

Abstract
Hawkes processes are temporal self-exciting point processes. They are well established in earthquake modelling or finance and their application is spreading to diverse areas. Most models from the literature have two major drawbacks regarding their potential application to insurance. First, they use an exponentially-decaying form of excitation, which does not allow a delay between the occurrence of an event and its excitation effect on the process and does not fit well on insurance data consequently. Second, theoretical results developed from these models are valid only when time of observation tends to infinity, whereas the time horizon for an insurance use case is of several months or years. In this paper, we define a complete framework of Hawkes processes with a Gamma density excitation function (i.e. estimation, simulation, goodness-of-fit) instead of an exponential-decaying function and we demonstrate some mathematical properties (i.e. expectation, variance) about the transient regime of the process. We illustrate our results with real insurance data about natural disasters in Luxembourg.
Keywords: Point processes, Hawkes processes, Insurance, EM algorithm, Natural disasters
Summary
Hawkes Processes
Hawkes processes form a specific category of point processes. Their main characteristic is that each event “self-excites” the process, which means that an occurrence increases the probability to have another arrival in a short time period. They were first introduced by Hawkes (1971) and are now commonly used for several applications: earthquake modelling Bacry and Muzy (2014), criminology Mohler (2011), finance Bacry et al. (2015), etc.
Hawkes Processes for Insurance
Since recently, insurance companies are developing an interest for Hawkes processes. They are used for calculating Solvency Capital Requirements and modelling different indicators of risks, such as ruin (improvement of Cramer-Lundberg model, see Cheng and Seol (2020)) or cyber-attacks (see Bessy-Roland et al. (2020)). Hawkes processes model claims arrival, considered to follow a Poisson process in classic approaches.
Article Purpose
Up to now, models using Hawkes processes in the literature mainly use an exponential excitation function, whose theory was developed in Hawkes’ original papers Hawkes (1971). For this excitation function, the self-exciting effect of each occurrence is maximal shortly after the event. However, for most insurance use cases, we need to take into account a delay between the event and its exciting effect on the process. The main originality of this paper is to propose the Gamma density as an excitation function suited to this context and to test on real data that this approach is a better choice in insurance situations. We introduce and discuss some practical situations on which the Gamma density fits better than exponential decay. The Gamma density excitation function allows us to deal with this delay and could be seen as a generalization of the exponential excitation function, since both are equivalent for a particular set of parameters.
At our best knowledge in the literature, there only exists limit results on first and second order statistics about this category of Hawkes processes. In Bacry and Muzy (2014), the authors state the Wiener-Hopf equations followed by the kernel matrix functions for all t. They only compute the expectation of a Hawkes process in a stationary state. In Bacry et al. (2012), the focus is on the asymptotic behaviour of multivariate Hawkes processes for a large time, by stating a law of large numbers and a functional central limit theorem. In Bordenave and Torrisi, Large deviations of Poisson cluster processes. Bordenave and Torrisi (2007) (Gao and Wang (2020) resp.), the authors prove a so-called large (moderate resp.) deviations principle on Hawkes processes. Such limit results established on the stationary regime are not suitable to deal with practical cases in the insurance context, where the time horizon is of several months. In this paper, we develop a framework for Hawkes processes with Gamma density excitation function regarding estimation and simulation. A new result in this context is the calculus of the mean and the variance of the process in the transient regime. To illustrate our work, we develop the use case of natural disasters in Luxembourg.
Main Contributions
The major contributions of this paper are to:
Define Hawkes processes and the elements needed for a complete use case study (estimation, goodness-of-fit, simulation, etc.);
Study mathematical expressions and properties of Hawkes processes (i.e. expectation, variance and central limit theorem) with a Gamma density as excitation function;
Model an insurance use case with real data by this specific form of Hawkes processes as an illustration of the mathematical tools.
Plan
The remainder of this paper is organized as follows. The second section defines a Hawkes process and introduces all useful notations. The third section contains the development of our results on mathematical properties of Hawkes processes. We also study a use case applied to insurance in the fourth section (natural disasters in Luxembourg).
Hawkes Processes Definition
In this section, we define the notion of Hawkes process, and we introduce useful notations for mathematical properties and algorithms (simulation, estimation).
Point Process
Hawkes processes are a particular class of point processes. We first propose a definition of a point process, inspired by Daley and Vere-Jones (2003).
Definition 1
(Point Process). A point process is an increasing sequence of random variables called occurrences which takes values in , such that .
Definition 2
(History of Occurrences). We define () the filtration and the history of the occurrences until time t.
Another useful representation of a sequence of occurrences is the counting notation.
Definition 3
(Counting Process). We say that N is a counting process if it is an almost surely finite stochastic process and a right-continuous step function with +1 increments after each step, taking values in , and .
The two notions of point process and counting process are interchangeable. Indeed, a counting process could be seen as the cumulative count of a point process. The link between and N is:
where denotes the cardinality of a set and is the time of the occurrence in the time interval [0, T], where Tis the final time of observation.
Intensity Function
The most frequently used characterization of a Hawkes process is by means of the conditional intensity function, . It is defined below.
Definition 4
(Conditional Intensity Function: Expected Rate of Occurrences Conditioned on ). Let us consider a counting process . If exists such that:
| 1 |
then is the conditional intensity function of . We denote by for the remainder of the paper.
The following proposition is inspired from Proposition 2.2 of Rasmussen (2018) and states that the conditional intensity function uniquely defines the point process. Thus in the following we use this characterization.
Proposition 1
Let us consider a conditional intensity function , defined for any time period [u, t], , such that:
non-negative and integrable on [u, t],
.
Then there exists an unique point process with conditional intensity function.
Hawkes Process Definition
We introduce now the definition of Hawkes processes.
Definition 5
(Hawkes Process). Let us consider , the background intensity, and , the excitation function. We denote the sequence of past occurrences until time t. A point process is a Hawkes process if its conditional intensity function is of the form:
| 2 |
where is defined in Definition 3.
Hawkes processes are point processes who have a so-called “self-exciting” property. It means that each occurrence increases the intensity, according to the excitation function. A higher intensity leads to more occurrences, leading to a higher frequency, etc. A Hawkes process with a null excitation function is a homogeneous Poisson process of rate .
Definition 6
(-Hawkes Processes). We define the -Hawkes processes, a Hawkes process whose excitation function is of form:
| 3 |
where is the Gamma function. is the scale parameter and is the shape parameter.
Remark 1
For , we obtain the exponential excitation function:
| 4 |
used for instance originally by Hawkes (1971). In this situation:
| 5 |
For , this excitation function allows to avoid a discontinuity in the intensity function when an event occurs, and introduce a delay between an event and its impact on the process. Indeed, in that case, . This property is very helpful when considering events for which an occurrence and the resulting self-excitation are delayed.
Mathematical Properties
In this section, we are going to explicit some mathematical properties of the -Hawkes processes (defined by Eq. (3)): we calculate the expectation and the variance for any time and we state a central limit theorem.
Assumption 1
For the whole Section 3, we consider a -Hawkes process of conditional intensity function:
| 6 |
where , (number of events occurred between 0 and t), , for which we are going to explicit results for and .
This study aims to understand the behaviour of the Hawkes processes in function of parameters introduced previously.
Behaviour in Function of Values of
In this section, we are going to see that the Hawkes process dynamics depend on values of (defined in Assumption 1). To do so, let us focus on , which will be used to calculate the expectation of the Hawkes process later.
We could show that g follows a renewal equation:
| 7 |
According to Asmussen (2003), the behaviour of g(t), when t goes to infinity, depends on the value of:
| 8 |
We distinguish, in the classic literature about point processes:
The defective case: ;
The proper case: ;
The excessive case: .
The Hawkes process intensity goes to infinity in the excessive case, leading to an explosion of the counting process. This situation does not suit to any real event we would like to model. The proper case is not studied here, because it does not correspond to a real case. We concentrate our attention in the defective case. In this case, g admits a finite limit in , which will be calculated later.
Assumption 2
For the rest of the Section 3, we consider a Hawkes process of conditional intensity function described in Assumption 1, with (defective case).
Expectation:
The first indicator that seems relevant for our study was the evaluation of the average number of events through time. We propose a calculation method which could be applied for any value of . We will develop the calculations for two values of the shape parameter: (exponential excitation function), and . Since a Hawkes process is the sum of a background part of intensity and an self-exciting part, we expect that the expectation is higher than for a Poisson process of parameter , which is for all time .
Proposition 2
The expectation of the -Hawkes process (i.e. conditional intensity function given by Eq. (6)) is:
- For (i.e. , exponential decay):
9 - For (i.e. ):
10 - For (i.e. ):
where11
See Appendix 1 for the proof, which is based on Laplace transform of and could be applied for any value of . We could notice that despite the formula complexity increases with , we could observe several common trends. We first notice that for (null excitation function), we obtain . This result is natural since we already mentioned that a Hawkes process with a null excitation function is equivalent to a Poisson process of parameter . For all values of the shape parameter, the expectation reveals three regimes for the -Hawkes process. As an example, we represent the expectation for , which follows Eq. (9), in Fig. 1. It contains four plots:
Top-left: expectation from Eq. (9) in blue and the so-called stationary regime in red, from t = 0 to 3000;
Bottom-left: the relative difference between the expectation and the stationary regime on this time period;
Top-right: focus on the expectation from t = 0 to 500;
Bottom-right: plot of the exponential term from Eq. (9), .
Fig. 1.

Number of claims per day processed by Foyer Assurances and labelled as natural disasters since 2015
We distinguish three regimes in this example:
The transient regime (from t = 0 to 500 approximately): it is the time period necessary for the exponential term in Eq. (9) to become null;
The intermediary regime (from t = 500 to 2000 approximately): the exponential term is null but the constant term could not be neglected before the stationary regime. On this period, the relative difference between the expectation and the stationary regime is above 5;
The stationary regime: for any value of the parameter scale, and for any Hawkes process (not only for -Hawkes processes), (see Gao (2018)). The constant term in Eq. (9) becomes negligible before the linear term. After the first two regimes, the average number of occurrences of the Hawkes process is the same as for a Poisson process of parameter .
We conclude in this discussion that the expectation could not be approximated correctly by the stationary regime from t = 0 to 2000. We will see that this point will have an impact on our use case study.
Variance:
We study now the variance of the Hawkes process, in order to see how the occurrences are spread out from the expectation calculated previously. We define as the stationary Hawkes process.
Proposition 3
The variance of the stationary -Hawkes process (i.e. the conditional intensity function is given by Eq. (6)) is:
- For (i.e. ):
12 - For (i.e. ):
13
See Appendix 2 for the proof, in which we use the classic assumption that covariance density does not depend on time, assumption valid only if the process is stationary. However, we remark that theoretical variance is close to the results from simulations (we propose a method to simulate Hawkes processes in Appendix 3), see Section 4.5 for a comparison between simulated and actual variance. A similar comparison in Bacry et al. (2015) shows that theoretical variance based on stationary assumptions is a fine approximation as well. Therefore, we consider that approximately equals from now on.
Let us observe the behaviour of the variance. We first notice that for (null excitation function), we obtain . This result is natural since we already mentioned that a Hawkes process with a null excitation function is equivalent to a Poisson process of parameter . Secondly, we remark that . We have seen previously that : it is natural that we obtain as a limit a variance greater than since a Hawkes process is more volatile than a Poisson process. The limit of the variance is calculated in Proposition 3 from Gao (2018), which gives the same result. It is also possible to do an analysis in terms of regimes similar to the expectation.
Central Limit Theorem for Hawkes Processes
From Theorem 2 of Bacry et al. (2012), we state a central limit theorem for Hawkes process, when . The following proposition is true for any :
Proposition 4
(Central Limit Theorem for Hawkes Processes)
| 14 |
where:
;
;
B(1) is a standard Brownian motion;
means equality in distribution.
We recognize in this central limit theorem the limits of expectation and variance calculated previously. The central limit theorem gives the distribution of the number of events at a large time horizon.
Use Case: Natural Disasters in Luxembourg
In this section, we present an insurance use case. Natural disasters are one of the types of rare events who could occur in any insurance setting. We apply it in the case of Luxembourg, with data from insurance. They are mainly storms and gusts of wind, whose frequency seems to increase for these last five years. This trend may be explained by climate imbalance (see public data about climate change in Luxembourg Online (2019)).
After introducing the data provided by Foyer Assurances in Section 4.1, we present the parameters estimated on these data in Section 4.2. Then we justify the choice of using a -Hawkes process and its study on a transient regime by first comparing the goodness-of-fit of our approach with several models by a statistical test, then simulating data and observing the number of events from these simulations to check whether our -Hawkes process fits with the data.
Presentation of the Data
Foyer Assurances has provided data about natural disasters and home insurance. Figure 2 shows the number of home insurance claims per day processed by Foyer Assurances for which the natural disasters cover was used, from January 2015 to December 2019.
Fig. 2.

Counting process and intensity since 2015 / Cumulated number of natural disasters events in Luxembourg since 2015 (in blue) and the intensity of the estimated Hawkes process (in red)
This timeline shows the low frequency and the high severity of this kind of event. The peaks correspond to specific weather conditions:
31/03/15: “Niklas” storm;
16/09/15: “Henri” ex-tropical storm;
09/02/16: gusts of wind in East France and Luxembourg;
13/01/17: “Egon” cyclone: storm, snow;
03/01/18: “Eleanor” storm;
10/03/19: gusts of wind in East France and Luxembourg;
09/08/19: exceptional tornado in Luxembourg.
We model the occurrence of claims thanks to a Hawkes process. The branching structure introduced in Appendix 4 may suggest that one claim must be triggered by one another specific claim, which is not the case in reality. But Hawkes processes are well suited for modelling high-frequency periods of occurrence where the causality between events is not trivial as well and where there is a clustering effect due to an underlying cause (i.e. a natural disaster). For instance, Hawkes processes are well established to model high-frequency trades in finance, while one trade is not directly triggered by another (see Bacry et al. (2015)).
Parameters Estimation
To model the type of event introduced previously, we propose a -Hawkes process:
| 15 |
where ND is an abbreviation for natural disasters and with . This choice of model could be justified a priori as follows:
Self-exciting property: a unique background event which occurs rarely (e.g. a storm) and is taken into account by the background intensity in the model, triggers a sequence of numerous claims around the country. The more claims there is, the more serious the event is, the more likely new claims are: this dynamic is modelled by the self-exciting part of the intensity. Thus, we are expecting that the exciting part of the process has more importance than the background part, which should lead to a value greater than .
Gamma density intensity function of parameter : there is a delay between the occurrence of claims on the different Luxembourgish cities. The storm reaches the Luxembourg regions at different times. This function allows us to model this delay. Also, even if we check that closed numerical values for performed similarly, we select to develop an interpretation of results based on closed-form formulae calculated above.
We estimate parameters thanks to EM algorithm, introduced in Appendix 4. Estimation leads to the following parameters in Table 1. We used the R library hawkes, developed by the authors of Halpin and De Boeck (2013), to implement the estimation. We also propose the standard deviation of the estimations, from the inverse of the Fisher information matrix that we compiled numerically (see Ly et al. (2017)).
Table 1.
Estimated values of the HP parameters by the EM algorithm
| Parameter | Estimated value | Standard deviation |
|---|---|---|
| 0.26 | 0.11 | |
| 0.92 | 0.34 | |
| 8.77 | 4.24 |
We see that , as expected, and that is close to 1. Since the expectation is proportional to (we recall that ), this value of should lead to a high average number of events.
Figure 3 presents the evolution of the cumulative number of events (in blue) and the estimated intensity of the -Hawkes process (in red). We see that intensity peaks correspond to the meteorological events described previously.
Fig. 3.

QQ-plot and Kolmogorov-Smirnov test for set of parameters estimated by EM algorithm
Goodness-of-Fit and Comparison with Other Models
After the parameters estimation, we need to check if this model makes sense. The following proposition from Daley and Vere-Jones (2003), called residual analysis, allows us to test the quality of the model.
Proposition 5
(Residual Analysis) We consider a sequence of occurrence times and a monotonic, continuous compensator such that almost surely. The sequence is a Poisson process with an unit rate if and only if is a realisation from the point process defined by .
Thanks to this proposition, we could test with many procedures whether our data fit with a Hawkes process. The previous proposition shows us that testing whether follows a Hawkes process with intensity function is equivalent to test whether form a Process process of parameter 1. It is also equivalent to test whether every interarrival time are independent and identically distributed and follow an Exponential law of parameter 1. This could be done by:
A Quantile-Quantile plot (QQ-plot), which represents quantiles of both distributions;
Performing a Kolmogorov-Smirnov test, whose statistic D is the maximum absolute difference between the two distributions.
Figure 4 is a QQ-plot which allows us to compare the distribution of our data and the distribution of the -Hawkes process with the estimated parameters. We also perform a Kolmogorov-Smirnov test.
Fig. 4.

QQ-plot and Kolmogorov-Smirnov test for an homogeneous Poisson process (left) and a Hawkes process with an exponential (center) and a power-law excitation function (right)
The p-value of the statistical test is greater than , which means that we cannot reject the hypothesis that the data follow the estimated -Hawkes process.
We compare the results with three other models:
An homogeneous Poisson process, since it is the simplest point process and is equivalent to a Hawkes process with no self-excitation, whose rate is the average number of events per day;
A Random Forest Regressor, a time series approach in order to take into account temporal dependencies;
- A Hawkes process with an exponential excitation function and a power-law kernel, in order to check whether another excitation function would have better performances than the Gamma density, whose parameters are estimated by the EM algorithm (see Table 2). The exponential excitation function is in Eq. (4). We propose for a power-law excitation function the following equation:
16
Table 2.
Estimated value of the HP parameters by the EM algorithm for an exponential and a power-law excitation function
| Parameter | Estimated value - exponential | Estimated value - power-law |
|---|---|---|
| 0.29 | 0.25 | |
| 0.91 | 0.92 | |
| 9.03 | - | |
| - | 0.71 | |
| - | 5.56 |
The QQ-plots for the two models are represented on Fig. 5:
Fig. 5.
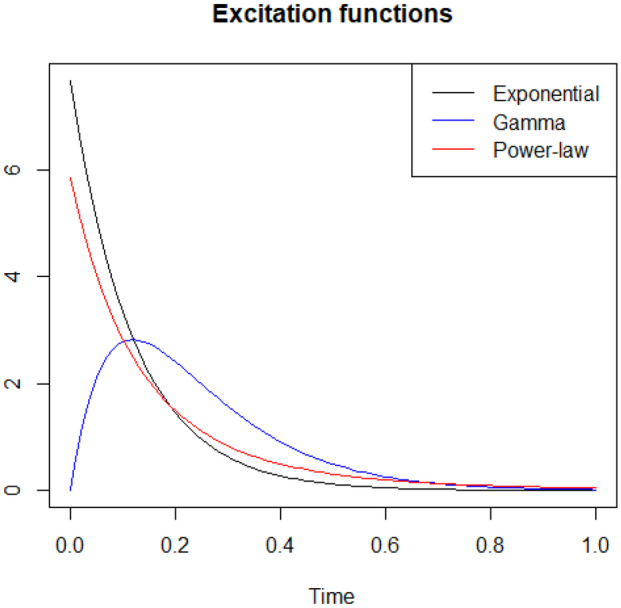
Excitation functions with respect to time : exponential (black), Gamma (blue), power-law (red)
As expected, an homogeneous Poisson process is not enough to model this type of event. We need to take into account the self-excitation property of the process. We could also see that the fitting is better with a Gamma excitation function than an exponential or a power-law decay, which validates our study a posteriori. We remark that the exponential and the power-law functions provide the same type of self-excitation with no delay, as we plot the fitted functions in Fig. 6.
Fig. 6.

Parameters used for Random Forest Regressor
Random Forest Regressor
In order to catch the temporal dependency of the natural disasters, we compare with a time series approach. We present here the results given by Random Forest Regressor (see Breiman and Forests (2001) for details about Random Forest), which fitted better that other types of time series models in terms of Kolmogorov-Smirnov test (ARIMA, ARMA, GARCH, Prophet). We used the scikit-learn estimator sklearn.ensemble.RandomForestRegressor and the parameters presented in Fig. 6.
We learned the time series from January 2015 to June 2019 and we predicted the number of events over 100 days from July 2019. Figures 7 and 8 shows the prediction (in blue) versus the real data (in orange, the peak corresponds to the tornado in August 2019).
Fig. 7.

Prediction of the time series by a Random Forest Regressor
Fig. 8.

Prediction of the time series by a Random Forest Regressor
We then compared the distribution of the interarrival times of the prediction with the distribution of the interarrival times of the actual time series with a QQ-plot in Fig. 9.
Fig. 9.

Simulation of 20 trajectories over five years for set of parameters estimated by EM algorithm
We could see that this approach does not allow to catch the severe peaks which characterize this time series. This kind of approach is more efficient on data with seasonality and a regular trend.
Simulations
Moreover, we must make sure that our model is able to replicate severe events like those observed in our data. We verify that simulated trajectories present the same structure than the actual time series: few severe events between very calm periods. Figure 10 shows the simulation of 20 trajectories over five years according to our estimated Hawkes process.
Fig. 10.

Simulation of 20 trajectories over five years for four set of parameters
Most of the simulated trajectories do not present the expected step function structure, observed with real insurance data. The evolution of the process counting is too smooth for these simulations, if we compare the dynamics between Figs. 3 and 6.
Let us see what happens with another set of parameters. Since the expectation of the process assuming stationarity is proportional to , we slighty change and so that stationary expectation remains the same. Moreover, as we would like to have larger jumps in the trajectory, it means that the importance of the self-exciting part of the process should be higher. Thus, we will increase the value of . We propose the same type of simulation over five years for different sets of in Fig. 11.
Fig. 11.
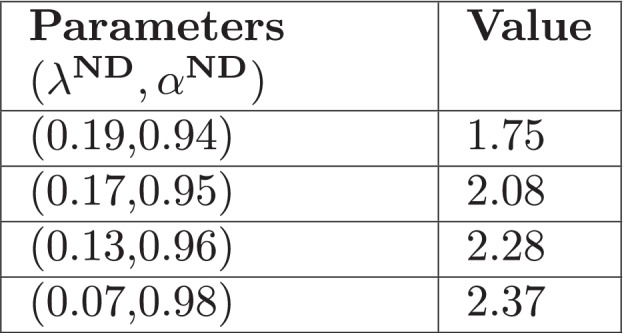
Average number of times the process reaches a threshold of 500 events in a period of time of 1825 days
Results show that increasing allows indeed the process to be more volatile and with more severe events. Simulated trajectories are more alike actual data for the different sets of parameters. The higher is , the larger are the jumps. In order to quantify the capacity to generate scenarios with severe events, we evaluate by a Monte-Carlo method the average number of times the process reaches a threshold of 500 events in a period of time of 1825 days (five years), by performing 1000 simulations. We present the results on Fig. 12.
Fig. 12.

QQ-plot and Kolmogorov-Smirnov test for four set of parameters
The Monte-Carlo estimation shows that the higher is , the higher is the average value of severe events. Therefore it confirms that another set of parameters could be more appropriate in terms of ability to generate disasters observed on real data.
In terms of goodness-of-fit, Fig. 13 shows QQ-plot for each set of parameters.
Fig. 13.
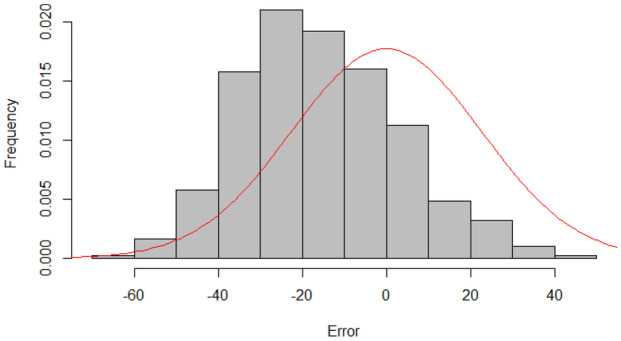
Distribution of errors at the end of the five years
Figure 13 illustrates that goodness-of-fit is worse for each set of parameters, when comparing to the first set of parameters we estimated by our approach (see Fig. 4). Indeed, for each set of parameters we could reject the hypothesis that the Hawkes process fits the data. We eventually have a set of parameters which maximizes the goodness-of-fit (the one estimated by the EM algorithm), but another which seems to catch better the dynamics of the time series (a set with a higher ). It is explained by the fact that the goodness-of-fit is evaluated on the entire distribution, by computing the distance on all the quantiles of the distribution. Whereas the dynamics of the natural disasters rely on the accumulation of grouped events, which are the smallest quantiles of the distribution. By the way we could see on Fig. 13 that the distribution gets worse on medium quantiles. There is an imbalance between the quality of simulations and the statistical tests, which illustrates the difficulty to estimate the right set of parameters for a Hawkes process.
Distribution of the Number of Events
In this subsection, we observe the distribution of N(t), where t = five years. We perform 1000 simulations of the Hawkes processes, with the first set of parameters estimated, for a time period of five years. We observe the errors distribution in Fig. 14, , and we compare with a Normal distribution of variance .
Fig. 14.

A realisation of a Hawkes process and its branching structure
We see that the mean of errors is different from zero. The distribution of errors does not follow the Normal distribution, as the process is not observed long enough to be close to its limit. This observation justifies our mathematical study a posteriori, since the study of limits is not enough. We need the transitory values of the expectation and the variance, even for a long five years period.
Numerically, from Eqs. (10) and (13) we obtain:
| 17 |
with t in days.
The following table presents the observed, calculated and limit value of expectation and variance at the final time of simulations.
This table confirms that calculated expectation and variance give the correct values and that focusing on limits is not sufficient to study a process over several years, which is a quite long period for insurance use cases. Thanks to numeric values provided by Eqs. (23) and (24), we could see that we are still in either the transient state or the intermediary state for years days: while exponential terms are close to zero for both expectation and variance, the difference between the actual value (third column of Table 3) and the limit value (fourth column) is explained by the constant terms. The order of magnitude of these constant terms shows that the limit values are not a good approximation for a period of several years. That justifies our study on the different regimes.
Table 3.
Observed, calculated and limit value of expectation and variance
| Quantity | Observed value | Calculated value | Limit value: linear term |
|---|---|---|---|
| Expectation | 5265.2 | 5275.8 | 5931.2 |
| Variance | 621988.3 | 618039.4 | 700177.6 |
Conclusion and Future Work
In this paper, we introduced a complete framework for the study of Hawkes process: definition, estimation and simulation. We presented a specific form of Hawkes processes, the -Hawkes process, and we developed mathematical properties for this category of process. We applied this model to an insurance use case, i.e. natural disasters, and we observed that the considered Hawkes process is well fitted with historical data.
For future work, we intend to apply this model to other insurance use cases, such that:
Life events prediction: births, marriage, job change, etc. We could use a multi-variate version of Hawkes processes (see Laub et al. (2015)), since one type of event could trigger another (e.g. a marriage could lead to a birth);
Epidemic: we already studied the dynamics of Covid-19 pandemic in Lesage (2020). We intend to adapt the study to a long class of diseases;
Workload prediction: we would like to anticipate peaks of workload for Foyer Assurances employees in order to optimize staffing.
Acknowledgements
We developed this work through a strong collaboration with Foyer Assurances, leader of individual and professional insurance in Luxembourg, which provided the domain specific knowledge and use cases. The first author also gratefully acknowledges the funding received towards our project (number 13659700) from the Luxembourgish National Research Fund (FNR).
Appendix
Appendix 1
Proof of the Proposition 2.
-
Laplace transform of Since , we first focus on , that we denote g(t). We saw that:
We recognize a convolution product of g and , denoted . Therefore it is much easier to work into Laplace domain, since . By transforming Eq. (25) into Laplace domain:18 By rearranging, we obtain:19 -
Inverse of g(t) Laplace transform We turn the Laplace transform into the temporal domain. In our study, is a Gamma density function and is given by Eq. (3). We can show that the Laplace transform is (see D’Azzo and Houpis (1988)):
20
Appendix 2
Proof of the Proposition 3, inspired from Appendix A.2 of Laub et al. (2015).
- Link between the variance and the covariance density We calculate the variance from the so-called covariance density , , defined in Hawkes (1971). According to Hawkes (1971), the covariance density is given by the following equation:
where . Considering the stationary Hawkes process , the variance and the covariance density are linked by the following equation:35 36 -
Laplace transform of We first calculate . We recognize a convolution product in Eq. (34). Thus we work in the Laplace domain:
37
For = 2:38 By using the definition of the Laplace transform:By replacing in Eq. (36) we obtain:39 To solve Eq. (38) and find , we need to calculate and . First, by substituting in Eq. (38), rearranging and using Eq. (27) for , we obtain:40 Second, by differentiating Eq. (38), we obtain:41 Equations (39) and (41) form a system of two equations with two variables, and . Solving this system leads to:43 We can now solve Eq. (38). After rearranging:44 - Inverse Laplace transform of We turn the Laplace transform of into the temporal domain. For , we can show that:
where:45 46
Appendix 3
Simulaion is performed thanks to Ogata’s thinning algorithm. The idea of Ogata’s thinning algorithm is that randomly removing points from a “faster” simulated Poisson process (i.e. with a higher intensity function than targeted Hawkes process) allows to simulate a Hawkes process. This idea is based on the proposition below, which is inspired from Theorem 4.2 of Chen (2016):
We consider a point process, with conditional intensity function . We also consider an upper-bound for , , and a Poisson process of parameter of jumping times . Then the point process defined by:
| 47 |
where are i.i.d and follow an uniform distribution on [0, 1], is a process of conditional intensity function .
A formulation of Ogata’s thinning algorithm is proposed in Laub et al. (2015) for instance. We notice that the use of a Gamma excitation function does not change the classic algorithm.
Appendix 4
We first present an interpretation of Hawkes processes introduced in Halpin and De Boeck (2013), useful to understand better the estimation algorithm. Events occurring in a Hawkes process could be seen as a population, which expands either by immigration or births. Immigrants correspond to occurrences due to the background intensity, which are spontaneous. Births correspond to occurrences due to the self-exciting part of the intensity, which are a consequence of the previous occurrences. We can consider that the Hawkes process is a sum of independent Poisson processes, where each occurrence would be a consequence of one of these Poisson processes:
| 48 |
where , and were introduced previously.
The number of spontaneous occurrences is a Poisson process of rate over , where is the final time of observation. We denote ;
The number of responses to each event is a Poisson process of rate over . We denote .
Definition 7
(Process of Response). For each event , we introduce the random variable , which indicates the process to which the event belongs.
As an example, we consider the realisation of a Hawkes process, represented in the Fig. 15.
: event is a spontaneous occurrence.
: event is a response to event .
: event is a response to event .
: event is a response to event .
: event is a spontaneous occurrence.
And so on.
We could now detail a method to estimate parameters of Hawkes processes, developed in Halpin and De Boeck (2013) in particular. First, we define the likelihood of Hawkes processes.
Fig. 15.

Expectation for
Definition 8
(Observations Likelihood). Let us consider a point process of intensity function , on time period , . We denote the jumping times until time . We observe and . Observations log-likelihood of is:
| 49 |
where is the set of parameters to estimate (i.e. and parameters of the excitation function ).
Then we define the so-called complete likelihood, when assuming that introduced in Definition 7 are observed.
Definition 9
(Complete Likelihood). Assuming we observe , then complete log-likelihood is:
| 50 |
where . This complete likelihood allows us to build the Expectation-Maximization algorithm (or EM algorithm), which will estimate the parameters of Hawkes processes by minimizing this likelihood. We first define the quantity below.
Definition 10
We define:
| 51 |
where and are two sets of parameters and whose computation is the E step of the EM algorithm (see Proposition 6).
We can show that:
| 52 |
This Eq. (52) will be useful to describe the EM algorithm. This algorithm is based on the following proposition, which states that the iterative maximization of allows to converge to a local maximum of the complete likelihood. In other words, maximizing allows to estimate parameters (see Section 1.5 of McLachlan and Krishnan (1996) for the proof).
Proposition 6
The sequence defined by converges to a local maximum of , the observations likelihood.
Then we write the EM algorithm:
Initialize ,
- While convergence:
- [E step] Compute
- [M step] Compute maximization by Nelder-Mead method (see Nelder (1965))
- .
To check the accuracy of the estimation, we simulate a Hawkes process over five years, we estimate the parameters and we compare estimation and actual parameters. We notice that the estimation is pretty accurate, except for the scale parameter but its impact is lower than the other parameters. Table 4 compares the two sets of parameters.
Table 4.
Comparison between actual and estimated parameters
| Parameter | Actual value | Estimated value |
|---|---|---|
| 0.25 | 0.252 | |
| 0.9 | 0.986 | |
| 1 | 1.172 | |
| 5 | 6.836 |
Data availability Statement
The data that support the findings of this study, that is to say the occurrences of natural disasters claims for Foyer’s customers, are not openly available because they are the property of Foyer Assurances. Anonymous and incomplete data could be available from the authors upon reasonable request.
Footnotes
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- Asmussen S (2003) Appl Prob Queues. 2003. Springer, Volume 51
- Bacry E, Delattre S, Hoffmann M, Muzy JF (2012) Scaling limits for Hawkes processes and application to financial statistics. arXiv: Probability
- Bacry E, Muzy JF (2014) Second order statistics characterization of Hawkes processes and non-parametric estimation. arXiv:1401.0903
- Bacry E, Mastromatteo I, Muzy JF (2015) Hawkes Processes in Finance. Market Microstructure and Liquidity 01(01)
- Bessy-Roland Y, Boumezoued A, Hillairet C (2020) Multivariate Hawkes process for cyber insurance. hal-02546343
- Bordenave C, Torrisi GL (2007) Large deviations of Poisson cluster processes. Stoch Models 23, 593–625
- Breiman L. Random Forests. Mach Learn. 2001;45:5–32. doi: 10.1023/A:1010933404324. [DOI] [Google Scholar]
- Chen Y (2016) Thinning Algorithms for Simulating Point Processes.
- Cheng Z, Seol Y. Diffusion Approximation of a Risk Model with Non-Stationary Hawkes Arrivals of Claims. Methodol Comput Appl Probab. 2020;22:555–571. doi: 10.1007/s11009-019-09722-8. [DOI] [Google Scholar]
- D'Azzo J, Houpis C (1988) Linear Control Systems Analysis and Design. McGraw-Hill Education (ISE Editions)
- Daley DJ, Vere-Jones D (2003) An Introduction to the Theory of Point Processes: Volume I: Elementary Theory and Methods. Springer, Volume 1
- Gao and Wang Functional central limit theorems and moderate deviations for Poisson cluster processes. Adv Appl Probab. 2020;52(3):916–941. doi: 10.1017/apr.2020.25. [DOI] [Google Scholar]
- Gao X, Zhu L. Functional central limit theorems for stationary Hawkes processes and application to infinite-server queues. Queueing Systems. 2018;90(1):161–206. doi: 10.1007/s11134-018-9570-5. [DOI] [Google Scholar]
- Halpin PF, De Boeck P (2013) Modelling Dyadic Interaction with Hawkes Processes. Psychometrika 78, 793-814 [DOI] [PubMed]
- https://statistiques.public.lu/en/news/territory/territory-climate/2019/10/20191001/index.html
- Hawkes AG (1971) Spectra of some self-exciting and mutually exciting point processes. Biometrika, vol. 58, pp. 83-90
- Laub PJ, Taimre T, Pollett PK (2015) Hawkes Processes. https://arxiv.org/abs/1507.02822
- Lesage L (2020) A Hawkes process to make aware people of the severity of COVID-19 outbreak: application to cases in France. https://hal.archives-ouvertes.fr/hal-02510642
- Ly A, Marsman M, Verhagen J, Grasman RP, Wagenmakers EJ (2017) A Tutorial on Fisher Information. https://arxiv.org/pdf/1705.01064.pdf
- McLachlan G, Krishnan T. The EM Algorithm and Extensions. New York: John Wiley and Sons; 1996. [Google Scholar]
- Mohler Short. Brantingham, Schoenberg, Self-Exciting Point Process Modeling of Crime. J Am Stat Assoc. 2011;106(493):100–108. doi: 10.1198/jasa.2011.ap09546. [DOI] [Google Scholar]
- Nelder JA, Mead R (1965) A Simplex Method for Function Minimization. Comp J 7(4):308-313
- Rasmussen JG (2018) Temporal Point Processes and the Conditional Intensity Function. arXiv:1806.00221v
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support the findings of this study, that is to say the occurrences of natural disasters claims for Foyer’s customers, are not openly available because they are the property of Foyer Assurances. Anonymous and incomplete data could be available from the authors upon reasonable request.