

Abstract
Diagnosing melanocytic lesions is one of the most challenging areas of pathology with extensive intra- and inter-observer variability. The gold standard for a diagnosis of invasive melanoma is the examination of histopathological whole slide skin biopsy images by an experienced dermatopathologist. Digitized whole slide images offer novel opportunities for computer programs to improve the diagnostic performance of pathologists. In order to automatically classify such images, representations that reflect the content and context of the input images are needed. In this paper, we introduce a novel self-attention-based network to learn representations from digital whole slide images of melanocytic skin lesions at multiple scales. Our model softly weighs representations from multiple scales, allowing it to discriminate between diagnosis-relevant and -irrelevant information automatically. Our experiments show that our method outperforms five other state-of-the-art whole slide image classification methods by a significant margin. Our method also achieves comparable performance to 187 practicing U.S. pathologists who interpreted the same cases in an independent study. To facilitate relevant research, full training and inference code is made publicly available at https://github.com/meredith-wenjunwu/ScATNet.
Keywords: Convolutional neural network, histopathological images, melanocytic risk lesions, melanoma, multi-scale, transformers, skin cancer diagnosis, whole-slide image classification
I. INTRODUCTION
Invasive melanoma, with more than 100,000 estimated new cases in 2021, is one of the most commonly diagnosed cancers in the U.S [1]. The ‘‘gold standard’’ for diagnosis of skin biopsy specimens relies on the visual assessments of pathologists. Unfortunately, diagnostic errors are common, and even expert pathologists may not reach consensus on diagnostically challenging cases in many areas within pathology [2]–[5]. For instance, pathologists disagree in up to 60% of melanoma in situ and stage T1a invasive cases [6]. Variability in diagnostic decisions is a serious problem and can cause substantial patient harm. A computer-aided diagnostic system can act as a second reader and help pathologists reduce classification uncertainties.
For a reliable diagnostic system, it is important to obtain representations that reflect both the content and context of the input biopsy image. This paper introduces a self-attention-based deep neural network called the Scale-Aware Transformer Network (ScATNet) for classifying melanocytic skin lesions in digital whole slide images (WSIs). ScATNet, shown in Figure 1, extends the standard transformer model of Vaswani et al. (2017) to learn representations from biopsy images at multiple input scales. The key idea is to learn patch-wise representations independently for each input scale using a convolutional neural network (CNN), and then learn inter-patch and inter-scale representations from concatenated multi-scale contextualized patch embeddings using transformers. This allows our system to learn diagnostic class-specific representations at different scales and helps improve the performance. Also, each WSI contains multiple tissue slices, while usually only one or two tissue slices help pathologists in diagnosis. We introduce a soft-label assignment method to (1) reduce the ambiguity between different tissue slices in a WSI and (2) improve the diagnostic classification performance.
FIGURE 1.
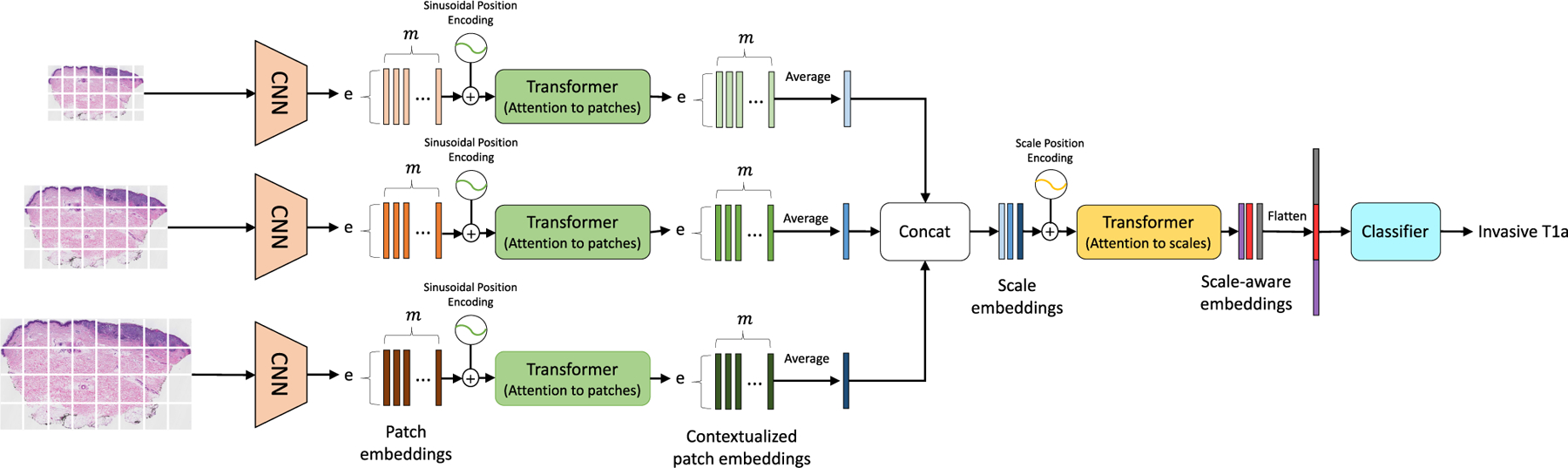
Overview of ScATNet for classifying skin biopsy images. To learn representations from these large WSIs at multiple input scales in an end-to-end fashion, ScATNet factorizes the classification pipeline into three steps. The first step involves learning local patch-wise embeddings using an off-the-shelf CNN for each input scale independently. In the second step, ScATNet learns inter-patch representations using transformers and produces contextualized patch embeddings for each input scale. In the last step, ScATNet learns inter-scale representations from concatenated multi-scale contextualized patch embeddings using another transformer network and produces scale-aware embeddings, which are then classified linearly into diagnostic categories.
We demonstrate the effectiveness of ScATNet on a skin biopsy image dataset [6]. Experimental results show that ScATNet outperforms state-of-the-art methods by a significant margin. For example, ScATNet is 8% more accurate than the method proposed by Chikontwe et al. [7] and 6% more accurate than the method proposed by Hashimoto et al. [8]. Importantly, ScATNet delivers comparable performance to 187 practicing pathologists who interpreted the same test set cases in an independent study.
To summarize, the main contributions of this paper are: (1) a novel self-attention-based end-to-end framework for classifying WSIs at multiple input scales (Section III-B), (2) a soft label assignment method to reduce ambiguities that arise by assigning the same label to all tissue slices in a WSI (Section III-C), and (3) experimental results, along with comparisons with state-of-the-art methods and practicing U.S. pathologists, demonstrating ScATNet’s competitive performance (Section IV).
II. RELATED WORK
ScATNet was inspired by the success of several works in the area of WSI image classification and transformers. We briefly discuss these approaches in the following sub-sections.
A. MULTIPLE INSTANCE LEARNING (MIL)
Convolutional neural networks (CNNs) are the de facto machine learning-based method for image classification, including WSIs [9]–[11]. Unlike the images in standard datasets (e.g., ImageNet [12]), WSIs are orders of magnitude larger and cannot be processed in an end-to-end fashion using CNNs. The MIL framework has been widely studied for classifying different types of WSIs, such as lung [11], kidney [13], and breast [14]. In general, the input WSI is divided into instances (or patches) and the same classification label is assigned to all instances during training. During evaluation, methods such as averaging and majority voting are used to aggregate the information from all instances in an image and produce an image-level classification label. Though these approaches are effective, they learn local instance-wise representations. This work extends the MIL framework with the transformers of Vaswani et al. (2017) to learn global representations in an end-to-end fashion. In our experiments, we compared our method to the MIL methods of Chikontwe et al. [7] and Hashimoto et al. [8]. In addition, we compared our system to a standard patch-based CNN classification framework. Details of these methods are described in section IV-D.
B. PATCH-BASED FEATURE AGGREGATION
Patch-based methods provide a solution to the gigapixel size of WSIs, while only requiring slide-level labels. However, learning robust instance representations is challenging due to the ambiguity in instance-level labels. To address this, many recent methods [11], [15] adopt a two-step approach that consists of (1) training an instance encoder for obtaining a prediction score or low-dimensional features, and (2) learning a model that aggregates the features extracted by the learned instance encoder to form instance-level information for slide-level prediction. Although this approach has had some success, it often suffers from worse performance when noisy labels are present, causing the features to not be representative of their given labels. In our experiments, we compared our method with a CNN-based deep-feature-aggregation framework developed by Mercan et al. [15]. Details of this method are described in section IV-D.
C. SEGMENTATION-BASED METHODS
These approaches use semantic information about tissues in a WSI to produce an image-level decision [16]–[20]. Typically, these approaches have three steps: (1) produce a tissue-level semantic segmentation mask using CNNs for an input WSI, (2) extract features, such as distribution of tissues, from these semantic masks, and (3) produce an image-level decision using the features extracted from the semantic masks. These approaches learn global representations (information from segmentation masks) and have been found to be more effective than plain patch- and MIL-based approaches. However, one key challenge with these approaches is that they require tissue-level segmentation masks whose collection is challenging, because (1) domain experts are required for annotations and (2) pixel-wise annotations on images of gigapixel order is very time consuming. In contrast, this work introduces a method for learning global representations from histopathological WSIs without the need for tissue-level segmentation masks.
D. END-TO-END LEARNING
Recent attempts at WSI classification focus on designing a single neural network that aggregates information from the entire image in a single shot [21], [22]. These methods extend the MIL-based approach with gradient check-pointing and advanced feature-fusion methods, such as self-attention. Inspired by model-level parallelism [9] and gradient check-pointing [23], these approaches break down the WSI classification pipeline into multiple stages and cache the intermediate results of CNN layers during forward and backward passes, allowing the systems to learn representations in an end-to-end fashion. For example, Mehta et al. [21] uses the transformers of Vaswani et al. (2017) to aggregate the information from all instances in a breast biopsy image, while Pinckaers et al. [22] stitches the instance-wise feature maps of a prostate cancer image at a very low-spatial resolution obtained from a CNN to produce an image-level feature map. ScATNet extends these approaches for classifying skin biopsies. Unlike these approaches that use WSIs at a single scale (typically at a zoom-level of 10×) for classification, this work proposes a scale-aware transformer that adapts to and uses the representations from multiple input scales to achieve higher classification performance. In our experiments, we compared our method with a CNNbased end-to-end WSI classification framework developed by Pinckaers et al. [22], details of this which are described in section IV-D.
E. VISION TRANSFORMERS
The transformers of Vaswani et al. [24], initially introduced for the task of machine translation (e.g., [25], [26]), are being explored for modeling images and computer vision tasks (e.g., [27], [28]). Transformers use self-attention, which allows the inputs (e.g., words in a sentence) to interact with each other and learn global representations. Carion et al. [29] extended the standard encoder-decoder network of Vaswani et al. [24] for the task of object detection. Recent work has extended transformers using a patch-based approach to image recognition at a large scale [27], [28]. Concurrent work has also utilized transformers and self-attention to medical image segmentation [30]–[33] and classification [34].
Motivated by (1) the success of transformers in vision, (2) the methods for learning representations from different input scales [35]–[37], and (3) the importance of input scales for diagnosis in clinical settings [38], [39], we propose a scale-aware transformer model that adapts to the information from different input scales using self-attention and predicts the classification label.
III. METHOD
This section first reviews the architecture of transformers and then elaborates on the details of the proposed method, scale-aware transformers (Section III-B), that allows our system to learn representations from histopathological images at multiple scales in an end-to-end fashion. In Section III-C, a soft-labeling method is discussed that reduces the ambiguity in instance-level (patches) labels and improves the learning of representations from skin-biopsy images. The software associated with this work will be made available.
A. TRANSFORMERS
The transformer unit, shown in Figure 2, is comprised of two modules: (1) self-attention and (2) feed-forward. The self-attention module allows the inputs to interact with each other and learn contextual relationships. This layer applies three projections, with each projection branch having multiple linear layers to the input to produce query (Q), key (K), and value (V) embeddings, where n is the number of inputs and e is the input dimensionality. A dot-product between query (Q) and key (K) is computed to produce an n×n matrix to which a row-wise softmax is applied to encode relationships between the n inputs. Finally, a weighted sum is computed between the resultant n × n matrix and V.
FIGURE 2.
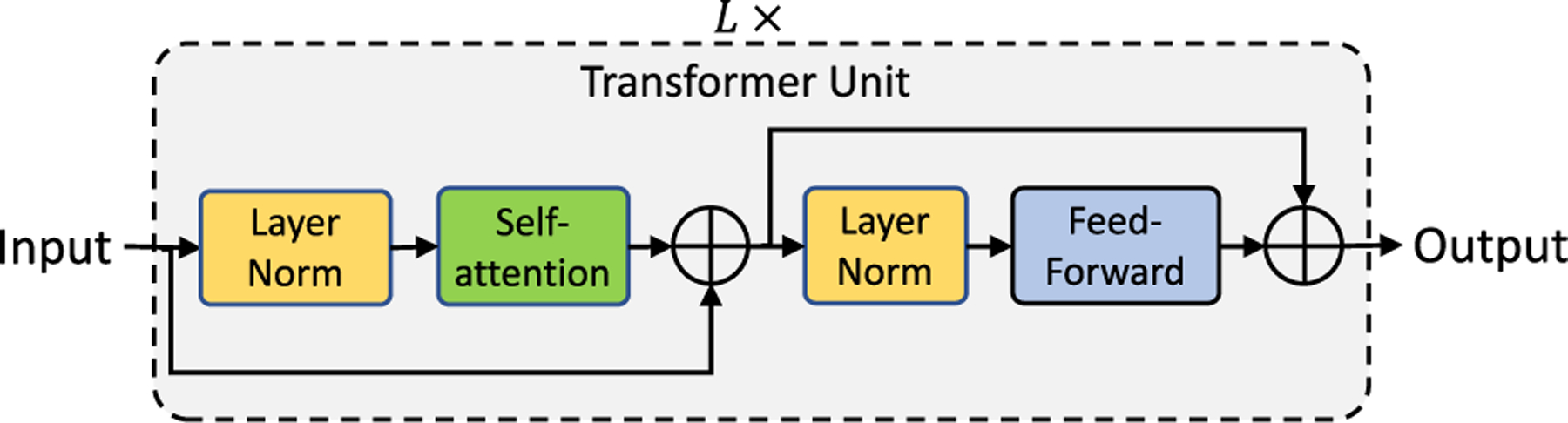
The transformer network stacks L transformer units sequentially. Each transformer unit consists of self-attention and feed-forward modules.
| (1) |
The feed-forward module stacks two linear layers, and is responsible for learning wider representations. The first linear layer projects the input to a high-dimensional space, while the second linear layer projects from the high-dimensional space to the same dimensionality as that of the input. This work extends the transformers model to learn scale-aware representations from skin biopsy images.
B. SCALE-AWARE TRANSFORMERS
Patch-based CNNs are state-of-the-art WSI classification methods that allow computer systems to learn representations from gigapixel size images (e.g. [11], [13], [14], [16], [40]). One of the main limitations of such systems is that they learn local representations, since the context capturing ability of such systems is limited to the patch-level. Another challenge is learning representations from multiple input scales. Because of limited GPU memory and the sheer size of these images, training multi-scale classification systems is computationally intractable. For example, the average size of a WSI (11K × 9.5K) in our dataset is 2000 times larger than the standard image classification dataset: the ImageNet [41] (224 × 224).
Motivated by the recent advancements in computer vision, especially vision transformers and the importance of input scales in clinical settings, this paper introduces scale-aware transformers in ScATNet, which allows our system to learn local and global representations from multiple input scales in an end-to-end fashion. Figure 1 shows the overview of ScATNet, which has three main steps: (1) learn local patch-wise embeddings using a CNN for each input scale, (2) learn contextualized patch-embeddings for each input scale using transformers, and (3) learn scale-aware embeddings across multiple input scales using transformers. These steps are described below.
1). PATCH EMBEDDINGS
The input WSI image at scale sc with width W and height H is divided into m non-overlapping patches , where is the i-th patch with width and height . Patch-wise feature representations, referred to as patch embeddings, are obtained using an off-the-shelf CNN. The patch embedding for the i-th patch is thus:
| (2) |
2). CONTEXTUALIZED PATCH EMBEDDINGS
The patch embeddings are produced independently for each patch. In other words, these embeddings PEsc do not encode inter-patch relationships. These embeddings PEsc are fed to a transformer to learn inter-patch relationships. Similar to vision transformers [27], patch-wise sinusoidal positional embeddings are added to PEsc to encode the position of input patches. The resultant embeddings are then fed to a transformer to produce contextualized patch embeddings .
| (3) |
These contextualized embeddings are then averaged along the m-dimension to produce an e-dimensional embedding vector encodes the local (from CNN) and global (from Transformer) information in an image Xsc.
3). CONTEXTUALIZED SCALE EMBEDDINGS.
The embedding encodes the information in an image Xsc at scale sc. Let us assume that we have scales. For each , we produce embedding vector and concatenate them to produce scale-level embeddings . These embeddings do not encode information about the relationships between the different scales. To learn scale-aware representations while retaining positional information about each scale, scale-level learnable positional embeddings are added1 to SEsc×e. The resultant embeddings are then fed to another transformer to produce contextualized scale embeddings .
| (4) |
For predicting the diagnostic class, ScATNet first flattens the scale-aware embeddings to produce a (sc·e)-dimensional vector and then classifies it using a linear classifier into C diagnostic categories.
C. SOFT-LABELS FOR SKIN BIOPSY IMAGES
Skin biopsy images often contain multiple tissue slices on a single WSI, as shown in Figure 4. In general, the representative regions-of-interest (ROIs; shown in red in Figure 4) that helped pathologists in diagnosis belong to one or two tissue slices, while the other tissue slices may correspond to other diagnosis categories. Assigning the same diagnostic label to all tissue slices (similar to MIL-based approaches) results in more false tissue-label pairs and hinders learning representations. To address this, we propose a soft labeling method, as illustrated in Figure 3.
FIGURE 4.
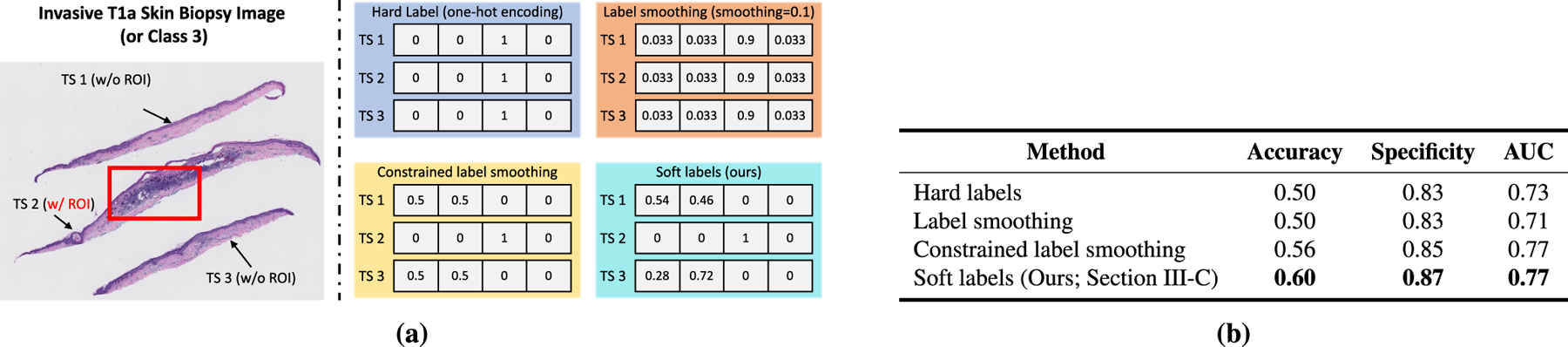
(a) shows different labeling methods, including our soft label method, for an pT1a skin biopsy image with three tissue slices and one representative region of interest (red box) that helped expert pathologists in diagnosing the image. (b) compares the performance of different labeling methods. Our soft labeling method is simple and effective; it reduces the ambiguity that arises during training because of multiple tissue slices in a WSI that do not have a ROI and helps improve the performance. In (b), we do not report sensitivity and specificity, because their values are the same as accuracy.
FIGURE 3.
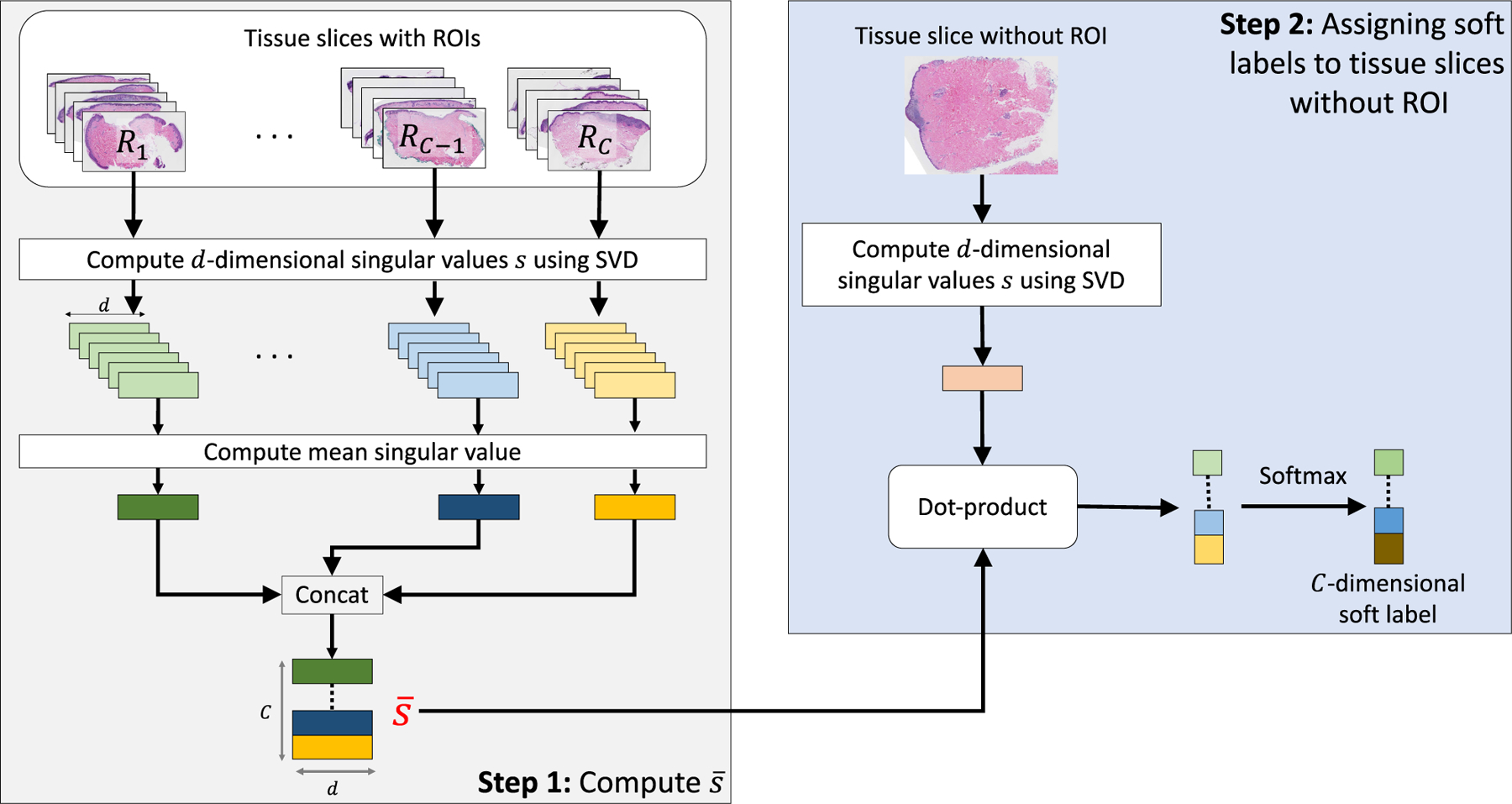
Overview of Soft labels calculation. Diagnostically constrained soft labels are calculated for tissue slices without an ROI using singular value decomposition (see Section III-C).
Given a dataset with N training WSIs along with representative ROIs for each WSI (each WSI contains multiple slices) that helped in diagnosis, we aim to assign soft labels to tissue slices that do not have ROIs. Tissue slices from each WSI are extracted and then categorized into one of the two sets: (1) tissue slices with an ROI and (2) tissue slices without an ROI. Since each slice in has a representative ROI, we further split into C subsets, , based on the diagnostic category, where Ri represents the subset for diagnostic category i and C denotes the number of diagnostic categories. Next, we compute the mean singular value vector for each subset Ri as:
| (5) |
where is the d-dimensional singular-value vector obtained after applying singular-value decomposition (SVD) to the j-th tissue slice in Ri. The idea is to use these vectors to represent the appearance of the diagnostic categories. We used singular values because of their uniqueness and robustness properties [42]–[45]. However, other dimensionality reduction methods could also be used.
For the j-th slice in , the C-dimensional soft label vector is computed as:
| (6) |
where is a d-dimensional singular value vector obtained after applying SVD to the j-th tissue slice in and .
Tissue slices without an ROI do not help in the diagnosis decisions. Clinically, such slices can often belong to lower diagnostic categories than the category assigned to the WSI they are part of. We incorporate this diagnostic constraint in our soft labeling method. For a four-class dataset (1: MMD, 2: MIS, 3: pT1a, and 4: pT1b), suppose that a WSI corresponding to class k has m tissue slices and one of the tissue slices has an ROI, as shown in Figure 4. Soft label vectors for the jth slices without ROI (j ∈ [0,m − 1]) can be obtained from equation 6. Then, to take one step further, diagnostically constrained soft label vector is computed as:
| (7) |
Figure 4 illustrated an example WSI corresponding to class 3 (pT1a), which has three tissue slices, and one of the tissue slices has an ROI. If the soft label vectors for these two slices without ROI are [0.46,0.39,0.08,0.07], [0.21,0.54,0.1,0.15], the resulting soft label vectors with the diagnostic constraint are [0.54,0.46,0,0], and [0.28,0.72,0,0] respectively.
IV. EXPERIMENTAL RESULTS
A. DATASET AND EVALUATION
1). SKIN BIOPSY DATASET AND GROUND TRUTH CONSENSUS
The data used for this study was acquired as a part of the MPATH study (R01CA151306) and consists of 240 skin biopsy images with hematoxylin and eosin (H&E) staining [6]. The study was approved by the Institutional Review Board at the University of Washington with protocol number STUDY00008506. These biopsy images were interpreted by a consensus panel of three experienced dermatopathologists using the modified Delphi approach [46]. The consensus panel assessments were grouped into five different MPATHDx (Melanocytic Pathology Assessment Tool and Hierarchy for Diagnosis) [47] simplified categories based on perceived risk for progression. These five classes were regrouped to four diagnostic classes for the classification task in this paper due to limited sample size in Classes I and II and because the clinical risk for progression of both Class I and Class II is extremely low. The diagnostic terms we use for each class are as follows: 1) Class I-II: mild and moderate dysplastic nevi (MMD), which is very low risk to low risk, 2) Class III: melanoma in situ (MIS), which is higher risk than MMD, 3) Class IV: invasive melanoma stage pT1a (pT1a) which is higher risk for local/regional progression, and 4) Class V: invasive melanoma stage ≥pT1b(pT1b)which is the greatest risk for regional and/or distant metastases. We randomly split 240 WSIs into 102 training, 23 validation and 115 test WSIs (see Table 1). Additionally, the consensus panel of three experienced dermatopathologists marked in total 240 regions of interest (ROIs) that best defined the diagnostic classification of each case during the review process. Information about these ROIs was used to produce soft labels for the training set (Section III-C).
TABLE 1.
Statistics of skin biopsy whole slide image (WSI) dataset. The average WSI size is computed at a magnification factor of 10x. Diagnostic terms for the dataset used in this study are as follows: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b).
| Diagnostic Category | Number of WSIs |
Average WSI size (in pixels) | |||
|---|---|---|---|---|---|
| Training | Validation | Test | Total | ||
| MMD | 26 | 6 | 29 | 61 | 11843 × 10315 |
| MIS | 25 | 5 | 30 | 60 | 9133 × 8501 |
| pT1a | 33 | 6 | 34 | 73 | 9490 × 7984 |
| pT1b | 18 | 6 | 22 | 46 | 14858 × 12154 |
|
| |||||
| Total | 102 | 23 | 115 | 240 | 11130 × 9603 |
2). OUTCOME METRICS
The performance of ScATNet is evaluated in terms of the following standard quantitative metrics: (1) classification (or Top-1) accuracy, (2) F1 score, (3) sensitivity, (4) specificity, and (5) area under receiver operating characteristic curves (ROC-AUC). The values of these metrics range between zero and one, and higher values of these metrics mean better performance. Multi-class F1 and specificity have the same value as accuracy.
3). ACCURACY DATA FROM U.S. PATHOLOGISTS
To compare the results from ScATNet with the interpretations of practicing U.S. pathologists, we used data from a prior clinical study in which 187 pathologists interpreted the same WSIs [6]. Each pathologist interpreted a random subset of 36 cases, and their diagnoses were classified into the same four diagnostic categories. This resulted in 10 independent diagnostic labels (on an average) per slide and provided a way to compare the classifications performed by human pathologist to ScATNet. These interpretations are only used for independent evaluation. The ground truth diagnosis of each slide is the consensus diagnosis of three experienced dermatopathologists.
B. IMPLEMENTATION DETAILS
1). EXTRACTING TISSUE SLICES FROM WSIs
The original WSIs were collected at a zoom level of 40×. Because WSIs at 40× require extensive computational resources, we extracted WSIs at lower zoom levels of 7.5× (average size 8348 × 7202), 10× (average size 11130 × 9603), and 12.5× (average size 13913 ×12003). These zoom levels were selected based on previous work on histopathological image classification for different tissues [11], [16], [40], since they provide a good tradeoff for 1) capturing sufficient local context without including irrelevant details and 2) providing variable local information without losing similar correlation. We refer to different zoom levels as ‘‘input scales’’ in this work. Each WSI has multiple tissue slices with a background region between the slices that does not aid in diagnosis (Figure 4). Therefore, individual tissue slices were extracted using a histogram-based segmentation method of Otsu [48] followed by morphological operations (opening-closing and hole filling) and contour-related operations available in OpenCV.
2). SOFT-LABELS
To assign soft labels for tissue slices without an ROI, SVD is applied to obtain d-dimensional singular-value vectors as described in the Methods section. In this study, d is set to 50.
a: ARCHITECTURE
We use MobileNetv2 [49] pretrained on the ImageNet dataset [41] as our CNN for extracting patch-wise embeddings. MobileNetv2 was chosen, because it is light-weight, fast, and delivers state-of-the-art performance across different machine vision tasks, such as classification, detection, and segmentation. ScATNet is not limited to a particular CNN and other CNNs, such as VGG [50] and ResNet [10] may also be suitable for extracting patch-wise embeddings.
MobileNetv2outputs1280-dimensionalpatch-wiseembeddings after global average pooling. ScATNet projects these patch-wise embeddings linearly to a 128-dimensional space (e = 128) and then learns contextualized patch-wise and scale-wise embeddings using transformers. For learning contextualized patch-wise and scale-wise representations, a stack of two transformer units is used. Also, in each transformer unit, the number of heads in the self-attention layer is set to 4, and the feed forward network dimension is set to 512.
C. TRAINING DETAILS
ScATNet is trained for 200 epochs in an end-to-end fashion using the ADAM optimizer with a linear learning rate warm-up strategy and step learning rate decay. The learning rate is first warmed up from 10−6 to 5 × 10−4 in 500 steps. In the next 50 epochs, the model is trained with a learning rate of 5 × 10−4. After that, the learning rate is reduced by half at the 100-th and 150-th epochs. Because of the large size of these images, extensive computational resources are required. To learn representations with limited computational resources, we freeze the convolutional layers in a CNN and train only the transformer networks. Our models are trained on a single NVIDIA GeForce 2080 GPU with 10 GB GPU memory. Similar to other medical imaging datasets, our dataset is small. Therefore, to improve its robustness against stochastic noise, we average best 3 and best 5 model checkpoints within a single training process [51] and select the one that performs best on the validation set. We then evaluate it on the (unseen) test set. A WSI in a test set may contain multiple tissue slices. To predict the final diagnostic label, we use max-voting. This choice is inspired by pathologists’ diagnosing behavior, i.e., if one of the tissue slices in a WSI is invasive melanoma, then the entire WSI corresponds to invasive melanoma and cannot be MMD or MIS.
D. BASELINE METHODS
ScATNet’s performance is compared with five recent whole slide image classification methods.
1). PATCH-BASED CLASSIFICATION
The first method is a standard patch-based CNN classification framework that was built following saliency-based methods, related to the work of Hou et al. [11] and that of Mercan et al. [39], (R1 and R2 in Table 2). This method treats each patch independently and assigns the same diagnostic label to all patches in the WSI during training. During evaluation, majority-voting is used for predicting the slide-level diagnostic label. Similar to the use of ScATNet, Mobilenetv2, pretrained on the ImageNet dataset was used as the CNN model.
TABLE 2.
Comparison of overall performance with state-of-the-art WSI classification methods across different metrics on the test set. Here, SSC denotes single input scale (10). MSC denotes multiple input scales (7.5, 10, 12.5). MSC* denotes multiple input scales (10, 20).
| Row # | Method | Accuracy | Fl | Sensitivity | Specificity | AUC |
|---|---|---|---|---|---|---|
| R1 | Patch-based (SSC) | 0.35 | 0.35 | 0.35 | 0.79 | 0.67 |
| R2 | Patch-based (MSC) | 0.40 | 0.40 | 0.40 | 0.80 | 0.68 |
| R3 | Penultimate-weighted (SSC) | 0.44 | 0.44 | 0.44 | 0.81 | 0.67 |
| R4 | Hypercolumn-weighted (SSC) | 0.43 | 0.43 | 0.43 | 0.81 | 0.67 |
| R5 | Streaming CNN (SSC) | 0.32 | 0.32 | 0.32 | 0.77 | 0.58 |
| R6 | ChikonMIL (SSC) | 0.56 | 0.56 | 0.56 | 0.85 | 0.74 |
| R7 | MS-DA-MIL (SSC) | 0.49 | 0.49 | 0.49 | 0.83 | 0.68 |
| R8 | MS-DA-MIL (MSC*) | 0.58 | 0.58 | 0.58 | 0.86 | 0.75 |
|
| ||||||
| R9 | ScATNet (SSC) | 0.60 | 0.60 | 0.60 | 0.87 | 0.77 |
| R10 | ScATNet (MSC) | 0.64 | 6.64 | 0.64 | 0.88 | 0.79 |
2). WEIGHTED FEATURE AGGREGATION
The second method is a CNN-based deep feature extraction framework developed by Mercan et al. [15] that builds slide-level feature representations via weighted aggregation of the patch representations (R3 and R4 in Table 2). Under this framework, feature extraction is performed in three steps: (1) using a CNN (e.g. VGG16) to extract features on a patch-by-patch basis; (2) concatenating the weighted instances of the extracted feature activations using either penultimate layer features (penultimate-weighted) or hypercolumn features (hypercolumn-weighted) to form patch-level feature representations; and (3) fusing the patch-level representations via average pooling to form the slide-level representation.
3). ChikonMIL
The method of Chikontwe et al. (ChikonMIL) (R3 in Table 2) [7] first selects the top-k patches, and then uses these patches for instance- and bag-representation learning. This method also uses a center loss that reduces intra-class variability and a soft assignment to learned diagnostic centroid for final diagnosis.
4). MS-DA-MIL
Multi-scale Domain-adversarial Multiple-instance (MS-DA-MIL) CNN developed by Hashimoto et al. [8] (R7 and R8 in Table 2) is a framework that learns from groups of patches extracted at different scales (x10 and x20) with attention mechanism. However, in contrast to the proposed end-to-end learning framework, MS-DA-MIL-CNN first trains a single-scale MIL network to classify for each scale. Then, a multi-scale network is trained using the features extracted using pre-trained single-scale MIL networks.
5). STREAMING CNN
Streaming CNN is a work of Pinckaers et al. [22] (R4 in Table 2). This method uses a patch-based approach with gradient checkpointing and streaming, which allows it to classify whole slide images in an end-to-end fashion.
E. RESULTS
1). HARD vs. SOFT LABELS
The performance of our soft labeling method (Section III-C) is compared with three other labeling methods. For illustration, for the four classes in our dataset (1: MMD, 2: MIS, 3: pT1a, and 4: pT1b), we use a WSI corresponding to pT1a (class 3; shown in Figure 4) with 3 slices, one having a ROI.
Hard labels: Similar to MIL-based approaches, all tissue slices in the WSI are assigned the same diagnostic label. For the above example, each tissue slice will have a label of [0, 0, 1, 0] (one-hot vector encoding).
Label smoothing: The label smoothing method of Szegedyet et al. [52] produces soft labels that are a weighted average of the hard labels and the uniform distribution over labels. It regularizes the network and helps improve the performance [53]. For the same example, the soft labels for each of these slices would be [0.033, 0.033, 0.9, 0.033] with a label smoothing value of 0.1. In other words, the label for class 3 is smoothed from 1 to 0.9 and the remaining mass of 0.1 is equally distributed among the remaining three classes.
Constrained label smoothing: This extends the hard labels and label smoothing methods by incorporating the diagnostic constraint that tissue slices without a ROI should belong to lower diagnostic categories. For example, if the WSI has a hard label of pT1a (i.e. class 3), then the tissue slices without a ROI can only belong to lower diagnostic categories (i.e., MMD and MIS). For the same example as above, the slice with an ROI will have a label of [0, 0, 1, 0] while the slices without an ROI will have constrained labels of [0.5, 0.5, 0, 0].
Figure 4a contrasts our soft labeling method with these methods while quantitative comparison between these methods is given in Figure 4b. These experiments demonstrated that our soft labeling method is more effective as compared to these existing methods. In subsequent experiments, we use our soft labeling method.
a: IMPACT OF NUMBER OF PATCHES m
Figure 5 compares the performance of single scale ScATNet with different numbers of crops m at three different input resolutions (7:5×, 10×, and 12:5×). Using fewer crops at larger resolution (e.g., 25 crops at a resolution of 12:5×) and more crops at smaller resolutions (e.g., 81 crops at a resolution of 7:5×) hurts the performance. This is likely because MobileNetv2, the CNN used in this work, is pre-trained on the ImageNet dataset at a fixed image size of 224 × 224. With very large (fewer number of crops at larger image resolution) or very small (larger number of crops at smaller image resolution) patch sizes, the CNNs may have difficulty in capturing representative features and yield poor patch embeddings, which hurts the performance. We note that scaling patch size alone may not be an optimal solution and future studies, especially compound model scaling in EfficientNet [54], may help improve the performance.
FIGURE 5.
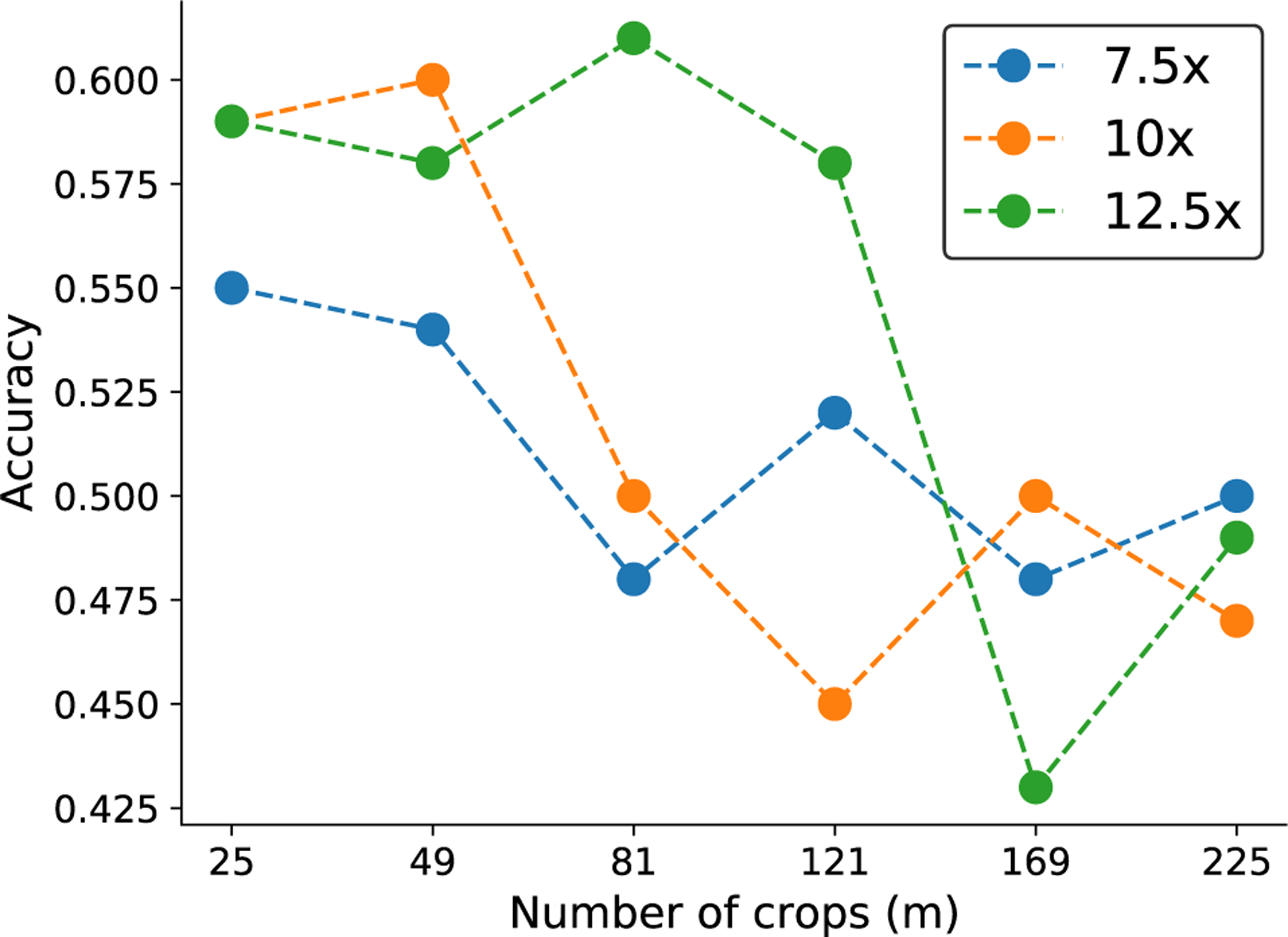
Effect of number of crops (m) on the performance of ScATNet (single scale) for inputs at three different scale levels (7.5x, 10x, and 12.5x).
In the rest of the experiments, we used m = 25 for 7.5× input resolution, m = 49 for 10× input resolution, and m = 81 for 12.5× input resolution, as these had the best performance.
b: Single vs. MULTIPLE INPUT SCALES
Figure 6a compares the overall performance of ScATNet across different metrics on single- and multi-scale inputs, while class-wise accuracy is given in Figure 6b. With inputs at multiple scales, we observe improvements in overall as well as class-wise performance. Notably, we observe significant improvement with multiple scales (two and three scales) in the pT1b invasive melanoma cancer category. Compared to two scales, the overall performance with three scales remains the same. However, with three scales, the performance across all diagnostic classes (Figure 6b) is much more evenly distributed, which is not seen in all other combinations.
FIGURE 6.
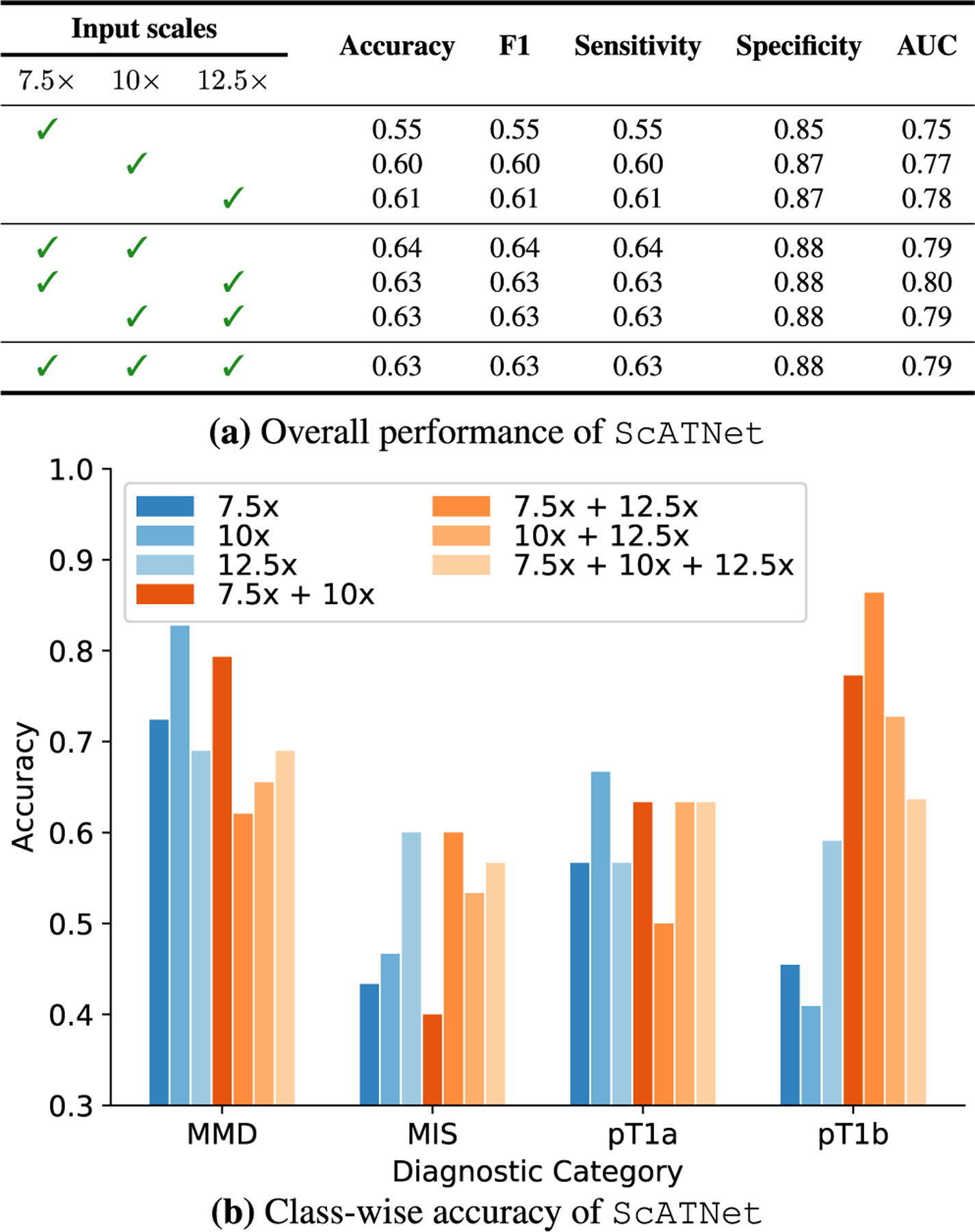
Effect of single and multiple input scales. For single and multiple input scales, we compared the overall performance of ScATNet across different metrics in (a) while in (b), we compared the class-wise accuracy. With multiple input scales, overall and class-wise performance, especially in invasive cancer categories (pT1a and pT1b), of ScATNet improved across all evaluation metrics. Diagnostic terms are defined as the following: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b).
c: COMPARISON WITH BASELINE METHODS
Figure 2 compares the classification performance of ScATNet with existing methods on the test set. ScATNet outperforms all five existing methods to which it was compared by a significant margin across different metrics. Furthermore, compared to the ChikonMIL method [7] and the MS-DA-MIL method [8] with multi-scale input, which delivered the two best performances among the five baseline methods, ScATNet delivered better performance across all diagnostic categories (see Figure 7), except the pT1b category. This is likely because the ChikonMIL method samples more relevant patches corresponding to the pT1b category as compared to other diagnostic categories, while the MS-DA-MIL method uses an input at higher resolution (x20), which might yield more information at the cellular level that helped to distinguish the pT1b category. We believe that complementing the proposed method with the patch sampling method of Chikontwe et al. (2020) would further improve the performance. We will investigate such methods in the future.
FIGURE 7.
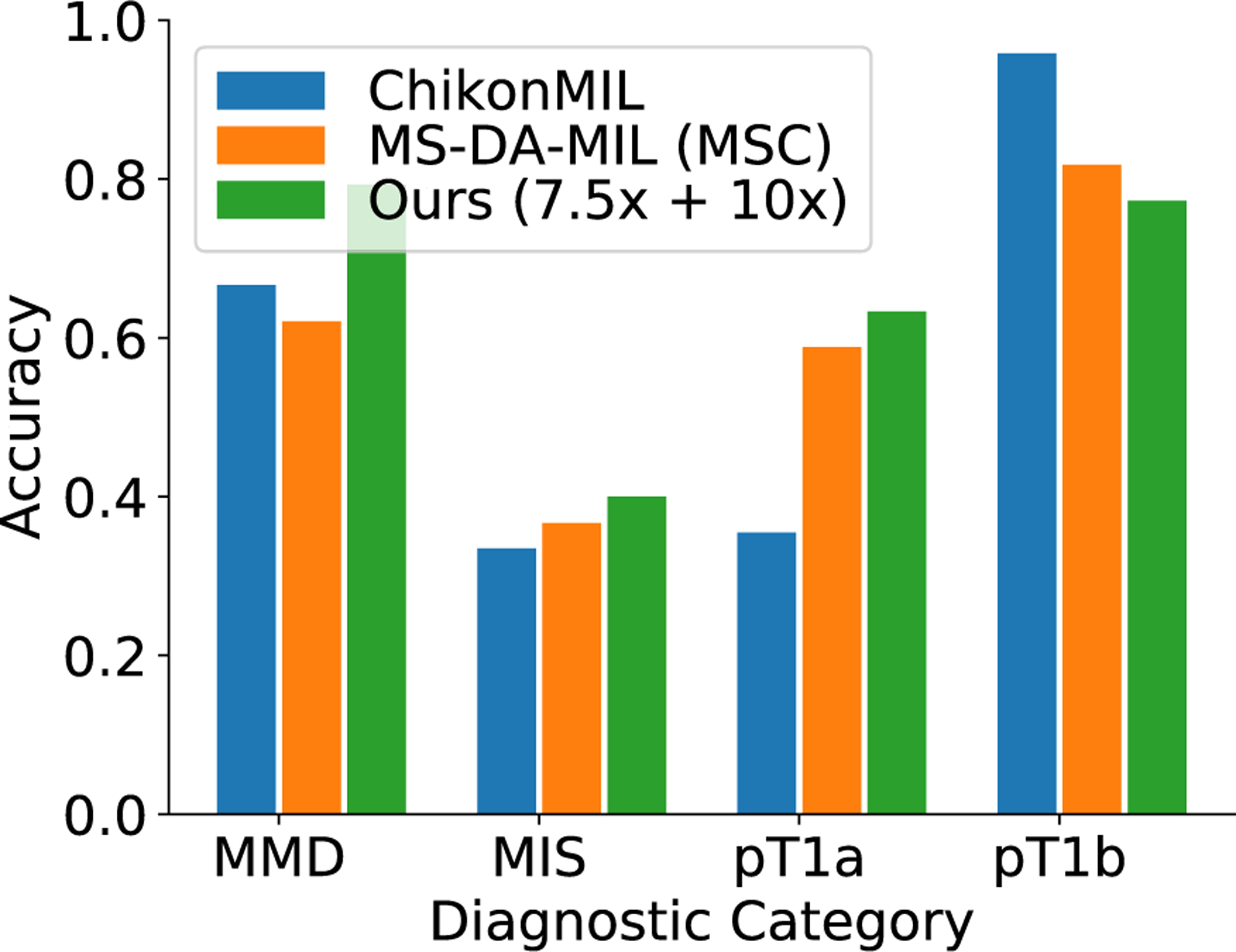
Comparison of class-wise accuracy with state-of-the-art WSI classification methods on the test set. Diagnostic terms are defined as the following: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b). Overall, ScATNet delivered better performance across all diagnostic categories except the pT1b category.
d: COMPARISON WITH U.S. PATHOLOGISTS
Table 3 shows that ScATNet achieves similar performance to practicing U.S. pathologists who interpreted these same cases in overall accuracy (pathologists vs. ScATNet: 0.65 vs. 0.64), suggesting its potential as a second reader to help pathologists in clinical settings for reducing classification uncertainties.
TABLE 3.
Comparison of ScATNet with pathologists’ (PG) performance. Pathologists’ performance data is from a prior independent clinical study of 187 pathologists [6] who interpreted these same 115 cases in our test set (Table 1). Diagnostic terms are defined as the following: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b).
| Diagnostic Category | Accuracy |
F1 |
Sensitivity |
Specificity |
||||
|---|---|---|---|---|---|---|---|---|
| PG | Ours | PG | Oars | PG | Ours | PG | Ours | |
| MMD | 0.92 | 0.79 | 0.71 | 0.75 | 0.92 | 0.79 | 0.76 | 0.89 |
| MIS | 0.46 | 0.40 | 0.49 | 0.44 | 0.46 | 0.40 | 0.85 | 0.84 |
| pT1a | 0.51 | 0.65 | 0.62 | 0.63 | 0.51 | 0.65 | 0.95 | 0.84 |
| pT1b | 0.72 | 0.77 | 0.72 | 0.74 | 0.78 | 0.77 | 0.97 | 0.92 |
|
| ||||||||
| Overall | 0.65 | 0.64 | 0.65 | 0.64 | 0.65 | 0.64 | 0.88 | 0.88 |
V. DISCUSSION
Previous studies on computer-aided skin lesion analysis have been mainly focused on using dermoscopic images due to its inexpensiveness and availability [55]–[57]. Although dermoscopic images showed improvement for diagnosis of skin cancer compared to bare visual inspection, the gold standard for the diagnosis of melanocytic lesions is the interpretation of histopathology slides. There has been limited application of deep learning techniques in whole slide skin biopsy images due to their gigapixel size and the lack of large public datasets. Earlier studies analyzing whole slide skin biopsy images using deep learning have focused on dermis and epidermis segmentation, as well as two- or three-class classification problems. For example, Phillips et al. [58] explored segmentation of dermis and epidermis as well as tumor segmentation using convolutional neural network with a dataset of 50 WSIs (Training/validation/test: 36/7/7). Hekler et al. [59], [60] studied the binary classification of nevi vs. melanoma with a dataset of 695 WSIs (Training/Test: 595/100). Similarly, Lu and Mandal [61] and Xu et al. [17] 17 melanocytic nevi, and 32 superficial spreading melanoma) performed a three-way classification task (17 normal skin, using 66 WSIs. Note that the dataset used by Lu and Mandal et al. [61] and Xu et al. [17] is much smaller than ours and limited to only two of our classes, making direct comparison impossible.
Unlike these studies, this work classifies the full spectrum of melanocytic skin biopsy lesions ranging from mildly atypical nevi and more advanced atypical pre-cursor lesions, to melanoma in situ to invasive melanoma. Our dataset consists of 240 WSIs, including 115 WSIs in an independent test set (Table1). An independent test set allows us to demonstrate the generalization ability of ScATNet. A key strength of our work is that we were able to compare the diagnostic classification of ScATNet with the performance of actively practicing U.S. pathologists who interpreted the same cases (test set) in an independent study.
Although the proposed method has shown great potential for automated melanocytic lesion classification, limitations are recognized. Our study is only relevant to melanocytic lesions, while only about one in four skin biopsies have melanocytic cells [62]. Moreover, despite having an independent test set, ScATNet was evaluated on only 115 WSIs. In order to demonstrate its application in clinical settings, ScATNet should be tested on a larger test set. Also, in this paper, we only studied skin biopsies. However, we believe that ScATNet is generic and can be extended to other types of biopsy images, such as breast and lung.
VI. CONCLUSION
Diagnosis of melanocytic lesions is among the most challenging areas of pathology. Previous studies indicate that diagnostic errors occur frequently [3]–[5]. False positive readings for suspected melanoma range from 6% to 17% [63], [64]. Diagnostic errors may lead to inappropriate treatment decisions and harm to patients. With FDA approval, digitized whole slide imaging systems show great potential for improving the diagnostic performance of pathologists. In this paper, we introduce the scale-aware transformer network ScATNet for learning representations from variably-sized whole slide skin biopsy images at multiple scales. Compared to existing methods, ScATNet delivered better performance. Importantly, ScATNet also delivered comparable performance to practicing U.S. pathologists who interpreted the same cases. The implementations of the models we use and algorithms we introduce are available at https://github.com/meredith-wenjunwu/ScATNet.
ACKNOWLEDGMENT
The funders had no role in the design and conduct of the study, collection, management, analysis, and interpretation of the data, preparation, review, or approval of the manuscript, nor decision to submit the manuscript for publication. (Wenjun Wu and Sachin Mehta are co-first authors.)
Research reported in this study was supported by grants R01CA200690 and U01CA231782 from the National Cancer Institute of the National Institutes of Health, 622600 from the Melanoma Research Alliance, and W81XWH-20–1-0798 from the United States Department of Defense. The funders had no role in the design and conduct of the study, collection, management, analysis, and interpretation of the data, preparation, review, or approval of the manuscript, nor decision to submit the manuscript for publication.
This work involved human subjects or animals in its research. Approval of all ethical and experimental procedures and protocols was granted by the University of Washington under Application STUDY00008506.
Biographies

WENJUN WU received the B.S. degree in biomedical engineering from the Georgia Institute of Technology, Atlanta, USA, in 2017. She is currently pursuing the Ph.D. degree in biomedical informatics with the University of Washington, Seattle, Washington, USA.
Since 2018, she has been a Research Assistant, advised by Linda Shapiro at the University of Washington. Her research interests include intersection of biomedical image analysis, machine learning, and computer vision.

SACHIN MEHTA (Member, IEEE) received the Ph.D. degree from the University of Washington, Seattle, Washington, USA.
He is currently an Affiliate Assistant Professor with the University of Washington and also an AI/ML Research Scientist with Apple Inc. His research interests include intersection of computer vision, NLP, and machine learning, especially in designing fast, light-weight, power efficient, and memory efficient neural architectures that can be used for modeling visual and textual data on resource-constrained devices across different domains, including computer vision for accessible technologies and health care.

SHIMA NOFALLAH (Graduate Student Member, IEEE) received the B.Sc. and M.Sc. degrees in biomedical engineering from the Amirkabir University of Technology, Tehran, Iran. She is currently pursuing the Ph.D. degree in electrical and computer engineering with the University of Washington, Seattle, WA, USA.
Her research interests include computer vision, machine learning, and medical image processing.

STEVAN KNEZEVICH received the degree from the University of Toronto Medical School, Ontario, Canada, in 2004, and the Ph.D. degree in pathology from the University of British Columbia, in 1999.
Then, he spent an additional year as a Post-doctoral Fellow at Lymphoma Research. His Residency and Surgical Pathology Fellowship were completed at Washington University in St. Louis, MO, USA, and Dermatopathology Fellowship at Stanford University. He worked at the VA Medical Center and worked as an Assistant Professor at the University of Washington, Seattle, prior to joining Pathology Associates, in July 2014. He is board certified in anatomic pathology, clinical pathology, and dermatopathology.

CAITLIN J. MAY received the M.D. degree from the School of Medicine, University of Washington, in 2013.
She received the Dermatology Residency and the Dermatopathology Fellowship at the University of Washington, in 2017 and 2018, respectively. She currently works as a Dermatopathologist at Dermatopathology Northwest, Bellevue, WA, USA, and a Teledermatologist at the VA Seattle Medical Center. She is a Collaborator on Dr. Elmore’s NIH funded grant, IMPACT, which utilizes novel computational methods to analyze whole slide digital images to improve the diagnosis of melanoma and related skin lesions. She also has ongoing projects with her research team that involve evaluating trends in immune her to chemical and molecular testing among U.S. pathologists in their diagnoses of melanocytic lesions. Her main research interest includes the diagnostic challenges associated with the histopathologic diagnoses of melanocytic lesions.

OLIVER H. CHANG received the B.A. degree at the University of Illinois Urbana–Champaign, in 2005, and the M.D. degree from the University of Illinois Chicago College of Medicine, in 2010.
He completed a residency at the University of Washington Medical Center, in 2015, and is board certified in anatomic pathology, clinical pathology, and dermatopathology. He is currently an Assistant Professor with the Department of Laboratory Medicine, University of Washington, where he serves as the Director for Medical Student Clerkships and Post-Sophomore Fellowship. His clinical practice is at the VA Puget Sound Hospital, Seattle, WA, USA. His research interests include medical education in pathology, melanocytic lesions, and AI/Machine learning.

JOANN G. ELMORE received the Medical degree from the Stanford University School of Medicine.
Her residency training in internal medicine at Yale-New Haven Hospital, with advanced epidemiology training from the Yale School of Epidemiology and Public Health and the RWJF Clinical Scholars Program. In addition, she was a RWJF Generalist Physician Faculty Scholar. She is board certified in internal medicine and serves on many national and international committees. She conducts scientific research on diagnostic accuracy of screening and medical tests and AI/machine learning to develop computer aid tools for the early detection of high-risk cancers. She previously held faculty and leadership positions at the University of Washington, Fred Hutchinson Cancer Research Center, Group Health Research Institute, and Yale University.
Dr. Elmore has been an Associate Director and a member of the National Advisory Committee for of the Robert Wood Johnson Clinical Scholars Program at Yale University and the University of Washington. She is the Rosalinde and Arthur Gilbert Foundation Endowed Chair at Health Care Delivery, a professor of medicine at the David Geffen School of Medicine, UCLA, and the Director of the UCLA National Clinician Scholars Program. She is the Editor-in-Chief of primary care at UpToDate and enjoys seeing patients as a primary care internist and teaching clinical medicine to students and residents.

LINDA G. SHAPIRO (Life Fellow, IEEE) received the B.S. degree in mathematics from the University of Illinois, Urbana, in 1970, and the M.S. and Ph.D. degrees in computer science from the University of Iowa, Iowa City, in 1972 and 1974, respectively.
She was an Assistant Professor of computer science at Kansas State University, Manhattan, from 1974 to 1978; an Assistant Professor of computer science, from 1979 to 1981; and an Associate Professor of computer science at Virginia Polytechnic Institute and State University, Blacksburg, from 1981 to 1984. She was the Director of intelligent systems at Machine Vision International, Ann Arbor, from 1984 to 1986. She is currently a Professor of computer science and engineering and electrical engineering with the University of Washington. She has coauthored three textbooks, one on Data Structures and two on Computer Vision. Her research interests include computer vision, image database systems, artificial intelligence, pattern recognition, and robotics.
Dr. Shapiro is a fellow of the IAPR. She is the Past Chair of the IEEE Computer Society Technical Committee on IEEE TRANSACTIONS ON PATTERN ANALYSISAND MACHINE INTELLIGENCE and currently an Editorial Board Member of Computer Vision and Image Understanding and Pattern Recognition. She has served as the Editor-in-Chief for CVGIP: Image Understanding, an Associate Editor for IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, the Co-Program Chair for the IEEE Conference on Computer Vision and Pattern Recognition, in 1994, and the General Chair for the IEEE Workshop on Directions in Automated CAD-Based Vision, in 1991, and the IEEE Conference on Computer Vision and Pattern Recognition, in 1986. She was the Co-Chair of the Medical and Multimedia Applications Track of the International Conference on Pattern Recognition for 2002 and 2008 CVPR. She has also served on the program committees of numerous vision and AI workshops and conferences.
APPENDIX
A. OUTCOME METRICS
The following metrics were used to evaluate the performance of ScATNet [65]:
-
Classification (or Top-1) accuracy counts the number of times the predicted label is the same as the ground truth label and is defined as:
where TP, FP, TN, and FN denotes the true positive, false positive, true negative, and false negatives respectively.
-
F1-score is a harmonic mean of precision P and recall R and is defined as:
where and .
- Sensitivity measures proportion of the positive cases that are correctly classified and is defined as:
- Specificity measures the proportion of the negative cases that are correctly classified and is defined as:
Area under receiver operating characteristics curve (ROC-AUC) is a graph obtained by varying the threshold for diagnostic decision, illustrating the discrimination ability of the classifier. We use a One-vs-rest scheme, which computes the AUC of each class against the rest [66].
The values of these metrics range between zero and one, and higher values of these metrics mean better performance.
B. SALIENCY ANALYSIS
Saliency analysis using gradients helps identify relevant areas in an input image that contributed to the prediction [67]. Figure 8 shows that both 7.5× and 10× contributed to the decision in the cases of MMD and pT1a, while 12.5× contributes more in the cases of MIS and pT1b. This pattern illustrates that depending on the input whole slide image, diagnosis-specific features exist at different input scales and ScATNet learns to weigh these features automatically.
FIGURE 8.
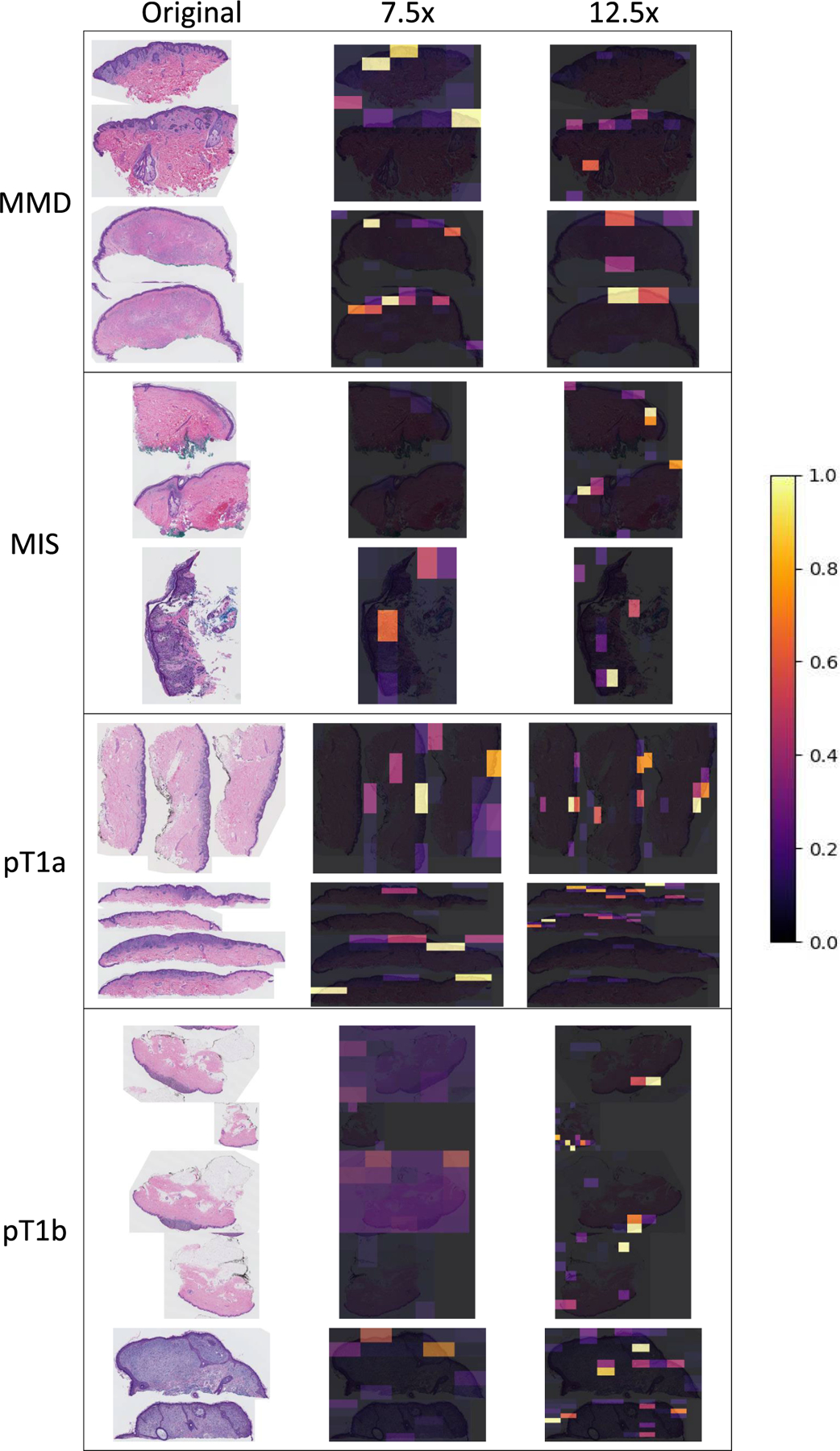
Visualization of gradient in ScATNet. The left column shows original whole slide images in all diagnostic categories: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b). The right two columns are the corresponding gradient maps calculated from 7.5x and 12.5x input scales. All examples shown were correctly classified into their diagnostic categories. Colors from purple to yellow are assigned to values between 0 and 1.
C. ROC CURVES
In Figure 9, we compared the Receiver Operating Characteristic (ROC) curves of the proposed method with different numbers of input scales. With a single scale, the overall area under the curve (AUC) score as well as the class-wise AUC score of invasive cancer categories (pT1a and pT1b) improve with larger input scale. With two scales, we observed the best performance in the combination of the smallest and the largest scale (7.5× and 12.5×).
FIGURE 9.
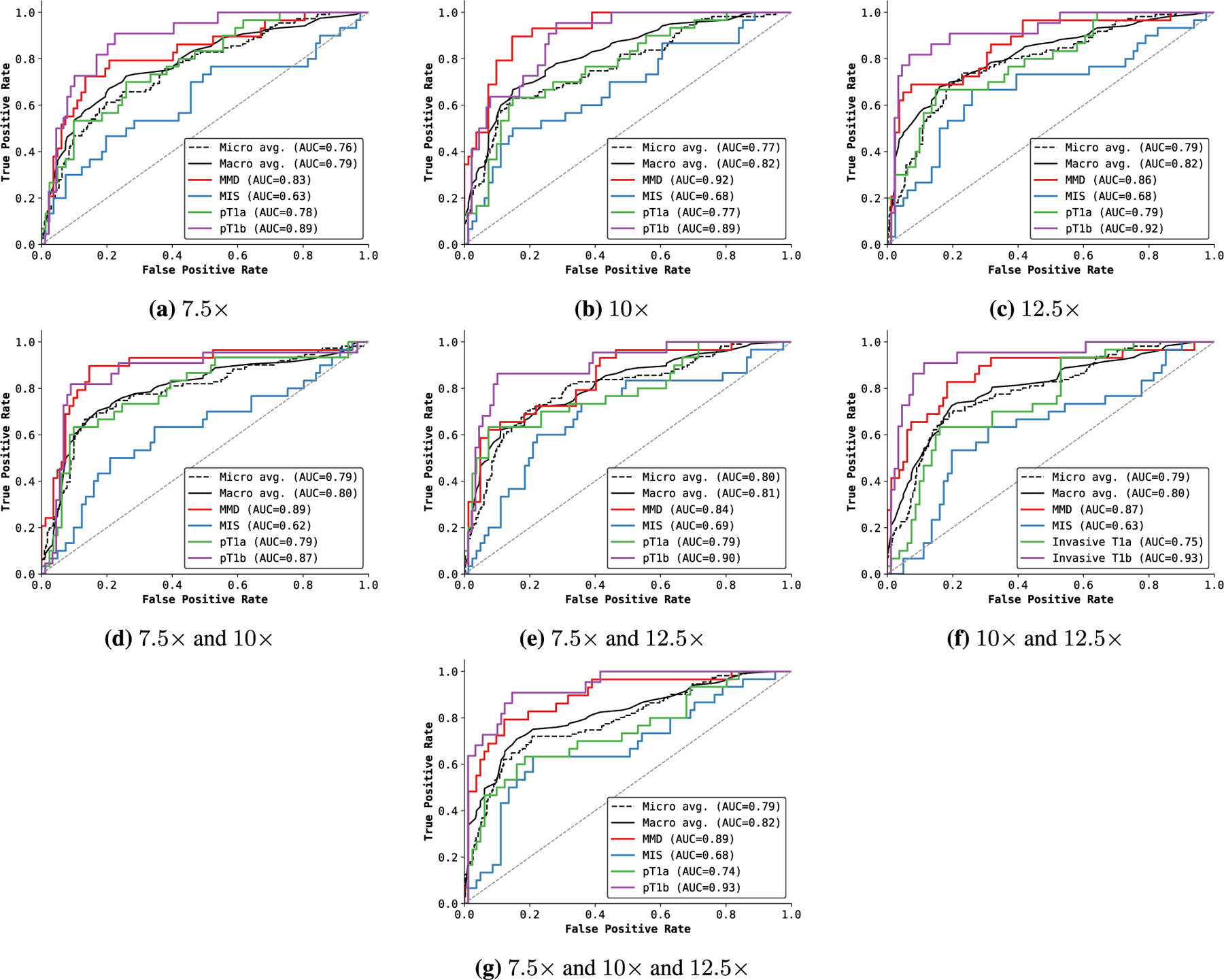
Receiver operating characteristic (ROC) curves of ScATNet with different numbers of input scales. For a single scale (a-c), the performance improves with the input scale, especially for invasive cancers. For two scale combinations (d-f), we do not observe significant gains. However, a combination of smaller and larger input scales (7.5x and 12.5x) delivered good performance across all diagnostic classes. Diagnostic terms are defined as the following: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b).
e: COMPARISON OF BASELINE METHODS
In Figure 10, we compared ROC curves of the baseline methods. The MS-DA-MIL method of Hashimoto et al. [8] delivered the best AUC score, compared to the weighted feature aggregation method by Mercan et al. [15], ChikonMIL method by Chikontwe et al. [7], the patch-based classification method [11], [39] and the Streaming CNN method [22]. With multiple input scales, the patch-based method did not show significant improvement in AUC score, but the performance across all classes is more evenly distributed.
FIGURE 10.
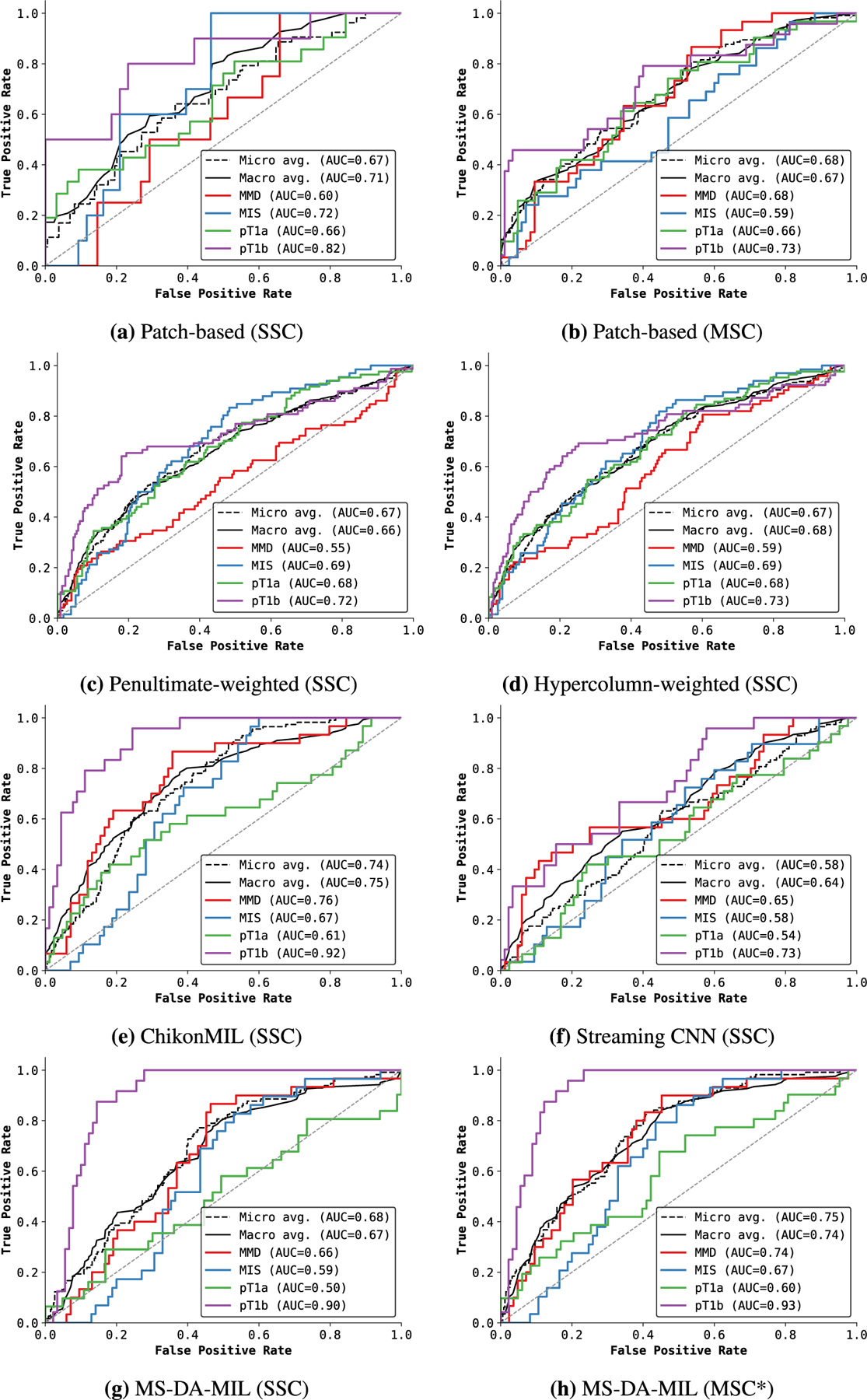
Comparison of ROC curves with state-of-the-art WSI classification methods on the test set. Here, SSC denotes single input scale (10 ). MSC denotes multiple input scales (7.5x, 10x, 12.5x), while MSC* denotes 10x, 20x. Overall, the MS-DA-MIL method of Hashimoto et al. [8] delivers the best performance of all other existing methods. Diagnostic terms are defined as the following: mild and moderate dysplastic nevi (MMD), melanoma in situ (MIS), invasive melanoma stage pT1a (pT1a), invasive melanoma stage ≥pT1b (pT1b).
Footnotes
The associate editor coordinating the review of this manuscript and approving it for publication was Juntao Fei http://orcid.org/0000-0001-7954-2125.
Unlike the number of patches m, the number of scales is fixed. Therefore, we learned the positional embeddings for each scale using torch.nn.Embedding in PyTorch. Compared to sinusoidal positional embeddings, learned embeddings improve the performance by about 0.5–1.0%.
REFERENCES
- [1].Siegel RL, Miller KD, Fuchs HE, and Jemal A, ‘‘Cancer statistics, 2021,’’ CA: Cancer J. Clinicians, vol. 71, no. 1, pp. 7–33, 2021. [DOI] [PubMed] [Google Scholar]
- [2].Wells WA, Carney PA, Eliassen MS, Tosteson AN, and Greenberg ER, ‘‘Statewide study of diagnostic agreement in breast pathology,’’ JNCI: J. Nat. Cancer Inst, vol. 90, no. 2, pp. 142–145, Jan. 1998. [DOI] [PubMed] [Google Scholar]
- [3].Della Mea V, Puglisi F, Bonzanini M, Forti S, Amoroso V, Visentin R, Dalla Palma P, and Beltrami CA, ‘‘Fine-needle aspiration cytology of the breast: A preliminary report on telepathology through internet multimedia electronic mail,’’ Mod. Pathol., Off. J. United States Can. Acad. Pathol, vol. 10, no. 6, pp. 636–641, 1997. [PubMed] [Google Scholar]
- [4].Allison KH, Reisch LM, Carney PA, Weaver DL, Schnitt SJ, O’Malley FP, Geller BM, and Elmore JG, ‘‘Understanding diagnostic variability in breast pathology: Lessons learned from an expert consensus review panel,’’ Histopathology, vol. 65, no. 2, pp. 240–251, Aug. 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Elmore JG, Longton GM, Carney PA, Geller BM, Onega T, Tosteson ANA, Nelson HD, Pepe MS, Allison KH, Schnitt SJ, O’Malley FP, and Weaver DL, ‘‘Diagnostic concordance among pathologists interpreting breast biopsy specimens,’’ JAMA, vol. 313, no. 11, p. 1122, Mar. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Elmore JG,Barnhill RL,Elder DE,andLongton GM,’’Pathologists’ diagnosis of invasive melanoma and melanocytic proliferations: Observer accuracy and reproducibility study,’’ Bmj, vol. 357, pp. 1–26, Jun. 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Chikontwe P, Kim M, Nam SJ, Go H, and Park SH, ‘‘Multiple instance learning with center embeddings for histopathology classification,’’ in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent Cham, Switzerland: Springer, 2020, pp. 519–528. [Google Scholar]
- [8].Hashimoto N, Fukushima D, Koga R, Takagi Y, Ko K, Kohno K, Nakaguro M, Nakamura S, Hontani H, and Takeuchi I, ‘‘Multi-scale domain-adversarial multiple-instance CNN for cancer subtype classificationwithunannotatedhistopathologicalimages,’’ in Proc.IEEE/CVFConf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 3852–3861. [Google Scholar]
- [9].Krizhevsky A, Sutskever I, and Hinton GE, ‘‘ImageNet classification with deep convolutional neural networks,’’ in Proc. Adv. Neural Inf. Process. Syst, vol. 25, 2012, pp. 1097–1105. [Google Scholar]
- [10].He K, Zhang X, Ren S, and Sun J, ‘‘Deep residual learning for image recognition,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778. [Google Scholar]
- [11].Hou L, Samaras D, Kurc TM, Gao Y, Davis JE, and Saltz H, ‘‘Patch-based convolutional neural network for wholeslide tissue image classification,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 2424–2433. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, and Bernstein M, ‘‘ImageNet large scale visual recognition challenge,’’ Int. J. Comput. Vis, vol. 115, no. 3, pp. 211–252, Dec. 2015. [Google Scholar]
- [13].Marsh JN, Liu T-C, Wilson PC, Swamidass SJ, and Gaut JP, ‘‘Development and validation of a deep learning model to quantify glomerulosclerosis in kidney biopsy specimens,’’ JAMA Netw. Open, vol. 4, no. 1, Jan. 2021, Art. no. e2030939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Mercan C, Aksoy S, Mercan E, Shapiro LG, Weaver DL, and Elmore JG, ‘‘Multi-instance multi-label learning for multi-class classification of whole slide breast histopathology images,’’ IEEE Trans. Med. Imag, vol. 37, no. 1, pp. 316–325, Jan. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Mercan C, Aygunes B, Aksoy S, Mercan E, Shapiro LG, Weaver DL, and Elmore JG, ‘‘Deep feature representations for variable-sized regions of interest in breast histopathology,’’ IEEE J. Biomed. Health Informat, vol. 25, no. 6, pp. 2041–2049, Jun. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Mehta S, Mercan E, Bartlett J, Weaver D, Elmore JG, and Shapiro L, ‘‘Y-Net: Joint segmentation and classification for diagnosis of breast biopsy images,’’ in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent Cham, Switzerland: Springer, 2018, pp. 893–901. [Google Scholar]
- [17].Xu H, Lu C, Berendt R, Jha N, and Mandal M, ‘‘Automated analysis and classification of melanocytic tumor on skin whole slide images,’’ Computerized Med. Imag. Graph, vol. 66, pp. 124–134, Jun. 2018. [DOI] [PubMed] [Google Scholar]
- [18].Mercan E, Mehta S, Bartlett J, Shapiro LG, Weaver DL, and Elmore JG, ‘‘Assessment of machine learning of breast pathology structures for automated differentiation of breast cancer and high-risk proliferative lesions,’’ JAMA Netw. Open, vol. 2, no. 8, Aug. 2019, Art. no. e198777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Ni H, Liu H, Wang K, Wang X, Zhou X, and Qian Y, ‘‘WSI-Net: Branch-based and hierarchy-aware network for segmentation and classification of breast histopathological whole-slide images,’’ in Proc. Int. Workshop Mach. Learn. Med. Imag Cham, Switzerland: Springer, 2019, pp. 36–44. [Google Scholar]
- [20].van Zon M, Stathonikos N, Blokx WAM, Komina S, Maas SLN, Pluim JPW, van Diest PJ, and Veta M, ‘‘Segmentation and classification of melanoma and nevus in whole slide images,’’ in Proc. IEEE 17th Int. Symp. Biomed. Imag. (ISBI), Apr. 2020, pp. 263–266. [Google Scholar]
- [21].Mehta S, Lu X, Weaver D, Elmore JG, Hajishirzi H, and Shapiro L, ‘‘HATNet: An end-to-end holistic attention network for diagnosis of breast biopsy images,’’ 2020, arXiv:2007.13007.
- [22].Pinckaers H, Bulten W, van der Laak J, and Litjens G, ‘‘Detection of prostate cancer in whole-slide images through end-to-end training with image-level labels,’’ IEEE Trans. Med. Imag, vol. 40, no. 7, pp. 1817–1826, Jul. 2021. [DOI] [PubMed] [Google Scholar]
- [23].Chen T, Xu B, Zhang C, and Guestrin C, ‘‘Training deep nets with sublinear memory cost,’’ 2016, arXiv:1604.06174.
- [24].Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser LU, and Polosukhin I, ‘‘Attention is all you need,’’ in Proc. Adv. Neural Inf. Process. Syst, vol. 30, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds. Red Hook, NY, USA: Curran Associates, 2017. [Google Scholar]
- [25].Raffel C, Shazeer N, Roberts A, Lee K, Narang S, Matena M, Zhou Y, Li W, and Liu PJ, ‘‘Exploring the limits of transfer learning with a unified text-to-text transformer,’’ J. Mach. Learn. Res, vol. 21, no. 140, pp. 1–67, 2020.34305477 [Google Scholar]
- [26].Brown T et al. , ‘‘Language models are few-shot learners,’’ in Proc. Adv. Neural Inf. Process. Syst, vol. 33, 2020, pp. 1877–1901. [Google Scholar]
- [27].Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, and Houlsby N, ‘‘An image is worth 16×16 words: Transformers for image recognition at scale,’’ in Proc. Int. Conf. Learn. Represent, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy [Google Scholar]
- [28].Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, and Jégou H, ‘‘Training data-efficient image transformers & distillation through attention,’’ 2020, arXiv:2012.12877.
- [29].Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, and Zagoruyko S, ‘‘End-to-end object detection with transformers,’’ in Proc. Eur. Conf. Comput. Vis Cham, Switzerland: Springer, 2020, pp. 213–229. [Google Scholar]
- [30].Maria Jose Valanarasu J, Oza P, Hacihaliloglu I, and Patel VM, ‘‘Medical transformer: Gated axial-attention for medical image segmentation,’’ 2021, arXiv:2102.10662.
- [31].Zhang Z, Sun B, and Zhang W, ‘‘Pyramid medical transformer for medical image segmentation,’’ 2021, arXiv:2104.14702.
- [32].Zhang Y, Higashita R, Fu H, Xu Y, Zhang Y, Liu H, Zhang J, and Liu J, ‘‘A multi-branch hybrid transformer network for corneal endothelial cell segmentation,’’ 2021, arXiv:2106.07557.
- [33].Petit O, Thome N, Rambour C, and Soler L, ‘‘U-net transformer: Self and cross attention for medical image segmentation,’’ 2021, arXiv:2103.06104.
- [34].Sitaula C and Hossain MB, ‘‘Attention-based VGG-16 model for COVID-19 chest X-ray image classification,’’ Int. J. Speech Technol, vol. 51, no. 5, pp. 2850–2863, May 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Chen L-C, Yang Y, Wang J, Xu W, and Yuille AL, ‘‘Attention to scale: Scale-aware semantic image segmentation,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 3640–3649. [Google Scholar]
- [36].Lin G, Milan A, Shen C, and Reid I, ‘‘RefineNet: Multi-path refinement networks for high-resolution semantic segmentation,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1925–1934. [Google Scholar]
- [37].Mehta S, Mercan E, Bartlett J, Weaver D, Elmore J, and Shapiro L, ‘‘Learning to segment breast biopsy whole slide images,’’ in Proc. IEEE Winter Conf. Appl. Comput. Vis. (WACV), Mar. 2018, pp. 663–672. [Google Scholar]
- [38].Brunyé TT, Mercan E, Weaver DL, and Elmore JG, ‘‘Accuracy is in the eyes of the pathologist: The visual interpretive process and diagnostic accuracy with digital whole slide images,’’ J. Biomed. Informat, vol. 66, pp. 171–179, Feb. 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [39].Mercan E, Shapiro LG, Brunyé TT, Weaver DL, and Elmore JG, ‘‘Characterizing diagnostic search patterns in digital breast pathology: Scanners and drillers,’’ J. Digit. Imag, vol. 31, no. 1, pp. 32–41, Feb. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Li B, Li Y, and Eliceiri KW, ‘‘Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning, ‘‘in Proc. IEEE/CVF Conf. Comput. V is. Pattern Recognit. (CVPR), Jun. 2021, pp. 14318–14328. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Deng J, Dong W, Socher R, Li L-J, Li K, and Fei-Fei L, ‘‘ImageNet: A large-scale hierarchical image database,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit, Jun. 2009, pp. 248–255. [Google Scholar]
- [42].Sarwar B, Karypis G, Konstan J, and Riedl J, ‘‘Application of dimensionality reduction in recommender system–A case study,’’ Dept. Comput. Sci., Univ. Minnesota, Minneapolis, MN, USA, Tech. Rep, 2000.
- [43].Liu R and Tan T, ‘‘An SVD-based watermarking scheme for protecting rightful ownership,’’ IEEE Trans. Multimedia, vol. 4, no. 1, pp. 121–128, Mar. 2002. [Google Scholar]
- [44].Chang C-C, Tsai P, and Lin C-C, ‘‘SVD-based digital image watermarking scheme,’’ Pattern Recognit. Lett, vol. 26, pp. 1577–1586, Jul. 2005. [Google Scholar]
- [45].Nilashi M, Ibrahi O, and Bagherifard K, ‘‘A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques,’’ Expert Syst. Appl, vol. 92, pp. 507–520, Feb. 2018. [Google Scholar]
- [46].Carney PA, Reisch LM, Piepkorn MW, Barnhill RL, Elder DE, Knezevich S, Geller BM, Longton G, and Elmore JG, ‘‘Achieving consensus for the histopathologic diagnosis of melanocytic lesions: Use of the modified delphi method,’’ J. Cutaneous Pathol, vol. 43, no. 10, pp. 830–837, Oct. 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Piepkorn MW, Barnhill RL, Elder DE, Knezevich SR, Carney PA, Reisch LM, and Elmore JG, ‘‘The MPATH-dx reporting schema for melanocytic proliferations and melanoma,’’ J. Amer. Acad. Dermatol, vol. 70, no. 1, pp. 131–141, Jan. 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [48].Otsu N, ‘‘A threshold selection method from gray-level histograms, ‘‘IEEE Trans. Syst., Man, Cybern, vol. 9, no. 1, pp. 62–66, Jan. 1979. [Google Scholar]
- [49].Sandler M, Howard A, Zhu M, Zhmoginov A, and Chen L-C, ‘‘MobileNetV2: Inverted residuals and linear bottlenecks,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit, Jun. 2018, pp. 4510–4520.
- [50].Simonyan K and Zisserman A, ‘‘Very deep convolutional networks for large-scale image recognition,’’ 2014, arXiv:1409.1556.
- [51].Chen H, Lundberg S, and Lee S-I, ‘‘Checkpoint ensembles: Ensemble methods from a single training process,’’ 2017, arXiv:1710.03282.
- [52].Szegedy C, Vanhoucke V, Ioffe S, Shlens J, and Wojna Z, ‘‘Rethinking the inception architecture for computer vision,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 2818–2826. [Google Scholar]
- [53].Müller R, Kornblith S, and Hinton G, ‘‘When does label smoothing help?’’ 2019, arXiv:1906.02629.
- [54].Tan M and Le Q, ‘‘Efficientnet: Rethinking model scaling for convolutional neural networks,’’ in Proc. Int. Conf. Mach. Learn, 2019, pp. 6105–6114.
- [55].Zhang J, Xie Y, Xia Y, and Shen C, ‘‘Attention residual learning for skin lesion classification,’’ IEEE Trans. Med. Imag, vol. 38, no. 9, pp. 2092–2103, Sep. 2019. [DOI] [PubMed] [Google Scholar]
- [56].Nida N, Irtaza A, Javed A, Yousaf MH, and Mahmood MT, ‘‘Melanoma lesion detection and segmentation using deep region based convolutional neural network and fuzzy C-means clustering,’’ Int. J. Med. Informat, vol. 124, pp. 37–48, Apr. 2019. [DOI] [PubMed] [Google Scholar]
- [57].Rotemberg V, Kurtansky N, Betz-Stablein B, Caffery L, Chousakos E, Codella N, Combalia M, Dusza S, Guitera P, and Gutman D, ‘‘A patient-centric dataset of images and metadata for identifying melanomas using clinical context,’’ Sci. Data, vol. 8, no. 1, pp. 1–8, Dec. 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [58].Phillips A, Teo I, and Lang J, ‘‘Segmentation of prognostic tissue structures in cutaneous melanoma using whole slide images,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jun. 2019, pp. 2738–2747. [Google Scholar]
- [59].Hekler A, Utikal JS, Enk AH, Solass W, Schmitt M, Klode J, Schadendorf D, Sondermann W, Franklin C, Bestvater F, Flaig MJ, Krahl D, von Kalle C, Fröhling S, and Brinker TJ, ‘‘Deep learning outperformed 11 pathologists in the classification of histopathological melanoma images,’’ Eur. J. Cancer, vol. 118, pp. 91–96, Sep. 2019. [DOI] [PubMed] [Google Scholar]
- [60].Hekler A, Utikal JS, Enk AH, Berking C, Klode J, Schadendorf D, Jansen P, Franklin C, Holland-Letz T, Krahl D, von Kalle C, Fröhling S, and Brinker TJ, ‘‘Pathologist-level classification of histopathological melanoma images with deep neural networks,’’ Eur. J. Cancer, vol. 115, pp. 79–83, Jul. 2019. [DOI] [PubMed] [Google Scholar]
- [61].Lu C and Mandal M, ‘‘Automated analysis and diagnosis of skin melanoma on whole slide histopathological images,’’ Pattern Recognit, vol. 48, no. 8, pp. 2738–2750, Aug. 2015. [Google Scholar]
- [62].Lott JP, Boudreau DM, Barnhill RL, Weinstock MA, Knopp E, Piepkorn MW, and Elder DE, ‘‘Population-based analysis of histologically confirmed melanocytic proliferations using natural language processing,’’ JAMA Dermatol, vol. 154, no. 1, pp. 24–29, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [63].Brochez L, Verhaeghe E, Grosshans E, Haneke E, Piérard G, Ruiter D, and Naeyaert J-M,’’Inter-observer variation in thehistopathological diagnosis of clinically suspicious pigmented skin lesions,’’ J. Pathol, vol. 196, no. 4, pp. 459–466, Apr. 2002. [DOI] [PubMed] [Google Scholar]
- [64].Cook MG, Clarke TJ, Humphreys S, Fletcher A, Mclaren KM, Smith NP, Stevens A, Theaker JM, and Melia J, ‘‘The evaluation of diagnostic and prognostic criteria and the terminology of thin cutaneous malignant melanoma by the CRC melanoma pathology panel,’’ Histopathology, vol. 28, no. 6, pp. 497–512, Jun. 1996. [DOI] [PubMed] [Google Scholar]
- [65].Tharwat A, ‘‘Classification assessment methods,’’ New England J. Entrepreneurship, vol. 17, no. 1, pp. 168–192, Aug. 2018. [Google Scholar]
- [66].Fawcett T, ‘‘An introduction to ROC analysis,’’ Pattern Recognit. Lett, vol. 27, no. 8, pp. 861–874, Jun. 2006. [Google Scholar]
- [67].Simonyan K, Vedaldi A, and Zisserman A, ‘‘Deep inside convolutional networks: Visualising image classification models and saliency maps,’’ 2013, arXiv:1312.6034.