

Abstract
Background:
Progressive neurodegenerative impairment with central language features, primary progressive aphasia (PPA), can be further distinguished for many individuals into one of three variants: semantic, non-fluent/agrammatic, and logopenic variant PPA. Variants differ in their relative preservation and deficits of language skills, particularly in word finding and grammar. The majority of elicited language assessments used in this population focus on single noun and verb production, while modifiers and inflectional morphemes are far less commonly examined.
Aims:
The purpose of the present study is to determine whether there was an interaction between PPA variant and production of high-frequency nouns, proper names, modifiers, and bound inflectional morphemes to better understand how the variants differ.
Methods & Procedures:
Forty-six people with PPA and 47 individuals with no known neurological diagnoses completed a morphosyntactic generation assessment designed to target differential production of high-frequency nouns, proper names, modifiers (number, size, color), and bound inflectional morphemes (plural -s and possessive ’s), the Morphosyntactic Generation test (MorGen). Performance is averaged for each of the seven morphosyntactic targets independently, resulting in seven separate performance scores.
Outcomes & Results:
Individuals with PPA performed significantly more poorly than controls on the assessed morphemes in a repeated-measures analysis of variance, as well as on each morpheme considered independently via t-test.
In a multivariable analysis of variance among PPA variants, the interaction of morpheme and PPA variant was significant, suggesting different variants produced the morphemes with a significantly different pattern of success. When morphemes were considered independently, only production of colour resulted in a significant difference between variants, driven by the performance of individuals with nfavPPA, who performed near-ceiling. When MorGen performance was used to predict PPA variant in a multinomial logistic regression the model was significant, with age, plural -s, noun, and number contributing significantly to the prediction. In a discriminate function analysis, classification of cases was best for agrammatic variant with 70% accuracy.
Conclusions:
Individuals with PPA, particularly semantic and logopenic variants, demonstrated difficulty on the MorGen compared to controls. The MorGen proved useful in predicting PPA variant. These findings highlight the potential benefit of examining a broader range of morphemes, particularly bound morphemes and modifiers, in addition to the more frequently investigated classes of nouns and verbs when understanding PPA.
Keywords: aphasia, dementia, production, plural, modifiers
Introduction
Primary progressive aphasia (PPA) is the term used to refer to progressive neurodegenerative impairment with central language features. It can be further distinguished for many individuals into one of three variants (Gorno-Tempini et al., 2011): semantic variant PPA (svPPA), non-fluent/agrammatic variant PPA (nfavPPA) and logopenic variant PPA (lvPPA). Variants are distinguishable by relative preservation and deficits within the domain of language. Individuals with svPPA have impaired word retrieval and object knowledge, but spared repetition and grammar. Those with nfavPPA, have relatively spared single-word comprehension and object knowledge, but experience agrammatism characterised by short, simple phrases and omission of grammatical morphemes (Montembeault et al., 2018) and/or apraxia of speech (Ash et al., 2010). People with nfavPPA often have impaired comprehension of sentences that are syntactically complex (Thompson & Mack, 2014). Impaired grammar further appears to be associated with particular difficulty using attributive modifiers or adjectives (e.g., red cat), which is thought to be due to the complexity of their syntactic computation (Meltzer-Asscher & Thompson, 2014). More recently, difficulty producing attributive modifiers has been observed in nfavPPA using a language elicitation task (Sostarics et al., 2020). LvPPA is characterised by impaired single word retrieval (though not to the extent observed in svPPA) and impaired repetition of sentences with spared grammar, object knowledge, and comprehension at the single word level (Montembeault et al., 2018). Unclassified or mixed profiles in PPA are not uncommon (Wicklund et al., 2014). These individuals meet the consensus criteria required for a diagnosis of PPA but do not fit the profiles of any of the variants, either because they do not have any of the core features of any variant or because they have core features of multiple variants.
Many researchers have observed poor word finding across PPA variants, primarily when examining nouns and verbs (Ash et al., 2006; Bird et al., 2000; Fraser et al., 2014; Kavé et al., 2007; Mack et al., 2015). Adjectives are among the least studied words in aphasic language production. Difficulties using inflectional morphemes have been inconsistently observed (Patterson et al., 2006; Patterson et al., 2001; Thompson et al., 2013). There are conflicting findings as to whether noun inflection is impaired (Kavé et al., 2012; Thompson et al., 2012) or preserved (Wilson et al., 2014).
The majority of elicited language assessments used in this population focus on single noun and verb production. Adjective and inflectional morpheme production is not targeted in part due to the difficulty in designing tasks that target bound morpheme production in the absence of significant confounds. Here, we report on the findings from a newly developed assessment tool designed to target differential production of high-frequency nouns, proper names, modifiers, and bound inflectional morphemes, the Morphosyntactic Generation test (MorGen). The investigational hypothesis is that there will be an interaction between PPA variant and performance on different morphemes that assists in understanding how the clinical variants differ. From prior work, it is unclear the extent to which success on the MorGen would follow trends observed in noun and verb production, which would lead one to expect that those with svPPA would perform more poorly than those with lvPPA, who would perform more poorly than those with nfavPPA, or lead to a different pattern of relative success, such as nfavPPA demonstrating the most consistent difficulty due to the MorGen’s high density probing of modifiers.
Materials & Methods
Recruitment
All work was conducted with the formal approval of the Johns Hopkins University School of Medicine Institutional Review Board. Fifty-two individuals with presumed PPA completed the MorGen. PPA diagnosis was made by a behavioral neurologist, based on language and cognitive testing, neurological exam, and magnetic resonance imaging (MRI), using consensus criteria (Gorno-Tempini et al., 2011). Six participants assessed for PPA were dropped from further analysis for not meeting consensus criteria for diagnosis (final N = 46: 16 lvPPA, 10 nfaPPA, 16 svPPA, 4 unclassified). In addition, 47 individuals with no known neurological diagnoses (control participants) were recruited to complete the same assessment.
Assessment
Administration of the MorGen involves two phases: a training phase and a feedback-free 60-item response phase. First, the administrator checks participants’ familiarity with the five highly imageable, high-frequency nouns used in the test: cat, shoe, chair, tree, and book. Accuracy in naming these five items is noted. Next, participants are trained in the response style of the assessment. For each item of the test, they see two pictures, which differ in only one morphologically relevant feature (see Figure 1). For example, a single apple and two apples (plurality). In each case, a large red arrow indicates the target picture they have to describe using only two words: one apple, two apples. Using the closed set of nouns, picture sets in an item vary to elicit the following morphological forms: number adjectives (one, two), size adjectives (big, small), colour adjectives (red, blue), plural -s, and possessive ’s. Two proper names are used throughout the test, paired with generic icons: Bob and Mary (see Figure 1). Their names are only used in the context of eliciting possessive ’s. Upon presentation of the picture, participants are prompted to provide two-word descriptions of the indicated picture for each of the test items. In the training phase, the desired response style is first modeled using the non-targeted noun, “apple,” for a series of 14 example trials. Next, participants have the opportunity to provide responses while receiving feedback on 10 additional trials that use the targeted set of five nouns. Once the participant provides a response to each of these trials, they see the targeted correct response and have it said aloud to them (regardless of whether their response was correct or incorrect) before moving to the next trial. As needed, the training phase also includes reminders of the test’s response format (two-word answers capturing the differing feature). Participants who are not able to produce at least some correct responses for the practice items or appear not to understand the directions do not receive the test (such individuals were not included in the study). After the training is over, the response phase begins, and no additional feedback is given. Responses are recorded and scored for accuracy and error type: omission, unrelated substitution, related substitution, or wrong word order. Accurate synonyms such as large/big are accepted as correct.
Figure 1: Example stimuli from the MorGen task.

Target responses are shown in quotations.
The MorGen items target each common noun 12 times, plural -s 31 times, number 8 times, size 16 times, colour 19 times, possessive ’s 17 times, and a proper name 17 times. Images for each noun were retrieved from the web using Google’s image search (under the United States “fair use” doctrine) and selected for clarity and rapid identifiability. Performance is averaged for each of the seven morphosyntactic targets independently, resulting in seven separate performance scores, represented as percent correctly included out of the total elicitations for each morpheme. Interrater reliability in scoring the MorGen (in tests of 35 patients and 31 controls) was 98.7 point-to-point percent agreement.
Analysis
Performance by individuals with PPA was compared with controls. In order to examine how profiles differed across PPA variants, performance in each morpheme was entered in a repeated-measures multivariable analysis with age entered as a covariate. The effectiveness of the MorGen in distinguishing PPA variants was addressed through complementary analysis via multinomial logistic regression and discriminate function analysis. LvPPA was selected as the reference category as it was the largest sampling and no directionality was hypothesised for overall performance. Where equality of variances was violated, corrected degrees of freedom are used to calculate test statistics.
Results
Individuals with PPA were compared with controls. Because the initial control sample of 47 participants was significantly younger than the clinical group (50-88 years old), only the 37 participants over 55 years of age were used for comparison with individuals with PPA. However, there were no significant differences in performance between older (N = 37) and younger (N = 10) controls on a repeated-measures analysis of variance, F(1, 45) = 0.65, p = 0.43. The older control participants were younger than individuals with PPA, t(77) = 2.07, p = 0.04.
Comparison of PPA to controls
Individuals with PPA (overall) performed significantly more poorly than controls on the assessed morphemes in a repeated-measures analysis of variance, F(1, 81) = 43.12, p<0.001, as well as on each morpheme considered independently via t-test (Table 1). There was a main effect of morpheme (Mauchly’s W = 0.06, p<0.001; Huynh-Feldt corrected F(4.13) = 9.51, p < 0.001) and a significant interaction between PPA presence and morpheme (F(4.13) = 9.20, p < 0.001).
Table 1:
Demographics and performance by group and PPA subtype
| PPA | Controls | Statistical comparison | |||||
|---|---|---|---|---|---|---|---|
| lvPPA | nfavPPA | svPPA | Unclassifiable | Total | PPA versus Controls | ||
| (N = 16) | (N = 10) | (N = 16) | (N = 4) | (N = 46) | (N = 37) | ||
| Age* | 70.88±8.28 | 73.10±7.80 | 70.00±8.69 | 67.25±9.61 | 70.74±8.30 | 66.91±7.90 | t(77) = 2.07, p = 0.04 |
| M:F | 9:7 | 7:3 | 7:9 | 1:3 | 24:22 | 17:18 | χ2(1) = 0.10, p = 0.82 |
| Edu | 16.00±2.22 | 16.50±3.16 | 15.43±3.78 | 18.00±2.00 | 16.05±3.06 | 16.50±2.79 | t(61) = 0.59, p = 0.56 |
| Years | 4.50±3.41 | 3.30±1.25 | 3.63±2.87 | 5.00±2.16 | 3.95±2.72 | -- | |
| -s** | 71.17±41.28 | 81.61±36.31 | 61.90±39.56 | 78.23±37.19 | 70.83±38.79 | 100±0 | t(45) = 5.10, p < 0.001 |
| ’s** | 41.18±46.52 | 66.47±45.14 | 23.90±35.26 | 44.12±40.04 | 40.92±43.58 | 99.84±0.97 | t(45) = 9.17, p < 0.001 |
| Noun** | 75.52±40.05 | 86.50±28.92 | 59.79±42.10 | 77.08±42.52 | 72.57±38.98 | 100±0 | t(45) = 4.77, p < 0.001 |
| Name** | 66.18±37.67 | 91.18±15.75 | 58.82±38.72 | 72.06±22.21 | 69.57±34.71 | 100±0 | t(45) = 5.95, p < 0.001 |
| Number** | 72.66±39.06 | 60.00±37.17 | 56.25±39.26 | 93.75±12.50 | 66.03±37.88 | 96.28±10.15 | t(53) = 5.19, p < 0.001 |
| Colour** | 65.79±38.96 | 94.74±13.13 | 50.66±40.03 | 60.53±30.54 | 66.36±37.50 | 99.15±3.62 | t(46) = 5.90, p < 0.001 |
| Size** | 60.94±36.19 | 75.63±33.26 | 45.70±36.92 | 59.38±29.09 | 58.70±35.98 | 97.13±6.00 | t(48) = 7.12, p < 0.001 |
| Total** | 63.60±37.10 | 79.44±27.19 | 51.00±32.06 | 69.31 ±19.59 | 63.57±32.67 | 98.91±1.71 | t(45) = 7.33, p < 0.001 |
p<0.05
p<0.001 in comparison of total PPA and controls. Data are presented as Mean±Standard Deviation. T-tests for age and education did not violate the equality of variances assumption (Levene’s Test for Equality of Variances), while t-tests for targeted morphemes did in all cases. Thus, reported statistics for morphemes are adjusted based on the (Cochran & Cox, 1957) adjustment of the standard error and the (Satterthwaite, 1946) adjustment of the degrees of freedom. Abbreviations: Years=years since diagnosis; Edu=education, lvPPA=logopenic variant, nfavPPA=non-fluent/agrammatic variant, svPPA=semantic variant. Age is reported in years. Performance is reported as percent correct. Nouns were elicited 12 times, plural -s 31 times, number 8 times, size 16 times, colour 19 times, possessive ’s 17 times, and a proper name 17 times.
When each PPA variant (not including unclassified PPA due to low N and mixed etiology) was compared to control performance separately in repeated-measures analyses of variance at a Bonferroni-corrected α = 0.05/3 = 0.02, the difference in overall performance between lvPPA (main effect of variant: F(1, 15) = 51.39, p < 0.001, main effect of morpheme: Mauchly’s W = 0.004, p < 0.001; Huynh-Feldt corrected F(2.71) = 6.04, p = 0.002), svPPA (main effect of variant: F(1, 15) = 40.48, p < 0.001, main effect of morpheme: Mauchly’s W = 0.02, p = 0.001; Huynh-Feldt corrected F(3.97) = 4.94, p = 0.002), nfavPPA (main effect of variant: F(1, 9) = 85.37, p < 0.001, main effect of morpheme: Mauchly’s W < 0.001, p < 0.001; Huynh-Feldt corrected F(2.96) = 5.13, p = 0.006) and controls each was significant independently.
Differences between PPA and controls were driven by individuals with svPPA, who had a performance that was significantly different from controls on all seven morphemes based on independent t-tests considered at a Bonferroni-corrected α = 0.05/3/7 = 0.002 (Table 2).
Table 2:
Statistical contrasts between each PPA subtype and controls by morpheme
| lvPPA | nfavPPA | svPPA | |
|---|---|---|---|
| (N = 16) | (N = 10) | (N = 16) | |
| -s | t(15) = 2.79, p = 0.01 | t(9) = 1.60, p = 0.14 | t(15) = 3.85, p = 0.002 |
| ’s | t(15) = 5.04, p < 0.001 | t(9) = 2.34, p = 0.04 | t(15) = 8.61, p < 0.001 |
| Noun | t(15) = 2.45, p = 0.03 | t(9) = 1.48, p = 0.17 | t(15) = 3.82, p = 0.002 |
| Name | t(15) = 3.59, p = 0.003 | t(9) = 1.77, p = 0.11 | t(15) = 4.25, p = 0.001 |
| Number | t(16) = 2.39, p = 0.03 | t(9) = 3.06, p = 0.01 | t(16) = 4.02, p = 0.001 |
| Colour | t(15) = 3.42, p = 0.004 | t(9) = 1.05, p = 0.32 | t(15) = 4.84, p < 0.001 |
| Size | t(15) = 3.98, p = 0.001 | t(9) = 2.04, p = 0.07 | t(15) = 5.54, p < 0.001 |
| Total | t(15) = 3.78, p = 0.002 | t(9) = 2.26, p = 0.05 | t(15) = 5.97, p < 0.001 |
Significant contrasts are bolded. lvPPA=logopenic variant, nfavPPA=non-fluent/agrammatic variant, svPPA=semantic variant. T-tests for targeted morphemes violated the equality of variances assumption (Levene’s Test for Equality of Variances) in all cases. Thus, reported statistics for morphemes are adjusted based on the (Cochran & Cox, 1957) adjustment of the standard error and the (Satterthwaite, 1946) adjustment of the degrees of freedom.
Characterization of PPA variants and comparison to one another
Comparing the four PPA profiles to one another without controls, groups did not differ in age (F(3, 42) = 0.53, p = 0.66), education (F(3, 33) = 0.64, p = 0.60), or years since diagnosis (F(3, 40) = 0.64, p = 0.59) based on individually conducted univariate analyses.
Performance by individuals with PPA was analyzed using a multivariable analysis of variance with morpheme as the within-subjects factor and PPA profile as the between-subjects factor. There was a significant main effect of the morpheme being targeted, Roy’s largest root = 0.66, F(6, 37) = 4.09, p = 0.003 and the interaction of morpheme and PPA variant was significant, Roy’s largest root = 0.66, F(6, 39) = 4.29, p = 0.002, suggesting different variants produced the morphemes with a significantly different pattern of success (see Figure 2 for the contrast of two relevant predictive modifiers). The between-subjects effect of PPA variant, F(3, 42) = 1.70, p = 0.18 was not significant.
Figure 2: Contrasting profiles of relative success in modifiers by PPA variant.
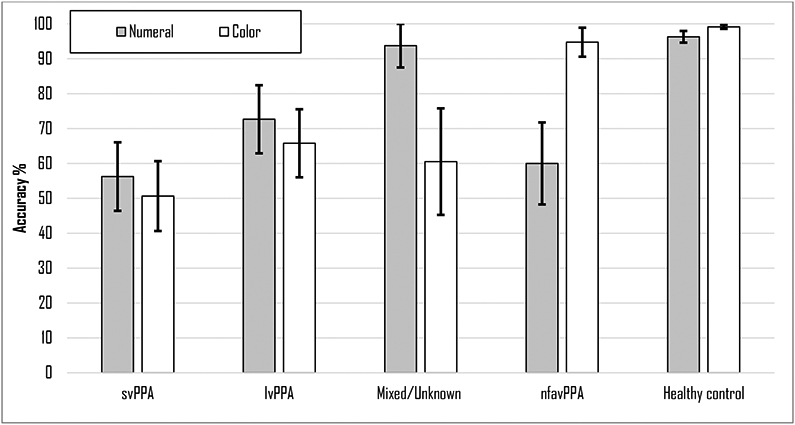
Error bars represent +/− 1 standard error. lvPPA=logopenic variant, nfavPPA=non-fluent/agrammatic variant, svPPA=semantic variant.
To better understand the nature of the interaction between morpheme and PPA variant, PPA variants (svPPA, nfavPPA, and lvPPA) first were considered independently in repeated-measures analyses (morpheme as the within-subjects variable) and then morphemes were considered independently in univariate analyses. Performance across morphemes was significant for all variants (i.e., a main effect of morpheme) when Huynh-Feldt corrections were applied: lvPPA, Mauchly’s W = 0.004, p<0.001; F(2.71) = 6.04, p = 0.002, nfavPPA, Mauchly’s W<0.001, p<0.001; F(2.96) = 5.13, p = 0.006, or svPPA, Mauchly’s W = 0.02, p = 0.001; F(3.97) = 4.94, p = 0.002. When morphemes were considered independently, only colour resulted in a significant difference between variants, F(3, 42) = 3.32, p = 0.03, driven by the relatively successful performance of individuals with nfavPPA (94.74±13.13). Other morphemes were not significant across PPA variants: plural (F(3, 42) = 0.57, p = 0.64), possessive (F(3, 42) = 2.11, p = 0.11), noun (F(3, 42) = 1.05, p = 0.38), name (F(3, 42) = 2.98, p = 0.13), number (F(3, 42) = 1.35, p = 0.27), and size (F(3, 42) = 1.50, p = 0.23).
All morphemes and age then were entered into a multinomial logistic regression to predict PPA variant, using logopenic variant as the reference category. The model was significant, χ2(24) = 53.74, p<0.001; R2 = 0.69 (Cox & Snell), 0.75 (Nagelkerke). Age, χ2(3) = 7.96, p = 0.047, plural, χ2(3) = 8.26, p = 0.041, noun, χ2(3) = 10.43, p = 0.015), and number, χ2(3) = 21.98, p<0.001 were significant predictors. Beta values for each contrast are reported in Table 3.
Table 3:
Multinomial logistic regression parameter estimates
| 95% CI for Odds Ratio | ||||
|---|---|---|---|---|
| B(SE) | Lower | Odds | Upper | |
| lvPPA vs. nfaPPA | ||||
| Intercept | −14.70(11.53) | |||
| Age | 0.13(0.12) | 0.89 | 1.14 | 1.44 |
| -s | 0.08(0.19) | 0.74 | 1.08 | 1.58 |
| ’s | 0.02(0.03) | 0.96 | 1.02 | 1.08 |
| Noun | −0.11(0.19) | 0.61 | 0.90 | 1.31 |
| Name | 0.05(0.12) | 0.83 | 1.05 | 1.34 |
| Number* | −0.14(0.06) | 0.77 | 0.87 | 0.98 |
| Colour | 0.12(0.12) | 0.89 | 1.13 | 1.43 |
| Size | 0.04(0.05) | 0.93 | 1.04 | 1.15 |
| lvPPA vs. svPPA | ||||
| Intercept | 1.47(4.34) | |||
| Age | −0.004(0.07) | 0.87 | 1.00 | 1.13 |
| -s | 0.25(0.13) | 1.00 | 1.28 | 1.67 |
| ’s | −0.02(0.01) | 0.95 | 0.98 | 1.01 |
| Noun | −0.24(0.13) | 0.61 | 0.78 | 1.00 |
| Name | 0.02(0.03) | 0.96 | 1.02 | 1.09 |
| Number | −0.03(0.03) | 0.92 | 0.97 | 1.02 |
| Colour | 0.01(0.03) | 0.95 | 1.01 | 1.07 |
| Size | −0.01(0.03) | 0.94 | 0.99 | 1.05 |
| lvPPA vs. Unclassifiable | ||||
| Intercept | 17.03(13.08) | |||
| Age | −0.38(0.24) | 0.43 | 0.68 | 1.09 |
| -s* | 0.45(0.23) | 1.01 | 1.57 | 2.46 |
| ’s | 0.01(0.05) | 0.91 | 1.01 | 1.12 |
| Noun* | −0.55(0.25) | 0.36 | 0.58 | 0.94 |
| Name | 0.01(0.09) | 0.85 | 1.01 | 1.19 |
| Number | 0.18(0.12) | 0.96 | 1.20 | 1.51 |
| Colour | 0.10(0.09) | 0.92 | 1.10 | 1.32 |
| Size | −0.13(0.11) | 0.71 | 0.88 | 1.09 |
p<0.05. This table contains the estimated multinomial logistic regression coefficients (B) and their standard errors (SE) for the contrasts based on the lvPPA referent group. lvPPA=logopenic variant, nfavPPA=non-fluent/agrammatic variant, svPPA=semantic variant.
Finally, a discriminate function analysis was conducted using the three clear variants of PPA as dependent variables. Two functions were calculated (Table 4). Function 1 had an eigenvalue of 0.80 and described 78.1% of the overall variance. It demonstrated a canonical correlation of 0.67 between the morpheme scores and the PPA variants, Wilks’ λ = 0.45, χ2(14) = 28.50, p = 0.01. Function 2 had an eigenvalue of 0.23 and described 21.9% of the variance, with a canonical correlation of 0.43, Wilks’ λ = 0.82, χ2(6) = 7.31, p = 0.29. Classification of cases was best for agrammatic variant with 70% accuracy (Table 5).
Table 4:
Discriminate function coefficients
| Function 1 | Function 2 | |
|---|---|---|
| -s | −0.60 | −3.41 |
| ’s | 0.47 | 0.36 |
| Noun | 0.36 | 3.86 |
| Name | 0.31 | −1.30 |
| Number | −1.27 | 0.59 |
| Colour | 1.27 | −0.17 |
| Size | −0.05 | 0.52 |
Table 5:
Classification table
| Predicted group membership | |||
|---|---|---|---|
| lvPPA | nfavPPA | svPPA | |
| lvPPA | 10(62.5%) | 1(6.3%) | 5(31.3%) |
| nfavPPA | 3(30.0%) | 7(70.0%) | 0(0%) |
| svPPA | 4(25.0%) | 2(12.5%) | 10(62.5%) |
lvPPA=logopenic variant, nfavPPA=non-fluent/agrammatic variant, svPPA=semantic variant.
Discussion
The purpose of this investigation was to illustrate differences among PPA variants in morphosyntactic production using the new tool for morphosyntactic elicitation, the MorGen. All individuals with PPA demonstrated difficulty on the MorGen, though logopenic and semantic variants were most consistently associated with difficulties. Our findings also support the proposal that individuals with any variant of PPA may have difficulty compared to healthy controls in the generation of bound morphemes. This deficit can be detected using a structured task. The central hypothesis of this investigation was supported: a significant interaction between PPA variant and morpheme was observed. However, interpreting this interaction proved more challenging, likely as a result of high individual variability in performance. Individuals with a given variant differed significantly in their performance of the morphemes overall, though only colour emerged as a morpheme on which variants differed from one another.
Despite the reliance on production of two-word responses, performance on the MorGen appeared most impacted by noun and verb retrieval difficulties characteristic of svPPA and lvPPA, rather than difficulty with attributive modifiers or multi-word constructions characteristic of nfavPPA. Those with svPPA experienced the greatest difficulty, while those with nfavPPA were the most successful. Performance by individuals with lvPPA and those with mixed/unknown variant profiles fell in the middle in all morphemes except number. Curiously, these two profiles performed with remarkable similarity across morphemes. It is possible that this sampling of individuals with nfavPPA were less severely impaired overall. As we only have the MorGen for these individuals, that is a limitation on interpreting this finding. In examining the utility of the MorGen in distinguishing PPA variants, number, plural, and noun were the only morphemes that emerged as significant predictors.
In the analyses completed here, significant findings emerged for number and colour. These were among the only adjectives examined by the MorGen, and adjectives are understudied in aphasia, dementia, and language research. Individuals with mixed/unknown variant were far more successful in including number than other variants. Impairment in number among individuals with nfavPPA is consistent with their syntactic role (i.e., requiring agreement). However, it was anticipated that individuals with nfavPPA may also have had difficulty with possessive and plural bound morpheme performance and, while this was the case relative to controls, this was not the case relative to other variants. Preserved inflectional morphology has been found in some prior studies of nfavPPA (Wilson et al., 2014), but not others (Kavé et al., 2012; Thompson et al., 2012). Anecdotally, although participants completed the training portion of the MorGen with high accuracy, many reverted from the coached form, “one chair,” to the more frequent and perhaps more intuitive response “a chair” when responding to these items, which constituted an “omission” error of the targeted number. Adding another adjective also was noted in labeling a single object in order to achieve a two-word answer (“green tree”), even though both trees in the example were green. In the current scoring of the MorGen, this was marked as an “omission” of the number “one” from the response. This pattern was not limited only to individuals with PPA; it is consistent across what few omissions of number occurred among healthy controls. As those with a mixed or unknown profile are often earlier in their syndrome and eventually do fit more clearly into one of the canonical variants, it is possible that this performance is driven by their relatively preserved frontotemporal and executive function at this stage (i.e., keeping the “rules” of the task in their mind and suppressing the prepotent response; Butts et al., 2015; Macoir et al., 2017). However, differences observed in colour are not so easily explained by external factors, and these findings invite future work that targets adjectives among individuals with PPA in order to better understand the effect of the syndrome on this class of words.
Ongoing and future work will examine performance on this elicitation task among individuals with aphasia following stroke. Use of the MorGen in assessment may help clinicians target production of specific morphemes with which the individual has difficulty. That is, therapy could focus on verbs, possessives, or other impaired morphemes. These findings provide a firm foundation for the clinical utility of the MorGen in understanding morpheme production in primary progressive aphasia.
Acknowledgments
Funding details: This work is supported by National Institutes of Health/National Institute on Deafness and Other Communication Disorders (NIH/NIDCD): R01 DC05375, P50 DC014664, and R01 DC011317.
Footnotes
Declaration of interest
The authors report no conflicts of interest.
Data availability statement:
Data are available on request from the authors.
References
- Ash S, McMillan C, Gunawardena D, Avants B, Morgan B, Khan A, Moore P, Gee J, & Grossman M (2010). Speech errors in progressive non-fluent aphasia. Brain and Language, 113(1), 13–20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ash S, Moore P, Antani S, McCawley G, Work M, & Grossman M (2006). Trying to tell a tale: Discourse impairments in progressive aphasia and frontotemporal dementia. Neurology, 66(9), 1405–1413. [DOI] [PubMed] [Google Scholar]
- Bird H, Ralph MAL, Patterson K, & Hodges JR (2000). The rise and fall of frequency and imageability: Noun and verb production in semantic dementia. Brain and Language, 73(1), 17–49. [DOI] [PubMed] [Google Scholar]
- Butts AM, Machulda MM, Duffy JR, Strand EA, Whitwell JL, & Josephs KA (2015). Neuropsychological profiles differ among the three variants of primary progressive aphasia. Journal of the International Neuropsychological Society, 21(6), 429–435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cochran W, & Cox G (1957). Experimental designs John Wiley and Sons Inc. New York. [Google Scholar]
- Fraser KC, Meltzer JA, Graham NL, Leonard C, Hirst G, Black SE, & Rochon E (2014). Automated classification of primary progressive aphasia subtypes from narrative speech transcripts. Cortex, 55, 43–60. [DOI] [PubMed] [Google Scholar]
- Gorno-Tempini ML, Hillis AE, Weintraub S, Kertesz A, Mendez M, Cappa SF, Ogar JM, Rohrer J, Black S, & Boeve BF (2011). Classification of primary progressive aphasia and its variants. Neurology, 76(11), 1006–1014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kavé G, Heinik J, & Biran I (2012). Preserved morphological processing in semantic dementia. Cognitive Neuropsychology, 29(7-8), 550–568. [DOI] [PubMed] [Google Scholar]
- Kavé G, Leonard C, Cupit J, & Rochon E (2007). Structurally well-formed narrative production in the face of severe conceptual deterioration: A longitudinal case study of a woman with semantic dementia. Journal of Neurolinguistics, 20(2), 161–177. [Google Scholar]
- Mack JE, Chandler SD, Meltzer-Asscher A, Rogalski E, Weintraub S, Mesulam M-M, & Thompson CK (2015). What do pauses in narrative production reveal about the nature of word retrieval deficits in PPA? Neuropsychologia, 77, 211–222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macoir J, Lavoie M, Laforce R Jr, Brambati SM, & Wilson MA (2017). Dysexecutive symptoms in primary progressive aphasia: beyond diagnostic criteria. Journal of Geriatric Psychiatry and Neurology, 30(3), 151–161. [DOI] [PubMed] [Google Scholar]
- Meltzer-Asscher A, & Thompson CK (2014). The forgotten grammatical category: Adjective use in agrammatic aphasia. Journal of Neurolinguistics, 30, 48–68. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Montembeault M, Brambati SM, Gorno-Tempini ML, & Migliaccio R (2018). Clinical, anatomical, and pathological features in the three variants of primary progressive aphasia: a review. Frontiers in Neurology, 9, 692. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patterson K, Ralph MAL, Jefferies E, Woollams A, Jones R, Hodges JR, & Rogers TT (2006). “Presemantic” cognition in semantic dementia: Six deficits in search of an explanation. Journal of Cognitive Neuroscience, 18(2), 169–183. [DOI] [PubMed] [Google Scholar]
- Patterson K, Ralph ML, Hodges JR, & McClelland JL (2001). Deficits in irregular past-tense verb morphology associated with degraded semantic knowledge. Neuropsychologia, 39(7), 709–724. [DOI] [PubMed] [Google Scholar]
- Satterthwaite FE (1946). An approximate distribution of estimates of variance components. Biometrics bulletin, 2(6), 110–114. [PubMed] [Google Scholar]
- Sostarics T, Walenski M, Mesulam M, & Thompson CJ (2020). Adjective use by individuals with agrammatic primary progressive aphasia. . 58th Academy of Aphasia Annual Meeting, Online. [Google Scholar]
- Thompson CK, Cho S, Hsu C-J, Wieneke C, Rademaker A, Weitner BB, Mesulam MM, & Weintraub S (2012). Dissociations between fluency and agrammatism in primary progressive aphasia. Aphasiology, 26(1), 20–43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson CK, & Mack JE (2014). Grammatical impairments in PPA. Aphasiology, 28(8-9), 1018–1037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson CK, Meltzer-Asscher A, Cho S, Lee J, Wieneke C, Weintraub S, & Mesulam M (2013). Syntactic and morphosyntactic processing in stroke-induced and primary progressive aphasia. Behavioural Neurology, 26(1-2), 35–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wicklund MR, Duffy JR, Strand EA, Machulda MM, Whitwell JL, & Josephs KA (2014). Quantitative application of the primary progressive aphasia consensus criteria. Neurology, 82(13), 1119–1126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson SM, Brandt TH, Henry ML, Babiak M, Ogar JM, Salli C, Wilson L, Peralta K, Miller BL, & Gorno-Tempini ML (2014). Inflectional morphology in primary progressive aphasia: An elicited production study. Brain and Language, 136, 58–68. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data are available on request from the authors.