

Abstract
Long‐term electrocardiogram data can be acquired by linking a Holter monitor to a mobile phone. However, most systems of this variety are simply designed to detect arrhythmia through heartbeat classification, and do not provide any additional support for clinical decisions. HeartSearcher identifies patients with similar arrhythmias from heartbeat classifications, by summarising each patient's typical heartbeat pattern in the form of a regular expression, and then ranking patients according to the similarities of their patterns. Results obtained using electrocardiogram data from the MIT‐BIH arrhythmia database show that this abstraction reduces the volume of heartbeat classifications by 98% on average, offering great potential to support clinical decisions.
Inspec keywords: electrocardiography, medical information systems, medical signal detection, medical signal processing, signal classification, pattern matching, diseases, patient monitoring, decision making, data mining, sorting, abstracting
Other keywords: clinical decision support, heartbeat classification volume reduction, abstraction, MIT‐BIH arrhythmia database, heartbeat pattern similarity ranking, patient ranking, regular expression, patient typical heartbeat pattern summarisation, similar arrhythmia patient identification, arrhythmia detection, mobile phone, Holter monitor, long‐term electrocardiogram data acquisition, similar arrhythmia patient search, HeartSearcher
1. Introduction
Arrhythmia is an irregular heartbeat or an abnormal heart rhythm. Early diagnosis is critical, but this requires patients to exhibit symptoms, even though they may be mild [1, 2]. Some patients remain in a consistent state of arrhythmia, but most arrhythmias occur briefly and unpredictably. Thus, reliable detection of arrhythmia requires that the electrical activity of a patient's cardiovascular system must be monitored continuously for a period of 24–48 h. This process is known as Holter monitoring.
Over the past 10 years, a number of successful heartbeat classification methods have been proposed for arrhythmia detection [3, 4, 5, 6, 7, 8, 9, 10]. These methods support the automatic analysis of heart activity, including the detection and classification of heartbeats in electrocardiogram (ECG) signals. For example, Gral et al. [11] developed a system for real‐time ECG monitoring and arrhythmia detection using Android‐based mobile devices. Recently, it has become possible to integrate Holter monitors with mobile devices such as smartphones, and thereby monitor a patient's heart while he or she continues with their normal routine, using a sensor that continuously acquires ECG data and sends it to the patient's mobile device. ECG signals can thus be accumulated over a long period, and they can then be managed as part of the patient's health records. However, most studies have focused on heartbeat classification, which is not in itself sufficient to support high‐level clinical decisions based on long‐term ECG data.
In this paper, we propose a search system called HeartSearcher, which identifies patients with similar arrhythmias based on the results of a heartbeat classification process. HeartSearcher uses an abstracting algorithm (Section 2.3) to formulate the heartbeat pattern that is typical of a particular patient, based on classified heartbeats. By searching this classified ECG data across many patients, HeartSearcher can identify those with typical heartbeat patterns that are similar to each other.
Our work makes two key contributions. First, it potentially offers high‐level decision support for clinical staff; the results of similar‐patient searches can offer diagnostic clues, contribute to treatment recommendations, and provide a statistical tool for epidemiological surveys. Second, HeartSearcher addresses the need for data management that has been created by the vast amount of data that is inevitably generated during arrhythmia detection. Search and analysis are facilitated by associating classified heartbeats with typical patterns of heart activity.
2. Materials and methods
2.1. Dataset
We applied HeartSearcher to the well‐known MIT‐BIH arrhythmia database [12]. This database contains 48 half‐hour recordings, amounting to approximately 109,000 heartbeats. Each recording contains signals from two ECG leads (identified as A and B), which were band‐pass filtered at 0.1–100 Hz and digitised at 360 Hz. The two leads do not have the same function in all the recordings: connections depend on the type of the arrhythmia that is suspected and the physical limitations of the patient's body. In 45 of the recordings, lead A is a modified limb lead II (MLII) and lead B is a lead V1; in the remaining recordings, lead A is a V5 and lead B is a V2 or an MLII. Twenty‐three of the 48 recordings in the database were arbitrarily selected from a much longer collection of 4000 recordings obtained from a mixed population of inpatients and outpatients. The remaining 25 recordings were selected from the same set as examples of less common but clinically significant conditions, such as complex ventricular, junctional, and supraventricular arrhythmias. The database includes validated annotations [13] by two cardiologists, where the locations of the QRS complexes and the types of the heartbeats are provided. An initial set of beat annotations was produced by a simple slope‐sensitive QRS detector and marked each detected event as a normal beat. For each record, the two charts (signals) were given to two cardiologists, who worked on them independently. The cardiologists added additional beat labels where the detector missed beats, deleted false detections as necessary, and changed the labels for all abnormal beats.
According to the recommendations of the Association for the Advancement of Medical Instrumentation (AAMI) [14], the heartbeats in the MIT‐BIH arrhythmia database can be assigned to five classes: normal (N), supraventricular (S), ventricular (V), fusion (F), and beats which cannot be classified (Q). We excluded beats in the AAMI's Q class from our analysis, since they are in any case marginally represented in the database. Table 1 shows how the heartbeats in the MIT‐BIH arrhythmia database map to these four classes.
Table 1.
Mapping the MIT‐BIH arrhythmia database heartbeat types to the AAMI heartbeat classes in our system
| AAMI heartbeat class | MIT‐BIH heartbeat type (description) [annotation] | Num. of heartbeats |
|---|---|---|
| N | NOR (normal beat) [N] | 74,546 |
| LBBB (left bundle branch block beat) [L] | 8075 | |
| RBBB (right bundle branch block beat) [R] | 7173 | |
| AE (atrial escape beat) [e] | 16 | |
| NE (nodal escape beat) [j] | 229 | |
| S | NP (nodal premature beat) [J] | 83 |
| BAP (blocked atrial premature beat) [x] | 193 | |
| aAP (aberrated atrial premature beat) [a] | 153 | |
| AP (atrial premature beat) [A] | 2614 | |
| V | PVC (premature ventricular contraction) [V] | 6832 |
| VE (ventricular escape beat) [E] | 106 | |
| VF (ventricular flutter wave) [!] | 472 | |
| F | fVN (fusion of ventricular and normal beat) [F] | 803 |
Abbreviations: AAMI, Association for the Advancement of Medical Instrumentation; N, normal; S, supraventricular; V, ventricular; F, fusion; Q, heartbeats that cannot be classified, Num., number.
2.2. Automatic heartbeat classification
A number of promising methods for automatic heartbeat classification have been proposed [3, 4, 5, 6, 7, 8, 9, 10], which are mostly based on feature extraction and classifier learning. Fiducial features based on waveform shapes have been used in several studies [3, 4, 6], but wavelet transform (WT) features can also be used [7, 8, 9, 10]. Osowski et al. [5] and de Lannoy et al. [9] used higher‐order statistics (HOS) and Hermite basis function (HBF) features. It is necessary to train a classifier using the chosen features, and this can be done using a variety of machine learning methods, including linear discriminants [3, 4], support vector machines [5, 10], decision trees [6], quadratic discriminants [8], and conditional random fields [9]. Many studies [3, 4, 8, 10] used a combination of the signals from two leads, while the others have been based on single‐lead signals. Studies can also be differentiated into two categories based on the evaluation scheme that was adopted [10]: ‘class‐oriented’ evaluation, for which there is currently no standard, and ‘subject‐oriented’ evaluation, which is recommended by the AAMI [14]. Subject‐oriented evaluation, introduced by de Chazal et al. [3], uses all the data available, but the records in the training dataset are excluded from the testing dataset. Table 2 summarises the results of previous studies of heartbeat classification. However, the accuracies obtained using the two types of evaluation are not directly comparable.
Table 2.
Results of previous studies of heartbeat classification
| Reference | Features | Classifier | Multi‐lead | Accuracy, % | Evaluation scheme |
|---|---|---|---|---|---|
| de Chazal et al. [3] | waveform | linear discriminants | yes | 85.90 | subject |
| de Chazal and Reilly [4] | waveform | linear discriminants | yes | 93.89 | class |
| Osowski et al. [5] | HOS and HBF | support vector machine | no | 98.18 | class |
| Rodriguez et al. [6] | waveform | decision tree | no | 96.13 | class |
| Faezipour et al. [7] | WT | patient adaptive profiling | no | 97.42 | class |
| Llamedo and Martinez [8] | WT | quadratic discriminant | yes | 78.00 | subject |
| de Lannoy et al. [9] | WT, HBF, HOS | conditional random field | no | 85.39 | subject |
| Ye et al. [10] | WT and ICA | support vector machine | yes | 99.32 | class (subject) |
‘subject’ indicates subject‐oriented evaluation scheme and ‘class’ indicates class‐oriented as defined in the study [10]. Abbreviations: HOS, higher‐order statistics; HBF, Hermite basis function; WT, wavelet transform; ICA, independent component analysis.
In this study, we have not investigated the problem of automatic heartbeat classification, but have instead used the heartbeat annotations from the MIT‐BIH arrhythmia database, which ensures that HeartSearcher has been applied to correct classifications.
2.3. Abstracting the results of heartbeat classification
HeartSearcher formulates a typical pattern by abstracting the results of heartbeat classifications, as shown in the Algorithm (see Fig. 1). A set of 13 heartbeat classes, X, is defined from the 13 annotations in the MIT‐BIH arrhythmia database as follows
| (1) |
Fig. 1.

Algorithm: Abstracting the results of heartbeat classification
Let P = {p 1, p 2, …, p w, …, P W} be a sequence of patterns, which are candidates to become the pattern that typifies a patient's heartbeats, P W. The variable of this sequence, w, corresponds to the width of a window that shrinks as the abstraction of a typical pattern proceeds. Each candidate pattern p w consists of a sequence of l w sub‐patterns, so that p w = {b 1, b 2, …, b t , …, b lw}, where each element bt is the abstraction of one or more heartbeats obtained by pw –i. This abstraction takes the form of a regular expression [15]. The regular expressions which we use only contain the elements of X, brackets/parentheses (for grouping), and the symbol ‘+’, which indicates the repetition of a symbol or group of symbols. We will now describe how a typical pattern is extracted from P.
This abstraction learns the heartbeat pattern in three stages. In the first stage, the width of window is initialised to w, and parentheses and ‘+’ signs are removed from the concatenated sub‐patterns (bt ,…, bt +w ), leaving a sequence of characters, which corresponds to a series of heartbeat classes. Next, the algorithm compares the concatenated sub‐patterns bc in the current window w c, with the concatenated sub‐patterns bc +1 in the subsequent window w c+1. If the characters in the concatenated sub‐patterns are the same, and they are in the same order, then a new regular expression is formulated from bc and b c+1, and this is written back into b c . For example, suppose that w = 2, b c = {b t , b t+1} and b c+1 = {b t+2, b t+3}. If b t = b t+2 and b t+1 = b t+3 then b c and b c+1 are replaced by (b c )+. Otherwise the start sub‐pattern of b c is reset in b t+1. Finally, the algorithm saves l w for subsequent candidate. At this time, l w is always less than or equal to l w−1, because the pattern has been reduced by substitution. The algorithm iterates the three stages from w = 1 to w greater than l w, such that the sequences p w are processed into a typical pattern P W. Consequentially, the algorithm formulates a typical pattern for a single patient.
2.4. Ranking the typical patterns
For any given patient, HeartSearcher performs a similar‐patient search that provides a ranked list of patients with similar heartbeat patterns. Before ranking the similarity between patients, HeartSearcher first measures the similarity between the typical patterns. We use string‐edit distance [16] to measure the similarity. To quantify the similarity of two strings, string‐edit distance is calculated by determining the minimum number of operations that are required to transform one string into the other.
This measure is applied to the typical pattern after removing regular expression symbols, such as the pluses and brackets. Let be a typical pattern for the kth patient, and let be the number of existing characters in the typical pattern . Then the similarity of two typical patterns extracted from the kth and the rth patients is obtained by the last element, , , of a similarity matrix. The similarity matrix is computed as follows
| (2) |
where and . If the ith character of and the jth character are equal, then δ(i, j) is 1; otherwise, it is 0. After calculating these values, HeartSearcher provides a ranking in the order of the dissimilarity value, and links the values in the order of the high‐ranked typical patterns. Finally, HeartSearcher identifies the patient in a similar‐patient list.
3. Results
3.1. Case study
We assessed the usability and effectiveness of HeartSearcher by means of a case study. We selected the sequence of annotations for heartbeats from record‐id 228 from the MIT‐BIH arrhythmia database, which included 2053 heartbeats. We have regarded the sequence of annotations as a sequence of heartbeat classification extracted from record‐id 228 and have summarised the sequence as a typical pattern P W, as presented in Table 3. Table 3 shows the abstracted results that were obtained by the iteration of Algorithm (Fig. 1) for a typical pattern of summarised record‐id 228. For illustrative purposes, let us consider the second iteration, as shown in this table. In p 2 = {b 1, …, b 14} = {(N)+, V, (N)+, V, (N)+, A, (N)+, V, (N)+, V, (N)+, A, (N)+, V}, the concatenation of {b 1, b 2} (b 1 b 2) is (N)+ V and the concatenation of {b 3, b 4} (b 3 b 4) is also (N)+ V, hence (b 1 b 2 b 3 b 4) were substituted into (b 1 b 2)+ as ((N)+ V)+. Subsequently, (b 1 b 2)+ was inserted into p 3. In addition, b 5 is (N)+ and b 6 is A were separately inserted into p 3 because the concatenated {b 5, b 6} is (N)+ A and {b 7, b 8} is (N)+ V, which are different, and {b 6, b 7} is A(N)+ and {b 8, b 9} is V(N)+, which are also different. In a similar way, the sub‐patterns (b 7 b 8 b 9 b 10) = (b 7 b 8)+ is ((N)+ V)+, b 11 is (N)+, b 12 is A, b 13 is (N)+ and b 14 is V. These were inserted into p 3 in order.
Table 3.
Results of successive iterations of Algorithm (Fig. 1) operating on a subset of classified heartbeats in record‐id 228
| Iteration | Candidates of typical patterns | Variables | |
|---|---|---|---|
| 1 | p 1 | N, N, V, N, N, N, V, N, N, A, N, N, V, N, N, N, V, N, N, A, N, N, N, V | w = 1, l 1 = 24 |
| p 2 | (N)+, V, (N)+, V, (N)+, A, (N)+, V, (N)+, V, (N)+, A, (N)+, V | ||
| 2 | p 2 ’ | N, V, N, V, N, A, N, V, N, V, N, A, N, V | w = 2, l 2 = 14 |
| p 3 | ((N)+ V)+, (N)+, A, ((N)+ V)+, (N)+, A, (N)+, V | ||
| 3 | p 3 ’ | NV, N, A., NV, N, A, N, V | w = 3, l 3 = 8 |
| p 4 | (((N)+ V)+(N)+ A)+, (N)+, V | ||
| 4 | p 4 ’ | NVNA, N, V | w = 4, l 4 = 3 |
| P 4 | (((N)+ V)+(N)+ A)+, (N)+, V | ||
Here, p 2’, p 3’, and p 4’ are sequences of sub‐patterns from which the regular expression symbols (such as brackets and pluses) have been removed. The length of the sequences of underlined symbols is equal to the current value of w.
After three iterations, the algorithm determines the typical heartbeat pattern for this record, which is expressed as (((N)+ V)+(N)+ A)+(N)+ V. This pattern is the same as the typical pattern for the original sequence of annotations for heartbeats with record‐id 228. As a result, this typical pattern offers a very compact alternative to the 2053 classified heartbeats that formed the original data. Accordingly, the use of these typical patterns should greatly simplify some clinical activities, as shown in Fig. 2.
Fig. 2.

Typical pattern for high‐level decision support
Similar‐patient search was then used to rank records, excepting the record‐id 228 pattern that was previously analysed. Fig. 3 shows an example of the similarity matrix for the string‐edit distance between the typical pattern for record 228 and the typical pattern ((N)+ A)+(N)+ for record 101. The final outcome of the distance , was computed as 3. The ranking ordered the records that had an edit‐distance of four or less. Table 4 summarises the results of the patient search using the typical pattern that was derived from record‐id 228. While record 116 had the most similar typical pattern, the others were distinguished from record 228 by their values. These results could provide diagnostic clues based on clinical data from patients on the similar‐patients list.
Fig. 3.
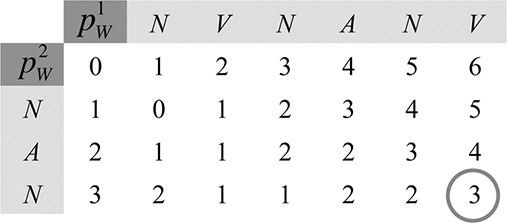
Similarity matrix for the string‐edit distance between the typical patterns of records 228 and 101; the string‐edit distance ,
Table 4.
Results of similar‐patient search for record 228
| Record‐id | Distance | Typical pattern |
|---|---|---|
| 116 | 1 | ((N)+ V)+(N)+ A((N)+ V)+(N)+ |
| 100 | 3 | ((N)+ A)+(N)+ V((N)+ A)+ |
| 101 | 3 | ((N)+ A)+(N)+ |
| 105 | 3 | ((N)+ V)+(N)+ |
| 121 | 3 | (N)+ ANV(N)+ |
| 215 | 3 | (((N)+ V)+ F(V(N)+)+)+ |
| 106 | 4 | ((N)+(V)+)+ |
| 113 | 4 | ((N)+ a)+(N)+ |
| 212 | 4 | ((R)+(N)+)+(N)+ |
3.2. Performance evaluation
HeartSearcher computes the typical pattern after performing the abstracting algorithm, which was the main aim of this paper. To evaluate the performance of the proposed abstracting algorithm, the MIT‐BIH arrhythmia database was used. This database contains 44 recordings. Ideally, an abstracting algorithm should simplify and summarise ECG data on heartbeat classification. Furthermore, a patient's typical heartbeat pattern should be simple enough for clinical experts to consider at a glance. Thus, in order to demonstrate the effectiveness of our abstracting algorithm, we have defined two forms of quantitative assessment criteria: the abstracting rate and the complexity of the typical pattern. The abstraction rate A k is the rate of reduction of the classification results for the kth patient, as follows
| (3) |
where is the number of the originally classified heartbeats, and is calculated as the number of characters, excluding the regular expression symbols (i.e. brackets/parentheses and plus signs).
The complexity of the kth patient's typical pattern, C k , is classified as either ‘complex’ or ‘non‐complex’ based on a calculation involving a constant parameter, λ, and the average value of the complexity per element,
| (4) |
where N denotes the number of complexity elements, and denotes the complexity per element of the kth patient's typical pattern C k . Here, we consider the lengths and types of the typical patterns as complexity elements. To analyse the correlation between the length and type complexities, we calculated the covariance, and obtained a positive value of 21.22. Thus, we used the average value of the two complexities for C k . Additional complexity elements, such as the depth of the regular expressions, could be added if the covariance between each element is a positive value. The length complexity equals A k , and the type complexity is calculated by dividing the number of types expressed in the kth patient's typical pattern, , by the total number of types, T, in the database
| (5) |
The number of whole types is fixed because HeartSearcher considers a total of 13 annotations. The complexity of each element is normalised into a value between −1 and 1. The normalised complexity, , is computed by the expectation and variance in each element as follows
| (6) |
where E(C j ) is computed as the expectation of complexities for all typical patterns in the database.
To evaluate the typical patterns obtained by applying the abstracting algorithm, we have first set the value of parameter λ empirically. As shown in Table 5, the number of ‘complex’ patterns can be varied by changing the value of parameter λ. When the value of λ was less than or equal to −0.17, the evaluations of typical patterns indicated that that all typical patterns were ‘complex’, even though those patterns consisted only of a single character, parentheses, and a plus sign [such as the typical pattern of record 115, (N)+]. In contrast, in analyses with λ greater than or equal to 1 typical patterns were not found to be complicated. Hence, to accurately determine the complexity of a typical pattern, the value of λ should be selected appropriately. In this paper, λ was set to −0.14, which is the average value of the normalised length and type complexities. In the complexity analysis of the typical patterns with λ set to −0.14, 16 ‘complex’ patterns (records) were identified in the database. However, clinicians may choose to change the definition of complexity by altering the λ value; indeed, different clinicians may have different opinions regarding the complexities of typical patterns.
Table 5.
The number of ‘complex’ patterns according to the value of parameter λ
| λ | Num. of complex patterns (rate), % | λ | Num. of complex patterns (rate), % | λ | Num. of complex patterns (rate), % |
|---|---|---|---|---|---|
| −0.18 | 44(100) | −0.11 | 13(30) | −0.04 | 4(9) |
| −0.17 | 44(100) | −0.10 | 11(25) | −0.03 | 4(9) |
| −0.16 | 30(68) | −0.09 | 10(23) | −0.02 | 4(9) |
| −0.15 | 18(41) | −0.08 | 6(14) | −0.01 | 4(9) |
| −0.14 | 16(36) | −0.07 | 6(14) | 0.00 | 4(9) |
| −0.13 | 15(34) | −0.06 | 6(14) | 0.05 | 1(2) |
| −0.12 | 13(30) | −0.05 | 5(11) | 1.00 | 0(0) |
Abbreviation: Num., number. The number of generated typical patterns is 44 in all cases. Rate refers to the number of complex patterns divided by typical pattern.
We also evaluated the abstracting rate of the typical pattern. Table 6 summarises the evaluation results for typical patterns that were obtained by applying the abstracting algorithm with λ set to −0.14. The abstracting algorithm generated 44 typical patterns and had an average abstraction rate of 98.01%. As shown in Table 6, the typical pattern of record 115 and 112, (N)+, was quite simple; indeed, it has only 1 character except for the regular expression symbols. In contrast, the most complex typical pattern of record 208 has 572 characters. However, considering all of the records, these results indicate that clinical experts would interpret 49 characters (on average) per typical pattern, instead of observing the full classification results of the 2304 heartbeats. Furthermore, when the very complex records were excluded (e.g. records 201, 208, 213, 222, and 223), HeartSearcher resulted in an average number of 16 characters for the typical patterns.
Table 6.
The evaluation results of typical patterns obtained by applying the abstracting algorithm to the MIT‐BIH arrhythmia database
| Rec. | L(p 1) | L(P W) | T(P W) | 1 −A(P W), % |
|
|
Complexity of the typical patterna | ||
|---|---|---|---|---|---|---|---|---|---|
| 100 | 2273 | 6 | 3 | 99.74 | −0.11306 | −0.19979 | ((N)+ A)+(N)+ V((N)+ A)+ | ||
| 101 | 1863 | 3 | 2 | 99.84 | −0.12018 | −0.19985 | ((N)+ A)+(N)+ | ||
| 103 | 2084 | 3 | 2 | 99.86 | −0.12136 | −0.19986 | ((N)+ A)+(N)+ | ||
| 105 | 2567 | 3 | 2 | 99.88 | −0.12323 | −0.19987 | ((N)+ V)+(N)+ | ||
| 106 | 2027 | 2 | 2 | 99.90 | −0.12449 | −0.19988 | ((N)+(V)+)+ | ||
| 108 | 1774 | 36 | 5 | 97.97 | 0.00905 | −0.19885 | complex | ||
| 109 | 2532 | 5 | 3 | 99.80 | −0.11766 | −0.19983 | ((L)+ F)+((L)+ V)+(L)+ | ||
| 111 | 2124 | 3 | 2 | 99.86 | −0.12155 | −0.19986 | (L)+ V(L)+ | ||
| 112 | 2539 | 3 | 2 | 99.88 | −0.12314 | −0.19987 | ((N)+ A)+(N)+ | ||
| 113 | 1795 | 3 | 2 | 99.83 | −0.11975 | −0.19984 | ((N)+ a)+(N)+ | ||
| 114 | 1879 | 21 | 5 | 98.88 | −0.05401 | −0.19934 | complex | ||
| 115 | 1953 | 1 | 1 | 99.95 | −0.12777 | −0.19991 | (N)+ | ||
| 116 | 2412 | 7 | 3 | 99.71 | −0.11124 | −0.19978 | ((N)+ V)+(N)+ A((N)+ V)+(N)+ | ||
| 117 | 1535 | 3 | 2 | 99.80 | −0.11780 | −0.19983 | (N)+ A(N)+ | ||
| 118 | 2288 | 65 | 3 | 97.16 | 0.06518 | −0.19841 | complex | ||
| 119 | 1987 | 3 | 2 | 99.85 | −0.12087 | −0.19985 | ((N)+ V)+(N)+ | ||
| 121 | 1863 | 5 | 3 | 99.73 | −0.11275 | −0.19979 | (N)+ ANV(N)+ | ||
| 122 | 2476 | 1 | 1 | 99.96 | −0.12852 | −0.19991 | (N)+ | ||
| 123 | 1518 | 3 | 2 | 99.80 | −0.11765 | −0.19983 | ((N)+ V)+(N)+ | ||
| 124 | 1619 | 28 | 6 | 98.27 | −0.01169 | −0.19901 | complex | ||
| 200 | 2601 | 62 | 4 | 97.62 | 0.03356 | −0.19866 | complex | ||
| 201 | 2000 | 209 | 7 | 89.55 | 0.59148 | −0.19434 | complex | ||
| 202 | 2136 | 50 | 5 | 97.66 | 0.03059 | −0.19868 | complex | ||
| 203 | 2976 | 14 | 4 | 99.53 | −0.09878 | −0.19968 | ((N)+(V)+)+ Na(N)+(V)+ Na((N)+ V)+ NF((N)+(V)+)+ | ||
| 205 | 2656 | 24 | 4 | 99.10 | −0.06881 | −0.19945 | complex | ||
| 207 | 2332 | 38 | 6 | 98.37 | −0.01861 | −0.19906 | complex | ||
| 208 | 2953 | 572 | 4 | 80.63 | 1.20845 | −0.18956 | complex | ||
| 209 | 3005 | 7 | 3 | 99.77 | −0.11520 | −0.19981 | ((N)+ A)+(N)+ V((N)+ A)+(N)+ | ||
| 210 | 2650 | 92 | 5 | 96.53 | 0.10881 | −0.19808 | complex | ||
| 212 | 2748 | 3 | 2 | 99.89 | −0.12376 | −0.19988 | ((R)+(N)+)+(N)+ | ||
| 213 | 3251 | 397 | 5 | 87.79 | 0.71332 | −0.19340 | complex | ||
| 214 | 2260 | 6 | 3 | 99.73 | −0.11295 | −0.19979 | ((L)+ V)+ F((L)+ V)+(L)+ | ||
| 215 | 3363 | 5 | 3 | 99.85 | −0.12103 | −0.19985 | (((N)+ V)+ F(V(N)+)+)+ | ||
| 219 | 2287 | 55 | 5 | 97.60 | 0.03502 | −0.19865 | complex | ||
| 220 | 2048 | 3 | 2 | 99.85 | −0.12118 | −0.19986 | ((N)+ A)+(N)+ | ||
| 221 | 2427 | 3 | 2 | 99.88 | −0.12276 | −0.19987 | ((N)+ V)+(N)+ | ||
| 222 | 2483 | 173 | 4 | 93.03 | 0.35060 | −0.19620 | complex | ||
| 223 | 2605 | 177 | 6 | 93.21 | 0.33865 | −0.19630 | complex | ||
| 228 | 2053 | 6 | 3 | 99.71 | −0.11110 | −0.19978 | (((N)+ V)+(N)+ A)+((N)+ V)+ | ||
| 230 | 2256 | 3 | 2 | 99.87 | −0.12212 | −0.19986 | (N)+ V(N)+ | ||
| 231 | 1573 | 10 | 5 | 99.36 | −0.08734 | −0.19959 | ((R)+ N)+(R)+ xARx(V)+((R)+ N)+ | ||
| 232 | 1780 | 5 | 3 | 99.72 | −0.11189 | −0.19978 | (R(A)+)+j(R(A)+)+ | ||
| 233 | 3079 | 39 | 4 | 98.73 | −0.04370 | −0.19926 | complex | ||
| 234 | 2753 | 5 | 3 | 99.82 | −0.11875 | −0.19984 | (N)+(J)+((N)+ V)+(N)+ | ||
| avg. | 2304 | 49 | 3 | 98.10 |
In the case of ‘non‐complex’, the typical patterns is provided; Abbreviations: Rec, record‐id; avg, average; L(p 1) is the number of results of heartbeat classification; L(P W) is the number of characters in the typical pattern after removing the regular expression symbols; T(P W) is the number of types; A(P W) is the abstraction rate of the typical pattern; is the normalised length complexity of the typical pattern; and is the normalised type complexity of the typical pattern.
In addition, HeartSearcher identified patients who had similar typical patterns. Fig. 4 shows the similarity matrix results for patients’ typical patterns. The intensity scale on the right‐hand side indicates the degree of similarity, with greater similarities shown by darker tones. Similarity was calculated using the edit distance, as described in Section 2.4. In the matrix, the similarity, d, has a value between zero and five. A smaller similarity value between two patients indicates that these patients have typical patterns that are more similar. For example, consider record 101 from Table 6. According to the similarity value, the typical pattern of record 101 was equivalent to the typical patterns of records 103, 112, 117, and 220. Furthermore, records 105 and 113 have the most similar typical patterns. These results suggest that HeartSearcher can offer diagnostic clues with additional clinical information for each patient (such as diagnostic or treatment data).
Fig. 4.
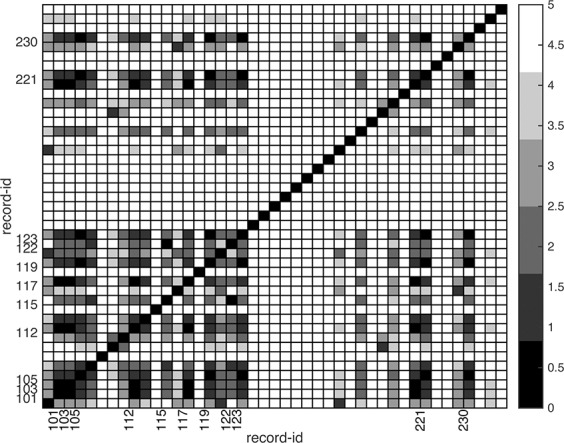
Similarity matrix of the typical patterns of different patients. Intensity scale on the right‐hand side indicates the degree of similarity, and greater similarity is shown with a darker colour. Records included in the cases of less‐common arrhythmia and complex typical patterns had the minimum possible similarity value (0)
4. Discussions
HeartSearcher searches for patients with similar arrhythmias by formulating the pattern of a patient's typical heartbeat as a regular expression of a restricted type, and subsequently ranks patients with similar typical heartbeat patterns. HeartSearcher is also able to provide a list of patients with similar arrhythmias to a given patient.
We believe that the use of typical patterns could simplify some clinical activities. However, further work is necessary to allow HeartSearcher to be used in a clinical setting. Many authors [17, 18] have sought to improve the efficiency of many processes through which healthcare is delivered, while improving patient safety, by removing the influence of human factor. The threshold value λ which we use to classify typical heartbeat patterns as ‘complex’ is intended to help clinicians engage with the output of HeartSearcher. Although the classification of arrhythmias is not directly related to life‐threatening situations, setting λ to a workable value is important.
Second, although HeartSearcher considers all the types of heartbeat in the MIT‐BIH arrhythmia database without bias, we have clustered these types into five classes, in line with the AAMI recommendations. Types that are in the same classes should be considered in addition to their weights. Similar‐patient search results for typical patterns have been improved through the adoption of AAMI recommendations.
Third, HeartSearcher only uses simple string‐edit distance after removing regular expression symbols. This might lead to the assessment of result of high similarity between strings that appear to be dissimilar. For example, the following results of heartbeat classification would be considered identical: (N)+(A)+(N)+(V)+ and (NANV)+. Our experimental results did not show these cases, and such a scenario seems to be a special case. However, this case should be considered when evaluating similarity between patients because special sequences of classification results will appear sometimes, and an individual ECG signal is unique enough to identify an individual [19, 20]. It could be improved simply by checking the difference between a character and a regular expression symbol, such as N and (N)+, when removing the symbols for the regular expression.
Fourth, the typical heartbeat pattern cannot be used to reproduce the original results of the heartbeat classification, although summarising the results of the heartbeat classification as typical patterns allows high‐level decision support with various applications. If the HeartSearcher system could perfectly reproduce the original classified results through decryption, then the vast data created by long‐term ECG signals could be managed effectively. This goal might be achieved by applying string compression algorithms [21, 22].
The detection of arrhythmia is outside the scope of this paper, and has already been the subject of considerable work [3, 4, 5, 6, 7, 8, 9, 10]. Nevertheless, we believe that our method of classifying heartbeats as regular expressions could make a contribution to classification research. In particular, many existing techniques for heartbeat classification need to be improved to cope with multi‐lead ECG recordings.
5. Conclusions
HeartSearcher formulates regular expressions, which characterise the typical heartbeats of a set of patient, and can then be used to identify patients with similar heartbeats. The matches found by HeartSearcher could provide diagnostic clues and thereby facilitate clinical decisions.
Supporting information
Supplementary Data 1
6. Acknowledgments
A preliminary version of this paper appeared in the proceedings of the IEEE BIBM 2014. This work was partly supported by a grant from the Institute for Information & Communications Technology Promotion (IITP), funded by the Korean Government (MSIP) (No. B0101–15‐0557, Resilient Cyber‐Physical Systems Research), and partly supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF), funded by the MSIP (NRF‐2013R1A1A1059188).
7 References
- 1. Noureddine, B. , Fethi, B.‐R. : ‘Bluetooth portable device for ECG and patient motion monitoring’, Nature Technol., 2011, 4, pp. 19–23 [Google Scholar]
- 2. de Werf, F.V. , Bax, J. , Betriu, A. , et al.: ‘Management of acute myocardial infarction in patients presenting with persistent ST‐segment elevation: the task force on the management of ST‐segment elevation acute myocardial infarction of the European society cardiology’, Eur. Heart J., 2008, 29, (23), pp. 2909–2945 (doi: 10.1093/eurheartj/ehn416) [DOI] [PubMed] [Google Scholar]
- 3. de Chazal, P. , O'Dwyer, M. , Reilly, R.B. : ‘Automatic classification of heartbeats using ECG morphology and heartbeat interval features’, IEEE Trans. Biomed. Eng., 2004, 51, (7), pp. 1196–1206 (doi: 10.1109/TBME.2004.827359) [DOI] [PubMed] [Google Scholar]
- 4. de Chazal, P. , Reilly, R.B. : ‘A patient‐adapting heartbeat classifier using ECG morphology and heartbeat interval features’, IEEE Trans. Biomed. Eng., 2006, 53, (12), pp. 2535–2543 (doi: 10.1109/TBME.2006.883802) [DOI] [PubMed] [Google Scholar]
- 5. Osowski, S. , Linh, T.H. , Markiewicz, T. : ‘Support vector machine‐based expert system for reliable heartbeat recognition’, IEEE Trans. Biomed. Eng., 2004, 51, (4), pp. 582–589 (doi: 10.1109/TBME.2004.824138) [DOI] [PubMed] [Google Scholar]
- 6. Rodriguez, J. , Goñi, A. , Illarramendi, A. : ‘Real‐time classification of ECG on a PDA’, IEEE Trans. Inf. Tech. Biomed., 2005, 9, (1), pp. 23–34 (doi: 10.1109/TITB.2004.838369) [DOI] [PubMed] [Google Scholar]
- 7. Faezipour, M. , Saeed, A. , Bulusu, S.C. , et al.: ‘A patient‐adaptive profiling scheme for ECG beat classification’, IEEE Trans. Inf. Tech. Biomed., 2010, 14, (5), pp. 1153–1165 (doi: 10.1109/TITB.2010.2055575) [DOI] [PubMed] [Google Scholar]
- 8. Llamedo, M. , Martinez, J.P. : ‘Heartbeat classification using feature selection driven by database generalization criteria’, IEEE Trans. Biomed. Eng., 2011, 58, (3), pp. 616–625 (doi: 10.1109/TBME.2010.2068048) [DOI] [PubMed] [Google Scholar]
- 9. de Lannoy, G. , Francois, D. , Delbeke, J. , et al.: ‘Weighted conditional random fields for supervised interpatient heartbeat classification’, IEEE Trans. Biomed. Eng., 2012, 59, (1), pp. 241–247 (doi: 10.1109/TBME.2011.2171037) [DOI] [PubMed] [Google Scholar]
- 10. Ye, C. , Kumar, B.V.K.V. , Coimbra, M.T. : ‘Heartbeat classification using morphological and dynamic features of ECG signals’, IEEE Trans. Biomed. Eng., 2012, 59, (10), pp. 2930–2941 (doi: 10.1109/TBME.2012.2213253) [DOI] [PubMed] [Google Scholar]
- 11. Gradl, S. , Kugler, P. , Lohmuller, C. , et al.: ‘Real‐time ECG monitoring and arrhythmia detection using android‐based mobile device’, Proc. Int. Conf. IEEE Engineering in Medicine and Biology Society, San Diego, CA, August–September 2012, pp. 2452–2455 [DOI] [PubMed] [Google Scholar]
- 12. Moody, G.B. , Mark, R.G. : ‘The impact of the MIT‐BIH arrhythmia database’, IEEE Eng. Med. Biol. Mag., 2001, 20, (3), pp. 45–50 (doi: 10.1109/51.932724) [DOI] [PubMed] [Google Scholar]
- 13.‘PhysioBank Annotations’, http://www.physionet.incor.usp.br/physiobank/annotations.shtml, accessed June 2015
- 14.Association for the Advancement of Medical Instrumentation: ‘Testing and reporting performance results of cardiac rhythm and ST segment measurement algorithms’ (ANSI/AAMI EC:57:1998 standard, 1998)
- 15. Thompson, K. : ‘Programming techniques: regular expression search algorithm’, ACM Commun., 1968, 11, (6), pp. 419–422 (doi: 10.1145/363347.363387) [DOI] [Google Scholar]
- 16. Ristad, E.S. , Yianilos, P.N. : ‘Learning string‐edit distance’, IEEE Trans. Pattern Anal. Mach. Intell., 1998, 20, (5), pp. 522–532 (doi: 10.1109/34.682181) [DOI] [Google Scholar]
- 17. Phansalkar, S. , Edworthy, J. , Hellier, E. , et al.: ‘A review of human factors principles for the design and implementation of medication alerts in clinical information systems’, J. Am. Med. Inf. Assoc., 2010, 17, (5) pp. 493–501 (doi: 10.1136/jamia.2010.005264) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Carayon, P. , Wetterneck, T.B. , Rivera‐Rodriguez, A.J. , et al.: ‘Human factor systems approach to healthcare quality and patient safety’, Appl. Ergon., 2014, 45, (1), pp. 14–25 (doi: 10.1016/j.apergo.2013.04.023) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Israel, S.A. , Irvine, J.M. , Cheng, A. , et al.: ‘ECG to identify individuals’, Pattern Recognit., 2005, 38, (1), pp. 133–142 (doi: 10.1016/j.patcog.2004.05.014) [DOI] [Google Scholar]
- 20. Sasikala, P. , Wahidabanu, R.S.D. : ‘Identification of individuals using electrocardiogram’, J. Com. Sci. Netw. Secur., 2010, 10, (12), pp. 147–153 [Google Scholar]
- 21. Ziv, J. , Lempel, A. : ‘A universal algorithm for sequential data compression’, IEEE Trans. Inf. Theory, 1977, 23, (3), pp. 337–343 (doi: 10.1109/TIT.1977.1055714) [DOI] [Google Scholar]
- 22. Rodeh, M. , Pratt, V.R. , Even, S. : ‘Linear algorithm for data compression via string matching’, J. ACM, 1981, 28, (1), pp. 16–24 (doi: 10.1145/322234.322237) [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Data 1