

Abstract
We present NeuralIL, a model for the potential energy of an ionic liquid that accurately reproduces first-principles results with orders-of-magnitude savings in computational cost. Built on the basis of a multilayer perceptron and spherical Bessel descriptors of the atomic environments, NeuralIL is implemented in such a way as to be fully automatically differentiable. It can thus be trained on ab initio forces instead of just energies, to make the most out of the available data, and can efficiently predict arbitrary derivatives of the potential energy. Using ethylammonium nitrate as the test system, we obtain out-of-sample accuracies better than 2 meV atom–1 (<0.05 kcal mol–1) in the energies and 70 meV Å–1 in the forces. We show that encoding the element-specific density in the spherical Bessel descriptors is key to achieving this. Harnessing the information provided by the forces drastically reduces the amount of atomic configurations required to train a neural network force field based on atom-centered descriptors. We choose the Swish-1 activation function and discuss the role of this choice in keeping the neural network differentiable. Furthermore, the possibility of training on small data sets allows for an ensemble-learning approach to the detection of extrapolation. Finally, we find that a separate treatment of long-range interactions is not required to achieve a high-quality representation of the potential energy surface of these dense ionic systems.
Introduction
Room-temperature ionic liquids1 (ILs) are ionized substances that exist in the liquid state at temperatures below 100 °C. Two broad classes can be defined: protic ILs, which are formed by a proton transfer from an acid to a base, and aprotic ILs based on an organic molecular cation and an anion that can range from a single atom to another complex structure. ILs are very interesting from a fundamental point of view because of the many peculiar features of their dynamics, arising from the competition of electrostatic, steric, and dispersion interactions among ions, but their prominence in the scientific literature is undoubtedly mostly due to their potential for applications in industry.2 ILs as a class have some desirable properties in this regard, the best known one being the negligible vapor pressure of aprotic ILs, which makes it possible to use them as “green solvents”3 free from leaks to the environment. However, their greatest promise lies in their diversity: a million binary and a quintillion ternary ILs are theoretically possible through the choice of anions and cations, compared to the ∼600 organic solvents in current use.4 Amid that vast landscape, compounds have been found that fulfill specific requirements such as stability (e.g., against thermal decomposition5 or in mixtures with water6), biocompatibility,7 or wide electrochemical windows.8 It is therefore plausible that tailored ILs could be found for many applications, leading to the inclusion of ILs under the label of “designer solvents” as well.
Unfortunately, that aprioristic enthusiasm has to coexist with the fact that brute-force exploration of the possible ILs is inconceivable. In this context, computer modeling and simulation are invaluable complements to experiment, providing insight into the connections between structure and functionality at the atomic level and suggesting new substances to explore. However, to properly reproduce the structural and dynamical correlations in a liquid, a significant quantity of substance must be included in a simulation, and the atomic trajectories must be traced for times of the order of nanoseconds or longer. Consequently, ab initio molecular dynamics (MD) studies are usually limited to those phenomena that can be understood in terms of the fine details of the behavior of a few ionic pairs.9,10
Classical MD simulations are a better fit for the scales of time and quantity of substance required and have been used extensively to study pure ILs and their mixtures.11−14 However, abandoning ab initio methods incurs a high cost in terms of accuracy and transferability. The centerpiece of an MD simulation of an IL is a molecular-mechanics force field (FF), of which OPLS-AA is a very representative example.15,16 While OPLS-AA contains a large number of parameters, they are easily interpretable and can be systematically fitted to modest amounts of ab initio data, eliminating the need for a prohibitively costly global fit. However, the predictions of molecular-mechanics FFs have a qualitative rather than quantitative value. An improvement over plain molecular-mechanics FFs comes from polarizable FFs,17 which try to add some flexibility by allowing an induced dipole moment to appear at each atom in reaction to the local electric field. The effect of polarizability has been compared to that of a solvent,17 making the predicted structure and dynamics less similar to those of an ionic solid. As an example, the predicted structural properties of 1-ethyl-3-methylimidazolium bis(trifluoromethylsulfonyl)-imide doped with a lithium salt barely change when switching to a polarizable FF, but the diffusion coefficients can change by up to an order of magnitude.18 The pinnacle of molecular mechanics can be considered to be ReaxFF,19 a reactive FF with a variable topology, a difficult parametrization process, and terms inspired by quantum chemistry. Still, even ReaxFF has run up against the limitations of “physically inspired” building blocks and has been forced to branch into specialized parametrizations.
Recently, a completely different approach to the understanding and development of FFs has emerged in the context of machine learning (ML) in computational chemistry. The parametrization of an FF is regarded as a regression problem, where a set of continuous inputs (Cartesian coordinates) must be mapped to a set of continuous outputs (energies and forces) in an optimal manner. The focus is hence shifted toward a sufficiently general functional form that can be efficiently trained on the available data. While alternatives exist, such as Gaussian process regression20 and the more recent Euclidean neural networks (NNs),21 one of the most fertile approaches to constructing MLFFs is based on fully connected NNs following a general template where the total energy is constructed as a sum of atomic energies.22−24 To preserve the fundamental symmetries of mechanics, the atomic energies depend on the local chemical environment through explicitly scalar atom-centered descriptors, rather than directly on the Cartesian coordinates.
In this paper we present NeuralIL, an NNFF for ILs based on atom-centered descriptors. We train it on and apply it to the IL ethylammonium nitrate (EAN) and show that the results offer quality comparable to first-principles calculations at a small fraction of the cost. The NNFF uses the second-generation spherical Bessel descriptors introduced by Kocer et al.25 Compared to the more widely used atom-centered symmetry functions26 and the smooth overlap of atomic positions27 descriptors, the spherical Bessel descriptors have been shown to minimize the amount of redundant information in the expansion.25 We generalize the spherical Bessel descriptors so that they do not rely on arbitrary weights for the different elements and show that this generalization is essential to precisely model the ab initio data. Furthermore, to fully capture the chemical nature of the atoms, the descriptors are augmented with an embedding vector.
NeuralIL puts a special emphasis on the forces. Through careful implementation choices, we show how the full data pipeline, from the Cartesian coordinates to the model, can be made automatically differentiable.28 Thereby our model can predict forces efficiently and can also be trained on them, making optimal use of the data obtained from the ab initio calculations. Compared to using only the total energy, where just one data point is obtained per atomic structure, 3natoms force components are routinely provided by ab initio calculations.
Automatic differentiation is a key piece of the modern ML landscape.28 As far as interatomic potentials are concerned, automatic differentiation often plays a role in equivariant convolutional NN models21,29,30 but has yet to be widely introduced for descriptor-based NNFFs.31 Automatic differentiation makes workarounds such as local Taylor approximations32 or atomic decompositions33 of density functional theory (DFT) energies unnecessary. A “hands-off” training of NNFFs is typically based on data sets ranging from hundreds of thousands to millions of atomic configurations.34,35 The present design and the possibility to train on forces do away with the idea that these large databases are required for descriptor-based NNFFs. At the same time, descriptor-based NNFFs still guarantee that a potential energy consistent with the forces exists (i.e., that forces are conservative), which cannot be taken for granted if the forces are regarded as an arbitrary vector field during training.
The next section contains the details of the descriptors, the NN, the implementation, and the training procedure. Then we analyze the results for EAN, discuss their implications for the model in general, and provide some comparisons with other ways to encode the chemical information. We furthermore show that a sufficiently flexible and accurate short-range potential provides a perfectly satisfactory description of this IL and that a molecular-mechanics-inspired treatment of Coulomb interactions in terms of static atomic charges in fact degrades the results. We also devise and demonstrate an inexpensive method to assess the transferability of the trained model to a new point in configuration space by using an ensemble of NNs. Finally, we summarize our main conclusions.
Methods
Ab Initio Calculations
The database of EAN configurations created for this work is provided as part of the Supporting Information. The main use case of FFs for ILs is to obtain improved results for MD simulations under conditions close to room temperature. Therefore, our data set is built on the basis of configurations sampled from a classical MD trajectory, which are then treated using DFT.
To run the classical MD simulations, we use Gromacs(36) with the OPLS-AA FF.15,16 The details of our parametrization of EAN are given in ref (37). Our starting point is a cubic box with a side length of 1.29 nm, filled with 15 ionic pairs in order to achieve a density similar to that of the pure IL. The initial positions are generated with Packmol(38) to avoid placing any pair of particles too close together. We then perform a conjugate-gradients minimization of the original coordinates, followed by a 10 ns stabilization run to bring the system to a reference temperature of 298.15 K using a velocity-rescaling thermostat with a time constant of 0.1 ns. Finally, we run a “production” simulation of 5 ns starting from the stabilized box and store the resulting trajectory. All integrations are performed using a velocity Verlet algorithm with a time step of 1 fs. A cutoff radius of 0.6 nm is adopted for the long-range interactions. The van der Waals term is truncated at that distance, while Coulomb interactions are evaluated using a fast smooth particle-mesh Ewald method,39 with that same radius acting as an upper bound for the real-space term. Dispersion corrections are applied to the energy to account for the truncated van der Waals interaction in a mean-field approximation.
The 5 ns trajectory is subsampled to extract 741 configurations. Each of those is used as an input to the Gpaw DFT package40,41 in the linear-combination-of-atomic-orbitals (LCAO) mode,42 with a double-ζ plus polarization basis set, the local density approximation (LDA) to exchange and correlation (XC), a grid spacing of 0.2 Å, and Γ-only sampling of the Brillouin zone. Since the DFT calculations are intended to generate a ground truth for the model, alternative XC parametrizations and semiempirical treatments of dispersive interactions are not explored. To improve the sampling in areas close to the local minima of the ab initio potential energy landscape, for 373 of those configurations we then run the quasi-Newton minimizer implemented in ASE(43) for five steps using the same DFT parameters. Using a fixed number of minimization steps helps avoid a situation where all initial configurations collapse around stationary points. The 373 final structures after each minimization along with the 368 remaining unminimized samples, each with their DFT energies and forces, make up the training data set.
Atom-Centered Descriptors
The first step in constructing the NNFF is to transform the 3natoms Cartesian coordinates of the system into a set of atom-centered descriptors. Those describe the atomic environments without encoding an absolute origin of coordinates or an absolute orientation of the axes and are thus explicitly translation- and rotation-invariant. Specifically, the quantity to be encoded is the local density of each chemical element J around each atom i in the system within a sphere of a predefined cutoff radius, which in the present study is set to an rc value of 3.5 Å.
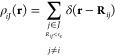 |
1 |
The cutoff radius was chosen after convergence tests for values up to 6.0 Å, which showed small improvements in accuracy with a significant impact on performance. Our descriptors are directly based on the density defined in eq 1 for each chemical element J. In contrast, most earlier work (with some exceptions like ref (35)) employs descriptors that encode one or more weighted densities of the form
| 2 |
with predefined weights like atomic numbers or atomic masses. As explained below, under our approach the number of descriptors per atom increases quadratically with the number of chemical species in the system, while premixed densities make those two numbers independent. The extensive comparisons between both possibilities reported in this article show that premixing leads to a significant loss of information in the descriptors and degrades the accuracy of the model.
Following the recipe for the spherical Bessel descriptors proposed by Kocer et al.,25 each density is projected on an orthonormal set of basis functions
| 3 |
with 0 ≤ n ≤ nmax, 0 ≤ l ≤ n, and −l ≤ m ≤ l. The parameter nmax controls the number of basis functions [nB = (nmax + 1) × (nmax + 2)/2] and can be adjusted according to the desired granularity of the encoding of the local environment around each atom. Ylm(r̂) is a spherical harmonic, while the radial parts, gnl(r), are built starting from the functions
| 4 |
and executing a Gram-Schmidt orthogonalization procedure for each value of l. In eq 4, jl stands for the l-th spherical Bessel function of the first kind, and ul,n is the (n + 1)-th positive value at which jl(u) = 0. Finally, rotational symmetry is enforced by contracting the angular parts of the projections ciJnlm of ρiJ on all basis set elements Bnlm(r).
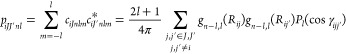 |
5 |
where γijk is the angle defined by atoms i, j, and j′ (with i at the vertex), and Pl is the l-th Legendre polynomial. We use piJJ′nl as our descriptors. Therefore, no complex arithmetic is required at any point of the calculation despite the fact that the basis functions are, in general, complex.
The orthogonality of the spherical harmonics and the explicit orthogonalization of the radial parts mean that any pair of basis functions are orthonormal. This minimizes the amount of redundant information in the expansion and makes this choice of descriptors very compact and systematic. Furthermore, not only do the gn,l(r) go to zero at r = rc but so do their first and second derivatives. All things considered, this scheme creates a symmetry-compatible density estimate or very smooth binning of the atomic positions around each atom. This can be readily appreciated in Figure 1, which depicts some example basis functions: both the radial and angular parts can be regarded as creating a grid in their respective domains, with their indices determining the number of divisions of that grid.
Figure 1.
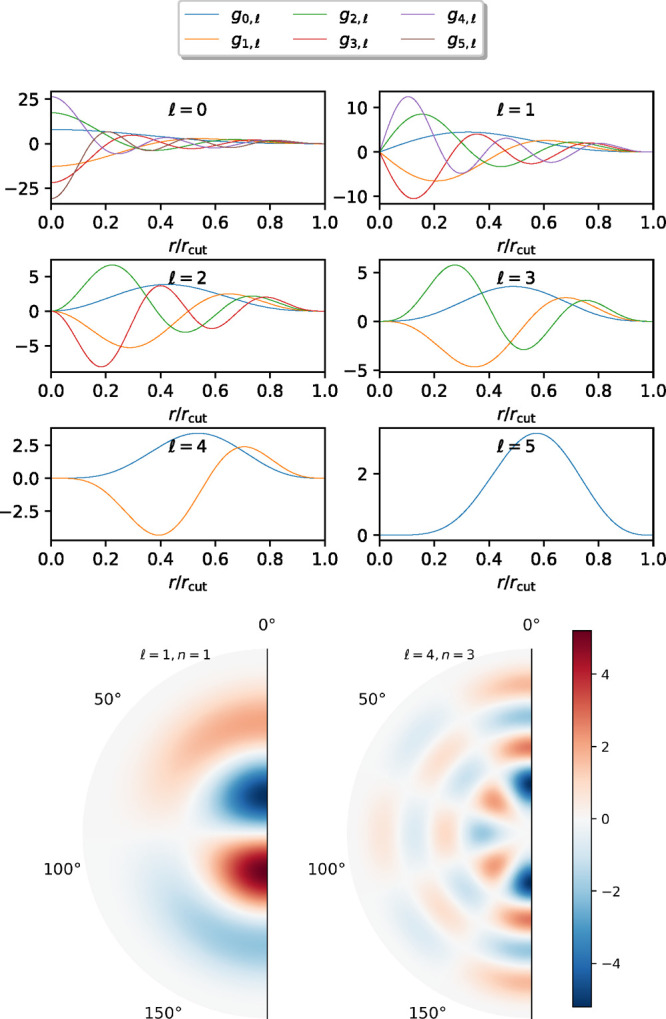
Examples of basis functions for the spherical Bessel descriptors. (top) Radial components of all basis functions for nmax = 5. (bottom) Angular components of two basis functions represented in the half-plane ϕ = 0.
The generalized power spectrum in eq 5 has
| 6 |
components for each atom, where nel represents the number of distinct elements to be considered. We use nmax = 4, and with four distinct elements (C, H, O and N) in EAN, the Cartesian coordinates of the 225 atoms in each configuration are converted into natoms × np = 33 750 descriptors. The choice of nmax is not directly connected to the number of chemical elements in the problem even though they are coincidentially the same in this instance: as mentioned above, nmax controls the resolution of the description of the environment in terms of both the radial and angular coordinates. Longer cutoff radii could require higher values of nmax to offer the same absolute spatial granularity. Since the number of descriptors increases quadratically with nmax, a relatively low value leads to a significantly faster force field.
The part of NeuralIL mapping sets of Cartesian coordinates to sets of descriptors is implemented on JAX,44 a library of composable function transformations with two key features. First, it uses a just-in-time compiler to translate Python code into instructions for accelerated linear algebra (XLA), a highly optimized framework that improves the performance of the code by several orders of magnitude. Through the use of that compiler, JAX aims for a different performance trade-off than the PyTorch autograd implementation used in TorchANI,31 which insteads focuses on optimizing dispatch times from the Python interface. Second, JAX implements both forward- and reverse-mode automatic (also known as algorithmic) differentiation. Therefore, it is possible to obtain the explicit representations of the Jacobian or Hessian of the descriptors with respect to the Cartesian coordinates but also, more importantly, a vector-Jacobian product operator, VJP in Figure 2, with a cost comparable to that of the descriptor calculation itself, a critical ingredient for the efficient calculation of the forces.
Figure 2.

Global schematic representation of the ML model, including the calculation of descriptors, the embedding, and the NN. natoms, np, and nemb are the number of atoms, the number of descriptors [see eq 6], and the dimension of the embedding, respectively. The diagram at the bottom illustrates, schematically, how reverse-mode automatic differentiation computes the forces; α is a shorthand index that runs over all descriptors for all atoms in the system. A cross-hatch fill represents full all-to-all connectivity between adjacent layers.
Embedding
The descriptors do not directly capture the chemical nature of the atom they are centered at. After the training, the model can infer that piece of information indirectly because the environment of each chemical species in the IL is very characteristic and through the descriptors centered at the surrounding atoms. Still, to make our FF as general as possible with a view to its application to, for instance, alloys whose constituents are chemically similar, we also supplement the descriptors to explicitly include that piece of data. We employ the general concept of embedding, that is, generating a low-dimensional, learned continuous representation of discrete data. This family of approaches is widely used in language processing45 and time-series analysis.46 We implement it by concatenating the descriptors with the outputs of a layer taking the element index as the input and returning an array of a predefined size nemb. The elements of the vector depend only on the chemical identity of the atom and are fitted as part of the training process. Therefore, during inference the embedding layer simply supplements the descriptors with an array of predefined length from a fixed lookup table indexed by the atomic species. Increasing the dimension of the embedding nemb does not add any more information to the input of the neural network, since the embedding array is completely determined by the chemical species at the center of each environment; however, it can impact how efficiently the model can incorporate that information. Moreover, the increase in computational cost associated with a larger nemb is negligible. In the case of EAN, we settle on nemb = 2 because longer embedding arrays do not lead to any significant improvements in accuracy, and the input thus consists in an natoms × (np + nemb) = 225 × 152 tensor.
Embedding has been used as part of NNFFs for solid-state calculations before,34 albeit in a different manner, namely, by employing the embedding coefficients as weights to mix the densities of eq 1 in proportions that depend on the chemical nature of the central atom. In other words, the approach of ref (34) amounts to allowing the weights in eq 2 to be systematically optimized and depend on the element at the center of the environment. This possibility will be discussed in more detail in the section on results.
Neural Network Architecture
In its most basic incarnation,
an NN regression model consists in the nested application of a nonlinear
activation function to a linear combination of the results of a previous
activation plus a constant. This is most easily visualized in terms
of a directed acyclic graph depicting the flow of data from the input
to the outputs. Each yellow box in Figure 2 represents a neuron that receives all the outputs
of all N neurons from the previous
layer as inputs, {Ii}i = 1N, and generates an output 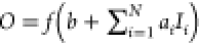 . Here, f is the activation
function, each ai is
a weight, and b is the bias. Each neuron has its
own weights and bias, and the collection of all of those make up the
parameters of the model, which are chosen so as to minimize a loss
function. Besides those coefficients, the flexibility of NNs lies
in the choice of the activation functions, the loss, and the number
and width of the layers.
. Here, f is the activation
function, each ai is
a weight, and b is the bias. Each neuron has its
own weights and bias, and the collection of all of those make up the
parameters of the model, which are chosen so as to minimize a loss
function. Besides those coefficients, the flexibility of NNs lies
in the choice of the activation functions, the loss, and the number
and width of the layers.
A useful FF must be applicable to systems with different numbers of atoms, and to be physically sound it must also be invariant with respect to any permutation of the labels of identical atoms. We use the well-known ansatz shown in eq 7.
| 7 |
That is, we consider that the energy can be decomposed into additive atomic contributions. In eq 7, Ω stands for the function implemented by the network (the contribution of atom i to the energy), pi is the collection of spherical Bessel descriptors pertaining to the environment around atom i, and ei is the array of embedding coefficients for the same atom. Therefore, {pi, ei} is the full set of information about atom i and its environment, as described in the previous sections. In contrast, α is a shorthand index that subsumes all indices (i, J, J′, n, l) from eq 5 and therefore runs over all descriptors for all atoms in the system. Likewise, β runs over all embedding coefficients for all atoms.
Although it was introduced heuristically, this formulation has met with great success.22 Besides the predictive skill shown by NNs built following this template, they are easy to integrate into high-performance MD packages, whose parallelization schemes expect global reduction operations to operate on contributions to the energy and other predefined quantities from each simulation domain.
The complete NeuralIL model is represented schematically in Figure 2, including the calculation of the spherical Bessel descriptors and the lookup of the embedding vectors. Our implementation is based on Flax,47 a high-performance ML framework built on top of JAX that enables the model to be run on central processing units (CPUs), graphics processing units (GPUs), and tensor processing units (TPUs) and benefit from quick and efficient automatic differentiation. The details of our final architecture are as follows. There are five hidden nonlinear layers, of widths 64:32:16:16:16. This sort of “pyramidal” architecture, with the initial layers significantly wider than subsequent ones, is found in other NN potential energy models for both molecular systems35 and crystals.34 We chose the 64:32:16:16:16 scheme after comparing other options found in the literature, like a shallow NN with two narrow layers of the same width48 and an architecture with extremely wide layers of 1000 and 500 neurons.34 “Local” modifications, such as expanding the sequence of widths to 128:64:32:16:16:16, do not significantly improve the results for our particular data set. After the final nonlinear layer, but before the sum over atoms, we introduce a linear layer with a single output, to account for the characteristic range and a possible offset of the potential energy.
For the nonlinear hidden layers in our networks we choose the Swish-1 activation function, that is, the β = 1 member of the Swish family.
| 8 |
These functions are themselves the result of an automated ML-based search.49 Like other modern activation functions (e.g., the very popular rectified linear unit (ReLU)), Swish-1 avoids the “vanishing gradient problem”50 of earlier choices like the hyperbolic tangent, whereby the gradient of the loss function with respect to the weights and biases becomes vanishingly small due to the saturation of the activation functions, greatly slowing the training. However, in contrast to many of those other functions, Swish-1 is smooth, making it ideal for our differentiable model.
To make the training of even moderately deep and wide architectures possible and efficient, we find it essential to apply a normalization scheme between each pair of intermediate hidden layers. As indicated in Figure 2, we choose LayerNorm,51 which centers and scales the intermediate quantities of each individual sample using their own mean and variance. LayerNorm does not require training during the forward passes and is therefore a very convenient choice for an automatically differentiable model.
Forces
Since the embedding coefficients do not depend on the positions, the force on atom i can be computed as
| 9 |
In our fully differentiable model, these forces
are obtained as a byproduct of the calculation of Epot as follows. The JAX code that generates the descriptors
uses a reverse-mode automatic differentiation to simultaneously create
the vector-Jacobian52 product operator 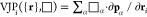 as shown in Figure 2, which does not
depend on the NN coefficients.
In our Flax-based implementation, this operator is seamlessly
compiled together with the NN itself, which provides ∂Epot/∂pα in Figure 2, into
a function that evaluates the forces in a cost- and memory-effective
manner. In particular, the very large Jacobian matrix of the descriptors
with respect to the atomic coordinates is never required. The total
cost of the calculation is only a small and roughly constant factor
higher than that of obtaining Epot alone.
as shown in Figure 2, which does not
depend on the NN coefficients.
In our Flax-based implementation, this operator is seamlessly
compiled together with the NN itself, which provides ∂Epot/∂pα in Figure 2, into
a function that evaluates the forces in a cost- and memory-effective
manner. In particular, the very large Jacobian matrix of the descriptors
with respect to the atomic coordinates is never required. The total
cost of the calculation is only a small and roughly constant factor
higher than that of obtaining Epot alone.
In practical terms, this means that the ML model can be trained on energies, forces, or both and used to predict energies, forces, or higher-order derivatives of the energy, based on a single set of weights and biases. Since each DFT calculation yields a single energy and 3natoms components of the forces, we find it most convenient to use only the latter. The only drawback is that the trained model is unaware of the origin of energies chosen in DFT, which is easily remedied by fitting a single constant offset under the condition that the average DFT and ML energies over the training set coincide.
Training
The configurations are randomly split into a training set (90% of the total) and a validation set (the remaining 10%). Our loss function is defined as
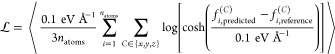 |
10 |
where ⟨·⟩ denotes an average over configurations in the current training batch. As stated above, the loss does not take into account the value of the predicted energy. This log-cosh loss53 can be considered a smooth approximation to the mean absolute error (MAE) in the forces. On the one hand, if the prediction error fi,predicted(C) – fi,reference is significantly larger in absolute value than the characteristic scale parameter of 0.1 eV Å–1, its contribution to the loss is proportional to |fi,predicted(C) – fi,reference|. On the other hand, for smaller values of the argument, log[cosh(Δ)] → Δ2/2, so the log-cosh can also be regarded as a robust version of the mean square error (MSE) with a built-in gradient clipping: compared to the MSE, this loss avoids an overwhelming influence on the training from possible outliers. We found that the result of training is relatively insensitive to changes in the scale parameter that we take as 0.1 eV Å–1. It can, for example, be safely increased to 1 eV Å–1. Taking it below the expected random errors in the force predictions (e.g., to 0.01 eV Å–1) leads to the same smoothness problems posed by the MAE, while making it too large (e.g., 10 eV Å–1) makes the gradient clipping less effective and gives outliers an excessive weight in the calculated gradients. In a different application where this scale could not be guessed based on experience, a standard cross-validation approach could be used instead.
A naive implementation of eq 10 runs into overflow issues because of the exponentially increasing behavior of the hyperbolic cosine. Therefore, each contribution to the loss is actually calculated using the equivalent but more stable expression
| 11 |
based on the JAX implementation of SoftPlusx = log(1 + ex).
The weights of the
network are initialized at random, according
to a Gaussian distribution with zero mean and a standard deviation
of 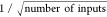 , and the
biases are initialized to zero.
We minimize the loss using the adaptive moment estimation (Adam) algorithm54 with a batch size of eight.
During the first 45% of the iterations in one epoch, we increase the
learning rate linearly from 10–3 to 10–2. We then decrease it linearly back to 10–3 in
the next 45%. For the last 10% of the iterations we reduce the learning
rate to 10–5. Like in other applications of NNs,
this so-called “one cycle” schedule55 significantly reduces the number of epochs required to
train the model, down to 500 from the more than 3000 needed with an
optimized constant learning rate of 4 × 10–4.
, and the
biases are initialized to zero.
We minimize the loss using the adaptive moment estimation (Adam) algorithm54 with a batch size of eight.
During the first 45% of the iterations in one epoch, we increase the
learning rate linearly from 10–3 to 10–2. We then decrease it linearly back to 10–3 in
the next 45%. For the last 10% of the iterations we reduce the learning
rate to 10–5. Like in other applications of NNs,
this so-called “one cycle” schedule55 significantly reduces the number of epochs required to
train the model, down to 500 from the more than 3000 needed with an
optimized constant learning rate of 4 × 10–4.
Results and Discussion
Training
Once trained to convergence, NeuralIL achieves a high accuracy in the prediction of forces, as evidenced by an MAE of 0.0656 eV Å–1 over a validation set with a mean absolute deviation of 1.11 eV Å–1. That MAE is comparable to the differences between forces computed using different DFT implementations (e.g., LCAO vs real-space56) and can thus be described as ab initio-like. Figure 3 shows a detailed comparison of the predicted and reference values of every component of the force on each atom in each configuration in the training and validation sets. Neither clear outliers nor particular regions with significantly worse predictions are detected. Moreover, there are no signs of overfitting during the training process or on the final result, with the validation statistics closely tracking those computed on the training set. As a first point of comparison, the accuracy of OPLS-AA as measured by its MAE with respect to DFT over the validation set for the forces is 1.97 eV Å–1, that is, 30 times higher. The accuracy of NeuralIL for predicting energies is also excellent, with a validation MAE of 1.86 meV atom–1 (or 0.0429 kcal mol–1) despite the fact that energies were not included in the loss function.
Figure 3.
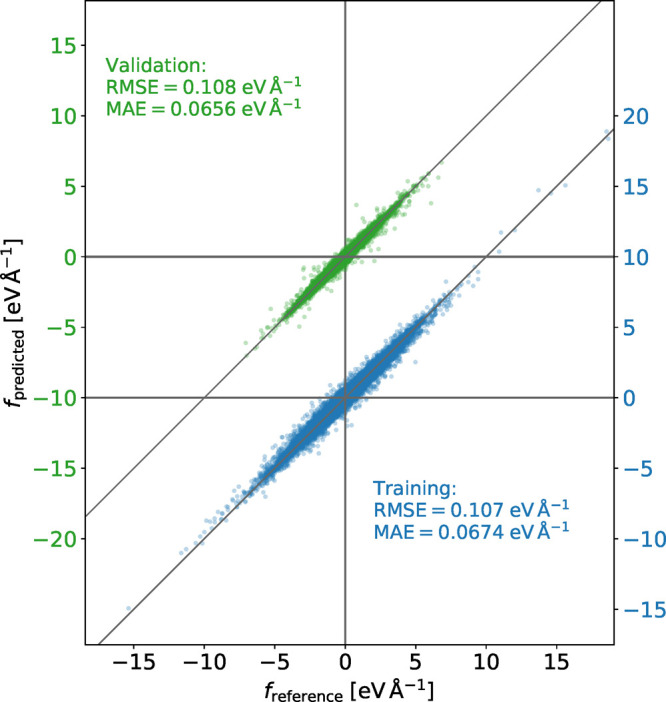
Predicted vs reference forces for the NeuralIL model over the training (blue) and validation (green) sets.
The possibility of training on forces is crucial to obtaining these results with a relatively small number of configurations. For comparison, we train the same architecture on the energies of the configurations. We use the same log-cosh loss of eq 10, but with a characteristic scale parameter of 10–2 eV atom–1, chosen based on arguments analogous to those presented for the forces. The learning rate schedule in this case goes from 10–5 to 10–4 and back for the first 90% of each epoch before dropping to 10–6 for the last 10%. When used to predict forces, the model so created, which we call EnergyOnly in Table 1, affords an MAE of 0.559 eV Å–1, rendering it unsuitable for any kind of predictive calculation. This shows that capturing the values of a function does not necessarily equate to correctly reproducing the derivatives of that function. Interestingly, with a validation MAE of 1.63 meV atom–1, EnergyOnly does not perform significantly better than NeuralIL when it comes to predicting energies, in keeping with the general observation that NNs trained using derivatives can achieve accuracy unmatched by those that do not take them into account.57 Taking the total potential energy as the only piece of information describing an atomic configuration leads to a small training data set; moreover, that single piece commingles the influence of many atomic environments, leading to poor discriminatory power: indeed, the energies of all configurations visited by a system along a molecular dynamics trajectory will be distributed in a relatively narrow band compatible with the predictions of the canonical ensemble. To tackle this problem atomic decompositions of the DFT energy33 and local Taylor expansions of the NN energies32 were devised. Training on forces, made possible by efficient automatic differentiation, makes those approximations unnecessary while achieving better accuracy. Nevertheless, we note that even EnergyOnly outperforms OPLS-AA drastically, by a factor of 3.5, in terms of accuracy for the forces.
Table 1. Mean Absolute Errors in the Forces and the Energies Achieved with Several Kinds of Models over the Validation Seta.
| model | MAE Epot | MAE f |
|---|---|---|
| (meV atom–1) | (meV Å–1) | |
| NeuralIL | 1.86 | 65.6 |
| NoEmbedding | 2.26 | 65.7 |
| χWeights | 11.8 | 167 |
| ZWeights | 16.9 | 171 |
| WeightEmbedding | 7.42 | 109 |
| EnergyOnly | 1.63 | 559 |
| SELUActivation | 3.10 | 71.3 |
| AtomicCharges | 12.0 | 91.0 |
| ChargeEquilibration | 1.93 | 60.8 |
| OPLS-AA | 856 | 1970 |
| DeepSets | 2.87 | 67.2 |
See Table 2 for a short description of each model, or see the main text for a more extended discussion.
In addition to its much poorer accuracy, the EnergyOnly model is extremely prone to overfitting. We were unable to train it below a validation energy MAE of ∼50 meV atom–1 using any fixed learning rate before that MAE started quickly diverging. Only the “one cycle” learning schedule fixed this problem.
To assess the effect of the other design features of our model, we train several alternatives, all of which are listed in Table 1 and summarized in Table 2. The NoEmbedding model differs from NeuralIL only in the fact that it lacks the embedding coefficients in the input layer. This means that the NN is, in principle, agnostic to the chemical nature of the atoms at the origins of each local density expressed by eq 1. However, as discussed previously, the model can still infer the element those atoms belong to from the distances and elements of the remaining atoms within the sphere. As a result, the performance NoEmbedding is comparable to that of NeuralIL for both forces and only slightly worse for energies. Since the computational cost of the embedding is negligible and it is likely to make a bigger difference in more complicated settings, it is sensible to include it.
Table 2. Summary of the Differences with Respect to NeuralIL of All Models Discussed in This Article and Listed in Table 1, for Quick Reference.
| NeuralIL: The main model proposed in this article, a short-range NN potential trained on forces that combines local spherical Bessel descriptors with an embedding array determined by the chemical species and uses Swish-1 as its activation function. |
| NoEmbedding: Like NeuralIL, but without the embedding. |
| χWeights: Like NoEmbedding, but the atomic descriptors associated with the same central atom and the same two chemical species are linearly mixed using electronegativities as weights. |
| ZWeights: Like χWeights, but the weights are atomic numbers instead. |
| WeightEmbedding: Like χWeights, but the weights are free parameters to be optimized during training along with the other coefficients of the model. |
| EnergyOnly: Like NeuralIL, but trained on total energies instead of on forces. |
| SELUActivation: Like NeuralIL, but using SELU activation functions and with no LayerNorm. |
| AtomicCharges: A combination of NeuralIL with a Coulomb contribution to the energy and forces computed on the basis of fixed atomic charges extracted from OPLS-AA. |
| ChargeEquilibration: Like AtomicCharges, but the atomic charges are flexible and determined using the CENT method: a second NN with the same inputs (descriptors and embedding array) as NeuralIL computes environment-dependent electronegativities, and the charges are calculated by solving a global optimization problem under the constraint that the system remains globally neutral. |
| OPLS-AA: A traditional molecular-mechanics force field that has been applied to ILs, used as a baseline. |
| DeepSets: Similar to NeuralIL, but atomic energies are not additive. Instead, the inputs for each atom are processed into a 16-element array of intermediate variables, which are summed over atoms and fed to a second NN that computes the total energy. |
The next two models
in Table 1 are based
on element-weighted descriptors 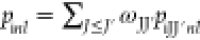 for some symmetric ωJJ′ and do not include any embedding vector.
χWeights uses ωJJ′ = χJχJ′, where χJ is the
electronegativity of element J. The second of these
models, ZWeights, takes ωJJ′ = ZJZJ′, to study the effect of weighting
density using atomic numbers as weights. With this change we intend
to analyze how a particular choice of weights affects the discriminatory
power of the model. The comparison between models that allow the NN
to mix the element-specific descriptors (eq 5) freely and the versions with fixed, predecided
weights reveals how critical it is that the NN can determine and efficiently
encode the type of atoms around each atomic site. Decoupling the descriptors
instead of premixing them improves the validation accuracy of the
forces almost by a factor of 3 and has an even more marked effect
on the predicted energies. Another noteworthy point is that the choice
of weights is not neutral, since χWeights yields more
accurate energies than ZWeights. When all possible sets of
weights are considered, some are much better than others, and there
is a vanishing likelihood of finding a particularly good set by random
chance or physical intuition, so the NN must adapt the remaining coefficients
to make up for a suboptimal choice instead. The best choice remains
to keep the descriptors for different pairs of elements as separate
inputs. The good accuracy of the ANI-1 FF,35 using a similar approach, provides additional support for this point.
for some symmetric ωJJ′ and do not include any embedding vector.
χWeights uses ωJJ′ = χJχJ′, where χJ is the
electronegativity of element J. The second of these
models, ZWeights, takes ωJJ′ = ZJZJ′, to study the effect of weighting
density using atomic numbers as weights. With this change we intend
to analyze how a particular choice of weights affects the discriminatory
power of the model. The comparison between models that allow the NN
to mix the element-specific descriptors (eq 5) freely and the versions with fixed, predecided
weights reveals how critical it is that the NN can determine and efficiently
encode the type of atoms around each atomic site. Decoupling the descriptors
instead of premixing them improves the validation accuracy of the
forces almost by a factor of 3 and has an even more marked effect
on the predicted energies. Another noteworthy point is that the choice
of weights is not neutral, since χWeights yields more
accurate energies than ZWeights. When all possible sets of
weights are considered, some are much better than others, and there
is a vanishing likelihood of finding a particularly good set by random
chance or physical intuition, so the NN must adapt the remaining coefficients
to make up for a suboptimal choice instead. The best choice remains
to keep the descriptors for different pairs of elements as separate
inputs. The good accuracy of the ANI-1 FF,35 using a similar approach, provides additional support for this point.
Finally, WeightEmbedding imitates the strategy introduced
in ref (34), where
the nel(nel + 1)/2 coefficients ωJJ′ form an embedding vector that is fitted during the training process
and depends on the chemical species at the center of the sphere. Remarkably,
the WeightEmbedding approach, which a priori could be expected
to show good performance by introducing the information about the
central atom more directly, yields a validation MAE roughly twice
as high as that of NeuralIL. A direct cause of this drop
in predictive ability may be that, even with adjustable weights, premixing
the densities prevents the NN from taking direct linear combinations
of descriptors belonging to different element pairs and different
values of (n,l). Another possible
factor is the multiplicative effect of those weights on 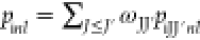 , the inputs to the first
layer of the NN.
Each change in the ωJJ′ affects
the normalization of the inputs to all successive layers, which can
be an obstacle to training. The key insight from the WeightEmbedding is that even an optimal choice of weights for premixing descriptors
corresponding to different pairs of elements, and even letting those
weights depend on the central element, is not as effective a strategy
as not premixing the descriptors in the first place.
, the inputs to the first
layer of the NN.
Each change in the ωJJ′ affects
the normalization of the inputs to all successive layers, which can
be an obstacle to training. The key insight from the WeightEmbedding is that even an optimal choice of weights for premixing descriptors
corresponding to different pairs of elements, and even letting those
weights depend on the central element, is not as effective a strategy
as not premixing the descriptors in the first place.
The Neural-Network Force Field
In contrast with molecular-mechanics force fields, our NNFF does not contain separate contributions from bond lengths, angles, and dihedrals. Its parameters come from a global fit, so to evaluate the influence of a change in one of those degrees of freedom the potential energy must be obtained along a particular trajectory that samples that deformation. The question then arises of whether this global fit leads to a loss of local detail. To explore if such a trade-off exists, we perform the following experiment. We select a random configuration from the validation set, a random anion, and a random oxygen atom in it. We then displace the oxygen atom in the direction of the bond so as to change the N–O distance, without displacing any other atom. We sample 151 points in the interval from 1.05 to 1.70 Å and, for each of those configurations, we calculate the forces using OPLS-AA, Gpaw (which represents the ground truth of the NNFF) and NeuralIL. We perform a similar experiment with a randomly selected C–N bond from the same configuration. The results are presented in the top and bottom panels of Figure 4, respectively. The OPLS-AA curves are dominated by the harmonic contribution from the stretching of each bond, with other minor bonded or nonbonded contributions that cause them to deviate from perfect straight segments. We note that the most obvious point of disagreement between the DFT and OPLS-AA results, a net average offset between the corresponding force versus distance curves, is actually a relatively trivial feature. It merely reflects the fact that the equilibrium bond lengths are different in each case and, if needed, could be corrected through a straightforward reparametrization of the OPLS-AA model. The most frequent bond lengths found in the training data are close to the OPLS-AA equilibrium value but with an asymmetric smearing due to the contributions from the samples partially relaxed toward DFT minima. Although the LDA has a known tendency toward overbinding, compared to OPLS-AA here it seems to underestimate the equilibrium length of the C–N bond but to overestimate that of the N–O bond. In contrast, OPLS-AA does not afford any flexibility to solve its more fundamental discrepancies with the first-principles calculations, namely, that it fails to reproduce either the local slope or the significant convexity of the force versus distance curves. In both respects, it is clearly outperformed by NeuralIL, which approximates the ab initio data accurately in a wide interval around the equilibrium bond lengths.
Figure 4.
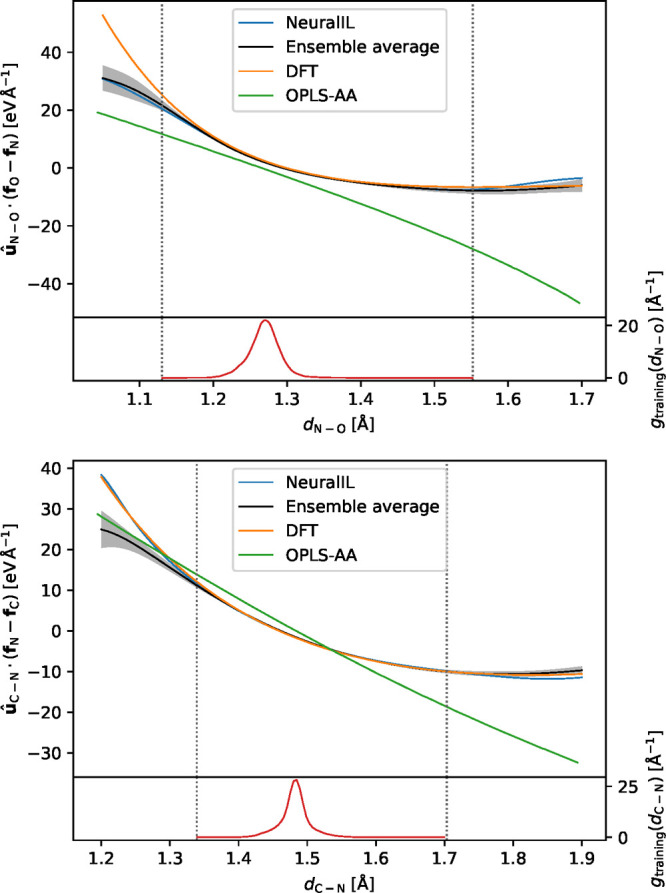
Ensemble predictions of the projections of the N–O force (in the anion, top panel) and C–N force (in the cation, bottom panel) on the segment joining both atoms, extracted from 18 instances of NeuralIL built based on random samples containing 50% of the training data each. The gray area spans a single standard deviation above and below the ensemble average. Also depicted: the main NeuralIL, the OPLS-AA value of the same force, and the ground truth of all the NN models, i.e., the forces extracted from a Gpaw DFT calculation. The bottom part of each panel shows a frequency density plot of the training data for the corresponding distance. The vertical dotted lines mark the minimum and maximum values found in the training set.
Activation Function
In our preliminary tests of different architectures we experimented with the scaled exponential linear unit (SELU) activation function.58
| 12 |
The SELU was designed specifically for deep feed-forward models. We set the parameters to α = 1.6732 and λ = 1.0507, carefully tuned by the original authors58 and shown to lead to so-called self-normalizing networks (SNNs) that naturally keep the inputs to the neurons in intermediate layers in the right range to promote fast training without additional normalization. Indeed, most of the results of this paper can be reproduced using the SELU instead of Swish-1 and removing the LayerNorm. However, the SELU has a discontinuity in its first derivative with some unfortunate consequences. First, the predicted forces can also have small jump discontinuities. Second, the discontinuity can be struck during training, leading to a divergence of the loss function and making the process crash. Although that problem was never observed with the 64:32:16:16:16 architecture, the probability of triggering it increases rapidly with the number of neurons and therefore constrains the complexity of the model.
To illustrate the advantage of the Swish-1 activation function for an NN used to predict forces, in Figure 5 we plot the same component of the NeuralIL-predicted force as in the second panel of Figure 4 together with the corresponding ground truth from DFT and with the predictions of a modified model where the activation functions have been replaced with the SELU. The SELU-based variation on NeuralIL, denoted as SELUActivation in Table 1, performs only slightly worse than the main model. However, as Figure 5 shows, the discontinuity in its derivative introduces unphysical artifacts in the forces, especially in regions with little or no training data. The problem becomes more apparent if the depth or the width of the NN is increased, and it renders this alternative architecture unsuitable for extracting higher-order derivatives of the energy, such as the Hessian. The lack of smoothness of most modern activation functions, including the exponential linear unit (ELU) used in TorchANI,31 highlights the importance of physical considerations in the design of an ML regression, where the most popular choices for mainstream applications of special commercial importance like image recognition might have disqualifying features in the context of atomistic calculations.
Figure 5.

Comparison of the predicted projections of the C–N force on a C–N bond from NeuralIL and from a model identical in all respects except in that it uses the SELU instead of Swish-1 as the activation function and that it does not require the use of LayerNorm. The vertical dotted lines mark the minimum and maximum values found in the training set. (inset) First derivatives of those two activation functions.
Ensembles
NNFFs can, moreover, provide some indication of whether their prediction is an interpolation within an area of configuration space rich in training data and, therefore, relatively safe, or an extrapolation that cannot be expected to have quantitative value. In fact, several different strategies have been proposed in the literature. Here we choose a subsampling aggregation approach,59 where we train an ensemble of 18 NNs with the same architecture but each of whose training sets contain 50% of the total training data, selected at random. This technique is a variation on “bagging”, which is better known for its use in the building of random-forest classification and regression models60 and is made possible by the abundance of data afforded by NeuralIL’s use of forces. We then use each of those NNs to evaluate the forces for each of the atomic configurations described in the preceding paragraph. Figure 4 shows both the average prediction of the ensemble (as a black line) and its standard deviation (as a gray area) for each bond length. For reference, the bottom part of each panel in the figure also shows the frequency density of bond lengths in the complete training set. Looking at the standard deviations first, it is apparent that the ensemble becomes more precise in the regions where training data are abundant, which are also those where NeuralIL more accurately reproduces the DFT forces. The bond lengths contained in the training configurations are tightly concentrated around their most frequent values, but this region of high accuracy and precision extends well into the tails of the bond-length distributions. Interestingly, the width of the region does not seem correlated to the characteristic spread of those distributions, since the prediction for the C–N bond remains relatively reasonable over the whole interval covered by the training data, whereas for the N–O bond, whose lengths are less concentrated, very significant deviations are observed close to the edges of the corresponding interval. This shows the importance of the ensemble, whose spread is indeed predictive of the relative accuracy at each point. For both bonds, extrapolations beyond the boundaries of the training set are very imprecise (as measured by the standard deviation of the ensemble of NNs) and contain clear inaccuracies in most cases, with the serendipitous exception of the small-distance region for the C–N bond. In that context, the ensemble average is also a valuable model in itself: it is not necessarily more accurate than the main model, but it is more robust with respect to outliers. In other words, it shifts the bias/variance balance toward the former in comparison with the full NeuralIL.
Treatment of the Electrostatic Interactions
OPLS-AA and other molecular-mechanics FFs contain electrostatic interactions in their nonbonded portions, characterized by a fixed set of atomic charges and an r–1 dependence on the interatomic distance. Likewise, proposals to overcome the limitations of those force fields are based on more sophisticated electrostatic contributions to the energy, like those from induced dipoles. To the extent that such contributions exist, strictly short-sighted descriptors like the ones employed by NeuralIL cannot capture them. The short-range complexities of the interactions among atoms can be reproduced by the NN with the required flexibility regardless of their physical origin (electrostatic or otherwise), but long-range effects not correlated with the local structure cannot.
The design of NeuralIL deliberately omits any provision for long-range interactions to serve as a case study on how well a short-sighted FF can work for ILs. Even for simple FFs like OPLS-AA, the evaluation of the Coulomb component of the nonbonded part is a significant source of implementation complexities, especially in massively parallel environments. Since NeuralIL by itself delivers ab initio-like performance, adding a long-range part to it would only be justified if that led to a significant improvement in the description of the dynamics at the atomistic level (i.e., to much more accurate energies and forces) or if it drastically reduced the error in a quantity derived from the trajectory.
Several specific methods to include electrostatic interactions in MLFFs have been proposed and demonstrated.61−63 To carefully assess whether it is necessary, or even convenient, to include such contributions for bulk ILs, the class of system treated in this article, we analyze the results of two extremely different approaches.
Our first strategy consists in subtracting the OPLS-AA electrostatic forces (ref (37)) from the DFT forces before training the NN. In other words, we combine the short-range interactions as described by the MLFF with the contribution of a system of static atomic charges fitted to the molecular electrostatic potential at the atomic centers of the isolated gas-phase ions obtained by quantum-chemical calculations at the LMP2/cc-pVTZ(-f)/HF/6-31G(d) level of theory.16 The resulting model, identical to NeuralIL in every other respect (architecture, training data, loss, learning rate schedule, etc.), is denoted as AtomicCharges and also included in Table 1. Its MAEs for the energies and forces are ∼550% and ∼40% worse than the respective statistics for NeuralIL.
Those bad results do not preclude the possibility that a more sophisticated treatment could change the picture. To explore that hypothesis, we supplement NeuralIL with the charge equilibration via neural network technique (CENT). The method (described in refs (61, 63, and 64)) consists in augmenting the NeuralIL total energy with a term describing the electrostatic long-range interaction
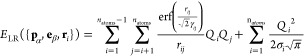 |
13 |
where rij = |ri – rj|, the
σi correspond to widths of the assumed
Gaussian charge density
distributions of each atom (taken to be the covalent radii of the
element), and 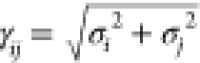 . The charges Qi are determined by a global charge equilibration
scheme,65 minimizing
. The charges Qi are determined by a global charge equilibration
scheme,65 minimizing
| 14 |
Here, the atomic hardnesses Ji are element-specific learnable parameters, while the electronegativities χi are predicted by a fully connected NN similar to the one used for the short-range part, but with a 16:16:16:1 sequence of layer widths. The overall charge conservation is enforced by introducing a Lagrange multiplier, and the minimization problem is then solved with standard linear algebra routines. The short- and long-range NNs use the same descriptors and embedding coefficients as inputs, which avoids duplication of work. The CENT component is also implemented on JAX and is fully automatically differentiable. The whole model containing both neural networks is trained simultaneously to achieve the best fit to the forces. Thus, we remain close to the original CENT method and deviate from the way it is used in ref (63), where the NN predicting the electronegativities is trained so as to reproduce atomic charges from known configurations.
The fully trained model combining NeuralIL and this long-range component with fully flexible charges is denoted as ChargeEquilibration in Table 1. With respect to NeuralIL alone, it affords an ∼8% improvement in the validation MAE of the forces together with an insignificant degradadation in the validation MAE of the potential energy. Given that the global equilibration step couples all the atoms in the system and therefore compromises the scalability of the model, an argument can be made that the small improvement does not justify the inclusion of the CENT component for this system. This impression is reinforced by an analysis of the mean and standard deviation of the predicted charges of anions and cations: typical values of those charges are compatible with zero and lie orders of magnitude below the ±1 ionic charges used by OPLS-AA or the reduced ±0.7 or ±0.8 that have been used in some MD simulations of other univalent ILs.66 The results show how the net effect of the electrostatic interaction is effectively accounted for by the short-range NN. While this at first sight might be a surprising conclusion for an IL, it agrees with a recent analysis for polarizable liquids67 and can be rationalized in terms of an efficient screening of electrostatic interactions in a bulk system.
As mentioned in the Introduction, one of the most well-known shortcomings of OPLS-AA and similar potentials is the misprediction of diffusion coefficients. Indeed, OPLS-AA describes room-temperature EAN as an almost solid ionic lattice with barely any diffusion, as evidenced by room-temperature self-diffusion coefficients of Danion = 1.30 × 10–12 m2/s and Dcation = 6.8 × 10–13 m2/s.68 In stark contrast, the experimentally reported diffusion coefficients are 1–2 orders of magnitude larger (Danion = 6.9 × 10–11 m2/s and Dcation = 4.6 × 10–11 m2/s).69 To see if NeuralIL overcomes these issues, we compute the diffusion coefficients. To further investigate whether it is necessary to directly include the long-range effects of polarization, we also compute those with the aforementioned ChargeEquilibration model. To this end, we use the JAX-MD framework70 to run MD simulations using each of the two models under study. We equilibrate the EAN simulation box at T = 298 K starting from the OPLS-AA trajectory and applying a Nosé–Hoover thermostat with a coupling constant τNH = 0.1 ps for 100 ps. For NeuralIL we use an integration time step of 1 fs, while the ChargeEquilibration model requires a much shorter time step of 0.1 fs because of an increased tendency of the hydrogen atoms to dissociate from the rest of the cation. We then run the simulation for a further 100 ps and store the resulting trajectory to compute the temporal velocity autocorrelation function for each ion type
| 15 |
where vI denotes the velocity of the center of mass of each ion of the corresponding type, and where the canonical ensemble average denoted by ⟨·⟩T is approximated by an average over the trajectory itself. We finally use the Green–Kubo relation
| 16 |
to estimate the diffusion coefficients, and we characterize its uncertainty by the oscillations of the numerical approximation to this integral in the last 10 ps. The results are Danion = 8.65(72) × 10–11 m2/s and Dcation = 8.24(73) × 10–11 m2/s with ChargeEquilibration, and Danion = 1.00(11) × 10–10 m2/s and Dcation = 7.2(13) × 10–11 m2/s with NeuralIL. Both models represent dramatic improvements over OPLS-AA and bring the coefficients in line with experimental measurements. The slight overestimation can be attributed to the lower density of the simulation box with respect to the actual IL at room temperature. However, the NeuralIL results have the advantage of capturing the Danion/Dcation ratio found in experiment far better, which seems to be distorted by the long-range contribution. All things considered, the fully flexible CENT term fails to add any advantageous feature to the strictly short-term NeuralIL. On the contrary, it hinders scalability, it requires smaller MD time steps, and it degrades the estimates of key dynamical quantities.
The conclusion is that an accurate parametrization of the potential energy of a dense ionic system does not require a specific treatment of long-range interactions. However, systems with less dense regions and correspondingly longer Debye lengths will definitely require such a treatment, and so will systems with surfaces.67 It is also conceivable that very specific aspects of the dynamics of a system (e.g., the frequency gap between longitudinal optical/transverse optical phonon branches in ionic solids) could hinge on particular features of the long-range interactions, but even those may be reflected in the local environment to some extent.
The nonbonded part of OPLS-AA also comprises van der Waals interactions parametrized as a 12–6 Lennard-Jones pair potential. As outlined in our description of the classical simulations, those are truncated at a distance of 6.0 Å. Therefore, thanks to the higher exponents of the power laws involved, those terms can still be captured by short-sighted descriptors.
The Additive Ansatz
The ansatz of additive atomic energies [eq 7] used by all the models discussed so far offers several important practical advantages. However, strictly speaking it can only express a subset of the permutation-invariant potential energy functions whose general form following the theory of “deep sets”71 is
| 17 |
There are two functions involved in the expression on the right-hand side. The first, Ω, maps the variables associated with each atom to a latent space where the information about the order of the inputs is destroyed (and thus permutation symmetry enforced) by a sum over atoms. The second, μ, transforms the result of that sum into the potential energy. In addition to the parallelization issues, building an NN-based model for a potential energy in the form of eq 17 poses several practical challenges. First, it has recently been reported72 that only a high-dimensional latent space can guarantee an adequate representation of any permutation-invariant function in practice. Second, μ must accept inputs in a broad range and still produce outputs suitable for any relevant value of natoms, which is a bad match for the normalization techniques commonly used when training NNs. All of these problems can be avoided by restricting the output of Ω to a single scalar and taking μ as the identity function or, in other words, by transferring the property of additivity from a latent space, where it is theoretically guaranteed, to the potential energy, where it becomes an approximation. Therefore, the decomposition expressed by eq 7 is a convenient trade-off between generality and practicality.
We now check whether switching to a more general architecture, beyond the bounds of eq 7, leads to a significant improvement upon the results of NeuralIL. We train a new model, designated as DeepSets in Table 1 and consisting of two NNs. The first one follows the scheme of NeuralIL, as represented in Figure 2, starting from the left and up to the last 16-neuron Swish-1 layer. That tensor, with 16 components per atom, acts as the intermediate quantity denoted by Ω in eq 17. Following that same equation, it is then summed over atoms and fed into the second NN that implements μ and outputs the total potential energy. That second NN is also a multilayer perceptron with Swish-1 as its activation function and LayerNorm between each pair of hidden layers, and with layer widths 32:32:32:1. We use a “one cycle” training schedule that switches the learning rate from 10–4 to 10–3 and back to 10–4 before dropping it to 10–5 and run the process for 500 iterations just like for the rest of the models. As shown in Table 1, the model is slightly worse than NeuralIL in terms of performance. On the one hand, this shows that the widely used additive ansatz expressed in eq 7 is not the only viable architecture for a fully connected feed-forward NN force field based on descriptors. On the other hand, it also dispels the suspicion that the ansatz could be very constraining or that dramatic boosts in accuracy are easy to obtain by generalizing it.
Summary and Conclusions
We develop a neural-network-based force field for the ionic liquid ethylammonium nitrate, using forces from density functional theory as training data and modified spherical Bessel descriptors as the inputs. The validation statistics show a level of accuracy in the energies and the forces comparable to the difference between DFT implementations and an improvement of orders of magnitude over traditional molecular-mechanics FFs like OPLS-AA, while keeping the time to evaluate the forces on a few hundreds of atoms on a single core in the range of milliseconds. This kind of FF can therefore be employed to calculate quantities requiring long trajectories or large samples of configurations (like thermodynamic potentials) with ab initio accuracy. Key to its performance and flexibility is the fact that the model is automatically differentiable from end to end.
Another critical choice lies in how to include the chemical information about the system in the descriptors. We opt to describe each pair of chemical elements separately and let the neural network combine these pieces of information freely. We compare this strategy with more conventional alternatives where a set of weights, either fixed or fitted during the optimization process, is used to mix the descriptors corresponding to different elements, and we show that it delivers superior results.
By training an ensemble of neural networks on random subsets of the training data, we also show how an extrapolation to unexplored areas of the configuration space can be detected from the ensemble standard deviation and how the ensemble average can provide a more robust prediction where training data are thin. This strategy can serve as a starting point to use this model as a surrogate potential energy in a first-principles calculation where the generation of training data takes place on the fly and where it is important to be able to assess how reliable the prediction of the neural network is for each new configuration.
Our model represents a radical departure from the template of molecular-mechanics FFs by way of its top-bottom training process but also in two defining features: it does not include either a topology or a separate treatment of Coulomb interactions. However, we show that these are not obstacles to achieving both a high global accuracy and a detailed description of individual degrees of freedom like bonds. This opens the door to the use of high-performance short-range potentials for this class of system where long-range electrostatic forces are traditionally considered to be critical. That should, however, be considered as valid only in the context of dense bulk systems and not as a completely general conclusion for ionic matter.
Acknowledgments
This work was supported by the Austrian Science Fund (FWF) (SFB F81 TACO). H.M.-C. thanks the Spanish Ministry of Education for his FPU grant.
Supporting Information Available
The Supporting Information is available free of charge at https://pubs.acs.org/doi/10.1021/acs.jcim.1c01380.
Author Contributions
§ These authors contributed equally to this work.
The authors declare no competing financial interest.
Notes
The software required to reproduce our calculations is publicly available at https://bitbucket.org/sousaw/neuralil_manuscript_software under an open-source license. The training and validation data are also included, along with the model parameters.
Supplementary Material
References
- MacFarlane D.; Kar M.; Pringle J.. Fundamentals of Ionic Liquids: From Chemistry to Applications ;Wiley: Weinheim, Germany, 2017. [Google Scholar]
- Liu H.; Liu Y.; Li J. Ionic Liquids in Surface Electrochemistry. Phys. Chem. Chem. Phys. 2010, 12, 1685–1697. 10.1039/b921469k. [DOI] [PubMed] [Google Scholar]
- Mallakpour S.; Dinari M. In Green Solvents II: Properties and Applications of Ionic Liquids ;Mohammad A., Inamuddin D., Eds.; Springer Netherlands: Dordrecht, Netherlands, 2012; pp 1–32. [Google Scholar]
- Rogers R. D.; Seddon K. R. Ionic Liquids-Solvents of the Future?. Science 2003, 302, 792–793. 10.1126/science.1090313. [DOI] [PubMed] [Google Scholar]
- Xu C.; Cheng Z. Thermal Stability of Ionic Liquids: Current Status and Prospects for Future Development. Processes 2021, 9, 337. 10.3390/pr9020337. [DOI] [Google Scholar]
- Kohno Y.; Ohno H. Ionic Liquid/Water Mixtures: from Hostility to Conciliation. Chem. Commun. 2012, 48, 7119–7130. 10.1039/c2cc31638b. [DOI] [PubMed] [Google Scholar]
- Gomes J. M.; Silva S. S.; Reis R. L. Biocompatible Ionic Liquids: Fundamental Behaviours and Applications. Chem. Soc. Rev. 2019, 48, 4317–4335. 10.1039/C9CS00016J. [DOI] [PubMed] [Google Scholar]
- Tiago G. A. O.; Matias I. A. S.; Ribeiro A. P. C.; Martins L. M. D. R. S. Application of Ionic Liquids in Electrochemistry–Recent Advances. Molecules 2020, 25, 5812. 10.3390/molecules25245812. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghatee M. H.; Ansari Y. Ab Initio Molecular Dynamics Simulation of Ionic Liquids. J. Chem. Phys. 2007, 126, 154502. 10.1063/1.2718531. [DOI] [PubMed] [Google Scholar]
- Byrne A.; Krishnan Y.; English N. J. Ab Initio Molecular Dynamics Studies of the Effect of Solvation by Room-Temperature Ionic Liquids on the Vibrational Properties of a N719-Chromophore/Titania Interface. J. Phys. Chem. C 2018, 122, 26464–26471. 10.1021/acs.jpcc.8b08248. [DOI] [Google Scholar]
- Köddermann T.; Paschek D.; Ludwig R. Molecular Dynamic Simulations of Ionic Liquids: A Reliable Description of Structure, Thermodynamics and Dynamics. ChemPhysChem 2007, 8, 2464–2470. 10.1002/cphc.200700552. [DOI] [PubMed] [Google Scholar]
- Méndez-Morales T.; Carrete J.; Cabeza O.; Gallego L. J.; Varela L. M. Molecular Dynamics Simulations of the Structural and Thermodynamic Properties of Imidazolium-Based Ionic Liquid Mixtures. J. Phys. Chem. B 2011, 115, 11170–11182. 10.1021/jp206341z. [DOI] [PubMed] [Google Scholar]
- Ori G.; Massobrio C.; Pradel A.; Ribes M.; Coasne B. Structure and Dynamics of Ionic Liquids Confined in Amorphous Porous Chalcogenides. Langmuir 2015, 31, 6742–6751. 10.1021/acs.langmuir.5b00982. [DOI] [PubMed] [Google Scholar]
- Voroshylova I. V.; Ferreira E. S. C.; Malček M.; Costa R.; Pereira C. M.; Cordeiro M. N. D. S. Influence of the Anion on the Properties of Ionic Liquid Mixtures: a Molecular Dynamics Study. Phys. Chem. Chem. Phys. 2018, 20, 14899–14918. 10.1039/C8CP01541D. [DOI] [PubMed] [Google Scholar]
- Jorgensen W. L.; Maxwell D. S.; Tirado-Rives J. Development and Testing of the OPLS All-Atom Force Field on Conformational Energetics and Properties of Organic Liquids. J. Am. Chem. Soc. 1996, 118, 11225–11236. 10.1021/ja9621760. [DOI] [Google Scholar]
- Sambasivarao S. V.; Acevedo O. Development of OPLS-AA Force Field Parameters for 68 Unique Ionic Liquids. J. Chem. Theory Comput. 2009, 5, 1038–1050. 10.1021/ct900009a. [DOI] [PubMed] [Google Scholar]
- Schmollngruber M.; Lesch V.; Schröder C.; Heuer A.; Steinhauser O. Comparing Induced Point-Dipoles and Drude Oscillators. Phys. Chem. Chem. Phys. 2015, 17, 14297–14306. 10.1039/C4CP04512B. [DOI] [PubMed] [Google Scholar]
- Lesch V.; Montes-Campos H.; Méndez-Morales T.; Gallego L. J.; Heuer A.; Schröder C.; Varela L. M. Molecular Dynamics Analysis of the Effect of Electronic Polarization on the Structure and Single-Particle Dynamics of mixtures of Ionic Liquids and Lithium Salts. J. Chem. Phys. 2016, 145, 204507. 10.1063/1.4968393. [DOI] [PubMed] [Google Scholar]
- Senftle T. P.; Hong S.; Islam M. M.; Kylasa S. B.; Zheng Y.; Shin Y. K.; Junkermeier C.; Engel-Herbert R.; Janik M. J.; Aktulga H. M.; Verstraelen T.; Grama A.; van Duin A. C. T. The ReaxFF Reactive Force-Field: Development, Applications and Future Directions. Npj Comput. Mater. 2016, 2, 15011. 10.1038/npjcompumats.2015.11. [DOI] [Google Scholar]
- Bartók A. P.; Csányi G. Gaussian Approximation Potentials: a Brief Tutorial Introduction. Int. J. Quantum Chem. 2015, 115, 1051–1057. 10.1002/qua.24927. [DOI] [Google Scholar]
- Batzner S.; Smidt T. E.; Sun L.; Mailoa J. P.; Kornbluth M.; Molinari N.; Kozinsky B.. SE(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials. arXiv:2101.03164 [physics.comp-ph], 2021. Online at https://arxiv.org/abs/2101.03164 [DOI] [PMC free article] [PubMed]
- Behler J. Constructing High-Dimensional Neural Network Potentials: A Tutorial Review. Int. J. Quantum Chem. 2015, 115, 1032–1–050. 10.1002/qua.24890. [DOI] [Google Scholar]
- Behler J. Four Generations of High-Dimensional Neural Network Potentials. Chem. Rev. 2021, 121, 10037–10072. 10.1021/acs.chemrev.0c00868. [DOI] [PubMed] [Google Scholar]
- Watanabe S.; Li W.; Jeong W.; Lee D.; Shimizu K.; Mimanitani E.; Ando Y.; Han S. High-Dimensional Neural Network Atomic Potentials for Examining Energy Materials: Some Recent Simulations. J. Phys. Energy 2021, 3, 012003. 10.1088/2515-7655/abc7f3. [DOI] [Google Scholar]
- Kocer E.; Mason J. K.; Erturk H. Continuous and Optimally Complete Description of Chemical Environments using Spherical Bessel Descriptors. AIP Adv. 2020, 10, 015021. 10.1063/1.5111045. [DOI] [Google Scholar]
- Behler J. Atom-centered symmetry functions for constructing high-dimensional neural network potentials. J. Chem. Phys. 2011, 134, 074106. 10.1063/1.3553717. [DOI] [PubMed] [Google Scholar]
- Bartók A. P.; Kondor R.; Csányi G. On representing chemical environments. Phys. Rev. B: Condens. Matter Mater. Phys. 2013, 87, 184115. 10.1103/PhysRevB.87.184115. [DOI] [Google Scholar]
- Baydin A. G.; Pearlmutter B. A.; Radul A. A.; Siskind J. M. Automatic Differentiation in Machine Learning: a Survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Schütt K. T.; Sauceda H. E.; Kindermans P.-J.; Tkatchenko A.; Müller K.-R. SchNet-A Deep Learning Architecture for Molecules and Materials. J. Chem. Phys. 2018, 148, 241722. 10.1063/1.5019779. [DOI] [PubMed] [Google Scholar]
- Anderson B.; Hy T.-S.; Kondor R.. Cormorant: Covariant Molecular Neural Networks. arXiv:1906.04015 [physics.comp-ph], 2019. Online at https://arxiv.org/abs/1906.04015
- Gao X.; Ramezanghorbani F.; Isayev O.; Smith J. S.; Roitberg A. E. TorchANI: A Free and Open Source PyTorch-Based Deep Learning Implementation of the ANI Neural Network Potentials. J. Chem. Inf. Model. 2020, 60, 3408–3415. 10.1021/acs.jcim.0c00451. [DOI] [PubMed] [Google Scholar]
- Cooper A. M.; Kästner J.; Urban A.; Artrith N. Efficient Training of ANN Potentials by Including Atomic Forces via Taylor Expansion and Application to Water and a Transition-Metal Oxide. Npj Comput. Mater. 2020, 6, 54. 10.1038/s41524-020-0323-8. [DOI] [Google Scholar]
- Huang Y.; Kang J.; Goddard W. A.; Wang L.-W. Density Functional Theory Based Neural Network Force Fields from Energy Decompositions. Phys. Rev. B: Condens. Matter Mater. Phys. 2019, 99, 064103. 10.1103/PhysRevB.99.064103. [DOI] [Google Scholar]
- Bochkarev A. S.; van Roekeghem A.; Mossa S.; Mingo N. Anharmonic Thermodynamics of Vacancies using a Neural Network Potential. Phys. Rev. Materials 2019, 3, 093803. 10.1103/PhysRevMaterials.3.093803. [DOI] [Google Scholar]
- Smith J. S.; Isayev O.; Roitberg A. E. ANI-1: an Extensible Neural Network Potential with DFT Accuracy at Force Field Computational Cost. Chem. Sci. 2017, 8, 3192–3203. 10.1039/C6SC05720A. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Der Spoel D.; Lindahl E.; Hess B.; Groenhof G.; Mark A. E.; Berendsen H. J. C. GROMACS: Fast, Flexible, and Free. J. Comput. Chem. 2005, 26, 1701–1718. 10.1002/jcc.20291. [DOI] [PubMed] [Google Scholar]
- Docampo-Álvarez B.; Gómez-González V.; Méndez-Morales T.; Carrete J.; Rodríguez J. R.; Cabeza O.; Gallego L. J.; Varela L. M. Mixtures of Protic Ionic Liquids and Molecular Cosolvents: A Molecular Dynamics Simulation. J. Chem. Phys. 2014, 140, 214502. 10.1063/1.4879660. [DOI] [PubMed] [Google Scholar]
- Martínez L.; Andrade R.; Birgin E. G.; Martínez J. M. Packmol: A Package for Building Initial Configurations for Molecular Dynamics Simulations. J. Comput. Chem. 2009, 30, 2157. 10.1002/jcc.21224. [DOI] [PubMed] [Google Scholar]
- Essmann U.; Perera L.; Berkowitz M. L.; Darden T.; Lee H.; Pedersen L. G. A Smooth Particle Mesh Ewald Method. J. Chem. Phys. 1995, 103, 8577–8593. 10.1063/1.470117. [DOI] [Google Scholar]
- Mortensen J. J.; Hansen L. B.; Jacobsen K. W. Real-space grid implementation of the projector augmented wave method. Phys. Rev. B: Condens. Matter Mater. Phys. 2005, 71, 035109. 10.1103/PhysRevB.71.035109. [DOI] [Google Scholar]
- Enkovaara J.; Rostgaard C.; Mortensen J. J.; Chen J.; Dułak M.; Ferrighi L.; Gavnholt J.; Glinsvad C.; Haikola V.; Hansen H. A.; Kristoffersen H. H.; Kuisma M.; Larsen A. H.; Lehtovaara L.; Ljungberg M.; Lopez-Acevedo O.; Moses P. G.; Ojanen J.; Olsen T.; Petzold V.; Romero N. A.; Stausholm-Møller J.; Strange M.; Tritsaris G. A.; Vanin M.; Walter M.; Hammer B.; Häkkinen H.; Madsen G. K. H.; Nieminen R. M.; Nørskov J. K.; Puska M.; Rantala T. T.; Schiøtz J.; Thygesen K. S.; Jacobsen K. W. Electronic structure calculations with GPAW: a real-space implementation of the projector augmented-wave method. J. Phys.: Condens. Matter 2010, 22, 253202. 10.1088/0953-8984/22/25/253202. [DOI] [PubMed] [Google Scholar]
- Larsen A. H.; Vanin M.; Mortensen J. J.; Thygesen K. S.; Jacobsen K. W. Localized Atomic Basis Set in the Projector Augmented Wave Method. Phys. Rev. B: Condens. Matter Mater. Phys. 2009, 80, 195112. 10.1103/PhysRevB.80.195112. [DOI] [Google Scholar]
- Hjorth Larsen A.; Jorgen Mortensen J.; Blomqvist J.; Castelli I. E.; Christensen R.; Dułak M.; Friis J.; Groves M. N.; Hammer B.; Hargus C.; et al. The Atomic Simulation Environment-a Python Library for Working with Atoms. J. Phys.: Condens. Matter 2017, 29, 273002. 10.1088/1361-648X/aa680e. [DOI] [PubMed] [Google Scholar]
- Bradbury J.; Frostig R.; Hawkins P.; Johnson M. J.; Leary C.; Maclaurin D.; Necula G.; Paszke A.; VanderPlas J.; Wanderman-Milne S.; Zhang Q. JAX: composable transformations of Python+NumPy programs. 2018; http://github.com/google/jax, accessed 2021-12-09.
- Gupta S.; Kanchinadam T.; Conathan D.; Fung G. Task-Optimized Word Embeddings for Text Classification Representations. Front. Appl. Math. Stat. 2020, 5, 67. 10.3389/fams.2019.00067. [DOI] [Google Scholar]
- Karingula S. R.; Ramanan N.; Tahsambi R.; Amjadi M.; Jung D.; Si R.; Thimmisetty C.; Coelho C. N. Jr.. Boosted Embeddings for Time Series Forecasting. arXiv:2104.04781 [cs.LG], 2021. Online at https://arxiv.org/abs/2104.04781
- Heek J.; Levskaya A.; Oliver A.; Ritter M.; Rondepierre B.; Steiner A.; van Zee M. Flax: A neural network library and ecosystem for JAX. 2020; http://github.com/google/flax, accessed on 2021–12–09.
- Singraber A.; Morawietz T.; Behler J.; Dellago C. Parallel Multistream Training of High-Dimensional Neural Network Potentials. J. Chem. Theory Comput. 2019, 15, 3075–3092. 10.1021/acs.jctc.8b01092. [DOI] [PubMed] [Google Scholar]
- Ramachandran P.; Zoph B.; Le Q. V.. Searching for Activation Functions. arXiv:1710.05941 [cs.NE], 2017. Online at https://arxiv.org/abs/1710.05941
- Goh G. B.; Hodas N. O.; Vishnu A. Deep Learning for Computational Chemistry. J. Comput. Chem. 2017, 38, 1291–1307. 10.1002/jcc.24764. [DOI] [PubMed] [Google Scholar]
- Ba J. L.; Kiros J. R.; Hinton G. E.. Layer Normalization. arXiv:1607.06450 [stat.ML]. Online at https://arxiv.org/abs/1607.06450
- Spivak M.Calculus On Manifolds: A Modern Approach To Classical Theorems Of Advanced Calculus ;CRC Press: Boca Raton, FL, 2018. [Google Scholar]
- Wang Q.; Ma Y.; Zhao K.; Tian Y. A Comprehensive Survey of Loss Functions in Machine Learning. Ann. Data Sci. 2020, 10.1007/s40745-020-00253-5. [DOI] [Google Scholar]
- Kingma D. P.; Ba J.. Adam: A method for stochastic optimization. 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, May 7–9, 2015, Conference Track Proceedings; 2015.
- Smith L. N.A Disciplined Approach to Neural Network Hyper-parameters: Part 1–Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv:1803.09820 [cs.LG], 2018. Online at https://arxiv.org/abs/1803.09820
- Larsen A. H.Localized Atomic Orbital Basis Sets in the Projector Augmented Wave Method. M.Sc. Thesis, Center for Atomic-scale Materials Design, Department of Physics, Technical University of Denmark, 2008. [Google Scholar]
- Avrutskiy V. I. Enhancing Function Approximation Abilities of Neural Networks by Training Derivatives. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 916–924. 10.1109/TNNLS.2020.2979706. [DOI] [PubMed] [Google Scholar]
- Klambauer G.; Unterthiner T.; Mayr A.; Hochreiter S.. Self-Normalizing Neural Networks. In Advances in Neural Information Processing Systems 30 , NIPS 2017, Long Beach, CA, 2017.
- Fort S.; Hu H.; Lakshminarayanan B.. Deep Ensembles: A Loss Landscape Perspective. arXiv:1912.02757 [stat.ML], 2020. Online at https://arxiv.org/abs/1912.02757
- Breiman L. Random Forests. Mach. Learn. 2001, 45, 5–32. 10.1023/A:1010933404324. [DOI] [Google Scholar]
- Ghasemi S. A.; Hofstetter A.; Saha S.; Goedecker S. Interatomic potentials for ionic systems with density functional accuracy based on charge densities obtained by a neural network. Phys. Rev. B: Condens. Matter Mater. Phys. 2015, 92, 045131. 10.1103/PhysRevB.92.045131. [DOI] [Google Scholar]
- Grisafi A.; Ceriotti M. Incorporating Long-Range Physics in Atomic-Scale Machine Learning. J. Chem. Phys. 2019, 151, 204105. 10.1063/1.5128375. [DOI] [PubMed] [Google Scholar]
- Ko T. W.; Finkler J. A.; Goedecker S.; Behler J. A Fourth-Generation High-Dimensional Neural Network Potential with Accurate Electrostatics including Non-Local Charge Transfer. Nat. Commun. 2021, 12, 398. 10.1038/s41467-020-20427-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Faraji S.; Ghasemi S. A.; Rostami S.; Rasoulkhani R.; Schaefer B.; Goedecker S.; Amsler M. High Accuracy and Transferability of a Neural Network Potential through Charge Equilibration for Calcium Fluoride. Phys. Rev. B: Condens. Matter Mater. Phys. 2017, 95, 104105. 10.1103/PhysRevB.95.104105. [DOI] [Google Scholar]
- Rappe A. K.; Goddard W. A. Charge Equilibration for Molecular Dynamics Simulations. J. Phys. Chem. 1991, 95, 3358–3363. 10.1021/j100161a070. [DOI] [Google Scholar]
- Lynden-Bell R. M.; Youngs T. G. A. J. Phys.: Condens. Matter 2009, 21, 424120. 10.1088/0953-8984/21/42/424120. [DOI] [PubMed] [Google Scholar]
- Niblett S. P.; Galib M.; Limmer D. T. Learning Intermolecular Forces at Liquid–Vapor Interfaces. J. Chem. Phys. 2021, 155, 164101. 10.1063/5.0067565. [DOI] [PubMed] [Google Scholar]
- Huang Y.; Zhou G.; Li Y.; Yang Z.; Shi M.; Wang X.; Chen X.; Zhang F.; Li W. Molecular Dynamics Simulations of Temperature-Dependent Structures and Dynamics of Ethylammonium Nitrate Protic ionic Liquid: The role of Hydrogen Bond. Chem. Phys. 2016, 472, 105–111. 10.1016/j.chemphys.2016.03.020. [DOI] [Google Scholar]
- Filippov A.Self-Diffusion and Microstructure of Some Ionic Liquids in Bulk and in Confinement. Ph.D. Thesis, Luleä University of Technology: Luleä, Sweden, 2016. [Google Scholar]
- Schoenholz S. S.; Cubuk E. D.. JAX, M.D.: A Framework for Differentiable Physics. arXiv 1912.04232, 2020. Online at https://arxiv.org/abs/1912.04232
- Zaheer M.; Kottur S.; Ravanbakhsh S.; Poczos B.; Salakhutdinov R. R.; Smola A. J.. Deep Sets. Advances in Neural Information Processing Systems. Long Beach, CA, 2017.
- Wagstaff E.; Fuchs F.; Engelcke M.; Posner I.; Osborne M. A.. On the Limitations of Representing Functions on Sets. Proceedings of the 36th International Conference on Machine Learning. Long Beach, CA, 2019; pp 6487–6494.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.