

Abstract
Extensive research has been performed on continuous and noninvasive cuff-less blood pressure (BP) measurement using artificial intelligence algorithms. This approach involves extracting certain features from physiological signals, such as ECG, PPG, ICG, and BCG, as independent variables and extracting features from arterial blood pressure (ABP) signals as dependent variables and then using machine-learning algorithms to develop a blood pressure estimation model based on these data. The greatest challenge of this field is the insufficient accuracy of estimation models. This paper proposes a novel blood pressure estimation method with a clustering step for accuracy improvement. The proposed method involves extracting pulse transit time (PTT), PPG intensity ratio (PIR), and heart rate (HR) features from electrocardiogram (ECG) and photoplethysmogram (PPG) signals as the inputs of clustering and regression, extracting systolic blood pressure (SBP) and diastolic blood pressure (DBP) features from ABP signals as dependent variables, and finally developing regression models by applying gradient boosting regression (GBR), random forest regression (RFR), and multilayer perceptron regression (MLP) on each cluster. The method was implemented using the MIMIC-II data set with the silhouette criterion used to determine the optimal number of clusters. The results showed that because of the inconsistency, high dispersion, and multitrend behavior of the extracted features vectors, the accuracy can be significantly improved by running a clustering algorithm and then developing a regression model on each cluster and finally weighted averaging of the results based on the error of each cluster. When implemented with 5 clusters and GBR, this approach yielded an MAE of 2.56 for SBP estimates and 2.23 for DBP estimates, which were significantly better than the best results without clustering (DBP: 6.27, SBP: 6.36).
1. Introduction
Blood pressure (BP) is one of the most important health indicators and can be used to diagnose various diseases. BP measurement techniques can be broken down into two categories of invasive methods and noninvasive methods. While the invasive approach tends to provide more accurate BP readings, it has some drawbacks and limitations. The World Health Organization has issued reports on the subject that each year, 9.4 million people die from excessive blood pressure around the world (hypertension), and roughly 30% of all men and 25% of all women suffer from this condition [1]. After diabetes, hypertension is the second leading cause of cardiovascular disease, but it also tends to be asymptomatic, so it has been called the silent killer. As one of the vital signs, blood pressure needs to be regularly controlled. In many clinical settings, BP monitoring needs to be constant, especially if the patient is old or is in the intensive care unit (ICU). Regular BP monitoring can also help prevent stroke, heart attack, and heart failure [2–4]. Unfortunately, most people with hypertension are unaware of their condition and how it harms their internal organs like the brain, eyes, and kidneys over time.
As mentioned earlier, there are two types of blood pressure measurement methods: invasive and noninvasive. In invasive blood pressure (IBP) monitoring, measurements are done by a sensor or cannula needle inserted in a blood vessel. This method can provide continuous accurate BP information but has drawbacks such as vessel blockage and potential area infection [5]. Noninvasive blood pressure (NIBP) monitoring methods can be classified into two categories: (1) the auditory methods and (2) the methods based on vital signals. The auditory method is the common BP measurement method which involves wrapping a cuff around the arm. Naturally, this method measures the blood pressure at one instant and cannot provide continuous BP readings. Also, using this multiple method consecutively leads to patient dissatisfaction [6]. Given the limitations of direct BP measurement methods, several indirect methods have also been developed for this purpose. As of this writing, researchers have not found a consistent relationship between blood pressure and electrocardiogram and photoplethysmogram signals, so that blood pressure cannot be reliably obtained from these signals. However, there are indeed some relationships between blood pressure and the features extracted from these signals [7, 8]. Therefore, these features can be used to create prediction models for BP estimates using data analysis methods and technologies. In the noninvasive and cuff-less BP estimation method, we first extract a vector of physiological features from ECG and PPG signals and then develop a regression model for BP estimation with these features used as input [9, 10]. The greatest weakness of noninvasive cuff-less methods compared to other BP measurement methods is their lower accuracy, which can be somewhat improved by using a combination of different features and different machine-learning and data mining methods.
Over the years, researchers have conducted many studies on feature extraction from physiological signals, such as ECG, PPG, ICG, and BCG, and also blood pressure (BP) estimation based on these features. As mentioned, the main challenge in this field is how to raise the accuracy of BP estimates. In this paper, we introduce a new clustering-based method to achieve significant accuracy improvement in this area. This method starts with extracting PTT, PIR, and HR features from ECG and PPG signals and extracting SBP and DBP features from the corresponding ABP signal. While previous methods of this field follow this step by developing a model based on the extracted features, in all the other works, no attention has been paid to the high dispersion of data that extracted from ECG, PPG, and ABP signals, which will have a negative effect on the accuracy of the model. In the proposed method, first, a clustering algorithm is applied to PTT, PIR, and HR, and then a model is developed separately for each resulting cluster using the corresponding SBP and DBP data. Since the data of the extracted features tend to have high dispersion and contain multiple trends, using the clustering algorithm in this way can greatly improve the accuracy of estimations. In many works, such as [11, 12], a large number of features are extracted from the raw ECG and PPG signals. According to research, by increasing the number of effective features in the development of the machine-learning model, the accuracy of the model can be significantly increased. On the contrary, it can be concluded that increasing the number of extracted features can lead to high computational complexity in real-world applications. However, in our work, only 3 features have been extracted from ECG and PPG signals. Finally, the accuracy has been improved by using the clustering algorithm.
Another noteworthy point is that in the various studies that used the MIMIC data set as their database, the researchers had no idea about the patient's physiological condition. However, in our work, after extracting the features and clustering, we noticed similarities in the raw ECG, PPG, and ABP signals corresponding to the data samples in each cluster, which can be used to patients clustering, which can have a positive effect on the accuracy or correctness of features.
In other works, which uses ECG and PPG signals, the appearance of each person's signal can be different, which will affect the accuracy of the extraction features and feature extraction algorithms [9, 13]. The extraction process can be more accurate by using the clustering technique and clustering the raw signals of patients based on their similarities.
2. Materials and Methods
2.1. Data Set
The MIMIC-II (multiparameter intelligent monitoring in intensive care) data set from the Physionet website was used in this research. This data set contains 12,000 records of vital signals captured from people admitted to American medical centers and hospitals. The signals of this data set include ECG, PPG, and arterial blood pressure (ABP) at a sampling rate of 125 Hz [14]. A preprocessed and cleaned version of this data set is publically available on the Kaggle website [15].
2.2. Features Extraction
The pulse transit time (PTT), which is the time it takes for the arterial pulse wave to move from the aortic valve to the peripheral artery, is a typical approach to make continuous BP measurements. In other words, the time difference between the R-peak of the ECG signal and a reference point on the PPG signal of the corresponding pulse wave is referred to as the PTT [14]. The heart of this strategy is the notion of pulse wave velocity (PWV), which is obtained from the Moens–Korteweg equation (MK) [16]:
| (1) |
In this equation, E is the elastic modulus of the arterial wall, h is the thickness of the wall, ρ is blood density, and d is the vessel radius. The following formula shows how PWV is inversely correlated to PTT [17]:
| (2) |
The distance between the heart and the reference peripheral (e.g., the fingertip) site is denoted by K. The use of PWV leads to obtaining a more accurate PTT but requires parameters, such as the person's physical characteristics [2, 15, 18, 19].
The ECG and PPG can derive the PTT features by taking the second derivative of the PPG or SDPPG signal. PTT indicates for the time interval between the peak of an ECG signal and a PPG signal reference point or the peak of a cycle in the SDPPG signal [10]. Unfortunately, PTT-based BP estimation alone is not accurate enough to be used for continuous cuff-less BP measurement in clinical settings [18]. However, this accuracy can be improved by the use of new BP-related features. One of the features that can increase the estimation accuracy of the regression model is heart rate (HR), as several studies have shown an improvement in the results after combining this feature with PTT [9]. Since the behavior of blood flow in vessels depends on various factors, PPG will also be a good signal to improve the results of BP estimation. This improvement can be made by combining PTT with several different features of PPG, one of which is the PPG intensity ratio (PIR).
In theory, changes in arterial diameter, △d, could be reflected by PIR throughout one cardiac cycle from systole to diastole. Moreover, there is an exponential relationship between PIR and △d that is shown by this expression [18, 20]:
| (3) |
Essentially, PIR has been defined as the maximum to minimum ratio of the amplitude of a PPG waveform. IH is the peak point of a PPG cycle or maximum amplitude, and IL is the bottommost point of a PPG cycle or minimum amplitude where α is a constant that is associated with the optical absorption coefficient in the light path. Physiologically, four variables largely influence BP, including cardiac output, arterial compliance, blood volume, and peripheral resistance. PTT could be used to evaluate arterial compliance because it has been proposed to be one of the indices of arterial stiffness [18, 21]. Moreover, there may be a relationship between cardiac output and PTT via the heart rate. Considering blood volume and peripheral resistance, changing the arterial diameter has been regarded as a main source to be evaluated by PIR that has been already illustrated. Therefore, BP changes could be directly captured by PIR and PTT employed to estimate BP [18].
The features used in this study are PTT, PIR, and HR, which are independent variables. Systolic blood pressure (SBP) and diastolic blood pressure (DBP) are the dependent variables. After extracting these features, we developed several models based on regression on the data, but these models were found to be not sufficiently accurate because of the inconsistency and multitude of trends in the data for different features and the high dispersion of feature values. Thus, we clustered the data and developed a regression model for each cluster and then obtained a final estimate by averaging the outputs of these models with attention to the number of samples in each cluster.
Figure 1 describes the block diagram of the process of PB estimation with the proposed method.
Figure 1.
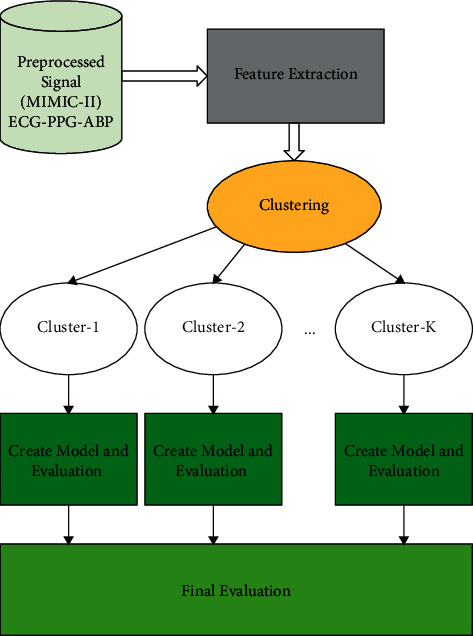
Cuff-less BP estimator with clustering block diagram.
Figure 2 depicts the extraction process of PIR and PTT. Now, PTT represents the time between the peak of the second derivative of PPG or SDPPG wave in the cardiac cycle and the peak of the ECG wave. As mentioned earlier, PIR has been proposed to be the ratio of minimum amplitude (IL) to maximum amplitude (IL) of a PPG signal in the cardiac cycle [10, 18, 20].
Figure 2.
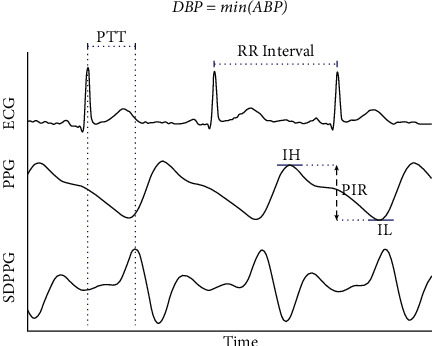
Computation of the ratio of photoplethysmogram (PPG) intensity (PIR) and pulse transit time (PTT). Here, IH refers to the PPG peak intensity, SDPPG the second derivative of PPG, and finally IL the valley intensity.
The interval between two successive QRS complexes can be used to measure the heart rate when the cardiac rhythm is regular. The heart cost is assumed on papers by dividing the number of big boxes between two subsequent QRS waves by 300.
SBP and DBP may be calculated by taking the maximum and minimum values of the ABP signal in each cycle. Mathematical equations are as follows [13]:
| (4) |
| (5) |
2.3. Clustering and Regression Models
2.3.1. Clustering
There are several methods and algorithms for dividing a set of items into identical or highly similar clusters. The k-means algorithm is one of the simplest and most popular clustering algorithms used in data mining and unsupervised machine learning.
In multivariate clustering, it is typically needed to use multiple features of items to cluster them, which raises the question of what distance functions to use for this purpose. In any case, what is important in this clustering is the way we measure the degree of similarity or dissimilarity between data samples.
The goal of the clustering operation is to form clusters so that the distance between items in each cluster is minimal. In contrast, if the similarity of items is measured by a similarity function, the goal will be to form clusters so as to maximize the value of that function for each cluster. Given the inconsistency and multitude of trends in the data for different features and the high dispersion of feature values, we tried to first obtain clusters of data or independent variables. This was done by assessing the appropriateness of the number of clusters based on the silhouette value and ultimately using the values of the independent variable in each cluster as the input of the regression model.
2.3.2. Random Forest Regression
Random forest is an easy-to-use machine-learning algorithm that tends to provide excellent results even without the adjustment of its meta-parameters. Thanks to its simplicity, this algorithm is one of the machine-learning algorithms that are widely used for both classification and regression.
Random forest falls in the category of supervised machine-learning algorithms. As the name implies, this algorithm builds a random forest made of a group of decision trees. This is often done by the method known as bagging; the basic idea is to use a combination of learning models to reach better results. Simply put, random forest builds several decision trees and merges them to make more accurate and consistent predictions [22].
2.3.3. Gradient Boosting Regression
Gradient boosting is a classification and regression machine-learning algorithm, which builds a prediction model using an ensemble of weak models. The goal of almost all machine-learning algorithms is to minimize a defined loss function during the learning process. The constructed model needs to be updated such that the value of the loss function value approaches zero and the predicted values approach the observed values as much as possible.
The core idea of the gradient boosting algorithm is to make stronger models by combining weaker models in an iterative process.
Here, it is necessary to first describe how boosting models are created. To build boosting models, we first perform a sampling with replacement in which samples have a fixed weight in the selection probability calculations. After building a model with these samples, the samples that have produced the highest errors are returned to the sample pool and the sample selection probabilities for the next iteration of modeling are updated according to the error of each sample, which also ensures that the models properly cover the entire solution space. In the end, an ensemble of all models made through this process is created.
In gradient boosting regression, we first construct a regression tree model for the samples and measure the error of this model, that is, the difference between the observed values and its predictions. We then build a new model for the data that the previous model have predicted incorrectly and recalculate the error. Next, we combine the new model with the previous one and update the ensemble. These steps are repeated until the sum of errors approaches a fixed value or the model becomes overfit [23].
2.3.4. Deep Multilayer Perceptron
MLP has been considered one of the supervised learning algorithms for learning a function f(.)=Rm⟶Ro via training on a data set so that m and o represent the number of dimensions for input and output, respectively.
According to the target y and a collection of features X=x1, x2,…, xm, MLP is capable of learning a nonlinear function approximator for regression and/or classification. In fact, there is a difference between it and logistic regression because one or more nonlinear layers, known as hidden layers, may exist between the output and input layers. In addition, the leftmost layer that is also called input layer contains a set of neurons {xi|x1, x2,…, xm} implying the input features. All neuron in the hidden layer transform values from the previous layer with a weighted linear summation ω1x1+ω2x2+⋯+ωmxm and then a nonlinear activation g(.) : R⟶R such as the hyperbolic tan function.
2.4. Model and Results Evaluation
2.4.1. MAE and RMSE
In this study, the modeling results are assessed in terms of root mean square error (RMSE) and mean absolute error (MAE). Provided in the following is a description of these model evaluation criteria. The root mean square error (RMSE) quantifies how far the model's or statistical estimator's predicted values differ from the observed values. RMSE is an excellent measure for evaluating the prediction error of a model for a given data set. This metric is basically the standard deviation of the difference between expected and observed values, shown as follows:
| (6) |
As many have pointed out, because of using the square root of the mean square error, RMSE is not as biased as other measures and is very suitable for medical and bioinformatics problems that are solved by regression. The other error measure used in this study is MAE. MAE measures the difference between predicted and observed values without considering the direction of this difference. Therefore, what is important for MAE is the magnitude of error in estimations not whether they have been overestimates or underestimates. In statistical discussions, this measure is sometimes referred to as L1 Loss.
Mathematically, MAE is the average absolute difference between predicted and observed value shown as follows:
| (7) |
2.4.2. BHS and AAMI
Many studies in the field of BP estimation use the protocol developed by the British Hypertension Society (BHS) for the evaluation of BP measuring devices and methods as the benchmark of their accuracy assessments. In this protocol, accuracy evaluations are performed based on the absolute error of measurements. More specifically, this protocol grades the methods and devices based on the ratio of the number of readings with an error of less than 5 mmHg, 10 mmHg, and 15 mmHg to the total number of readings.
Another standard for evaluating BP measuring devices and methods is the AAMI standard. In this standard, a device or method is approvable only if the mean error and standard deviation of readings are less than 5 mmHg and 8 mmHg, respectively. In this study, the accuracy of SBP and DBP estimates is evaluated using BHS and AAMI standards.
3. Results
First, the data and the extracted features were visualized, and the correlation between the features was measured. A very important section of creation regression model is the preparation of data, which in this study involved a scaling operation. This phase is very important because it affects how much time it takes to construct the regression model and the length of the convergence process. Next, we developed several machine-learning regression models, including random forest regression, gradient boosting regression, and multilayer perceptron regression, and evaluated the model outputs by different criteria. The next step was to implement the main approach of the study, that is, to cluster the extracted data or features and variables while using the silhouette value to determine the best number of clusters and then develop a model for each cluster with the regression algorithms mentioned above. The model outputs were compiled by weighted averaging, and the final results were compared in terms of different measures to identify the best regression model.
Figure 3 shows the histogram and scatter diagram of PTT, PIR, BPMIN, and BPMAX. We used the scatter diagram to create a graphical representation of the relationship between independent and dependent features, and we plotted a density diagram to gain an overview of the distribution of values for each feature.
Figure 3.
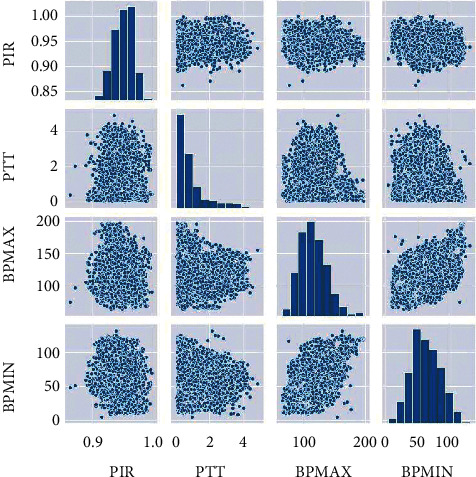
Histogram and scatter diagram of the features PTT, PIR, BPMIN, and BPMAX.
The next step was to obtain and examine the results of the machine-learning regression models described in the previous sections. In this step, the machine-learning models were developed with the features PTT, PIR, and HR as independent variables (input) and bpmin and bpmax as dependent variables (output). First, we developed the model by regression on the entire data using random forest regression, gradient boosting regression, and multilayer perceptron regression. The results of this process are presented in Table 1. It should be noted that in all steps, the regression models were evaluated in terms of RMSE and MAE.
Table 1.
Comparison of the performance without clustering and regression algorithms.
| Learner/performance | Systolic blood pressure (mmHg) | Diastolic blood pressure (mmHg) | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | r | MAE | RMSE | r | |
| Random forest regression | 7.426 | 12.250 | 0.65 | 7.410 | 12.110 | 0.68 |
| Gradient boosting regression | 6.367 | 10.395 | 0.67 | 6.276 | 10.221 | 0.71 |
| Multilayer perceptron regression | 9.422 | 14.120 | 0.59 | 9.323 | 14.099 | 0.64 |
We used the k-means method to cluster the data using the Silhouette criteria to identify the optimal number of clusters, given the inconsistency and variety of trends in the data for different features. Figure 4 shows the optimal number of clusters for the clustering algorithm according to the Silhouette criterion.
Figure 4.
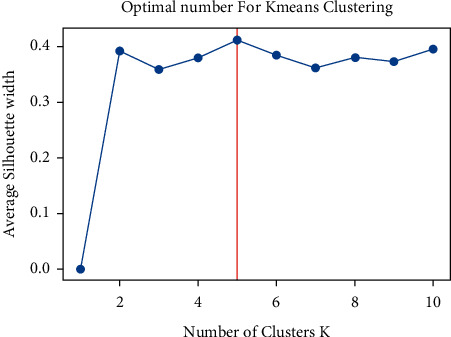
Optimal number of clustering with Silhouette criteria.
Figure 5 shows the cohesion and dispersion of data in one of the clusters extracted from the data PIR, PTT, SBP, and DBP.
Figure 5.
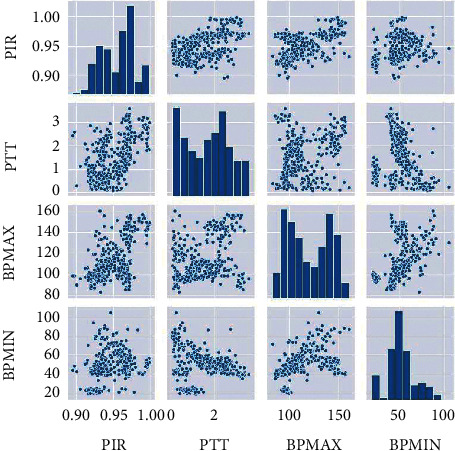
Histogram and scatter diagram of the features PTT, PIR, BPMIN, and BPMAX in one of the clusters.
Next, we used random forest regression, gradient boosting regression, and multilayer perceptron regression algorithms to develop a separate model for each cluster.
The model error for each cluster was then determined in terms of RMSE and MAE and target-estimation correlation coefficient (r) for gradient boosting regression. Finally, the total error of the model and correlation coefficient for all clusters was determined by weighted arithmetic mean. Finally, the error rate for the whole data and the total error rate are also provided. The results of the proposed clustering-based approach are presented in Table 2.
Table 2.
Comparison of the performance with clustering and regression algorithms.
| Systolic blood pressure (mmHg) | Diastolic blood pressure (mmHg) | |||||||
|---|---|---|---|---|---|---|---|---|
| Learner/performance | Cluster | Count of data per cluster | MAE | RMSE | r | MAE | RMSE | r |
| Random forest regression | Cluster1 | 6282 | 3.407 | 5.830 | — | 3.250 | 5.698 | — |
| Cluster2 | 6276 | 3.468 | 5.724 | — | 3.038 | 5.136 | — | |
| Cluster3 | 3355 | 3.521 | 5.586 | — | 2.813 | 5.408 | — | |
| Cluster4 | 8300 | 3.396 | 5.500 | — | 2.870 | 4.852 | — | |
| Cluster5 | 2390 | 2.434 | 4.567 | — | 2.677 | 4.879 | — | |
| Total | 26,603 | 3.344 | 5.557 | — | 2.974 | 5.191 | — | |
|
| ||||||||
| Gradient boosting regression | Cluster1 | 6282 | 2.644 | 5.841 | 0.96 | 2.486 | 5.648 | 0.98 |
| Cluster2 | 6276 | 2.781 | 5.694 | 0.93 | 2.468 | 5.232 | 0.96 | |
| Cluster3 | 3355 | 2.533 | 6.123 | 0.76 | 2.003 | 5.491 | 0.80 | |
| Cluster4 | 8300 | 2.610 | 5.522 | 0.85 | 2.161 | 4.675 | 0.95 | |
| Cluster5 | 2390 | 1.643 | 4.709 | 0.85 | 1.504 | 4.467 | 0.95 | |
| Total | 26,603 | 2.561 | 5.635 | 0.88 | 2.231 | 5.012 | 0.94 | |
|
| ||||||||
| Multilayer perceptron regression | Cluster1 | 6282 | 5.230 | 8.244 | — | 4.896 | 7.262 | — |
| Cluster2 | 6276 | 5.340 | 8.754 | — | 5.263 | 8.956 | — | |
| Cluster3 | 3355 | 6.235 | 9.523 | — | 6.094 | 8.852 | — | |
| Cluster4 | 8300 | 7.261 | 11.920 | — | 6.288 | 9.003 | — | |
| Cluster5 | 2390 | 4.326 | 8.156 | — | 4.160 | 6.875 | — | |
| Total | 26,603 | 5.937 | 9.664 | — | 5.501 | 8.370 | — | |
Figure 6 shows the Bland–Altman plot of each cluster for SBP and DBP estimations. As shown in the figure, most errors are in the range of 8 mmHg for DBP and 12 mmHg for SBP.
Figure 6.
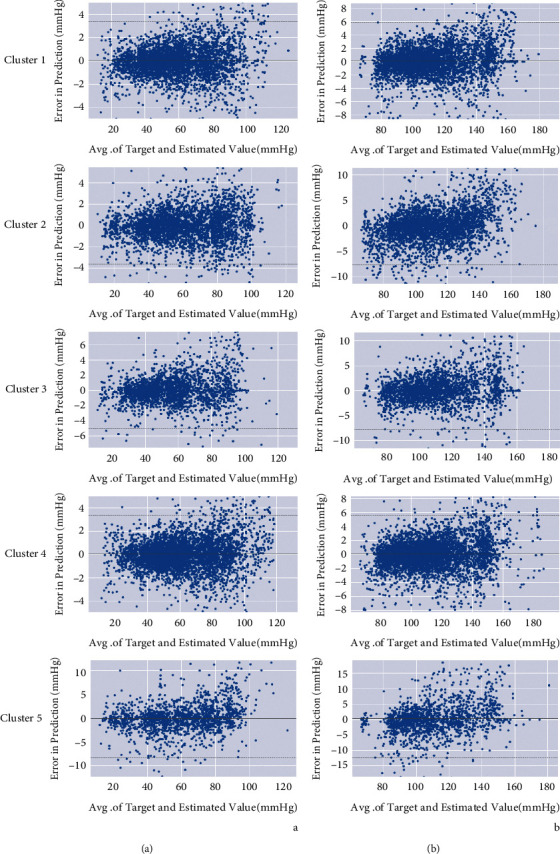
Bland–Altman plot for DBP (a) and SBP (b) estimations in each cluster.
However, there are also some outliers in these plots, which are more frequent in the one for SBP estimation.
Figure 7 shows the correlation plots of DBP and SBP estimation for our suggested technique versus reference BP. The overall calculated DBP and SBP had a correlation value of 0.94 and 0.88, respectively, which was obtained by weighted averaging of correlation coefficient in each cluster.
Figure 7.
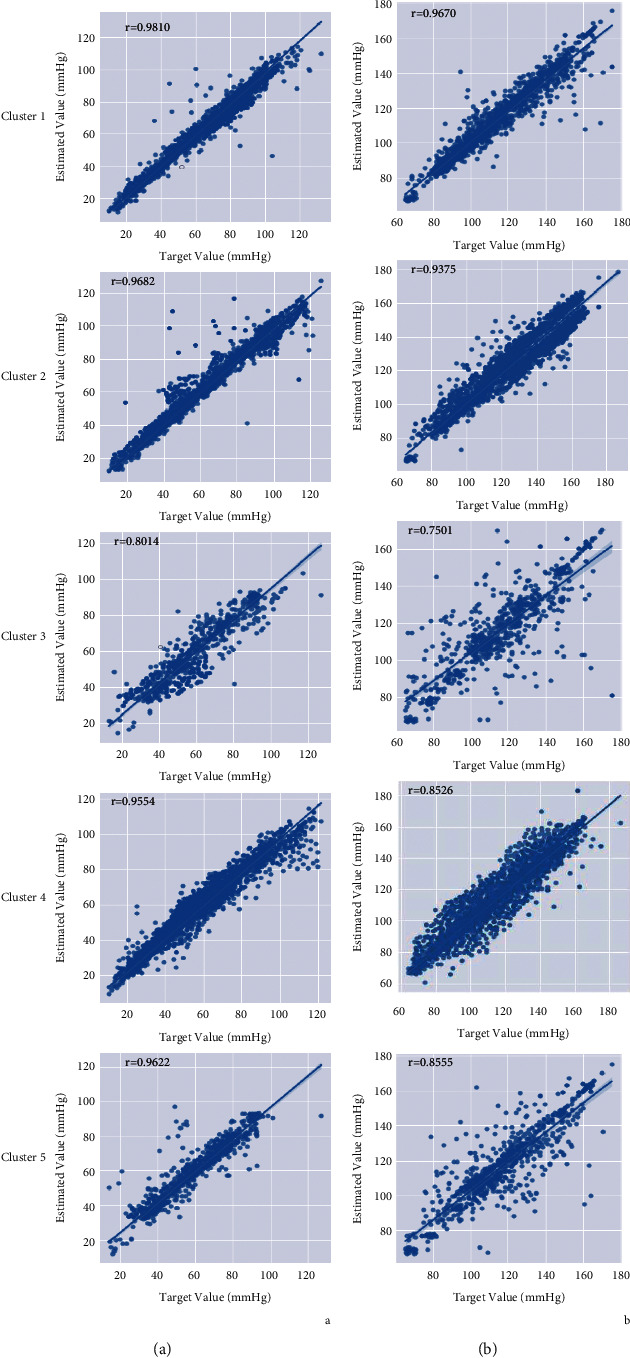
Correlation plot for DBP (a) and SBP (b) estimations in each cluster.
After applying clustering on the sample of features extracted from ECG, PPG, and ABP signals, we investigated the raw signal corresponding to each data sample in each cluster. Evidence showed that the ECG, PPG, and ABP signals corresponding to each data sample in each cluster are very similar in appearance and signal shape, which can be used to study the physiological characteristics of patients.
Figure 8 shows the ECG, PPG, and ABP signals of two different patients in cluster 1 and cluster 2 which are very similar to same cluster samples and very different from other cluster samples:
Figure 8.
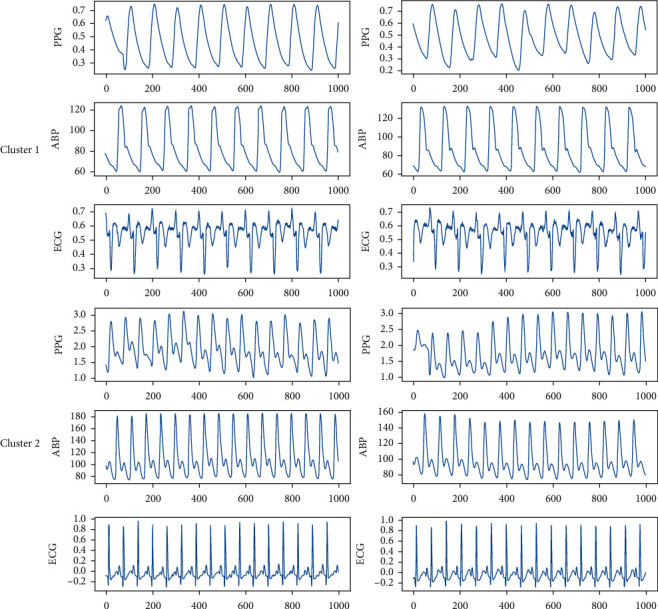
PPG, ABP, and ECG signals related to two patients in cluster1 and cluster2.
The results of the accuracy evaluation of the proposed method based on the BHS standard are presented in Table 3. According to this standard, the proposed method will be of Grade A in DBP estimation and SBP estimation.
Table 3.
BHS standard assessment for all clusters with weighted averaging.
| Cumulative error percentage | ||||
|---|---|---|---|---|
| ≤5 mmHg | ≤10 mmHg | ≤15 mmHg | ||
| Our results | DBP | 73.05% | 90.12% | 97.34% |
| SBP | 65.59% | 86.54% | 96.32% | |
| BHS | Grade A | 60% | 85% | 95% |
| Grade B | 50% | 75% | 90% | |
| Grade C | 40% | 65% | 85% | |
Table 4 shows the results of the accuracy evaluation of the proposed method based on the AAMI standard. According to this standard, the method produces acceptably accurate estimates for DBP and SBP.
Table 4.
AAMI standard assessment for all clusters with weighted averaging.
| ME (mmHg) | STD (mmHg) | Number of subjects | ||
|---|---|---|---|---|
| Our results | DBP | 2.811 | 5.596 | 942 |
| SBP | 3.987 | 5.715 | 942 | |
| AAMI standard | ≤5 | ≤8 | ≥85 | |
4. Discussion
It should be noted that while a large number of studies have been conducted in the field of BP estimation, many of these studies have used their own data sets, the majority of which are not publically available due to confidentiality and privacy considerations. Therefore, we cannot compare our results with all of the previous studies. In this section, we first compare our results with the results of studies that have used MIMIC/PhysioNet data sets and then make some comparisons with studies that have used their own data sets. A noteworthy point regarding the MIMIC-II data set is that it comprises readings from ICU patients, who tend to be older and under medication [9]. Another important point regarding MIMIC-II is the lack of physiological data (e.g., age, height, and weight), which can affect the accuracy of the extracted features and the model. While we could potentially use these data to include physiological and biological parameters in the clusters and examine their effects on the estimation accuracy, unfortunately, this could not be done with MIMIC-II. Because of using MIMIC-II, in this study, we only had access to ECG, PPG, and ABP signals, and therefore our feature extraction was limited to these signals. Thus, using a richer data set containing other signals such as SCG and BCG in addition to ECG, PPG, and ABP may be able to improve the accuracy of the extracted features and the resulting model [24].
The studies that have used publicly available MIMIC data sets include [9, 19], where PAT, HR, AI, LASI, and IPA features were extracted from ECG and PPG signals and then the Adaboost algorithm was used to develop BP estimation models based on these features. Our method outperforms the models of [9, 19] in terms of MAE and r as well as BHS and AAMI standards. Our results are also better than those reported in by Miao et al. [11], where an estimation model was developed by multisample regression based on 35 features extracted from the same ECG and PPG signals.
Ibtehaz et al. [13] developed their estimation model with the CNN algorithm using only the PPG signal. Our method also performs better than this model in terms of MAE and BHS and AAMI standards. Our results are also more accurate than the results of Kurylyak et al. [12], where they used 21 features extracted from ECG and PPG signals of MIMIC-II and an ANN algorithm to develop their model. The same can also be said for few previous studies [25, 26], where estimation was performed using the features extracted from the MIMIC data set of the PhysioNet website.
We also compared our method with some of the methods that have used their own data sets, which are listed in Table 5. Chen et al. [17] created their own data set by compiling the data of 98 subjects and developed their model using the multiple regression method based on features like PTT. Our method showed better performance in estimating SBP and DBP than this model. Our results are also better than the results of Radha et al.[27], where they used a data set consisting of the data collected from 106 healthy individuals with random forest and dense network, and also the results of Esmaili et al. [29], where they used a data set compiled from the data of 32 subjects with a calibration step. The results of the present work are also more accurate than those of Dong et al., Agham and Chaskar [28, 31], and other listed works that have used their own data sets.
Table 5.
Comparison with other works.
| Machine-learning comparison (DBP) | Machine-learning comparison (SBP) | ||||||
|---|---|---|---|---|---|---|---|
| Studies | Method | MAE | RMSE | r | MAE | RMSE | r |
| Our proposed method | Clustering and gradient boosting regression | 2.23 | 5.01 | 0.94 | 2.56 | 5.63 | 0.88 |
| Our proposed method | Gradient boosting regression without clustering | 6.27 | 10.22 | 0.71 | 6.36 | 10.39 | 0.67 |
| [16] | SVM | 6.34 | — | — | 12.38 | — | — |
| [9] | Adaboosting | 5.35 | — | 0.48 | 11.17 | — | 0.59 |
| [17] | MLR | 2.82 | — | 0.97 | 2.83 | — | 0.96 |
| [27] | LSTM and perceptron | — | 6.49 | 7.86 | |||
| [11] | Multisensor features | 4.54 | — | 0.90 | 6.13 | — | 0.84 |
| [13] | PPG + CNN-regression | 3.45 | — | 0.89 | 5.73 | — | 0.93 |
| [18] | PTT + PIR + nonlinear regression | 3.18 | — | 0.88 | 4.09 | — | 0.91 |
| [28] | — | 3.27 | — | 0.87 | 4.46 | — | 0.93 |
| [29] | (PPG + ECG) | 4.44 | — | 0.84 | 4.71 | — | 0.89 |
| [30] | SVM | 3.36 | — | 0.82 | 11.86 | — | 0.69 |
| [31] | MLP | 4.96 | — | 0.70 | 5.46 | — | 0.87 |
| [32] | ECG: wrist and foot PPG: Finger | 4.4 | — | — | 6.0 | — | — |
| [33] | ANN with 15 hidden neurons | Not mentioned | — | — | 3.03 | — | — |
| [34] | PTT and PIR, regression-MARS | 4.86 | — | 0.93 | 7.83 | — | 0.95 |
| [25] | AutoML (TPOT) | 4.19 | — | — | 6.52 | — | — |
| [12] | ANN | 2.21 ± 2.09 | — | — | 3.80 ± 3.46 | — | — |
| [26] | DNN | 6.88 | — | — | 9.43 | — | — |
| [35] | Res-LSTM | 4.61 | — | 0.74 | 7.10 | — | 0.96 |
| [36] | LSTM-based autoencoder | 4.05 | — | — | 2.41 | — | — |
5. Conclusion and Future Works
This study developed a new clustering-based algorithm to improve the accuracy of the blood pressure estimation, which uses the k-means algorithm for clustering extracted features and uses random forest regression algorithm, gradient boosting regression algorithm, and multilayer perceptron regression algorithm to estimate systolic blood pressure (SBP) and diastolic blood pressure (DBP) in each cluster. The results showed that according to high dispersion and the multitude of trends in the data and extracted features, the clustering algorithm can increase the prediction accuracy for each model. Overall, it can be concluded that since previous works have chosen not to deal with high dispersion and multitude of trends in the data before developing their learning models, it is indeed possible to reach considerably better prediction results by applying a clustering algorithm to the extracted data and then building a separate model for each cluster. In future works, we hope to develop a method for real-time feature extraction and sample clustering and ultimately create a real-time procedure for receiving vital signals such as ECG and PPG from thousands of people, performing feature extraction and signal processing, clustering the data, and producing BP estimates with the least possible delay and the highest possible accuracy; a task that will require using Big Data-related platforms, tools, and algorithms.
Data Availability
The data for this study are originated from PhysioNet and the well-known MIMIC-II database; however, a preprocessed data set from the MIMIC-II database is available at https://www.kaggle.com/mkachuee/BloodPressureDataset, which we utilized, and can be accessed through this link.
Disclosure
The authors published a preprint version of this work on the arxiv open-access repository which is available via the link https://arxiv.org/abs/2110.06996 [37].
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- 1.World Health Organization. World Health Statistics 2015 . Geneva, Switzerland: World Health Organization; 2015. [Google Scholar]
- 2.Poon C., Zhang Y. Cuff-less and noninvasive measurements of arterial blood pressure by pulse transit time. Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference; January 2005; Shanghai, China. pp. 5877–5880. [DOI] [PubMed] [Google Scholar]
- 3.Liu M., Po L.-M., Fu H. Cuffless blood pressure estimation based on photoplethysmography signal and its second derivative. International Journal of Computer Theory and Engineering. . 2017;9(3) doi: 10.7763/ijcte.2017.v9.1138. [DOI] [Google Scholar]
- 4.Shahabi M., Nafisi V. R., Pak F. Prediction of intradialytic hypotension using PPG signal features. Proceedings of the 2015 22nd Iranian Conference on Biomedical Engineering (ICBME); November 2015; Tehran, Iran. pp. 399–404. [Google Scholar]
- 5.Kitterman J. A., Phibbs R. H., Tooley W. H. Catheterization of umbilical vessels in newborn infants. Pediatric Clinics of North America . 1970;17(4):895–912. doi: 10.1016/s0031-3955(16)32486-5. [DOI] [PubMed] [Google Scholar]
- 6.Chung E., Chen G., Alexander B., Cannesson M. Non-invasive continuous blood pressure monitoring: a review of current applications. Frontiers of Medicine . 2013;7(1):91–101. doi: 10.1007/s11684-013-0239-5. [DOI] [PubMed] [Google Scholar]
- 7.Buxi D., Redouté J. M., Yuce M. R. A survey on signals and systems in ambulatory blood pressure monitoring using pulse transit time. Physiological Measurement . 2015;36(3):p. R1. doi: 10.1088/0967-3334/36/3/R1. [DOI] [PubMed] [Google Scholar]
- 8.Peter L., Noury N., Cerny M. A review of methods for non-invasive and continuous blood pressure monitoring: pulse transit time method is promising? Irbm . 2014;35(5) doi: 10.1016/j.irbm.2014.07.002. [DOI] [Google Scholar]
- 9.Kachuee M., Kiani M. M., Mohammadzade H., Shabany M. Cuffless blood pressure estimation algorithms for continuous health-care monitoring. IEEE Transactions on Biomedical Engineering . 2016;64(4) doi: 10.1109/TBME.2016.2580904. [DOI] [PubMed] [Google Scholar]
- 10.Thambiraj G., Gandhi U., Devanand V., Mangalanathan U. Noninvasive cuffless blood pressure estimation using pulse transit time, Womersley number, and photoplethysmogram intensity ratio. Physiological Measurement . 2019;40(7) doi: 10.1088/1361-6579/ab1f17.075001 [DOI] [PubMed] [Google Scholar]
- 11.Miao F., Liu Z.-D., Liu J.-K., Wen B., He Q.-Y., Li Y. Multi-sensor fusion approach for cuff-less blood pressure measurement. IEEE Journal of Biomedical and Health Informatics . 2020;24(1):79–91. doi: 10.1109/JBHI.2019.2901724. [DOI] [PubMed] [Google Scholar]
- 12.Kurylyak Y., Lamonaca F., Grimaldi D. A Neural Network-based method for continuous blood pressure estimation from a PPG signal. Proceedings of the 2013 IEEE International Instrumentation and Measurement Technology Conference (I2MTC); May 2013; Minneapolis, MN, USA. pp. 280–283. [DOI] [Google Scholar]
- 13.Ibtehaz N., Rahman M. S. PPG2ABP: translating photoplethysmogram (PPG) signals to arterial blood pressure (ABP) waveforms using fully convolutional neural networks. 2020. http://arxiv.org/abs/2005.01669 . [DOI] [PMC free article] [PubMed]
- 14.Le T., Ellington F., Lee T.-Y., et al. Continuous non-invasive blood pressure monitoring: a methodological review on measurement techniques. IEEE Access . 2020;8:212478–212498. doi: 10.1109/ACCESS.2020.3040257. [DOI] [Google Scholar]
- 15.Chen Y., Wen C., Tao G., Bi M., Li G. Continuous and noninvasive blood pressure measurement: a novel modeling methodology of the relationship between blood pressure and pulse wave velocity. Annals of Biomedical Engineering . 2009;37(11):p. 2222. doi: 10.1007/s10439-009-9759-1. [DOI] [PubMed] [Google Scholar]
- 16.Vlachopoulos C., O’Rourke M., Nichols W. W. McDonald’s Blood Flow in Arteries: Theoretical, Experimental and Clinical Principles . Florida, United States: CRC Press; 2011. [Google Scholar]
- 17.Chen K., Zhang X., Zou Q., Wang X. Individual-based cuffless continue estimation of blood pressure measurement: using multiple pulse transmit time. Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data Smart City (ICITBS); January 2020; Vientiane, Laos. pp. 889–892. [DOI] [Google Scholar]
- 18.Ding X.-R., Zhang Y.-T., Liu J., Dai W.-X., Tsang H. K. Continuous cuffless blood pressure estimation using pulse transit time and photoplethysmogram intensity ratio. IEEE Transactions on Biomedical Engineering . 2016;63(5):964–972. doi: 10.1109/TBME.2015.2480679. [DOI] [PubMed] [Google Scholar]
- 19.Kachuee M., Kiani M. M., Mohammadzade H., Shabany M. Cuff-less high-accuracy calibration-free blood pressure estimation using pulse transit time. Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS); May 2015; Lisbon, Portugal. pp. 1006–1009. [Google Scholar]
- 20.Ding X.-R., Zhang Y.-T. Photoplethysmogram intensity ratio: a potential indicator for improving the accuracy of PTT-based cuffless blood pressure estimation. Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC); August 2015; Milan, Italy. pp. 398–401. [DOI] [PubMed] [Google Scholar]
- 21.Zhang Y. L., Zheng Y. Y., Ma Z. C., Sun Y. N. Radial pulse transit time is an index of arterial stiffness. Hypertension Research: Official Journal of the Japanese Society of Hypertension . 2011;34(7):p. 884. doi: 10.1038/hr.2011.41. [DOI] [PubMed] [Google Scholar]
- 22.Segal M. R. Machine learning benchmarks and random forest regression. Center for Bioinformatics and Molecular Biostatistics . 2004, https://escholarship.org/uc/item/35x3v9t4. [Google Scholar]
- 23.Friedman J. H. Stochastic gradient boosting. Computational Statistics & Data Analysis . 2002;38(4) doi: 10.1016/s0167-9473(01)00065-2. [DOI] [Google Scholar]
- 24.Kim C.-S., Carek A. M., Mukkamala R., Inan O. T., Hahn J.-O. Ballistocardiogram as proximal timing reference for pulse transit time measurement: potential for cuffless blood pressure monitoring. IEEE Transactions on Biomedical Engineering . 2015;62(11):2657–2664. doi: 10.1109/TBME.2015.2440291. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Fati S. M., Muneer A., Akbar N. A., Taib S. M. A continuous cuffless blood pressure estimation using tree-based pipeline optimization tool. Symmetry . 2021;13(4):p. 686. doi: 10.3390/sym13040686. [DOI] [Google Scholar]
- 26.Slapničar G., Mlakar N., Luštrek M. Blood pressure estimation from photoplethysmogram using a spectro-temporal deep neural Network. Sensors . 2019;19(15):p. 3420. doi: 10.3390/s19153420. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Radha M., de Groot K., Rajani N., et al. Estimating blood pressure trends and the nocturnal dip from photoplethysmography. Physiological Measurement . 2019;40(2) doi: 10.1088/1361-6579/ab030e.025006 [DOI] [PubMed] [Google Scholar]
- 28.Dong Y., Kang J., Yu Y., Zhang K., Li Z., Zhai Y. A novel model for continuous cuff-less blood pressure estimation. Proceedings of the 2018 11th International Symposium on Communication Systems, Networks & Digital Signal Processing (CSNDSP); Jul. 2018; Budapest, Hungary. pp. 1–6. [DOI] [Google Scholar]
- 29.Esmaili A., Kachuee M., Shabany M. Nonlinear cuffless blood pressure estimation of healthy subjects using pulse transit time and arrival time. IEEE Transactions on Instrumentation and Measurement . 017;66(12):3299–3308. doi: 10.1109/TIM.2017.2745081. [DOI] [Google Scholar]
- 30.Anvari S. M., Kayvanpour A. H., Jafari Tadi M., Koivisto T., Yazdchi M., Nayebpour S. M. H. Design and implementation of a non-invasive and cuff-less arterial blood pressure monitoring system. Computing in Cardiology Conference (CinC) . 2017;44 doi: 10.22489/CinC.2017.325-471. [DOI] [Google Scholar]
- 31.Agham N., Chaskar U. Prevalent approach of learning based cuffless blood pressure measurement system for continuous health-care monitoring. Proceedings of the 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA); June 2019; Istanbul, Turkey. pp. 1–5. [DOI] [Google Scholar]
- 32.Shao J., Shi P., Hu S. A unified calibration paradigm for a better cuffless blood pressure estimation with modes of elastic tube and vascular elasticity. Journal of Sensors . 2021;2021:12. doi: 10.1155/2021/8868083. [DOI] [Google Scholar]
- 33.Zheng J., Yu Z. A novel machine learning-based systolic blood pressure predicting model. Journal of Nanomaterials . 2021;2021:8. doi: 10.1155/2021/9934998. [DOI] [Google Scholar]
- 34.Sharifi I., Goudarzi S., Khodabakhshi M. B. A novel dynamical approach in continuous cuffless blood pressure estimation based on ECG and PPG signals. Artificial Intelligence in Medicine . 2019;97:143–151. doi: 10.1016/j.artmed.2018.12.005. [DOI] [PubMed] [Google Scholar]
- 35.Miao F., Wen B., Hu Z., et al. Continuous blood pressure measurement from one-channel electrocardiogram signal using deep-learning techniques. Artificial Intelligence in Medicine . 2020;108 doi: 10.1016/j.artmed.2020.101919.101919 [DOI] [PubMed] [Google Scholar]
- 36.Harfiya L. N., Chang C.-C., Li Y.-H. Continuous blood pressure estimation using exclusively photopletysmography by LSTM-based signal-to-signal translation. Sensors . 2021;21(9):p. 2952. doi: 10.3390/s21092952. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Farki A., Kazemzadeh R. B., Noughabi E. A. A novel clustering-based algorithm for continuous and non-invasive cuff-less blood pressure estimation. 2021. http://arxiv.org/abs/2110.06996 . [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data for this study are originated from PhysioNet and the well-known MIMIC-II database; however, a preprocessed data set from the MIMIC-II database is available at https://www.kaggle.com/mkachuee/BloodPressureDataset, which we utilized, and can be accessed through this link.