

L’ntelligence artificielle (IA) et l’apprentissage automatique1,2* transforment la pratique clinique3-9. Il est nécessaire que les utilisateurs finaux suivent une formation adaptée et que les intervenants en soins primaires se mobilisent davantage durant l’élaboration et la mise à l’essai d’outils fondés sur l’IA3. Les cliniciens n’ont pas besoin d’une compréhension approfondie ou technique de l’IA pour apporter d’importantes contributions aux initiatives liées à l’IA; par ailleurs, la plupart des ressources pédagogiques actuelles sont axées sur les méthodes et ne sont pas spécifiques aux soins primaires. Cet abécédaire compte 4 sections, et a pour but de combler ces lacunes et de susciter un remue-méninges et des discussions initiales dans les équipes de recherche interdisciplinaires à propos de possibles utilisations et applications de l’IA dans la pratique clinique et la recherche. Son objectif secondaire est de servir d’introduction à l’IA à l’intention des intervenants en soins primaires.
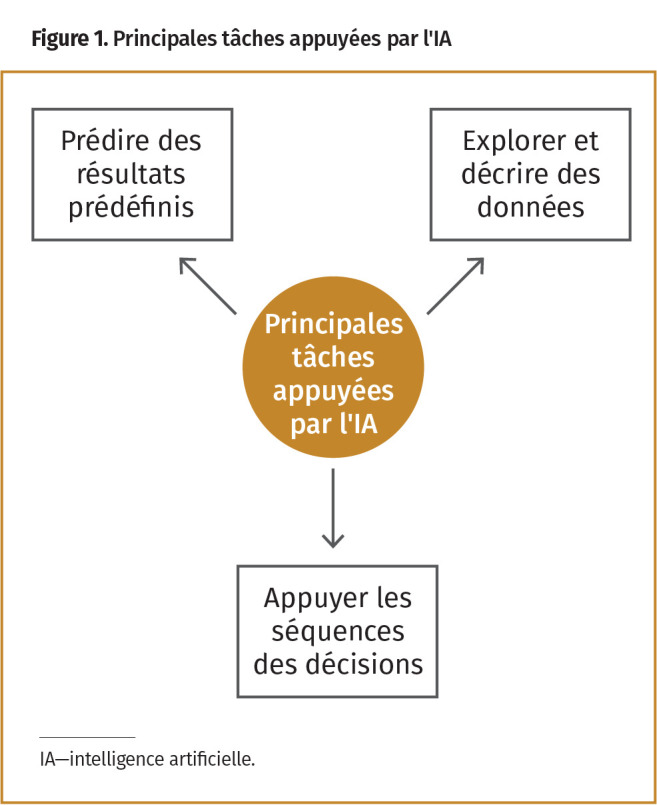
La section 1 présente l’IA et l’apprentissage automatique; la section 2 décrit 3 tâches principales que les méthodes de l’IA sont actuellement capables d’exécuter (Figure 1) et donne des exemples d’applications en soins primaires; la section 3 aborde les techniques spécialisées susceptibles d’être nécessaires pour effectuer des tâches au moyen de données langagières et d’images; la section 4 fait état d’approches antérieures à l’IA, avant l’accessibilité à de grandes sources de données.
Figure 1.
Principales tâches appuyées par l’IA
Section 1 : l’IA et l’apprentissage automatique
Le domaine de l’IA est vaste et se développe rapidement. Il se concentre sur la façon dont les ordinateurs pourraient être capables, comme un humain, d’exécuter des « tâches intelligentes », comme résumer de grandes quantités de renseignements ou faire des inférences à propos d’une situation. Les 3 principaux types de tâches que les méthodes d’IA sont actuellement capables d’effectuer sont résumés à la Figure 1 et seront expliqués avec des exemples dans la section 2.
Il n’est pas nécessaire de connaître en détail les façons dont l’IA est en mesure d’exécuter ces tâches pour imaginer des usages potentiels de l’IA ou pour voir son éventuelle utilité dans la pratique; par ailleurs, il pourrait être intéressant de savoir que l’IA fonctionne principalement en utilisant les mathématiques pour trouver et étayer des tendances, un processus selon lequel les équations sont en partie définies par des humains (p. ex. concepteurs d’IA) et en partie tirées des données. Les données peuvent initialement comprendre des chiffres, des lettres, du matériel audio ou des images; ces données peuvent ensuite être rigoureusement transformées en formats que l’IA peut traiter.
À l’heure actuelle, une bonne part de la fonctionnalité de l’IA, qui sera décrite dans les sections 2 et 3, est obtenue à l’aide de l’apprentissage automatique, notamment un ensemble de méthodes capables d’effectuer des tâches intelligentes en identifiant des tendances dans les données. Le potentiel qu’a l’apprentissage automatique d’appuyer la recherche et les soins cliniques vient largement de son habileté à saisir des relations bien plus complexes entre les éléments de données que celles qu’un algorithme humain ou simple serait habituellement capable de cerner. Même si l’apprentissage automatique peut s’appliquer à de petites quantités de données, ce sont les sources de données plus nombreuses, comme les bases de données des dossiers médicaux électroniques (DME) contenant des années d’information sur les patients, qui procurent suffisamment de données pour que les méthodes d’apprentissage automatique puissent découvrir ces relations complexes. L’intelligence artificielle a fait l’objet d’une attention bien plus soutenue récemment, en raison de l’accessibilité accrue à des données ces dernières années, ce qui a permis des progrès dans le développement des méthodes d’apprentissage automatique, de sorte qu’une bonne performance peut désormais être atteinte pour des applications concrètes.
Même si cet abécédaire présente les tâches séparément, dans la pratique, les tâches et les méthodes d’IA utilisées pour les réaliser peuvent se chevaucher. Une tâche donnée pourrait être effectuée par plusieurs types de méthodes d’apprentissage automatique, et une méthode donnée pourrait s’appliquer à différentes tâches. Par exemple, les réseaux de neurones artificiels, qui comptent parmi les méthodes d’IA de la souscatégorie de l’apprentissage automatique profond, ont été utilisés pour exécuter les 3 types de tâches mentionnés. Pour lire la suite du présent abécédaire, il n’est pas nécessaire de connaître les méthodes spécifiques; par ailleurs, les lecteurs intéressés aux aspects plus techniques sont invités à consulter, comme points de départ, les 3 premières références citées1-3.
Section 2 : principales tâches que peut appuyer l’IA
Prédire des résultats prédéfinis. La première tâche consiste à utiliser une information existante connue (p. ex. données d’entrée) pour prédire ou estimer des renseignements inconnus ou des résultats. Ces résultats peuvent être actuels (p. ex. cette personne a-t-elle maintenant un diabète non diagnostiqué?) ou être des événements futurs (p. ex. cette personne développera-t-elle le diabète durant la prochaine année?) La description de cette principale tâche se trouve à la Figure 2.
Figure 2.

Prédire des résultats prédéfinis
Ces principaux types de tâches sont en grande partie effectués par des méthodes d’apprentissage automatique supervisées, qui recherchent des tendances reliant des données d’entrée à un résultat prédéfini. Les tendances sont apprises durant une étape d’entraînement selon laquelle un algorithme d’IA a accès à des données étiquetées pour lesquelles les entrées (p. ex. anamnèses cliniques saisies dans les DME) et les résultats (p. ex. diagnostic de diabète existant) sont connus. Le produit final serait un outil qui repose sur des données d’entrée connues (p. ex. données des DME de nouveaux patients à la clinique qui n’ont pas de diagnostic de diabète existant) pour faire d’utiles prédictions dans des situations où le résultat est véritablement inconnu (p. ex. développeront-ils ou non le diabète?) Ces types d’outils fondés sur l’IA peuvent être classés comme étant verrouillés ou adaptatifs, selon que les prédictions des tendances sousjacentes restent les mêmes ou peuvent changer activement à mesure que l’outil est utilisé avec le temps.
Les prédictions peuvent être faites sur le plan individuel ou collectif. Par exemple, un modèle qui prédit le risque que court une personne de progresser du prédiabète au diabète pourrait appuyer les décisions cliniques liées à la prévention ou au dépistage10, tandis qu’un modèle qui prédit l’incidence du diabète dans une population pourrait éclairer la planification des ressources ou les décisions de politiques11,12. Il faudrait déterminer tôt dans le processus du développement du modèle à quel niveau il sera utilisé.
Exemple d’application pour prédiction de problème : un outil13 pouvant s’appliquer aux soins primaires a été conçu pour optimiser la prise de rendez-vous en clinique et réduire les temps d’attente des patients. Les données d’entrée comprennent des données de base sur la démographie et les rendez-vous, tirées du système d’établissement des horaires; les résultats prédits incluent les rendez-vous manqués et annulés. Le personnel administratif peut se servir de l’outil pour déterminer les rendez-vous pour lesquels le risque est élevé que le patient ne se présente pas ou qu’il l’annule, ce qui donne la possibilité de faire un suivi bien avant la date prévue du rendez-vous.
Explorer et décrire les données. Le deuxième type de tâches peut être effectué avec des sources de données semblables à celles utilisées dans la première tâche, mais les tendances intéressantes ne concernent plus la prédiction d’un résultat prédéfini. L’objectif est plutôt de cerner la structure globale, les tendances ou d’autres sortes de renseignements descriptifs à propos des données. Une tâche commune est l’agrégation, qui peut être utilisée pour mieux comprendre un ensemble de données et générer des hypothèses au sujet de la population représentée dans ces données (Figure 3).14
Figure 3.

Explorer et décrire les données
Les types de méthodes d’IA utilisés pour la réalisation de tâches d’exploration et de description des données sont souvent appelés des méthodes d’apprentissage automatique non supervisées.
Appuyer les séquences des décisions. Le troisième type de tâches est d’appuyer les séquences des décisions pour des résultats tant à court qu’à long terme. Cette tâche est effectuée à l’aide de données recueillies avec le temps. À n’importe quel moment donné (p. ex. un rendez-vous clinique), il pourrait y avoir de multiples choix d’actions possibles (p. ex. options de traitements); les méthodes d’IA peuvent servir à prédire quelle action optimisera une « fonction de récompense » qui représente le ou les résultats voulus. Après la prise de décision quant à l’action à prendre, la rétroaction est saisie et utilisée pour actualiser les prédictions sur ce que pourraient être la ou les prochaines meilleures actions (Figure 4).
Figure 4.

Appuyer les séquences des décisions
Les tâches liées à l’appui aux décisions ou aux actions avec le temps sont habituellement exécutées au moyen des méthodes qui appartiennent à la sous-catégorie de l’apprentissage automatique appelée apprentissage par renforcement.
Section 3 : méthodes spécialisées
Il existe des sous-catégories spécialisées d’IA conçues pour analyser et interpréter des types de données, comme des données vocales et des images, qui peuvent exiger des méthodes et des approches supplémentaires ou différentes pour être en mesure d’appuyer ce qu’on considérerait comme des tâches « intelligentes » pour ce genre de données.
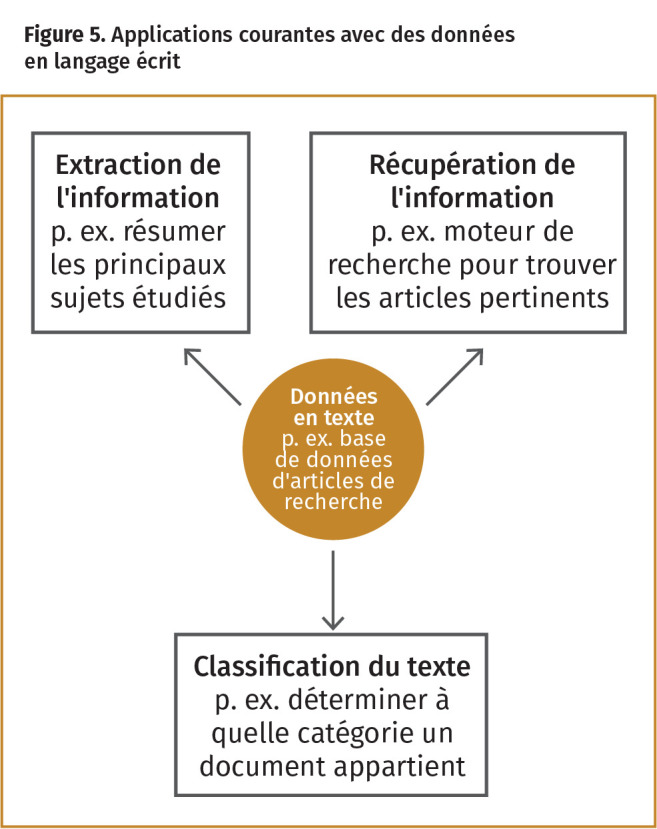
Analyser des données langagières. La sous-catégorie d’IA appelée le traitement du langage naturel concerne l’identification des tendances dans les données langagières et la réaction à ces tendances. Parmi les applications habituelles pour les données du langage oral figure la reconnaissance de la voix, comme l’exécution de tâches de questions et réponses dans les appels téléphoniques automatisés. Des applications communes pour les données en langage écrit sont présentées à la Figure 5.
Figure 5.
Applications courantes avec des données en langage écrit
Exemple d’application clinique du traitement du langage naturel : un outil15-17 qui s’appuie sur les processus du langage naturel a été élaboré pour aider le médecin avec la documentation pendant une rencontre clinique. Il peut extraire et consigner automatiquement des notes importantes et des diagnostics tirés d’une conversation entre un clinicien et un patient.
Analyser des données sous forme d’images. La sous-catégorie de l’IA appelée la vision par ordinateur est axée sur le traitement et l’interprétation des données sous forme d’images. Les applications cliniques de la vision par ordinateur comportent souvent l’objectif ultime de la classification, comme le fait de prédire si le contenu d’une image se situe dans les limites prévues de variations saines ou s’il est inquiétant et demande une investigation plus approfondie.
Exemple d’application de la vision par ordinateur : un exemple d’outil18 a été conçu pour détecter une rétinopathie diabétique en 60 secondes; il fonctionne avec les caméras les plus spécialisées pour l’œil, qui fournissent des images de grande qualité. Il fait des recommandations quant à la nécessité d’une consultation en ophtalmologie.
Section 4 : avant les systèmes alimentés par des données et au-delà
Des méthodes centrées sur les données aux méthodes centrées sur les règles. On réfléchit souvent à l’IA de pair avec le type et la qualité des données disponibles. Les données font partie intégrante de la plupart des méthodes d’IA à la fine pointe de la technologie, y compris les méthodes actuellement utilisées pour exécuter les tâches mentionnées précédemment; toutefois, cela n’a pas toujours été le cas. On peut envisager le domaine de l’IA comme étant situé sur un spectre allant de méthodes centrées sur les données jusqu’à des méthodes centrées sur les règles. À une extrémité du spectre, il peut se trouver un outil d’apprentissage automatique fortement « alimenté par des données » selon lequel les décisions, tout au long du processus de développement, partant des types de données qui devraient être considérés comme des données d’entrée jusqu’aux formes que prendront les données de sortie, découlent presque entièrement des données. À l’autre extrémité du spectre se trouvent certains des plus anciens outils d’IA, y compris les systèmes experts d’avant l’ère des « métadonnées ». Pour effectuer des tâches comme la suggestion de diagnostics ou de traitements, les systèmes experts pouvaient utiliser la programmation logique pour naviguer à travers des collections de règles, comme des énoncés du genre « si, alors », extraits des lignes directrices de pratique clinique (Figure 6). Les systèmes experts modernes pourraient se fonder sur une combinaison de méthodes centrées sur les règles et centrées sur les données.
Figure 6.

Structure des systèmes experts
Exemple historique d’application de systèmes experts : l’exemple le plus ancien d’une application d’IA conçue pour appuyer la pratique clinique, le MYCIN, était un système expert développé durant les années 1970 pour appuyer la prise de décisions thérapeutiques pour les infections bactériennes. La base de connaissances incluait des centaines de règles extraites de l’expertise humaine, de manuels et de rapports de cas. Chaque règle comptait 2 parties principales : une condition préalable et une action. L’information sur la condition préalable était obtenue au moyen d’un processus de questions et réponses avec un clinicien jusqu’à ce que tous les renseignements pertinents aient été saisis, et c’est alors que le MYCIN proposait des suggestions de diagnostics et de traitements19.
Conclusion
Cet abécédaire a donné un aperçu conceptuel des types de tâches que l’IA peut exécuter, de même que des exemples d’applications dans les soins primaires. Il peut servir de ressource éducative pour répondre à un intérêt personnel ou pour faciliter des discussions initiales entre équipes interdisciplinaires. À mesure que progressent les discussions, il importera de prendre en compte les considérations additionnelles nécessaires pour produire des applications sécuritaires et efficaces d’IA, comme les biais, l’équité, la facilité d’explication, la possibilité de généralisation, la qualité des données et la protection des renseignements personnels.
Footnotes
Les exemples mentionnés dans le texte ne constituent ni une approbation, ni une évaluation de la qualité des outils.
Remerciements
Je remercie Ravninder Bahniwal, MPH, de son aide pour le formatage des diagrammes et les exemples en soins primaires, de même que Dan Lizotte, PhD, Ravninder Bahniwal, MPH, Amanda Terry, PhD, Leslie Meredith et Jason Black, MSc, qui ont tous apporté leur aide pour améliorer cette ressource par leurs révisions et leurs critiques constructives. AMS Healthcare soutient le poste de fellow du CMFC et de l’AMS que j’occupe.
Intérêts concurrents
Aucun déclaré
Les opinions exprimées dans les commentaires sont celles des auteurs. Leur publication ne signifie pas qu’elles soient sanctionnées par le Collège des médecins de famille du Canada.
The English version of this article is available at www.cfp.ca on the table of contents for the December 2021 issue on page 889.
Références
- 1.Russell S, Norvig P.. Artificial intelligence: a modern approach. 3e éd. Upper Saddle River, NJ: Pearson Education Inc; 2010. [Google Scholar]
- 2.Hastie T, Tibshirani R, Friedman J.. The elements of statistical learning: data mining, inference, and prediction. 2e éd. New York, NY: Springer; 2008. [Google Scholar]
- 3.Kueper JK, Terry AL, Zwarenstein M, Lizotte DJ.. Artificial intelligence and primary care research: a scoping review. Ann Fam Med 2020;18(3):250-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Liaw W, Kakadiaris IA.. Primary care artificial intelligence: a branch hiding in plain sight. Ann Fam Med 2020;18(3):194-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wiens J, Shenoy ES.. Machine learning for healthcare: on the verge of a major shift in healthcare epidemiology. Clin Infect Dis 2018;66(1):149-53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Sendak M, Gao M, Nichols M, Lin A, Balu S.. Machine learning in health care: a critical appraisal of challenges and opportunities. EGEMs (Wash DC) 2019;7(1):1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Beam AL, Kohane IS.. Big data and machine learning in health care. JAMA 2018;319(13):1317-8. [DOI] [PubMed] [Google Scholar]
- 8.Celi LA, Fine B, Stone DJ.. An awakening in medicine: the partnership of humanity and intelligent machines. Lancet Digit Health 2019;1(6):e255-7. Publ. en ligne du 26 sept. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lin SY, Mahoney MR, Sinsky CA.. Ten ways artificial intelligence will transform primary care. J Gen Intern Med 2019;34(8):1626-30. Publ. en ligne du 14 mai 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Cahn A, Shoshan A, Sagiv T, Yesharim R, Goshen R, Shalev Vet al. Prediction of progression from pre-diabetes to diabetes: development and validation of a machine learning model. Diabetes Metab Res Rev 2020;36(2):e3252. Publ. en ligne du 14 janv. 2020. [DOI] [PubMed] [Google Scholar]
- 11.Rosella LC, Manuel DG, Burchill C, Stukel TA; PHIAT-DM Team . A population-based risk algorithm for the development of diabetes: development and validation of the Diabetes Population Risk Tool (DPoRT). J Epidemiol Community Health 2011;65(7):613-20. Publ. en ligne du 1er juin 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Rosella LC, Peirson L, Bornbaum C, Kotnowski K, Lebenbaum M, Fransoo Ret al. Supporting collaborative use of the Diabetes Population Risk Tool (DPoRT) in health-related practice: a multiple case study research protocol. Implement Sci 2014;9(1):35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Optimize your schedule with Attendance Predictor. Orlando, FL: Mend. Accessible à : https://www.mend.com/no-show-predictor/. Réf. du 5 nov. 2021. [Google Scholar]
- 14.Newcomer SR, Steiner JF, Bayliss EA.. Identifying subgroups of complex patients with cluster analysis. Am J Manag Care 2011;17(8):e324-32. [PubMed] [Google Scholar]
- 15.Khattak FK, Jeblee S, Crampton N, Mamdani M, Rudzicz F.. AutoScribe: extracting clinically pertinent information from patient-clinician dialogues. Stud Health Technol Inform 2019;264:1512-3. [DOI] [PubMed] [Google Scholar]
- 16.Jeblee S, Khattak FK, Crampton N, Mamdani M, Rudzicz F.. Extracting relevant information from physician-patient dialogues for automated clinical note taking. In: Proceedings of the Tenth International Workshop on Health Text Mining and Information Analysis (LOUHI 2019). Hong Kong: Association for Computational Linguistics; 2019. p. 65-74. [Google Scholar]
- 17.AutoScribe. Toronto, ON: Mutuo Health Solutions. Accessible à : https://mutuohealth.com. Réf. du 23 avr. 2021. [Google Scholar]
- 18.EyeArt AI eye screening system. Woodland Hills, CA: Eyenuk, Inc. Accessible à : https://www.eyenuk.com/en/products/eyeart/. Réf. du 20 févr. 2021. [Google Scholar]
- 19.Shortliffe EH, Davis R, Axline SG, Buchanan BG, Green CC, Cohen SN.. Computer-based consultations in clinical therapeutics: explanation and rule acquisition capabilities of the MYCIN system. Comput Biomed Res 1975;8(4):303-20. [DOI] [PubMed] [Google Scholar]