lagged effect is practically identical to the random intercept and is thus not included as a level 2 variable (Hamaker & Grasman, 2015). The F and M subscripts denote the model for females (F) and males (M).
Scale model
Equivalently, the scale part of the model follows Equation (5) with level 1:
| (7) |
The predictor for the scale is the person-mean centered negative affect of the partner (NAPartner) for the same day. Negative affect has been shown to influence affect, both positive and negative (e.g., Röcke, Li, & Smith, 2009) and here we test its effect on the scale parameter. It is worthwhile reconsidering what predictions from Equation (5) signify in terms of observed values. For days where the partner reports higher NA, will result in larger (or smaller, depending on the valence) values resulting in more (or less) variance around the location parameter for that same day. In other words, NAPartner influences the daily changes in uncertainty or unreliability that surround the location estimate.
Level 2 is defined for the female as
and for the male
At level 2, we have again Rel.satki, the grand mean centered relationship satisfaction that moderates the level 1 effects in the within-person variance, and , the person-mean of NAPartner,ij.
Random effects variance model
All level 1 parameters (location intercept, PALag1 slope, PAPartner slope, scale intercept and NAPartner slope) for both female and male, have associated random effects that allow individual departures from the individual (male or female) mean. As described earlier, this is true for both the location and scale components, and all random effects are assumed ui ~ N(0, Σi). Σi contains the variances of the random effects of the location and the scale as well as all covariances. Hence, the off-diagonal elements of Σi contain information on how individual differences are related both within individuals and within dyads. That is, we obtain relations within and between females and males but also across the location and the scale components. As noted earlier, this is a unique feature of the MELSM as it not only models dependencies among partners via level 2 predictors but it also identifies the relatedness within dyads as correlated random effects throughout the location and the scale.
As described in Equation (3) we also include a between-person model to govern the random effects standard deviations across different conditions. We re-expressed Σi as , where Ω is a (q + p) × (q + p) correlation matrix and τi are the SD’s. The final model contains three location random effects for each partner (Female: , , ; Male: , , ) resulting in q = 6 random effect variances and two scale random effects for each partner (Female: , ; Male: , ), resulting in p = 4 variances for the scale. Hence, the dimension of the final covariance matrix Σi is 10 × 10 with the diagonal . Note that only the scale elements have a subscript i, indicating that they are allowed to vary between participants.
In order to capture changes in the scale random effects only, we introduce a submodel for the four elements , where g1 = log(years in the relationship) influences the random effect SD of the scale as
| (8) |
The first two lines in Equation (8) refer to the random effects SDs of the females and the last two lines refer to the SD’s of males. The ιkp0’s (e.g. ιF30) are the intercepts that define the average random effect SD of the scale for partners who were, on average, one year in their relationship (note that years in relationship was on the log scale where log(1) = 0). The ιkp1’s (e.g., ιF31) capture the change in the average random effects variance given the relationship length, resulting in possibly different random effect variances for the scale component of the model. That is, individual differences in the scale random effects are not constant but are allowed to vary across individuals as a function of differences in relationship length.
A note on centering
Once we include time-varying predictors, we need to decide on how they should enter the model. There are mainly three options on how we can include these variables: uncentered, grand-mean centered, and person-mean centered (Wang & Maxwell, 2015). Uncentered predictors that are included at level 1 can be conceptualized as carrying two kinds of information. An average, between-person part for each individual, and a within-person fluctuation around that average. In the logic of multilevel models, we can separate these two sources of variation and place them in the corresponding levels: level 1 for the within-person fluctuation and level 2 for the between person effect. As such, uncentered variables confound within- and between-person effects and potentially bias the results (Curran, Lee, Howard, Lane, & MacCallum, 2012; Raudenbush & Bryk, 2002). This issue cannot be resolved by grand-mean centering level 1 variables, as the within-person effect remains confounded with the between-person differences, and hence, only within-person centering can resolve this issue. A viable approach is to extract the person-mean from time-varying predictors and introduce it as a level 2 predictor while the centered within-person time-varying effects enter the model as a level 1 predictor (for a discussion on different versions of centering and detrending, see Curran & Bauer, 2011).
In the case of autoregressive effects, the decision on whether or not to center is less clear. For example, Hamaker and Grasman (2015) noted that person-mean centering autoregressive effects can downward bias the within-person slope of the lagged parameter while no centering does not lead to bias in the level 1 parameter. However, once level 2 predictors are added, the person-mean centered autoregressive parameters fares better than the noncentered. For the current application, we chose to person-mean center all time-varying level 1 predictors, including the autoregressive predictors.
Software, estimation and prior specification
All models were fitted in Stan with the NUTS algorithm using the RStan package (Stan Development Team, 2016a), with four chains and a warm-up period of half the total chain length. To ensure good quality of the parameter estimates, we chose to keep the number of iterations at a level where the models converged with potential scale reduction factors smaller than 1.1 (cf. Gelman, 2006). As measures of relative model fit, we report the deviance and the Pareto smoothed importance sampling-Leave-one-out cross-validation (PSIS-LOO; Vehtari, Gelman, & Gabry, 2017) with the corresponding standard errors. PSIS-LOO is a fully Bayesian approach to assess predictive accuracy of the converged model and it is asymptotically equivalent to the widely applicable information criterion (WAIC; Watanabe, 2010) which is, in turn, asymptotically equivalent to the Akaike information criterion (Akaike, 1973). Further, we report 95% credible intervals (C.I.) to indicate the statistical relevance of the parameters. If a given point estimate (e.g., zero) is included in the C.I., the estimate may not be considered to be different from zero or a null-effect – and vice-versa, if the point estimate is not within the reach of the C.I. we conclude that the parameter is relevant. Models were compared on their respective differences in the values of PSIS-LOO and standard errors are reported as units of reference. We report a sequence of comparisons starting with a standard mixed effects model and ending with the final MELSM (cf. Table 1). PSIS-LOO or WAIC can be used to select among (nested or nonnested) models with respect to their predictive performance as long as few models are compared. As the number of compared models increases, the estimated predictive performance becomes increasingly biased (Gelman et al., 2013; Piironen & Vehtari, 2017). Approaches for variable selection are described elsewhere in the literature (e.g., O’Hara & Sillanpää, 2009).
Table 1.
Sequence of estimated models and fit statistics.
| Model | Deviance | PSIS-LOO (S.E.) | Difference in PSIS-LOO (S.E) |
|---|---|---|---|
| Mixed Model | 36205.3 | −18102.7 (169.3) | – |
| MELSM 1 | 33544.8 | −16772.4 (165.5) | 1330.3 (116.3) |
| MELSM 2 | 30416.9 | −15208.5 (157.8) | 1563.9 (81.8) |
| MELSM 3 | 30436.3 | −15218.1 (158.0) | −9.7 (3.2) |
Note. The difference in the PSIS-LOO is always with respect to the previous model reported in the row above. The first reference model (Mixed Model) is a standard linear mixed effects model with all predictors in the location part and different error variances for females and males. MELSM 1 extends the mixed model with random intercepts in the scale part for females and males. MELSM 2 introduces the partners same-day NA rating in the scale. MELSM 3 is the final model with the additional between-person submodel.
Given the complexity of the models, we first started with a mixed effects model with all location predictors (Rel.sat and ), then added random intercepts for females and males in the scale (uF3i and uM3i) to obtain MELSM 1. MELSM 2 was obtained by adding the remaining predictors in the scale (Rel.sat and ). Finally, we added the submodel for the random effects variance of the scale [see Equation (8)] to obtain MELSM 3.
The likelihood for the MELSMs was specified as
MELSM 1 and 2 were given the same weakly informative priors
Regardless of their sample mean and variance, the priors for the location and scale parameters in the MELSM were set to cover a parameter space that was considerably larger than the admissible parameter space in the observed data. For example, given the range of the PA scale, we know that the intercept can only lie between 1 and 5. Our prior was defined to have mean of zero and a SD of 100, as such, this approach regularizes the parameters only mildly and the data easily overwhelm the prior.
For the covariance matrix Σ, we followed standard recommendations (Barnard, McCulloch, & Meng, 2000) and modeled it in terms of its corresponding correlation matrix Ω (Σ = τΩτ′). Hence, instead of specifying a (scaled) inverse-Wishart as prior for the random effects (cf. Rast et al., 2012), we use the Lewandowski-Kurowicka-Joe (LKJ; Lewandowski, Kurowicka, & Joe, 2009) correlation prior with shape ν ≥ 1, Ω ~ LKJcorr(ν). ν governs the correlation among the parameters, and with ν = 1, the LKJ correlation distribution can be considered uninformative. This approach adds the benefit of reducing issues that arise from the Wishart distribution that biases posteriors either toward the variance or the covariances (Gelman, 2006). Note that there are several alternative approaches to parameterize the covariance matrix. For example, Kapur et al. (2015) successfully used the spherical parameterization (as discussed in Barnard et al., 2000) to assign weak priors to the elements of the correlation matrix in a simulation study on a multivariate MELSM. The SDs of the random effects were assumed to come from a heavy tailed half-Cauchy (HC+) distribution with location 0 and scale 2.
For the final MELSM 3, we re-specified the priors for the random effects.
Notably, the HC+ prior was replaced by a log-normal distribution for the parameters in the random effects SD’s submodel (τi = exp(giι)). The priors for ι were defined separately for the location (ι1, …ι7) and the scale elements (ι8, …ι10). Although they are set to be the same here, one could define different priors for the location and the scale elements. Overall, the priors for the final model were more informative to increase regularization and reduce computation time. For example, the prior for ι which defines the random effects SD was set to −1.5 with a SD of 3 on the log-scale. The mode of this prior is at exp(−1.5) = 0.2 SDs and it puts 95% of the probability mass between exp(−1.5±2 × 3) = [0.0006, 90.02] SDs – which is still largely unspecific. The location and scale parameters were not expected to change substantially from MELSM 2 to MELSM 3. Hence, the priors were informed by the previous model; the prior means were close to the posterior means of MELSM 2 and the SDs of 0.5 were more narrow. This approach mainly reduced the computation time to 15 h in 3000 iterations while hardly influencing the posterior estimates, compared to an earlier model with less informed priors that took almost the double amount of time with 5000 iterations to converge.
Results
We investigated a sequence of models, starting with a standard linear mixed-effects model, as described in Equation (1), and ending with the final MELSM described in Equations (4), (5) and (8). This sequence allowed us to verify the plausibility of results and model fit. All PSIS-LOO and deviance values as well as their increment in model fit are reported in Table 1. A positive difference denotes an increment in model fit while a negative difference indicates a decrement in fit. Note that PSIS-LOO from MELSM 3 indicates a somewhat poorer fit compared to MELSM 2 but we decided to report this model to illustrate the use of the between-subject variance submodel defined in Equation (3).
The final model was fit using four chains and 3000 iterations, with 1500 warm-up iterations. The values in the priors were all chosen to be mildly informative and the range of the parameter space was inferred from previous models in the sequence. ν, the LKJ prior for the correlation matrix of random effects Ω, was set to ν = 1.5 to reflect our assumption that we would see correlations among the random effects. The final model converged after 15 h on a Linux operated system with an IntelCore i7 at 3.4 GHz, with four cores (8 threads) and 16 GiB RAM.
Fixed location
The results for the full location and scale parameters, for both females and males, are reported in Table 2. All fixed location parameters are interpretable as in any standard mixed-effects model. The overall pattern and effect sizes of the parameter estimates for both female and male were very similar. All main effects were relevant (more than 99.2% of the posterior probability mass was above a parameter value of zero) and contributed to changes in their reported PA. While the males reported, on average, higher PA (compared via the posterior density of the difference between males and females; Kruschke, 2013), all other effects were very similar in size across both genders. Given that all predictors were grand-mean and person-mean centered, the intercept represents the average PA rating across the study. The level 2 predictors, overall relationship satisfaction (Rel.sat.) and the average partner PA rating () were positively linked to the average PA of the respondent. That is, the average respondent’s PA was higher for those who reported higher than average satisfaction with their relationship and for those who’s partners also reported higher than average PA. The time-varying level 1 predictors, the lagged PA rating (PALag1) and the daily changes in the partners PA (PAPartner.pc) were also positively related to the daily PA reports. Hence, the mood from the previous day carried forward to the next day, and the daily partner’s changes in PA affected the respondents’ same day PA in the same direction. The interaction term between the average partner’s PA and the daily changes in the partner’s PA () was positive, indicating that the effect of the daily partner’s changes in PA was amplified (reduced) for partners who reported on average higher (lower) PA. Figure 1 shows individual predictions for PA as a function of changes in partner’s PA ratings (while keeping the PALag1 effect constant at the person average, panel a) and lagged PA response (while keeping the PAPartner effect constant at the person average, panel b). Both panels show an obvious positive effect on PA.
Table 2.
Fixed effects from a mixed effects location scale model for positive affect.
| Female | Male | |||||
|---|---|---|---|---|---|---|
| Parameters | Mean | 2.5% | 97.5% | Mean | 2.5% | 97.5% |
| Fixed location | ||||||
| Intercept (γk00) | 3.45 | 3.39 | 3.51 | 3.55 | 3.50 | 3.61 |
| Rel.sat. (γk01) | 0.30 | 0.21 | 0.38 | 0.24 | 0.15 | 0.33 |
| 0.55 | 0.46 | 0.64 | 0.48 | 0.39 | 0.57 | |
| PALag1 (γk10) | 0.24 | 0.21 | 0.26 | 0.26 | 0.23 | 0.28 |
| PALag1 × Rel.sat. (γk11) | −0.03 | −0.07 | 0.01 | −0.01 | −0.05 | 0.03 |
| −0.03 | −0.07 | 0.02 | −0.03 | −0.08 | 0.01 | |
| PAPartner.pc (γk20) | 0.36 | 0.32 | 0.39 | 0.30 | 0.26 | 0.33 |
| PAPartner.pc × Rel.sat. (γk21) | 0.04 | −0.01 | 0.09 | 0.05 | −0.00 | 0.10 |
| 0.06 | 0.00 | 0.12 | 0.06 | 0.00 | 0.11 | |
| Fixed scale | ||||||
| Intercept (ξk00) | −0.83 | −0.87 | −0.78 | −0.91 | −0.95 | −0.87 |
| Rel.sat. (ξk01) | −0.08 | −0.14 | −0.02 | −0.06 | −0.12 | −0.00 |
| 0.18 | 0.07 | 0.29 | 0.28 | 0.16 | 0.39 | |
| NAPartner.pc (ξk10) | 0.20 | 0.15 | 0.26 | 0.19 | 0.15 | 0.24 |
| NAPartner.pc × Rel.sat. (ξk11) | 0.10 | 0.04 | 0.16 | 0.08 | 0.02 | 0.14 |
| −0.27 | −0.39 | −0.15 | −0.16 | −0.27 | −0.05 | |
Note. All estimates are posterior means. The 2.5 and 97.5% represent the boundary of the lower and upper credible intervals (CI). Bolded estimates represent means where the according CI’s exclude 0. Fixed Scale estimates are the SD’s of the random effects on the log scale. Rel.sat. is relationship satisfaction, is the time-invariant partner’s person-mean PA (NA), PA(NA)Partner.pc is the partner’s daily person-mean-centered PA (NA), and PALag1 is the person-mean-centered previous day PA.
Figure 1.
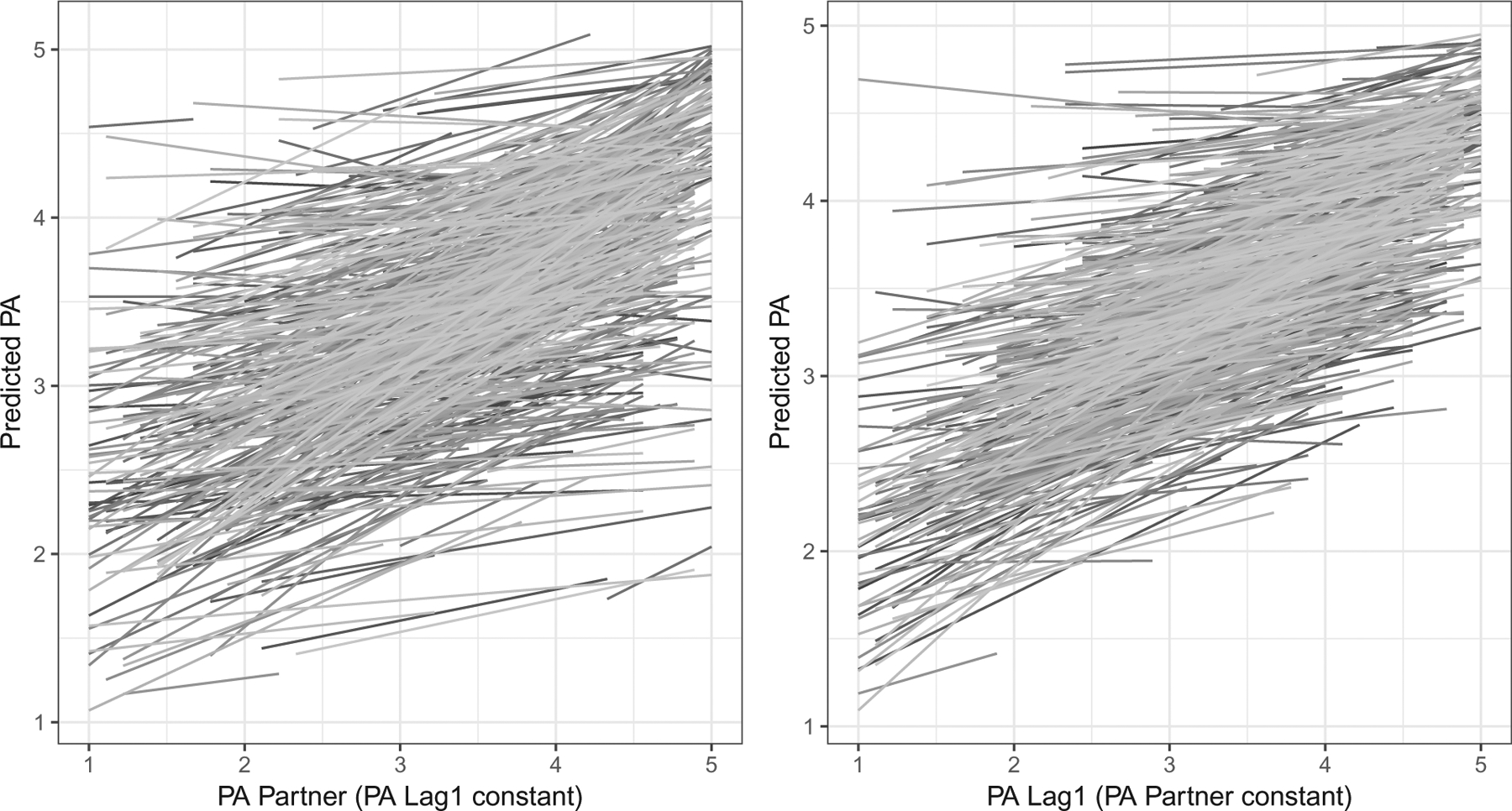
Predicted slopes of positive affect versus PA Lag 1 (PA partner) holding the PA partner (PA Lag 1) effects constant at the person-level. Each line represents the predicted line for an individual.
Fixed scale
The effects for the fixed scale are reported on the log-metric. In order to obtain the average within-person SDs, the parameters need be exponentiated (e.g., exp(−.83) = 0.44). All predictors (Rel.sat., , and NAPartner.pc) contributed to changes in the average within-person SD. The time-invariant level 2 predictors had opposite effects on the average within-person variance. The association from relationship satisfaction was negative so, on average, higher satisfaction ratings were associated with smaller within-person SDs. That is, the PA ratings tended to be more stable over time for participants with higher relationship satisfaction, whereas the PA ratings from participants with lower relationship satisfaction, on average, tended to fluctuate more. These effects were similar in size for both genders, except for the intercept which was considerably smaller for the males (more than 99.7% of the posterior probability mass for the difference between males and females was below zero). In turn, average partner NA influenced the variance positively, indicating that the overall within-person variance was higher for those respondents whose partners, on average, reported higher NA.
At level 1, there was only one time-varying predictor (NAPartner.pc). The partner’s daily changes in NA ratings had a positive effect on the within-person SDs. That is, on days when the partner reported higher than average NA, variability increased, whereas on days when NA was lower than average, variability decreased. This relation is depicted in Figure 2, where partner’s NA ratings are related to larger within-person SDs. The positive interaction between daily fluctuations in partner’s NA and relationship satisfaction (NAPartner.pc × Rel.sat.) suggests that increased relationship satisfaction amplifies the effect of daily fluctuations in the partner’s NA on the within-person variance. That is, those who were more satisfied with their relationship also reacted more strongly to changes in their partner’s NA and vice versa. The interaction between the partners daily changes with their average NA rating () was negative and thus larger average partner NA attenuated the effect of the daily changes in the partners NA on the respondents within-person variance.
Figure 2.
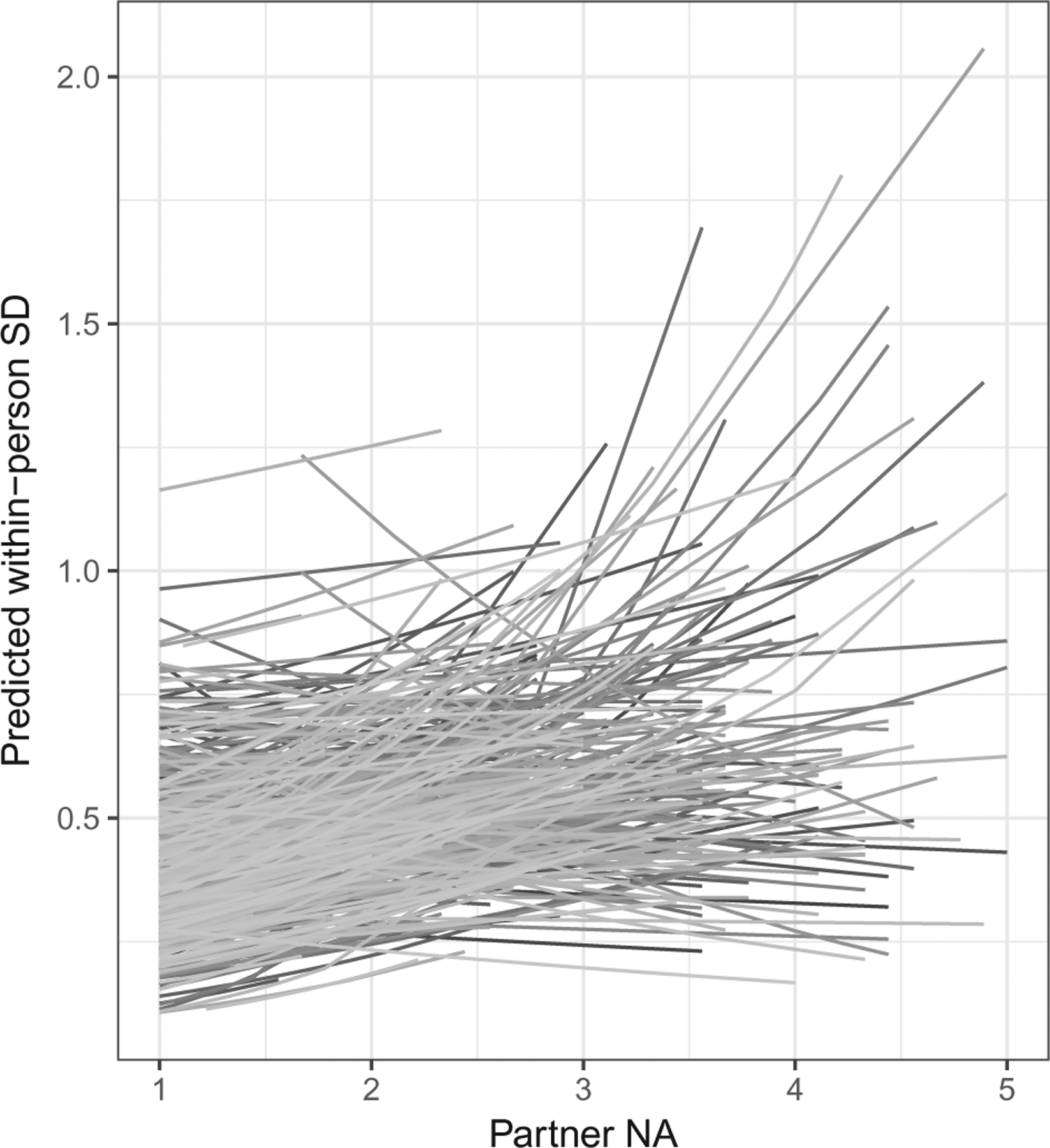
Predicted within-person SD’s for each individual with respect to different Partner NA ratings. Overall, increasing Partner NA ratings result in higher within-person variability. The individual lines indicate large heterogeneity among individuals in terms of reactivity to NA ratings of the partner.
Random effects
From Figures 1 and 2 it is apparent that there were considerable amounts of individual differences around the fixed effects in both the scale and the location components. These individual differences are captured by the random effects reported in the diagonal of Table 3. The first three diagonal elements (τLF1, τLF2, τLF3) are the random effects for the intercept, the PALag1 and the PAPartner.pc of the location component, for the females. The following three elements (τLM1, τLM2, τLM3) are the same parameters for the males. Note that all three parameters showed large variation across individuals, for both females and males.
Table 3.
Random effects and correlations within and across location and scale for positive affect.
| Parameter | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1. τLF1 | 0.22 | [−0.24,0.01] | [−0.19,0.06] | [−0.61,0.43] | [−0.55,0.44] | [−0.52,0.39] | [−0.38,−0.17] | [0.23,0.54] | [−0.51,0.53] | [−0.57,0.43] |
| 2. τLF2 | −0.10 | 0.03 | [−0.50,−0.25] | [−0.52,0.42] | [−0.52,0.47] | [−0.50,0.41] | [−0.06,0.21] | [−0.42,−0.06] | [−0.53,0.41] | [−0.56,0.43] |
| 3. τLF3 | −0.05 | −0.36 | 0.07 | [−0.57,0.48] | [−0.58,0.36] | [−0.56,0.42] | [−0.01,0.24] | [−0.13,0.25] | [−0.54,0.38] | [−0.53,0.45] |
| 4. τLM1 | −0.01 | −0.00 | 0.01 | 0.23 | [−0.32,−0.06] | [−0.28,−0.03] | [−0.60,0.39] | [−0.52,0.43] | [−0.40,−0.19] | [0.15,0.48] |
| 5. τLM2 | 0.01 | 0.03 | −0.04 | −0.17 | 0.03 | [−0.51,−0.25] | [−0.58,0.40] | [−0.53,0.43] | [−0.07,0.21] | [−0.41,−0.01] |
| 6. τLM3 | −0.02 | 0.00 | 0.02 | −0.14 | −0.36 | 0.05 | [−0.63,0.47] | [−0.55,0.41] | [0.01,0.27] | [−0.13,0.25] |
| 7. τSF1 | −0.26 | 0.10 | 0.14 | −0.03 | −0.04 | −0.02 | 0.11 | [−0.57,−0.26] | [−0.50,0.39] | [−0.52,0.41] |
| 8. τSF2 | 0.41 | −0.21 | 0.09 | 0.01 | −0.00 | 0.00 | −0.40 | 0.07 | [−0.59,0.45] | [−0.56,0.43] |
| 9. τSM1 | 0.07 | 0.00 | −0.01 | −0.28 | 0.09 | 0.16 | 0.01 | −0.00 | 0.11 | [−0.56,−0.24] |
| 10. τSM2 | −0.02 | −0.00 | 0.02 | 0.34 | −0.19 | 0.09 | −0.00 | 0.01 | −0.38 | 0.04 |
Note. Brackets contain the 95% credible intervals (CI) for the corresponding correlations in the lower triangular. Bolded parameters exclude zero in the CI. In the diagonal we report the random effects variances for couples who’s partnership duration was on average 1 year. τLF1 is the intercept parameter where F is for females (and M for males) and L is location. τLk2 corresponds to PALAG1 and τLk3 to PAPartner.pc. The scale effects are denoted by the S subscript. τSk1 is the intercept and τSk2 the NAPartner.pc.
The top left quadrant (6 × 6 matrix) of Table 3 captures the correlations among the location parameters. The brackets contain the 95% credible intervals of the corresponding correlations in the lower triangular. The pattern of correlations among females and males was remarkably similar, except for the correlation between the intercept and the PA partner effects (τLF1 with τLF2) and the lagged effect (τLF1 with τLF3). For both females and males, the relevant correlations were negative. However, males had two additional correlations indicating that individuals who reported higher than average PA tended to have smaller carry-over effects from one day to the next (correlation r among τLM1 and τLM2 = −.18) and were less susceptible to their partner’s PA the same day (r among τLM1 and τLM3 = −.14). Both, females and males, showed a negative correlation among τLk2 and τLk3 (r = −.36) suggesting that larger lag effects are associated with smaller effects from partner’s PA the same day (and vice versa).
The lower right quadrant (4 × 4 matrix) includes the scale effects. Given that we introduced a variance model for the four diagonal random effect variances (see Equation (3)), these values represent the average random effects for participants who had been in their relationship for one year. The two correlations among τSk1 and τSk2 indicated that increasing the partner’s NA the same day correlated negatively with the variance of average PA ratings. In other words, those participants with larger than average PA variance estimates were less reactive to their partners’ NA ratings. And, alternatively, those with generally low PA variability reacted more strongly to their partners’ increase in NA with an increase in PA variability (for a similar result with stress reactivity, see Rast et al., 2012).
The lower left quadrant (4 × 6 matrix) captures the correlations of the random effects across the location and the scale components. The negative correlations indicate that higher average PA ratings were associated with smaller within-person variances, whereas larger PALag1 effects were associated with smaller changes in the within-person variance due to increased partner NA. The positive correlation among the random intercept of the location and the partner NA (τLk1 with τSk2) indicates that those who reported higher overall PA values also showed larger effects from daily fluctuations in their partners’ NA.
Between-person variance prediction
In Equation (8), we specified a submodel for between-person differences in the scale component. This model predicts differences in the random effects of the scale due to relationship duration (RelDur). Note that this variable RelDur was transformed via the natural logarithm to account for very long partnership lengths. Hence, the intercept represents a relationship length of one year (since ln(1) = 0). Results from these analyses are reported in Table 4. The reported SD ιk30 and ιk40 parameters reproduced the corresponding variances in the diagonal of Table 3. Relationship duration only had a perceptible effect for the males in the sample. That is, on average, males who had been in their relationship for longer were more heterogeneous (i.e., showed larger random effects in their intercept). In other words, all participants showed individual differences in their PA variability and in the change in such variability as a response to their partner’s NA. However, relative to females, only males were more heterogeneous in their variability estimates as their relationship length increased, and vice versa.
Table 4.
Between-person estimates for scale effects.
| Female | Male | |||||
|---|---|---|---|---|---|---|
| Parameters | Mean SD | 2.5% | 97.5% | Mean SD | 2.5% | 97.5% |
| Random scale | ||||||
| SD int. (ιk30) | 0.33 | 0.30 | 0.37 | 0.33 | 0.30 | 0.37 |
| RelDur (ιk31) | 1.05 | .96 | 1.14 | 1.10 | 1.01 | 1.19 |
| NAPartner.pc (ιk40) | 0.26 | 0.20 | 0.32 | 0.21 | 0.16 | 0.27 |
| NApartner.pc × RelDur (ιk41) | 0.95 | 0.77 | 1.15 | 1.05 | 0.87 | 1.28 |
Note. All estimates are posterior means. The 2.5% and 97.5% represent the boundary of the lower and upper credible intervals (CI). Bolded estimates represent means where the according CI’s on the log scale exclude 0.
Discussion
In this paper, we expanded the standard actor-partner and multilevel models onto a mixed-effects location scale model (MELSM) for dyadic interactions. This model was built to identify and account for IIV in each of the dyad members as well as their interrelations, as their interaction unfolds over time. Modeling and explaining dyadic interactions at both the mean and variance level requires repeated measurement data and flexible methods that are able to capture changes within and differences between individuals over time as well as the partner effects. The MELSM is one such model. This approach introduces predictors for both the mean structure, in the location component, and the variance structure, in the scale part, in a single modeling step. Moreover, partner interactions can be added at either the location or the scale submodel, or both, and they may include predictors that operate at the location and/or scale part. This approach also results in the estimation of random effects for both the location and the scale parts. This is done, for one, controlling for effects of mean and variance dependency (resulting in heteroscedasticity) but also obtaining correlations across these two parts and across both partners in the dyad (or more units in higher-order systems such as triads).
The information extracted from the covariance across the location and the scale is a unique feature of the MELSM. In our empirical illustration, we found that partners’ average and same day NA resulted in larger within-person variability. At the same time, not all participants conformed to this relation. The negative correlation between the intercept of the within-person SD and the within-person NA partner slope (females: r of τSF2 with τSF1 = −.41; males: r of τSF2 with τSF1 = −.38) indicated that those who were generally stable in their PA ratings (small PA SD) were reactive to their partners’ NA. However, those who were, on average, inconsistent in their PA ratings (large overall PA SD) did not react with an increase of within-person variability. This association was depicted in Figure 2, where some individuals showed a decrease in within-person variability. Again, these types of findings, with a fine-grained level of detail about IIV, are unique to the MELSM and would be hard to obtain with other standard models.
Another unique feature of the MELSM is the possibility of including between-person factors that could moderate the person-level variables at both the location and the scale components. In our example, we used time in the relationship as such factor. This variable affected the magnitude of individual differences in the within-person intercept variance. In our analyses, males who were at earlier stages in their relationship were more similar to each other than those who had been in their relationship for a longer time. This effect, however, was not evident for females.
Whenever variances are the focus of a model, one needs to take into account that their magnitude is also defined by the location of the average response. That is, in variables that are bounded (either at one or both ends), the variance will be a function of the person’s mean (Baird, Le, & Lucas, 2006; Eid & Diener, 1999; Kalmijn & Veenhoven, 2005) and, thus, covariances among the random location and scale intercepts merely reflect this constraint. This problem persists in the MELSM (but see Mestdagh et al., n.d., for a solution in multi-stage approaches). In the current application this correlation was medium (r ≈ −.30 among τLk1 and τSk1), and negative, as one would expect for PA. In general, participants reported PA that was closer to the ceiling than the floor. While the magnitude of the correlation was rather moderate, it could be substantial in other applications involving NA ratings (Rast et al., 2012) or reaction time data (Rast & MacDonald, 2014). This does not necessarily reflect a problem for the MELSM but it should be taken into account when interpreting the random effects correlations – some of these effects are dictated by the design and might not necessarily reflect the actual relation in a setting with unbounded variables.
One of the key strengths of the MELSM is its flexibility, as it allows researchers to include person- and time-varying predictors at both the location and scale components. However, it is important to keep in mind that the relation among the random effects of the location and scale are modeled as covariances, and they do not imply any sense of directionality or hierarchy. One alternative parameterization to counter this issue partially is to include the estimated individual mean as a predictor of the variance in the scale part of the model. Rast and Zimprich (2011) used this approach to predict within-person variability in a reaction time task to account for the heteroscedasticity arising from slower reaction times being related to larger variances (see also chapters 7.2.2 and 10.3 in Gałecki & Burzykowski, 2013, for a general description of variance functions in the context of linear mixed effect models). However, for researchers who are interested in modeling within-person variability, dynamics, and lead-lagged relations, one limitation is that IIV itself cannot serve as a predictor. To circumvent this issue, approaches such as multi-stage studies first extract IIV and then use it as a predictor in a subsequent regression-type analysis (cf. MacDonald, Hultsch, & Dixon, 2008).
Another point worth mentioning is that, in the current form, the MELSM does not differentiate between within-person variability due to actual fluctuations in the individuals’ behavior from fluctuations that arise from measurement error. Here, these two sources of variability are confounded. Although, if we are willing to assume that the measurement error variance is constant over time and situations, the intercept term will likely absorb a larger portion of the error variance than the slope term. With other designs, and other variables, however, one might include an additional term in the variance model that captures measurement error (for an application with EMA data. see Vansteelandt & Verbeke, 2016).
The models discussed here, especially the final model, comprise a large number of parameters. This raises questions regarding data requirements for obtaining accurate parameter estimates. Most studies examining data requirements for estimating IIV made use of two-stage approaches and are not directly transferable to the MELSM, as the latter models all variances jointly from a constrained covariance matrix. Hence, the MELSM should benefit from regularization in the sense that the random effects (co)-variances can only vary within a certain limit. In fact, the few simulations using a MELSM suggest that, in simple cases with only one random location and scale intercept, the MELSM parameters can be recovered with relatively few within-group or subject data points. For example, Leckie et al. (2014) recovered the variance parameters in a simulation with N = 250 and 10 repeated measurements. Similarly, Leckie (2014) was able to recover all parameters in another simulation study with 50 schools and 25 students per school. Given that our model was much more complex, we ran a small scale simulation with 200 replications using the parameters from the males in our final model. Due to convergence time, we limited ourselves to two random effects, an intercept and slope, for the location and the scale resulting in a 4 × 4 covariance matrix and no between-person predictors. The simulation was based on posteriors from the estimated population model (see Kruschke, 2015, Chapter 13) and suggested that large correlations (r ≈ .40) were recoverable with approximately 75 participants and 75 repeated measurements while medium sized correlations (r ≈ .20) required up to 180 participants and 100 repeated measurement. The parameters that defined the minimal requirements for N and number of repeated measurements were the covariances among the location and the scale random effects. This fits the findings in Table 3 where the smallest detectable correlation between location and scale was r = 0.16 with a credible interval of [0.01, 0.27]. It is very likely that the design and sample size requirements needed to obtain accurate estimates in demanding settings, such as the one presented here with 10 random effects, will increase. However, from the small simulation, it seems that the requirements for sample size grows faster than that for the repeated measurements. As such, our data example with N > 500 and up to 90 repeated measurements probably covered the requirements for our full model. These are speculations and future simulation work needs to formally address the data and design requirements in a broader context.
Likewise, the extent to which missing data affects the quality of the estimates or whether the location and scale parameters are similarly impacted is currently unknown. In our application we assumed a missing at random process (Rubin, 1976), but this assumption is not necessarily reasonable or tenable. In cases where data are missing not at random one could implement an imputation mechanism into the model that estimates all missing and nonmissing parameters simultaneously (Molenberghs, Fitzmaurice, Kenward, Tsiatis, & Verbeke, 2014).
The model presented in this paper serves as an illustration of a linear MELSM for dyads. This model can be modified easily in either the location or the scale functions to accommodate different structures (Goldstein, Leckie, Charlton, Tilling, & Browne, 2017). Some possible modifications include, for example, adding inherently nonlinear mean or variance structures, or altering the random-effects covariance matrix Σ to follow prespecified covariance structures. It is important to note, however, that each addition to the random effects increases the computational demand dramatically. Thus, our recommendation would be to start with a basic model and add terms at basic and manageable steps.
The purpose of this paper was to present the MELSM as a flexible model for longitudinal research on dyads. Our proposed MELSM is suited to model dyadic interactions in processes that show fluctuations, and where such ups and downs can have structure that is predictive of individual and dyadic behaviors. In principle, such a model could be applied to any dyadic interaction where the interdependence between the dyadic members is of key interest, given certain data conditions. Consider, for example, the interrelations between a therapist and a client, either over time, or in the course of a therapy session. Or, alternatively, the interaction between a mother and her infant child, during play time or through the development of the child. In either case, there will most likely be ups and downs in the individuals’ emotions, bonding, or adherence to therapy that can be modeled with the MELSM to detect aspects of the interactions that would otherwise go unnoticed (for additional examples, see Estrada, Sbarra, & Ferrer, n.d.). By focusing on the within-person variance, this approach opened up possibilities for modeling a component that is often disregarded as unexplained residuals. We hope that we illustrated such possibilities and the fact that such residuals may show systematic patterns that are important to understand psychological processes.
Acknowledgments:
The authors would like to thank the referees for their comments on prior versions of this manuscript. The ideas and opinions expressed herein are those of the authors alone, and endorsement by the authors’ institution or the NIH is not intended and should not be inferred.
Funding:
This work was supported by Grant 5R01AG050720-02 from the National Institutes of Health (NIH).
Role of the funders/sponsors:
None of the funders or sponsors of this research had any role in the design and conduct of the study; collection, management, analysis, and interpretation of data; preparation, review, or approval of the manuscript; or decision to submit the manuscript for publication.
Appendix
Stan code for models 2 and 3. Model 2 was the best fitting model and served to provide priors for model 3. Parameter names are chosen to reflect the multilevel model specifications in the manuscript. The code and example data for the full sequence can be obtained from https://github.com/phrast/MELSM
model_2 <- ′
data {
int < lower =0> nobs; //num of observations
int < lower =1> J; //number of groups or subjects
int < lower =1, upper = J> group[nobs]; //vector with group ID
matrix[nobs,6] x; //design matrix w. time-varying wp predictors for location
matrix[nobs,4] w; //design matrix w. time-varying wp predictors for scale
matrix[J,3] z; //between person predictors at level 2 for location
matrix[J,3] m; //between person predictors at level 2 for scale
vector < lower =1, upper =5 > [nobs] y; //column vector with outcomes
}
parameters { //Parameters to be estimated
cholesky_factor_corr[10] L_Omega; //Cholesky decomposition of Omega
matrix[6,3] gamma; //Location fixed effects
matrix[4,3] xi; //Scale fixed effects
matrix[10,J] stdnorm; //Standard normal, multiply w. cholesky factor to
//obtain multivariate normal beta
vector < lower =0 > [10] tau; //Vector of random effect SDs
}
transformed parameters {
matrix[J,6] z_gamma;
matrix[J,4] m_xi;
matrix[J,10] mu;
matrix[J,10] beta;
//Level 2
z_gamma = z * transpose(gamma);
m_xi = m * transpose(xi);
mu = append_col(z_gamma, m_xi);
beta = mu+transpose(diag_pre_multiply(tau, L_Omega)*stdnorm);
}
model {
//Priors
tau~cauchy(0, 2);
to_vector(stdnorm) ~normal(0,1);
L_Omega~lkj_corr_cholesky(1);
to_vector(xi) ~normal(0, 100);
to_vector(gamma) ~normal(0, 100);
//likelihood
y~normal(rows_dot_product(beta[group, 1:6], x),
exp(rows_dot_product(beta[group, 7:10], w)));}
generated quantities { //This section is not necessary, but contains useful
//transformations and generates data for posterior checks.
corr_matrix[10] Omega;//Obtain Omega from Cholesky factor to print in output
Omega = L_Omega*transpose(L_Omega);//Correlation matrix for output
}′
Model 3: Note that the priors were kept informative for the γ and ξ parameters in order alleviate model complexity. This model takes considerably more time to converge compared to the MELSM 2 as we also need to estimate parameters in the submodel for the scale random effects.
model_3<-’
data {
int < lower =0> nobs; //number of observations
int < lower =1> J; //number of groups or subjects
int < lower =1, upper = J> group[nobs]; //vector with group ID
matrix[nobs,6] x; //design matrix w. time-varying wp predictors for location
matrix[nobs,4] w; //design matrix w. time-varying wp predictors for scale
matrix[J,3] z; //between person predictors at level 2 for location
matrix[J,3] m; //between person predictors at level 2 for scale
matrix[J,1] g; //between person predictors for location ranefvar (intercept only)
matrix[J,2] a; //between person predictors for scale ranefvar (intercept and slope)
vector < lower =1, upper =5 > [nobs] y; //column vector with outcomes
}
parameters {
cholesky_factor_corr[10] L_Omega; //Cholesky decomposition of Omega
matrix[6,3] gamma; //Location Fixed effects
matrix[4,3] xi; //Scale fixed effects
matrix[6,1] iota_l; //iota, SD, for location random effects
matrix[4,2] iota_s; //iota, SD, for scale random effects
//(modeled with predictors in a)
matrix[10,J] stdnorm; //Standard normal, used to multiply w. cholesky
//factor to obtain multivariate normal beta
}
transformed parameters {
matrix[J, 6] z_gamma;
matrix[J, 4] m_xi;
matrix[J,10] mu;
matrix[J, 6] g_iota_l;
matrix[J, 4] a_iota_s;
matrix[J,10] tau;
matrix[J,10] beta;
z_gamma = z * transpose(gamma);
m_xi = m * transpose(xi);
mu = append_col(z_gamma, m_xi);
g_iota_l = exp(g*transpose(iota_l)); //submodel for location random effect SDs
//(intercept only)
a_iota_s = exp(a*transpose(iota_s)); //submodel for scale random effect SDs
//(intercept and slope)
tau = append_col(g_iota_l, a_iota_s);
for(j in 1:J){
beta[j,] = mu[j, ]+transpose(diag_pre_multiply(tau[j, ], L_Omega)*stdnorm[ ,j]);
}
}
model {
//priors
to_vector(stdnorm) ~n;ormal(0,1);
L_Omega~lkj_corr_cholesky(1.5);
to_vector(gamma) ~normal(0.1, 0.5);
gamma[1,1]~normal(3.45, 0.5);//intercepts obtain mean from MELSM 2
gamma[4,1]~normal(3.60, 0.5);
to_vector(xi)~normal(−0.5, 0.5);
to_vector(iota_l) ~normal(−1.5, 3);
to_vector(iota_s) ~normal(−1.5, 3);
//likelihood
y ~normal(rows_dot_product(beta[group, 1:6], x),
exp(rows_dot_product(beta[group, 7:10], w)));
}
generated quantities {//Obtain Omega from Cholesky factor.
corr_matrix[10] Omega;
Omega = L_Omega transpose(L_Omega);
}′Footnotes
Conflict of interest disclosures: Each author signed a form for disclosure of potential conflicts of interest. No authors reported any financial or other conflicts of interest in relation to the work described.
Ethical principles: The authors affirm having followed professional ethical guidelines in preparing this work. These guidelines include obtaining informed consent from human participants, maintaining ethical treatment and respect for the rights of human or animal participants, and ensuring the privacy of participants and their data, such as ensuring that individual participants cannot be identified in reported results or from publicly available original or archival data.
The annotated Stan-code for the final two models is in the Appendix and the code for all models can be obtained from https://github.com/phrast/MELSM
References
- Aitkin M (1987). Modelling variance heterogeneity in normal regression using GLIM. Journal of the Royal Statistical Society Series C – Applied Statistics, 36(3), 332–339. doi: 10.2307/2347792 [DOI] [Google Scholar]
- Akaike H (1973). Information Theory and an Extension of the Maximum Likelihood Principle. In Petrov BN & Csaki F (Eds.), Second International Symposium on Information Theory, (pp. 267–281). Budapest: Akademiai Kiado. [Google Scholar]
- Baird BM, Le K, & Lucas RE (2006). On the nature of intraindividual personality variability: Reliability, validity, and associations with well-being. Journal of Personality and Social Psychology, 90(3), 512–527. Retrieved from http://doi.apa.org/getdoi.cfm?doi=10.1037/0022-3514.90.3.512 doi: 10.1037/0022-3514.90.3.512 [DOI] [PubMed] [Google Scholar]
- Baltes PB, Reese HW, & Nesselroade JR (1977). Lifespan developmental psychology: Introduction to research methods. Hillsdale, NJ: Erlbaum. [Google Scholar]
- Barnard J, McCulloch R, & Meng X-L (2000). Modeling covariance matrices in terms of standard deviations and correlations, with application to shrinkage. Statistica Sinica, 10, 1281–1311. Retrieved from papers2://publication/uuid/1F624B87-D87A-4BBF-82A2-EECB31D73B7C doi: 10.2307/24306780 [DOI] [Google Scholar]
- Boker SM, & Laurenceau J-P (2006). Dynamical systems modeling: An application to the regulation of intimacy and disclosure in marriage. In Models for intensive longitudinal data eds. Walls TA & Schafer JL (Vol. 63, pp. 195–218). Oxford, UK: Oxford University Press. doi: 10.1093/acprof:oso/9780195173444.003.0009 [DOI] [Google Scholar]
- Bolger N, Davis A, & Rafaeli E (2003). Diary methods: Capturing life as it is lived. Annual Review of Psychology, 54, 579–616. doi: 10.1146/annurev.psych.54.101601.145030. [DOI] [PubMed] [Google Scholar]
- Bolger N, & Laurenceau J-P (2013). Intensive longitudinal methods: An introduction to diary and experience sampling research. New York, NY: Guilford Press. [Google Scholar]
- Bollerslev T (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3), 307–327. doi: 10.1016/0304-4076(86)90063-1 [DOI] [Google Scholar]
- Browne MW, & Nesselroade JR (2005). Representing psychological processes with dynamic factor models: Some promising uses and extensions of autoregressive moving average time series models. In Contemporary psychometrics: A festschrift for Roderick P. McDonald, Maydeu-Olivares A & McArdle JJ (pp. 415–452). Mahwah, NJ: Erlbaum. doi: 10.4324/9781410612977 [DOI] [Google Scholar]
- Butner J, Diamond LM, & Hicks AM (2007). Attachment style and two forms of affect coregulation between romantic partners. Personal Relationships, 14(3), 431–455. doi: 10.1111/j.1475-6811.2007.00164.x [DOI] [Google Scholar]
- Campbell L, & Kashy DA (2002). Estimating actor, partner, and interaction effects for dyadic data using PROC MIXED and HLM: A user-friendly guide. Personal Relationships, 9(3), 327–342. doi: 10.1111/1475-6811.00023 [DOI] [Google Scholar]
- Cattell RB, Cattell AKS, & Rhymer RM (1947). P-technique demonstrated in determining psychophysio-logical source traits in a normal individual. Psychometrika, 12(4), 267–288. Retrieved from http://link.springer.com/article/10.1007/BF02288941 doi: 10.1007/BF02288941 [DOI] [PubMed] [Google Scholar]
- Chow S-M, Ferrer E, & Nesselroade JR (2007). An unscented Kalman filter approach to the estimation of nonlinear dynamical systems models. Multivariate Behavioral Research, 42(2), 283–321. doi: 10.1080/00273170701360423 [DOI] [PubMed] [Google Scholar]
- Cleveland WS, Denby L, & Liu C (2002). Random scale effects (Tech. Rep.). Murray Hill, NJ: Statistics Research Dept. Bell Labs. Retrieved from http://stat.bell-labs.com/wsc/publish.html [Google Scholar]
- Curran PJ, & Bauer DJ (2011). The disaggregation of within-person and between-person effects in longitudinal models of change. Annual Review of Psychology, 62(1), 583–619. Retrieved from http://www.annualreviews.org/doi/10.1146/annurev.psych.093008.100356 doi: 10.1146/annurev.psych.093008.100356 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Curran PJ, Lee T, Howard AL, Lane S, & MacCallum RC (2012). Disaggregating within-person and between-person effects in multilevel and structural equation growth models. In Harring JR & Hancock GR (Eds.), Advances in longitudinal methods in the social and behavioral sciences (pp. 217–253). Charlotte, NC: Information Age Publishing. Retrieved from http://curran.web.unc.edu/chapters/ [Google Scholar]
- de Almeida D, Hotta LK, & Ruiz E (2018). MGARCH models: Trade-off between feasibility and flexibility. International Journal of Forecasting, 34(1), 45–63. Retrieved from https://www.sciencedirect.com/science/article/pii/S0169207017300894 doi: 10.1016/J.IJFORECAST.2017.08.003 [DOI] [Google Scholar]
- Eid M, & Diener E (1999). Intraindividual variability in affect: Reliability, validity, and personality correlates. Journal of Personality and Social Psychology, 76(4), 662–676. Retrieved from http://doi.apa.org/getdoi.cfm?doi=10.1037/0022-3514.76.4.662 doi: 10.1037/0022-3514.76.4.662 [DOI] [Google Scholar]
- Eizenman DR, Nesselroade JR, Featherman DL, & Rowe JW (1997). Intraindividual variability in perceived control in a older sample: The MacArthur successful aging studies. Psychology and Aging, 12(3), 489–502. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/9308096 doi: 10.1037/0882-7974.12.3.489 [DOI] [PubMed] [Google Scholar]
- Engle R (2002). Dynamic conditional correlation. Journal of Business & Economic Statistics, 20(3), 339–350. Retrieved from http://www.tandfonline.com/doi/abs/10.1198/073500102288618487 doi: 10.1198/073500102288618487 [DOI] [Google Scholar]
- Estabrook R, Grimm KJ, & Bowles RP (2012). A Monte Carlo simulation study of the reliability of intraindividual variability. Psychology and Aging, 27(3), 560–576. Retrieved from http://ezproxy.library.uvic.ca/login?url=http://search.ebscohost.com/login.aspx?direct=true{&}db=pdh{&}AN=2012-02078-001{&}site=ehost-live{&}scope=sitehttp://content.ebscohost.com/ContentServer.asp?T=P{&}P=AN{&}K=2012-02078-001{&}S=L{&}D=pdh{&}EbscoContent=dGJyMNXb4kSep7Y doi:0.1037/a0026669 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Estrada E, Sbarra DA, & Ferrer E (n.d.). Models for dyadic data. In Wright AGC & Hallquist MN (Eds.), Handbook of research methods in clinical psychology. Cambridge, MA: Cambridge University Press. [Google Scholar]
- Felmlee DH (2006). Application of dynamic systems analysis to dyadic interactions. Oxford Handbook of Methods in Positive Psychology, 23, 409–422. [Google Scholar]
- Felmlee DH, & Greenberg DF (1999). A dynamic systems model of dyadic interaction. The Journal of Mathematical Sociology, 23(3), 155–180. doi: 10.1080/0022250X.1999.9990218 [DOI] [Google Scholar]
- Ferrer E, Gonzales JE, & Steele J (2013). Intra- and interindividual variability of daily affect in adult couples. GeroPsych: The Journal of Gerontopsychology and Geriatric Psychiatry, 26(3), 163–172. doi: 10.1024/1662-9647/a000095 [DOI] [Google Scholar]
- Ferrer E, & Nesselroade JR (2003). Modeling affective processes in dyadic relations via dynamic factor analysis. Emotion, 3(4), 344–360. Retrieved from http://doi.apa.org/getdoi.cfm?doi=10.1037/1528-3542.3.4.344 doi: 10.1037/1528-3542.3.4.344 [DOI] [PubMed] [Google Scholar]
- Ferrer E, & Rast P (2017). Partitioning the variability of daily emotion dynamics in dyadic interactions with a mixed-effects location scale model. Current Opinion in Behavioral Sciences, 15, 10–15. Retrieved from http://www.sciencedirect.com/science/article/pii/S2352154617300141 doi: 10.1016/j.cobeha.2017.05.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferrer E, & Steele J (2014). Differential equations for evaluating theoretical models of dyadic interactions. In Molenaar PCM, Newell KM, & Lerner RM (Eds.), Handbook of developmental systems theory and methodology (pp. 345–368). New York, NY: Guilford. [Google Scholar]
- Ferrer E, Steele JS, & Hsieh F (2012). Analyzing the dynamics of affective dyadic interactions using patterns of intra- and interindividual variability. Multivariate Behavioral Research, 47(1), 136–171. doi: 10.1080/00273171.2012.640605 [DOI] [Google Scholar]
- Ferrer E, & Widaman KF (2008). Dynamic factor analysis of dyadic affective processes with inter-group differences. In Card NA, Selig JP, & Little TD (Eds.), Modeling dyadic and interdependent data in the developmental and behavioural sciences (pp. 107–137). Hillsdale, NJ: Psychology Press. [Google Scholar]
- Ferrer E, & Zhang G (2009). Time series models for examining psychological processes: Applications and new developments. In Handbook of quantitative methods in psychology, eds. Millsap RE & Maydeu-Olivares A (pp. 637–657). London, UK: Sage. [Google Scholar]
- Fiske DW, & Rice L (1955). Intra-Individual response variability. Psychological Bulletin, 52(3), 217–251. doi: 10.1037/h0045276 [DOI] [PubMed] [Google Scholar]
- Fletcher GJO, Simpson JA, & Thomas G (2000). The Measurement of Perceived Relationship Quality Components: A Confirmatory Factor Analytic Approach. Personality and Social Psychology Bulletin, 26(3), 340–354. 10.1177/0146167200265007 [DOI] [Google Scholar]
- Gałecki AT, & Burzykowski T (2013). Linear mixed-effects models using R: A step-by-step approach. New York: Springer. [Google Scholar]
- Gelman A (2006). Prior distributions for variance parameters in hierarchical models. Bayesian Analysis, 1(3), 515–533. doi: 10.1214/06-BA117A [DOI] [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Dunson DB, Vehtari A, & Rubin DB (2013). Bayesian data analysis (3rd ed.). New York, NY: Chapman and Hall/CRC. [Google Scholar]
- Goldstein H, Leckie G, Charlton C, Tilling K, & Browne WJN (2017). Multilevel growth curve models that incorporate a random coefficient model for the level 1 variance function. Statistical Methods in Medical Research, 1–14. Retrieved from, http://journals.sagepub.com/doi/pdf/10.1177/0962280217706728 doi: 10.1177/0962280217706728 [DOI] [PubMed] [Google Scholar]
- Gottman JM (2002). The mathematics of marriage: Dynamic nonlinear models. Boston, MA: MITPress. [Google Scholar]
- Hamaker EL, & Grasman RP (2015). To center or not to center? Investigating inertia with a multilevel autoregressive model. Frontiers in Psychology, 5(Oct), 1–15. doi: 10.3389/fpsyg.2014.01492 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hedeker D, Mermelstein RJ, Berbaum ML, & Campbell RT (2009). Modeling mood variation associated with smoking: an application of a heterogeneous mixed-effects model for analysis of ecological momentary assessment (EMA) data. Addiction, 104(2), 297–307. doi: 10.1111/j.1360-0443.2008.02435.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hedeker D, Mermelstein RJ, & Demirtas H (2008). An application of a mixed-effects location scale model for analysis of ecological momentary assessment (EMA) data. Biometrics, 64(2), 627–634. doi: 10.1111/j.1541-0420.2007.00924.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hedeker D, & Nordgren R (2013). MIXREGLS: A program for mixed-effects location scale analysis. Journal of Statistical Software, 52(12), 1–38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoffman L (2007). Multilevel models for examining individual differences in within-person variation and covariation over time. Multivariate Behavioral Research, 42(4), 609–629. doi: 10.1080/00273170701710072 [DOI] [Google Scholar]
- Hoffman MD, & Gelman A (2014). The No-U-Turn Sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. Journal of Machine Learning Research, 15, 1351–1381. Retrieved from http://www.stat.columbia.edu/{~}gelman/research/published/nuts.pdf [Google Scholar]
- Horn JL (1972). State, trait and change dimensions of intelligence. British Journal of Educational Psychology, 42(2), 159–185. doi: 10.1111/j.2044-8279.1972.tb00709.x [DOI] [Google Scholar]
- Hultsch DF, Hertzog C, Small BJ, McDonald-Miszczak L, & Dixon RA (1992). Short-term longitudinal change in cognitive performance in late life. Psychology and Aging, 7, 571–584. doi: 10.1037/0882-7974.7.4.571 [DOI] [PubMed] [Google Scholar]
- Hultsch DF, Strauss E, Hunter MA, & MacDonald SWS (2008). Intraindividual variability, cognition, and aging. In The Handbook of aging and cognition Craik FIM & Salthouse TA (Eds.) (3rd ed., pp. 491–556). New York, NY: Psychology Press. [Google Scholar]
- Kalmijn W, & Veenhoven R (2005). Measuring inequality of happiness in nations: In search for proper statistics. Journal of Happiness Studies, 6(4), 357–396. Retrieved from http://link.springer.com/10.1007/s10902-005-8855-7 doi: 10.1007/s10902-005-8855-7 [DOI] [Google Scholar]
- Kapur K, Li X, Blood EA, & Hedeker D (2015). Bayesian mixed-effects location and scale models for multivariate longitudinal outcomes: An application to ecological momentary assessment data. Statistics in Medicine, 34(4), 630–651. Retrieved from doi: 10.1002/sim.6345 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kenny DA (1996). Models of non-independence in dyadic research. Journal of Social and Personal Relationships, 13(2), 279–294. Retrieved from http://journals.sagepub.com/doi/10.1177/0265407596132007 doi: 10.1177/0265407596132007 [DOI] [Google Scholar]
- Kenny DA, Kashy DA, & Cook WL (2006). Dyadic data analysis. New York, NY: Guilford Press. [Google Scholar]
- Kruschke JK (2013). Bayesian estimation supersedes the t test. Journal of Experimental Psychology: General, 142(2), 573–603. Retrieved from http://doi.apa.org/getdoi.cfm?doi=10.1037/a0029146 doi: 10.1037/a0029146 [DOI] [PubMed] [Google Scholar]
- Kruschke JK (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd ed.). London, UK: Elsevier. doi: 10.1016/B978-0-12-405888-0.09999-2 [DOI] [Google Scholar]
- Laurenceau J-P, Troy AB, & Carver CS (2005). Two distinct emotional experiences in romantic relationships: Effects of perceptions regarding approach of intimacy and avoidance of conflict. Personality and Social Psychology Bulletin, 31(8), 1123–1133. doi: 10.1177/0146167205274447 [DOI] [PubMed] [Google Scholar]
- Laurent S, Rombouts JVK, & Violante F (2012). On the forecasting accuracy of multivariate GARCH models. Journal of Applied Econometrics, 27(6), 934–955. Retrieved from http://doi.wiley.com/10.1002/jae.1248 doi: 10.1002/jae.1248 [DOI] [Google Scholar]
- Leckie G (2014). runmixregls: A program to run the MIXREGLS mixed-effects location scale software from within Stata. Journal of Statistical Software, 59(Code Snippet 2), 1–39.26917999 [Google Scholar]
- Leckie G, French R, Charlton C, Browne W, & Langford B (2014). Modeling heterogeneous variance-covariance components in two-level models. Journal of Educational and Behavioral Statistics, 39(5), 307–332. Retrieved from http://www.bristol.ac.uk/cmm/media/leckie/leckieetal2015.pdf doi: 10.3102/1076998614546494 [DOI] [Google Scholar]
- Lewandowski D, Kurowicka D, & Joe H (2009). Generating random correlation matrices based on vines and extended onion method. Journal of Multivariate Analysis, 100(9), 1989–2001. Retrieved from http://lg5jh7pa3n.scholar.serialssolutions.com/?sid=google{&}auinit=D{&}aulast=Lewandowski{&}atitle=Generating+random+correlation+matrices+based+on+vines+and+extended+onion+method{&}id=doi:10.1016/j.jmva.2009.04.008{&}title=Journal+of+multivariate+analysis{&}volume=1 doi: 10.1016/j.jmva.2009.04.008 [DOI] [Google Scholar]
- MacDonald SWS, Hultsch DF, & Dixon RA (2008). Predicting impending death: Inconsistency in speed is a selective and early marker. Psychology and Aging, 23(3), 595–607. Retrieved from http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2562863/ doi: 10.1037/0882-7974.23.3.595 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mestdagh M, Pe M, Pestman W, Verdonck S, Kuppens P, & Tuerlinckx F (2018). Sidelining the mean: The relative variability index as a generic mean-corrected variability measure for bounded variables. Psychological Methods. doi: 10.1037/met0000153 [DOI] [PubMed] [Google Scholar]
- Molenaar PCM (1985). A dynamic factor model for the analysis of multivariate time series. Psychometrika, 50(2), 181–202. doi: 10.1007/BF02294246 [DOI] [Google Scholar]
- Molenberghs G, Fitzmaurice GM, Kenward MG, Tsiatis AAAA, & Verbeke G (2014). Handbook of missing data methodology. Boca Raton, FL: Chapman & Hall/CRC. [Google Scholar]
- Myles JP, Price GM, Hunter N, Day M, & Duffy SW (2003). A potentially useful distribution model for dietary intake data. Public Health Nutrition, 6(5), 513–519. doi: 10.1079/PHN2003459 [DOI] [PubMed] [Google Scholar]
- Nesselroade JR (1991a). Interindividual differences in intraindividual change. In Best methods for the analysis of change: Recent advances, unanswered questions, future directions, Collins LM & Horn JL (Eds.) (pp. 92–105). Washington, DC: American Psychological Association. [Google Scholar]
- Nesselroade JR (1991b). The warp and the woof of the developmental fabric. In Visions of aesthetics, the environment & development: The legacy of Joachim F. Wohlwill Downs R, Liben L, & Palermo DS (Eds.) (pp. 213–240). Hillsdale, NJ: Erlbaum. [Google Scholar]
- Nesselroade JR, & Salthouse TA (2004). Methodological and theoretical implications of intraindividual variability in perceptual-motor performance. The Journals of Gerontology Series B: Psychological Sciences and Social Sciences, 59(2), P49–P55. doi: 10.1093/geronb/59.2.P49 [DOI] [PubMed] [Google Scholar]
- O’Hara RB, & Sillanpää MJ (2009). A review of Bayesian variable selection methods: What, how and which. Bayesian Analysis, 4(1), 85–117. Retrieved from http://projecteuclid.org/euclid.ba/1340370391 doi: 10.1214/09-BA403 [DOI] [Google Scholar]
- Piironen J, & Vehtari A (2017). Comparison of Bayesian predictive methods for model selection. Statistics and Computing, 27(3), 711–735. Retrieved from http://link.springer.com/10.1007/s11222-016-9649-y doi: 10.1007/s11222-016-9649-y [DOI] [Google Scholar]
- Ram N, & Gerstorf D (2009). Time-structured and net intraindividual variability: Tools for examining the development of dynamic characteristics and processes. Psychology and Aging, 24(4), 778–791. doi: 10.1037/a0017915 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rast P, Hofer S, & Sparks C (2012). Modeling individual differences in within-person variation of negative and positive affect in a mixed effects location scale model using BUGS/JAGS. Multivariate Behavioral Research, 47(2), 177–200. doi: 10.1080/00273171.2012.658328 [DOI] [PubMed] [Google Scholar]
- Rast P, & MacDonald SWS (2014). Exploring the relations among different levels of intraindividual variability and longitudinal change using a mixed effects location scale model. health policy statistics section. Alexandria, VA: American Statistical Association. [Google Scholar]
- Rast P, & Zimprich D (2011). Modeling variability in reaction time data in older adults. GeroPsych, 24(4), 169–176. doi: 10.1024/1662-9647/a000045 [DOI] [Google Scholar]
- Raudenbush SW, Brennan RT, & Barnett RC (1995). A multivariate hierarchical model for studying psychological change within married couples. Journal of Family Psychology, 9(2), 161–174. doi: 10.1037/0893-3200.9.2.161 [DOI] [Google Scholar]
- Raudenbush SW, & Bryk AS (2002). Hierarchical linear models: Applications and data analysis methods (Vol. 1). Thousand Oaks, CA: Sage Publications, Inc. [Google Scholar]
- Röcke C, & Brose A (2013). Intraindividual variability and stability of affect and well-being: Short-term and long-term change and stabilization processes. GeroPsych: The Journal of Gerontopsychology and Geriatric Psychiatry, 26(3), 185–199. doi: 10.1024/1662-9647/a000094 [DOI] [Google Scholar]
- Röcke C, Li S-C, & Smith J (2009). Intraindividual variability in positive and negative affect over 45 days: Do older adults fluctuate less than young adults? Psychology and Aging, 24(4), 863–878. doi: 10.1037/a0016276 [DOI] [PubMed] [Google Scholar]
- Rubin DB (1976). Inference and missing data. Biometrika, 63(3), 581–592. doi: 10.2307/2335739 [DOI] [Google Scholar]
- Shiffman S, Stone AA, & Hufford MR (2008). Ecological momentary assessment. Annual Review of Clinical Psychology, 4, 1–32. doi: 10.1146/annurev.clinpsy.3.022806.091415 [DOI] [PubMed] [Google Scholar]
- Sliwinski MJ (2008). Measurement-burst designs for social health research. Social and Personality Psychology Compass, 2(1), 245–261. doi: 10.1111/j.1751-9004.2007.00043.x [DOI] [Google Scholar]
- Stan Development Team. (2016a). {RStan}: the {R} interface to {Stan}. Retrieved from http://mc-stan.org/
- Stan Development Team. (2016b). The Stan C++ Library (2.14.0 ed.). Retrieved from http://mc-stan.org [Google Scholar]
- Steele JS, Ferrer E, & Nesselroade JR (2014). An idio-graphic approach to estimating models of dyadic interactions with differential equations. Psychometrika, 79(4), 675–700. doi: 10.1007/s11336-013-9366-9 [DOI] [PubMed] [Google Scholar]
- Thompson A, & Bolger N (1999). Emotional transmission in couples under stress. Journal of Marriage and the Family, 61(1), 38. doi: 10.2307/353881 [DOI] [Google Scholar]
- Tse YK, & Tsui AKC (2002). A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. Source Journal of Business & Economic Statistics, 20(3), 351–362. Retrieved from http://www.jstor.org/stable/1392122 doi: 10.1198/073500102288618496 [DOI] [Google Scholar]
- Vansteelandt K, & Verbeke G (2016). A mixed model to disentangle variance and serial autocorrelation in affective instability using ecological momentary assessment data. Multivariate Behavioral Research, 51(4), 446–465. Retrieved from 10.1080/00273171.2016.1159177 doi: 10.1080/00273171.2016.1159177 [DOI] [PubMed] [Google Scholar]
- Vehtari A, Gelman A, & Gabry J (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Statistics and Computing, 27(5), 1413–1432. doi: 10.1007/s11222-016-9696-4 [DOI] [Google Scholar]
- Verbeke G, & Davidian M (2009). Joint models for longitudinal data: Introduction and overview. In Fitzmaurice G, Davidian M, Verbeke G, & Molenberghs G (Eds.), Longitudinal data analysis (pp. 319–326). Boca Raton, FL: Chapman & Hall/CRC. [Google Scholar]
- Wang LP, & Grimm KJ (2012). Investigating reliabilities of intraindividual variability indicators. Multivariate Behavioral Research, 47(5), 771–802. Retrieved from http://www.tandfonline.com/doi/abs/10.1080/00273171.2012.715842 doi: 10.1080/00273171.2012.715842 [DOI] [PubMed] [Google Scholar]
- Wang LP, Hamaker E, & Bergeman CS (2012). Investigating inter-individual differences in short-term intra-individual variability. Psychological Methods, 17(4), 567–581. doi: 10.1037/a0029317 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang LP, & Maxwell SE (2015). On disaggregating between-person and within-person effects with longitudinal data using multilevel models. Psychological Methods, 20(1), 63–83. Retrieved from http://doi.apa.org/getdoi.cfm?doi=10.1037/met0000030 doi: 10.1037/met0000030 [DOI] [PubMed] [Google Scholar]
- Watanabe S (2010). Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. Journal of Machine Learning Research, 11, 3571–3594. Retrieved from http://jmlr.csail.mit.edu/papers/volume11/watanabe10a/watanabe10a.pdf [Google Scholar]
- Woodrow H (1932). Quotidian variability. Psychological Review, 39(3), 245–256. doi: 10.1037/h0073076 [DOI] [Google Scholar]