

Abstract
During the outbreak of the Coronavirus disease 2019 (COVID-19), while bringing various serious threats to the world, it reminds us that we need to take precautions to control the transmission of the virus. The rise of the Internet of Medical Things (IoMT) has made related data collection and processing, including healthcare monitoring systems, more convenient on the one hand, and requirements of public health prevention are also changing and more challengeable on the other hand. One of the most effective nonpharmaceutical medical intervention measures is mask wearing. Therefore, there is an urgent need for an automatic real-time mask detection method to help prevent the public epidemic. In this article, we put forward an edge computing-based mask (ECMask) identification framework to help public health precautions, which can ensure real-time performance on the low-power camera devices of buses. Our ECMask consists of three main stages: 1) video restoration; 2) face detection; and 3) mask identification. The related models are trained and evaluated on our bus drive monitoring data set and public data set. We construct extensive experiments to validate the good performance based on real video data, in consideration of detection accuracy and execution time efficiency of the whole video analysis, which have valuable application in COVID-19 prevention.
Keywords: Coronavirus disease 2019 (COVID-19), deep learning, edge computing, Internet of Things (IoT), mask identification, public health prevention
I. Introduction
The Coronavirus disease 2019 (COVID-19) caused by the severe acute respiratory syndrome Coronavirus 2 (SARS-CoV-2) has given rise to a global epidemic [1]. According to the report of World Health Organization (WHO) on the 3rd July, 2020, there were over more than 10 million confirmed cased and 500 thousand deaths, which are alarming numbers [2]. Besides, the growing number still reminds us that we need to take preventive measures. Based on previous studies and measures taken in many regions [3], mask wearing is proved to be an effective nonpharmaceutical intervention measure, which is noninvasive, convenient, and cheap to lower the infection and spread of COVID-19 [4]. Especially in China, a populous country with Mega cities, the interaction and contact between people are frequent in the process of daily travel and work. If there is no timely prevention, the possibility of infection is higher. Therefore, it is essential to develop a method to automatically detect mask wearing, which can prevent public epidemic.
During COVID-19, as one of the public transportation, bus is not only a common way to travel but also a public place where people gather. Due to the crowd, some medical prevention measures have been taken, including sterilization on time and social distance of passengers. Besides, bus drivers are more likely to have certain interactions with passengers. Therefore, it is necessary for bus drivers to detect mask wearing for the prevention and control of COVID-19.
For the past few years, as the technology of the Internet of Things (IoT) is developing rapidly [5], the data sensing, collection, and analysis become efficient [6]. IoT will bring revolutionary changes to work and life [7], [8]. Online interactive classrooms have difficulties with large bandwidth, long link transmission, and wide coverage. Alibaba Cloud uses IoT and mobile-edge computing (MEC) to provide services on the edge of the network closer to the terminal, which significantly improves the overall low-latency and strong interactive experience in interactive classroom business scenarios. For some campus monitoring scenarios, Huawei uses IoT to solve the problem that WiFi/fiber cannot be used in the factory environment, which prevents data from leaving the campus. In the medical field, the application of IoT is typically named IoMT, which makes a significant contribution to healthcare systems from medical monitoring to smart sensors [9], [10]. Meanwhile, deep learning and artificial intelligence applications with high computational overhead could be implemented and applied in the real industry environment [11], [12]. In particular, under the low-cost and low-power processing capabilities of camera sensing devices, video analysis is not processed directly on the device. Instead, the video data can be transmitted to the cloud service platform for analysis through cloud computing [13], which shortens a degree of analysis time.
However, the actual application has higher requirements for real-time performance, especially in healthcare systems. For example, time-effective alerting and notification to patients can ensure preventive care and medical management [14]. Facing a huge amounts of data generated by edge devices, video analysis through cloud computing requires a large amount of bandwidth, which results in the latency for detection. Therefore, edge computing is proposed to execute deep learning with high computational overhead and reduce the network latency by data transmission [15]. With the rise of edge computing, it has become possible to improve efficiency of the various tasks [16], [17]. Besides, due to the limitation of single edge device, cooperation in edge computing is considered to take full advantage of storage computing power [18]. As shown in Fig. 1, the whole process of cooperative edge computing mainly consists of terminal equipment and cooperative edge devices, which perform the calculation of required algorithms. Near the data source, that is, the edge of the network, the shared resources are deployed to perform computation and inference on the edge device [19].
Fig. 1.

Basic paradigm of cooperative edge computing under IoT.
The latest advances in computer vision provide opportunities for practical healthcare applications. Among them, deep neural networks (DNNs), particularly convolutional neural networks (CNNs), have wide application in various fields, such as object detection, image segmentation, and image classification. Benefiting from them, face detection, as one of the object detection, has made much progress from two aspects of face detection accuracy and speed [20]–[24]. However, in order to expand coverage and lower costs, camera sensing devices cannot guarantee the high-quality images that lead to some problems, such as noise, blur, and shake for industrial applications. Therefore, it is necessary to improve the video superresolution, which is video restoration (VR) [25]. Different from image restoration, there exists a temporal correlation among neighboring frames of video. After VR, the low-quality video is improved, and subsequent detection and recognition are more reliable and accurate.
In this article, we describe our efforts to propose a framework of the mask identification on the facial image (ECMask) to identify mask wearing in real-time during COVID-19 based on edge computing. First, based on real video data of bus driver monitoring, we utilize blur detection method and VR to improve detection accuracy for the video data with blur problems from low-cost cameras, which could be regarded as a part of the video preprocessing. Then, the face detector is trained and verified by the public data sets and our bus drive monitoring data set. After obtaining and cropping face areas of the bus drive monitoring data set, the mask identification model can be trained, which is also the image classification task of faces (a binary classification), that is, those who wear a mask (wearing correctly, masked) and those who are not (including wearing incorrectly, nonmasked). Finally, in order to achieve edge computing of the above deep learning models on a low-cost device, the Intel Neural Compute Stick 2 (NCS) is added in edge devices and used to accelerate the models through its high performance operation.
The main contributions can be summarized as follows.
-
1)
We present a framework, edge computing-based mask (ECMask), to detect mask wearing with deep learning, including VR, face detection, and mask identification, which is able to prevent infection of COVID-19 and provide public health precaution reminders in real time.
-
2)
We apply edge computing in the video analysis process to enhance the effectiveness of detection and identification at the edge devices through Intel NCS.
-
3)
We have constructed comprehensive experiments to verify the excellent efficiency of our ECMask. Based on the real bus drive monitoring data set, the outcomes indicate that VR can heighten detection accuracy, and the edge computing-based method has excellent performance in inference time efficiency of the whole video analysis.
The remainder of this article is structured as follows. In Section II, we briefly introduce the related work. Section III mainly explains the details of our proposed model and framework (ECMask). Data description and analysis of experiment result will be given in Section IV. Finally, we will conclude and provide further discussion in Section V.
II. Related Work
In this section, we illustrate the existing works closely related to the content of this article.
A. IoMT With Edge Computing
As an emerging field of research, edge computing plays a significant role in IoMT, due to its advantages, including faster processing data, reducing the budget, offloading network traffic, improving application efficiency, and security and privacy protection. Pace et al. [26] proposed an IoMT system architecture, BodyEdge, which was designed to support different healthcare scenarios, including workers in a factory, athletes, and patients in a hospital. Focusing on sustainability and energy utilization, Han et al. [27] proposed a clustering model for medical applications (CMMAs) for cluster head selection, which considered additional factors specially for the IoMT network, such as capacity and queue of the medical devices. Dong et al. constructed an edge computing-based healthcare system in IoMT, which applied Nath bargaining solution in intra-WBANs and developed a noncooperative game-based decentralized method to minimize the costs in beyond-WBANs. Besides, the deep learning model can also be combined with edge computing in IoMT. Pustokhina et al. [28] proposed an effective training scheme for the deep learning neural network (ETS-DNN) in edge computing-enabled IoMT systems, which incorporated a hybrid modified water wave optimization technique to improve the healthcare system efficiency.
B. Video Restoration
As deep learning is developing gradually, the realization of the superresolution of images and videos becomes better. On the one hand, as the pioneering work, SRCNN [29] designed a simple architecture with CNN, which achieved the optimal efficiency in terms of image superresolution. From here, more and more related work about image superresolution was inspired [30]. On the other hand, video superresolution contains more temporal information that is different from image superresolution and leads to the challenge of temporal alignment and fusion. Tian et al. [31] proposed TDAN, which introduces deformable convolutions, instead of computing optical flow, to address the problem about temporal alignment of the frames of video. Xue et al. [32] proposed TOFlow, which estimated the optical flow field and used a flow image as a motion representation. For video deblurring, Su et al. [33] introduced a deep learning solution to fuse the neighboring frames, which lessen the requirements for accurate temporal alignment. In [25], enhanced deformable convolution (EDVR) was proposed to solve the problem of video superresolution and deblurring, which utilized pyramid structure with deformable convolution and attention mechanism to improve efficiency. In our ECMask, we focus on the effect of VR when needed. Therefore, considering the computational overhead of the whole process, we try to employ EDVR to improve the subsequent detection and identification, if the raw video data have problems, such as noise and blur.
C. Face Detection
Face detectors based on CNN have been extensively studied in recent years. Zhang et al.
[24] developed a multitask cascaded architecture using CNN to extract the locations of the face and landmark from coarse to fine. Following that Faster R-CNN [34] proposed the concept of the anchor, it was widely used in object detectors to ensure accuracy and speed up at the same time, including face detectors. Besides, the pyramid network structure can improve the small object detection. Zhang et al.
[35] put forward a novel face detector, named single shot scale-invariant (
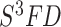 ), which uses different scale anchors at different convolutional layers and lowers threshold to enhance the recall rate of tiny faces outline detection. Moreover, the contextual information is important in face detection. For example, Najibi et al.
[36] introduced the single stage headless (SSH) face detector, which integrates context layers into the detection modules to improve the mean average precision. Meanwhile, to apply detectors to the actual system, real time is an important consideration. Redmon et al.
[37] proposed YOLO, which is an anchor-based detector and can select feature maps directly to achieve real-time performance. In [38], anchor-based FaceBoxes designed the rapidly digested convolutional layers (RDCLs) for acceleration on the CPU devices to ensure real time. Inspired by FaceBoxes, our ECMask adopts C.ReLu [39] and inception module [40] to achieve real time of face detection.
), which uses different scale anchors at different convolutional layers and lowers threshold to enhance the recall rate of tiny faces outline detection. Moreover, the contextual information is important in face detection. For example, Najibi et al.
[36] introduced the single stage headless (SSH) face detector, which integrates context layers into the detection modules to improve the mean average precision. Meanwhile, to apply detectors to the actual system, real time is an important consideration. Redmon et al.
[37] proposed YOLO, which is an anchor-based detector and can select feature maps directly to achieve real-time performance. In [38], anchor-based FaceBoxes designed the rapidly digested convolutional layers (RDCLs) for acceleration on the CPU devices to ensure real time. Inspired by FaceBoxes, our ECMask adopts C.ReLu [39] and inception module [40] to achieve real time of face detection.
III. Design of Framework
This details of the procedures and modules will be illustrated in our proposed ECMask shown in Fig. 2.
Fig. 2.

Architecture of our ECMask.
A. Overview
ECMask is shown in Fig. 2 and mainly includes model training and real-time video analysis at the edge nodes. According to the goal of video analysis, ECMask needs to train three models, including VR, face detection, and mask identification after collecting and preprocessing our bus drive monitoring data set and the public data set. These trained models will be deployed on the edge devices, which are also optimized to maximize the performance. Therefore, in the framework, monitoring data will be transmitted to high-performance equipment for auxiliary model training, and then transmitted to the edge equipment for real-time inspection. To be specific, in the part of real-time video analysis, we will execute the video blur detection with the Laplacian operator to determine whether VR is needed, which can reduce the huge computational overhead brought by VR. Then, the real-time video data are inputted on the subsequent models to obtain the results of detection and identification, which are transmitted back to show to management.
B. Model Inference With Cooperative Edge Computing
The high computing power is required in the most effective deep learning algorithms. In thes traditional research, there may be no concern about power consumption and computational complexity. However, in actual application and deployment, it is a challenging task, which has led to the demand for low cost but powerful inference processors for deep learning. Therefore, edge computing has been promoted and become popular due to its ability of low network latency, and privacy protection with low cost. In our framework, we apply Intel’s NCS in the edge computing device, which is a small USB 3.0 Type-A deep learning device and can be used in computer vision methods at the edge and IoT. Compared with CPU, its Intel Movidius Myriad vision processing unit (VPU) is a chip, which is dedicated to computer vision. It has low-power consumption to process images and videos, thus can be regarded as a micro GPU to accelerate calculation in neural networks. Besides, the OpenVINO toolkit provides model optimizer, inference engine, and distributed computing, which will be used with multiple NCSs to implement cooperative edge computing. The trained deep learning model is optimized and stored in NCSs with the inference engine. In the end, the input video data are obtained from the connected camera devices.
C. Video Restoration
The first stage of ECMask is to restore and deblur the raw video data to enhance the accuracy of subsequent detection. Therefore, we employ the VR framework with EDVRs as the first stage of ECMask due to its good performance in VR. The architecture of EDVR mainly includes four modules, such as PreDeblur module, PCD alignment module, TSA fusion module, and Reconstruction module.
-
1)
The PreDeblur module is similar to the encoder–decoder network, which is a pyramid structure and consists of downsampling layers using convolution layers of two stride and upsampling layers. Furthermore, the feature map is extracted through the residual block at each layer of the pyramid. In this way, the frames of video can be deblurred, which is the preprocessing part before the alignment module and fusion module.
-
2)
In the PCD alignment module, to avoid the disadvantages of optical flow-based methods, such as higher computation overhead, the deformable convolution is employed to align features of each neighboring frame to its reference frame. For the three-level pyramid structure, the cascade deformable alignment method is used to refine the coarsely aligned feature, that is, the method from coarse to fine is designed to enhance the pixel alignment accuracy.
-
3)In the TSA fusion module, fusing feature information of the aligned neighboring frames is its main goal. For VR task, some unavoidable reasons, such as object moving and camera shaking, could produce different degrees of blur of frames, which lead to the different contributions of neighboring frames to the restored reference frames. Therefore, the attention mechanism is used to assign different pixel-level aggregation weights in the temporal and spatial dimensions of feature maps. To be specific, in the temporal attention mechanism, the features of each frame
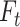 are embedded in lower dimension space. Then, their similarity is computed to indicate the attention, which is a temporal attention map. The similarity of neighboring frames is calculated as follows:
are embedded in lower dimension space. Then, their similarity is computed to indicate the attention, which is a temporal attention map. The similarity of neighboring frames is calculated as follows:
where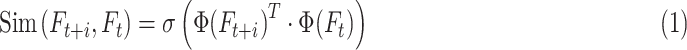
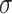 is an activation function (like sigmoid), and
is an activation function (like sigmoid), and
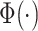 is the embedding of features obtained by a simple convolutional operation. Therefore, the attention-modulated feature is written as
is the embedding of features obtained by a simple convolutional operation. Therefore, the attention-modulated feature is written as
where
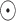 denotes the elementwise multiplication. These attention-modulated features are fused in the fusion convolutional layer. Similarly, the pyramid structure is employed to increase attention receptive field for spatial attention map.
denotes the elementwise multiplication. These attention-modulated features are fused in the fusion convolutional layer. Similarly, the pyramid structure is employed to increase attention receptive field for spatial attention map. -
4)The reconstruction module is composed of several residual blocks. Besides, the Charbonnier penalty function is used as the loss function
where
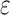 is set to
is set to
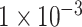 .
.
D. Face Detection
Considering the demand for real time, the inference process of our face detection is carried out at the low-power edge device. Inspired by end-to-end FaceBoxes [38], the architecture of the face detector is shown in Fig. 3, which is an anchor-based face detector. The network structure of the face detector can be divided into two stages that make the detector accurate and efficient on the edge devices with shrinking of the spatial size of input, enriching the receptive fields.
Fig. 3.
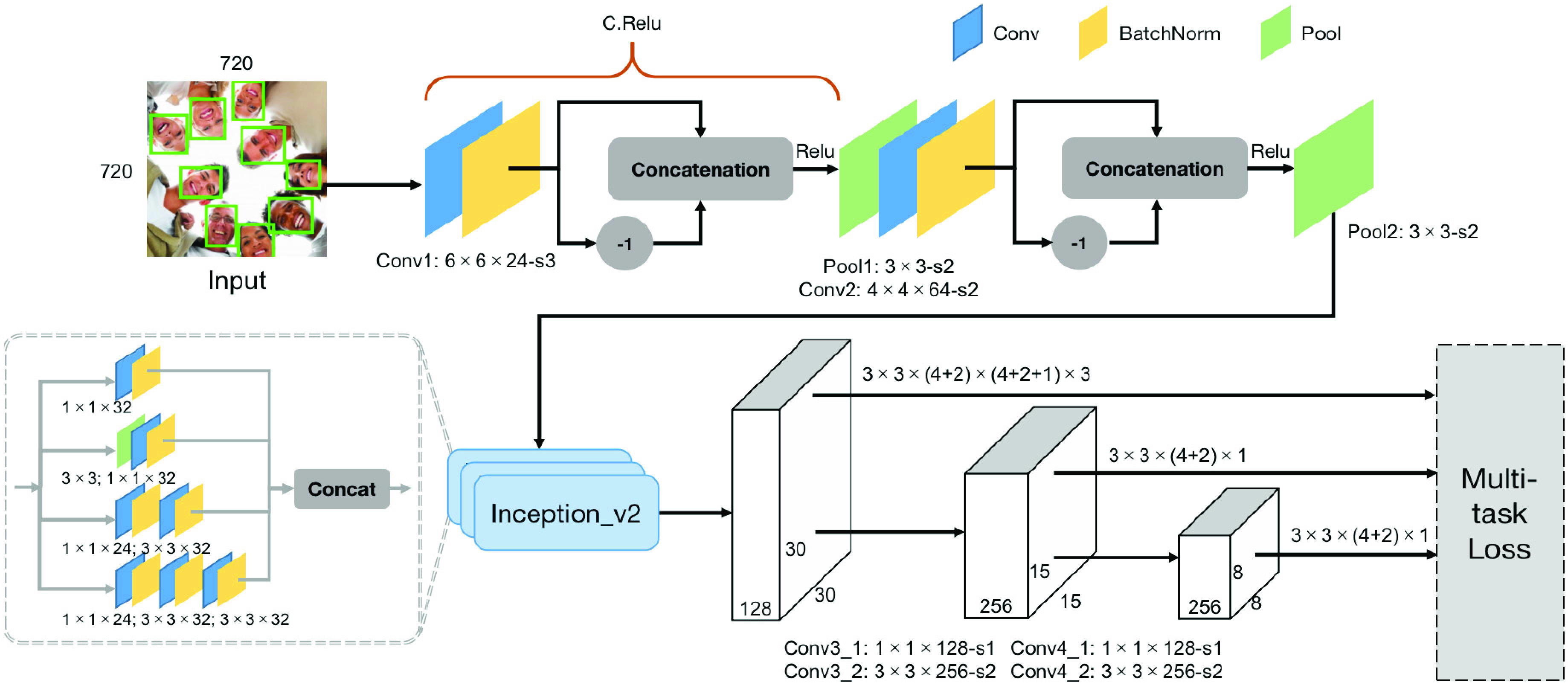
Architecture and details of our face detector.
In practical application, the frames of video as input images have high resolution. Therefore, in order to reduce the computational cost, we need to accelerate downsampling as soon as possible, that is, most of the reduction in the width and height of the feature map could be completed due to suitable stride size and kernel size at the first stage. The stride value of the convolutional layer and pooling layer is shown in Fig. 3. If the pixel size of the input image is
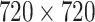 , the total stride size of the first stage is 24 (
, the total stride size of the first stage is 24 (
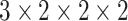 ), which means that it achieves 24 times downsampling. Besides, the C.ReLU activation function [39] is utilized to help to further reduce computing overhead. C.ReLU is designed from the statistical observation that there is a negative correlation in the lower layers. Based on this, the number of output channels is concatenated with its negation before the ReLU activation function.
), which means that it achieves 24 times downsampling. Besides, the C.ReLU activation function [39] is utilized to help to further reduce computing overhead. C.ReLU is designed from the statistical observation that there is a negative correlation in the lower layers. Based on this, the number of output channels is concatenated with its negation before the ReLU activation function.
In the second stage, three inception modules [40] are used to enrich the receptive fields, which are able to detect various scales of faces. The inception module can factorize convolution into smaller convolutions, which makes the whole network wider, but with the smaller number of parameters and computation. In this way, it provides multiple branches with different kernels, which are different receptive fields. Then, through the several convolutional layers, the last two downsampling is completed. Similar to SSD, multiscale feature maps are generated for detection. Besides, considering that most of the face box is square, this part uses default boxes with 1:1 aspect ratio for prediction, which is anchor-based methods. We also employ the anchor densification strategy from [38]. As the definition of the tiling density of anchor, the equation can be written as follows:
 |
where
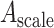 is the scale of default anchor boxes, and
is the scale of default anchor boxes, and
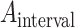 is the interval of the anchor. In our face detector,
is the interval of the anchor. In our face detector,
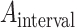 also denotes the multiple of downsampling (i.e., 24, 24, 24, 48, and 96 for default anchors). We set the scale of default anchor to 24, 48, and 96 pixels for the third inception modules, 192 pixels for Conv3_2, and 384 pixels for Conv4_2, respectively. Therefore, we obtain
also denotes the multiple of downsampling (i.e., 24, 24, 24, 48, and 96 for default anchors). We set the scale of default anchor to 24, 48, and 96 pixels for the third inception modules, 192 pixels for Conv3_2, and 384 pixels for Conv4_2, respectively. Therefore, we obtain
 of each anchor (i.e., 1, 2, 4, 4, and 4). To have a better ability of the detection of small size faces, the anchor densification strategy is used that keeps the value of
of each anchor (i.e., 1, 2, 4, 4, and 4). To have a better ability of the detection of small size faces, the anchor densification strategy is used that keeps the value of
 constant (i.e., 4), that is, increase the number of anchors at a center point by translating anchors.
constant (i.e., 4), that is, increase the number of anchors at a center point by translating anchors.
In the end, we adopt the loss function, which is the same as Faster R-CNN [34], that is, binary cross-entropy for classification and the smooth L1 loss for regression are employed as loss function
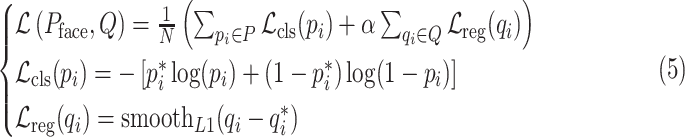 |
where
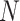 is the number of positive samples in one batch, and
is the number of positive samples in one batch, and
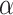 is the balancing parameter.
is the balancing parameter.
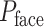 is the set of all predicted probability of anchor as the face object (
is the set of all predicted probability of anchor as the face object (
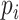 ), and
), and
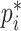 is an indicator function of
is an indicator function of
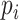 , that is, the positive anchor is
, that is, the positive anchor is
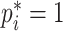 ; otherwise,
; otherwise,
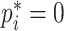 .
.
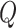 is the set of vectors representing of the predicted bounding box (
is the set of vectors representing of the predicted bounding box (
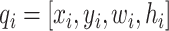 ), and
), and
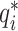 denotes the ground-truth box related with a positive anchor. Besides, the probability in
denotes the ground-truth box related with a positive anchor. Besides, the probability in
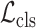 is computed by the softmax loss function.
is computed by the softmax loss function.
E. Mask Identification
After face detection, our goal is to identify the condition of mask wearing based on the cropped faces (i.e., masked and nonmasked). In essence, it is also an image binary classification task, and it can be regarded as a function,
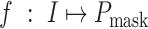 , where
, where
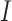 is the face image as input, and
is the face image as input, and
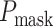 is the output probability of mask wearing that is used to obtain the classification result. In our bus drive monitoring data set, we label incorrect mask wearing as nonmasked, which may only be slightly different from masked. Therefore, the network puts forward some requirements for the ability of extracting feature.
is the output probability of mask wearing that is used to obtain the classification result. In our bus drive monitoring data set, we label incorrect mask wearing as nonmasked, which may only be slightly different from masked. Therefore, the network puts forward some requirements for the ability of extracting feature.
As the image classification performance of CNN, Mobilenet-V2 is adopted to identify the condition of mask-wearing, which not only has high accuracy but also is a lightweight image classification network. Therefore, Mobilenet-V2 is well suited for edge devices. Compared with the traditional CNN, Mobilenet-V2 can decrease the amount of computation and the number of model parameters by replacing the standard convolutional layer with the depthwise separable convolution, which can ensure the high image classification accuracy. The depthwith separable convolution includes two parts that are depthwise convolution and pointwise convolution, which are used to filter and combine, respectively. Besides, the inverted residuals are used to enhance the ability of propagating the gradient to multiplier layers and memory efficiency, which increase and then decrease the number of channels. In the bottleneck inverted residual (BIR) block, the linear bottleneck is used instead of ReLU after the second pointwise convolution to retain feature diversity. The network structure of Mobilenet-V2 is shown in Table I, where
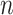 is the number of repetitions and
is the number of repetitions and
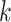 is expansion ratio.
is expansion ratio.
TABLE I. Network Structure of Mobilenet-V2.
| Input | Operator | Output | n | k |
|---|---|---|---|---|
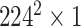 |
Conv2d |
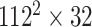 |
1 | - |
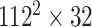 |
BIR |
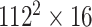 |
1 | 1 |
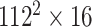 |
BIR |
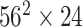 |
2 | 6 |
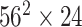 |
BIR |
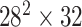 |
3 | 6 |
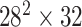 |
BIR |
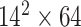 |
4 | 6 |
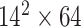 |
BIR |
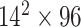 |
3 | 6 |
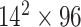 |
BIR |
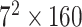 |
3 | 6 |
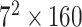 |
BIR |
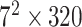 |
1 | 6 |
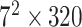 |
Conv2d
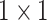
|
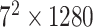 |
1 | - |
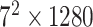 |
AvgPool
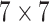
|
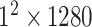 |
1 | - |
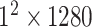 |
Conv2d
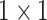
|
1 | - | - |
Similarly, for the classification task, the softmax function is utilized to compute the confidence of classes (i.e., masked and nonmasked), and the cross-entropy is till utilized as the object function. Considering the problem of overfitting, we add an L2 regularization term to the object function, which is written as follows:
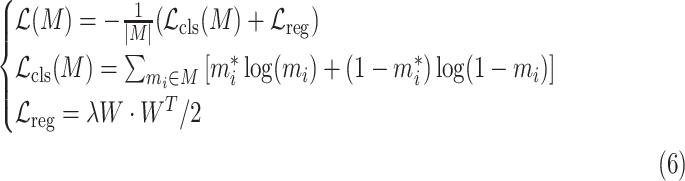 |
where
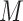 is the set of predicted probabilities of samples (cropped faces), and
is the set of predicted probabilities of samples (cropped faces), and
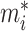 is the indicator function of
is the indicator function of
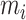 , that is,
, that is,
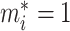 , which denotes face image
, which denotes face image
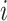 that belongs to label masked, otherwise,
that belongs to label masked, otherwise,
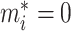 . For the rest term of
. For the rest term of
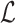 , L2 regularization term (
, L2 regularization term (
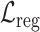 ),
),
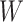 is the learned parameters of network, and
is the learned parameters of network, and
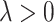 is the regularization coefficient.
is the regularization coefficient.
IV. Experiments
In this section, we first describe the collected bus driver monitoring data set and training details. Then, we show the performance and evaluation of three analysis tasks in our ECMask, including VR, face detection, and mask identification. Finally, we present the inference time efficiency of ECMask at the edge nodes.
A. Data set Description and Training Details
1). Data set Description:
For the pubic health prevention and the mask identification during COVID-19, we collect the real bus driver monitoring video clips (each with 104 consecutive frames) as the bus drive monitoring data set, which are standard quality (
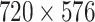 ), provided by Panda Bus Company. The data set contains 642 video clips, which are labeled as masked and nonmasked. After labeling, the data set is divided into 488 clips with label masked and 154 clips with label nonmasked. The bus drive monitoring data set consists of 80% training clips, 10% validation clips, and 10% testing clips (i.e., 516, 63, and 63, respectively). For the training of VR, we execute specific processing, which is downsampling to
), provided by Panda Bus Company. The data set contains 642 video clips, which are labeled as masked and nonmasked. After labeling, the data set is divided into 488 clips with label masked and 154 clips with label nonmasked. The bus drive monitoring data set consists of 80% training clips, 10% validation clips, and 10% testing clips (i.e., 516, 63, and 63, respectively). For the training of VR, we execute specific processing, which is downsampling to
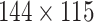 and Gaussian Blur with
and Gaussian Blur with
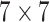 kernel size and five standard deviation, to complete the training data set.
kernel size and five standard deviation, to complete the training data set.
2). Training Details:
a). VR:
The training of VR is the same as EDVR [25], except that our bus drive monitoring data set is added for training.
b). Face detection:
The training of face detection utilizes 12 880 images of the WIDER FACE training set.1 The training data are augmented with random 90° rotations and horizontal flips. The model is trained with SGD, which sets
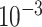 initial learning rate, 0.9 momentum, and
initial learning rate, 0.9 momentum, and
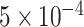 weight decay. Besides, the learning rate is adjusted with a drop factor of 0.9 every 30 epochs. During training, the threshold of Jaccard overlap of matching anchors to faces is set to 0.35.
weight decay. Besides, the learning rate is adjusted with a drop factor of 0.9 every 30 epochs. During training, the threshold of Jaccard overlap of matching anchors to faces is set to 0.35.
c). Mask identification:
After face detection on the bus drive monitoring data set, we obtain the position of the faces, which are cropped as the inputs of the model of mask identification. Similarly, we use SGD to train the model with 0.045 initial learning rate and 0.9 momentum, and the learning rate is adjusted with cosine decay. Besides,
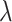 , the factor of L2 regularization, is
, the factor of L2 regularization, is
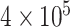 .
.
Our models are implemented based on the PyTorch framework, and trained using NVIDIA GPU with CUDA and cuDNN enabled in the edge server.
B. Experiment Results
1). Video Restoration:
For the blur detection, we make sure that the number of clips that need to be restored is few. Therefore, we set the threshold to 115 with the variance of the Laplacian operator based on the statistic analysis on the bus drive monitoring data set. There are a small number of clips that require VR, accounting for 3% (i.e., 13 masked clips, and six Nonmasked clips). We evaluate the performance of VR on two quality metrics.
-
1)Peak Signal-to-Noise Ratio (PSNR): PSNR is extensively applied to evaluate the quality of an image after processing compared with its original image. The higher value of PSNR means they have smaller difference. The formula is as follows:
where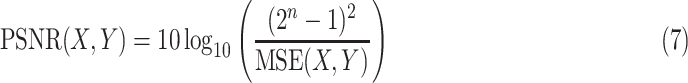
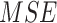 means mean square error operation, and
means mean square error operation, and
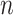 denotes the number of bits per pixel (generally
denotes the number of bits per pixel (generally
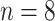 ).
). -
2)Structural Similarity Index (SSIM): As a common image standard evaluation index, SSIM can evaluate the similarity between two images from different perspectives, including brightness, contrast, and structure. The value range of SSIM is [0, 1], and the closer to 1, the higher similarity. Its equation can be defined as
where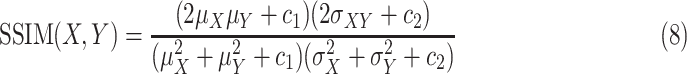
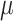 and
and
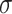 are the mean and covariance operations.
are the mean and covariance operations.
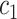 and
and
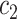 are positive constants to avoid the denominator being 0.
are positive constants to avoid the denominator being 0.
Table II demonstrates the calculation results of the quantitative metrics compared with ground-truth clips. The experiments present that the effect of VR is verified, and the values of PSNR and SSIM after restoration are higher than those after downsampling and Gaussian Blur. Moreover, the visualized results are shown in Fig. 4, including three masked clips and one nonmasked clip whose scores of the variance of the Laplacian operator are less than 115, which present that our VR can enhance face details.
TABLE II. Quantitative Results of VR.
| Approach | PSNR | SSIM |
|---|---|---|
| Downsample | 28.79 | 0.8730 |
| Gaussian Blur | 30.55 | 0.9037 |
| Video Restoration | 35.56 | 0.9495 |
Fig. 4.
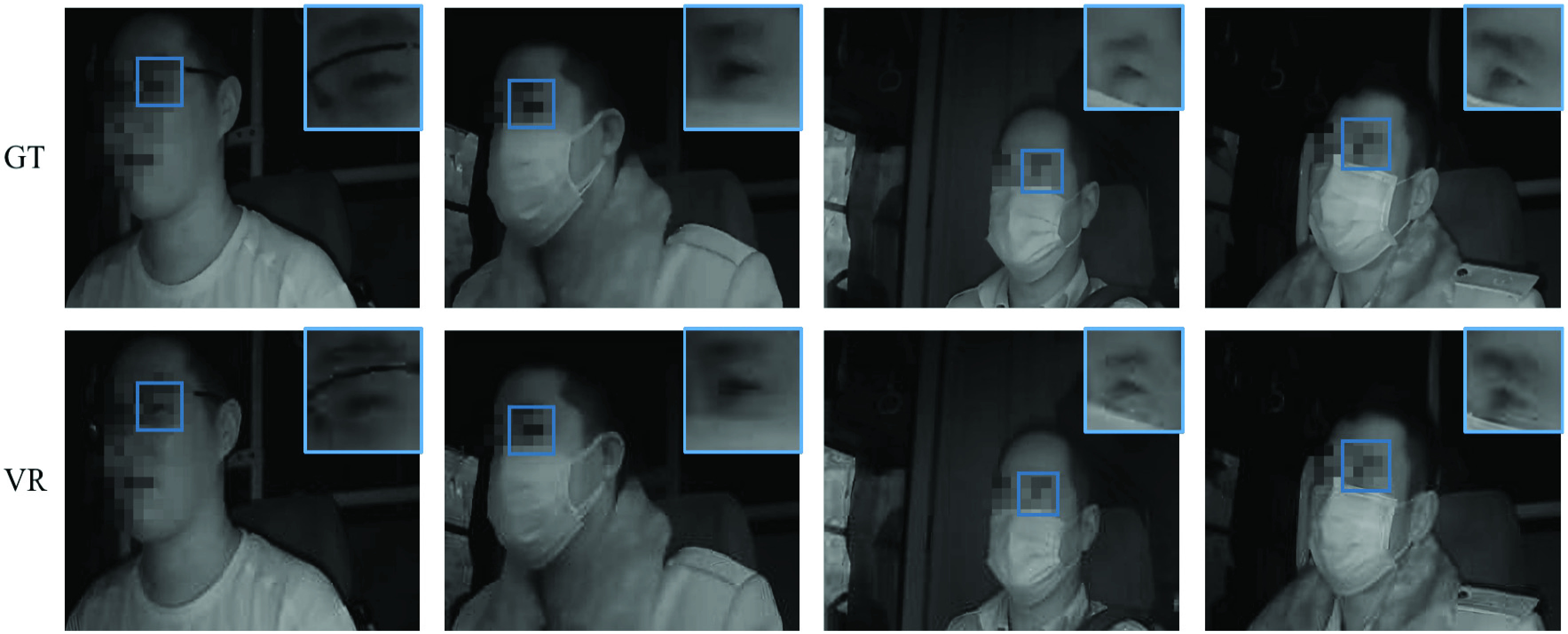
Visualized results of VR compared with ground truth (GT) on bus drive monitoring data set, including one Nonmask frame and three masked frames. (Zoom in for suitable view, and faces portions are pixelated for keep anonymity.)
2). Face Detection:
For face detection, our fade detector is evaluated against other methods [20]–[24] on the popular face detection benchmarks, including the FDDB data set and WIDER FACE data set (easy and medium subsets) in Table III. Our face detector almost outperforms others on two subsets of WIDER FACE. ScaleFace has similar performance to ours on the FDDB. Furthermore, we design the simple ablation experiment to illustrate the effect of VR based on our bus driver monitoring data set, that is, each frame of clips is detected after VR or not. As shown in Table IV, the performance evaluation results with and without VR are compared. These results prove that VR can improve the accuracy of face detection, that is, VR effectively increases accuracy by 1.23%. Our face detector reaches a high accuracy of 97.98%, which can meet the needs of face detection accuracy for most industrial environments. The examples of visualized results are shown in Fig. 5.
TABLE III. Accuracy Results of Our Face Detector Compared With Different Methods.
| Approach | Dataset | ||
|---|---|---|---|
| FDDB | WIDER FACE (easy) | WIDER FACE (medium) | |
| Faceness | 90.3% | 71.6% | 60.4% |
| CMS-RCNN | 90.6% | 89.2% | 87.0% |
| LDCF+ | 93.3% | 79.7% | 77.2% |
| MTCNN | 95.0% | 85.1% | 82.0% |
| ScaleFace | 96.0% | 86.7% | 86.6% |
| Ours | 95.9% | 89.8% | 87.1% |
TABLE IV. Accuracy Results of Our Face Detector With VR and Without VR.
| Approach | Bus Drive Monitoring Dataset | |
|---|---|---|
| VR |
 |
✓ |
| Accuracy | 96.75% | 97.98% |
Fig. 5.

Visualized results of our face detector with VR and without VR on bus drive monitoring data set, including one Nonmask frame and three masked frames. (Faces portions are pixelated for keep anonymity.)
3). Mask Identification:
After face detection, we perform mask identification based on the previous results of faces obtained in each frame of clips. Similarly, we compute the confusion matrixes to demonstrate the performance of mask identification including those with and without VR as shown in Fig. 6. Our mask identification method can correctly classify 6382 frames of 6552 frames (the accuracy is 97.41%), which is better than those without VR. In addition, we observed and analyzed the failed cases of mask identification, and found several reasons for identification errors, that is, low clip quality, the arm covering a large area of the face, and incomplete face (looking back). The examples of mask identification results are given in Fig. 7.
Fig. 6.

Confusion matrix results of mask identification (a) with VR, and (b) without VR on Bus Drive Monitoring Dataset.
Fig. 7.

Visualized results of mask identification with VR and without VR on bus drive monitoring data set, including one nonmask frame and three masked frames. (Faces portions are pixelated for keep anonymity.)
C. Inference Time Efficiency
In order to evaluate runtime efficiency, we calculate the average inference time of face detection and mask identification, and use their sum as the whole inference time. In our experiments, we use the NCS and Raspberry Pi 4 as the low-cost edge device, which is compared with the higher prices hardware, CPU (Intel Xeon E5-2690 v4@2.60). In addition, the distributed computing method is adopted with multiple NCSs to further reduce the inference time and achieve real time, which can be regarded as cooperation between the edge devices. Fig. 8 shows the results of average inference time. Obviously, the performance on one single NCS is reluctant for real time, that is, our ECMask can run at the average 6.09 FPS by using one NCS to accelerate. However, through the distributed computing method, the more NCSs are used to accelerate, the more efficiency ECMask has. Moreover, the efficiency of three NCSs with distributed computing can be increased by 2.1 times, which is enough to meet the real-time industrial requirement of video analysis. As the number of NCS reaches 4, the increase in efficiency is no longer obvious. Therefore, as the number of NCSs increases, the growth curve of FPS would tend to smooth. Furthermore, on the basis of saving costs and improving performance as much as possible, low-cost edge devices with edge computing through NCSs can reach mostly the performance of the higher prices CPU hardware.
Fig. 8.

Inference time and accuracy results for mask identification on the multiple NCSs and CPU (E5-2690 v4@2.60), respectively.
V. Conclusion
In this article, we developed an ECMask identification framework, which can identify the condition of mask wearing in the videos from bus driver monitoring in real time. First, the blur detection with the Laplacian operator is used to determine whether VR is needed. Then, after possible VR, the accuracy of face detection can be improved. Finally, the cropped face images are further used for mask identification. Cooperative edge computing is implemented by the distributed computing with multiple NCSs as low-cost devices. The trained deep learning model is optimized and stored in NCSs with the inference engine. Our results present that ECMask has not only high accuracy in face detection and mask identification but also has the real-time ability of video analysis, which is significant for the healthcare systems of COVID-19 in public places, such as buses.
Biographies

Xiangjie Kong (Senior Member, IEEE) received the B.Sc. and Ph.D. degrees from Zhejiang University, Hangzhou, China, in 2004 and 2009, respectively.
He is currently a Full Professor with the College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou. He was an Associate Professor with the School of Software, Dalian University of Technology, Dalian, China. He has published over 130 scientific papers in international journals and conferences (with over 100 indexed by ISI SCIE). His research interests include network science, mobile computing, and computational social science.

Kailai Wang received the B.Sc. degree in software engineering from Dalian University of Technology, Dalian, China, in 2019, where he is currently pursuing the master’s degree with the School of Software.
His research interests include analysis of complex networks, network science, and urban computing.

Shupeng Wang (Member, IEEE) received the M.S. and Ph.D. degrees from Harbin Institute of Technology, Harbin, China, in 2004 and 2007, respectively.
He is currently a Senior Engineer with the Institute of Information Engineering, Chinese Academy of Sciences (CAS), Beijing, China. His research interests include big data management and analytics, network storage, etc.

Xiaojie Wang received the M.S. degree from Northeastern University, Shenyang, China, in 2011, and the Ph.D. degree from Dalian University of Technology, Dalian, China, in 2019.
From 2011 to 2015, she was a Software Engineer with NeuSoft Corporation, Shenyang, China. She is currently a Distinguished Professor with Chongqing University of Posts and Telecommunications, Chongqing, China. Her research interests are wireless networks, mobile-edge computing, and machine learning.

Xin Jiang received the Ph.D. degree from Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China, in 2008.
From 2009 to 2010, she was a Visiting Scholar with the Prince of Wales Hospital, Chinese University of Hong Kong, Hong Kong. She also studied at the Global Clinical Scholars Research Training Program from 2015 to 2016. She is the Chief Physician, an Associate Professor, and the Deputy Director of Geriatrics with Jinan University, Guangzhou, China.

Yi Guo received the Ph.D. degree from the University of Greifswald, Greifswald, Germany, in 1997.
He is currently the Chief of Neurology with the Second Clinical Medical College, Jinan University, Guangzhou, China, a Member of the Cerebrovascular Disease Group, Chinese Medical Association Neurology Branch, Shenzhen, China, and the Chairman of the Shenzhen Medical Association of Neurology, and the Shenzhen Medical Association of Psychosomatic Medicine. His major research areas are cerebrovascular diseases, dementia, movement disorder diseases, sleep disorder, and depression and anxiety.

Guojiang Shen received the B.Sc. degree in control theory and control engineering and the Ph.D. degree in control science and engineering from Zhejiang University, Hangzhou, China, in 1999 and 2004, respectively.
He is currently a Professor with the College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou. His current research interests include artificial intelligence theory, big data analytics, and intelligent transportation systems.

Xin Chen received B.Sc. degree in information security (security technology) from Harbin Engineering University, Harbin, China, in 2020.
He is currently pursuing the MasterŠs degree at the School of Software, Dalian University of Technology, Dalian, China. His research interests include graph neural network, mobile computing, and big data analytics.

Qichao Ni received the B.Sc. degree in automation (program for excellent engineers) from Yanshan University, Qinhuangdao, China, in 2019. He is currently pursuing the master’s degree with the School of Software, Dalian University of Technology, Dalian, China.
His research interests include urban data mining, network embedding, and multiple heterogeneous data fusion.
Funding Statement
This work was supported in part by the National Natural Science Foundation of China under Grant 62072409, Grant 62073295, Grant 61931019, and Grant 62001073; in part by Zhejiang Provincial Natural Science Foundation under Grant LR21F020003; and in part by Fundamental Research Funds for the Provincial Universities of Zhejiang under Grant RFB2020001.
Footnotes
The data set is available at http://shuoyang1213.me/WIDERFACE/.
Contributor Information
Xiangjie Kong, Email: xjkong@ieee.org.
Kailai Wang, Email: kailai.w@outlook.com.
Shupeng Wang, Email: wangshupeng@iie.ac.cn.
Xiaojie Wang, Email: xiaojie.kara.wang@ieee.org.
Xin Jiang, Email: jiangxinsz@163.com.
Yi Guo, Email: xuanyi_guo@163.com.
Guojiang Shen, Email: gjshen1975@zjut.edu.cn.
Xin Chen, Email: chenxin20@mail.dlut.edu.cn.
Qichao Ni, Email: niqichao666@gmail.com.
References
- [1].Sharma A., Tiwari S., Deb M. K., and Marty J. L., “Severe acute respiratory syndrome coronavirus-2 (SARS-COV-2): A global pandemic and treatment strategies,” Int. J. Antimicrob. Agents, vol. 56, no. 2, 2020, Art. no. 106054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].“Coronavirus disease (Covid 19): situation report, 165,” World Health Org., Geneva, Switzerland: 2020. [Google Scholar]
- [3].Kraemer M. U.et al. , “The effect of human mobility and control measures on the covid-19 epidemic in china,” Science, vol. 368, no. 6490, pp. 493–497, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Feng S., Shen C., Xia N., Song W., Fan M., and Cowling B. J., “Rational use of face masks in the covid-19 pandemic,” The Lancet Respiratory Medicine, vol. 8, no. 5, pp. 434–436, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Ning Z.et al. , “Partial computation offloading and adaptive task scheduling for 5g-enabled vehicular networks,” IEEE Trans. Mobile Comput., early access, Sep. 18, 2020, doi: 10.1109/TMC.2020.3025116. [DOI]
- [6].Kong X., Liu X., Jedari B., Li M., Wan L., and Xia F., “Mobile crowdsourcing in smart cities: Technologies, applications, and future challenges,” IEEE Internet Things J., vol. 6, no. 5, pp. 8095–8113, Oct. 2019. [Google Scholar]
- [7].Chen D., Bovornkeeratiroj P., Irwin D. E., and Shenoy P. J., “Private memoirs of iot devices: Safeguarding user privacy in the iot era,” in Proc. IEEE 38th Int. Conf. Distrib. Comput. Syst. (ICDCS), 2018, pp. 1327–1336. [Google Scholar]
- [8].Ning Z., Sun S., Wang X., Guo L., Wang G., Gao X., and Kwok R. Y., “Intelligent resource allocation in mobile blockchain for privacy and security transactions: A deep reinforcement learning based approach,” Sci. China Inf. Sci., 2020.
- [9].Gatouillat A., Badr Y., Massot B., and Sejdic E., “Internet of Medical Things: A review of recent contributions dealing with cyber-physical systems in medicine,” IEEE Internet Things J., vol. 5, no. 5, pp. 3810–3822, Oct. 2018. [Google Scholar]
- [10].Zhou X., Liang W., Wang K.-I., Wang H., Yang L. T., and Jin Q., “Deep-learning-enhanced human activity recognition for Internet of Healthcare Things,” IEEE Internet Things J., vol. 7, no. 7, pp. 6429–6438, Jul. 2020. [Google Scholar]
- [11].Al-Turjman F., Nawaz M. H., and Ulusar U. D., “Intelligence in the Internet of Medical Things era: A systematic review of current and future trends,” Comput. Commun., vol. 150, pp. 644–660, Jan. 2020. [Google Scholar]
- [12].Zhou X., Hu Y., Liang W., Ma J., and Jin Q., “Variational lstm enhanced anomaly detection for industrial big data,” IEEE Trans. Ind. Informat., early access, Sep. 11, 2020, doi: 10.1109/TII.2020.3022432. [DOI]
- [13].Deng Z., Zhou Y., Wu D., Ye G., Chen M., and Xiao L., “Utility maximization of cloud-based in-car video recording over vehicular access networks,” IEEE Internet Things J., vol. 5, no. 6, pp. 5213–5226, Dec. 2018. [Google Scholar]
- [14].Basatneh R., Najafi B., and Armstrong D. G., “Health sensors, smart home devices, and the Internet of Medical Things: An opportunity for dramatic improvement in care for the lower extremity complications of diabetes,” J. Diabetes Sci. Technol., vol. 12, no. 3, pp. 577–586, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Ning Z.et al. , “Distributed and dynamic service placement in pervasive edge computing networks,” IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 6, pp. 1277–1292, Jun. 2020. [Google Scholar]
- [16].Wang X., Ning Z., and Guo S., “Multi-agent imitation learning for pervasive edge computing: A decentralized computation offloading algorithm,” IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 2, pp. 411–425, Feb. 2021. [Google Scholar]
- [17].Ning Z.et al. , “Mobile edge computing enabled 5g health monitoring for Internet of Medical Things: A decentralized game theoretic approach,” IEEE J. Sel. Areas Commun., vol. 39, no. 2, pp. 463–478, Feb. 2021. [Google Scholar]
- [18].Kong X.et al. , “Mobile edge cooperation optimization for wearable Internet of Things: A network representation-based framework,” IEEE Trans. Ind. Informat., early access, Aug. 12, 2020, doi: 10.1109/TII.2020.3016037. [DOI]
- [19].Ning Z.et al. , “Intelligent edge computing in Internet of Vehicles: A joint computation offloading and caching solution,” IEEE Trans. Intell. Transp. Syst., early access, Jun. 5, 2020, doi: 10.1109/TITS.2020.2997832. [DOI]
- [20].Yang S., Luo P., Loy C.-C., and Tang X., “From facial parts responses to face detection: A deep learning approach,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 3676–3684. [Google Scholar]
- [21].Ohn-Bar E. and Trivedi M. M., “To boost or not to boost? on the limits of boosted trees for object detection,” in Proc. 23rd Int. Conf. Pattern Recognit. (ICPR), 2016, pp. 3350–3355. [Google Scholar]
- [22].Zhu C., Zheng Y., Luu K., and Savvides M., “CMS-RCNN: Contextual multi-scale region-based cnn for unconstrained face detection,” in Deep Learn. Biometrics. Cham, Switzerland: Springer, 2017, pp. 57–79. [Google Scholar]
- [23].Yang S., Xiong Y., Loy C. C., and Tang X., “Face detection through scale-friendly deep convolutional networks,” 2017, http://arXiv:1706.02863 [Google Scholar]
- [24].Zhang K., Zhang Z., Li Z., and Qiao Y., “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Process. Lett., vol. 23, no. 10, pp. 1499–1503, Oct. 2016. [Google Scholar]
- [25].Wang X., Chan K. C., Yu K., Dong C., and Loy C. C., “Edvr: Video restoration with enhanced deformable convolutional networks,” in Proc. IEEE/CVF Conf. Comput. Vis..Pattern Recognit. (CVPR) Workshops, Jun. 2019, pp. 1954–1963. [Google Scholar]
- [26].Pace P., Aloi G., Gravina R., Caliciuri G., Fortino G., and Liotta A., “An edge-based architecture to support efficient applications for healthcare industry 4.0,” IEEE Trans. Ind. Informat., vol. 15, no. 1, pp. 481–489, Jan. 2019. [Google Scholar]
- [27].Han T., Zhang L., Pirbhulal S., Wu W., and de Albuquerque V. H. C., “A novel cluster head selection technique for edge-computing based IoMT systems,” Comput. Netw., vol. 158, pp. 114–122, Jul. 2019. [Google Scholar]
- [28].Pustokhina I. V., Pustokhin D. A., Gupta D., Khanna A., Shankar K., and Nguyen G. N., “An effective training scheme for deep neural network in edge computing enabled Internet of Medical Things (IoMT) systems,” IEEE Access, vol. 8, pp. 107112–107123, 2020. [Google Scholar]
- [29].Dong C., Loy C. C., He K., and Tang X., “Learning a deep convolutional network for image super-resolution,” in Proc. Eur. Conf. Comput. Vis.. 2014, pp. 184–199. [Google Scholar]
- [30].Lim B., Son S., Kim H., Nah S., and Mu Lee K., “Enhanced deep residual networks for single image super-resolution,” in Proc. IEEE Conference Comput. Vis. Pattern Recognit. (CVPR) Workshops, Jul. 2017, pp. 1132–1140. [Google Scholar]
- [31].Tian Y., Zhang Y., Fu Y., and Xu C., “TDAN: Temporally-deformable alignment network for video super-resolution,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 3357–3366. [Google Scholar]
- [32].Xue T., Chen B., Wu J., Wei D., and Freeman W. T., “Video enhancement with task-oriented flow,” Int. J. Comput. Vis., vol. 127, no. 8, pp. 1106–1125, 2019. [Google Scholar]
- [33].Su S., Delbracio M., Wang J., Sapiro G., Heidrich W., and Wang O., “Deep video deblurring for hand-held cameras,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 1279–1288. [Google Scholar]
- [34].Ren S., He K., Girshick R., and Sun J., “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 91–99. [DOI] [PubMed] [Google Scholar]
- [35].Zhang S., Zhu X., Lei Z., Shi H., Wang X., and Li S. Z., “S3FD: Single shot scale-invariant face detector,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 192–201. [Google Scholar]
- [36].Najibi M., Samangouei P., Chellappa R., and Davis L. S., “SSH: Single stage headless face detector,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 4885–4894. [Google Scholar]
- [37].Redmon J., Divvala S., Girshick R., and Farhadi A., “You only look once: Unified, real-time object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 779–788. [Google Scholar]
- [38].Zhang S., Zhu X., Lei Z., Shi H., Wang X., and Li S. Z., “Faceboxes: A CPU real-time face detector with high accuracy,” in Proc. IEEE Int. Joint Conf. Biomet. (IJCB), 2017, pp. 1–9. [Google Scholar]
- [39].Shang W., Sohn K., Almeida D., and Lee H., “Understanding and improving convolutional neural networks via concatenated rectified linear units,” in Proc. Int. Conf. Mach. Learn., 2016, pp. 2217–2225. [Google Scholar]
- [40].Szegedy C., Vanhoucke V., Ioffe S., Shlens J., and Wojna Z., “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 2818–2826. [Google Scholar]