

Abstract

In this work, an artificial neural network was first achieved and optimized for evaluating product distribution and studying the octane number of the sulfuric acid-catalyzed C4 alkylation process in the stirred tank and rotating packed bed. The feedstock compositions, operating conditions, and reactor types were considered as input parameters into the artificial neural network model. Algorithm, transfer function, and framework were investigated to select the optimal artificial neural network model. The optimal artificial neural network model was confirmed as a network topology of 10-20-30-5 with Bayesian Regularization backpropagation and tan-sigmoid transfer function. Research octane number and product distribution were specified as output parameters. The artificial neural network model was examined, and 5.8 × 10–4 training mean square error, 8.66 × 10–3 testing mean square error, and ±22% deviation were obtained. The correlation coefficient was 0.9997, and the standard deviation of error was 0.5592. Parameter analysis of the artificial neural network model was employed to investigate the influence of operating conditions on the research octane number and product distribution. It displays a bright prospect for evaluating complex systems with an artificial neural network model in different reactors.
1. Introduction
As the number of motor vehicles increases, the gasoline quality of vehicles is of great significance to the environment.1 Alkylate oil is considered as a typical clean fuel blending component with a low-sulfur content and high research octane number (RON),2 which is obtained from the alkylation process of isobutane and butene catalyzed by strong acid. Currently, large-scale industrial plants still adopt concentrated sulfuric acid (H2SO4) as the mainstream alkylation catalyst.3 The alkylation process has several rapid reactions with a large number of products, many of them isomers, which make the reaction network and product distribution not easy to deal with,4 and the trimethylpentanes (TMPs, RON = 100–109.6) are main products.5 Besides, there are various byproduct components with different RONs, including C5–7 (light ends, LEs, RON = 24.8–93.0), dimethylhexanes (DMHs, RON = 55.5–76.3), methylheptanes (RON = 21.7–26.8), and C9+ (heavy ends, HEs, RON = 70–91).6 Moreover, RON is regarded as a core index of alkylate oil, and it can be measured by running the fuel in a cooperative fuel research engine with a standard test condition.7 This method is time-consuming, expensive, and labor-intensive. In the lab, product components are usually analyzed by gas chromatography, and RON is calculated by eq 1
| 1 |
where RONi is the RON of each component and yi represents the yield of each component.6
Owing to the low reciprocal solubility of hydrocarbons and H2SO4, the isobutane/butene alkylation system is heterogeneous,8 and reactions occur either in the acid phase or phase interface,9 which lead to the complex product component distribution. Therefore, mass transfer among the different phases plays a vital role in the alkylation process.10 Various reactors have been applied to intensify alkylation processes, such as the stirred tank reactor (STR), STRATCO horizontal stirred reactor,8 eductor reactor,11 liquid–liquid cyclone reactor,12 microstructured reactor,13 rotating packed bed (RPB),14 and so forth. Lots of research studies indicate that the RON and product components are dramatically affected by feedstock compositions, reactor structure, operating conditions, and so on. Thus, some mathematical and correlation models were proposed for the estimation on RON and distribution of products in the specified reactors. Nurmakanova et al. calculated the thermodynamic characteristics and reaction kinetics factors using density functional theory (DFT) to build a mathematical model of isobutane alkylation with olefins catalyzed by H2SO4 in a hollow horizontal cylinder, which was used to predict the product distribution of alkylation caused by the changes in the feedstock compositions.15 Ivashkina et al. also employed the DFT calculation and developed a mathematical model in a STRATCO reactor to define the influence of feedstock compositions on product distribution and RON of alkylate oil.16 Besides, Liu et al. established a correlation model of the ionic liquid catalyzed alkylation process in STR, and the effects of different operating conditions on the product distribution and RON were associated effectively in this model.6 These mathematical models demanded plenty of foundational data based on thermodynamic characteristics, reaction kinetics factors, reaction mechanisms, and reactor characteristics, which were difficult to be acquired entirely for complex alkylation processes. Various reactors have different equipment structures and hydrodynamics parameters. Hence, the existing correlation model relied heavily on each variable used and only worked for the specified reactor, where the RON and product components are simply related to operating conditions. In the view of different alkylated reactors, three features significantly influence the accurate prediction of the alkylation process, which is given as follows: (1) the different feedstock components and operating conditions on alkylation processes;17 (2) the intricate reaction mechanisms for complex product distribution;18 and (3) the diverse mass transfer characteristic of each reactor. Therefore, the RON and product distribution in different research systems is a multidimensional nonlinear issue, and a novel model is worthy of construction for effectively solving multidimensional nonlinear problems.
Deep learning has made a significant progress in addressing the issues that have been resisting the artificial intelligence community for many years,19 and it has been proven to be excellent in discovering a intricate structure of the multidimensional data.20,21 There were kinds of successful applications in deep learning, such as crystal identification and discovery,22 thermodynamic properties prediction for complex materials,23 predictions of chemical reactions,24 process performances,25−31 and so forth. The artificial neural network (ANN), as a typical sort of deep learning, is prevalently and widely employed in the chemistry and chemical industry.32−40 The ANN can learn and adapt in response to the given input–output patterns and adjust itself to minimize the fitting error. Furthermore, the ANN can ascertain the essential of relationships.41 When the ANN was applied, there is no need to consider the inherent mechanism of processes or phenomena. Some highly nonlinear, multidimensional, and complex problems can be solved efficiently by the ANN model. As a part of intelligent engineering, the ANN displays the tremendous potential for different chemical systems via the training of experimental data.
In this work, the ANN model was first adopted and optimized to evaluate the C4 alkylation process catalyzed by H2SO4 in the STR and RPB. Ten-independent input parameters, including feedstock compositions, operating conditions, and reactor types, were involved in the ANN model. Three significant elements of the ANN model, which contained algorithm, transfer function, and framework, were investigated to select the most suitable model. The product distribution and RON of the H2SO4-catalyzed isobutane/butene alkylation process both in the STR and RPB were predicted, and the parameter analysis was conducted.
2. Model Section
As a basic building block, we used a fundamental ANN model, which had the feedback and feedforward capabilities to fitting the multidimensional and nonlinear issue. The ANN framework and result analysis process were stated in the following text.
2.1. Data Preparation
Limited by the publicly reported data, the feasibility of the ANN model as a general model for multiple reactors was demonstrated by taking the STR and RPB data as examples. 36% data points were obtained in the STR, and 64% data points were obtained in the RPB.14,42 The detail data sets are given in Tables S1–S3 of the Supporting Information. The structures of STR and RPB are presented in Figure 1. The operating conditions and reactor types were considered as input parameters of the ANN model, and the detailed data have been listed in Table 1. Particularly, as the input parameters, the mixing state in STR was set as Boolean, who only has the value of true or false. The true represented the mixing with feeding in STR, and the false represented the mixing after feeding in STR.
Figure 1.

Schematic diagram of STR and RPB. (a) Structure diagram of stirring paddle and vessel body in STR; (b) structure diagram of RPB and size of packing.
Table 1. Input Parameters of the ANN Model.
| no. | input parameters | ranges | data type |
|---|---|---|---|
| 1 | reaction time(t) | 2–15 min in STR 2–10 min in RPB | numeric |
| 2 | temperature (T) | 0–8 °C | numeric |
| 3 | volume ratio of acid to hydrocarbon (A/HC) | 0.5–2 | numeric |
| 4 | stirring speed of STR (NSTR) | 0–1400 rpm | numeric |
| 5 | rotational speed of RPB (NRPB) | none or 150–1200 rpm | numeric |
| 6 | pressure (P) | 0.3–1 MPa | numeric |
| 7 | mole percentage of isobutane (n1) | 86.5–96.8% | numeric |
| 8 | mole percentage of 2-butene (n2) | 0–13.5% | numeric |
| 9 | mole percentage of isobutene (n3) | 0–3.2% | numeric |
| 10 | mixing with/after feeding in STR (mSTR) | mixing with feeding or mixing after feeding in STRa | Boolean |
In the STR, mixing with feeding or mixing after feeding would affect the product distribution.42
RON was determined by the product distribution of alkylate oil. In this work, the yield of C5–7 (yC5–7), C8 (yC8), C9+ (yC9+), TMPs (yTMPs), and DMHs (yDMHs), the yield ratio of TMPs to DMHs (TMPs/DMHs), and RON were considered as the output parameters. The relationship of the product distribution is shown in eq 2. TMPs and DMHs were the two components with the highest and lowest RON in octane, respectively, and their ratio was considered as eq 3.
| 2 |
| 3 |
Equations 2 and 3 reveal the two simple linear programming problems in this multidimensional issue. Hence, yC5–7, yC9+, yTMPs, yDMHs, and RON were training in this model. TMPs/DMHs and yC8 were marked as checking parameters through linear programming. At first, the absolute value of the maximum fitting error was required below 100% for the preliminary selection. When the most maximum error absolute value of some ANN models below 50% frequently, the check standard limited as 50%. In other words, if the absolute value of maximum error over 50%, the ANN results would be given up and retrained again.
In the training step, the data were divided into the training (70%), testing (15%), and validation (15%) groups, randomly. All data were normalized in −1 to 1 at first avoiding a large gap among the original data. The mapping relations of data normalization were retained to reverse the fitting results.
2.2. ANN Framework
The ANN model was trained by the most input data with the corresponding output data (input/output pairs), which obtained from literatures.14,42 Each set of inputs produced a specific set of target outputs.43
Figure 2 shows the calculation flow chart of the ANN model. It is well known that main elements of the ANN, such as transfer function, algorithm, and framework,43 which needs to be considered carefully during the process of designing and training. The term “framework” refers to the layer number of the ANN and the neuron number of each layer. In general, the layers are consisted of an input layer, one or more hidden layers, and an output layer. The number of neurons in the input layer and the output layer is determined by the numbers of input and output parameters, respectively. In order to explore the optimal framework, the number of neurons in each hidden layer and the number of the hidden layers need to be determined. The nodes are similar to the neurons of the nervous system of humans communicating with the brain. The nodes of the input layer triggered signals to the nodes of the hidden layer, and the hidden layer may be single or multilayered. Afterward, these signals from the hidden nodes propagate to the output layer and generate the output signal.44 The training process consists of adjusting the weight associated with each connection between neurons until the predicted outputs for each set of input–output data were as close as possible to the experimental data.
Figure 2.

Calculation flow chart of the ANN model. (k1i and b1i are the weights and biases of the first hidden layer; kju and bju are the weights and biases of each next hidden layer; kov and bov are the weights and biases of the output layer).
The most widely widespread use of the network type is a multilayered feedforward network trained with the back-propagation learning algorithm. The back-propagation learning algorithm is based on the selection of a suitable error function, whose values are determined by the experimental and predicted outputs of the network.
2.3. Statistical Analysis
The mean square error (MSE) was employed as a standard index to investigate the model accuracy, which can be computed via eq 4.
| 4 |
where si represents the predicted value, ei means the experimental value (including yC5–7, yC8, yC9+, yTMPs, yDMHs, TMPs/DMHs, and RON), and n is the number of the aggregate data.
The definition of the correlation coefficient (R2) was on behalf of the percentage of the predicted value matching the experimental value. R2 is determined as follows
| 5 |
where e̅ shows the average value of the experimental results. R2 is always between 0 and 1. In general, the higher the R2, the better the model fits the data.
The standard deviation of error (STDerror) can be regarded as an essential indicator of the estimation and was mostly used by researchers, which refers to a group of statistics that provide information about the dispersion of the predicted values.29 STDerror was calculated as given below
| 6 |
where the error indicates the residual of
the predicted and experimental value and 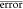 means the average of errors.
means the average of errors.
3. Results and Discussion
We used a workstation (Dawning Information Industry Co., LTD.) with double Intel Xeon Silver 4116 CPUs (2.1 GHz and 12 cores 24 threads), 128 GB DDR4 2666 MHz error correcting code memory, and a NVIDIA Quadro P2000 GPU. The data normalization, ANN model realization, and result check were performed in MATLAB.
3.1. Transfer Function Choosing
The transfer function was the ligament between the upper and lower neural network layers. The tan-sigmoid transfer function, log-sigmoid transfer function, and purelin function were considered in this model, and the functions were as follows
| 7 |
| 8 |
| 9 |
where xi was input data, f(xi) stood for on behalf of output data.
From the input layer to the final hidden layer, the data were learned and feedbacked to modify the weights and biases. Nonlinear functions were more suitable in these parts. Because of the input-data normalization in −1 to 1, only the tan-sigmoid can hold the data integrity. Herein, the tan-sigmoid was chosen as the transfer function from the input layer to the hidden layers. The output layer was just a data export without data learning ability, which means that the purelin function was an appropriate choice between the final hidden layer and the output layer.
3.2. Algorithm Selection
As the core of the model, the algorithm should be considered cautiously. There were 13 algorithms listed in Table 2. Besides, the number of neurons in the first hidden layer was dependent on both the number of inputs and inner relationship of inputs. Each neuron covered some characteristic of all the inputs. When several input variables had the apparent linear fitting relationship, the number of neurons can be reduced. In the alkylation process, the effects of each operating condition are nonlinear and irreplaceable. Hence, the inputs constituted a multidimensional and multicharacteristic matrix and needed at least 10 neurons to achieve the ANN model. In order to achieve the quick calculation and comparison,43 an ANN model with 10 nodes in the single hidden layer was applied to test 13 algorithms.
Table 2. Thirteen Tested Algorithms in the ANN Model.
| no. | algorithm name | abbreviation |
|---|---|---|
| 1 | BFGS quasi-Newton backpropagation | BFG |
| 2 | conjugate gradient backpropagation with Powell–Beale restarts | CGB |
| 3 | conjugate gradient backpropagation with Fletcher–Reeves updates | CGF |
| 4 | conjugate gradient backpropagation with Polak–Ribiére updates | CGP |
| 5 | gradient descent backpropagation | GD |
| 6 | gradient descent with adaptive learning rate backpropagation | GDA |
| 7 | gradient descent with momentum backpropagation | GDM |
| 8 | gradient descent with momentum and adaptive learning rate backpropagation | GDX |
| 9 | Levenberg–Marquardt backpropagation | LM |
| 10 | one-step secant backpropagation | OSS |
| 11 | resilient backpropagation | RP |
| 12 | scaled conjugate gradient backpropagation | SCG |
| 13 | bayesian regularization backpropagation | BR |
Figure 3 displays the MSEs of different algorithms in the ANN model with the tan-sigmoid as transfer function, and the separated figures are listed in Figure S1 in the Supporting Information. From the comparison of algorithms, the MSE curves of BFG, CGF, CGB, SCG, and OSS had some similar features, where the training MSE curves were divergent and the testing MSE curves were prone to fall in local nadir. Local nadir affected the convergence significantly, and it was difficult to seek out the authentic convergence. The GD and its derivative algorithms (GDX, GDM, and GDA) had the problem of slow convergence. Besides, the MSE curves of GDA were oscillating. The CGP and RP were also not recommended because they both had the issue that the testing MSE curves had local valley and the training MSE curves did not converge totally. Based on the LM model, training MSE had a sharp gradient decline, which had the apparent local valley point and influenced the training MSE curve to converge. However, testing the MSE curve was divergent directly. The convergence speed of the BR algorithm was fast, and the BR model was not dropped into the local nadir. Hence, BR was the optimal choice, and it was adopted in the following models. The training MSE was 1.624 × 10–3 and the testing MSE was 5.245 × 10–2, and all the MSEs of each algorithm are presented in Table 3.
Figure 3.

MSEs of different algorithms in the ANN model.
Table 3. Comparison of Different Algorithms in ANN Models.
| no. | algorithms | hidden nodes | max. error % | training MSE × 102 | testing MSE × 102 |
|---|---|---|---|---|---|
| 1 | BFG | 10 | 55% | 0.164 | 1.651 |
| 2 | CGB | 10 | 50% | 0.156 | 3.036 |
| 3 | CGF | 10 | 67% | 0.078 | 12.848 |
| 4 | CGP | 10 | 67% | 0.207 | 2.200 |
| 5 | GD | 10 | 86% | 0.891 | 3.757 |
| 6 | GDA | 10 | 86% | 0.541 | 2.107 |
| 7 | GDM | 10 | 95% | 1.484 | 2.355 |
| 8 | GDX | 10 | 75% | 4.641 | 3.462 |
| 9 | LM | 10 | 61% | 0.082 | 263.479 |
| 10 | OSS | 10 | 55% | 0.277 | 2.738 |
| 11 | RP | 10 | 61% | 0.216 | 3.783 |
| 12 | SCP | 10 | 68% | 0.178 | 19.883 |
| 13 | BR | 10 | 46% | 0.162 | 5.245 |
3.3. Network Optimization
Because the algorithm was determined, the number of layer nodes and number of hidden layers were further optimized. ANN models with different numbers of nodes and different hidden layers were investigated in Table 4. When node numbers in the first hidden layer increased to 20, the max error was decreased from 46 to 40% of 10 nodes. The training MSE of 20 nodes was close to the model of 10 nodes, but the testing MSE decreased to 3.159 × 10–2. Therefore, 20 nodes in the first hidden layer were the optimal choice. Although the number of nodes in the first hidden layer increased, the model still cannot fit well with the data due to the fitting error and the MSEs were large. Afterward, double hidden layers were explored with 20 nodes in the first layer. As a consequence, the model with 30 nodes in the second layer has the lowest MSE and deviation. The max error declined to 22%. The training MSE was only 5.8 × 10–4, and the testing MSE dropped to 8.66 × 10–3. When nodes in the second hidden layer were further added, the overfitting phenomenon would occur in the model. The overfitting would appear excellent fitting of training data, but it would lose the equal fitting effect of the testing data. Therefore, the optimal ANN model consists of 20–30 hidden topological layers, tan-sigmoid transfer function from the input layer to the second hidden layer, and purelin transfer function in the output layer.
Table 4. Comparison of Different Structures in ANN Models.
| no. | algorithms | hidden nodes | max. error % | training MSE × 102 | testing MSE × 102 |
|---|---|---|---|---|---|
| 1 | BR | 10 | 46% | 0.162 | 5.245 |
| 2 | BR | 20 | 40% | 0.170 | 3.159 |
| 3 | BR | 20, 10a | 44% | 0.075 | 1.221 |
| 4 | BR | 20, 20a | 25% | 0.074 | 1.200 |
| 5 | BR | 20, 30a | 22% | 0.058 | 0.866 |
| 6 | BR | 20, 40a | 22% | 0.071 | 0.950 |
| 7 | BR | 20, 50a | 31% | 0.063 | 2.070 |
It is a double-hidden layer network.
Figures 4 and 5 exhibit convergence and deviations of the double hidden layer model with 20 and 30 nodes. As displayed in Figure 4, the MSE converged within 2245 epochs. The training MSE and testing MSE were 5.8 × 10–3 and 8.66 × 10–3, respectively. The linear correlation equation between experimental results and ANN predicted values was y = 0.9992x (fairly close to y = x), and R2 was 0.9997. STDerror of this model was 0.5592. Consequently, the model output was fitting to the experimental data dramatically. In Figure 5a, the deviation among the whole experimental data and ANN predicted data was within ±22%. Figure 5b–h representsdeviations of yC5–7, yC8, yC9+, RON, yTMPs, yDMHs, and TMPs/DMHs. Especially, the deviation of RON was within ±2%, as presented in Figure 5e. Herein, an optimal ANN model was completed as the network topology of 10-20-30-5 with Bayesian Regularization backpropagation and tan-sigmoid transfer function.
Figure 4.

Convergence curves of training MSE and testing MSE with epochs in 20 and 30 nodes in double hidden layers.
Figure 5.

Deviations of 20 and 30 nodes in two hidden layers. (a) Whole deviation between the experimental results and ANN predicted values; (b) deviations of yC5–7; (c) deviations of yC8; (d) deviations of yC9+; (e) deviations of RON; (f) deviations of yTMPs; (g) deviations of yDMHs; and (h) deviations of TMPs/DMHs.
Furthermore, the influence of input parameters on output parameters was obtained by parameter analysis from the optimal ANN model. Parameter analysis was obtained by multiplying weights between each layer, as shown in eq 10,28 and it is shown in Figure 6.
| 10 |
Figure 6.

Parameter analysis among inputs and outputs.
The numerical value of parameter analysis indicated whether the input parameter has a positive or passive effect on the output parameter including the influence degree. According to weights comparison of parameter analysis in RON, A/HC > t > NRPB > n1 ≈ P ≈ NSTR (positive effects), and n3 > T > n2 (negative effects). By contrast, A/HC and t has dramatic effects on the RON. In the view of current reports and industrial processes, A/HC was usually around 1.8,45−47 However, the mass transfer and micromixing of the reactor would affect t; thus, 5–6 min was the optimal choice both in RPB and STR.14,42 Then, raising the ratio of isobutane to butene (n1/n2 or n1/n3), increasing NRPB, and decreasing T were important for producing the better alkylate oil. When the weight of n3 is larger than that of n2, 2-butene was beneficial for obtaining higher quality alkylate oil rather than isobutene. In Figure 5, mSTR was beneficial for improving the high-RON components, indicating that the hydrocarbon should be fed along with liquid acid during the process. Last but not the least, P and NSTR, which were able to control the liquid phase of hydrocarbon and the liquid–liquid mixing, respectively, were considered as experimental conditions. NRPB > NSTR meant that the RPB was more suitable than the STR to intensify the liquid–liquid two-phase mass transfer and micromixing for the H2SO4 alkylation process.14 The ANN model was able to learn the experimental data of various reactors independently and obtain a multidimensional nonlinear model. By the method of parameter analysis, the effects of different conditions on product quality were obtained and assessed. RPB and STR were also compared and evaluated in the ANN model. As a consequence, the ANN model has excellent prospects in the field of multidimensional data simulation.
4. Conclusions
ANN has been adopted successfully to develop an optimal model for the prediction and estimation of the product distribution and RON synchronously in the RPB and STR. Various influential variables (including feedstock compositions, operating conditions, and reactor types) were considered as independent factors. Three significant factors, transfer function, training algorithm, and framework, were investigated to obtain the optimal ANN model: a network topology of 10-20-30-5 with the BR main algorithm and tan-sigmoid transfer function. By the method of the ANN model, the obtained results were more realistic, and it has the ability to tolerate greater noise in the data set, where a similar level of correlation was obtained between the experimental and predicted product qualities for the training set, the testing set, and the validation set. The ANN model was examined to obtain the 0.58 × 10–3 training MSE, 0.866 × 10–2 testing MSE, and ±22% deviation for the global data set, occupying R2 = 0.9997 and STDerror = 0.5592. Particularly, the ANN model shows a much higher correlation with a deviation of ±2% between the experimental and predicted values for predicting RON. Parameter analysis of the ANN model was applied to obtain the influence of operating conditions on products in STR and RPB, displaying that the rotational speed deeply affected the alkylation process. The unified ANN model has an obvious superiority in quickly predicting the product distribution and RON for the alkylation process, expressing a promising application prospect in solving multidimensional nonlinear complex systems.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (no. U1662123) and Key Technologies R&D Program (no. 2014BAE13B01).
Glossary
Nomenclatures2-col
- RON
research octane number, dimensionless
- MSE
mean square error, dimensionless
- R2
correlation coefficient, dimensionless
- STDerror
standard deviation of error, dimensionless
- RONi
RON of each component, dimensionless
- yi
yield of each component, %
- t
reaction time, min
- T
reaction temperature, °C
- A/HC
volume ratio of acid to hydrocarbon, dimensionless
- NSTR
stirring speed of STR, rpm
- NRPB
rotational speed of RPB, rpm
- P
system pressure, MPa
- n1
mole percentage of isobutane in the feed, %
- n2
mole percentage of 2-butene in the feed, %
- n3
mole percentage of isobutene in the feed, %
- mSTR
mixing with/after feeding especially in STR, Boolean
- yC5–7
yield of C5–7, %
- yC8
yield of C8, %
- yC9+
yield of C9+, %
- yTMPs
yield of TMPs, %
- yDMHs
yield of DMHs, %
- TMPs/DMHs
ratio of TMPs to DMHs, dimensionless
- k1i
weights of first hidden layer, dimensionless
- kju
weights of each next hidden layer, dimensionless
- kov
weights of output layer, dimensionless
- b1i
biases of first hidden layer, dimensionless
- bju
biases of each next hidden layer, dimensionless
- bov
biases of output layer, dimensionless
- si
predicted value (including yC5–7, yC8, yC9+, yTMPs, yDMHs, TMPs/DMHs, and RON)
- ei
experimental value (including yC5–7, yC8, yC9+, yTMPs, yDMHs, TMPs/DMHs, and RON)
- n
number of the aggregate data
- e̅
average value of the experimental results
- error
residual of predicted and experimental value

average of errors
- xi
input data
- f(xi)
output data
Glossary
Abbreviations
- ANN
artificial neural network
- H2SO4
concentrated sulfuric acid
- TMPs
trimethylpentanes
- LEs
light ends, including C5–7
- DMHs
dimethylhexanes
- HEs
heavy ends, including C9+
- STR
stirred tank reactor
- RPB
rotating packed bed
- DFT
density functional theory
- BFG
BFGS quasi-Newton backpropagation
- CGB
conjugate gradient backpropagation with Powell–Beale restarts
- CGF
conjugate gradient backpropagation with Fletcher–Reeves updates
- CGP
conjugate gradient backpropagation with Polak–Ribiére updates
- GD
gradient descent backpropagation
- GDA
gradient descent with adaptive learning rate backpropagation
- GDM
gradient descent with momentum backpropagation
- GDX
gradient descent with momentum and adaptive learning rate backpropagation
- LM
Levenberg–Marquardt backpropagation
- OSS
one-step secant backpropagation
- RP
resilient backpropagation
- SCG
scaled conjugate gradient backpropagation
- BR
Bayesian regularization backpropagation
Supporting Information Available
The Supporting Information is available free of charge at https://pubs.acs.org/doi/10.1021/acsomega.1c04757.
(PDF)
The authors declare no competing financial interest.
Supplementary Material
References
- Al Ibrahim E.; Farooq A. Octane prediction from infrared spectroscopic data. Energy Fuels 2019, 34, 817–826. 10.1021/acs.energyfuels.9b02816. [DOI] [Google Scholar]
- Egloff G.; Hulla G. The alkylation of alkanes. Chem. Rev. 1945, 37, 323–399. 10.1021/cr60118a001. [DOI] [PubMed] [Google Scholar]
- Mrstik A. V.; Smith K. A.; Pinkerton R. D.. Commercial alkylation of isobutane. Progress in Petroleum Technology; American Chemical Society: Washington DC, 1951; pp 97–108. [Google Scholar]
- Albright L. F.; Wood K. V. Alkylation of isobutane with C3–C4 olefins: identification and chemistry of heavy-end production. Ind. Eng. Chem. Res. 1997, 36, 2110–2120. 10.1021/ie960265f. [DOI] [Google Scholar]
- Sun W.; Shi Y.; Chen J.; Xi Z.; Zhao L. Alkylation kinetics of isobutane by c4 olefins using sulfuric acid as catalyst. Ind. Eng. Chem. Res. 2013, 52, 15262–15269. 10.1021/ie400415p. [DOI] [Google Scholar]
- Liu Z.; Meng X.; Zhang R.; Xu C.; Dong H.; Hu Y. Reaction performance of isobutane alkylation catalyzed by a composite ionic liquid at a short contact time. AIChE J. 2014, 60, 2244–2253. 10.1002/aic.14394. [DOI] [Google Scholar]
- Int., A. Standard Test Method for Research Octane Number of Spark-ignition Engine Fuel; ASTM International: West Conshohocken, PA, 2019. ASTM D2699-19. [Google Scholar]
- Busca G. Acid catalysts in industrial hydrocarbon chemistry. Chem. Rev. 2007, 107, 5366–5410. 10.1021/cr068042e. [DOI] [PubMed] [Google Scholar]
- Corma A.; Martínez A. Chemistry, catalysts, and processes for isoparaffin–olefin alkylation: actual situation and future trends. Catal. Rev. 1993, 35, 483–570. 10.1080/01614949308013916. [DOI] [Google Scholar]
- Li K. W.; Eckert R. E.; Albright L. F. Alkylation of isobutane with light olefins using sulfuric acid. operating variables affecting physical phenomena Only. Ind. Eng. Chem. Process Des. Dev. 1970, 9, 434–440. 10.1021/i260035a011. [DOI] [Google Scholar]
- Bakshi A. S.Sulfuric Acid Alkylation Process. U.S. Patent 7,652,187 B2, 2010.
- Zhang M.; Zhu L.; Wang Z.; Liu Z.; Liu Z.; Xu C.; Jin Y. Flow field in a liquid–liquid cyclone reactor for isobutane alkylation catalyzed by ionic liquid. Chem. Eng. Res. Des. 2017, 125, 282–290. 10.1016/j.cherd.2017.07.001. [DOI] [Google Scholar]
- Li L.; Zhang J.; Du C.; Luo G. Process intensification of sulfuric acid alkylation using a microstructured chemical system. Ind. Eng. Chem. Res. 2018, 57, 3523–3529. 10.1021/acs.iecr.8b00040. [DOI] [Google Scholar]
- Tian Y.; Li Z.; Mei S.; Sheng M.; Chen J.-f.; Chu G.; Zhang L.; Fisher A. C.; Zou H. Alkylation of isobutane and 2-butene by concentrated sulfuric acid in a rotating packed bed reactor. Ind. Eng. Chem. Res. 2018, 57, 13362–13371. 10.1021/acs.iecr.8b02570. [DOI] [Google Scholar]
- Nurmakanova A. E.; Ivashkina E. N.; Ivanchina E. D.; Dolganov I. A.; Boychenko S. S. Predicting alkylate yield and its hydrocarbon composition for sulfuric acid catalyzed isobutane alkylation with olefins using the method of mathematical modeling. Procedia Chem. 2015, 15, 54–64. 10.1016/j.proche.2015.10.009. [DOI] [Google Scholar]
- Ivashkina E. N.; Ivanchina E. D.; Nurmakanova A. E.; Boychenko S. S.; Ushakov A. S.; Dolganova I. O. Mathematical modeling sulfuric acid catalyzed alkylation of isobutane with olefins. Procedia Eng. 2016, 152, 81–86. 10.1016/j.proeng.2016.07.632. [DOI] [Google Scholar]
- Albright L. F. Alkylation of isobutane with C3–C5 olefins: feedstock consumption, acid usage, and alkylate quality for different processes. Ind. Eng. Chem. Res. 2002, 41, 5627–5631. 10.1021/ie020323z. [DOI] [Google Scholar]
- Lee L.-m.; Harriott P. The kinetics of isobutane alkylation in sulfuric acid. Ind. Eng. Chem. Process Des. Dev. 2002, 16, 282–287. 10.1021/i260063a006. [DOI] [Google Scholar]
- LeCun Y.; Bengio Y.; Hinton G. Deep learning. Nature 2015, 521, 436–444. 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- Zhao W.; Du S. Spectral-spatial feature extraction for hyperspectral image classification: a dimension reduction and deep learning approach. IEEE Trans. Geosci. Rem. Sens. 2016, 54, 4544–4554. 10.1109/tgrs.2016.2543748. [DOI] [Google Scholar]
- Xu L.; Jiang C.; Ren Y.; Chen H.-H. Microblog dimensionality reduction-a deep learning approach. IEEE Trans. Knowl. Data Eng. 2016, 28, 1779–1789. 10.1109/tkde.2016.2540639. [DOI] [Google Scholar]
- Spellings M.; Glotzer S. C. Machine learning for crystal identification and discovery. AIChE J. 2018, 64, 2198–2206. 10.1002/aic.16157. [DOI] [Google Scholar]
- Chen H.-A.; Pao C.-W. Fast and accurate artificial neural network potential model for MAPbI3 perovskite materials. ACS Omega 2019, 4, 10950–10959. 10.1021/acsomega.9b00378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ahneman D. T.; Estrada J. G.; Lin S.; Dreher S. D.; Doyle A. G. Predicting reaction performance in C-N cross-coupling using machine learning. Science 2018, 360, 186–190. 10.1126/science.aar5169. [DOI] [PubMed] [Google Scholar]
- Chen J.-F.; Chen G.-Z.; Wang J.-X.; Shao L.; Li P.-F. High-throughput microporous tube-in-tube microreactor as novel gas-liquid contactor: Mass Transfer Study. AIChE J. 2011, 57, 239–249. 10.1002/aic.12260. [DOI] [Google Scholar]
- Wu S.; Zhang L.; Sun B.; Zou H.; Zeng X.; Luo Y.; Li Q.; Chen J. Mass-transfer performance for CO2 absorption by 2-(2-aminoethylamino)ethanol solution in a rotating packed bed. Energy Fuels 2017, 31, 14053–14059. 10.1021/acs.energyfuels.7b03002. [DOI] [Google Scholar]
- Sheng M.; Xie C.; Zeng X.; Sun B.; Zhang L.; Chu G.; Luo Y.; Chen J.-F.; Zou H. Intensification of CO2 capture using aqueous diethylenetriamine (DETA) solution from simulated flue gas in a rotating packed bed. Fuel 2018, 234, 1518–1527. 10.1016/j.fuel.2018.07.136. [DOI] [Google Scholar]
- Zhan Y.-Y.; Wan Y.-F.; Su M.-J.; Luo Y.; Chu G.-W.; Zhang L.-L.; Chen J.-F. Spent caustic regeneration in a rotating packed bed: reaction and separation process intensification. Ind. Eng. Chem. Res. 2019, 58, 14588–14594. 10.1021/acs.iecr.9b02664. [DOI] [Google Scholar]
- Zarei F.; Rahimi M. R.; Razavi R.; Baghban A. Insight into the experimental and modeling study of process intensification for post-combustion CO2 capture by rotating packed bed. J. Clean. Prod. 2019, 211, 953–961. 10.1016/j.jclepro.2018.11.239. [DOI] [Google Scholar]
- Li W.; Wu X.; Jiao W.; Qi G.; Liu Y. Modelling of dust removal in rotating packed bed using artificial neural networks (ANN). Appl. Therm. Eng. 2017, 112, 208–213. 10.1016/j.applthermaleng.2016.09.159. [DOI] [Google Scholar]
- Mei H.; Wang Z.; Huang B. Molecular-based bayesian regression model of petroleum fractions. Ind. Eng. Chem. Res. 2017, 56, 14865–14872. 10.1021/acs.iecr.7b02905. [DOI] [Google Scholar]
- Psichogios D. C.; Ungar L. H. A hybrid neural network-first principles approach to process modeling. AIChE J. 1992, 38, 1499–1511. 10.1002/aic.690381003. [DOI] [Google Scholar]
- Venkatasubramanian V.; Chan K. A neural network methodology for process fault diagnosis. AIChE J. 1989, 35, 1993–2002. 10.1002/aic.690351210. [DOI] [Google Scholar]
- Cai G.; Liu Z.; Zhang L.; Zhao S.; Xu C. Quantitative structure–property relationship model for hydrocarbon liquid viscosity prediction. Energy Fuels 2018, 32, 3290–3298. 10.1021/acs.energyfuels.7b04075. [DOI] [Google Scholar]
- Schäfer P.; Caspari A.; Kleinhans K.; Mhamdi A.; Mitsos A. Reduced dynamic modeling approach for rectification columns based on compartmentalization and artificial neural networks. AIChE J. 2019, 65, e16568 10.1002/aic.16568. [DOI] [Google Scholar]
- Izadi M.; Rahimi M.; Beigzadeh R. Evaluation of micromixing in helically coiled microreactors using artificial intelligence approaches. Chem. Eng. J. 2019, 356, 570–579. 10.1016/j.cej.2018.09.052. [DOI] [Google Scholar]
- Shi S.; Xu G. Novel performance prediction model of a biofilm system treating domestic wastewater based on stacked denoising auto-encoders deep learning network. Chem. Eng. J. 2018, 347, 280–290. 10.1016/j.cej.2018.04.087. [DOI] [Google Scholar]
- Venkatasubramanian V. The promise of artificial intelligence in chemical engineering: Is it here, finally?. AIChE J. 2019, 65, 466–478. 10.1002/aic.16489. [DOI] [Google Scholar]
- Jadhav A. J.; Srivastava V. C. Multicomponent adsorption isotherm modeling using thermodynamically inconsistent and consistent models. AIChE J. 2019, 65, e16727 10.1002/aic.16727. [DOI] [Google Scholar]
- Yu Y.; Liu S.; Liu Y.; Bao Y.; Zhang L.; Dong Y. Data-driven proxy model for forecasting of cumulative oil production during the steam-assisted gravity drainage process. ACS Omega 2021, 6, 11497–11509. 10.1021/acsomega.1c00617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quantrille T. E.; liu Y. A.. Introduction to artificial neural networks. Artificial Intelligence in Chemical Engineering; Quantrille T. E., liu Y. A., Eds.; Academic Press: New York, USA, 1991; pp 441–487. [Google Scholar]
- Li Z. X.Study on the process of C4 alkylation catalyzed by concentrated sulfuric acid in a novel rotating packed bed, M.S. Thesis, Beijing University of Chemical Technology, Beijing, China, 2017. [Google Scholar]
- Mirzazadeh T.; Mohammadi F.; Soltanieh M.; Joudaki E. Optimization of caustic current efficiency in a zero-gap advanced chlor-alkali cell with application of genetic algorithm assisted by artificial neural networks. Chem. Eng. J. 2008, 140, 157–164. 10.1016/j.cej.2007.09.028. [DOI] [Google Scholar]
- Chaudhuri U. R.; Ghosh D. Modeling & simulation of a crude petroleum desalter using artificial neural network. Petrol. Sci. Technol. 2009, 27, 1233–1250. 10.1080/10916460802108579. [DOI] [Google Scholar]
- Li L.; Zhang J.; Wang K.; Luo G. Caprolactam as a new additive to enhance alkylation of isobutane and butene in H2SO4. Ind. Eng. Chem. Res. 2016, 55, 12818–12824. 10.1021/acs.iecr.6b04557. [DOI] [Google Scholar]
- Albright L. F. Alkylation of isobutane with C3–C5 olefins to produce high-quality gasolines: physicochemical sequence of events. Ind. Eng. Chem. Res. 2003, 42, 4283–4289. 10.1021/ie0303294. [DOI] [Google Scholar]
- Shlegeris R. J.; Albright L. F. Alkylation of isobutane with various olefins in the presence of sulfuric acid. Ind. Eng. Chem. Process Des. Dev. 1969, 8, 92–98. 10.1021/i260029a016. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.