

Abstract
The success of correctly identifying all the components of a nonlinear mixed‐effects model is far from straightforward: it is a question of finding the best structural model, determining the type of relationship between covariates and individual parameters, detecting possible correlations between random effects, or also modeling residual errors. We present the Stochastic Approximation for Model Building Algorithm (SAMBA) procedure and show how this algorithm can be used to speed up this process of model building by identifying at each step how best to improve some of the model components. The principle of this algorithm basically consists in “learning something” about the “best model,” even when a “poor model” is used to fit the data. A comparison study of the SAMBA procedure with Stepwise Covariate Modeling (SCM) and COnditional Sampling use for Stepwise Approach (COSSAC) show similar performances on several real data examples but with a much reduced computing time. This algorithm is now implemented in Monolix and in the R package Rsmlx.
Study Highlights.
WHAT IS THE CURRENT KNOWLEDGE ON THE TOPIC?
Existing model‐building methods for nonlinear mixed‐effects models have high computational time, especially for selecting the covariate model.
WHAT QUESTION DID THIS STUDY ADDRESS?
The study describes the principle of the Stochastic Approximation for Model Building Algorithm (SAMBA) procedure, which allows to build a covariate, a correlation, and an error model automatically and compares it with Stepwise Covariate Modeling (SCM) and COnditional Sampling use for Stepwise Approach (COSSAC) procedures.
WHAT DOES THIS STUDY ADD TO OUR KNOWLEDGE?
SAMBA allows to select the best covariate model without having to fit the complete nonlinear mixed‐effects model to the data for each possible covariate model. This study confirms that it is possible to obtain relevant information on the model we are looking for, even when another model is fitted to the data. This allows to drastically reduce the computation time with respect to other existing procedures while keeping the same performances. We also show that it is possible to perform correlation and error model selection in nonlinear mixed‐effects models.
HOW MIGHT THIS CHANGE DRUG DISCOVERY, DEVELOPMENT, AND/OR THERAPEUTICS?
This method will allow the practitioner to very quickly find a set of very good models in terms of data fitting and parsimony, even when the number of parameters or the number of covariates available is large.
INTRODUCTION
Construction of a complex (nonlinear) mixed‐effects model 1 is a challenging process which requires confirmed expertise, advanced statistical methods, and the use of sophisticated software tools, but, above all, time and patience. Indeed, the success of correctly identifying all the components of the model is far from straightforward: it is a question of finding the best structural model, determining the type of relationship between covariates and individual parameters, detecting possible correlations between random effects, or also modeling residual errors. Our goal is to accelerate and optimize this process of model building by identifying at each step how best to improve some of the model components.
The procedure for constructing a model is usually iterative: one adjusts a first model to the data, and diagnosis plots and statistical tests allow to detect possible misspecifications in the proposed model. A new model must then be proposed to correct these defects and improve the predictive abilities of the model. Most of the common approaches consist in stepwise procedures consisting in testing the addition of variable forward and their elimination backward alternatively and progressing through the choice of models using a criterion derived from the log‐likelihood. A widely used approach is Stepwise Covariate Modeling (SCM), 2 which consists in an exhaustive search in the covariates space. Each covariate addition or deletion is tested in turn selecting models at each step leading to the best adjustment according to the objective criterion. Approaches such as Wald Approximation Method (WAM) 3 and COnditional Sampling use for Stepwise Approach based on Correlation tests (COSSAC) 4 are less computationally intensive as they use, respectively, a likelihood ratio test and a correlation test to move in the covariates space, which allows the testing of less models. All these methods are nevertheless computationally intensive as they require to re‐estimate the model parameters and the likelihood many times. In particular, these methods are very sensitive to “the curse of dimensionality” when the number of covariates to test on parameters is large.
The Generalized Additive Model (GAM) method 5 , 6 is computationally appealing as it does not require as many models fitting. Indeed, it is based on a regression on the empirical Bayes estimates (EBEs). The EBEs are the modes of the conditional distributions of the individual parameters. In other words, they are the most likely value of the individual parameters, given the estimated population parameters and the data. These estimates are known to be misleading and prone to shrinkage when data are sparse. 7 An efficient method which can correct the bias caused by the shrinkage of the EBEs have been recently proposed for covariate analysis. 8 , 9 In this paper, we propose to develop similar method which relies on the use of random samples from the conditional distribution of each individual parameters instead of EBEs. Indeed, the random sample of the posterior distribution has been shown to correctly control the type I error when performing tests to detect misspecifications in the model. 10
As for most of the model‐building procedures, the objective of Stochastic Approximation for Model Building Algorithm (SAMBA) is to find a model that minimizes some information criterion, such as Akaike information criterion (AIC), Bayesian Information Criteria (BIC), or corrected BIC (BICc). 11 The main principle of SAMBA is to use the results obtained with a wrong model to learn the right model. Then, SAMBA is an iterative procedure where a new model is used at each iteration of the algorithm. The values of the population parameters of the model are found by maximum likelihood estimation, and, then, the individual parameters are sampled from the conditional distribution defined under this estimated model. These simulated individual parameters combined with the observed data can now be used to select a new statistical model. It is important to underline that, as most of the iterative procedures for non‐convex optimization, SAMBA does not pretend to be capable of always finding the global minimum of the used criterion, but it always allows to quickly find a very good solution.
Two contributions mainly constitute the content of this paper. First, we describe the novel algorithm called SAMBA for fast automatic model building in nonlinear mixed‐effects models (section 1). Second, we benchmark its performances compared with reference methods SCM and COSSAC in real‐world examples (section 2).
METHODS
Model description
Let be the vector of observations for subject i, where . The model that describes the observations yi is assumed to be a parametric probabilistic model that depends on a vector of L (individual) parameters . In a population framework, the vector of parameters is assumed to be drawn from a population distribution . Then, defining a model consists in defining a joint probability distribution for the observations and for the individual parameters . For the sake of notation simplicity, we focus on models for continuous longitudinal data. However, extension to models for discrete data and time to event data is straightforward.
Let y ij, the observation obtained from subject i at time tij be described as:
| (1) |
The structural model f is a fundamental component of the model because it defines the individual predictions of the observed kinetics for a given set of parameters. The residual errors are assumed to be standardized Gaussian random variables (mean zero and variance 1). The residual error model is represented by function g in model (1) and may depends on some additional parameter . Finally, one can use the function u to transform the observations, assuming for instance that they are log‐normally distributed. In the following, we will assume u to be the identity.
We assume a linear model for the individual parameters (up to some transformation h):
| (2) |
where is a vector of random effects and where is a vector of individual covariates used to explain part of the variability of the 's. The and are fixed effects. The joint model of and then depends on a set of parameters .
Selecting a model described by Equations 1 and 2 consists for the modeler in selecting: (i) the structural model , (ii) the transformation of the individual parameters , (iii) the residual error model , (iv) the list of covariates that have an impact on individual parameters, and (v) the structure of the variance‐covariance matrix of the random effects in the linear model . The selection of the two first items is problem‐specific, and their selection is out of the scope of this paper. We will therefore assume, in this paper, that and are given. The SAMBA procedure proposes solutions to address the selection of the three other components of the model.
The SAMBA procedure
Automatic model building is a difficult task because it is generally not possible to fit and compare all possible models. Moreover, it is necessary to define what is the “best model” among all the possible models. A classical approach consists in searching for the model , that minimizes a criterion, such as the penalized likelihood 12 , 13 :
| (3) |
The objective of this approach is to find a model that best fits the data (by minimizing ) while being as simple as possible (it is the role of to favor models with few parameters). When the space of possible models is large, an exhaustive search is clearly impossible, and an efficient minimization strategy must be implemented. It is precisely for this purpose that SAMBA was developed: to obtain very quickly the “best” model , or a model with an objective criterion value very close to that of .
SAMBA is an iterative procedure alternating three steps. Assume that model was obtained at iteration of the algorithm. We first compute , the maximum likelihood estimate of for model . We then generate a set of individual parameters from the conditional distribution of individual parameters . The selection step finally consists in building a new model using the complete data and minimizing the complete penalized criterion:
| (4) |
As already mentioned, the statistical model to be built consists of a covariate model, a correlation model, and a residual error model. Then, the selection of model is composed of three model selection procedures: the selection of the covariate model , the selection of the correlation model , and the selection of the error model . Note that not all these components are necessarily selected: some may have been set arbitrarily because of existing knowledge. By noticing that , it appears that the problem of selecting the error model is independent from the problem of selecting the covariate and correlation models. Figure 1 provides a flowchart of the complete procedure. Let us now take a closer look at what each step of the model selection process consists of.
FIGURE 1.
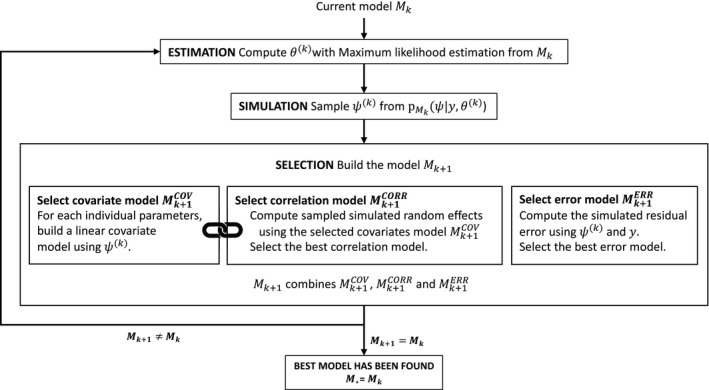
Scheme of the Stochastic Approximation for Model Building Algorithm (SAMBA)
The covariate model selection
The sample has been generated conditionally to the data y and the model . For the ‐th parameter, we build a linear model between and covariates c, such as in Equation 2:
| (5) |
with the transformation associated to the ‐th parameter and where is supposed normally distributed with mean zero and variance . We define . Best covariate model for parameter , denoted , is selected as being the one minimizing a penalized criterion:
We denote the number of non‐null elements in for model . The penalization depends on the criterion selected for optimization: if AIC then , if BIC or BICc then . Equation 5 tells us that the covariate selection problem has become here a classical problem of variable selection in a linear model. 14 This problem is much more easily tractable than the original one. The overall best covariate model combines the best model for each parameter such that .
In the implemented version of package Rsmlx (R speaks Monolix), two different strategies are implemented depending on the dimension of the selection problem. If the number of available covariates is less than 11, an exhaustive search is performed over all the possible covariate models for each parameter. Otherwise, the stepwise variable selection procedure implemented in the function stepAIC from package MASS is used. It consists of iteratively adding and removing covariates in stepwise manner to lower the objective criterion.
The correlation model selection
Using the selected covariate model and the sample of individual parameters , it is possible to extract the vector of individual random effects from Equation 5. Assuming that where is a block diagonal matrix, the problem of correlation model selection consists in selecting the block structure of . We then select the correlation model denoted by minimizing a penalized criterion:
We denote the number of non‐zero elements in the upper triangular part of the matrix . The penalization depends on the criterion selected for global optimization: if AIC then , if BIC or BICc then .
In the implemented version of package Rsmlx, we limit the size of the block‐structure that can be considered at each iteration. For , no correlation can be added and a diagonal matrix is used for ; for only blocks of size two are considered. At iteration for selection of model , block size cannot be larger than , leading to no more than non‐zero covariance terms in .
The error model selection
For a given set of simulated individual parameters , the residual errors can easily be computed:
We then fit several error models with standard deviation of the form for and select the one minimizing a penalized criterion:
We denote the length of (i.e., the number of parameters in model ). The penalization depends on the criterion selected for global optimization: if AIC then , if BIC then , and if BICc then where is the total number of observations, including below the limit of quantification data.
In the implemented version of package Rsmlx, five error models (provided by function in Equation 1) are tested by default: constant (), proportional (), combined1 (), combined2 (), or exponential in which a constant error model is fitted to the using the transformation in Equation 1. Note that it is currently not possible to perform the selection on a restricted number of error models, but such a feature could be easily implemented.
Stopping rule procedure
At each iteration of the algorithm, we combine , , and to get the new selected model , which is passed forward on to the next estimation‐simulation run. It is important to select the covariate model before the correlation model. On the other hand, the error model can be updated before or after the other two components of the model. The algorithm stops when is strictly identical to for all components and the last model is the selected one.
Remark
In the above, represents a single realization of the conditional distribution for each . Instead of considering only one realization of this distribution, we could use a sample of size . If so, the linear covariate model described in Equation 5 rewrites:
where:
Procedures for covariate model selection and correlation model selection remains the same, but using now and at iteration k. On the other hand, the R series of residual errors are used for selecting the residual error model.
RESULTS
Step‐by‐step example of the SAMBA procedure
To illustrate how SAMBA works in practice, we will describe step‐by‐step the complete procedure on the example of remifentanil. 15 We use here the SAMBA implementation in function buildmlx of the R package Rsmlx, using the default settings.
The remifentanil data
The dataset is composed of 65 healthy adults who have received remifentanil i.v. infusion at a constant infusion rate between 1 and 8 μg−1 kg−1 min−1 for 4 to 20 minutes. Time and rate of infusion are known for each individual. The pharmacokinetic (PK) data consists in the plasma concentration of remifentanil, which is measured during and after infusion for a total of 19 to 53 observations by patients, totaling 2057 observations. A total of six covariates are available: one qualitative covariate, the sex (SEX) and five continuous covariates: the age (AGE), the height (HT), the weight (WT), the lean body mass (LBM), and the body surface area (BSA). All the latter are normalized and log‐transformed for the analysis. In the following, we adopt the notation , where is a typical value to normalize on (e.g., the mean value of age in the population).
The model
The PK model for i.v. infusion has a central compartment (volume V1), two peripheral compartments (volumes V2 and V3, and intercompartmental clearances Q2 and Q3), and a linear elimination (Cl). Log‐normal distributions are used for the six individual parameters. The 26 = 64 possible covariate models will be considered for each of the six individual parameters. Note that if we had to test all possible models, we would have had to test 646 combinations, which would have made the problem intractable.
SAMBA iterations
We start the SAMBA procedure with a model without any covariate on all parameters, with no correlation between random effects and the so‐called combined1 error model. Figure 2 illustrates the selection steps on this specific example. One can notice that the BICc, which has been chosen as target criterion, decreases from 7186 for to 6985 for , 6957 for , and 6903 for , which is finally selected as the best model for this example.
Run 0 (BICc = 7185.8) + Iteration 1: Model is fitted to data and individual parameters are sampled conditionally on the data and this model. Each of the 64 possible linear covariate models is fitted to each individual parameters and the one with lowest BICc is selected. Let us take the example of Cl: the three best models include (1) an effect of logAGE and logWT (BICc = −55.0), (2) an effect of logAGE and logLBM (BICc = −56.1), and (3) an effect of logAGE and logBSA (BICc = −57.5). The latter is chosen as the best model for parameter Cl as it provides the lowest BICc (). Altogether, for all parameters, the best covariate model () includes logAGE on all parameters, logBSA on Cl, and logLBM on V1 and V2. No correlation is added to the model because no correlation is allowed at first iteration. Then, is a diagonal variance‐covariance matrix for the random effects. Among the tested error models, the three best ones are proportional (BICc = 5815.2), combined1 (BICc = 5811.2), and combined2 (BICc = 5807.0), which is selected for . These covariate, correlation, and error models are then passed on to run 1: }.
Run 1 (BICc = 6984.9) + Iteration 2: Model is fitted to the data and individual parameters are sampled. Again, the three best model for each covariate are provided. The best covariate model includes logAGE on all parameters except V1, logBSA on Cl, logLBM on V1, and SEX on V2 (). Block‐structured correlation with blocks up to size 2 are compared (i.e., up to one correlation term). The best three models are with a correlation between parameters Cl and V2 (BICc = 1082.9), between parameters Cl and Q2 (BICc = 1093.8), and between parameters V2 and Q2 (BICc = 1072.0). The latter correlation model is selected for . Residual error model combined2 remains the best one (). These covariate, correlation, and error models are then passed on to run 2.
Run 2 (BICc = 6956.9) + Iteration 3: Model is fitted to data and individual parameters are sampled. The best covariate model includes logAGE on all parameters except V1, logBSA on Cl, and logLBM on V1 and V2 (). Block‐structured correlation with blocks up to size 3 are compared (i.e., up to three correlation terms), a correlation block is selected between Cl, Q2, and V2 (). Residual error model combined2 remains the best one (). These covariate, correlation, and error models are then passed on to run 3.
Run 3 (BICc = 6903.4) + Iteration 4: Model is fitted to data and individual parameters are sampled. Of note, regarding the correlation model selection, block‐structured correlation with blocks up to size 4 are compared (i.e., up to six correlation terms). During this iteration, the same model as the one in the previous iteration is selected () resulting in the stopping of the procedure. Model is therefore the final model selected with the SAMBA procedure.
FIGURE 2.
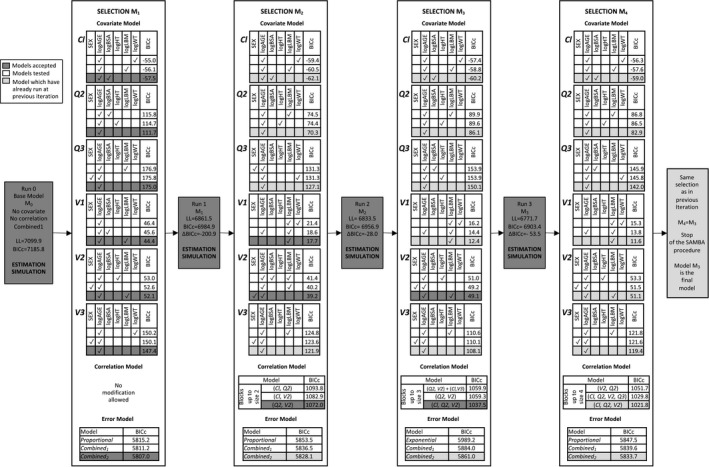
Step‐by‐step Stochastic Approximation for Model Building Algorithm (SAMBA) procedure on the remifentanil example with six covariates (SEX, logAGE, logBSA, logHT, logLBM, and logWT) and six model parameters (Cl, Q2, Q3, V1, V2 and V3). For each selection (covariate, correlation, and error model), the three best models in term of corrected Bayesian Information Criteria (BICc) are displayed. Non selected models are in white, newly accepted models are in darker grey, and models which have been already accepted at previous run are in lighter grey
Converging toward a global optimal model
Even if the selected criterion decreases at each iteration, there is no guarantee that SAMBA converges toward a global minimum of this criterion. The quality and the robustness of the convergence of SAMBA can then be assessed by running SAMBA several times from different starting models. In particular, a good practice is to: (1) launch SAMBA from several initial models, (2) compare the best models found (if there is not only one) in terms of objective criterion (e.g., BICc), and (3) make a thorough analysis and interpretation of the nearby models in order to choose the most relevant one for a given application. Regarding the choice of the starting model, similarly to the Expectation Maximization and Stochastic Approximation Expectation Maximization algorithms, there is no optimal choice. 16 , 17 We recommend to test in priority the following three starting models: (1) an empty model, (2) (when possible) a complete model, and (3) a model (or models) that make sense for the biological application. Note that this robustness assessment is standard for all non‐convex optimization algorithms and should also be performed for SCM and COSSAC in routine.
Performances on real examples, and comparison with the SCM and COSSAC procedures
To assess the performances of the SAMBA procedure compared to SCM and COSSAC procedures, we replicate the illustration provided in ref. 4. We applied the three routines to a collection of 10 representative datasets, including PKs, pharmacodynamics, and disease models. Of note, the SCM method for variable selection used here is exactly the same as the one implemented in PsN (Pearl Speaks NONMEM), differences lie in the algorithms used to estimate the parameters of a model and to calculate the likelihood. We restricted the SAMBA procedure to the covariate model selection as correlation and error model selection are not implemented in COSSAC and SCM. The results can be found in Table 1.
TABLE 1.
Comparison of the SAMBA procedure with the SCM and COSSAC procedure on 10 representative datasets
| Dataset | Characteristics | SCM | COSSAC | SAMBA | BICc | ||||
|---|---|---|---|---|---|---|---|---|---|
| #Runs b | Final Model a | #Runs b | Final Model 1 | #Runs b | Final Model a | SAMBA‐SCM | SAMBA‐COSSAC | ||
| Warfarin | 32 ind. ‐ 247 obs. | 44 | logtWt ‐ V, Cl | 4 | Identical | 2 | Identical | 0 | 0 |
| Linear PK | 4 param. ‐ 3 cov. | logtAge ‐ C | |||||||
| 4 re ‐ 1 outcome | |||||||||
| Remifentanil | 65 ind. ‐ 1992 obs. | 295 | logLBM – V1 | 13 | logLBM ‐ V1, V 2 | 4 | logLBM ‐ V1 | 0.8 | 0.5 |
| Linear PK | 6 param. ‐ 6 cov. | logAGE ‐ Cl, Q2, , , | logAGE ‐ , , , | logAGE ‐ , , , , | |||||
| 4 re ‐ 1 outcome | logBSA ‐ | logBSA ‐ | logBSA ‐ | ||||||
| logHT ‐ | |||||||||
| SEX ‐ | SEX ‐ | ||||||||
| Theophylline | 12 ind. ‐ 20 obs. | 12 | logtWEIGHT ‐ | 4 | Identical | 2 | Identical | 0 | 0 |
| Linear PK | 3 param. ‐ 2 cov. | ||||||||
| 4 re ‐ 1 outcome | |||||||||
| Quinidine | 136 ind. ‐ 361 obs. | 22 | none | 11 | Identical | 1 | Identical | 0 | 0 |
| Sparse PK | 3 param. ‐ 2 cov. | ||||||||
| 3 re ‐ 1 outcome | |||||||||
| Tobramycin | 97 ind. ‐ 322 obs. | 22 | logCLCR ‐ | 6 | logCLCR ‐ | 2 | logCLCR ‐ | 4.2 | 4.2 |
| Sparse PK | 3 param. ‐ 2 cov. | logWT ‐ | logWT ‐ | logWT ‐ | |||||
| 2 re ‐ 1 outcome | |||||||||
| Theophylline | 18 ind. ‐ 362 obs. | 98 | logWT ‐ | 8 | logWT ‐ | 6 | logWT ‐ | −11.7 | −27 |
| Ext. Rel. | 7 param. ‐ 3 cov. | logAGE ‐ | logAGE ‐ | ||||||
| Linear PK | 7 re ‐ 1 outcome | logHT ‐ | |||||||
| Warfarin | 32 ind. ‐ 247+232 obs. | 92 | logWT ‐ | 10 | logWT ‐ | 2 | logWT ‐ , | −1.4 | −1.4 |
| PK/PD | 8 param. ‐ 3 cov. | logAGE ‐ | |||||||
| Joint | 8 re ‐ 2 outcomes | ||||||||
| Cholesterol | 200 ind. ‐ 1044 obs. | 12 | logAGE ‐ , | 5 | logAGE ‐ , | 2 | logAGE ‐ | 13.5 | 13.5 |
| Disease | 2 param. ‐ 2 cov. | SEX ‐ | SEX ‐ | ||||||
| Progression | 2 re ‐ 1 outcome | ||||||||
| Alzheimer | 896 ind. ‐ 3707 obs. | 73 | APOE ‐ , | 8 | APOE ‐ , | 2 | APOE ‐ , | 6 | 1.5 |
| Sparse PK | 2 param. ‐ 7 cov. | logAGE ‐ , | logAGE ‐ , | logAGE ‐ | |||||
| 2 re ‐ 1 outcome | logBMI ‐ | logBMI ‐ | |||||||
| logWT ‐ | logWT ‐ | logWT ‐ | |||||||
| Tranexamic | 166 ind. ‐ 817 obs. | 298 | GROUP ‐ , | 12 | Identical | 2 | Identical | 0 | 0 |
| PK | 4 param. ‐ 10 cov. | logBMI ‐ Cl | |||||||
| 4 re ‐ 1 outcome | logCOCK ‐ Cl | ||||||||
| logLBW ‐ Q | |||||||||
| logWeight ‐ V2 | |||||||||
Differences of variable selection between different methods are highlighted in bold.
The number of runs is defined as the number of time the estimation and the simulation steps are performed (which is the most time‐consuming).
Because the datasets are real data illustrations, there is no “true” model. It is only possible to compare them in terms of BIC. Of 10 examples, the same best model was proposed by the three procedures in four examples. In two examples, the best model selected by SAMBA was better in terms of BICc than with SCM and COSSAC (Theophylline Ext. Rel. and Warfarin PK/PD). In three other examples, the model with the lowest BICc was not selected by SAMBA. However, the difference in BICc was, respectively, smaller than six in comparison with the SCM procedure and 4.2 in comparison with the COSSAC procedure. We insist on the fact that a difference in BICc does not necessarily have any biological meaning. This is an arbitrary criterion that allows to quantify the goodness of fit with respect to the sparsity of the model chosen. We thus argue that the three procedures lead to rather similar models, which all constitute very good starting points for the modeler to build a model based on biological hypothesis. Finally, in only one example discussed below, the difference in BICc was larger than 10 points of BICc both compared with the SCM and COSSAC procedures.
Regarding the cholesterol dataset, we again ran the SAMBA procedure starting from a full model in which all covariates are supposed to have an effect on all parameters. The new model selected by SAMBA is the full model with an effect of logAGE on (Chol0, slope) and SEX on (Chol0, slope) is much closer in term of BICc than the one selected starting from an empty model ( BICc = −2). We can finally notice with this example that it is sometimes possible to improve the convergence of SAMBA by improving the convergence of SAEM. Indeed, using 10 Markov chains instead of only one, SAMBA also finds the model selected by SCM and COSSAC. Finding the optimal settings that minimizes computation time while maximizing the probability of finding the best model is an extremely difficult problem that remains open. We can claim that the default settings used in Rsmlx and Monolix give very good results in most cases, but not in all cases with absolute certainty.
In terms of computational effort, it is important to note that the SAMBA procedure completes the model‐building process in much less runs, hence much less CPU time than SCM and COSSAC. In the considered problems, the number of runs and the CPU computation time are equivalent because the other computation times are negligible in the order of a few seconds. Actually, the computation times are six to 149 smaller than for SCM and two to 11 times smaller than for COSSAC. Note that the number of evaluations required by SAMBA is always lower or equal to the number of evaluations performed by COSSAC and SCM.
Simulation study
Data generation and analysis
We simulated data from a one‐compartment PK model. The model has three population parameters , and . All individual parameters are log‐normally distributed around the population parameters (, and ). We simulated five individual covariates from standard normal distributions. The covariate model is such that there only exists linear relationships between and (), and (), and and (). The correlation model is such that there exists a linear correlation between and (). Finally, the error model is a combined2 model with and . A clinical trial could then be simulated by generating PK data from this model for 100 individuals and 11 timepoints (0.25, 0.5, 1, 2, 5, 8, 12, 16, 20, 24, and 30). In order to evaluate the properties of SAMBA by Monte‐Carlo, we simulated 100 replicates of the same trial and built the model for each replicate using SAMBA as implemented in Rsmlx and Monolix for minimizing BICc. The initial model did not include any covariate‐parameter relationship and any correlation between random effect. The initial residual error model was a combined1 model. The R code used for this Monte‐Carlo study is available as Supplementary Material.
Performances
Table 2 summarizes the results obtained for the covariate model selection. On the one hand, we can see that, for this particular example, SAMBA finds the three existing covariate‐parameter relationships in 100% of the cases. On the other hand, very few spurious relationships are detected (less than 2%). Importantly, in all cases for which the final covariate model included more covariates than the true model , the BICc of the selected model was lower than that of (the differences ranging from 3 to 14.7 with Rsmlx and from 2.4 to 14.6 for Monolix). In other words, SAMBA always finds a covariate model as good or better than in terms of BICc. Regarding the selection of the correlation model, the correct model was selected for all the replicates. Finally, the correct error model was selected in 86% of the times with Rsmlx and 85% of the times with Monolix. Note that all the wrong selected error models were all combined1 model (instead of combined2) with a slightly larger BICc most of the time. Actually, these two models are quite similar and difficult to distinguish on the basis of a criterion like BICc. SAMBA then may get stuck in a local minimum in such a situation. Finally, and importantly, the final selected models obtained with Rsmlx and Monolix are different in only 6% of cases. These small differences are due to small differences in the implementation of the algorithm (see the Discussion section for more details).
TABLE 2.
Performance of the SAMBA algorithm for the selection of the covariate model in a simulation study using a one‐compartment PK model
| Covariates | Rsmlx | Monolix | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
||||||
|
|
2 | 100 | 100 | 2 | 100 | 100 | |||||
|
|
0 | 1 | 100 | 0 | 1 | 100 | |||||
|
|
1 | 2 | 1 | 2 | 2 | 1 | |||||
|
|
0 | 3 | 4 | 0 | 3 | 4 | |||||
|
|
0 | 1 | 1 | 1 | 2 | 1 | |||||
One hundred datasets of 100 individuals with 11 observations each have been generated. True model includes an effect of on and and an effect of on . The percentages of times (over 100 replicates) each covariate‐parameter relationship is selected in the final model are displayed. Implementation of SAMBA in Rsmlx and Monolix are compared.
Abbreviations: Cl, linear elimination; ka, absorption rate constant; PK, pharmacokinetic; SAMBA, Stochastic Approximation for Model Building Algorithm; V, volume.
DISCUSSION
This paper presents a novel model‐building procedure which offers covariate, correlation, and error model selection. It is fast as it requires only a limited number of runs of population parameter estimation and simulation compared to SCM and COSSAC. It allows to explore the space of models rapidly and provides to the modeler a very good model in term of the selection criterion. However, we insist on the fact that this procedure does not aim at replacing model‐building based on biological knowledge, which is, in essence, the strength of mechanistic modeling. Thus, it should not be blindly used and the best—potentially few best—models should be interpreted and compared.
SAMBA is an efficient algorithm for minimizing an objective function. In this paper, we do not aim at evaluating the quality of the criterion used for model selection. 18 What is of interest here is the convergence of SAMBA. As it is also the case for SCM and COSSAC, SAMBA may not converge to the global minimum. This is particularly the case when the amount of data is too small compared to the complexity of the model to build. This phenomenon will be particularly critical when the number of covariates is high and/or when these are highly correlated. We then strongly encourage the user to build strategies to assess the robustness of the results. Extensions of the proposed algorithm are possible but are outside the scope of this paper and constitute a possible new research direction.
When there is a large number of available covariates, COSSAC and mainly SCM often fail in finding the best model in a reasonable time. In this case, SAMBA represents a particularly appealing approach because the covariate model selection is based on a stepwise variable selection procedure for linear models, which is known to handle high‐dimension problems. Although stepwise AIC/BIC are designed to obtain a sparse estimator that works well on the training set, other methods, such as the lasso, 19 where the penalty is chosen with cross validation, is designed to obtain the sparse linear model that minimize the prediction error. A lasso type approach 20 can sometimes present better performances than an approach based on an information criterion, such as AIC or BIC, in particular when the number of covariates is very high. However, it should be noted that the choice of the penalty parameter by cross‐validation can be complicated to implement and require a large number of runs. This type of method could be alternatively implemented in the covariate selection procedure and compared in further works. Note finally that it would be interesting to study the behavior of SAMBA using the EBEs (corrected as proposed in ref. 8, 9), rather than the individual simulated parameters, to build the covariate model.
The SAMBA procedure is implemented the R Package Rsmlx in the function buildmlx. 21 Minimal required input is a Monolix project used as initial model. Additional arguments can be used to enable specific features (all not listed): select the components of the model to optimize among the covariate, correlation, and error model, restrict the number of parameters or covariates to use, select a specific objective criterion, etc. Rsmlx is on CRAN and the R code can be modified to investigate any of the alternative implementations mentioned above for a specific problem. Note that the execution of Rsmlx requires the Monolix software, because it is only an algorithm combining tasks implemented in Monolix. The R codes allowing to replicate the analyses of this paper are available in the Supplementary Material. All the illustration datasets can be downloaded from the Supporting Information Appendix S2 of ref. 4.
Finally, the SAMBA procedure is also implemented in the Monolix‐GUI software starting from version 2019. Implementation is similar to the one in Rsmlx with two noteworthy differences. First, for the selection of covariates, a stepwise procedure is used even if the number of covariates d is small. Second, compiling differences exist between C++ and R. The full SAMBA procedure is available in the model‐building perspective, under a task called automatic statistical model building method. A single iteration of the SAMBA procedure is also proposed in the section Proposal in the tab Results after running a single estimation and simulation step for a model in Monolix. 22
CONFLICT OF INTEREST
Marc Lavielle is chief scientist of Lixoft, the company that develops and distributes the Monolix Suite. The other author declared no competing interests for this work.
AUTHOR CONTRIBUTION
M.P. and M.L. wrote the manuscript, designed the research, performed the research, and analyzed the data. M.L. contributed new reagents/analytical tools.
Supporting information
Supplementary Material
Prague M, Lavielle M. SAMBA: A novel method for fast automatic model building in nonlinear mixed‐effects models. CPT Pharmacometrics Syst Pharmacol. 2022;11:161‐172. doi: 10.1002/psp4.12742
Funding information
This study has received funding from the Nipah virus project financed by the French Ministry of Higher Education, Research, and Innovation
REFERENCES
- 1. Lavielle M. Mixed‐effects Models for the Population Approach: Models, Tasks, Methods and Tools. CRC Press; 2014. [Google Scholar]
- 2. Jonsson EN, Karlsson MO. Automated covariate model building within NONMEM. Pharm Res. 1998;15(9):1463‐1468. [DOI] [PubMed] [Google Scholar]
- 3. Kowalski KG, Hutmacher MM. Efficient screening of covariates in population models using Wald’s approximation to the likelihood ratio test. J Pharmacokinet Pharmacodyn. 2001;28(3):253‐275. [DOI] [PubMed] [Google Scholar]
- 4. Ayral G, Si Abdallah J‐F, Magnard C, Chauvin J. A novel method based on unbiased correlations tests for covariate selection in nonlinear mixed‐effects models–the COSSAC approach. CPT Pharmacomentrics Sys Pharmacol. 2021;10(4):318‐329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Hastie T, Tibshirani R. Generalized additive models: some applications. J Am Stat Assoc. 1987;82(398):371‐386. [Google Scholar]
- 6. Mandema JW, Verotta D, Sheiner LB. Building population pharmacokinetic/pharmacodynamic models. I. models for covariate effects. J Pharmacokinet Biopharm. 1992;20(5):511‐528. [DOI] [PubMed] [Google Scholar]
- 7. Nguyen T, Mouksassi M‐S, Holford N, et al. Model evaluation of continuous data pharmacometric models: metrics and graphics. CPT: Pharmacom Sys Pharmacol. 2017;6(2):87‐109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Yuan M, Xu XS, Yang Y, et al. A quick and accurate method for the estimation of covariate effects based on empirical bayes estimates in mixed‐effects modeling: correction of bias due to shrinkage. Stat Methods Med Res. 2019;28(12):3568‐3578. [DOI] [PubMed] [Google Scholar]
- 9. Yuan M, Zhu Z, Yang Y, et al. Efficient algorithms for covariate analysis with dynamic data using nonlinear mixed‐effects model. Stat Methods Med Res. 2021;30(1):233‐243. [DOI] [PubMed] [Google Scholar]
- 10. Lavielle M, Ribba B. Enhanced method for diagnosing pharmacometric models: random sampling from conditional distributions. Pharm Res. 2016;33(12):2979‐2988. [DOI] [PubMed] [Google Scholar]
- 11. Delattre M, Lavielle M, Poursat M‐A. A note on BIC in mixed‐effects models. Elect J Stat. 2014;8(1):456‐475. [Google Scholar]
- 12. Green PJ. Penalized likelihood. Encyclopedia Stat Sci. 1998;2:578‐586. [Google Scholar]
- 13. James G, Witten D, Hastie T, Tibshirani R. An Introduction to Statistical Learning, volume 112. Springer; 2013. [Google Scholar]
- 14. George EI. The variable selection problem. J Am Stat Assoc. 2000;95(452):1304‐1308. [Google Scholar]
- 15. Minto CF, Schnider TW, Egan TD, et al. Influence of age and gender on the pharmacokinetics and pharmacodynamics of remifentanil: I. model development. J Am Soc Anesthesiol. 1997;86(1):10‐23. [DOI] [PubMed] [Google Scholar]
- 16. Baudry J‐P, Celeux G. EM for mixtures. Stat Comp. 2015;25(4):713‐726. [Google Scholar]
- 17. Biernacki C, Celeux G, Govaert G. Choosing starting values for the EM algorithm for getting the highest likelihood in multivariate gaussian mixture models. Comput Stat Data Anal. 2003;41(3–4):561‐575. [Google Scholar]
- 18. Buatois S, Ueckert S, Frey N, Retout S & Mentré F. Comparison of model averaging and model selection in dose finding trials analyzed by nonlinear mixed effect models. The AAPS J. 2018;20(3):1‐9. [DOI] [PubMed] [Google Scholar]
- 19. Tibshirani R. Regression shrinkage and selection via the lasso. J Roy Stat Soc: Ser B (Methodol). 1996;58(1):267‐288. [Google Scholar]
- 20. Hastie T, Tibshirani R, Tibshirani R. Best subset, forward stepwise or lasso? analysis and recommendations based on extensive comparisons. Stat Sci. 2020;35(4):579‐592. [Google Scholar]
- 21. Lavielle M. Rsmlx: R Speaks ’Monolix’. 2021. http://rsmlx.webpopix.org. R package version 3.0.3.
- 22. Monolix Online Documentation ‐ Proposal Tab Description. https://monolix.lixoft.com/tasks/proposal/. Accessed September 15, 2021.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Material