

Abstract
We consider a game for a continuum of non-identical players evolving on a finite state space. Their heterogeneous interactions are represented with a graphon, which can be viewed as the limit of a dense random graph. A player’s transition rates between the states depend on their control and the strength of interaction with the other players. We develop a rigorous mathematical framework for the game and analyze Nash equilibria. We provide a sufficient condition for a Nash equilibrium and prove existence of solutions to a continuum of fully coupled forward-backward ordinary differential equations characterizing Nash equilibria. Moreover, we propose a numerical approach based on machine learning methods and we present experimental results on different applications to compartmental models in epidemiology.
Keywords: Graphon games, Epidemiological models, Machine learning
Introduction
With the recent pandemic of COVID-19, the importance of management of large populations in order to control the evolution of the disease has been recognized globally. How a pandemic plays out is a consequence of the interplay of many complex processes, e.g., disease specific spread mechanisms, the network of social interactions, and society-wide efforts to stop or slow the spread. As individuals, we have all made choices during the ongoing pandemic about the extent to which we minimize our personal risk of being infected. However, there is a trade-off between being careful and the pursuit of happiness. As we all have learned by now, our risk is not only determined by our own vigilance but also by others’ choices and our environment.
In the framework of rational agents1, each individual anticipates the action of their neighbours, neighbours’ neighbours, etc., and any other external influence, then selects their action as a best response to others’ actions. In other words, they want optimize their private outcome while taking into account their surrounding environment, which includes other agents’ actions. This type of strategic interaction is a non-cooperative game. The communication between agents in the game may be restricted by geography, social circles, and other factors. Moreover, people interact with different intensity, depending on their occupation and personality. Hence, the agents in the game, each with their own predisposition for risk, will act in a wide variety of ways and thus naturally form a heterogeneous crowd.
Consider the game discussed above where all agents anticipate the others’ action and then selfishly plays a best response. Strategy profiles (the collection of all players’ actions) consistent with such behavior are Nash equilibria, i.e., profiles such that no player profits from a unilateral deviation. Computing Nash equilibria in games with large number of players is particularly hard; under some specific assumptions, approximate equilibria can be found by using the mean field game approach developed independently by Lasry-Lions [45, 46] and Huang-Malhamé-Caines [35]. The approach has found many practical applications, examples include the mathematical modeling of price movement in energy markets; pedestrian crowd motion and evacuation; and epidemic disease spread.
One of the fundamental assumptions in mean field game theory is that agents are indistinguishable and interact homogeneously. However, in some real-world applications such as the modeling of epidemics, the diversity of individuals and the variation of their interactions are important factors to consider. Examples of such include the effects of travel restrictions, multiple age groups with distinct social behavior and risk profiles, and the spectrum of preexisting health conditions. The aspects listed above require the game to have a non-uniform underlying network structure. Games with a large number of non-identical players can be analyzed with so-called graphon games whenever the network specifying the interactions is dense2.
Epidemics are driven by the spread of the disease from infected to susceptible agents. The set of susceptible agents is not necessarily the whole non-infected population, for certain diseases immunity is gained after exposure. The evidence suggests that the COVID-19 virus mainly spreads through close contact3. Fortunately, the disease transmission probability can be decreased by efforts of the individual. For example, an individual can choose to avoid public and closed spaces, wear a protective mask or do their shopping online. When two people meet the disease transmission probability depends on both sides’ effort. The disease is less likely to occur if both parts wear protective masks than if just one part does. However, the decrease in risk of transmission is not additive in the interacting agents’ efforts. Using this intuition, we assume in this paper that disease transmission likelihood depends on efforts in a multiplicative way. The effort of the agents will therefore be given the name “contact factor control”, in line with the game-based model introduced in [2].
Before giving the full description of the epidemiological graphon game model, how it can be approached numerically, and all technical details, we expand upon the heuristics of graphon-based interaction with contact factor control and review the literature of related fields of research in the next sections.
The SIR Graphon Game with Contact Factor Control
The most famous compartmental model in epidemics is arguably the classical Susceptible-Infected-Removed (SIR) model4. In this section, we take advantage of its wide familiarity and compact formulation to further motivate for the concept of contact factor control and graphon-type interaction.
In order to give a description of the rate at which agents become infected, we need to first introduce some notation. Consider N individuals who transition between the states Susceptible (), Infected (), and Removed (). An individual in state has either gained immunity or deceased. Denote the state of agent at time t by . A susceptible individual might encounter infected individuals, resulting in disease transmission. Encounters occur pairwise and randomly throughout the population with intensity . The number of encounters with infected agents in a short time interval is approximately proportional to the the share of the population in state at t. Between each agent pair (j, k), we set the interaction strength to , where w is a graphon (see Definition 1 for its definition) and are random variables uniformly distributed on [0, 1]. Hence agent k’s transition rate from state to is scaled by w and of the form . Upon infection, an individual starts the path to recovery. The jump from state to happens after an exponentially distributed time with rate . The state is absorbing.
Denoting , the transition rate matrix for player is
| 1 |
Here we use the order for the columns and the rows. For instance, the term encodes the rate at which an agent arrives in coming from . As explained above, this rate is proportional to the weighted average of infected agents interacting with player j. At this stage, the distinguishability of the players is seen in the aggregate variables which in general differ in value. As , we expect the probability distribution flow of player j to converge to the solution of the ordinary differential equation (ODE)
| 2 |
where is some given initial distribution over the states and
| 3 |
Here is understood as a vector of length 3 whose coordinates correspond to the probability for player of being in state , and , respectively at time t. Equation (2) encodes the evolution of these probabilities. is the average number of infected agents around player , weighted by the pairwise interaction strength . Scaling , , by a population size N, , we retrieve a formulation of the compartmental SIR model with graphon-based interactions
So far we have considered a model without action. Assuming agents choose a “contact factor” in order to decrease their risk of getting infected, which enters the model in line with the discussion above, we express this new feature mathematically as follows: Given that the meeting frequency is , pairing is random, disease spreads from infected agents to susceptible, and the spread probability is scaled by the efforts of the individuals that meet in a multiplicative way, the transition rate for individual j from to the is
| 4 |
where denotes the (contact factor) action of individual at time t, selected from set of actions A. Along the lines of the heuristics of mean field game theory, we anticipate that in an appropriate approximation of our interacting system in the limit , agent x transitions from susceptible to infected with rate
| 5 |
where is the joint distribution of action and state of player y at time t and is the action of individual x.
Related Literature
Graphon Games and Finite State Space Mean Field Games
Challenges related to large populations arise in the game theory, and mean field game (MFG) theory presents a toolbox to compute equilibria in these games with large number of players. MFGs were first developed for continuous state space models [35, 45, 46] and later for a finite state space models [32, 33, 42]. The theory for finite state MFGs has been extended in many directions, with contributions including a probabilistic approach [14], the master equation approach [4], minor-major player games [12], and extended games5 [13]. Further, finite state mean field control, risk-sensitive control, and zero-sum games are treated in [17–19] which cover cases of unbounded jump intensities. Graphon games [3, 7–9, 23, 30, 49] have recently been receiving an increasing research interest. The motivation is the study of strategic decision making in the face of a large non-complete dense networks of distinguishable agents. The graphon game’s rising popularity stems from its ability to handle heterogeneity of agents to an extent far beyond the MFG theory.
Mean Field Games and Related Models for Epidemics
Decision making in compartmental models (e.g., the SIR model) have been studied intensively for a long time, with an increasing interest recently with the COVID-19 pandemic. In the form of games and optimal control problems, disease-combating efforts ranging from strategies for social contracts to vaccination have been analyzed in the literature. Here, we focus on work relying on the graphon game theory and the mean-field approach.
During an epidemic where the disease is prone to close-contact transmission (one example being COVID-19) control of the contact rate or other social distancing protocols are go-to solutions in the fight against the disease. Such strategies and related variations have been studied in the context of mean field games [16, 28], mean field optimal control [47], and mean field type games [55]. In reality the population needs to be tested for the disease in order to accurately asses the risks in the decision making process. Two recent papers studying optimal testing policies are [15, 36]. The effects of vaccination and accompanying decision making problems are not studied in this paper; they have been analyzed in MFG-related settings since before the COVID-19 pandemic [27, 31, 37, 43, 44, 50]. Recently, the interplay between a population in which a disease spreads and a regulator has been studied in the form of Stackelberg games. In such models, the members in the populations are taking actions based on policies issued by the regulator, while the regulator anticipates the population’s reaction and optimizes the policy. The case of a cooperative population has been studied in [36], while in [2] a population of selfish agents with contact factor control has been studied.
An example of a deterministic optimal control problem for centralized decision making during a pandemic in a society with multiple communicating subpopulations is given in [29]. The subpopulations interact over a non-uniform graph. A central planner wants to flatten the (global) curve of infections, leading to the optimal control problem. Sending the number of subpopulations to infinity, we anticipate a limit where each interaction is weighted by a graphon and the limit model would be reminiscent of the interacting system of Kolmogorov equations studied in this paper.
Networks and Graphons in Epidemiology
There is a vast body of literature on epidemiology modeling with network interactions. A review of the studies that use idealized networks6 in epidemiology models can be found in [39]. More closely related to the ideas in this paper, there are recent contributions connecting epidemic models and graphons. In [57] a sensitivity analysis on the graphon SIS epidemic model is conducted. An infinite dimensional SIS model with application to targeted vaccination is considered in [24]. The paper [40] proposes a model with local-density dependent Markov processes interacting through a graphon structure, and considers applications to epidemiology. In a similar but more general setting to the SIR model with graphon interaction, [1] studies convergence of a stochastic particle system to an SIR-like system of PDEs with spatial interaction. We note [1] and its continuation [25, 26] may be relevant for a future study of the convergence of N-player Nash equilibria to the equilibria in the finite state graphon game. The works mentioned in this section only consider the dynamics of the population without taking the agents’ decision making into account.
Contributions and Paper Structure
This paper is, to the best of our knowledge, the first to address the analysis and numerical resolution of graphon games that are time-dependent and with a discrete state space. The application to epidemiology model departs from the traditional literature on epidemiology models and graphon models by the incorporation of a game theoretical aspect: here we go beyond dynamic graphon systems and find Nash equilibria for rational agents. We construct a probabilistic particle model for a continuum of interacting agents and prove that graphon aggregates must be deterministic (as in e.g. (5)) under a set of natural conditions on the strategies and transition rates. This motivates the study of the asymptotic deterministic model formulation and gives a transparent interpretation of the agent’s control in the applied context. We derive theoretical results for the deterministic model: a verification theorem and an existence theorem for the coupled continuum of forward-backward ordinary differential equations (FBODEs) that characterize the finite state graphon game at equilibrium are proven. This is reminiscent of the mean field game framework, except that here the population is heterogeneous due to the graphon-based interactions. This makes the computation of solutions much more challenging. We then propose a machine learning method to solve the FBODE system. Finally, we consider a graphon game model for epidemic disease spread. Multiple test cases are solved with the proposed numerical method and the experimental results are discussed.
The outline of the rest of the paper is as follows: In Sect. 2, we introduce the model and analyze its deterministic formulation. In Sect. 3, we introduce the numerical approach and give experiment results. In Sect. 4, a theoretical framework for the model’s probabilistic framework is presented and we rigorously define the graphon game. For the sake of conciseness, the proofs are postponed to the appendices.
Model
Setup and Preliminaries
Let and let E be the finite set . For each define the difference operator acting on functions on E by the formula . We identify the set of probability measures on E, , with the simplex and endow it with the Euclidean distance. Throughout the paper, the notation will be used to denote the set of Borel probability measures.
Let be a finite time horizon. A process will be denoted with its bold letter symbol . Let be the space of continuous real-valued functions from [0, T], be the space of real-valued functions from [0, T] càdlàg at and continuous at . We denote the uniform norm by , . We note that and are both Banach spaces, only the former is separable. Let be the set of functions in such that . Since is a closed subset of , is a complete metric space.
Let I be the unit interval equipped with the Euclidean distance. We denote by and the Lebesgue measure and Borel -field on I, respectively. The set I is indexing the continuum of players in the graphon game. Throughout the paper, we will employ the notation for functions with domain I. Furthermore, in most cases we will denote the index argument with a superscript: .
This paper studies games with heterogeneous interactions. When the players in the game interact, the weight they give to each others’ action is parameterized by their indices. This weighted averaging is captured as the integration with respect to a graphon kernel function (see Section 1 for the discussion). Here, we give the most prevalent definition of a graphon.
Definition 1
A graphon is a symmetric Borel-measurable function, .
The graphon induces an operator W from to itself: for any ,
| 6 |
Remark 1
The definition of a graphon varies somewhat in the literature. Some authors require neither symmetry nor a non-negative range. As mentioned in the introduction, the graphon as defined here can be used to represent the limit of a sequence of dense random graphs as the number of nodes (players) goes to infinity. For example, the constant graphon is in a sense the limit of a sequence of Erdős-Rényi graphs with parameter . Conversely, random graphs can be sampled from a graphon in at least two different ways: either we sample points in I and construct a weighted graph whose weights are given by the graphon, or we sample points in I and then sample edges with probabilities given by the graphon.
A Q-matrix with real-valued entries , , is an matrix with non-negative off-diagonal entries such that:
| 7 |
In this paper, we will consider controlled Q-matrices with entries that depend on population aggregates. More specifically, we let for each , , , be bounded measurable functions such that is a Q-matrix for all . We are going to work under the following assumption on the rates :
Condition 1
-
(i)There is a finite constant such that for all , , , and :
8 -
(ii)There is a finite constant , possibly depending on n, such that for and for all , , , , and
Since the state space is finite and the rates are assumed to be uniformly bounded in Condition 1.(i), the Hölder-continuity assumption of Condition 1.(ii) is less restrictive than it otherwise would have been.
The Finite State Graphon Games Model for Epidemiology
In this section, we give a descriptive introduction to the epidemiological graphon game without going in to all the technical details. A rigorous mathematical motivation, built on the theory of Fubini extensions to accommodate for a continuum of independent jump processes, is presented in Sect. 4.
On a probability space , we consider a continuum of E-valued pure jump processes indexed over . That is, for each , . The stochastic process models the state trajectory of player x. The initial state is sampled from a distribution . Each player implements a strategy , a process taking values in the compact interval described in more detail below. The players interact and each player’s state trajectory is potentially influenced by the whole strategy profile . To emphasize dependence we denote the state trajectory of player x as given a strategy profile . For all , is a E-valued pure jump process with rate matrix at time . The rate matrix is controlled by and influenced by the population aggregate . The aggregates we consider are averages weighted by a graphon w, more specifically of the form (cf. (6)) for some function . In Sect. 4 we prove that the aggregate is a deterministic function of time, henceforth we write
| 9 |
where w is a graphon.
K will be called the impact function since it quantifies how much a player’s joint state and control distribution impacts the aggregate variable. One example is the impact function in Sect. 1.1 where , where the interpretation being that the aggregate is the averaged contact factor control of infected players. We have the following assumption on K:
Condition 2
There exist finite constants such that for all and :
Our (for now formal) probabilistic definition of the interacting system of players is complete. The rigorous analysis of the system, the construction of a continuum of state trajectories, and conditions under which the aggregate is deterministic, i.e., of the form (9), is treated in detail in Sect. 4.
The key feature of the graphon game is that the aggregate variable is in general not the same for two distinct players. The players are therefore distinguishable and there is no “representative agent", as in MFGs7. As a direct consequence, there is no flow of player state distributions common to all players. Instead, each player has their private flow. Denote by the probability that player that is in state at time , given that the population plays the strategy profile . We shall argue that player x’s state distribution flow solves the Kolmogorov forward equation
| 10 |
with initial condition and the player’s aggregate variable is
| 11 |
with being the joint probability law of control and state, .
We turn our focus to the players’ actions. We will make three standing assumptions that directly affect which strategies the players will choose. The first is that the environment that endogenously affects the players (but is known to the players) is varying smoothly over time, with no abrupt changes for example in lockdown penalties or expected recovery time. Secondly, if the players can impact their environment with their control, then the environment varies smoothly with their control too. For example, the risk of infection depends continuously on the agent’s level of cautiousness. Finally, the players’ strategies are decentralized, i.e., are unaffected by the transition of any agent other than themselves. Under these circumstances, the players have no apparent reason to discontinuously change their action over time except at times of transition between states. Such strategies (A-valued; decentralized; continuous in time between changes of the player’s own state) will be called admissible and the set of admissible strategies denoted by . The setting is further discussed in Sect. 4.
In this paper, we focus on the finite horizon problem where the cost is composed of two components: a running cost and a terminal cost. For each player , the assumptions on the conditions that the running and terminal cost functions, and , satisfy are given later in the text together with the theoretical results. The total expected cost to player x for playing the strategy while the population plays the strategy profile is
| 12 |
As we shall see, a change in player x’s control has no effect on the aggregate. Hence, the expected cost depends on the strategy profile only indirectly through the value of the aggregate variable. See Sect. 4 for the details. Therefore, hereinafter we shall use the notation for the right-hand side of (12). In light of this, we employ the following definition of a Nash equilibrium in the graphon game:
Definition 2
The strategy profile is a Nash equilibrium if it is admissible and no player can gain from a unilateral deviation, i.e.,
Analysis of Finite State Graphon Games
By Definition 2, an admissible strategy profile is a Nash equilibrium if there exists an aggregate profile such that
for all , minimizes ;
for all , is the aggregate perceived by player x if the population uses strategy profile .
This alternative formulation has the advantage to split the characterization of the equilibrium into two parts and in the first part, the optimization problem faced by a single agent is performed with while the aggregate is fixed.
With a flow being fixed, we define the value function of player as, for and ,
where is an E-valued pure jump process with transition rate matrix at time and initial distribution .
To derive optimality conditions, we introduce the Hamiltonian of player x:
| 13 |
where and is the coordinate (row) vector in direction e in . We assume that admits a unique measurable minimizer for all (t, z, h) and define the minimized Hamiltonian of player x:
| 14 |
The dynamic programming principle of optimal control leads to the HJB equation for that reads
| 15 |
where denotes the time derivative of . Noting that , (15) can be equivalently written as
| 16 |
In the following theorem, we verify that the solution of the HJB equation indeed is the value function of the infinitesimal agent’s control problem, and we provide an expression for an optimal Markovian control in terms of this value function and the aggregate.
Theorem 1
If is a continuously differentiable solution to the HJB equation (15), then is the value function of the optimal control problem when the flow is given. Moreover, the function
| 17 |
gives an optimal Markovian control.
Next, we prove the existence of a solution to the coupled Kolmogorov-HJB system at equilibrium. For that purpose we place the following condition:
Condition 3
-
(i)
There exist two functions and with locally Lipschitz such that for all .
-
(ii)
is continuously differentiable, and as a function of a it is strongly convex, uniformly in (t, e, z) with constant ; is locally Lipschitz continuous, uniformly in .
-
(iii)
f and g are uniformly bounded and is continuous.
As a consequence of Condition 3(i) and 3(ii) is once continuously differentiable and strictly convex, and is locally Lipschitz continuous (see Lemma 1 in Appendix A.2). We denote Lipschitz constant of by , which can be bounded from above using smoothness properties of and . More specifically, depends on the local Lipschitz coefficients of and , see the proof of Lemma 1). Recall that denotes the uniform upper bound of the impact function K guaranteed by Condition 2.
Theorem 2
Assume Conditions 1, 2, 3 hold. If , then the coupled Kolmogorov–HJB forward-backward system at equilibrium
| 18 |
admits a bounded solution (u, p) in such that for each , is a probability mass function on E.
The Finite State Graphon Game for SIR with Contact Factor Control
Here, we introduce a model which we shall use as a test bed for the numerical algorithm presented in Sect. 3. It is inspired by the first example scenario in [2] and builds on the case discussed in Sect. 1.1. It is a compartmental model with four possible states: usceptible, nfected, ecovered and eceased. The agents choose their level of contact factor. A regulator (government or health care authority) recommends state-dependent contact factor levels to the agents, denoted by , . For enforcement purposes, it also sets penalties for deviation from these levels. The cost has 3 components: The first component penalizes the agent for not following the regulator’s recommended contact factor level, the second is the cost of treatment for an infected agent (this cost can be player specific due to individual differences in health care plan coverage, etc.), and the last one is the cost for being deceased. In this setting, the running cost is written as
| 19 |
where and are nonnegative costs functions (of the player index). We set the terminal cost to be identically zero, for all . The transition rate matrix for player x is given as:
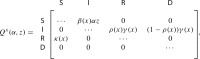 |
20 |
where are nonnegative parameter functions, , determining the rates of infection, recovery, reinfection, and decease, and where in each row, the diagonal entry is the negative of the sum of the other terms on the same row. In line with the discussion in Sect. 1.1, the transition rate from state to depends on the agent’s own decision and the aggregate variable8. Furthermore, when an infected agent transitions, she goes to state with probability and to state with probability . Then, for player x the optimality conditions yield
and the forward-backward graphon ODE system reads:
We note that with a careful choice of , , and this system will satisfy the sufficient condition for existence from Theorem 2.
Numerical Approach
We rewrite the continuum of FBODEs (18) as the solution of a minimization problem: minimize
| 21 |
where solve the forward-forward continuous system of ODEs:
| 22 |
This “shooting” strategy is reminiscent of the one used e.g. in [20, 21, 41] for stochastic optimal control problem and e.g. in [2, 11] for mean field games in a numerical context. However, here we deal with a continuum of ODEs rather than a finite number of stochastic differential equations. Here is the parameter in the function replacing the initial condition of u. Typically, is a real-valued vector of dimension the number of degrees of freedom in the parametric function . In general, the true initial condition for is a nonlinear function with a potentially complicated shape. So we need to choose a rich enough class of parametric functions. In the implementation, we used a deep neural network with a feedforward architecture. See, e.g., [10] for a description of the feedforward neural network architecture we used in the implementation.
Our strategy to find is to run a gradient-descent based method. To alleviate the computational cost and to introduce some randomness, at each iteration we replace the above cost by an empirical average over a finite set of indices x, which is also used to approximate the value of the aggregate quantities. More precisely, for a finite set of indices, we introduce
| 23 |
where solves the forward-forward (finite) system of ODEs:
| 24 |
Piecewise Constant Graphon
Let be non-negative numbers such that . We divide the player population into K groups, , placing all players with index into group , etc. We assume that players belonging to the same group are indistinguishable. For example, all players within a group must have the same recovery rate and if are the indices of two players in the same group, then for all . In this situation, we only need to specify the graphon’s values on each block of indices corresponding to a group, since the graphon is a constant on each block. Let us identify the group with its index block (or set). We can compactly represent the interaction weights between the blocks with a connection matrix , where is the connection strength between players in block and players in block . Then, for all players x in block
| 25 |
which is constant over . This is a feature of that we sometimes see when the piecewise constant graphon is used. Furthermore, we assume , , constant over each block but can differ between blocks. It opens up the possibility for us to solve the graphon game with classical numerical methods9 and a way of evaluating the DeepGraphonGame algorithm.
Turning to the remaining example set up, we specify the cost structure as a particular case of the general formulation of Sect. 2.4. We assume that the regulator has set , , different for each block.
In this scenario, we first study the policy effects on the death ratio in the age groups. The policies compared are no lockdown (NL); quarantine for infected (QI); age specific lockdown (AL); full lockdown (FL). We can see in Fig. 1 that the death ratio decreases nearly 30% if infected individuals are quarantined, compared to no lockdown. Furthermore, if an age specific lockdown is implemented, we see that even more lives are saved while not deteriorating the economy. Zooming in on the comparison of no lockdown and quarantine for infected (second row of Fig. 1), we note that susceptible individuals are using a smaller contact factor when there is no quarantine in place. They optimize their risk and hence want to be more cautious, since the risk of getting infected is higher (Tables 1 and 2).
Fig. 1.

Top: Density of deceased people for age groups 45-65 (left) and 65+ (right) under different policies where NL: No Lockdown, QI: Quarantine for Infected, AL: Age Specific Lockdown, FL: Full Lockdown. Bottom: Comparison Plots for No Lockdown and Quarantine for Infected policies: Density of infected people (left), Aggregate (middle), Control of susceptible people (right) are plotted for each 4 age groups under both policies
Table 1.
Parameters of the experiment with different age groups
| Age | 0–20 | 20–45 | 45–65 | 65+ | Age | m | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0-20 | 1.0 | 0.9 | 0.8 | 0.7 | 0-20 | 0.4 | 0.1 | 1.0 | 0.95 | 0.27 |
| 20-45 | 0.9 | 0.9 | 0.8 | 0.8 | 20-45 | 0.3 | 0.1 | 1.0 | 0.97 | 0.33 |
| 45-65 | 0.8 | 0.8 | 0.9 | 0.8 | 45-65 | 0.3 | 0.05 | 0.9 | 0.97 | 0.27 |
| 65+ | 0.7 | 0.8 | 0.8 | 0.8 | 65+ | 0.3 | 0.05 | 0.75 | 0.97 | 0.13 |
Table 2.
Parameters used in the experiments with age-groups specific lockdowns (NL: No Lockdown, QI: Quarantine for Infected, AL: Age Specific Lockdown, FL: Full Lockdown): and vary between the age groups.
| Parameters | T | ||||||
|---|---|---|---|---|---|---|---|
| NL | 200 | [1.0, 1.0, 1.0, 1.0] | [1.0, 1.0, 1.0, 1.0] | 1.0 | 10 | 1 | 1 |
| QI | 200 | [1.0, 1.0, 1.0, 1.0] | [0.5, 0.5, 0.5, 0.5] | 1.0 | 10 | 1 | 1 |
| AL | 200 | [0.5, 1.0, 1.0, 0.5] | [0.5, 0.5, 0.5, 0.5] | 1.0 | 10 | 1 | 1 |
| FL | 200 | [0.5, 0.5, 0.5, 0.5] | [0.5, 0.5, 0.5, 0.5] | 1.0 | 10 | 1 | 1 |
The lockdown is imposed by decreasing the and values of the corresponding age groups
Secondly, in the same scenario, we model multiple cities with different attributes and study the effects of the travel restrictions. In this experiment, we compare a universal no-travel policy to the policy where traveling in or out of one of the cities is restricted (totaling four policies in the comparison). City 1 is a highly populated city with a more contagious virus variant, city 2 also has this variant; however, it is a small city. City 3 is a highly populated city but with a less contagious virus variant. For visual simplification, we assume that there are no deaths (i.e. ). In Fig. 2, we can see that the infected-density curve can be flattened the most if city 1 has travel restrictions. The reason is the existence of the more contagious variant and the large size of the city 1. We note that when this restriction is implemented the susceptible individuals feel relieved and increase their contact factor control (Tables 3 and 4).
Fig. 2.

Density of infected people in the whole population (including all cities) under 4 different policies, NL: No Lockdown, C1L: City 1 Lockdown, C2L: City 2 Lockdown, C3L: City 3 Lockdown (left). Comparison Plots for No Lockdown and City 1 Lockdown policies: Density of infected people in each city (middle left), Aggregate in each city (middle right), Control of susceptible people in each city (right)
Table 3.
Connection matrix (left) and Parameters (right) used in the experiment with different cities
| Block | City 1 | City 2 | City 3 | Block | m | ||
|---|---|---|---|---|---|---|---|
| City 1 | 0.3 | 0.3 | 0.3 | City 1 | 0.4 | 0.95 | 0.4 |
| City 2 | 0.3 | 1.0 | 0.7 | City 2 | 0.4 | 0.95 | 0.2 |
| City 3 | 0.3 | 0.7 | 1.0 | City 3 | 0.3 | 0.95 | 0.4 |
The connection matrix shown here is the case where there is a lockdown in City 1. When there is no lockdown the interaction weights are as follows: , and
Table 4.
Parameters used in the experiment with different cities
| Parameters | T | |||||||
|---|---|---|---|---|---|---|---|---|
| All policies | 40 | 0.1 | 1.0 | 0.9 | 1.0 | 10 | 1 | 1 |
Sanity Check for the Numerical Approach
Here, we test the DeepGraphonGame algorithm by comparing its solution to the solution obtained by solving the ODE system for the cities-example when city 1 has travel restrictions (Table 4). As can be seen in Fig. 3, the DeepGraphonGame algorithm approximates the exact result well. A plot of the function , where is the numerically computed value function, can be seen on the right side of the bottom row in Fig. 3. We can clearly see that agents in the same block have the same values. From this we infer that the DeepGraphonGame algorithm is preforming well when learning this piecewise constant function.
Fig. 3.

Comparison of the ODE and NN results when there is a lockdown for City 1: Top: State densities in City 1 (left), City 2 (middle) and City 3 (right). Middle: Value functions given each state in City 1 (left), City 2 (middle) and City 3 (right). Bottom: Aggregate (left), Control of susceptible people (middle) and value function at time 0 given state is susceptible as a function of index, (right)
General Graphon
To show scalability of the proposed numerical approach now we focus on the second example in [2] with the SEIRD model where the state xposed is added. An individual is in state when infected but is not yet infectious. Hence, the agents evolve from to and then to , and the infection rate from to depends on the proportion of the infected agents. The diagram of the dynamics can be seen in Fig. 4. The cost structure is similar to the one used in Sect. 2.4. After introducing the state , we set
In this example, we focus on an application where the agents are not homogeneous over blocks. The interaction strength between individual x and y is now given by the power law graphon: where is a constant10. Intuitively, the power law graphon models interactions in a population where a small number of individuals are responsible for a large number of the interactions. For example, a population with superspreaders11 can be modeled with this graphon. The model with an underlying power law graphon interaction requires us to solve a continuum of coupled ODEs which is not computationally feasible. However, by using the DeepGraphonGame algorithm, the solution can be learned by using simulated particles, i.e. agents.
Fig. 4.
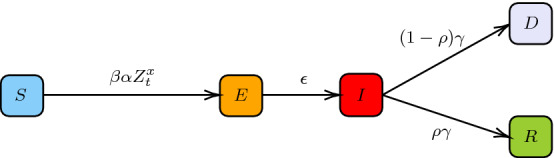
Diagram of SEIRD model for individual x
According to CDC, COVID-19 reinfection is very rare12; therefore, we assume that there is no reinfection (i.e. ). Furthermore, the recovery duration is around 10 days since the symptom onset13. For this reason, we assume that . According to the recent study conducted by Lauer et al. [56], an exposed person begins to show symptoms after around 5 days. Based on this observation, we choose . Finally, the Basic Reproduction Number estimate used by CDC14 leads us to set in our simulations (Table 5).
Table 5.
Parameters in the SEIRD model experiments with power law graphon
| Param. | T | g | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Values | 40 | 0.2 | 0.1 | 0.2 | 0.95 | 10 | 1 | 1 | 0.2 | 1.0 | 1.0 | 0.9 | 1.0 |
The experiment results for a sampled finite subset of the agent population are presented in Fig. 5. In the figure, each line corresponds to one agent and the color of the plot gets darker as the index of the agent (i.e. x) increases. Our first observation is that as the index of the agent increases, the aggregate also increases. In response to this high aggregate, the agent lower its contact rate, in order to protect itself. However, this protection is not enough to neutralize the effects of the high levels of the aggregate and the probability of the agent to be infected is still elevated.
Fig. 5.

Results of agents from a sampled population. In each plot, colors are chosen from a continuous colormap to represent the index of the agents with the following convention: If the index x of a player is higher, the color of the line is darker. Top: Probability of being susceptible (left), exposed (middle) and infected (right). Bottom: Probability of being recovered (left), Aggregate (middle), Control at the susceptible state (right)
The Probabilistic Approach to Finite State Graphon Games
This section contains a closer study of the continuum of interacting jump processes that constitute the graphon game dynamics. Going back to the informal discussion in the introductory Sect. 1.1, it is not clear that there would be an adequate law of large numbers so that (4) converges to (5) since the averaged random variables are dependent. A common approach in economic theory for this situation is to consider the continuum limit and average the continuum of random variables with respect to a non-atomic probability measure over I. Using the example from Sect. 1.1 again, a continuum limit of (4) is
However, the integral in the expression above is ill-defined. There is an issue of constructing a continuum of independent random variables (here, that would be the driving Poisson noise) that are jointly measurable in the sample and the index. If the construction is done in the usual way via the Kolmogorov construction, then almost all random variables are essentially equal to an arbitrarily given function on the index space (i.e., as random variables they are constants). Hence, in any interesting case the function will not be measurable with respect to the Lebesgue measure. One solution proposed by economists is to extend the usual probability space to a so-called a Fubini extension [52], a probability space over where Fubini’s theorem holds. On the Fubini extension a continuum of random variables can be constructed that are essentially pairwise independent (e.p.i.; see Theorem 3 for the definition) and jointly measurable in sample and index. Moreover, there is hope for an exact law of large numbers [53], justifying our assumption about the determinism of the aggregate variable in the previous sections. We will construct a Fubini extension that carries a continuum of e.p.i. Poisson random measures. Then, each player path will be defined in the representation of the counting processes associated to the pure jump process as a stochastic integral with respect to a family of independent Poisson random measures with Lebesgue mean measure on as suggested in Skorokhod [51] and Grigelionis [34].
Theoretical Background and Definitions
Poisson Random Measures
Let us denote by the measure space . We first recall the definition of a Poisson random measure. A family of random variables defined on some probability space is said to be a Poisson random measure with measure if
for all such that , is a Poisson random variable with rate ;
the random variables are mutually independent whenever the sets have finite -measures and are disjoint;
for all , is a measure on .
We define and the subset of locally finite measures by
For all bounded measurable , define the mappings Let and be the -algebras induced by the mappings on and M respectively. For us, a random measure will be a measurable function from into that almost surely takes values in . We shall also use the fact that M (equipped with the vague topology) is a Polish space [22]. We denote the law of N on by .
The Poisson random measure N has an accompanying martingale. For all bounded , is a square integrable zero-mean martingale.
The Fubini Extension
In the model, state dynamics are given as E-valued jump processes. We will construct such a process from independent Poisson random measures. The possible jumps will be those so that the state process jumps between two integers in E, at most steps up or down. The initial state of player is randomly sampled from a pre-selected distribution .
In order to model idiosyncratic random shocks affecting the dynamics of the individual states, we use the framework of Fubini extensions. It allows us to capture a form of independence for a continuum of random variables, while preserving joint measurability.
Definition 3
If and are probability spaces, a probability space extending the usual product space is said to be a Fubini extension if for any real-valued -integrable function f on
-
(i)
the two functions and are integrable, respectively, on for -a.e. , and on for -a.e. ;
-
(ii)and are integrable, respectively, on and , with the Fubini property
The following theorem summarizes the results by Sun and collaborators, see for example [53] and [54], which we use as a foundation for our model.
Theorem 3
There exists a probability space extending , a probability space , and a Fubini extension such that for any measurable mapping from to there is an -measurable process such that the random variables are essentially pairwise independent (e.p.i.), i.e., for -a.e. , is independent of for -a.e. , and for all .
We set , where is the probability law of the Poisson random measure introduced above, and is the initial distribution of player x. By Theorem 3 (which holds for since E and M are Polish spaces) there exists a collection of random variables on a Fubini extension , that are e.p.i. and -distributed for all . With the model in Sect. 2 in mind, we assume that the mapping is Lebesgue-measurable (this assumption is however not necessary for the analysis that follows).
We denote by the Bochner space of all (equivalence classes of) strongly -measurable functions for which
We define in the same way, with replacing above. By e.g. [38, Ch. 1.2.b], and are Banach spaces.
For later reference, we define also the set as the subset of of -a.e. -valued functions. One can show that is a closed subset of , hence is a complete metric space.
The Set of Admissible Strategies
We can now give a rigorous definition of the set of admissible strategy profiles. Recall that A is a compact subset of .
Definition 4
We define the set of admissible strategy profiles in feedback form as the set of A-valued, -measurable functions on such that is a continuous function on [0, T] for every .
We will sometimes use the same notation for the set of admissible control processes associated to an admissible strategy profile in feedback form . At time t, for player , the value of such a control process is the action where is the state of player x just before time t. These control processes are predictable with respect to the filtration generated by the player’s private state, and decentralized since they do not depend directly on other players’ states.
The continuity in time is a strong assumption and prohibits the player from immediately reacting to abrupt changes in their environment. However, if a player transitions between two states at time t their control can be discontinuous at that time (as a multivariate function of time and state). In Sect. 2, a rationale was given for restricting our attention to such controls.
The Finite State Graphon Game in the Fubini Extension
We begin by describing an interacting system of a continuum of particles. First, we define the decoupled system where the aggregate variable vector has been “frozen”. Then, we define the aggregate with a fixed point argument. Finally, we prove that the aggregate is in fact deterministic.
Consider the pure jump stochastic integral equation (here written formally)
| 26 |
where , , for some admissible strategy profile , , for any , , , , ,
| 27 |
is the rate of jumps from state i to state given the action and the aggregate value z. The proposition below asserts that (26) has a unique solution in , the subset of defined in the end of Sect. 4.1.2.
Proposition 1
Assume that Condition 1 holds. Let and be fixed. Then there is a unique strong solution to (26), i.e., a -a.e. -valued process satisfying (26) -a.s.
Note that the quantity
appearing in the right-hand side of (26), is a counting process with intensity at time so by construction the solution to (26) (granted by Proposition 1) is almost surely an E-valued pure jump process with intensity matrix at time .
For a fixed admissible strategy profile , consider now the coupled system
| 28 |
The next theorem proves that (28) is well-posed with a unique solution in -sense. It further specifies the regularity of the solution: the aggregate variable must -a.s. be a deterministic and a continuous function of time.
Theorem 4
Let Condition 1 and 2 hold, and let .
-
(i)
There exists a unique solution to (28). The corresponding aggregate is a random variable in .
-
(ii)
The aggregate is -a.s. equal to a deterministic (i.e., constant in ) function in .
-
(iii)
There is a unique pair and of versions of and , respectively, solving (28) for all in the standard -sense. Moreover is deterministic and continuous in time for all .
Theorem 4 justifies working with a model defined for all with a deterministic, continuous-in-time aggregate in Sect. 2. From here on, we will represent the -elements solving system (28) with the version defined for all and drop the check in the notation.
Remark 2
If admissible strategy profiles did not have the prescribed continuity property we could not expect the aggregate to be a continuous function of time. One example of such a case is found in [2] where a regulator imposes a penalty that is discontinuous in time, resulting in equilibrium controls and aggregates discontinuous in time. We leave the analysis of the more general case to future work.
We now turn to the notion of player costs and equilibrium. Denote by the set of A-valued and -measurable functions on , continuous for every that. If the player population plays according to an admissible strategy profile and player decides to play strategy where and
then is an admissible strategy profile and the player’s expected cost for using is
In fact, is the set of strategies a player can deviate to without destroying the admissibility of the strategy profile. Therefore, we say that if satisfies
the is a Nash equilibrium of the graphon game. The dependence of the cost on the whole strategy profile is unnecessarily complicated, as the following reasoning shows. Notice that since for -a.e. . The other players’ actions appear in player x’s cost indirectly, through the aggregate , which is unaffected if one specific player changes control (it is an integral with respect to a non-atomic measure). Thus, we write as a function taking an admissible strategy and an aggregate variable trajectory:
In light of this, an equivalent definition of the Nash equilibrium is that a strategy profile is a Nash equilibrium in the graphon game if it satisfies
further justifying the game setup in Sect. 2.
Conclusion and outlook
In this paper, we introduced stochastic graphon games in which the agents evolve in a finite state space. We provided optimality conditions in the form of a continuum of forward-backward ODE system, for which we established existence of solutions. We proposed a numerical method based on a neural network approximation of the initial condition of the FBODE. We then applied our theoretical framework and numerical method to a class of models from epidemiology and we provided several test cases. From here, several directions can be considered for future work. An interesting aspect would be to incorporate a regulator with a Stackelberg type model as was done in [2] without graphon structure. The theoretical analysis would probably rely on a combination of the tools developed in the present work together with tools from optimal contract theory. However there would be some important challenges depending on the class of controls that are admissible for the regulator. Their controls could indeed lead to discontinuities in the incentives to the population, which would raise subtle measurability questions. This is left for future work. Another direction is to consider more realistic epidemiological models (e.g., with more compartments). Such models would be more complex and we expect our proposed machine learning numerical method to be helpful from this point of view. Furthermore, to be able to use graphon games to make epidemiological predictions, it would be interesting to investigate further how to use real data in the model and in the numerical method.
Acknowledgements
The authors would like to thank Boualem Djehiche and Yeneng Sun for helpful discussions.
A Proofs for Section 2
A.1 Theorem 1
First, assume player x uses control and, using the HJB equation (15) and the definition of the minimized Hamiltonian (14), note that
where is a zero-mean martingale. Hence, we write
Note that the second expectation in the right hand side is non-negative since minimizes by assumption. In fact, since it is the unique minimizer, this term is strictly positive unless .
By taking the expectation and by recalling the terminal condition we deduce that:
where, for the last equality, we used the interpretation of as player x’s value function. Furthermore the inequality above is an equality if and only if .
A.2 Regularity of the Optimal Control
Here we show that is continuous in (t, z, h).
Lemma 1
Assume Conditions 3.3 and 3.3 hold. For every and , defined by the Hamiltonian minimizer in (14) is continuous. Moreover is locally Lipschitz continuous, i.e., for every positive constants and , for every the function is Lipschitz continuous on (with a Lipschitz constant possibly depending on ).
Proof
By the assumption on the dependence of on a, is the unique solution of the variational inequality (with unknown a):
Let and be positive constants. Let and with (t, z, h), . Let and . We deduce from the above inequality that:
By the assumption on the strict convexity of f, we have
So, combining the above inequalities and the property , we get
where C can depend on , , and . We conclude by using the continuity and local Lipschitz continuity properties of and .
A.3 Theorem 2
Step 1: Definition of the solution space
We start by letting, for every , be the closed ball of continuous functions (u, p) from [0, T] into such that for all , for and , and such that (u, p) is bounded by in uniform norm. In other words, is the subset of for which the second component is a probability on E and for which the uniform norm is bounded by , whose value will be fixed in Step 5 below.
Step 2: Definition of the aggregate mapping
For each we define the map which takes into
We now prove that, if we choose the space of aggregates properly, has a unique fixed point, say , which depends continuously in . Indeed, let where
In light of Condition 2, . Moreover, is a closed subset of the Banach space , hence a complete metric space. Using Cauchy-Schwarz inequality and the Lipschitz continuity of K and (given by Condition 2 and Lemma 1), we get
where we used the fact that and . Recall that we assume . With Banach fixed point theorem we conclude that there exists a unique fixed point in to . We denote it .
Step 3: Solving the Kolmogorov equation
Given and u, we solve the Kolmogorov equation and we get the solution . Existence and uniqueness of the solution is provided by the Cauchy-Lipschitz-Picard theorem; see, e.g., [5, Theorem 7.3] (viewing q as a linear operator acting on the Banach space ). Furthermore, given Condition 1.1, the time derivative of is bounded. Therefore, we conclude that is equicontinuous.
Step 4: Solving the HJB equation
Given and , we solve the HJB equation and we get the solution . Here again, existence and uniqueness of the solution is provided by the Cauchy-Lipschitz-Picard theorem (viewing as a Lipschitz operator acting on the Banach space ). Furthermore, there is a uniform bound on the time derivative of since the Hamiltonian is bounded given Condition 3.3 and Condition 1.1. Hence is equicontinuous.
Step 5: Application of Schauder’s theorem
Let us call the mapping constructed by the above steps, namely, . By steps 3 and 4 above, if we choose large enough, maps onto , so it is well-defined. Furthermore, by the same steps and the Arzela-Ascoli theorem is compact. Finally we argue the continuity as follows:
We first show the continuity of in u and p. Consider a sequence such that for every n, and . We denote and prove below that . By Lipschitz continuity of K and :
for some constants , and where . Hence
which tends to 0 as .
Next, we study the continuity of . We have, for :
where we used Condition 1.1 and a uniform (i.e., independent of n) bound on (since q is bounded independently of n). By Grönwall’s inequality, we obtain
which tends to 0 as , and we concluded by using the continuity of q (given by Condition 1.1).
Finally, we study the continuity of . For , we have:
Using the boundedness of and (given by Condition 3.3) and the boundedness of q (given by Condition 1.1), we deduce with Grönwall’s inequality:
which tends to zero as by the continuity of f and q (given by Condition 3.3 and Condition 1.1 respectively) and the fact that .
We conclude the proof by applying Schauder’s theorem, see e.g., [5, Excercise 6.26], which yields the existence of a fixed point to .
B Proofs for Sect. 4
B.1 Proposition 1
The proof is inspired by [17, Thm. 3.2] where the authors study problems of optimal control of McKean-Vlasov-type pure jump processes and propose the use of the identities found between (29) and (30) below.
Consider the mapping defined by
We note that is well-defined. Indeed, for any , is a linear combination of the initial condition and the Poisson random measures evaluated at measurable sets, hence -measurable. By construction is -a.e. -valued which implies the integrability.
To conclude the proof, we show that has the contraction property, i.e., that there exists a constant such that
By independence of the Poisson measures for any fixed , the compensated martingales (cf. Sect. 4.1.1) are orthogonal. Hence, for any and ,
where is a zero-mean stochastic integral, and we have that
| 29 |
where the process is the equivalent of but for . The predictable quadratic variation of the process is
where the -dependence has been suppressed in the notation. Expanding the square and integrating, using the identities
and for , we obtain
From the Lipschitz continuity imposed by Condition 1.1, we get
| 30 |
After taking expectation of (29), we get using Doob’s inequality and (30) that
Iterating the inequality, we get for any that
where denotes the N-fold composition of . Thus, for some N large enough, is a contraction and if follows from the Banach fixed-point theorem for iterated mappings (see, e.g. [6]) that has a unique fixed point in the set . The fixed point is the unique (up to -modification) strong solution that was sought.
B.2 Theorem 4
The first step of the proof is to show that the aggregate variable is well-defined as a fixed point to the mapping
| 31 |
where is the solution to (26) characterized in Proposition 1.
Lemma 2
Let Condition 1 hold. For each the mapping has a unique fixed point in .
Denoting the fixed point by , the next lemma uses the Exact Law of Large Numbers [53] to guarantee that is -valued -a.s. for each .
Lemma 3
Let Conditions 1 and 2 hold, and let . Then for each .
This proves the part (i) of the theorem. Part (ii) and (iii) can be shown along the same lines of proof as is used in [3, Thm. 2]
B.2.1 Proof of Lemma 2
Let . We have for :
| 32 |
Following similar lines of proof as in Proposition 1, get the initial -a.e. estimates
| 33 |
and
In view of Condition 1
| 34 |
Taking expectation in (32) we get (using the Fubini property) that
Then, by (33), Doob’s inequality, and (34) we get
Hence, after one use of Gronwall’s inequality, we have that
and we conclude the proof in the same way as in Proposition 1.
B.2.2 Proof of Lemma 3
Consider the function
Recall that means that for and . It follows from the Lipschitz assumption on K, compactness of A, and definition of that
Let , , be a sequence converging to . Without loss of generality, assume that the sequence is non-decreasing. Recall that denotes the uniform upper bound for the intensity rates, see Condition 1.1. For ,
where is for each a Poisson-distributed random variable with intensity , since the summands , are independent Poisson-distributed with intensity . Moreover, are e.p.i., so by the Exact Law of Large Numbers
Hence, by the boundedness of A, it holds for all and -a.e. that
and in particular for -a.e. . Measurability and square-integrability of follows by the same lines of proof as Lemma 1 in [3].
Declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
We will interchangeably use the words agent, player, and individual.
Loosely speaking, a dense network or graph is one in which the number of edges is close to the maximal number of edges. For such graphs, there is a functional limit of the adjacency matrix interpreted as a step function. See [48] for an exposé of the theory of such limits.
https://www.cdc.gov/coronavirus/2019-ncov/prevent-getting-sick/how-covid-spreads.html (last accessed on 10 April, 2021)
Depending on the modeling, R can refer to “Removed” or “Recovered”.
In MFG theory “extended" refers to formulations where interaction is modelled with the joint distribution of action and state of players.
Some examples of idealized networks given in this work are Small-World Networks, Scale-Free Networks, Exponential Random Graph Models.
This is of course not the case if the graphon is constant. In this case, the graphon game is in fact equivalent to an MFG, so there is a representative agent. There are a few more examples of this kind, such as the piecewise constant graphon yielding a game equivalent to a multipopulation MFG with one representative agent for each subpopulation.
The rate is presented in (20) as . For an arbitrary impact function K this would lead to a violation of Condition 1.1. Here we are however considering contact factor control and aggregates of the form (11), which are bounded by Condition 2 and the compactness of A. The Q-matrix (20) can be modified without changing the model so that Condition 1.1 is satisfied; we defer from this for the sake of presentation.
These methods are referring to solving an ODE system similar to the one given in Sect. 2.4 for a finite (and possibly a small) number of x’s.
We can realize that if , the setting is equivalent to a mean field game.
A superspreader is an infected person who is able to transmit the disease to a disproportionately high number of people.
https://www.cdc.gov/coronavirus/2019-ncov/your-health/reinfection.html (last accessed on 10 April, 2021)
https://www.cdc.gov/coronavirus/2019-ncov/hcp/duration-isolation.html (last accessed on 10 April, 2021)
https://www.cdc.gov/coronavirus/2019-ncov/hcp/duration-isolation.html (last accessed on 10 April, 2021)
This article is part of the topical collection “Modeling and Control of Epidemics” edited by Quanyan Zhu, Elena Gubar and Eitan Altman.
This work was done with the support of NSF DMS-1716673, ARO W911NF-17-1-0578, and AFOSR # FA9550-19-1-0291.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Alexander Aurell, Email: aaurell@princeton.edu.
René Carmona, Email: rcarmona@princeton.edu.
Gökçe Dayanıklı, Email: gokced@princeton.edu.
Mathieu Laurière, Email: lauriere@princeton.edu.
References
- 1.The Incubation Period of Coronavirus Disease (COVID-19) (2020) From publicly reported confirmed cases: estimation and application. Ann Intern Med. 2019;172(9):577–582. doi: 10.7326/M20-0504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Andersson H, Djehiche B. Limit theorems for multitype epidemics. Stochast Process Appl. 1995;56(1):57–75. doi: 10.1016/0304-4149(94)00059-3. [DOI] [Google Scholar]
- 3.Alexander A, Rene C, Gokce D, Mathieu L (2020) Optimal incentives to mitigate epidemics: a Stackelberg mean field game approach. arXiv:2011.03105
- 4.Alexander A, Rene C, Mathieu L (2021) Stochastic graphon games: II. the linear-quadratic case. arXiv:2105.12320
- 5.Bayraktar E, Cohen A. Analysis of a finite state many player game using its master equation. SIAM J Control Opt. 2018;56(5):3538–3568. doi: 10.1137/17M113887X. [DOI] [Google Scholar]
- 6.Brezis H. Functional analysis. Sobolev spaces and partial differential equations. New York: Universitext, Springer; 2011. [Google Scholar]
- 7.Bryant VW. A remark on a fixed-point theorem for iterated mappings. Am Math Monthly. 1968;75:399–400. doi: 10.2307/2313440. [DOI] [Google Scholar]
- 8.Caines PE, Huang M (2019) Graphon Mean field games and the GMFG equations: -nash equilibria. In: 2019 IEEE 58th conference on decision and control (CDC), pp 286–292
- 9.Caines PE, Huang M (2018) Graphon mean field games and the GMFG equations.2018 IEEE conference on decision and control (CDC)
- 10.Carmona R, Cooney D, Graves C, Lauriere M (2021) Stochastic graphon games: I. The static case. To appear in Math Oper Res
- 11.Carmona R, Laurière M. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games I: the ergodic case. SIAM J Numer Anal. 2021;59(3):1455–1485. doi: 10.1137/19M1274377. [DOI] [Google Scholar]
- 12.Carmona R., Laurière M (2021) Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: II–the finite horizon case. arXiv:1908.01613
- 13.Carmona R, Wang P (2016) Finite state mean field games with major and minor players. arXiv:1610.05408
- 14.Carmona R, Wang P (2021) A probabilistic approach to extended finite state mean field games. Math Oper Res
- 15.Cecchin A, Fischer M (2018) Probabilistic approach to finite state mean field games. Appl Math Opt, pp 1–48
- 16.Charpentier A, Elie R, Laurière M, Tran VC. Covid-19 pandemic control: balancing detection policy and lockdown intervention under icu sustainability. Math Modell Nat Phenomena. 2020;15:57. doi: 10.1051/mmnp/2020045. [DOI] [Google Scholar]
- 17.Cho S (2020) Mean-field game analysis of sir model with social distancing. arXiv:2005.06758
- 18.Choutri SE, Djehiche B. Mean-field risk sensitive control and zero-sum games for Markov chains. Bulletin des Sciences Mathématiques. 2019;152:1–39. doi: 10.1016/j.bulsci.2019.01.004. [DOI] [Google Scholar]
- 19.Choutri SE, Djehiche B, Tembine H. Optimal control and zero-sum games for Markov chains of mean-field type. Math Control Related Fields. 2019;9(3):571. doi: 10.3934/mcrf.2019026. [DOI] [Google Scholar]
- 20.Choutri SE, Hamidou T. A stochastic maximum principle for Markov chains of mean-field type. Games. 2018;9(4):84. doi: 10.3390/g9040084. [DOI] [Google Scholar]
- 21.Cvitanić J, Possamaï D, Touzi N. Dynamic programming approach to principal-agent problems. Finance Stoch. 2018;22(1):1–37. doi: 10.1007/s00780-017-0344-4. [DOI] [Google Scholar]
- 22.Jakša Cvitanić, Jianfeng Zhang. Contract theory in continuous-time models. Heidelberg: Springer Finance, Springer; 2013. [Google Scholar]
- 23.Andrew DD, Edwin P (2012) Superprocesses at Saint-Flour. Springer
- 24.Delarue F (2017) Mean field games: a toy model on an Erdös-Renyi graph. ESAIM: Procs, 60:1–26
- 25.Delmas JF, Dronnier D , Zitt P (2021) Targeted Vaccination Strategies for an Infinite-Dimensional SIS Model. arXiv:2103.10330
- 26.Djehiche Boualem, Kaj Ingemar (1995) The rate function for some measure-valued jump processes. The annals of probability, pages 1414–1438
- 27.Djehiche B, Alexander Schied. Large deviations for hierarchical systems of interacting jump processes. J Theor Prob. 1998;11(1):1–24. doi: 10.1023/A:1021690707556. [DOI] [Google Scholar]
- 28.Doncel J, Gast N, Gaujal B(2020) A mean-field game analysis of SIR dynamics with vaccination. Prob Eng Inf Sci, pp 1–18
- 29.Romuald Elie, Emma Hubert, Gabriel Turinici. Contact rate epidemic control of COVID-19: an equilibrium view. Math Modell Nat Phenomena. 2020;15:35. doi: 10.1051/mmnp/2020022. [DOI] [Google Scholar]
- 30.Gao S, Caines PE (2019) Spectral representations of graphons in very large network systems control. 2019 IEEE 58th conference on decision and Control (CDC)
- 31.Gao S, Caines PE, Huang M (2020) LQG graphon mean field games. arXiv:2004.00679
- 32.Gaujal B, Doncel J, Gast N (2021) Vaccination in a large population: mean field equilibrium versus social optimum. In: netgcoop’20, Cargèse, France, September
- 33.Gomes AD, Mohr J, Rigao Souza Rafael. Discrete time, finite state space mean field games. Journal de mathématiques pures et appliquées. 2010;93(3):308–328. doi: 10.1016/j.matpur.2009.10.010. [DOI] [Google Scholar]
- 34.Gomes Diogo A, Joana Mohr, Rigao Souza Rafael. Continuous time finite state mean field games. Appl Math Opt. 2013;68(1):99–143. doi: 10.1007/s00245-013-9202-8. [DOI] [Google Scholar]
- 35.Grigelionis B. On representation of integer-valued random measures by means of stochastic integrals with respect to the Poisson measure. Lithuanian Math J. 1971;1:93–108. doi: 10.15388/LMJ.1971.20963. [DOI] [Google Scholar]
- 36.Huang M, Malhamé RP, Caines Peter E, et al. Large population stochastic dynamic games: closed-loop McKean-Vlasov systems and the Nash certainty equivalence principle. Commun Inf Syst. 2006;6(3):221–252. doi: 10.4310/CIS.2006.v6.n3.a5. [DOI] [Google Scholar]
- 37.Hubert E, Mastrolia T, Possamaï D, Warin X (2020) Incentives, lockdown, and testing: from Thucydides’s analysis to the COVID-19 pandemic. arXiv:2009.00484 [DOI] [PMC free article] [PubMed]
- 38.Hubert E, Turinici G. Nash-MFG equilibrium in a SIR model with time dependent newborn vaccination. Ricerche di Matematica. 2018;67(1):227–246. doi: 10.1007/s11587-018-0365-0. [DOI] [Google Scholar]
- 39.Hytönen T, Van Neerven J, Veraar M, Weis L (2016) Anal Banach spaces, vol 12. Springer
- 40.Keeling JM, Eames TDK. Networks and epidemic models. J R Soc Interface. 2005;2(4):295–307. doi: 10.1098/rsif.2005.0051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Keliger D, Horvath I, Takacs B (2020) Local-density dependent Markov processes on graphons with epidemiological applications. arXiv:2008.08109
- 42.Kohlmann M, Zhou XY (2000) Relationship between backward stochastic differential equations and stochastic controls: a linear-quadratic approach. SIAM J Control Optim 38(5):1392–1407
- 43.Kolokoltsov VN. Nonlinear Markov games on a finite state space (mean-field and binary interactions) Int J Stat Prob. 2012;1(1):77–91. doi: 10.5539/ijsp.v1n1p77. [DOI] [Google Scholar]
- 44.Laguzet L, Turinici G. Individual vaccination as Nash equilibrium in a SIR model with application to the 2009–2010 influenza A (H1N1) epidemic in France. Bull Math Biol. 2015;77(10):1955–1984. doi: 10.1007/s11538-015-0111-7. [DOI] [PubMed] [Google Scholar]
- 45.Laguzet L, Turinici G, Yahiaoui G (2016) Equilibrium in an individual-societal SIR vaccination model in presence of discounting and finite vaccination capacity. In: New trends in differential equations, control theory and optimization: proceedings of the 8th congress of Romanian mathematicians, pp 201–214. World Scientific
- 46.Lasry JM, Lions PL (2006) Jeux à champ moyen. i-le cas stationnaire. Comptes Rendus Mathématique 343(9):619–625
- 47.Lasry JM, Lions PL (2006) Jeux à champ moyen. ii-horizon fini et contrôle optimal. Comptes Rendus Mathématique 343(10):679–684
- 48.Lee W, Liu S, Tembine H, Li W, Osher S (2020) Controlling propagation of epidemics via mean-field games. arXib:2006.01249
- 49.László Lovász. Large networks and graph limits. American Mathematical Society, Providence, RI: American Mathematical Society Colloquium Publications; 2012. [Google Scholar]
- 50.Parise F, Ozdaglar AE (2019) Graphon games: a statistical framework for network games and interventions. SSRN Electron J
- 51.Francesco Salvarani, Gabriel Turinici. Optimal individual strategies for influenza vaccines with imperfect efficacy and durability of protection. Mathematical Biosciences & Engineering. 2018;15(3):629. doi: 10.3934/mbe.2018028. [DOI] [PubMed] [Google Scholar]
- 52.Skorokhod AV (1982) Studies in the theory of random processes, vol 7021. Courier Dover Publications
- 53.Sun Y. A theory of hyperfinite processes: the complete removal of individual uncertainty via exact LLN. Math. Econom. 1998;29(4):419–503. doi: 10.1016/S0304-4068(97)00036-0. [DOI] [Google Scholar]
- 54.Sun Y. The exact law of large numbers via Fubini extension and characterization of insurable risks. J Econom Theory. 2006;126(1):31–69. doi: 10.1016/j.jet.2004.10.005. [DOI] [Google Scholar]
- 55.Sun Y, Zhang Y. Individual risk and Lebesgue extension without aggregate uncertainty. J Econom Theory. 2009;144(1):432–443. doi: 10.1016/j.jet.2008.05.001. [DOI] [Google Scholar]
- 56.Tembine T. Covid-19: data-driven mean-field-type game perspective. Games. 2020;11(4):51. doi: 10.3390/g11040051. [DOI] [Google Scholar]
- 57.Vizuete R, Frasca P, Frasca F. Graphon-based sensitivity analysis of SIS epidemics. IEEE Control Syst Lett. 2020;4(3):542–547. doi: 10.1109/LCSYS.2020.2971021. [DOI] [Google Scholar]