

Abstract
We present the -statistic permutation (USP) test of independence in the context of discrete data displayed in a contingency table. Either Pearson’s -test of independence, or the -test, are typically used for this task, but we argue that these tests have serious deficiencies, both in terms of their inability to control the size of the test, and their power properties. By contrast, the USP test is guaranteed to control the size of the test at the nominal level for all sample sizes, has no issues with small (or zero) cell counts, and is able to detect distributions that violate independence in only a minimal way. The test statistic is derived from a -statistic estimator of a natural population measure of dependence, and we prove that this is the unique minimum variance unbiased estimator of this population quantity. The practical utility of the USP test is demonstrated on both simulated data, where its power can be dramatically greater than those of Pearson’s test, the -test and Fisher’s exact test, and on real data. The USP test is implemented in the R package USP.
Keywords: independence, Pearson’s -test, G-test, permutation test, statistic, Fisher’s exact test
1. Introduction
Pearson’s -test of independence [1] is one of the most commonly used of all statistical procedures. It is typically employed in situations where we have discrete data consisting of independent copies of a pair , with taking the value with probability , for , and taking the value with probability , for . For example, might represent marital status, taking values ‘Never married’, ‘Married’, ‘Divorced’, ‘Widowed’ and might represent level of education, with values ‘Middle school or lower’, ‘High school’, ‘Bachelor’s’, ‘Master’s’, ‘PhD or higher’, so that and . From a random sample of size , we can summarize the resulting data in a contingency table with rows and columns, where the th entry of the table denotes the observed number of data pairs equal to ; see table 1 for an illustration.
Table 1.
Contingency table summarizing the marital status and education level of 300 survey respondents. Source: https://www.spss-tutorials.com/chi-square-independence-test/.
| Middle school or Lower | High school | Bachelor’s | Master’s | PhD or Higher | |
|---|---|---|---|---|---|
| Never married | 18 | 36 | 21 | 9 | 6 |
| Married | 12 | 36 | 45 | 36 | 21 |
| Divorced | 6 | 9 | 9 | 3 | 3 |
| Widowed | 3 | 9 | 9 | 6 | 3 |
Writing for the probability that an observation falls in the th cell, a test of the null hypothesis that and are independent is equivalent to testing whether for all . Letting denote the number of observations falling in the th row and denote the number in the th column, Pearson’s famous formula can be expressed as
| 1.1 |
where is the ‘expected’ number of observations in the th cell under the null hypothesis. Usually, for a test of size approximately , the statistic is compared with the -level quantile of the distribution with degrees of freedom1. For instance, for the data in table 1, we find that , corresponding to a p-value of . This analysis would therefore lead us to reject the null hypothesis at the 5% significance level, but not at the 1% level.
Pearson’s -test is so well established that we suspect many researchers would rarely pause to question whether or not it is a good test. The formula (1.1) arises as a second-order Taylor approximation to the generalized likelihood ratio test, or -test as it is now becoming known (e.g. [4]):
The -test statistic is compared with the same quantile as Pearson’s statistic, and its use is advocated in certain application areas, such as computational linguistics [5]. There is also a second motivation for the statistic (1.1), which relies on the idea of the divergence between two probability distributions and for our pair :
| 1.2 |
The word ‘divergence’ here is used by statisticians to indicate that is a quantity that behaves in some ways like a (squared) distance, e.g. is non-negative, and is zero if and only if , but does not satisfy all of the properties that we would like a genuine notion of distance to have. For instance, it is not symmetric in and —we can have . Pearson’s statistic can be regarded as the natural empirical estimate of the divergence between the joint distribution and the product of the marginal distributions and . This makes some sense when we recall that the null hypothesis of independence holds if and only if the joint distribution is equal to the product of the marginal distributions (e.g. [6, theorem 3B]).
Nevertheless, both Pearson’s -test and the -test suffer from three major drawbacks:
-
1.
The tests do not in general control the probability of Type I error at the claimed level. In fact, we show in appendix Aa that even in the simplest setting of a table, and no matter how large the sample size , it is possible to construct a joint distribution that satisfies the null hypothesis of independence, but for which the probability of Type I error is far from the desired level! Practitioners are aware of this deficiency of Pearson’s test and the -test (e.g. [7, p. 40]), but our example provides an explicit demonstration.
-
2.
If there are no observations in any row or column of the table, then both test statistics are undefined.
-
3.
Perhaps most importantly, the power properties of both Pearson’s -test and the -test are poorly understood. The well-known optimality of likelihood ratio tests in many settings where the null hypothesis consists of a single distribution, which follows from the famous Neyman–Pearson lemma [8], does not translate over to independence tests, where the null hypothesis is composite—i.e. there is more than one distribution that satisfies its constraints.
The first two concerns mentioned above are related to small cell counts, which are known to cause issues for both Pearson’s -test and the -test. Indeed, elementary Statistics textbooks typically make sensible but ad hoc recommendations, such as:
[Pearson’s -test statistic] approximately follows the distribution provided that (1) all expected frequencies are greater than or equal to 1 and (2) no more than 20% of the expected frequencies are less than 5 (Sullivan III [9, p. 623]).
The statistic has approximately a distribution, for large The approximation improves as increase, and 2 is usually sufficient for a decent approximation (Agresti [7, p. 35]).
Unfortunately, these recommendations (and others in different sources) may be contradictory, leaving the practitioner unsure of whether or not they can apply the tests. For instance, for the data in table 1, we obtain the expected frequencies given in table 2. From this table, we see that all of the expected frequencies are greater than 1 but four of the 20 cells, i.e. exactly 20%, have expected frequencies less than 5, meaning that this table just satisfies Sullivan, III’s criteria, but it does not satisfy Agresti’s.
Table 2.
Expected frequencies for the data in table 1, with the th entry computed as .
| Middle school or Lower | High school | Bachelor’s | Master’s | PhD or Higher | |
|---|---|---|---|---|---|
| Never married | 11.7 | 27 | 25.2 | 16.2 | 9.9 |
| Married | 19.5 | 45 | 42 | 27 | 16.5 |
| Divorced | 3.9 | 9 | 8.4 | 5.4 | 3.3 |
| Widowed | 3.9 | 9 | 8.4 | 5.4 | 3.3 |
Fortunately, there is a well-known, though surprisingly rarely applied, fix for the first numbered problem above, for both Pearson’s test and the -test: we can obtain the critical value via a permutation test. We will discuss permutation tests in detail in §2, but for now it suffices to note that this approach guarantees that the tests control the size of the tests at the nominal level , in the sense that for every sample size , the tests have Type I error probability no greater than .
Our second concern above would typically be handled by removing rows or columns with no observations. If such a row or column had positive probability, however, then this amounts to changing the test being conducted. For instance, if we suppose for simplicity that the th row has no observations, but , then we are only testing the null hypothesis that for and . This is not sufficient to verify that and are independent.
It is, however, the third drawback listed above that is arguably the most significant. When the null hypothesis is false, we would like to reject it with as large a probability as possible. It is too much to hope here that a single test of a given size will have the greatest power to reject every departure from the null hypothesis. If we have two reasonable tests, and , then typically Test will be better at detecting departures from the null hypothesis of a particular form, while Test will have greater power for other alternatives. Even so, it remains important to provide guarantees on the power of a proposed test to justify its use in practice, as we discuss in §2, yet the seminal monograph on statistical tests of Lehmann & Romano [3] is silent on the power of both Pearson’s test and the -test.
The aim of this work, then, is to describe an alternative test of independence, called the USP test (short for -Statistic Permutation test), which simultaneously remedies all of the drawbacks mentioned above. Since it is a permutation test, it controls the Type I error probability at the desired level3 for every sample size . It has no problems in handling small (or zero) cell counts. Finally, we present its strong theoretical guarantees, which come in two forms: first, the USP test is able to detect departures that are minimally separated, in terms of the sample size-dependent rate, from the null hypothesis. Second, we show that the USP test statistic is derived from the unique minimum variance unbiased estimator of a natural measure of dependence in a contingency table. To complement these theoretical results, we present several numerical comparisons between the USP test and both Pearson’s test and the -test, as well as another alternative, namely Fisher’s exact test (e.g. [7, §2.6]), which provide further insight into the departures from the null hypothesis for which the USP test will represent an especially large improvement.
The USP test was originally proposed by Berrett et al. [10], who worked in a much more abstract framework that allows categorical, continuous and even functional data to be treated in a unified manner. Here, we focus on the most important case for applied science, namely categorical data, and seek to make the presentation as accessible as possible, in the hope that it will convince practitioners of the merits of the approach.
2. The USP test of independence
One starting point to motivate the USP test is to note that many of the difficulties of Pearson’s -test and the -test stem from the presence of the terms in the denominators of the summands. When is small, this can make the test statistics rather unstable to small perturbations of the observed table. This suggests that a more natural (squared) distance measure than the -divergence (1.2) is
Unlike the -divergence, this definition is symmetric in and . In independence testing, we are interested in the case where is the product of the marginal distributions of and , i.e. . We can therefore define a measure of dependence in our contingency table by
Under the null hypothesis of independence, we have for all , so . In fact, the only way we can have is if and are independent. More generally, the non-negative quantity represents the extent of the departure of from the null hypothesis of independence.
Note that , and are population-level quantities, so we cannot compute directly from our observed contingency table. We can, however, seek to estimate it, and indeed this is the approach taken by Berrett et al. [10]. To understand the main idea, suppose for simplicity that can take values from 1 to , and and take values from 1 to . Consider the function
where, for instance, the indicator function is 1 if and , and is zero otherwise. We claim that is an unbiased estimator of ; this follows because
However, on its own is not a good estimator of , because it only uses the first four data pairs, so it would have high variance. Instead, what we can do is to construct an estimator of as the average value of as the indices of its arguments range over all possible sets of four distinct data pairs within our dataset. In other words,
where the sum is over all distinct indices between 1 and . Thus, we have choices for the first data pair, choices for the second data pair, for the third and for the fourth, meaning that is an average of terms, each of which has the same distribution, and therefore in particular, the same expectation, namely . It follows that is an unbiased estimator of , but since it is an average, it will have much smaller variance than the naive estimator .
Estimators constructed as averages of so-called kernels over all possible sets of distinct data points are called -statistics, and the fact that there are four data pairs to choose means that is a fourth-order -statistic. For more information about -statistics, see, for example, Serfling [11, ch. 5].
The final formula for does simplify somewhat, but remains rather unwieldy; it is given for the interested reader in appendix Ab. Fortunately, and as we explain in detail below, for the purposes of constructing a permutation test of independence, only part of the estimator is relevant. This leads to the definition of the USP test statistic, for , as
| 2.1 |
This formula appears a little complicated at first glance, so let us try to understand how the terms arise. Notice that is an unbiased estimator of , and, under the null hypothesis, is an unbiased estimator of . Thus the first term in (2.1) can be regarded as the leading order term in the estimate of . The second term (2.1) can be seen as a higher-order bias correction term that accounts for the fact that the same data are used to estimate and ; in other words, and are dependent.
To carry out the USP test, we first compute the statistic on the original data . We then choose to be a large integer ( is a common choice), and, for each , generate an independent permutation of uniformly at random among all possible choices. This allows us to construct permuted datasets4 , and to compute the test statistics that we would have obtained if our data were instead of . The key point here is that, since the original data consisted of independent pairs, we certainly know for instance that and are independent under the null hypothesis. Thus the pseudo-test statistics can be regarded as being drawn from the null distribution of . This means that, in order to assess whether or not our real test statistic is extreme by comparison with what we would expect under the null hypothesis, we can compute its rank among all test statistics , where we break ties at random. If we seek a test of Type I error probability , then we should reject the null hypothesis of independence if is at least the th largest of these test statistics.
It is a standard fact (e.g. [12, lemma 2]) about permutation tests such as this that, even when the null hypothesis is composite (as is the case for independence tests in contingency tables), the Type I error probability of the test is at most , for all sample sizes for which the test is defined ( in our case). Comparing (2.1) with the long formula for in (A 2), we see that we have ignored some additional terms that only depend on the observed row and column totals and . To understand why we can do this, imagine that instead of computing , we instead computed the corresponding quantities , on the original and permuted datasets, respectively. Since the row and column totals and are identical for the permuted datasets as for the original data5, we see that the rank of among is the same as the rank of among . Therefore, when working with the simplified test statistic , we will reject the null hypothesis if and only if we would also reject the null hypothesis when working with the full unbiased estimator .
As mentioned in the introduction, Berrett et al. [10] showed that the USP test is able to detect alternatives that are minimally separated from the null hypothesis, as measured by . More precisely, given an arbitrarily small , we can find , depending only on , such that for any joint distribution with , the sum of the two error probabilities of the USP test is smaller than . Moreover, no other test can do better than this in terms of the rate: again, given any and any other test, there exists , depending only on , and a joint distribution with , such that the sum of the two error probabilities of this other test is greater than . This result provides a sense in which the USP test is optimal for independence testing for categorical data.
To complement the result above, we now derive a new and highly desirable property of the -statistic in (A 2).
Theorem 2.1. —
The statistic is the unique minimum variance unbiased estimator of .
The proof of theorem 2.1 is given in appendix Ac. Once one accepts that is a sensible measure of dependence in our contingency table, theorem 2.1 is reassuring in that it provides a sense in which is a very good estimator of . Since is equally as good a test statistic as , as explained above, this provides further theoretical support for the USP test.
3. Numerical results
(a) . Software
The USP test is implemented in the R package USP [13]. Once the package has been installed and loaded, it can be run on the data in table 1 as follows:
-
>
Data = matrix(c(18,12,6,3,36,36,9,9,21,45,9,9,9,36,3,6,6,21,3,3),4,5)
-
>
USP.test(Data)
As with all permutation tests, the p-values obtained using the USP test will typically not be identical on different runs with the same data, due to the randomness of the permutations. The default choice of for the USP.test function is 999, which in our experience, yields quite stable p-values over different runs. This stability could be increased by running
-
>
USP.test(Data,B = 9999)
for example (although this will increase the computational time). Using yielded a -value of 0.001, so with the USP test, we would reject the null hypothesis of independence even at the 1% level. For comparison, the -test -value is 0.0205, while Fisher’s exact test has a p-value of 0.02, so like Pearson’s test, they fail to reject the null hypothesis at the 1% level.
(b) . Simulated data
In this subsection, we compare the performance of the USP test, Pearson’s test, the -test and Fisher's exact test on various simulated examples. For each example, we need to choose the sample size , as well as the number of rows and columns of our contingency table. However, the most important choice is that of the type of alternative that we seek to detect. Recall that the null hypothesis holds if and only if for all . There are many ways in which this family of equalities might be violated, but it is natural to draw a distinction between situations where only a small number of the equalities fail to hold (sparse alternatives), and those where many fail to hold (dense alternatives). It turns out that the smallest possible non-zero number of violations is four, and our initial example will consider such a setting.
The starting point for this first example is a family of cell probabilities that satisfy the null hypothesis
| 3.1 |
for and . A pictorial representation of these cell probabilities is given in figure 1, which illustrates that the cell probability halves every time we move one cell to the right, or one cell down in the table. The corresponding marginal probabilities for the th row and th column are and respectively. Now, to construct a family of cell probabilities that can violate the null hypothesis in a small number of cells, we will fix and define modified cell probabilities
Note that is just the original cell probability , and that, for , we can consider the new cell probabilities to be a sparse perturbation of the original ones, because we only change the probabilities in the top-left block of four cells. The parameter , which needs to be chosen small enough that all of the cell probabilities lie between 0 and 1, controls the extent of the dependence in the table; in fact, we can calculate that our dependence measure is equal to in this example.
Figure 1.
Pictorial representation of the cell probabilities in (3.1). (Online version in colour.)
We first study how well our estimator is able to estimate . In figure 2, we present violin plots giving a graphical representation of the values of obtained from 10 000 contingency tables generated with and , for 11 different values of and for and ; we also plot the quadratic function . This figure provides numerical support for the fact that is an unbiased estimator of , and illustrates the way that the variance of decreases as the sample size increases from 100 to 400.
Figure 2.

Violin plots of the values of with , and with (a) and (b) for different values of . The function is shown as a red line. (Online version in colour.)
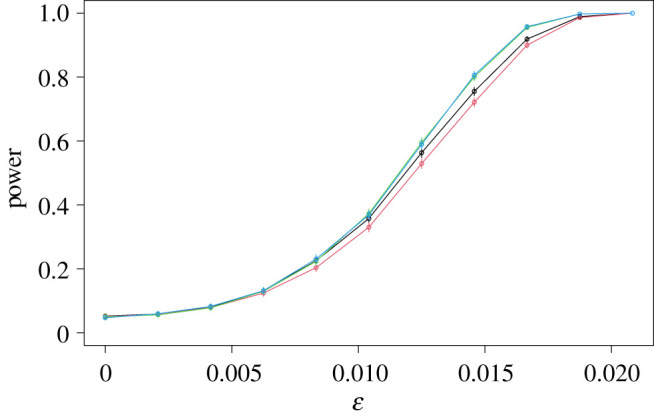
Next, we turn to the size and power of the USP test, and compare them with those of Pearson’s test, the -test and Fisher’s exact test. Figure 3 shows the way in which the power of these tests increases with , for a test of nominal size 5%, with (the corresponding plot with , which is qualitatively similar, is given in figure 8). For both Pearson’s test and the -test, we plot power curves for both the version of the test that takes the critical value from the distribution with degrees of freedom, and the version that obtains the critical value using a permutation test, like the USP test. Here and below, for all permutation tests, we took .
Figure 3.

Power curves of the USP test in the sparse example, compared with Pearson’s test (a) and both the -test and Fisher’s exact test (b). In each case, the power of the USP test is given in black. The power functions of the quantile versions of the first two comparators are shown in blue (a) and purple (b), while those of the permutation versions of these tests are given in red (a) and green (b). The power curve of Fisher’s exact test is shown in cyan on the right. In this plot, as in the other power curve plots, vertical lines through each data point indicate three standard errors (though with 10 000 repetitions, these are barely visible). (Online version in colour.)
The most striking feature of figure 3 is the extent of the improvement of the USP test over its competitors. When , for instance, the USP test is able to reject the null hypothesis in 89% of the experiments, whereas even the better (permutation) version of Pearson’s test only achieves a power of 29%. The permutation version of the -test and Fisher’s exact test do slightly better in this example, achieving powers of 59% and 66% respectively, but remain uncompetitive with the USP test. The version of the -test that uses the chi-squared quantile for the critical value performs poorly in this example, because it is conservative (i.e. its true size is less than the nominal level 5% level). This can be seen from the fact that the leftmost data point of the purple curve on the right-hand plot in figure 3, which corresponds to the proportion of the experiments for which the null hypothesis was rejected when it was true, is considerably less than 5%. It is also straightforward to construct examples for which the versions of Pearson’s test and the -test that use the quantile are anti-conservative (i.e. do not control the size of the test at the nominal level) as in appendix Aa or figure 8 in appendix Ae, and for this reason, we will henceforth compare the USP test with the permutation versions of the competing tests.
To give an intuitive explanation of why Pearson’s test struggles so much in this example, recall that the statistic (1.1) can be regarded as an estimator of the divergence (1.2). Since, when , the only departures from independence occur in the four top-left cells of our contingency table, we should hope that the contributions to the test statistic from these cells would be large, to allow us to reject the null hypothesis. But these are also the cells for which the cell probabilities are highest, so it is likely that the denominators in the test statistic will be large for these cells. In that case, the contributions to the overall test statistic from these cells will be reduced relative to the corresponding contributions to the USP test statistic, for instance, which has no such denominator (or equivalently, the denominator is 1). In fact, the denominators in Pearson’s statistic mean that it is designed to have good power against alternatives that depart from independence only in low probability cells. The irony of this is that such cells will typically have low cell counts, meaning that the usual ( quantile) version of the test cannot be trusted.
Our second example is designed to be at the other end of the sparse/dense alternative spectrum: we will perturb all cell probabilities away from a uniform distribution. More precisely, for , we set
| 3.2 |
for and . When , this is just the uniform distribution across all cells (which satisfies the null hypothesis of independence), while when , cells with even have slightly higher probability, and those with odd have slightly lower probability; see figure 4 for a pictorial representation. In this example, , so again the null hypothesis is only satisfied when . Figure 5 plots the power curves, and reveals that all four tests have similar power; in other words, the improved performance of the USP test in the first, sparse example does not come at the expense of worse performance in this dense case. This is not too surprising, because the denominators of Pearson’s statistic are nearly constant in this example, so Pearson’s statistic is close to a scaled version of the dominant term in the USP test statistic.
Figure 4.

Pictorial representation of the cell probabilities in (3.2). (Online version in colour.)
Figure 5.
Power curves in the dense example, with the USP test in black, Pearson’s test in red, the -test in green and Fisher’s exact test in cyan. (Online version in colour.)
Further simulated examples are presented in appendix Ae.
(c) . Real data
Table 3 shows the eye colours of 167 individuals, 85 of whom were female and 82 of whom were male. The -values of the USP test, Pearson’s test, the -test and Fisher’s exact test were 0.080, 0.169, 0.148 and 0.170, respectively (for the middle two tests, we used the permutation versions of the tests).
Table 3.
Contingency table summarizing the eye colours of 85 females and 82 males. Source: www.mathandstatistics.com/learn-stats/probability-and-percentage/using-contingency-tables-for-probability-and-dependence.
| black | brown | blue | green | grey | |
|---|---|---|---|---|---|
| female | 20 | 30 | 10 | 15 | 10 |
| male | 25 | 15 | 12 | 20 | 10 |
To explore this example further, we repeatedly generated further tables of the same size using the empirical cell probabilities from the real data, and computed the proportion of times that the null hypothesis was rejected at the 5% level. Over 1000 repetitions, these proportions were 0.578, 0.491, 0.497 and 0.499 for the USP test, Pearson’s test, the -test and Fisher’s exact test, respectively, giving further evidence that the USP test is more powerful in this example.
For a second example, we return to the marital status data in table 1. Since the powers for all tests were very high when we resampled as above, we instead repeatedly subsampled 150 observations uniformly at random from the table, again computing the proportion of times that the null hypothesis was rejected at the 5% level. Over 1000 subsamples, the proportions of occasions on which the null hypothesis was rejected at the 5% level were 0.700, 0.583, 0.585 and 0.633 for the USP test, Pearson’s test, the -test and Fisher’s exact test, respectively, so again the USP test has greatest power over the subsamples.
4. Conclusion
-tests of independence are ubiquitous in scientific studies, but the two most common tests, namely Pearson’s test and the -test, can both fail to control the probability of Type I error at the desired level (this can be serious when some cell counts are low), and have poor power. The USP test, by contrast, has guaranteed size control for all sample sizes, can be used without difficulty when there are low or zero cell counts, and has two strong theoretical guarantees related to its power. The first provides a sense in which the USP test is optimal: it is able to detect alternatives for which the measure of dependence converges to zero at the fastest possible rate as the sample size increases (i.e. no other test could detect alternatives that converge to zero at a faster rate). The second, which is the main new theoretical result of this paper, reveals that the USP test statistic is derived from the unique minimum variance unbiased estimator of . This provides reassurance about the test not just in terms of the rate, but also at the level of constants. These desirable theoretical properties have been shown to translate into excellent performance on both simulated and real data. Specifically, while no test of independence can hope to be most powerful against all departures from independence, we have shown that the USP test is particularly effective when departures from independence occur primarily in high probability cells.
A further extension of our methodology is to the problem of testing homogeneity of the distributions of the different rows of our contingency table. Since the permutations used to generate our p-values preserve the marginal row totals, the USP test can be used without modification in this setting, in an analogous way to Pearson’s test and the -test.
Supplementary Material
Appendix A
(a) An example to show that Pearson’s -test and the -test can have unreliable Type I error
The aim of this subsection is to show that both Pearson’s -test and the -test can have highly unreliable Type I error, even in the simplest setting of a contingency table, and for arbitrarily large sample sizes. Fix a sample size , fix , and let . Consider a contingency table with cell probabilities given in table 4.
Table 4.
Cell probabilities for our contingency table example.
It can be checked that this table satisfies the null hypothesis of independence, since
Now suppose that we draw a random sample of size from this contingency table, obtaining the cell counts in table 5:
Table 5.
Cell counts for our contingency table example.
It is convenient to write and . Then by some simple but tedious algebra,
| A 1 |
We are now in a position to study the asymptotic distribution of the statistic in this model, when is large and is fixed. First, note that , the number of observations in the top-left cell, has a binomial distribution with parameters and , so its limiting distribution is Poisson with parameter , by the law of small numbers (e.g. [14, pp. 2–3]). On the other hand, the other terms in the final expression in (A 1) are converging to constants: , the proportion of observations in the first row of the table, is converging to zero in the sense that as for every , and likewise for , the proportion of observations in the first column. Finally, we turn to , and note that we can write . Now, has the same distribution as , where has a binomial random variable with parameters and . Thus has expectation and variance , which converges to zero as . Since has the same distribution as , we deduce that , where converges to zero in the same sense as . These calculations allow us to conclude that the asymptotic distribution of the statistic in this example is that of
where has a Poisson distribution with parameter . We can immediately see from this that, even in the limit as , Pearson’s test will not have the desired Type I error probability, because this distribution differs from the distribution with 1 d.f., which is what would be expected according to the traditional asymptotic theory where the cell probabilities do not change with the sample size. As another way of comparing the actual asymptotic Type I error probability with the desired level, see figure 6. Here, we plot the asymptotic Type I error probability
as a function of , where is the th quantile of the distribution. For an ideal test of exact size , this should produce a constant flat line at level , but in fact we see that the Type I error probability oscillates quite wildly, due to the discreteness of the Poisson distribution. For a test at a desired 1% significance level, we may end up with a test whose Type I error probability is 10 times larger!
Figure 6.

Plots of the asymptotic Type I error of Pearson’s test for the table with cell probabilities given in table 4 when (a) and (b).
These issues are not resolved by working with the -test instead. Indeed, similar but more involved calculations, given in appendix Ad, reveal that in this example, the asymptotic distribution of the -test statistic is that of
where has a Poisson distribution with parameter . Since this asymptotic distribution is not a distribution with 1 d.f., we again see that the asymptotic size of the -test will not be correct in general. The corresponding asymptotic size plots, which are presented in figure 7, reveal similarly wild behaviour as for Pearson’s test. The biggest jumps in the Type I error probabilities in figure 7 occur when , because when exceeds this level, we will reject the null hypothesis on observing , whereas for smaller we will not. A similar transition occurs when for Pearson’s test in figure 6, though this is barely detectable when , in which case is approximately 2.58.
Figure 7.

Plots of the asymptotic Type I error of the -test for the table with cell probabilities given in table 4 when (a) and (b).
We conclude from this example that the sizes of both Pearson’s test and the -test can be extremely unreliable, even when the overall sample size in the contingency table is very large. Moreover, these problems can be even further exacerbated when we move beyond contingency tables, with asymptotic Type I error probabilities that deviate even further from their desired levels.
To explain what is going on in this example in a more general but abstract way, let denote the set of all possible distributions on contingency tables that satisfy the null hypothesis of independence. By, e.g. Fienberg & Gilbert [15], all such distributions have cell probabilities of the form given in table 6 for some and .
Table 6.
Cell probabilities for a general contingency table satisfying the null hypothesis of independence.
In our example, we simplified this general case by taking . The justification for using as the critical value for Pearson’s -test comes from the fact that for each in the set , we have that
as . Here, the notation indicates that the probability is computed under the distribution . On the other hand, the crucial point about our example is that the speed at which this probability converges to may depend on the particular choice of that we make; more formally, this convergence is not uniform over the class
as . It is this fact that allows us to find, for each , a distribution in for which the Type I error probability is not approaching as increases.
(b) An unbiased estimator of
When , the unbiased estimator of obtained from the fourth-order -statistic of Berrett et al. [10] is
| A 2 |
(c) Proof of theorem 2.1
Since we know that is an unbiased estimator of , it remains to show that has minimal variance among all unbiased estimators of and that no other unbiased estimator of can match this minimal variance. We may again assume without loss of generality that takes values in and takes values in . Our basic strategy is to apply the Lehmann–Scheffé theorem [16,17], which can be regarded as an extension of the Rao–Blackwell theorem [18,19]. The Lehmann–Scheffé theorem relies on the notions of a sufficient statistic and a complete statistic. Intuitively, a statistic is sufficient for if it encapsulates all of the information in the data that is relevant for making inference about . More formally, is sufficient in our contingency table setting if the conditional distribution of given does not depend on . We claim that the matrix of observed counts is sufficient for , and this follows because the conditional distribution of interest is given by
whenever for all . In other words, once the cell counts are fixed, every ordering of the way in which those cells counts could have arisen is equally likely. This probability does not depend on , so the matrix of observed counts is sufficient for .
Informally, we say is a complete statistic if there are no non-trivial unbiased estimators of zero that are functions of . This means that whenever , we must have . The main part of our proof is devoted to proving that the matrix is complete. To this end, let , and let denote the simplex of all -dimensional probability vectors, so that
Note that we are now thinking of stacking the columns of our matrix as a -dimensional vector. We let denote the set of all possible -dimensional vectors of observed counts with a total sample size of , so that
In the multinomial sampling model for our data, the probability of seeing observed counts is
Suppose without loss of generality that (if it were zero then we could simply choose a different index). In order to study completeness, we should consider a function with
| A 3 |
Here, in moving from the first line to the second, we have used the fact that , and in the final step, we exploited the fact that . Now let
for , and note that each can take any non-negative real value if we choose the probabilities appropriately. Then from (A 3), we deduce that
Thus, a polynomial in is identically zero, so its coefficients must be zero. Hence, for all , so our matrix of observed counts is complete.
The Lehmann–Scheffé theorem states that an unbiased estimator that is a function of a complete, sufficient statistic is the unique minimum variance unbiased estimator. Our estimator is an unbiased estimator of that depends on the data only through the matrix of observed counts, which is a complete, sufficient statistic, so is indeed the unique minimum variance unbiased estimator of .
(d) Asymptotic distribution of the -test statistic
We return to the contingency table example of appendix Aa. We claim that the asymptotic distribution of the four-dimensional standardized multinomial random vector
| A 4 |
is that of , where and are independent, with having a centred Poisson distribution with parameter and with having a trivariate normal distribution with mean vector zero and singular covariance matrix
To see this, note that the random vector can be written as a sum of independent and identically distributed random variables as
| A 5 |
where, for instance, . One way to study the asymptotic distribution of , then, is to compute its limiting moment generating function, which is the moment generating function of each summand in (A 5) raised to the power . It will also be convenient to have notation for terms that will be asymptotically negligible: if and are sequences, we write if as ; thus , for example. Each summand in (A 5) can take four possible values, since must be one of , , or . Now fixing , we can compute as follows:
This limiting moment generating function agrees with the moment generating function of , and therefore establishes the claimed asymptotic distribution (e.g. [20, p. 390]). In other words,
| A 6 |
where the distribution of converges to that of as . Note that, since the sum of the entries of this matrix is , we must have that . Similarly to our ‘little o’ notation for negligible deterministic sequences, we now introduce a notation for negligible random sequences: we write if as , for every . We can now calculate further that
Hence
By a Taylor expansion of the logarithms in the second, third and fourth terms, we conclude that the asymptotic distribution of is that of
as claimed in appendix Aa.
(e) Additional simulation results
Here, we present further numerical comparisons between the USP test, Pearson’s test, the -test and Fisher’s exact test. Figure 8 shows power functions for the first (sparse alternative) example in §2b, but with instead of . The figure is qualitatively similar in most respects to figure 3, and reveals that the improved performance of the USP test is not diminished by increasing the sample size. One slight difference is that we can see that the version of Pearson’s test with the quantile is anti-conservative (fails to control the size at the nominal level) for this sample size.
Figure 8.

Power curves of the USP test in the sparse example with , compared with Pearson’s test (a) and both the -test and Fisher’s exact test (b). In each case, the power of the USP test is given in black. The power functions of the quantile versions of the first two comparators are shown in blue (a) and purple (b), while those of the permutation versions of these tests are given in red (a) and green (b). The power curve of Fisher’s exact test is shown in cyan on the right. (Online version in colour.)
A feature of both our sparse and dense examples is that the perturbations from the null distribution are additive. An alternative mechanism for departing from the null distribution that is also of interest is where the perturbations are multiplicative. For example, for and , consider the cell probabilities
| A 7 |
where is a normalization constant; see figure 9. Figure 10 shows the power curves of our four permutation tests with . Despite the fact that the perturbations here are dense, we see that the USP test is best able to detect the violations of independence for small and moderate values of , while Fisher’s test slightly outperforms it for larger .
Figure 9.

Pictorial representation of the cell probabilities in (A 7). (Online version in colour.)
Figure 10.
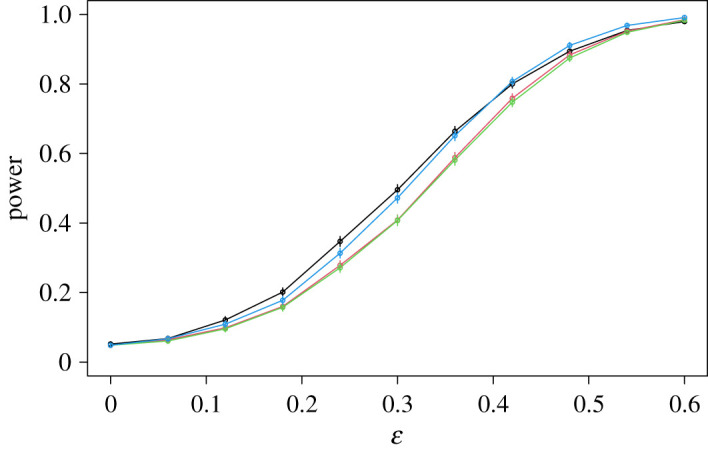
Power curves of the USP test (black), Pearson’s test (red), the -test (green) and Fisher’s exact test (cyan) for the multiplicative example with . (Online version in colour.)
Footnotes
As an interesting historical footnote, Pearson’s original calculation of the number of degrees of freedom contained an error, which was corrected by Fisher [2]; e.g. Lehmann & Romano [3, p. 741].
in our notation.
In fact, this represents an important advantage of permutation tests over the bootstrap (another natural choice to obtain -values) in independence-testing problems.
In fact, as shown in Berrett et al. [10], we only require the original cell counts to compute the cell counts for the permuted data. This dramatically simplifies the computation of the contingency tables for permuted datasets.
Interestingly, this is another advantage of using permutations as opposed to the bootstrap to generate p-values.
Data accessibility
This article has no additional data.
Authors' contributions
T.B.B. conceived of the general framework and helped draft the manuscript. R.J.S. helped formulate the general framework and drafted the manuscript. Both authors gave final approval for publication and agree to be held accountable for the work performed therein.
Competing interests
We declare we have no competing interests.
Funding
The research of R.J.S. was supported by EPSRC grant nos EP/P031447/1 and EP/N031938/1, as well as ERC grant no. 101019498. The authors are grateful for helpful feedback from Sergio Bacallado, Rajen Shah and Qingyuan Zhao.
References
- 1.Pearson K. 1900. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Phil. Mag. Ser. 5 50, 157-175. (Reprinted in: Karl Pearson’s Early Statistical Papers, Cambridge University Press, 1956). ( 10.1080/14786440009463897) [DOI] [Google Scholar]
- 2.Fisher RA. 1924. The conditions under which chi square measures the discrepancy between observations and hypothesis. J. R. Stat. Soc. 87, 442-450. ( 10.2307/2341292) [DOI] [Google Scholar]
- 3.Lehmann EL, Romano JP. 2005. Testing statistical hypotheses. New York, NY: Springer Science+Business Media, Inc.. [Google Scholar]
- 4.McDonald JH. 2014. -test of goodness-of-fit. In Handbook of biological statistics, 3rd edn., pp. 53–58. Baltimore, MD: Sparky House Publishing.
- 5.Dunning T. 1993. Accurate methods for the statistics of surprise and coincidence. Comput. Linguist. 19, 61-74. [Google Scholar]
- 6.Grimmett G, Welsh D. 1986. Probability: an introduction. Oxford, UK: Oxford Science Publications. [Google Scholar]
- 7.Agresti A. 2007. An introduction to categorical data analysis. 2nd edn. Hoboken, NJ: John Wiley & Sons. [Google Scholar]
- 8.Neyman J, Pearson ES. 1933. IX. On the problem of the most efficient tests of statistical hypotheses. Phil. Trans. R. Soc. Lond. A. 231, 289-337. ( 10.1098/rsta.1933.0009) [DOI] [Google Scholar]
- 9.Sullivan M III. 2017. Statistics: informed decisions using data. 5th edn. Harlow, UK: Pearson. [Google Scholar]
- 10.Berrett TB, Kontoyiannis I, Samworth RJ. 2021. Optimal rates for independence testing via -statistic permutation tests. Ann. Stat. 49, 2457-2490. ( 10.1214/20-AOS2041) [DOI] [Google Scholar]
- 11.Serfling RJ. 1980. Approximation theorems of mathematical statistics. Wiley Series in Probability and Statistics. New York, NY: John Wiley & Sons. [Google Scholar]
- 12.Berrett TB, Samworth RJ. 2019. Nonparametric independence testing via mutual information. Biometrika 106, 547-566. ( 10.1093/biomet/asz024) [DOI] [Google Scholar]
- 13.Berrett TB, Kontoyiannis I, Samworth RJ. 2020. USP: U-statistic permutation tests of independence for all data types. R package version 0.1.1. See https://cran.r-project.org/web/packages/USP/index.html.
- 14.Kingman JFC. 1993. Poisson processes. Oxford, UK: Oxford University Press. [Google Scholar]
- 15.Fienberg SE, Gilbert JP. 1970. The geometry of a two by two contingency table. J. Am. Stat. Assoc. 65, 694-701. ( 10.1080/01621459.1970.10481117) [DOI] [Google Scholar]
- 16.Lehmann EL, Scheffé H. 1950. Completeness, similar regions, and unbiased estimation. I. Sankhyā 10, 305-340. [Google Scholar]
- 17.Lehmann EL, Scheffé H. 1955. Completeness, similar regions, and unbiased estimation. II. Sankhyā 15, 219-236. [Google Scholar]
- 18.Blackwell D. 1947. Conditional expectation and unbiased sequential estimation. Ann. Math. Stat. 18, 105-110. ( 10.1214/aoms/1177730497) [DOI] [Google Scholar]
- 19.Rao CR. 1945. Information and accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 37, 81-91. [Google Scholar]
- 20.Billingsley P. 1995. Probability and measure. Wiley Series in Probability and Statistics. New York, NY: John Wiley & Sons. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
This article has no additional data.