

Abstract
In cluster randomized trials (CRTs) groups rather than individuals are randomized to different interventions. Individuals’ responses within clusters are commonly more similar than those across clusters. This dependency introduces complexity when calculating the number of clusters required to reach a specified statistical power for nominal significance levels and effect sizes. Current CRTs’ sample size estimation approaches rely on asymptotic-based formulae or Monte Carlo methods. We propose a new Monte Carlo procedure which is based on the potential outcomes framework. By explicitly defining the causal estimand, the data generating, the sampling, and the treatment assignment mechanisms, this procedure allows for sample size calculations in a broad range of study designs including sample size calculations in finite and infinite populations. It can also address financial and administrative considerations by allowing for unequal allocation of clusters. The R package CRTsampleSearch implements the method and we provide examples for using this package.
Keywords: cluster randomized trials, sample size estimation, potential outcomes framework, causal estimand
1. Introduction
Cluster randomized trials (CRTs) have been increasingly used to evaluate public health and public policy interventions in groups defined by social organizations or geographical areas [1]. In CRTs, groups of subjects rather than individual units are randomized to treatment arms. Randomization at the cluster level may be preferred in order to reduce costs and administrative burden, or necessary when the implementation of the treatment at the individual level is impractical [2]. CRTs can also help reduce experimental contamination, which may occur when individuals assigned to different treatment arms are in frequent contact or influence one another [3]. For example, in a vaccine trial, individuals are protected by the administered vaccine as well as by the vaccination status of other individuals with whom they interact. Using CRTs, researchers can reduce the possible ‘spillover’ effect and estimate the effect of vaccination more precisely. However, responses from individuals within a cluster are likely to be more similar than those from different clusters. This potential dependency introduces complexity to the design and analysis of CRTs.
An important component of clinical trial design is determining the minimal sample size that is required to reach a specific statistical power for a given significance level, a null hypothesis, and an alternative hypothesis. In CRTs, both the number of clusters and the size of the clusters influence the power. However, with large within-cluster correlation and clusters with many units, an increase in the number of units within clusters may only add little to the statistical power [3]. Therefore, in order to increase the statistical power, increasing the number of clusters in a study is preferred to increasing the number of units in existing clusters [4]. As a result, the focus of sample size estimation for CRTs is on the number of clusters, while cluster sizes are commonly assumed to be fixed or follow a prespecified distribution.
Many papers propose closed-form formulae for calculating the required number of clusters for CRTs [2,5,6]. These formulae generally rely on the asymptotic Normal approximation of the difference in means, proportions, or rates under the randomization and sampling distributions. However, these approximations may not be accurate because in many CRTs only a small number of clusters are randomized. In addition, the formulae are derived for specific distributions. Specifically, the Normal distribution for continuous outcomes, the Bernoulli distribution for binary outcomes, and the Poisson distribution for event count outcomes. These distributional assumptions could lead to inaccurate sample size estimation when the outcome variable does not follow one of these three distributions. In addition, these formulae assume that the assignment of clusters to treatments follows simple randomization, and limited attention was given to other assignment mechanisms such as stratified randomization [7]. Lastly, when the test statistic is not the difference in expectations, the relationship between power and the number of clusters can be difficult to derive analytically. For example, the treatment effect estimated from a Generalized Estimating Equation (GEE) is of particular interest in CRTs, and sample size estimation formulae have only been derived under specific restrictions on the covariance structure [2,7].
To address some of these limitations, Monte Carlo approaches have been used to approximate the relationship between statistical power and sample size [8-10]. To simulate a study’s data, three mechanisms should be considered: the data generating mechanism, the sampling mechanism, and the treatment assignment mechanism. The data generating mechanism defines the distribution of the outcomes in the two treatment arms. The sampling mechanism defines the procedure for sampling units from the population. The treatment assignment mechanism defines the procedure for allocating units to the different treatment arms. Previously proposed simulation procedures concentrate on defining the data generating mechanism while implicitly assuming that the clusters are selected into the study using simple random sampling [11], and that clusters are allocated to the treatment arms using simple randomization [12]. To test for an effect of the treatment, these Monte Carlo procedures commonly use a parameter in a model as the test statistic and rely on asymptotic approximations to examine whether this parameter is different from a null value. In many CRTs, other forms of randomization (e.g. stratified randomization) are adopted to achieve better covariates’ balanced across treatment arms. These assignment mechanisms are not implemented in current Monte Carlo procedures. In addition, the asymptotic approximations for the variance of the test parameter may not be accurate when the number of clusters is small.
In many CRTs, researchers have access to datasets that can inform various design aspects of the trials. Recently, the NIH created a funding mechanism that involves a pilot phase and the main trial phase [13]. These pilots are implemented within healthcare systems and they could result in individual-level information on current patients from electronic health records. This information is extremely valuable when designing a future trial [13].
The goal of randomized experiments is to estimate the causal effects of treatments. The Neyman–Rubin potential outcomes framework provides the theoretical basis for statistical analysis of causal effects [14]. We propose a new simulation-based approach for sample size estimation for CRTs based on the potential outcomes framework. The proposed procedure explicitly defines the causal estimand, the data generating mechanism, the sampling mechanism, and the treatment assignment mechanism. These mechanisms can be flexibly defined using hypothetical and empirical distributions. The procedure can also incorporate hypothesis tests for any population parameter, as well as the permutation test for Fisher’s sharp null hypothesis. Lastly, the proposed procedure allows for unequal allocation of units across treatment arms to adjust for financial or administrative considerations. We provide an R package, CRTsampleSearch, that takes as input user-defined mechanisms and returns the required number of clusters to reach a prespecified power for a given nominal level.
The manuscript proceeds as follows: Section 2 provides a brief introduction to the potential outcome framework for CRTs. Section 3 summarizes existing approaches for sample size estimation for CRTs. The newly proposed approach to estimate the power of a test is described in Section 4 and an efficient binary search algorithm for estimating the optimal sample size is described in Section 5. Section 6 provides simulation experiments comparing the proposed simulation-based approach with the asymptotic formulae. Section 7 demonstrates the flexibility of the simulation-based approach using data from a recent CRT and discusses the effects of sampling correlation when there is a finite number of clusters. Section 8 provides discussion and conclusions.
2. Notation and causal framework
Consider a two-arm CRT aimed at evaluating the effects of a binary treatment W on an outcome Y. Let N be the number of clusters in the target population and Mi be the size of cluster i ∈ {1, … , N}, both of N and Mi are possibly infinite. Before the receipt of the treatment, individual j in cluster i has two potential outcomes: Yij(1), the outcome to be observed for individual j if cluster i is assigned to the treatment arm (Wij = 1), and Yij(0), the outcome to be observed for individual j if cluster i is assigned to the control arm (Wij = 0). We assume the Stable Unit Treatment Value Assumption (SUTVA) so that these potential outcomes are well-defined [14,15]. Because an individual can only be assigned to either the control or the treatment arm, only one of the two potential outcomes is observable. The observed outcome for individual j in cluster i is
| (1) |
Let Rij ∈ {0, 1} be an indicator representing if unit j in cluster i is included in the study, and indicates if cluster i is included in the study, where is an indicator function that is equal to 1 if any Rij = 1 and 0 otherwise. With a sample of n ≤ N clusters of sizes m = (m1, m2, … , mn), the two potential outcomes vectors are Y(0) = (Y11(0), Y12(0), … , Yn,mn(0))⊤ and Y(1) = (Y11(1), Y12(1), … , Yn,mn(1))⊤. Denote the indicator for treatment assignment as W = (W11, W12, …, Wn,mn)⊤. In a CRT the treatment is assigned at the cluster-level, Wij = Wi ∀ i ∈ 1, 2, … , n and j ∈ 1, 2, … , mi. The observed data is and a test statistic T is a function of the observed values. Formally,
where X = {Xij} is a set of pre-treatment covariates representing characteristics of the enrolled clusters and individuals, and ⊙ represents component-wise multiplication.
In the context of sample size estimation, T is stochastic through the data generating mechanism, the sampling mechanism, and the treatment assignment mechanism. The data generating mechanism defines the ‘science’, P(Y(0), Y(1), X) [16], which is the joint distribution of the potential outcomes and the covariates. The effect of the treatment under the null and the alternative hypotheses are explicitly defined by the data generating mechanism. The sampling mechanism, P(Rij ∣ X), also referred to as the recording mechanism [17], defines the process of selecting the n clusters and m units into the study. In CRTs, it is commonly assumed that clusters are selected into the study based on a predefined sampling mechanism, while units within clusters are sampled completely at random from their target population. Thus, the sampling mechanism is commonly defined by P(Ri ∣ X, n). The treatment assignment mechanism, P(W ∣ X), defines the process by which the sampled units are assigned to different treatment arms. For example, treatments can be assigned completely at random to clusters or with different randomization schemes.
Hypothesis testing examines the distribution of the test statistic T under the null hypothesis, H0. The null hypothesis is rejected if the probability of observing the value T or more extreme values are smaller than a prespecified significance level. The power of a hypothesis test represents the likelihood of rejecting H0 when the alternative hypothesis, Ha, is true. Let PH0 and PHa be the distribution of T under P(Y(0), Y(1), X) such that H0 or Ha is satisfied, respectively. Let θi be the αi quantile of the distribution of the test statistic under H0 : PH0 (T ≤ θi) = αi. For a given significance level α, the statistical power of a two-sided test comparing H0 against Ha is
| (2) |
where α1 + (1 – α2) = α. In many applications θ1 and θ2 are chosen such that α1 = 1 – α2 = α/2.
A key component of sample size estimation is to examine the relationship between statistical power and sample size, for a given data-generating mechanism, assignment mechanism, and sampling mechanism.
3. Existing sample size estimation methods
3.1. Formulae for CRTs
The statistics literature includes sample size estimation formulae for continuous, binary, event count, or time-to-event outcomes, and when the test statistic is the difference in sample means or parameters estimated from a GEE model [2,5,7,18]. We summarize some of the existing formulae using the potential outcome framework and discuss the implied assumptions regarding the data generating, sampling, and treatment assignment mechanisms. All of the formulae require the identification of five basic parameters: the significance level (α), the average effect size (δ), the minimum power (β), a measure of the intraclass correlation (ρ), and the size of clusters (m).
3.1.1. Continuous outcomes
When the outcome variable is continuous, Donner et al. [18] proposed a formula to calculate the required number of clusters for a two-arm CRT with an equal allocation of clusters to each treatment arm. Let n be the total number of clusters enrolled in the trial and each cluster includes the same number of units, mi = m, ∀ i ∈ {1, … , n}. Assume Yij(0) and Yij(1) are random variables with equal variance, σ2. When the clusters are sampled using simple random sampling from the study population and are assigned completely at random to one of the treatment arms, the average outcome in each arm and their variances are
where ρ is the intraclass correlation coefficient (ICC), which measures the degree of correlation among outcomes within the same cluster [2]. Assuming that ρ ≥ 0, it can be estimated as the ratio of the between-cluster variance to the overall variance.
The distributions of and are asymptotically Normal as n → ∞. Hence, the test statistic, , is also asymptotically Normal. Under Neyman’s null hypothesis, H0 : E(Y(0)) – E(Y(1)) = 0 and under the alternative hypothesis Ha : E(Y(0)) – E(Y(1)) = δ ≠ 0, the number of clusters per arm required to reach a desired power can be approximated by
| (3) |
where Zk is the kth quantile of the Standard Normal distribution. When n < 30, Rotondi [6] argued that such asymptotic normal approximation could be inaccurate and proposed to use the t-distribution instead. Using the t-distribution results in adding two or three clusters per treatment arm for a two-tailed hypothesis with α = 5%, or four additional clusters if α = 1% [19].
In many trials, the size of clusters varies, which may influence the power of the hypothesis test [20]. To address the variation in cluster sizes, let μm and σm be the mean and standard deviation of the distribution of cluster sizes, respectively. Equation (3) can be adjusted [21]:
| (4) |
where is the coefficient of variation. A different adjustment based on Taylor expansion to approximation the distribution of cluster sizes is given by van Breukelen et al. [22],
| (5) |
For a throughout summary of other adjustments for differing cluster sizes, see Rutterford et al. [7].
3.1.2. Binary outcomes
When the outcome variable is binary, a common test statistic is the difference in proportions between the two arms. Using the asymptotic approximation, the required number of clusters per arm is
| (6) |
where p0 is the expected proportion of successes in the control and treated arms under H0, and p1 is the expected proportion of successes in the treatment arm under Ha [18]. Multiple procedures have been proposed to estimate the ICC with binary outcomes [23]. These methods may result in different estimates of the ICC, and investigators should be aware of the limitations of different ICC estimators [24].
3.1.3. Event count outcomes
When the outcome variable is event count, the difference in rates between the two arms is typically used as the test statistic. The following formula was proposed to approximate the number of clusters needed per arm:
| (7) |
where λ0 is the population event rate in the treated and control arms under H0, λ1 is the population event rate in the treatment arm under H1, is the average amount of unit-time contributed by each cluster, and CVB = σB/μB is the coefficient of variation, where μB and σB are the mean and standard deviation of the between-cluster rates, respectively [5].
3.2. Monte Carlo approaches
Monte Carlo approaches approximate the relationship between sample size and statistical power by repeatedly sampling from P(Y(0), Y(1), X) and analysing the simulated data using a similar statistical model.
The program MLPowSim [8] focuses on multilevel models. To simulate data for CRTs with continuous outcomes, it generates study data from the following two-level hierarchical model with a cluster effect at the second level:
| (8) |
where zi’s are the cluster-level random intercepts and β1 is defined as the treatment effect. When the outcome is binary or event counts, a multilevel generalized linear model with a corresponding link function is used instead. The values of , , β0, and β1 are set by the investigators. With fixed (n, m), data is repeatedly simulated from Model (8) and a two-level hierarchical regression model is estimated at every simulated data set. The study power is approximated by the percentage of simulation replications in which the null hypothesis, H0 : β1 = 0, is rejected at a prespecified significance level, α. MLPowSim generates modifiable R or SPSS code, but the software is limited in the types of outcomes, covariates, and models that it can simulate. Only standard distributions and regression models are available. To reflect the assignment mechanism of CRT, the generated code should be modified to ensure that Wij = Wik ∀ j, k ∈ {1, … , mi}. This modification is not straightforward and requires some technical knowledge.
A similar but more flexible simulation approach is implemented in the simsam Stata function [9,25]. This approach enables investigators to generate samples from P(Y(0), Y(1), X) using common distributions. As with MLPowSim, simsam approximates the statistical power by examining the number of simulation replications in which the null hypothesis that a regression parameter differs from zero is rejected. The statistical test is performed using the asymptotic distribution of the regression parameter under the null hypothesis. A binary search algorithm is utilized to identify the minimal number of clusters that are required to reach a certain statistical power.
A different approach to sample from P(Y(0), Y(1), X) is by using the empirical distribution of existing data sets [10]. The procedure samples with replacement from an empirical distribution to get the outcomes under the control exposure. The outcomes in the treatment group are generated by applying a deterministic function g to the sampled outcomes in control, . This approach assumes that previously collected data represent the distribution of covariates and outcomes under the control arm in future studies. As with the previous simulation-based algorithms, it enables a flexible definition of the test statistic; however, this algorithm assumes that g is a deterministic function, which limits the treatment effects that can be generated. In addition, sampling with replacement implies that the study population is infinite, whereas in many CRTs only a small number of clusters are available or of interest. In such cases, sampling without replacement resembles the study population better than sampling with replacement.
4. Simulation-based power estimating procedures
We propose a new simulation-based approach to approximate the distributions of the test statistic under H0 and Ha without relying on asymptotic approximations of the test statistic. The approach is flexible and explicitly defines the data generating mechanism, the sampling mechanism, and treatment assignment mechanism under H0 and Ha.
In many CRTs, clusters are assumed to be selected completely at random from the population of clusters. Under this assumption an important component of sample size calculation in CRTs is the distribution of cluster sizes. Given a CRT with n clusters, fcs(·) := f(m1, m2, … , mn ∣ n) is the distribution of cluster sizes in CRTs with n clusters. When N = ∞, the distribution of cluster sizes can be assumed to be independent and identically distributed, . In finite samples, a correlation between sample sizes may exists. For example, when each cluster is comprised of a unique number of individuals, there are only possible cluster size configurations under simple random sampling. The distribution of the science f(Y(0), Y(1), X ∣ n, m) depends on the null and alternative hypotheses. Under Neyman’s null hypothesis, H0 : E(Y(0)) = E(Y(1)), this implies that f(Y(0), Y(1), X ∣ n, m) is defined such that the distributions of the two potential outcomes have equal means. In contrast, Fisher’s sharp null hypothesis assumes that Yij(0) = Yij(1) ∀i, j and f(Y(0), Y(1), X ∣ n, m) = f(Y(0), Y(1) = Y(0), X ∣ n, m). Commonly, Neyman’s type null is being hypothesized in CRTs. However, Fisher’s null has also been considered in the context of cluster randomized trials [26-28]. For further discussion on choosing between these two hypotheses, see Kempthorne and Hinkelmann [29], Rosenbaum [30] and Ding et al. [31].
It should be noted that f(Y(0), Y(1), X ∣ n, m) can be based on hypothetical distributions, empirical distributions or a combination of both. In Section 6, we provide examples with hypothetical distributions and in Section 7, we describe a combination of empirical and hypothetical distributions.
Given a sample of units with their corresponding potential outcomes we can examine different assignment mechanisms. For example, in a balanced two-armed CRT, a complete randomization implies that , i = 1, 2, … , n such that . In a stratified randomization, , i ∈ {k : Xk ∈ s}, where Xi are the pre-treatment characteristics of cluster i used to define randomization stratum s such that and is the number of clusters in stratum s and is an indicator function. Using the data distribution of sample sizes, the generating mechanism and the treatment assignment mechanism we define our new simulation-based algorithm to estimate the expected power for a random sample of n clusters under Neyman’s and Fisher’s null hypotheses.
4.1. Testing Neyman’s null hypothesis
The power of a test statistic T for comparing Neyman’s null hypothesis against an alternative hypothesis, Ha : f(Yij(0), Yij(1) ∣ n, m) in which E(Y(0)) ≠ E(Y(1)), can be approximated by the following procedure:
Simulate n integers from fcs(·) as the sizes of the clusters in the study sample, m.
Simulate the treatment assignment indicator Wi ~ f(W ∣ X).
For individuals in each of the sampled clusters, simulate their potential outcomes under H0 from f(Y(0), Y(1) ∣ n, m, X) in which E(Y(0)) = E(Y(1)), and calculate the test statistic TH0 = T(Yobs, W) using the simulated data.
For individuals in each of the sampled clusters, simulate their potential outcomes under Ha from f(Y(0), Y(1) ∣ n, m, X) in which E(Y(0)) ≠ E(Y(1)), and calculate the test statistic THa = T(Yobs, W) using the simulated data.
Repeat the above steps for r times, where r is large enough so that the distributions of TH0 and THa are well approximated.
Calculate the power of the test as the proportion of THa within the rejection region defined by TH0 using Equation (2).
4.2. Testing Fisher’s null hypothesis
The power of a test statistic T for comparing Fisher’s null hypothesis against an alternative hypothesis, Ha : f(Yij(0), Yij(1) ∣ n, m) in which Yij(0) ≠ Yij(1) for at least one i and j, can be approximated by the following procedure:
Simulate n integers from fcs(·) as the sizes of the clusters in the study sample, m.
For individuals in each of the sampled clusters, simulate their potential outcomes under H0 from f(Yij(0), Yij(1) ∣ n, m) where Yij(0) = Yij(1).
For individuals in each of the sampled clusters, simulate their potential outcomes under Ha from f(Yij(0), Yij(1) ∣ n, m) where Yij(0) ≠ Yij(1) for at least one i, j.
Simulate the treatment assignment indicator Wi ~ f(W ∣ X) according to the designed treatment assignment mechanism in the study.
Calculate the test statistic TH0 and THa using the simulated data in Steps 2, 3 and 4.
Repeat Step 4 and 5 for t times, where t is large enough so that the distributions of TH0 and THa are well approximated. This step mimics a permutation test.
Calculate the power of the test as the proportion of THa within the rejection region defined by TH0 using Equation (2).
Repeat the above steps for r times, the permutation test power can be approximated by the mean of all r powers calculated in Step 7.
5. Binary search for the optimal sample size
To find the optimal sample size, we explore the sample size domain n ∈ {1, 2, … , N} for the minimum number of clusters such that the power is equal or greater than the predefined level. This optimization problem can be formally defined as
| (9) |
where p is the power calculated for nc control clusters and nt treatment clusters.
Solving this optimization problem by traversing the space of all possible nt and nc values is computationally intensive. To simplify the problem, we assume that nt = [qnc], where nc ∈ {1, 2, 3, …} and q ∈ (0, +∞), under this assumption we use a binary search algorithm to find the optimum nt. When N is finite, the binary search algorithm converges to the optimum with comparisons [32].
Balanced study design, where nt = nc, is assumed in Equations (3)-(7) because it provides the largest efficiency in sampling variance when the test statistic is the difference in expectations and the ICCs in both arms are equal. However, a balanced design may not always be preferred. For example, in some studies, enrolling a facility in the treatment arm requires additional costs compared to enrolling a facility in the control arm. In these cases, an unbalanced study design with more clusters in the control group may result in a higher power for the same budget. By allowing q to be greater than 1, the search algorithm can identify optimal unbalanced designs that incorporate these budget or administrative considerations. The simulation procedures for estimating the power for a statistical test for n clusters and the binary search algorithm are implemented in the R package CRTsampleSearch available on GitHub (https://github.com/RuoshuiAqua/CRTsampleSearch).
6. Simulation examples
We compare the proposed simulation-based approach with the formulae described in Section 3 under realistic scenarios in which the distributional assumptions in Equations (3)-(7) are violated. In all of the comparisons, the significance level is set at 0.05, the minimal power is set at 0.8, the test statistic is defined as the difference in the expectations of the two arms, and clusters’ assignment to treatments is completely random. In practice, researchers may want to consider alternative test statistics to the ones considered here. The CRTsampleSearch package allows for any test statistic to be considered.
6.1. Unequal cluster sizes
In many practical situations, the clusters in CRTs are of different sizes. In addition, the distribution of cluster sizes might not follow a Normal distribution. We examine the effect of skewness of fcs(·) on the minimal number of clusters estimated using Equations (3)-(5), and we compare them with the proposed simulation-based approach. Formally, the size of clusters, mi, is generated from a log-Normal distribution:
| (10) |
where γ1 is the expectation of the log-Normal distribution, γ2 is the variance of log-Normal distribution, and is the variance on the logarithm scale. As increases, the distribution of cluster sizes becomes more skewed Figure 1.
Figure 1.

The log-Normal distribution of cluster sizes in Simulation 6.1.
The two potential outcomes under H0 : E(Y(0)) = E(Y(1)) are generated from a hierarchical Normal-Normal model,
| (11) |
For simplicity, let , , and assume the effect of the treatment is constant for every individual. The potential outcomes under Ha : E(Y(0)) ≠ E(Y(1)) are generated from the following model:
| (12) |
With the above specification, the average cluster size varies from 100 to 164, and the ICC is in all of the simulation configurations. The test statistic was defined as the difference in the average of the units in clusters with Wi = 1 and the average of units in clusters with Wi = 0:
| (13) |
Figure 2(a) shows the required number of clusters calculated using Equations (3)-(5) and CRTsampleSearch. Both CRTsampleSearch and Equation (4) result in an increasing number of clusters as increases. This is a result of having more clusters with a small number of units and a few clusters with a very large number of units, which inflates the overall mean number of units within a cluster. Equation (3) results in a slightly decreasing trend as increases because it only accounts for the average cluster size, which increases from 100 to 165 as increases. Equation (5) suggests a slightly increasing trend for the required number of clusters. Equations (3) and (5) underestimates the required number of clusters for the test statistic (13) as the skewness in cluster sizes increases. Equation (4) overestimates the required sample size compared to CRTsampleSearch because as increases, fcs(·) is more skewed and only relying on the first two moments of the cluster size distribution cannot capture the entire distribution.
Figure 2.
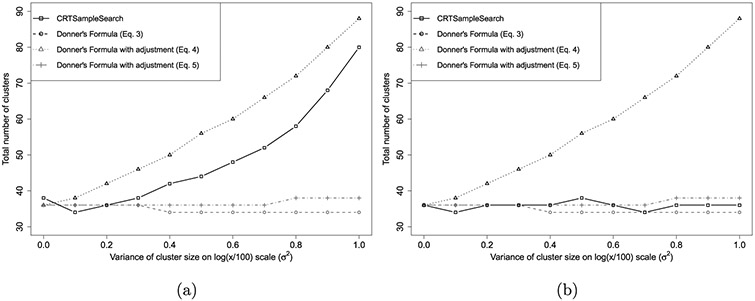
The total number of clusters needed when the size of clusters are generated from a log-Normal in Simulation 6.1. (a) Estimand (13), (b) Estimand (14).
One reason for the large differences in the required number of clusters observed for CRTsampleSearch and Equation (4) compared to Equations (3) and (5) is that they rely on different test statistics. Equations (3) and (5) were derived assuming that Yij(Wi) = β0 + β1Wi + μi + eij, where and . Based on this model, β1 is the estimand of the treatment effect. If and are known the maximum likelihood estimator for β1 is
| (14) |
where and . Using this test statistic, van Breukelen et al. [22] showed that the loss of efficiency that stems from variation in cluster sizes rarely exceeds 10%. Figure 2(b) shows the required number of clusters calculated using Equations (3)-(5) and CRTsampleSearch when the test statistic is (14). Compared to CRTsampleSearch, Equation (3) slightly underestimates the number of required clusters and Equation (5) slightly overestimates the number of required clusters as increases. This agrees with the minimal loss of efficiency that was described previously. Because (4) calculates power for a different test statistic it significantly overestimates the number of required clusters. This analysis shows that the choice of test statistic can have a significant impact on the power of a statistical test in unbalanced designs. Similar issues are presented in Section 7 with event rates.
6.2. Non-Normal continuous outcomes
Many quantitative outcomes in healthcare studies do not follow a Normal distribution. For example, facilities’ average health expenditures may follow a log-Normal distribution and patients’ expenditure may follow a zero-inflated log-Normal distribution. Some patients have zero expenditures, some patients spend small to moderate amounts, and a few patients have extremely high expenditures [33]. To represent such cases, we generate the two potential outcomes under H0 : E(Y(0)) = E(Y(1)) from a hierarchical zero-inflated log-Normal model as follows:
| (15) |
Here, μi is the expectation of the log-Normal part of Yij(0) and Yij(1) in cluster i and the corresponding variance, γ2, is set at 10. For simplicity, we assume that mi = 100, ∀ i ∈ {1, … , n},, p0 = 0.2, and the effect of the treatment is constant for every individual. The potential outcomes under Ha : E(Y(0)) ≠ E(Y(1)) are generated from the following model,
| (16) |
Figure 3 shows the required number clusters calculated using Equation (3), the CRTSize package and CRTsampleSearch for different values of the between cluster variance, ψ. As ψ increases, the overall variances for the control and treated groups increase. As a result, more clusters would be required to observe a significant difference in the sample means of the two arms. This trend is captured by all three methods. However, compared to CRTsampleSearch, sample sizes derived using Equation (3) and the CRTSize package increase at higher rates. This is because the ICC in Equation (3) and CRTSize is a linear function of ψ in this simulation setting (see Appendix A.1). As ψ increases while γ1 is constant, the log-Normal distribution is more concentrated around γ1 with some clusters having very high values. The ICC in Equation (3) only considers the between cluster variance which is heavily influenced by extreme values. With a finite number of clusters, this results in a poor approximation of the distribution of the test statistic.
Figure 3.
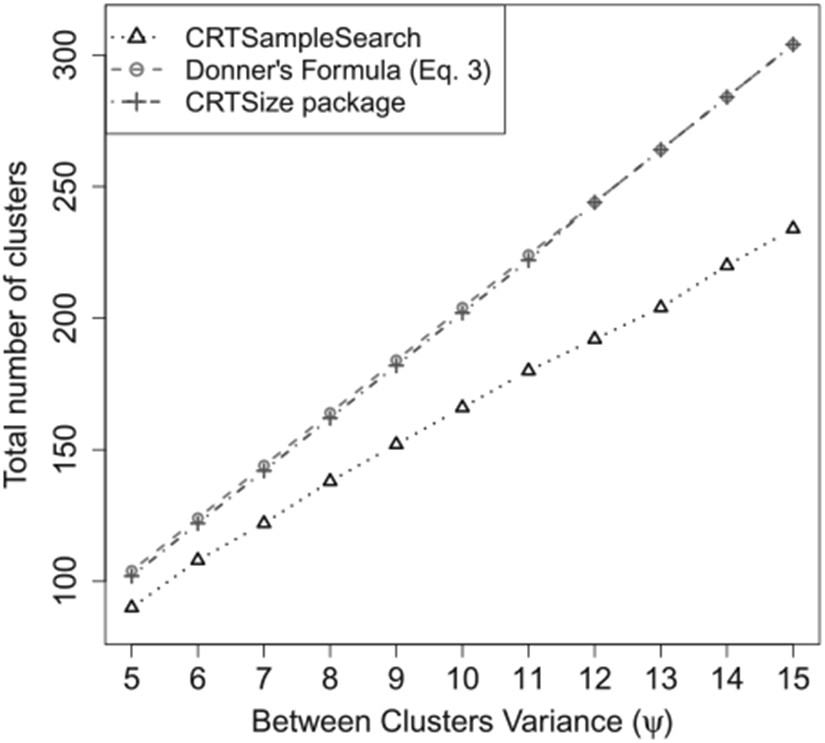
The total number of clusters needed when the outcomes are generated from a zero-inflated log-Normal model in Simulation 6.2.
When the outcome data follow a skewed distribution, other test statistics such as the difference in medians may be preferred. These statistics can be examined with the proposed simulation algorithm. However, in order to compare the proposed simulation algorithm and the currently existing formulae, we only examined Equation (13) as the test statistic.
6.3. Binary outcomes
When the outcomes are binary, the effect of the treatment is commonly estimated using the difference in proportions between the two study arms. The two potential outcomes under H0 : E(Y(0)) = E(Y(1)) are generated from a Beta-Bernoulli model,
| (17) |
For simplicity, we assume that mi = 100, ∀i ∈ {1, … , n}. The potential outcomes under Ha : E(Y(0)) ≠ E(Y(1)) are generated from the following model:
| (18) |
This fHa implies that the treatment only affects individuals whose outcome under the control is 0. The average effect size is . The test statistic is defined in Equation (13). In the context of binary outcomes, this test statistic is the difference between the proportions of successes among units in clusters with Wi = 1 and units in clusters with Wi = 0.
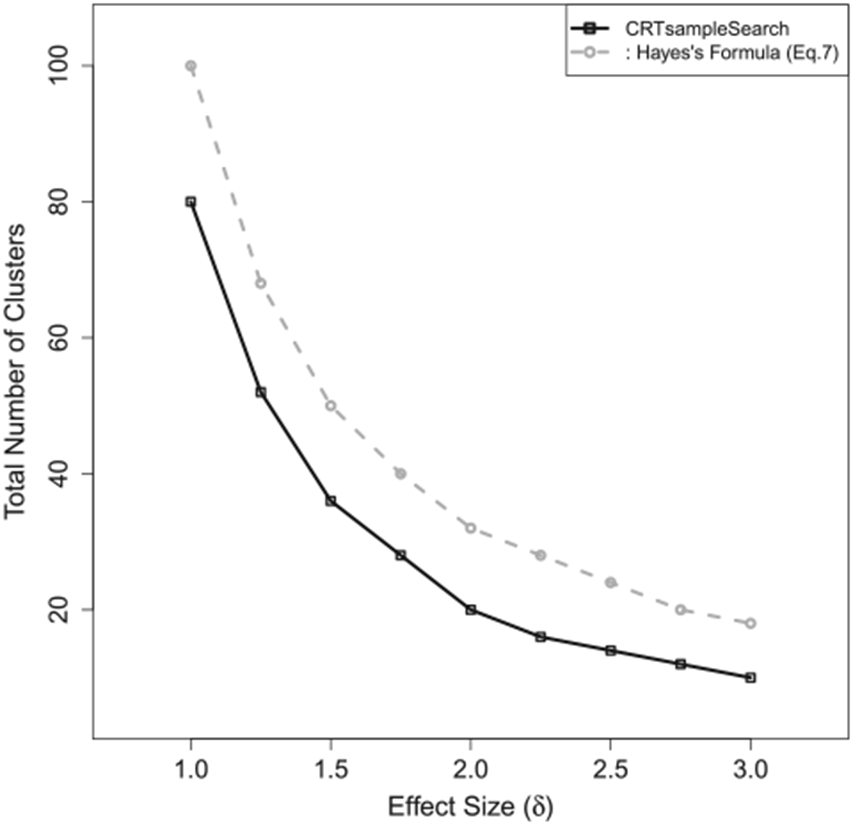
Figure 4 shows that the required number of clusters from CRTsampleSearch is smaller than those derived from Equation (6). This is expected because var(Yij(1)) > var(Yij(0)) under Ha (see Appendix A.2). Thus, the ICC in the treatment arm is smaller than the ICC in the control arm, while Equation (6) treats them as equal. The effect of the treatment can take any form in reality, whereas this specific simulation setting is one example in which the formulae might result in inaccurate estimations compared to CRTsampleSearch.
Figure 4.
The total number of clusters needed when the outcomes are from a Beta-Bernoulli model in Simulation 6.3.
6.4. Count outcomes
Count data is commonly modelled using a Poisson distribution or a Negative Binomial distribution [34]. Equation (7) is derived assuming that the outcome follows a Poisson distribution. In some applications, the observed data include more 0 counts than expected from a Poisson or a Negative Binomial distribution. For example, the number of hospital visits in the population is a mixture of patients who do not have any visits and those that visit the hospital multiple times [33]. More appropriate models for such outcomes are the Zero-Inflated-Poisson (ZIP) or the Zero-Inflated-Negative-Binomial distribution [35]. We examined two types of data-generating mechanisms.
6.4.1. Gamma–Poisson model
The two potential outcomes under H0 : E(Y(0)) = E(Y(1)) are generated from a Gamma–Poisson model,
| (19) |
The overall event rate under H0 is λ0 = 5. We assume that mi = 100, ∈ i ∈ {1, … , n}, and that the effect of the treatment across units is δ on average. The potential outcomes under Ha : E(Y(0)) ≠ E(Y(1)) are generated from
| (20) |
The follow-up time, tij, is assumed to be equal for all individuals in all of the clusters. As in the previous examples, the test statistic is defined in Equation (13). In the context of count outcomes with equal follow-up times, this statistic represents the difference between the average event rates among units in clusters with Wi = 1 and units in clusters with Wi = 0.
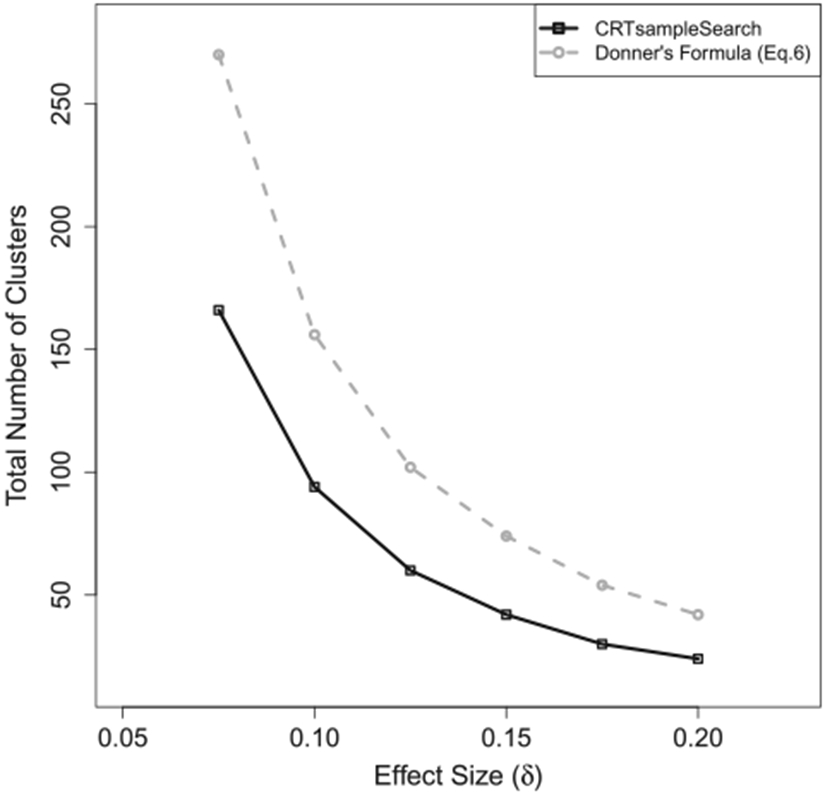
Figure 5 shows the required number of clusters estimated by CRTsampleSearch and Equation (7) with different effect sizes. As δ increases, the required number of clusters decreases according to both methods. Compared to the simulation-based method, Equation (7) overestimates the sample size by more than 25%.
Figure 5.
The total number of clusters needed when the outcomes are generated from a Gamma–Poisson model in Simulation 6.4.1.
6.4.2. Gamma-Zero-inflated-Poisson model
In this simulation configuration, the two potential outcomes under H0 : E(Y(0)) = E(Y(1)) are generated from a Gamma-ZIP model,
| (21) |
The overall event rate under H0 is λ0 = 5(1 – p0). We assume that mi = 100, ∀i ∈ {1, … , n}, and that the effect of the treatment across units is δ = 1 on average. The potential outcomes under Ha : E(Y(0)) ≠ E(Y(1)) are generated from the following model:
| (22) |
The follow-up time, tij, is assumed to be equal for all individuals in all clusters, and the test statistic is defined in Equation (13). Figure 6 presents the required number of clusters estimated by CRTsampleSearch and Equation (7). As p0 increases, the required number of clusters decreases according to both methods. Compared to the simulation-based method, Equation (7) overestimates the sample size by more than 24%.
Figure 6.
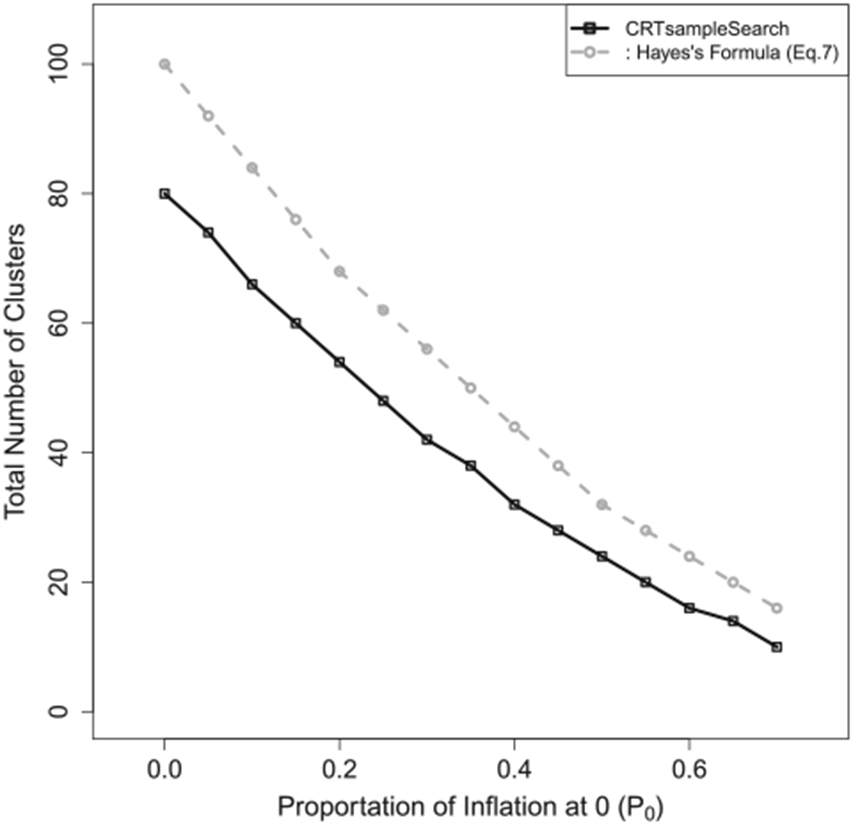
The total number of clusters needed when the outcomes are generated from a Gamma-ZIP model in Simulation 6.4.2.
7. Real data example: hospitalization count in nursing homes
In many practical situations, researchers have prior information on their study population and the expected effect size. For example, data or summary statistics from previous studies provide information on the distributions of the potential outcomes in the control arms. We implement the proposed simulation-based approach using hospitalization data collected from a CRT performed in US nursing homes during the flu season of 2013–2014 [36] and compare it with MLPowSim [8].
The flu vaccine data comprise 817 nursing homes and 52,964 patients. We removed patients with less than 10 days of follow-up and nursing homes with fewer than 10 patients because they may suffer from very high hospitalization rates. Including these patients and nursing homes results in large sampling variances and a large number of required clusters. As a consequence, a CRT of this size is financially and logistically impractical.
After removing patients with less than 10 days of follow-up time and nursing homes with less than 10 patients, there are 814 nursing homes and 52,522 patients. The number of patients enrolled in each cluster varies from 14 to 492 with an average of 65 patients per nursing home Figure 7. Each nursing home accumulated 34 person-years on average. The average patient-level hospitalization rate, , is 0.74 per person-year. The average cluster-level pooled hospitalization rate, , is 0.56 per person-year. The pooled hospitalization rate, , is 0.55 per person-year. Table 1 presents the individual-level hospitalization rates. It is heavily inflated at 0 compared to a Poisson distribution with a rate of 0.55. Approximately 80% of the patients never experienced any hospitalization during their follow-up time. Figure 8 shows the ZIP model estimates from each of the nursing homes. The proportions of zeros in the binary component vary from 0 to 1 with a mean of 0.71 Figure 8(a). The event rates in the Poisson component range from 0 to 4 per person-year in most nursing homes except for a few with rates over 12 per person-year Figure 8(b).
Figure 7.
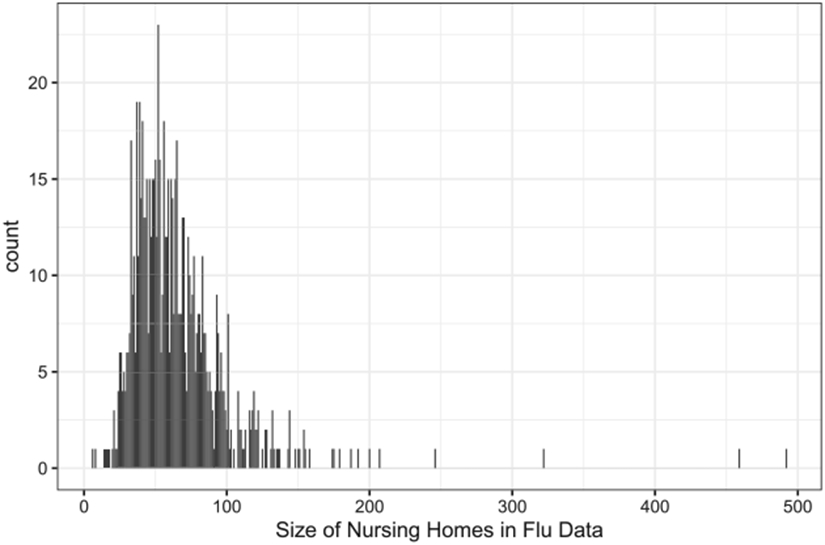
The size of nursing homes recruited in the influenza study.
Table 1.
Distribution of individual-level hospitalization rate (λ, count/year) in the flu vaccine data.
| λ | 0 | (0,3] | (3,5] | (5,10] | (10,50] | (50, 60.875] |
|---|---|---|---|---|---|---|
| Counts | 41818 | 6315 | 2251 | 1587 | 550 | 2 |
| Percent | 79.620 | 12.023 | 4.286 | 3.020 | 1.047 | 0.004 |
Figure 8. Estimations from the ZIP(P0, λ0) model for every nursing homes in the flu vaccine data.
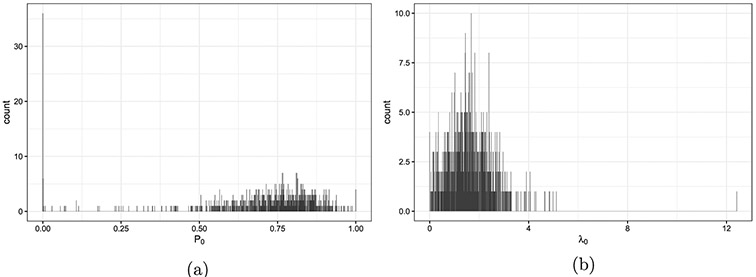
Note: (a) The proportion of zeros (P0) in the binary component. (b) The event rate (λ0) in the Poisson component.
7.1. Number of clusters required for a new CRT
7.1.1. Data generating and sampling mechanisms
If a new CRT study will be performed on a similar population, the flu vaccine data provide a reasonable approximation for the distribution of cluster sizes and the potential outcomes in the control arm. Formally, a new CRT with n clusters can be simulated from the following model:
| (23) |
Denote Model (23) as . Under the null hypothesis, we assume that Yij(1) = Yij(0) and tij(1) = tij(0) ∀i, j, where tij(w) is the follow-up time for patient j in cluster i if the cluster is assigned to treatment w. Both Neyman’s null and Fisher’s null are valid under this data generating model.
One possible data generating mechanism under Ha is that the treatment is expected to reduce the hospitalization rate component by 0.5
| (24) |
A different possible data generating mechanism under Ha assumes that the new treatment would only reduce the number of hospitalizations for nursing home residents who would experience hospitalizations in the control arm. For this data generating model, the potential outcomes under Ha are generated from
| (25) |
where is the estimated proportion of inflation at 0 for nursing home i and is the estimated event rate for nursing home i in the ZIP model, which is defined similarly to Equation (21) with and for subjects in cluster i.
The race of patients is known to be correlated with the hospitalizations rates [37]. Another possible data generating mechanism under Ha assumes that the new treatment will reduce the number of hospitalizations for African American nursing home residents less than residents from other race groups. For this data generating model, the potential outcomes under can be generated from
| (26) |
where Aij = 1 if patient j in nursing home i is not African American and Aij = 0 otherwise, and , ∀i = 1, 2, … , n, j = 1, 2, … mi.
7.1.2. Randomization mechanisms
Complete randomization.
If the treatment is assigned completely at random in a new CRT, then the assignment indicator at the nursing home level can be generated from f(W ∣ X) : , i = 1, 2, …, n such that for balanced study design.
Stratified randomization.
Stratified randomization has been proposed as a technique to balance pre-treatment characteristics of participating clusters and increase power [38]. In the flu vaccine data, the proportions of African American residents vary across different nursing homes as shown in Figure 9. A new CRT may balance the number of African Americans across study arms using stratified randomization. Let Xi be the proportion of African American residents in nursing home i, the assignment indicator at the nursing home level will be generated from where s ∈ {[Q0, Q1], (Q1, Q2], (Q2, Q3], (Q3, Q4]} and Qq is the q th quartile of Xi. These partitions are nursing homes into distinct groups by the quartiles of the observed proportions of African American residents in the nursing homes.
Figure 9. The percentage of African American residents per nursing home in the flu vaccine data.

Note: Stratum 1: ≤ 1.47% (204 nursing homes, 25.06% of the total); stratum 2: (1.47%, 6.25%] (204 nursing homes, 25.06% of the total); stratum 3: (6.25%, 17.9%] (204 nursing homes, 25.06% of the total); stratum 4: > 17.9% (202 nursing homes, 24.82% of the total).
7.1.3. Test statistics
Difference in hospitalization rates.
Equation (7) assumes that the population rates in the control and treatment arms are λ0 and λ1, respectively. When clusters and units within clusters contribute an equal amount of time, λi can be approximated by averaging unit level rates, , or by the pooled rates, , where . This equivalence in estimates does not hold when the time contributed by each unit is different. Because CRTsampleSearch requires to explicitly define the test statistic we estimated both the difference between the pooled rates and the difference between the average unit-level rates.
Treatment effect estimated from Hierarchical models.
Hierarchical models have been proposed to estimate the effects of intervention in CRTs [39]. Generalized Linear Mixed Effect Model (GLMM) estimates the effect of the treatment while adjusting for clustering at the second level. When using GLMM, the test statistic, T, is the estimated coefficient corresponding to the treatment assignment indicator.
7.1.4. Required number of clusters
Assuming a significance level of 0.05 and minimal power of 0.8, Table 2 summarizes results from Hayes’s formula, MLPowSim, and CRTsampleSearch for the data generating mechanisms described in Equations (24)-(26). For the data generating mechanisms in Equations (24) and (26), when the difference in the pooled event rates between the two study arms is the test statistic, the minimal number of clusters estimated by CRTsampleSearch are 11% to 40% larger than those estimated using Equation (7). This is because Equation (7) ignores the variability in patients’ follow-up time accumulated by each nursing home. When the difference in the average patient-level event rates between the two study arms is the test statistic, CRTsampleSearch results in a significantly larger number of required clusters than Equation (7). This is because the variation of patient-level event rate is bigger than the pooled event rate in each study arm. When using the treatment effect estimated from a GLMM model, CRTsampleSearch results in a larger number of required clusters compared to MLPowSim. This is because MLPowSim assumes that all nursing homes would enroll the same number of patients and every patient would be followed for the same amount of time. For the data generating model in Equation (25), CRTsampleSearch results in fewer clusters than Equation (6) when the difference in average patient-level event rates between the two study arms is the test statistic. The data generating model in Equation (25) assumes that Yij(1) is independent from Yij(0) given the clusters’ data generating parameters. The correlation between Yij(1) and Yij(0) is much smaller than the data generating models in Equations (24) and (26). Under , the pooled event rate and patient-level event rate in the treatment arm are both around 0.36 times per person year. However, under H0, the pooled event rate is around 0.55 times per person year, while the patient-level event rate is around 0.74 times per person year.
Table 2.
The total number of clusters required (N) to test the Neyman’s null H0 : E(Y(0)) = E(Y(1)) against three different Ha using Equation (7), MLPowSim and CRTsampleSearch.
| MLPowSim |
CRTsampleSearch
|
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Equation (7) a | β2 = 0b | β2 = 0.23c | Complete randomization |
Stratified randomization |
||||||||
|
|
|
|
|
|
||||||||
| Y(1) | λ 1 | N | β 1 | N | β 1 | N | A | B | C | A | B | C |
| 0.460 | 224 | −0.2087 | 164 | −0.2089 | 156 | 292 | 586 | 184 | 274 | 560 | 176 | |
| 0.464 | 242 | −0.2003 | 178 | −0.2005 | 170 | 314 | 640 | 196 | 298 | 604 | 190 | |
| 0.362 | 50 | −0.4825 | 32 | −0.4830 | 30 | 68 | 36 | 44 | 64 | 34 | 38 | |
Notes: MLPowSim fits a 2-level regression model Yij ~ Poisson(λij) and log(λij) = β0 + β1Wij + β2Xij + zi where and Wij = Wik ∀i, j ≠ k assuming equal size of clusters as 65. CRTsampleSearch (A) uses the difference in the pooled event rates in the two study arms as the test statistic; (B) uses the difference in the average person-level event rates in the two study arms as the test statistic; (C) uses the treatment effect estimated from a GLMM model as the test statistic; Stratified randomization uses the percentage of African American in nursing homes to define the strata.
λ0 = 0.557, and CVB = 0.442.
With no extra covariate. β0 = −0.68 and .
Includes patient-level indicator for African American as the extra covariate. β0 = −0.71 and .
For all three types of data-generating models in Equations (24)-(26), MLPowSim adjusted for an indicator for individual’s race resulted in a smaller number of required samples. Similarly, using stratified randomization with CRTsampleSearch resulted in a smaller number of required clusters compared to complete randomization. However, while the estimand used in CRTsampleSearch for the different randomization procedures is the same, the estimands obtained from MLPowSim are different.
7.2. Finite population of clusters
The flu vaccine data provides information on 814 nursing homes, which is generally considered a large trial. In other trials, the population of interest may comprise a subset of these 814 nursing homes. We selected a random sample of 16 nursing homes from the flu vaccine data and assume that they represent the entire population of nursing homes in a new CRT. When the population of clusters is infinite, the data generating and recording mechanisms should sample with replacement from these 16 nursing homes. When the population is finite, the data generating and recording mechanisms should sample without replacement from these 16 nursing homes. In addition, when the number of nursing homes is small, a permutation test at the cluster level might be more appropriate than asymptotic approximations.
Table 3 presents the power estimated using CRTsampleSearch under Neyman’s null and under Fisher’s null using a permutation test when the population is either infinite or finite. The test statistic is the difference in the pooled hospitalization rates between the two study arms. The potential outcomes are generated under . Generally, the permutation test for Fisher’s null is more powerful than the test for Neyman’s null because Fisher’s null is more conservative than Neyman’s null. The differences in statistical power generally decrease with an increasing number of clusters in the population. The powers of both tests are similar when sampling is performed without replacement and the number of sampled clusters equals the number of clusters in the population. This result is expected because inferences under the two null hypotheses are often asymptotically similar for the difference in expectations [30].
Table 3.
The power testing Neyman’s null and Fisher’s null against using a random subset of 16 nursing homes from the flu vaccine data.
| Sample WITHOUT replacement |
Sample WITH replacement |
|||
|---|---|---|---|---|
| N a | Neyman’s null | Fisher’s null | Neyman’s null | Fisher’s null |
| 10 | 0.147 | 0.177 | 0.132 | 0.205 |
| 12 | 0.167 | 0.185 | 0.150 | 0.207 |
| 14 | 0.185 | 0.195 | 0.168 | 0.218 |
| 16 | 0.207 | 0.206 | 0.188 | 0.233 |
| 18 | 0.204 | 0.250 | ||
| 20 | 0.222 | 0.270 | ||
Notes: The test statistic is the difference in the pooled hospitalization rates between the two arms and randomization mechanism is complete randomization.
The total number of clusters in the CRT.
8. Discussion
We propose a new simulation-based approach for estimating the minimum number of required clusters to identify an effect size for a predefined statistical power for CRTs. The simulation procedure is defined using the potential outcome framework, which allows for an explicit definition of the data generating, recording, and treatment assignment mechanisms. By explicitly defining the data generating mechanism, researchers can examine the power of any null and alternative hypotheses. Using real data, we demonstrated that the power under Neyman’s and Fisher’s null hypotheses can differ even when the same test statistic is used.
Most formulae and simulation-based algorithms for sample size estimation in CRT ignore the treatment assignment mechanism and concentrate on the data generating mechanism. Our proposed algorithm enables the examination of different assignment mechanisms. We provide examples for implementing complete randomization and stratified randomization. Other randomization schemes can be easily implemented as well.
Another key feature that sets the proposed approach apart from existing sample size estimation methods for CRTs is that the proposed approach allows for the definition of any test statistic and it does not rely on the asymptotic approximation of the distribution of the test statistic to calculate statistical power. When the number of clusters, as well as the sizes of clusters, are large and the test statistic is the difference in means or maximum likelihood-based estimators, the asymptotic approximations are generally accurate. However, when the number of clusters is small or when the outcomes do not follow standard distributions, these asymptotic approximations may not be accurate and result in over or underestimation of the minimal required number of clusters. This was shown with simulated data as well as data from a CRT. The proposed procedure also enables the estimation of the required sample size for permutation tests. For these tests, asymptotic approximations can be complex to derive analytically for different statistics.
When using previously collected data, one should ensure that the collected data represent the population that the new intervention would be applied to. For example, because of recording errors or censoring, outliers may exist in previously collected data. In a new study, these may not exist or the analysis would be limited only to specific individuals. Including outliers in sample size calculations may result in a large sampling variance, which would require a large number of clusters to reach a prespecified power.
To take full advantage of the simulation-based approach, researchers should provide the cluster size distribution, the data generating model, the randomization distribution and the test statistics. However, researchers can still gain important insights on the required sample size when only some of these mechanisms are known. The test statistic is defined by the researchers and it should be selected based on the scientific question and the intended audience of the results, and not only its statistical properties. Information on the cluster-size distribution is commonly available from previous data and can be incorporated into the proposed simulation-based approach. If applicable, multiple randomization schemes should be considered at the design stage to identify the ones that are most efficient. The data generating distribution may suffer from limited information in some applications. In such cases, researchers should examine several plausible mechanisms in order to identify the effects of the different mechanisms. Some of these mechanisms can be similar to the ones assumed by the analytically derived formulae. Results based on deviations from the analytical formulae can inform researchers regarding the possible need for a different number of required clusters to ensure sufficient power when the assumed mechanisms are misspecified.
Simulation-based approaches are computationally intensive compared to analytically derived sample size formulae, which may impede their use in practice [9]. Moreover, the proposed simulation approach requires some programming knowledge to implement. To address these limitations, an R package CRTsampleSearch is developed. The package relies on the binary search algorithm and parallel computing to reduce the computational burden. In addition, we provide code examples to ease implementation (https://ruoshuiaqua.github.io/CRTsampleSearchExamples.io/).
In conclusion, we describe a flexible simulation-based algorithm to estimate the minimal number of clusters that are required to identify an effect in CRTs for a specified power. The procedure can rely on summary statistics, hypothetical distributions, or previously collected data to approximate the required optimal number of clusters for a new CRT.
Acknowledgements
The authors thank the associate editor and the anonymous referees for their valuable comments.
Funding
This work was supported in part by the National Institute of Health (NIH) grant the Pragmatic Trial of Video Education in Nursing Homes (PROVEN) (H3AG049619-02; NCT02612688).
Appendix 1. Additional material
A.1. Zero-inflated log-Normal model in Section 6.2
Under H0 and Ha, the total variance of the potential outcome Yij(0):
where p0 is the inflation parameter and μi is the expectation of the log-Normal part of Yij (0)’s distribution as defined in Equation (15). We assume that μi ~ log-Normal(γ1 = η0, ψ) and we denote the variance of the log-Normal part of Yij(0)’s distribution as γ2. In Equation (15), η0 = 1. The total variance of Yij(0) is
Therefore,
The between cluster variance is var(E(Yij(0) ∣ μi, p0)) = (1 – p0)2ψ, and the ICC in this model is . Estimation for the required number of clusters using Equation (3) is
when α, β, m, p0, γ2, η0 and δ are fixed in these simulations.
A.2. Beta-Bernoulli model in Section 6.3
Under H0 and Ha, the total variance of the potential outcome Yij(0) is:
This is the same as the total variance of the potential outcome Yij(1) under H0. Hence, ICC in the control arm under H0 and Ha and ICC in the treatment are under H0 all equal to .
Under Ha, the total variance of the potential outcome Yij(1) is
And the between cluster variance is
Hence, ICC in the treatment arm under Ha is when δ ∈ (0, 1)
Footnotes
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- [1].Moberg J, Kramer M. A brief history of the cluster randomised trial design. J R Soc Med. 2015;108(5):192–198. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Donner A, Klar N. Design and analysis of cluster randomization trials in health research. London: Arnold; 2000. [Google Scholar]
- [3].Donner A, Klar N. Pitfalls of and controversies in cluster randomization trials. Am J Public Health. 2004;94(3):416–422. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Rotondi MA, Donner A. Sample size estimation in cluster randomized educational trials: an empirical Bayes approach. J Educ Behav Stat. 2009;34(2):229–237. [Google Scholar]
- [5].Hayes RJ, Bennett S. Simple sample size calculation for cluster-randomized trials. Int J Epidemiol. 1999;28(2):319–326. [DOI] [PubMed] [Google Scholar]
- [6].Rotondi MA. CRTSize: sample size estimation functions for cluster randomized trials; 2015. R package version 1.0. Available from: https://CRAN.R-project.org/package=CRTSize. [Google Scholar]
- [7].Rutterford C, Copas A, Eldridge S. Methods for sample size determination in cluster randomized trials. Int J Epidemiol. 2015;44(3):1051–1067. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Browne WJ, Lahi MG, Parker RMA. A guide to sample size calculations for random effect models via simulation and the MLPowSim software package. Bristol (UK): University of Bristol; 2009. [Google Scholar]
- [9].Hooper R Versatile sample-size calculation using simulation. Stata J. 2013;13(1):21–38. [Google Scholar]
- [10].Kleinman K, Huang SS. Calculating power by bootstrap, with an application to cluster-randomized trials. eGEMs. 2016;4(1):1202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Lohr SL. Sampling: design and analysis: design and analysis. Boca Raton: Chapman and Hall/CRC; 2019. [Google Scholar]
- [12].Rosenberger WF, Lachin JM. Randomization in clinical trials: theory and practice. New York: John Wiley & Sons; 2015. [Google Scholar]
- [13].Cook AJ, Delong E, Murray DM, et al. Statistical lessons learned for designing cluster randomized pragmatic clinical trials from the NIH health care systems collaboratory biostatistics and design core. Clinical Trials. 2016;13(5):504–512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Imbens GW, Rubin DB. Causal inference in statistics, social, and biomedical sciences. New York: Cambridge University Press; 2015. [Google Scholar]
- [15].Rubin DB. Comment. J Am Stat Assoc. 1980;75(371):591–593. [Google Scholar]
- [16].Rubin DB. 2 statistical inference for causal effects, with emphasis on applications in epidemiology and medical statistics. Handbook Stat. 2007;27:28–63. [Google Scholar]
- [17].Rubin DB. Bayesian inference for causal effects: the role of randomization. Ann Stat. 1978;6:34–58. [Google Scholar]
- [18].Donner A, Birkett N, Buck C. Randomization by cluster: sample size requirements and analysis. Am J Epidemiol. 1981;114(6):906–914. [DOI] [PubMed] [Google Scholar]
- [19].van Breukelen GJP, Candel MJJM. How to design and analyse cluster randomized trials with a small number of clusters? Comment on Leyrat et al. Int J Epidemiol. 2018;47(3):998–1001. [DOI] [PubMed] [Google Scholar]
- [20].Lauer SA, Kleinman KP, Reich NG. The effect of cluster size variability on statistical power in cluster-randomized trials. PLoS ONE. 2015;10(4):e0119074. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Manatunga AK, Hudgens MG, Chen S. Sample size estimation in cluster randomized studies with varying cluster size. Biom J. 2001;43(1):75–86. [Google Scholar]
- [22].van Breukelen GJP, Candel MJJM, Berger MPF. Relative efficiency of unequal versus equal cluster sizes in cluster randomized and multicentre trials. Stat Med. 2007;26(13):2589–2603. [DOI] [PubMed] [Google Scholar]
- [23].Ridout MS, Demetrio CGB, Firth D. Estimating intraclass correlation for binary data. Biometrics. 1999;55(1):137–148. [DOI] [PubMed] [Google Scholar]
- [24].Wu S, Crespi CM, Weng KW. Comparison of methods for estimating the intraclass correlation coefficient for binary responses in cancer prevention cluster randomized trials. Contemp Clin Trials. 2012;33(5):869–880. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].StataCorp. Stata statistical software: release 16. College Station (TX): StataCorp LLC; 2019. [Google Scholar]
- [26].Gail MH, Mark SD, Carroll RJ, et al. On design considerations and randomization-based inference for community intervention trials. Stat Med. 1996;15(11):1069–1092. [DOI] [PubMed] [Google Scholar]
- [27].Small DS, Ten Have TR, Rosenbaum PR. Randomization inference in a group–randomized trial of treatments for depression: covariate adjustment, noncompliance, and quantile effects. J Am Stat Assoc. 2008;103(481):271–279. [Google Scholar]
- [28].Wang R, De Gruttola V. The use of permutation tests for the analysis of parallel and stepped-wedge cluster-randomized trials. Stat Med. 2017;36(18):2831–2843. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Kempthorne O, Hinkelmann K. Design and analysis of experiments. Vol. 1: Introduction to Experimental Design. Hoboken, NJ: Wiley; 2007. [Google Scholar]
- [30].Rosenbaum PR. Observational studies. New York: Springer; 2010. [Google Scholar]
- [31].Ding P et al. A paradox from randomization-based causal inference. Stat Sci. 2017;32(3): 331–345. [Google Scholar]
- [32].Flores I, Madpis G. Average binary search length for dense ordered lists. Commun ACM. 1971;14(9):602–603. [Google Scholar]
- [33].Steiner C, Elixhauser A, Schnaier J. The healthcare cost and utilization project: an overview. Eff Clin Pract. 2002;5(3):143–151. [PubMed] [Google Scholar]
- [34].Cameron AC, Trivedi PK. Regression analysis of count data. Vol. 53. Cambridge, United Kingdom: Cambridge University Press; 2013. [Google Scholar]
- [35].Zuur AF, Ieno EN, Walker NJ, et al. Zero-truncated and zero-inflated models for count data. Mixed effects models and extensions in ecology with R. New York, NY: Springer; 2009. p. 261–291. [Google Scholar]
- [36].Gravenstein S, Davidson HE, Taljaard M, et al. Comparative effectiveness of high-dose versus standard-dose influenza vaccination on numbers of us nursing home residents admitted to hospital: a cluster-randomised trial. Lancet Respir Med. 2017;5(9):738–746. [DOI] [PubMed] [Google Scholar]
- [37].Schulz AJ, Ed Mullings L. Gender, race, class, & health: intersectional approaches. San Francisco, CA: Jossey-Bass; 2006. [Google Scholar]
- [38].Kernan WN, Viscoli CM, Makuch RW, et al. Stratified randomization for clinical trials. J Clin Epidemiol. 1999;52(1):19–26. [DOI] [PubMed] [Google Scholar]
- [39].Raudenbush SW. Statistical analysis and optimal design for cluster randomized trials. Psychol Meth. 1997;2(2):173–185. [DOI] [PubMed] [Google Scholar]