

Abstract
Since the beginning of 2020, the outbreak of a new strain of Coronavirus has caused hundreds of thousands of deaths and put under heavy pressure the world’s most advanced healthcare systems. In order to slow down the spread of the disease, known as COVID-19, and reduce the stress on healthcare structures and intensive care units, many governments have taken drastic and unprecedented measures, such as closure of schools, shops and entire industries, and enforced drastic social distancing regulations, including local and national lockdowns. To effectively address such pandemics in a systematic and informed manner in the future, it is of fundamental importance to develop mathematical models and algorithms to predict the evolution of the spread of the disease to support policy and decision making at the governmental level. There is a strong literature describing the application of Bayesian sequential and adaptive dynamic estimation to surveillance (tracking and prediction) of objects such as missiles and ships; and in this article, we transfer some of its key lessons to epidemiology. We show that we can reliably estimate and forecast the evolution of the infections from daily — and possibly uncertain — publicly available information provided by authorities, e.g., daily numbers of infected and recovered individuals. The proposed method is able to estimate infection and recovery parameters, and to track and predict the epidemiological curve with good accuracy when applied to real data from Lombardia region in Italy, and from the USA. In these scenarios, the mean absolute percentage error computed after the lockdown is on average below 5% when the forecast is at 7 days, and below 10% when the forecast horizon is 14 days.
Keywords: SARS-CoV-2, Bayesian sequential estimation, ensemble forecasting, compartmental model, pandemic tracking, pandemic prediction
I. Introduction
A. Motivation and Background
Beginning in early December 2019, Chinese health authorities have been detecting and monitoring an increasing number of pneumonia cases in the city of Wuhan, a province of Hubei. The pneumonia, later named COVID-19, is caused by a new strain of Coronavirus, and is technically referred to as the severe acute respiratory syndrome Coronavirus 2 (SARS-CoV-2) [1]. As of August 23, 2020, more than 23 million people worldwide have been infected, and over 800 thousand have died. In March 2020, a series of events have pushed many governments to take extraordinary social measures. These events include the lack of effective cures and vaccines, the exponentially increasing number of individuals requiring recovery in intensive care units, and the announcement by the World Health Organization (WHO) of a Coronavirus pandemic on March 11, 2020 [2]. The adopted measures included closure of schools, universities, shops, industries, public and cultural places, the prohibition of mass gatherings, travel bans, and extreme social distancing, including local and national lockdowns. The main aim of these measures is to slow down the infection rate and alleviate the pressure on healthcare systems, in order to ensure care to all individuals stricken by the virus. Indeed, after the adoption of these measures, most countries have seen a decrease in the daily numbers of infected individuals. In order to prevent another exponential rise in infections as the restrictive measures are progressively relaxed, it is of crucial importance to develop mathematical models and algorithms to track and forecast the evolution of the infection with acceptable accuracy, which can help authorities to make informed and timely decisions. Improving our ability to model and forecast is also of paramount importance to better address future pandemic outbreaks [3].
The algorithm proposed in this article builds on the concept of compartmental epidemiological models, which assume that a given population is divided into a fixed number of compartments. Each compartment represents an epidemic state that an individual can occupy. The flow dynamics from one compartment to another are modeled as a set of stochastic differential equations that we discretize according to the discrete nature of the available data, i.e., daily update on the number of infected, recovered, dead, etc. In the standard SIR model, proposed in the pioneering study on mathematical theory of epidemics by Kermack and McKendrick [4], it is assumed that the entire population, e.g., of a city, a region, or a nation, is constant and divided into three compartments (population subgroups), namely, susceptible (S), infected (I), and recovered (R) individuals. Moreover, it is assumed that an infected individual infects a susceptible one at a given rate
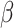 [5]. Once infected, the individual is removed from the compartment of susceptibles and enters the infected compartment. Each infected person runs through the course of the disease, and eventually is removed from the number of those who are still infected either by recovery or death, thus exiting the system at “recovery” rate
[5]. Once infected, the individual is removed from the compartment of susceptibles and enters the infected compartment. Each infected person runs through the course of the disease, and eventually is removed from the number of those who are still infected either by recovery or death, thus exiting the system at “recovery” rate
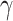 ; the recovered people are considered permanently immune.1 The ratio
; the recovered people are considered permanently immune.1 The ratio
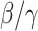 is called the contact ratio, and represents the mean number of people the infected individual comes in contact with.
is called the contact ratio, and represents the mean number of people the infected individual comes in contact with.
The SIR model is simple, yet very successful and useful in practice. Over the years, several more sophisticated extensions have been proposed to account for more compartments and other salient aspects of the epidemics. For example, a person who comes in contact with an infected individual and contracts the infection might not develop the symptoms immediately but only with a certain delay, called incubation period; in the case of COVID-19, this delay is around 3-15 days with a median of 5.2 days [6]. The SEIR model accounts for this circumstance by adding a further compartment that represents exposed — but not yet contagious — people [7], [8]. That is, susceptible individuals who contract the virus, pass to the exposed compartment (E) before evident symptoms appear and the person is confirmed as infected. The SEIRQ model is a further extension that also accounts for quarantined people [9]. Restriction measures are directly taken into account in the recently proposed SIR-X model [10] that, introducing an additional mechanism, removes susceptibles from the transmission process when the measures become effective.
A critical epidemiological characteristic for the pandemic potential of an emergent respiratory virus is represented by the undocumented, but infectious, cases. In contrast with the documented infectious cases, they often experience mild, limited, or no symptoms at all, and therefore, since they are generally not tested, remain undetected. These are the so-called asymptomatic cases in the context of COVID-19 pandemic. Based on their contagiousness and numbers, they can expose a far greater portion of the population to the virus than would otherwise occur. Li et al. [11] present a model-inference framework to estimate the contagiousness and proportion of undocumented infections in China before and after the lockdown in Wuhan.
Most of the compartmental models described so far consider the disease spread inside a unique and single population: a city, a region, a nation. In contrast, metapopulation models add a further spatial dimension, by interpreting the population as a network of multiple spatially separated subpopulations (nodes), e.g., multiple cities in the same region; the connections from one subpopulation to another are represented by movements (“diffusion”) of persons. Such interconnections represent contacts such as commuting to work, second homes, or national and international travels. In such a scenario, the diffusion of the infection is not only caused by the contacts among susceptibles and infectious people within each subpopulation, but also by the spatial interactions among the different subpopulations [12]–[15]. Li et al. [11] utilize a stochastic metapopulation model to simulate the spatiotemporal dynamics among 375 Chinese cities. The spatial spread of COVID-19 across cities is captured by the daily number of travelers from a city to another during the Spring Festival before the lockdown. Chinazzi et al. [16] model both the domestic (within Wuhan) and the international spread of the Coronavirus epidemic. The effects of the travel bans imposed in the city of Wuhan and the international travel ban adopted by several countries in early February 2020 are estimated. To model the international spread of the COVID-19 outbreak, the authors employ the stochastic global epidemic and mobility model. This metapopulation model is integrated with real-world data and relies on a network wherein each node represents a subpopulation located near major transportation hubs, e.g., airports; there are more than 3200 subpopulations, in roughly 200 different countries and territories. The degree of connection among subpopulations is represented by the number of people traveling daily among them. Within each subpopulation, there exist four states of the compartmental model, i.e., susceptible, latent (similar to exposed), infectious, and removed. The model generates an ensemble of possible epidemic scenarios described by the number of newly generated infections, time of disease onset in each subpopulation, and the number of traveling infection carriers.
B. Contributions and Paper Organization
Most of the aforementioned epidemic models assume that relevant model parameters, e.g., the infection rate
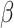 and the recovery rate
and the recovery rate
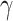 , are time-invariant, and several approaches have been proposed in the literature for tuning or estimating them [17]–[19]. However, the sudden imposition of restriction measures — and their subsequent relaxations — means that a static stochastic model is inappropriate. Moreover, even in the absence of dramatic restriction measures, there is no doubt that a time-varying model for the key epidemic parameters would better reflect the ground-truth.2
, are time-invariant, and several approaches have been proposed in the literature for tuning or estimating them [17]–[19]. However, the sudden imposition of restriction measures — and their subsequent relaxations — means that a static stochastic model is inappropriate. Moreover, even in the absence of dramatic restriction measures, there is no doubt that a time-varying model for the key epidemic parameters would better reflect the ground-truth.2
The main contribution of this article is to propose a Bayesian sequential learning and forecasting framework of the epidemic curve based on the data that authorities provide on a daily basis, e.g., number infected and number recovered. We leverage our recent research on unknown covariance matrix estimation [20] and self-tuning multisensor multitarget tracking [21]. Indeed, similarly to the target tracking problem, where the objective is to automatically detect the time instants when a target sharply maneuvers in order to improve the overall tracking performance, here we aim to closely track the epidemic curve and the model parameters in order to provide reliable and accurate forecast of the contagion. Adapting ideas and tools from those works, our approach to Bayesian sequential learning and forecasting of epidemic evolution is as follows. First, the model parameters are assumed to take on values from rich but prespecified finite sets; their time-evolution is modeled by Markov chains. Second, in order to capture the effects of mitigation strategies (e.g., mobility restriction, lockdown, wearing masks, and social distancing), the marginal posterior distributions of both the variable states (number of infected and recovered people) and model parameters (infection rate
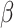 and recovery rate
and recovery rate
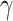 ), are calculated at each time by means of recursive prediction and update formulae. Finally, we develop an efficient implementation of the proposed method based on mixture models and provide a concrete example of application using the stochastic SIR model. The proposed method is validated on real datasets acquired during the recent COVID-19 outbreak in the Lombardia region, Italy, and in the USA. As we shall see, even adopting the simple stochastic SIR model, we obtain superior forecast accuracy when compared to prediction algorithms that use time-invariant parameter models. The approach developed in this article is general enough to be applied to more-sophisticated stochastic epidemiological models [8]–[10], including more-complex metapopulation models [11], [16]; these extensions are left for future investigations.
), are calculated at each time by means of recursive prediction and update formulae. Finally, we develop an efficient implementation of the proposed method based on mixture models and provide a concrete example of application using the stochastic SIR model. The proposed method is validated on real datasets acquired during the recent COVID-19 outbreak in the Lombardia region, Italy, and in the USA. As we shall see, even adopting the simple stochastic SIR model, we obtain superior forecast accuracy when compared to prediction algorithms that use time-invariant parameter models. The approach developed in this article is general enough to be applied to more-sophisticated stochastic epidemiological models [8]–[10], including more-complex metapopulation models [11], [16]; these extensions are left for future investigations.
The remainder of the paper is organized as follows. In Section II, we describe a general Bayesian adaptive framework that can be tailored to any discrete-time epidemiological model, and in Section III we propose an implementation thereof based on the use of mixture models. In Section IV, we develop the mixture-based Bayesian sequential approach in the context of the stochastic SIR model. Section V presents results using synthetic as well as real data. Finally, in Section VI we provide some conclusions and possible directions for future investigations.
C. Notation
Vectors are denoted by boldface lower-case letters (e.g.,
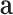 ), matrices by boldface upper-case letters (e.g.,
), matrices by boldface upper-case letters (e.g.,
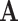 ), and sets by calligraphic letters (e.g.,
), and sets by calligraphic letters (e.g.,
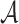 ). The transpose is written as
). The transpose is written as
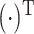 . We write
. We write
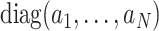 for an
for an
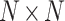 diagonal matrix with diagonal entries
diagonal matrix with diagonal entries
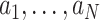 ,
,
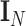 for the
for the
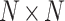 identity matrix,
identity matrix,
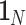 for the
for the
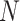 -dimensional vector of all ones, and
-dimensional vector of all ones, and
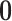 for the zero vector.
for the zero vector.
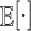 denotes statistical expectation, and
denotes statistical expectation, and
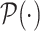 refers to both the probability density function (pdf) of a continuous random variable or vector and the probability mass function (pmf) of a discrete random variable or vector; the difference will be clear from the context.
refers to both the probability density function (pdf) of a continuous random variable or vector and the probability mass function (pmf) of a discrete random variable or vector; the difference will be clear from the context.
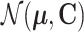 indicates a Gaussian distributed vector with mean
indicates a Gaussian distributed vector with mean
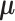 and covariance matrix
and covariance matrix
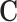 , and
, and
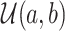 represents a uniformly distributed variable between
represents a uniformly distributed variable between
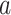 and
and
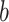 . Finally,
. Finally,
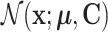 refers to a multivariate Gaussian pdf of random vector
refers to a multivariate Gaussian pdf of random vector
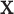 with mean
with mean
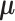 and covariance matrix
and covariance matrix
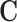 .
.
II. Proposed Algorithm
We present a sequential Bayesian framework that, at each time interval, jointly computes the posterior distribution of
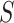 unknown time-varying states and of
unknown time-varying states and of
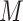 unknown time-varying parameters. These unknown quantities are inferred at times
unknown time-varying parameters. These unknown quantities are inferred at times
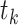 , with
, with
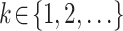 , using noisy observations (e.g., information on the number of infected, discharged COVID-19 patients from the hospitals, dead). We assume that the time interval
, using noisy observations (e.g., information on the number of infected, discharged COVID-19 patients from the hospitals, dead). We assume that the time interval
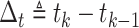 between consecutive observations is one day, unless otherwise stated. We denote
between consecutive observations is one day, unless otherwise stated. We denote
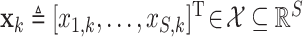 as the state vector comprising the
as the state vector comprising the
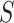 epidemic states
epidemic states
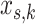 at time
at time
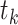 (e.g., numbers of infected and recovered individuals), and
(e.g., numbers of infected and recovered individuals), and
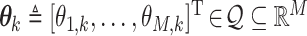 as the parameter vector comprising the
as the parameter vector comprising the
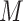 model parameters
model parameters
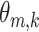 at time
at time
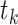 (e.g., infection and recovery rates).
(e.g., infection and recovery rates).
The objective of the proposed algorithm is twofold: to estimate, at each time
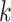 , the epidemic state vector
, the epidemic state vector
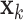 and the model parameter vector
and the model parameter vector
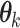 ; and, at a fixed time
; and, at a fixed time
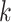 , to forecast the epidemic evolution up to time
, to forecast the epidemic evolution up to time
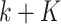 with associated uncertainty in the form of prediction variance. Both tasks are based on the past and present observations. Hereafter, Section II-A describes the dynamic and observation models, and Section II-B and Section II-C present the proposed Bayesian sequential estimation and forecasting tasks, respectively. The reader who is already familiar with dynamic estimation of a hybrid state, that is, comprising the state of the dynamic model and nuisance parameters [20]–[22], might skip ahead to Section II-C.
with associated uncertainty in the form of prediction variance. Both tasks are based on the past and present observations. Hereafter, Section II-A describes the dynamic and observation models, and Section II-B and Section II-C present the proposed Bayesian sequential estimation and forecasting tasks, respectively. The reader who is already familiar with dynamic estimation of a hybrid state, that is, comprising the state of the dynamic model and nuisance parameters [20]–[22], might skip ahead to Section II-C.
A. Dynamic and Observation Models
The dynamic model that describes the evolution of the epidemic is formally expressed as
 |
where
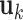 is a random vector — whose dimension depends on
is a random vector — whose dimension depends on
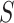 ,
,
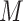 , and
, and
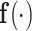 — with known distribution modeling the stochastic variation of the epidemic state in the time interval
— with known distribution modeling the stochastic variation of the epidemic state in the time interval
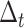 . Note that function
. Note that function
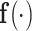 might embed additional known (either time-varying or time-invariant) parameters. We assume that, conditioned on
might embed additional known (either time-varying or time-invariant) parameters. We assume that, conditioned on
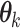 ,
,
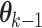 , and
, and
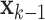 , the state vector
, the state vector
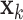 is independent of the previous states and parameters, that is,
is independent of the previous states and parameters, that is,
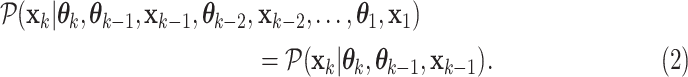 |
Given appropriate initial conditions, the pdf in (2) is fully determined by the dynamic model in (1) and the statistics of
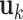 . Moreover, we assume that the parameter vector evolves according to a first-order Markov model fully described by the transition pdf
. Moreover, we assume that the parameter vector evolves according to a first-order Markov model fully described by the transition pdf
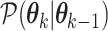 , assumed known. From these assumptions, it follows that the adopted Bayesian framework is a hierarchical Markov model (an event-driven dynamic process): firstly, the parameter vector evolves according to the Markov model described by
, assumed known. From these assumptions, it follows that the adopted Bayesian framework is a hierarchical Markov model (an event-driven dynamic process): firstly, the parameter vector evolves according to the Markov model described by
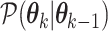 ; then the state vector evolves, given the current parameter vector as well as the previous state and parameter vectors, according to (1). Furthermore, it is easy to verify that
; then the state vector evolves, given the current parameter vector as well as the previous state and parameter vectors, according to (1). Furthermore, it is easy to verify that
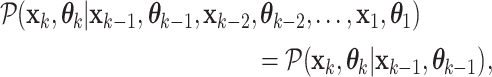 |
that is, the joint evolution of
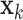 and
and
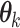 follows a first-order Markov model.
follows a first-order Markov model.
The observation vector at time
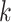 is denoted by
is denoted by
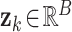 , and consists of up-to-date information on the state of the epidemic at time
, and consists of up-to-date information on the state of the epidemic at time
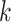 . To take into account the randomness unavoidably present in real-word measurements, it is assumed that this information is uncertain, i.e., affected by noise (e.g., due to data collection errors, biases, holidays), and is modeled as
. To take into account the randomness unavoidably present in real-word measurements, it is assumed that this information is uncertain, i.e., affected by noise (e.g., due to data collection errors, biases, holidays), and is modeled as
 |
where
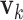 is a random vector with known distribution and whose dimension depends on
is a random vector with known distribution and whose dimension depends on
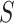 ,
,
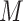 ,
,
 , and
, and
 . The model in (3) and the statistics of
. The model in (3) and the statistics of
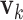 determine the likelihood
determine the likelihood
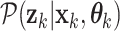 . For convenience, we define the vector
. For convenience, we define the vector
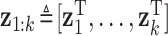 containing all the observations up to time
containing all the observations up to time
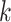 , that is, past and present observations.
, that is, past and present observations.
B. Bayesian Sequential Estimation
The basic principles of Bayesian sequential estimation are now recalled. The reader is referred to [23] for further details. In the Bayesian setting, the estimation of state and parameters amounts to calculating the posterior pdf
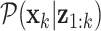 of the state vector
of the state vector
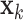 , and the posterior pdf
, and the posterior pdf
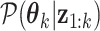 of the parameter vector
of the parameter vector
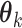 , respectively. The minimum mean square estimators (MMSEs) of
, respectively. The minimum mean square estimators (MMSEs) of
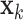 and
and
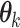 are given by [23, Ch. 4]
are given by [23, Ch. 4]
 |
and
 |
respectively.3 We further note that, using the law of total probability, the pdf
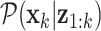 can be expressed as
can be expressed as
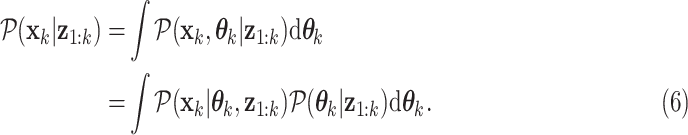 |
Thus, the estimation problem boils down to calculation of the posterior pdfs
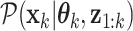 and
and
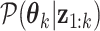 . In the following, we show how they can be obtained sequentially through the implementation of recursive update and prediction steps.
. In the following, we show how they can be obtained sequentially through the implementation of recursive update and prediction steps.
1). Update Step
Let us assume that we know the pdf of the parameter vector at time
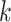 given the observations up to time
given the observations up to time
 , i.e.,
, i.e.,
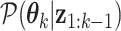 , and the pdf of the state vector at time
, and the pdf of the state vector at time
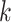 given the parameter vector at time
given the parameter vector at time
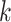 and the observations up to time
and the observations up to time
 , i.e.,
, i.e.,
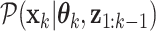 . Then, when a new observation
. Then, when a new observation
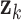 becomes available, the parameter vector pdf and the state vector pdf are updated through Bayes’ rule as
becomes available, the parameter vector pdf and the state vector pdf are updated through Bayes’ rule as
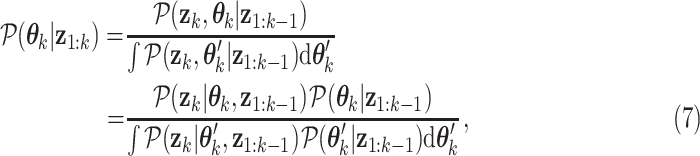 |
and
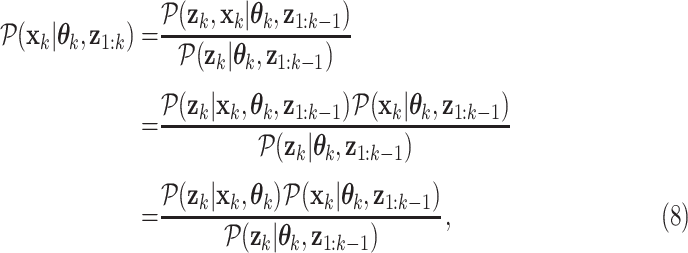 |
respectively, where the last equality of (8) exploits the assumption that the observation at time
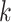 is conditionally independent of all the previous observations, given the state and parameter vectors at time
is conditionally independent of all the previous observations, given the state and parameter vectors at time
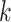 , i.e.,
, i.e.,
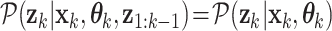 . Using the same assumption and the law of total probability, the pdf
. Using the same assumption and the law of total probability, the pdf
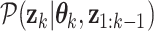 appearing in (7) is calculated as
appearing in (7) is calculated as
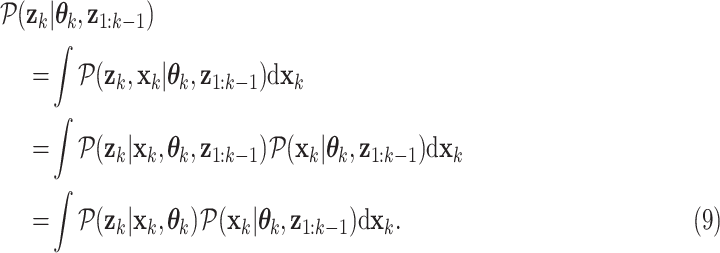 |
2). Prediction Step
In the prediction step, we assume that the posterior pdf
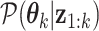 in (7) and the posterior pdf
in (7) and the posterior pdf
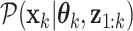 in (8) are known, and derive the pdfs
in (8) are known, and derive the pdfs
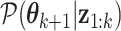 and
and
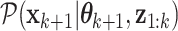 . The former, i.e., the pdf of the predicted parameter vector at time
. The former, i.e., the pdf of the predicted parameter vector at time
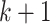 , is obtained using the law of total probability and the Markovian assumption as follows:
, is obtained using the law of total probability and the Markovian assumption as follows:
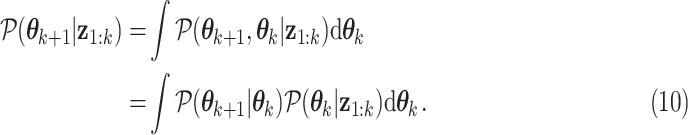 |
Analogously, using the law of total probability, the pdf of the predicted state vector at time
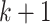 is given by
is given by
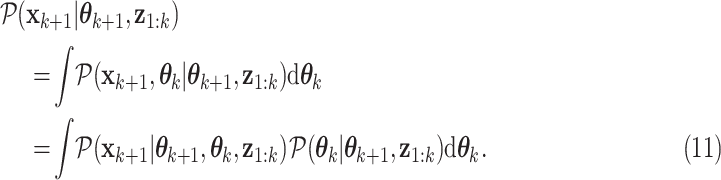 |
The first term within the integral (11), i.e.,
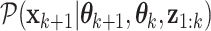 , is calculated using the law of total probability and assuming that
, is calculated using the law of total probability and assuming that
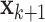 is conditionally independent of
is conditionally independent of
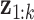 given
given
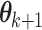 ,
,
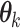 , and
, and
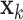 , i.e.,
, i.e.,
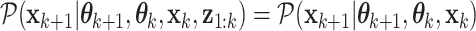 . Thus,
. Thus,
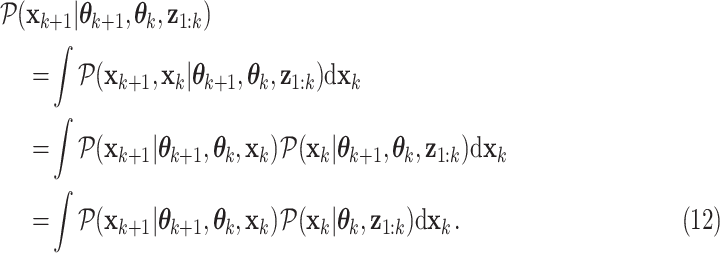 |
The last step follows from the Markov property of the parameter vector. Indeed, the pdf
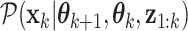 can be calculated as
can be calculated as
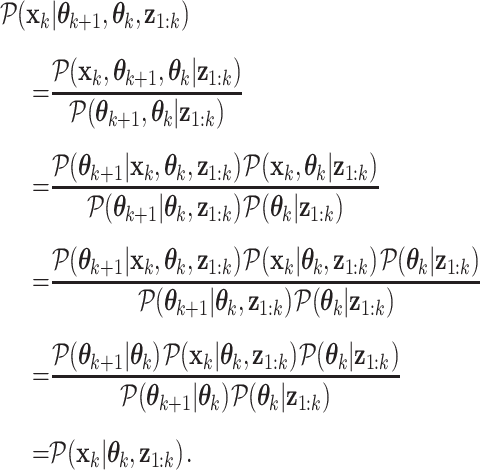 |
The second term within the integral (11), i.e.,
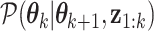 , is obtained using Bayes’ rule and exploiting again the Markov property of the parameter vector, that is,
, is obtained using Bayes’ rule and exploiting again the Markov property of the parameter vector, that is,
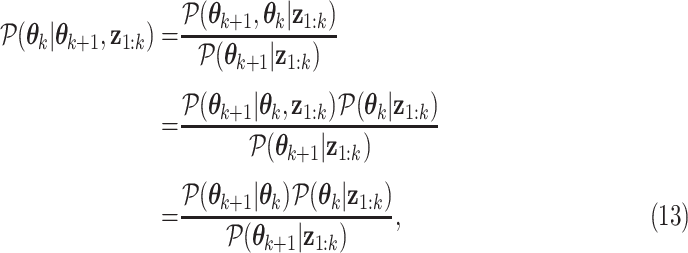 |
where
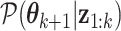 is given by (10).
is given by (10).
C. Forecasting
As the model we consider is nonlinear, the forecast of the epidemic evolution is assessed numerically through a methodology known as ensemble forecasting [24]–[28], that consists of generating a collection of possible evolutions of the epidemic — given the state and parameter vectors estimated so far — and provide a single mean forecast with associated uncertainty. Let us assume that the latest available observation is
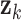 , and that the posterior pdfs
, and that the posterior pdfs
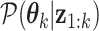 and
and
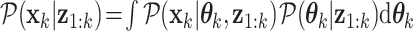 (cf. (6)) are known; the proposed ensemble forecasting approach is a Monte-Carlo technique that samples the posterior distribution of
(cf. (6)) are known; the proposed ensemble forecasting approach is a Monte-Carlo technique that samples the posterior distribution of
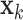 and
and
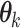 , and evolves these sampled initial vectors up to time
, and evolves these sampled initial vectors up to time
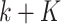 , where
, where
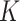 is the forecast horizon. Specifically, let
is the forecast horizon. Specifically, let
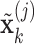 and
and
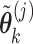 be the
be the
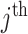 state vector and parameter vector samples extracted from
state vector and parameter vector samples extracted from
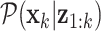 and
and
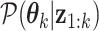 , respectively, where
, respectively, where
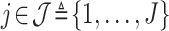 and
and
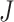 is the ensemble size. The sampled state and parameter vectors are then allowed to evolve4 according to the state vector forecast transition distribution
is the ensemble size. The sampled state and parameter vectors are then allowed to evolve4 according to the state vector forecast transition distribution
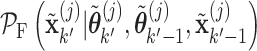 and the parameter vector forecast transition distribution
and the parameter vector forecast transition distribution
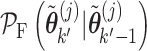 , respectively, for
, respectively, for
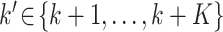 . We observe that these transition distributions can be equal to the transition distributions used within the Bayesian sequential estimation procedure described in the previous section, that is,
. We observe that these transition distributions can be equal to the transition distributions used within the Bayesian sequential estimation procedure described in the previous section, that is,
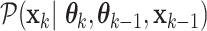 and
and
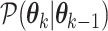 , respectively, or can be suitably devised to improve the forecast performance. Finally, defining the ensemble state matrix as
, respectively, or can be suitably devised to improve the forecast performance. Finally, defining the ensemble state matrix as
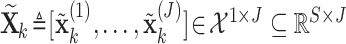 , and the ensemble parameter matrix as
, and the ensemble parameter matrix as
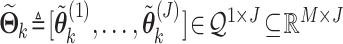 , the mean of the epidemic state and model parameter at any time step
, the mean of the epidemic state and model parameter at any time step
 can be calculated as sample means of
can be calculated as sample means of
 and
and
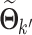 , respectively; that is [29],
, respectively; that is [29],
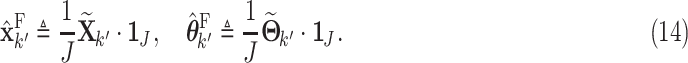 |
Higher order moments, such as sample covariance matrices, can also be computed [29].
III. Mixture Model Implementation
This section describes a mixture model implementation — similar to the approach proposed in [20] — of the Bayesian sequential estimation procedure presented in Section II-B. For computational efficiency, the first step is the discretization of the parameter vector
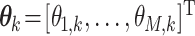 , such that each element
, such that each element
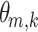 ,
,
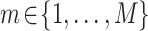 , takes on values from a finite set
, takes on values from a finite set
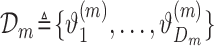 . It follows that
. It follows that
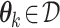 , where
, where
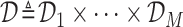 is the discretized finite set with cardinality
is the discretized finite set with cardinality
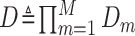 . We note that all the expressions in Section II-B remain valid, provided that integrals
. We note that all the expressions in Section II-B remain valid, provided that integrals
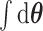 are replaced with summations
are replaced with summations
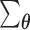 ; e.g., the MMSE estimator of
; e.g., the MMSE estimator of
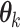 in (5) is rewritten as
in (5) is rewritten as
 |
The key aspect of the formulation is to model the pdf
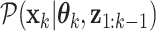 as a mixture of
as a mixture of
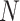 components, that is,
components, that is,
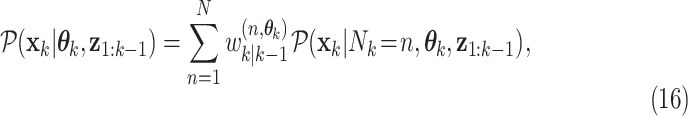 |
where
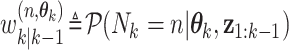 and
and
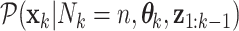 are weight and pdf of the
are weight and pdf of the
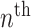 component, respectively. The auxiliary variable
component, respectively. The auxiliary variable
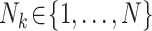 models the switch between the
models the switch between the
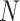 mixture components; hereafter, for notational convenience, we will simply use
mixture components; hereafter, for notational convenience, we will simply use
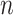 to denote that
to denote that
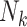 takes on the value
takes on the value
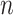 , i.e.,
, i.e.,
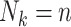 . In the next two subsections, exploiting the development presented in Section II-B1 and Section II-B2, we provide the expressions for the sequential update and prediction of the state and parameter vectors according to the mixture model.
. In the next two subsections, exploiting the development presented in Section II-B1 and Section II-B2, we provide the expressions for the sequential update and prediction of the state and parameter vectors according to the mixture model.
A. Update Step
The posterior pdf
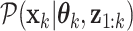 appearing in (8) can be written through the law of total probability as
appearing in (8) can be written through the law of total probability as
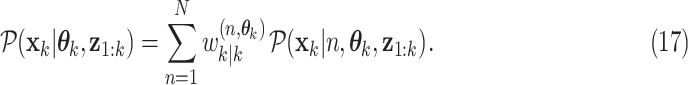 |
The updated weight
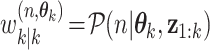 is calculated through Bayes’s rule as
is calculated through Bayes’s rule as
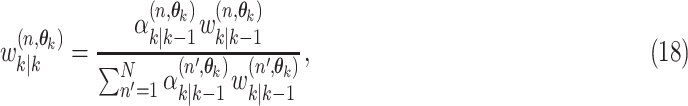 |
where the update coefficient
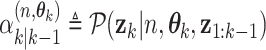 can be derived from (9) assuming the conditional independence of the observation
can be derived from (9) assuming the conditional independence of the observation
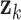 from the previous observations
from the previous observations
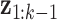 and the specific mixand
and the specific mixand
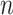 , given
, given
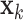 and
and
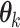 , i.e.,
, i.e.,
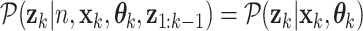 . That is,
. That is,
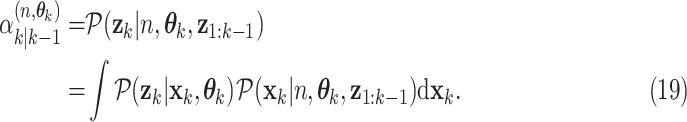 |
Using the same assumption, the posterior pdf of the
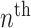 mixture component is calculated from (8) as
mixture component is calculated from (8) as
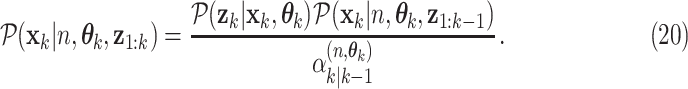 |
Then, using (7) with integrals replaced by summations, the posterior pmf of the parameter vector is obtained as
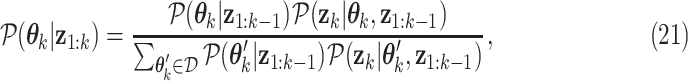 |
where, through the law of total probability,
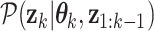 can be calculated as
can be calculated as
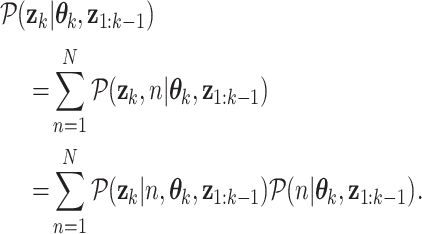 |
Here, we recognize the update coefficient
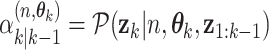 and the weight
and the weight
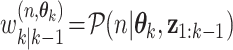 . Therefore, the posterior pmf in (21) can be finally recast as
. Therefore, the posterior pmf in (21) can be finally recast as
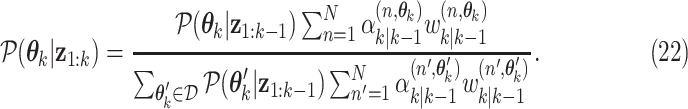 |
B. Prediction Step
The pmf of the predicted parameter vector at time
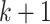 , i.e.,
, i.e.,
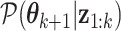 , is simply obtained by inserting (22) into (10), where the integral is replaced by summation. To derive the pdf of the predicted state vector at time
, is simply obtained by inserting (22) into (10), where the integral is replaced by summation. To derive the pdf of the predicted state vector at time
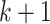 , i.e.,
, i.e.,
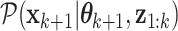 , instead, we consider the discrete version of (11), that is,
, instead, we consider the discrete version of (11), that is,
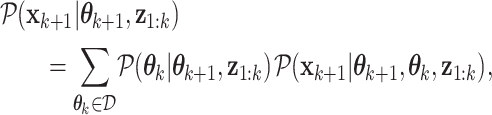 |
and insert therein (12) and (13) to obtain
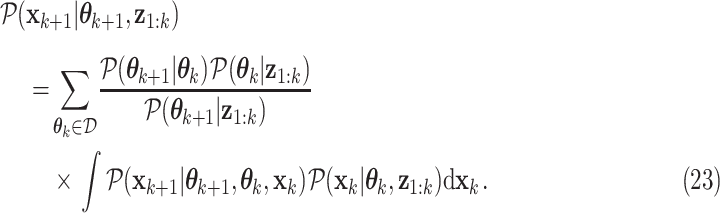 |
Finally, by using (17) into (23), the latter can be recast as
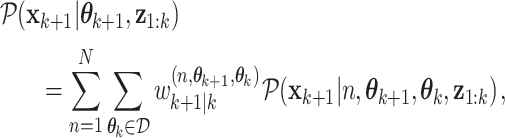 |
where the pdf of the
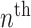 component, i.e.,
component, i.e.,
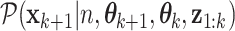 , is
, is
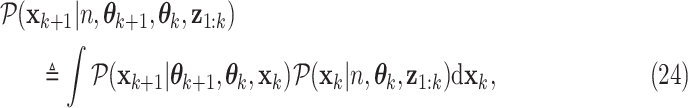 |
and the predicted weights are defined as
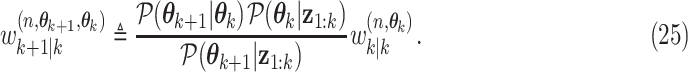 |
We note that in the prediction step the number of mixture components increases from
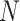 to
to
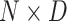 , thus a suitable merging/pruning criterion is required to avoid the exponential growth of the computational complexity [30], [31].
, thus a suitable merging/pruning criterion is required to avoid the exponential growth of the computational complexity [30], [31].
Remark:
We aim to provide a general framework for adaptive Bayesian estimation of epidemic evolution, here implemented via an efficient mixture model. Nonetheless, the same nonlinear problem could have been approached and implemented differently, for example by using an extended or unscented Kalman filter (EKF or UKF), or by means of sequential Monte Carlo (SMC) methods, e.g., particle filters [32]. These are not alternate to our approach, but can be possibly combined, as noted later in Section IV-B. However, we also observe that direct use of the aforementioned techniques — if not adequately tailored to the specific problem — may lead to poor or unexpected results. For example, the EKF approximation of the nonlinear behaviour of the system through local linearization, might fail in the presence of strong nonlinearities, leading to unreliable estimates or even to divergence. The UKF can potentially provide higher-order estimation accuracy using the unscented transform, but this usually has the effect of simply delaying the unavoidable divergence that will still happen in the case of severe process or measurement nonlinearities. On the other hand, SMC methods generally provide reliable numerical approximations to sequential nonlinear estimation problems. However, in real-world applications, where the system also depends on unknown time-varying parameters to be inferred from uncertain data, conventional particle filters could fail to detect and track the change in parameters, quickly leading to implementation issues, such as sample impoverishment. In addition, high performance of particle methods comes at the expense of increased computational demands.
Another class of methods is based on system identification/machine learning (ML) techniques. Canonical approaches here include expectation-maximization, variational Bayes methods, and the variety of nonlinear auto-regressive models with external inputs, recurrent neural networks, long short-term memory networks [33]–[36]. The non-parametric ML methods suffer from lack of explainability and causal reasoning needed for policy decisions in pandemics.
IV. Estimation and Forecasting With Stochastic Sir Model
A. Dynamic and Observation Model
The SIR model [4], [5] subdivides the population of a community into three interacting groups: susceptible, infectious, and recovered individuals. The interactions are governed by the infection rate, usually denoted by
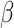 , that is the average rate at which an infected individual can infect a susceptible one, and by the recovery rate, generally called
, that is the average rate at which an infected individual can infect a susceptible one, and by the recovery rate, generally called
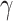 . Let
. Let
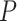 be the total population size5;
be the total population size5;
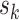 ,
,
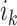 , and
, and
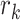 be the normalized (to
be the normalized (to
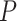 ) number of susceptible, infectious, and recovered individuals at time
) number of susceptible, infectious, and recovered individuals at time
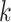 , such that
, such that
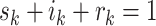 ; and
; and
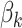 and
and
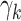 be the infection and recovery rates at time
be the infection and recovery rates at time
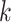 . The discrete-time stochastic SIR system of equations is expressed as [17], [37]
. The discrete-time stochastic SIR system of equations is expressed as [17], [37]
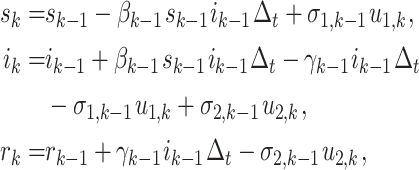 |
where
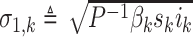 ,
,
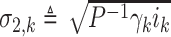 , and
, and
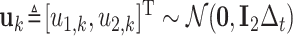 . Since
. Since
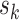 and
and
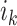 determine
determine
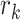 , we define the state vector as
, we define the state vector as
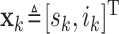 , and the parameter vector as
, and the parameter vector as
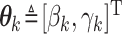 ; hence, we have
; hence, we have
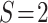 and
and
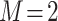 . The dynamic model of the epidemic is then expressed as (cf. (1))
. The dynamic model of the epidemic is then expressed as (cf. (1))
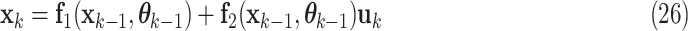 |
where
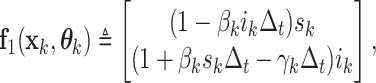 |
and
 |
From (26) it then follows that the state transition pdf (cf. (2)) is independent of the current parameter vector
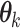 , i.e.,
, i.e.,
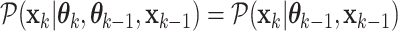 , and is distributed according to
, and is distributed according to
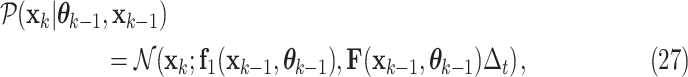 |
where
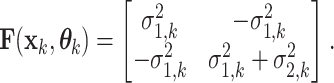 |
We observe the (uncertain) normalized number of infected and of recovered individuals at each time
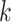 . Therefore,
. Therefore,
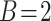 , and the observation model (cf. (3)) is
, and the observation model (cf. (3)) is
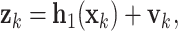 |
where
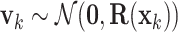 models the observation uncertainty, and
models the observation uncertainty, and
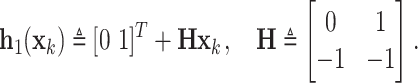 |
The covariance matrix
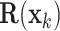 depends on the state vector at time
depends on the state vector at time
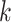 : since we assume that the observation “noise” accrues from the sum of uncertainties of each individual epidemic state, the variances are linear in the number of infected and recovered individuals, respectively. Hence, we define
: since we assume that the observation “noise” accrues from the sum of uncertainties of each individual epidemic state, the variances are linear in the number of infected and recovered individuals, respectively. Hence, we define
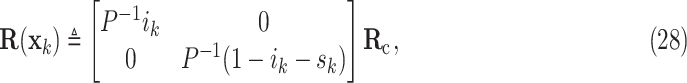 |
where
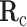 is a constant diagonal matrix. Thus, the likelihood is independent of
is a constant diagonal matrix. Thus, the likelihood is independent of
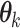 , i.e.,
, i.e.,
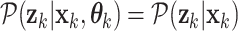 , and distributed according to
, and distributed according to
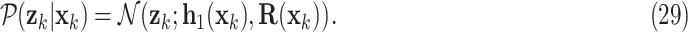 |
B. Gaussian Mixture Filter
Given the Gaussian nature of the dynamic and observation models, we adopt a Gaussian mixture implementation of the Bayesian sequential estimation. That is, we assume that the pdf of the
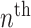 mixture component in (16) is Gaussian with mean
mixture component in (16) is Gaussian with mean
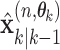 and covariance matrix
and covariance matrix
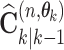 , i.e.,
, i.e.,
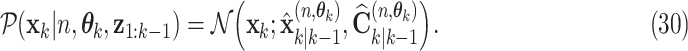 |
When the observation
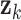 is available, mean, covariance matrix, and weight are updated. Specifically, the weight of the
is available, mean, covariance matrix, and weight are updated. Specifically, the weight of the
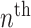 mixand is updated as in (18) through the coefficient
mixand is updated as in (18) through the coefficient
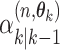 ; this, in turn, is calculated recalling that the likelihood in (29) is independent of
; this, in turn, is calculated recalling that the likelihood in (29) is independent of
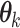 , and inserting (29) and (30) into (19), that is,
, and inserting (29) and (30) into (19), that is,
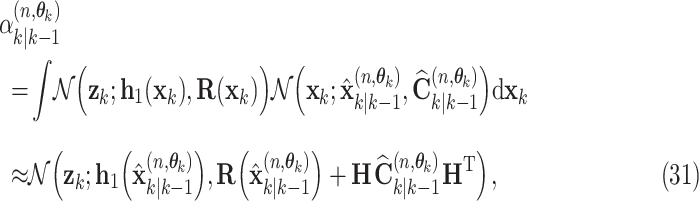 |
where we made the approximation
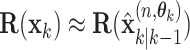 . We observe that the last step would be an equality — rather than an approximation — if the observation covariance matrix was independent of the state
. We observe that the last step would be an equality — rather than an approximation — if the observation covariance matrix was independent of the state
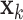 . Then, the updated pdf of the
. Then, the updated pdf of the
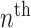 Gaussian component is obtained by inserting (29), (30), and (31) into (20), and is equal to [30]
Gaussian component is obtained by inserting (29), (30), and (31) into (20), and is equal to [30]
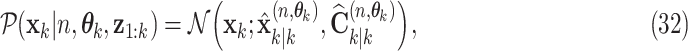 |
where
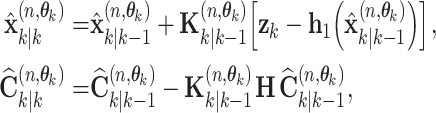 |
and
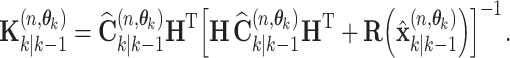 |
This is similar to a standard Kalman update, per mixture element, with essential difference that the measurement noise covariance is state-dependent.
Let us now consider the evolution of the mixands according to the dynamic model. The
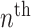 predicted weight is computed using (25) where, assuming that infection rate
predicted weight is computed using (25) where, assuming that infection rate
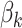 and recovery rate
and recovery rate
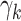 evolve independently, the parameter vector transition pmf can be written as
evolve independently, the parameter vector transition pmf can be written as
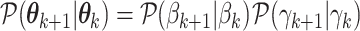 ; the marginal transition pmfs
; the marginal transition pmfs
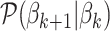 and
and
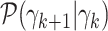 are specified later in this section. The pdf of the
are specified later in this section. The pdf of the
 predicted mixand is obtained by recalling that the transition pdf in (27) is independent of the current parameter vector
predicted mixand is obtained by recalling that the transition pdf in (27) is independent of the current parameter vector
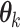 , and inserting (27) and (32) into (24). This yields
, and inserting (27) and (32) into (24). This yields
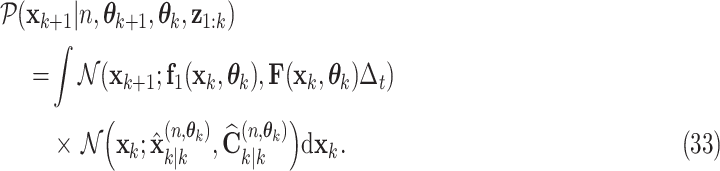 |
Given the nonlinearity of the dynamic model (26), the integral (33) cannot be computed explicitly. A viable alternative is to approximate the pdf
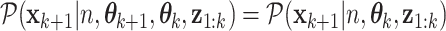 as a Gaussian via moment matching, that is,
as a Gaussian via moment matching, that is,
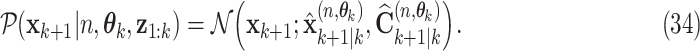 |
The computation of
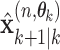 and of
and of
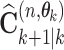 by moment matching is detailed in Appendix A. An alternative method to solve integral (33) is via the unscented transformation used within the UKF.
by moment matching is detailed in Appendix A. An alternative method to solve integral (33) is via the unscented transformation used within the UKF.
As described in Section III, the parameter vector
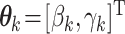 is discretized for computational efficiency. Specifically,
is discretized for computational efficiency. Specifically,
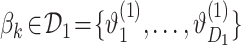 and
and
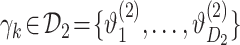 . For concreteness, we assume that
. For concreteness, we assume that
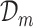 (
(
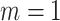 or 2) is an ordered set, i.e., such that for any
or 2) is an ordered set, i.e., such that for any
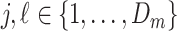 with
with
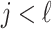 , we have
, we have
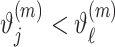 ; and that the elements of
; and that the elements of
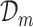 are selected to be equally spaced between
are selected to be equally spaced between
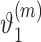 and
and
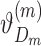 . The marginal transition pmfs
. The marginal transition pmfs
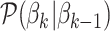 and
and
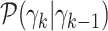 are therefore fully described by the matrix
are therefore fully described by the matrix
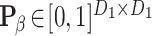 and matrix
and matrix
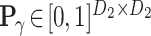 , respectively, where
, respectively, where
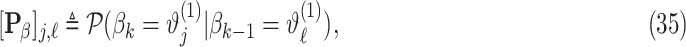 |
and
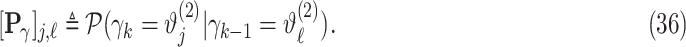 |
We note that
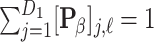 and that
and that
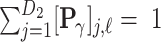 . Eventually, according to (4) and (6), and replacing the integral in (6) with the summation, the MMSE estimates of the normalized numbers of susceptible and infectious are
. Eventually, according to (4) and (6), and replacing the integral in (6) with the summation, the MMSE estimates of the normalized numbers of susceptible and infectious are
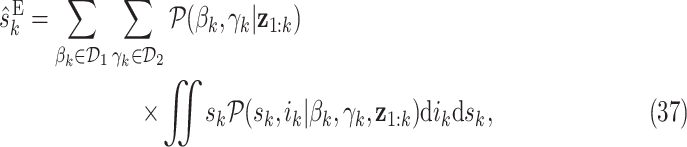 |
and
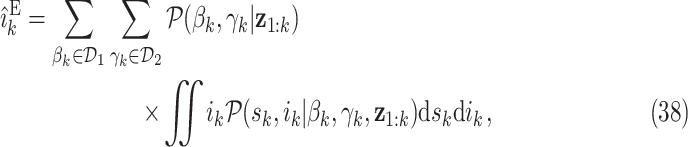 |
respectively; and, according to (15), the MMSE estimates of the infection and recovery rates are
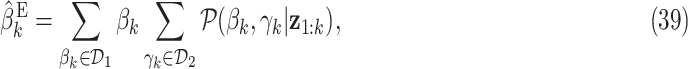 |
and
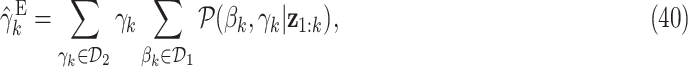 |
respectively. Note that the estimates for the parameters
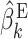 and
and
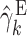 are updated automatically based on the attractiveness (measured in terms of the relative likelihoods) of the estimates that assume them. Finally, the prior pmfs of the infection and recovery rates at time
are updated automatically based on the attractiveness (measured in terms of the relative likelihoods) of the estimates that assume them. Finally, the prior pmfs of the infection and recovery rates at time
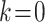 are set to
are set to
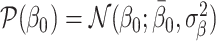 and
and
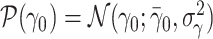 ; the prior pdf of the
; the prior pdf of the
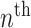 Gaussian component at time
Gaussian component at time
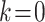 is
is
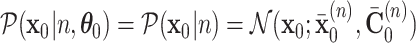 .
.
A detailed statement of the proposed Gaussian mixture filter for the Bayesian estimation of the epidemic evolution with the stochastic SIR model is provided in Algorithm 1.
Algorithm 1 Epidemic Estimation With Stochastic SIR Model
-
Input:
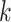 ,
,
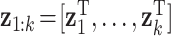 ,
,
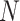 ,
,
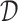 ,
,
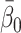 ,
,
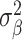 ,
,
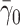 ,
,
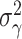 ,
,
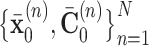
-
Output:
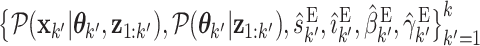
Initialization
-
1:
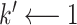
-
2:
for
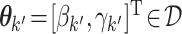 do
do -
3:
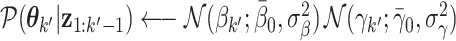
-
4:
for
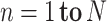 do
do -
5:
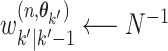
-
6:
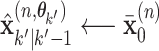
-
7:
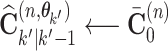
-
8:
end for
-
9:
end for
-
10:
for
 to
to
 do
do Update
-
11:
for
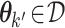 do
do -
12:
for
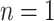 to
to
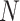 do
do -
13:
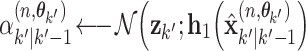 ,
,
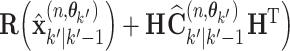
-
14:
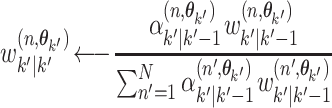
-
15:
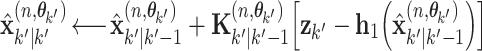
-
16:
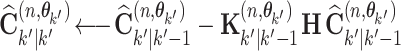
-
17:
end for
-
18:
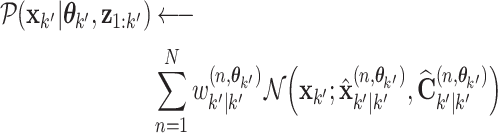
-
19:
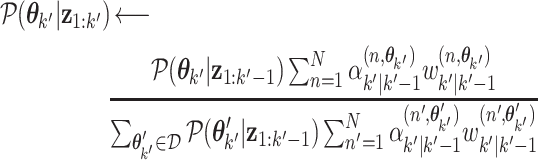
-
20:
end for
- 21:
Prediction
-
22:
for
 do
do -
23:
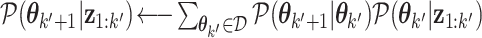
-
24:
-
25:
for
 do
do -
26:
for
 do
do -
27:
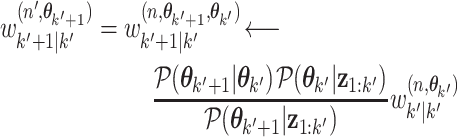
-
28:
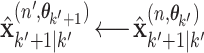 (via moment matching)
(via moment matching) -
29:
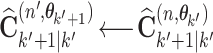 (via moment matching)
(via moment matching) -
30:
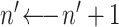
-
31:
end for
-
32:
end for
-
33:
end for
Pruning
-
34:
for
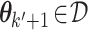 do
do -
35:
Sort in descending order the
 mixture components according to the weights
mixture components according to the weights
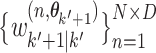 , and retain the first
, and retain the first
 elements
elements -
36:
for
 do
do -
37:
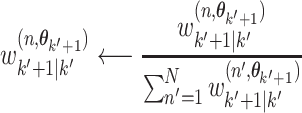
-
38:
end for
-
39:
end for
-
40:
end for
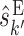
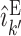
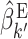
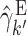
C. Forecasting
The forecasting is as described in Section II-C. Let us assume that
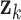 is the most recent available observation, and that the posterior pdf
is the most recent available observation, and that the posterior pdf
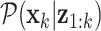 and pmf
and pmf
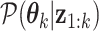 are known.
are known.
The
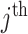 sample state vector extracted from the posterior pdf
sample state vector extracted from the posterior pdf
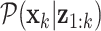 is
is
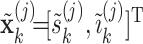 ,
,
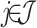 , and evolves according to the state vector forecast transition distribution
, and evolves according to the state vector forecast transition distribution
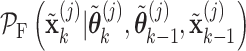 ; we assume that this forecast transition distribution coincides with that used within the sequential Bayesian estimation procedure (cf. (27)), i.e., we assume that the sampled state vector
; we assume that this forecast transition distribution coincides with that used within the sequential Bayesian estimation procedure (cf. (27)), i.e., we assume that the sampled state vector
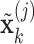 evolves according to the dynamic model in (26).
evolves according to the dynamic model in (26).
Concerning the parameter vectors, in order to obtain samples
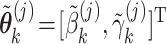 ,
,
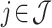 , from the infinite set
, from the infinite set
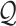 — rather than the discrete finite set
— rather than the discrete finite set
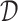 —, the posterior pmf
—, the posterior pmf
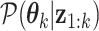 is approximated with a suitable continuous distribution; here,
is approximated with a suitable continuous distribution; here,
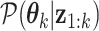 is approximated with a bivariate Gaussian pdf and samples
is approximated with a bivariate Gaussian pdf and samples
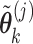 are extracted from it. Then, these sampled parameter vectors are allowed to evolve according to the parameter vector forecast transition distribution
are extracted from it. Then, these sampled parameter vectors are allowed to evolve according to the parameter vector forecast transition distribution
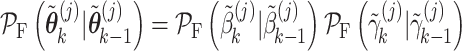 , where we assumed the infection and recovery rates to change independently. We recall that the inverse of the recovery rate expresses the average time that an individual takes to move from the group of infected (I) to the group of recovered (R) people; in our model, the latter includes both those discharged from hospitals, and those for whom the infection was fatal. Even though it is likely that the recovery rate will change during the forecast period (due to, e.g., reporting delays or the application of different criteria used to declare an individual recovered), there are no prior information that would suggest when and how this will happen; it is therefore reasonable to assume the recovery rate to be constant and deterministic during the forecast period. This equals to set the recovery rate forecast transition distribution to
, where we assumed the infection and recovery rates to change independently. We recall that the inverse of the recovery rate expresses the average time that an individual takes to move from the group of infected (I) to the group of recovered (R) people; in our model, the latter includes both those discharged from hospitals, and those for whom the infection was fatal. Even though it is likely that the recovery rate will change during the forecast period (due to, e.g., reporting delays or the application of different criteria used to declare an individual recovered), there are no prior information that would suggest when and how this will happen; it is therefore reasonable to assume the recovery rate to be constant and deterministic during the forecast period. This equals to set the recovery rate forecast transition distribution to
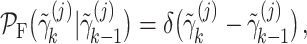 |
where
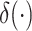 is the Dirac delta. The infection rate, instead, models the interaction between people, and it is therefore affected by the restriction measures. Therefore, once its time evolution is captured, it is reasonable to assume — in the absence of further knowledge — that it keeps the same trend linearly. That is, the infection rate samples
is the Dirac delta. The infection rate, instead, models the interaction between people, and it is therefore affected by the restriction measures. Therefore, once its time evolution is captured, it is reasonable to assume — in the absence of further knowledge — that it keeps the same trend linearly. That is, the infection rate samples
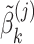 ,
,
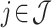 , are assumed to evolve according to
, are assumed to evolve according to
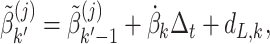 |
for
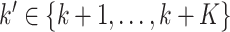 , where
, where
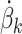 is a constant slope, and
is a constant slope, and
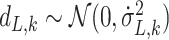 ; hence, the infection rate forecast transition distribution is
; hence, the infection rate forecast transition distribution is
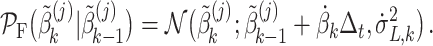 |
Appendix B provides details on the estimation of the slope
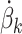 over the time interval
over the time interval
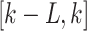 , on the selection of
, on the selection of
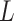 , with
, with
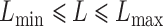 , and on the computation of
, and on the computation of
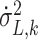 .
.
Eventually, defining the ensemble state and parameter matrices as
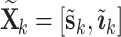 and
and
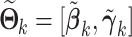 , respectively, where
, respectively, where
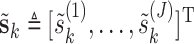 ,
,
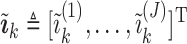 ,
,
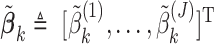 , and
, and
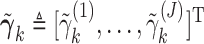 , the mean of the epidemic states and model parameters at any time step
, the mean of the epidemic states and model parameters at any time step
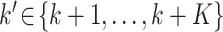 are calculated as (cf. (14))
are calculated as (cf. (14))
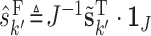 ,
,
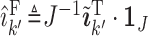 ,
,
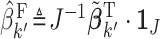 , and
, and
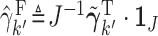 .
.
The steps of the proposed forecasting algorithm with stochastic SIR model are detailed in Algorithm 2.
Algorithm 2 Epidemic Forecasting With Stochastic SIR Model
-
Input:
 ,
,
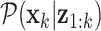 ,
,
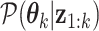 ,
,
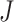 ,
,
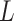 ,
,
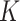 ,
,
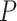 ,
,
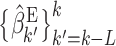
-
Output:
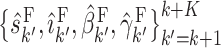
Initialization
-
1:
Draw
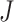 samples
samples
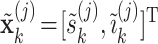 from
from
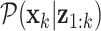
-
2:
Draw
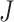 samples
samples
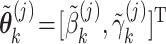 from
from
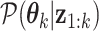
-
3:
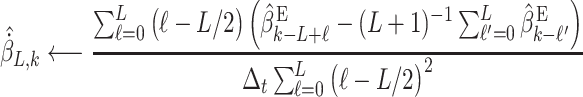
-
4:
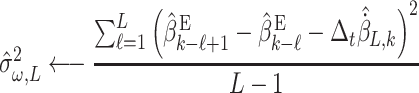
-
5:
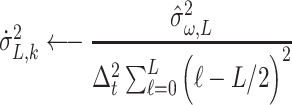
Forecasting
-
6:
for
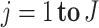 do
do -
7:
for
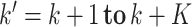 do
do State Evolution
-
8:
Draw
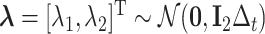
-
9:
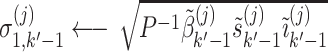
-
10:
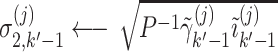
-
11:
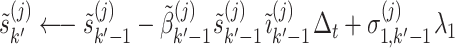
-
12:
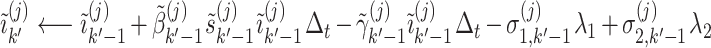
Parameters Evolution
-
13:
Draw
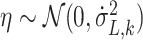
-
14:
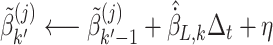
-
15:
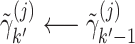
Ensemble Mean
-
16:
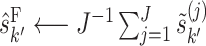
-
17:
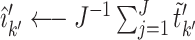
-
18:
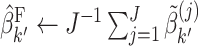
-
19:
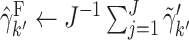
-
20:
end for
-
21:
end for
V. Forecast Performance Analysis: Synthetic Data and Real COVID-19 Outbreak Data
We present numerical results obtained with the sequential estimation and forecasting algorithm described in Section IV. In Section V-A the algorithm is applied to synthetic data, while real data from the recent COVID-19 outbreak are considered in Section V-B.
A. Synthetic Data Experiment
The effectiveness of the proposed algorithm is validated in two simulated epidemic scenarios involving a community of
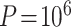 individuals. The simulations span 80 days, during which the infection rate changes as shown in Fig. 1 The variations of the infection rate model the effects of the restriction measures established by the authorities: in the first scenario, the epidemic outbreak is controlled by long-term soft restriction measures that cause a slow, yet consistent, decrease in the infection rate; in the second scenario, an initial strict lockdown is then followed by a relaxation of the restriction measures that leads to a slight increase in the infection rate. The recovery rate is fixed and set to
individuals. The simulations span 80 days, during which the infection rate changes as shown in Fig. 1 The variations of the infection rate model the effects of the restriction measures established by the authorities: in the first scenario, the epidemic outbreak is controlled by long-term soft restriction measures that cause a slow, yet consistent, decrease in the infection rate; in the second scenario, an initial strict lockdown is then followed by a relaxation of the restriction measures that leads to a slight increase in the infection rate. The recovery rate is fixed and set to
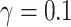 . The initial state of the epidemic is described by the normalized numbers of susceptible, infected, and recovered individuals at time
. The initial state of the epidemic is described by the normalized numbers of susceptible, infected, and recovered individuals at time
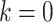 , that are
, that are
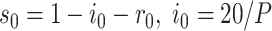 , and
, and
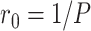 . The infection rate is discretized with
. The infection rate is discretized with
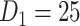 values between
values between
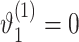 and
and
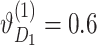 ; the recovery rate with
; the recovery rate with
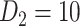 values between
values between
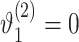 and
and
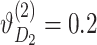 . The prior pmf of the infection rate has mean
. The prior pmf of the infection rate has mean
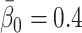 in the first scenario, and
in the first scenario, and
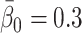 in the second scenario; the standard deviation is
in the second scenario; the standard deviation is
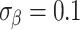 for both the scenarios. Mean and standard deviation of the prior pmf of the recovery rate are
for both the scenarios. Mean and standard deviation of the prior pmf of the recovery rate are
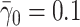 and
and
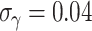 , respectively, for both the scenarios. The transition matrix for the parameter
, respectively, for both the scenarios. The transition matrix for the parameter
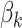 defined in (35) is set to
defined in (35) is set to
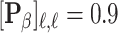 for
for
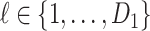 ,
,
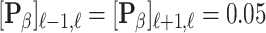 for
for
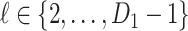 , and
, and
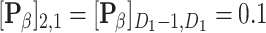 . The transition matrix for the parameter
. The transition matrix for the parameter
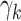 defined in (36) is analogously set to
defined in (36) is analogously set to
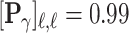 for
for
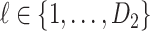 ,
,
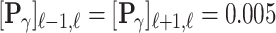 for
for
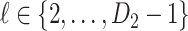 , and
, and
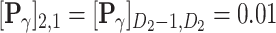 . The number of mixture components is
. The number of mixture components is
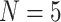 , and mean and covariance matrix of the prior pdf of the
, and mean and covariance matrix of the prior pdf of the
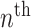 component are
component are
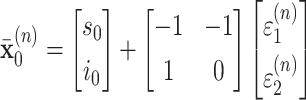 |
and
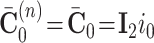 , respectively, where
, respectively, where
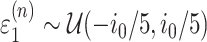 and
and
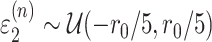 . Finally, the observation noise covariance matrix in (28) is
. Finally, the observation noise covariance matrix in (28) is
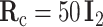 . As for the forecasting, the ensemble size is
. As for the forecasting, the ensemble size is
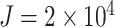 , and the minimum and maximum numbers of points used to estimate the slope of the infection rate are
, and the minimum and maximum numbers of points used to estimate the slope of the infection rate are
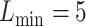 and
and
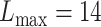 , respectively.
, respectively.
FIGURE 1.

Evolution of the infection rate in the simulated scenarios.
Fig. 2 shows the infection and recovery rates estimated in the first scenario over the 80 days, along with their 90% confidence intervals. Analogously, Fig. 3 shows the estimated infection and recovery rates in the second scenario. The results demonstrate the capability of proposed Bayesian sequential estimation algorithm to closely follow the time variation of the infection rates even in the presence of abrupt fluctuations, as well as to accurately estimate the recovery rate.
FIGURE 2.

Estimated (top) infection rate and (bottom) recovery rate in the first simulated scenario. The shaded areas represent the 90% confidence interval.
FIGURE 3.

Estimated (top) infection rate and (bottom) recovery rate in the second simulated scenario. The shaded areas represent the 90% confidence interval.
In turn, the accuracy of the proposed algorithm allows one to reliably forecast the epidemic evolution. Fig. 4 presents the estimation and forecast on the infection rate and of the number of infected in the first scenario; we assume that the latest available observation is on day
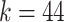 — so that the estimation stops on this day —, and the forecast is up to day
— so that the estimation stops on this day —, and the forecast is up to day
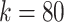 . The forecast of the number of infected individuals well represents the evolution of the epidemic, suggesting a peak between days 55 and 65. Furthermore, we observe how both the true infection rate and the true number of infected is always enveloped within the 90% confidence interval, showing the high reliability of the proposed algorithm. Finally, in Fig. 5, we show the forecast of the epidemic evolution in the second scenario. Here, the estimation is performed up to day
. The forecast of the number of infected individuals well represents the evolution of the epidemic, suggesting a peak between days 55 and 65. Furthermore, we observe how both the true infection rate and the true number of infected is always enveloped within the 90% confidence interval, showing the high reliability of the proposed algorithm. Finally, in Fig. 5, we show the forecast of the epidemic evolution in the second scenario. Here, the estimation is performed up to day
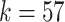 ; the capability of the proposed algorithm to accurately estimate the large variation in the infection rate and forecast its future average value, allows one to forecast the evolution of the number infected, even though a further small variation of the infection rate will start at
; the capability of the proposed algorithm to accurately estimate the large variation in the infection rate and forecast its future average value, allows one to forecast the evolution of the number infected, even though a further small variation of the infection rate will start at
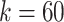 .
.
FIGURE 4.

Estimation and forecasting, respectively in solid and dashed lines, of (top) the infection rate and (bottom) the number of infected individuals in the first scenario; the superscripts E and F stand for estimate and forecast, respectively. The estimation is up to
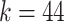 (marked by a vertical dotted line), and the forecast is up to
(marked by a vertical dotted line), and the forecast is up to
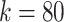 . The shaded areas represent the 90% confidence interval.
. The shaded areas represent the 90% confidence interval.
FIGURE 5.

Estimation and forecasting, respectively in solid and dashed lines, of (top) the infection rate and (bottom) the number of infected individuals in the second scenario; the superscripts E and F stand for estimate and forecast, respectively. The estimation is up to
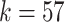 (marked by a vertical dotted line), and the forecast is up to
(marked by a vertical dotted line), and the forecast is up to
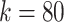 . The shaded areas represent the 90% confidence interval.
. The shaded areas represent the 90% confidence interval.
B. Real Data: COVID-19 Outbreak
This section presents the results obtained with the proposed estimation and forecasting algorithm when applied to real data obtained from the recent COVID-19 outbreak. The focus is on two very different areas in terms of population and interactions: Lombardia region in Italy, and the USA.
1). Lombardia Region, Italy
Official data on the COVID-19 epidemic outbreak in Italy are made available from Protezione Civile on a daily basis [38]. This includes many entries, both nationwide and per region, as the total number of cases, total number of current positive cases, new positive cases per day, number of hospitalised patients, number of tests performed, number of discharged COVID-19 patients from the hospitals, and number of deaths. Here, we focus on the data from Lombardia region, the centre of Italy’s COVID-19 outbreak, whose population is
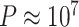 people. We used the normalized (to
people. We used the normalized (to
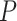 ) total number of current positive cases as number of infected
) total number of current positive cases as number of infected
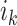 , and the normalized sum of number of discharged patients and number of deaths as the number of recovered
, and the normalized sum of number of discharged patients and number of deaths as the number of recovered
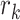 . These are reported in Fig. 6 and refer to the period between February 24, 2020, and June 30, 2020. The figure also shows the beginning of the lockdown established by the Italian government on March 8, 2020. Furthermore, we observe that, on May 6, the number of infected and number of recovered individuals present large steps, which hardly reflect physical reality. These steps are due to the fact that the numbers reported on May 6 include not only data referring to that day, but also data collected on previous days, and, erroneously, not reported in the correct day [38].
. These are reported in Fig. 6 and refer to the period between February 24, 2020, and June 30, 2020. The figure also shows the beginning of the lockdown established by the Italian government on March 8, 2020. Furthermore, we observe that, on May 6, the number of infected and number of recovered individuals present large steps, which hardly reflect physical reality. These steps are due to the fact that the numbers reported on May 6 include not only data referring to that day, but also data collected on previous days, and, erroneously, not reported in the correct day [38].
FIGURE 6.

Numbers of infected and recovered (i.e., hospital releases plus deaths) individuals in Lombardia, Italy, from February 24, 2020, to June 30, 2020 (data from Protezione Civile [38]). The vertical dashed line indicates March 8, 2020, the beginning of the lockdown. The large steps on May 6 are due to an inaccurate reporting of the data, as explained in Section V-B1.
The setting of the Bayesian sequential estimation and forecasting algorithm is as described in Section V-A, except that the smallest and largest values used for the discretization of the infection rate are
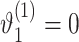 and
and
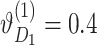 , respectively; the smallest and largest values used for the discretization of the recovery rate are
, respectively; the smallest and largest values used for the discretization of the recovery rate are
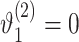 and
and
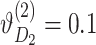 , respectively; mean and standard deviation of their prior pmfs are
, respectively; mean and standard deviation of their prior pmfs are
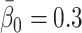 and
and
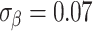 , and
, and
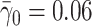 and
and
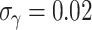 ; and the observation noise covariance matrix is
; and the observation noise covariance matrix is
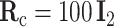 . The initial state of the epidemic is given by the normalized numbers of susceptible, infected, and recovered on February 24, that are
. The initial state of the epidemic is given by the normalized numbers of susceptible, infected, and recovered on February 24, that are
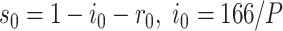 , and
, and
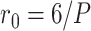 .
.
The estimated infection and recovery rates are shown in Fig. 7. The decrease in the infection rate, which represents the slowdown of the epidemic, clearly reflects the restriction measures established on March 8. The recovery rate, instead, decreases up to May 6, when it then shows a slight increase. The reduction of the recovery rate balances the decrease in the infection rate; indeed, up to May 6, the number of infected is still growing, which suggests that the infection rate is greater than the recovery rate, i.e.,
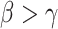 . After May 6, this trend changes.
. After May 6, this trend changes.
FIGURE 7.

Estimated (top) infection rate and (bottom) recovery rate for Lombardia. The vertical dashed line indicates March 8, 2020, the beginning of the lockdown. The shaded areas represent the 90% confidence interval.
Fig. 8 reports the forecasts of the epidemic evolution assessed every five days in the time period between April 13 and June 7, and Table 1 presents the mean absolute percentage errors (MAPEs) calculated for each forecast and for different forecast horizons, that is, 3, 7, and 14 days. We note that the forecasts made on April 13, 18, and 23, follow the future observations well, with an average MAPE below 3% at a forecast horizon of 7 days. On April 28 and May 3 the forecasts are not reliable, since the future observations are not contained within the 90% confidence interval. However, this poor performance is related to the inaccurate data provided later on May 6; indeed, the next forecasts made from May 8, to June 7, present again low MAPEs, with an average of 3.49%, 4.24%, and 6.1%, at forecast horizons of 3, 7, and 14 days, respectively. Neglecting the forecasts whose horizon includes May 6 (marked with an asterisk in Table 1), the average MAPE from April 13, to June 7, is 3.6% for forecasts at 7 days, and below 6% when the forecast horizon is 14 days.
FIGURE 8.
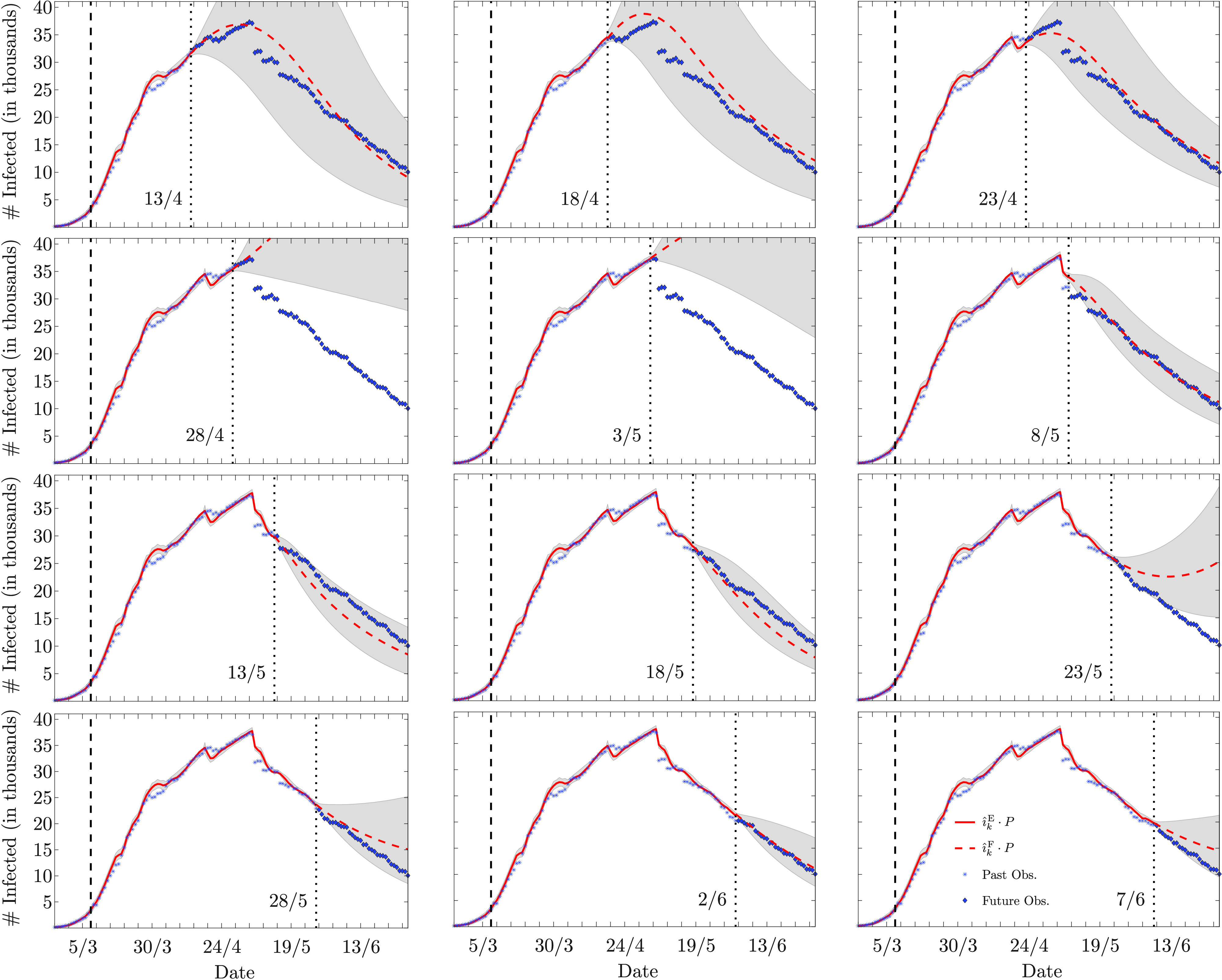
Estimation and forecasting, respectively in solid and dashed lines, of the number of infected individuals in Lombardia, Italy (legend is reported in the bottom-right corner image; the superscript E stands for estimate, and the superscript F stands for forecast). The date corresponding to the end of the estimation and the beginning of the forecast is marked by a vertical dotted line (the leftmost vertical dashed line marks March 8, the beginning of the lockdown). In all the cases, the forecast horizon is June 30. The shaded area represents the 90% confidence interval. The poor forecasts made on April 28, and May 3, relate to the inaccurate data later provided on May 6, as explained in Section V-B1.
TABLE 1. Mean Absolute Percentage Errors (MAPEs) of the Forecasts of the Epidemic Evolution in Lombardia, Italy, Performed at Different Dates and Calculated for Different Forecast Horizons, That is, 3, 7, and 14 Days. The Asterisk Means That the Forecast Performed at a Given Date and With a Given Forecast Horizon Includes May 6, When Inaccurate Numbers of Infected and Recovered Individuals Were Reported. The Average (Last Row) Does Not Take Into Account These Cases.
| Forecast Date | 3 Days (%) | 7 Days (%) | 14 Days (%) |
|---|---|---|---|
| April 13 | 0.54 | 0.50 | 2.49 |
| April 18 | 3.47 | 6.48 | 6.84 |
| April 23 | 1.25 | 1.91 | 3.88* |
| April 28 | 0.42 | 1.07 | 14.91* |
| May 3 | 8.02* | 18.44* | 30.07* |
| May 8 | 9.14 | 7.47 | 6.31 |
| May 13 | 2.30 | 2.59 | 6.48 |
| May 18 | 0.92 | 2.24 | 3.29 |
| May 23 | 0.69 | 3.78 | 9.02 |
| May 28 | 4.67 | 5.10 | 4.99 |
| June 2 | 2.70 | 1.87 | 1.93 |
| June 7 | 4.02 | 6.61 | 10.76 |
| Average | 2.74 | 3.60 | 5.79 |
The proposed algorithm is compared with two alternative curve-fitting approaches. The first one, hereafter named SIR-fit, employs a nonlinear least squares fitting algorithm that, using the number of infected and recovered individuals, computes the best6 time-invariant infection and recovery rates of the deterministic SIR model. These best rates are then used to forecast the evolution of the epidemic. The second curve-fitting approach follows the same methodology applied on a more-sophisticated recently proposed generalized SEIR (GSEIR) model [39], for this reason hereafter called GSEIR-fit. The GSEIR model consists of seven compartments — three more compartments than those in the standard SEIR model, i.e., insusceptible, quarantined, and death — and six parameters. Table 2 compares the average MAPEs obtained with the proposed algorithm, the SIR-fit, and the GSEIR-fit. The comparison is made averaging the MAPEs over two different time intervals. The first interval is from March 4, i.e., the 10th day since the beginning of the data collection, to June 16; the second interval is from April 1, i.e., approximately three weeks after the lockdown, to June 16. The proposed algorithm clearly outperforms the SIR-fit for all the forecast horizons. The GSEIR-fit, instead, presents a single lower average MAPE over the interval from March 4 to June 16 when the forecast horizon is 14 days; however, when the interval from April 1 to June 16 is considered, the proposed algorithm outperforms the GSEIR-fit in all the cases. This confirms the benefit of sequentially estimating the time-varying model parameters, in order to have reliable and accurate forecasts.
TABLE 2. Average Mean Absolute Percentage Errors (MAPEs) of the Forecasts of the Epidemic Evolution in Lombardia, Italy, Obtained With the Proposed Algorithm, and With the SIR-Fit and GSEIR-Fit Curve-Fitting approaches, for Different Forecast Horizons, That is, 3, 7, and 14 Days. The Uppermost Table Reports the Average MAPEs Computed Over the Interval From March 4 to June 16; the Lowermost Table Reports the Average MAPEs Computed Over the Interval From April 1 to June 16.
| Algorithm | 3 Days (%) | 7 Days (%) | 14 Days (%) |
|---|---|---|---|
| Proposed | 6.2 | 10.4 | 23.5 |
| SIR-fit | 77.5 | 115.3 | 225.8 |
| GSEIR-fit | 10.3 | 13.0 | 18.5 |
| Average over the interval from March 4 to June 16 | |||
| Algorithm | 3 Days (%) | 7 Days (%) | 14 Days (%) |
| Proposed | 3.3 | 4.9 | 9.4 |
| SIR-fit | 88.2 | 123.0 | 213.2 |
| GSEIR-fit | 11.6 | 13.6 | 16.8 |
| Average over the interval from April 1 to June 16 | |||
2). United States of America
Since the beginning of the COVID-19 epidemic outbreak, the Johns Hopkins University (JHU) has tracked the evolution of the contagion and made the collected data publicly available [40], [41]. The repository includes the total number of cases, the number of deaths, and the number of discharged COVID-19 patients from the hospitals from the USA and other countries at different levels of details, i.e., for the country as a whole and, when available, for single states and regions. Here, we use the overall dataset from the USA, whose population is
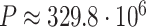 people. As for the experiment made on the dataset from Lombardia, the normalized (to
people. As for the experiment made on the dataset from Lombardia, the normalized (to
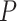 ) sum of number of discharged patients and number of deaths is used as the number of recovered
) sum of number of discharged patients and number of deaths is used as the number of recovered
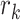 ; the normalized number of infected
; the normalized number of infected
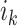 is then given by the normalized difference between the total number of cases and the number of recovered. These are reported in Fig. 9 and refer to the period between March 1, 2020, and July 31, 2020.
is then given by the normalized difference between the total number of cases and the number of recovered. These are reported in Fig. 9 and refer to the period between March 1, 2020, and July 31, 2020.
FIGURE 9.

Numbers of infected and recovered (i.e., hospital releases plus deaths) individuals in the USA, from March 1, 2020, to July 31, 2020 (data from JHU [41]).
The setting of the Bayesian sequential estimation and forecasting algorithm is unchanged, except that for the discretization and initialization of the parameters, and the initialization of the epidemic state. Specifically, the smallest and largest values used for the discretization of the infection rate are
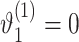 and
and
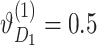 , respectively; the smallest and largest values used for the discretization of the recovery rate are
, respectively; the smallest and largest values used for the discretization of the recovery rate are
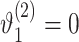 and
and
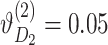 , respectively; mean and standard deviation of their prior pmfs are
, respectively; mean and standard deviation of their prior pmfs are
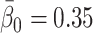 and
and
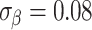 , and
, and
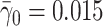 and
and
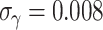 ; and the observation noise covariance matrix is
; and the observation noise covariance matrix is
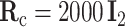 . The initial state of the epidemic is given by the normalized numbers of susceptible, infected, and recovered on March 1, that are
. The initial state of the epidemic is given by the normalized numbers of susceptible, infected, and recovered on March 1, that are
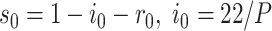 , and
, and
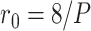 .
.
Fig. 10 shows the estimated infection and recovery rates. From the second half of March and through April the infection rate decreases, presumably due to the restriction measures established by each single State. Here, we cannot mark a specific date as the beginning of the lockdown; nevertheless, it is reasonable to assume that about three out of four US citizens were under some form of lockdown by early April [42]. Around April 30, the estimated recovery rate shows a slight increase followed by an abrupt decrease. On that day, 35 thousand new recovered (i.e., hospital releases plus deaths) individuals were reported against a decrease of infected individuals of only 6 thousand (cf. Fig. 9); this results in a sudden increase of the recovery rate. Large numbers of new recovered individuals are also reported on May 22 and July 4, that are, 53 thousand and 104 thousand, respectively; however, these are better balanced by the numbers of people leaving the infected group, that are, 29 thousand and 58 thousand, respectively, thus not significantly affecting the estimates of the infection and recovery rates.
FIGURE 10.

Estimated (top) infection rate and (bottom) recovery rate for the USA. The shaded areas represent the 90% confidence interval.
Overall, the estimated recovery rate is roughly 0.01, which translates into an average number of 100 days that an individual takes to move from the group of infected (I) to the group of recovered (R). Although the recovery duration seems overestimated, it is worth highlighting that this is an aggregate estimate of the recovery rate from multiple States, which therefore suffers from multiple different reporting delays, as well as from the different criteria used to declare an individual as fully recovered. It underscores the need for the USA to provide timely and consistent data, similar to that just analysed in Lombardia, if public health policy is to be driven by reliable estimation and prediction.
Forecasts of the epidemic evolution evaluated every five days in the time period between May 6 and June 30 are reported in Fig. 11. Table 3 presents the MAPEs calculated for each forecast and for different forecast horizons, that is, 3, 7, and 14 days.
FIGURE 11.
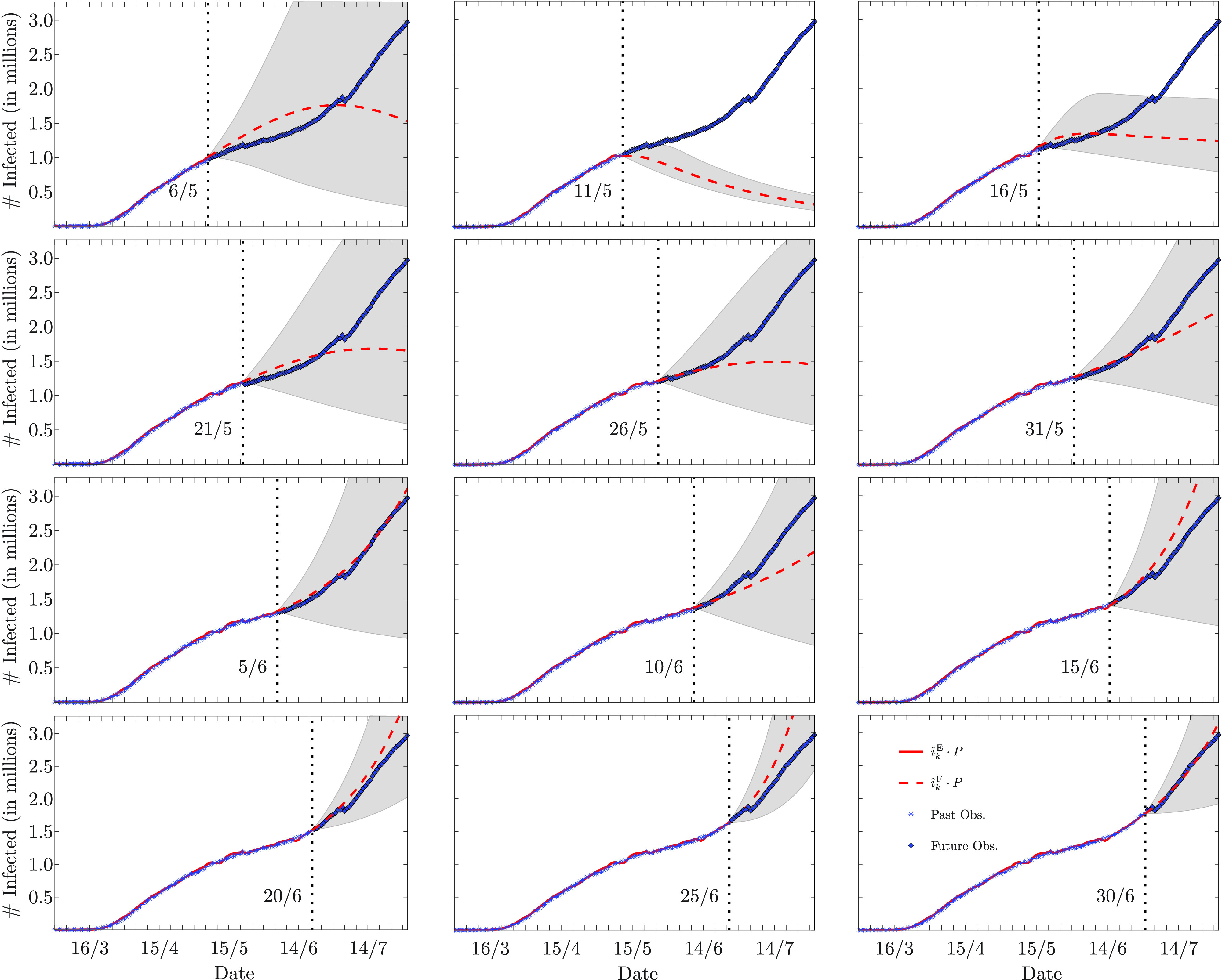
Estimation and forecasting, respectively in solid and dashed lines, of the number of infected individuals in the USA (legend is reported in the bottom-right corner image; the superscript E stands for estimate, and the superscript F stands for forecast). The date corresponding to the end of the estimation and the beginning of the forecast is marked by a vertical dotted line. In all the cases, the forecast horizon is July 31. The shaded area represents the 90% confidence interval. The poor forecasts made on May 11 and 16, relate to the abrupt decrease of the estimated recovery rate that follows April 30 (cf. Fig. 10, bottom image).
TABLE 3. Mean Absolute Percentage Errors (MAPEs) of the Forecasts of the Epidemic Evolution in the USA, Performed at Different Dates and Calculated for Different Forecast Horizons, That is, 3, 7, and 14 Days.
| Forecast Date | 3 Days (%) | 7 Days (%) | 14 Days (%) |
|---|---|---|---|
| May 6 | 4.31 | 5.73 | 7.44 |
| May 11 | 4.55 | 7.25 | 11.80 |
| May 16 | 4.84 | 5.97 | 6.87 |
| May 21 | 5.01 | 5.61 | 6.71 |
| May 26 | 0.61 | 0.98 | 0.96 |
| May 31 | 2.58 | 2.58 | 2.87 |
| June 5 | 2.29 | 2.86 | 3.49 |
| June 10 | 1.09 | 0.90 | 1.25 |
| June 15 | 0.26 | 0.70 | 1.51 |
| June 20 | 1.15 | 1.04 | 1.52 |
| June 25 | 0.40 | 0.49 | 3.93 |
| June 30 | 1.11 | 2.28 | 1.52 |
| Average | 2.35 | 3.03 | 4.16 |
We note that the forecasts made on May 6, 11, 16, and 21, present the highest MAPEs; these forecasts, however, are negatively affected by the abrupt decrease of the recovery rate that follows April 30, as described above. The forecasts made from May 26, to June 30, instead, present MAPEs that are always below 3% at forecast horizons of 3 and 7 days, and always below 4% when the forecast horizon is 14 days. Overall, the results in Table 3 confirm those obtained with the data from Lombardia: the average MAPE for forecast horizons of 3, 7, and 14 days, is, respectively, 2.35%, 3.03%, and 4.16%. Table 4 compares the average MAPEs obtained with the proposed algorithm, with those obtained with the SIR-fit and the GSEIR-fit curve-fitting approaches. The proposed algorithm consistently outperforms both the curve-fitting approaches, in both the considered time intervals. Moreover, we observe a significant improvement of the MAPE for the proposed algorithm when considering the interval from April 1 to July 17, compared to the interval from March 10 to July 17, which again confirms the benefit of sequentially estimating the time-varying model parameters in pursuance of reliable and accurate forecasts.
TABLE 4. Average Mean Absolute Percentage Errors (MAPEs) of the Forecasts of the Epidemic Evolution in the USA, Obtained With the Proposed Algorithm, and With the SIR-Fit and GSEIR-Fit Curve-Fitting Approaches, for Different Forecast Horizons, That is, 3, 7, and 14 Days. The Uppermost Table Reports the Average MAPEs Computed Over the Interval From March 10 to July 17; the Lowermost Table Reports the Average MAPEs Computed Over the Interval From April 1 to July 17.
| Algorithm | 3 Days (%) | 7 Days (%) | 14 Days (%) |
|---|---|---|---|
| Proposed | 7.3 | 11.9 | 29.8 |
| SIR-fit | 81.6 | 122.4 | 232.4 |
| GSEIR-fit | 14.0 | 20.0 | 35.2 |
| Average over the interval from March 10 to July 17 | |||
| Algorithm | 3 Days (%) | 7 Days (%) | 14 Days (%) |
| Proposed | 3.4 | 4.5 | 7.2 |
| SIR-fit | 91.4 | 138.8 | 267.6 |
| GSEIR-fit | 12.1 | 17.0 | 28.7 |
| Average over the interval from April 1 to June 17 | |||
C. Limitations and Extensions
The proposed analysis presents some limitations that may lead to future extensions and these are worth exploring. First, the considered stochastic SIR model may be broadened to include the fraction of undocumented (or asymptomatic) and quarantined infected individuals. Undocumented infections usually include mild or asymptomatic cases that go undetected and, hence, based on their proportion and contagiousness, can potentially increase the spread of the disease. The portion of undocumented infectious cases is suspected to be a critical epidemiological characteristic that is not easy to quantify. Most of the available evidence on asymptomatic SARS-CoV-2 infections, reviewed and summarised in [43] for different circumscribed cohorts, suggests that this is a significant factor in the fast progression of the COVID-19 pandemic. However, the difficulty in quantification of undocumented cases is largely due to the imperfection of the data available, which does not accurately reflect a large, representative sample of the general population. Moreover, in order to distinguish asymptomatic and presymptomatic cases, longitudinal data — that is, repeated observations of the individuals over time — should be available.
Another possible extension may be to separate people who are confirmed infected and home-quarantined into a dedicated epidemic compartment. In addition, the recovered compartment typical of the SIR model may be separated into two distinct recovery and death compartments in the detection phase so that the available data on reported cases can be taken into account separately. Furthermore, the considered stochastic SIR model describes the spread of the disease inside a single and confined population, e.g., a city, a region (Lombardia, Italy), a nation (USA). However, the approach presented in this article could be extended to more complicated metapopulation models, which introduce a further spatial travel/diffusion dimension in the dynamic and observation models. In particular, the population could be represented as a network of multiple spatially separated subpopulations nodes, such as multiple cities in the same region or nation. The interconnections among different populations represents the diffusion of people, thus contributing to the disease spread among the different subpopulations. All these limitations can be addressed in future studies because they mainly affect data analysis, and do not restrict the application and the effectiveness of the proposed approach to learning and forecasting the evolution of the critical epidemiological characteristics.
VI. Conclusions
The recent worldwide epidemic outbreak, due to a new strain of Coronavirus, has intensified research into novel mathematical models and algorithms that are able to reliably estimate and predict the epidemiological curve of the infection. In this article, we proposed a Bayesian sequential estimation and forecasting algorithm that, based on the information that authorities provide on a daily basis, is able to estimate the state of the epidemic and the parameters of the underlying model, as well as to forecast the evolution of the epidemiological curve. We developed an efficient implementation of the above-mentioned Bayesian framework, specifically tailored to the stochastic SIR model of pandemic evolution. The proposed algorithm is validated using synthetic data simulating two epidemic scenarios, and on real data acquired during the recent COVID-19 outbreak in the Lombardia region, Italy, and in the USA. Results show that the mean absolute percentage error computed after the lockdown is on average below 5% when the forecast is at 7 days, and below 10% when the forecast horizon is 14 days. Moreover, the described Bayesian framework outperforms curve-fitting approaches that use deterministic epidemiological models (e.g., SIR and GSEIR), particularly when a clear change of model parameters occur, e.g., a decrease of the infection rate following the lockdown. Finally, accurate and timely data collection, especially on recovered individuals, hospitalizations, intensive care unit admissions, and intubations, is essential for reliable model-based decisions.
There exists an enormous amount of very recent literature related to the forecast of COVID-19 pandemic evolution, part of which has been reviewed at the beginning of this article. The analysis of this literature makes clear the effectiveness of model-based approaches, over less structured data-centric methodologies. In this respect, one lesson learned by the present study is that accurate epidemic modeling requires accurate estimation of time-varying parameters, such as the infection rate
 . This is obviously true in the presence of abrupt changes of the underlying physical situation (e.g., adoption of drastic countermeasures) but, more interestingly, it is by no means limited to these extreme situations. One consequence is that, once the epidemic is under control, small variations in the estimated
. This is obviously true in the presence of abrupt changes of the underlying physical situation (e.g., adoption of drastic countermeasures) but, more interestingly, it is by no means limited to these extreme situations. One consequence is that, once the epidemic is under control, small variations in the estimated
 may be used as a sensible proxy for the incipient detection of possible pandemic recrudescence.
may be used as a sensible proxy for the incipient detection of possible pandemic recrudescence.
Biographies

Domenico Gaglione (Member, IEEE) received the B.Sc. and M.Sc. degrees (summa cum laude) in telecommunications engineering from the Università degli Studi di Napoli “Federico II”, Naples, Italy, in 2011 and 2013, respectively, and the Ph.D. degree from the Department of Electronic and Electrical Engineering, University of Strathclyde, Glasgow, U.K., in 2017. Since 2016, he has been a Research Assistant with the University of Strathclyde. He joined the NATO STO Centre for Maritime Research & Experimentation (CMRE), La Spezia, Italy, in 2017 as a Junior Scientist. His research interests include statistical signal processing with emphasis on state estimation, data fusion, and multisensor multitarget tracking. He was a recipient of the Best Student Paper Award at the 2015 IEEE International Radar Conference (RadarCon), Arlington, VA, USA, and of the NATO STO Scientific Achievement Award in 2020 as a member of the Data Knowledge and Operational Effectiveness (DKOE) Research Group, CMRE for “Advances in Artificial Intelligence and Information Fusion for Maritime Situational Awareness.”

Paolo Braca (Senior Member, IEEE) received the Laurea degree (summa cum laude) in electronic engineering and the Ph.D. degree (Hons.) in information engineering from the University of Salerno, Italy, in 2006 and 2010, respectively. In 2009, he was a Visiting Scholar with the Department of Electrical and Computer Engineering, University of Connecticut, Storrs, CT, USA. From 2010 to 2011, he was a Postdoctoral Associate with the University of Salerno. In 2011, he joined the NATO Science & Technology Organization Centre for Maritime Research and Experimentation (CMRE), where he is currently a Senior Scientist with the Research Department and a Project Manager of the Data Knowledge and Operational Effectiveness (DKOE) Program. Furthermore, he leaded a number of research projects funded by the EU Horizon 2020 programme, by the U.S. Office of Naval Research (ONR), and by DRDC. He conducts research in the general area of statistical signal processing with emphasis on detection and estimation theory, wireless sensor network, multi-agent algorithms, target tracking and data fusion, adaptation and learning over graphs, and radar (sonar) signal processing. He has coauthored more than 100 publications in international scientific journals and conference proceedings. He was awarded with the National Scientific Qualification to function as an Associate and a Full Professor in Italian Universities, in 2017 and 2018, respectively. He is in the technical committee of the major international conferences in the field of signal processing and data fusion. He was a recipient of the Best Student Paper Award (first runner-up) at the 12th International Conference on Information Fusion, in 2009, and the NATO STO Scientific Achievement Award 2017 for its contribution to “Development and Demonstration of Networked Autonomous ASW” from the NATO Chief Scientist. His coauthored the paper received the Best Paper Award (first runner-up) at the Sensor Signal Processing for Defence (SSPD), in 2019. He was also a recipient of the NATO STO Scientific Achievement Award, in 2020, as a Team Leader for the “Advances in Artificial Intelligence and Information Fusion for Maritime Situational Awareness.” He serves as an Associate Editor for the IEEE Transactions on Signal Processing, the IEEE Transactions on Aerospace and Electronic Systems, ISIF Journal of Advances in Information Fusion, EURASIP Journal on Advances in Signal Processing, and IET Radar, Sonar & Navigation. In 2017, he was a Lead Guest Editor of the Special Issue “Sonar Multi-Sensor Applications and Techniques” in IET Radar, Sonar &Navigation. He served as an Associate Editor for the IEEE Signal Processing Magazine (E-Newsletter), from 2014 to 2016.

Leonardo Maria Millefiori (Member, IEEE) received the B.Sc. degree in aerospace information engineering and the M.Sc. degree (summa cum laude) in communication engineering with focus on radar systems and remote sensing from the Sapienza University of Rome, Italy, in 2010 and 2013, respectively. He was a Visiting Researcher with the NATO Science and Technology Organization Center for Maritime Research and Experimentation (CMRE), La Spezia, where he joined the Research Department as a Research Scientist in 2014. His research interests include target motion modeling, statistical learning and signal processing, and target tracking and data fusion. He was a recipient of the NATO STO Scientific Achievement Award, in 2020, as a member of the Data Knowledge and Operational Effectiveness (DKOE) Research Group, CMRE for “Advances in Artificial Intelligence and Information Fusion for Maritime Situational Awareness.”

Giovanni Soldi received the master’s degree in applied mathematics from the University of Milan, in 2011, and the Ph.D. degree in signal processing from Télécom ParisTech, in 2016. Since 2016, he has been a Scientist with the Centre for Maritime Research and Experimentation (CMRE), La Spezia, Italy. His current research interests include statistical signal processing with a focus on state estimation, data fusion, and multisensor-multitarget tracking techniques. He was a recipient of the NATO STO Scientific Achievement Award, in 2020, as a member of the Data Knowledge and Operational Effectiveness (DKOE) Research Group, CMRE for “Advances in Artificial Intelligence and Information Fusion for Maritime Situational Awareness.”

Nicola Forti received the M.S. degree in automation engineering and the Ph.D. degree in information engineering from the University of Florence, Italy, in 2013 and 2016, respectively. From 2015 to 2016, he was a Visiting Researcher with the Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA, USA. He is currently a Scientist with the Research Department, NATO Science & Technology Organization—Centre for Maritime Research and Experimentation (CMRE). His current research interests include state estimation and control theory, statistical signal processing, machine learning, target tracking, and data fusion. He was a recipient of the NATO STO Scientific Achievement Award, in 2020, as a member of the Data Knowledge and Operational Effectiveness (DKOE) Research Group, CMRE for “Advances in Artificial Intelligence and Information Fusion for Maritime Situational Awareness.”

Stefano Marano (Senior Member, IEEE) received the Laurea degree in electronic engineering and the Ph.D. degree in electronic engineering and computer science from the University of Naples, Italy, in 1993 and 1997, respectively. He has held visiting positions at the Physics Department, University of Wales, College of Cardiff, and also at the ECE Department, University of California at San Diego, in 1996 and 2013, respectively. Since 1999, he has been with the University of Salerno, Italy, where he is currently a Professor with DIEM. His current research interests include statistical signal processing with emphasis on distributed inference, sensor networks, and information theory. He was a recipient of the IEEE Transactions on Antennas and Propagation 1999 Best Paper Award, and coauthored the paper winning the Best Student Paper Award (2nd place) at the 12th Conference on Information Fusion in 2009. He was in the Organizing Committee of FUSION 2006 and RADARCON 2008. He is a member of the EURASIP Special Area Team in Theoretical and Methodological Trends in Signal Processing and a Guest Editor of a Special Issue of EURASIP Journal on Advances in Signal Processing. From 2010 to 2014, he served as an Associate Editor for the IEEE Transactions on Signal Processing. He also served as an Associate Editor and a Technical Editor for the IEEE Transactions on Aerospace and Electronic Systems from 2009 to 2016.

Peter K. Willett (Fellow, IEEE) has been a Faculty Member with the Electrical and Computer Engineering Department, University of Connecticut, since 1986. Since 1998, he has also been a Professor. His current research interests include statistical signal processing, detection, machine learning, communications, data fusion, and tracking. He is a member of the IEEE Fellows Committee and of the Ethics Committee and Periodicals Committee, and was of the IEEE Signal Processing Society’s Technical Activities and Conference Boards. He is a member of the IEEE AESS Board of Governors and was the Chair of the IEEE Signal Processing Society’s Sensor-Array and Multichannel (SAM) Technical Committee. He is a Chief Editor of the IEEE AESS Magazine, from 2018 to 2020. He was an Editor-in-Chief of the IEEE Transactions on Aerospace and Electronic Systems from 2006 to 2011 and the IEEE Signal Processing Letters, from 2014 to 2016. He was also an AESS Vice President for Publications from 2012 to 2014.

Krishna R. Pattipati (Life Fellow, IEEE) received the B.Tech. degree (Hons.) in electrical engineering from IIT Kharagpur, in 1975, and the M.S. and Ph.D. degrees in systems engineering from the University of Connecticut (UConn), Storrs, CT, USA, in 1977 and 1980, respectively. He was with ALPHATECH, Inc., Burlington, MA, USA, from 1980 to 1986. He has been with the Department of Electrical and Computer Engineering, UConn, where he is currently the Board of Trustees Distinguished Professor and the UTC Chair Professor in systems engineering. He is also a Co-Founder of Qualtech Systems, Inc., a firm specializing in advanced integrated diagnostics software tools (TEAMS, TEAMS-RT, TEAMS-RDS, and TEAMATE), and serves on the board for Aptima, Inc. His research interests include proactive decision support, uncertainty quantification, smart manufacturing, autonomy, knowledge representation, and optimization-based learning and inference. A common theme among these applications is that they are characterized by a great deal of uncertainty, complexity, and computational intractability. He is an Elected Fellow of the Connecticut Academy of Science and Engineering. He was selected by the IEEE Systems, Man, and Cybernetics (SMC) Society as the Outstanding Young Engineer of 1984, and received the Centennial Key to the Future Award. He was a co-recipient of the Andrew P. Sage Award for the Best SMC Transactions Paper in 1999, the Barry Carlton Award for the Best AES Transactions Paper in 2000, the 2002 and 2008 NASA Space Act Awards for A Comprehensive Toolset for Model-based Health Monitoring and Diagnosis, and Real-time Update of Fault-Test Dependencies of Dynamic Systems: A Comprehensive Toolset for Model-Based Health Monitoring and Diagnostics, and the 2003 AAUP Research Excellence Award at UConn. He received the best technical paper awards at the 1985, 1990, 1994, 2002, 2004, 2005, and 2011 IEEE AUTOTEST Conferences, and at the 1997, 2004 Command and Control Conference. He was the Vice-President for Technical Activities of the IEEE SMC Society, from 1998 to 1999, and as the Vice-President for Conferences and Meetings of the IEEE SMC Society, from 2000 to 2001. He served as the Editor-in-Chief for the IEEE Transactions on Systems, Man, and Cybernetics—Part B, from 1998 to 2001.
Appendix A. Moment Matching
This section reports the expressions, derived by moment matching, used to compute
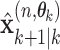 and
and
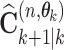 in (34). Let
in (34). Let
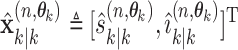 and
and
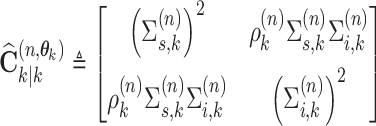 |
be mean and covariance matrix of the
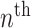 posterior mixand
posterior mixand
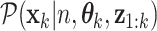 . We aim to approximate the
. We aim to approximate the
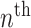 predicted mixand
predicted mixand
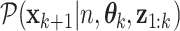 to be Gaussian with mean
to be Gaussian with mean
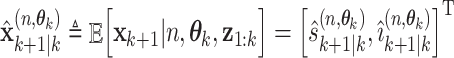 |
and covariance matrix
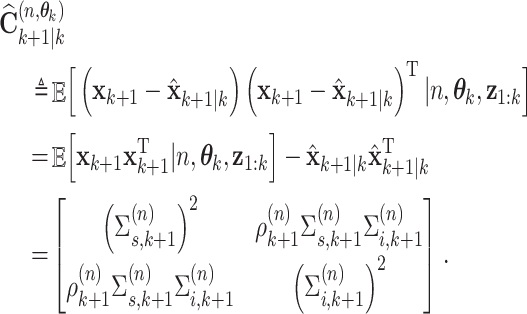 |
To simplify the notation, we hereafter omit the index
 and the dependence on the parameter vector
and the dependence on the parameter vector
 . Following simple algebraic calculations, the components of the mean vector are obtained as
. Following simple algebraic calculations, the components of the mean vector are obtained as
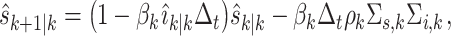 |
and
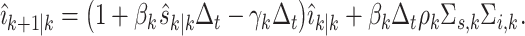 |
We note that the products
 induce nonlinearity in their predicted values, and hence require extra calculation for the associated uncertainties; indeed, the components of the covariance matrix are
induce nonlinearity in their predicted values, and hence require extra calculation for the associated uncertainties; indeed, the components of the covariance matrix are
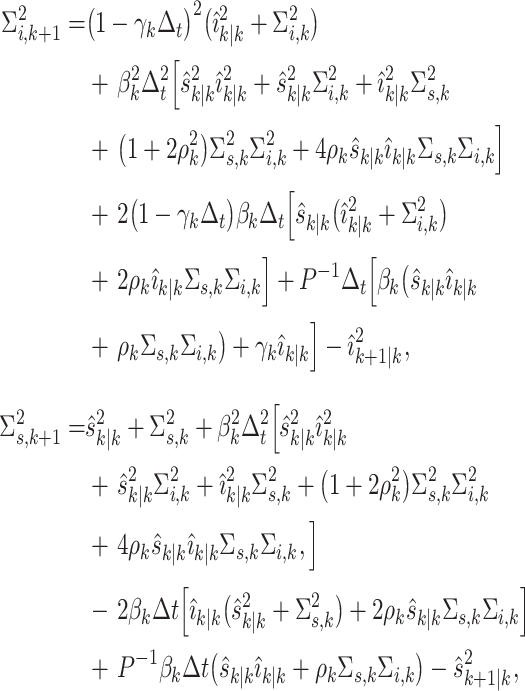 |
and
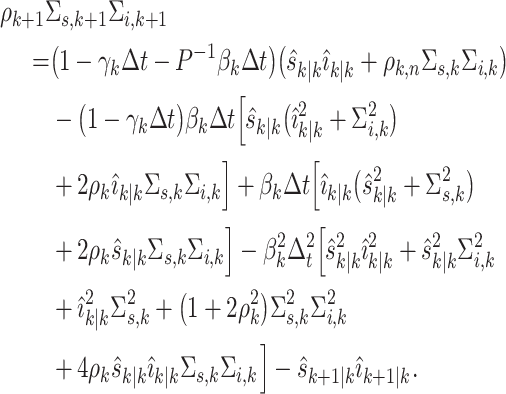 |
Appendix B. Adaptive Estimation of the Infection Rate Slope
Let us assume that the infection rate in the time interval
 is linearly changing according to the following model
is linearly changing according to the following model
 |
for
 , where
, where
 and
and
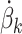 is a constant slope. An estimate of the slope can be obtained through the simple linear regression estimator [44] using the
is a constant slope. An estimate of the slope can be obtained through the simple linear regression estimator [44] using the
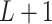 most recent MMSE estimates of the infection rate, that is,
most recent MMSE estimates of the infection rate, that is,
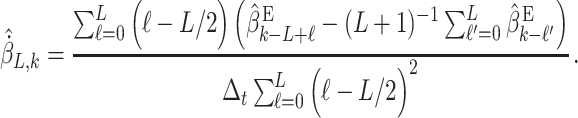 |
The estimator
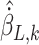 is unbiased, and its variance is
is unbiased, and its variance is
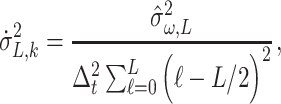 |
where
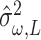 is an estimate of
is an estimate of
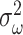 , i.e., the variance of the noise term
, i.e., the variance of the noise term
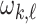 , given by
, given by
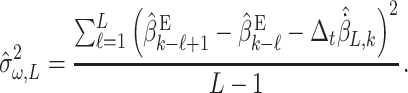 |
In practice, the slope
 is piecewise constant, that is, constant over subintervals of the entire interval
is piecewise constant, that is, constant over subintervals of the entire interval
 . Therefore, we aim to find the value
. Therefore, we aim to find the value
 ,
,
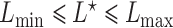 , — hence, the subinterval
, — hence, the subinterval
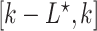 — such that the linear model with constant slope in (41) is a valid assumption for the time evolution of the infection rate. Let
— such that the linear model with constant slope in (41) is a valid assumption for the time evolution of the infection rate. Let
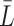 be the candidate value for
be the candidate value for
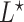 , and let us define the auxiliary variable
, and let us define the auxiliary variable
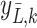 as
as
 |
It is easy to verify that, if the linear model (41) is valid and
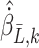 represents an accurate estimate of the constant slope over the interval
represents an accurate estimate of the constant slope over the interval
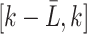 , then
, then
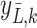 is a central chi-square distributed variable with one degree of freedom, i.e.,
is a central chi-square distributed variable with one degree of freedom, i.e.,
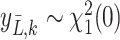 ; otherwise,
; otherwise,
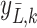 is a non-central chi-square distributed variable with one degree of freedom and non-centrality parameter
is a non-central chi-square distributed variable with one degree of freedom and non-centrality parameter
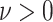 , i.e.,
, i.e.,
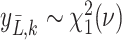 . The problem of finding
. The problem of finding
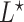 can therefore be recast as a hypothesis test: the null hypothesis (
can therefore be recast as a hypothesis test: the null hypothesis (
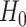 ) states that the linear assumption is valid and
) states that the linear assumption is valid and
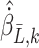 is a good estimate of the constant slope; the alternate hypothesis (
is a good estimate of the constant slope; the alternate hypothesis (
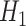 ) states that the linear hypothesis with constant slope is invalid. The hypothesis test can be formally written as
) states that the linear hypothesis with constant slope is invalid. The hypothesis test can be formally written as
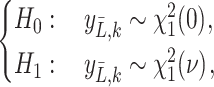 |
and the decision rule is
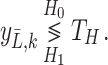 |
The threshold
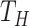 is obtained as
is obtained as
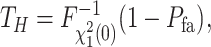 |
where
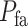 is the probability to reject hypothesis
is the probability to reject hypothesis
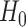 when it is true and
when it is true and
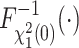 is the inverse cumulative density function of a central chi-square variable with one degree of freedom. In order to select
is the inverse cumulative density function of a central chi-square variable with one degree of freedom. In order to select
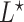 , we employ the following iterative procedure: if with
, we employ the following iterative procedure: if with
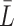 hypothesis
hypothesis
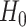 is accepted, and with
is accepted, and with
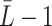 hypothesis
hypothesis
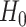 is rejected, then
is rejected, then
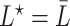 ; otherwise,
; otherwise,
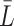 is decreased and the test is repeated. This iterative procedure starts with
is decreased and the test is repeated. This iterative procedure starts with
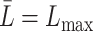 . Note that, alternatively, the threshold could be obtained by fixing the probability to accept hypothesis
. Note that, alternatively, the threshold could be obtained by fixing the probability to accept hypothesis
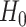 when it is false; in such a case, the non-centrality parameter
when it is false; in such a case, the non-centrality parameter
 is approximated with the numerator of (42).
is approximated with the numerator of (42).
Funding Statement
The work of Domenico Gaglione, Paolo Braca, Leonardo Maria Millefiori, Giovanni Soldi, and Nicola Forti was supported by the Data Knowledge and Operational Effectiveness (DKOE) program, sponsored by the North Atlantic Treaty Organization (NATO) Allied Command Transformation (ACT). The work of Peter K. Willett was supported in part by Air Force Office of Scientific Research (AFOSR) under Contract FA9500-18-1-0463 and in part by Centre for Maritime Research and Experimentation (CMRE). The work of Krishna R. Pattipati was supported in part by the U.S. Office of Naval Research, in part by the U.S. Naval Research Laboratory under Grant N00014-18-1-1238 and Grant N00173-16-1-G905, and in part by the Space Technology Research Institutes from National Aeronautics and Space Administration’s (NASA’s) Space Technology Research Grants Program under Grant 80NSSC19K1076.
Footnotes
At the time of writing, permanent immunity of recovered COVID-19 patients is uncertain. However, it is a bedrock feature of the SIR epidemiological model.
This applies, e.g., to the influenza virus, as its infection rate periodically increases and decreases depending on the season.
The superscript E stands for estimate, and is used to distinguish the estimate from the forecast, later identified by the superscript F.
By “evolving” is meant a simple procedure of recursively (in time) generating random variables according to a transition distribution; colloquially, this is a process of “rolling the dice”.
Best is meant in the least-squares sense.
References
- [1].WHO. (Jan. 2020). Novel Coronavirus—China. [Online]. Available: http://www.who.int/csr/don/12-january-2020-novel-coronavirus-china/en/
- [2].WHO. (Mar. 2020). Coronavirus Disease (COVID-19) Pandemic. [Online]. Available: http://www.euro.who.int/en/health-topics/health-emergencies/coronavirus-covid-19/novel-coronavirus-2019-ncov
- [3].Heesterbeek H.et al. , “Modeling infectious disease dynamics in the complex landscape of global health,” Science, vol. 347, no. 6227, pp. 1–12, Mar. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Kermack W. O., McKendrick A. G., and Walker G. T., “A contribution to the mathematical theory of epidemics,” Proc. Roy. Soc. London A, vol. 115, no. 772, pp. 700–721, Aug. 1927. [Google Scholar]
- [5].Bjørnstad O. N., Shea K., Krzywinski M., and Altman N., “Modeling infectious epidemics,” Nature Methods, vol. 17, no. 5, pp. 455–456, Apr. 2020. [DOI] [PubMed] [Google Scholar]
- [6].Lauer S. A., Grantz K. H., Bi Q., Jones F. K., Zheng Q., Meredith H. R., Azman A. S., Reich N. G., and Lessler J., “The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: Estimation and application,” Ann. Internal Med., vol. 172, no. 9, pp. 577–582, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Yi N., Zhang Q., Mao K., Yang D., and Li Q., “Analysis and control of an SEIR epidemic system with nonlinear transmission rate,” Math. Comput. Model., vol. 50, no. 9, pp. 1498–1513, Nov. 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Hou C., Chen J., Zhou Y., Hua L., Yuan J., He S., Guo Y., Zhang S., Jia Q., Zhao C., Zhang J., Xu G., and Jia E., “The effectiveness of quarantine of Wuhan city against the corona virus disease 2019 (COVID-19): A well-mixed SEIR model analysis,” J. Med. Virol., vol. 92, no. 7, pp. 841–848, Apr. 2020. [DOI] [PubMed] [Google Scholar]
- [9].Hu Z., Cui Q., Han J., Wang X., Sha W. E. I., and Teng Z., “Evaluation and prediction of the COVID-19 variations at different input population and quarantine strategies, a case study in guangdong province, China,” Int. J. Infectious Diseases, vol. 95, pp. 231–240, Jun. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Maier B. F. and Brockmann D., “Effective containment explains subexponential growth in recent confirmed COVID-19 cases in China,” Science, vol. 368, no. 6492, pp. 742–746, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Li R., Pei S., Chen B., Song Y., Zhang T., Yang W., and Shaman J., “Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2),” Science, vol. 368, no. 6490, pp. 489–493, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Arino J. and Driessche P., “Metapopulation epidemic models. A survey,” Fields Inst. Commun., vol. 48, pp. 1–12, Jan. 2006. [Google Scholar]
- [13].Nowzari C., Preciado V. M., and Pappas G. J., “Analysis and control of epidemics: A survey of spreading processes on complex networks,” IEEE Control Syst. Mag., vol. 36, no. 1, pp. 26–46, Feb. 2016. [Google Scholar]
- [14].Jia J. S., Lu X., Yuan Y., Xu G., Jia J., and Christakis N. A., “Population flow drives spatio-temporal distribution of COVID-19 in China,” Nature, vol. 582, no. 7812, pp. 389–394, Apr. 2020. [DOI] [PubMed] [Google Scholar]
- [15].Kraemer M. U. G., Yang C.-H., Gutierrez B., Wu C.-H., Klein B., Pigott D. M., du Plessis L., Faria N. R., Li R., Hanage W. P., Brownstein J. S., Layan M., Vespignani A., Tian H., Dye C., Pybus O. G., and Scarpino S. V., “The effect of human mobility and control measures on the COVID-19 epidemic in China,” Science, vol. 368, no. 6490, pp. 493–497, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Chinazzi M., Davis J. T., Ajelli M., Gioannini C., Litvinova M., Merler S., Pastore Piontti A. Y., Mu K., Rossi L., Sun K., Viboud C., Xiong X., Yu H., Halloran M. E., Longini I. M., and Vespignani A., “The effect of travel restrictions on the spread of the 2019 novel Coronavirus (COVID-19) outbreak,” Science, vol. 368, no. 6489, pp. 395–400, Apr. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Skvortsov A. and Ristic B., “Monitoring and prediction of an epidemic outbreak using syndromic observations,” Math. Biosci., vol. 240, no. 1, pp. 12–19, Nov. 2012. [DOI] [PubMed] [Google Scholar]
- [18].Sheinson D. M., Niemi J., and Meiring W., “Comparison of the performance of particle filter algorithms applied to tracking of a disease epidemic,” Math. Biosci., vol. 255, pp. 21–32, Sep. 2014. [DOI] [PubMed] [Google Scholar]
- [19].Shahtori N. M., Scoglio C., Pourhabib A., and Sahneh F. D., “Sequential Monte Carlo filtering estimation of Ebola progression in West Africa,” in Proc. ACC, Boston, MA, USA, Jul. 2016, pp. 1277–1282. [Google Scholar]
- [20].Braca P., Aubry A., Millefiori L. M., De Maio A., and Marano S., “Multi-class random matrix filtering for adaptive learning,” IEEE Trans. Signal Process., vol. 68, pp. 359–373, Nov. 2020. [Google Scholar]
- [21].Soldi G., Meyer F., Braca P., and Hlawatsch F., “Self-tuning algorithms for multisensor-multitarget tracking using belief propagation,” IEEE Trans. Signal Process., vol. 67, no. 15, pp. 3922–3937, Aug. 2019. [Google Scholar]
- [22].Bar-Shalom Y., Willett P. K., and Tian X., Tracking Data Fusion: A Handbook Algorithms. Storrs, CT, USA: YBS Publishing, 2011. [Google Scholar]
- [23].Poor H. V., An Introduction to Signal Detection Estimation. New York, NY, USA: Springer, 1994. [Google Scholar]
- [24].Lewis J. M., “Roots of ensemble forecasting,” Monthly Weather Rev., vol. 133, no. 7, pp. 1865–1885, Jul. 2005. [Google Scholar]
- [25].Leutbecher M. and Palmer T., “Ensemble forecasting,” J. Comput. Phys., vol. 227, no. 7, pp. 3515–3539, Mar. 2008. [Google Scholar]
- [26].Leutbecher M., “Ensemble size: How suboptimal is less than infinity?” Quart. J. Roy. Meteorol. Soc., vol. 145, no. S1, pp. 107–128, Sep. 2019. [Google Scholar]
- [27].Ray E. L. and Reich N. G., “Prediction of infectious disease epidemics via weighted density ensembles,” PLoS Comput. Biol, vol. 14, no. 2, pp. 1–23, Feb. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Chowell G., Luo R., Sun K., Roosa K., Tariq A., and Viboud C., “Real-time forecasting of epidemic trajectories using computational dynamic ensembles,” Epidemics, vol. 30, pp. 1–10, Mar. 2020. [DOI] [PubMed] [Google Scholar]
- [29].Evensen G., “The ensemble Kalman filter: Theoretical formulation and practical implementation,” Ocean Dyn., vol. 53, no. 4, pp. 343–367, Nov. 2003. [Google Scholar]
- [30].Kotecha J. H. and Djuric P. M., “Gaussian sum particle filtering,” IEEE Trans. Signal Process., vol. 51, no. 10, pp. 2602–2612, Oct. 2003. [Google Scholar]
- [31].Crouse D. F., Willett P., Pattipati K., and Svensson L., “A look at Gaussian mixture reduction algorithms,” in Proc. FUSION, Chicago, IL, USA, Jul. 2011, pp. 1–8. [Google Scholar]
- [32].Simon D., Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches. Hoboken, NJ, USA: Wiley, 2006. [Google Scholar]
- [33].Bishop C., Pattern Recognition and Machine Learning. New York, NY, USA: Springer, 2006. [Google Scholar]
- [34].Goodfellow I., Bengio Y., and Courville A., Deep Learning. Cambridge, MA, USA: MIT Press, 2016. [Google Scholar]
- [35].Theodoridis S., Machine Learning. Cambridge, MA, USA: Academic Press, 2015. [Google Scholar]
- [36].Ljung L., System Identification. Hoboken, NJ, USA: Wiley, 1999. [Google Scholar]
- [37].Allen L. J. S., “A primer on stochastic epidemic models: Formulation, numerical simulation, and analysis,” Infectious Disease Model., vol. 2, no. 2, pp. 128–142, May 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Dati COVID-19 Italia. Accessed: Aug. 4, 2020. [Online]. Available: https://github.com/pcm-dpc/COVID-19
- [39].Peng L., Yang W., Zhang D., Zhuge C., and Hong L., “Epidemic analysis of COVID-19 in China by dynamical modeling,” 2020, arXiv:2002.06563. [Online]. Available: http://arxiv.org/abs/2002.06563 [Google Scholar]
- [40].Dong E., Du H., and Gardner L., “An interactive Web-based dashboard to track COVID-19 in real time,” Lancet Infectious Diseases, vol. 20, no. 5, pp. 533–534, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. Accessed: Aug. 4, 2020. [Online]. Available: https://github.com/CSSEGISandData/COVID-19
- [42].BBC. (Mar. 2020). Coronavirus: Three Out of Four Americans Under Some Form of Lockdown. [Online]. Available: https://www.bbc.com/news/world-us-canada-52103066
- [43].Oran D. P. and Topol E. J., “Prevalence of asymptomatic SARS-CoV-2 infection,” Ann. Internal Med., vol. 173, no. 5, pp. 362–367, Sep. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Rice J., Mathematical Statistics and Data Analysis. Boston, MA, USA: Cengage Learning, 2006. [Google Scholar]