

Abstract
Detecting COVID-19 early may help in devising an appropriate treatment plan and disease containment decisions. In this study, we demonstrate how transfer learning from deep learning models can be used to perform COVID-19 detection using images from three most commonly used medical imaging modes X-Ray, Ultrasound, and CT scan. The aim is to provide over-stressed medical professionals a second pair of eyes through intelligent deep learning image classification models. We identify a suitable Convolutional Neural Network (CNN) model through initial comparative study of several popular CNN models. We then optimize the selected VGG19 model for the image modalities to show how the models can be used for the highly scarce and challenging COVID-19 datasets. We highlight the challenges (including dataset size and quality) in utilizing current publicly available COVID-19 datasets for developing useful deep learning models and how it adversely impacts the trainability of complex models. We also propose an image pre-processing stage to create a trustworthy image dataset for developing and testing the deep learning models. The new approach is aimed to reduce unwanted noise from the images so that deep learning models can focus on detecting diseases with specific features from them. Our results indicate that Ultrasound images provide superior detection accuracy compared to X-Ray and CT scans. The experimental results highlight that with limited data, most of the deeper networks struggle to train well and provides less consistency over the three imaging modes we are using. The selected VGG19 model, which is then extensively tuned with appropriate parameters, performs in considerable levels of COVID-19 detection against pneumonia or normal for all three lung image modes with the precision of up to 86% for X-Ray, 100% for Ultrasound and 84% for CT scans.
Keywords: COVID-19 detection, image processing, model comparison, CNN models, X-ray, ultrasound and CT based detection
I. Introduction
The current COVID-19 pandemic has impacted the world with over 18.35 million
infections and over 6,96,147 deaths so far (as of
 August
2020) [1]. Early identifying, isolation and
care for patients is a key strategy for a better management of this pandemic. Our
study aims to provide a conceptual transfer learning framework to support COVID-19
detection with the use of image classification using deep learning models for
multiple imaging modes including X-Ray, Ultrasound, and CT scan. The acquisition of
a sufficiently large, publicly available corpus of medical image sample data for
fully training deep learning models is challenging for novel medical conditions such
as COVID-19 since collection and labelling of images requires significant time and
resources to compile. An alternative method of training deep learning models is
“transfer learning” whereby a deep learning network is pre-weighted
with the results of a previous training cycle from a different domain. This
technique is commonly used as a basis for initializing deep learning models which
are then fine-tuned using the limited available medical sample data set with results
that have been documented to outperform fully trained networks under certain
circumstances [2], [3]. The study will demonstrate how transfer learning can be
used for COVID-19 detection for three commonly used imaging modes X-Ray, Ultrasound,
and CT scan. This could assist practitioners and researchers in developing a
supporting tool for highly constrained health professionals in determining the
course of treatment. The study further demonstrates a pre-processing pipeline for
improving the image quality, for deep learning-based predictions. An initial testing
is also conducted to understand the suitability of various popular deep learning
models for the limited available dataset in order to select a model for the proposed
image classification demonstrations on multiple image modes.
August
2020) [1]. Early identifying, isolation and
care for patients is a key strategy for a better management of this pandemic. Our
study aims to provide a conceptual transfer learning framework to support COVID-19
detection with the use of image classification using deep learning models for
multiple imaging modes including X-Ray, Ultrasound, and CT scan. The acquisition of
a sufficiently large, publicly available corpus of medical image sample data for
fully training deep learning models is challenging for novel medical conditions such
as COVID-19 since collection and labelling of images requires significant time and
resources to compile. An alternative method of training deep learning models is
“transfer learning” whereby a deep learning network is pre-weighted
with the results of a previous training cycle from a different domain. This
technique is commonly used as a basis for initializing deep learning models which
are then fine-tuned using the limited available medical sample data set with results
that have been documented to outperform fully trained networks under certain
circumstances [2], [3]. The study will demonstrate how transfer learning can be
used for COVID-19 detection for three commonly used imaging modes X-Ray, Ultrasound,
and CT scan. This could assist practitioners and researchers in developing a
supporting tool for highly constrained health professionals in determining the
course of treatment. The study further demonstrates a pre-processing pipeline for
improving the image quality, for deep learning-based predictions. An initial testing
is also conducted to understand the suitability of various popular deep learning
models for the limited available dataset in order to select a model for the proposed
image classification demonstrations on multiple image modes.
Fast, accessible, affordable and reliable identification of COVID-19 pathology in an individual is key to slowing the transmission of COVID-19 infection. Currently, reverse transcriptase quantitative polymerase chain reaction (RT-qPCR) tests are the gold standard for diagnosing COVID-19 [4]. During this test small amounts of viral RNA are extracted from a nasal swab, amplified, and quantified with virus detection indicated visually using a fluorescent dye. Unfortunately, the RT-qPCR test is manual and time-consuming, with results taking up to two days. Some studies have also shown false positive Polymerase Chain Reaction PCR testing [5]. Other testing approaches include imaging technology-based approaches including computed tomography (CT) imaging [6] and X-Ray imaging based [7], [8] and Ultrasound imaging [9].
The CT scan-based COVID-19 detection is time consuming and manual with the requirement of expert involvements. CT scanning machines are also difficult to use for COVID patients, as the patients often need to be transferred to the CT room, the machines would require extensive cleaning after each usage, and higher radiation risks [10]. Although CT is not recommended as a primary diagnostic tool, it has been successfully used as a supporting tool for COVID-19 condition assessment [6]. Common CT findings include ground-glass opacities (GGO) at the early stage, during progressive stage, air space consolidation during peak stage, Broncho vascular thickening in the lesion, and traction bronchiectasis are visible during absorption stage [10]. Several studies have shown promising results in using deep learning models to automated diagnosis of COVID-19 from CT images [6], [11], [12]. Both the PCR tests and CT scans are comparatively costly [13], [14] and with an overwhelming demand many countries are forced to perform selective testing for only high-risk population.
X-Ray imaging is relatively cost effective and commonly utilized for lung infection detection and is useful for COVID-19 detection as well [15]. Medical observations were made by one of the co-authors of this research (Dr. Saha) who is also a medical professional, as well as by treating doctors of the COVID-19 dataset [16] patients. The common features observed in the X-Ray images of patients with COVID-19 are patchy infiltrates or opacities that bear similarities to other viral pneumonia features. X-Ray images do not show any abnormalities in the early stages of COVID-19. However, as the disease progresses, COVID-19 gradually manifests as a typical unilateral patchy infiltration involving mid zone and upper or lower zone of the lungs, occasionally with evidence of a consolidation.
Ultrasound imaging has also been recommended as a tool for COVID-19 lung condition assessment since it can be used at bedside with minimal infection spreading risks and has excellent ability to detect lung conditions related to COVID-19 [17]. Progression of COVID-19 infection is evident as B-lines aeration in early stages of consolidation in critical stages [10], [18].
Fig. 1 shows the progression of evidence for the patient in the COVID-19 datasets for X-Ray, CT and Ultrasound imaging.
FIGURE 1.

COVID-19 progression over several days as evident in different imaging modes.
Computer vision diagnostic tools for COVID-19 from multiple imaging modes such as X-Ray, Ultrasound, and CT would provide an automated “second reading” to clinicians, assisting in the diagnosis and criticality assessment of COVID-19 patients to assist in better decision making in the global fight against the disease. COVID-19 often results in pneumonia, and for radiologists and practitioners differentiating between the COVID-19 pneumonia and other types of pneumonia (viral and bacterial) solely based on diagnostic images could be challenging [19].
Deep learning artificial neural networks, and the Convolutional Neural Networks (CNNs) have proven to be highly effective in a vast range of medical image classification applications [20], [21]. In this study, we present three key contributions. Primarily, we demonstrate how transfer learning capabilities of off the shelf deep learning models can be utilized to perform classifications in two distinct scenarios for three imaging modes X-Ray, Ultrasound, and CT scan:
-
1)
Identifying the pneumonia (both COVID-19 and other types) affected lung against the normal lung.
-
2)
Identifying COVID-19 affected lung from non COVID-19 pneumonia affected lung.
Secondly, we present a comparative study in order to select a suitable deep learning model for our demonstration. We performed a comparative testing of several common off-the-shelf CNN models namely VGG16/VGG19 [22], Resnet50 [23], Inception V3 [24], Xception [25], InceptionResNet [26], DenseNet [27], and NASNetLarge [28]. The testing is not intended for exhaustive performance comparison of these methods, rather we wanted to select the most suitable one for our multi-modal image classification, which performs decently with minimal tuning. The source X-Ray, Ultrasound, and CT image samples, especially those from the COVID-19 data sets, have been harvested from multiple sources and are of inconsistent quality. In our final contribution, we have implemented a pre-processing pipeline to reduce unwanted signal noise such as non-lung area visible in X-Rays, and thereby reduce the impact of sampling bias on this comparison. Through this pre-processing pipeline, we minimize the image quality imbalances in the image samples. This would allow models to train on lung features only thus having a greater chance of learning disease features and ignoring other noise features. The study would provide timely model selection guidelines to the practitioners who often are resorted to utilise certain mode of imaging due to time and resource scarcity.
In the following sections we first present a brief review of recent scholarly works related to this study, followed by a discussion on the datasets we used and related challenges. We then present the dataset generation process along with our proposed pre-processing pipeline for data quality balancing. We then present the deep learning model selection process along with comparison results. Finally, we present the performance results with discussions for our selected model on all three image modes.
II. Related Work
Computer aided detection and diagnosis of pulmonary pathologies from X-Ray images is a field of research that started in the 1960s and steadily progressed in the following decades with papers describing highly accurate diagnosis of a range of conditions including osteoporosis [29], breast cancer [30], and cardiac disease [31].
CT scans also use X-Rays as a radiation source, however, they provide much higher image resolution and contrast compared to standard X-Ray images because of a much more focused X-Ray beam used to produce cross-sectional images of the patient [32]. CT is generally considered as the best imaging modality for lung parenchyma and is widely accepted by clinicians as the “gold standard” [33]. A large corpus of research exists relating to the use of machine learning to improve the efficiency and accuracy of lung cancer diagnosis – largely driven by extensive CT based lung cancer screening programs in many parts of the world. Several researches have achieved incredibly accurate results using CNNs with transfer learning to detect lung nodules [34]–[37]. Recently a deep learning system built by Google achieved state-of-the-art performance using patients’ current and prior CT volumes to predict the risk of lung cancer. This system outperformed human radiologists where prior CT scans were not available, and equaled human radiologist performance where historical CT scans were available [38]. Although X-Ray is the current reference diagnosis for pneumonia, some studies point out that CT generally outperforms X-Ray as a diagnostic tool for pneumonia, albeit at higher cost and convenience [39], [40].
Ultrasound has traditionally been used diagnostically in the fields of cardiology and obstetrics and more recently for a range of other conditions covering most organs. One of the reasons for this increase in the use of ultrasound is that technical advancements including machine learning have allowed useful information to be determined from the low quality and high signal-to-noise images that are typical of the Ultrasound imaging modality [41]. Several researchers have recently used Ultrasound as an effective diagnostic aid in hepatic steatosis, adenomyosis, and craniosynostosis [42], Pancreatic cancer [43], Breast cancer [44] and prostate cancer [45]. Use of bedside ultrasound in critically ill patients compared favorably against chest X-Ray and approached the diagnostic accuracy of CT scans for a range of thoracic conditions [46]. The combination of lung ultrasound with machine learning techniques was found to be valuable in providing faster and more accurate bedside interpretation of lung ultrasound for acute respiratory failure [47].
Difficulties in distinguishing soft tissue caused by poor contrast in X-Ray images have led some researchers to implement contrast enhancement [48] as a pre-processing step in X-Ray based diagnosis. In addition, lung segmentation of X-Ray images is an important step in the identification of lung nodules and various segmentation approaches are proposed in the literature based on linear filtering/thresholding, rolling ball filters and more recently CNNs [49].
Although CT scans are much higher contrast/resolution compared to X-Ray factors such as low dose and improper use of image enhancement can lead to poor quality images. A number of researchers have noted that histogram equalization techniques, particularly adaptive histogram equalization can improve the contrast of CT images [50]. A combination of histogram normalization, gamma correction and contrast limited adaptive histogram equalization has been shown to objectively improve the quality of poor contrast CT images [51].
Ultrasound images tend to be noisy due to the relatively low penetration of soundwaves into organic tissue compared to X-Rays. This limitation has led a number of researchers to develop methods to improve the quality of ultrasound images by various means including noise filtering, wavelet transformation and deconvolution [52]. Contrast Limited Adaptive Histogram Equalization (CLAHE) has been used as part of a pre-processing pipeline to enhance the quality of ultrasound images [53].
In the literature review we noted a small number of very recent studies that have used deep learning systems for COVID-19 screening and diagnosis. A custom-built 18-layer residual network pre-trained on the ImageNet weights against COVID-19 (100 images) and Pneumonia (1431 images) X-Ray image datasets [54]. A range of deep learning frameworks coined as COVIDX-Net trained on a small data set of 25 confirmed COVID-19 cases [55]. A custom curated dataset of COVID-19, viral pneumonia and normal X-Ray images [56]. A custom residual CNN that was highly effective in distinguishing between COVID-19, Pneumonia and normal condition X-Ray images [57]. These studies used the COVID-19 dataset [16] for the COVID-19 X-Ray samples, and the RSNA dataset [58] was used to get pneumonia and normal X-Ray samples.
Automated COVID-19 Pneumonia diagnosis from CT scans has been the focus of recent studies with promising results [59]–[62]. A combined U-Net segmentation and 3D classification CNN has been used to accurately predict the presence of COVID-19 with an accuracy of 90% using a non-public dataset of CT images [63]. A ResNet50 based CNN with transfer learning from the ImageNet weights was able to classify COVID-19 with 94% accuracy [64] against a normal condition CT slice using unspecified multiple international datasets as a corpus. In a recent work, [65] addressed the challenge of automatically distinguishing between COVID-19 and community acquired pneumonia using machine learning. This system uses a U-Net pre-processor model for lung field segmentation, followed by a 3D ResNet50 model using transferred ImageNet weights. This study achieved a sensitivity of 87% against a large non-public dataset collected from 6 hospitals. The DenseNet-169 CNN has been used [66] to detect COVID-19 vs non-COVID-19 CT slices. Without segmentation this system achieved an accuracy of 79.5% with an F1 score of 76%. Using joint segmentation, the classification accuracy was raised to 83.3% with an F1 score of 84.6%.
There has been less attention given to the use of machine learning to automate COVID-19 diagnosis from Ultrasound images, however a ResNet based CNN trained on the available Ultrasound COVID-19 data has achieved an accuracy of 89% with recall accuracy for COVID-19 of 96% [9].
Each imaging mode differs in terms of cost/availability and the level of clinical expertise required to accurately interpret the generated medical images. Different imaging modes are therefore suitable to different contexts – for example both X-Ray and Ultrasound can be implemented as low-cost portable units that may be used as bedside or even as field diagnostic tools. CT scanning equipment is typically physically fixed at high cost and is therefore only available within the confines of hospitals and medical clinics. Our main aim is to first select one suitable deep learning model through comparative testing of a range of off-the-shelf deep learning models against each of these imaging modes using transfer learning. The comparison results are then used to address limited sample data size and data variability. We then applied image pre-preprocessing to improve image quality and reduce inter and intra dataset systematic differences in brightness and contrast level. Finally, we performed extensive parameter tuning on the selected model and compared the performance of this model for each imaging mode.
III. Dataset Development
A. Data Sourcing
Large numbers of X-Ray, CT and Ultrasound images are available from several publicly accessible datasets. With the emergence of COVID-19 being very recent none of these large repositories contain any COVID-19 labelled data, thereby requiring that we rely upon multiple datasets for Normal, Pneumonia, COVID-19 and other non COVID-19 source images.
COVID-19 chest X-Rays were obtained from the publicly accessible COVID-19 Image Data Collection [16]. This collection has been sourced from websites and pdf format publications. Unsurprisingly, the images from this collection are of variable size and quality. Image contrast levels, brightness and subject positioning are all highly variable within this dataset. Our analysis in this article is based on a download of this dataset made on 11 May 2020.
The selection of a dataset for Normal and Pneumonia condition X-Rays posed a
dilemma since a highly curated data set is not comparable to the available
COVID-19 chest X-Ray dataset. Our early tests against one such dataset gave an
unrealistically high classification accuracy for the quality of the data under
test. We found that the National Institute of Health (NIH) Chest X-Ray [67] dataset – provided images are
of a similar size, [68] quality and
aspect ratio to the typical images in the COVID-19 dataset with dimensions being
uniformly
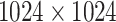 pixels in a portrait orientation.
pixels in a portrait orientation.
CT scans for COVID-19 and non COVID-19 were obtained from the publicly accessible COVID-CT Dataset [66]. This dataset has been sourced by extracting CT slice images showing the COVID-19 pathology from preprint papers. Once again, the images from this collection are of variable size and quality. Moreover, the process of CT scanning is dynamic, with a full scan consisting of many discrete slices taken in a helical pattern along the thoracic cavity. The images in this collection only present a single, or small number of slices per patient. As CT slice images progress along the thoracic cavity, the structural features visible in the generated image change dramatically. Ideally all slices would be available for analysis in order to equalize the distribution/prominence in the image of these features, however this is not the case with this dataset. Our analysis in this article is based on a download of this dataset made on 11 May 2020.
Ultrasound images for COVID-19, Pneumonia and Normal conditions were obtained from the publicly accessible POCOVID-Net data set [9]. These images have been sampled from video sourced from various online sources. We noticed a huge variation in the quality in the images within each condition caused by the position of the ultrasound apparatus on the patients’ chest. Ideally ultrasound video would be taken in a systematic way to allow for greater comparability of the condition datasets with every frame in the video subject to analysis. Neither of these conditions are satisfied by this dataset. Our analysis in this article is based on a download of this dataset made on 11 May 2020.
The number of images of each dataset along with a description of the characteristics of the datasets is described in Table 1. We believe the significant quality variations between data from different classes need to be balanced for deep learning models to learn actual disease related variations. Therefore, our study stresses the importance of sampling bias/signal noise removal from the image datasets prior to using them for model development and classification in order to obtain meaningful and trustworthy classification results. Some illustrative examples of this variability of these datasets is shown in Fig. 2. Of these examples images (b), (c) and (f) appear to have been cropped from journal articles and in the case of (f) scanned. These images are of poor quality and lacking detail that would indicate a pathology to our machine learning models. Images (g), (j) and (k) also lack detail as a result of apparatus positioning. Images (d) and (l) show high brightness and low contrast, thus hiding pathological details. Despite the variability of the datasets we chose to only very lightly curate data as described in Section III(C) Data Pre-processing and shown in Table 2. Our reasoning for this is twofold. Firstly we wish to avoid biasing the data corpus with a non-expert subjective opinion of pathological indications, and secondly we consider the usefulness of this study to potentially extend to future pandemic situations where similar data quality issues will be likely if not inevitable.
TABLE 1. Summary of Data Sources Used.
| Collection | Number of Images | Characteristics | Notes |
|---|---|---|---|
| COVID-19 Image Data Collection [16] | 115: COVID-19 (PA) | Variable size, quality, contrast and brightness. | Only source of publicly accessible COVID-19 PA X-Ray images and used in this study. |
| NIH Chest X-Ray [67] | 322: Pneumonia 60361: No Finding | Intra-dataset uniformity similar to COVID-19 dataset. All images are 1024 x1024 in size. | Objectively similar in quality to the COVID-19 Image Data Collection. Used in this study. |
| COVID-CT Dataset [66] | 349: COVID-19 397: Non COVID | Variable size, contrast and brightness | Only source of publicly accessible COVID-19 CT images and used in this study. |
| POCOVID-Net Dataset [9] | 654: COVID-19 277: Pneumonia 172: No Finding | Variable size, contrast and brightness | Only source of publicly accessible COVID-19 Ultrasound images and used in this study. |
FIGURE 2.

Different variations observed in the COVID-19 datasets.
TABLE 2. Sampled Dataset for Experiments.
| Image Mode | Condition | Source images | Curated images | Number of augmented images | Source |
|---|---|---|---|---|---|
| X-Ray | COVID-19 | 140 | 139 | 2,920 | [16] |
| Pneumonia | 322 | 190 | 2,920 | [67] | |
| Normal | 60361 | 400 | 5,840 | [67] | |
| CT | COVID-19 | 349 | 349 | 6,000 | [66] |
| Non COVID | 397 | 397 | 6,000 | [66] | |
| Ultrasound | COVID-19 | 399 | 399 | 2,720 | [9] |
| Pneumonia | 277 | 277 | 2,720 | [9] | |
| Normal | 235 | 235 | 5,440 | [9] |
B. Data Sampling
In this study, we aim to use real X-Ray, Ultrasound and CT scan data only, and not considering creation and use of synthetic data at this stage. We also used a relatively balanced dataset size for our model experiments, with imbalance addressed using calculated class training weights. From the source datasets shown in Table 1, we created a master dataset for our experiments.
The X-Ray COVID-19 dataset was lightly curated to remove a single image that was an incorrectly labelled projection. All other COVID-19 images were included for the various modes. The non-COVID-19 images were also lightly curated to remove images that were mislabeled projections or dominated by intrusive medical devices. This left us with usable image samples for X-Ray, Ultrasound and CT scan to work with. Since the resulting sample corpus was still relatively small for a deep learning application, we applied several data augmentation transformations including horizontal flip, horizontal and vertical shift and rotation during the experiment process to increase the volume and variety of the sample set as summarized in Table 2.
We recognized that although we were using only a small number of image collections for our experiments; we were in fact relying upon data sourced from an unknown number and variety of X-Ray, CT, and Ultrasound machines, each with variable exposure parameters and operator behaviors. Systematic image exposure and brightness differences within and between the datasets of each imaging mode proved to be particularly concerning, and several researchers have indicated that medical image analysis methods are highly sensitive to variations of image intensities [69]. Research has shown that the feasibility of an automated analysis system requires that “the intensity of the same tissue should always be similar in one image and not vary with the location of the tissue” [69]. This principle, when extrapolated to the many images utilized in machine learning algorithms, implies that all images in the sample data sets should have similar intensity for the same tissue over the entire set of images as well as within a single image.
Since the machine learning classifiers, use a pixel array as a data source, any systematic difference in pixel intensity between the datasets would introduce sampling bias in the results. This would have the consequence of training the machine learning classifiers on systematic image histogram differences rather than the actual clinical image content of interest.
To minimize the effect of sampling bias, we applied histogram equalization to images using the N-CLAHE method described by [70]. The method both normalizes images and enhances small details, textures and local contrast by first globally normalizing the image histogram followed by application of Contrast Limited Adaptive Histogram Equalization (CLAHE) [71]. This was implemented using the OpenCV equalizeHist and createCLAHE functions [72].
As shown in Fig. 3, the N-CLAHE pre-process greatly improved the image brightness/contrast consistency across the datasets as well as enhancing the fine details of these images. The same effect was observed within each data set. Subjectively, the authors can no longer easily tell which image has been drawn from which dataset purely on image brightness and contrast characteristics alone.
FIGURE 3.
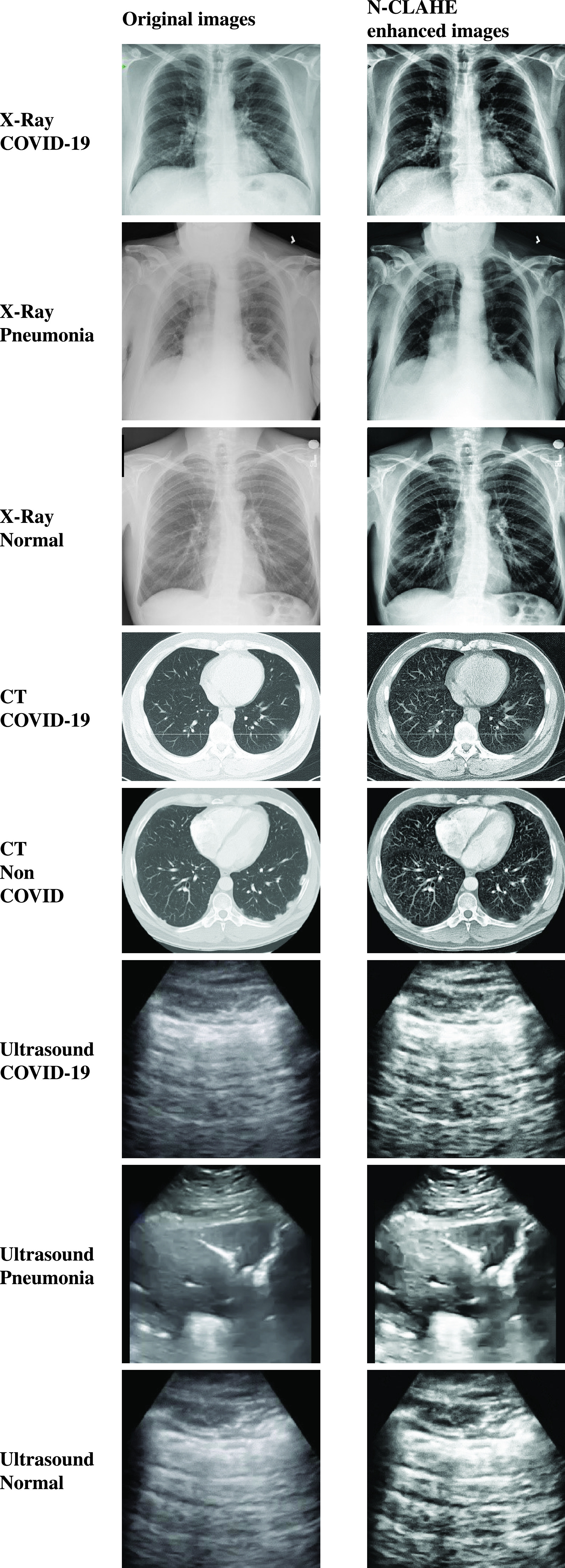
Results of enhancement preprocessing on original samples for COVID-19, Pneumonia and Normal images.
IV. Model Development
A. Classification Pipeline
The experiment pipeline is shown in Fig.
4. Unprocessed images are read with directory names used as class labels.
N-CLAHE is then applied to normalize images and highlight the finer details for
the attention of the machine learning classifiers. Images are then resized to
the classifier default size, for example
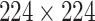 pixels for VGG16/19 and
pixels for VGG16/19 and
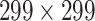 pixels for InceptionV3. Following image resizing, data augmentation is applied
to increase the number and variation of images provided to the classifier.
Augmentations applied include horizontal flip, rotation, width shift, and height
shift. Vertical flip was not applied since X-Ray images are not vertically
symmetrical, and the resulting flipped image would not resemble a real chest
X-Ray. Finally, the augmented images are utilized by the machine learning
classifier using an 80:20 Train/Test split.
pixels for InceptionV3. Following image resizing, data augmentation is applied
to increase the number and variation of images provided to the classifier.
Augmentations applied include horizontal flip, rotation, width shift, and height
shift. Vertical flip was not applied since X-Ray images are not vertically
symmetrical, and the resulting flipped image would not resemble a real chest
X-Ray. Finally, the augmented images are utilized by the machine learning
classifier using an 80:20 Train/Test split.
FIGURE 4.

Experiment pipeline for preprocessing and classification.
B. Model Consideration
One of the key objectives of this study was to achieve reliable classification results using publicly accessible data and “out-of-the-box” models with transfer learning to both compensate for the limited size of the sample data sets, and to accelerate the training process so that this could be reasonably performed on modest hardware.
CNN based models are well utilized for image classification purposes and we want to initially select a suitable CNN based deep learning model for our multimodal image classification study. Our primary aim is not to perform exhaustive performance evaluation among all available models, rather we aim to show the generic applicability of popular model genres for the challenging and limited time critical dataset for COVID-19 chest images in multiple modes including X-Ray, CT and Ultrasound to provide reasonable precision.
Since the ImageNet challenge (ILSVRC) 2012 [73], there has been a flurry of development in deep learning models for image classification and computer vision applications. These developed models can be broadly grouped into several distinct model families such as AlexNet, VGG Nets, Inception Nets, ResNets, MobileNets, DenseNets and NASNets based on their distinct architectures [74], [75]. Over the years, these basic model families produced several versions [74] and they have been extensively used by other researchers to develop modified and hybrid models [76]. Recent studies attempted to improve performance of the base models by proposing new layers and filters such as Sparse Shift Filter [77], Asymmetric Convolution Block [78], Adder Networks [79], Virtual Pooling [80], Discrete Wavelet Transform [81], and HetConv [82], etc. Some recent substantial models have been developed based on the base models, such as Res2Net [83] and Wide ResNet [84] using the ResNet model; while Log Dense Net [85] and Sparse Net [86] using the DenseNet model. Another path of development combining multiple base models has resulted in a number of hybrid models including AOGNet [87], PNASNet [88], AmoebaNet [89], DPN [90], HCGNet [76], GCNet [91], ThiNet [92], and SKNet [93] etc.
In order to find the most suitable model for our study, we focused on widely popular models, suitable for transfer learning, and readily available in packaged form through trusted public libraries such as Keras. Hence, we only considered representatives of the base models in this domain as discussed below. Conveniently, these models are all available as part of the Keras API and each support transfer learning [94] in the form of supporting the pre-application to the model of the ImageNet [95] weights.
1). VGG16 and VGG19
VGG16 and VGG19 [22] are
convolutional neural network (CNN) architectures with very small convolution
filters (
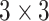 ) and
a stride of 1 designed to achieve high accuracy in large-scale image
recognition applications. The two implementations differ in depth of
convolution/max-pooling and fully connected layers, with VGG16 having 16
layers in the base model and VGG19 having 19 layers.
) and
a stride of 1 designed to achieve high accuracy in large-scale image
recognition applications. The two implementations differ in depth of
convolution/max-pooling and fully connected layers, with VGG16 having 16
layers in the base model and VGG19 having 19 layers.
2). ResNet50 V2
The ResNet [23] CNN was developed as a means of avoiding the vanishing gradient problem inherent in deep neural networks by implementing a system of skip connections between layers – known as residual learning. This architecture results in a network that is more efficient to train, allowing for deeper networks to be designed that positively impact the model accuracy. ResNet50 is such a network with 50 layers of implementing residual learning.
3). Inception V3
The Inception V3 [24] CNN aimed to improve utilization of computing resources inside the network by increasing the depth and width of the network whilst keeping computation operations constant. The designers of this network coined the term “inception modules” to describe an optimized network structure with skipped connections that is used as a building block. This inception module is repeated spatially by stacking with occasional max-pooling layers to reduce dimensionality to a manageable level for computation.
4). Xception
The Xception [25] CNN was developed by Google Inc. as an “extreme” version of the Inception model. The Inception modules described above are replaced with depth wise separable convolutions. This Xception was shown to outperform Inception on a large-scale image classification dataset (comprising 350 million images of 17,000 classes).
5). Inceptionresnet V2
The InceptionResNetV2 CNN [26] combines the Inception and Resnet architecture with the objective of achieving high classification performance using a ResNet architecture with the low computation cost of the Inception architecture.
6). NASNetLarge
The NASNet (Large) CNN [28] has been developed by Google Brain as a data driven dynamic network that uses reinforcement learning to determine an optimal network structure for the image classification task at hand.
7). DenseNet121
The DenseNet 121 CNN [27] uses shorter connections between layers in order to allow more accurate and efficient training on very deep networks.
C. Model Selection
The Models discussed in the earlier section was firstly tuned using Keras-tune to determine an optimum range of learning rate, hidden network size and dropout rate. From this process, optimal hyperparameter ranges were determined to be:
-
•
Learning Rate = 10−3 – 10−5,
-
•
Hidden Layer Size = 8 – 96 neurons,
-
•
Dropout =0.1 – 0.2
Each model was then trained 5 times over 100 epochs with precision, recall, training/testing accuracy and loss metrics captured along with training curves and confusion matrices for further analysis.
The test was repeated for learning rates between 10−3 and 10−5 with order-of-magnitude increments. The hidden layer size was also varied between 8 and 96. The batch size was varied between 2 and 16. Each classifier was trained on the ImageNet [95] weights for transfer learning. Finally, where models converged well, the best training hyperparameters were selected by inspection of training curves. The number of training epochs was then adjusted to prevent overfitting. The training and testing were then repeated with selected epochs and optimized hyperparameters to obtain performance scores.
The testing results as shown in Table 3 that the simpler VGG classifiers were more trainable on all three image modes and provided more consistent results across all three image modes. We also noted that ultrasound provided best classification results across all deep learning models compared to the CT and X-Ray image modes. The more complex models tended to either overfit in early epochs (<10) or failed to converge at all. Where reasonable results were obtained from the more complex models training curves typically showed overfitting and somewhat erratic training behavior in several cases. We also found that the more complex model trainability was highly dependent upon initial model hyperparameter choice, whereas the VGG classifiers produce good results for a wider range of hyperparameter choices.
TABLE 3. Model Performance Summary.
| Model | Image mode | Training Notes | Testing F1 (avg) |
|---|---|---|---|
| VGG16 | X-Ray | Converged well. Overfitting evident at 30 epochs. | 0.79 |
| Ultrasound | Converged well. Overfitting not evident at 100 epochs. | 0.99 | |
| CT | Converged. Overfitting evident from 5 epochs. | 0.79 | |
| VGG19 | X-Ray | Converged well. Overfitting not evident at 100 epochs. | 0.87 |
| Ultrasound | Converged well. Overfitting not evident at 100 epochs. | 0.99 | |
| CT | Converged. Overfitting evident after 20 epochs. | 0.78 | |
| Xception | X-Ray | Converged poorly. Overfitting evident after 10 epochs | 0.76 |
| Ultrasound | Converged. Overfitting evident after 20 epochs. | 0.82 | |
| CT | Did not converge. Overfitting evident immediately | 0.70 | |
| InceptionResNet | X-Ray | Converged poorly. Overfitting evident after 10 epochs. | 0.73 |
| Ultrasound | Converged. Overfitting evident after 5 epochs. | 0.89 | |
| CT | Did not converge. Overfitting evident after 1st epoch. | 0.63 | |
| InceptionV3 | X-Ray | Converged poorly. Overfitting evident after 10 epochs. | 0.75 |
| Ultrasound | Converged. Overfitting evident after 10 epochs. | 0.87 | |
| CT | Did not converge. Overfitting evident after 2 epochs. | 0.71 | |
| NASNetLarge | X-Ray | Did not converge. Overfitting evident after 10 epochs. | 0.64 |
| Ultrasound | Converged. Overfitting evident after 10 epochs. | 0.80 | |
| CT | Did not converge. Overfitting evident immediately. | 0.64 | |
| DenseNet121 | X-Ray | Converged poorly. Overfitting evident after 10 epochs. | 0.74 |
| Ultrasound | Converged poorly. Overfitting evident immediately. | 0.66 | |
| CT | Converged. Overfitting evident after 8 epochs. | 0.75 | |
| ResNet50V2 | X-Ray | Converged. Overfitting evident after 20 epochs. | 0.75 |
| Ultrasound | Converged well. Overfitting evident immediately. | 0.93 | |
| CT | Converged poorly. Overfitting evident immediately. | 0.66 |
Finally, we noticed that the more complex models exhibited a higher training metrics deviation between epochs with randomly selected train/test splits. We believe the smaller data size and high fine-grained variability within the datasets were detected by the sensitive complex models, thus resulting in poorer performances. We expect complex model performance to improve with larger and better-quality data.
Based on our initial testing results, we have chosen the VGG19 model for our multimodal image classification testing in this study. We anticipate that future novel pandemics can also be expected to initially produce small, low quality medical image datasets and suggest that our findings are likely to extend to similar future applications with such challenging datasets.
The three modes of data (X-Ray, CT and Ultrasound) mainly used to understand lung conditions for a covid-19 patient. Through popular deep learning models, we try to understand their individual strength and weakness to detect COVID-19 lung condition for reasonable precision performance. This is vital for a doctor for decision making as each has advantages and disadvantages. Moreover, when there is limited time, resource, and patient condition, the doctor may need to take decision based on one modality. These results would help practitioners in selecting appropriate models for different imaging modes thus providing critical support when time and resources are stretched in a pandemic situation like the current COVID19.
V. Experiments With Selected VGG19 Model
A. Computing Equipment
All the experiments were performed on the University of Technology Sydney Interactive HPC environment under an Anaconda 3 software environment. Experiments were programmed using the Keras APIs with a TensorFlow 2 backend.
The server used was specified as an Intel Xeon Gold 6150 2.7GHz 18 cores (16 cores enabled) with 24.75MB L3 Cache (Max Turbo Freq. 3.7GHz, Min 3.4GHz). The server had 360GB RAM (Six Channel). This server hosted a NVIDIA Quadro P5000 GPU (2,560 Cores, 16GB Memory).
B. Experiment Setup
VGG19 model was tuned for each image mode and each individual experiment to achieve the best possible results for the collated datasets. Learning rates were varied between 10−3 to 10−6 with order-of-magnitude increments. The batch sizes between 2 to 16 were applied. The hidden layer was varied between 4 and 96 nodes. Dropout rates of 0.1 and 0.2 were applied. These hyperparameter ranges generated an output head architecture as shown in Fig. 5.
FIGURE 5.

Head architecture of the proposed models.
C. Experiment Dataset
The master dataset was utilized for training and testing with the VGG19 classifier over 5 experiments as shown in Table 4.
TABLE 4. Datasets Used for Experiments.
| Exp ID | Image Mode | Experiment | Dataset |
|---|---|---|---|
| 1A | X-Ray | Normal vs (COVID-19 and Pneumonia) | (400
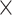 Normal) vs (190 Normal) vs (190
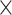 Pneumonia 139 Pneumonia 139
 COVID-19) COVID-19) |
| 1B | Ultrasound | Normal vs (COVID-19 and Pneumonia) | 226
 Normal vs (235 Normal vs (235
 COVID-19 220 COVID-19 220
 Pneumonia) Pneumonia) |
| 2A | X-Ray | COVID-19 vs Pneumonia | 139
 COVID-19 vs 190 COVID-19 vs 190
 Pneumonia Pneumonia |
| 2B | Ultrasound | COVID-19 vs Pneumonia | 235
 COVID-19 vs 220 COVID-19 vs 220
 Pneumonia Pneumonia |
| 3A | CT | COVID-19 vs Non COVID | 349
 COVID-19 vs 397 COVID-19 vs 397
 Non COVID Non COVID |
Processed dataset is available at: https://github.com/mhorry/N-CLAHE-MEDICAL-IMAGES
D. Results and Discussions
With the selected VGG19 model for each experiment listed in Table 4, we first conducted the extensive performance tuning by adjusting multiple parameters including learning rate, batch size, node size and drop rate. The effects of learning rate, batch size and hidden layer size hyperparameter selection on the accuracy metric of experiment 1A is shown in Fig. 6. We noted that dropout rate had only a minimal effect on the model accuracy except at the highest learning rate of 10−3 and lowest learning rate of 10−6 where a dropout rate of 0.2 proved to be more stable than a dropout rate of 0.1. For learning rates for 10−3 and 10−4 the dropout rate selection has no discernable effect on model accuracy.
FIGURE 6.
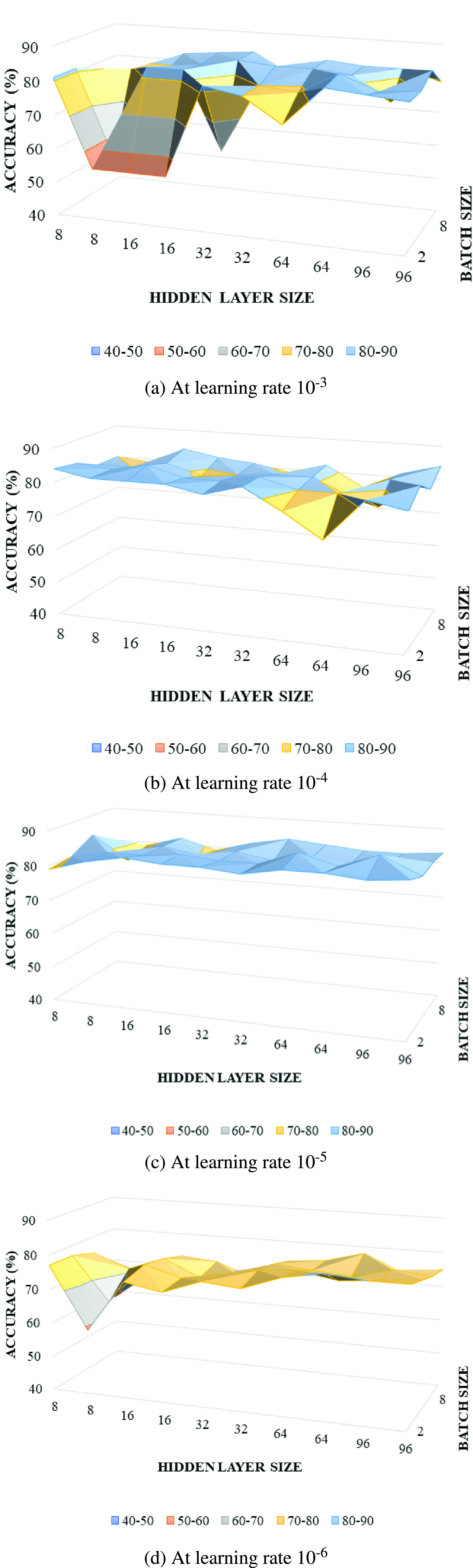
Model sensitivity to hyperparameters for experiment 1A.
Learning rate, batch size and hidden layer size all affected model accuracy. The first observation is that learning rates of 10−4 and 10−5 provided higher model accuracy with 10−5 achieving more consistent results. There is a tendency for accuracy to improve with batch size increase at learning rates of 10−3 and 10−6 but at learning rates of 10−4 and 10−5 this tendency is not apparent. Finally, there is also a trend towards higher accuracy with a larger hidden layer size that is most noticeable at 10−3. Taking a learning rate of 10−5 as achieving consistent high accuracy, we can then suggest from this analysis that a hidden layer size ranging from 64 to 96 and batch size of 4 could generally be expected to provide the most accurate results for this experiment. Through similar analysis for each experiment in Table 4, we have identified the best parameter settings for each experiment as shown in Table 5.
TABLE 5. Experiment Results for Three Image Modes.
| Image mode | Experiment | Parameters | Classification | Results |
|---|---|---|---|---|
| X-Ray | 1A | LR:
10−5 DR: 0.1 BS: 4 HS: 64 Epochs: 100 |
COVID-19 + Pneumonia | P: 0.85 R: 0.83 F1: 0.84 |
| Normal | P: 0.86 R: 0.88 F1: 0.87 |
|||
| Ultrasound | 2A | LR:
10−5 DR: 0.2 BS: 2 HS: 64 Epochs: 100 |
COVID-19 + Pneumonia | P: 0.99 R: 0.97 F1: 0.98 |
| Normal | P: 0.94 R: 0.98 F1: 0.96 |
|||
| X-Ray | 1B | LR:
10−3 DR: 0.2 BS: 8 HS: 8 Epochs: 100 |
COVID-19 | P: 0.86 R: 0.86 F1: 0.86 |
| Pneumonia | P: 0.89 R: 0.89 F1: 0.89 |
|||
| Ultrasound | 2B | LR:
10−5 DR: 0.2 BS: 2 HS: 64 Epochs: 100 |
COVID-19 | P: 1.00 R: 1.00 F1: 1.00 |
| Pneumonia | P: 1.00 R: 1.00 F1: 1,00 |
|||
| CT | 3A | LR:
10−3 DR: 0.2 BS: 4 HS: 16 Epochs: 70 |
COVID-19 | P: 0.79 R: 0.83 F1: 0.81 |
| Non COVID | P: 0.84 R: 0.81 F1: 0.83 |
The results of the five experiments are listed in Table 5. For experiments classifying COVID-19 and Pneumonia vs Normal (1A and 2A) we found that the Ultrasound mode provided the best results with a sensitivity of 97% and positive predictive value of 99% compared to X-Ray with 83% and 85% respectively. For experiments classifying COVID-19 vs Pneumonia (1B and 2B) we again found that the Ultrasound mode provided the best results with a sensitivity of 100% and a positive predictive value of 100% compared to X-Ray with sensitivity of 86% and positive predictive value of 86%. The CT imaging mode was found to have a sensitivity of 83% and positive predictive value of 79% in classifying COVID-19 vs non COVID-19 scans. All experiments resulted in F1 scores exceeding 80% which is a good result given the relatively small and variable quality data corpus available.
The learning curves for each experiment are shown in Fig. 7. The training curves for both Ultrasound experiments (2A and 2B) are close to ideal. The training curves for the X-Ray experiments (1A and 2A) are also very good, although the curve for experiment 1B does show some signs of erratic learning patterns, which is the expected result of the highly variable image quality in the COVID-19 data set. The learning curve for the CT mode experiment (3A) is very erratic – even though the model did train, overfitting is arguably apparent after the epoch 50. Once again this is the expected result considering significant variation in the CT image data sets.
FIGURE 7.

Learning curves for different modes.
The confusion matrices in Fig. 8 provides an indication of the false-negative and false-positive results of our experiments. Minimization of false negative predictions is important in the medical context since false reassurance may lead to diagnostic and treatment delay resulting in poor medical outcomes, patient mental distress, community loss in confidence relating to medical services and legal consequences [96]. False negative predictions for the Ultrasound mode experiments were very low at 1 and 0 for experiments 2A and 2B, respectively. False negative predictions for the X-Ray mode experiments were higher with 11 and 4 for experiments 1A and 1B respectively. The CT mode (experiment 3A) also performed poorly in this respect with 12 false negatives. Once again, the limited sample size and variable quality of the COVID-19 data sets used for the X-Ray and CT experiments are the most likely cause of the relatively high number of false negatives for experiments 1A, 1B and 3A.
FIGURE 8.

Confusion matrix for different modes.
As previously noted, false negatives generated by the Keras class prediction threshold of 0.5 were high in the case of the CT and X-Ray imaging modes. We then performed adjustments in the class prediction threshold in 5% increments from 0.5 to 0.75. We successfully reduced false negatives, at the cost of increasing false positives. For experiment 1A we reduced false negatives from 11 to 8 using a threshold of 0.65. This raised the sensitivity of this test from 83% to 85% with a loss in positive predictive value from 85% to 73%. For experiment 1B we reduced false negatives from 4 to 2 using a threshold of 0.75. This raised the sensitivity of this test from 86% to 93% whilst reducing positive predictive value from 86% to 79%. For experiment 3A we reduced false negatives from 12 to 7 using a threshold of 0.7. This raised the sensitivity of this test from 83% to 90% with a reduction in positive predictive value from 79% to 78%. The confusion matrices associated with these results are shown in Fig. 9.
FIGURE 9.

Reduction of false negatives using thresholding.
Overall, the results show that deep learning models were performing extremely well with the ultrasound image mode. The X-Ray and CT modes are challenging with the available COVID-19 datasets.
VI. Conclusion
We have demonstrated that with current limited and challenging COVID-19 datasets, VGG19 model could be used to develop suitable deep learning-based tools for COVID-19 detection. The model is capable of classifying both Pneumonia vs Normal and COVID-19 vs Pneumonia conditions for multiple imaging modes including X-Ray, Ultrasound, and CT scan.
With very little data curation, we achieved considerable classification results using VGG19 from all imaging modes. Perhaps the most interesting observation is that the pre-trained models tuned very effectively for the Ultrasound image samples, which to the untrained eye appeared noisy and difficult to interpret. Both training curves and confusion matrix for both Ultrasound experiments are close to ideal. VGG19 also trained well against the X-Ray image corpus however, without modified thresholding we found that the proportion of false negatives was concerning but not unexpected given data quality challenges. Our finding that experiment 1A/2A yielded lower F1 scores and higher false negatives than experiments 1B/2B was unexpected since the manifestation of COVID-19 is itself a form of viral pneumonia. This may indicate that despite our attempts to remove sampling bias using N-CLAHE pre-processing there may still be systematic differences in the COVID-19 image data sets that leads the VGG19 classifier to more easily distinguish the COVID-19 images from the pneumonia images. A future research direction could be to isolate the lung field by segmentation for all image samples in order to remove noise and further reduce sampling bias. Our lower results against the CT image corpus were not surprising since the CT image slices available were not from a uniform patient location and displayed extremely high variability in both form and content.
Our study uncovers the challenging characteristics of the limited COVID-19 image datasets. This should be helpful for practitioners aiming to use these datasets for their research and development. We provided a pre-processing pipeline aimed to remove the sampling bias and improve image quality. Our preprocessed images are also made openly available for others to use. During our initial model selection experiment, we also found that both VGG16 and VGG19 classifiers provided good results within the experimental constraints of the small number of currently available COVID-19 medical images. While deeper networks generally struggled, they will perform better when larger datasets are available which will reduce the impact of data quality variation.
It is inevitable that the initial publicly available medical images for novel medical conditions such as COVID-19 will be low in number and poor in quality. In this situation we conclude that the VGG19 classifier with transfer learning provides a fast and simple to implement machine learning model for multiple imaging modes providing good results that may lead to clinically useful diagnostic tools.
Despite our promising results, we would urge great caution in the development of clinical diagnostic models using currently available COVID-19 image dataset. The effect of a false positive diagnosis of COVID-19 on an individual is the isolation of the individual and their contract traces and the mental anguish and stress caused by both the prognosis and the social isolation. A false positive COVID-19 diagnosis could result in an inappropriate course of treatment. The effects of a false negative COVID-19 diagnosis would also be devastating for the individual if that diagnosis led to an inappropriate lack of treatment, and also for the community since cautions against COVID-19 transmission may not be appropriately applied resulting in the further community spread of the disease.
As a higher quality corpus of COVID-19 diagnostic image data becomes available, it may be possible to produce clinically trusted deep learning-based models for the fast diagnosis of COVID-19 as distinguished from similar conditions such as pneumonia. Such a tool would prove invaluable in practice, where other diagnostic tests for COVID-19 are either unavailable or unreliable. As the COVID-19 spread progresses throughout remote and economically challenged locations, an ability to diagnose COVID-19 from a readily available and portable medical imaging equipment such as X-Ray and Ultrasound machines would help slow the spread of the disease and result in a better medical outcome for the population.
Data fusion concept allows us to combine multiple modes of data to improve model classification performance. Although data fusion comes with its own set of challenges [97], [98], it has been used successfully in other application areas such as remote sensing [99]–[101], action detection [102], and medical diagnosis and imaging [103], [104]. We plan to extend our study with multimodal data fusion when sufficient data is available.
Acknowledgment
Michael J. Horry would like to thank IBM Australia for providing work time release to perform modelling and experimentation work and to contribute to the writing of this article.
Biographies

Michael J. Horry (Graduate Student Member, IEEE) received the Engineering and Laws degrees from the University of NSW, in 1998. Since that time, he has held various industry roles. He is currently an Executive Architect with IBM responsible for solution design across the partner and SI community. He is an Open Group Master Certified IT Architect and TOGAF 9 certified and a member of the Enterprise Architects Association of Australia. He has developed an interest in machine learning and particularly computer vision applications. He commenced his Ph.D. with UTS in 2020 to research automated diagnosis of pulmonary pathologies using machine learning.

Subrata Chakraborty (Senior Member, IEEE) received the Ph.D. degree in decision support systems from Monash University, Australia. He is currently a Senior Lecturer with the School of Information, Systems, and Modeling, Faculty of Engineering and IT, University of Technology Sydney (UTS), Australia. He is also a Core Member of the Centre for Advanced Modelling and Geospatial Information Systems (CAMGIS), UTS. Previously, he worked as an academic with the University of Southern Queensland, Charles Sturt University, Queensland University of Technology, and Monash University. His current research interests include optimisation models, data analytics, machine learning, and image processing with decision support applications in diverse domains including business, agriculture, transport, health, and education. He is a Certified Professional Senior Member of ACS.

Manoranjan Paul (Senior Member, IEEE) received the Ph.D. degree from Monash University, Australia, in 2005. He was a Postdoctoral Research Fellow with the University of New South Wales, Monash University, and Nanyang Technological University. He is currently a Full Professor, the Director of Computer Vision Laboratory, and the Leader of Machine Vision and Digital Health (MaViDH) Research Group, Charles Sturt University, Australia. He has published around 200 peer reviewed publications including 72 journals. His major research interests include video coding, image processing, digital health, wine technology, machine learning, EEG signal processing, eye tracking, and computer vision. He was an invited keynote speaker in IEEE DICTA-17 & 13, CWCN-17, WoWMoM-14, and ICCIT-10. He received more than $3.6 million competitive external grant including Australian Research Council (ARC) Discovery grants, Australia-China grant. He has supervised 15 Ph.D. students to completion. He is an Associate Editor of three top ranked journals including the IEEE Transactions on Multimedia, the IEEE Transactions on Circuits and Systems for Video Technology, and the EURASIP Journal in Advances on Signal Processing. He was a General Chair of PSIVT-19 and a Program Chair of PSIVT-17 and DICTA-18. He was awarded the ICT Researcher of the Year 2017 by Australian Computer Society.

Anwaar Ulhaq (Member, IEEE) received the Ph.D. degree in artificial intelligence from Monash University, Australia. He is serving as a Lecturer with the School of Computing and Mathematics, Charles Sturt University. He has worked a Research Fellow with the Institute for Sustainable Industries and Livable Cities, Victoria University, Australia. His research interests include signal and image processing, deep learning, data analytics, and computer vision.

Biswajeet Pradhan (Senior Member, IEEE) received the B.Sc. degree (Hons.) from Berhampur University, India, the M.Sc. degree from IIT Bombay, Bombay, India, the M.Tech. degree in civil engineering from IIT Kanpur, Kanpur, India, and the Dresden University of Technology, Dresden, Germany, and the Ph.D. degree in GIS and geomatics engineering from the University Putra Malaysia, Serdang, Malaysia. He is currently a Distinguished Professor with the School of Information, Systems, and Modelling and the Director of Centre for Advanced Modelling and Geospatial lnformation Systems, University of Technology Sydney. Before joining the School of Information, Systems and Modelling, Faculty of Engineering and IT, he was a Full Professor of GIS and remote sensing with the Faculty of Engineering, Universiti Putra Malaysia. He has more than 19 years of teaching, research, and industrial experience in the field of Geospatial Information Systems. He is listed as the World’s most Highly Cited researcher by Clarivate Analytic’s Report, in 2017 and 2016, as one of the world’s most influential mind. He was a recipient of Alexander von Humboldt Research Fellowship from Germany. In 2011, he received his habituation in remote sensing from the Dresden University of Technology, Germany. He was also a recipient of German Academic Exchange Research (DAAD) Fellowship Award, the Saxony State Fellowship, from 1999 to 2002, the Keith Aurtherton Research Award, and the Georg Forster Research Award from the German Government. Since February 2015, he has been serving as the Ambassador Scientist for Alexander Humboldt Foundation, Germany. He has widely travelled abroad visiting more than 55 countries to present his research findings.

Manas Saha received the M.B.B.S. degree from the Dhaka Medical College, Dhaka University, in 1996, the F.C.P.S. degree in general medicine from the Bangladesh College of Physicians, the M.D. degree in nephrology from Bangabandhu Sheik Mujib Medical University, and the Ph.D. degree from Macquarie University. He is currently a Clinician Scientist, trained as a General and Renal Physician in Bangladesh and Australia. During his tenure of Ph.D., he identified a new underlying mechanism of hypertension and cardiovascular events in patients with CKD. He is currently working as a Staff Specialist with the Department of Medicine, Hunter New England Local Health District (HNELHD), NSW, and involving in different research groups including Machine Vision and Digital Health (MaViDH) Group, Charles Sturt University, Australia. He has been awarded Deputy Vice-Chancellor (Research) Commendation and International Society of Nephrology (ISN) Scholar. He has published many original articles in peer reviewed journals. His main research interests include cardiovascular diseases in CKD, community-based modeling for prevention of chronic disease including DM, HTN, CKD, and weight disorders, and use of artificial intelligence in risk assessment of different diseases including cardiovascular and respiratory diseases. He is a Fellow of the Royal Australasian College of Physicians.

Nagesh Shukla is currently a Senior Lecturer in business analytics with the University of Technology Sydney, Ultimo, SW, Australia. He is working in the area of business data analytics, simulation modeling and optimization (applied to healthcare and supply chain/logistics management). He has contributed to more than 50 research publications in journals, conferences, patents, book chapters, and research reports. He is also a member of the editorial boards in a number of leading journals. His research interests include the development of models that deal with making complex business processes efficient and effective, analytical models for system-level optimization and decision making, and data-driven algorithms for decision making.
References
- [1].(2020). Who COVID-19 Situation Reports. [Online]. Available: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports
- [2].Ravishankar H., Sudhakar P., Venkataramani R., Thiruvenkadam S., Annangi P., Babu N., and Vaidya V., “Understanding the mechanisms of deep transfer learning for medical images,” in Deep Learning and Data Labeling for Medical Applications (Lecture Notes in Computer Science), vol. 10008, Carneiro G., Ed. Cham, Switzerland: Springer, 2016, pp. 188–196, doi: 10.1007/978-3-319-46976-820. [DOI] [Google Scholar]
- [3].Yu Y., Lin H., Meng J., Wei X., Guo H., and Zhao Z., “Deep transfer learning for modality classification of medical images,” Information, vol. 8, no. , p. 91, Jul. 2017, doi: 10.3390/info8030091. [DOI] [Google Scholar]
- [4].Wang W., Xu Y., Gao R., Lu R., Han K., Wu G., and Tan W., “Detection of SARS-CoV-2 in different types of clinical specimens,” JAMA, vol. 323, pp. 1843–1844, Mar. 2020, doi: 10.1001/jama.2020.3786. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Chen C., Gao G., Xu Y., Pu L., Wang Q., Wang L., Wang W., Song Y., Chen M., Wang L., Yu F., Yang S., Tang Y., Zhao L., Wang H., Wang Y., Zeng H., and Zhang F., “SARS-CoV-2–positive sputum and feces after conversion of pharyngeal samples in patients with COVID-19,” Ann. Internal Med., vol. 172, no. 12, pp. 832–834, Jun. 2020, doi: 10.7326/M20-0991. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Ai T., Yang Z., Hou H., Zhan C., Chen C., Lv W., Tao Q., Sun Z., and Xia L., “Correlation of chest CT and RT-PCR testing for coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases,” Radiology, vol. 296, no. 2, pp. E32–E40, Aug. 2020, doi: 10.1148/radiol.2020200642. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Hosseiny M., Kooraki S., Gholamrezanezhad A., Reddy S., and Myers L., “Radiology perspective of coronavirus disease 2019 (COVID-19): Lessons from severe acute respiratory syndrome and middle east respiratory syndrome,” Amer. J. Roentgenology, vol. 214, no. 5, pp. 1078–1082, May 2020, doi: 10.2214/AJR.20.22969. [DOI] [PubMed] [Google Scholar]
- [8].Ulhaq A., Khan A., Gomes D., and Paul M., “Computer vision for COVID-19 control: A survey,” 2020, arXiv:2004.09420. [Online]. Available: http://arxiv.org/abs/2004.09420 [DOI] [PMC free article] [PubMed]
- [9].Born J., Brändle G., Cossio M., Disdier M., Goulet J., Roulin J., and Wiedemann N., “POCOVID-net: Automatic detection of COVID-19 from a new lung ultrasound imaging dataset (POCUS),” 2020, arXiv:2004.12084. [Online]. Available: http://arxiv.org/abs/2004.12084
- [10].Bell D. J.. (2020). COVID-19 Radiopaedia. [Online]. Available: https://radiopaedia.org/articles/covid-19-4?lang=us
- [11].Chen J., Wu L., Zhang J., Zhang L., Gong D., Zhao Y., Hu S., Wang Y., Hu X., Zheng B., Zhang K., Wu H., Dong Z., Xu Y., Zhu Y., Chen X., Yu L., and Yu H.. (2020). Deep Learning-Based Model for Detecting 2019 Novel Coronavirus Pneumonia on High-Resolution Computed Tomography: A Prospective Study. [Online]. Available: https://medRxiv:2020.02.25.20021568 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Wang S., Kang B., Ma J., Zeng X., Xiao M., Guo J., Cai M., Yang J., Li Y., Meng X., and Xu B.. (2020). A Deep Learning Algorithm Using CT Images to Screen for Corona Virus Disease (COVID-19). [Online]. Available: https://medRxiv:2020.02.14.20023028 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Livingston E., Desai A., and Berkwits M., “Sourcing personal protective equipment during the COVID-19 pandemic,” JAMA, vol. 323, no. 19, pp. 1912–1914, 2020, doi: 10.1001/jama.2020.5317. [DOI] [PubMed] [Google Scholar]
- [14].Kroft L. J. M., van der Velden L., Girón I. H., Roelofs J. J. H., de Roos A., and Geleijns J., “Added value of ultra–low-dose computed tomography, dose equivalent to chest X-ray radiography, for diagnosing chest pathology,” J. Thoracic Imag., vol. 34, no. 3, pp. 179–186, May 2019, doi: 10.1097/RTI.0000000000000404. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Wong H. Y. F., Lam H. Y. S., Fong A. H.-T., Leung S. T., Chin T. W.-Y., Lo C. S. Y., Lui M. M.-S., Lee J. C. Y., Chiu K. W.-H., Chung T. W.-H., Lee E. Y. P., Wan E. Y. F., Hung I. F. N., Lam T. P. W., Kuo M. D., and Ng M.-Y., “Frequency and distribution of chest radiographic findings in patients positive for COVID-19,” Radiology, vol. 296, no. 2, pp. E72–E78, Aug. 2020, doi: 10.1148/radiol.2020201160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Cohen J. P., Morrison P., Dao L., Roth K., Duong T. Q., and Ghassemi M., “COVID-19 image data collection: Prospective predictions are the future,” 2020, arXiv:2006.11988. [Online]. Available: http://arxiv.org/abs/2006.11988
- [17].Buonsenso D., Pata D., and Chiaretti A., “COVID-19 outbreak: Less stethoscope, more ultrasound,” Lancet Respiratory Med., vol. 8, no. 5, 2020, Art no. E27 doi: 10.1016/S2213-2600(20)30120-X. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Smith M. J., Hayward S. A., Innes S. M., and Miller A. S. C., “Point-of-care lung ultrasound in patients with COVID-19—A narrative review,” Anaesthesia, vol. 75, no. 8, pp. 1096–1104, Aug. 2020, doi: 10.1111/anae.15082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].(2020). ACR Recommendations. [Online]. Available: https://www.acr.org/Advocacy-and-Economics/ACR-Position-Statements/Recommendations-for-Chest-Radiography-and-CT-for-Suspected-COVID19-Infection
- [20].Yamashita R., Nishio M., Do R. K. G., and Togashi K., “Convolutional neural networks: An overview and application in radiology,” Insights into Imag., vol. 9, no. 4, pp. 611–629, Aug. 2018, doi: 10.1007/s13244-018-0639-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Mazurowski M. A., Buda M., Saha A., and Bashir M. R., “Deep learning in radiology: An overview of the concepts and a survey of the state of the art with focus on MRI,” J. Magn. Reson. Imag., vol. 49, no. 4, pp. 939–954, Apr. 2019, doi: 10.1002/jmri.26534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Simonyan K. and Zisserman A., “Very deep convolutional networks for large-scale image recognition,” 2014, arXiv:1409.1556. [Online]. Available: http://arxiv.org/abs/1409.1556
- [23].He K., Zhang X., Ren S., and Sun J., “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV, USA, Jun. 2016, pp. 770–778, doi: 10.1109/CVPR.2016.90. [DOI] [Google Scholar]
- [24].Szegedy C., Vanhoucke V., Ioffe S., Shlens J., and Wojna Z., “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV, USA, Jun. 2016, pp. 2818–2826, doi: 10.1109/CVPR.2016.308. [DOI] [Google Scholar]
- [25].Chollet F., “Xception: Deep learning with depthwise separable convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, Jul. 2017, pp. 1800–1807, doi: 10.1109/CVPR.2017.195. [DOI] [Google Scholar]
- [26].Szegedy C., Ioffe S., Vanhoucke V., and Alemi A., “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Proc. AAAI Conf. Artif. Intell., San Francisco, CA, USA: AAAI Press, 2017, pp. 4278–4284, doi: 10.5555/3298023.3298188. [DOI] [Google Scholar]
- [27].Huang G., Liu Z., Van Der Maaten L., and Weinberger K. Q., “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, Jul. 2017, pp. 2261–2269, doi: 10.1109/CVPR.2017.243. [DOI] [Google Scholar]
- [28].Zoph B., Vasudevan V., Shlens J., and Le Q. V., “Learning transferable architectures for scalable image recognition,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, Jun. 2018, pp. 8697–8710, doi: 10.1109/CVPR.2018.00907. [DOI] [Google Scholar]
- [29].Pisani P., Renna M. D., Conversano F., Casciaro E., Muratore M., Quarta E., Paola M. D., and Casciaro S., “Screening and early diagnosis of osteoporosis through X-ray and ultrasound based techniques,” World J. Radiol., vol. 5, no. 11, pp. 398–410, 2013, doi: 10.4329/wjr.v5.i11.398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Al-antari M. A., Al-masni M. A., Choi M.-T., Han S.-M., and Kim T.-S., “A fully integrated computer-aided diagnosis system for digital X-ray mammograms via deep learning detection, segmentation, and classification,” Int. J. Med. Informat., vol. 117, pp. 44–54, Sep. 2018, doi: 10.1016/j.ijmedinf.2018.06.003. [DOI] [PubMed] [Google Scholar]
- [31].Speidel M. A., Wilfley B. P., Star-Lack J. M., Heanue J. A., and Van Lysel M. S., “Scanning-beam digital X-ray (SBDX) technology for interventional and diagnostic cardiac angiography,” Med. Phys., vol. 33, no. 8, pp. 2714–2727, Jul. 2006, doi: 10.1118/1.2208736. [DOI] [PubMed] [Google Scholar]
- [32].Mamourian A. C., CT Imaging: Practical Physics, Artifacts, and Pitfalls. New York, NY, USA: Oxford Univ. Press, 2013. [Google Scholar]
- [33].Verschakelen J. A. and de Wever W., Computed Tomography of the Lung: A Pattern Approach (Medical Radiology), 2nd ed. Berlin, Germany: Springer-Verlag, 2018. [Google Scholar]
- [34].Sajja T., Devarapalli R., and Kalluri H., “Lung cancer detection based on CT scan images by using deep transfer learning,” Traitement du Signal, vol. 36, no. 4, pp. 339–344, Oct. 2019, doi: 10.18280/ts.360406. [DOI] [Google Scholar]
- [35].Shen W., Zhou M., Yang F., Yang C., and Tian J., “Multi-scale convolutional neural networks for lung nodule classification,” in Information Processing in Medical Imaging (Lecture Notes in Computer Science), vol. 9123, Ourselin S., Alexander D., Westin C., and Cardoso M., Eds. Cham, Switzerland: Springer, 2015, pp. 588–599, doi: 10.1007/978-3-319-19992-4_46. [DOI] [PubMed] [Google Scholar]
- [36].Sun W., Zheng B., and Qian W., “Automatic feature learning using multichannel ROI based on deep structured algorithms for computerized lung cancer diagnosis,” Comput. Biol. Med., vol. 89, pp. 530–539, Oct. 2017, doi: 10.1016/j.compbiomed.2017.04.006. [DOI] [PubMed] [Google Scholar]
- [37].Masood A., Yang P., Sheng B., Li H., Li P., Qin J., Lanfranchi V., Kim J., and Feng D. D., “Cloud-based automated clinical decision support system for detection and diagnosis of lung cancer in chest CT,” IEEE J. Transl. Eng. Health Med., vol. 8, Dec. 2020, Art. no.4300113, doi: 10.1109/JTEHM.2019.2955458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Ardila D., Kiraly A. P., Bharadwaj S., Choi B., Reicher J. J., Peng L., Tse D., Etemadi M., Ye W., Corrado G., Naidich D. P., and Shetty S., “End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography,” Nature Med., vol. 25, no. 6, pp. 954–961, Jun. 2019, doi: 10.1038/s41591-019-0447-x. [DOI] [PubMed] [Google Scholar]
- [39].Garin N., Marti C., Carballo S., Farhoumand P. D., Montet X., Roux X., Scheffler M., Serratrice C., Serratrice J., Claessens Y.-E., Duval X., Loubet P., Stirnemann J., and Prendki V., “Rational use of CT-scan for the diagnosis of pneumonia: Comparative accuracy of different strategies,” J. Clin. Med., vol. 8, no. 4, p. 514, Apr. 2019, doi: 10.3390/jcm8040514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Self W. H., Courtney D. M., McNaughton C. D., Wunderink R. G., and Kline J. A., “High discordance of chest X-ray and computed tomography for detection of pulmonary opacities in ED patients: Implications for diagnosing pneumonia,” Amer. J. Emergency Med., vol. 31, no. 2, pp. 401–405, Feb. 2013, doi: 10.1016/j.ajem.2012.08.041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Sanches J. M., Laine A., and Suri J. S., Ultrasound Imaging: Advances and Applications. New York, NY, USA: Springer, 2012. [Google Scholar]
- [42].Wu J. Y., Tuomi A., Beland M. D., Konrad J., Glidden D., Grand D., and Merck D., “Quantitative analysis of ultrasound images for computer-aided diagnosis,” J. Med. Imag., vol. 3, no. 1, Jan. 2016, Art. no.014501, doi: 10.1117/1.jmi.3.1.014501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Zhu M., Xu C., Yu J., Wu Y., Li C., Zhang M., Jin Z., and Li Z., “Differentiation of pancreatic cancer and chronic pancreatitis using computer-aided diagnosis of endoscopic ultrasound (EUS) images: A diagnostic test,” PLoS ONE, vol. 8, no. 5, May 2013, Art. no. e63820, doi: 10.1371/journal.pone.0063820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Wang Y., Wang H., Guo Y., Ning C., Liu B., Cheng H. D., and Tian J., “Novel computer-aided diagnosis algorithms on ultrasound image: Effects on solid breast masses discrimination,” J. Digit. Imag., vol. 23, no. 5, pp. 581–591, Oct. 2010, doi: 10.1007/s10278-009-9245-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Hassanien A. E., Al-Qaheri H., Snasel V., and Peters J. F., “Machine learning techniques for prostate ultrasound image diagnosis,” in Advances in Machine Learning I (Studies in Computational Intelligence), vol. 262, Koronacki J., Ras Z. W., Wierzchon S. T., and Kacprzyk J., Eds. Berlin, Germany: Springer, 2010, pp. 385–403, doi: 10.1007/978-3-642-05177-719. [DOI] [Google Scholar]
- [46].Xirouchaki N., Magkanas E., Vaporidi K., Kondili E., Plataki M., Patrianakos A., Akoumianaki E., and Georgopoulos D., “Lung ultrasound in critically ill patients: Comparison with bedside chest radiography,” Intensive Care Med., vol. 37, no. 9, pp. 1488–1493, Sep. 2011, doi: 10.1007/s00134-011-2317-y. [DOI] [PubMed] [Google Scholar]
- [47].Bataille B., Riu B., Ferre F., Moussot P. E., Mari A., Brunel E., Ruiz J., Mora M., Fourcade O., Genestal M., and Silva S., “Integrated use of bedside lung ultrasound and echocardiography in acute respiratory failure,” Chest, vol. 146, no. 6, pp. 1586–1593, Dec. 2014. [DOI] [PubMed] [Google Scholar]
- [48].Kanwal N., Girdhar A., and Gupta S., “Region based adaptive contrast enhancement of medical X-ray images,” in Proc. 5th Int. Conf. Bioinf. Biomed. Eng., May 2011, pp. 1–5, doi: 10.1109/icbbe.2011.5780221. [DOI] [Google Scholar]
- [49].Arbabshirani M. R., Dallal A. H., Agarwal C., Patel A., and Moore G., “Accurate segmentation of lung fields on chest radiographs using deep convolutional networks,” Proc. SPIE, vol. 10133, Feb. 2017, Art. no.1013305, doi: 10.1117/12.2254526. [DOI] [Google Scholar]
- [50].Zohair A.-A., Shamil A.-A., and Ghazali S., “Latest methods of image enhancement and restoration for computed tomography: A concise review,” Appl. Med. Inform., vol. 36, no. 1, pp. 1–12, 2015. [Google Scholar]
- [51].Al-Ameen Z., Sulong G., Rehman A., Al-Dhelaan A., Saba T., and Al-Rodhaan M., “An innovative technique for contrast enhancement of computed tomography images using normalized gamma-corrected contrast-limited adaptive histogram equalization,” EURASIP J. Adv. Signal Process., vol. 2015, no. 1, pp. 1–12, Dec. 2015, doi: 10.1186/s13634-015-0214-1. [DOI] [Google Scholar]
- [52].Contreras Ortiz S. H., Chiu T., and Fox M. D., “Ultrasound image enhancement: A review,” Biomed. Signal Process. Control, vol. 7, no. 5, pp. 419–428, Sep. 2012, doi: 10.1016/j.bspc.2012.02.002. [DOI] [Google Scholar]
- [53].Singh P., Mukundan R., and De Ryke R., “Feature enhancement in medical ultrasound videos using contrast-limited adaptive histogram equalization,” J. Digit. Imag., vol. 33, no. 1, pp. 273–285, Feb. 2020, doi: 10.1007/s10278-019-00211-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [54].Zhang J., Xie Y., Liao Z., Pang G., Verjans J., Li W., Sun Z., He J., Li Y., Shen C., and Xia Y., “COVID-19 screening on chest X-ray images using deep learning based anomaly detection,” 2020, arXiv:2003.12338. [Online]. Available: http://arxiv.org/abs/2003.12338
- [55].El-Din Hemdan E., Shouman M. A., and Esmail Karar M., “COVIDX-net: A framework of deep learning classifiers to diagnose COVID-19 in X-ray images,” 2020, arXiv:2003.11055. [Online]. Available: http://arxiv.org/abs/2003.11055
- [56].Chowdhury M. E. H., Rahman T., Khandakar A., Mazhar R., Abdul Kadir M., Bin Mahbub Z., Reajul Islam K., Salman Khan M., Iqbal A., Al-Emadi N., Reaz M. B. I., and Islam T. I., “Can AI help in screening viral and COVID-19 pneumonia?” 2020, arXiv:2003.13145. [Online]. Available: http://arxiv.org/abs/2003.13145
- [57].Wang L. and Wong A., “COVID-net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images,” 2020, arXiv:2003.09871. [Online]. Available: http://arxiv.org/abs/2003.09871 [DOI] [PMC free article] [PubMed]
- [58].(2020). RSNA Challenge. [Online]. Available: https://www.kaggle.com/c/rsna-pneumonia-detection-challenge
- [59].Polsinelli M., Cinque L., and Placidi G., “A light CNN for detecting COVID-19 from CT scans of the chest,” 2020, arXiv:2004.12837. [Online]. Available: http://arxiv.org/abs/2004.12837 [DOI] [PMC free article] [PubMed]
- [60].Singh D., Kumar V., Vaishali K., and Kaur M., “Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks,” Eur. J. Clin. Microbiology Infectious Diseases, vol. 39, no. 7, pp. 1379–1389, Jul. 2020, doi: 10.1007/s10096-020-03901-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [61].Ouyang X., Huo J., Xia L., Shan F., Liu J., Mo Z., Yan F., Ding Z., Yang Q., Song B., Shi F., Yuan H., Wei Y., Cao X., Gao Y., Wu D., Wang Q., and Shen D., “Dual-sampling attention network for diagnosis of COVID-19 from community acquired pneumonia,” IEEE Trans. Med. Imag., vol. 39, no. 8, pp. 2595–2605, Aug. 2020, doi: 10.1109/TMI.2020.2995508. [DOI] [PubMed] [Google Scholar]
- [62].Maghdid H. S., Asaad A. T., Ghafoor K. Z., Sadiq A. S., and Khan M. K., “Diagnosing COVID-19 pneumonia from X-ray and CT images using deep learning and transfer learning algorithms,” 2020, arXiv:2004.00038. [Online]. Available: http://arxiv.org/abs/2004.00038
- [63].Zheng C., Deng X., Fu Q., Zhou Q., Feng J., Ma H., Liu W., and Wang X.. (2020). Deep Learning-Based Detection for COVID-19 From Chest CT Using Weak Label. [Online]. Available: http://medRxiv:2020.03.12.20027185 [Google Scholar]
- [64].Gozes O., Frid-Adar M., Greenspan H., Browning P. D., Zhang H., Ji W., Bernheim A., and Siegel E., “Rapid AI development cycle for the coronavirus (COVID-19) pandemic: Initial results for automated detection & patient monitoring using deep learning CT image analysis,” 2020, arXiv:2003.05037. [Online]. Available: http://arxiv.org/abs/2003.05037
- [65].Li L., Qin L., Xu Z., Yin Y., Wang X., Kong B., Bai J., Lu Y., Fang Z., Song Q., Cao K., Liu D., Wang G., Xu Q., Fang X., Zhang S., Xia J., and Xia J., “Using artificial intelligence to detect COVID-19 and community-acquired pneumonia based on pulmonary CT: Evaluation of the diagnostic accuracy,” Radiology, vol. 296, no. 2, pp. E65–E71, Aug. 2020, doi: 10.1148/radiol.2020200905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Yang X., He X., Zhao J., Zhang Y., Zhang S., and Xie P., “COVID-CT-dataset: A CT scan dataset about COVID-19,” 2020, arXiv:2003.13865. [Online]. Available: http://arxiv.org/abs/2003.13865
- [67].Wang X., Peng Y., Lu L., Lu Z., Bagheri M., and Summers R. M., “ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, Jul. 2017, pp. 3462–3471, doi: 10.1109/CVPR.2017.369. [DOI] [Google Scholar]
- [68].(2020). Nih Dataset. [Online]. Available: https://www.nih.gov/news-events/news-releases/nih-clinical-center-provides-one-largest-publicly-available-chest-x-ray-datasets-scientific-community
- [69].Song S., Zheng Y., and He Y., “A review of methods for bias correction in medical images,” Biomed. Eng. Rev., vol. 1, no. 1, 2017, doi: 10.18103/bme.v3i1.1550. [DOI] [Google Scholar]
- [70].Koonsanit K., Thongvigitmanee S., Pongnapang N., and Thajchayapong P., “Image enhancement on digital X-ray images using N-CLAHE,” in Proc. 10th Biomed. Eng. Int. Conf. (BMEiCON), Hokkaido, Japan, Aug. 2017, pp. 1–4, doi: 10.1109/BMEiCON.2017.8229130. [DOI] [Google Scholar]
- [71].Zuiderveld K., “Contrast limited adaptive histogram equalization,” in Graphics Gems IV. New York, NY, USA: Academic, 1994. [Google Scholar]
- [72].(2020). OPENCV: Histograms-2: Histogram Equalization. [Online]. Available: https://docs.opencv.org/master/d5/daf/tutorial-py-histogram-equalization.html
- [73].Russakovsky O., Deng J., Su H., Krause J., Satheesh S., Ma S., Huang Z., Karpathy A., Khosla A., Bernstein M., Berg A. C., and Fei-Fei L., “ImageNet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015, doi: 10.1007/s11263-015-0816-y. [DOI] [Google Scholar]
- [74].Su D., Zhang H., Chen H., Yi J., Chen P.-Y., and Gao Y., “Is robustness the cost of accuracy?—A comprehensive study on the robustness of 18 deep image classification models,” in Computer Vision—ECCV (Lecture Notes in Computer Science), vol. 11216, Ferrari V., Hebert M., Sminchisescu C., and Weiss Y., Eds. Cham, Switzerland: Springer, Cham, 2018, pp. 631–648, doi: 10.1007/978-3-030-01258-8_39. [DOI] [Google Scholar]
- [75].Kornblith S., Shlens J., and Le Q. V., “Do better ImageNet models transfer better?” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 2656–2666, doi: 10.1109/CVPR.2019.00277. [DOI] [Google Scholar]
- [76].Yang C., An Z., Zhu H., Hu X., Zhang K., Xu K., Li C., and Xu Y., “Gated convolutional networks with hybrid connectivity for image classification,” in Proc. AAAI Conf. Artifi. Intell. New York, NY, USA: AAAI Press, 2020, pp. 12581–12588. [Google Scholar]
- [77].Chen W., Xie D., Zhang Y., and Pu S., “All you need is a few shifts: Designing efficient convolutional neural networks for image classification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 7234–7243, doi: 10.1109/CVPR.2019.00741. [DOI] [Google Scholar]
- [78].Ding X., Guo Y., Ding G., and Han J., “ACNet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Seoul, South Korea, Oct. 2019, pp. 1911–1920, doi: 10.1109/ICCV.2019.00200. [DOI] [Google Scholar]
- [79].Chen H., Wang Y., Xu C., Shi B., Xu C., Tian Q., and Xu C., “AdderNet: Do we really need multiplications in deep learning?” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 1468–1477. [Google Scholar]
- [80].Chen Z., Zhang J., Ding R., and Marculescu D., “ViP: Virtual pooling for accelerating CNN-based image classification and object detection,” in Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Snowmass Village, CO, USA, Mar. 2020, pp. 1169–1178, doi: 10.1109/WACV45572.2020.9093418. [DOI] [Google Scholar]
- [81].Li Q., Shen L., Guo S., and Lai Z., “Wavelet integrated CNNs for noise-robust image classification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 7245–7254. [Google Scholar]
- [82].Singh P., Verma V. K., Rai P., and Namboodiri V. P., “HetConv: Heterogeneous kernel-based convolutions for deep CNNs,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 4830–4839, doi: 10.1109/CVPR.2019.00497. [DOI] [Google Scholar]
- [83].Gao S., Cheng M.-M., Zhao K., Zhang X.-Y., Yang M.-H., and Torr P. H. S., “Res2Net: A new multi-scale backbone architecture,” IEEE Trans. Pattern Anal. Mach. Intell., early access, Aug. 30, 2019, doi: 10.1109/TPAMI.2019.2938758. [DOI] [PubMed]
- [84].Zagoruyko S. and Komodakis N., “Wide residual networks,” 2016, arXiv:1605.07146. [Online]. Available: http://arxiv.org/abs/1605.07146
- [85].Hu H., Dey D., Del Giorno A., Hebert M., and Andrew Bagnell J., “Log-DenseNet: How to sparsify a DenseNet,” 2017, arXiv:1711.00002. [Online]. Available: http://arxiv.org/abs/1711.00002
- [86].Zhu L., Deng R., Maire M., Deng Z., Mori G., and Tan P., “Sparsely aggregated convolutional networks,” in Computer Vision—ECCV (Lecture Notes in Computer Science), vol. 11216, Ferrari V., Hebert M., Sminchisescu C., and Weiss Y., Eds. Cham, Switzerland: Springer, 2018, pp. 192–208, doi: 10.1007/978-3-030-01258-8_12. [DOI] [Google Scholar]
- [87].Li X., Song X., and Wu T., “AOGNets: Compositional grammatical architectures for deep learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 6213–6223, doi: 10.1109/CVPR.2019.00638. [DOI] [Google Scholar]
- [88].Liu C., Zoph B., Neumann M., Shlens J., Hua W., Li L.-J., Fei-Fei L., Yuille A., Huang J., and Murphy K., “Progressive neural architecture search,” in Computer Vision—ECCV (Lecture Notes in Computer Science), Ferrari V., Hebert M., Sminchisescu C., and Weiss Y., Eds. Cham, Switzerland: Springer, 2018, pp. 19–35, doi: 10.1007/978-3-030-01246-5_2. [DOI] [Google Scholar]
- [89].Real E., Aggarwal A., Huang Y., and Le Q. V., “Regularized evolution for image classifier architecture search,” in Proc. AAAI Conf. on Artifi. Intell., vol. 33. Honolulu, HI, USA: AAAI Press, 2019, pp. 4780–4789, doi: 10.1609/aaai.v33i01.33014780. [DOI] [Google Scholar]
- [90].Chen Y., Li J., Xiao H., Jin X., Yan S., and Feng J., “Dual path networks,” in Proc. 31st Int. Conf. Neural Inf. Process. Sys. (NIPS). Long Beach, CA, USA: NIPS, 2017, pp. 4470–4478. [Google Scholar]
- [91].Cao Y., Xu J., Lin S., Wei F., and Hu H., “GCNet: Non-local networks meet squeeze-excitation networks and beyond,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshop (ICCVW), Seoul, South Korea, Oct. 2019, pp. 1971–1980, doi: 10.1109/ICCVW.2019.00246. [DOI] [Google Scholar]
- [92].Luo J.-H., Zhang H., Zhou H.-Y., Xie C.-W., Wu J., and Lin W., “ThiNet: Pruning CNN filters for a thinner net,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 10, pp. 2525–2538, Oct. 2019, doi: 10.1109/TPAMI.2018.2858232. [DOI] [PubMed] [Google Scholar]
- [93].Li X., Wang W., Hu X., and Yang J., “Selective kernel networks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019, pp. 510–519, doi: 10.1109/CVPR.2019.00060. [DOI] [Google Scholar]
- [94].Shermin T., Teng S. W., Murshed M., Lu G., Sohel F., and Paul M., “Enhanced transfer learning with imagenet trained classification layer,” in Image and Video Technology (Lecture Notes in Computer Science), vol. 11854, Lee C., Su Z., and Sugimoto A., Eds. Cham, Switzerland: Springer, 2019, pp. 142–155, doi: 10.1007/978-3-030-34879-3_12. [DOI] [Google Scholar]
- [95].Deng J., Dong W., Socher R., Li L.-J., Li K., and Fei-Fei L., “ImageNet: A large-scale hierarchical image database,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Miami, FL, USA, Jun. 2009, pp. 248–255, doi: 10.1109/CVPR.2009.5206848. [DOI] [Google Scholar]
- [96].Petticrew , Sowden , Lister-Sharp , and Wright , “False-negative results in screening programmes: Systematic review of impact and implications,” Health Technol. Assessment, vol. 4, no. 5, pp. 1–120, 2000, doi: 10.3310/hta4050. [DOI] [PubMed] [Google Scholar]
- [97].Baltrusaitis T., Ahuja C., and Morency L.-P., “Multimodal machine learning: A survey and taxonomy,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 2, pp. 423–443, Feb. 2019, doi: 10.1109/TPAMI.2018.2798607. [DOI] [PubMed] [Google Scholar]
- [98].Wang W., Tran D., and Feiszli M., “What makes training multi-modal classification networks hard?” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 12695–12705. [Google Scholar]
- [99].Chen Y., Li C., Ghamisi P., Jia X., and Gu Y., “Deep fusion of remote sensing data for accurate classification,” IEEE Geosci. Remote Sens. Lett., vol. 14, no. 8, pp. 1253–1257, Aug. 2017, doi: 10.1109/LGRS.2017.2704625. [DOI] [Google Scholar]
- [100].Zhang M., Li W., and Du Q., “Diverse region-based CNN for hyperspectral image classification,” IEEE Trans. Image Process., vol. 27, no. 6, pp. 2623–2634, Jun. 2018, doi: 10.1109/TIP.2018.2809606. [DOI] [PubMed] [Google Scholar]
- [101].Ghamisi P., Hofle B., and Zhu X. X., “Hyperspectral and LiDAR data fusion using extinction profiles and deep convolutional neural network,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 10, no. 6, pp. 3011–3024, Jun. 2017, doi: 10.1109/JSTARS.2016.2634863. [DOI] [Google Scholar]
- [102].Munro J. and Damen D., “Multi-modal domain adaptation for fine-grained action recognition,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 122–132. [Google Scholar]
- [103].Khvostikov A., Aderghal K., Krylov A., Catheline G., and Benois-Pineau J., “3D inception-based CNN with sMRI and MD-DTI data fusion for Alzheimer’s disease diagnostics,” 2018, arXiv:1809.03972. [Online]. Available: http://arxiv.org/abs/1809.03972
- [104].Cheng X., Zhang L., and Zheng Y., “Deep similarity learning for multimodal medical images,” Comput. Methods Biomechanics Biomed. Eng., Imag. Vis., vol. 6, no. 3, pp. 248–252, May 2018, doi: 10.1080/21681163.2015.1135299. [DOI] [Google Scholar]