

Abstract
Deep learning based reconstruction methods deliver outstanding results for solving inverse problems and are therefore becoming increasingly important. A recently invented class of learning-based reconstruction methods is the so-called NETT (for Network Tikhonov Regularization), which contains a trained neural network as regularizer in generalized Tikhonov regularization. The existing analysis of NETT considers fixed operators and fixed regularizers and analyzes the convergence as the noise level in the data approaches zero. In this paper, we extend the frameworks and analysis considerably to reflect various practical aspects and take into account discretization of the data space, the solution space, the forward operator and the neural network defining the regularizer. We show the asymptotic convergence of the discretized NETT approach for decreasing noise levels and discretization errors. Additionally, we derive convergence rates and present numerical results for a limited data problem in photoacoustic tomography.
Keywords: deep learning, inverse problems, discretization of NETT, regularization, convergence analysis, learned regularizer, limited data, photoacoustic tomography
1. Introduction
In this paper, we are interested in neural network based solutions to inverse problems of the form
| (1) |
Here is a potentially non-linear operator between Banach spaces and , are the given noisy data, x is the unknown to be recovered, is the unknown noise perturbation and indicates the noise level. Numerous image reconstruction problems, parameter identification tasks and geophysical applications can be stated as such inverse problems [1,2,3,4]. Special challenges in solving inverse problems are the non-uniqueness of the solutions and the instability of the solutions with respect to the given data. To overcome these issues, regularization methods are needed, which select specific solutions and at the same time stabilize the inversion process.
1.1. Reconstruction with Learned Regularizers
One of the most established class of methods for solving inverse problems is variational regularization where regularized solutions are defined as minimizers of the generelaized Tikhonov functional [2,5,6]
| (2) |
Here is a distance like function measuring closeness of the data, a regularization term enforcing regularity of the minimizer and is the regularization parameter. Taking minimizers of this functional as regularized solution is also called (generalized) Tikhonov regularization. In the case that and the regularizer are defined by the Hilbert space norms, (2) is classical Tikhonov regularization for which the theory is quite complete [1,7]. In particular, in this case, convergence rates, which name quantitative estimates for the distance between the true noise-free solution and regularized solutions from noisy data, are well known. Convergence rates for non-convex regularizers are derived in [8].
Typical regularization techniques are based on simple hand crafted regularization terms such as the total variation or quadratic Sobolev norms on some function space. However, these regularizers are quite simplistic and might not well reflect the actual complexity of the underlying class of functions. Therefore, recently, it has been proposed and analyzed in [9] to use machine learning to construct regularizers in a data driven manner. In particular, the strategy in [9] is to construct a data-driven regularizer via the following consecutive steps:
-
(T1)
Choose a family of desired reconstructions .
-
(T2)
For some , construct undesired reconstructions .
-
(T3)
Choose a class of functions (networks) .
-
(T4)
Determine with .
-
(T5)
Define with for some .
For imaging applications, the function class can be chosen as convolutional neural networks which have demonstrated to give powerful classes of mappings between image spaces. The function r measures distance between a potential reconstruction x and the output of the network , and possibly contains additional regularization [10,11]. According to the training strategy in item (T4) the value of the regularizer will be small if the reconstruction is similar to elements in and large for elements in . A simple example that we will use for our numerical results is the learned regularizer .
Convergence analysis and convergence rates for NETT (which stands for Network Tikhonov; referring to variants of (2), where the regularization term is given by a neural network) as well as training strategies have been established in [9,11,12]. A different training strategy for learning a regularizer has been proposed in [13,14]. Note that learning the regularizer first and then minimizing the Tikhonov functional is different from variational and iterative networks [15,16,17,18,19,20] where an iterative scheme is applied to enroll the functional which is then trained in an end to end fashion. Training the regularizer first has the advantage of being more modular, sharing some similarity with plug and play techniques [21], and the network training is independent of the forward operator . Moreover, it enables to derive a convergence analysis as the noise level tends to zero and therefore comes with theoretical recovery guarantees.
1.2. Discrete NETT
The existing analysis of NETT considers minimizers of the Tikhonov functional (2) with regularizer of the form before discretization, typically in an infinite dimensional setting. However, in practice, only finite dimensional approximations of the unknown, the operator and the neural network are given. To address these issues, in this paper, we study discrete NETT regularization which considers minimizers of
| (3) |
Here , and are families of subspaces of , mappings and regularizers , respectively, which reflect discretization of all involved operations. We present a full convergence analysis as the noise level converges to zero and are chosen accordingly. Discretization of variational regularization has studied in [22] for the case that is given by the norm distance and the regularizer is taken convex and fixed. However, in the case of discrete NETT regularization it is natural to consider the case where the regularization depends on the discretization as regularization is learned in a discretized setting based on actual data. For that purpose our analysis includes non-convex regularizers that are allowed to depend on the discretization and the noise level.
1.3. Outline
The convergence analysis including convergence rates is presented in Section 2. In Section 3 we will present numerical results for a non-standard limited data problem in photoacoustic tomography that can be considered as simultaneous inpainting and artifact removal problem. We conclude the paper with a short summary and conclusion presented in Section 4.
2. Convergence Analysis
In this section we study the convergence of (3) and derive convergence rates.
2.1. Well-Posedness
First we state the assumptions that we will use for well-posedness (existence and stability) of minimizing NETT.
Assumption 1
(Conditions for well-posedness).
- (W1)
, are Banach spaces, reflexive, weakly sequentially closed.
- (W2)
The distance measure satisfies
- (a)
.
- (b)
.
- (c)
.
- (d)
.
- (e)
is weakly sequentially lower semi-continuous (wslsc).
- (W3)
is proper and wslsc.
- (W4)
is weakly sequentially continuous.
- (W5)
is nonempty and bounded.
- (W6)
is a sequence of subspaces of .
- (W7)
is a family of weakly sequentially continuous .
- (W8)
is a family of proper wslsc regularizers .
- (W9)
is nonempty and bounded.
Conditions (W2)–(W5) are quite standard for Tikhonov regularization in Banach spaces to guarantee the existence and stability of minimizers of the Tikhonov functional and the given conditions are similar to [2,8,9,10,12,23,24]. In particular, (W2) describes the properties that the distance measure should have. Clearly, the norm distance on fulfills these properties. Moreover, (W2a) holds for the norm with since it then corresponds to the triangle inequality. Item (W2c) is the continuity of while (W2d) considers the continuity of at y. While (W2c) is not needed for existence and convergence of NETT it is required for the stability result as shown in [10] (Example 2.7). On the other hand (W2e) implies that the Tikhonov functional is wslsc which is needed for existence. Assumption (W5) is a coercivity condition; see [9] (Remark 2.4f.) on how to achieve this for a regularizer defined by neural networks. Item (W8) poses some restrictions on the regularizers. For NETT this is not an issue as neural networks used in practice are continuous. Note that for convergence and convergence rates we will require additional conditions that concern the discretization of the reconstruction space, the forward operator and regularizer.
The references [8,9,10,23] all consider general distance measures and allow non-convex regularizers. However, existence and stability of minimizing (2) are shown under assumptions slightly different from (W1)–(W5). Below we therefore give a short proof of the existence and stability results.
Theorem 1
(Existence and Stability). Let Assumption 1 hold. Then for all , , the following assertions hold true:
- (a)
.
- (b)
Let with and consider .
has at least one weak accumulation point.
Every weak accumulation point is a minimizer of .
- (c)
The statements in (a),(b) also hold for in place of ,
Proof.
Since (W1), (W6)–(W9) for when are fixed give the same assumption as (W1), (W3)–(W5) for the non-discrete counterpart , it is sufficient to verify (a), (b) for the latter. Existence of minimizers follows from (W1), (W2e), (W3)–(W5), because these items imply that the is a wslsc coercive functional defined on a nonempty weakly sequentially closed subset of a reflexive Banach space. To show stability one notes that according to (W2a) for all we have
According to (W2c), (W2d), (W5) there exists such that the right hand side is bounded, which by (W5) shows that has a weak accumulation point. Following the standard proof [2] (Theorem 3.23) shows the weak accumulation points are minimizers of . This uses the fact that the weak topology is indeed weaker than the norm topology, and that the involved functionals are wslsc. □
In the following we write for minimizers of . For we call an -minimizing solution of .
Lemma 1
(Existence of -minimizing solutions). Let Assumption 1 hold. For any an -minimizing solution of exists. Likewise, if and an -minimizing solution of exists.
Proof.
Again is is sufficient the verify the claim for -minimizing solution. Because , the set is non-empty. Hence we can choose a sequence in with . Due to (W2b), is contained in for some which is bounded according to (W5). By (W1) is reflexive and therefore has a weak accumulation point . From (W1), (W4), (W3) we conclude that is an -minimizing solution of . The case of -minimizing solutions follows analogous. □
2.2. Convergence
Next we proof that discrete NETT converges as the noise level goes to zero and the discretization as well as the regularization parameter are chosen properly. We write and formulate the following approximation conditions for obtaining convergence.
Assumption 2
(Conditions for convergence).
Element satisfies the following for all :
- (C1)
with .
- (C2)
.
- (C3)
.
- (C4)
.
Conditions (C1) and (C3) concerns the approximation of the true unknown x with elements in the discretization space, that is compatible with the discretization of the forward operator and regularizer. Conditions (C2) and (C4) are uniform approximation properties of the operator and the regularizer on -bounded sets.
Theorem 2
(Convergence). Let (W1)–(W9) hold, and let be an -minimizing solution of that satisfies (C1)–(C4). Moreover, suppose converges to zero and satisfies . Choose and such that as we have
(4)
(5)
(6) Then for the following hold:
- (a)
has a weakly convergent subsequence
- (b)
The weak limit of is an -minimizing solution of .
- (c)
, where is the weak limit of .
- (d)
If the -minimizing solution of is unique, then .
Proof.
For convenience and some abuse of notation we use the abbreviations , , , and . Because is a minimizer of the discrete NETT functional by (W2) we have
According to (C1), (4), we get
(7)
(8) According to (C1), (C3), (5), (6) the right hand side in (7) converges to zero and the right hand side in (8) to . Together with (C2) we obtain and . This shows that is bounded and by (W1), (W9) there exists a weakly convergent subsequence . We denote the weak limit by . From (W2), (W4) we obtain . The weak lower semi-continuity of assumed in (W3) shows
Consequently, is an -minimizing solution of and . If the -minimizing solution is unique then is the only weak accumulation point of which concludes the proof. □
2.3. Convergence Rates
Next we derive quantitative error estimates (convergence rates) in terms of the absolute Bregman distance. Recall that a function is Gâteaux differentiable at some if the directional derivative exist for every . We denote by the Gâteaux derivative of at x. In [9] we introduced the absolute Bregman distance of a Gâteaux differentiable functional at with respect to defined by
| (9) |
We write . Convergence rates in terms of the Bregman distance are derived under a smoothness assumption on the true solution in the form of a certain variational inequality. More precisely we assume the following:
Assumption 3
(Conditions for convergence rates).
Element satisfies the following for all :
- (R1)
Items (C1), (C2) hold.
- (R2)
.
- (R3)
.
- (R4)
is Gâteaux differentiable at
- (R5)
There exist a concave, continuous, strictly increasing with and such that for all
According to (R5) the inverse function exists and is convex. We denote by its Fenchel conjugate.
Proposition 1
(Error estimates). Let and be an -minimizing solution of such that (W1)–(W9) and (R1)–(R5) are satisfied. For with let . Then for sufficient small and sufficiently large , we have the error estimate
(10)
Proof.
According to Theorem 2 we can assume and with (R5) we obtain
For the second inequality we used (C1) and (C2). We have and thus we get an estimate for which we used for the third inequality. For the next inequality we used (R2) and (R3). Finally we used Young’s inequality for the last step. □
Remark 1.
The error estimate (10) includes the approximation quality of the discrete or inexact forward operator and the discrete or inexact regularizer described by and , respectively. What might be unexpected at first is the inclusion of two new parameters and . These factors both arise from the approximation of by the finite dimensional spaces , where reflects approximation accuracy in the image of the operator and approximation accuracy with respect to the true regularization functional . Note that in the case where the forward operator, the regularizer, and the solution space are given precisely, we have . In this particular case we recover the estimate derived for the NETT in [9].
Theorem 3
(Convergence rates). Let the assumptions of Proposition 1 hold and consider the parameter choice rule and let the approximation errors satisfy , . Then we have the convergence rate
(11)
Proof.
Noting that remains bounded as , this directly follows from Proposition 1. □
Next we verify that a variational inequality of the form (R5) is satisfied with under a typical source like condition.
Lemma 2
(Variational inequality under source condition). Let , be Gâteaux differentiable at , consider the distance measure and assume there exist and with such that for all with we have
(12) Then (R5) holds with and .
Proof.
Let with . Using the Cauchy-Schwarz inequality and Equation (12), we can estimate
Additionally, if , we have , and on the other hand if , we have . Putting this together we get
and thus . □
Corollary 1
(Convergence rates under source condition). Let the conditions of Lemma 2 hold and suppose
Then we have the convergence rates result
(13)
Proof.
Follows from Theorem 3 and Lemma 2. Note that we use in the theorem, while uses the squared norm and thus the approximation rates for the terms concerning are order instead of as in Theorem 3. □
In Corollary 1, the approximation quality of the discrete operator and the discrete and inexact regularization functional need to be of the same order.
3. Application to a Limited Data Problem in PAT
Photoacoustic Tomography (PAT) is an emerging non-invasive coupled-physics biomedical imaging technique with high contrast and high spatial resolution [25,26]. It works by illuminating a semi-transparent sample with short optical pulses which causes heating of the sample followed by expansion and the subsequent emission of an acoustic wave. Sensors on the outside of the sample measure the acoustic wave and these measurements are then used to reconstruct the initial pressure , which provides information about the interior of the object. The cases and are relevant for applications in PAT. Here we only consider the case and assume a circular measurement geometry. The 2D case arises for example when using integrating line detectors in PAT [26].
3.1. Discrete Forward Operator
The pressure data satisfies the wave equation with initial data and . In the case of circular measurement geometry one assumes that f vanishes outside the unit disc and the measurement sensors are located on the boundary . We assume that the phantom will not generate any data for some region , for example when the acoustic pressure generated inside I is too small to be recorded. This masked PAT problem consists in the recovery of the function f from sampled noisy measurements of where denotes the solution operator of the wave equation and the indicator function on . Note that the resulting inverse problem can be seen of the combination of an inpainting problem and in inverse problems for the wave equation.
In order to implement the PAT forward operator we use a basis ansatz where are basis coefficients and a generalized Kaiser-Bessel (KB) and with . The generalized KB functions are popular in tomographic inverse problems [27,28,29,30] and denote radially symmetric functions with support in defined by
| (14) |
Here is the modified Bessel function of the first kind of order and the parameters and R denote the window taper and support radius, respectively. Since is linear we have . For convenience we will use a pseudo-3D approach where use the 3D solution of for which there exists an analytical representation [29]. Denote by uniformly spaced sensor locations on and by uniformly sampled measurement times in . Define the model matrix by and an diagonal matrix by if and zero otherwise. Let be the singular valued decomposition. We then consider the discrete forward matrix where is the diagonal matrix derived from by setting singular values smaller than some to zero. This allows us to easily calculate where is calculated by inverting all diagonal elements of that are greater than zero. In our experiments we use , and take I fixed as a diagonal stripe of width .
3.2. Discrete NETT
We consider the discrete NETT with discrepancy term and regularizer given by
| (15) |
where with is a smooth version of the total variation [31] and is a learnable network. We take as the U-Net [32] with residual connection, which has first been applied to PAT image reconstruction in [33]. Here m stands for the number of down-/upsampling steps performed in the U-Net (the original one had i.e., . This means that larger m yield a deeper network with more parameters. We generate training data that consist of square shaped rings with random profile and random location. See Figure 1 for an example of one such phantom (note that all plots in signal space use the same colorbar) and the corresponding data. We get a set of phantoms and corresponding basic reconstructions , where is the pseudo-inverse and is Gaussian noise with standard deviation of with . The networks are trained by minimizing where we used the Adam optimizer with learning rate 0.01 and . The considered loss is that we want the trained regularizer to give small values for and large values for . The strategy is similar to [9] but we use the final output of the network for the regularizer as proposed in [34]. To minimize (15) we use Algorithm 1 which implements a forward-backward scheme [35]. The most expensive step of this algorithm is the matrix inversion but since we use constant stepsize one also has to option to only calculate the inverse of the matrix once and reuse it. Thus one only has to perform two matrix-vector multiplications which are of the order and since is the dimension of our phantoms. On the other hand calculating the gradient has similar complexity than applying the neural network which is in the order with F the number of convolution channels and L the number of layers.
| Algorithm 1: NETT optimization. |
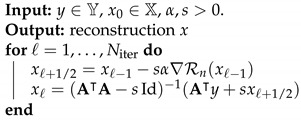 |
Figure 1.

Top from left to right: phantom, masked phantom, and initial reconstruction . The difference between the phantoms on the left and the middle one shows the mask region where no data is generated. Bottom from left to right: data without noise, low noise , and high noise .
3.3. Numerical Results
For the numerical results we train two regularizers and as described in Section 3.2. The networks are implemented using PyTorch [36]. We also use PyTorch in order to calculate the gradient . We take , and in Algorithm 1 and compute the inverse only once and then use it for all examples. We set for the noise-free case, for the low noise case and for the high noise cases, respectively, and selected a fixed . We expect that the NETT functional will yield better results due to data consistency, which is mainly helpful outside the masked center diagonal.
First we use the phantom from the testdata shown in Figure 1. The results using post processing and NETT are shown in Figure 2. One sees that all results with higher noise than used during training are not very good. This indicates that one should use similar noise as in the later applications even for the NETT. Figure 3 shows the average error using 10 test phantoms similar to the on in Figure 1. Careful numerical comparison of the numerical convergence rates and the theoretical results of Theorem 1 is an interesting aspect of further research. To investigate the stability of our method with respect to phantoms that are different from the training data we create a phantom with different structures as seen in Figure 4. As expected, the post processing network is not really able to reconstruct the circles object, since it is quite different from the training data, but it also does not break down completely. On the other hand, the NETT approach yields good results due to data consistency.
Figure 2.

Top row: reconstructions using post-processing network . Middle row: NETT reconstructions using . Bottom row: NETT reconstructions using . From Left to Right: Reconstructions from data without noise, low noise () and high noise (.
Figure 3.

Semilogarithmic plot of the mean squared errors of the NETT using and depending on the noise level. The crosses are the values for the phantoms in Figure 2.
Figure 4.

Left column: phantom with a structure not contained in the training data (top) and pseudo inverse reconstruction (bottom). Middle column: Post-processing reconstructions with using exact (top) and noisy data (bottom). Right column: NETT reconstructions with using exact (top) and noisy data (bottom).
4. Conclusions
We have analyzed the convergence a discretized NETT approach and derived the convergence rates under certain assumptions on the approximation quality of the involved operators. We performed numerical experiments using a limited data problem for PAT that is the combination of an inverse problem for the wave equation and an inpainting problem. To the best of our knowledge this is the first such problem studied with deep learning. The NETT approach yields better results that post processing for phantoms different from the training data. NETT still fails to recover some missing parts of the phantom in cases the data contains more noise than the training data. This highlights the relevance of using different regularizers for different noise levels. Finding ways to make the regularizers less dependent on the noise level used during training is a possible future research direction. Another interesting question is if this results can be combined with with approximation error estimates for neural networks e.g., [37,38]. It seems not obvious how these two approaches can be combined. Furthermore, studying how one can define neural network based regularizers that fulfill (12) might also be an interesting line of future research.
Author Contributions
M.H. prosed the conceptualization, framework and the long term vision of the work. M.H and S.A. developed the ideas, performed the formal analysis and have written and edited the paper. S.A. conducted the numerical experiments and has written the software. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported bay the Austrian Science Fund (FWF), project P 30747-N32.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data and code are freely available upon request.
Conflicts of Interest
The authors declare no conflict of interest.
Footnotes
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Engl H.W., Hanke M., Neubauer A. Mathematics and Its Applications. Volume 375 Kluwer Academic Publishers Group; Dordrecht, The Netherlands: 1996. Regularization of Inverse Problems. [Google Scholar]
- 2.Scherzer O., Grasmair M., Grossauer H., Haltmeier M., Lenzen F. Applied Mathematical Sciences. Volume 167 Springer; New York, NY, USA: 2009. Variational methods in imaging. [Google Scholar]
- 3.Natterer F., Wübbeling F. Monographs on Mathematical Modeling and Computation. Volume 5 SIAM; Philadelphia, PA, USA: 2001. Mathematical Methods in Image Reconstruction. [Google Scholar]
- 4.Zhdanov M.S. Geophysical Inverse Theory and Regularization Problems. Volume 36 Elsevier; Amsterdam, The Netherlands: 2002. [Google Scholar]
- 5.Morozov V.A. Methods for Solving Incorrectly Posed Problems. Springer; New York, NY, USA: 1984. [Google Scholar]
- 6.Tikhonov A.N., Arsenin V.Y. Solutions of Ill-Posed Problems. John Wiley & Sons; Washington, DC, USA: 1977. [Google Scholar]
- 7.Ivanov V.K., Vasin V.V., Tanana V.P. Theory of Linear Ill-Posed Problems and Its Applications. 2nd ed. VSP; Utrecht, The Netherlands: 2002. (Inverse and Ill-posed Problems Series). [Google Scholar]
- 8.Grasmair M. Generalized Bregman distances and convergence rates for non-convex regularization methods. Inverse Probl. 2010;26:115014. doi: 10.1088/0266-5611/26/11/115014. [DOI] [Google Scholar]
- 9.Li H., Schwab J., Antholzer S., Haltmeier M. NETT: Solving inverse problems with deep neural networks. Inverse Probl. 2020;36:065005. doi: 10.1088/1361-6420/ab6d57. [DOI] [Google Scholar]
- 10.Obmann D., Nguyen L., Schwab J., Haltmeier M. Sparse ℓq-regularization of Inverse Problems Using Deep Learning. arXiv. 20191908.03006 [Google Scholar]
- 11.Obmann D., Nguyen L., Schwab J., Haltmeier M. Augmented NETT regularization of inverse problems. J. Phys. Commun. 2021;5:105002. doi: 10.1088/2399-6528/ac26aa. [DOI] [Google Scholar]
- 12.Haltmeier M., Nguyen L.V. Regularization of Inverse Problems by Neural Networks. arXiv. 20202006.03972 [Google Scholar]
- 13.Lunz S., Öktem O., Schönlieb C.B. Adversarial Regularizers in Inverse Problems. NIPS; Montreal, QC, Canada: 2018. pp. 8507–8516. [Google Scholar]
- 14.Mukherjee S., Dittmer S., Shumaylov Z., Lunz S., Öktem O., Schönlieb C.B. Learned convex regularizers for inverse problems. arXiv. 20202008.02839 [Google Scholar]
- 15.Adler J., Öktem O. Solving ill-posed inverse problems using iterative deep neural networks. Inverse Probl. 2017;33:124007. doi: 10.1088/1361-6420/aa9581. [DOI] [Google Scholar]
- 16.Aggarwal H.K., Mani M.P., Jacob M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans. Med. Imaging. 2018;38:394–405. doi: 10.1109/TMI.2018.2865356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.de Hoop M.V., Lassas M., Wong C.A. Deep learning architectures for nonlinear operator functions and nonlinear inverse problems. arXiv. 20191912.11090 [Google Scholar]
- 18.Kobler E., Klatzer T., Hammernik K., Pock T. Variational networks: Connecting variational methods and deep learning; Proceedings of the German Conference on Pattern Recognition; Basel, Switzerland. 12–15 September 2017; Cham, Switzerland: Springer; 2017. pp. 281–293. [Google Scholar]
- 19.Yang Y., Sun J., Li H., Xu Z. Deep ADMM-Net for Compressive Sensing MRI; Proceedings of the 30th International Conference on Neural Information Processing Systems; Barcelona, Spain. 5–10 December 2016; pp. 10–18. [Google Scholar]
- 20.Shang Y. Subspace confinement for switched linear systems. Forum Math. 2017;29:693–699. doi: 10.1515/forum-2015-0188. [DOI] [Google Scholar]
- 21.Romano Y., Elad M., Milanfar P. The little engine that could: Regularization by denoising (RED) SIAM J. Imaging Sci. 2017;10:1804–1844. doi: 10.1137/16M1102884. [DOI] [Google Scholar]
- 22.Pöschl C., Resmerita E., Scherzer O. Discretization of variational regularization in Banach spaces. Inverse Probl. 2010;26:105017. doi: 10.1088/0266-5611/26/10/105017. [DOI] [Google Scholar]
- 23.Pöschl C. Ph.D. Thesis. University of Innsbruck; Innsbruck, Austria: 2008. Tikhonov Regularization with General Residual Term. [Google Scholar]
- 24.Tikhonov A.N., Leonov A.S., Yagola A.G. Applied Mathematics and Mathematical Computation. Volumes 1, 2 and 14 Chapman & Hall; London, UK: 1998. Nonlinear ill-posed problems. Translated from the Russian. [Google Scholar]
- 25.Kruger R., Lui P., Fang Y., Appledorn R. Photoacoustic ultrasound (PAUS)—Reconstruction tomography. Med. Phys. 1995;22:1605–1609. doi: 10.1118/1.597429. [DOI] [PubMed] [Google Scholar]
- 26.Paltauf G., Nuster R., Haltmeier M., Burgholzer P. Photoacoustic tomography using a Mach-Zehnder interferometer as an acoustic line detector. Appl. Opt. 2007;46:3352–3358. doi: 10.1364/AO.46.003352. [DOI] [PubMed] [Google Scholar]
- 27.Matej S., Lewitt R.M. Practical considerations for 3-D image reconstruction using spherically symmetric volume elements. IEEE Trans. Med. Imaging. 1996;15:68–78. doi: 10.1109/42.481442. [DOI] [PubMed] [Google Scholar]
- 28.Schwab J., Pereverzyev S., Jr., Haltmeier M. A Galerkin least squares approach for photoacoustic tomography. SIAM J. Numer. Anal. 2018;56:160–184. doi: 10.1137/16M1109114. [DOI] [Google Scholar]
- 29.Wang K., Schoonover R.W., Su R., Oraevsky A., Anastasio M.A. Discrete Imaging Models for Three-Dimensional Optoacoustic Tomography Using Radially Symmetric Expansion Functions. IEEE Trans. Med. Imaging. 2014;33:1180–1193. doi: 10.1109/TMI.2014.2308478. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Wang K., Su R., Oraevsky A.A., Anastasio M.A. Investigation of iterative image reconstruction in three-dimensional optoacoustic tomography. Phys. Med. Biol. 2012;57:5399. doi: 10.1088/0031-9155/57/17/5399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Acar R., Vogel C.R. Analysis of bounded variation penalty methods for ill-posed problems. Inverse Probl. 1994;10:1217. doi: 10.1088/0266-5611/10/6/003. [DOI] [Google Scholar]
- 32.Ronneberger O., Fischer P., Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab N., Hornegger J., Wells W.M., Frangi A.F., editors. Proceedings of the MICCAI 2015; Munich, Germany. 5–9 October 2015; Cham, Switzerland: Springer; 2015. pp. 234–241. [Google Scholar]
- 33.Antholzer S., Haltmeier M., Schwab J. Deep learning for photoacoustic tomography from sparse data. Inverse Probl. Sci. Eng. 2019;27:987–1005. doi: 10.1080/17415977.2018.1518444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Antholzer S., Schwab J., Bauer-Marschallinger J., Burgholzer P., Haltmeier M. NETT regularization for compressed sensing photoacoustic tomography; Proceedings of the Photons Plus Ultrasound: Imaging and Sensing 2019; San Francisco, CA, USA. 3–6 February 2019; p. 108783B. [Google Scholar]
- 35.Combettes P.L., Pesquet J.C. Fixed-Point Algorithms for Inverse Problems in Science and Engineering. Springer; Berlin/Heidelberg, Germany: 2011. Proximal splitting methods in signal processing; pp. 185–212. [Google Scholar]
- 36.Paszke A., Gross S. PyTorch: An Imperative Style, High-Performance Deep Learning Library. NIPS; Montreal, QC, Canada: 2018. pp. 8024–8035. [Google Scholar]
- 37.Hornik K. Some new results on neural network approximation. Neural Netw. 1993;6:1069–1072. doi: 10.1016/S0893-6080(09)80018-X. [DOI] [Google Scholar]
- 38.Barron A.R. Approximation and estimation bounds for artificial neural networks. Mach. Learn. 1994;14:115–133. doi: 10.1007/BF00993164. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data and code are freely available upon request.