

Abstract
For a two-group comparative study, a stratified inference procedure is routinely used to estimate an overall group contrast to increase the precision of the simple two-sample estimator. Unfortunately, most commonly used methods including the Cochran-Mantel-Haenszel statistic for a binary outcome and the stratified Cox procedure for the event time endpoint do not serve this purpose well. In fact, these procedures may be worse than their two-sample counterparts even when the observed treatment allocations are imbalanced across strata. Various procedures beyond the conventional stratified methods have been proposed to increase the precision of estimation when the naive estimator is consistent. In this paper, we are interested in the case when the treatment allocation proportions vary markedly across strata. We study the stochastic properties of the two-sample naive estimator conditional on the ancillary statistics, the observed treatment allocation proportions and/or the stratum sizes, and present a biased-adjusted estimator. This adjusted estimator is asymptotically equivalent to the augmentation estimators proposed under the unconditional setting. Moreover, this consistent estimation procedure is also equivalent to a rather simple procedure, which estimates the mean response of each treatment group first via a stratum-size weighted average and then constructs the group contrast estimate. This simple procedure is flexible and readily applicable to any target patient population by choosing appropriate stratum weights. All the proposals are illustrated with the data from a cardiovascular clinical trial, whose treatment allocations are imbalanced.
Keywords: ancillary statistic, augmentation estimation procedure, conditional inference, CMH statistic, mixture population
1 |. INTRODUCTION
In a comparative randomized study, suppose that we are interested in estimating an overall group difference, ie, θ, between a treatment and a control via their individual population parameters, ie, τ2 and τ1, respectively. For example, τ is the mean value of the study subject’s outcome variable and θ = τ2 – τ1. Assume that the study utilizes a M : 1 random treatment allocation rule for assigning patients to the treatment and control groups. Although the primary analysis of the study is generally based on a two-sample empirical counterpart of , a stratified inference procedure is often utilized to increase the estimation precision for .1,2 Moreover, when the observed allocation proportions of patients assigned to either arm vary substantially across strata, a stratified estimator has been generally perceived as less biased than .
Unfortunately, a number of routinely used stratified procedures cannot be guaranteed to either increase the precision or reduce the bias for estimating θ, especially when θ is nonlinearly related to τ1 and τ2. As an example, consider a simple case where the outcome is a binary variable and θ is the odds ratio (OR) of the event rates , that is,
The two-sample empirical counterpart is
where is the observed empirical counterpart of τj, j = 1, 2. For a large randomized study, is consistent for θ. Now, suppose that one considers a stratified inference procedure with K strata to estimate θ. Let the observed stratum sizes be n1, n2, …, nK and . For the jth group in the kth stratum, let the group size be njk, the true event rate be and . A commonly used stratified estimate for θ is based on the Cochran-Mantel-Haenszel (CMH) statistics,3 which results in
where is the observed empirical counterpart of τjk Note that, even when nk → ∞ and , converges to
where wk, the limit of , is the mixing proportion of the kth stratum in the study population. In general, θS ≠ θ, and therefore, is an inconsistent estimator. Moreover, θS is not a simple weighted average of the stratum-specific OR’s as usually interpreted by the practitioners. Here, the kth weight is proportional to (1 − τ2k)τ1kwk, a rather complex form of the underlying stratum-specific event rates.
In survival analysis, a stratified inference procedure, which is routinely used for comparing two groups, is to estimate the hazard ratio (HR) θ under a two-sample proportional hazards model.4 Here, the outcome variable is the time to a specific event. The corresponding stratified method is the stratified Cox procedure,4,5 which suffers from the same limitation of the CMH method for the binary outcome. More details will be given in Section 4 of this paper.
Alternatives to the aforementioned conventional stratified procedures have been studied extensively when the simple estimator is consistent. For this case, the goal is mainly to increase the estimation precision of with the baseline covariate information.6–10 The performance of such alternative estimation procedures are assessed under an “unconditional” setting by considering all possible realizations of the estimator generated from the random sampling in the study. Now, suppose that (i) , the observed proportions of study patients assigned to the treatment group, vary substantially across strata, and/or (ii) , the observed proportions of the patients in each stratum, are substantially different from the underlying . Then, generally, for the case with a practical sample size, the observed naive estimate would not be close to θ. It is not clear, however, how to empirically quantify the bias of . One possible approach to handle this problem would be based on a conditional inference principle via ancillary statistics for the treatment difference θ.11 For the present case, both the empirical proportions of patients assigned to the treatment and the empirical proportions of the strata are ancillary statistics. The distribution of ( – θ) conditional on such ancillary statistics would be more “relevant” and informative than its unconditional counterpart to study the stochastic behavior of .12,13 Specifically, we consider realizations of generated from the random sampling in the study, but of each realized sample would be the same as its observed counterparts. By doing so, the individual realizations in the aforementioned conditional sample space are obtained under the experimental condition similar to the observed one. In this paper, using this procedure, one can empirically quantify the bias of and then obtain a consistent estimator for θ by modifying . It is interesting to note that the aforementioned modified estimator is identical or asymptotically equivalent to the augmentation estimators proposed by Zhang et al,6 Wei and Zhang,14 Tsiatis et al,15 and Tian et al10 under the unconditional setting. Moreover, the aforementioned modified estimator is also equivalent to a rather simple estimator obtained via a mixture estimation procedure across strata. Specifically, for the aforementioned example for θ being the OR, we first estimate the overall event rate for the control arm using a weighted average of stratum-specific event rate estimates, where the weight for the kth stratum-specific estimate is wk, the target proportion of patients from the kth stratum. Similarly, we estimate the overall event rate for the treated arm. Then, we construct the OR estimate with these two overall event rate estimates. The details are given in Sections 2 and 3. In Section 4, we apply the proposal to the case with the censored event time observations. All the procedures are illustrated with the data from a comparative randomized cardiovascular clinical trial.
2 |. MODIFYING THE NAIVE ESTIMATOR IN THE PRESENCE OF TREATMENT ALLOCATION IMBALANCE
Using the notations in the introduction for the general case, that is, let τj and be the population mean and its empirical counterpart of the subject’s outcome variable for the jth group, respectively, and let τjk and be the corresponding quantities in the kth stratum, k = 1, … , K;j = 1, 2. Let θ = g(τ1, τ2) and , where g(·, ·) is a given smooth function. For example, g(τ1, τ2) = τ1 – τ2, if we are interested in the mean difference, and log(τ1/τ2), if we are interested in the log ratio of two means. With a random assignment allocation rule and the random sampling assumption of subjects in each group and stratum, for large nk, k = 1, … , K, it is straightforward to show that the joint distribution of and approximately normal with mean 0 and covariance matrix given in the Appendix A, where . Heuristically, it follows that the conditional distribution of
is approximately normal with a mean of
and a variance of
| (1) |
where
is the partial derivative of g(τ1,τ2) with respect to τj and is a consistent estimator for the variance of . Note that the aforementioned large sample normal approximation is not straightforward. The theoretical justification of this approximation to the conditional distribution is given in Appendix A. The aforementioned conditional distribution shows that is in general not root n consistent for θ, when there are treatment allocation imbalances within individual strata or are different from . An obvious consistent estimator for θ by directly adjusting is
Note that is a sum of and a linear combination of and , k = 1, …, K and is asymptotically equivalent to the augmentation estimators proposed and discussed in Zhang et al,6 Moor and van der Laan,8 and Tian et al.10 Note also that the augmentation procedures in the literature do not have , k = 1, … , K, as one of the augmented terms. On the other hand, from the semiparametric efficiency argument, it is a trivial extension to do so, when wk, k = 1, … , K are known. Note that one of the fundamental principles for conducting a randomized clinical trial is to define and characterize the study population in which the treatment effect is to be estimated. For the present case, this means the mixture proportions wks should be prespecified in the study protocol. As a result, unconditionally, minimizes the asymptotic variance of the sum of and any linear combination of {, , k = 1, … , K}. However, all the augmented estimators were developed to improve efficiency over the naive estimator , under an unconditional setting for which the naive estimator is consistent.
When wk for the study population is unknown, one may consider an adjusted estimator based on the conditional distribution of given only. Specifically, , where
The variance of can be estimated consistently by
| (2) |
where
It is interesting to note that is greater than due to the sampling variation from . This adjusted estimator would not be unbiased under the conditional setting with the additional conditioning event, {}. It is important to note that there is no general rule on the choice of ancillary statistics. This topic has been discussed extensively in the literature. In practice, the choice of the ancillary statistics would be made on a case-by-case basis. For our present case, the choice of the ancillary statistics, ie, and , was similar to those in the conditional inference for analyzing multiple 2 × 2 tables.16 The choice of the ancillary statistic only was also discussed by Senn12 and Pocock et al.13
As an example, consider the data from a cardiovascular trial “Valsartan in acute myocardial infarction (VALIANT) study”17 to illustrate the aforementioned estimation procedures. There were three arms in this study, the patients in the first group were treated by ARB valsartan, the second group was with ACE inhibitor captopril, and the third one was a combination of these two drugs. For illustration, we consider the time to the first hospitalization or death as the endpoint and compare the monotherapy (combing two treatment groups) with the combo therapy. The study enrolled a total of 14 703 patients, who were equally assigned to three arms. The median follow-up time was 24.7 months after randomization. For the entire study, there is no difference with respect to the endpoint considered here. In Figure 1, we show the Kaplan-Meier curves for this endpoint for two comparators. On the other hand, with the data from 302 patients in Australia, the monotherapy somehow appears to be statistically significantly better than its combo counterpart (see Figure 2). Note that Australia was the only country among 24 countries participated in the VALIANT study, whose patients tend to have better outcomes for the monotherapy than those for the combo therapy.
FIGURE 1.
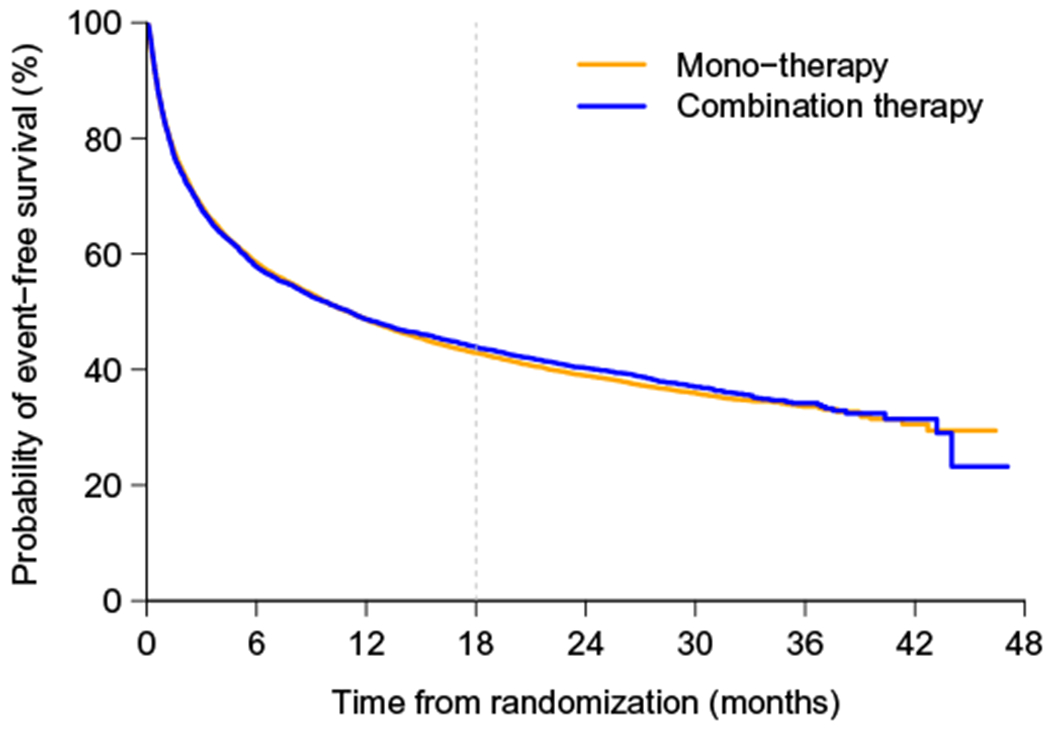
The survival curves for entire VALIANT study by arms: monotherapy and combo therapy arms [Colour figure can be viewed at wileyonlinelibrary.com]
FIGURE 2.
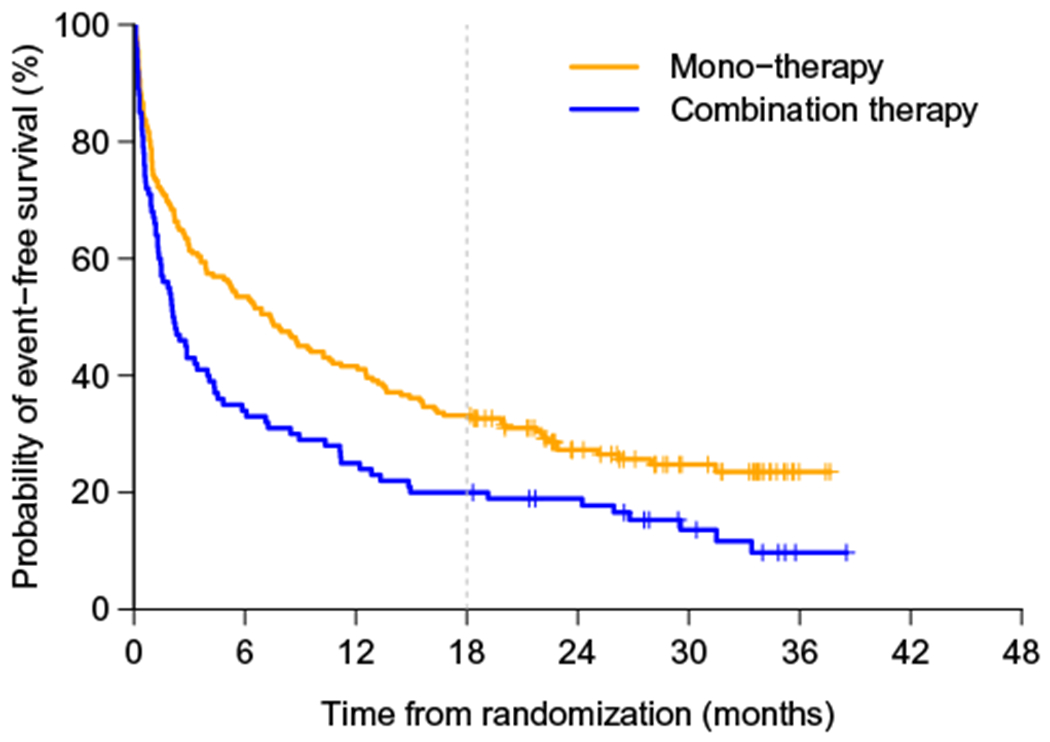
The survival curves for Australian patients in Valsartan in acute myocardial infarction study by arms: monotherapy and combo therapy arms [Colour figure can be viewed at wileyonlinelibrary.com]
We will discuss the case with an event time as the endpoint in Section 4. Here, let us consider the outcome from the aforementioned study to be a binary, either the patient had event by or at month 18. Note that there were no censored observations in the study before month 18. There are two important patient’s covariates, which are related to this binary endpoint, BMI and history of diabetes. For simplicity, we dichotomize BMI with a cutoff value of 25 and create four strata (ie, 1: low BMI and no diabetic history; 2: low BMI and with diabetic history; 3: high BMI and no diabetic history; 4: high BMI and with diabetic history). Table 1 shows the number of 302 Australian patients assigned to each treatment group with respect to the four strata, whose sizes . Note that, if the randomization scheme worked well, the treatment allocation ratio (mono vs combo) would be around 2:1. From Table 1, it seems that there is a nontrivial treatment allocation imbalance with respect to these two factors.
TABLE 1.
Stratified event rate of death or hospitalization up to 18 months in Australia region of Valsartan in acute myocardial infarction Study
| Stratification Factors | Australia Data (# of events / # of patients) | OR | |||
|---|---|---|---|---|---|
| BMI | History of Diabetes | Mono-therapy | Combo-therapy | ||
| 1 < 25 | No | 43/60 | 8/13 | 0.82 | 0.63 |
|
| |||||
| < 25 | Yes | 9/10 | 6/8 | 0.56 | 0.33 |
|
| |||||
| ≥ 25 | No | 65/108 | 44/54 | 0.67 | 2.91 |
|
| |||||
| ≥ 25 | Yes | 18/24 | 22/25 | 0.49 | 2.44 |
Abbreviations: BMI, body mass index; OR, odds ratio.
The naive estimate for the log(OR) of two event rates (combo vs mono) at month 18 is 0.69 with a standard error of 0.29. Therefore, the corresponding estimator of OR is 1.99 with a 95% confidence interval (CI) of (1.12, 3.51) in favor of monotherapy. The corresponding CMH estimate is 1.83 with a 95% CI of (1.03, 3.25). Using the empirical strata weights , the bias adjusted estimate is 1.73 with a 95% CI of (0.96, 3.12) for OR. The CI includes one, suggesting that the group difference is not statistically significant based on the bias adjusted estimator. If we assume that the true mixing proportions for the Australia substudy are identical to the observed proportions in the entire VALIANT study, ie, (w1, w2, w3, w4) = (0.24, 0.04, 0.53, 0.19), then for OR becomes 1.75 with a slightly different 95% CI of (0.97, 3.13), also indicating an insignificant treatment effect.
3 |. A SIMPLE CONSISTENT STRATIFIED ESTIMATOR FOR θ WITH TWO GROUP-SPECIFIC WEIGHTED AVERAGES OF THE STRATUM MEAN OUTCOMES
Under a stratification setting with K strata, the mean of the outcome τj can be rewritten as and can be estimated consistently with , j = 1, 2. It follows that
is a consistent estimator unconditionally or conditionally on and/or . It is interesting to note that this new estimator is asymptotically equivalent to the bias-adjusted estimator conditional on and . This equivalence is due to the fact that
and
Because of this equivalence, the variance of can be estimated by given in (1). Note also that, when {wk, k = 1, … , K} is not known, can be replaced by
with , j = 1, 2. For this case, the resulting is asymptotically equivalent to discussed in Section 2. Consequently, the variance of can be approximated by given in (2).
Considering the estimator with as the weights, first, estimates the mean response of the subjects in arm j by a weighted average with the observed proportion of the stratum size as the weight. One then constructs a group contrast measure with these two resulting treatment group-specific estimators. Note that this estimation procedure for the between-group difference is constructed in a rather different way from the conventional stratified counterparts. For the conventional stratification methods, we first estimate the stratum specific group contrasts and then empirically combine them across strata, whose weights may not have clinical or physical interpretation. Moreover, the conventional stratified methods for the case with a nonlinear g(τ1, τ2) may not increase the estimation efficiency and introduce nontrivial bias, as discussed in the previous section. Since or is asymptotically equivalent to its augmentation estimation procedure, this estimator is always more efficient than asymptotically.
As an estimator for the marginal mean response, not only serves as the building block for adjusting the bias of the naive estimator but also provides important reference level in interpreting the group contrast measure θ. For example, although both and (0.500, 0.667) yield the same OR of 2.0, they may have quite different implications in practice. The conventional stratified estimator and the estimators and its corresponding equivalent augmented counterparts do not have the benchmark value from the control arm for assisting clinical decision making.
In the VALIANT example, the estimated event rate is with a 95% CI of (0.61, 0.74) for monotherapy and with a 95% CI of (0.72, 0.83) for combo therapy based on the observed stratum sizes. Note that, if we are interested in a different group contrast measure, for instance, the event rate difference as θ, these values are readily available from this simple new procedure to make inferences.
4 |. APPLICATION TO THE CASE WITH THE EVENT TIME OUTCOME VARIABLE
The most commonly used stratification estimation procedure is based on the stratified Cox model.5 Here, the parameter of interest is the overall HR by assuming that the two hazard functions are proportional of each other over the entire study time. As discussed extensively in the statistical and medical literature, the HR estimate is difficult to interpret especially when the proportional hazards (PHs) assumption is violated.18,19 The stratified Cox procedure follows the same approach as other conventional stratified methods for analyzing noncensored outcomes. That is, for each stratum, we assume that the PH assumption is plausible. We then obtain the HR estimate for each stratum and combine those estimates. The resulting estimator is asymptotically equivalent to linearly combining the log-transformed stratum-specific HR estimators over K strata. The weight of the combination is proportional to the inverse of the variance estimate for the log-transformed stratum-specific HR estimate. However, even when PH assumption holds within each stratum, the PH assumption for entire study population is violated, if the survival distributions are not identical across strata in the control group and two groups have different survival distributions in at least one stratum (see Appendix B). Consequently, the combined HR estimator from the stratified Cox procedure cannot be interpreted as the HR for the entire population. Now, the question is whether we can apply the marginal treatment effect method discussed in Section 3 to deal with the HR. Unfortunately, since the hazard function is not a probability measure, the overall hazard function cannot be expressed as a weighted average of stratum-specific hazard functions. The simple estimation approach discussed in Section 3 cannot be applied to the case using HR as the group contrast.
There are several alternative summary measures to quantify survivorship for each treatment group. For example, one may consider the median survival time. However, it is in general not a weighted average of stratum-specific median failure times either. Two other alternatives are the event rate and restricted survival time at a specific time point.18,19
For the t-year event rate τj, j = 1, 2, we can use the same approach discussed in Section 3. That is, we estimate τj by
where and is the Kaplan-Meier estimator for the survival function of the kth stratum in the jth group. Then, and are unbiased for estimating θ even when there are markedly observed treatment allocation imbalance.
As an example, we also consider the substudy analysis for Australia in VALIANT study. The estimated event rate (death or hospitalization) at t = 1000 days is 0.88 in the combo therapy group and 0.77 in the monotherapy group. The naive estimate of the OR of two event rates is 2.33 with a 95% CI of [1.39, 3.93], suggesting that the event rate by t = 1000 days for patients receiving monotherapy is significantly lower than that for combo therapy. Recall that there are four strata defined by BMI and diabetic history with the stratum size, ie, . With the aforementioned simple procedure, the adjusted event rate is 0.87 in the combo therapy group and 0.77 in the monotherapy group. The resulting estimator of the log(OR) is 0.65 (standard error: 0.40). Therefore, the estimated OR is 1.92 (95% CI: 0.88 to 4.22). It is smaller than the unadjusted counterpart of 1.99 and the p-value based on the Wald test using this new log(OR) estimator is 0.103.
The second alternative is the t-year mean survival time (t-MST) up to time point t or coined as the restrictive mean survival time. That is, E{min(T, t)} for survival time T, which is the area under the survival function up to the time point t.18,19 In contrast to the survival probability at a single time point, the t-MST is proportional to the average survival probability over the entire interval [0, t] and thus a better global summary of the survival profile in a patient population. It also can be interpreted as the life expectancy before time t. The corresponding parameter summarizing the treatment effect is g(τ1, τ2), a contrast between t-MSTs from two groups, where τj is the t-MST in group j. For instance, g(τ1, τ2) can be the ratio of two t-MSTs. The parameter g(τ1, τ2) can be estimated by replacing τj by the area under the Kaplan-Meier curves in group j. Unlike Cox regression for estimating HR, this estimation procedure for treatment effect based on t-MST does not rely on any strong model assumption such as the PH assumption. Furthermore, as the survival probability, the t-MST is also additive in that the overall t-MST is a weighted average of stratum-specific t-MST and thus a suitable summary of survival distribution in stratified analysis. For the aforementioned VALIANT study, the area under the Kaplan-Meier curves for the monotherapy and combo therapy arms are days and days up to t = 1000 days, respectively. That means, in the future, if we treat the patient with the new treatment up to 1000 days, we expect on average, the patient receiving monotherapy will have 395 event-free days, and 260 event-free days for patients receiving combo therapy. If we let θ be the log-transformed ratio of two t-MSTs at 1000 days, with a 95% CI of (1.12, 2.05) and a p-value less than 0.01.
Now, for a stratified analysis with respect to the t-MST measure, we first estimate this parameter with a weighted sum of stratum-specific t-MSTs, that is,
where . The variance of can be estimated by , where
and is the Kaplan Meier estimator for survival function of the censoring time in stratum k of group j. Furthermore, the variance of can be estimated by . For the aforementioned numerical example, days and days based on observed . The log-ratio of these two, (standard error: 0.16). Thus, the estimated ratio is 1.41 with a 95% CI of (1.03, 1.92). Although, statistically, the monotherapy is significantly better than the combo, the CI of the ratio of two t-MSTs is shifted toward the null value of one. Similar analysis can be conducted to estimate the difference in t-MST by letting g(τ1, τ2) = τ1 − τ2. In this example, the proposed new estimator of the difference is (standard error: 47) days with a 95% CI of (22, 206) days compared with the naive estimator of 135 (95% CI: 46 to 223) days. Note that, if we are willing to assume that the censoring time is independent of stratum, then we also may estimate and based on weighted Kaplan-Meier estimator with observations in the stratum k of group j weighted by wk/njk and , respectively.
5 |. NUMERICAL STUDY
In this section, we performed an extensive simulation study to investigate the finite sample performance of the proposed estimators under different settings. In order to mimic realistic settings, we simulated the data based on the VALIANT study. Specifically, we considered four strata with (w1, w2, w3, w4) = (0.242, 0.045, 0.526, 0.187), the proportions of the aforementioned four strata defined by BMI and diabetic history in the entire VALIANT study. The randomization allocation ratio was 1:2, ie, M = 2. The binary response was a Bernoulli random variable with the incidence rate (τ11, τ12, τ13, τ14) = (0.717, 0.900, 0.602, 0.750) and (τ21, τ22, τ23, τ24) = (0.615, 0.750, 0.815, 0.880) depending on the stratum indexed by 1,2,3, and 4 and treatment arm indexed by 1 and 2. These incidence rates were chosen to be identical to their observed counterparts in Australian data. Under this model, the true marginal incidence rate was 0.671 in arm 1 and 0.776 in arm 2, suggesting a log(OR) of −0.530.
In the first setting, the data were generated conditional on the observed imbalances in Australian data, where and with . For each set of simulated data, we obtained four estimators for log(OR): the naive estimator , the bias corrected estimator , the stratified , and the CMH estimator . Based on 10 000 simulations, their performance was summarized by empirical bias, standard error, and the coverage probability of two one-sided 97.5% CIs in Table 2. In this setting, the naive estimator was downwardly biased by 0.172, resulting OR estimates 16% lower than the true value. On the other hand, both and were almost unbiased, suggesting satisfactory bias correction. While CMH estimator aims for a different parameter, it was actually less biased than the naive estimator conditional on this specified randomization allocation ratios across strata. The CMH estimator was also downwardly biased with a bias of −0.089. To interpret the size of biases, we may use the true parameter value as well as the standard error of the naive estimate as references. The bias of the naive estimator was 32% of the true log(OR) and 59% of the standard error. As a result, the coverage probabilities were 99.5% and 93.6% for lower and upper one-sided CIs, respectively. Considering the nominal level of 97.5%, the downward bias of the naive estimator resulted in conservativeness of the lower one-sided CI but sacrificed the coverage level of the upper one-sided CI. On the other hand, the coverage levels of the CIs based on and were fairly close to the nominal level of 97.5%. The coverage probabilities were 98.7% and 96.4% for lower and upper one-sided CIs based on CMH estimator, respectively, also due to the bias of CMH estimator. To examine the proposed method under more balanced setting, we generated additional data conditional on the observed imbalances in Great Britain data, where n = 723, and . It can be seen from Table 2 that, with this relatively balanced allocation, the naive estimator was almost unbiased with a bias being only −0.014, which was negligible, comparing with either the true log(OR) or the standard error of the naive estimator. As a result, the coverage levels of two one-sided 97.5% CIs were close to 97.5%. In this case, both and were also unbiased with standard errors similar to that of the naive estimator. Therefore, there was no real sacrifice in using the bias corrected estimators when there was no bias. Estimating the bias correction term only slightly increased the standard error of the estimator, approximately 1% in this case. Interestingly, the CMH estimator was also almost unbiased in this case. If the sample size increased, the balance between two arms should be improved and we investigated such a case by generating data conditional on the observed imbalances in USA data, where , and . The results were also summarized in Table 2. The bias of the naive estimator was −0.052, which indeed is substantially smaller than that conditioning on the imbalances of Australia data and less than 10% of the true log(OR). However, the bias was still big relative to the standard error of the naive estimator, which also decreased with the increasing sample size. As a result, the coverage levels of the two one-sided CIs were 99.7% and 91.1%, away from the nominal level of 97.5%. In this case, the bias correction in either or was still needed. Therefore, the large sample size does not necessarily solve all the concerns of bias.
TABLE 2.
Conditional inferences for binary outcomes: and in Australia; and in Britain; and in USA. Bias stands for the empirical bias. ESE stands for the empirical standard errors. CP1 and CP2 stand for the empirical coverage levels of upper and lower 97.5% confidence intervals, respectively
| Country | n | θ | Bias | ESE | CP1 | CP2 |
|---|---|---|---|---|---|---|
| Australia | 302 | −0.172 | 0.291 | 0.995 | 0.936 | |
| −0.025 | 0.307 | 0.972 | 0.975 | |||
| −0.018 | 0.308 | 0.970 | 0.976 | |||
| −0.089 | 0.294 | 0.987 | 0.964 | |||
|
| ||||||
| GBR | 723 | −0.014 | 0.180 | 0.978 | 0.976 | |
| −0.005 | 0.182 | 0.972 | 0.975 | |||
| −0.005 | 0.182 | 0.972 | 0.975 | |||
| 0.011 | 0.178 | 0.971 | 0.984 | |||
|
| ||||||
| USA | 3894 | −0.052 | 0.079 | 0.997 | 0.911 | |
| −0.001 | 0.080 | 0.973 | 0.975 | |||
| 0.000 | 0.080 | 0.972 | 0.977 | |||
| −0.059 | 0.079 | 0.997 | 0.898 | |||
In the second set of simulations, the data were generated unconditionally, ie, the patients were randomly assigned to arm 1 and 2 with probability of π = 1/3 and 1 – π = 2/3, respectively. For each simulated dataset of n = 302, 723, and 3894, we calculated the aforementioned four estimators for log(OR). The randomization ensured that except , all other three estimators should be asymptotically unbiased and the associated conventional inferences were valid. Based on 10 000 simulated datasets, we summarized the performance of these estimators by their empirical bias, standard error, and coverage probability of one-sided 97.5% CIs in Table 3. We also calculated the bias of the naive estimator conditional on the realized treatment allocation at each of the simulated dataset, ie, conditional on and , using
TABLE 3.
Unconditional inferences for binary outcomes:(w1, w2, w3, w4) = (0.242, 0.045, 0.526, 0.187)′ and π = 1/3. (τ11, τ12, τ13, τ14) = (0.717, 0.900, 0.602, 0.750) and (τ21, τ22, τ23, τ24) = (0.615, 0.750, 0.815, 0.880). Bias stands for the empirical bias. ESE stands for the empirical standard errors. CP1 and CP2 stand for the empirical coverage levels of upper and lower 97.5% confidence intervals, respectively. is the empirical probability that the absolute bias is greater than one third of the standard error of the naive estimator
| n | θ | Bias | ESE | CP1 | CP2 | |
|---|---|---|---|---|---|---|
| 302 | −0.013 | 0.289 | 0.974 | 0.978 | 0.108 | |
| −0.013 | 0.286 | 0.972 | 0.975 | |||
| −0.011 | 0.286 | 0.972 | 0.975 | |||
| −0.012 | 0.286 | 0.976 | 0.979 | |||
|
| ||||||
| 723 | −0.008 | 0.184 | 0.976 | 0.976 | 0.118 | |
| −0.008 | 0.181 | 0.976 | 0.976 | |||
| −0.008 | 0.181 | 0.976 | 0.976 | |||
| −0.005 | 0.182 | 0.976 | 0.978 | |||
|
| ||||||
| 3894 | −0.001 | 0.079 | 0.975 | 0.976 | 0.119 | |
| −0.001 | 0.077 | 0.974 | 0.975 | |||
| −0.001 | 0.077 | 0.974 | 0.975 | |||
| 0.004 | 0.078 | 0.973 | 0.980 | |||
We examined the proportion that this absolute bias was greater than 1/3 of the standard error of the naive estimator. There was approximately 11% chance that the conditional bias of the naive estimator exceeded one third of its standard error regardless of the sample size n, which would either inflate the coverage level of the one-sided 97.5% confidence interval to ≥ 98.9% or deflate the level to ≤ 94.8%. This result highlighted the fact that, while the bias adjustment may not be needed for majority of the cases, there was a nontrivial probability that the random imbalances are big enough to negatively affect the validity of statistical inference based on the naive estimator and bias correction was desirable. The slightly smaller standard error of two bias corrected estimators was due to the fact that the correction of conditional bias reduced the unconditional variance of the naive estimator.
We also noted that the CHM stratified estimator was almost unbiased and the empirical coverage levels of the associated 97.5% confidence intervals were acceptable. Indeed, the log-transformed CHM estimator converged to log(θS) = −0.524, very close to the marginal log(OR) = −0.530 of our interest. This was not a coincidence: θS was in general very similar to the marginal OR. If we considered the case where all the arm-stratum response rates τij were within the interval [0.6, 0.9], then the biggest difference between log(θS) and log(OR) is 0.079, when {θS, OR} = (0.382, 0.353).
Next, we considered survival time as the primary endpoint, which was generated from log normal distributions, whose parameters were estimated based on Australia data. Specifically, the survival time followed LN(4.96, 2.152), LN(3.90, 1.772), LN(5.67, 2.302), and LN(5.15, 1.762) at stratum 1, 2, 3, and 4 of arm 1, respectively. Similarly, the survival time followed LN(5.02, 2.622), LN(4.69, 2.232), LN(4.48, 1.832), and LN(4.14, 1.772) at stratum 1, 2, 3, and 4 of arm 2, respectively. Under this model, the t-MST at t = 1000 days was 336, 156, 455, and 340 days at the four strata of arm 1 and 370, 302, 237, and 185 days at the four strata of arm 2. The marginal t-MST was 391 days at arm 1 and 262 days at arm 2 with a ratio of 1.49, whose log-transformation was the parameter to be estimated. Furthermore, the censoring time was generated uniformly from the interval [540, 1170] days.
As in the binary case, we conducted three sets of simulations conditional on and observed in Australia, Great Britain, and USA data, separately. For each simulated dataset, we calculated the naive estimator , the bias adjusted estimator , and the proposed stratified estimator . In this simulation, we extrapolated the Kaplan Meier curve to t = 1000 days, when the largest survival time in a stratum is censored before 1000 days. The finite sample performance based 10 000 simulated data was summarized by their empirical bias, standard error, and coverage level of two one-sided 97.5% CIs in Table 4. In this setting, the naive estimator was 0.067 away from the true parameter, ie, over-estimated the ratio by approximately 7%. On the other hand, both and were almost unbiased, suggesting satisfactory bias correction. Furthermore, while the CIs based on the naive estimator were either too conservative or too liberal, those based on and had appropriate coverage level. For more balanced setting based on the Great Britain data, the naive estimator was almost unbiased. In this case, all three estimators performed similarly well. For the simulation study based on the observed imbalance from the USA data, the bias of the naive estimator was less than 50% of that conditional on the Australia data due to increased sample size. However, it was clear that the bias correction based on either or was still needed based on the coverage level of one-sided CIs.
TABLE 4.
Conditional inferences for survival outcomes: and in Australia; and in Britain; and and in USA. Bias stands for the empirical bias. ESE stands for the empirical standard errors. CP1 and CP2 stand for the empirical coverage levels of upper and lower 97.5% confidence intervals, respectively
| Country | n | θ | Bias | ESE | CP1 | CP2 |
|---|---|---|---|---|---|---|
| Australia | 302 | 0.067 | 0.149 | 0.945 | 0.990 | |
| 0.003 | 0.161 | 0.967 | 0.961 | |||
| 0.006 | 0.160 | 0.966 | 0.962 | |||
|
| ||||||
| GBR | 723 | 0.002 | 0.093 | 0.980 | 0.976 | |
| 0.000 | 0.093 | 0.976 | 0.969 | |||
| 0.000 | 0.094 | 0.977 | 0.970 | |||
|
| ||||||
| USA | 3894 | 0.029 | 0.041 | 0.907 | 0.997 | |
| 0.000 | 0.042 | 0.976 | 0.974 | |||
| −0.000 | 0.042 | 0.976 | 0.976 | |||
Finally, we generated survival time unconditionally with the patients being randomly assigned to two arms. The sample sizes used were 302, 723, and 3894. Table 5 showed that the three estimators had similar estimation biases, variances, and coverage probabilities. We also examined the proportion that the absolute bias of the naive estimator was greater than one third of the standard error of the naive estimator. There were approximately 8% chances that the conditional bias of the naive estimator was greater than one third of its standard error. This result also supported the claim that there was oftentimes a need of bias correction due to imperfect randomization.
TABLE 5.
Unconditional inferences for survival outcomes: (w1, w2, w3, w4) = (0.242, 0.045, 0.526, 0.187) and π = 1/3. Bias stands for the bias. ESE stands for the empirical standard errors. CP1 and CP2 stand for the empirical coverage levels of upper and lower 97.5% confidence intervals, respectively. is the empirical probability that the absolute bias is greater than one third of the standard error of the naive estimator
| n | Bias | ESE | CP1 | CP2 | ||
|---|---|---|---|---|---|---|
| 302 | 0.004 | 0.149 | 0.976 | 0.972 | 0.081 | |
| 0.003 | 0.148 | 0.970 | 0.965 | |||
| 0.004 | 0.148 | 0.969 | 0.965 | |||
|
| ||||||
| 723 | 0.001 | 0.097 | 0.975 | 0.972 | 0.081 | |
| 0.000 | 0.096 | 0.974 | 0.970 | |||
| 0.000 | 0.096 | 0.974 | 0.970 | |||
|
| ||||||
| 3894 | 0.000 | 0.041 | 0.978 | 0.974 | 0.084 | |
| 0.000 | 0.040 | 0.977 | 0.975 | |||
| 0.000 | 0.040 | 0.977 | 0.974 | |||
6 |. REMARKS
The conventional stratified analysis, for example, the CMH, has been perceived as an analytic approach to increase the precision of the inference procedure about the between-group-difference in a comparative study. If the between-group-difference θ is quantified with a contrast via the group mean values of the primary study outcome (eg, the odds ratio of a binary endpoint), the parameter or estimand for which the conventional stratified procedure estimates can be quite different from our target parameter θ. This is the first topic we emphasized in this paper. Using the data from a randomized clinical study, the simple naive estimator is asymptotically unbiased “unconditionally.” That is, the sample space of consists of all realizations generated from the random treatment assignment rule utilized in this study. For this case, the two-sample estimator is consistent and the “efficiency augmentation method” with the stratification factors would improve the variance of . However, when the treatment assignment rule, by chance, results in a nontrivial imbalance in the number of patients between two comparative groups across strata, it is not clear how to justify that the conventional stratified methods or the aforementioned augmentation procedure would reduce bias. In fact, we did not know how to quantify the potential bias. In this paper, we use a “conditional argument” to quantify the bias of and derive an adjusted estimator , which would be closer to θ than stochastically. To our pleasant surprise, this is asymptotically equivalent to an augmented estimator “unconditionally.” This connection further enhances our understanding of the efficiency augmentation procedure via the perspective of conditional bias correction. Moreover, in our paper, we find that is also asymptotically equivalent to a very simple intuitive estimator , which is based on the weighted average of the stratum-specific means, where the weights are the mixture proportions of the strata. The present paper sheds light on the potential utility of stratification procedures when there is an imbalance between two groups in the numbers of patients across strata and proposes a simple intuitively interpretable inference procedure. This proposed that marginal treatment effect approach is rather flexible, which can handle the case when the target patient population is different from the study population. For example, in a cardiovascular clinical study, the majority of study patients is male. The target future population may be evenly divided with respect to gender. Unlike the new proposal, it is difficult to figure out the overall treatment difference for the target population with the conventional stratified analysis.
The choice of the stratification factors is important. If we overly stratify the study, that is, some factors are not related or mildly related to the outcome, the precision of the stratified inference procedure can be worse than the naive two-sample estimate. Therefore, as a general principle, we suggest to select stratification factors having the strongest association with the outcome and maintain reasonable number of patients within each stratum. In practice, it is desirable to automatically select the stratification factors based on the observed data to avoid subjectivity in the analysis. Recently, Tian et al10 and Bloniarz et al20 generalized the augmentation method originally proposed by Zhang et al6 to efficiently select relevant baseline covariates among a set of prespecified candidates under an unconditional setting for adjusting the consistent two-sample estimator. It is not clear how to apply this idea to handle the case when there is a potential imbalance with respect to a large set of stratification factors to avoid overstratification. Further research on appropriate selection of stratification factors is warranted. Lastly, we want to emphasize that theoretical properties of the proposed estimators are derived under the standard assumption that the sample size goes to infinity, whereas the number of strata is fixed.
ACKNOWLEDGEMENTS
We are grateful to the Editor, Associate Editor, and two referees for their constructive comments on the article. The research is partially supported by the US NIH grant R01-HL089778-05.
Funding information
National Heart, Lung, and Blood Institute, Grant/Award Number: R01 HL089778-05
Abbreviations:
- CMH
Cochran-Mantel-Haenszel
- OR
odds ratio
- VILIANT study
Valsartan in acute myocardial infraction study
- HR
hazard ratio
- PH
proportional hazards
- t-MST
t-year mean survival time
APPENDIX A
ASYMPTOTIC PROPERTIES OF THE NAIVE ESTIMATOR CONDITIONAL ON OBSERVED ALLOCATION IMBALANCES
Firstly, we assume that the observed data consist of n i.i.d observations (Yi, Ri, Xi), i = 1, … , n, where Yi is the response; Ri = 1 or 2 is the treatment indicator for group 1 and 2, respectively; and Xi takes values 1, 2, … , K, representing the stratum of the ith subject. Without loss of generality, let , where is the observed mean response in arm j and is the observed mean response in arm j of stratum k, j = 1, 2; k = 1, … , K. Our goal is to derive the limiting distribution of
conditional on
where .
To this end, we first have the expansion
where π = pr(Ri = 2) and almost surely. Let
where
and
By central limit theorem, ’ converges weakly to , a multivariate normal with mean 0 and a variance-covariance matrix
where
and
It follows from the work of Steck,21 as n → ∞, Un|Vn = v converges weakly to a limiting distribution in the sense that for any sequence {vn} such that vn ∈ An, the range of Vn, and limn → ∞vn = v,
where is the cumulative distribution function of Un conditional on Vn = vn and Fv(u) is the cumulative distribution function of U0 conditional on V0 = v. Furthermore, since almost surely, for any ,
where . Therefore, the conditional distribution converges to the normal distribution with a mean bθ and variance . Next, we will derive the explicit expression for mean bθ and variance . We first note that the variance-covariance matrices Σππ and Σww are singular, the conditional distribution U0|V0 is the same as that only conditioning on the components corresponding to (w1, … ,wK−1, π1, … , πK−1)′. Let , and be the associated covariance vectors and variance matrices
which is asymptotically equivalent to . It is clear that the bias of can then be consistently estimated by .
For the conditional variance, we first have
Since
and , we have
where . Furthermore, the conditional variance of − θ can be consistently estimated by . In the aforementioned derivation, we used the fact that
and
APPENDIX B
INCOMPATIBILITY OF PH ASSUMPTION IN THE ENTIRE STUDY AND WITHIN STRATUM
Assume that the PH assumption holds within each of the K strata. Let Sjk(t) denote the survival function in the kth stratum of arm j,j = 1, 2. Then, we have
for k = 1, …, K and a common HR r0. Furthermore, the marginal survival function for the entire study population is
for arm j, where w1 + ⋯ + wK = 1, wk ∈ (0, 1), k = 1, … , K. If the PH assumption holds for the marginal survival function, then S2(t) = S1(t)r for a constant r, ie,
Taking derivative with respect to t for both sides at t = 0, we obtain that
Without loss of generality, we assume that r0 ≥ 1, otherwise we always can switch two groups of interest to ensure that the HR is greater than or equal to 1. Under this assumption,
for 0 < S1k(t) < 1 due to the convexity of the function xr0. The equality holds only when S11(t) = ⋯ = S1K(t) or r0 = 1. Thus, the PH model with a HR of r0 is not true for the entire study population unless S11(t) = ⋯ = S1K(t), ie, the survival distributions are the same across strata or r0 = 1, ie, there is no difference in survivorship in any stratum.
REFERENCES
- 1.Valliant R Post-stratification and conditional variance estimation. J Am Stat Assoc. 1993;88(421):89–96. [Google Scholar]
- 2.Miratrix LW, Sekhon JS, Yu B. Adjusting treatment effect estimates by post-stratification in randomized experiments. J Royal Stat Soc Ser B. 2013;75:369–396. [Google Scholar]
- 3.Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst. 1959;22(4):719–748. [PubMed] [Google Scholar]
- 4.Cox D Regression models and life-tables. J Royal Stat Soc, Ser B (Methodol). 1972;34(2):187–220. [Google Scholar]
- 5.Mehrotra D, Su S, Li X. An efficient alternative to the stratified Cox model analysis. Statist Med. 2012;31(17):1849–1856. [DOI] [PubMed] [Google Scholar]
- 6.Zhang M, Tsiatis A, Davidian M. Improving efficiency of inferences in randomized clinical trials using auxiliary covariates. Biometrics. 2008;64(3):707–715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Koch G, Tangen C, Jung J, Amara I. Issues for covariance analysis of dichotomous and ordered categorical data from randomized clinical trials and non-parametric strategies for addressing them. Statist Med. 1998;17:1863–1892. [DOI] [PubMed] [Google Scholar]
- 8.Moore K, van der Laan M. Covariate adjustment in randomized trials with binary outcomes: targeted maximum likelihood estimation. Statist Med. 2009;28(1):39–64. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Rosenblum M, van der Laan M. Targeted maximum likelihood estimation of the parameter of a marginal structural model. Int J Biostat. 2010;6(2):19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Tian L, Cai T, Zhao L, Wei LJ. On the covariate-adjusted estimation for an overall treatment difference with data from a randomized comparative clinical trial. Biostatistics. 2012;13(2):256–273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Kalbfleisch J. Sufficiency and conditionality. Biometrika. 1975;62(2):251–259. [Google Scholar]
- 12.Senn SJ. Covariate imbalance and random allocation in clinical trials. Statist Med. 1989;8(4):467–475. [DOI] [PubMed] [Google Scholar]
- 13.Pocock SJ, Assmann SE, Enos LE, Kasten LE. Subgroup analysis, covariate adjustment and baseline comparisons in clinical trial reporting: current practice and problems. Statist Med. 2002;21(19):2917–2930. [DOI] [PubMed] [Google Scholar]
- 14.Wei L, Zhang J. Analysis of data with imbalance in the baseline outcome variable for randomized clinical trials. Drug Inf J. 2001;35:1201–1214. [Google Scholar]
- 15.Tsiatis A, Davidian M, Zhang M, Lu X. Covariate adjustment for two-sample treatment comparisons in randomized clinical trials: a principled yet flexible approach. Statist Med. 2008;27:4658–4677. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Fraser DAS. Ancillaries and conditional inference. Stat Sci. 2004;19(2):333–369. [Google Scholar]
- 17.Pfeffer M, McMurray J, Velazquez E, et al. Valsartan, captopril, or both in myocardial infarction complicated by heart failure, left ventricular dysfunction, or both. N Engl J Med. 2003;349(20):1893–1906. [DOI] [PubMed] [Google Scholar]
- 18.Uno H, Claggett B, Tian L, et al. Moving beyond the hazard ratio in quantifying the between-group difference in survival analysis. J Clin Oncol. 2014;32(22):2380–2385. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Uno H, Wittes J, Fu H, et al. Alternatives to hazard ratios for comparing the efficacy or safety of therapies in noninferiority studies. Ann Intern Med. 2015;163(2):127–134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Bloniarz A, Liu H, Zhang C, Sekhon J, Yu B. Lasso adjustments of treatment effect estimates in randomized experiments. Proc Natl Acad Sci. 2016;113(27):7383–7390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Steck GP. Limit Theorem for Conditional Distribution. Berkeley, CA: University of California Press; 1957. [Google Scholar]