

Abstract
With the worldwide large-scale outbreak of COVID-19, the Internet of Medical Things (IoMT), as a new type of Internet of Things (IoT)-based intelligent medical system, is being used for COVID-19 prevention and detection. However, since the widespread use of IoMT will generate a large amount of sensitive information related to patients, it is becoming more and more important yet challenging to ensure data security and privacy of COVID-19 applications in IoMT. The leakage of private information during IoMT data fusion process will cause serious problems and affect people’s willingness to contribute data in IoMT. To address these challenges, this article proposes a new privacy-enhanced data fusion strategy (PDFS). The proposed PDFS consists of four important components, i.e., sensitive task classification, task completion assessment, incentive mechanism-based task contract design, and homomorphic encryption-based data fusion. The extensive simulation experiments demonstrate that PDFS can achieve high task classification accuracy, task completion rate, task data reliability and task participation rate, and low average error rate, while improving the privacy protection for data fusion under COVID-19 application environments based on IoMT.
Keywords: COVID-19, data fusion, deep reinforcement learning, Internet of Medical Things (IoMT), privacy protection
I. Introduction
With the application and development of the Internet of Things (IoT) technology in the medical field, the Internet of Medical Things (IoMT) that collects, processes, and analyzes the medical data generated by various IoT devices, has also seen rapid progress [1]. IoMT can effectively improve the accessibility and efficiency of disease treatment, reduce errors, improve patient experience, and provide lower costs [2]. Recently, the worldwide large-scale outbreak of COVID-19 has brought tremendous pressure and challenges to existing medical detection systems, and has put forward new requirements for the timeliness, accuracy, and reliability of medical detection data. In this situation, IoMT is expected to be used to collect and analyze the main symptoms of COVID-19 patients by providing large-scale real-time detection data and tracking the source of the disease outbreak [3]. However, since the widespread use of IoMT especially during the data fusion process will generate a large amount of sensitive information related to patients, and the leakage of private information will cause serious problems and affect people’s willingness to contribute data in IoMT, it is becoming more and more important yet challenging to design privacy-enhanced data fusion technologies for ensuring data privacy for COVID-19 applications in IoMT [4]–[6].
In the IoMT-based COVID-19 applications, various IoT-based medical detection equipment will generate a large amount of application data [7], [8]. According to the actual needs of the COVID-19 applications, these data need real-time processing for fast decision making. However, most existing IoMT systems store data in the cloud, completely relying on remote cloud servers for data processing and analysis [9]. As the number of IoMT devices and the generated data continues to increase, the network pressure grows and the delay increases, which may lead to failures or erroneous diagnosis and seriously affect COVID-19 data detection and service response. To overcome the above deficiencies and provide better services for COVID-19 applications, the traditional cloud IoMT architecture needs to be improved. Based on the above analysis, this article builds a new IoMT architecture MEC-IoMT combining IoMT and multiaccess edge computing (MEC) [10], [11]. As shown in Fig. 1, the new MEC-IoMT consists of three important components, i.e., intelligent medical data collection terminals, the multiaccess edge network, and the remote COVID-19 applications and services center. Specifically, the intelligent medical data collection terminals, such as cameras, electronic thermometer and wearable detection sensors, and so on, are responsible for intelligent collection of COVID-19 disease detection data. The multiaccess edge network composed of MEC servers and wireless access stations is employed to provide various COVID-19 applications, implement communication, and data exchange among MEC servers. Furthermore, the remote COVID-19 applications and services centers are responsible for the storage, processing, and analysis of large-scale COVID-19 disease detection data or detection results. In MEC-IoMT, first, pervasive smart data collection terminals are employed to collect various COVID-19 disease detection data by using the mobile-edge crowdsensing technology. Next, the collected data is transmitted over the wireless network to the COVID-19 applications deployed on the edge network servers, which implements the large scale and effective COVID-19 data fusion, analysis, and processing. Finally, the results of analysis and processing are sent to the individuals and COVID-19 control centers, which stores these data, further analyzes and processes the data, and forecasts the development trend of the COVID-19 disease. The MEC-IoMT architecture migrates services located in the remote cloud center to the distributed edge network, closer to the user, thereby reduces the service delay and communication overhead [12].
Fig. 1.

Architecture of MEC-IoMT.
In the prevention and treatment of COVID-19, the data fusion process consists of data collection, analysis, and processing. It is one of the most important links that decides whether the spreading can be controlled in time. At the same time, it is also the premise and basis for patients to be treated in time. However, the heterogeneous data in the data fusion process contain much privacy information related to patients, while the collection terminal and processing center cannot be fully trusted [13], [14]. They may launch active attacks, or passive attacks after being captured by the attacker, which lead to the leakage of private information. To address this challenge, we integrate artificial intelligence technology, such as deep deterministic policy gradient (DDPG) [11] into privacy strategy and propose a new privacy-enhanced data fusion strategy (PDFS) for IoMT. The main contributions of our work are as follows.
-
1)
To protect sensitive information from malicious test subjects, a novel task security level-based privacy-aware data fusion tasks classification mechanism is proposed to assure that a task can be accepted and the sensitive information in the task can be obtained only if the test subject’s security level is higher than that of the task.
-
2)
To design a reasonable task contract, a deep reinforcement learning algorithm, DDPG, is applied to reward/punish test subjects for their superior/poor performances in task completion and meanwhile to help the center for disease control (CDC) to set the appropriate payments with respect to test subjects’ performances. In addition, the data reliability is validated utilizing DDPG as well for validation accuracy improvement.
-
3)
To protect the test subject’s security from both the fusion center and the detection center, a homomorphic encryption-based data fusion mechanism is proposed by introducing random numbers for real identities perturbation to hide the true identities of test subjects in the data fusion process.
-
4)
The theoretical analysis and validation experiments demonstrate that: a) PDFS has advantages in task classification accuracy, average error rate, completion rate, data reliability, and participation rate compared with baseline strategies and b) PDFS is efficient against both task privacy attack and identity privacy attack.
II. Related Work
Data fusion, as one of the most important links in the prevention and treatment of the COVID-19 in Intelligent IoMT, has received extensive attention, and some relevant research results have emerged. In [15] and [16], researchers summarize the data security and privacy protection requirements and challenges in IoMT systems, and suggest the future directions for research on security and privacy. Tang et al. [5] proposed a privacy protection and incentives-based data fusion strategy to implement privacy security and fair incentives for contributing patients in the process of health data collection. Guan et al. [17] proposed a privacy preserving and authentication-based data fusion scheme to provide device-oriented anonymous privacy protection in fog-aided IoMT. Yang et al. [18] proposed a differential privacy and machine-learning-based multifunctional data fusion strategy to provide statistical fusion functions for IoMT applications. Li et al. [19] proposed a data fusion scheme supporting privacy preserving and publicly fusion result verification in IoT application systems such as IoMT. Wu et al. [20] proposed a novel data fusion mechanism to assist the fusion servers to realize the privacy-preserving data fusion by integrating fog computing and homomorphic encryption techniques. Yang et al. [21] proposed a blockchain-based privacy preservation framework, which uses the anonymous nature of blockchain to protect workers privacy during data fusion. Li et al. [22] proposed a novel decentralized framework to realize privacy preservation through the use of blockchain, pseudonym, and encryption-based distributed storage technology.
Although these works contribute to privacy-preserving data fusion in IoMT, there still remain two challenges: 1) how to prevent the leakage of private information contained in sensitive tasks and 2) how to prevent the different task receivers who accept the task from colluding to share the fragmented privacy contained in the task. In this article, a new PDFS is proposed to address these two problems.
III. System Model
In this article, a new PDFS is proposed to defend the collusion attacks and prevent the leakage of private information contained in sensitive tasks. As shown in Fig. 2, the system model of PDFS mainly considers three entities, i.e., the CDC, the test subjects, and the data fusion center (DFC).
Fig. 2.

System model of the proposed PDFS.
Specifically, the single CDC case is considered in this article. For COVID-19 surveillance, the CDC posts a series of health condition fusion task
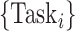 . Each task
. Each task
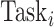 has one of
has one of
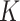 specific security levels and a corresponding payment. Once the task is completed, the CDC will determine whether to pay the test subjects based on the reliability reports provided by the DFC. In addition, PDFS includes two types of test subjects are considered, i.e., the type one test subjects, the
specific security levels and a corresponding payment. Once the task is completed, the CDC will determine whether to pay the test subjects based on the reliability reports provided by the DFC. In addition, PDFS includes two types of test subjects are considered, i.e., the type one test subjects, the
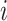 th of which is denoted by
th of which is denoted by
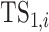 , are only responsible for providing the personal health condition data; and the type two test subjects, the
, are only responsible for providing the personal health condition data; and the type two test subjects, the
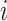 th of which is denoted by
th of which is denoted by
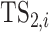 , provide health condition data of type one test subjects and their own as well. Due to the privacy concern, each test subject has a security level
, provide health condition data of type one test subjects and their own as well. Due to the privacy concern, each test subject has a security level
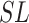 , i.e.,
, i.e.,
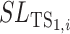 for a type one test subject while
for a type one test subject while
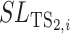 for a type two test subject. A task
for a type two test subject. A task
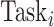 is accepted only if the security level of the task
is accepted only if the security level of the task
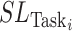 is inferior to that of a test subject, which is
is inferior to that of a test subject, which is
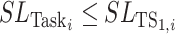 or
or
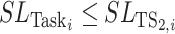 . The DFC, which is employed by the CDC and built on MEC servers with high-performance computing infrastructures, classifies the task set into groups according to the privacy requirements and performs the task completion assessment. Moreover, based on the assessment report, the DFC aids the task contract design by calculating the payment to the test subject who claims to have completed the task.
. The DFC, which is employed by the CDC and built on MEC servers with high-performance computing infrastructures, classifies the task set into groups according to the privacy requirements and performs the task completion assessment. Moreover, based on the assessment report, the DFC aids the task contract design by calculating the payment to the test subject who claims to have completed the task.
In general, to prevent the COVID-19, the CDC posts a series of data fusion tasks, i.e., gathering personal health data, for the COVID-19 vaccine development. Then, test subjects, who sign the contract of data fusion tasks, provide health data of their own or others’ to the CDC via DFC. Due to the privacy concern, test subjects might provide inaccurate health data or even fake ones. In this case, DFC assesses the reliability of each data to determine whether the test subject should be given the payment, i.e., the test subject whoever provides the reliable data will receive the payment. Due to the computation resources required in data reliability validation and contract design for data fusion task, all computations are implemented on MEC servers connected by the core networks.
We consider the privacy disclosure problem among all three entities: 1) the CDC; 2) the test subjects; and 3) the DFC. In fact, the CDC suffers the task privacy attack from both malicious test subjects and the DFC, while the test subjects are vulnerable to the identity privacy attack.
-
1)
Task Privacy Attack: The task privacy attack is defined as the unauthorized access launched by the malicious test subjects and the DFC to the sensitive information contained in tasks.
-
2)
Identity Privacy Attack: The identity privacy attack is defined as the test subjects’ true identities is disclosed and theft by malicious DFC and center for disease control.
IV. Implementation Details of the PDFS
The proposed PDFS consists of four important components, i.e., sensitive task classification, task completion assessment, task contract design, and homomorphic encryption-based data fusion.
A. Sensitive Task Classification
We develop a
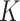 -means-based privacy-preserving classification mechanism for sensitive tasks partition with the task privacy hidden from DFC. Note that the traditional
-means-based privacy-preserving classification mechanism for sensitive tasks partition with the task privacy hidden from DFC. Note that the traditional
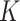 -means-based classification simply assigns each data to the nearest group center. For example, the Euclidean distance between a group
-means-based classification simply assigns each data to the nearest group center. For example, the Euclidean distance between a group
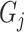 and a task
and a task
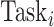 is calculated as
is calculated as
 |
where
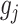 denotes the center of group
denotes the center of group
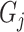 . Then, we compute the deviation of the distance from
. Then, we compute the deviation of the distance from
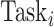 to group
to group
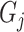 and the distance from
and the distance from
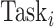 to group
to group
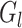 as
as
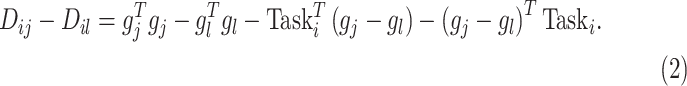 |
Obviously,
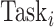 should be assigned to group
should be assigned to group
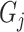 if
if
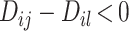 ; otherwise,
; otherwise,
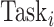 belongs to group
belongs to group
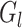 . The closest group center to each task
. The closest group center to each task
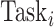 can be repeatedly identified
can be repeatedly identified
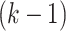 times. However, the DFC can directly obtain sensitive information contained in task
times. However, the DFC can directly obtain sensitive information contained in task
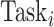 during the process that results in the privacy disclosure.
during the process that results in the privacy disclosure.
To solve this problem, a privacy-preserving k-means strategy is proposed to ensure the privacy protection of each task data
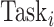 . The details are given as follows. DFC generates a set of fake centers
. The details are given as follows. DFC generates a set of fake centers
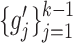 under the constraint that
under the constraint that
 |
where
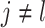 . Then, DFC sends the set of distances between fake centers, i.e.,
. Then, DFC sends the set of distances between fake centers, i.e.,
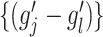 , to the CDC. For each task
, to the CDC. For each task
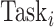 , the CDC calculates the perturbed task
, the CDC calculates the perturbed task
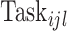 as
as
 |
where
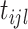 represents a random number used to perturb
represents a random number used to perturb
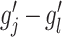 against the exposure of
against the exposure of
 . Then, the CDC sends each perturbed task
. Then, the CDC sends each perturbed task
 to the DFC. Accordingly, the distance deviation can be rewritten as
to the DFC. Accordingly, the distance deviation can be rewritten as
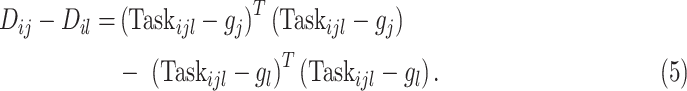 |
Similarly, if
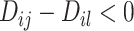 , then
, then
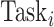 is assigned to group
is assigned to group
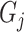 otherwise
otherwise
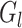 . This process is still repeated
. This process is still repeated
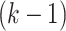 times to determine the nearest center to
times to determine the nearest center to
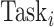 . Through the data perturbation, the DFC knows neither the original task
. Through the data perturbation, the DFC knows neither the original task
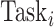 nor the group it belongs to such that the privacy of the CDC is preserved. The correctness of the propose privacy-preserving k-means-based classification is proved in the following theorem.
nor the group it belongs to such that the privacy of the CDC is preserved. The correctness of the propose privacy-preserving k-means-based classification is proved in the following theorem.
Theorem 1:
Both fake centers and data perturbation will not affect the result of the proposed privacy-preserving k-means strategy.
Proof:
We prove this theorem, by verifying whether the result of
calculated by our strategy is the same as that calculated by the original k-means algorithm.
For each perturbed task
, the distance deviation between
to center
and
can be calculated in the exactly form of (2) as
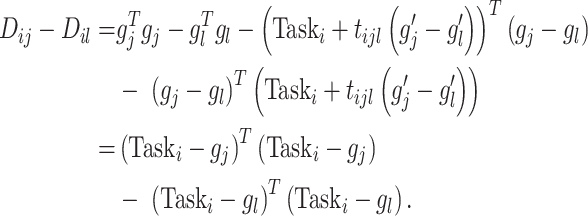
Once the classification is completed, each group
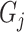 ,
,
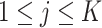 , is given a specific security level such that test subjects are only allowed to accept the tasks of corresponding security levels.
, is given a specific security level such that test subjects are only allowed to accept the tasks of corresponding security levels.
B. Task Contract Design
How much money should be paid for task fulfillment is determined by the CDC. In fact, two dominant factors should be considered in the payment determination. For example, test subjects might be reluctant accepting the tasks even if their security levels are above that of the task. That suggests the CDC should give an “appeal” offer to attract test subjects. On the other hand, even if test subjects are paid enough, their works could fail to reach the requirement, i.e., data provided by test subjects are unreliable. These two cases suggest the payment to the test subjects should be set dynamically with respect to the assessment of task completion.
To solve this problem, we develop a DRL-based task contract design utilizing the DDPG to meet the satisfaction of both CDC and test subjects. In fact, reinforcement learning algorithms, i.e., DQN, could be useful in discovering optimal strategies. However, the optimal threshold searching is implemented in a continuous space to ensure the assessment accuracy. That suggests traditional reinforcement learning-based methods cannot meet our requirement. For example, DQN can only work well in a discretized action space. We therefore apply the DDPG to learn the optimal threshold. In general, a DDPG decision system consists of a critic network
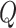 , a target critic network
, a target critic network
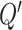 , an actor networks
, an actor networks
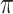 , and the corresponding target actor networks
, and the corresponding target actor networks
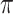 , the parameters of which are denoted by
, the parameters of which are denoted by
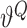 ,
,
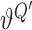 ,
,
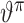 , and
, and
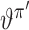 , respectively. In addition, the experience is stored in an experience pool
, respectively. In addition, the experience is stored in an experience pool
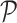 in the form of a transition of a quadruple
in the form of a transition of a quadruple
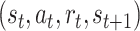 , the structure of the DDPG-based task contract design is given in Fig. 3.
, the structure of the DDPG-based task contract design is given in Fig. 3.
Fig. 3.

DDPG-based task contract design.
As a DRL, DDPG requires three basic components, i.e., state, action, and reward. The action is given at a state to obtain the reward and then the next state is observed from the environment. In the incentive mechanism design, we consider the triple
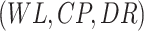 as a state
as a state
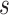 , where
, where
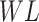 ,
,
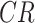 , and
, and
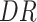 represent the workload, completion rate, and data reliability of the task, respectively. The payment
represent the workload, completion rate, and data reliability of the task, respectively. The payment
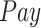 from the CDC to the test subject is used as the action
from the CDC to the test subject is used as the action
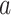 , while the reward is denoted by
, while the reward is denoted by
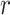 . This is because a test subject
. This is because a test subject
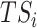 who accepts a task
who accepts a task
 might not complete
might not complete
 as he/she claims. Besides, the data aggregated in the
as he/she claims. Besides, the data aggregated in the
 could be unreliable. That indicates the ratio between the utility of the CDC
could be unreliable. That indicates the ratio between the utility of the CDC
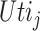 and the payment
and the payment
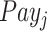 to the test subject on this task
to the test subject on this task
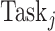 is eligible to determine whether the task completed by the test subject is worth the payment. Thus, we calculate the
is eligible to determine whether the task completed by the test subject is worth the payment. Thus, we calculate the
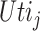 with the consideration of the workload of a specific task
with the consideration of the workload of a specific task
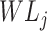 , the ratio of task completion
, the ratio of task completion
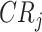 , and the reliability of data collected in the task
, and the reliability of data collected in the task
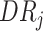 , i.e.,
, i.e.,
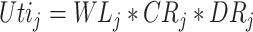 . Accordingly, in timeslot
. Accordingly, in timeslot
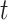 , the reward
, the reward
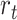 is calculated based on the state–action pair
is calculated based on the state–action pair
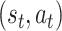 by
by
 |
As a DRL, the goal of DDPG is to find the optimal action
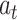 for each state
for each state
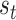 in order to maximize the reward
in order to maximize the reward
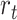 . Therefore, we choose the one of the maximal
. Therefore, we choose the one of the maximal
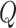 value, which is
value, which is
 |
Then, experience
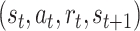 is stored in experience poor
is stored in experience poor
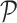 .
.
In the training process, we sample
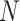 experience from
experience from
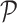 to update the critic network utilizing the following loss function:
to update the critic network utilizing the following loss function:
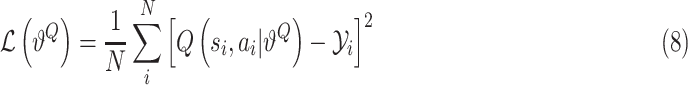 |
where
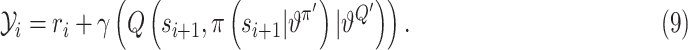 |
Accordingly, we update
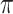 utilizing policy gradient as
utilizing policy gradient as
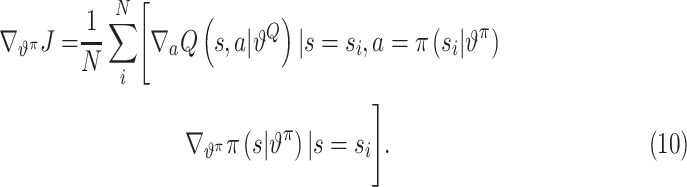 |
Target networks are copies of the actor
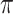 and critic
and critic
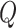 networks of different update rules. Once networks
networks of different update rules. Once networks
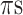 and
and
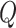 are updated, we then update the parameters of target networks
are updated, we then update the parameters of target networks
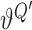 and
and
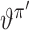 with a learning rate
with a learning rate
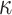
 |
It is worth to mention that the budget of the CDC is limited. That suggests if the test subject who accepts task
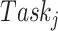 fails to provide reliable personal health data, then the payment
fails to provide reliable personal health data, then the payment
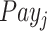 will be shared by other test subjects as a reward–punishment mechanism. We summarize task contract design in Algorithm 1.
will be shared by other test subjects as a reward–punishment mechanism. We summarize task contract design in Algorithm 1.
Algorithm 1 Task Contract Design With DDPG
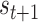
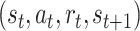
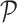
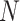
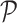
C. Task Completion Assessment
Once a test subject
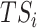 claims the data fusion task
claims the data fusion task
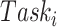 is complete, the task completion should be assessed to determine whether the
is complete, the task completion should be assessed to determine whether the
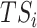 should be paid, i.e., the test subject who provides reliable data is paid according to the task contract designed in the previous section. Since more than one test subject of type two might be responsible for data fusion on the same group of test subjects of type two, the personal health data collected by each test subject should not deviate much from each other. That suggests the hypothesis test can be applied to validate the data reliability. We use
should be paid, i.e., the test subject who provides reliable data is paid according to the task contract designed in the previous section. Since more than one test subject of type two might be responsible for data fusion on the same group of test subjects of type two, the personal health data collected by each test subject should not deviate much from each other. That suggests the hypothesis test can be applied to validate the data reliability. We use
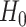 to represent the hypothesis of the data being reliable, while the data being unreliable is represented by the hypothesis
to represent the hypothesis of the data being reliable, while the data being unreliable is represented by the hypothesis
 . We define the false alarm rate (FAR) as the probability of judging a reliable data as an unreliable one. And the missing detection rate (MDR) is defined as the probability of judging an unreliable data as a reliable one. Then, we construct the test static as
. We define the false alarm rate (FAR) as the probability of judging a reliable data as an unreliable one. And the missing detection rate (MDR) is defined as the probability of judging an unreliable data as a reliable one. Then, we construct the test static as
 |
Note that no matter the test statistic is constructed as the deviation between the test data and the reference or the ratio of the deviation, the DRL algorithm DDPG employed by the proposed strategy PDFS can discover the optimal threshold considering the test cost, the FAR, and the MDR. Besides, all test data are normalized within the range of 0 to 1. According to (13), we know that the test statistic falls into the range of (0, 1) such that the searching space is significantly narrowed down. The hypothesis test is then followed as
 |
We update the reference
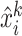 by
by
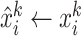 only if the data
only if the data
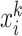 are reliable; otherwise, we let
are reliable; otherwise, we let
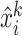 equal to
equal to
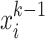 . The reason for that is as follows. It is difficult to determine the true value of the reference in each reliability validation process. Besides, there exists a certain resemblance between the data provided in two sequential timeslots, i.e., the
. The reason for that is as follows. It is difficult to determine the true value of the reference in each reliability validation process. Besides, there exists a certain resemblance between the data provided in two sequential timeslots, i.e., the
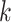 th timeslot and the
th timeslot and the
 th timeslot. Specifically, the data provided by two test subjects on a specific test subject should be resemble. That suggests the reliable data in the previous timeslot can be used as the reference in the current timeslot for data reliability validation at the beginning until another reliable data is found. Furthermore, if all data provided in the current timeslot fail to pass the validation process, then the reliable data in the previous timeslot could be used as the reference for the reliability validation in the next timeslot.
th timeslot. Specifically, the data provided by two test subjects on a specific test subject should be resemble. That suggests the reliable data in the previous timeslot can be used as the reference in the current timeslot for data reliability validation at the beginning until another reliable data is found. Furthermore, if all data provided in the current timeslot fail to pass the validation process, then the reliable data in the previous timeslot could be used as the reference for the reliability validation in the next timeslot.
The utility of the CDC, denoted by
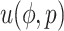 , is calculated as
, is calculated as
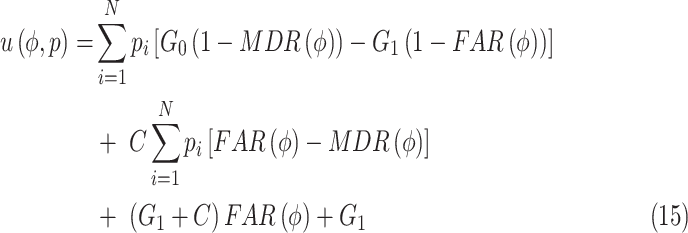 |
where
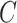 represents the validation cost;
represents the validation cost;
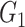 and
and
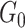 denote the gain of receiving a reliable data and an unreliable data, respectively; and
denote the gain of receiving a reliable data and an unreliable data, respectively; and
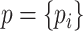 represents the probability set of data being unreliable.
represents the probability set of data being unreliable.
The hypothesis test in (14) determines the reliability of each data based on the test threshold
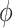 . Again, we apply DDPG for the optimal threshold estimation due to its advantage in continuous space searching. Accordingly, we first introduce the state space and action space. Let the state in the
. Again, we apply DDPG for the optimal threshold estimation due to its advantage in continuous space searching. Accordingly, we first introduce the state space and action space. Let the state in the
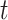 th time slot consist of the FAR and the MDR of validation in the previous time slot be denoted by
th time slot consist of the FAR and the MDR of validation in the previous time slot be denoted by
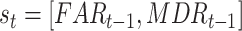 . For each state
. For each state
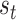 , each potential action
, each potential action
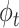 is chosen by
is chosen by
 |
where
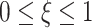 . Based on
. Based on
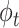 , we obtain the utility
, we obtain the utility
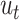 as
as
 |
Let
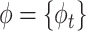 represent the action set. Thus, we choose the action of the maximal
represent the action set. Thus, we choose the action of the maximal
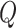 value by
value by
 |
Once the action
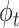 is taken, we can calculate utility
is taken, we can calculate utility
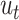 and observe the next state
and observe the next state
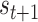 from the environment, meanwhile,
from the environment, meanwhile,
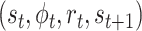 is stored in experience poor
is stored in experience poor
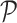 .
.
In the training process, we sample
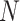 experience from
experience from
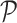 to update the critic network through the following loss function with
to update the critic network through the following loss function with
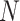 randomly sampled experience from
randomly sampled experience from
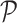 as:
as:
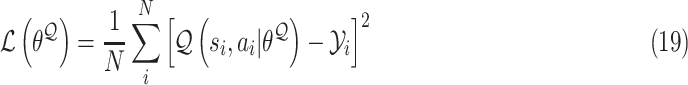 |
where
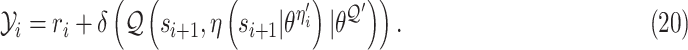 |
Then, the actor network is updated utilizing the policy gradient
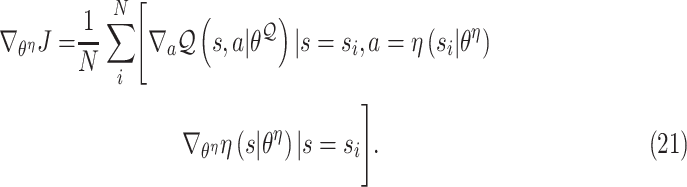 |
Then, the parameters of target networks
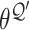 and
and
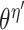 are updated with a learning rate
are updated with a learning rate
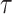 as
as
 |
We summarize the DDPG-based data reliability validation in Algorithm 2.
Algorithm 2 Data Reliability Validation Based on DDPG
for
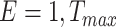 do
dofor
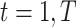 do
dofor
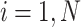 do
doCalculate
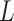 via (14)
via (14)if
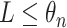 then
then
Output the
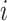 th data is reliable
th data is reliableelse
Output the
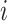 th data is unreliable
th data is unreliableend if
end for
Calculate the utility according to (17) and observe the
Store
 in experience poor
in experience poor
Randomly sample
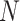 experiences from
experiences from
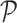
Update actor network via (21)
Update target networks via (22) and (23)
end for
end for
D. Homomorphic Encryption-Based Data Fusion
Once the reliability of personal health data is validated by the task completion assessment, all reliable data should be sent to the CDC. Due to the privacy concern, each test subject is unwilling to use his/her real identity. To achieve identity privacy, homomorphic encryption is employed in data fusion. And, the details are given as follows.
-
1)Encryption: CA generates a pair of public key
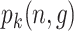 and private key
and private key
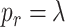 to encrypt the data
to encrypt the data
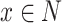 with a random number
with a random number
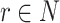 as
as 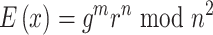
-
2)Decryption: The data
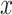 can be obtained by decrypting ciphertext
can be obtained by decrypting ciphertext
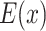 with private key
with private key
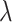 as
as
where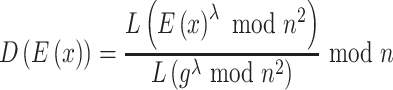
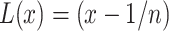 .
.
In fact, a Paillier cryptosystem has the following property:
 |
where
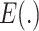 is the encryption function. Equation (24) allows us to design a three-steps data fusion mechanism without identity exposure. Let Idi denote the identity of the
is the encryption function. Equation (24) allows us to design a three-steps data fusion mechanism without identity exposure. Let Idi denote the identity of the
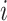 th test subject. Then, we introduce the data fusion mechanism as follows.
th test subject. Then, we introduce the data fusion mechanism as follows.
-
1)
DFC chooses a random number
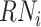 and encrypt it with the public key of the CDC, then sends
and encrypt it with the public key of the CDC, then sends
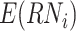 to the test subject.
to the test subject. -
2)
The test subject calculates a perturbed identity
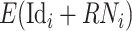 by
by
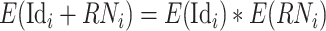 with CDC’s public key, then sends the data–identity pair (
with CDC’s public key, then sends the data–identity pair (
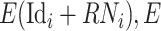 (data)) back to the DFC.
(data)) back to the DFC. -
3)
DFC signs the encrypted data–identity pair and relay it to the CDC.
According to (24), the DFC cannot decrypt the
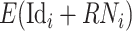 due to the lack of the private key of the CDC, meanwhile, the CDC can only obtain the perturbed identity
due to the lack of the private key of the CDC, meanwhile, the CDC can only obtain the perturbed identity
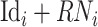 instead of the genuine one of the
instead of the genuine one of the
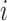 th test subject Idi. It is worth to mention that the perturbed identity generated by adding a random number to a specific real identity might accidentally be identical to the real identity of a certain test subject. In this case, according to such perturbation rule, the CDC might mistake that real identity as one of the perturbed ones. Thereby, the real identity is still kept from the CDC. However, in order to prevent this case and further improve the privacy preservation of test subjects, the random number is generated each time while new data are sent to the CDC.
th test subject Idi. It is worth to mention that the perturbed identity generated by adding a random number to a specific real identity might accidentally be identical to the real identity of a certain test subject. In this case, according to such perturbation rule, the CDC might mistake that real identity as one of the perturbed ones. Thereby, the real identity is still kept from the CDC. However, in order to prevent this case and further improve the privacy preservation of test subjects, the random number is generated each time while new data are sent to the CDC.
V. Performance Evaluation
A. Simulation Setup
The simulation is implemented to validate the performance of the proposed strategy PDFS in Python on a computer equipped with Intel Core i7 processor, 64-GB running memory, CPU frequency 6.4GHZ 64-bit win7 system. Table I gives the parameters of this simulation. The data set utilized is about the survival of 306 patients who experienced breast cancer surgery [25].
TABLE I. Experiment Parameter Setup.
 |
 |
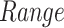 |
|---|---|---|
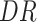 |
Data radius of normalized data | [0.05,0.5] |
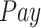 |
Normalized payment to test subjects | [0.1, 1] |
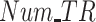 |
Number of task releaser | 1 |
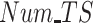 |
Number of test subjects | 500 |
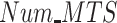 |
Number of malicious test subjects | [55, 100] |
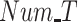 |
Number of tasks | [50, 500] |
1). Performance Index:
We validate the performance of PDFS in clustering accuracy, average error rate, completion rate, data reliability, and participation rate while considering different values of payment, the number of tasks, and data radius, respectively.
-
1)
Classification Accuracy: The deviation between the classification result of different classification algorithms.
-
2)
Average Error Rate: Both FAR and MDR compose the average error rate.
-
3)
Completion Rate: The ratio of the quantity of completed work to the entire work load.
-
4)
Data Reliability: The deviation between a data and the reference should be less than a proper threshold.
-
5)
Participation Rate: The percentage of test subjects who participate the data fusion tasks.
B. Experiment Results
1). Classification Accuracy:
Fig. 4 shows the comparison result of the classification accuracy among PDFS,
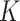 -means clustering, and SVM through calculating the positions of group centers established by these four methods. From the comparison result, it can be found that each pair of group centers are close to each other. Compared with
-means clustering, and SVM through calculating the positions of group centers established by these four methods. From the comparison result, it can be found that each pair of group centers are close to each other. Compared with
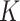 -means clustering and SVM, although PDFS adds perturbation into task information for privacy-preserving classification, the established task groups only differ slightly from that of either
-means clustering and SVM, although PDFS adds perturbation into task information for privacy-preserving classification, the established task groups only differ slightly from that of either
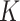 -means clustering or SVM. That suggests PDFS is more suitable for privacy-enhanced data fusion in MEC-IoMT.
-means clustering or SVM. That suggests PDFS is more suitable for privacy-enhanced data fusion in MEC-IoMT.
Fig. 4.

Clustering accuracy comparison.
2). Average Error Rate:
Fig. 5 shows how
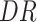 and
and
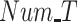 affect FAR and MDR while either DDPG, DQN, or
affect FAR and MDR while either DDPG, DQN, or
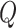 -learning is employed by PDFS. The comparison results of FAR of DDPG, DQN, and
-learning is employed by PDFS. The comparison results of FAR of DDPG, DQN, and
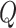 -learning are shown in Fig. 5(a), it can be found that because less data provided will results in a larger FAR, so the FAR of all three methods increase as the data radius at first and eventually gets stabilized for each approaches. In addition, it is obvious that the FAR of the proposed PDFS is lower than that of either DQN or Q-learning. The reason lies in that enough data will make the reliability validation more accurate, and then the FAR will drop. In PDFS, by using the DDPG, it can discover the optimal threshold for accurate data reliability assessment. So the FAR of the proposed PDFS is the lowest. The comparison results of MDR of the three methods are shown in Fig. 5(b). As observed from Fig. 5(b), we know that the data radius affects the DDPG much less than that to either DQN or Q-learning due to the similar reason of DDPG having a much less FAR compared with DQN and Q-learning. In Fig. 5(c) and (d), it is clear that the FAR of DDPG is only 6% on average compared with DQN 28% and
-learning are shown in Fig. 5(a), it can be found that because less data provided will results in a larger FAR, so the FAR of all three methods increase as the data radius at first and eventually gets stabilized for each approaches. In addition, it is obvious that the FAR of the proposed PDFS is lower than that of either DQN or Q-learning. The reason lies in that enough data will make the reliability validation more accurate, and then the FAR will drop. In PDFS, by using the DDPG, it can discover the optimal threshold for accurate data reliability assessment. So the FAR of the proposed PDFS is the lowest. The comparison results of MDR of the three methods are shown in Fig. 5(b). As observed from Fig. 5(b), we know that the data radius affects the DDPG much less than that to either DQN or Q-learning due to the similar reason of DDPG having a much less FAR compared with DQN and Q-learning. In Fig. 5(c) and (d), it is clear that the FAR of DDPG is only 6% on average compared with DQN 28% and
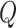 -Learning 34%, while the MDR of DDPG is less than 5% compared with DQN 10% and Q-Learning 16% on average as the growth of
-Learning 34%, while the MDR of DDPG is less than 5% compared with DQN 10% and Q-Learning 16% on average as the growth of
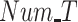 . This is because once the unreliable data is detected by either DDPG, DQN, or Q-Learning the reward–punishment mechanism will be executed to ensure the test subjects to provide more reliable data. The results in Fig. 5 indicate that DDPG is more effective in data reliability validation compared with DQN and
. This is because once the unreliable data is detected by either DDPG, DQN, or Q-Learning the reward–punishment mechanism will be executed to ensure the test subjects to provide more reliable data. The results in Fig. 5 indicate that DDPG is more effective in data reliability validation compared with DQN and
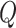 -Learning.
-Learning.
Fig. 5.

FAR and MDR while varying (a) and (b) data radius DR, (c) and (d) number of tasks Num_T.
3). Completion Rate:
Fig. 6 shows the completion rate of PDFS, PPCC [23], and REAP [24] under different value of payment and number of tasks. First, we compared the completion rates of the three methods with different values of
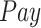 . As shown in Fig. 6(a), since the more rewards can get, the more people are willing to participate in test, so the completion rate of all the three methods increases with the increase of payment. Especially, the completion rate of PDFS is higher than the other two methods due to the reward–punishment mechanism employed by PDFS. Then, we compare the completion rate with different
. As shown in Fig. 6(a), since the more rewards can get, the more people are willing to participate in test, so the completion rate of all the three methods increases with the increase of payment. Especially, the completion rate of PDFS is higher than the other two methods due to the reward–punishment mechanism employed by PDFS. Then, we compare the completion rate with different
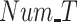 , the results are shown in Fig. 6(b), it is clear that PDFs obtain 78% completion rate on average compared with 55% of REAP and 58% of PPCC. Next, the completion rate is compared among three methods with different
, the results are shown in Fig. 6(b), it is clear that PDFs obtain 78% completion rate on average compared with 55% of REAP and 58% of PPCC. Next, the completion rate is compared among three methods with different
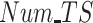 as shown in Fig. 6(c). It is obvious that PDFS outperforms baseline approaches with the highest completion rate 85% compared with 57% of PPCC and 53% of REAP. The reason is the proposed PDFS employs the DRL-based data reliability assessment for unreliable data detection, which makes the malicious test subjects receiving no payment as a punishment once they are detected providing unreliable data. So the PDFS is capable of ensuring the highest completion rate.
as shown in Fig. 6(c). It is obvious that PDFS outperforms baseline approaches with the highest completion rate 85% compared with 57% of PPCC and 53% of REAP. The reason is the proposed PDFS employs the DRL-based data reliability assessment for unreliable data detection, which makes the malicious test subjects receiving no payment as a punishment once they are detected providing unreliable data. So the PDFS is capable of ensuring the highest completion rate.
Fig. 6.
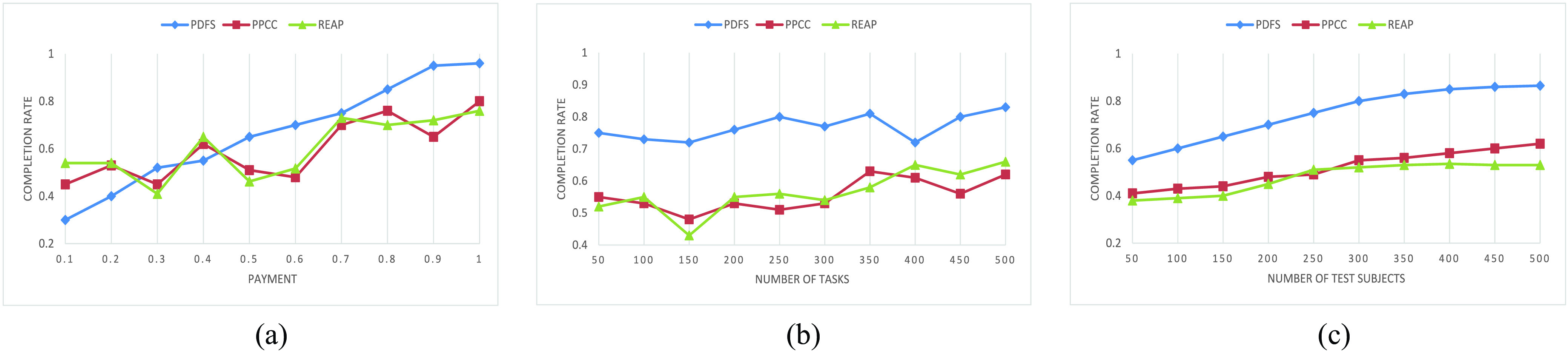
Completion rate while varying (a) payment
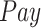 , (b) number of tasks
, (b) number of tasks
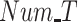 , and (c) number of test subjects
, and (c) number of test subjects
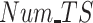 .
.
4). Data Reliability:
The reliability of the data will have a great impact on the accuracy and validity of the COVID-19 disease test results. Therefore, we compare the reliability of the data of the PPCC and REAP, PDFS with different values of payment and number of tasks. Fig. 7(a) shows the data reliability comparison results of the three methods under different values of payment, and it is obvious that data reliability increases with the payment for each approaches. That is because each test subject is willing to provide reliable if the CDC pays them enough. In addition, we can find that compared with PPCC and REAP, the proposed PDFS obtains the highest data reliability because it adopts the reward–punishment mechanism while the other methods do not use any measures to encourage test subjects participation. Moreover, from the results in Fig. 7(b), we can observed that PDFS achieves the highest data reliability 88% under different number of tasks, while PPCC and REAP only accomplish the data reliability of 58% and 60%, respectively.
Fig. 7.
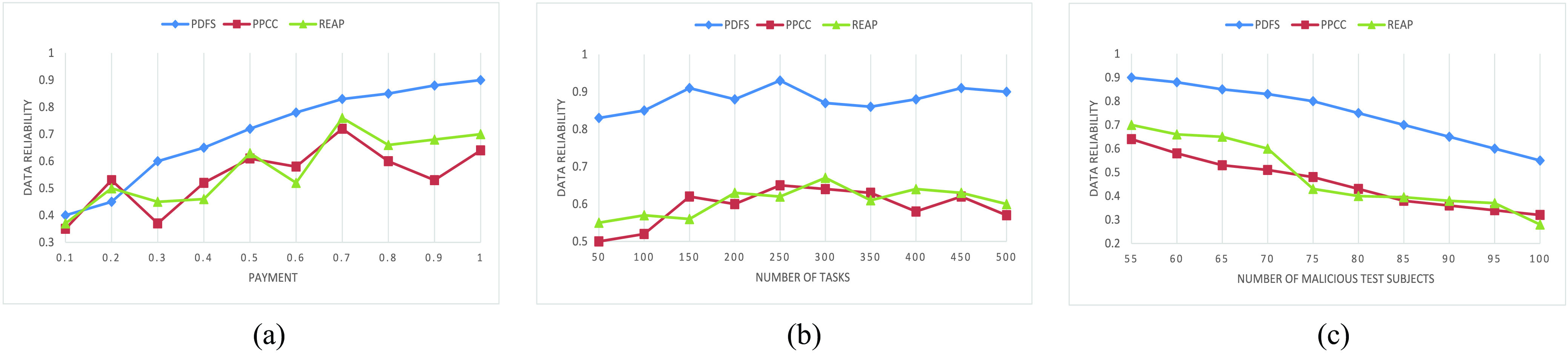
Data reliability while varying (a) payment
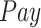 , (b) number of tasks
, (b) number of tasks
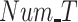 , and (c) number of malicious test subjects
, and (c) number of malicious test subjects
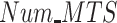 .
.
The impact of
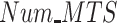 on data reliability is shown in Fig. 7(c). It is obvious that although data reliability decrease for all approaches as the
on data reliability is shown in Fig. 7(c). It is obvious that although data reliability decrease for all approaches as the
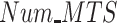 increases, the proposed PDFS still has the highest data reliability. The reason behind that is as follows. Even more malicious test subjects join in the data fusion tasks providing unreliable data, the proposed PDFS can efficiently detect unreliable data and refuses to pay malicious test subjects. No doubt that it is effective to impede malicious test subjects to provide unreliable data.
increases, the proposed PDFS still has the highest data reliability. The reason behind that is as follows. Even more malicious test subjects join in the data fusion tasks providing unreliable data, the proposed PDFS can efficiently detect unreliable data and refuses to pay malicious test subjects. No doubt that it is effective to impede malicious test subjects to provide unreliable data.
5). Participation Rate:
Fig. 8 shows the participation rate of PDFS, PPCC, and REAP under different values of
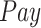 ,
,
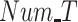 , and
, and
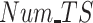 . First, we compared the participation rates of the three methods with different values of
. First, we compared the participation rates of the three methods with different values of
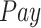 . As shown in Fig. 8(a), more rewards will encourage more test subjects to participate in data fusion task, so the participation rate of all the three methods increases with the growth of
. As shown in Fig. 8(a), more rewards will encourage more test subjects to participate in data fusion task, so the participation rate of all the three methods increases with the growth of
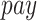 . Obviously, the participation rate of PDFS is higher than the other two methods due to the reward–punishment mechanism employed by PDFS. Then, we compare the participation rate with different
. Obviously, the participation rate of PDFS is higher than the other two methods due to the reward–punishment mechanism employed by PDFS. Then, we compare the participation rate with different
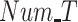 , the results are shown in Fig. 8(b). Finally, the participation rate is compared between all three methods with different
, the results are shown in Fig. 8(b). Finally, the participation rate is compared between all three methods with different
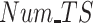 as shown in Fig. 8(c). It is obvious that the participation rate increases as the
as shown in Fig. 8(c). It is obvious that the participation rate increases as the
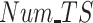 and gets stable eventually. The proposed PDFS obtains the highest participation rate 93% compared with 63% of PPCC and 60% of REAP due to PDFS adopts the dynamic payment instead of that depending on availability and privacy degree only as PPCC and REAP.
and gets stable eventually. The proposed PDFS obtains the highest participation rate 93% compared with 63% of PPCC and 60% of REAP due to PDFS adopts the dynamic payment instead of that depending on availability and privacy degree only as PPCC and REAP.
Fig. 8.
Participation rate while varying (a) payment
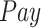 , (b) number of Tasks
, (b) number of Tasks
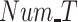 , and (c) number of Test Subjects
, and (c) number of Test Subjects
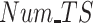 .
.
VI. Conclusion
In this article, aiming at the lack of internal attacks defense and privacy protection faced by the data fusion process, and the need to ensure the real time and accuracy of massive data collection, analysis, and processing required by the COVID-19 detection based on IoMT, a new PDFS is proposed. In PDFS,
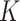 -means-based privacy-preserving classification mechanism, DRL-based incentive mechanism, DDPG-based task completion assessment method, and homomorphic encryption-based data fusion are deeply integrated into the data fusion process of the COVID-19 detection application to achieve the internal attacks defense and privacy protection of the CDC and test subjects. The simulation experimental results show that PDFS has advantages in task classification accuracy, average error rate, task completion rate, task data reliability, and task participation rate compared with contemporary strategies. The PDFS is efficient against internal collusion attack to enhance privacy security during the data fusion process while improve system performance according to actual needs.
-means-based privacy-preserving classification mechanism, DRL-based incentive mechanism, DDPG-based task completion assessment method, and homomorphic encryption-based data fusion are deeply integrated into the data fusion process of the COVID-19 detection application to achieve the internal attacks defense and privacy protection of the CDC and test subjects. The simulation experimental results show that PDFS has advantages in task classification accuracy, average error rate, task completion rate, task data reliability, and task participation rate compared with contemporary strategies. The PDFS is efficient against internal collusion attack to enhance privacy security during the data fusion process while improve system performance according to actual needs.
Biographies

Hui Lin received the Ph.D. degree in computing system architecture from the College of Computer Science, Xidian University, Xi’an, China, in 2013.
He is a Professor with the College of Mathematics and Informatics, Fujian Normal University, Fuzhou, China, where he is currently an M.E. Supervisor. He has published more than 50 papers in international journals and conferences. His research interests include mobile cloud computing systems, blockchain, and network security.

Sahil Garg (Member, IEEE) received the Ph.D. degree from the Thapar Institute of Engineering and Technology, Patiala, India, in 2018, where he was the recipient of a prestigious Visvesvaraya Ph.D. Fellowship from the Ministry of Electronics and Information Technology, Government of India.
He is currently a Postdoctoral Research Fellow with École de Technologie Supérieure, Montreal, Canada, and a MITACS Intern with the Global AI Accelerator, Ericsson, Montreal, QC, Canada. He is also a Visiting Researcher with the School of Computer Science and Engineering, Nanyang Technological University, Singapore. His research interests are mainly in the areas of machine learning, big data analytics, knowledge discovery, cloud computing, Internet of Things, software defined networking, and vehicular ad-hoc networks. He has over 60 publications in high ranked journals and conferences, including more than over 40 top-tier journal papers and over 20 reputed conference articles. He has been awarded the IEEE ICC Best Paper Award in 2018. He is currently a Managing Editor of Human-Centric Computing and Information Sciences journal (Springer). In addition, he also serves as the Workshops and Symposia Officer for the IEEE ComSoc Emerging Technology Initiative on Aerial Communications. He also serves as the special Sessions/Workshop Chair and Publication Chair for CCCI’20 and ICICC’20. He is also the Workshop Chair/Publicity Co-Chair for several IEEE/ACM conferences, including IEEE Infocom, IEEE Globecom, IEEE ICC, and ACM MobiCom. He Guest Edited/Editing a number of special issues in top-cited journals, including IEEE Transactions on Intelligent Transportation Systems, IEEE Transactions on Industrial Informatics, IEEE Internet of Things Journal, IEEE Network Magazine, Future Generation Computer Systems (Elsevier), and Neural Computing and Applications (Springer). He is also an Associate Editor of IEEE Network Magazine, IEEE Systems Journal, Future Generation Computer Systems (Elsevier), Applied Soft Computing (Elsevier), and International Journal of Communication Systems (Wiley). He is a Member of ACM and IAENG, and also actively involved in various technical societies, including IEEE Communications Society, IEEE Computer Society, IEEE Industrial Electronics Society, and IEEE Smart Grid Community.

Jia Hu received the B.Eng. and M.Eng. degrees in electronic engineering from the Huazhong University of Science and Technology, Wuhan, China, in 2006 and 2004, respectively, and the Ph.D. degree in computer science from the University of Bradford, Bradford, U.K., in 2010.
He is a Senior Lecturer of Computer Science with the University of Exeter, Exeter, U.K. His research interests include edge-cloud computing, resource optimization, applied machine learning, and network security. He has published over 70 research papers within the above areas in prestigious international journals and reputable international conferences.
Dr. Hu has received the Best Paper Awards at IEEE SOSE’16 and IUCC14. He serves on the editorial board of Computers and Electrical Engineering (Elsevier) and has guest-edited many special issues on major international journals, such as IEEE Internet of Things Journal, Computer Networks, and Ad Hoc Networks. He has served as the General Co-Chair of IEEE CIT’15 and IUCC’15, and the Program Co-Chair of IEEE ISPA’20, ScalCom’19, SmartCity’18, CYBCONF’17, and EAI SmartGIFT’2016.

Xiaoding Wang received the Ph.D. degree from the College of Mathematics and Informatics, Fujian Normal University, Fuzhou, China, in 2016.
He is an Associate Professor with the School of Fujian Normal University. His main research interests include network optimization and fault tolerance.

Md. Jalil Piran (Member, IEEE) received the Ph.D. degree in electronics engineering from Kyung Hee University, Seoul, South Korea, in 2016.
He is an Assistant Professor with the Department of Computer Science and Engineering, Sejong University, Seoul. Subsequently, he continued his work as a Postdoctoral Research Fellow in the field of Resource Management and Quality of Experience in 5G and Beyond and Internet of Things with the Networking Laboratory, Kyung Hee University. He published substantial number of technical papers in well-known international journals and conferences in research fields of wireless communications and networking, Internet of Things, multimedia communication, applied machine learning, security, and smart grid.
Dr. Piran received the IAAM Scientist Medal of the year 2017 for notable and outstanding research in the field of New Age Technology and Innovation, Stockholm, Sweden. Moreover, he has been recognized as the Outstanding Emerging Researcher by the Iranian Ministry of Science, Technology, and Research in 2017. In addition, his Ph.D. dissertation has been selected as the Dissertation of the Year 2016 by the Iranian Academic Center for Education, Culture, and Research in the field of Electrical and Communications Engineering. In the worldwide communities, he has been an Active Member of the Institute of Electrical and Electronics Engineering since 2010, an Active Delegate from South Korea in Moving Picture Experts Group since 2013, and an Active Member of the International Association of Advanced Materials since 2017.
M. Shamim Hossain (Senior Member, IEEE) received the Ph.D. degree in electrical and computer engineering from the University of Ottawa, Ottawa, ON, Canada, in 2019.
He is a Professor with the Department of Software Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, Saudi Arabia. He is also an Adjunct Professor with the School of Electrical Engineering and Computer Science, University of Ottawa. He has authored and coauthored more than 300 publications, including refereed journals conference papers, books, and book chapters. Recently, he co-edited a book Connected Health in Smart Cities (Springer). His research interests include cloud networking, smart environment (smart city and smart health), AI, deep learning, edge computing, Internet of Things, multimedia for healthcare, and multimedia big data.
Prof. Hossain currently serves as a Lead Guest Editor of IEEE Network, the ACM Transactions on Internet Technology, the ACM Transactions on Multimedia Computing, Communications, and Applications, and Multimedia Systems. He is on the editorial board of several SCI/ISI-indexed journals/transactions, including the IEEE Transactions on Multimedia, IEEE Multimedia, IEEE Network, IEEE Wireless Communications, IEEE Access, the Journal of Network and Computer Applications (Elsevier), and the International Journal of Multimedia Tools and Applications (Springer). He is a Senior Member of ACM.
Funding Statement
This work was supported by the Deanship of Scientific Research at King Saud University, Riyadh, Saudi Arabia, through the Vice Deanship of Scientific Research Chairs: Chair of Pervasive and Mobile Computing.
Contributor Information
Hui Lin, Email: linhui@fjnu.edu.cn.
Sahil Garg, Email: sahil.garg@ieee.org.
Jia Hu, Email: j.hu@exeter.ac.uk.
Xiaoding Wang, Email: wangdin1982@fjnu.edu.cn.
Md. Jalil Piran, Email: piran@sejong.ac.kr.
M. Shamim Hossain, Email: mshossain@ksu.edu.sa.
References
- [1].Islam S. M. R., Kwak D., Kabir M. H., Hossain M., and Kwak K. S., “The Internet of Things for health care: A comprehensive survey,” IEEE Access, vol. 3, pp. 678–708, 2015. [Google Scholar]
- [2].Baker S. B., Xiang W., and Atkinson I., “Internet of Things for smart healthcare: Technologies, challenges, and opportunities,” IEEE Access, vol. 5, pp. 26521–26544, 2017. [Google Scholar]
- [3].Yang T., Gentile M., Shen C. F., and Cheng C. M., “Combining point-of-care diagnostics and Internet of Medical Things (IoMT) to combat the COVID-19 pandemic,” Diagnostics, vol. 10, no. 4, p. 224, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Wang R., Liu H., Wang H., Yang Q., and Wu D., “Distributed security architecture based on blockchain for connected health: Architecture, challenges, and approaches,” IEEE Wireless Commun., vol. 26, no. 6, pp. 30–36, Dec. 2019. [Google Scholar]
- [5].Tang W., Ren J., Deng K., and Zhang Y., “Secure data aggregation of lightweight E-healthcare IoT devices with fair incentives,” IEEE Internet Things J., vol. 6, no. 5, pp. 8714–8726, Oct. 2019. [Google Scholar]
- [6].Sun Y., Lo F. P. W., and Lo B., “Security and privacy for the Internet of Medical Things enabled healthcare systems: A survey,” IEEE Access, vol. 7, pp. 183339–183355, 2019. [Google Scholar]
- [7].Hossain M. S., Muhammad G., and Guizani N., “Explainable AI and mass surveillance system-based healthcare framework to combat COVID-I9 like pandemics,” IEEE Netw., vol. 34, no. 4, pp. 126–132, Jul./Aug. 2020. [Google Scholar]
- [8].Rahman M. A., Hossain M. S., and Alrajeh N. A., “Adversarial examples—Security threats to COVID-19 deep learning systems in medical IoT devices,” IEEE Internet Things J., early access, Aug. 3, 2021, doi: 10.1109/JIOT.2020.3013710. [DOI] [PMC free article] [PubMed]
- [9].Hossain M. S., “Cloud-supported cyber–physical localization framework for patients monitoring,” IEEE Syst. J., vol. 11, no. 1, pp. 118–127, Mar. 2017. [Google Scholar]
- [10].Abbas N., Zhang Y., Taherkordi A., and Skeie T., “Mobile edge computing: A survey,” IEEE Internet Things J., vol. 5, no. 1, pp. 450–465, Feb. 2018. [Google Scholar]
- [11].Guo X., Lin H., Li Z., and Peng M., “Deep-reinforcement-learning-based QoS-aware secure routing for SDN-IoT,” IEEE Internet Things J., vol. 7, no. 7, pp. 6242–6251, Jul. 2020. [Google Scholar]
- [12].Farahani B., Firouzi F., Chang V., Badaroglu M., Constant N., and Mankodiya K., “Towards fog-driven IoT eHealth: Promises and challenges of IoT in medicine and healthcare,” Future Gener. Comput. Syst., vol. 78, pp. 659–676, Jan. 2018. [Google Scholar]
- [13].He D., Ye R., Chan S., Guizani M., and Xu Y., “Privacy in the Internet of Things for smart healthcare,” IEEE Commun. Mag., vol. 56, no. 4, pp. 38–44, Apr. 2018. [Google Scholar]
- [14].Hu J., Lin H., Guo X., and Yang J., “DTCS: An integrated strategy for enhancing data trustworthiness in mobile crowdsourcing,” IEEE Internet Things J., vol. 5, no. 6, pp. 4663–4671, Dec. 2018. [Google Scholar]
- [15].Hathaliya J. J. and Tanwar S., “An exhaustive survey on security and privacy issues in healthcare 4.0,” Comput. Commun., vol. 153, pp. 311–335, Mar. 2020. [Google Scholar]
- [16].Sun W., Cai Z., Li Y., Liu F., Fang S., and Wang G., “Security and privacy in the medical Internet of Things: A review,” Security Commun. Netw., vol. 2018, Mar. 2018, Art. no. 5978636. [Google Scholar]
- [17].Guan Z.et al. , “APPA: An anonymous and privacy preserving data aggregation scheme for fog-enhanced IoT,” J. Netw. Comput. Appl., vol. 125, pp. 82–92, Jan. 2019. [Google Scholar]
- [18].Yang M., Zhu T., Liu B., Xiang Y., and Zhou W., “Machine learning differential privacy with multifunctional aggregation in a fog computing architecture,” IEEE Access, vol. 6, pp. 17119–17129, 2018. [Google Scholar]
- [19].Li T., Gao C., Jiang L., Pedrycz W., and Shen J., “Publicly verifiable privacy-preserving aggregation and its application in IoT,” J. Netw. Comput. Appl., vol. 126, pp. 39–44, Jan. 2019. [Google Scholar]
- [20].Wu H., Wang L., Xue G., “Privacy-aware task allocation and data aggregation in fog-assisted spatial crowdsourcing,” IEEE Trans. Netw. Sci. Eng., vol. 7, no. 1, pp. 589–602, Jan.–Mar. 2020. [Google Scholar]
- [21].Yang M., Zhu T., Liang K., Zhou W., and Deng R. H., “A blockchain-based location privacy-preserving crowdsensing system,” Future Gener. Comput. Syst., vol. 94, pp. 408–418, May 2019. [Google Scholar]
- [22].Li M.et al. , “CrowdBC: A blockchain-based decentralized framework for crowdsourcing,” IEEE Trans. Parallel Distrib. Syst., vol. 30, no. 6, pp. 1251–1266, Jun. 2019. [Google Scholar]
- [23].Wang X., He J., Cheng P., and Chen J., “Privacy preserving collaborative computing: Heterogeneous privacy guarantee and efficient incentive mechanism,” IEEE Trans. Signal Process., vol. 67, no. 1, pp. 221–233, Jan. 2019. [Google Scholar]
- [24].Zhang Z., He S., Chen J., and Zhang J., “REAP: An efficient incentive mechanism for reconciling aggregation accuracy and individual privacy in crowdsensing,” IEEE Trans. Inf. Forensics Security, vol. 13, pp. 2995–3007, 2018. [Google Scholar]
- [25].Lim T. S.. (1999). Haberman’s Survival Data Set. [Online]. Available: http://archive.ics.uci.edu/ml/datasets/Haberman [Google Scholar]