

Abstract
The Adolescent Brain Cognitive Development (ABCD) Study is the largest single-cohort prospective longitudinal study of neurodevelopment and children’s health in the United States. A cohort of n= 11,880 children aged 9–10 years (and their parents/guardians) were recruited across 22 sites and are being followed with in-person visits on an annual basis for at least 10 years. The study approximates the US population on several key sociodemographic variables, including sex, race, ethnicity, household income, and parental education. Data collected include assessments of health, mental health, substance use, culture and environment and neurocognition, as well as geocoded exposures, structural and functional magnetic resonance imaging (MRI), and whole-genome genotyping. Here, we describe the ABCD Study aims and design, as well as issues surrounding estimation of meaningful associations using its data, including population inferences, hypothesis testing, power and precision, control of covariates, interpretation of associations, and recommended best practices for reproducible research, analytical procedures and reporting of results.
Keywords: Adolescent Brain Cognitive Development Study, Population Neuroscience, Genetics, Hypothesis Testing, Reproducibility, Covariate Adjustments, Effect Sizes
1.0. Introduction
The Adolescent Brain Cognitive DevelopmentSM (ABCD) Study is the largest single-cohort long-term longitudinal study of neurodevelopment and child and adolescent health in the United States. The study was conceived and initiated by the United States’ National Institutes of Health (NIH), with funding beginning on September 30, 2015. The ABCD Study® collects observational data to characterize US population trait distributions and to assess how biological, psychological, and environmental factors (including interpersonal, institutional, cultural, and physical environments) can relate to how individuals live and develop in today’s society. From the outset, the NIH and ABCD scientific investigators were motivated to develop a baseline sample that reflected the sociodemographic variation present in the US population of 9–10 year-old children, and to follow them longitudinally through adolescence and into early adulthood.
The ABCD Study was designed to address some of the most important public health questions facing today’s children and adolescents1. These questions include identifying factors leading to the initiation and consumption patterns of psychoactive substances, substance-related problems, and substance use disorders as well as their subsequent impact on the brain, neurocognition, health, and mental health over the course of adolescence and into early adulthood. More broadly, a large epidemiologically informed longitudinal study beginning in childhood and continuing on through early adulthood will provide a wealth of unique data on normative development, as well as environmental and biological factors associated with variation in developmental trajectories. This broader perspective has led to the involvement of multiple NIH Institutes that are stakeholders in the range of health outcomes targeted in the ABCD design. (Information regarding funding agencies, recruitment sites, investigators, and project organization can be obtained at https://abcdstudy.org).
Population representativeness, or more precisely, absence of uncorrected selection bias in the subject pool, is important in achieving external validity, i.e., the ability to generalize specific results of the study to US society at large. As described below, the ABCD Study attempted to match the diverse US population of 9–10 year-old children on key demographic characteristics. However, even with a largely representative sample, failure to account for key confounders can affect internal validity, i.e., the degree to which observed associations accurately reflect the effects of underlying causal mechanisms. Moreover, it is crucial that the study collects a rich array of variables that may act as moderators or mediators, including biological and environmental variables, in order to aid in identifying potentially causal pathways of interest, to quantify individualized risk for (or resilience to) poor outcomes, and to inform public policy decisions. External and internal validity also depend on assessing the impact of random and systematic measurement error, implementing analytical methods that incorporate relevant aspects of study design, and emphasizing robust and replicable estimation of associations.
The ABCD Study primary aims are given in the Supplementary Materials (SM) Section S.1. We describe the study design and outline analytic strategies to address the primary study aims, including worked examples, with emphasis on approaches that incorporate relevant aspects of study design (Section 2: Study Design; Section 3: Population Weighting). We emphasize the impact of sample size on the precision of association estimates and thoughtful control of covariates in the context of the large-scale population neuroscience data produced by the ABCD Study (Section 4: Hypothesis Testing and Power; Section 5: Effect Sizes; Section 6: Control and Confounding Variables), and we briefly outline state-of-the-field recommendations for promoting reproducible science (Section SM.5) and best practices for statistical analyses and reporting of results using the ABCD Study data (Section SM.6). For readability, more technical subject matter is also largely left to SM sections.
2.0. Study Design
The ABCD Study is a prospective longitudinal cohort study of US children born between 2006–2008. A total cohort of n = 11880 children aged 9–10 years at baseline (and their parents/guardians) was recruited from 22 sites (with one site no longer active) and are being followed for at least ten years. Eligible children were recruited from the household populations in defined catchment areas for each of the study sites during the roughly two-year period beginning September 2016 and ending in October 2018.
2.1. Recruitment
Within study sites, consenting parents and assenting children were primarily recruited through a probability sample of public and private schools augmented to a smaller extent by special recruitment through summer camp programs and community volunteers. ABCD employed a probability sampling strategy to identify schools within the catchment areas as the primary method for contacting and recruiting eligible children and their parents. This method has been used in other large national studies (e.g., Monitoring the Future2; the Add Health Study3; the National Comorbidity Replication-Adolescent Supplement4; and the National Education Longitudinal Studies5). Twins at four “twin-hub” sites were recruited from birth registries (see6,7 for participant recruitment details). A minority of participants were recruited through non-school-based community outreach and word-of-mouth referrals.
2.2. Inclusion Criteria
Across recruitment sites, inclusion criteria consisted of being in the required age range and able to provide informed consent (parents) and assent (child). Exclusions were minimal and were limited to lack of English language proficiency in the children, the presence of severe sensory, intellectual, medical or neurological issues that would impact the validity of collected data or the child’s ability to comply with the protocol, and contraindications to MRI scanning6. Parents must be fluent in either English or Spanish.
2.3. Measures
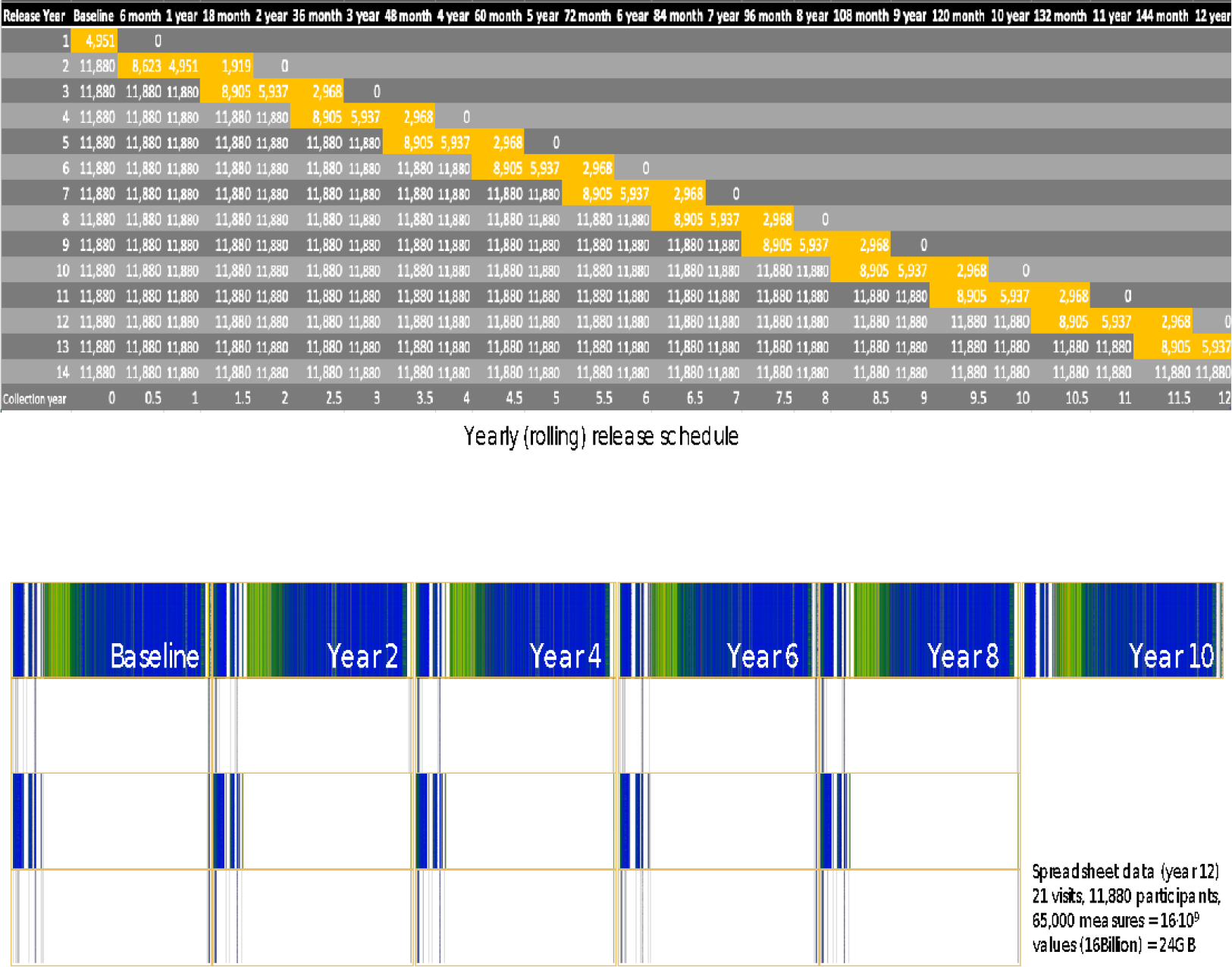
Measures collected in the ABCD Study include a neurocognitive battery8,9, mental and physical health assessments10, measures of culture and environment11, biospecimens12, structural and functional brain imaging13,14, geolocation-based environmental exposure data, wearables and mobile technology15, and whole genome genotyping16. Many of these measures are collected at in-person annual visits, with brain imaging collected at baseline and at every other year going forward. A limited number of assessments are collected in semi-annual telephone interviews between in-person visits. Data are publicly released on an annual basis through the NIMH Data Archive (NDA, https://nda.nih.gov/abcd). Figure 1 graphically displays the measures that have been collected as part of the ABCD NDA 3.0. Release. Figure 2 depicts the planned data collection and release schedule over the initial 10 years of the study.
Figure 1: ABCD Study Assessments for NDA 2.0.1 Release Data.
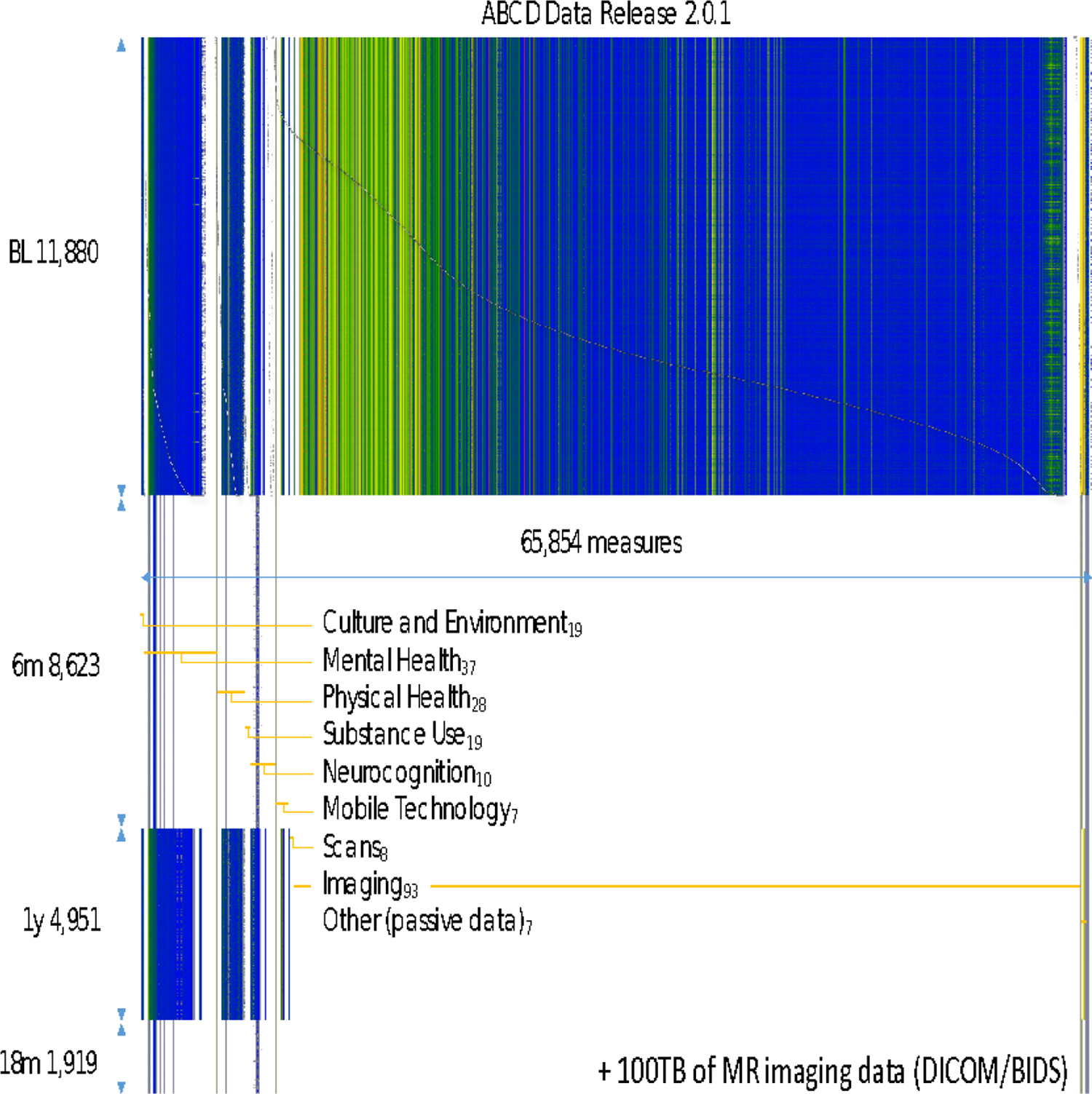
Figure 2: ABCD Data Collection and NDA Release Schedule.
2.4. Sociodemographics
ABCD sample baseline demographics (from NDA Release 2.0.1, which contains data from n = 11879 subjects) are presented in Table 1, along with a comparison to the corresponding statistics from the American Community Survey (ACS). The ACS is a large probability sample survey of US households conducted annually by the US Bureau of Census and provides a benchmark for selected demographic and socio-economic characteristics of US children aged 9–10 years. The 2011–2015 ACS Public Use Microsample (PUMS) file provides data on over 8,000,000 sample US households. Included in this five-year national sample of households are 376,370 individual observations for children aged 9–10 and their households.
Table 1:
ABCD Baseline and ACS 2011–2015 Demographic Characteristics
| Characteristic | Category | ABCD n=11,879 | ACS 2011–2015 | |
|---|---|---|---|---|
|
| ||||
| % | N | % | ||
|
|
||||
| Population | Total | 100 | 8,211,605 | 100 |
| Age | 9 | 52.3 | 4,074,807 | 49.6 |
| 10 | 47.7 | 4,136,798 | 50.4 | |
| Sex | Male | 52.2 | 4,205,925 | 51.2 |
| Female | 47.8 | 4,005,860 | 48.8 | |
| Race/Ethnicity | NH White | 52.2 | 4,305,552 | 52.4 |
| NH Black | 15.1 | 1,101,297 | 13.4 | |
| Hispanic | 20.4 | 1,973,827 | 24.0 | |
| Asian, AIAN, NHPI | 3.2 | 487,673 | 5.9 | |
| Multiple | 9.2 | 343,256 | 4.2 | |
| Family Income | <$25k | 16.1 | 1,762,415 | 21.5 |
| $25k–$49k | 15.1 | 1,784,747 | 21.7 | |
| $50k–$74k | 14.0 | 1,397,641 | 17.0 | |
| $75k–$99k | 14.1 | 1,023,127 | 12.5 | |
| $100k–$199k | 29.5 | 1,685,036 | 20.5 | |
| $200k + | 11.2 | 558,639 | 6.8 | |
| Family Type | Married Parents | 73.4 | 5,426,131 | 66.1 |
| Other Family Type | 26.6 | 2,785,474 | 33.9 | |
| Parent Employment | Married, 2 in LF | 50.2 | 3,353,572 | 40.8 |
| Married, 1 in LF | 21.9 | 1,949,288 | 23.7 | |
| Married, 0 in LF | 1.3 | 156,807 | 1.9 | |
| Single, in LF | 21.1 | 2,174,365 | 26.5 | |
| Single, Not in LF | 5.4 | 577,573 | 7.0 | |
| Region | Northeast | 16.9 | 1,336,183 | 16.3 |
| Midwest | 20.4 | 1,775,723 | 21.6 | |
| South | 28.3 | 3,117,158 | 38.0 | |
| West | 34.4 | 1,982,541 | 24.1 | |
| Household Size | 2 to 3 | 17.3 | 1,522,216 | 18.5 |
| 4 | 33.5 | 2,751,942 | 33.5 | |
| 5 | 24.9 | 2,085,666 | 25.4 | |
| 6 | 14.0 | 1,025,285 | 12.5 | |
| 7+ | 10.3 | 826,496 | 10.1 | |
LF=labor force
With some minor differences, the unweighted distributions for the ABCD baseline sample closely match the ACS-based national estimates for demographic characteristics including age, sex, and household size. The general concordance of the samples can be attributed in large part to three factors: 1) the inherent demographic diversity across the ABCD study sites; 2) stratification (by race/ethnicity) in the probability sampling of schools within sites; and 3) demographic controls employed in the recruitment by site teams. Likewise, the unweighted percentages of ABCD children for the most prevalent race/ethnicity categories are an approximate match to the ACS estimates for US children age 9 and 10. Collectively, children of Asian, American Indian/Alaska Native (AIAN) and Native Hawaiian/Pacific Islander (NHPI) ancestry are under-represented in the unweighted ABCD data (3.2%) compared with ACS national estimates (5.9%). This outcome, which primarily affects ABCD’s sample of Asian children, may be due in part to differences in how the parent/caregiver of the child reports multiple race/ethnicity ancestry in ABCD and the ACS.
3.0. Population Inferences
The ABCD recruitment effort worked very hard to maintain similarity of the ABCD sample and the US population with respect to sex and race/ethnicity of the children in the study. The predominantly probability sampling methodology for recruiting children within each study site was intended to randomize over confounding factors that were not explicitly controlled (or subsequently reflected in the population weighting). Nevertheless, school consent and parental consent were strong forces that certainly may have altered the effectiveness of the randomization over these uncontrolled confounders.
3.1. Population Weighting
The purpose of population weighting is to control for specific sources of selection bias and restore unbiasedness to descriptive and analytical estimates of the population characteristics and relationships17. Briefly, construction of the population weights required identification of a key set of demographic and socio-economic variables for the children and their households that are measured in both the ABCD Study and in the ACS household interviews. For the ABCD eligible children, the common variables include 1) age; 2) sex; and 3) race/ethnicity. For the child’s household, additional variables include: 4) family income; 5) family type (married parents, single parent); 6) household size 7) parents’ work force status (family type by parent employment status); 8) Census Region. A multiple logistic regression model using these variables was then fit to the concatenated ACS and ABCD data to predict study membership. The construction of the population weights for the ABCD Study is described in detail in Heeringa and Berglund (2020)18. R scripts for computing the ABCD population weights and for applying them in analyses are available at https://github.com/ABCD-STUDY/abcd_acs_raked_propensity. The population weights are available in the NDA data releases 2.0.1 and 3.0.
3.2. Recommendations
Heeringa and Berglund (2020)18 present regression analyses with and without using the population weights. Although it is important not to over-generalize from a small set of comparisons to all possible analyses of the ABCD data, the results described therein lead to recommendations for researchers who are analyzing the ABCD baseline data. First, unweighted analysis may result in biased estimates of descriptive population statistics. The potential for bias in unweighted estimates from the ABCD data is strongest when the variable of interest is highly correlated with socio-economic variables including family income, family type and parental work force participation. Second, for regression models of the ABCD baseline data, an unweighted analysis using mixed-effects models (e.g., site, family, individual) is the preferred choice. Presently, there is no empirical evidence from comparative analyses that methods for multi-level weighting19 will improve the accuracy or precision of the model fit, although additional research on this topic is ongoing.
3.3. Example: Application to Baseline Brain Volumes
As a demonstration of the implications of the weighting strategy employed in the ABCD Study, weighted and unweighted means and standard errors for ABCD baseline brain morphometry - volumes of cortical Desikan parcels20 - are presented in Table 2. Missing observations were first imputed using the R package mice21 before applying weights to the completed sample. Differences between unweighted and weighted means are quite small in the baseline sample in this case. As longitudinal MRI data become available in ABCD (starting with the second post-baseline annual follow-up visit), population-valid mean trajectories of brain-related outcomes will also be computable using a similar population weighting scheme, also allowing for characterization of variation of trajectories from the population mean.
Table 2:
Unweighted and Weighted Means of Desikan Cortical Volumes
| Mean | SE | Weighted Mean | SE | |
|---|---|---|---|---|
|
|
||||
| bankssts | 3238.48 | 473.95 | 3227.70 | 472.83 |
| caudalanteriorcingulate | 2571.23 | 476.91 | 2559.34 | 478.06 |
| caudalmiddlefrontal | 8326.70 | 1408.47 | 8277.25 | 1398.77 |
| cuneus | 3645.25 | 582.41 | 3626.44 | 582.07 |
| entorhinal | 1843.15 | 339.44 | 1835.95 | 339.10 |
| fusiform | 12050.11 | 1552.79 | 12009.48 | 1558.06 |
| inferiorparietal | 18387.31 | 2432.67 | 18325.23 | 2428.86 |
| inferiortemporal | 13182.85 | 1879.13 | 13133.08 | 1870.21 |
| isthmuscingulate | 3252.16 | 534.48 | 3239.51 | 538.27 |
| lateraloccipital | 13334.05 | 1870.71 | 13283.90 | 1848.41 |
| lateralorbitofrontal | 9295.28 | 1036.65 | 9258.68 | 1035.60 |
| lingual | 8031.18 | 1132.35 | 7998.54 | 1132.13 |
| medialorbitofrontal | 5976.38 | 731.09 | 5954.65 | 725.41 |
| middletemporal | 14275.50 | 1796.11 | 14230.8 | 1786.83 |
| parahippocampal | 2586.48 | 378.94 | 2576.70 | 378.86 |
| paracentral | 4674.33 | 672.68 | 4660.61 | 674.30 |
| parsopercularis | 5701.08 | 849.03 | 5683.61 | 846.91 |
| parsorbitalis | 3097.73 | 371.12 | 3084.29 | 371.66 |
| parstriangularis | 5178.54 | 733.71 | 5159.42 | 732.41 |
| pericalcarine | 2505.86 | 425.52 | 2489.51 | 424.71 |
| postcentral | 11822.49 | 1599.97 | 11788.14 | 1593.43 |
| posteriorcingulate | 4196.07 | 603.72 | 4181.46 | 606.51 |
| precentral | 15990.94 | 1796.68 | 15929.85 | 1791.05 |
| precuneus | 12865.56 | 1618.69 | 12819.36 | 1616.69 |
| rostralanteriorcingulate | 2963.47 | 479.55 | 2949.78 | 479.97 |
| rostralmiddlefrontal | 21292.13 | 2684.14 | 21165.50 | 2669.35 |
| superiorfrontal | 28758.00 | 3204.70 | 28616.28 | 3197.22 |
| superiorparietal | 17020.90 | 2172.80 | 16961.33 | 2161.06 |
| superiortemporal | 14575.38 | 1645.94 | 14519.78 | 1652.24 |
| supramarginal | 13827.92 | 1891.34 | 13772.95 | 1894.80 |
| frontalpole | 1153.78 | 185.07 | 1150.68 | 186.20 |
| temporalpole | 2478.08 | 309.09 | 2472.20 | 308.04 |
| transversetemporal | 1339.14 | 216.87 | 1333.57 | 217.62 |
| insula | 7586.56 | 857.66 | 7556.20 | 856.70 |
|
| ||||
| total | 297024.05 | 28733.94 | 295831.76 | 28686.91 |
4.0. Hypothesis Testing and Power
Developing an operational approach to evaluate the meaningfulness of research findings has been a subject of consistent debate throughout the history of statistics22. Even with the continued efforts to synthesize systems of statistical inference23, the resolution of this issue is unlikely to occur any time soon. Most neuroscientists continue to work within the context of the classical frequentist null-hypothesis significance testing (NHST) paradigm24,25, although non-frequentist approaches (e.g. Bayesian, machine learning prediction26,27) are increasingly common and may be more appropriate for large datasets like the ABCD Study.
Despite growing enthusiasm for these alternatives, p-values continue to be important data points in the presentation of results in the behavioral and neurosciences. The NHST p-value “…is the probability under a specified statistical model that a statistical summary of the data…would be equal to or more extreme than its observed value”28. The utility of NHST and the arbitrariness of the 0. 05 significance threshold has been debated extensively28–30. While we will not relitigate these issues here, we will attempt to address how best to present statistical evidence that leverages the ABCD Study’s large sample size (affecting statistical power), population sampling frame, and rich longitudinal assessment protocol to enable meaningful and valid insights into child and adolescent neurodevelopment.
4.1. Power
Statistical power in the NHST framework is defined as the probability of rejecting a false null hypothesis. Power is determined by three factors: 1) the significance level α; 2) the magnitude of the population parameter; and 3) the accuracy (precision and bias) of the model estimates. Increasing power while maintaining a specified Type I error rate depends largely on obtaining more precise association parameter estimates from improved study designs, more efficient statistical methods, and, importantly, increasing sample size31–33.
The ABCD Study has a large sample compared to typical neurodevelopmental studies, so much so that one might expect even very small associations to be statistically significant. In our experience, not all associations in the ABCD Study are guaranteed to have small p-values. For example, a recent study attempting to replicate the often-cited bilingual executive function advantage failed to find evidence for the advantage in the first data release (NDA 1.0) of the ABCD Study (n = 4524)34.
Nevertheless, even very small associations are well-powered in the ABCD Study. Figure 3 displays power curves as a function of sample size for different values of absolute Pearson correlations |r|. The dashed line in Figure 3 indicates the full ABCD baseline sample size of n = 11880. As can be seen, Pearson correlations |r|=0.04 and above have power > 0. 99 at α = 0. 05. Simply rejecting a null hypothesis without reporting on other aspects of the study design and statistical analyses (including discussion of plausible alternative explanatory models and threats to validity), as well as the observed magnitude of associations, is uninformative, perhaps particularly so in the context of very well-powered studies35.
Figure 3: Power vs. Sample Size for Pearson |r|.

5.0. Effect Sizes
Because p-values may be less informative in the context of very well-powered studies like ABCD, effect sizes become important data points in determining the importance of the findings. Effect sizes quantify relationships between two or more variables, e.g., correlation coefficients, proportion of variance explained (R2), Cohen’s d, relative risk, number needed to treat, and so forth36,37, with one variable often thought of as independent (exposure) and the other dependent (outcome)31. Effect sizes are independent of sample size, e.g., t-tests and p-values are not effect sizes; however, the precision of effect size estimators depend on sample size as described earlier. Consensus best practice recommendations are that effect size point estimates be accompanied by intervals to illustrate the precision of the estimate and the consequent range of plausible values indicated by the data28. Table 3 presents a number of commonly used effect size metrics39,40. We wish to avoid being overly prescriptive for which of these effect sizes to employ in ABCD applications, as researchers should think carefully about the intended use of their analyses and pick an effect size metric that addresses their particular research question.
Table 3:
Measures of Effect Size Relevant for ABCD
| Measures of Strength of Association |
|
|
| r, rpb, r2, R, R2, ϕ, η, η2 |
| Cohen’s f2 |
| Cramér’s V |
| Fisher’s Z |
| Measures of Strength of Association Relevant for Multiple Regression |
|
|
| Standardized regression slope or path coefficient β |
| Semi-partial correlation ry(x,z) |
| Measures of Effect Size |
|
|
| Cohen’s d, f, g, h, q, w |
| Glass’ g′ |
| Hedges’ g |
| Other Measures |
|
|
| Odds ratio (ω2) |
| Relative risk |
5.1. Small Effects
As much as the choice of which effect size statistic to report is driven by context, the interpretation of the practical utility of the observed effect size is even more so. While small p-values do not imply that reported effects are inherently substantive, “small” effect sizes might have practical or even clinical significance in the right context37.
As described in SM Section S.2, known problems of publication bias and incentives for researchers to find significant associations32,41 combined with the predominantly small sample sizes of most prior neurodevelopmental studies lead us to expect that true brain-behavior effect sizes are smaller than have been described in the past42,43. Indeed, Ioannidis (2005)44 has argued that most claimed research findings in the scientific literature are actually false. Although details of the concerns are disputed45, some analyses of existing literature provide support for the possibility46. It is possible, then, that many published neurodevelopmental associations represent severely inflated effect sizes32,47 and may be severely attenuated in investigations of ABCD data.
It is also possible that actual (causal) associations found in nature are in reality small for many outcomes. There is already strong evidence for this possibility: Myer and colleagues (2001)48 reviewed 125 meta-analyses in psychology and psychiatry and found that most relationships between clinically important variables are in the r=0.15 to 0.3 range, with many clinically important effects even smaller. Miller et al. (2016)49 analyzed associations between multimodal imaging and health-related outcomes in the UKBiobank data. Even the most significant of these explained only around 1% of the variance in the outcomes.
5.2. Pre-Registration
While not of course completely immune to these problems (especially in subgroup and/or high-dimensional analyses), because its large sample size reduces random fluctuations in effect size estimates that occur within small n studies, the ABCD Study is much more resistant than is typical. However, with the large number of reseachers analyzing the data, high-dimensional space of covariates and outcomes and an essentially infinite number of possible modeling strategies, p-hacking and exploitation of random chance remains a possible source of irreproducible results. Pre-registration may mitigate exposure to some of these sources of irreproducibility. Indeed, a recent meta-analysis50 found that effects from publications without pre-registration (median r = 0. 36) skewed larger than effects from publications with pre-registration (median r = 0. 16), suggesting that pre-registration is a practical step toward reporting research results that reflect the actual effects under investigation.
For ABCD Study data, we recommend that researchers consider hypothesis pre-registration (e.g., using the Open Science Foundation framework: https://osf.io/prereg/) and using a registered reports option for publishing results51. A template for hypothesis pre-registration for the ABCD Study data can be found in the NDA-hosted ABCD Data Exploration and Analysis Portal (ABCD DEAP, https://deap.nimhda.org/index.php), which is freely accessible to all users with a valid NDA ABCD user ID and password. Over 200 peer-review journals now offer registered reports as a publication format; two of these (Cerebral Cortex and Developmental Cognitive Neuroscience) have created registered reports options specifically geared for publishing results from the ABCD Study. Recommended best practices for promoting reproducible science are given in Section SM.5 and for statistical analyses and reporting of results using the ABCD Study data in Section SM.6. In the next section, we provide a brief example to illustrate the issues we have just discussed as they relate to ABCD.
5.3. Example: Effect Size Estimates
In examining the ABCD data, we advocate for a focus on effect sizes over p-values, but this is not as simple as it appears, and researchers often require some guidance on how to choose and interpret effect sizes. Here, we illustrate how the choice of effect size, and the interpretation of its substantive effect, must be made in the context of the research question. For example, Cohen’s d and related metrics (see Table 3) assess the magnitude of mean differences between two conditions or groups. But what is not often appreciated is that Cohen’s d is insensitive to the proportion of subjects in each group52. Conversely, base-rate-sensitive effect size metrics take into account the difficulty of differentiating phenomena in rare events. If the goal is to assess the impact of an exposure on a population, it is arguable that researchers should opt for an effect size metric that takes the sample base rate into account. For example, the point-biserial correlation rbs52 (Table 3) is a similar metric that, unlike d, is sensitive to variation in sample base rates.
To illustrate this, we used Cohen’s d and point-biserial rbs to estimate the effect size of a dichotomous “exposure” index: very obese (here defined as a body mass index (BMI) ≥30) and a continuous brain “outcome”: restriction spectrum imaging component (N0), a measure sometimes related to cellularity, in the Nucleus Accumbens (NAcc). Recent work has highlighted a potential role of neuroinflammation in the NAcc in animal models of diet-induced obesity53. We included baseline data from subjects without missing BMI and NAcc N0 data, also excluding 5 subjects with NAcc N0 values < 0 (leaving n = 10659 subjects, of which 184 subjects had BMI ≥30, or 1. 7%). As can be seen in Figure 4 (upper panels), NAcc N0 values are heavy tailed. We thus use a bootstrap hypothesis testing procedure to obtain quantiles of d and rbs54. To account for nesting of subjects within families, at each iteration of the bootstrap one member of each family was first selected at random, and these subjects (along with all singletons) were sampled with replacement 10000 times. Figure 4 (lower panels) presents the bootstrap p-value plots for different null hypotheses31. The bootstrap median d = 0. 801 (95% CI: [0. 588, 0. 907]) and median rbs = 0. 106 [0. 081, 0. 127]. Thus, while in terms of d the effect might be considered “large”, rbs corresponds to a variance explained of roughly 1% and hence would be considered “small” by many researchers.
Figure 4: Association Between Obesity and Nucleus Accumbens RSI N0.

So, what effect size should the researcher report, and which should be emphasized in the interpretation? Our general guidance would be to carefully consider the answer in the context of the research question. Perhaps both could be reported, but if the public health impact of an intervention is considered the rbs might be more strongly focused on in the discussion of results.
Finally, caution is warranted in interpreting these results as “effect sizes,” as the causal relationship could be from obesity to NAcc N0, from NAcc N0 to obesity, bidirectional, or even non-existent (i.e., due to confounding). We do not adjust for potential confounding factors or their proxies in this example. In light of this, it would be more appropriate to call d and rbs as computed here “association sizes”. We examine the question of direction of causality using the twin data55 in SM Section S.3.
6.0. Control of Confounding Variables
An important challenge to the internal validity of effect estimates from the ABCD Study (and from any observational study) is the likely presence of confounding variables for observed associations. Necessary but not sufficient conditions for a variable to confound an observed association between an independent variable (IV) and a dependent variable (DV) are that the factor is associated with both the exposure and the outcome in the population, but not causally affected by either56 (if a variable is causally downstream of the IV or the DV or both, it may be a collider or a mediator31). Conditioning on confounders (or their proxies) in regression analyses will tend to reduce bias in effect size estimates, whereas conditioning on colliders or mediators (or their proxies) will tend to increase bias. To make matters more difficult, assessed variables can be proxies for both confounding factors and mediators or colliders simultaneously, in which case it is not clear whether conditioning will improve or worsen bias in effect size estimates. We thus recommend that investigators using ABCD data think carefully about challenges to estimating effects of exposures and perform sensitivity analyses that examine the impact of including/excluding covariates on associations. In the next sections we discuss these topics more thoroughly in the context of conditioning on covariates in regression models.
6.1. Covariate Adjustment
Although the inclusion of covariates in statistical models is a widespread practice, determining which covariates to include is necessarily complex and presents an analytical conundrum. The advantages and disadvantages of covariate inclusion in statistical models has been widely debated57,58 and reviewed elsewhere59–61, so we focus our discussion on the practical implications of covariate adjustment in the ABCD Study.
Datasets with a rich set of demographic and other variables lend themselves to the inclusion of any number of covariates. In many respects, this can be seen as a strength of the ABCD Study, but this can also complicate the interpretation of findings when research groups adopt different strategies for what covariates to include in their models. For instance, a recent comprehensive review of neuroimaging studies62 found that the number of covariates used in models ranged from 0 to 14, with 37 different sets of covariates across the 68 models reviewed. This review showed that brain-behavior associations varied substantially as a function of which covariates were included in models: some sets of covariates influenced observed associations only a little, whereas others resulted in dramatically different patterns of results compared to models with no covariates. Which variables are appropriately included as confounders in any given analysis depends on the research question, highlighting the need for thoughtful use of covariates.
Covariates are often used in an attempt to yield more “accurate,” or “purified”61 estimates of the relationships among the IVs and DV, thereby revealing their “true” associations59 (i.e., to eliminate the impact of confounding on observed associations31). Under this assumption, the inclusion of covariates implicitly assumes that they are somehow influencing the variables of interest, either contaminating the relationship between the IV and DV or the measurement of the variables of interest. Thus, not controlling for covariates presumably distorts observed associations among the IVs and DV57,61. Note that we use “somehow” to emphasize frequent researcher agnosticism regarding the specific role of the covariates included in the model. Because statistical control carries with it major assumptions about the relationships among the observed variables and latent constructs, some of which are generally unspecified and others of which are potentially unknowable, conclusions drawn from models that mis-specify the role of the covariate will be incorrect.
When covariates are thought to influence the observed variables of interest but not the latent construct, this is thought of as measurement contamination (Figure 5A). Measurement contamination ostensibly occurs when a covariate influences the observed variables (x and y in Figure 5A). Importantly, a major assumption surrounding the presumption of measurement contamination is that the covariate does not affect the underlying constructs (X and Y in Figure 5A), only their measures. Removing the influence of covariates by controlling for them presumes that absent such control, the association between the IVs and DV is artefactual.
Figure 5: Models for Measurement Contamination, Spuriousness, and Mediation.
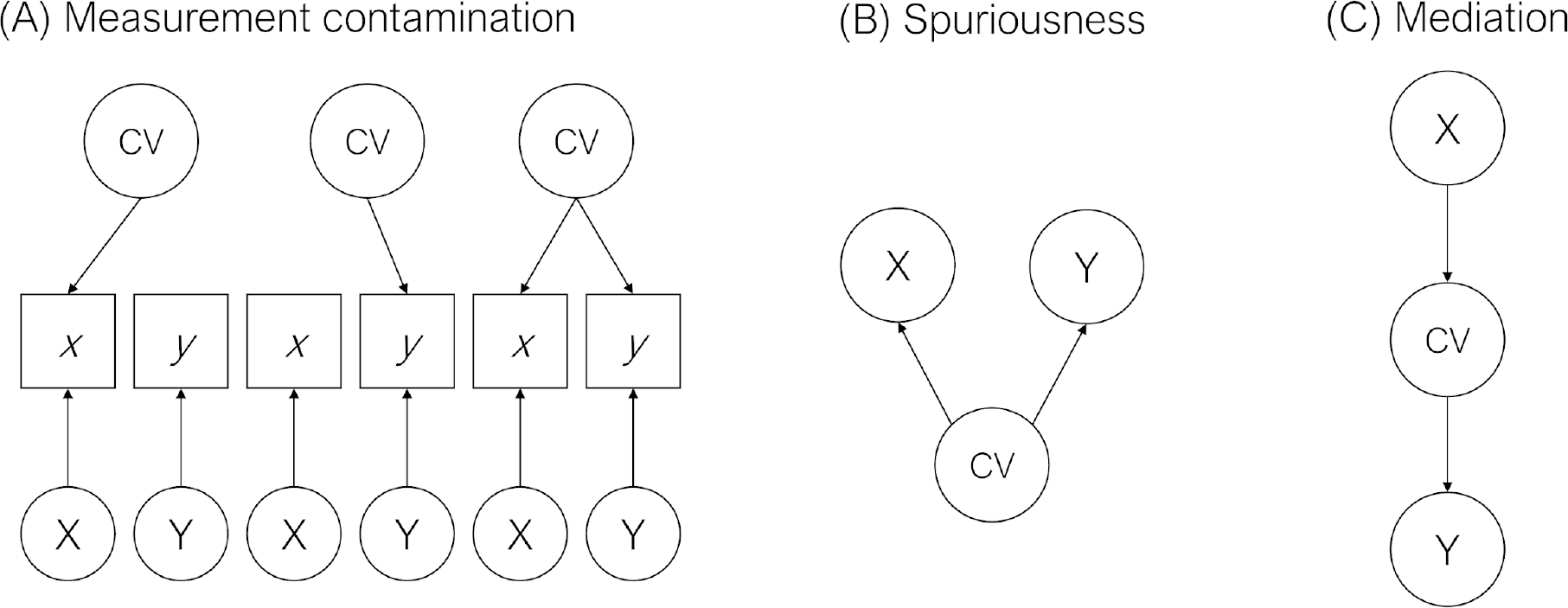
Note. This figure is adapted from Spector and Brannick (2011). Lowercase letters refer to observed indicators (in boxes), whereas uppercase letters refer to latent indicators (constructs, in circles).
There are also a number of ways in which covariates are thought to influence the latent constructs and not just the measurement of them (see Meehl (1971)57 for a thorough discussion). Two such models are spuriousness (Figure 5B) and mediation (Figure 5C). Under a spuriousness (confounding) model, the IV (X) and DV (Y) are not directly causally associated but are both caused by the covariate. Therefore, any observed association between the IV and DV is spurious given that it is caused by the covariate. Under a mediation model, the IV (X) and DV (Y) are statistically associated only through the covariate. Spuriousness and mediation models are generally statistically indistinguishable (though temporal ordering can sometimes assist in appropriate intepretations), and under both models, controlling for the covariate results in a reduced association between the IV and DV. In either case, including covariates can effectively remove effects of interest from the model. At best, this practice obscures rather than purifies relationships among our variables of interest. At worst, this practice can render incorrect interpretations of the true effect. Rather than suggesting that covariates should be avoided altogether, we view them as having an important role in testing competing hypotheses.
Thorough treatments of covariate use in statistical modeling are given by others59–61. In the next section we review steps in reasoning about which covariates to include and how to think about resulting associations.
6.1.1. Covariate Adjustment: Researcher Considerations
What is the role of the covariate? What is the theoretical model? Could the exclusion and inclusion of the covariate inform the theoretical model?
Addressing these questions through the practice of simply explicitly specifying the role of the covariate in the model, and even more specifically its hypothesized role in the IV-DV associations, helps avoid including covariates in the model when doing so is poorly justified. Moreover, it encourages thoughtful hypothesis testing. Ideally, explicit justification of the inclusion of each covariate in the model should be included in the reporting of our results. Better yet, as opposed to treating control variables as nuisance variables, a more ideal model would include covariates in hypotheses60. We also encourage considering the extent to which the exclusion and inclusion of the covariate could inform the theoretical model. In an explanatory framework, all covariates should be specified a priori. In a predictive framework, one can conduct nested cross-validations and model comparisons to find the most robust model with procedurally-selected covariates.
How do my models differ with and without covariates?
We recommend running models with and without covariates and comparing their results. This practice encourages researchers to better consider the effect of covariates on observed associations. At the same time, engaging in multiple testing can increase Type I error rates. Regarding our suggestion, we encourage a shift away from comparing models on the basis of p-values and instead encourage researchers to compare effect sizes of the predictor of interest in models with and without the covariates. Confidence intervals are critical to compare across models, as the range of plausible effects is more important than the point differences in effect size estimates. The focus on effect sizes as opposed to statistical significance is important given that including many covariates in the statistical model reduces degrees of freedom, in turn increasing standard errors and decreasing statistical power for any given IV. Covariates may be correlated with one another as well, reducing precision and producing large differences in p-values when some variables are included or omitted from a model.
If the effect sizes do not differ as a function of the inclusion of the covariate (e.g., their confidence intervals substantially overlap), one might consider dropping it from the model, but noting this information somewhere in the text. Becker (2005)63 offers more suggestions regarding what to do when results from models with and without covariates differ (see also Becker et al. (2016)60). Additionally, should one choose to adopt models with covariates included, we recommend placing analyses from models without covariates in an appendix or in the supplemental materials; such a practice will aid in comparison of results across studies, particularly across studies with different sets of covariates in the models.
Causal effects from observational data
It is worth formalizing this discussion for situations when there is interest in estimating causal effects: the comparison of potential outcomes, e.g., comparing outcomes for children in ABCD as if all of their parents had alcohol problems, vs. none of their parents having alcohol problems. Two methods that are particularly relevant for estimating causal effects in cohort studies such as ABCD are instrumental variables analyses and propensity score methods. Instrumental variables analyses rely on finding some “instrument” that is plausibly randomly assigned (conditional on covariates), affects the exposure of interest, and is not directly related to outcomes64,65.
Here we will focus, though, on propensity score methods as a fairly general purpose tool for estimating causal effects. In general, interpreting a difference in outcomes between exposure groups as a causal effect requires two things: 1) “overlap” (individuals in the two exposure groups are similar to one another on the confounders), and 2) “unconfounded treatment assignment”; that there are no unobserved differences between exposure groups once the groups are equated on the observed characteristics. Propensity score methods66 can help assess whether overlap exists, and equate the exposure groups using matching, weighting, or subclassification. Covariates should thus be selected in order to satisfy unconfounded treatment assignment, and as noted above, factors that are “post-treatment” (and thus potentially mediators) should not be included. A benefit of the ABCD Study design is that longitudinal data is available, to measure confounders before exposure and exposure before outcomes, and the large set of potential confounders observed and available to be adjusted for. Sensitivity analyses also exist to assess robustness of effect estimates to a potential unobserved confounder (e.g.,67).
In SM Section S.4, we give a worked example of a sensitivity analysis for the potential impact of omitting unmeasured confounders using ABCD data on breastfeeding and neurocognition. Finally, methods should be used that account for the probability sample nature of the ABCD cohort, in order to ensure effects are being estimated for the population of interest69,70.
6.1.2. Example: Covariate Adjustment
Here, we provide a worked example focusing on the associations between parental history of alcohol problems and child psychopathology, an important substantive question that has received attention in the literature71. The ABCD Study contains a rich assessment of family history of psychiatric problems (e.g., alcohol problems, drug problems, trouble with the law, depression, nerves, visions, suicide) and child psychopathology, including child- and parent-reported dimensional and diagnostic assessments. We examined the relation between parental history of alcohol problems (four levels: neither parent with alcohol problems, father only, mother only, both parents) and child externalizing assessed with the parent-reported Child Behavior Checklist (CBCL). Based on the earlier-described considerations, we delineated several tiers of covariates to include in the models in sequence (or in a stepwise fashion). The first tier included “essential” covariates that the researcher views as required to include in the models, the second tier included “non-essential” covariates, and the third tier included “substantive” covariates that can inform the robustness of the model, or more generally inform the theoretical model.
Our first tier includes age, sex at birth, and a composite of maternal alcohol consumption while pregnant. The inclusion of this latter covariate is deemed as essential to rule out the possibility that any associations between parental history of alcohol problems and child psychopathology was not due to prenatal alcohol exposure. In this context, maternal alcohol consumption was considered a construct confound. The second-tier covariates included race/ethnicity, household income, parental education, and parental marital status. In the context of this research question, these covariates might be deemed “non-essential” for three reasons. First, the researcher may not have any clear hypotheses surrounding the role of these covariates in the IV-DV associations. Second, the researcher may not think that there are important group differences in the second-tier covariates that are worth exploring and reporting. Third, the researcher might expect that some of the “non-essential” covariates may be causally related to the IVs and DV or may share common causes with them (e.g., they may be proxies for both confounders and mediators or colliders simultaneously). We did not have specific hypotheses regarding race/ethnicity differences in these associations, but exploratory analyses may be informative. At the same time, race/ethnicity may be strongly associated with other covariates (e.g., socioecomomic status, adversity), and so researchers must take care when interpreting the impact of its inclusion in the model.
Other “non-essential” covariates (e.g., household income, parental education, and parental marital status) may be either causally related to the IVs or DV or may share a common cause. For instance, parental externalizing – which likely overlaps with parental history of alcohol problems – are associated with both increased likelihood of divorce and child externalizing, but the two are not causally related72,73. Thus, demographics may, at least in part, proxy our variables of interest. Moreover, parental history of alcohol problems may proxy the broader construct of externalizing psychopathology. Controlling for indicators that share a common cause with our IVs and DVs partials out an important, etiologically relevant part of the phenotype, which can obscure true IV-DV associations. Based on this information, one might decide to report models with and without these covariates and consider the extent to which differences in these sets of models inform a particular theoretical model.
There was a significant linear association between parental history of alcohol problems with tier 1 covariates included, and there is no major difference between the models with and without tier 2 covariates (Figure 6A). Because we deemed tier 2 covariates as “nonessential,” we elected to move forward only with tier 1 covariates.
Figure 6: The association between parental history of alcohol problems and CBCL Externalizing.

Finally, a third tier of covariates may be used to test the robustness of the associations between parental history of alcohol problems and child psychopathology. Here, we see that other forms of parental history of psychiatric problems, particularly externalizing (i.e., parental history of drugs, trouble with the law) display similar, if not more robust associations, with CBCL Externalizing (Figure 6B). Including other forms of parental externalizing (e.g., drug use, trouble with the law), may inform the extent to which the associations between parental history of alcohol problems and child psychopathology are more general to parental history of other externalizing74). Indeed, the associations between parental history of alcohol problems and CBCL Externalizing became attenuated when parental history of drug problems and trouble with the law were included in the model (Figure 6C), which suggests that the associations are general with respect to parental history of externalizing. In one further robustness check, we see that including parental history of internalizing problems (e.g., nerves, depression) slightly attenuates the associations between parental history of alcohol problems and CBCL Externalizing, though the effects of covarying parental history of externalizing were stronger (Figure 6C).
Altogether, we learned from the tier 3 covariates that the associations between parental history of alcohol problems and CBCL Externalizing may be more general to history of externalizing, or even psychiatric problems more generally. These covariates were not treated as covariates per se, but as variables whose inclusion and exclusion informed the theoretical model.
In sum, we hope it is clear that determining which covariates should be included in our statistical models is complex and requires considerable thought. We caution against the over-inclusion of covariates in statistical models, and against the assumption that including covariates purifies the associations among our variables of interest; instead their inclusion can obscure rather than purify such associations75.
7.0. Summary and Conclusions
The sample size of the ABCD Study is large enough to reliably detect and estimate small effect size relationships among a multiplicity of genetic and environmental factors, potential biological mechanisms, and behavioral and health-related trajectories across the course of adolescence. Thus, the ABCD Study will be a crucial resource for avoiding Type I errors (false positive findings) when discovering novel relationships, as well as failures to replicate that result from the replication sample being too small to have sufficient power. Moreover, ABCD will allow for stronger interpretation of non-significant results as they will not be due to low power for all but the tiniest of effect sizes, or researchers may opt to take advantage of the high power to assess the absence of differences using other statistical procedures like equivalency tests76. Other studies in the field suffer from false positives that do not replicate, and overestimation of effect sizes in general, which typically arise from a research environment consisting of many small studies, p-hacking, and publication bias towards positive findings77. ABCD will therefore help directly address the replication problems afflicting much of current neuroscience research32, and which would be bolstered by pre-registration steps that we outline above for ABCD data.
ABCD may also help researchers to address questions of “practical significance” for effects that may be small by traditional standards (e.g., explaining 1% of variation or less), but may be statistically significant due to the large sample size of the ABCD Study. As we noted, we expect that ABCD report will predominantly report small effect sizes, simply reflecting the fact that many, if not most, real-world relationships are in fact small. But in this scenario, it would be a mistake to dismiss all small effect size relationships. Indeed, an ostensibly small effect size might still be of clinical or public health interest37 despite appearing “small” by traditional standards78,79. The effect may also be small due to imprecise measurement even if the underlying relationships are far from weak. Finally, even if the “noise-free” effects of individual factors are small, they may cumulatively explain a sizeable proportion of the variation in neurodevelopmental trajectories a scenario which has recently played out in genome-wide association studies (GWAS) of complex traits80.
At the same time, it is important to interpret these effects in the context of potentially confounding covariates, and like the interpretation of the effects themselves, the choice of inclusion of covariates must be principled. Misspecification can lead to serious threats to internal validity of the conclusions. For both effects of primary interest and covariates, that the focus remains on effect sizes, rather than binary “yes or no” assessments of whether data support or reject a particular hypothesis. For example, for the goal of obtaining personally relevant modifiable predictors of substance abuse or other clinical outcomes, prediction accuracy of 75% would correspond to a very-large effect size of around 1.4, accounting for about 30% of the variance. (However, for modifications of variables targeted at a population level or for policy interventions, a smaller effect size might still be important.) Thus, binary judgements on whether associations are “significant” can be fraught with error and give rise to misleading headlines81. Worse, Type I or Type II errors (declaring an effect to be significant when it is not real, or absent when it is, respectively) can mislead the field for long periods. Such results could delay the much needed progress in reducing the human and financial costs of mental health and other disorders. Thus, the careful consideration of the statistical and methodological factors we have outlined should be considered essential for the investigation of this prominent public dataset.
In summary, the ABCD Study is collecting longitudinal data on a rich variety of genetic and environmental data, biological samples, markers of brain development, substance use, and mental and physical health, enabling the construction of realistically complex etiological models incorporating factors from many domains simultaneously. While establishing reproducible relationships between pairs (or small collections of measures) in a limited set of domains will still be important, it will be crucial to develop more complex models from these building blocks to explain enough variation in outcomes to reach a more complete understanding or to obtain clinically-useful individual predictions. Multidimensional statistical models must then incorporate knowledge from a diverse array of domains (e.g., genetics and epigenetics, environmental factors, policy environment, ecological momentary assessment, school-based assessments, and so forth) with brain imaging and other biologically-based measures, behavior, psychopathology, and physical health, and do this in a longitudinal context. The sample size, population nature, duration of study, and, importantly, the richness of data collected in ABCD will be important for attaining this goal.
Supplementary Material
Acknowledgments
We thank the families who have participated in this research. We also thank the ABCD Biostatistics Work Group. The corresponding author was supported by United States National Institutes of Health, National Institute on Drug Abuse: 1U24DA041123-01 (Dale).
Data used in the preparation of this article were obtained from the Adolescent Brain Cognitive DevelopmentSM (ABCD) Study (https://abcdstudy.org), held in the NIMH Data Archive (NDA). This is a multisite, longitudinal study designed to recruit more than 10,000 children age 9–10 and follow them over 10 years into early adulthood. The ABCD Study® is supported by the National Institutes of Health and additional federal partners under award numbers U01DA041048, U01DA050989, U01DA051016, U01DA041022, U01DA051018, U01DA051037, U01DA050987, U01DA041174, U01DA041106, U01DA041117, U01DA041028, U01DA041134, U01DA050988, U01DA051039, U01DA041156, U01DA041025, U01DA041120, U01DA051038, U01DA041148, U01DA041093, U01DA041089, U24DA041123, U24DA041147. A full list of supporters is available at https://abcdstudy.org/federal-partners.html. A listing of participating sites and a complete listing of the study investigators can be found at https://abcdstudy.org/consortium_members/. ABCD consortium investigators designed and implemented the study and/or provided data but did not necessarily participate in analysis or writing of this report. This manuscript reflects the views of the authors and may not reflect the opinions or views of the NIH or ABCD consortium investigators. The ABCD data repository grows and changes over time. The ABCD data used in this report came from NIMH Data Archive Release 2.0.1 (DOI 10.15154/1506087). DOIs can be found at https://nda.nih.gov/abcd.
Bibliography
- 1.Volkow ND et al. The conception of the abcd study: From substance use to a broad nih collaboration. Developmental Cognitive Neuroscience 32, 4–7 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Bachman JG, Johnston LD, O’Malley PM & Schulenberg JE The monitoring the future project after thirty-seven years: Design and procedures. (2011).
- 3.Chantala K & Tabor J National longitudinal study of adolescent health. Strategies to perform a design-based analysis using the add health data (1999). [Google Scholar]
- 4.Conway KP, Swendsen J, Husky MM, He J-P & Merikangas KR Association of lifetime mental disorders and subsequent alcohol and illicit drug use: Results from the national comorbidity survey–adolescent supplement. Journal of the American Academy of Child & Adolescent Psychiatry 55, 280–288 (2016). [DOI] [PubMed] [Google Scholar]
- 5.Ingels S, Abraham S, Karr R, Spenser B & Frankel M National education longitudinal survey of 1988. Technical Report. National Opinion Research Center, University of Chicago; (1990). [Google Scholar]
- 6.Garavan H et al. Recruiting the abcd sample: Design considerations and procedures. Developmental Cognitive Neuroscience (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Iacono WG et al. The utility of twins in developmental clinical neuroscience research: How twins strengthen the abcd research design. Developmental cognitive neuroscience (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Luciana M et al. Adolescent neurocognitive development and impacts of substance use: Overview of the adolescent brain cognitive development (abcd) baseline neurocognition battery. Developmental cognitive neuroscience (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Thompson WK et al. The structure of cognition in 9 and 10 year-old children and associations with problem behaviors: Findings from the abcd study’s baseline neurocognitive battery. Developmental cognitive neuroscience 36, 100606 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Barch DM et al. Demographic, physical and mental health assessments in the adolescent brain and cognitive development study: Rationale and description. Developmental cognitive neuroscience 32, 55–66 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Zucker RA et al. Assessment of culture and environment in the adolescent brain and cognitive development study: Rationale, description of measures, and early data. Developmental cognitive neuroscience 32, 107–120 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Uban KA et al. Biospecimens and the abcd study: Rationale, methods of collection, measurement and early data. Developmental cognitive neuroscience 32, 97–106 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Casey B et al. The adolescent brain cognitive development (abcd) study: Imaging acquisition across 21 sites. Developmental cognitive neuroscience 32, 43–54 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Hagler DJ et al. Image processing and analysis methods for the adolescent brain cognitive development study. bioRxiv 457739 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bagot K et al. Current, future and potential use of mobile and wearable technologies and social media data in the abcd study to increase understanding of contributors to child health. Developmental cognitive neuroscience 32, 121–129 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Loughnan R et al. Polygenic score of intelligence is more predictive of crystallized than fluid performance among children. bioRxiv 637512 (2020). [Google Scholar]
- 17.Heeringa SG, West BT & Berglund PA Applied survey data analysis. (Chapman; Hall/CRC, 2017). [Google Scholar]
- 18.Heeringa SG & Berglund PA A guide for population-based analysis of the adolescent brain cognitive development (abcd) study baseline data. BioRxiv (2020). [Google Scholar]
- 19.Rabe-Hesketh S & Skrondal A Multilevel modelling of complex survey data. Journal of the Royal Statistical Society: Series A (Statistics in Society) 169, 805–827 (2006). [Google Scholar]
- 20.Desikan RS et al. An automated labeling system for subdividing the human cerebral cortex on mri scans into gyral based regions of interest. Neuroimage 31, 968–980 (2006). [DOI] [PubMed] [Google Scholar]
- 21.van Buuren S & Groothuis-Oudshoorn K mice: Multivariate imputation by chained equations in r. Journal of Statistical Software 45, 1–67 (2011). [Google Scholar]
- 22.Stigler SM The history of statistics: The measurement of uncertainty before 1900. (Harvard University Press, 1986). [Google Scholar]
- 23.Efron B & Hastie T Computer age statistical inference. 5, (Cambridge University Press, 2016). [Google Scholar]
- 24.Efron B RA fisher in the 21st century. Statistical Science 95–114 (1998). [Google Scholar]
- 25.Lehmann EL The fisher, neyman-pearson theories of testing hypotheses: One theory or two? Journal of the American statistical Association 88, 1242–1249 (1993). [Google Scholar]
- 26.Efron B Bayes’ theorem in the 21st century. Science 340, 1177–1178 (2013). [DOI] [PubMed] [Google Scholar]
- 27.Efron B Prediction, estimation, and attribution. Journal of the American Statistical Association 115, 636–655 (2020). [Google Scholar]
- 28.Wasserstein RL & Lazar NA The asa statement on p-values: Context, process, and purpose. (2016).
- 29.Nickerson RS Null hypothesis significance testing: A review of an old and continuing controversy. Psychological methods 5, 241 (2000). [DOI] [PubMed] [Google Scholar]
- 30.Harlow LL, Mulaik SA & Steiger JH What if there were no significance tests? (Psychology Press, 2013). [Google Scholar]
- 31.Rothman KJ, Greenland S & Lash TL Modern epidemiology. (Lippincott Williams & Wilkins, 2008). [Google Scholar]
- 32.Button KS et al. Power failure: Why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience 14, 365 (2013). [DOI] [PubMed] [Google Scholar]
- 33.Hong EP & Park JW Sample size and statistical power calculation in genetic association studies. Genomics & informatics 10, 117 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dick AS et al. No evidence for a bilingual executive function advantage in the abcd study. Nature human behaviour 3, 692–701 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Abadie A Statistical nonsignificance in empirical economics. American Economic Review: Insights 2, 193–208 (2020). [Google Scholar]
- 36.Cohen J Statistical power analysis. (1988).
- 37.Rosenthal R, Rosnow RL & Rubin DB Contrasts and effect sizes in behavioral research: A correlational approach. (Cambridge University Press, 2000). [Google Scholar]
- 38.Kraemer HC Reporting the size of effects in research studies to facilitate assessment of practical or clinical significance. Psychoneuroendocrinology 17, 527–536 (1992). [DOI] [PubMed] [Google Scholar]
- 39.Kirk RE Practical significance: A concept whose time has come. Educational and psychological measurement 56, 746–759 (1996). [Google Scholar]
- 40.Fidler F, Thomason N, Cumming G, Finch S & Leeman J Editors can lead researchers to confidence intervals, but can’t make them think: Statistical reform lessons from medicine. Psychological Science 15, 119–126 (2004). [DOI] [PubMed] [Google Scholar]
- 41.Simonsohn U, Nelson LD & Simmons JP P-curve: A key to the file-drawer. Journal of experimental psychology: General 143, 534 (2014). [DOI] [PubMed] [Google Scholar]
- 42.Paulus MP & Thompson WK The challenges and opportunities of small effects: The new normal in academic psychiatry. JAMA psychiatry 76, 353–354 (2019). [DOI] [PubMed] [Google Scholar]
- 43.Kendler KS From many to one to many—the search for causes of psychiatric illness. JAMA psychiatry 76, 1085–1091 (2019). [DOI] [PubMed] [Google Scholar]
- 44.Ioannidis JP Why most published research findings are false. PLos med 2, e124 (2005). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Ashton JC It has not been proven why or that most research findings are false. Medical hypotheses 113, 27–29 (2018). [DOI] [PubMed] [Google Scholar]
- 46.Bakker M, Dijk A. van & Wicherts JM The rules of the game called psychological science. Perspectives on Psychological Science 7, 543–554 (2012). [DOI] [PubMed] [Google Scholar]
- 47.Ioannidis JP Why most discovered true associations are inflated. Epidemiology 640–648 (2008). [DOI] [PubMed] [Google Scholar]
- 48.Meyer GJ et al. Psychological testing and psychological assessment: A review of evidence and issues. American psychologist 56, 128 (2001). [PubMed] [Google Scholar]
- 49.Miller KL et al. Multimodal population brain imaging in the uk biobank prospective epidemiological study. Nature neuroscience 19, 1523 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Schäfer T & Schwarz MA The meaningfulness of effect sizes in psychological research: Differences between sub-disciplines and the impact of potential biases. Frontiers in Psychology 10, 813 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Chambers CD, Dienes Z, McIntosh RD, Rotshtein P & Willmes K Registered reports: Realigning incentives in scientific publishing. Cortex 66, A1–A2 (2015). [DOI] [PubMed] [Google Scholar]
- 52.McGrath RE & Meyer GJ When effect sizes disagree: The case of r and d. Psychological methods 11, 386 (2006). [DOI] [PubMed] [Google Scholar]
- 53.Décarie-Spain L et al. Nucleus accumbens inflammation mediates anxiodepressive behavior and compulsive sucrose seeking elicited by saturated dietary fat. Molecular metabolism 10, 1–13 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Martin MA Bootstrap hypothesis testing for some common statistical problems: A critical evaluation of size and power properties. Computational Statistics & Data Analysis 51, 6321–6342 (2007). [Google Scholar]
- 55.Heath AC et al. Testing hypotheses about direction of causation using cross-sectional family data. Behavior Genetics 23, 29–50 (1993). [DOI] [PubMed] [Google Scholar]
- 56.VanderWeele TJ & Shpitser I On the definition of a confounder. Annals of statistics 41, 196 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Meehl PE High school yearbooks: A reply to schwarz. (1971). [DOI] [PubMed]
- 58.Schwarz JC Comment on” high school yearbooks: A nonreactive measure of social isolation in graduates who later became schizophrenic.”. Journal of abnormal psychology 75, 317 (1970). [DOI] [PubMed] [Google Scholar]
- 59.Atinc G, Simmering MJ & Kroll MJ Control variable use and reporting in macro and micro management research. Organizational Research Methods 15, 57–74 (2012). [Google Scholar]
- 60.Becker TE et al. Statistical control in correlational studies: 10 essential recommendations for organizational researchers. Journal of Organizational Behavior 37, 157–167 (2016). [Google Scholar]
- 61.Spector PE & Brannick MT Methodological urban legends: The misuse of statistical control variables. Organizational Research Methods 14, 287–305 (2011). [Google Scholar]
- 62.Hyatt CS et al. The quandary of covarying: A brief review and empirical examination of covariate use in structural neuroimaging studies on psychological variables. NeuroImage 205, 116225 (2020). [DOI] [PubMed] [Google Scholar]
- 63.Becker TE Potential problems in the statistical control of variables in organizational research: A qualitative analysis with recommendations. Organizational Research Methods 8, 274–289 (2005). [Google Scholar]
- 64.Angrist JD, Imbens GW & Rubin DB Identification of causal effects using instrumental variables. Journal of the American statistical Association 91, 444–455 (1996). [Google Scholar]
- 65.Hernán MA & Robins JM Instruments for causal inference: An epidemiologist’s dream? Epidemiology 360–372 (2006). [DOI] [PubMed] [Google Scholar]
- 66.Stuart EA Matching methods for causal inference: A review and a look forward. Statistical science: a review journal of the Institute of Mathematical Statistics 25, 1 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Liu W, Kuramoto SJ & Stuart EA An introduction to sensitivity analysis for unobserved confounding in nonexperimental prevention research. Prevention science 14, 570–580 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.VanderWeele TJ & Ding P Sensitivity analysis in observational research: Introducing the e-value. Annals of internal medicine 167, 268–274 (2017). [DOI] [PubMed] [Google Scholar]
- 69.Lenis D, Nguyen TQ, Dong N & Stuart EA It’s all about balance: Propensity score matching in the context of complex survey data. Biostatistics 20, 147–163 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Ridgeway G, Kovalchik SA, Griffin BA & Kabeto MU Propensity score analysis with survey weighted data. Journal of causal inference 3, 237–249 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Hesselbrock MN & Hesselbrock VM Relationship of family history, antisocial personality disorder and personality traits in young men at risk for alcoholism. Journal of Studies on Alcohol 53, 619–625 (1992). [DOI] [PubMed] [Google Scholar]
- 72.Lahey BB et al. Conduct disorder: Parsing the confounded relation to parental divorce and antisocial personality. Journal of Abnormal Psychology 97, 334 (1988). [DOI] [PubMed] [Google Scholar]
- 73.Salvatore JE et al. Alcohol use disorder and divorce: Evidence for a genetic correlation in a population-based swedish sample. Addiction 112, 586–593 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Kendler KS et al. The structure of genetic and environmental risk factors for syndromal and subsyndromal common dsm-iv axis i and all axis ii disorders. American Journal of Psychiatry 168, 29–39 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Schisterman EF, Cole SR & Platt RW Overadjustment bias and unnecessary adjustment in epidemiologic studies. Epidemiology (Cambridge, Mass.) 20, 488 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Lakens D Equivalence tests: A practical primer for t tests, correlations, and meta-analyses. Social psychological and personality science 8, 355–362 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Walum H, Waldman ID & Young LJ Statistical and methodological considerations for the interpretation of intranasal oxytocin studies. Biological psychiatry 79, 251–257 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.McClelland GH & Judd CM Statistical difficulties of detecting interactions and moderator effects. Psychological bulletin 114, 376 (1993). [DOI] [PubMed] [Google Scholar]
- 79.Wray NR, Wijmenga C, Sullivan PF, Yang J & Visscher PM Common disease is more complex than implied by the core gene omnigenic model. Cell 173, 1573–1580 (2018). [DOI] [PubMed] [Google Scholar]
- 80.Boyle EA, Li YI & Pritchard JK An expanded view of complex traits: From polygenic to omnigenic. Cell 169, 1177–1186 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Goodman S A dirty dozen: Twelve p-value misconceptions. in Seminars in hematology 45, 135–140 (Elsevier, 2008). [DOI] [PubMed] [Google Scholar]
- 82.Gelman A The failure of null hypothesis significance testing when studying incremental changes, and what to do about it. Personality and Social Psychology Bulletin 44, 16–23 (2018). [DOI] [PubMed] [Google Scholar]
- 83.Fisher RA Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika 10, 507–521 (1915). [Google Scholar]
- 84.Boker S et al. OpenMx: An open source extended structural equation modeling framework. Psychometrika 76, 306–317 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Cinelli C & Hazlett C Making sense of sensitivity: Extending omitted variable bias. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 82, 39–67 (2020). [Google Scholar]
- 86.Cinelli C, Ferwerda J & Hazlett C Sensemakr: Sensitivity analysis tools for ols in r and stata. Submitted to the Journal of Statistical Software (2020). [Google Scholar]
- 87.Slotkin J et al. NIH toolbox. Technical Manual.[Google Scholar] (2012). [Google Scholar]
- 88.Silberzahn R et al. Many analysts, one data set: Making transparent how variations in analytic choices affect results. Advances in Methods and Practices in Psychological Science 1, 337–356 (2018). [Google Scholar]
- 89.Preacher KJ Extreme groups designs. The encyclopedia of clinical psychology 1–4 (2014). [Google Scholar]
- 90.Preacher KJ, Rucker DD, MacCallum RC & Nicewander WA Use of the extreme groups approach: A critical reexamination and new recommendations. Psychological methods 10, 178 (2005). [DOI] [PubMed] [Google Scholar]
- 91.Appelbaum M et al. Journal article reporting standards for quantitative research in psychology: The apa publications and communications board task force report. American Psychologist 73, 3 (2018). [DOI] [PubMed] [Google Scholar]
- 92.Jin Y et al. Does the medical literature remain inadequately described despite having reporting guidelines for 21 years?–a systematic review of reviews: An update. Journal of multidisciplinary healthcare 11, 495 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.