

Abstract
Steering law reveals a linear relationship between the movement time (MT) and the index of difficulty (ID) in trajectory-based steering tasks. However, it does not relate the variance or distribution of MT to ID. In this paper, we propose and evaluate models that predict the variance and distribution of MT based on ID for steering tasks. We first propose a quadratic variance model which reveals that the variance of MT is quadratically related to ID with the linear coefficient being 0. Empirical evaluation on a new and a previously collected dataset show that the quadratic variance model accounts for between 78% and 97% of variance of observed MT variances; it outperforms other model candidates such as linear and constant models; adding the linear coefficient leads to no improvement on the model fitness. The variance model enables predicting the distribution of MT given ID: we can use the variance model to predict the variance (or scale) parameter and Steering law to predict the mean (or location) parameter of a distribution. We have evaluated six types of distributions for predicting the distribution of MT. Our investigation also shows that positively skewed distribution such as Gamma, Lognormal, Exponentially Modified Gaussian (ExGaussian), and Extreme value distributions outperformed the symmetric distribution such as Gaussian and truncated Gaussian distribution in predicting the MT distribution, and Gamma distribution performed slightly better than other positively skewed distributions. Overall, our research advances the MT prediction of steering tasks from a point estimate to variance and distribution estimates, which provides a more complete understanding of steering behavior and quantifies the uncertainty of MT prediction.
Keywords: Steering law, probabilistic modeling
1. INTRODUCTION
Steering law [1] predicts that the movement time (MT) for steering a pointer through a tunnel with width W and length A is determined by the ratio of , that is:
| (1) |
where a and b are empirically determined parameters. Past research [1] has shown that Steering law well predicts MT in a wide range of trajectory-based HCI tasks including steering through straight, circular, or narrowing tunnels. Steering law has also been widely used in interface and interaction design such as modeling the selection time in hierarchical menus [1], and game-playing behaviors [4].
Despite its success, however, one limitation of Steering law is that it provides only a point estimate on MT – namely the mean of MT. While there is no doubt that the mean is an important statistic, it reflects only the central tendency and provides no information on the dispersion of the data. Summarizing a distribution into one statistic inevitably introduces information loss. To provide a more complete understanding of steering movement, could we also estimate the variance of MT, and then predict the full distribution of MT? In addition to deepening our understanding on steering movement behavior, variance and distribution estimates can predict the probability of observing a particular MT value or range, and quantify the uncertainty of the MT estimate.
Modeling the variance and distribution of interaction time has gained attention as it provides a more complete understanding of users’ behaviors and quantifies the prediction uncertainty. For example, past research [23] has shown that the variance of MT in pointing tasks increases as the index of difficulty (ID) of a pointing task increase, and the MT distribution of pointing tasks can be modeled by Lognormal [20], Gamma [14], Extreme value [6], and Exponentially Modified Gaussian (exGaussian) [11, 12] distributions.
However, in contrast to Fitts’ law, our understanding of the variance and distribution of MT of steering law tasks is limited. Is the variance of MT of steering law tasks also related to ID of a task? Is it constant or does it increase as ID increases? What is the distribution of MT? Can we also develop mathematical models that can predict the variance and distribution of MT based on ID? We aim to answer these questions in this research.
In this paper, we have proposed models for predicting the variance and full distribution of MT in trajectory-based movements [1]. We first propose a quadratic variance model, which predicts that the variance of MT is quadratically related to the index of difficulty ID:
| (2) |
where c, and d are empirically determined parameters. The ID is defined as [1]. We refer it as quadratic variance model, which reveals that the variance of MT is quadratically related to ID with the linear coefficient being 0. Our evaluation on two steering law datasets shows that this variance model can well predict the variance of MT in different types of steering tasks including steering through straight, narrowing and circular tunnels. It accounts for 78% to 97% of variance of observed MT variances, and outperforms other models including constant, linear, and quadratic models with a linear term.
Second, we combine the quadratic variance model with the typical Steering law to predict the distribution of MT. We use Steering law to predict the mean (or location) parameter, and the quadratic variance model to predict the variance (or scale parameter) of MT distribution. We evaluated six types of distributions, including Gaussian, truncated Gaussian, Lognormal, Gamma, Extreme Value, and Exponentially Modified Gaussian (exGaussian) distributions. These distributions have been used to model MT distributions in pointing tasks. In the present research, we extend them to model the variance and distribution of MT in steering tasks. Our investigation showed that using the quadratic variance model and Steering law can well predict the distribution of MT, and positively skewed distributions such as Gamma, exGaussian, Lognormal, and Extreme value distributions better model the MT distributions than other types of distributions such as Gaussian and Truncated Gaussian distributions. Next, we will review the literature, and discuss the explanation and validation of the quadratic variance and distribution models.
2. RELATED WORK
We review previous research on Steering law and probabilistic modeling, and discuss how our work is built on and contrasts with them.
2.1. Steering Law Research in General
Steering law [1, 8, 22] has played an important role in interface design, optimization, and evaluation along with the Fitts’ law [9] in which Steering law is derived from. It has been proposed three separate times by Rashevsky [22] on automobile driving, Drury [8] on drawing tasks, and Accot and Zhai [1] on trajectory-based tasks on computer interfaces. Because the steering tasks are crucial in the interaction on graphical user interfaces, understanding, evaluating, and predicting the steering performance is of great interest to HCI practitioners and researchers. Steering law has various applications, for example: to help navigate through immersive virtual environments [18, 30], to design and evaluate input devices [2, 16, 24], to optimize user interfaces [3] and so on.
Researchers [15, 17, 19, 25, 31] have provided various refinements and interpretations of ID. For example, by accounting for the subjective operational biases, Zhou [31] suggested for a standard deviation of sample points SD. Furthermore, Kulikov [15] introduced an effective index of difficulty IDc that includes the spatial variability in steering law models to replace the original index of difficulty ID. Nancel and Lank [19] recently combined Steering law with path curvature radius R and they showed that steering speed increases when R increases. This result is different from Montazer et al’s [17] findings which state that the movement speed increases as 1/R decreases. These different results are solved by Yamanaka and Miyashita [25] through integrating different formulas to be a united one. As customary, we have adopted Accot and Zhai’s formulation of ID [1], which is , since it is the most widely used in HCI.
Some other researchers [21] have provided various models to accommodate different path shapes. For example, models are proposed for steering through a corner [21], narrowing and widening paths [26, 27], and constrained path segments [28, 29].
Although the models mentioned above explain why MT is linearly related to ID, they do not reveal the relationship between variance and distribution of MT with ID. Our research built upon Accot’s steering model [1], extending it to reveal the relationship between variance and distribution of MT and ID.
2.2. Variance and Distribution of Movement Time in Motor Control Tasks
Although there is a sizable amount of work investigating how the mean of MT relates to the ID, the investigation on the variance and distribution of MT is sparse. One of the relevant works was the research conducted by Zhou and Ren [31], which showed that the standard deviation of MT increases as A and W increases. However, Zhou and Ren [31] did not investigate how the distribution of MT related to the task parameters.
Although the literature on variance and distribution of Steering law is sparse, there has been a sizeable amount of interest in understanding and modeling the variance and distribution of MT in other motor control tasks, such as Fitts’ law. Our research is particularly related to the previous research investigating the variance and distribution of MT in Fitts’ law tasks because both Fitts’ law and Steering law reflect the regularity of the human motor control system.
Regarding Fitts’ law, it has been observed that the variance of MT is not constant across IDs (e.g., [6, 11, 14]). In contrast, it is positively related to the ID of the tasks: the higher the ID, the wide the dispersion of MT. It coincides with many psychophysics observations that the standard deviation of a quantity increases with its mean value [23]. Our quadratic variance model reveals that the variance of MT on steering task is quadratically related to ID, which is similar to previous findings on Fitts’ law.
There is also plenty of research investigating the distribution of MT in Fitts’ law. Previous research (e.g., [6, 11, 14, 20]) suggested that the distribution of MT in Fitts’ law tasks tends to have a positive skew: it has a long tail in the positive direction. To account for both characteristics, a number of possible models including Gamma [14], Log-normal [20], Generalized Extreme Value [6], or exponentially modified Gaussian (called exGaussian) distributions [11] have been suggested.
Inspired by the aforementioned previous research on Fitts’ law, this research investigated whether these distributions can be applied to model MT distribution in Steering tasks. Next, we describe the intuition-driven explanation of the quadratic-variance model and distribution models for steering tasks, followed by model evaluation.
3. MODELING THE VARIANCE OF MOVEMENT TIME
We first investigated how to model the variance σ2 of MT given ID of a steering task. Our intuition-driven explanation shows that σ2 is likely quadratically related to ID:
| (3) |
where c and d are empirically determined parameters. Equation 3 is also referred to as quadratic variance model.
3.1. Explanation of Quadratic Variance Model
We hypothesize this quadratic relationship by assuming that (1) the movement of the pointer in the steering task consists of multiple sub-movements and (2) each sub-movement takes a unit time which is a random variable t with a fixed mean (μt) and variance (σt2) across all sub-movements. The first assumption is consistent with the observation in other motor control tasks (e.g., Fitts’ law) that the pointer movement can be broken into multiple sub-movements.
Based on these two assumptions, we can obtain the quadratic variance model (Equation 3) as follows. First, it is straightforward to obtain that the number of sub-movements is proportional to ID (explained later). Second, as the variance of submovements accumulates during the process, the variance of MT will increase if ID increases. If the duration of submovement is represented by a random variable t with a fixed mean (μt) and variance (σt2), simple analysis as shown below reveals that the variance of MT is quadratically related to ID.
Take the constant tunnel as an example. The instantaneous speed form of steering law [1] specifies that the instantaneous speed v of the pointer is proportional to the tunnel width W:
| (4) |
where b is a constant. Under the aforementioned assumptions, the average travel distance of the pointer in each sub-movement (denoted by Δ) is calculated as follows:
| (5) |
where μt is the mean duration of each sub-movement, W is the width of the tunnel and b is an empirically determined constant. The number of sub-movements (denoted by n) a user needs to complete the steering task is calculated as:
| (6) |
where A is the length of the tunnel. Equation 6 indicates that the number of sub-movements n is proportional to ID. Therefore, the total time MT for completing the task is
| (7) |
where t is a random variable, representing the duration of each submovement.
Equation 7 shows that MT is the product of a random variable t and the number of sub-movements n. It implies that variance of MT will be , where is the variance of t, regardless of the distribution type of t. Plugging in Equation 6, we can calculate σ2 as:
| (8) |
where b, μt, and σt are all constant. Equation 8 shows that σ2 is proportional to ID2.
If it is assumed that the initial sub-movement takes some extra time to activate the movement, this extra time should be added to MT. MT then becomes the summation of two random variables. The μ is expressed as the summation of the means containing two random variables and the σ2 is the summation of the variances of these two random variables:
| (9) |
where c and d are all constants. Equation 9 implies that variance of MT is quadratically related to ID.
Extending quadratic variance model to non-constant tunnels.
For non-constant tunnel, the instantaneous speed of the pointer at the location s is expressed in Equation 10:
| (10) |
where v(s) is the instantaneous speed of a pointer at position s along the tunnel, W(s) is the width of the tunnel at point s, and b is a constant. The mean travel distance in a sub-movement at location s (denoted by Δ(s)) then becomes:
| (11) |
where W(s) is the width of tunnel at location s. The number of sub-movements then becomes:
| (12) |
As shown in Equation 12, the number of submovements will also be linearly related to ID for non-constant tunnels. Simple derivation as shown from Equations 7 to 9 reveals that the variance of MT is quadratically related to ID.
Alternative Explanation of Quadratic Variance Model.
We can alternatively explain the quadratic relationship between variance of MT and ID based on the common observation in psychology experiments that the variability of response time increases with task difficulty increases [11, 23].
More specifically, previous research [23] shows that the standard deviation of response time is often linearly related to its mean. A greater mean results in greater variability. The MT in steering task is one type of such response times and we expect it will also follow this relationship. Therefore, it implies that the standard deviation of MT is linearly related to the mean of MT. A similar explanation was made about the variance of Fitts’ law tasks in the previous research [11]. We expect the variability of MT in steering tasks conforms to this relationship too, drawing on the findings from previous work [11, 23].
Because variance is the square of standard deviation, it implies that the variance of MT is quadratically related to the mean of MT. As mean of MT is linearly related to ID (Steering law, Equation 1), it implies that variance of MT is quadratically related to ID. This simple alternative explanation also lead to a similar conclusion as the quadratic variance model (Equation 3), confirming the validity of explanation in the previous section.
3.2. Other Variance Model Candidates.
Besides the quadratic variance model, we also introduce 5 other candidates to model variances. They are constant, linear, and quadratic forms with different complexity levels. All of the six model candidates are listed in Table 1. Among these 6 candidates, constant (#1) and linear (#3) models are used to investigate whether quadratic term would help to improve the fitting accuracy while #2, #5 and #6 models are compared with quadratic variance model #4 to see whether a candidate with higher or lower complexity would benefit model fitness.
Table 1:
Six variance model candidates, all of which are used for predicting variance of MT based on ID where c, d, and e are empirically determined parameters. The quadratic variance model (Equations 9) is #4.
| Candidate Number | Variance Model |
|---|---|
| #1 | σ2 = c |
| #2 | σ2 = (c · ID)2 |
| #3 | σ2 = c + d · ID |
| #4 | σ2 = c + d · ID2 |
| #5 | σ2 = (c + d · ID)2 |
| #6 | σ2 = c + d · ID + e · ID2 |
4. MODELING THE DISTRIBUTION OF MOVEMENT TIME
Combining variance models and Steering law, we can predict the distribution of MT according to different ID. We introduced six kinds of distributions which are Gaussian, Truncated Gaussian with lower bound 0, Lognormal [20], Gamma [14], Extreme value (GEV) [6], and Exponentially modified Gaussian (ExGaussian) [11, 12] distributions.
The reasons why we bring these models into comparison are as follows. The Gaussian distribution is the model with a maximum entropy given a mean and variance. And it is usually a good candidate as the least-informative default [13]. While truncated Gaussian reflect that MT has a natural lower bound. So, we proposed both Gaussian and truncated Gaussian models. In addition, the distribution of MT in Fitts’ law is suggested as positively skewed. Previous work showed that the distribution of Lognormal [20], Gamma [14], Extreme value (GEV) [6], and Exponentially modifed Gaussian (exGaussian) [11, 12] can be used to model the MT distribution in Fitts’ law. Since Fitts’ law and Steering law both reflect the regularity of the human motor control system, we included the models that have been used to model Fitts’ law MT distributions as candidates for MT distribution in Steering tasks too. Among three types of Extreme value distributions, we chose Extreme value type I, the one with a shape parameter as zero. In the previous Fitts’ law study [6], the shape parameter fitted was approximately 0 (ranging between 0 and 0.4) when the authors used Generalized Extreme value distribution to model distribution of MT. This suggested that type I could serve as a suitable candidate. All the distributions mentioned above are described in Table 2.
Table 2:
Models adopted to predict the distribution of MT given ID. We used the quadratic variance model with constant term (Equation 9) as an example to explain parameter derivation. Each of the variance models listed in Table 1 can be used to substitute quadratic variance model to predict MT variance of the distribution. M and V stand for the mean and variance. In truncated Gaussian, ϕ(x) and Φ(x) stands for probability density function (PDF) and cumulative distribution function (CDF).
| Distribution type | Models and parameters | Predicting model parameters based on ID using quadratic variance model as an example (M: mean, V: variance) | Empirically determined parameters |
|---|---|---|---|
| Gaussian |
M = a + b · ID V = c + d · ID2 |
a, b, c, d | |
| Truncated Gaussian with lower bound 0 |
μ : location σ : scale |
μ = a + b · ID σ2 = c + d · ID2 Z = 1 – Φ(α) |
a, b, c, d |
| Lognormal |
X ~ Lognormal(μ, σ) μ : location σ : scale |
M = a + b · ID
V = c + d · ID 2 |
a, b, c, d |
| Gamma |
X ~ Γ(α, β) α : shape β : inverse scale |
M = a + b · ID V = c + d · ID2 |
a, b, c, d |
| Extreme value |
X ~ Gumbel(μ, β) μ : location β : scale |
M = a + b · ID V = c + d · ID2 μ = M – β · γ γ : Euler-Mascheroni constant |
a, b, c, d |
| ExGaussian |
X ~ EMG(μ, σ, λ) μ : location σ : scale λ : shape |
M = a + b · ID V = c + d · ID2 [11] |
a, b, c, d, k |
We constructed a distribution model in three steps. (1) Give a distribution type f(Θ) parameterized by a vector Θ, we expressed its mean (M) using Steering law: M = a + b · ID, and expressed its variance (V) using one of the six variance models in Table 1. For example, if we adopt the quadratic variance model, it means V = c + d·ID2. (2) We expressed the parameter vector Θ using M and V. Take the Gamma distribution as an example. As a Gamma distribution can be parameterized as X ~ Γ(α, β), we used M and V to express the parameters α and β as , and . Table 2 shows how the parameter vector Θ of each distribution is expressed using M and V. (3) We matched the distribution model with the empirical MT data to estimate the parameter values, such as a, b, c, and d in the aforementioned Gamma distribution example. This procedure was also called model fitting. We achieve so using the probabilistic modeling language Stan [5]. Stan used a Bayesian method to fit the model. After we described the model and provided the data, Stan calculated the posterior distribution of the model parameters using the Hamiltonian Monte Carlo (MCMC) sampling method. Please refer to Appendix B for sample Stan code of describing the Gamma model. Note that for a truncated Gaussian distribution we used the Steering law and a variance model to predict the mean and variance for the original Gaussian distribution before the truncation (which are also called location and scale parameters in the truncated Gaussian), because (a) we view a truncated Gaussian is a simple modification of the original Gaussian distribution by reflecting the natural lower bound of movement time (i.e., 0), (b) there is no analytical form to express the parameters of a truncated Gaussian (i.e., location μ and scale σ) using M and V.
In total we have 31 distribution model candidates. For 5 distribution types, namely Gaussian, Truncated Gaussian, Lognormal, Gamma, and Extreme value distributions, each of the 6 variance models in Table 1 can be used to predict the variance parameters. For the ExGaussian distribution, previous research [11] shows that it naturally implies a quadratic relationship between variance and ID, so we use only the quadratic variance model for this distribution as shown in Table 2. Therefor we have 31 models in total:
Next, we evaluate the variance models and distribution models using a stylus-based steering task data set (Zhou and Ren’s dataset [31]), and a mouse cursor-based steering law data set collected in the present research.
5. EVALUATION ON A STYLUS-BASED STEERING LAW DATASET
We first evaluate the variance and distribution models on a stylus-based steering law data set collected by Zhou and Ren [31].
5.1. Zhou and Ren’s Steering Law Dataset
This Zhou and Ren’s dataset [31] was collected from 10 participants who were divided into two groups randomly. The participants in each of the groups were required to perform a straight tunnel and a circular tunnel steering task with a stylus. Both tasks had 9 conditions with 3 amplitude (66.1, 92.6, 119.1 mm) and 3 width (2.6, 6.6, 10.6 mm) pairs with 9 distinct IDs. We only choose the operation strategy with neutral (N) because neutral instruction means the experiment accuracy and speed have the same level of importance in our study while other strategies would result in bias. There were 9 trials for each participant under each ID condition. Therefore, in each task, we obtained 810 trials (10 · 9 · 9 = 810) totally. Zhou and Ren’s steering law dataset was a stylus-based mouse movement, complementing our dataset (explained later) which was based on mouse steering movement. Evaluating this data set would help us further identify the fitness of variance and distribution models.
5.2. Evaluating Variance Models
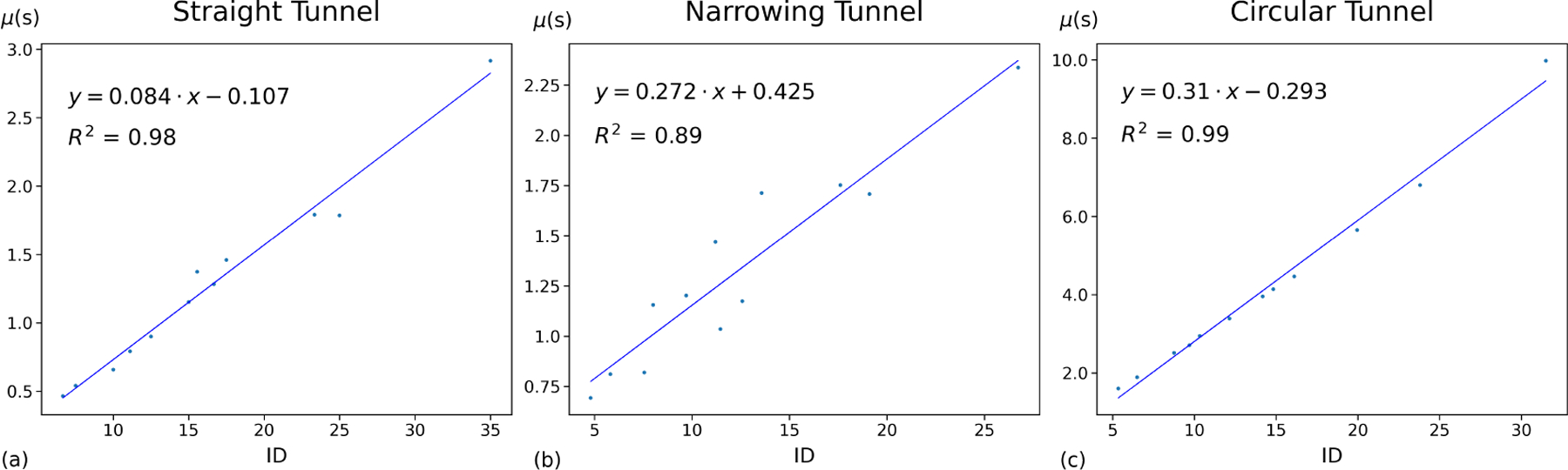
In order to model the MT variance, we introduced six model candidates (Table 1). In each condition of the two tasks, we calculated the MT variance and used a typical MLE method to fit these six candidates. Table 3 shows model parameters, R2 value, leave-one(A, W)-out cross-validation Root mean square error (RMSE), Akaike information criterion (AIC), and Widely Applicable Information Criterion (WAIC) for the three tasks. For the leave-one(A, W)-out cross-validation, we separated the dataset into testing data and training data. The testing data contained one (A, W) condition while the training data contained the rest of them. We fitted the training data to get the model parameter and calculated the RMSE based on the testing data. We repeated this procedure 12 times since each of the (A, W) conditions was chosen as testing data once. We calculated the mean and standard deviation of RMSE based on 12 cross-validations to verify whether the overfitting occurred in the variance model candidates. AIC and WAIC metrics are widely adopted as information criteria to compare the fitness of the dataset and the complexity of the model (i.e., the number of parameters) between different models. Figures 2 – 3 visualizes variance prediction against observed variance of MT of six variance candidates in each of the straight, and circular tasks.
Table 3:
Model parameters, evaluation results, and WAIC metrics for 6 variance models (Table 1) on Zhou and Ren’s steering law dataset. As shown, the quadratic-variance model outperformed other models in both straight and circular tasks, after taking into account the complexity of the model (i.e., the number of parameters).
| Conditions | Variance Models | c | d | e | R 2 | RMSE [SD] | AIC | WAIC |
|---|---|---|---|---|---|---|---|---|
| Straight | σ2 = c | 0.228 [0.1, 0.353] | N/A | N/A | 0 | 128.54 [107.87] | 246.37 | 245.2 |
| σ2 = (c · ID)2 | 0.017 [0.012, 0.021] | N/A | N/A | 0.382 | 100.38 [63.56] | 242.34 | 239.66 | |
| σ2 = c + d · ID | 0.03 [−0.1, 1.7] | 0.01 [0.004, 0.016] | N/A | 0.735 | 95.37 [67.32] | 238.11 | 234.96 | |
| σ2 = c + d · ID2 | 0.121 [0.034, 0.208] | 0.0002 [0.0001, 0.0003] | N/A | 0.785 | 83.08 [48.10] | 236.20 | 232.72 | |
| σ2 = (c + d · ID)2 | 0.23 [0.2, 0.4] | 0.01 [0.009, 0.02] | N/A | 0.752 | 98.28 [77.12] | 237.43 | 234.38 | |
| σ2 = c + d · ID + e · ID2 | 0.156 [−0.149, 0.47] | −0.0038 [−0.037, 0.027] | 0.0003 [−0.0003, 0.0009] | 0.788 | 117.10 [100.84] | 240.17 | 235.96 | |
| Circular | σ2 = c | 0.593 [0.368, 0.802] | N/A | N/A | 0 | 225.82 [174.39] | 255.92 | 254.12 |
| σ2 = (c · ID)2 | 0.025 [0.016, 0.032] | N/A | N/A | 0 | 318.13 [146.48] | 260.79 | 257.9 | |
| σ2 = c + d · ID | 0.241 [0.013, 0.445] | 0.018 [0.009, 0.028] | N/A | 0.808 | 130.88 [80.87] | 244.92 | 241.24 | |
| σ 2 = c + d · ID 2 | 0.4 [0.273, 0.522] | 0.0003 [0.0002, 0.0005] | N/A | 0.844 | 105.70 [60.04] | 242.87 | 239.08 | |
| σ2 = (c + d · ID)2 | 0.54 [0.39, 0.66] | 0.01 [0.006, 0.02] | N/A | 0.827 | 126.21 [76.33] | 243.95 | 240.26 | |
| σ2 = c + d · ID + e · ID2 | 0.393 [−0.176, 0.889] | 0.0009 [−0.051, 0.058] | 0.0003 [−0.0008, 0.0014] | 0.844 | 136.62 [84.80] | 247.48 | 243.04 |
Figure 2:
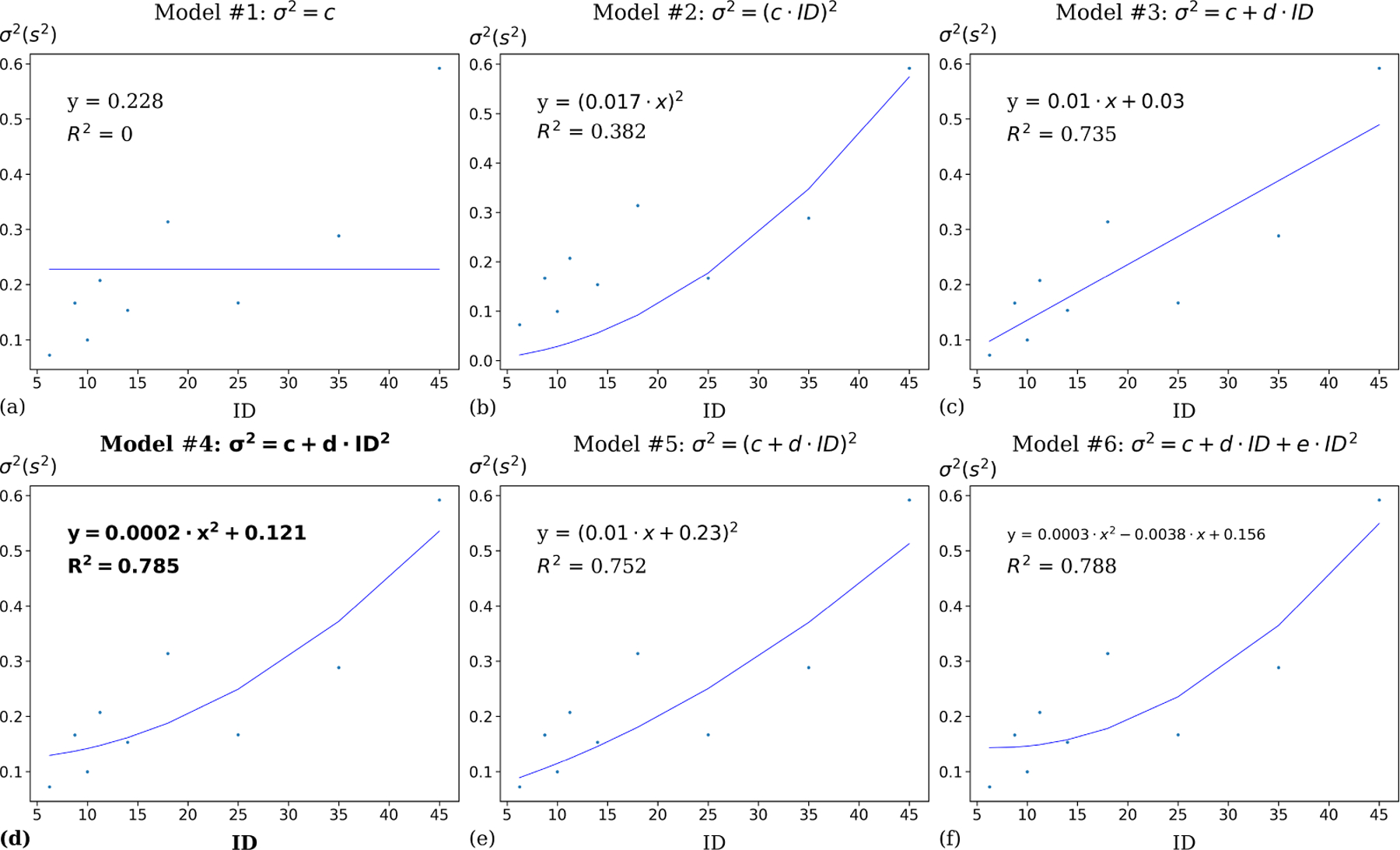
σ2 vs. ID regression for 6 variance models on the Zhou and Ren’s straight tunnel dataset. As shown, the quadratic-variance model (Model #4 in Table 1) accounts for 78.5% of variance in the observed variance of MT. It performs the best according to AIC, WAIC, and leave-one-(A, W)-out cross-validation. Model #6 in Table 1 has the highest R2, but overfits the data because it has higher RMSE in leave-one-(A, W)-out cross-validation compared with quadratic variance model.
Figure 3:
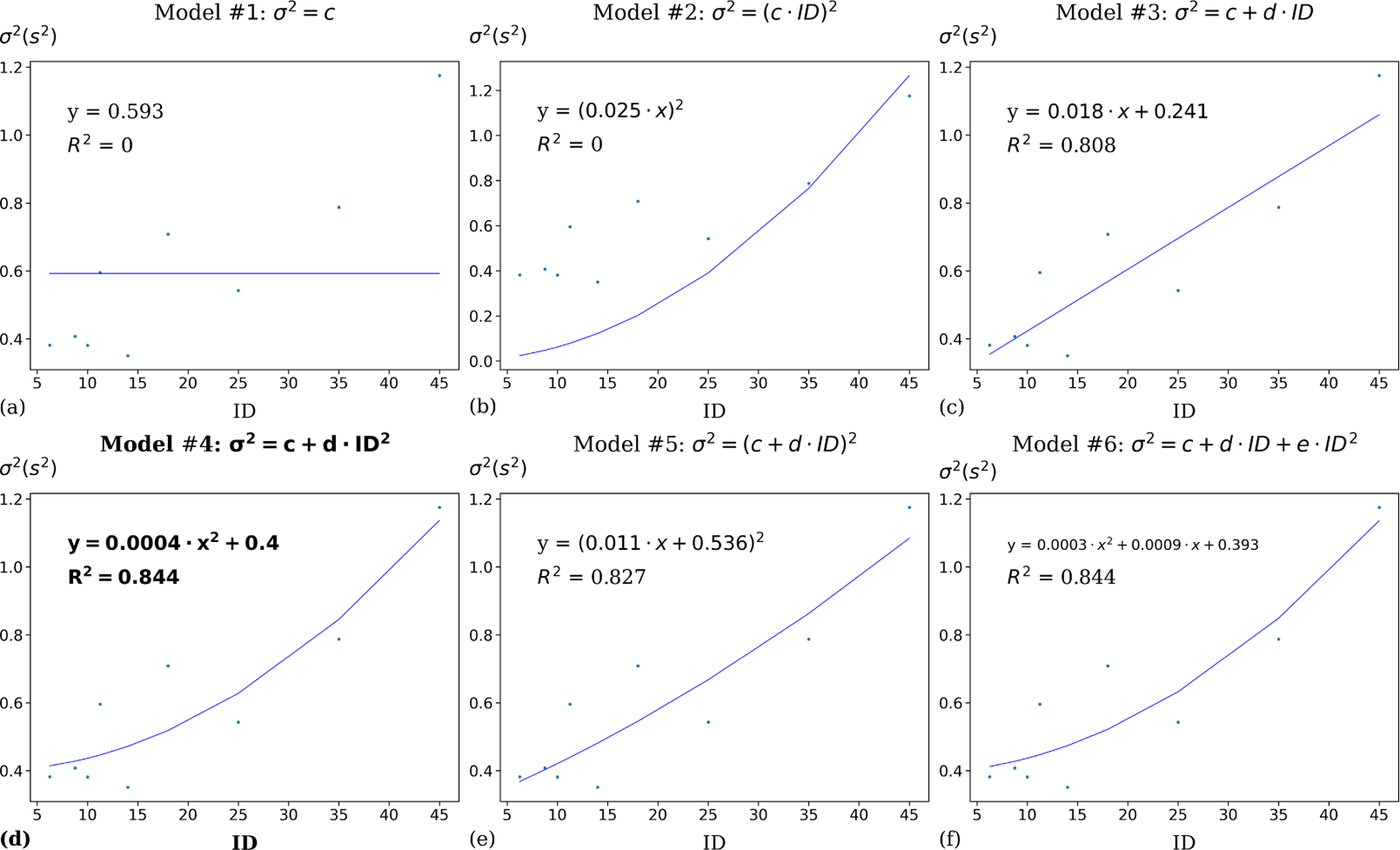
σ2 vs. ID regression for 6 variance models on the Zhou and Ren’s circular tunnel dataset. As shown, the quadratic-variance model (Model #4 in Table 1) accounts for 84.4% of variance in the observed variance of MT. It performs the best according to AIC, WAIC, and leave-one-(A, W)-out cross-validation. The R2 value of Model #6 in Table 1 is the same with Model #4, but Model #6 overfits the data because it has higher RMSE in leave-one-(A, W)-out cross-validation compared with quadratic variance model.
As shown in Table 3 and Figures 2 – 3, the quadratic-variance model (Model #4 in Table 1) proposed according to the instantaneous form of Steering law performs well in modeling variance. This model outperforms other variance model candidates in AIC, WAIC, and leave-one-(A, W)-out cross-validation in both straight tunnel and circular tunnel tasks. In the observed MT variance, although the quadratic variance model (#4) accounts for around 78.5% variation for the straight task and 84.4% for the circular task which are lower than or equal to the quadratic variance model with a linear coefficient (78.8% variation for the straight task and 84.4% variation for the circular task) correspondingly, the latter one (Model #6 in Table 1) overfits the data in both tasks since the RMSE of leave-one-(A, W)-out cross-validation increases compared with the quadratic variance model (#4). Besides, the AIC and WAIC results also suggest that the quadratic variance model (#4) in both straight and circular tunnel performs the best among all variance candidates within its task after taking the model complexity into account.
We also compared the quadratic variance model (Model #4 in Table 1) with models that use A or W only to predict variance. Zhou and Ren [31] observed that standard deviation of MT increased as A or W increased, and further proposed to model σ by σ = c + d · A, or σ = c + d · W. Their models indicated that variance can be modeled as:
| (13) |
or
| (14) |
where c and d are all constant. We evaluated these two models on this data set. The R2 value for Equation 13 were 0.248 (straight tunnel), and 0.268 (circular tunnel), and for Equation 14 were 0.053 (straight tunnel) and 0.093 (circular tunnel). All of them were much lower than the quadratic variance model. It indicates that it is more appropriate to use ID, rather than A or W to model variance.
5.3. Evaluating Distribution Models
In addition, we introduced 6 distribution model candidates (Table 2) to model the distribution of MT. As explained in Section 4, we used Steering law (Equation 1) to predict its mean (or location parameter) and variance models (Table 1) to predict its variance (or scale parameter). As a result, we end up having 31 model candidates
Fitting Models.
We calculated the parameters for 31 model candidates using the Bayesian method. We used Stan [5] to fit these models and obtained the distribution of their parameters. Since we have no prior knowledge of the parameters, We set the parameters priors as uniform distribution. We adopted the default setting that used 4 chains in Markov chain sampling. Each chain contained 1000 iterations. The Rhat values were often used as an indicator to measure whether chains had converged or not. These values in our models were all close to 1.0, meaning the Markov chains had converged. Table 4 described the distribution of model parameters (mean and 95% credible interval).
Table 4:
Fitting results for quadratic variance models (Model #4 in Table 1) in both straight and circular tunnel tasks on Zhou and Ren’s steering law dataset. For each type of distribution, we use Steering law (Equation 1) to predict the mean (or location) parameter, and quadratic variance model (#4) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, and d are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics.
| Distribution Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | ||||||
|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | k | AIC | WAIC |
|
σ2 = c + d · ID2 (Straight tunnel) |
Gaussian | 0.53 [0.47, 0.59] | 0.029 [0.026, 0.032] | 0.133 [0.111, 0.158] | 0.0002 [0.0002, 0.0003] | N/A | 12252.0 | 12249.2 |
| Truncated Gaussian | 0.492 [0.424, 0.557] | 0.029 [0.026, 0.033] | 0.162 [0.13, 0.201] | 0.0002 [0.0001, 0.0003] | N/A | 12223.2 | 12220.7 | |
| Lognormal | 0.526 [0.465, 0.589] | 0.029 [0.026, 0.033] | 0.14 [0.102, 0.182] | 0.0003 [0.0002, 0.0005] | N/A | 12128.4 | 12124.3 | |
| Gamma | 0.532 [0.475, 0.587] | 0.029 [0.025, 0.032] | 0.12 [0.097, 0.146] | 0.0002 [0.0002, 0.0003] | N/A | 12120.5 | 12116.2 | |
| Extreme value | 0.512 [0.452, 0.569] | 0.03 [0.026, 0.033] | 0.111 [0.088, 0.137] | 0.0003 [0.0002, 0.0004] | N/A | 12129.4 | 12124.9 | |
| exGaussian | 0.44 [0.377, 0.5] | 0.035 [0.031, 0.04] | 0.06 [0.037, 0.086] | 0.00006 [0.00004, 0.00008] | 0.04 [0.04, 0.05] | 12193.7 | 12194.7 | |
|
σ2 = c + d · ID2 (Circular tunnel) |
Gaussian | 0.646 [0.552, 0.74] | 0.085 [0.08, 0.09] | 0.419 [0.356, 0.489] | 0.0004 [0.0003, 0.0006] | N/A | 13058.7 | 13055.4 |
| Truncated Gaussian | 0.587 [0.48, 0.69] | 0.086 [0.081, 0.092] | 0.483 [0.406, 0.574] | 0.0003 [0.0002, 0.0005] | N/A | 13040.1 | 13039.9 | |
| Lognormal | 0.608 [0.509, 0.71] | 0.087 [0.081, 0.093] | 0.36 [0.274, 0.463] | 0.0008 [0.0005, 0.0011] | N/A | 12959.3 | 12957.5 | |
| Gamma | 0.637 [0.545, 0.73] | 0.085 [0.08, 0.091] | 0.344 [0.276, 0.417] | 0.0006 [0.0004, 0.0008] | N/A | 12954.4 | 12951.5 | |
| Extreme value | 0.55 [0.46, 0.65] | 0.091 [0.085, 0.097] | 0.258 [0.196, 0.327] | 0.0011 [0.0009, 0.0014] | N/A | 12974.1 | 12971.1 | |
| exGaussian | 0.342 [0.131, 0.652] | 0.107 [0.085, 0.124] | 0.119 [0.001, 0.369] | 0.0002 [0.00006, 0.0004] | 0.03 [0.02, 0.05] | 13039.6 | 13074.5 | |
We compared the prediction accuracy of 31 model candidates on probability MT distribution to evaluate these models. Concretely, we used the three following metrics to investigate prediction accuracy. The results of 31 model candidates were showed in Tables 8 – 9 from Appendix.
Information Criteria.
We used WAIC (Widely Applicable Information Criterion) and AIC (Akaike Information Criterion) [10] to compare prediction accuracy for 31 distribution model candidates regarding MT distribution. For WAIC and AIC, a lower value indicated better prediction accuracy of the model. These two metrics also took the penalty of the number of parameters, over-fitting control, and model complexity into account.
Tables 4 shows the fitting results for quadratic variance models (Model #4 in Table 1) in both straight and circular tasks on Zhou and Ren’s steering law dataset. As shown in both tasks, the Gamma, Lognormal, Extreme value and exGaussian distributions outperformed Gaussian and truncated Gaussian distributions.
Posterior Predictive Checking on Probability Density Function.
We also provided further evaluation for 6 model candidates by performing posterior predictive checking on Probability Density Function (PDF) of MT. In straight and circular tunnel tasks, the variance predicted by the quadratic variance model (Table 4) performed best (or second-best) among all distribution types in both tasks. We draw simulated curves from the posterior predictive distribution from randomly generated variables according to the parameters learned from each dataset and compared the simulated curve with the observed curve. In order to estimate a random variable’s PDF, we used kernel density estimation (a.k.a Parzen–Rosenblatt window method) [7] to simulate the observed probability density function. The simulated curve and observed curve should be similar to each other if the model fits well. This method showed the degree of similarity between the predicted PDFs and the observed PDFs regarding MT distributions.
In each of the two tasks, posterior predictive checks on PDF of MT a cross (A, W) pairs were simulated. Concretely, we first generated 100 samples based on model parameters’ posterior distributions, providing 100 sample models. Then, for each model generated, we sampled 2000 data points and used these points to plot the probability density functions (PDF) against the observed PDF regarding MT. As a result, 100 predicted PDFs were presented for each (A, W) condition using each distribution model. We included all the predicted PDFs associated with the observed MT PDF (Figure 4). The simulated curve and observed curve should be similar to each other if the model fits well.
Figure 4:
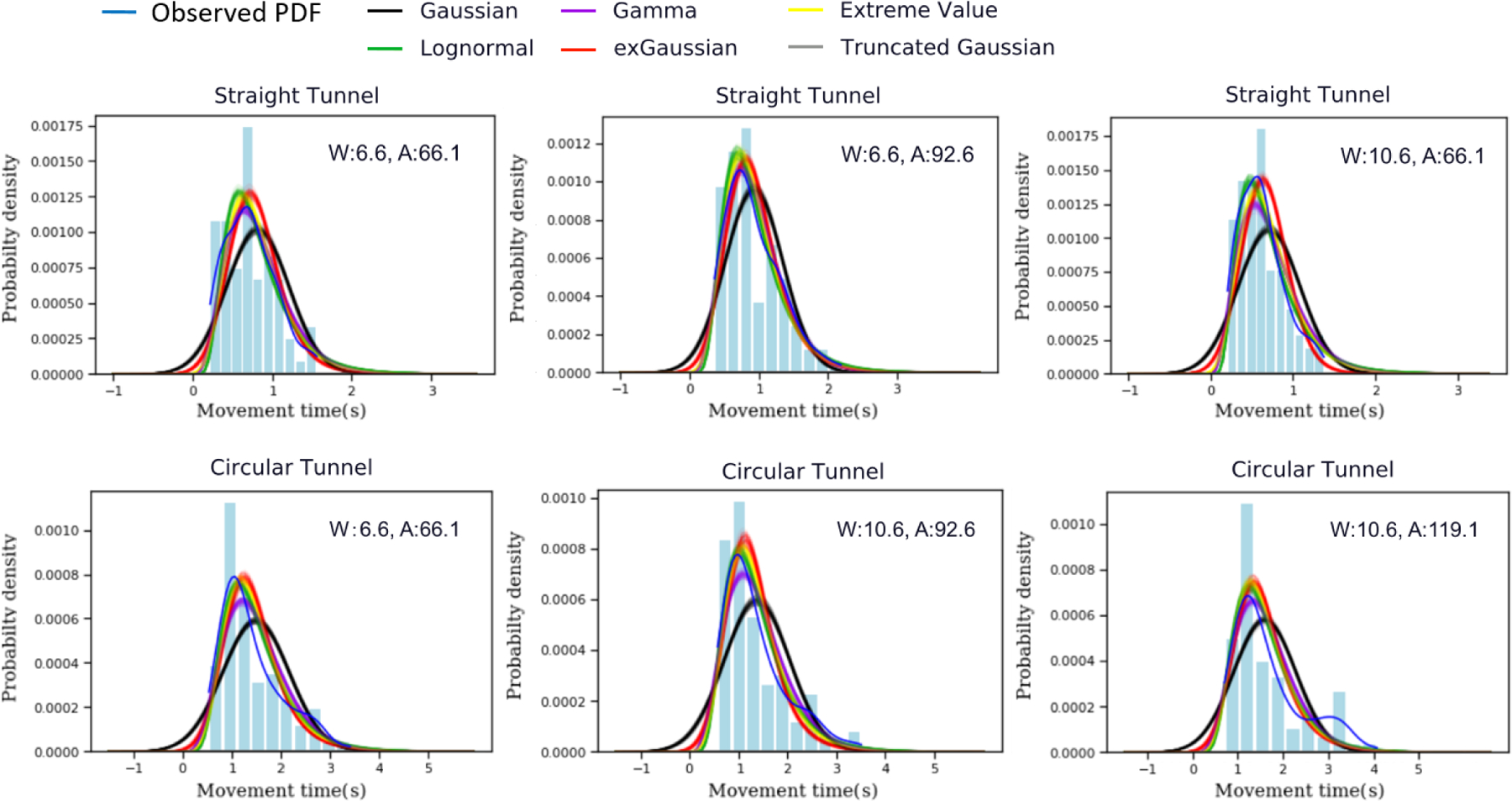
Posterior Predictive Checking on Probability Density Functions (PDF) of MT in 3 amplitude-width (A, W) conditions in each of the straight and circular tunnel tasks on the Zhou and Ren’s steering law dataset. The blue curves are the observed PDF and the light blue bars are observed histogram. The other colored curves are predictions made by different models. All the predictions were drawn from 100 simulations. The narrow bands represent the uncertainty. As shown, the Lognormal (green), Gamma (violet), Extreme value (yellow), and exGaussian (red) looked very similar to the observed PDF (blue), and outperformed models with Gaussian and truncated Gaussian (black and grey).
Figure 4 shows the results for 3 conditions in each of the straight and circular tunnel tasks. As shown, the predicted PDFs from Gamma, lognormal, Extreme value, and exGaussian models resembled the observed data, indicating a strong fit.
Next, we carried out an experiment to evaluate 6 variance models and 31 distribution models on our newly collected steering law dataset.
6. EVALUATING VARIANCE AND DISTRIBUTION MODELS VIA A TUNNEL STEERING EXPERIMENT
In order to further evaluate the variance and distribution models introduced, we conducted a mouse cursor-based steering law study.
6.1. Participants and Apparatus
Twelve participants (5 females, 7 males) aged from 21 to 44 (mean = 28.9, std = 6.2) participated in our user study. All of them claimed that they used GUI on a daily basis and had laptops using experience. An ASUS Q551L laptop computer with a Windows 10 operating system was adopted as the main device to run the user study. It had a screen size of 15.4 inches and a resolution of 1920 × 1080. Before the study, we turned of the mouse acceleration and adjusted the cursor speed to the midpoint (10/20) in the system settings.
6.2. Procedure and Design
Three steering tasks were considered in our study: a straight tunnel task, a narrowing tunnel task, and a circular tunnel task. Each of them contained 12 (A, W) pairs with 12 unique IDs due to unrepeatable ID. Table 5 shows the amplitude (A) and width (W) chosen for each of the three tasks. In each (A, W) condition, the participant was instructed to steer the cursor through the tunnel as quickly and accurately as possible. The order of three types of tunnels (straight, narrowing, and circular tunnels) were fully counter-balanced across participants. The orders of 12 (A, W) conditions in each task were randomly chosen for each subject.
Table 5:
Amplitude and width pairs (A, W) chosen for each of the three tasks. All the values are in mm.
| Task | Amplitude and Width Pairs (A, W) |
|---|---|
| Straight tunnel | (150, 10), (150, 15), (150, 20), (150, 22.5), (250, 10), (250, 15), (250, 20), (250, 22.5), (350, 10), (350, 15), (350, 20), (350, 22.5) |
| Narrowing tunnel | (150, 20), (150, 40), (150, 60), (150, 80), (250, 20), (250, 40), (250, 60), (250, 80), (350, 20), (350, 40), (350, 60), (350, 80) |
| Circular tunnel | (127.3, 22.8), (135.7, 20), (151.3, 15), (167, 10), (206.6, 22.8), (215.1, 20), (230.7, 15), (246.3, 10), (286, 22.8), (294.5, 20), (310.1, 15), (325.7, 10) |
At the beginning of a trial, one of the three types of tunnels was displayed in grey on the computer screen (Figure 5). A participant was instructed to move the cursor across the starting line to start the trial. Upon crossing the starting line, the tunnel turns in green, indicating that the trails started. The mouse trajectory was displayed in blue once the trial started. After the cursor was steered through the tunnel and crossed the ending line, the trail ended successfully and a new trial appeared. If the cursor crossed the boundary of the tunnel in the middle of the trial, the tunnel turned red, indicating a failure. The participant was then required to re-do the trial. For a narrowing tunnel (Figure 8(b)), the width instantaneous changed at each position along the tunnel, which resulted in a shrinking width from the left to the right. For both straight and narrowing tunnels (Figure 8(a, b)), participants were instructed to steer from left to right, and for a circular tunnel (Figure 8(c)), the subject steered in the counter-clockwise direction. A participant was required to successfully complete 10 trials in each (A, W) condition for a specific type of tunnel, in order to move to the next (A, W) condition.
Figure 5:
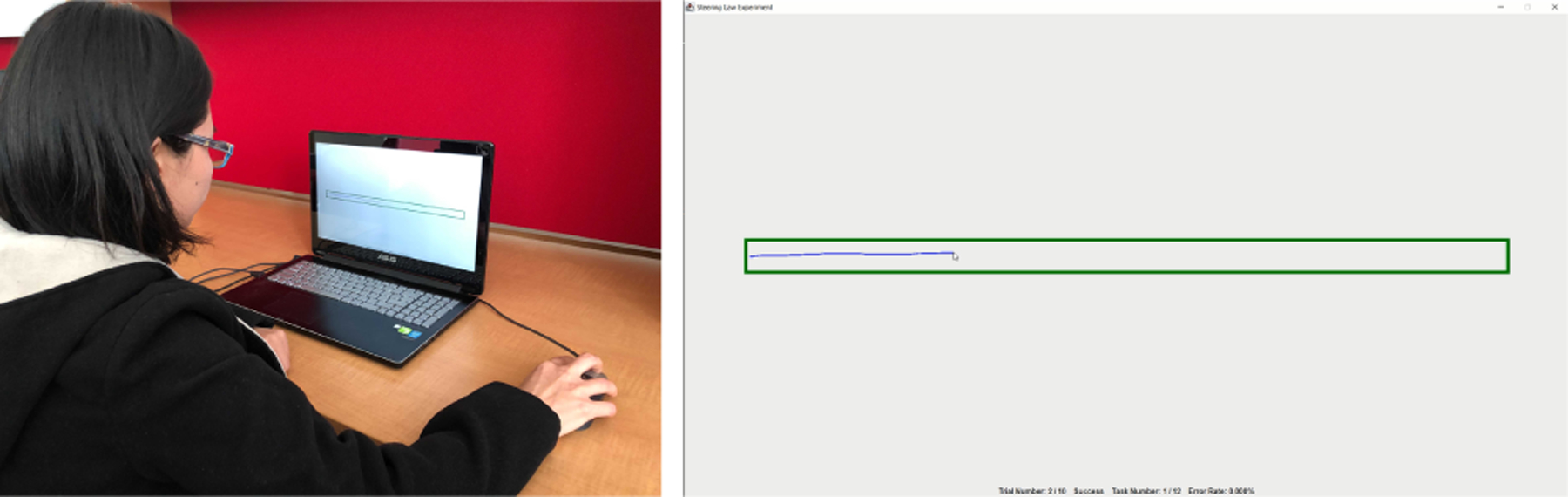
Left: a participant is doing the study. Right: a screenshot of a straight tunnel steering task.
Figure 8:
(a): a straight tunnel. (b): a narrowing tunnel. (c): a circular tunnel.
In total, our study included:
6.3. Data
In the three tasks, we collected 1511 trials for the straight tunnel, 1559 trials for the narrowing tunnel, and 1700 trials for the circular tunnel. After removing unsuccessful trials, we ended up with 1440 (12 · 12 · 10 = 1440) trials for each tunnel. In each condition, the data points outside the 5 standard deviations were considered as outliers. Only one trial in the narrowing tunnel was removed according to this criterion. We ended up with 4319 successful trials. The error rate for the straight tunnel, narrowing tunnel and circular tunnel were 4.7%, 7.6% and 15.3%.
We first ran steering law regression of collected data for each type of tunnel. As shown in Figure 6, the mean of MT under each (A, W) can be well modeled by steering law (Equation 1).
Figure 6:
Steering law mean prediction against observed MT in straight, narrowing and circular tunnel tasks.
As shown in Figure 6, the offsets of some models are negative. These negative offsets were the outcome of the fitting process, which are common in steering regressions. For example, negative offsets were observed in the steering law regressions in the Accot and Zhai’s seminal work (e.g., Equations 8 and 11 in [1]).
6.4. Evaluating Variance Models
Similar to the previous experiment, We first introduced 6 variance model candidates (Table 1) to model MT variance on both straight, narrowing, and circular tunnel tasks, and then compared the model fitness within each task. The results of R2, Root mean square error (RMSE) of leave-one-(A, W)-out cross-validation, AIC, and WAIC metrics are shown in Table 6. Also, Figure 7 visualizes variance prediction against observed variance of MT using quadratic variance model (Model #4 in Table 1) in each of straight, narrowing and circular tunnel tasks.
Table 6:
Model parameters, evaluation results, and WAIC metrics for 6 variance models (Table 1) of each task on our dataset. As shown, although there is no clear winner, the quadratic-variance model (Model #4 in Table 1) performed the best (or second-best) in three tasks, after taking into account the complexity of the model (i.e., the number of parameters).
| Conditions | Variance Models | c | d | e | R 2 | RMSE [SD] | AIC | WAIC |
|---|---|---|---|---|---|---|---|---|
| Straight tunnel | σ2 = c | 0.979 [0.344, 1.627] | N/A | N/A | 0 | 767.0 [655.0] | 370.05 | 368.76 |
| σ2 = (c · ID)2 | 0.054 [0.051, 0.056] | N/A | N/A | 0.966 | 148.2 [178.0] | 329.4 | 329.68 | |
| σ2 = c + d · ID | −0.899 [−1.275, −0.519] | 0.115 [0.095, 0.136] | N/A | 0.948 | 239.0 [138.7] | 338.09 | 334.64 | |
| σ 2 = c + d · ID 2 | 0.052 [−0.126, 0.229] | 0.003 [0.002, 0.003] | N/A | 0.968 | 163.3 [139.0] | 332.06 | 330.12 | |
| σ2 = (c + d · ID)2 | 0.068 [−0.11,0.24] | 0.051 [0.045, 0.058] | N/A | 0.970 | 185.2 [212.5] | 331.57 | 329.82 | |
| σ2 = c + d · ID + e · ID2 | −0.237 [−0.871, 0.398] | 0.034 [−0.037, 0.106] | 0.002 [0.0003, 0.004] | 0.972 | 206.6 [241.9] | 333.91 | 330.42 | |
| Narrowing tunnel | σ2 = c | 0.694 [0.283, 1.075] | N/A | N/A | 0 | 444.3 [435.5] | 358.50 | 358.72 |
| c2 = (c · ID)2 | 0.058 [0.054, 0.061] | N/A | N/A | 0.918 | 152.3 [82.5] | 328.62 | 326.06 | |
| σ2 = c + d · ID | −0.405 [−0.77, −0.067] | 0.089 [0.064, 0.115] | N/A | 0.869 | 233.8 [238.3] | 337.47 | 335.66 | |
| σ2 = c + d · ID2 | 0.135 [0.0008, 0.273] | 0.003 [0.002, 0.003] | N/A | 0.946 | 147.6 [141.2] | 326.91 | 323.84 | |
| σ2 = (c + d · ID)2 | 0.142 [−0.048, 0.315] | 0.05 [0.041, 0.06] | N/A | 0.939 | 176.4 [174.5] | 328.47 | 325.72 | |
| σ2 = c + d · ID + e · ID2 | 0.329 [−0.191, 0.876] | −0.029 [−0.109, 0.049] | 0.004 [0.001, 0.006] | 0.950 | 196.5 [227.8] | 329.39 | 325.14 | |
| Circular tunnel | σ2 = c | 1.853 [0.576, 3.215] | N/A | N/A | 0 | 1517.1 [1581.3] | 388.6 | 389 |
| σ2 = (c · ID)2 | 0.085 [0.08, 0.089] | N/A | N/A | 0.950 | 431.2 [543.8] | 352.62 | 353.4 | |
| σ2 = c + d · ID | −1.873 [−3.088, −0.647] | 0.257 [0.177, 0.337] | N/A | 0.863 | 830.9 [933.6] | 368.26 | 367.76 | |
| σ2 = c + d · ID2 | −0.076 [−0.544, 0.424] | 0.007 [0.006, 0.009] | N/A | 0.951 | 530.4 [644.6] | 355.96 | 354.68 | |
| σ2 = (c + d · ID)2 | −0.177 [−0.694, 0.185] | 0.092 [0.076, 0.112] | N/A | 0.953 | 552.4 [708.5] | 355.37 | 354.22 | |
| σ2 = c + d · ID + e · ID2 | 0.821 [−0.778, 2.346] | −0.118 [−0.316, 0.088] | 0.01 [0.005, 0.02] | 0.960 | 613.6 [901.3] | 356.92 | 353.8 |
Figure 7:
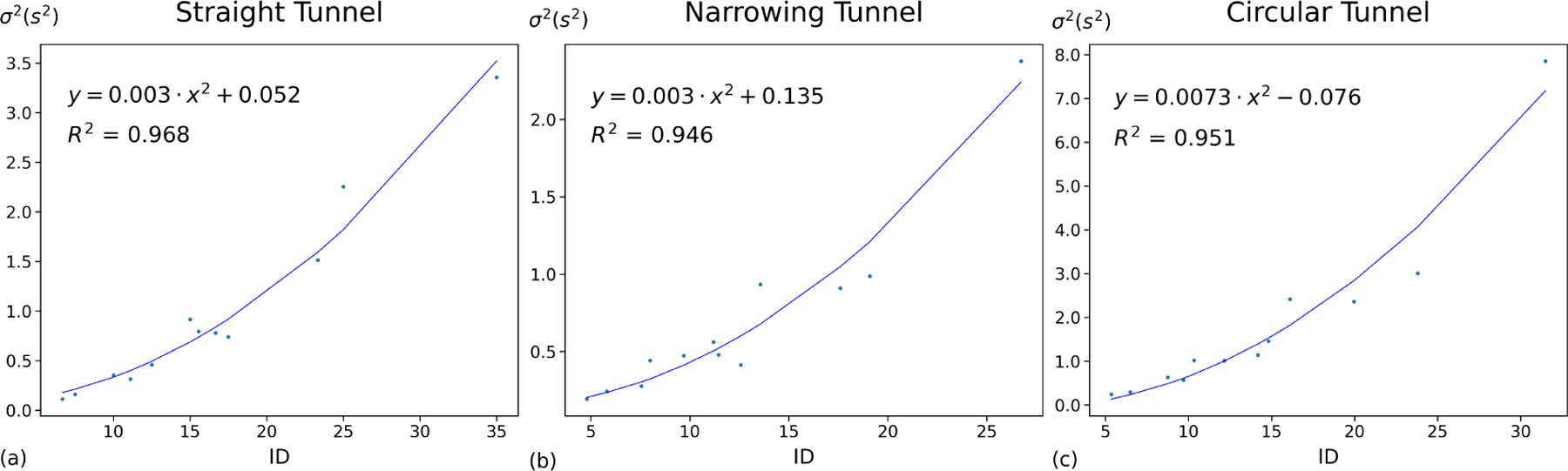
Steering law variance prediction against observed variance of MT using quadratic variance model (Model #4 in Table 1) in each of straight, narrowing and circular tunnel tasks.
Although no single model performed the best across all conditions, the results (Table 6 and Fig 7) showed that the quadratic variance model (Model #4 in Table 1) proposed according to the instantaneous form of Steering law [1] performs well in modeling variance. This model performs the best (or second-best) among the three tasks in R2, RMSE, AIC, and WAIC. In each task, the corresponding quadratic variance model accounts for more than 94% variation in the observed variance of MT. Although it improves R2 value by adding linear coefficient (Model #6 in Table 1), the results of quadratic variance model with a linear coefficient (#6) in RMSE, AIC, and WAIC are higher compared to quadratic variance model (#4), indicating overfitting regarding the variance of MT.
Similar to the analysis of Zhou and Ren’s dataset [31], we also compared the quadratic variance model (Model #4 in Table 1) with models that use A or W only to predict variance. The R2 value for Equation 13 were 0.145 (straight tunnel), 0.293 (narrowing tunnel), and 0.037 (circular tunnel), and for Equation 14 were 0.513 (straight tunnel), 0.152 (narrowing tunnel), and 0.517 (circular tunnel). All of them are much lower than the R2 values of the quadratic variance models, confirming the finding that it is more appropriate to use ID, rather than A or W to model variance.
6.5. Evaluating Distribution Models
Likewise, 31 distribution model candidates were adopted to predict the distribution of MT. Stan [5] was used to perform Bayesian modeling without informative priors as parameters. The process for building models was the same as our previous experiment. Table 7 showed the posterior distribution generated from model parameters of three tasks using quadratic variance model (Model #4 in Table 1).
Table 7:
Fitting results for quadratic variance model (Model #4 in Table 1) for each of our straight, narrowing, and circular tunnel tasks. For each type of distribution, we use Steering law 1 to predict mean (or location) parameter, and quadratic variance model(Model #4 in Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c and d are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown in the three tasks, the Gamma, Lognormal, Extreme value and exGaussian distributions outperformed Gaussian and truncated Gaussian distributions.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | ||||||
|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | k | AIC | WAIC |
|
σ2 = c + d · ID2 (Straight tunnel) |
Gaussian | −0.1 [−0.2, −0.03] | 0.08 [0.08, 0.09] | −0.019 [−0.05, 0.016] | 0.003 [0.003, 0.004] | N/A | 23371.9 | 23368.4 |
| Truncated Gaussian | −0.448 [−1.059, 0.031] | 0.047 [0.008, 0.081] | 0.121 [−0.106, 0.371] | 0.007 [0.005, 0.009] | N/A | 22896.4 | 22891.7 | |
| Lognormal | −0.14 [−0.23, −0.028] | 0.088 [0.08, 0.097] | −0.053 [−0.165, 0.118] | 0.005 [0.004, 0.006] | N/A | 22713.5 | 22709.0 | |
| Gamma | −0.112 [−0.183, −0.034] | 0.084 [0.078, 0.091] | −0.022 [−0.061, 0.026] | 0.003 [0.003, 0.003] | N/A | 22732.1 | 22727.4 | |
| Extreme value | −0.108 [−0.175, −0.04] | 0.082 [0.076, 0.088] | −0.016 [−0.045, 0.018] | 0.002 [0.002, 0.003] | N/A | 22909.5 | 22905.1 | |
| exGaussian | −0.056 [−0.092, −0.022] | 0.08 [0.076, 0.084] | 0.0004 [0.00001, 0.001] | 0.004 [0.0003, 0.004] | 0.02 [0.02, 0.002] | 22692.1 | 22685.9 | |
|
σ2 = c + d · ID2 (Narrowing tunnel) |
Gaussian | 0.365 [0.282, 0.45] | 0.078 [0.07, 0.086] | 0.158 [0.109, 0.209] | 0.003 [0.003, 0.004] | N/A | 23179.9 | 23176.1 |
| Truncated Gaussian | 0.257 [0.08, 0.422] | 0.066 [0.048, 0.082] | 0.26 [0.156, 0.395] | 0.005 [0.003, 0.006] | N/A | 22955.6 | 22951.2 | |
| Lognormal | 0.453 [0.338, 0.575] | 0.074 [0.064, 0.085] | 0.565 [0.354, 0.789] | 0.003 [0.002, 0.005] | N/A | 22956.1 | 22951.7 | |
| Gamma | 0.378 [0.289, 0.47] | 0.077 [0.068, 0.086] | 0.226 [0.157, 0.302] | 0.003 [0.002, 0.004] | N/A | 22866.0 | 22861.2 | |
| Extreme value | 0.372 [0.281, 0.457] | 0.077 [0.068, 0.085] | 0.19 [0.134, 0.249] | 0.003 [0.002, 0.003] | N/A | 22948.3 | 22943.6 | |
| exGaussian | 0.223 [0.153, 0.298] | 0.092 [0.084, 0.1] | 0.055 [0.037, 0.075] | 0.005 [0.005, 0.006] | 0.01 [0.01, 0.01] | 22943.5 | 22937.3 | |
|
σ2 = c + d · ID2 (Circular tunnel) |
Gaussian | −0.005 [−0.11, 0.099] | 0.277 [0.267, 0.286] | 0.032 [−0.026, 0.102] | 0.007 [0.006, 0.007] | N/A | 24253.4 | 24249.7 |
| Truncated Gaussian | −0.01 [−0.122, 0.097] | 0.277 [0.267, 0.287] | 0.035 [−0.021, 0.103] | 0.007 [0.006, 0.007] | N/A | 24252.2 | 24248.3 | |
| Lognormal | −0.008 [−0.104, 0.095] | 0.278 [0.268, 0.287] | 0.002 [−0.065, 0.077] | 0.007 [0.007, 0.008] | N/A | 24177.5 | 24172.9 | |
| Gamma | −0.006 [−0.11, 0.097] | 0.277 [0.267, 0.287] | 0.012 [−0.043, 0.075] | 0.007 [0.006, 0.008] | N/A | 24166.3 | 24161.8 | |
| Extreme value | −0.009 [−0.115, 0.098] | 0.278 [0.269, 0.289] | −0.006 [−0.074, 0.067] | 0.008 [0.007, 0.009] | N/A | 24197.0 | 24192.4 | |
| exGaussian | −0.012 [−0.112, 0.09] | 0.277 [0.268, 0.287] | 0.023 [0.0008, 0.067] | 0.007 [0.006, 0.008] | 0.02 [0.02, 0.02] | 24210.8 | 24204.7 | |
As in our previous experiment, the same method was used to evaluate model performance by AIC and WAIC metrics and the results of 31 distribution model candidates were showed in Tables 10 – 12 from Appendix. Then posterior predictive checks on probability density functions (PDFs) were introduced to compare distribution model candidates.
Information Criteria.
Similarly, we used AIC and WAIC information criteria to compare prediction accuracy for 31 distribution model candidates. As shown in Table 7, Lognormal, Gamma, exGaussian, and Extreme value outperform Gaussian and truncated Gaussian in predicting the MT distribution.
Posterior Predictive Checking on Probability Density Function.
Adopting previous experimental methodology, we extracted 100 samples from the posterior distribution of model parameters, and used the extracted samples to plot the probability density function (PDF) of MT predicted by the model. Next, we compared the predicted PDF with the PDF of MT observed in Figure 9. As shown, the PDF simulated by the quadratic variance Lognormal, Gamma, Extreme value, and exGaussian models looks more similar to the observed data while other models show a discrepancy.
Figure 9:
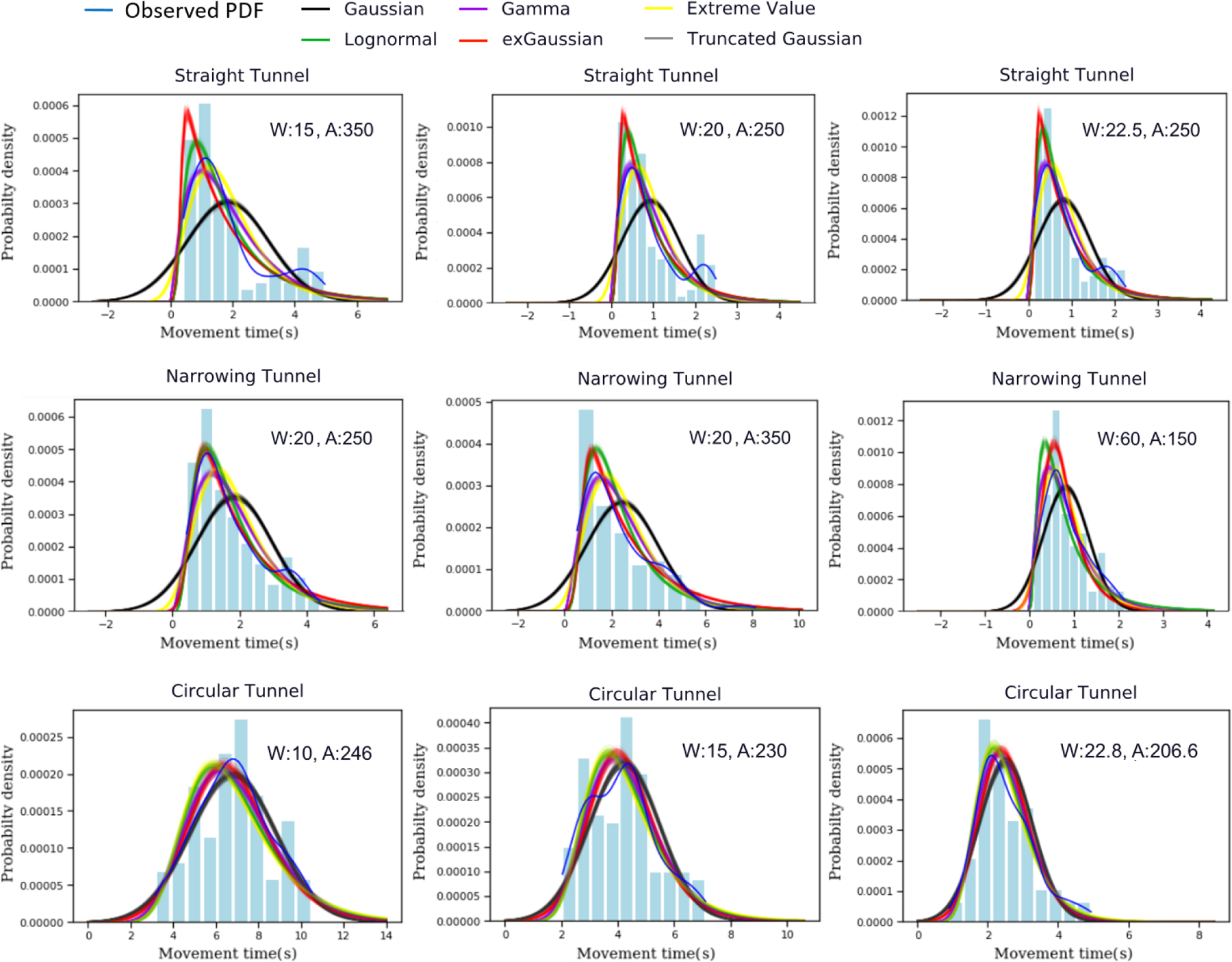
Posterior Predictive Checking on Probability Density Functions (PDF) of MT in 3 amplitude-width (A, W) conditions for each of the three tasks. The blue curves are the observed PDF and the light blue bars are observed histogram. The other colored curves are predictions made by different models. All the predictions were drawn from 100 simulations. The narrow bands represent the uncertainty. As shown, the Lognormal (green), Gamma (violet), Extreme value (yellow), and exGaussian (red) looked very similar to the observed PDF (blue), and outperformed models with Gaussian and truncated Gaussian (black and grey) across all the 9 examples.
7. GENERAL DISCUSSION AND FUTURE WORK
7.1. Modeling Variance of MT
Our investigation on two steering law datasets shows that the quadratic variance model (Equation 9, Model #4 in Table 1) perform wells in predicting the MT variance across different steering tasks. On Zhou and Ren’s dataset [31], the quadratic variance model (#4) performs the best. It has the lowest in AIC, WAIC, and RMSE of leave-one-(A, W)-out cross-validation values among the six model candidates, and can account for more than 78% of the variation in the observed MT variance. On our cursor-based dataset, the quadratic variance model (#4) performs the best (or second-best) among 6 variance models in three types of steering tasks. It also accounts for more than 94% of variance in observed MT variance, showing a strong model fitness. Adding the linear coefficient (Model #6 in Table 1) increases the RMSE in leave-one-(A, W)-out cross-validation, indicating that further increasing the complexity of the quadratic variance model causes overfitting. This provided further validation that the quadratic variance model (#4) is an appropriate candidate for modeling the variance of MT.
7.2. Modeling Distribution of MT
Our results indicates that a combination of quadratic variance model (Equation 9, Model #4 in Table 1) and Steering law (Equation 1) can well predict MT distribution, especially when assuming that the MT distributions follow positively skewed distributions such as Gamma, Lognormal, Extreme value, and exGaussian distributions. The posterior predict check on Probability Density Function (PDF) prediction shows that the predicted PDF under these distributions well resembled the observed PDF. They especially performed better than Gaussian and Truncated Gaussian distributions. The AIC and WAIC metrics, which reflect the prediction accuracy, also showed that Gamma, Lognormal, Extreme value and exGaussian distributions performed better than other distributions. The Gamma distribution performs slightly better than Lognormal, Extreme value in most of the steering tasks.. These findings are similar to the previous findings on MT distribution for Fitts’ law that MT is positively skewed (e.g., [6, 11, 14, 20]).
7.3. The Source of Variance and Dynamics of Steering Tasks.
Variability is commonly observed in response times in psychology experiments [23]. There is no exception in MT of steering tasks. Variability in MT could be caused by (1) different motor control abilities across users, and (2) neuromotor noises in the perceptual and motor systems. Take the steering task on the straight tunnel (in mm) with A = 350 and W = 10 as an example. The mean MT (insecond) ranges from 1.175 to 6.676 across 12 users, indicating that users’ abilities of steering are different. Additionally, as the steering action involves perceptual and motor systems, the neuromotor noises in these systems could contribute to the variability in MT too. Previous research(e.g., [23]) has shown that variability has widely existed in task completion time in psychological experiments, and we expect steering tasks to conform.
We also analyzed the dynamics of the steering movement including speed, acceleration, and traveling distance. The analysis showed there are variances in these measures. Take the steering task on the straight tunnel (in mm) with A = 250 and W = 20 as an example. The mean (std) of travel distance (in mm) is 316.4 (3.97); the mean (std dev) of moving speed (mm per second) is 352 (339); the mean (std dev) of acceleration (mm per second squared) is 53 (10583). It showed that variability widely exists in the steering process.
7.4. Applications of Variance and Distribution Models.
The variance and distribution models advance the MT prediction from a point estimate to variance and distribution estimates, which ofers the following benefits. First, the results’ uncertainty can be predicted through distribution models. For instance, given an amplitude-width (A, W) condition’s distribution, we can calculate the probability of MT occurring in any range.
Second, the distribution model of MT could lay the cornerstone for establishing probabilistic models for interactions of higher-level in consideration of the key role Steering law serves in behavior modeling. For instance, selecting a target from a nested menu can be regarded as a sequence of steering tasks and can be modeled by Steering law. The distribution of target selection speed could be known based on the distribution of steering time. This is more informative compared with estimating the mean speed from Steering law only.
7.5. Limitation and Future Work
The quadratic variance model accounts for between 78% and 97% of variation in observed σ2 on two tested datasets. Such prediction accuracy is lower than the prediction on the mean of MT which is typically higher than 95% [1]. Figures 7 shows the error of prediction increases when ID increases. As shown, the observed variance close to the ending position of the curve increases faster than predicted, which suggests that there might exist other factors affecting the variance. The quadratic variance model is just the starting point to study the distribution of MT variance and it is worth exploring what these factors are in future research.
8. CONCLUSION
We propose and evaluate models that predict the variance and distribution of MT in steering tasks. Our investigation led to the following contributions.
First, we have proposed the quadratic-variance model, which reveals that the variance of MT of the steering task is quadratically related to the index of difficulty of the task , with the linear coefficient being 0:
| (15) |
where c and d are empirically determined parameters. We proposed this model according to the instantaneous form of steering law, assuming that the steering movement is comprised of multiple sub-movements.
The evaluation on two steering law datasets, one for stylus-based and the other for cursor-based input, show that the quadratic variance model (Equation 15) can account for between 78% and 97% of variance of observed MT variances, and outperforms other model candidates such as the constant and linear models. Further increasing the complexity of the model, such as adding the linear coefficient, does not improve the fitness of the model.
Second, combining the quadratic variance model (Equation 15) and Steering law, we are able to predict the MT distribution given ID: we use the quadratic variance model (Equation 15) to predict the variance and use Steering law to predict the mean (or location) parameters of a distribution. Among six types of distribution, positively skewed distributions such as Lognormal, Gamma, and Extreme value, and exGaussian distributions have better prediction accuracy than Gaussian and Truncated Gaussian (lower bound is 0) distributions. The Gamma distribution performs slightly better than other models in most of the steering tasks. Overall, our research advances the MT prediction from a mean estimate to variance and distribution estimates for steering tasks.
Figure 1:
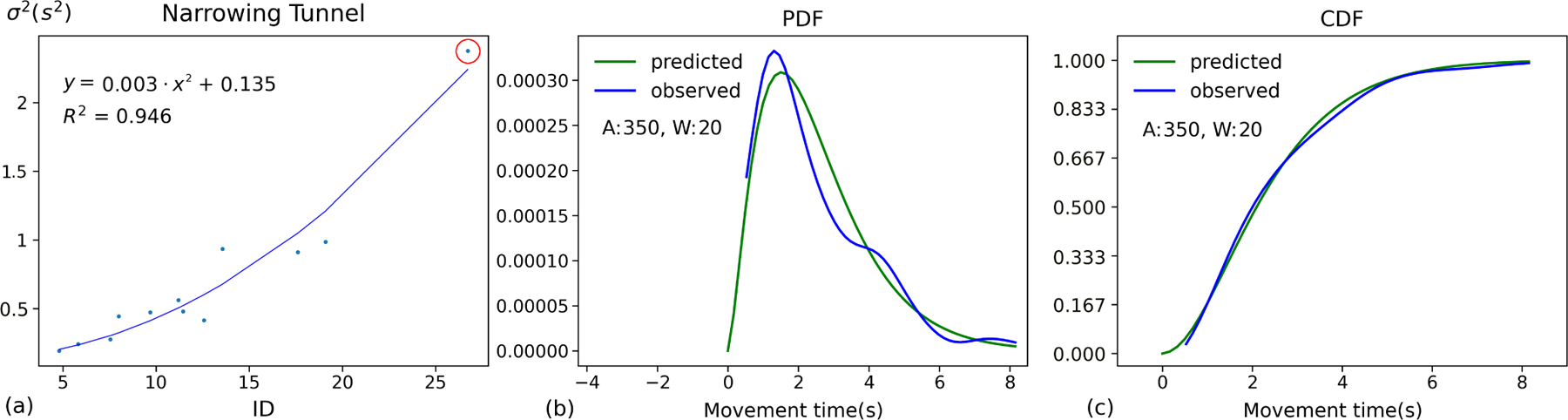
(a) An example of MT variance vs. ID Regression using quadratic variance model (Equation 2), evaluated on the steering task data collected in our user study. (b) and (c): one example of predicting MT distribution selected from the red circle in (a). The blue curve in (b) represents the observed probability density function (PDF) of MT under a particular (A, W) condition, and the green curve is the predicted PDF using the quadratic variance model (Equation 2) in a Gamma distribution. The blue curve in (c) represents the observed cumulative distribution function (CDF), and the green curve is the predicted CDF.
CCS CONCEPTS.
• Human-centered computing → Human computer interaction (HCI); User studies.
ACKNOWLEDGMENTS
We thank anonymous reviewers for their insightful comments, and our user study participants. This work was supported by NSF awards 2113485, 1815514, and NIH award R01EY030085.
9. APPENDIX
Table 8:
Fitting results for 31 distributing models on Zhou and Ren’s straight tunnel dataset. As explained in Section 4, we use Steering law (Equation 1) to predict the mean (or location) parameter, and one of the six variance models (Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, d and e are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown, the quadratic variance model (Model #4 in Table 1) has the best (or second-best) fitting results across all distribution types, measured by AIC, and WAIC.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | e | k | AIC | WAIC |
| #1. σ2 = c | Gaussian | 0.529 [0.467, 0.59] | 0.029 [0.026, 0.031] | 0.24 [0.218, 0.265] | N/A | N/A | N/A | 12336.8 | 12335.9 |
| Truncated Gaussian | 0.402 [0.31, 0.485] | 0.032 [0.029, 0.035] | 0.293 [0.258, 0.334] | N/A | N/A | N/A | 12271.1 | 12270.3 | |
| Lognormal | 0.704 [0.652, 0.756] | 0.021 [0.019, 0.023] | 0.319 [0.276, 0.37] | N/A | N/A | N/A | 12186.8 | 12184.9 | |
| Gamma | 0.681 [0.628, 0.734] | 0.022 [0.02, 0.024] | 0.25 [0.223, 0.28] | N/A | N/A | N/A | 12203.4 | 12201.5 | |
| Extreme value | 0.721 [0.669, 0.773] | 0.019 [0.017, 0.021] | 0.262 [0.235, 0.292] | N/A | N/A | N/A | 12248.0 | 12246.7 | |
| #2. σ2 = (c · ID)2 | Gaussian | 0.469 [0.417, 0.522] | 0.033 [0.028, 0.037] | 0.033 [0.031, 0.035] | N/A | N/A | N/A | 12439.5 | 12437.5 |
| Truncated Gaussian | 0.564 [0.496, 0.639] | 0.02 [0.013, 0.027] | 0.037 [0.035, 0.04] | N/A | N/A | N/A | 12357.4 | 12355.1 | |
| Lognormal | 0.32 [0.279, 0.359] | 0.045 [0.042, 0.049] | 0.036 [0.034, 0.039] | N/A | N/A | N/A | 12203.0 | 12200.1 | |
| Gamma | 0.324 [0.281, 0.366] | 0.045 [0.042, 0.049] | 0.033 [0.031, 0.035] | N/A | N/A | N/A | 12246.4 | 12243.5 | |
| Extreme value | 0.292 [0.252, 0.329] | 0.046 [0.042, 0.049] | 0.032 [0.03, 0.033] | N/A | N/A | N/A | 12262.0 | 12259.1 | |
| #3. σ2 = c + d · ID | Gaussian | 0.519 [0.465, 0.573] | 0.029 [0.026, 0.032] | 0.046 [0.009, 0.084] | 0.01 [0.008, 0.013] | N/A | N/A | 12245.1 | 12242.2 |
| Truncated Gaussian | 0.489 [0.426, 0.547] | 0.029 [0.026, 0.033] | 0.067 [0.017, 0.12] | 0.011 [0.007, 0.014] | N/A | N/A | 12218.0 | 12215.3 | |
| Lognormal | 0.527 [0.466, 0.59] | 0.029 [0.026, 0.033] | 0.046 [−0.01, 0.104] | 0.013 [0.009, 0.018] | N/A | N/A | 12131.4 | 12127.4 | |
| Gamma | 0.522 [0.468, 0.58] | 0.029 [0.026, 0.032] | 0.038 [0.0001, 0.052] | 0.011 [0.008, 0.014] | N/A | N/A | 12119.7 | 12115.6 | |
| Extreme value | 0.511 [0.456, 0.567] | 0.03 [0.026, 0.033] | 0.023 [−0.012, 0.061] | 0.012 [0.01, 0.015] | N/A | N/A | 12131.4 | 12124.6 | |
| #4. σ2 = c + d · ID2 | Gaussian | 0.531 [0.473, 0.587] | 0.029 [0.026, 0.032] | 0.133 [0.111, 0.158] | 0.0002 [0.0001, 0.0003] | N/A | N/A | 12252.0 | 12249.2 |
| Truncated Gaussian | 0.492 [0.424, 0.557] | 0.029 [0.026, 0.033] | 0.162 [0.13, 0.201] | 0.0002 [0.0001, 0.0003] | N/A | N/A | 12223.2 | 12220.7 | |
| Lognormal | 0.526 [0.465, 0.589] | 0.029 [0.026, 0.033] | 0.14 [0.102, 0.182] | 0.324 [0.211, 0.462] | N/A | N/A | 12128.4 | 12124.3 | |
| Gamma | 0.533 [0.475, 0.587] | 0.029 [0.025, 0.032] | 0.12 [0.097, 0.146] | 0.0002 [0.0002, 0.0003] | N/A | N/A | 12120.5 | 12116.2 | |
| Extreme value | 0.512 [0.452, 0.569] | 0.03 [0.026, 0.033] | 0.111 [0.088, 0.137] | 0.0003 [0.0002, 0.0004] | N/A | N/A | 12129.4 | 12124.9 | |
| exGaussian | 0.44 [0.377, 0.5] | 0.035 [0.031, 0.04] | 0.06 [0.037, 0.086] | 0.00006 [0.00004, 0.00008] | N/A | 0.04 [0.04, 0.05] | 12193.7 | 12194.7 | |
| #5. σ2 = (c + d · ID)2 | Gaussian | 0.524 [0.47, 0.582] | 0.029 [0.026, 0.032] | 0.291 [0.252, 0.332] | 0.01 [0.007, 0.012] | N/A | N/A | 12247.1 | 12244.3 |
| Truncated Gaussian | 0.491 [0.427, 0.553] | 0.029 [0.026, 0.033] | 0.325 [0.274, 0.379] | 0.009 [0.007, 0.012] | N/A | N/A | 12219.6 | 12216.9 | |
| Lognormal | 0.52 [0.458, 0.579] | 0.03 [0.026, 0.033] | 0.286 [0.222, 0.348] | 0.013 [0.009, 0.017] | N/A | N/A | 12128.5 | 12124.4 | |
| Gamma | 0.523 [0.471, 0.579] | 0.029 [0.026, 0.032] | 0.269 [0.224, 0.315] | 0.011 [0.008, 0.014] | N/A | N/A | 12118.5 | 12114.3 | |
| Extreme value | 0.508 [0.456, 0.564] | 0.03 [0.027, 0.033] | 0.252 [0.212, 0.298] | 0.012 [0.01, 0.015] | N/A | N/A | 12127.9 | 12123.8 | |
| #6. σ2 = c + d · ID + e · ID2 | Gaussian | 0.522 [0.465, 0.578] | 0.029 [0.026, 0.032] | 0.069 [0.023, 0.134] | 0.007 [0.0001, 0.01] | 0.00007 [0.000002, 0.0002] | N/A | 12248.5 | 12243.8 |
| Truncated Gaussian | 0.49 [0.424, 0.553] | 0.029 [0.026, 0.033] | 0.099 [0.031, 0.188] | 0.007 [−0.002, 0.013] | 0.00008 [0.000003, 0.0003] | N/A | 12221.9 | 12217.8 | |
| Lognormal | 0.525 [0.462, 0.588] | 0.03 [0.026, 0.033] | 0.123 [0.028, 0.228] | 0.002 [−0.01, 0.014] | 0.0003 [0.000009, 0.0006] | N/A | 12131.2 | 12126.1 | |
| Gamma | 0.525 [0.469, 0.581] | 0.029 [0.026, 0.032] | 0.082 [0.022, 0.156] | 0.005 [−0.004, 0.011] | 0.0001 [0.00001, 0.0003] | N/A | 12121.5 | 12116.1 | |
| Extreme value | 0.509 [0.453, 0.565] | 0.03 [0.027, 0.033] | 0.077 [0.013,0.151] | 0.005 [−0.005, 0.013] | 0.0002 [0.000002, 0.0004] | N/A | 12131.1 | 12125.4 | |
Table 9:
Fitting results for 31 Zhou and Ren’s circular tunnel dataset. As explained in Section 4, we use Steering law (Equation 1) to predict the mean (or location) parameter, and one of the six variance models (Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, d and e are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown, the quadratic variance model (Model #4 in Table 1) has the best fitting results across all distribution types, measured by AIC, and WAIC.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | e | k | AIC | WAIC |
| #1. σ2 = c | Gaussian | 0.65 [0.55, 0.75] | 0.084 [0.08, 0.089] | 0.617 [0.559, 0.681] | N/A | N/A | N/A | 13103.7 | 13102.0 |
| Truncated Gaussian | 0.538 [0.421, 0.65] | 0.088 [0.083, 0.092] | 0.69 [0.617, 0.771] | N/A | N/A | N/A | 13066.4 | 13064.3 | |
| Lognormal | 0.88 [0.80, 0.97] | 0.075 [0.071, 0.079] | 0.825 [0.722, 0.941] | N/A | N/A | N/A | 13022.3 | 13022.8 | |
| Gamma | 0.84 [0.76, 0.93] | 0.076 [0.072, 0.080] | 0.665 [0.595, 0.742] | N/A | N/A | N/A | 13025.3 | 13024.3 | |
| Extreme value | 1.024 [0.928, 1.123] | 0.68 [0.063, 0.072] | 0.901 [0.815, 0.996] | N/A | N/A | N/A | 13154.4 | 13157.9 | |
| #2. σ2 = (c · ID)2 | Gaussian | 0.56 [0.46, 0.65] | 0.090 [0.082, 0.099] | 0.058 [0.056, 0.061] | N/A | N/A | N/A | 13356.1 | 13354.9 |
| Truncated Gaussian | 0.612 [0.507, 0.716] | 0.083 [0.073, 0.092] | 0.062 [0.058, 0.066] | N/A | N/A | N/A | 13322.9 | 13321.5 | |
| Lognormal | 0.24 [0.17, 0.31] | 0.12 [0.11, 0.12] | 0.056 [0.053, 0.060] | N/A | N/A | N/A | 13077.3 | 13074.8 | |
| Gamma | 0.27 [0.20, 0.35] | 0.11 [0.11, 0.12] | 0.054 [0.052, 0.058] | N/A | N/A | N/A | 13140.9 | 13138.5 | |
| Extreme value | 0.22 [0.159, 0.282] | 0.114 [0.109, 0.12] | 0.052 [0.049, 0.054] | N/A | N/A | N/A | 13081.6 | 12078.9 | |
| #3. σ2 = c + d · ID | Gaussian | 0.64 [0.54, 0.73] | 0.085 [0.080, 0.90] | 0.269 [0.179, 0.362] | 0.02 [0.01, 0.03] | N/A | N/A | 13057.2 | 13053.7 |
| Truncated Gaussian | 0.583 [0.48, 0.68] | 0.087 [0.082, 0.092] | 0.345 [0.233, 0.469] | 0.016 [0.01, 0.023] | N/A | N/A | 13040.2 | 13037.0 | |
| Lognormal | 0.62 [0.53, 0.72] | 0.086 [0.081, 0.092] | 0.166 [0.0445, 0.306] | 0.03 [0.02, 0.04] | N/A | N/A | 12965.4 | 12963.3 | |
| Gamma | 0.63 [0.54, 0.72] | 0.085 [0.080, 0.091] | 0.171 [0.0781, 0.273] | 0.02 [0.175, 0.031] | N/A | N/A | 12956.8 | 12953.8 | |
| Extreme value | 0.578 [0.487, 0.67] | 0.089 [0.084, 0.095] | 0.003 [−0.081, 0.093] | 0.042 [0.035, 0.049] | N/A | N/A | 12985.3 | 12985.1 | |
| #4. σ2 = c + d · ID2 | Gaussian | 0.65 [0.55, 0.74] | 0.085 [0.080, 0.090] | 0.419 [0.356, 0.489] | 0.0004 [0.0003, 0.0006] | N/A | N/A | 13058.7 | 13055.4 |
| Truncated Gaussian | 0.587 [0.48, 0.69] | 0.086 [0.081, 0.092] | 0.483 [0.406, 0.574] | 0.0003 [0.0002, 0.0005] | N/A | N/A | 13040.1 | 13036.9 | |
| Lognormal | 0.61 [0.51, 0.71] | 0.087 [0.081, 0.093] | 0.360 [0.274, 0.463] | 0.0008 [0.0006, 0.001] | N/A | N/A | 12959.3 | 12957.5 | |
| Gamma | 0.64 [0.54, 0.73] | 0.085 [0.080, 0.091] | 0.344 [0.276, 0.417] | 0.0006 [0.0004, 0.0008] | N/A | N/A | 12954.4 | 12951.5 | |
| Extreme value | 0.55 [0.46, 0.65] | 0.091 [0.085, 0.097] | 0.258 [0.196, 0.327] | 0.0011 [0.0009, 0.0014] | N/A | N/A | 12974.1 | 12971.1 | |
| exGaussian | 0.342 [0.131, 0.652] | 0.107 [0.085, 0.124] | 0.119 [0.001, 0.369] | 0.0002 [0.00006, 0.0004] | N/A | 0.03 [0.02, 0.05] | 13039.6 | 13074.5 | |
| #5. = (c + d · ID)2 | Gaussian | 0.64 [0.55, 0.73] | 0.085 [0.080, 0.090] | 0.56 [0.50, 0.63] | 0.011 [0.008, 0.015] | N/A | N/A | 13057.2 | 13053.7 |
| Truncated Gaussian | 0.585 [0.477, 0.683] | 0.087 [0.082, 0.092] | 0.615 [0.538, 0.697] | 0.01 [0.006, 0.013] | N/A | N/A | 13039.9 | 13036.6 | |
| Lognormal | 0.60 [0.50, 0.70] | 0.087 [0.082, 0.094] | 0.48 [0.39, 0.57] | 0.019 [0.014, 0.024] | N/A | N/A | 12961.8 | 12960.2 | |
| Gamma | 0.63 [0.53, 0.72] | 0.086 [0.080, 0.091] | 0.48 [0.41, 0.56] | 0.015 [0.012, 0.020] | N/A | N/A | 12954.9 | 12952.1 | |
| Extreme value | 0.546 [0.453, 0.642] | 0.091 [0.085, 0.097] | 0.356 [0.28, 0.434] | 0.026 [0.022, 0.031] | N/A | N/A | 12976.9 | 12974.9 | |
| #6. σ2 = c + d · ID + e · ID2 | Gaussian | 0.64 [0.55, 0.74] | 0.085 [0.080, 0.090] | 0.358 [0.221, 0.521] | 0.007 [−0.102, 0.021] | 0.0003 [0.00001, 0.0006] | N/A | 13060.2 | 13055.4 |
| Truncated Gaussian | 0.587 [0.469, 0.7] | 0.087 [0.081, 0.092] | 0.477 [0.0.299, 0.7] | 0.0004 [−0.022, 0.017] | 0.0003 [0.00002, 0.0008] | N/A | 13042.7 | 13038.1 | |
| Lognormal | 0.61 [0.52, 0.72] | 0.087 [0.081, 0.093] | 0.454 [0.174, 0.766] | −0.012 [−0.047, 0.022] | 0.001 [0.0002, 0.002] | N/A | 12962.2 | 12960.2 | |
| Gamma | 0.63 [0.54, 0.73] | 0.086 [0.080, 0.091] | 0.326 [0.147, 0.539] | 0.002 [−0.02, 0.02] | 0.0005 [0.00005, 0.001] | N/A | 12957.2 | 12953.3 | |
| Extreme value | 0.551 [0.456, 0.65] | 0.091 [0.085, 0.098] | 0.3 [0.118, 0.499] | −0.006 [−0.032, 0.02] | 0.001 [0.0006, 0.002] | N/A | 12976.9 | 12973.7 | |
Table 10:
Fitting results for 31 straight tunnel dataset. As explained in Section 4, we use Steering law (Equation 1) to predict the mean (or location) parameter, and one of the six variance models (Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, d and e are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown, the quadratic variance model (Model #4 in Table 1) has the best (or second-best) fitting results across all distribution types, measured by AIC, and WAIC.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | e | k | AIC | WAIC |
| #1. σ2 = c | Gaussian | −0.11 [−0.23, 0.005] | 0.084 [0.078, 0.091] | 0.991 [0.92, 1.069] | N/A | N/A | N/A | 23972.6 | 23972.2 |
| Truncated Gaussian | −4.96 [−6.41, −3.84] | 0.23 [0.196, 0.273] | 1.834 [1.643, 2.054] | N/A | N/A | N/A | 23008.5 | 23005.6 | |
| Lognormal | 0.42 [0.36, 0.5] | 0.056 [0.051, 0.06] | 1.545 [1.318, 1.817] | N/A | N/A | N/A | 22796.5 | 22793.4 | |
| Gamma | 0.57 [0.50, 0.65] | 0.047 [0.042, 0.052] | 0.972 [0.882, 1.0729] | N/A | N/A | N/A | 23021.4 | 23018.5 | |
| Extreme value | 0.424 [0.348, 0.504] | 0.048 [0.044, 0.053] | 0.645 [0.59, 0.708] | N/A | N/A | N/A | 23310.1 | 23307.5 | |
| #2. σ2 = (c · ID)2 | Gaussian | −0.1 [−0.18, −0.021] | 0.083 [0.077, 0.09] | 0.055 [0.053, 0.057] | N/A | N/A | N/A | 23370.5 | 23367.8 |
| Truncated Gaussian | −0.249 [−0.464, −0.044] | 0.035 [0.011, 0.055] | 0.087 [0.079, 0.096] | N/A | N/A | N/A | 22893.9 | 22890.8 | |
| Lognormal | −0.1 [−0.16, −0.055] | 0.085 [0.080, 0.091] | 0.068 [0.064, 0.074] | N/A | N/A | N/A | 22711.5 | 22708.0 | |
| Gamma | −0.086 [−0.14, −0.033] | 0.082 [0.077, 0.088] | 0.053 [0.051, 0.056] | N/A | N/A | N/A | 22730.5 | 22726.7 | |
| Extreme value | −0.086 [−0.145, −0.031] | 0.08 [0.075, 0.085] | 0.049 [0.046, 0.051] | N/A | N/A | N/A | 22907.8 | 22904.6 | |
| #3. σ2 = c + d · ID | Gaussian | −0.095 [−0.17, −0.021] | 0.083 [0.077, 0.089] | −0.457 [−0.518, −0.396] | 0.0837 [0.0761, 0.0918] | N/A | N/A | 23389.8 | 23386.4 |
| Truncated Gaussian | −1.269 [−1.949, −0.693] | 0.093 [0.064, 0.123] | −0.473 [−0.809, −0.085] | 0.163 [0.128, 0.203] | N/A | N/A | 22901.4 | 22897.2 | |
| Lognormal | −0.072 [−0.15, 0.013] | 0.083 [0.076, 0.09] | −0.633 [−0.827, −0.437] | 1.216 [0.099, 1.477] | N/A | N/A | 22698.7 | 22694.2 | |
| Gamma | −0.059 [−0.13, 0.013] | 0.081 [0.075, 0.087] | −0.4 [−0.475, −0.325] | 0.076 [0.067, 0.085] | N/A | N/A | 22733.8 | 22729.2 | |
| Extreme value | −0.058 [−0.119, 0.008] | 0.078 [0.073, 0.083] | −0.327 [−0.381, −0.272] | 0.062 [0.055, 0.069] | N/A | N/A | 22915.3 | 22908.4 | |
| #4. σ2 = c + d · ID2 | Gaussian | −0.1 [−0.18, −0.025] | 0.083 [0.077, 0.091] | −0.019 [−0.051, 0.016] | 0.003 [0.003, 0.004] | N/A | N/A | 23371.9 | 23368.4 |
| Truncated Gaussian | −0.448 [−1.059, 0.031] | 0.047 [0.008, 0.081] | 0.098 [−0.106, 0.371] | 0.007 [0.005, 0.009] | N/A | N/A | 22896.4 | 22891.7 | |
| Lognormal | −0.14 [−0.23, −0.028] | 0.088 [0.08, 0.097] | −0.053 [−0.165, 0.118] | 0.005 [0.004, 0.007] | N/A | N/A | 22713.5 | 22709.0 | |
| Gamma | −0.11 [−0.18, −0.034] | 0.084 [0.078, 0.091] | −0.022 [−0.061, 0.026] | 0.003 [0.0026, 0.0034] | N/A | N/A | 22732.1 | 22727.4 | |
| Extreme value | −0.108 [−0.175, −0.04] | 0.082 [0.076, 0.088] | −0.016 [−0.045, 0.018] | 0.002 [0.002, 0.003] | N/A | N/A | 22909.5 | 22905.1 | |
| exGaussian | −0.056 [−0.092, −0.022] | 0.08 [0.076, 0.084] | 0.0004 [0.00001, 0.001] | 0.004 [0.0003, 0.004] | N/A | 0.02 [0.02, 0.002] | 22692.1 | 22685.9 | |
| #5. σ2 = (c + d · ID)2 | Gaussian | −0.1 [−0.17, −0.022] | 0.083 [0.077, 0.09] | −0.025 [−0.082, 0.035] | 0.057 [0.052, 0.062] | N/A | N/A | 23372.5 | 23369.1 |
| Truncated Gaussian | 0.071 [0.003, 0.217] | 0.012 [0.0006, 0.027] | −0.123 [−0.22, −0.024] | 0.096 [0.085, 0.11] | N/A | N/A | 22898.6 | 22893.3 | |
| Lognormal | −0.078 [−0.19, 0.034] | 0.084 [0.075, 0.092] | 0.057 [−0.12, 0.26] | 0.065 [0.05, 0.079] | N/A | N/A | 22714.1 | 22709.6 | |
| Gamma | −0.093 [−0.17, −0.015] | 0.083 [0.076, 0.089] | −0.01 [−0.084, 0.072] | 0.054 [0.048, 0.061] | N/A | N/A | 22733.3 | 22728.5 | |
| Extreme value | −0.097 [−0.166, −0.03] | 0.081 [0.075, 0.087] | −0.014 [−0.077, 0.047] | 0.05 [0.045, 0.055] | N/A | N/A | 22910.5 | 22906.4 | |
| #6. σ2 = c + d · ID + e · ID2 | Gaussian | −0.099 [−0.18, −0.026] | 0.083 [0.077, 0.09] | −0.103 [−0.279, 0.081] | 0.016 [−0.018, 0.049] | 0.003 [0.001, 0.004] | N/A | 23373.7 | 23369.4 |
| Truncated Gaussian | −0.64 [−1.38, −0.024] | 0.058 [0.013, 0.098] | −0.073 [−0.533, 0.426] | 0.045 [−0.059, 0.149] | 0.005 [0.0008, 0.01] | N/A | 22898.7 | 22893.0 | |
| Lognormal | −0.094 [−0.18, −0.007] | 0.085 [0.078, 0.092] | −0.535 [−0.773, −0.292] | 0.099 [0.055, 0.135] | 0.001 [0.00005, 0.003] | N/A | 22701.1 | 22694.6 | |
| Gamma | −0.095 [−0.17, −0.024] | 0.083 [0.077, 0.09] | −0.21 [−0.353, −0.068] | 0.037 [0.009, 0.063] | 0.002 [0.0006, 0.003] | N/A | 22728.1 | 22722.0 | |
| Extreme value | −0.093 [−0.157, −0.023] | 0.081 [0.075, 0.086] | −0.147 [−0.273, −0.022] | 0.025 [0.002, 0.049] | 0.001 [0.0006, 0.003] | N/A | 22907.6 | 22904.1 | |
Table 11:
Fitting results for 31 narrowing tunnel dataset. As explained in Section 4, we use Steering law (Equation 1) to predict the mean (or location) parameter, and one of the six variance models (Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, d and e are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown, the quadratic variance model (Model #4 in Table 1) has the best fitting results across all distribution types, measured by AIC, and WAIC.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | e | k | AIC | WAIC |
| #1. σ2 = c | Gaussian | 0.42 [0.32, 0.52] | 0.073 [0.066, 0.080] | 0.719 [0.667, 0.776] | N/A | N/A | N/A | 23491.6 | 23491.4 |
| Truncated Gaussian | −0.71 [−1.028, −0.433] | 0.119 [0.105, 0.135] | 1.159 [1.084, 1.248] | N/A | N/A | N/A | 23071.0 | 23069.5 | |
| Lognormal | 0.75 [0.67, 0.82] | 0.051 [0.046, 0.057] | 1.208 [1.0437, 1.400] | N/A | N/A | N/A | 22988.7 | 22985.9 | |
| Gamma | 0.80 [0.73, 0.88] | 0.045 [0.039, 0.051] | 0.755 [0.687, 0.830] | N/A | N/A | N/A | 22997.6 | 22994.7 | |
| Extreme value | 0.786 [0.716, 0.855] | 0.042 [0.037, 0.047] | 0.617 [0.567, 0.67] | N/A | N/A | N/A | 23113.2 | 23110.3 | |
| #2. σ2 = (c · ID)2 | Gaussian | 0.33 [0.26, 0.41] | 0.081 [0.072, 0.090] | 0.071 [0.068, 0.073] | N/A | N/A | N/A | 23245.2 | 23242.5 |
| Truncated Gaussian | 0.511 [0.39, 0.632] | 0.035 [0.018, 0.052] | 0.09 [0.084, 0.096] | N/A | N/A | N/A | 22980.2 | 22977.2 | |
| Lognormal | 0.12 [0.064, 0.18] | 0.107 [0.1, 0.114] | 0.951 [0.088, 0.102] | N/A | N/A | N/A | 22994.9 | 22992.1 | |
| Gamma | 0.13 [0.715, 0.191] | 0.102 [0.095, 0.109] | 0.074 [0.702, 0.077] | N/A | N/A | N/A | 22920.5 | 22917.3 | |
| Extreme value | 0.142 [0.085, 0.203] | 0.099 [0.092, 0.106] | 0.07 [0.067, 0.073] | N/A | N/A | N/A | 23014.0 | 23010.7 | |
| #3. σ2 = c + d · ID | Gaussian | 0.366 [0.284, 0.442] | 0.078 [0.07, 0.085] | −0.146 [−0.21, −0.077] | 0.068 [0.059, 0.077] | N/A | N/A | 23183.9 | 23180.2 |
| Truncated Gaussian | 0.238 [0.079, 0.377] | 0.066 [0.052, 0.08] | −0.209 [−0.366, −0.042] | 0.104 [0.084, 0.127] | N/A | N/A | 22953.1 | 22948.8 | |
| Lognormal | 0.447 [0.333, 0.568] | 0.074 [0.064, 0.084] | 0.136 [−0.141, 0.461] | 0.081 [0.052, 0.111] | N/A | N/A | 22957.3 | 22953.1 | |
| Gamma | 0.394 [0.310, 0.478] | 0.075 [0.068, 0.083] | −0.06 [−0.16, 0.043] | 0.063 [0.052, 0.075] | N/A | N/A | 22869.4 | 22864.8 | |
| Extreme value | 0.405 [0.325, 0.486] | 0.073 [0.066, 0.08] | −0.064 [−0.141, 0.02] | 0.058 [0.048, 0.068] | N/A | N/A | 22949.3 | 22939.3 | |
| #4. σ2 = c + d · ID2 | Gaussian | 0.365 [0.282, 0.450] | 0.078 [0.07, 0.086] | 0.158 [0.109, 0.209] | 0.003 [0.003, 0.004] | N/A | N/A | 23179.9 | 23176.1 |
| Truncated Gaussian | 0.257 [0.08, 0.422] | 0.066 [0.048, 0.082] | 0.26 [0.156, 0.395] | 0.005 [0.003, 0.006] | N/A | N/A | 22955.6 | 22951.2 | |
| Lognormal | 0.454 [0.338, 0.575] | 0.074 [0.064, 0.085] | 0.565 [0.354, 0.789] | 0.003 [0.002, 0.005] | N/A | N/A | 22956.1 | 22951.7 | |
| Gamma | 0.378 [0.289, 0.47] | 0.077 [0.068, 0.086] | 0.226 [0.157, 0.302] | 0.003 [0.002, 0.004] | N/A | N/A | 22866.0 | 22861.2 | |
| Extreme value | 0.372 [0.281, 0.457] | 0.077 [0.068, 0.085] | 0.19 [0.134, 0.249] | 0.003 [0.002, 0.003] | N/A | N/A | 22948.3 | 22943.6 | |
| exGaussian | 0.223 [0.153, 0.298] | 0.092 [0.084, 0.1] | 0.055 [0.037, 0.075] | 0.005 [0.005, 0.006] | N/A | 0.01 [0.01, 0.01] | 22943.5 | 22937.3 | |
| #5. σ2 = (c + d · ID)2 | Gaussian | 0.364 [0.283, 0.449] | 0.078 [0.07, 0.086] | 0.237 [0.18, 0.3] | 0.046 [0.04, 0.052] | N/A | N/A | 23177.0 | 23173.2 |
| Truncated Gaussian | 0.247 [0.071, 0.403] | 0.066 [0.051, 0.081] | 0.317 [0.207, 0.438] | 0.055 [0.044, 0.066] | N/A | N/A | 22952.4 | 22948.2 | |
| Lognormal | 0.421 [0.278, 0.565] | 0.077 [0.064, 0.09] | 0.527 [0.331, 0.74] | 0.042 [0.025, 0.06] | N/A | N/A | 22955.6 | 22951.7 | |
| Gamma | 0.373 [0.286, 0.462] | 0.078 [0.069, 0.086] | 0.309 [0.224, 0.397] | 0.042 [0.033, 0.05] | N/A | N/A | 22863.6 | 22859.0 | |
| Extreme value | 0.377 [0.295, 0.46] | 0.076 [0.068, 0.084] | 0.285 [0.215, 0.354] | 0.041 [0.034, 0.047] | N/A | N/A | 22944.3 | 22939.8 | |
| #6. σ2 = c + d · ID + e · ID2 | Gaussian | 0.365 [0.285, 0.444] | 0.078 [0.07, 0.086] | 0.034 [−0.116, 0.208] | 0.027 [−0.009, 0.058] | 0.002 [0.0005, 0.004] | N/A | 23179.9 | 23175.2 |
| Truncated Gaussian | 0.262 [0.095, 0.418] | 0.065 [0.049, 0.079] | −0.017 [−0.255, 0.275] | 0.058 [−0.0004, 0.105] | 0.002 [0.0002, 0.005] | N/A | 22954.1 | 22948.7 | |
| Lognormal | 0.437 [0.323, 0.554] | 0.076 [0.065, 0.086] | 0.341 [0.05, 0.666] | 0.038 [0.002, 0.081] | 0.002 [0.0001,0.004] | N/A | 22957.5 | 22951.5 | |
| Gamma | 0.373 [0.285, 0.464] | 0.077 [0.069, 0.086] | 0.106 [−0.054, 0.288] | 0.024 [−0.011, 0.055] | 0.002 [0.0005, 0.003] | N/A | 22866.6 | 22860.5 | |
| Extreme value | 0.378 [0.294, 0.46] | 0.076 [0.068, 0.084] | 0.061 [−0.074, 0.206] | 0.028 [−0.0005, 0.055] | 0.001 [0.0002, 0.003] | N/A | 22947.2 | 22939.7 | |
Table 12:
Fitting results for 31 circular tunnel dataset. As explained in Section 4, we use Steering law (Equation 1) to predict the mean (or location) parameter, and one of the six variance models (Table 1) to predict the variance (or scale) parameter, as explained in Table 2. a and b are parameters of Steering law, and c, d and e are parameters of variance models. Parameter estimations are shown in mean and 95% credible interval of posterior distributions. Fitness results are reported in AIC and WAIC metrics. As shown, the quadratic variance model (Model #4 in Table 1) and the quadratic variance model without constant term (Model #2 in Table 1) has the best (or second-best) fitting results across all distribution types, measured by AIC, and WAIC.
| Model | Model Parameters (Mean and 95% Credible Interval) | Information Criteria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Variance Model | Distribution Type | a | b | c | d | e | k | AIC | WAIC |
| #1. σ2 = c | Gaussian | −0.336 [−0.487, −0.171] | 0.301 [0.292, 0.31] | 1.89 [1.756, 2.032] | N/A | N/A | N/A | 24901.4 | 24900.9 |
| Truncated Gaussian | −0.717 [−0.917, −0.518] | 0.318 [0.306, 0.329] | 2.145 [1.97, 2.334] | N/A | N/A | N/A | 24788.8 | 24788.4 | |
| Lognormal | 0.756 [0.619, 0.891] | 0.24 [0.231, 0.249] | 2.443 [2.212, 2.698] | N/A | N/A | N/A | 24634.7 | 24633.0 | |
| Gamma | 0.587 [0.444, 0.736] | 0.251 [0.241, 0.26] | 2.085 [1.92, 2.259] | N/A | N/A | N/A | 24768.0 | 24766.9 | |
| Extreme value | 0.961 [0.83, 1.089] | 0.215 [0.207, 0.223] | 2.152 [1.996, 2.342] | N/A | N/A | N/A | 24822.0 | 24821.5 | |
| #2. σ2 = (c · ID)2 | Gaussian | −0.0005 [−0.097, 0.102] | 0.276 [0.267, 0.286] | 0.083 [0.08, 0.086] | N/A | N/A | N/A | 24251.3 | 24248.5 |
| Truncated Gaussian | −0.003 [−0.103, 0.102] | 0.276 [0.267, 0.286] | 0.083 [0.08, 0.086] | N/A | N/A | N/A | 24250.1 | 24247.2 | |
| Lognormal | −0.0106 [−0.105, 0.086] | 0.278 [0.268, 0.287] | 0.086 [0.083, 0.09] | N/A | N/A | N/A | 24174.5 | 24171.4 | |
| Gamma | −0.007 [−0.1, 0.087] | 0.277 [0.268, 0.286] | 0.083 [0.08, 0.086] | N/A | N/A | N/A | 24163.3 | 24160.0 | |
| Extreme value | −0.006 [−0.097, 0.084] | 0.278 [0.269, 0.287] | 0.09 [0.087, 0.094] | N/A | N/A | N/A | 24194.0 | 24190.6 | |
| #3. σ2 = c + d · ID | Gaussian | −0.038 [−0.143, 0.065] | 0.281 [0.272, 0.29] | −0.681 [−0.778, −0.577] | 0.157 [0.143, 0.172] | N/A | N/A | 24295.9 | 24292.4 |
| Truncated Gaussian | −0.039 [−0.139, 0.059] | 0.281 [0.272, 0.29] | −0.686 [−0.792, −0.584] | 0.158 [0.144, 0.174] | N/A | N/A | 24293.5 | 24289.8 | |
| Lognormal | 0.029 [−0.004, 0.127] | 0.276 [0.267, 0.285] | −0.787 [−0.918, −0.656] | 0.177 [0.158, 0.198] | N/A | N/A | 24202.6 | 24198.3 | |
| Gamma | 0.012 [−0.085, 0.106] | 0.277 [0.269, 0.286] | −0.713 [−0.815, −0.608] | 0.161 [0.146, 0.176] | N/A | N/A | 24199.7 | 24195.5 | |
| Extreme value | 0.065 [−0.03, 0.164] | 0.273 [0.264, 0.282] | −0.844 [−0.972, −0.716] | 0.191 [0.173, 0.21] | N/A | N/A | 24238.8 | 24237.2 | |
| #4. σ2 = c + d · ID2 | Gaussian | −0.005 [−0.11, 0.099] | 0.277 [0.267, 0.286] | 0.033 [−0.026, 0.102] | 0.007 [0.006, 0.007] | N/A | N/A | 24253.4 | 24249.7 |
| Truncated Gaussian | −0.013 [−0.122, 0.097] | 0.277 [0.267, 0.287] | 0.035 [−0.21, 0.103] | 0.007 [0.006, 0.007] | N/A | N/A | 24252.2 | 24248.3 | |
| Lognormal | −0.008 [−0.104, 0.095] | 0.278 [0.268, 0.287] | 0.002 [−0.07, 0.077] | 0.007 [0.007, 0.008] | N/A | N/A | 24177.5 | 24172.9 | |
| Gamma | −0.006 [−0.11, 0.097] | 0.277 [0.267, 0.287] | 0.012 [−0.043, 0.075] | 0.0068 [0.006, 0.008] | N/A | N/A | 24166.3 | 24161.8 | |
| Extreme value | −0.009 [−0.115, 0.098] | 0.278 [0.269, 0.289] | −0.006 [−0.074, 0.067] | 0.008 [0.007, 0.009] | N/A | N/A | 24197.0 | 24192.4 | |
| exGaussian | −0.012 [−0.112, 0.09] | 0.277 [0.268, 0.287] | 0.023 [0.0008, 0.067] | 0.007 [0.006, 0.008] | N/A | 0.02 [0.02, 0.02] | 24210.8 | 24204.7 | |
| #5. σ2 = (c + d · ID)2 | Gaussian | −0.008 [−0.112, 0.096] | 0.277 [0.267, 0.286] | 0.037 [−0.035,0.112] | 0.08 [0.07, 0.09] | N/A | N/A | 24253.3 | 24249.3 |
| Truncated Gaussian | −0.01 [−0.118, 0.097] | 0.277 [0.267, 0.287] | 0.039 [−0.035, 0.12] | 0.08 [0.073, 0.087] | N/A | N/A | 24252.3 | 24248.4 | |
| Lognormal | −0.002 [−0.104, 0.102] | 0.277 [0.267, 0.287] | 0.012 [−0.075, 0.102] | 0.085 [0.077, 0.094] | N/A | N/A | 24177.5 | 24173.1 | |
| Gamma | −0.003 [−0.106, 0.1] | 0.277 [0.267, 0.287] | 0.018 [−0.058, 0.095] | 0.081 [0.074, 0.089] | N/A | N/A | 24166.3 | 24161.9 | |
| Extreme value | −0.006 [−0.113, 0.101] | 0.278 [0.268, 0.288] | −0.005 [−0.087, 0.086] | 0.091 [0.083, 0.099] | N/A | N/A | 24197.0 | 24192.4 | |
| #6. σ2 = c+ d · ID + e · ID2 | Gaussian | −0.008 [−0.112, 0.097] | 0.277 [0.267, 0.287] | 0.072 [−0.178, 0.338] | −0.008 [−0.061, 0.044] | 0.007 [0.005, 0.01]] | N/A | 24256.3 | 24251.4 |
| Truncated Gaussian | −0.008 [−0.11, 0.096] | 0.277 [0.267, 0.286] | 0.08 [−0.18, 0.367] | −0.009 [−0.069, 0.041] | 0.007 [0.005, 0.01] | N/A | 24255.0 | 24250.0 | |
| Lognormal | −0.003 [−0.098, 0.102] | 0.277 [0.267, 0.287] | −0.121 [−0.403, 0.171] | 0.027 [−0.034, 0.086] | 0.006 [0.004, 0.009] | N/A | 24179.5 | 24173.7 | |
| Gamma | −0.003 [−0.101, 0.093] | 0.277 [0.268, 0.286] | −0.043 [−0.298, 0.209] | 0.012 [−0.04, 0.065] | 0.006 [0.004, 0.009] | N/A | 24169.0 | 24163.2 | |
| Extreme value | −0.006 [−0.117, 0.104] | 0.278 [0.268, 0.289] | −0.058 [−0.334, 0.222] | 0.011 [−0.049, 0.069] | 0.008 [0.005, 0.011] | N/A | 24200.0 | 24193.7 | |
10. APPENDIX
This is the Stan code fitting the movement time data with Gamma distribution and quadratic variance model (Model #4 in Table 1). We assumed the mean is expressed by Steering law: M = a + b · ID and the variance is expressed by quadratic variance model: V = c + d · ID2.

|
Contributor Information
Michael Wang, University of Maryland and Stony Brook University, College Park and Stony Brook, MD and NY, USA.
Hang Zhao, Stony Brook University, Stony Brook, NY, USA.
Xiaolei Zhou, Capital University of Economics and Business, Beijing, China.
Xiangshi Ren, Kochi University of Technology, Kami, Kochi, Japan.
Xiaojun Bi, Stony Brook University, Stony Brook, NY, USA.
REFERENCES
- [1].Accot Johnny and Zhai Shumin. 1997. Beyond Fitts’ Law: Models for Trajectory-Based HCI Tasks. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (Atlanta, Georgia, USA) (CHI ‘97). Association for Computing Machinery, New York, NY, USA, 295–302. 10.1145/258549.258760 [DOI] [Google Scholar]
- [2].Accot Johnny and Zhai Shumin. 1999. Performance Evaluation of Input Devices in Trajectory-Based Tasks: An Application of the Steering Law. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Pittsburgh, Pennsylvania, USA) (CHI ‘99). Association for Computing Machinery, New York, NY, USA, 466–472. 10.1145/302979.303133 [DOI] [Google Scholar]
- [3].Ahlström David. 2005. Modeling and Improving Selection in Cascading Pull-down Menus Using Fitts’ Law, the Steering Law and Force Fields. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Portland, Oregon, USA) (CHI ‘05). Association for Computing Machinery, New York, NY, USA, 61–70. 10.1145/1054972.1054982 [DOI] [Google Scholar]
- [4].Bateman Scott, Doucette Andre, Xiao Robert, Gutwin Carl, Mandryk Regan L, and Cockburn Andy. 2011. Effects of view, input device, and track width on video game driving.. In Graphics Interface, Vol. 2011. 207–214. [Google Scholar]
- [5].Carpenter Bob, Gelman Andrew, Hoffman Matthew, Lee Daniel, Goodrich Ben, Betancourt Michael, Brubaker Marcus, Guo Jiqiang, Li Peter, and Riddell Allen. 2017. Stan : A Probabilistic Programming Language. Journal of Statistical Software 76 (01 2017). 10.18637/jss.v076.i01 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Chapuis Olivier, Blanch Renaud, and Beaudouin-Lafon Michel. 2007. Fitts’ Law in the Wild: A Field Study of Aimed Movements. Technical Report. https://hal.archives-ouvertes.fr/hal-00612026 LRI Technical Repport Number 1480, Univ. Paris-Sud, 11 pages.
- [7].Davis Richard A, Lii Keh-Shin, and Politis Dimitris N. 2011. Remarks on some nonparametric estimates of a density function. In Selected Works of Murray Rosenblatt. Springer, 95–100. [Google Scholar]
- [8].DRURY CG. 1971. Movements with Lateral Constraint. Ergonomics 14, 2 (1971), 293–305. 10.1080/00140137108931246arXiv:10.1080/00140137108931246. [DOI] [PubMed] [Google Scholar]
- [9].Fitts Paul M. 1954. The information capacity of the human motor system in controlling the amplitude of movement. Journal of experimental psychology 47, 6 (1954), 381. [PubMed] [Google Scholar]
- [10].Gelman Andrew, Hwang Jessica, and Vehtari Aki. 2014. Understanding predictive information criteria for Bayesian models. Statistics and computing 24, 6 (2014), 997–1016. [Google Scholar]
- [11].Gori Julien. 2018. Modeling the speed-accuracy tradeoff using the tools of information theory. Theses. Université Paris-Saclay. https://pastel.archives-ouvertes.fr/tel-02005752 [Google Scholar]
- [12].Gori Julien and Rioul Olivier. 2019. Regression to a linear lower bound with outliers: An exponentially modified Gaussian noise model. Ph.D. Dissertation. https://hal.archives-ouvertes.fr/hal-02191051 [Google Scholar]
- [13].Jaynes Edwin T. 1957. Information theory and statistical mechanics. Physical review 106, 4 (1957), 620. [Google Scholar]
- [14].Jude Alvin, Guinness Darren, and Poor G Michael. 2016. Reporting and Visualizing Fitts’s Law: Dataset, Tools and Methodologies. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems. 2519–2525. [Google Scholar]
- [15].Sergey Kulikov I MacKenzie Scott, and Stuerzlinger Wolfgang. 2005. Measuring the Effective Parameters of Steering Motions. In CHI ‘05 Extended Abstracts on Human Factors in Computing Systems (Portland, OR, USA) (CHI EA ‘05). Association for Computing Machinery, New York, NY, USA, 1569–1572. 10.1145/1056808.1056968 [DOI] [Google Scholar]
- [16].Scott MacKenzie I and Zhang Shawn X.. 1999. The Design and Evaluation of a High-Performance Soft Keyboard. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Pittsburgh, Pennsylvania, USA) (CHI ‘99). Association for Computing Machinery, New York, NY, USA, 25–31. 10.1145/302979.302983 [DOI] [Google Scholar]
- [17].Montazer M Ali, Drury Colin G, and Karwan Mark H. 1988. An optimization model for self-paced tracking on circular courses. IEEE transactions on systems, man, and cybernetics 18, 6 (1988), 908–916. [Google Scholar]
- [18].Monteiro Pedro, Carvalho Diana, Melo Miguel, Branco Frederico, and Bessa Maximino. 2018. Application of the steering law to virtual reality walking navigation interfaces. Computers & Graphics 77 (2018), 80–87. 10.1016/j.cag.2018.10.003 [DOI] [Google Scholar]
- [19].Nancel Mathieu and Lank Edward. 2017. Modeling user performance on curved constrained paths. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems. 244–254. [Google Scholar]
- [20].Nieuwenhuizen Karin and Martens Jean-Bernard. 2016. Advanced modeling of selection and steering data: beyond Fitts’ law. International Journal of Human-Computer Studies 94 (2016), 35–52. [Google Scholar]
- [21].Pastel Robert. 2006. Measuring the Difficulty of Steering through Corners. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Montréal, Québec, Canada) (CHI ‘06). Association for Computing Machinery, New York, NY, USA, 1087–1096. 10.1145/1124772.1124934 [DOI] [Google Scholar]
- [22].Rashevsky N. 1960. Further contributions to the mathematical biophysics of automobile driving. Bulletin of Mathematical Biophysics 22 (1960), 257–262. 10.1007/BF02478348 [DOI] [Google Scholar]
- [23].Wagenmakers Eric-Jan and Brown Scott. 2007. On the linear relation between the mean and the standard deviation of a response time distribution. Psychological review 114, 3 (2007), 830. [DOI] [PubMed] [Google Scholar]
- [24].Wanderley Marcelo Mortensen and Orio Nicola. 2002. Evaluation of Input Devices for Musical Expression: Borrowing Tools from HCI. Computer Music Journal 26, 3 (2002), 62–76. http://www.jstor.org/stable/3681979 [Google Scholar]
- [25].Yamanaka Shota. 2018. Risk Effects of Surrounding Distractors Imposing Time Penalty in Touch-Pointing Tasks. In Proceedings of the 2018 ACM International Conference on Interactive Surfaces and Spaces (Tokyo, Japan) (ISS ‘18). ACM, New York, NY, USA, 129–135. 10.1145/3279778.3279781 [DOI] [Google Scholar]
- [26].Yamanaka Shota and Miyashita Homei. 2016. Modeling the Steering Time Difference between Narrowing and Widening Tunnels. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (San Jose, California, USA) (CHI ‘16). Association for Computing Machinery, New York, NY, USA, 1846–1856. 10.1145/2858036.2858037 [DOI] [Google Scholar]
- [27].Yamanaka Shota and Miyashita Homei. 2016. Scale Effects in the Steering Time Difference between Narrowing and Widening Linear Tunnels. In Proceedings of the 9th Nordic Conference on Human-Computer Interaction (Gothenburg, Sweden) (NordiCHI ‘16). Association for Computing Machinery, New York, NY, USA, Article 12, 10 pages. 10.1145/2971485.2971486 [DOI] [Google Scholar]
- [28].Yamanaka Shota, Stuerzlinger Wolfgang, and Miyashita Homei. 2017. Steering Through Sequential Linear Path Segments. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (Denver, Colorado, USA) (CHI ‘17). Association for Computing Machinery, New York, NY, USA, 232–243. 10.1145/3025453.3025836 [DOI] [Google Scholar]
- [29].Yamanaka Shota, Stuerzlinger Wolfgang, and Miyashita Homei. 2018. Steering through Successive Objects. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (Montreal QC, Canada) (CHI ‘18). Association for Computing Machinery, New York, NY, USA, 1–13. 10.1145/3173574.3174177 [DOI] [Google Scholar]
- [30].Zhai S, Accot J, and Woltjer R. 2004. Human Action Laws in Electronic Virtual Worlds: An Empirical Study of Path Steering Performance in VR. Presence 13, 2 (2004), 113–127. 10.1162/1054746041382393 [DOI] [Google Scholar]
- [31].Zhou Xiaolei and Ren Xiangshi. 2010. An investigation of subjective operational biases in steering tasks evaluation. Behaviour & Information Technology 29, 2 (March 2010), 125–135. 10.1080/01449290701773701 [DOI] [Google Scholar]