

Abstract
Objective: Since its outbreak, the rapid spread of COrona VIrus Disease 2019 (COVID-19) across the globe has pushed the health care system in many countries to the verge of collapse. Therefore, it is imperative to correctly identify COVID-19 positive patients and isolate them as soon as possible to contain the spread of the disease and reduce the ongoing burden on the healthcare system. The primary COVID-19 screening test, RT-PCR although accurate and reliable, has a long turn-around time. In the recent past, several researchers have demonstrated the use of Deep Learning (DL) methods on chest radiography (such as X-ray and CT) for COVID-19 detection. However, existing CNN based DL methods fail to capture the global context due to their inherent image-specific inductive bias. Methods: Motivated by this, in this work, we propose the use of vision transformers (instead of convolutional networks) for COVID-19 screening using the X-ray and CT images. We employ a multi-stage transfer learning technique to address the issue of data scarcity. Furthermore, we show that the features learned by our transformer networks are explainable. Results: We demonstrate that our method not only quantitatively outperforms the recent benchmarks but also focuses on meaningful regions in the images for detection (as confirmed by Radiologists), aiding not only in accurate diagnosis of COVID-19 but also in localization of the infected area. The code for our implementation can be found here - https://github.com/arnabkmondal/xViTCOS. Conclusion: The proposed method will help in timely identification of COVID-19 and efficient utilization of limited resources.
Keywords: AI for COVID-19 detection, CT scan and CXR, deep learning, vision transformer
I. Introduction
A. Background
The novel COronaVIrus Disease 2019 (COVID-19) is a viral respiratory disease caused by Severe Acute Respiratory Syndrome COronaVirus 2 (SARS-CoV2). The World Health Organization (WHO) has declared COVID-19 a pandemic on 11 March 2020 [1]. This has pushed the health systems of several nations to the verge of collapse. It is, therefore, of utmost importance to screen the positive COVID-19 patients accurately for efficient utilization of limited resources. Two types of viral tests are currently popularly used to detect COVID-19 infection: Nucleic Acid Amplification Tests (NAATs) [2] and Antigen Tests [3]. NAATs can reliably detect SARS-CoV-2 and are unlikely to return a false-negative result of SARS-CoV-2. NAATs can use many different methods, among which Reverse Transcription Polymerase Chain Reaction (RT-PCR) is the most preferred test for COVID-19 due to its high specificity and sensitivity [4]. However, this test is expensive as it has an elaborate kit and time-consuming. An RT-PCR test uses nose or throat swabs to detect SARS-CoV-2 and requires trained professionals instructed for the RT-PCR kit to carry out the RT-PCR test. RT-PCR requires a complete set-up that includes the trained practitioners, laboratory, and RT-PCR machine for detection and analysis.
B. Scope and Contributions
Motivated by the success of the Deep Learning in diagnosing respiratory disorders [5], several recent works have proposed the use of chest radiography images (X-ray and Computed Tomography, CT) as alternate modality to detect COVID-19 positive cases [6]–[12] (Elaborated in Sec. II). Unlike in the chest CT/X-ray of a healthy person, the lungs of COVID-19 affected patients show some visual marks like ground-glass opacity and/or mixed ground-glass opacity, and mixed consolidation [6].
While there has been a large body of literature on use of Deep Learning for Covid detection, most of them are based on Convolutional Neural Networks (CNNs) [12]–[15]. CNN, albeit powerful, lacks a global understanding of images because of its image-specific inductive biases. To capture long-range dependencies, CNNs require a large receptive field, which necessitates designing large kernels or immensely deep networks, leading to a complex model challenging to train. Recently, Vision transformers [16] have provided an alternative framework for learning tasks and overcome the issues associated with convolutional inductive bias as they can learn the most suitable inductive bias depending on the task at hand. Motivated by this, in this work, we propose to employ a vision transformer (ViT) based transfer learning method to detect COVID-19 infection from the chest radiography (X-ray and CT scan imaging). Specifically, the below are our contributions:
-
1)
We propose a vision transformer based deep neural classifier, xViTCOS for screening of COVID-19 from chest radiography.
-
2)
We provide explanability-driven, clinically interpretable visualizations where the patches responsible for the model’s prediction are highlighted on the input image.
-
3)
We employ a multi-stage transfer learning approach to address the problem of need for large-scale data.
-
4)
We demonstrate the efficacy of the proposed framework in distinguishing COVID-19 positive cases from non-COVID-19 Pneumonia and Normal control using both chest CT scan and X-ray modality, through several experiments on benchmark datasets.
II. Related Work
A. COVID-19 Detection Using Chest CT
Chest Computed Tomography (CT) imaging has been proposed as an alternative screening tool for COVID-19 infection [6], [7]. In [17] multiple features, such as Volume, Radiomics features, Infected lesion number, Histogram distribution and Surface area are extracted first from the CT images following which a deep forest algorithm, consisting of cascaded layers of multiple random forests, is used for discriminative feature selection and classification.
The work in [13] performs a comparative study by exploiting transfer-learning to optimize 10 pre-trained CNN models viz AlexNet [18], VGG-16 [19], VGG-19 [19], SqueezeNet [20], GoogleNet [21], MobileNet-V2 [22], ResNet-18 [23], ResNet-50 [23], ResNet-101 [23], and Xception [24] on CT-scan images to differentiate between COVID-19 and non-COVID-19 cases. As per the results reported in [13], ResNet-101 and Xception achieve best performance. [25] segment out candidate infection regions from the pulmonary CT image set using a 3D CNN segmentation model and categorize these segments into the COVID-19, IAVP, and irrelevant to infection (ITI) groups, together with the corresponding confidence scores, using a location-attention classification model. COVNet [26] is a ResNet50 based CNN architecture that takes as input a series of CT slices and compute features from each slice of the CT series, which are combined by a max-pooling operation, and the resulting feature map is fed to a fully connected layer to generate a probability score for each class. Ref. [27] uses a pre-trained EfficientNet as the backbone and extracts features from each slice of CT data, and makes a binary prediction. Next, the slice level predictions are combined using a multi-layer perceptron (MLP) to make a final prediction at the patient level. COVIDNet-CT [15] on the other hand offers architectural diversity, selective long-range connectivity, and lightweight design patterns. Ref. [28] proposes Contrastive COVIDNet which is built upon the COVIDNet [11] architecture by introducing domain specific batch normalization layers along with a cross entropy classification and a contrastive loss. In [29] a custom CNN model is built with two separate lines of forward pass and deep feature aggregation to classify COVID and non-COVID. The network is trained to work both on CT and X-ray data. It employs a deep feature aggregation strategy by aggregating layer outputs from varying depths following a classifier network. ResGNet-C [30] exploits Graph Convolution Network (GCN) [31] to perform binary classification task using the Resnet-101 [23] extracted features. Ref. [32] proposes an hybrid model based on deep features and Parameter Free BAT (PF-BAT) optimized Fuzzy K-nearest neighbor (PF-FKNN) classifier for COVID-19 prognosis.
B. COVID-19 Detection Using Chest X-Ray
Although chest-CT has more sensitivity as compared to RT-PCR [8], [9], associated cost and resource constraints makes routine CT screening for COVID-19 detection a less accessible solution to the third world’s teeming millions. Therefore, digital X-ray based Covid detection is considered an easily accessible alternative.
In [34] the authors propose a two-stage pipeline for binary classification. In the first stage, the significant lung region is cropped from the chest X-ray images using a bounding box segmentation. In the second stage, a GAN inspired class – inherent transformation network is used to generate two class inherent transformations which are then used to solve a four-class classification problem using a CNN. However, as the number of classes increase, the number of generators to be trained in the second stage of this method will increase accordingly, making it difficult to scale for multi class classification. COVID-Net [11] leveraged a human-machine collaborative design strategy to produce a network architecture tailored for COVID-19 detection from chest X-ray images. CoroNet [12] uses Xception [24] backbone for extracting CXR image features which are classified using a multi-layer perceptron (MLP) classification head. CovidAID [35] finetunes a pretrained CheXNet [5]. Ref. [36] proposes a novel architecture with multiscale attention-based generation augmentation and guidance for training a CNN model for COVID-19 diagnosis. The multi-scale attention features are computed from the intermediate feature maps of a Resnet-50 [23] based feature extractor and are combined with the final feature map to obtain the predictions. Ref. [37] proposes another attention based CNN model incorporating a teacher-student transfer learning framework for COVID-19 diagnosis from Chest X-ray and CT images. CHP-Net [38] consists of three networks: a bounding box regression network to extract bi-pulmonary region coordinates, a discriminator deep learning model to predict a differentiating probability distribution, and a localization deep network that represents all potential pulmonary locations. In [10] the authors propose using shape dependent Fibonacci p patterns to extract features from chest X-ray images and then apply conventional machine learning algorithms. Ref. [39] first extracts orthogonal moment features using Fractional Multichannel Exponent Moments (FrMEMs). Next, the most significant features are selected using a differential evolution based modified Manta-Ray Foraging Optimization (MRFO). Finally a KNN classifier is trained to distinguish COVID-19 positive cases from negative cases.
C. Transformers and Self Attention in Vision
Images can be naively represented using a sequence of pixels for analysis using transformers but that would lead to huge computational expenses with a quadratic increase in costs. This has led to a number of approximations. For example, [40] used self attention in local neighbourhoods of query pixels instead of performing calculation globally with the entire rest of the image. Such local multi head attentions can be shown to replace convolutions ([41], [42], [43]). Ref. [44] proposed Sparse Transformers where scalable approximations to global self attention are employed for images. Ref. [45] used an alternative way of scaling attention by applying them in blocks of varying sizes. Ref. [46] applies full attention after extracting patches of size
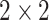 from the input image. The use of small patch size, however, enables the model to be used only for small resolution images. Other than transformers, a number of researchers have combined convolutional neural networks with different forms of self attention. Ref. [47] uses attention to augment feature maps for image classification. A lot of work has come up where the authors have used self attention for further processing the output of a CNN for a number of tasks including, object detection ([48]) image classification ([49]), video analysis ([50], [51]), etc. A recent approach by [52] applies Transformers to pixel level patches after reducing image resolution and color space. The model named image GPT is trained like a generative model whose representations are then fine tuned or linearly probed for performing classification tasks.
from the input image. The use of small patch size, however, enables the model to be used only for small resolution images. Other than transformers, a number of researchers have combined convolutional neural networks with different forms of self attention. Ref. [47] uses attention to augment feature maps for image classification. A lot of work has come up where the authors have used self attention for further processing the output of a CNN for a number of tasks including, object detection ([48]) image classification ([49]), video analysis ([50], [51]), etc. A recent approach by [52] applies Transformers to pixel level patches after reducing image resolution and color space. The model named image GPT is trained like a generative model whose representations are then fine tuned or linearly probed for performing classification tasks.
III. Proposed Method
Unlike the existing methods that incorporate CNNs, we propose a vision transformer (ViT) [16] based model for automated COVID-19 screening and call it xViTCOS, illustrated in Figure 1. Since we use xViTCOS on two chest radiography modalities CT scan images and chest X-ray images, we refer to them as xViTCOS-CT and xViTCOS-CXR respectively.
FIGURE 1.
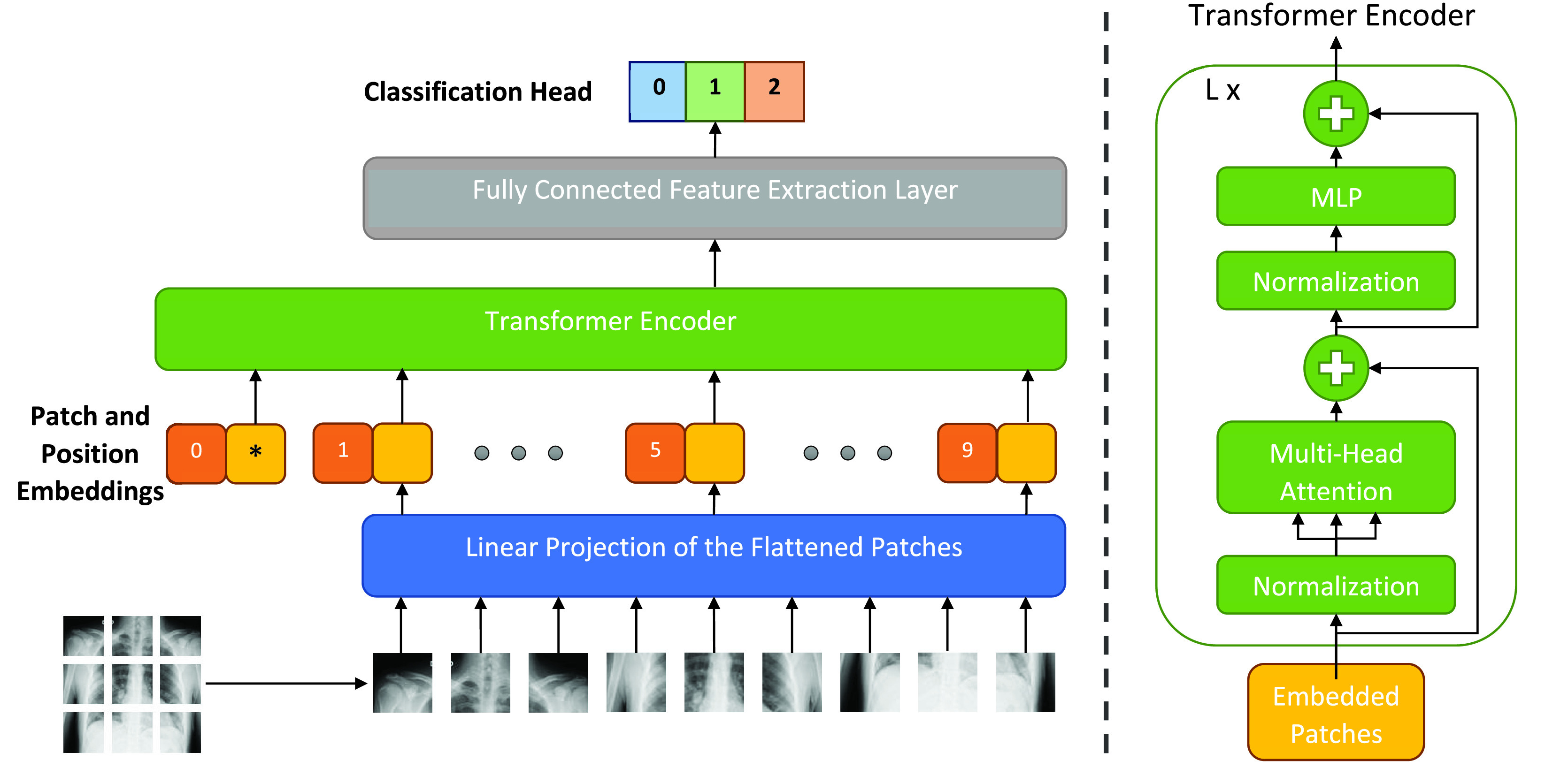
xViTCOS: Illustration of our proposed network for COVID-19 detection using chest radiography (CT scan/CXR image). The input image is split into equal-sized patches and embedded using linear projection. Position embedding are added and the resulting sequence is fed to a Transformer encoder [33].
A. Vision Transformers
A Vision Transformer [16] is a deep neural model that adapts the attention-based transformer architecture [33] prevalent in the domain of natural language processing (NLP) to make it suitable for pattern recognition in visual image data. While the original transformer architecture comprises of an encoder and a decoder, vision transformer is an encoder-only architecture. For non-sequential image analysis tasks, like image classification, the input image,
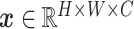 is broken down into
is broken down into
 image patches,
image patches,
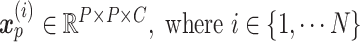 , and each patch is of shape
, and each patch is of shape
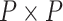 in 2-D,
in 2-D,
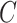 denotes the number of channels (e.g.
denotes the number of channels (e.g.
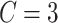 for RGB images) and
for RGB images) and
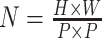 . These patches derived from the image is then effectively used as a sequence of input images for the Transformer. The input patches are first flattened and then mapped to a D dimensional latent vector through a trainable linear projection layer, leading to the generation of patch embeddings. Throughout its layers, the transformer maintains a constant latent vector size of D. Similar to the [class] token in BERT [53], a learnable embedding is embedded to the sequence of the patch embeddings (
. These patches derived from the image is then effectively used as a sequence of input images for the Transformer. The input patches are first flattened and then mapped to a D dimensional latent vector through a trainable linear projection layer, leading to the generation of patch embeddings. Throughout its layers, the transformer maintains a constant latent vector size of D. Similar to the [class] token in BERT [53], a learnable embedding is embedded to the sequence of the patch embeddings (
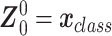 ). The final transformer layer state corresponding to this class token,
). The final transformer layer state corresponding to this class token,
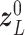 , represents in a compact form the classification information that the model is able to extract from the image(
, represents in a compact form the classification information that the model is able to extract from the image(
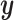 ). The classification head is attached to
). The classification head is attached to
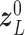 during both pre-training and fine-tuning. In order to retain crucial positional information, standard learnable 1D position embeddings are added to the patch embeddings. The final resulting sequence is provided as input to the encoder. During pre-training, an MLP is used to represent the classification head and it is replaced by a single linear layer during the fine-tuning stage. As illustrated in the Figure 1, the transformer encoder of a vision transformer consists of alternating layers of multiheaded self-attention (MSA) and MLP blocks. Layernorm (LN) is applied before every block, and residual or skip connections after every block. The workings of the vision transformer can be mathematically described in Equations below:
during both pre-training and fine-tuning. In order to retain crucial positional information, standard learnable 1D position embeddings are added to the patch embeddings. The final resulting sequence is provided as input to the encoder. During pre-training, an MLP is used to represent the classification head and it is replaced by a single linear layer during the fine-tuning stage. As illustrated in the Figure 1, the transformer encoder of a vision transformer consists of alternating layers of multiheaded self-attention (MSA) and MLP blocks. Layernorm (LN) is applied before every block, and residual or skip connections after every block. The workings of the vision transformer can be mathematically described in Equations below:
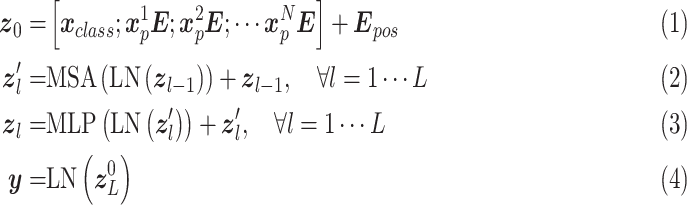 |
where
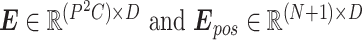
B. Inductive Bias in ViT
Unlike CNN based models that impose inherent bias such as translation invariance and a local receptive field, vision transformer (ViT) [16] has much less image specific inductive bias. This is because ViT treats an image as a sequence, hence loses any structural and neighborhood information a CNN can easily recognize. Although MLP layers are local and translationally equivariant, the self-attention layers are global. The only mechanism that adds inductive bias and provides structural information about the image to the encoder are the position embeddings, that are concatenated with the patch embeddings. Without those, the Vision Encoder might find it difficult to make sense of the image patch sequence. Consequently, ViT does not generalize well when trained using insufficient amount of data. This might be a bit discouraging but the entire status quo changes as the size of the dataset increases. The large size of the training dataset overshadows the dependence of the model on inductive bias for generalization. As can be expected, using a ViT model pretrained on a large training dataset under a transfer learning framework on a smaller target dataset leads to improved performance. Next, we propose a multi-stage transfer learning strategy.
C. Multi-Stage Transfer Learning
A domain and a task are the two main components of a typical learning problem. For the specific case of a supervised classification problem, the domain,
 might be defined as the tuple of the feature space,
might be defined as the tuple of the feature space,
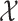 , and the marginal feature distribution,
, and the marginal feature distribution,
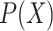 , i.e.
, i.e.
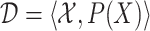 . The task,
. The task,
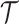 is a tuple of label space,
is a tuple of label space,
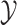 , and the posterior of the labels conditioned on features,
, and the posterior of the labels conditioned on features,
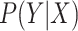 , i.e.
, i.e.
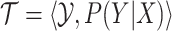 . Any change in either of the two components of a machine learning problem would cause severe degradation in the performance of the trained model and necessitates rebuilding the model from scratch. Transfer Learning is a way to combat this issue.
. Any change in either of the two components of a machine learning problem would cause severe degradation in the performance of the trained model and necessitates rebuilding the model from scratch. Transfer Learning is a way to combat this issue.
Given a source domain,
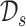 and a corresponding task,
and a corresponding task,
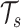 , and a target domain,
, and a target domain,
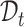 and a corresponding task,
and a corresponding task,
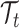 , the objective of transfer learning is to improve the performance of a machine learning model in
, the objective of transfer learning is to improve the performance of a machine learning model in
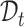 using the knowledge acquired in
using the knowledge acquired in
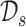 and
and
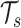 [54]. Transfer learning has played a significant role in the facilitating the use of deep learning in numerous applications [55]–[57]. In this work, we empirically demonstrate how knowledge transfer is equally effective for vision transformer based framework in medical image classification.
[54]. Transfer learning has played a significant role in the facilitating the use of deep learning in numerous applications [55]–[57]. In this work, we empirically demonstrate how knowledge transfer is equally effective for vision transformer based framework in medical image classification.
In the current problem, the target domain consists of chest radiography image data i.e., for xViTCOS-CXR, the target data is the COVID-19 CXR dataset and for the xViTCOS-CT model, the target data consists of the COVIDx-CT-2A dataset [58] with three classes – COVID-19 Pneumonia, non-COVID-19 Pneumonia, and normal.
The first source domain
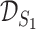 that our proposed ViT model is trained on consists of a large-scale general-purpose image dataset, ImageNet [59]. Since effective ViT training demands access to a sufficiently large number of data points, we choose a model which is pretrained on ImageNet-21k [59]
that our proposed ViT model is trained on consists of a large-scale general-purpose image dataset, ImageNet [59]. Since effective ViT training demands access to a sufficiently large number of data points, we choose a model which is pretrained on ImageNet-21k [59]
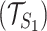 in a self-supervised manner and later finetuned on ImageNet-2012 [60]
in a self-supervised manner and later finetuned on ImageNet-2012 [60]
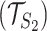 . This pre-training aims to ensure that the model learns to extract crucial but generic image representations to classify natural images.
. This pre-training aims to ensure that the model learns to extract crucial but generic image representations to classify natural images.
The underlying distribution of clinical radiographic images is vastly different from an unconnected set of natural images like those in ImageNet, and distributional divergence is very high between the two domains. Hence in cases where the target dataset is of insufficient capacity, the pre-trained ViT model might find it highly difficult to bridge the domain shift between the learned source domain and the unseen target domain. However, with a sufficient number of training examples available from the target domain, the ViT model can overcome the gap between these two domains. Keeping this in mind, an intermediate stage of knowledge transfer is used in this paper to train our proposed model depending on the size of the target domain training data. The primary goal of this stage of transfer learning is to help the ViT model, pre-trained on a generic image domains
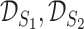 , to learn chest radiography specific representations to overcome the existing domain shift. In order to achieve this, we further finetune the pre-trained ViT model on a large collection of chest radiographic data
, to learn chest radiography specific representations to overcome the existing domain shift. In order to achieve this, we further finetune the pre-trained ViT model on a large collection of chest radiographic data
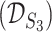 [61] after replacing its existing classification head with one suitable for the corresponding classification task
[61] after replacing its existing classification head with one suitable for the corresponding classification task
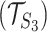 .
.
With the COVIDx-CT-2A dataset [58] a moderate-sized dataset (refer to Table 1), xViTCOS-CT model was able to overcome the domain shift and achieved state-of-the-art performance without the need for the intermediate finetuning stage. However, due to a limited number of COVID-19 CXR images (refer to Table 2), an intermediate stage of knowledge transfer was employed to improve the performance of xViTCOS-CXR model. A publicly available large-scale CXR dataset, CheXpert [61] was used, and xViTCOS-CXR was finetuned to classify five medical conditions (Atelectasis, Cardiomegaly, Consolidation, Edema, and Pleural Effusion) and the case of no finding on that dataset. Following this, the existing classification head of the ViT network was replaced by a new head suited for the particular target task, i.e., COVID-19 detection, and the model was further finetuned on the target domain. Refer to supplementary material for an ablation study to understand the impact of multi-stage transfer.
TABLE 1. Summary of COVIDx CT-2A Dataset [58].
| Split | Normal | Pneumonia | COVID-19 | Total |
|---|---|---|---|---|
| Train | 35996 | 25496 | 82286 | 143778 |
| Validation | 11842 | 7400 | 6244 | 25486 |
| Test | 12245 | 7395 | 6018 | 25658 |
TABLE 2. Summarized Description of CXR Dataset.
| Split | Normal | Pneumonia | COVID-19 | Total |
|---|---|---|---|---|
| Train | 1079 | 3106 | 1726 | 5911 |
| Validation | 270 | 777 | 432 | 1479 |
| Test | 234 | 390 | 200 | 824 |
D. Implementation Details
A number of Vision Transformers architectures have been proposed in literature. In this paper we have tested our algorithm on architectures proposed in [53] and [16] over the task of classification on the Chest X-Ray dataset. A detailed study on all the architectures tested, namely ViT-B/16, ViT-B/32, ViT-L/16 and ViT-L/32, and the results obtained has been added in the supplementary. On the basis of classification performance and computational expense, we choose the ViT-B/16 network as the most suitable amongst those tested for further experimentation. For further details, please refer to the Supplementary. ViT-B/16 architecture has the following configuration- Patch size:
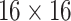 , Fraction of the units to drop for dense layers (Dropout rate): 0.1, Dimensions of the MLP output in the transformers: 3072, Number of transformer heads: 12, Number of transformer layers: 12, Hidden size: 768. The model parameters are initialized with the parameters of a model pretrained on ImageNet-21k [59] and fine-tuned on ImageNet-2012 [60].
, Fraction of the units to drop for dense layers (Dropout rate): 0.1, Dimensions of the MLP output in the transformers: 3072, Number of transformer heads: 12, Number of transformer layers: 12, Hidden size: 768. The model parameters are initialized with the parameters of a model pretrained on ImageNet-21k [59] and fine-tuned on ImageNet-2012 [60].
While training xViTCOS-CXR, for the intermediate finetuning step using CheXpert [61], we use standard binary cross-entropy loss. This is because the classification task using CheXpert is a multi-label classification problem. Finally, while finetuning in the target COVID-19 CXR images, categorical cross-entropy loss is used to solve a multi-class classification problem. While training xViTCOS-CT, we utilize categorical cross-entropy. We use Keras [62] with Tensorflow [63] backend and vit-Keras.1
IV. Experiments and Results
A. Datasets
Some of the existing works validate their methods using private datasets [30], and several other works [12], [14], [15], [35] combine data from different publicly available sources. While combining data from different public repository, researchers should be careful to avoid duplication as a contributor might upload the same image to many of the repositories. Another interesting way to mitigate the issue of data scarcity is through generative data augmentation where a neural generative framework [64]–[67] is trained to generate novel data samples. However in this work, we use the datasets described in the next section. We have rerun the codes of the baseline models using same dataset and same split to ensure a fair comparison.
1). CT Scan Dataset
To demonstrate the efficacy of xViTCOS-CT, we use COVIDx CT-2A dataset [58], derived from several public repositories [68]–[75]. This dataset contains 194,922 CT scans from 3,745 patients across the globe with clinically verified findings. Table 1 summarizes the important statistics of COVIDx CT-2A dataset.
2). Chest X-Ray Dataset
To benchmark xViTCOS-CXR against other deep learning based methods for COVID-19 detection using CXR images, we construct a custom dataset consisting of three cases: Normal, Pneumonia, and COVID-19. Like in [12], [35], Normal and Pneumonia CXR images were obtained from the Kaggle repository ‘Chest X-Ray Images (Pneumonia)’ [76], which is derived from [77]. COVID-19 images were collected from the Kaggle repository ‘COVIDx CXR-2’ [78], which is a compilation of several public repositories [79]–[84].
COVIDx-CXR-2 [78] provides only Train-Test split of the data. To automatically select the best model based on validation-set performance, we split Training set in 80:20 ratio as train and validation set. This would have caused huge class imbalance in the validation set as ‘Chest X-Ray Images (Pneumonia)’ [77] contains only 8 images per class in the validation set. Therefore, we combine the training and validation split and reconstruct the training and validation split in 80:20 ratio. Table 2 summarizes split-wise image distribution. Note that, we have kept the test split intact in both the datasets to prevent patient-wise information leakage as multiple images for the same patient could be present in the dataset.
B. Data Preprocessing and Augmentation
1). CT Images
COVIDx CT-2A dataset [58] provides bounding box annotations for the body regions within the CT images. To standardize the field-of-view in the CT images, we crop the images to the body region using this additional information. Next each cropped image is resized to a fixed size of
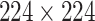 pixels. To improve generalizability of the model, we augment the training data on the fly by applying random affine transformations such as rotation, scaling and translation, random horizontal flip and random shear.
pixels. To improve generalizability of the model, we augment the training data on the fly by applying random affine transformations such as rotation, scaling and translation, random horizontal flip and random shear.
2). CXR Images
In the compiled dataset, the chest X-ray images are of various sizes. To fix this issue, all the images were resized to a fixed size of
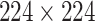 pixels. Again as in the case of CT images, to improve the generalizability of the model, we apply the same sets of augmentation techniques (refer to Section IV-B.1). In addition, we apply random zoom in and zoom out, and random channel shift.
pixels. Again as in the case of CT images, to improve the generalizability of the model, we apply the same sets of augmentation techniques (refer to Section IV-B.1). In addition, we apply random zoom in and zoom out, and random channel shift.
C. Quantitative Results
To quantify and benchmark the performance of xViTCOS, we compute and report Accuracy, Precision (Positive Prediction Value), Recall (Sensitivity), F1 score, Specificity, and Negative Prediction Value (NPV) as defined and compared in the standard literature such as [14], [32].
1). xViTCOS-CT
Table 3 presents the overall accuracy of xViTCOS-CT on the test split of COVID-CT-2A dataset [58]. As can be observed, the proposed method achieves the best accuracy score of 98.1%, surpassing the current state of art methods. Next, we discuss the precision, recall, specificity, PPV, NPV, and F1-scores attained by the model on test COVID CT images and interpret their significance in determining the classification caliber of the model. From table 3, it can be observed that xViTCOS-CT achieves a high value of recall or sensitivity at 96%, implying that a small proportion of pneumonia cases caused due to COVID-19 are incorrectly classified as having non-COVID-19 origin. This implies a significantly low number of false-negative cases, which is a highly sought-after characteristic in a medical data classifier as in such cases, a false negative situation may lead to denial or delay of treatment to a person genuinely infected by the disease. The proposed method also attains a high precision or positive predictive value of 96% for COVID-19 cases, implying a little chance of the model classifying a non-COVID case as having a COVID-19 origin. However, the usefulness of our proposed method lies in the fact that it achieves the highest F1 scores for all the classes, implying that in terms of both precision and recall, the proposed method is the most balanced amongst all the baseline models. Also, it is well able to differentiate between the normal and Pneumonia cases of patients as well. Similarly, we can see that the proposed model attains high specificity and NPV values of 98.8% for the COVID-19 case, implying that false positives are also very low. This is a useful characteristic in clinical scenarios since the model correctly rejects all the negative cases, facilitating efficient utilization of limited resources.
TABLE 3. Comparison of Performance of xViTCOS-CT on CT Scan Dataset Against State-of-the-Art Methods.
| Method | Class Label | Precision | Recall | F1-score | Specificity | NPV | Overall Accuracy |
|---|---|---|---|---|---|---|---|
| Resnet + Location Attention [25] | Normal | 0.920 | 0.989 | 0.954 | 0.922 | 0.989 | 0.932 |
| Pneumonia | 0.963 | 0.799 | 0.873 | 0.987 | 0.924 | ||
| COVID-19 | 0.906 | 0.955 | 0.930 | 0.969 | 0.986 | ||
| Weighted Avg. | 0.929 | 0.926 | 0.925 | 0.952 | 0.970 | ||
| Macro Avg. | 0.930 | 0.914 | 0.919 | 0.959 | 0.966 | ||
| COVIDNet-CT [15] | Normal | 0.958 | 0.987 | 0.973 | 0.957 | 0.986 | 0.949 |
| Pneumonia | 0.981 | 0.805 | 0.884 | 0.989 | 0.942 | ||
| COVID-19 | 0.906 | 0.988 | 0.945 | 0.960 | 0.995 | ||
| Weighted Avg. | 0.952 | 0.935 | 0.941 | 0.967 | 0.975 | ||
| Macro Avg. | 0.948 | 0.927 | 0.934 | 0.969 | 0.974 | ||
| Teacher-student Attention [37] | Normal | 0.969 | 0.989 | 0.979 | 0.971 | 0.990 | 0.964 |
| Pneumonia | 0.951 | 0.982 | 0.966 | 0.979 | 0.992 | ||
| COVID-19 | 0.957 | 0.877 | 0.915 | 0.987 | 0.963 | ||
| Weighted Avg. | 0.961 | 0.961 | 0.960 | 0.977 | 0.984 | ||
| Macro Avg. | 0.959 | 0.949 | 0.953 | 0.979 | 0.982 | ||
| ResGNet-C [30] | Normal | 0.942 | 0.974 | 0.958 | 0.946 | 0.975 | 0.939 |
| Pneumonia | 0.951 | 0.855 | 0.901 | 0.982 | 0.944 | ||
| COVID-19 | 0.910 | 0.961 | 0.934 | 0.971 | 0.987 | ||
| Weighted Avg. | 0.937 | 0.937 | 0.936 | 0.962 | 0.957 | ||
| Macro Avg. | 0.934 | 0.930 | 0.931 | 0.966 | 0.952 | ||
| xViTCOS-CT (Proposed) | Normal | 0.997 | 0.990 | 0.993 | 0.997 | 0.991 | 0.981 |
| Pneumonia | 0.971 | 0.982 | 0.977 | 0.988 | 0.993 | ||
| COVID-19 | 0.960 | 0.961 | 0.961 | 0.988 | 0.988 | ||
| Weighted Avg. | 0.981 | 0.981 | 0.981 | 0.992 | 0.991 | ||
| Macro Avg. | 0.976 | 0.978 | 0.977 | 0.991 | 0.991 |
The prowess of the proposed model can be further understood from examining the confusion matrix (Figure 2). The proposed model can distinguish the healthy patients from both covid and non-covid pneumonia cases very efficiently, with an accuracy of almost 99%. Particularly, out of a total of 12245 normal cases, 12120 have been classified correctly, while 11 (0.09%) and 114 (0.93%) cases have been wrongly classified as non-COVID pneumonia and COVID pneumonia classes, respectively. Another interesting point to note here is that while 114 normal cases have been misclassified as COVID-19 and 204 COVID-19 cases have been assigned the non-COVID pneumonia label; the classifier has assigned only 31 COVID-19 originated pneumonia cases a normal class. This implies that the proposed method can distinguish the normal cases from the diseased cases.
FIGURE 2.

Confusion Matrix: The horizontal and vertical axis consists of the ground true and predicted labels, respectively.
2). xViTCOS-CXR
The observations regarding the performance of xViTCOS-CXR compared to its contemporaries are on the same lines as that of xViTCOS-CT, if not better. In terms of classification accuracy, xViTCOS-CXR achieves an accuracy of 96%, outperforming the baseline methods by a considerable margin as can be seen from Table 4. Further, it can be observed that xViTCOS-CXR achieves high recall (100%) and precision values (99%) on the COVID-19 cases, implying that the number of occasions on which the proposed model classified a COVID-19 model as a non-COVID-19 model or vice-versa is extremely low. Examining the entries of Table 4, one can observe that the proposed method is the most balanced in terms of precision-recall when compared with the state-of-the-art baselines. Similarly, we can see that the proposed model attains high specificity and NPV values of almost 100% for the COVID-19 case implying that the number of false positives is almost negligible. This is a valuable characteristic in clinical scenarios since it allows for rapid identification of patients who do not have COVID-19.
TABLE 4. Comparison of Performance of xViTCOS-CXR on Chest X-Ray Dataset Against State-of-the-Art Methods.
| Method | Class Label | Precision | Recall | F1-score | Specificity | NPV | Overall Accuracy |
|---|---|---|---|---|---|---|---|
| InceptionV3 [85], [86] | Normal | 0.932 | 0.876 | 0.903 | 0.974 | 0.952 | 0.946 |
| Pneumonia | 0.933 | 0.964 | 0.948 | 0.937 | 0.967 | ||
| COVID-19 | 0.990 | 0.995 | 0.992 | 0.997 | 0.998 | ||
| Weighted Avg. | 0.947 | 0.947 | 0.946 | 0.962 | 0.970 | ||
| Macro Avg. | 0.952 | 0.945 | 0.948 | 0.969 | 0.972 | ||
| CoroNet [12] | Normal | 0.812 | 0.923 | 0.864 | 0.915 | 0.967 | 0.917 |
| Pneumonia | 0.953 | 0.941 | 0.947 | 0.958 | 0.947 | ||
| COVID-19 | 1.000 | 0.865 | 0.927 | 1.000 | 0.958 | ||
| Weighted Avg. | 0.924 | 0.917 | 0.919 | 0.956 | 0.955 | ||
| Macro Avg. | 0.922 | 0.910 | 0.913 | 0.958 | 0.957 | ||
| CovidNet [14] | Normal | 0.826 | 0.918 | 0.870 | 0.923 | 0.966 | 0.919 |
| Pneumonia | 0.950 | 0.882 | 0.915 | 0.958 | 0.900 | ||
| COVID-19 | 0.985 | 0.995 | 0.990 | 0.995 | 0.998 | ||
| Weighted Avg. | 0.923 | 0.920 | 0.920 | 0.957 | 0.943 | ||
| Macro Avg. | 0.920 | 0.932 | 0.925 | 0.959 | 0.955 | ||
| Teacher Student Attention [37] | Normal | 0.913 | 0.902 | 0.908 | 0.966 | 0.961 | 0.932 |
| Pneumonia | 0.918 | 0.974 | 0.945 | 0.922 | 0.976 | ||
| COVID-19 | 0.989 | 0.885 | 0.934 | 0.997 | 0.964 | ||
| Weighted Avg. | 0.934 | 0.932 | 0.932 | 0.953 | 0.969 | ||
| Macro Avg. | 0.940 | 0.920 | 0.929 | 0.962 | 0.967 | ||
| MAG-SD [36] | Normal | 0.954 | 0.901 | 0.927 | 0.983 | 0.962 | 0.951 |
| Pneumonia | 0.931 | 0.974 | 0.952 | 0.935 | 0.975 | ||
| COVID-19 | 0.989 | 0.965 | 0.977 | 0.996 | 0.988 | ||
| Weighted Avg. | 0.952 | 0.951 | 0.951 | 0.963 | 0.974 | ||
| Macro Avg. | 0.958 | 0.947 | 0.952 | 0.971 | 0.975 | ||
| xViTCOS-CXR (Proposed) | Normal | 0.959 | 0.902 | 0.929 | 0.985 | 0.962 | 0.960 |
| Pneumonia | 0.945 | 0.974 | 0.959 | 0.949 | 0.976 | ||
| COVID-19 | 0.990 | 1.000 | 0.995 | 0.997 | 1.000 | ||
| Weighted Avg. | 0.959 | 0.960 | 0.959 | 0.971 | 0.978 | ||
| Macro Avg. | 0.965 | 0.959 | 0.961 | 0.977 | 0.979 |
Analysing figure 2b, it can be seen that the class-wise accuracy of COVID-19 is 100%, i.e., all the ground truth COVID-19 cases have been classified as COVID-19, implying that the number of false negatives is zero. This confirms the efficacy of the proposed model in distinguishing between COVID and non-COVID cases.
D. Qualitative Results
1). Visualization of Feature Space
To visually analyze how clustered the feature space is, we perform a t-SNE visualization of the penultimate layer’s features for both the models using the test splits. As can be seen from Figure 3, the features in the penultimate layer clusters distinctively for the three different classes.
FIGURE 3.

t-SNE plots of penultimate layers of xViTCOS.
2). Explainability
For qualitative evaluation of xViTCOS we present samples of CXR images and CT scans along with their ground truth labels and corresponding saliency maps along with the prediction in Figure 4. In order to analyse the explainability properties of our proposed method, we use the Gradient Attention Rollout algorithm as outlined in [87]. Further details can be found in Section I of the supplementary document. Figure 4a, 4b and 4c presents CT scans of normal, Pneumonia and COVID-19 cases respectively; Figure 4d, 4e and 4f presents CXR images of normal, Pneumonia and COVID-19 cases respectively.
FIGURE 5.

A case of failure. xViTCOS-CT fails to predict the ground truth non-COVID-19 Pneumonia with confidence as it predicts non-COVID-19 Pneumonia with
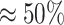 probability and COVID-19 with
probability and COVID-19 with
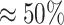 probability. This might happen as the findings on chest imaging in COVID-19 are not exclusive and overlap with many other type of infections [88]. In such cases, human expert intervention is necessary. For a detailed discussion refer to Section V.
probability. This might happen as the findings on chest imaging in COVID-19 are not exclusive and overlap with many other type of infections [88]. In such cases, human expert intervention is necessary. For a detailed discussion refer to Section V.
FIGURE 4.
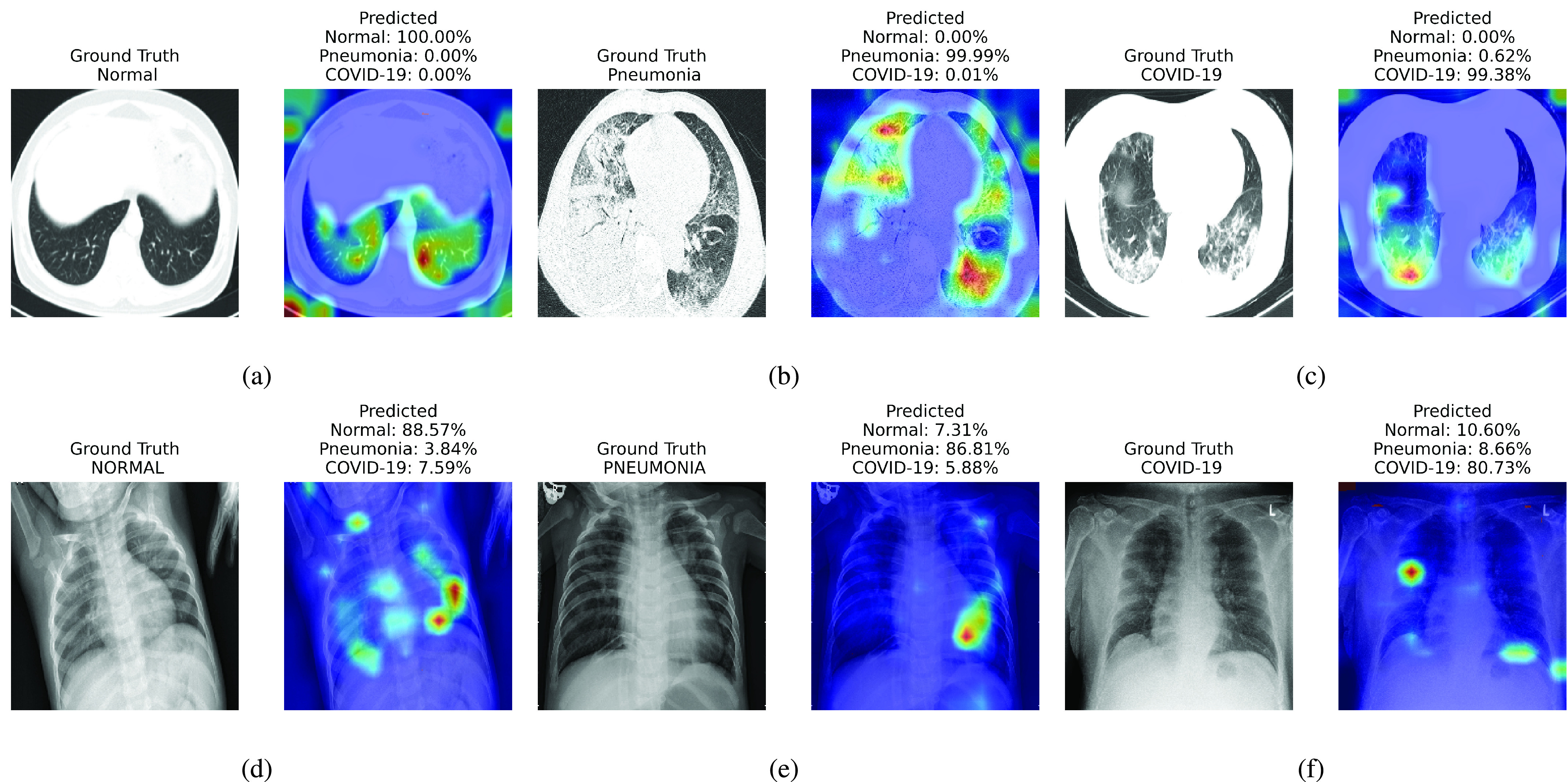
Visualization of different cases (normal, Pneumonia, COVID-19) considered in this study and their associated critical factors in decision making by xViTCOS as identified using the explanability method laid out in [87] for transformers [16]. In each subfigure, the left figure presents the input to xViTCOS and its ground truth label; the right figure presents the predicted probabilities for each class and highlight the factors critical corresponding to the top predicted class. Figure 4a, 4b and 4c corresponds to CT scan and Figure 4d, 4e and 4f corresponds to CXR images.
Report corresponding to Figure 4b as interpreted by a practicing radiologist: ground glass opacities, consolidation and secondary interlobar septal thickening, in bilateral lung, more extensive in right. xViTCOS-CT correctly highlighted these suspected regions. In Figure 4c xViTCOS-CT localized suspicious lesion regions exhibiting ground glass opacities, consolidation, reticulations in bilateral postero basal lung with subpleural predominance. In Figure 4e Patchy air space opacities noted in right upper and midzone matches the regions highlighted by xViTCOS-CXR. In Figure 4f, radiologist’s interpretation is: thick walled cavity in right middle zone with surrounding consolidation. xViTCOS-CXR is able to correctly identify it. For the cases, where no abnormality is detected (Figure 4a and 4d), xViTCOS focuses on the entire lungs and chest respectively to make a final decision.
V. Conclusion
In this study, we introduce a novel vision transformer based method, xViTCOS for COVID-19 screening using chest radiography. We have empirically demonstrated the efficacy of the proposed method over CNN based SOTA methods as measured by various metrics such as precision, recall, F1 score. Additionally, we examine the predictive performance of xViTCOS utilizing explanability-driven heatmap plot to highlight the important factors for the predictive decision it makes. These interpretable visual cues are not only a step towards explainable AI, also might aid practicing radiologists in diagnosis. We also analyzed the failure cases of our method. Thus, to enhance the effectiveness of diagnosis we suggest that xViTCOS be used to complement RT-PCR testing. In the next phase of this project, we aim to extend this work to automate the analysis of the severity of infection using vision transformers.
Footnotes
References
- [1].WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19. Accessed: Mar. 11, 2020. [Online]. Available: https://www.who.int/director-general/speeches/detail
- [2].Hellou M. M.et al. , “Nucleic acid amplification tests on respiratory samples for the diagnosis of coronavirus infections: A systematic review and meta-analysis,” Clin. Microbiol. Infection, vol. 27, no. 3, pp. 341–351, Mar. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Colavita F.et al. , “COVID-19 rapid antigen test as screening strategy at points of entry: Experience in Lazio region, central Italy, August–October 2020,” Biomolecules, vol. 11, no. 3, p. 425, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Munne K., Bhanothu V., Bhor V., Patel V., Mahale S. D., and Pande S., “Detection of SARS-CoV-2 infection by RT-PCR test: Factors influencing interpretation of results,” VirusDisease, vol. 32, no. 2, pp. 187–189, Jun. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Rajpurkar P.et al. , “ChexNet: Radiologist-level pneumonia detection on chest X-rays with deep learning,” CoRR, vol. abs/1711.05225, pp. 1–7, Nov. 2017. [Google Scholar]
- [6].Xie X., Zhong Z., Zhao W., Zheng C., Wang F., and Liu J., “Chest CT for typical coronavirus disease 2019 (COVID-19) pneumonia: Relationship to negative RT-PCR testing,” Radiology, vol. 296, no. 2, pp. E41–E45, Aug. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Bernheim A.et al. , “Chest CT findings in coronavirus disease-19 (COVID-19): Relationship to duration of infection,” Radiology, vol. 295, no. 3, Jun. 2020, Art. no. 200463. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Fang Y.et al. , “Sensitivity of chest CT for COVID-19: Comparison to RT-PCR,” Radiology, vol. 296, no. 2, pp. E115–E117, Aug. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Ai T.et al. , “Correlation of chest CT and RT-PCR testing for coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases,” Radiology, vol. 296, no. 2, pp. E32–E40, Aug. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Panetta K., Sanghavi F., Agaian S., and Madan N., “Automated detection of COVID-19 cases on radiographs using shape-dependent fibonacci-P patterns,” IEEE J. Biomed. Health Informat., vol. 25, no. 6, pp. 1852–1863, Jun. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Wang L., Lin Z. Q., and Wong A., “COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images,” Sci. Rep., vol. 10, no. 1, Dec. 2020, Art. no. 19549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Khan A. I., Shah J. L., and Bhat M. M., “CoroNet: A deep neural network for detection and diagnosis of COVID-19 from chest X-ray images,” Comput. Methods Programs Biomed., vol. 196, Nov. 2020, Art. no. 105581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Ardakani A. A., Kanafi A. R., Acharya U. R., Khadem N., and Mohammadi A., “Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks,” Comput. Biol. Med., vol. 121, Jun. 2020, Art. no. 103795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Wang L., Lin Z. Q., and Wong A., “COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images,” Sci. Rep., vol. 10, no. 1, 2020, Art. no. 19549. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Gunraj H., Wang L., and Wong A., “COVIDNet-CT: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest CT images,” Frontiers Med., vol. 7, Dec. 2020, Art. no. 608525. [DOI] [PMC free article] [PubMed] [Google Scholar]
-
[16].Dosovitskiy A.et al. , “An image is worth
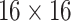 words: Transformers for image recognition at scale,” in Proc. ICLR, 2021, pp. 1–22. [Google Scholar]
words: Transformers for image recognition at scale,” in Proc. ICLR, 2021, pp. 1–22. [Google Scholar] - [17].Sun L.et al. , “Adaptive feature selection guided deep forest for COVID-19 classification with chest CT,” IEEE J. Biomed. Health Informat., vol. 24, no. 10, pp. 2798–2805, Oct. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Krizhevsky A., Sutskever I., and Hinton G. E., “Imagenet classification with deep convolutional neural networks,” in NeurIPS, Pereira F., Burges C. J. C., Bottou L., and Weinberger K. Q., Eds. Red Hook, NY, USA: Curran Associates, 2012. [Google Scholar]
- [19].Simonyan K. and Zisserman A., “Very deep convolutional networks for large-scale image recognition,” in Proc. ICLR, 2015, pp. 1–14. [Google Scholar]
- [20].Iandola F. N., Han S., Moskewicz M. W., Ashraf K., Dally W. J., and Keutzer K., “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 model size,” 2016, arXiv:1602.07360.
- [21].Szegedy C.et al. , “Going deeper with convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 1–9. [Google Scholar]
- [22].Sandler M., Howard A., Zhu M., Zhmoginov A., and Chen L.-C., “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 4510–4520. [Google Scholar]
- [23].He K., Zhang X., Ren S., and Sun J., “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778. [Google Scholar]
- [24].Chollet F., “Xception: Deep learning with depthwise separable convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1251–1258. [Google Scholar]
- [25].Xu X.et al. , “A deep learning system to screen novel coronavirus disease 2019 pneumonia,” Engineering, vol. 6, no. 10, pp. 1122–1129, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Li L.et al. , “Using artificial intelligence to detect COVID-19 and community-acquired pneumonia based on pulmonary CT: Evaluation of the diagnostic accuracy,” Radiology, vol. 296, no. 2, pp. E65–E71, Aug. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Bai H. X.et al. , “Artificial intelligence augmentation of radiologist performance in distinguishing COVID-19 from pneumonia of other origin at chest ct,” Radiology, vol. 296, no. 3, pp. E156–E165, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Wang Z., Liu Q., and Dou Q., “Contrastive cross-site learning with redesigned net for COVID-19 CT classification,” IEEE J. Biomed. Health Informat., vol. 24, no. 10, pp. 2806–2813, Oct. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Owais M., Lee Y. W., Mahmood T., Haider A., Sultan H., and Park K. R., “Multilevel deep-aggregated boosted network to recognize COVID-19 infection from large-scale heterogeneous radiographic data,” IEEE J. Biomed. Health Informat., vol. 25, no. 6, pp. 1881–1891, Jun. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Yu X., Lu S., Guo L., Wang S.-H., and Zhang Y.-D., “ResGNet-C: A graph convolutional neural network for detection of COVID-19,” Neurocomputing, vol. 452, pp. 592–605, Sep. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Kipf T. N. and Welling M., “Semi-supervised classification with graph convolutional networks,” in Proc. ICLR, 2017, pp. 1–5. [Google Scholar]
- [32].Kaur T., Gandhi T. K., and Panigrahi B. K., “Automated diagnosis of COVID-19 using deep features and parameter free BAT optimization,” IEEE J. Transl. Eng. Health Med., vol. 9, 2021, Art. no. 1800209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Waswani A.et al. , “Attention CS all you need,” in Proc. NeurIPS, 2017, pp. 5998–6008. [Google Scholar]
- [34].Tabik S.et al. , “COVIDGR dataset and COVID-SDNet methodology for predicting COVID-19 based on Chest X-Ray images,” IEEE J. Biomed. Health Informat., vol. 24, no. 12, pp. 3595–3605, Dec. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Mangal A.et al. , “CovidAID: COVID-19 detection using chest X-ray,” 2020, arXiv 2004.09803.
- [36].Li J.et al. , “Multiscale attention guided network for COVID-19 diagnosis using chest X-ray images,” IEEE J. Biomed. Health Informat., vol. 25, no. 5, pp. 1336–1346, May 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Shi W., Tong L., Zhu Y., and Wang M. D., “COVID-19 automatic diagnosis with radiographic imaging: Explainable attention transfer deep neural networks,” IEEE J. Biomed. Health Informat., vol. 25, no. 7, pp. 2376–2387, Jul. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Wang Z.et al. , “Automatically discriminating and localizing COVID-19 from community-acquired pneumonia on chest X-rays,” Pattern Recognit., vol. 110, Feb. 2021, Art. no. 107613. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Elaziz M. A., Hosny K. M., Salah A., Darwish M. M., Lu S., and Sahlol A. T., “New machine learning method for image-based diagnosis of COVID-19,” PLoS ONE, vol. 15, no. 6, Jun. 2020, Art. no. e0235187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Parmar N.et al. , “Image transformer,” in Proc. Int. Conf. Mach. Learn., PMLR, Jul. 2018, pp. 4055–4064. [Google Scholar]
- [41].Hu H., Zhang Z., Xie Z., and Lin S., “Local relation networks for image recognition,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 3464–3473. [Google Scholar]
- [42].Zhao H., Jia J., and Koltun V., “Exploring self-attention for image recognition,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 10076–10085. [Google Scholar]
- [43].Ramachandran P., Parmar N., Vaswani A., Bello I., Levskaya A., and Shlens J., “Stand-alone self-attention in vision models,” in Advances in Neural Information Processing Systems, vol. 32, Wallach H., Larochelle H., Beygelzimer A., Alché-Buc F., Fox E., and Garnett R., Eds. Red Hook, NY, USA: Curran Associates, 2019. [Google Scholar]
- [44].Child R., Gray S., Radford A., and Sutskever I., “Generating long sequences with sparse transformers,” 2019, arXiv:1904.10509.
- [45].Weissenborn D., Täckström O., and Uszkoreit J., “Scaling autoregressive video models,” in Proc. Int. Conf. Learn. Represent., 2020, pp. 1–24. [Google Scholar]
- [46].Cordonnier J.-B., Loukas A., and Jaggi M., “On the relationship between self-attention and convolutional layers,” in Int. Conf. Learn. Represent., 2020, pp. 1–18. [Google Scholar]
- [47].Bello I., Zoph B., Le Q., Vaswani A., and Shlens J., “Attention augmented convolutional networks,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 3286–3295. [Google Scholar]
- [48].Hu H., Gu J., Zhang Z., Dai J., and Wei Y., “Relation networks for object detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3588–3597. [Google Scholar]
- [49].Wu B.et al. , “Visual transformers: Token-based image representation and processing for computer vision,” 2020, arXiv:2006.03677.
- [50].Wang X., Girshick R., Gupta A., and He K., “Non-local neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 7794–7803. [Google Scholar]
- [51].Sun C., Myers A., Vondrick C., Murphy K., and Schmid C., “VideoBERT: A joint model for video and language representation learning,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 7463–7472. [Google Scholar]
- [52].Chen M.et al. , “Generative pretraining from pixels,” in Proc. 37th Int. Conf. Mach. Learn. (ICML), vol. 119, Jul. 2020, pp. 1691–1703. [Google Scholar]
- [53].Devlin J., Chang M.-W., Lee K., and Toutanova K., “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol., vol. 1, Jun. 2019, pp. 4171–4186. [Google Scholar]
- [54].Pan S. and Yang Q., “A survey on transfer learning,” IEEE Trans. Knowl. Data Eng., vol. 22, no. 4, pp. 1345–1359, Nov. 2010. [Google Scholar]
- [55].Volpp M.et al. , “Meta-learning acquisition functions for transfer learning in Bayesian optimization,” in Int. Conf. Learn. Represent., 2020, pp. 1–22. [Google Scholar]
- [56].Bhattacharjee A., Verma A., Mishra S., and Saha T. K., “Estimating state of charge for xEV batteries using 1D convolutional neural networks and transfer learning,” IEEE Trans. Veh. Technol., vol. 70, no. 4, pp. 3123–3135, Apr. 2021. [Google Scholar]
- [57].Tan C., Sun F., Kong T., Zhang W., Yang C., and Liu C., “A survey on deep transfer learning,” in Proc. Int. Conf. Artif. Neural Netw. Cham, Switzerland: Springer, Oct. 2018, pp. 270–279. [Google Scholar]
- [58].Gunraj H.. (2021). COVIDx CT-2A: A Large-Scale Chest CT Dataset for COVID-19 Detection. [Online]. Available: https://www.kaggle.com/hgunraj/covidxct [Google Scholar]
- [59].Deng J., Dong W., Socher R., Li L.-J., Li K., and Fei-Fei L., “ImageNet: A large-scale hierarchical image database,” in Proc. CVPR, 2009, pp. 248–255. [Google Scholar]
- [60].Russakovsky O.et al. , “ImageNet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015. [Google Scholar]
- [61].Irvin J.et al. , “Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison,” in Proc. AAAI, 2019, pp. 590–597. [Google Scholar]
- [62].Chollet F.. (2015). Keras. [Online]. Available: https://keras.io [Google Scholar]
- [63].Abadi M.. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. https://Software.available.from.tensorflow.org [Google Scholar]
- [64].Goodfellow I.et al. , “Generative adversarial nets,” in Proc. NeuRIPS, 2014, pp. 1–9. [Google Scholar]
- [65].Tolstikhin I., Bousquet O., Gelly S., and Scholkopf B., “Wasserstein auto-encoders,” in Proc. ICLR, 2018, pp. 1–20. [Google Scholar]
- [66].Mondal A. K., Chowdhury S. P., Jayendran A., Singla P., Asnani H., and Prathosh A., “MaskAAE: Latent space optimization for adversarial auto-encoders,” in Proc. UAI, 2020, pp. 1–18. [Google Scholar]
- [67].Mondal A. K., Asnani H., Singla P., and Prathosh A., “FlexAE: Flexibly learning latent priors for wasserstein auto-encoders,” in Proc. UAI, 2021, pp. 525–535. [Google Scholar]
- [68].Zhang K.et al. , “Clinically applicable ai system for accurate diagnosis, quantitative measurements, and prognosis of COVID-19 pneumonia using computed tomography,” Cell, vol. 181, no. 6, pp. 1423–1433, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [69].An P.et al. , “CT images in COVID-19,” Cancer Imag. Arch., Jun. 2020.
- [70].Rahimzadeh M., Attar A., and Sakhaei S. M., “A fully automated deep learning-based network for detecting COVID-19 from a new and large lung ct scan dataset,” Biomed. Signal Process. Control, vol. 68, Dec. 2021, Art. no. 102588. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].Ning W.et al. , “Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via deep learning,” Nature Biomed. Eng., vol. 4, no. 12, pp. 1197–1207, Dec. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [72].Ma J.et al. , “Towards data-efficient learning: A benchmark for COVID-19 CT lung and infection segmentation,” 2020, arXiv:2004.12537. [DOI] [PubMed]
- [73].Armato III S. G.et al. , “Data from LIDC-IDRI,” Cancer Imag. Arch., Dec. 2015.
- [74].Radiopaedia. COVID-19. Accessed: Feb. 4, 2021. [Online]. Available: https://radiopaedia.org/articles/covid-19-4 [Google Scholar]
- [75].Morozov S. P.et al. , “MosMedData: Chest CT scans with COVID-19 related findings dataset,” 2020, arXiv:2005.06465.
- [76].Mooney P.. (2018). Chest X-ray Images (Pneumonia). [Online]. Available: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia [Google Scholar]
- [77].Kermany D., Zhang K., and Goldbaum M., “Labeled optical coherence tomography (oct) and chest X-ray images for classification,” Mendeley Data, vol. 2, no. 2, Jun. 2018. [Google Scholar]
- [78].Zhao A.. (2021). COVIDx CXR-2: Chest X-ray Images for the Detection of COVID-19. [Online]. Available: https://www.kaggle.com/andyczhao/covidx-cxr2 [Google Scholar]
- [79].Paul Cohen J., Morrison P., Dao L., Roth K., Duong T. Q, and Ghassemi M., “COVID-19 image data collection: Prospective predictions are the future,” 2020, arXiv:2006.11988.
- [80].Wang L.. (2020). Figure 1 COVID-19 Chest X-ray Dataset Initiative. [Online]. Available: https://github.com/agchung/Figure1-COVID-chestxray-dataset [Google Scholar]
- [81].Wang L.. (2020). Actualmed COVID-19 Chest X-ray Dataset Initiative. [Online]. Available: https://github.com/agchung/Actualmed-COVID-chestxray-dataset [Google Scholar]
- [82].Chowdhury M. E.et al. , “Can ai help in screening viral and COVID-19 pneumonia?” IEEE Access, vol. 8, pp. 132665–132676, 2020. [Google Scholar]
- [83].RS North America (2018). RSNA Pneumonia Detection Challenge: Can You Build an Algorithm That Automatically Detects Potential Pneumonia Cases. [Online]. Available: https://www.kaggle.com/c/rsna-pneumonia-detection-challenge [Google Scholar]
- [84].Tsai E. B.et al. , “Data from medical imaging data resource center (MIDRC)-RSNA international covid radiology database (RICORD) release 1C—Chest X-ray, covid+ (MIDRC-RICORD-1C),” Tech. Rep., 2021.
- [85].Szegedy C., Vanhoucke V., Ioffe S., Shlens J., and Wojna Z., “Rethinking the inception architecture for computer vision,” in Proc. CVPR, 2016, pp. 2818–2826. [Google Scholar]
- [86].Tsiknakis N. and Trivizakis E., “Interpretable artificial intelligence framework for COVID-19 screening on chest X-rays,” Exp. Ther. Med., vol. 20, no. 2, pp. 727–735, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [87].Chefer H., Gur S., and Wolf L., “Transformer interpretability beyond attention visualization,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2021, pp. 782–791. [Google Scholar]
- [88].ACR Recommendations for the Use of Chest Radiography and Computed Tomography (CT) for Suspected COVID-19 Infection, American College of Radiology, Richmond, VA, USA, 2020. [Google Scholar]