

Abstract
Just-In-Time Adaptive Intervention (JITAI) is an emerging technique with great potential to support health behavior by providing the right type and amount of support at the right time. A crucial aspect of JITAIs is properly timing the delivery of interventions, to ensure that a user is receptive and ready to process and use the support provided. Some prior works have explored the association of context and some user-specific traits on receptivity, and have built post-study machine-learning models to detect receptivity. For effective intervention delivery, however, a JITAI system needs to make in-the-moment decisions about a user’s receptivity. To this end, we conducted a study in which we deployed machine-learning models to detect receptivity in the natural environment, i.e., in free-living conditions.
We leveraged prior work regarding receptivity to JITAIs and deployed a chatbot-based digital coach – Ally – that provided physical-activity interventions and motivated participants to achieve their step goals. We extended the original Ally app to include two types of machine-learning model that used contextual information about a person to predict when a person is receptive: a static model that was built before the study started and remained constant for all participants and an adaptive model that continuously learned the receptivity of individual participants and updated itself as the study progressed. For comparison, we included a control model that sent intervention messages at random times. The app randomly selected a delivery model for each intervention message. We observed that the machine-learning models led up to a 40% improvement in receptivity as compared to the control model. Further, we evaluated the temporal dynamics of the different models and observed that receptivity to messages from the adaptive model increased over the course of the study.
Keywords: Receptivity, Intervention, Interruption, Mobile Health, Engagement
1. INTRODUCTION
The ubiquituous presence of mobile technologies has enabled a wide array of research into mobile health (mHealth), from sensing health conditions to providing behavior-change interventions. In the past, ubiquitous technologies like smartphones and wearables have shown promise in detecting stress, anxiety, mood, depression, personality change, addictive behavior, physical activity and a host of other conditions [15, 29, 44, 45]. Furthermore, several studies have demonstrated the potential of smartphone-based digital interventions to affect positive behavior change for a range of conditions like smoking, alcohol disorder, eating disorders, and physical inactivity [12, 16, 23, 40]. The eventual goal in mHealth is to be able to combine the two components of accurate sensing and effective interventions to improve the quality of life amongst people suffering from various conditions.
JITAI is a novel intervention design that aims to deliver the right type and amount of support, at the right time, while adapting as-needed to the users’ internal and external contextual change [31, 32]. Several studies have employed JITAI-like interventions to affect behavior change for physical inactivity [8, 19], alcohol use [13], mental illness [4], smoking [38], and obesity [3]. For JITAIs to be effective they must deliver the intervention at “the right time,” one aspect of the “right time” is when a person enters a state of vulnerability, i.e., a period of heightened susceptibility for a negative health outcome [32]. For example, an intervention to alleviate stress levels should be delivered when a person is stressed or about to be stressed; delivering it when a person is not actually stressed would not be useful. Furthermore, it is also important to deliver interventions at a time when the participant is in a state of receptivity, i.e., a period when the participant is able to receive, process, and use the intervention provided [32]. For example, an intervention targeted at reducing sedentary behavior would be effective when a person is “available” to act on it; delivering it when a person is driving is not only sub-optimal but may also be dangerous.
Although prior mHealth research focuses on detecting states of vulnerability or on developing effective intervention mechanisms, little research has been done in identifying states-of-receptivity. In our prior work, we developed the original Ally app to deliver physical-activity interventions and explored how the passively collected contextual factors associated with receptivity in a study with 189 participants [22]. In the same prior work, we also evaluated the feasibility of building machine-learning models to detect receptivity and achieved a 77% improvement in F1-score over a biased random model. Choi et al. conducted a 3-week study with 31 participants in which the authors collected self-reports about the participants’ context and cognitive/physical state to understand association with the response to relevant Just-In-Time (JIT) support targeted towards sedentary behavior [6]. Koch et al. observed how drivers interact with and respond to affective well-being interventions while driving in their daily lives, with 10 participants over two months [17]. Sarker et al. conducted a study with 30 participants to explore discriminative features and built machine-learning models to detect receptivity to Just-In-Time Intervention (JITI) with a reported 77.9% accuracy. The authors, however, did not deliver interventions; instead they used Ecological Momentary Assessment (EMA) and claimed that interactions with EMA prompts would be similar to interactions with intervention prompts.
All of those prior works, however, focused on data collection followed by post-study analysis and evaluation of post-study machine-learning models, with the expectation that the models would perform similarly when deployed in real-life conditions. In this paper, we go beyond post-study analysis: we deployed two different machine-learning models to predict in-the-moment receptivity, and used that prediction to decide when to deliver the intervention. We deployed these models in a physical-activity app used by 83 participants in free-living conditions over a period of 3 weeks. Our goal was to evaluate whether such models actually helped increase receptivity to interventions.
Given the promising results from our previous study, we decided to build upon that work [22]. We used the data from the previous study to build two different machine-learning models, which we later deployed in our field study: (a) a static model that remained constant for all participants through out the study, and (b) an adaptive model that continuously learnt the receptivity of individual participants from their enrollment in the study and updated the model as the study progressed; we delayed activation of this model until the participant had been in the study for 7 days, however, to ensure that enough data was collected for that participant before using the model’s predictions. To compare the utility of these models, we also included (c) a control model that would send the intervention messages at a random time. We extended the original Ally app [22], to incorporate the different models and enable in-the-moment detection of receptivity.1 We also translated all of their intervention messages from German to English as our new study was conducted in an English-speaking population.
We explore three core research questions (RQs):
-
RQ-1: On a population level, i.e., across intervention messages and across all users, does delivering interventions at a machine learning (ML)-detected time lead to higher receptivity than delivering interventions at a random time?
For all the messages sent in the study (across all participants), we evaluated how receptivity differed between messages delivered at ‘opportune’ moments, i.e., using the static and adaptive models, as compared to random times.
-
RQ-2: How does receptivity of individual users change when interventions are delivered through ML-based intervention timing vs. at random times?
For individual participants who received intervention messages at both (a) model-based times and (b) at random times, we evaluated how their individual receptivity changed with the different models.
-
RQ-3: How do the different models for predicting receptivity perform over time?
We evaluated how the participants’ daily receptivity changed as the study progressed. Our goal was to understand whether the models performed consistently throughout the study or whether their effectiveness improved (or worsened) as the study progressed.
While exploring the three research questions, we make the following contributions:
We built two separate models: (a) static and (b) adaptive, using previously collected data to model receptivity to chat-based JITAIs. We deployed both the models in a 3-week long field study with 83 participants, and actually used the output of the model predictions to deliver JITAIs in-the-moment. Our work moves beyond post-study evaluations, and tests the effectiveness of deploying receptivity-detection models trained using data from a previous study. Further, this is the first work to deploy an adaptive model to detect receptivity to JITAI and observe how the model performance changes as the study progresses.
We evaluated the performance of the two models with a control model (which sent intervention messages at random times), both on a population level and a participant level. We observed that the static model led to significantly higher receptivity than the control model in most instances, for both population level and participant level analyses, suggesting that it is possible to use machine-learning models to predict in-the-moment receptivity. We observed that a participant was more likely to respond to a message delivered at a predicted opportune moment than at a random moment.
We evaluated the temporal dynamics of the different models to understand how they performed over the course of the study. We observed that while receptivity from the random model decreased over time, the static model was able to maintain consistent receptivity over time, and receptivity to messages delivered by the adaptive model improved as participants progressed in the study.
We begin with a review of related work in receptivity towards interventions, as well as closely related concepts of interruptibility and engagement. We then provide a background of the Ally app and operationalization of the different receptivity metrics, followed by our study design methodology and the results for our research questions. Finally, we conclude with a discussion of the implications, future work, and limitations of our work.
2. RELATED WORK
In the domain of ubiquitous computing, researchers have extensively explored a related concept of interruptibility. In the context of smartphone notifications, interruptibility is defined as a person’s ability to be interrupted by an incoming notification by taking an action to open or view the notification content [26]. This stream of research has focused on the use of push notifications to attract users’ attention, while making the recipients feel less ‘interrupted’ by the notifications. In this section, we discuss the prior research on interruptibility to smartphone notifications. We also discuss prior work in capturing participant receptivity in mHealth research.
Most prior ‘interruptibility’ research has focused on analyzing and understanding user interruptibility and on the association between various contextual factors and interruptibility. Researchers have studied factors such as time of day and day of week [2, 24, 35, 37], location [26, 36, 39], Bluetooth information (as a proxy for social context) [35], call and SMS logs (another proxy for social context) [11, 37], Wi-Fi connectivity [35, 37], and phone battery information [36]. While most of these factors were found to be a predictor of users’ interruptibility, some studies have also contradicted those findings. For example, some have found time to be a significant predictor [35, 37], while others have found the opposite [24, 46]. The same applies for location, where Sarker et al. and others [35, 37, 39] found location was an important indicator of interruptibility and Mehrotra et al. found otherwise [26].
Other research investigated personality traits and mental state as potential predictors for receptivity. Happy and energetic participants showed a higher availability to interruptions, compared to stressed study participants [39]. Other researchers have shown the significance of personality traits to predict the response delay; in particular, neuroticism and extroversion were found to be significant [27].
Many studies have found a significant correlation between physical activity and interruptibility [14, 26, 33, 39]. The type of physical activity was also found to be significant; for example, people driving in a vehicle replied more slowly than people walking outside [39]. Further, ‘breakpoints’ in physical activity, e.g., from walking to standing, were found to be favorable times to trigger notifications [33]. Generalizing results, however, is difficult as small sample size and homogeneity of study participants is a common problem in this research area [21].
A few researchers have explored the concept of engagement. In the context of smartphone notifications, engagement usually follows after a person is interrupted and refers to the involvement of an user in a task or app that attracts and holds the user’s attention [36]. Pielot et al. conducted a study (n > 330) in which they delivered eight different types of content and observed participants’ engagement and responsiveness [36]. They then built predictive models to classify whether a participant would engage with the notification content, and found that their models led to an improvement of more than 66% over a baseline classifier. Related to engagement, Dingler et al. built an app aimed at improving users’ foreign-language vocabulary through notifications and app usage through out the day [9]. The authors found that several contextual factors relating to phone usage, e.g., number of phone unlocks in the last 5 minutes, time since last unlock, and number of notifications in the last 5 minutes, showed significant correlations to predict users’ engagement with the content.
Some works have even deployed a machine-learning classifier to infer interruptibility. Okoshi et al. deployed a breakpoint-detection system to time notifications [34]. Based on a study with over 680,000 users, they found that response time to notifications was up to 49% lower if they were delivered during activity breakpoints. Pielot et al. deployed a model that allowed them to deliver entertaining content when the participant was likely bored; at such times, they found participants were more likely to engage [37].
In the domain of JITAIs and mHealth interventions, receptivity is defined as the person’s ability to receive, process, and use the support (intervention) provided [32]. To compare with interruptibility and engagement, as highlighted by Künzler et al., “receptivity may be (loosely) conceptualized to encompass the combination of interruptibility (willingness to receive an intervention), engagement (receive the intervention), and the person’s subjective perception of the intervention provided (process and use the intervention)” [22].
There have been a growing number of works exploring receptivity and interruptibility in the domain of mHealth. Sarker et al. conducted a study with 30 participants, and identified various contextual and physiological features for their machine-learning model to detect receptivity to EMA prompts [39]. The authors drew a parallel between EMA and interventions by claiming that interaction with self-report or EMA prompts and interaction with interventions would be similar. The authors also provided monetary incentives for EMA completion, however, which may have influenced the participants’ receptivity. Further, Mishra et al. investigated contextual breakpoints and how they could be used to detect receptivity to EMA [28].
Choi et al. conducted a 3-week study with 31 participants in which the participants reported information about their context and cognitive/physical state; the paper explores the association of context and cognitive state with the relevant JIT support targeted towards sedentary behavior [6]. The authors identified several key factors relating to receptivity and showed that receptivity to JIT interventions is nuanced and context-dependant.
In our prior work, we developed a smartphone app to deliver physical-activity interventions and deployed it in a study with 189 participants [22]. We explored how passively collected contextual factors, like location, physical activity, time of day, type of day, phone interaction, and phone battery level, are associated with receptivity to interventions. We also explored the relationship between receptivity and participant-specific characteristics, like age, gender, personality and device type, and receptivity. We further built machine-learning models to detect receptivity and achieved a 77% improvement in F1-score over a biased random model.
Morrison et al. focused on a mobile stress-management intervention [30]. Their system randomly assigned study participants to one of three groups. Each group was using a different method for receiving push notifications. One group received the notifications occasionally (not daily), one group received them daily, and one group used a machine-learning model to receive ‘intelligent’ notifications. However, the authors did not find any difference in how the participants interacted with notifications delivered at opportune times (as determined by their model) vs. those delivered at random times. We argue the negative result was because of the following challenges, and also highlight how we address those challenges in our work.
Based on prior work on interruptibility to generic phone notification, Morrison et al. used location labels (home, work, and other), movement from accelerometer, and time variables as the features [30]. While these features might be useful to detect interruptible moments for generic notifications, they might not translate to detecting receptivity to interventions. In fact, our prior work showed that some features like location labels had no significant associations with receptivity to interventions. In comparison, we used more effective features that had shown prior associations with receptivity to interventions [22].
Morrison et al. built static personalized Naive Bayes models for each participant based on the data collected during an initial “learning period.” Since the model was static and did not update after the “learning period,” it is possible that their models did not have enough data during to be adequately trained. On the contrary, we used data from a prior study with 148 participants to build our static model, which resulted in a more robust and better-trained model.
Hence, we argue that our methodology of feature selection and model development could provide better insights towards the effectiveness of machine-learning models for detecting receptivity.
In our current work, we build upon the prior research by deploying machine-learning models to detect receptivity in real-life situations. We used the data collected from our previous study [22] to build and deploy two machine-learning models to detect receptivity to physical-activity interventions. We deployed a static model that stayed unchanged through out the study, and an adaptive model that re-trained itself over the course of the study as participants interacted with the notifications. Our current work moves beyond “post-study” model-evaluations, and evaluates the effectiveness of deploying receptivity-detection models trained using data from a previous study. Further, this is the first work to deploy an adaptive model to detect receptivity to JITAI and observe how the model performance changes as the study progresses.
3. BACKGROUND
In this section, we discuss the app used and dataset collected from our prior work by Künzler et al. [22], followed by the operationalization of receptivity, and finally discuss how receptivity fits within the JITAI framework.
3.1. The Ally Study
In an effort to understand receptivity to JITAIs, in our prior work we developed a mobile JITAI system to promote physical activity. The “Ally” app – based on the open-source MobileCoach framework – was a chat-based digital coach (for Android and iOS phones) that delivered an actual behavior-change intervention aimed at increasing the participant’s daily step count [10, 18]. The previous study was conducted with 189 participants in Switzerland, over a period of 6 weeks. Participants received notifications that encouraged them to engage in conversation with the digital coach, which was a German-speaking chatbot motivating participants to increase their physical activity as measured by daily step count [22].
Through that study, we reported interesting findings about the association between receptivity and participant-specific traits (like age, gender, device type and personality) and contextual factors (like battery level, device interaction, physical activity, location, and time of day). We also built several machine-learning models to infer different aspects of receptivity, and reported a 77% increase in F1-score for detecting just-in-time receptivity, over a biased random classifier (with a combination of participant specific traits and contextual factors), and a 50% improvement in F1-score with contextual factors alone [22].
Given the promising results in the post-study analyses, we decided to build upon that work by deploying in-the-moment receptivity-detection models to evaluate how these models perform in real-world situations.
Another reason to build upon that prior Ally study was the assumption we made about receptivity. In the intervention design, all conversations started with a generic greeting message like “Hello [participantName]” or “Good morning [participantName]”. Only when the participant responded to the greeting message, did the coach start sending the actual intervention messages. Hence, when we refer to receptivity to a message, we refer to receptivity to the initiating message or “start-of-conversation” message. Given that the Ally participants responded to initiating messages without looking at the actual intervention, we believe it might be possible to build models using the data collected in the Ally study and deploy it in a different study following a similar “start-of-conversation” message strategy.
3.2. Receptivity within JITAI
As proposed by Nahum-Shani et al., JITAI has six key elements: a distal outcome, proximal outcomes, decision points, intervention options, tailoring variables, and decision rules [32]. Distal outcome is the ultimate goal the intervention is intended to achieve, proximal outcomes are short-term goals the intervention aims to achieve, decision points are points in time at which an intervention decision must be made, tailoring variables are information concerning the individual that is used to decide when (i.e., under what conditions) to provide an intervention and which intervention to provide, intervention options are an array of possible treatments/actions that might be employed at any given decision point, and decision rules link the tailoring variables and intervention options in a systematic way.
Within this model, receptivity can be considered as a tailoring variable, one that indicates whether the user is available to receive an intervention at any given time. At a decision point, the decision rules can check the receptivity tailoring variable to choose from the various intervention options, which could include postponing the intervention or delivering no interventions at that decision point. Hence, receptivity as a tailoring variable can help determine if, what, and when an intervention should be delivered.
3.3. Operationalizing Receptivity
Before discussing our methodology, it is important to establish precise metrics about what the models are trying to achieve. These definitions are consistent with the metrics we used in our prior work [22].
Just-in-time response: If a user views and responds to the initiating message within 10 minutes2 of receiving the prompt, then the user is said to be in a receptive state and it counts as a ‘just-in-time response’.
Response: If the user responds to the initiating message at any time, even after the first 10 minutes, it counts as a ‘response’.
Response delay: the time (in seconds) elapsed between receipt of the initiating message and the user’s first reply to it.
Conversation engagement: If the user replies to more than one message in a 10-minute window following the initiating message, it counts as ‘conversation engagement’.
In some contexts we aggregate these metrics over a period of time, e.g., over one day or over the duration of the study. For a given period of time, the just-in-time response rate is the fraction of initiating messages for which there was a just-in-time response, the overall response rate is the fraction of initiating messages for which there was a response, the conversation rate is the fraction of initiating messages that counted as conversation engagement, and the average response delay is the mean response delay [22].
4. APPROACH
In this section, we discuss how we extended the Ally app, to fit our research goals, the models deployed in the app, and the study methodology.
4.1. The Ally+ app
We modified the iOS version of the Ally app to create a new app we call Ally+. Similar to Ally, Ally+ is a chat-based digital coach aimed at increasing daily step count. We show a screenshot of the app in Figure 1. The app calculated a personalized step goal each day, based on the participants’ 60th percentile step count in the previous 9 days. The intervention components were chat-based conversational messages that were delivered by the digital coach and the participants had to choose from a set of pre-defined responses. The coach initiated the starting message of each conversation to each user at random times within certain time periods. In our study, we used three of the four intervention components used in the original Ally study [19, 22]: (1) The goal-setting prompt set the step goals for the day; it was delivered between 8 and 10 a.m daily. (2) The self-monitoring prompt informed participants about their progress and aimed to motivate them to complete their step goals; it was delivered at a random time between 10 a.m. and 6 p.m. to a randomly selected 50% of participants each day. (3) The goal-achievement prompt informed the participants whether they achieved their goal for the day and aimed to motivate them to complete future goals; it was delivered at 9 p.m. daily.
Fig. 1.
Two screenshots showing Ally+’s dashboard (left) and the chat screen for the interventions (right).
Further, Ally+ had a context-based receptivity module that continuously tracked several contextual features; Ally+ used this module to time the delivery of notifications, as follows. For each day, for each participant, the server randomly chose three times (one in each of the three time blocks) to send a silent push notification to that participant’s app. When Ally+ received the silent push from the server, it triggered the receptivity module to determine when to deliver that notification to the participant. During the first seven days, the receptivity module randomly selected either the control or static model, with equal weight. On the eighth day and after, the receptivity module randomly selected one of three models, with equal weight. (The seven-day ‘warm-up’ period allowed accumulation of participant-specific receptivity data before enabling the adaptive model.) For each initiating message received, the app recorded which model was used to time its delivery – control, static or adaptive. We detail the three models in Section 4.2.
Ally+ then delivered the notification about the initiation prompt if and only if the selected model inferred the user would be receptive at the current time. The control module always agreed. The static and adaptive models used their classifier to determine whether the current moment is ‘receptive’. If the models did not find the current moment to be receptive,3 the app would try again by asking the same model every 5 minutes. If after 30 minutes the model never inferred an opportune moment, Ally+ delivered the notification on the 31st minute;4 in this case, it recorded the delivery mechanism as “control”, since the notification was delivered at a random time, and not at an opportune moment.5
We used the Ally+ app to conduct a within subjects study with three experimental conditions for delivering the interventions: control, static, and adaptive. It is important to note that the intervention delivery conditions did not affect the actual content of the interventions delivered by the app.
Regardless of the chosen delivery model, the participant’s response to any initiating message provided new data for use by the adaptive model. There were three cases: (a) just-in-time response: the contextual state at the time of notification delivery was added with label ‘receptive’; (b) later response: the contextual state at the time of notification delivery was added with label ‘non-receptive’, and the contextual state at the moment of response was added with label ‘receptive’ (since the participant was in a state-of-receptivity when they responded); (c) no response: the contextual state at the time of notification delivery was added with label ‘non-receptive’. Whenever the adaptive model was selected as the delivery model, it first re-trained its model using any new data points added.
We diagram the system design in Figure 2.
Fig. 2.

System design of the Ally+ app.
4.2. Building the Detection Models
We leveraged the data collected from iOS users in the previous Ally study to build new models that we deployed in Ally+. We first discuss the features we selected to use in our models, followed by a description of the models themselves.
4.2.1. Choice of Features.
In our prior work, we considered a variety of contextual features, like physical activity, device interaction, location type, type of day, time of day, and phone battery status [22]. Although most of those features can be calculated in real-time on an iOS device, one particular feature, location type (like home, work or transit), is more complicated. To accurately compute the location type, algorithms need several weeks of location data to meaningfully cluster and derive categories of location (such as ‘home’ or ‘work’). In our 2–3 week study there was insufficient data to derive the location-type feature; furthermore, we had found that (for Ally) iOS users’ location type showed no significant associations with any receptivity metric [22]. We thus decided not to include location type as a feature in our models.
A list of features used in our models is shown in Table 1.
Table 1.
List of features used in our models.
| Category | Features | Type |
|---|---|---|
| Date/Time | Type of day | Categorical (weekday/weekend) |
| Time of day | Categorical (morning, afternoon, evening) | |
|
| ||
| Phone Battery | Battery Status | Categorical (charging, discharging, full) |
| Battery Level | Numerical (1%−100%) | |
|
| ||
| Device Interaction | Lock State | Categorical (locked, unlocked) |
| Lock change time | Numerical (in seconds) | |
| Wi-Fi connection | Categorical (connected, disconnected) | |
|
| ||
| Activity | Physical Activity | Categorical (still, on foot, on bike, running in vehicle) |
4.2.2. The Static and Adaptive Models.
We implemented two machine-learning models in Ally+, our iOS app. We trained the static model before deployment (using data from the previous Ally study) and used it, unchanged, for all participants and all days throughout the study. The adaptive model used the receptivity data of individual participants as they progressed through the study; it was re-built (within the app) every time a new receptivity the system trigerred the adaptive model.
Both these models were trained to predict just-in-time response. While we use several metrics of receptivity in our work, the main emphasis is on the presence of a just-in-time response. For completeness, however, we report the effect of our models on the various receptivity metrics.
We next provide the details of each model.
Static Model:
We used CoreML to build and integrate the static model with the iOS app [1]. We split the original Ally iOS data (with 141 users) into five equal non-overlapping groups. We used Leave-One-Group-Out (LOGO) cross-validation to evaluate two built-in models within CoreML – MLRandomForestClassifier and MLSupportVectorClassifier. These classifiers are CoreML’s implementation of RandomForest and SVM, respectively.
We tuned the models to have higher recall, since we wanted Ally+ to recognize most opportune moments, even if it was at the cost of precision. We compared the models with a random classifier as a baseline and chose the model that demonstrated a greater improvement in F1 score. The SVM classifier achieved a mean F1 score of 0.36, whereas the random baseline classifier achieved only F1 score of 0.25, which is an improvement of 40% over the baseline. The RandomForest classifier achieved a mean F1 score of 0.33, only 32% improvement over baseline. We thus chose the SVM classifier as the static model to be included in our app. We show the comparison between Precision, Recall and F1 score of these three models in Figure 3.
Fig. 3.

Comparison of the different models. All models were evaluated using 5-fold LOGO cross-validation
Adaptive Model:
Implementing the adaptive model was more complicated because we needed to re-build the model every time a new receptivity data point was available. In iOS 13, Apple added functionality to update CoreML models on-the-fly. Because iOS 13 was released just a couple of months before our study, however, we chose not to depend on this new feature of CoreML. To do so may have unnecessarily narrowed our potential participant population by excluding those who had not yet updated to the latest iOS version. We instead used an open-source library called AIToolBox [7]. This library, however, had not been modified in a few years, so we had to make significant changes to make it compliant with the newer versions of iOS and Swift. Since the adaptive model would be re-trained for every notification, we wanted a model that would not be resource-intensive while being re-trained. Based on preliminary tests, Logistic Regression (LR) had the fastest training time on the device, without significantly sacrificing detection performance.
In the adaptive model, the participant’s recent receptivity data was added to the model’s training dataset to help with future detection. Given the structure of our study, however, each participant was prompted at most three times per day and there were thus few data points even after seven days. We thus followed a ‘dual-model’ approach: the adaptive model’s output probability was the average of the output probability from ‘P1’, an LR model trained on data from the prior Ally study, and ‘P2’, an LR model trained on the participant’s personalized data accumulated thus far.6 If the output probability was greater than 0.50, the adaptive model classified that instance as ‘receptive’. This dual-model approach enabled us to introduce a degree of personalization without being concerned about high variance of the personalized model developed from a limited set of data points.
As ours is one of the first works to deploy adaptive models to detect receptivity, we made several decisions based on what we thought might work. We considered the possibility of adding data to a single batch and training a single model. In our case, the base P1 model had 600 data points. Based on our study design, over the course of the study, each participant was expected to receive between 40–50 initiating messages. Since, at best, there would be fewer than 10% participant-specific data points in our base model, we did not know the extent to which a single model would learn participant-specific characteristics from the data. Hence, we decided to use a dual-model approach.
To assign weights to the individual models, a sophisticated approach would be to initially start out with a low weight on the personalized component and increase the weights as data is accumulated over time. This method, however, needed more decisions to be made, like what the starting weights should be, or whether weights should vary based on the number of days in the study or the number of available instances, or what degree should the weight vary with new data. Lack of any prior work in this domain made these decisions non-trivial. Hence, as an exploratory evaluation we decided to start with fixed weights for each model for the duration of our study. Further, due to lack of a better choice, we assigned a weight of 0.5 to each model. Our rationale was that equal weights would help handle disagreements between the models, e.g., if P2’s output probability was 0.90, and the P1’s output probability was 0.20 (or vice-versa), then equal weights ensured that adaptive model would trigger an alert.
We trained the P1 model using data from the previous Ally study. To ensure the model was light enough to run on the phone, we had to under-sample our training data.7 We chose the Instance Hardening Threshold (IHT) method, which generates a balanced under-sampled dataset by eliminating instances that are frequently misclassified, i.e., have high instance hardness [41]. We evaluated the P1 model by LOGO cross-validation with the same non-overlapping groups we used for evaluating the static model. See Figure 3; P1 achieved an F1 score of 0.31, which is slightly lower than the F1 score for the static model, perhaps because P1 used LR whereas the static model used SVM, or perhaps because we had to train P1 on a trimmed dataset.
To evaluate the effectiveness of P2, we ran simulations over the previously collected Ally data. During each fold of the 5-Fold cross-validation, we used the 20% users data to simulate the effectiveness of the P2 model. We used the P1 model trained on the 80% of users in each fold. We evaluated P2 on the entire study duration of each participant, which was a maximum of 6 weeks. It is worth noting that while we conducted the previous Ally study for 6 weeks, there were several participants who dropped out before completing the the full 6 weeks. The new result is shown as ‘Adaptive (P1 & P2) in Figure 3. We observe that the complete adaptive model led to an F1 score of 0.38, which is a 52% improvement over the random baseline. However, there is much higher deviation in the Adaptive model as compared to the other models. We believe this is because of the difference in the participation duration of each participant, thus resulting in varied performance of the P2 model.
Please note the purpose of deploying both static and adaptive models was not to compare these models with each other, but instead to observe (a) how did each model perform compared to the control model, and (b) how did the performance of the adaptive model change over time?
4.3. Study Logistics and Procedure
Unlike the Ally app, the Ally+ app was released only for iOS users. Also, instead of releasing it through the App Store, we used Apple’s in-house distribution program to distribute the apps to the participants, who could download the app by navigating to a specific webpage. Since the goal of the study was to evaluate participant receptivity, we did not want to bias the participant’s interaction and usage of the app by providing monetary incentives for using the app or for engaging with the app. Instead, our study strategy used ‘deception’ to mask the actual goals of the study. During recruitment, we told the participants the goal of the study was to understand how different contexts affect the physical activity levels of a person throughout their day. We asked participants to interact naturally with the Ally+ app and compensated them the equivalent of USD 25 if they installed the app for at least two-thirds of the study duration, i.e., 14 days.
The study protocol (including the use of deception) was approved by the Institutional Review Board (IRB) of the respective institutions. As required by the IRB, at the end of the 3-week period we emailed the participants informing them of the real goal of the study with an explanation of why deception was needed.
We used Facebook advertisements to reach potential participants, with the hope of reaching a diverse participant pool. Our search criteria was set to adults over 18 years, and belonging to a single timezone (due to technical limitations). Participants who clicked on the advertisement were taken to a landing page where we explained the study; and if interested, people could digitally sign the consent form. Once the consent form was signed we emailed the app download link and instructions to the prospective participants. The Facebook advertisement had a reach of over 30,000 people, out of which over 750 participants were redirected to our landing page; of those, 189 interested people filled out the consent form, of which 83 users downloaded the app and started the intervention. Of the 83 participants, 64 were female and 19 were male. The median age was 30 years ±10.8 years. We had a staggered recruitment approach, and not all participants had the same start and end dates. While each participant was enrolled in the study for 3 weeks, our total data-collection period spanned a period of 6 weeks (between September 2019 and November 2019). We show a detailed demographic breakdown of participants along with their average response rates in Table 2.
Table 2.
Participant demographics with average response rates.
| Male | Female | Undisclosed | Total | |
|---|---|---|---|---|
| Showed interest in participating | 47 | 142 | 1 | 190 |
|
| ||||
| Installed the app | 19 | 64 | 0 | 83 |
| Age | 34 ± 11.7 | 30 ± 10.6 | 30 ± 10.8 | |
| Overall response rate | 69.45% | 70.67% | 70.39% | |
Prior research papers on ‘receptivity for interventions’ and ‘interruptibility to phone notifications’ have defined a ‘participant selection criteria’ and included only data from those selected participants in their analysis [6, 22, 27, 36], like response to at least 14 questionnaires [27], or data collection for at least 10 days and 20 responses [36], or top 95 percentile of users who responded [22]. In our work, however, we avoid use of any such selection criteria and report results for data from all the 83 users for most of the analysis. Across the 83 users, we had 1091 messages delivered by the control model, 691 messages delivered by the static model, and 241 messages delivered by the adaptive model; resulting in a total of 2023 delivered messages. We present a distribution of the number of times each model was used to deliver a message over the course of the study in Figure 4.
Fig. 4.

Daily distribution of the models used to trigger intervention alerts.
4.4. Problem with Deployment
Approximately two or three weeks from the start of data collection we realized the adaptive model was never getting triggered for participants. Even after the initial 7 days, the Ally+ app was triggering only the control and static models, because a bug was preventing the app from triggering the adaptive model. We fixed the bug, and released an update and asked all users to update to the new version. Unfortunately some users had already completed their study duration, whereas others did not update the app. In the end, we eventually had only 61 users who received one or more initiating messages through the adaptive model. For these 61 users, we had 785 messages delivered by the control model, 541 messages delivered by the static model, and 241 messages delivered by the adaptive model, leading to a total of 1567 delivered messages.8
5. OUR HYPOTHESES
Before evaluating the results, we formed the following hypotheses based on our expectation of the outcomes if the models performed as intended.
For RQ-1,
H-1: We hypothesize that on a population level, across all initiating messages, there would be a significant difference in receptivity across the three delivery models. The static and adaptive models should both have significantly higher receptivity than the control model.
For RQ-2,
H-2: We hypothesize that individual participants would have higher receptivity when interventions were delivered through the static and adaptive models, as compared to the control model.
For RQ-3,
H-3: We hypothesize that the receptivity to interventions delivered by the static model would remain constant over the course of the study.
H-4: We hypothesize that the receptivity to interventions delivered by the adaptive model would increase as the study progressed.
Note that while the hypotheses mention receptivity, our primary focus is on just-in-time response. For completeness, however, we also report the other metrics of receptivity, which we term “secondary metrics”. Hence, based on the type of metric, “better” receptivity would mean an increase in just-in-time response rate, increase in response rate, increase in conversation engagement rate, and a decrease in response delay.
6. EVALUATION
In this section we analyze the receptivity data and evaluate our hypotheses. For clarity, we break the evaluation into three parts, to reflect the three research questions we seek to answer. Note, we adjusted all the p-values to account for multiple comparisons: we used the Benjamini-Hochberg (BH) procedure [5] to correct for the expected proportion of Type I errors (or False Discovery Rate) across all hypotheses.
6.1. Exploring RQ-1
On a population level, i.e., across intervention messages and across all users, does delivering interventions at a ML-detected time lead to higher receptivity than delivering interventions at a random time?
We start by analyzing the receptivity metrics for each initiating message. We fit a binomial Generalized Linear Model (GLM) to evaluate the associations the ML models had on just-in-time response as compared to the control model.9 We found that the different delivery modes (control, static, and adaptive) had a significant effect on the just-in-time response (χ2(2) = 23.189, p < 0.001).10 On post-hoc analysis with Dunnett’s Test, we observed that the static model showed a significant improvement of over 38% in just-in-time receptivity when compared to the control model (p < 0.001). The adaptive model had an improvement of more than 15% over the control model, but the improvement was not significant (p = 0.271).
Next, we discuss the secondary metrics; we observed that the type of machine-learning model had a significant effect on the likelihood of “response”, i.e., if the participant ever responded to the initiating message (irrespective of time), χ2(2) = 15.001, p = 0.003. Post-hoc analysis with Dunnett’s Test revealed that, when compared with the control model, both the static and adaptive models led to a significant increase in likelihood of response, of approximately 12% each (p = 0.003 and p = 0.048, respectively). This is an interesting observation as it suggests that participants were more likely to respond to initiating messages that were generated through the static and adaptive models as compared to the control model, even though the adaptive model did not lead to a significantly higher likelihood of just-in-time response. Further, the type of machine-learning model showed a significant effect on conversation engagement, χ2(2) = 18.741, p = 0.001. Post-hoc analysis revealed that the static model led to a 34% increase in the likelihood of conversation engagement relative to the random model (p < 0.001). As in the case of just-in-time response, the adaptive model did not result in a significant improvement in conversation engagement, with an increase of 12% over the control model (p = 0.439). Finally, for response delay, one-way ANOVA did not reveal a significant effect of model type, F (2, 1382) = 1.576, p = 0.310; we nonetheless conducted Dunnett’s test to observe the differences. Although the difference was not statistically significant, the static model – on average – led to a slightly shorter response delay of 16 minutes, about 17% faster than in the control model. The adaptive model did not show any differences as compared to the control model. We present the detailed results in Table 3.
Table 3.
Detailed analysis across all initiating messages. We report the absolute change of the static and dynamic models over the control model, along with the percentage improvement in brackets.
| Comparison | Mean Difference (% change) | Std. Error | 95% Confidence Interval |
Adj. | p-value | |
|---|---|---|---|---|---|---|
| Lower Bound | UpperBound | |||||
|
Just-in-time response (as likelihood; control = 0.284) | ||||||
| static – control | +0.108 (+38.02%) | 0.022 | 0.057 | 0.164 | <0.001 | *** |
| adaptive – control | +0.044 (+15.49%) | 0.033 | −0.034 | 0.122 | 0.270 | |
|
| ||||||
|
Overall response (as likelihood; control = 0.656) | ||||||
| static – control | +0.080 (+12.19%) | 0.022 | 0.028 | 0.133 | 0.003 | ** |
| adaptive – control | +0.077 (+11.73%) | 0.032 | 0.006 | 0.154 | 0.048 | * |
|
| ||||||
|
Conversation engagement (as likelihood; control = 0.268) | ||||||
| static – control | +0.093 (+34.70%) | 0.022 | 0.045 | 0.150 | <0.001 | *** |
| adaptive – control | +0.030 (+11.19%) | 0.032 | −0.044 | 0.109 | 0.439 | |
|
| ||||||
|
Response delay (in minutes; control = 90.530) | ||||||
| static – control | −16.670 (−18.41%) | 9.465 | −38.870 | 5.532 | 0.144 | |
| adaptive – control | −4.006 (−4.42%) | 13.733 | −36.227 | 28.213 | 0.819 | |
. p < 0.1,
p < 0.05,
p < 0.01,
p < 0.001
6.2. Exploring RQ-2
How does receptivity of individual users change when interventions are delivered through ML-based intervention timing vs. at random times?
While investigating the hypotheses for RQ 1, we found that overall, across the population, the static model led to a significant improvement in just-in-time response, overall response, and conversation engagement. While such an analysis provides a good representation of receptivity across all users, our second research question aimed to evaluate within-participant differences when they received a static or adaptive model as compared to the control model. The goal is to evaluate whether an individual participant’s receptivity changed based on the model used to deliver the initiating message.
We used generalized linear mixed effects models for our analysis. Since the goal was to observe how individual participant’s receptivity changed based on the model used to deliver the message, each user should receive at least one message through each model for a proper comparison. As noted in Section 4.4, however, a software problem meant only 61 participants received at least one initiating message through the adaptive model. Hence, for this analysis, we included data only from these 61 participants.
We observed that the model type had a significant effect on the just-in-time response rate (χ2(2) = 13.433, p = 0.001). On post-hoc analysis, we observed that the static model showed a significant improvement of over 36% in just-in-time receptivity when compared to the control model (p = 0.002). This result suggests that if a participant received a prompt from the static model, they were more likely to be receptive than if the same participant received the prompt through the control model. The adaptive model led to an increase of almost 10% over the control model, but the result was not significant (p = 0.558).
For the secondary metrics, we observed that the type of model had an effect on the likelihood of response (χ2(2) = 8.364, p = 0.00). Post-hoc analysis revealed that only the static model had a significant improvement over the control model, with an improvement of almost 10% (p = 0.015). Further, our analysis showed that the model type had a significant effect on the likelihood of conversation engagement (χ2(2) = 10.407, p = 0.017), with post-hoc analysis revealing that the static model led to an improvement of over 32% in the likelihood of conversation engagement over the control model (p = 0.007). Finally, using a repeated measures ANOVA, we did not find any significant effect of model type on the response delay. Although not statistically significant, the static and adaptive model led to a 20% and 13% reduction in time taken to respond to interventions, respectively. We present the detailed findings in Table 4.
Table 4.
Detailed analysis to understand within-participant differences. We report the absolute change of the static and dynamic models over the control model, along with the percentage improvement in brackets.
| Comparison | Mean Difference (% change) | Std. Error | 95% Confidence Interval |
Adj. | p-value | |
|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | |||||
|
Just-in-time response (as likelihood; control = 0.276) | ||||||
| static – control | +0.101 (+36.60%) | 0.033 | 0.035 | 0.170 | 0.002 | ** |
| adaptive – control | +0.027 (+9.58%) | 0.041 | −0.044 | 0.109 | 0.558 | |
|
| ||||||
|
Overall response (as likelihood; control = 0.738) | ||||||
| static – control | +0.072 (+9.75%) | 0.028 | 0.015 | 0.116 | 0.015 | * |
| adaptive – control | +0.031 (+4.20%) | 0.038 | −0.046 | 0.092 | 0.493 | |
|
| ||||||
|
Conversation engagement (as likelihood; control = 0.261) | ||||||
| static – control | +0.084 (+32.18%) | 0.034 | 0.021 | 0.153 | 0.007 | ** |
| adaptive – control | +0.009 (+3.44%) | 0.040 | −0.057 | 0.089 | 0.819 | |
|
| ||||||
|
Response delay (as minutes; control = 99.500) | ||||||
| static – control | −19.950 (−20.05%) | 11.725 | −39.500 | 3.500 | 0.124 | |
| adaptive – control | −13.830 (−13.89%) | 13.585 | −41.000 | 13.500 | 0.439 | |
. p < 0.1,
p < 0.05,
p < 0.01,
p < 0.001
Further, when we added a random slope for ‘model type’ to the mixed effects model, a comparison between the two did not reveal any difference (p = 1.00), thus suggesting that the within-participant differences were similar across all participants. These results are promising, and indicate that individual participants were more receptive when they received prompts by the static model as compared to the control model.
Given our inclusion criteria for this analysis, we have some users who received just one message from the adaptive model. It can be argued that including such users might introduce some outliers in our data, which might affect the analyses. However, given the lack of a better (and scientifically justifiable) inclusion criteria, we nonetheless included users who received only one message. To explore how a more stringent criterion would affect the results, we briefly analyzed the data from participants who received at least 5 messages in each category. Doing so ensured that we only included participants who were active (or stayed) in the study for a longer duration. We observed that the static model led to a significant increase in the just-in-time response rate, over 40% higher than the control model. This result suggests that the difference in models becomes more prominent as we evaluate the more “active” users. In a way, our results (presented in Table 4) can be thought of as the “worst-case” results.
6.3. Exploring RQ-3
How do the different models for predicting receptivity perform over time?
As we report in the preceding sections, the messages delivered by the static model led to receptivity metrics that were significantly higher than those the control model, for most situations. The adaptive model, however, did not seem to perform significantly better. Those results were based on an analysis across the full study period. A day-by-day analysis, however, may provide more insights regarding whether and how the adaptive model’s performance changed over the days – in short, whether it adapted well to each participant. This analysis also helps to evaluate our third research question. Given the nature of the adaptive model, we expected it to improve over time as more individual-specific data was added to the model.
To this end, we added a new variable – the participants’ day in study (from day 1 to day 21) – as an interaction effect to the binomial generalized linear mixed effects model used for RQ-2. To best understand and vizualize the results, we plot the effects of the model types over time as estimated from mixed effect model in Figure 5. While visualizing the trends, it is important to note that the confidence interval for the adaptive model is quite wide for the first few days, because the adaptive model was not triggered till day 8 and hence no actual data points for the adaptive model during that period.
Fig. 5.
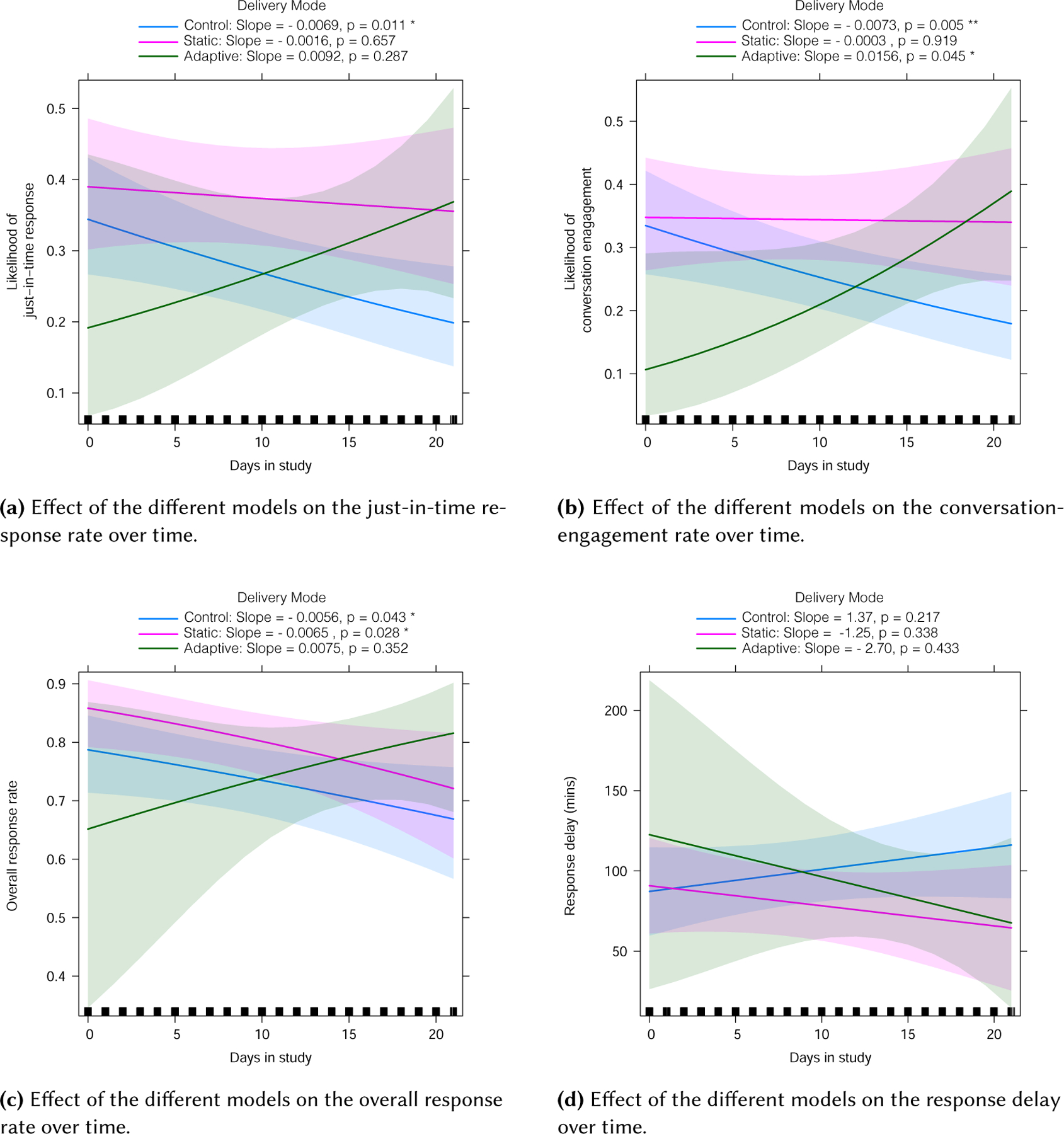
The performance over time of the models on the receptivity metrics. The adaptive model was only activated starting day 8; the dotted lines represent the projection of the trend for the adaptive model from day 1 to day 7.
As the study progressed, we found that the just-in-time response rate dropped significantly for the control model (p = 0.011) (Figure 5a). For the static model, there was a slight downward trend, but it was not significant. For the adaptive model there was a steep upward trend with a slope of 0.0092, suggesting that the just-in-time response to adaptive model increased by almost 1 percentage-point each day; this trend was not statistically significant (p = 0.287). The observation – although not statistically significant – is encouraging, suggesting that the adaptive model was able to learn and personalize over time, and eventually improving the just-in-time response. In fact, after day 19, the adaptive model seems to have had higher just-in-time response rate than the static model. Further, on Day 21, the adaptive model had an increase of over 51% in just-in-time response rate as compared to Day 8.
Looking at the conversation-engagement rate (Figure 5b), the control model showed a significant downward trend (p = 0.005), suggesting that for messages delivered by the control model, the conversation-engagement rate declined over the course of the study. The static model had a slight, yet insignificant, downward trend, similar to the just-in-time response rate. The adaptive model had a significant positive trend (p = 0.045), with a slope of 0.0156, which translates to a 1.56 percentage-point increase in conversation-engagement rate each day. This result further supports our expectation that the adaptive model would be able to learn from the personalized data and improve itself. Although conversation engagement was not the primary metric of focus, it still is an important part of the overall concept of receptivity, especially to chat-based interventions like Ally.
Next we evaluated the effect on the overall response rate (Figure 5c). Consistent with the two previous metrics, the control model had a significant downward trend, suggesting that overall response rate for messages delivered by the control model decreased over the course of the study (p = 0.043). The static model was more interesting: although the just-in-time response rate to messages from the static model did not reduce over the days, there was a decline in the overall response rate (p = 0.028). The static model led to a higher just-in-time response rate than the control model, and kept it high as the just-in-time response rate for the control model fell over time. However, just like the control model, if the participant did not respond just-in-time, the overall response rate reduced over the days, following the trend of attrition common in mobile sensing and mHealth studies [42, 45].
The adaptive model was able to maintain a satisfying response rate throughout.
Finally, for response delay (Figure 5d), we did not discover a trend that was significant in any of the three models. We make several encouraging observations, however. At the beginning, the response delay for the control and static models was approximately the same, but they diverged as the study progressed; the control model had an increasing trend, whereas the static model had a decreasing trend, suggesting that the participants’ response time to the static model improved as the study progressed. The adaptive model shows an even steeper improvement, with a slope of −2.70, suggesting an improvement of almost 3 minutes each day. It is important to note that the results for response delay were not significant, and more research is needed.
6.4. Summary of Results
Based on our analysis of RQ-1 and RQ-2, our first two hypotheses (H-1 and H-2) were partially true. The static model led to a significant improvement over the control model in just-in-time response rate, overall response rate, and conversation engagement. The adaptive model led to slight improvements over the control model, though the results were not significant. The results for RQ-3 provide some insights on the lack of significant improvement in the adaptive model. As shown in Figure 5, the receptivity to the adaptive model started similar to that of the control model, but it kept improving as the study progressed, although the average over the study was not significantly higher than the control model.
Furthermore, we observed that after Day 19, the just-in-time response rate from the adaptive model was higher than that from the static model. Similarly, after Day 18, the conversation engagement from adaptive model was higher than that from the static models. While these are encouraging results that indicate the adaptive model continued to improve over time, in our short study we could not observe the trend over a longer period of time. We hypothesize the adaptive model would continue to improve beyond Day 21, outperforming the static model, although it would eventually plateau. We anticipate future research will be able to test this hypothesis.
7. DISCUSSION
In our work, we show that machine-learning models can be used to predict receptivity to interventions. We found that intervention alerts delivered by a static model performed significantly better than delivering interventions at random times. Further, we found that receptivity to an adaptive model – which learnt user specific features over the course of the study – improved as the study progressed. In this section, we discuss the implications of our results in three broad categories, along with the limitations, and future directions for each.
7.1. Domain-specific Models to Detect Receptivity
In prior work, Mehrotra et al. found that notification category was one of the top features to determine whether users would react to notifications [26], thus highlighting the importance of who or what is sending an alert. Along with who and what is sending an alert, Visuri et al. showed that the actual content of a prompt is also important [43]. Using a semantic analysis of a notification’s content (along with contextual features) drastically improved the detection of opportune moments to smartphone notifications [43]. These findings show the importance of the content of a notification and could potentially affect the generalizability of ML models to different interventions.
In our work, we considered receptivity to the initial greeting message. The initial message was a generic greeting message like “Hello [participantName]” or “Good morning [participantName]”. Only after the participants replied back to the greeting did the actual intervention conversation start. Since the receptivity to interventions was not affected by the content of intervention, we argue that our results and models could be generalizable to other JITAIs with a similar level of intervention engagement, or to other JITAI that use chatbots for digital coaching. However, more deployments with different intervention types are needed to get a better sense of generalizability of our results.
It is important, however, to be mindful of the findings by Mehrotra et al. [26] and Visuri et al. [43]. We do not know whether and how our results might generalize to interventions that are more involved, or require the user to actively perform some task, e.g., to take 10 deep breaths or to take some medications. More research is needed, especially in the domain of cognitive availability, to explore how receptivity changes with intervention burden.
7.2. Dependence on Intervention Design and Effectiveness
Based on the definition of JITAI proposed by Nahum-Shani et al. [32], receptivity can be considered a tailoring variable, which indicates whether a user is available to receive an intervention at any given time. For receptivity to be an informative parameter, it is imperative that the actual intervention being delivered is effective. Intervention designs that are ineffective or cumbersome might not lead to engagement, regardless of whether a user is available to receive the information.
We used an intervention design similar to that proposed by Kramer et al. [19, 20]. Although evaluating the effectiveness of interventions is beyond the scope of this paper, Kramer et al. found that when compared to a baseline (no intervention) period, on average the participants in their study significantly improved their daily step counts by 438 steps [20].
Another aspect to consider is the determination of a time-window for receptivity. Based on prior work by Künzler et al. [22] and Mehrotra et al. [26], in our exploratory work we considered receptivity to interventions if a participant responded to an intervention message within 10-minutes of delivery. We believe that the choice of the time-window to determine receptivity would eventually depend on the intervention type and what is considered as an acceptable receptive duration for that intervention. Some time-critical intervention designs might require response within a 1-minute window to be considered “receptive”, whereas others might consider a 1-hour response time acceptable. Depending on what is considered receptive, the models and their subsequent performance could significantly change. As a preliminary evaluation, we used the previous Ally data and tested feasibility of models with other window sizes (1 minute, 3 minutes, and 5 minutes). We found that for each of these windows, the machine-learning models consistently out-performed the random baseline classifier. For instance, the F1-score of the random classifier for the 1-minute window was 0.11, whereas the SVM model had an F1-score of 0.18, an improvement of over 60%. Hence, it seems that training models for different time-windows is feasible, and we plan to explore receptivity to varying time-windows further in future work and delve deeper into the influence of intervention design and intervention effectiveness on receptivity-detection models.
7.3. Personalized Models to Detect Receptivity
In prior work, Morrison et al. deployed a mobile stress-management intervention system, where they built personalized Naive Bayes models to deliver interventions at opportune moments [30]. They found, however, that there was no difference in how the participants interacted with notifications at opportune times vs. those delivered at random times. One reason could be that they used a static personalized model trained after an initial “learning period.” It is possible that the model did not have enough data to be adequately trained, i.e., the cold-start problem.
Our results show that the adaptive model (which followed a dual-model approach) started with poor performance, but the performance improved as more data was available. Further, even in our results, we observed that the adaptive model did not perform significantly better than the control model if we considered the entire study duration (RQ-1 and RQ-2). It was when we evaluated the day-by-day performance (RQ3), did we notice the increasing trend. These results suggest that personalized models can improve over time with more data. Further, given that the static model performed significantly better over the control model, a dual-model solution could be appropriate to deal with the cold-start problem. We discuss some potential approaches in the next section.
7.4. Building better Models
As an exploratory study, our work used several in-the-moment contextual features, like phone battery level, device interaction, date/time, and physical activity. Since our models led to significantly higher receptivity than a random model, it is natural to question whether incorporating more features could further improve receptivity. In our work, we did not consider the location of a user; although in our prior work we did not find any significant association between a user’s location and his/her receptivity, several other works have noted the effect of location type on notification engagement [36, 39]. Other features like demographic information [22, 36, 37] and personality traits [22, 27] have shown to correlate with receptivity and interruptibility.
Further, our results show that the performance of the adaptive model improved as the study progressed. This is one of the first works to show the improvement of an adaptive model to detect receptivity in a real-world deployment, and highlights the potential of deploying adaptive models that can be tuned to each participant for optimal performance in the long term. In our work, the adaptive model included two models (P1 & P2), and both had equal weights. Given the promising results, we now hope to explore models with adaptive weights based on the relative number of data points to train each model; thus, initially P1 would have a higher weight, but over time as P2 accumulates more data points its weight would increase and eventually be higher than P1. In the future, we plan to understand how adding new features would affect model performance, and explore what type of adaptive model might be best, how to best change the weights of a personalized model, and also how to determine the optimal number of days to enable the personalized component.
Finally, although our results are promising, they are still preliminary. We had 83 users in our study who participated for only 3 weeks; most behavior change programs last longer than 3 weeks. Hence, more research is needed to evaluate model performance and how receptivity changes over a longer period of time.
8. IMPLICATIONS ON JITAI DESIGN
As highlighted in Section 3.2, a JITAI has six key elements: a distal outcome, proximal outcomes, decision points, intervention options, tailoring variables, and decision rules. Our results show that it is indeed possible to detect receptivity. Hence future studies could design JITAIs such that the intervention components and decisions rules can account for receptivity as a tailoring variable before making a determination on whether to deliver an intervention.
In our work, we considered receptivity as a binary outcome, i.e., a person is either receptive or not. This is just the first step towards enabling effective delivery of interventions. We argue that receptivity is a spectrum and not an absolute yes/no. It could be possible that – in a given moment – a person is receptive to a particular type of intervention and be non-receptive to a different type of intervention. Given the promising results in our study, we lay solid groundwork for future researchers to move forward to other dimensions of receptivity. The treatment of receptivity as a spectrum would enable intervention designers to decide not only if an intervention should be delivered but also what interventions to deliver in that moment – JITAIs could be developed that consider the degree of vulnerability (tailoring variable), the level of receptivity (tailoring variable), and the expected effectiveness of various interventions (intervention options) and decide which intervention to maximize the distal and proximal outcomes.
9. SUMMARY AND CONCLUSION
We conducted a study in which we deployed machine-learning models that detect momentary receptivity in the natural environment. We leveraged prior work in receptivity to JITAIs and deployed a chatbot-based digital coach – Ally+ – that provided physical-activity interventions and motivated participants to achieve their step goals. The Ally+ app was available for iOS and included two machine-learning models that used information about the app user’s context to predict whether that person was likely to be receptive at that moment. We used two types of machine-learning models: (a) a static model, that was built before the study started and remained constant for all participants and all time; and (b) an adaptive model, that continuously learnt the receptivity of individual participants and updated itself as the study progressed. For comparison, we deployed (c) a control model that sent intervention messages at random times. The choice of model to be used for delivery was randomized for each intervention message. We observed that messages delivered using the machine-learning models led up to a 40% improvement in receptivity as compared to the control model. Further, we evaluated the temporal dynamics of the different models over time, and observed that while the receptivity to messages from the control model declined, receptivity to messages from the adaptive model increased over the course of the study.
CCS Concepts:
Human-centered computing → Ubiquitous and mobile computing
Applied computing → Health care information systems.
ACKNOWLEDGMENTS
The authors thank the anonymous reviewers and editors for their helpful feedback. This research results from a joint research effort of the Centre for Digital Health Interventions at ETH Zürich and the Center for Technology and Behavioral Health at Dartmouth College. It was supported by the NIH National Institute of Drug Abuse under award number NIH/NIDA P30DA029926, and by CSS Health Insurance, Switzerland. The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.
Footnotes
During the first 7 days, the app randomly chose between the control and static models. After 7 days, the app randomly chose between the control, static, and adaptive models.
We chose a 10-minute window to remain consistent with our prior work, where we also used a 10-minute window to define the receptivity metrics [22]. Further, prior work by Mehrotra et al. found that smartphone users accept (i.e., view the content of) over 60% of phone notifications within 10 minutes of delivery, after which the notifications are left unhandled for a long time. They concluded that the maximum time a user should take to handle a notification arriving in an interruptible moment is 10 minutes [26]. Since ours is one of the early works to deploy receptivity detection models, we decided to follow this evidence and also use a 10-minute window.
A receptive moment is one at which the model predicts that the participant will respond to the initiating message within the next 10 minutes.
It is important to note that the app only delivered one prompt for each initiating message, either immediately after receiving the silent push from the server, or after 5, 10, 15, 20, 25, 30, or 31 minutes after the initial silent push, depending on the delivery mode and detection of receptive moments. There were no reminder prompts.
It can be argued that a notification delivered at the 31st minute might not be exactly like ‘control’, since a machine-learning model has already passed it as non-receptive. We argue, however, that since the ‘control’ model delivers notifications at random times, and since 31 minutes later than a random time is still a random time, it can be assumed that the ‘control’ model delivered the notification. The goal of this work is to distinguish between moments identified as receptive by the machine-learning models and random moments.We argue all moments are either receptive or random, and the machine-learning models simply identify receptive moments from a series of random moments.
We explain the rationale for a dual-model approach in the supplementary document.
Unlike CoreML, which we used for the static model, the AIToolBox library does not export a pre-built model. The library trains and re-builds the model every time classification tasks need to be performed. Hence we had to include a trimmed version of the training data in the app so that the P1 model could train itself.
Given our intervention design, 1567 messages might seem less for 61 participants receiving and average of 2.5 messages per day for 21 days. However, we had several participants who dropped out over the course of the study. Since we did not want to enforce an arbitrary “inclusion criteria” – based on the number of days or the number of messages – we decided to follow an intention-to-treat approach and included all participants who installed the app and started the study in our analysis.
We choose the appropriate test based on the type of the dependent variable. We used a binomial GLM for the just-in-time response, response, and conversation-engagement metrics. We used a one-way Analysis of Variance (ANOVA) for response delay. From a typical statistical analysis perspective, it may initially seem that a population level analysis (across all intervention messages) violates the independence assumptions of GLM. However, it is important to consider the research question we aim to answer, i.e., how did the static and adaptive models perform when compared to the control model, across all intervention prompts. We argue that, from a machine-learning model’s perspective, each new prediction is independent of prior predictions and hence can be considered independent. Thus, in this regard we are not violating the assumption for GLM. Such population level analyses is consistent with prior works in receptivity [22] and interruptibility [25, 27].
The Chi Square test compares the GLM to a null model.
Contributor Information
VARUN MISHRA, Dartmouth College.
FLORIAN KÜNZLER, ETH Zürich.
JAN-NIKLAS KRAMER, University of St. Gallen.
ELGAR FLEISCH, ETH Zürich and University of St. Gallen.
TOBIAS KOWATSCH, ETH Zürich, University of St. Gallen, and National University of Singapore.
DAVID KOTZ, Dartmouth College.
REFERENCES
- [1].Apple. 2020. CoreML https://developer.apple.com/documentation/coreml. [Online; accessed 04-February-2020].
- [2].Avrahami Daniel and Hudson Scott E. 2006. Responsiveness in instant messaging: predictive models supporting inter-personal communication. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) ACM, 731–740. [Google Scholar]
- [3].Bauer Stephanie, Niet Judith de, Timman Reinier, and Kordy Hans. 2010. Enhancement of care through self-monitoring and tailored feedback via text messaging and their use in the treatment of childhood overweight. Patient education and counseling 79, 3 (2010), 315–319. [DOI] [PubMed] [Google Scholar]
- [4].Ben-Zeev Dror, Brenner Christopher J, Begale Mark, Duffecy Jennifer, Mohr David C, and Mueser Kim T. 2014. Feasibility, acceptability, and preliminary efficacy of a smartphone intervention for schizophrenia. Schizophrenia bulletin 40, 6 (2014), 1244–1253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Benjamini Yoav and Hochberg Yosef. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological) 57, 1 (1995), 289–300. [Google Scholar]
- [6].Choi Woohyeok, Park Sangkeun, Kim Duyeon, Lim Youn-kyung, and Lee Uichin. 2019. Multi-Stage Receptivity Model for Mobile Just-In-Time Health Intervention. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol 3, 2, Article 39 (June 2019), 26 pages. 10.1145/3328910 [DOI] [Google Scholar]
- [7].Coble Kevin. 2020. AIToolBox https://github.com/KevinCoble/AIToolbox. [Online; accessed 04-February-2020; Git commit bada633].
- [8].Consolvo Sunny, McDonald David W, Toscos Tammy, Chen Mike Y, Froehlich Jon, Harrison Beverly, Klasnja Predrag, LaMarca Anthony, LeGrand Louis, Libby Ryan, et al. 2008. Activity Sensing in the Wild: A Field Trial of UbiFit Garden. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) ACM, 1797–1806. [Google Scholar]
- [9].Dingler Tilman, Weber Dominik, Pielot Martin, Cooper Jennifer, Chang Chung-Cheng, and Henze Niels. 2017. Language Learning On-the-Go: Opportune Moments and Design of Mobile Microlearning Sessions. In Proceedings of the 19th International Conference on Human-Computer Interaction with Mobile Devices and Services (Vienna, Austria) (MobileHCI ‘17). Association for Computing Machinery, New York, NY, USA, Article 28, 12 pages. 10.1145/3098279.3098565 [DOI] [Google Scholar]
- [10].Filler Andreas, Kowatsch Tobias, Haug Severin, Wahle Fabian, Staake Thorsten, and Fleisch Elgar. 2015. MobileCoach: A novel open source platform for the design of evidence-based, scalable and low-cost behavioral health interventions: overview and preliminary evaluation in the public health context. In Wireless Telecommunications Symposium (WTS), 2015 IEEE, 1–6. [Google Scholar]
- [11].Fischer Joel E, Greenhalgh Chris, and Benford Steve. 2011. Investigating episodes of mobile phone activity as indicators of opportune moments to deliver notifications. In Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services ACM, 181–190. [Google Scholar]
- [12].Ghorai Koel, Akter Shahriar, Khatun Fatema, and Ray Pradeep. 2014. mHealth for smoking cessation programs: a systematic review. Journal of personalized medicine 4, 3 (2014), 412–423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Gustafson David H, McTavish Fiona M, Chih Ming-Yuan, Atwood Amy K, Johnson Roberta A, Boyle Michael G, Levy Michael S, Driscoll Hilary, Chisholm Steven M, Dillenburg Lisa, et al. 2014. A smartphone application to support recovery from alcoholism: a randomized clinical trial. JAMA Psychiatry 71, 5 (2014), 566–572. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Ho Joyce and Intille Stephen S. 2005. Using context-aware computing to reduce the perceived burden of interruptions from mobile devices. In Proceedings of the SIGCHI conference on Human factors in computing systems ACM, 909–918. [Google Scholar]
- [15].Hovsepian Karen, Al’Absi Mustafa, Ertin Emre, Kamarck Thomas, Nakajima Motohiro, and Kumar Santosh. 2015. cStress: Towards a Gold Standard for Continuous Stress Assessment in the Mobile Environment. Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp) (2015), 493–504. 10.1145/2750858.2807526 [DOI] [PMC free article] [PubMed]
- [16].Kazemi Donna M, Borsari Brian, Levine Maureen J, Li Shaoyu, Lamberson Katie A, and Matta Laura A. 2017. A systematic review of the mHealth interventions to prevent alcohol and substance abuse. Journal of health communication 22, 5 (2017), 413–432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Koch Kevin, Mishra Varun, Liu Shu, Berger Thomas, Fleisch Elgar, Kotz David, and Wortmann Felix. 2021. When Do Drivers Interact with In-vehicle Well-being Interventions? An Exploratory Analysis of a Longitudinal Study on Public Roads. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 5, 1, Article 19 (March 2021), 30 pages. 10.1145/3448116 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Kowatsch Tobias, Volland Dirk, Shih Iris, Rüegger Dominik, Künzler Florian, Barata Filipe, Filler Andreas, Büchter Dirk, Brogle Björn, Heldt Katrin, et al. 2017. Design and Evaluation of a Mobile Chat App for the Open Source Behavioral Health Intervention Platform MobileCoach. In International Conference on Design Science Research in Information Systems Springer, 485–489. [Google Scholar]
- [19].Kramer Jan-Niklas, Künzler Florian, Mishra Varun, Presset Bastien, Kotz David, Smith Shawna, Scholz Urte, and Kowatsch Tobias. 2019. Investigating intervention components and exploring states of receptivity for a smartphone app to promote physical activity: protocol of a microrandomized trial. JMIR research protocols 8, 1 (2019), e11540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Kramer Jan-Niklas, Künzler Florian, Mishra Varun, Smith Shawna N., Kotz David, Scholz Urte, Fleisch Elgar, and Kowatsch Tobias. 2020. Which Components of a Smartphone Walking App Help Users to Reach Personalized Step Goals? Results From an Optimization Trial. Annals of Behavioral Medicine (March 2020), 1–11. 10.1093/abm/kaaa002 [DOI] [PMC free article] [PubMed]
- [21].Künzler Florian, Kramer Jan-Niklas, and Kowatsch Tobias. 2017. Efficacy of mobile context-aware notification management systems: A systematic literature review and meta-analysis. In Wireless and Mobile Computing, Networking and Communications (WiMob),. IEEE, 131–138. [Google Scholar]
- [22].Künzler Florian, Mishra Varun, Kramer Jan-Niklas, Kotz David, Fleisch Elgar, and Kowatsch Tobias. 2019. Exploring the State-of-Receptivity for MHealth Interventions. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. (IMWUT) 3, 4, Article 140 (December. 2019), 27 pages. 10.1145/3369805 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Martin Seth S, Feldman David I, Blumenthal Roger S, Jones Steven R, Post Wendy S, McKibben Rebeccah A, Michos Erin D, Ndumele Chiadi E, Ratchford Elizabeth V, Coresh Josef, et al. 2015. mActive: a randomized clinical trial of an automated mHealth intervention for physical activity promotion. Journal of the American Heart Association 4, 11 (2015), e002239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Mashhadi Afra, Mathur Akhil, and Kawsar Fahim. 2014. The myth of subtle notifications. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication ACM, 111–114. [Google Scholar]
- [25].Mehrotra Abhinav, Müller Sandrine R, Harari Gabriella M, Gosling Samuel D, Mascolo Cecilia, Musolesi Mirco, and Rentfrow Peter J. 2017. Understanding the role of places and activities on mobile phone interaction and usage patterns. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 1, 3 (2017), 1–22. [Google Scholar]
- [26].Mehrotra Abhinav, Musolesi Mirco, Hendley Robert, and Pejovic Veljko. 2015. Designing content-driven intelligent notification mechanisms for mobile applications. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing ACM, 813–824. [Google Scholar]
- [27].Mehrotra Abhinav, Pejovic Veljko, Vermeulen Jo, Hendley Robert, and Musolesi Mirco. 2016. My phone and me: understanding people’s receptivity to mobile notifications. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI) ACM, 1021–1032. [Google Scholar]
- [28].Mishra Varun, Lowens Byron, Lord Sarah, Caine Kelly, and Kotz David. 2017. Investigating Contextual Cues As Indicators for EMA Delivery. In Proceedings of the International Workshop on Smart & Ambient Notification and Attention Management (UbiTtention) ACM, 935–940. 10.1145/3123024.3124571 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Mishra Varun, Sen Sougata, Chen Grace, Hao Tian, Rogers Jeffrey, Chen Ching-Hua, and Kotz David. 2020. Evaluating the Reproducibility of Physiological Stress Detection Models. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 4, 4, Article 147 (December 2020), 29 pages. 10.1145/3432220 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Morrison Leanne G, Hargood Charlie, Pejovic Veljko, Geraghty Adam WA, Lloyd Scott, Goodman Natalie, Michaelides Danius T, Weston Anna, Musolesi Mirco, Weal Mark J, et al. 2017. The Effect of Timing and Frequency of Push Notifications on Usage of a Smartphone-Based Stress Management Intervention: An Exploratory Trial. PloS one 12, 1 (2017), e0169162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Nahum-Shani Inbal, Hekler Eric B, and Spruijt-Metz Donna. 2015. Building health behavior models to guide the development of just-in-time adaptive interventions: A pragmatic framework. Health Psychology 34, S (2015), 1209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Nahum-Shani Inbal, Smith Shawna N, Spring Bonnie J, Collins Linda M, Witkiewitz Katie, Tewari Ambuj, and Murphy Susan A. 2016. Just-in-Time Adaptive Interventions (JITAIs) in mobile health: key components and design principles for ongoing health behavior support. Annals of Behavioral Medicine (2016), 1–17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Okoshi Tadashi, Ramos Julian, Nozaki Hiroki, Nakazawa Jin, Dey Anind K, and Tokuda Hideyuki. 2015. Reducing users’ perceived mental effort due to interruptive notifications in multi-device mobile environments. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing ACM, 475–486. [Google Scholar]
- [34].Okoshi T, Tsubouchi K, Taji M, Ichikawa T, and Tokuda H 2017. Attention and engagement-awareness in the wild: A large-scale study with adaptive notifications. In 2017 IEEE International Conference on Pervasive Computing and Communications (PerCom) 100–110. 10.1109/PERCOM.2017.7917856 [DOI]
- [35].Pejovic Veljko and Musolesi Mirco. 2014. InterruptMe: designing intelligent prompting mechanisms for pervasive applications. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing ACM, 897–908. [Google Scholar]
- [36].Pielot Martin, Cardoso Bruno, Katevas Kleomenis, Serrà Joan, Matic Aleksandar, and Oliver Nuria. 2017. Beyond interruptibility: Predicting opportune moments to engage mobile phone users. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 1, 3 (2017), 91. [Google Scholar]
- [37].Pielot Martin, Dingler Tilman, Pedro Jose San, and Oliver Nuria. 2015. When attention is not scarce-detecting boredom from mobile phone usage. In Proceedings of the 2015 ACM international joint conference on pervasive and ubiquitous computing ACM, 825–836. [Google Scholar]
- [38].Riley William, Obermayer Jami, and Jean-Mary Jersino. 2008. Internet and mobile phone text messaging intervention for college smokers. Journal of American College Health 57, 2 (2008), 245–248. [DOI] [PubMed] [Google Scholar]
- [39].Sarker Hillol, Sharmin Moushumi, Ali Amin Ahsan, Rahman Md Mahbubur, Bari Rummana, Hossain Syed Monowar, and Kumar Santosh. 2014. Assessing the availability of users to engage in just-in-time intervention in the natural environment. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing ACM, 909–920. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Shih Chen-Hsuan, Tomita Naofumi, Lukic Yanick X, Reguera Álvaro Hernández, Fleisch Elgar, and Kowatsch Tobias. 2019. Breeze: Smartphone-based Acoustic Real-time Detection of Breathing Phases for a Gamified Biofeedback Breathing Training. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 3, 4 (2019), 1–30. [Google Scholar]
- [41].Smith Michael R., Martinez Tony, and Giraud-Carrier Christophe. 2014. An instance level analysis of data complexity. Machine Learning 95, 2 (01 May 2014), 225–256. 10.1007/s10994-013-5422-z [DOI] [Google Scholar]
- [42].Tseng Vincent W. S., Merrill Michael, Wittleder Franziska, Abdullah Saeed, Aung Min Hane, and Choudhury Tanzeem. 2016. Assessing Mental Health Issues on College Campuses: Preliminary Findings from a Pilot Study. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct (Heidelberg, Germany) (UbiComp ‘16) ACM, New York, NY, USA, 1200–1208. 10.1145/2968219.2968308 [DOI] [Google Scholar]
- [43].Visuri Aku, van Berkel Niels, Okoshi Tadashi, Goncalves Jorge, and Kostakos Vassilis. 2019. Understanding smartphone notifications’ user interactions and content importance. International Journal of Human-Computer Studies 128 (2019), 72–85. 10.1016/j.ijhcs.2019.03.001 [DOI] [Google Scholar]
- [44].Wang Rui, Aung Min S. H., Abdullah Saeed, Brian Rachel, Campbell Andrew T., Choudhury Tanzeem, Hauser Marta, Kane John, Merrill Michael, Scherer Emily A., and et al. 2016. CrossCheck: Toward Passive Sensing and Detection of Mental Health Changes in People with Schizophrenia. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing (Heidelberg, Germany) (UbiComp ‘16) ACM, New York, NY, USA, 886–897. 10.1145/2971648.2971740 [DOI] [Google Scholar]
- [45].Wang Rui, Chen Fanglin, Chen Zhenyu, Li Tianxing, Harari Gabriella, Tignor Stefanie, Zhou Xia, Ben-Zeev Dror, and Campbell Andrew T. 2014. StudentLife: Assessing Mental Health, Academic Performance and Behavioral Trends of College Students Using Smartphones. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing (Seattle, Washington) (UbiComp ‘14) ACM, New York, NY, USA, 3–14. 10.1145/2632048.2632054 [DOI] [Google Scholar]
- [46].Westermann Tilo, Wechsung Ina, and Möller Sebastian. 2016. Smartphone Notifications in Context: A Case Study on Receptivity by the Example of an Advertising Service. In Proceedings of the CHI Conference Extended Abstracts on Human Factors in Computing Systems ACM, 2355–2361. [Google Scholar]