

Abstract
Model explainability is essential for the creation of trustworthy Machine Learning models in healthcare. An ideal explanation resembles the decision-making process of a domain expert and is expressed using concepts or terminology that is meaningful to the clinicians. To provide such explanation, we first associate the hidden units of the classifier to clinically relevant concepts. We take advantage of radiology reports accompanying the chest X-ray images to define concepts. We discover sparse associations between concepts and hidden units using a linear sparse logistic regression. To ensure that the identified units truly influence the classifier’s outcome, we adopt tools from Causal Inference literature and, more specifically, mediation analysis through counterfactual interventions. Finally, we construct a low-depth decision tree to translate all the discovered concepts into a straightforward decision rule, expressed to the radiologist. We evaluated our approach on a large chest x-ray dataset, where our model produces a global explanation consistent with clinical knowledge.
1. Introduction
Machine Learning, specifically, Deep Learning (DL) methods are increasingly adopted in healthcare applications. Model explainability is essential to build trust in the AI system [5] and to receive clinicians’ feedback. Standard explanation methods for image classification delineates regions in the input image that significantly contribute to the model’s outcome [13,17,19]. However, it is challenging to explain how and why variations in identified regions are relevant to the model’s decision. Ideally, an explanation should resemble the decision-making process of a domain expert. This paper aims to map a DL model’s neuron activation patterns to the radiographic features and constructs a simple rule-based model that partially explains the Black-box.
Methods based on feature attribution have been commonly used for explaining DL models for medical imaging [1]. However, an alignment between feature attribution and radiology concepts is difficult to achieve, especially when a single region may correspond to several radiographic concepts. Recently, researchers have focused on providing explanations in the form of human-defined concepts [2,12,23]. In medical imaging, such methods have been adopted to derive an explanation for breast mammograms [22], breast histopathology [6] and cardiac MRIs [4]. A major drawback of the current approach is their dependence on explicit concept-annotations, either in the form of a representative set of images [12] or semantic segmentation [2], to learn explanations. Such annotations are expensive to acquire, especially in the medical domain. We use weak annotations from radiology reports to derive concept annotations. Furthermore, these methods measure correlations between concept perturbations and classification predictions to quantify the concept’s relevance. However, the neural network may not use the discovered concepts to arrive at its decision. We borrow tools from causal analysis literature to address that drawback [21].
In this work, we used radiographic features mentioned in radiology reports to define concepts. Using a National Language Processing (NLP) pipeline, we extract weak annotations from text and classify them based on their positive or negative mention [9]. Next, we use sparse logistic regression to identify sets of hidden-units correlated with the presence of a concept. To quantify the causal influence of the discovered concept-units on the model’s outcome, we view concept-units as a mediator in the treatment-mediator-outcome framework [8]. Using measures from mediation analysis, we provide an effective ranking of the concepts based on their causal relevance to the model’s outcome. Finally, we construct a low-depth decision tree to express discovered concepts in simple decision rules, providing the global explanation for the model. The rule-based nature of the decision tree resembles many decision-making procedures by clinicians.
2. Method
We consider a pre-trained black-box classifier f : x → y that takes an image x as input and process it using a sequence of hidden layers to produce a final output . Without loss of generality, we decompose function f as , where is the output of the initial few layers of the network and Φ2 denotes the rest of the network. We assume access to a dataset , where xn is input image, yn is a d-dimensional one-hot encoding of the class labels and is a k-dimensional concept-label vector. We define concepts as the radiographic observations mentioned in radiology reports to describe and provide reasoning for a diagnosis. We used a NLP pipeline [9] to extract concept annotations. The NLP pipeline follows a rule-based approach to extract and classify observations from the free-text radiology report. The extracted kth concept-label cn[k] is either 0 (negative-mention), 1(positive-mention) or −1 (uncertain or missing-mention). An overview of our method is shown in Fig. 1. Our method consists of three sequential steps:
Fig.1.
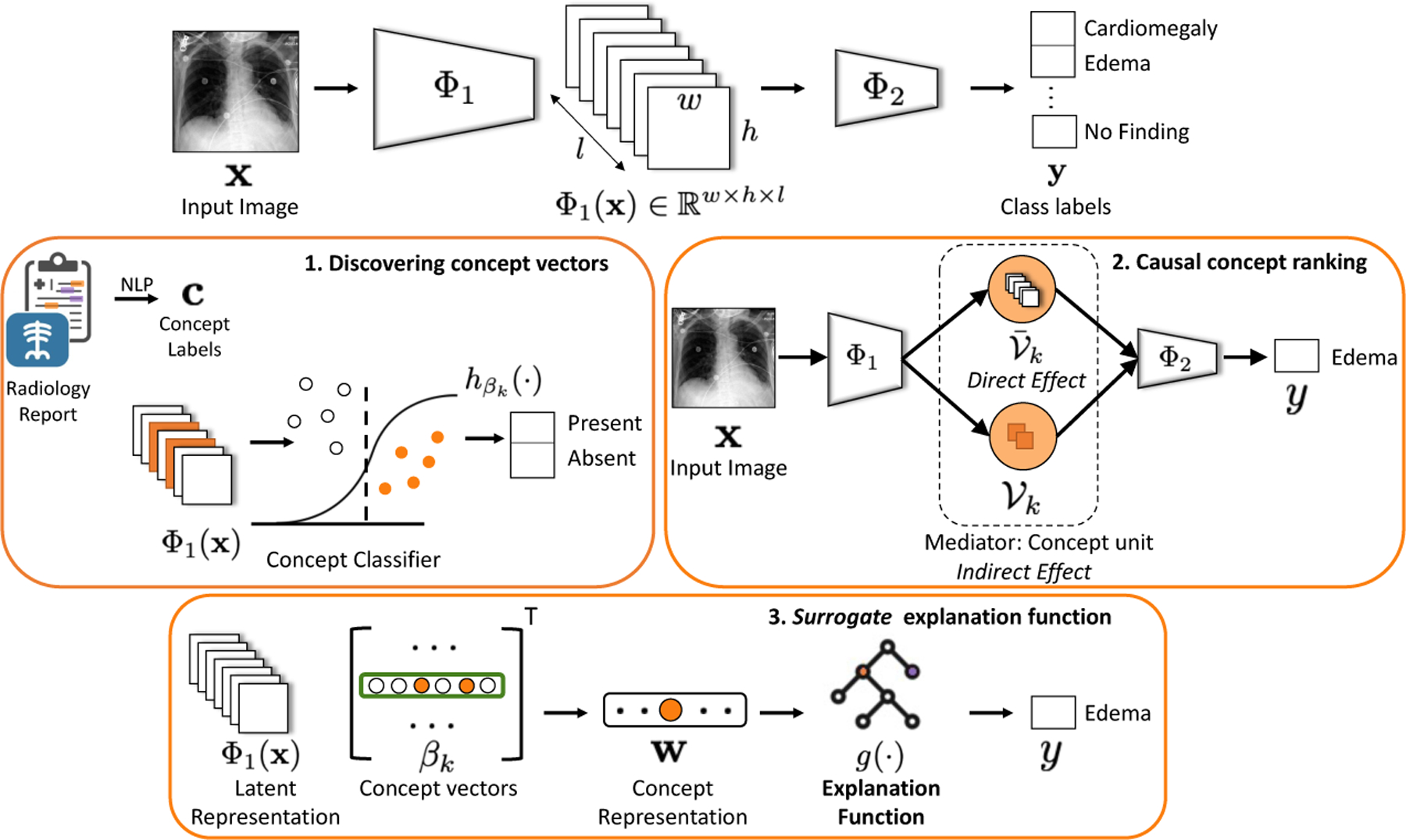
Method overview: We provide explanation for the black-box function f(x) interms of concepts, that are radiographic observations mentioned in radiology reports. 1) The intermediate representation Φ1(x) is used to learn a sparse logistic regression to classify kth concept. 2) The non-zero coefficients of βk represents a set of concept units that serves as a mediator in the causal path connecting input x and outcome y. 3) A decision tree function is learned to map concepts to class labels.
Concept associations: We seek to discover sparse associations between concepts and the hidden-units of f(·). We express kth concept as a sparse vector that represents a linear direction in the intermediate space Φ1(·).
Causal concept ranking: Using tools from causal inference, we find an effective ranking of the concepts based on their relevance to the classification decision. Specifically, we consider each concept as a mediator in the causal path between the input and the outcome. We measure concept relevance as the effect of a counterfactual intervention on the outcome that passes indirectly through the concept-mediator.
Surrogate explanation function: We learn an easy-to-interpret function g(·) that mimics function f(·) in its decision. Using g(·), we seek to learn a global explanation for f(·) in terms of the concepts.
2.1. Concept associations
We discover concept associations with intermediate representation Φ1(·) by learning a binary classifier that maps Φ1(x) to the concept-labels [12]. We treat each concept as a separate binary classification problem and extract a representative set of images , in which concept cn[k] is present and a random negative set. We define concept vector (βk) as the solution to the logistic regression model , where σ(·) is the sigmoid function. For a convolutional neural network, is the output activation of a convolutional layer with width w, height h and number of channels l. We experimented with two vectorization for Φ1. In first, we flatten Φ1(x) to be a whl-dimensional vector. In second, we applied a spatial aggregation by max-pooling along the width and height to obtain l-dimensional vector. Unlike TCAV [12] that uses linear regression, we used lasso regression to enable sparse feature selection and minimize the following loss function,
| (1) |
where ℓ(·,·) is the cross entropy loss, and λ is the regularization parameter. We performed 10-fold nested-cross validation to find λ with least error. The non-zero elements in the concept vector βk forms the set of hidden units that are most relevant to the kth concept.
2.2. Causal concept ranking
Concept associations identified hidden units that are strongly correlated with a concept. However, the neural network may or may not use the discovered concepts to arrive at its decision. We use tools from causal inference, to quantify what fraction of the outcome is mediated through the discovered concepts.
To enable causal inference, we first define counterfactual x׳ as a perturbation of the input image x such that the decision of the classifier is flipped. Following the approach proposed in [20], we used a conditional generative adversarial network (cGAN) to learn the counterfactual perturbation. We conditioned on the output of the classifier, to ensure that cGAN learns a classifier-specific perturbation for the given image x. Next, we used theory from causal mediation analysis to causally relate a concept with the classification outcome. Specifically, we consider concept as a mediator in the causal pathway from the input x to the outcome y. We specify following effects to quantify the causal effect of the counterfactual perturbation and the role of a mediator in transferring such effect,
Average treatment effect (ATE): ATE is the total change in the classification outcome y as a result of the counterfactual perturbation.
Direct effect (DE): DE is the effect of the counterfactual perturbation that comprises of any causal mechanism that do not pass through a given mediator. It captures how the perturbation of input image changes classification decision directly, without considering a given concept.
Indirect effect (IE): IE is the effect of the counterfactual perturbation which is mediated by a set of mediators. It captures how the perturbation of input image changes classification decision indirectly through a given concept.
Following the potential outcome framework from [18,21], we define the ATE as the proportional difference between the factual and the counterfactual classification outcome,
| (2) |
To enable causal inference through a mediator, we borrow Pearl’s definitions of natural direct and indirect effects [16] (ref Fig. 2). We consider set of concept-units as a mediator, representing the kth concept. We decompose the latent representation Φ1(x) as concatenation of response of concept-units and rest of the hidden units i.e., . We can re-write classification outcome as . To disentangle the direct effect from the indirect effect, we use the concept of do-operation on the unit level of the learnt network. Specifically, we use to denote that we set the value of the concept-units to the value obtained by using the original image as input. By intervening on the network and setting the value of the concept units, we can compute the direct effect as the proportional difference between the factual and the counterfactual classification outcome, while holding mediator i.e., fixed to its value before the perturbation,
| (3) |
Fig.2.
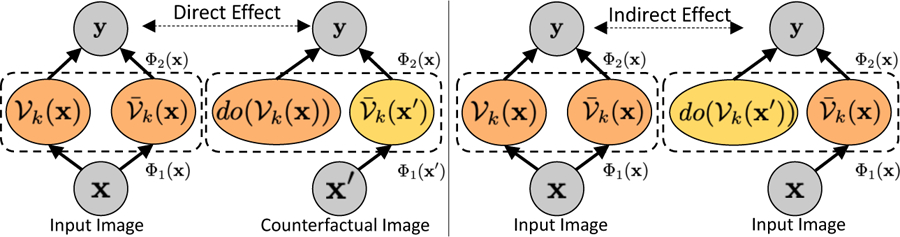
Illustration of direct and indirect effects in causal mediation analysis.
We compute indirect effect as the expected change in the outcome, if we change the mediator from its original value to its value using counterfactual, while holding everything else fixed to its original value,
| (4) |
If the perturbation has no effect on the mediator, then the causal indirect effect will be zero. Finally, we use the indirect effect associated with a concept, as a measure of its relevance to the classification decision.
2.3. Surrogate explanation function
We aim to learn a surrogate function g(·), such that it reproduces the outcome of the function f(·) using an interpretable and straightforward function. We formulated g(·) as a decision tree as many clinical decision-making procedures follow a rule-based pattern. We summarize the internal state of the function f(·) using output of k concept regression functions as follows,
| (5) |
Next, we fit a decision tree function, g(·), to mimic the outcome of the function f(·) as,
| (6) |
where is the splitting criterion based on minimizing entropy for highest information gain from every split.
3. Experiments
We first evaluated the concept classification performance and visualized concept-units to demonstrate their effectiveness in localizing a concept. Next, we summarized the indirect effects associated with different concepts across different layers of the classifier. We evaluated a proposing ranking of the concepts based on their causal contribution to the classification decision. Finally, we used the top-ranked concepts to learn a surrogate explanation function in the form of a decision tree. Data preprocessing: We perform experiments on the MIMIC-CXR [10] dataset, which is a multi-modal dataset consisting of 473K chest X-ray images and 206K reports. The dataset is labeled for 14 radiographic observations, including 12 pathologies. We used state-of-the-art DenseNet-121 [7] architecture for our classification function [9]. DenseNet-121 architecture is composed of four dense blocks. We experimented with three versions of Φ1(·) to represent the network until the second, third, and fourth dense block. For concept annotations, we considered radiographic features that are frequently mentioned in radiology reports in the context of labeled pathologies. Next, we used Stanford CheXpert [9] to extract and classify these observations from free-text radiology reports.
3.1. Evaluation of concept classifiers
The intermediate representations from third dense-block consistently outperformed other layers in concept classification. In Fig. 3, we show the testing-ROC-AUC and recall metric for different concept classifiers. All the concept classifiers achieved high recall, demonstrating a low false-negative (type-2) error.
Fig.3.
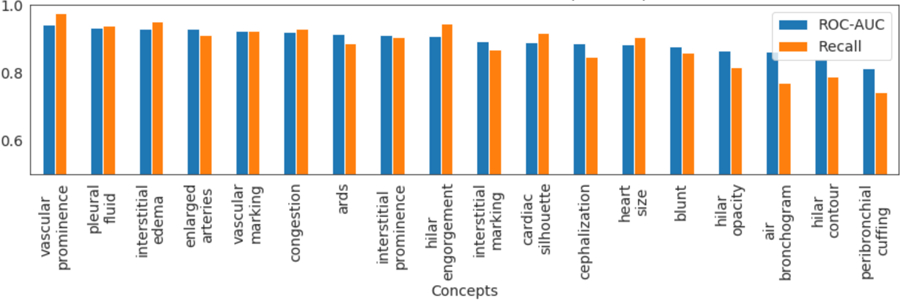
AUC-ROC and recall metric for different concept classifiers.
In Fig. 4, we visualize the activation map of hidden units associated with the concept vector . For each concept, we visualize hidden units that have large logistic regression-coefficient (βk). To highlight the most activated region for a unit, we threshold activation map by the top 1% quantile of the distribution of the selected units’ activations [2]. Consistent with prior work [3], we observed that several hidden units have emerged as concept detectors, even though concept labels were not used while training f. For cardiac-silhouette, different hidden units highlight different regions of the heart and its boundary with the lung. For localized concept such as blunt costophrenic angle, multiple relevant units were identified that all focused on the lower-lobe regions. Same hidden unit can be relevant for multiple concepts. The top label in Fig. 4. shows the top two important concepts for each hidden unit.
Fig.4.
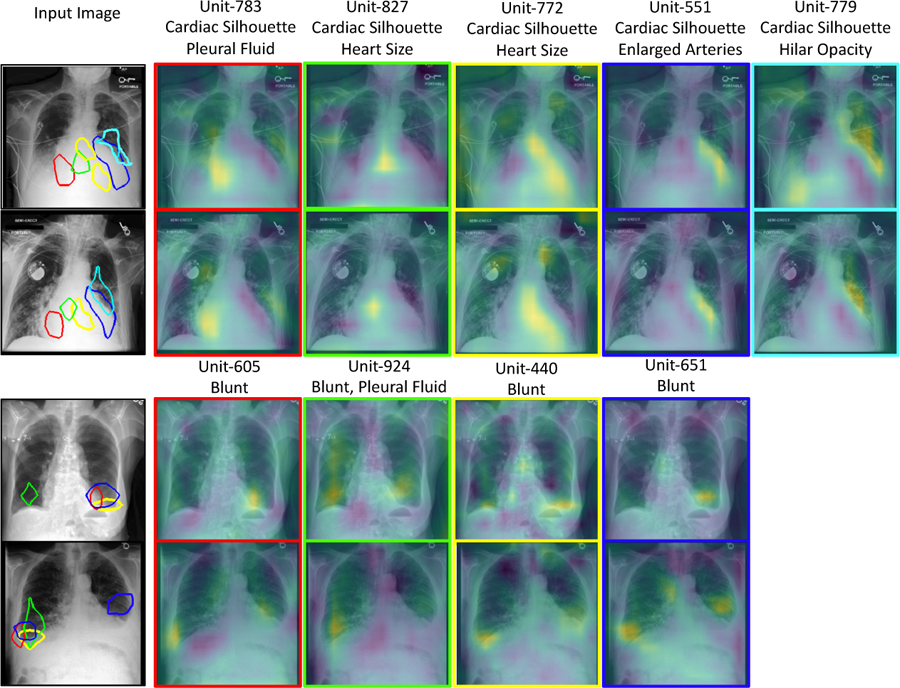
A qualitative demonstration of the activation maps of the hidden units that act as visual concept detectors. Each column represents one hidden unit identified as part of concept vector . Top two rows show k = cardiac-silhouette and bottom rows have k =blunt costophrenic angle.
3.2. Evaluating causal concepts using explanation function
We evaluate the success of the counterfactual intervention by measuring ATE. High values for ATE confirms that counterfactual image generated by [20] successfully flips the classification decision. We achieved an ATE of 0.97 for cardiomegaly, 0.89 for pleural effusion and 0.96 for edema. In Fig. 1 (heat-map), we show the distribution of the indirect effect associated with concepts, across different layers. The middle layer demonstrates a large indirect effect across all concepts. This shows that the hidden units in dense-block 3 played a significant role in mediating the effect of counterfactual intervention.
Fig.5.
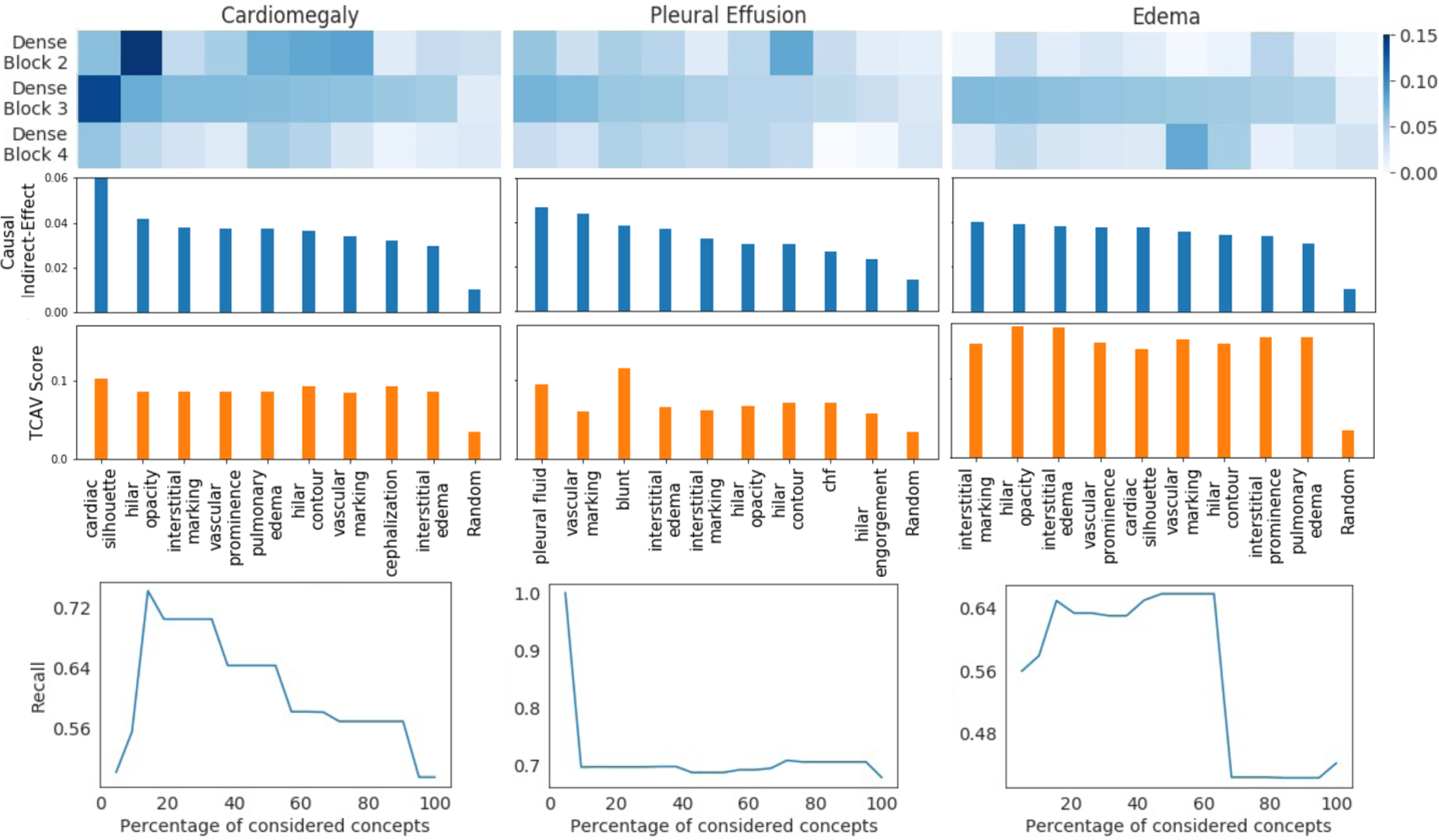
Indirect effects of the concepts, calculated over different layers of the DenseNet-121 architecture (heat-map). The derived ranking of the concepts based on their causal relevance to the diagnosis (bar-graph). A comparative ranking based on concept sensitivity score from TCAV [12]. The trend of recall metric for the decision tree function g(·), while training using top x% of top-ranked concepts (trend-plot).
In Fig. 5 (bar-graph), we rank the concepts based on their indirect effect. The top-ranked concepts recovered by our ranking are consistent with the radiographic features that clinicians associates with the examined three diagnoses [11,14,15]. Further, we used the concept sensitivity score from TCAV [12] to rank concepts for each diagnosis. The top-10 concepts identified by our indirect effect and TCAV are the same, while their order is different. The top-3 concepts are also the same, with minor differences in ranking. Both the methods have low importance score for random concept. This confirms that the trend in importance score is unlikely to be caused by chance. For our approach, random concept represents an ablation of the concept-association step. Here, rather than performing lasso regression to identify relevant units, we randomly select units.
To quantitatively demonstrate the effectiveness of our ranking, we iteratively consider x% of top-ranked concepts and retrain the explanation function g(w). In Fig. 5 (bottom-plot), we observe the change in recall metric for the classifier g(·) as we consider more concepts. In the beginning, as we add relevant concepts, the true positive rate increases resulting in a high recall. However, as less relevant concepts are considered, the noise in input features increased, resulting in a lower recall. Fig. 6 visualize the decision tree learned for the best performing model.
Fig.6.
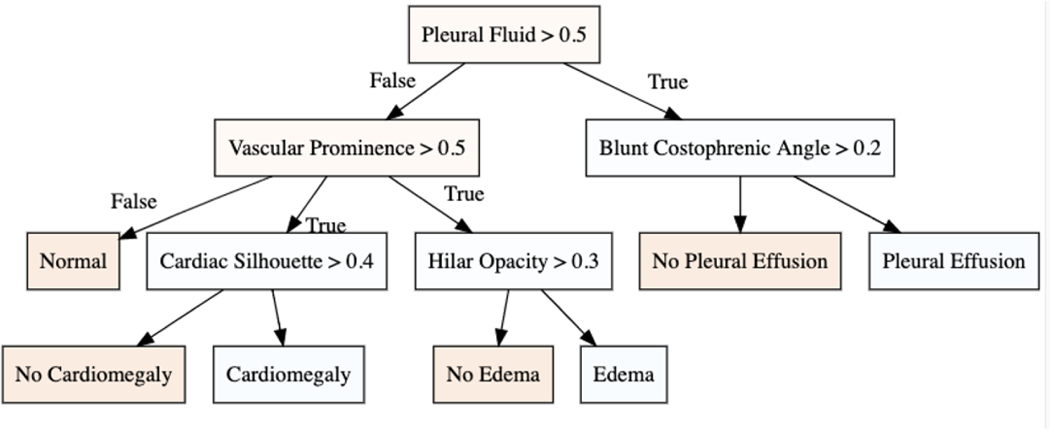
The decision tree for the three diagnosis with best performance on recall metric.
4. Conclusion
We proposed a novel framework to derive global explanation for a black-box model. Our explanation is grounded in terms of clinically relevant concepts that are causally influencing the model’s decision. As a future direction, we plan to extend our definition of concepts to include a broader set of clinical metrics.
Acknowledgement
This work was partially supported by NIH Award Number 1R01HL141813–01, NSF 1839332 Tripod+X, SAP SE, and Pennsylvania’s Department of Health. We are grateful for the computational resources provided by Pittsburgh SuperComputing grant number TG-ASC170024.
References
- 1.Basu S, Mitra S, Saha N: Deep learning for screening covid-19 using chest x-ray images In: IEEE Symposium Series on Computational Intelligence (SSCI) (2020) [Google Scholar]
- 2.Bau D, Zhou B, Khosla A, Oliva A, Torralba A: Network dissection: Quantifying interpretability of deep visual representations. In: IEEE Computer Vision and Pattern Recognition (CVPR) pp. 6541–6549 (2017) [Google Scholar]
- 3.Bau D, Zhu JY, Strobelt H, Lapedriza A, Zhou B, Torralba A: Understanding the role of individual units in a deep neural network. National Academy of Sciences 117(48), 30071–30078 (2020) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Clough JR, Oksuz I, Puyol-Antón E, Ruijsink B, King AP, Schnabel JA: Global and local interpretability for cardiac mri classification In: Medical Image Computing and Computer-Assisted Intervention (MICCAI). pp. 656–664 (2019) [Google Scholar]
- 5.Glass A, McGuinness DL, Wolverton M: Toward establishing trust in adaptive agents In: International Conference on Intelligent User Interfaces (2008) [Google Scholar]
- 6.Graziani M, Andrearczyk V, Marchand-Maillet S, Müller H: Concept attribution: Explaining cnn decisions to physicians. Computers in Biology and Medicine 123, 103865 (2020) [DOI] [PubMed] [Google Scholar]
- 7.Huang G, Liu Z, Van Der Maaten L, Weinberger KQ: Densely connected convolutional networks In: IEEE Computer Vision and Pattern Recognition (CVPR). pp. 4700–4708 (2017) [Google Scholar]
- 8.Imai K, Jo B, Stuart EA: Commentary: Using potential outcomes to understand causal mediation analysis. Multivariate Behavioral Research 46(5) (2011) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Irvin J, Rajpurkar P, Ko M, Yu Y, Ciurea-Ilcus S, Chute C, Marklund H, Haghgoo B, Ball R, Shpanskaya K, et al. : Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison In: AAAI Conference on Artificial Intelligence. vol. 33, pp. 590–597 (2019) [Google Scholar]
- 10.Johnson AE, Pollard TJ, Berkowitz SJ, Greenbaum NR, Lungren MP, Deng CY, Mark RG, Horng S: Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6(1) (2019) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Karkhanis VS, Joshi JM: Pleural effusion: diagnosis, treatment, and management. Open Access Emergency Medicine (OAEM) 4, 31 (2012) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Kim B, Wattenberg M, Gilmer J, Cai C, Wexler J, Viegas F, et al. : Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) In: International Conference on Machine Learning (ICML). pp. 2668–2677 (2018) [Google Scholar]
- 13.Lundberg SM, Lee SI: A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30, 4765–4774 (2017) [Google Scholar]
- 14.Milne E, Pistolesi M, Miniati M, Giuntini C: The radiologic distinction of cardiogenic and noncardiogenic edema. American Journal of Roentgenology 144(5), 879–894 (1985) [DOI] [PubMed] [Google Scholar]
- 15.Nakamori N, MacMahon H, Sasaki Y, Montner S, et al. : Effect of heart-size parameters computed from digital chest radiographs on detection of cardiomegaly. potential usefulness for computer-aided diagnosis. Investigative radiology 26(6), 546–550 (1991) [DOI] [PubMed] [Google Scholar]
- 16.Pearl J: Direct and indirect effects In: Conference on Uncertainty and Artificial Intelligence (UAI). pp. 411–420 (2001) [Google Scholar]
- 17.Ribeiro MT, Singh S, Guestrin C: “why should i trust you?” explaining the predictions of any classifier In: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 1135–1144 (2016) [Google Scholar]
- 18.Rubin DB: Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology 66(5), 688 (1974) [Google Scholar]
- 19.Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D: Grad-cam: Visual explanations from deep networks via gradient-based localization In: International Conference on Computer Vision (ICCV). pp. 618–626 (2017) [Google Scholar]
- 20.Singla S, Pollack B, Chen J, Batmanghelich K: Explanation by progressive exaggeration In: International Conference on Learning Representations (ICLR) (2019) [Google Scholar]
- 21.Vig J, Gehrmann S, Belinkov Y, Qian S, Nevo D, Singer Y, Shieber S: Investigating gender bias in language models using causal mediation analysis. In: Larochelle H, Ranzato M, Hadsell R, Balcan MF, Lin H (eds.) Advances in Neural Information Processing Systems vol. 33, pp. 12388–12401 (2020) [Google Scholar]
- 22.Yeche H, Harrison J, Berthier T: Ubs: A dimension-agnostic metric for concept vector interpretability applied to radiomics. In: Interpretability of Machine Intelligence in Medical Image Computing and Multimodal Learning for Clinical Decision Support (IMI-MICML-CDS), pp. 12–20. Springer; (2019) [Google Scholar]
- 23.Zhou B, Sun Y, Bau D, Torralba A: Interpretable basis decomposition for visual explanation In: European Conference on Computer Vision (ECCV). pp. 119–134 (2018) [Google Scholar]