

Abstract
Objective: This study aimed to explore topics and sentiments using tweets from Ontario, Canada, during the second wave of the COVID-19 pandemic.
Methods: Tweets were collected from December 5, 2020, to March 6, 2021, excluding non-individual accounts. Dates of vaccine-related events and policy changes were collected from public health units in Ontario. The daily number of COVID-19 cases was retrieved from the Ontario provincial government’s public health database. Latent Dirichlet Allocation was used for unsupervised topic modelling. VADER was used to calculate daily and average sentiment compound scores for topics identified.
Results: Vaccine, pandemic, business, lockdown, mask, and Ontario were six topics identified from the unsupervised topic modelling. The average sentiment compound score for each topic appeared to be slightly positive, yet the daily sentiment compound scores varied greatly between positive and negative emotions for each topic.
Conclusion: Our study results have shown a slightly positive sentiment on average during the second wave of the COVID-19 pandemic in Ontario, along with six topics. Our research has also demonstrated a social listening approach to identify what the public sentiments and opinions are in a timely manner.
Keywords: social media, COVID-19, sentiment analysis, lockdown, topic modelling, mask, vaccine
Introduction
The Coronavirus disease (COVID-19) pandemic has persisted for more than a year and resulted in over 141 million infections with over 3 million deaths worldwide [1]. In Canada, it has led to over 1 million positive cases and caused more than 24,000 deaths [2]. During this global crisis, when people have been forced to stay at home and connect virtually, social media platforms have played an increasingly significant role in communications now more than ever before. Therefore, social media data, such as tweets, have become even more important in health research associated with the current pandemic. Understanding public discourses and sentiments from social media data has been critical for researchers and decision makers since it correlates with our behaviours that help or fail to eliminate the COVID-19 infections. Scholars have conducted various topic modelling and sentiment analysis to understand public concerns or attitudes toward the pandemic and public health measures, such as mask wearing, handwashing, travel restrictions, and lockdowns since the early pandemic [3–6]. For example, Abd-Alrazaq et al identified 10 themes with positive sentiments and two topics with negative sentiments from 2.8 million English tweets between February 2 and March 15, 2020 [3]. Furthermore, Boon-Itt and Skunkan found topics changed over time, but negative sentiments persisted when analyzing almost 11 million English tweets from December 13, 2019, to March 9, 2020 [4]. Similarly, Chandrasekaran et al. collected 13.9 million English tweets posted by individuals between January 1 and May 9, 2020. Their findings show a consistent negative sentiment towards topics related to the spread and growth of COVID-19, origin of virus, political perspectives, and racial discrimination, whereas sentiments toward topics associated with preventive measures and treatments, economic impacts, government implementations, healthcare industry changed from negative to positive [5]. Additionally, Valdez et al. collected 86 million English tweets from the United States (US) between January 22 and April 9, 2020 and found the number of tweets and ranking of eight identified topics—“China, Trump, US, lockdown, pandemic, social distancing, home, deaths”—rose and fell over time with the overall sentiment steadily shifting from negative to positive [6].
Machine learning (ML) techniques have been applied to such research in topic modelling and sentiment analysis. For instance, Latent Dirichlet Allocation (LDA) is commonly applied to topic modelling, and Valence Aware Dictionary and sEntiment Reasoner (VADER) is widely used for sentiment analysis [4–6]. LDA identifies topics from documents by classifying relevant individual words or phrases together modelled by Dirichlet distributions [7].VADER is a lexicon and rule-based sentiment analysis tool that classifies words as positive or negative [8]. Such advanced ML approaches have gained popularity among quantitative studies in which scholars analyze a large volume of social media data. For example, the World Health Organization (WHO) has developed an Early AI-supported Response with Social Listening (EARS) to understand the public discourses in different countries with data from social media and Internet search queries using a semi-supervised ML algorithm [9].
Social media and Internet query data have also been used to predict the number of COVID-19 cases [10–13], especially in China, where about 1 billion of its 1.4 billion population have access to the Internet and social media [14]. Although methods to construct predictive models vary across these studies, researchers, in general, can correctly predict the number of COVID-19 cases in China 6–14 days before these cases are officially confirmed by lab tests [9–11]. On the other hand, Shen et al. found a ratio of 1:4 between the number of cases and social posts in Wuhan, China [13]. Additionally, social media data with self-disclosed geolocations have been used to explore the public adherence to social distancing to eliminate the COVID transmissions [15, 16] or the spread of the pandemic [17, 18].
Although recent literature has demonstrated the utility of social media data for various research, unsupervised ML approaches have not been studied as extensively as supervised ML techniques. In other words, data collection in current literature is conducted with pre-identified keywords or hashtags of research interest, and these pre-defined keywords have also been used as criteria for topic classifications [3–6, 10–18]. In addition, each country has its unique context that may not be reflected in global studies as scholars have collected and analyzed social media data limiting to English but not specific countries. In Canada, the second wave of COVID 19 pandemic occurred from December 5, 2020, to March 6, 2021, and Ontario implemented its second lockdown between December 26, 2020, and January 2021. Mask-wearing was mandated after the province moved out of the lockdown. However, in the United States (US), lockdowns were rarely implemented throughout the pandemic, except New York and California states. Futtheremore, mask-wearing wasn’t mandated. Jang et al. compared tweets from Canada with those from US and found that while Canadians shared some similar topics with Americans in factors associated with COVID-19 transmissions, US president, and Wuhan initial outbreak, Canadians expressed appreciation and border restrictions for travel, whereas Americans discussed the similarity between COVID-19 and influenza and lockdown impacts [19]. In the case of face mask-wearing, people in Asian countries have higher adherence to wearing masks as recommended by public health authorities than those in western culture [20].
While LDA and VADER have been commonly used for topic modelling and sentiment analysis, respectively, deep learning techniques, such as Long Short-Term Memory (LSTM) and Bidirectional Encoder Representations from Transformers (BERT), have become more successful and have been adopted in more recent literature for sentiment analysis [21–24]. For example, Chandra and Krishna [21] used deep learning models for COVID-19 tweet sentiment analysis in India from March to September 2021. The study has classified more granular 11 emotions than three general sentiments (i.e., positive, negative, and neutral) from the conventional VADER [21]. Similarly, Imran et al. [22] used a supervised multi-layer LSTM to classify and compare six emotions across Pakistan, India, Norway, Sweden, Canada, and the US [22]. Das and Kolya [23] also proposed a supervised deep convolutional neural network (CNN) to evaluate sentiments and predict COVID-19 cases globally since data were retrieved from 15 countries [23]. Yet they classified emotions expressed in tweets only as either positive or negative [23]. However, deep learning techniques still have some limitations. For instance, supervised deep learning techniques demonstrated in existing literature have been conducted in a supervised manner, and this requires large and correctly labelled training datasets [22–24]. Interpretability is another issue because public health professionals may not have deep understanding of deep learning models, which have been more complicated than conventional LDA and VADER. In other words, although deep learning has more optimal performance than conventional techniques, it has been a “black box” viewed by many public health professionals [24]. Additionally, compared to conventional methods, deep learning techniques generally require more computing power, leading to limited implementation in practice.
On the other hand, most studies conducted in the first wave analyzed data with a relatively shorter time frame, several weeks or 1 month, for example [3–6]. Furthermore, given existing literature, it still lacks follow-up research to investigate how sentiments and topics have changed over time after the first wave of the COVID-19 pandemic in Canada. Furthermore, given Canada’s cultural diversity and the greater provincial autonomy than the federal, each province has tackled the pandemic differently in Canada. It is of our research interest to investigate at a more focused, local level. Therefore, this study aimed to apply an unsupervised ML approach with minimal manual validations to explore both topics and corresponding sentiments using tweets from Ontario, Canada, from December 5, 2020, to March 6, 2021.
Methods
Tweet Collection
English tweets originated in Ontario, Canada, were collected between December 5, 2020, and March 6, 2021, without being filtered by COVID-19 related keywords or hashtags. This is because our study aimed to apply an unsupervised ML approach to identify possible patterns beyond those explicitly mentioning COVID-19 related keywords or hashtags. Instead, major metropolitan areas in Ontario, namely geolocation tags from Toronto and Ottawa, were identified to limit the scope of data collection to a level allowed by available resources. With these query parameters limited to two cities and the timeframe, 569,467 tweets from Toronto and 141,469 tweets from Ottawa were returned from December 5, 2020, to March 6, 2021, via the Twitter Developer API [25].
Public Health Policy Data Collection
Data were collected on Ontario public health policy changes by each public health unit as a means of comparison against daily case changes and Twitter sentiment from December 5, 2020, to March 6, 2021. Public health policy changes include major vaccine approvals, lockdown announcements, school closures and other public health related enforcement of policies regarding COVID-19 by reviewing each public health unit’s COVID-19 information page within the applicable regions.
Daily Case Count Collection
The daily case counts of all public health units in Ontario from December 5, 2020, to March 6, 2021 were retrieved from the Ontario provincial government’s public health database. The extracted data were organized by active cases, resolved cases, and deaths as defined by the Government of Ontario’s health unit.
Data Processing
Figure 1 shows the overall flow diagram. All tweets were transformed to lowercase. Next, non-texts were removed, including punctuations (“[”, “]”, “,”, “\”, “.”, “:”, “!”, “/”), special characters (“#”, “%”, “$”, “@”), uniform resource locator (URL), emoji, and stop words following standard data preprocessing procedure as previous studies [3–6]. Unsupervised LDA topic modelling was firstly applied by using Python’s Gensim package to generate potential keywords for each identified topic in previous literature [3–6]. Three researchers—S-FT, HC, and ZB—then reviewed the preliminary keywords for each topic generated by the unsupervised topic modelling to collaboratively interpret topics for further data cleansing before conducting the sentiment analysis. All disagreements were resolved through discussions among the three researchers. To reduce noise irrelevant to the pandemic, such as the 2020 United States presidential election, from the sample and to better understand the sentiment around various components of the public discourses in Ontario, Canada, the full dataset was further filtered down, and a subset was created by using the topics and keywords identified. The filtering was done by searching for substrings in a tweet matching one of the keywords for a given topic. In addition, to ensure that the sentiment score reflects public sentiment as closely as possible, emojis were added back to the tweets since VADER can recognise them when calculating sentiment scores [8]. Furthurmore, tweets from public health, governments agencies and political organizations were excluded in the subset as described in a previous study [26].
FIGURE 1.
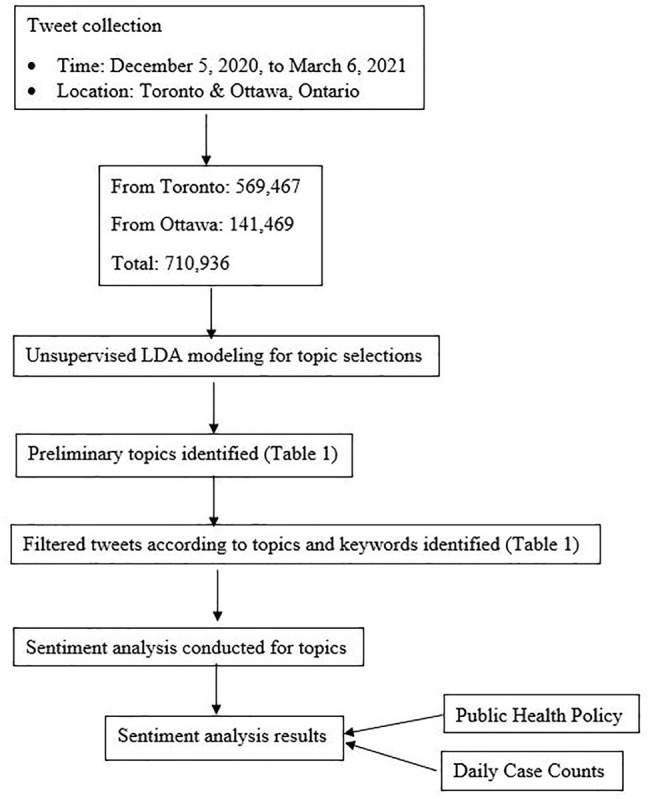
Flow diagram [Public Attitudes during the Second Lockdown: Sentiment and Topic Analyses using Tweets from Ontario, Canada, Canada, 2020].
VADER is used to identify sentiment as it calculates the sentiment attached to individual tokens in text and is adjusted to understand specific tokens commonly used in English social media text [8]. For each tweet, VADER provides an empirically found sentiment value for individual terms, emoticons, and punctuation marks, modified by defined rules for combinations of terms. From these values, a compound overall sentiment score is calculated by taking the sum of the individual sentiments, with positive values for positive sentiments and negative values for negative ones. This raw score is normalized using the equation , where α is set to the value of 15 based on the maximum values seen by the authors in training sets and then normalized to ensure that the normalized value is indeed between −1 and +1 [8]. The compound score was therefore used for our sentiment analysis. However, it is difficult for humans to understand numeric sentiment scores. Therefore, the compound sentiment scores are categorized as “positive” if they are equal or greater than +0.05, “negative” if they are equal to or lower than −0.05 and “neutral” if neither based on prior research [27].
Manual Validation
To determine the accuracy of the unsupervised LDA topic modelling and sentiment analysis. Three researchers—S-FT, HC, and ZB—conducted inter-rater manual validations for 3% of random tweets from each topic and their sentiment. S-FT was the primary rater, HC and ZB served as secondary raters. The 3% random sample is calculated according to Krippendorff’s sampling method with 10% probability of the rarest relevant instances and 95% desired significance level of the answers to our research question [28]. Inter-rater agreement percentage and validation results were reported in Supplement A.
Results
Table 1 shows the topics given by the unsupervised LDA topic modelling. These topics were chosen based on the research questions, i.e. public sentiment with regard to lockdown policies and researchers’ interpretations with corresponding keywords and synonyms from each topic’s keyword outputs generated by the unsupervised LDA topic modelling and manual validation.
TABLE 1.
Topics, keywords, and synonyms generated from the unsupervised LDA [Public Attitudes during the Second Lockdown: Sentiment and Topic Analyses using Tweets from Ontario, Canada, Canada, 2020].
| Topics | Human interpretations | Keywords and synonyms | Number of tweets included |
|---|---|---|---|
| Vaccine | Opinions toward COVID-19 vaccine approval, access, availability, etc. | vaccine, vaccinations, vaccination, vaccines, vaccinated, immunization | 6,932 |
| Pandemic | Impacts of the COVID-19 on life | pandemic, covid-19, covid19, covid 19, covid_19, covid, sars, coronavirus, corona virus, corona, sars-cov-2, outbreak, cases | 17,285 |
| Business | Reviews, supports, and impacts of the COVID-19 pandemic on busniesses, markets, and economics | business, binesses, biness, businesses, biz | 5,148 |
| Lockdown | Opinions toward the second lockdown | lockdown, lockdowns, lock down, shutdown, shut down, shutdowns, grey zone | 4,884 |
| Mask | Opinions toward wearing masks | mask, wearing, wear, face cover, facial cover, facemasking, face mask, masks, maskwearing | 6,893 |
| Ontario | Things happended in Ontario | fordnation, ford, ontario | 25,401 |
The numbers of active COVID-19 cases and deaths between December 5, 2020, and March 6, 2021, in Toronto and Ottawa, Ontario, are shown in Figure 2. Figure 3 demonstrates the sentiment score for each identified topic altogether. Compound sentiment scores for each topic in Ontario are shown in Supplementary Figures S4–S9 in Supplement B, with purple lines representing vaccine events, orange lines indicating policy change events, and red lines demonstrating extended lockdown in Toronto and Peel regions. The light green line shows the mean compound sentiment score for that topic on a particular day, while the dark green line shows the sentiment score smoothed by averaging using an 11-day rolling window. Examples of positive and negative tweets for each topic are shown in Supplementary Tables S2–S7 in Supplement C.
FIGURE 2.

COVID-19 cases in Toronto and Ottawa [Public Attitudes during the Second Lockdown: Sentiment and Topic Analyses using Tweets from Ontario, Canada, Canada, 2020].
FIGURE 3.

The overall sentiment compund score [Public Attitudes during the Second Lockdown: Sentiment and Topic Analyses using Tweets from Ontario, Canada, Canada, 2020].
The average sentiment compound score for the topic “lockdown” (in Supplement B Supplementary Figure S4) started neutral but remained slightly positive afterwards. It went up during the Christmas 2020 break and went down after the second provincial emergency was declared.
The average sentiment compound score for the topic “mask” (in Supplement B Supplementary Figure S5) has remained slightly positive during the study period. Similar to the previous topic, the score went up during the Christmas 2020 break and also spiked after the AstraZeneca vaccine was approved in Canada, but it went down shortly afterwards.
The average sentiment compound score for the topic “Ontario” (in Supplement B Supplementary Figure S6) has overall remained slightly positive during the study period, while it consistently declined and plateaued until the second state of emergency ended.
The average sentiment compound score for the topic “pandemic” (in Supplement B Supplementary Figure S7) has been almost neutral over time. However, the score especially decreased after the Pfizer vaccines were delayed and toward the end of the study period.
The average sentiment compound score for the topic “vaccine” (in Supplement B Supplementary Figure S8) began relatively more positive but went down quickly afterwards. It went up shortly before the Christmas 2020 break but declined and plateaued after that.
Like the “vaccine” topic, the average sentiment compound score for the topic “business” (in Supplement B Supplementary Figure S9) started positively but stably dropped afterwards until around January 24, 2021, when the COVID-19 case counts were relatively lower (Figure 2). Interestingly, the average sentiment compound score of the topic “business” was slightly more positive than all the other topics. However, businesses should have been negatively impacted by the lockdown.
Discussion
To our surprise but understandable, there was no obvious correlation between sentiments and cases or key events on average when the pandemic had lasted over 6 months when Ontario, Canada declared its second provincial emergency and lockdown. Sentiments were more related to holidays as positivity was higher from Christmas 2020 to New Year Day, 2021, although the second provincial shutdown kicked in on December 26, 2020. As Table 1 shows, the “Ontario” topic includes the highest number of tweets, followed by the “pandemic” topic. Regardless of vaccine or policy events, the average sentiment compound score during the studied period appeared to be slightly positive across all topics of interest, with daily sentiment compound scores greatly varied between positive and negative emotions (Supplementary Figures S4–S9). Positive sentiments spiked on December 25, 2020 (Christmas). However, when the second province-wide lockdown began on December 26, 2020, the sentiment scores went downward regardless of topics. In other words, during the second provincial lockdown, there were weak correlations between sentiment scores and vaccine or policy events.
Positive sentiments across topics are mainly associated with holidays and support for the recommended public health practices such as wearing masks and vaccinations. In contrast, negative sentiment across topics largely reflected frustrations and blame on incompetent political leadership. It is also interesting to observe that Greg Abbott, Texas Governor in the United States, was negatively discussed on Twitter among Canadian users when he lifted the mask mandate in Texas on March 2, 2021 [29]. He was a major subject for several days for “business” and “mask” topics.
We did not expect the unsupervised LDA approach for topic modelling to show very limited interpretability in our study. In Table 1, we identified just 66,543 out of 710,936 (9.36%) tweets that can be understood and grouped into six meaningful topics related to our research questions. While we anticipated that the unsupervised ML approach would not generate results as meaningful as supervised ML techniques in previous studies [3–6], we did not foresee such restricted interpretability. Therefore, for future studies, we recommend collecting more data and more thorough data preprocessing to achieve higher data quality to train the unsupervised algorithm and avoid “garbage in, garbage out.” Additionally, for future sentiment analysis, it would be better if emojis could be included to further improve the sentiment scores with a caution that emoji usage can be culturally sensitive in a multicultural country like Canada.
Most existing studies used tweets no later than August 2020, when the first wave of the COVID-19 pandemic was over. In addition, most countries had several lockdowns during the first wave [3–6]. However, in contrast to previous studies showing consistently negative sentiments during the first wave [3–6], our tweets showed that Ontarians had a slightly positive sentiment on average during the second wave in Canada. Unlike previous studies [3–6], symptoms, severity, and/or spread of COVID-19 pandemic are no longer major topics in our sample, demonstrating that Twitter users might have accepted and adjusted daily life under the ongoing pandemic. Similar to existing research showing negative emotions toward government responses [30], especially shutdowns during the first wave, negative tweets in our sample also called political leaders “incompetent” or “failure” across all topics during the second wave, but the average sentiment compound score remains slightly positive, although the daily sentiment compound scores vary a lot.
In addition, our study collected and analyzed tweets over 3 months, which is very different from existing research that collected and analyzed data rarely more than a month [3–6]. Although we did not collect all the possible data given our geolocation restrictions, our research has provided local evidence solely from an aspect of Ontario, Canada, because each country and sub-national entities are unique. This is different from current global sentiment studies that combine and compare different countries together [30–32]. Furthermore, our research is one of a few studies [19] that demonstrated a combination of unsupervised topic modelling and qualitative checks, which can generate human-interpretable and meaningful topics or insights from large amounts of data under a time-sensitive nature without an extremely time-consuming process. However, to avoid “garbage in, garbage out” resulting from the unsupervised ML approach, it remains an important issue to properly specify inclusion and exclusion criteria for data collection, such as keywords or geolocation, to achieve optimized data quality by filtering out meaningless data as much as possible without introducing selection bias in the data.
However, our study has several limitations. First of all, due to Twitter’s geolocation query methods, only a subset of tweets has geotags identified. It has been estimated that only about 2.31% of tweets with locations are attached to the tweets, and an even smaller number of those have precise locations [33]. As such, the tweets we were able to identify and use in our analysis represent only a small amount of the actual discourse occurring within the defined temporal and geographical parameters. Additionally, we limited our search to two very specific municipalities—Toronto and Ottawa in Ontario, Canada—because, during the data collection period, we realized that it was difficult to distinguish “Ontario, Canada” from “Ontario, California” given that their common abbreviation is “Ontario, CA” if we did not specify cities. We also did not collect data from other social media platforms, such as Facebook and Reddit, which has limited our generalizability.
Furthermore, our manual quality validation identified that although small, there is a chance that VADER can misclassify sentiments. For instance, a tweet with sarcasm was regarded as positive but in fact, it should have been considered negative. On the other hand, a tweet with a “surprised” mood was regarded as negative because the word “shocking” was repeated many times. Therefore, it is possible that our sentiment analysis is not perfectly accurate as it should have been. Moreover, tweets classified in each topic were not exclusive to other topics. If a user mentioned several topics within a tweet, it would be assigned to multiple topics, such as the case of Greg Abbott that showed up in both “Ontario” and “business” topics. However, we decided to leave them as they were because it would be inappropriate to assign only one topic to tweets with multiple topics as they naturally occurred. This observation actually showed that some topics could be highly correlated. Accordingly, how to properly choose keywords and their synonyms as filters remains an important challenge to be addressed.
In conclusion, our results have shown that Ontarians in Toronto and Ottawa have remained a slightly positive sentiment during the second wave of the COVID-19 pandemic regardless of topics. We also identified six topics that emerged from data over time, and these topics have been highly correlated with the ongoing pandemic, although the average positive sentiment could be driven by the Christmas-New Year holiday break amid the second wave rather than by the public health interventions. Compared with prior studies conducted during the first wave [19], our study has shown different narratives from public discourse during the second wave. That is, people have shifted their focus on COVID-19 related symptoms, transmissions, risk factors, and origin of the virus to how the pandemic has influenced their daily life without specifically mentioning COVID-19. Our research also demonstrated that a mixed approach of unsupervised topic modelling and manual validation could generate timely evidence when experienced experts get involved. However, data quality and limited utility from unsupervised LDA modelling remain a critical issue for future research, and the possibility of misclassification is acknowledged. Therefore, our results show that it is feasible to use social media data to practice social listening as recommended by the World Health Organization (WHO) to understand narratives from the general public [9] to make informed decisions.
Acknowledgments
We are thankful to Therese Tisseverasinghe for her continuous support and help with the review.
Author Contributions
S-FT and ZB conceived of the presented idea. AM and LL performed the computations and verified the analytical methods with S-FT, ZB, HC, and YY. ZB and HC supervised the findings of this work. All authors discussed the results and contributed to the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.ssph-journal.org/articles/10.3389/ijph.2022.1604658/full#supplementary-material
Abbreviations
COVID-19, Coronavirus disease; LDA, Latent Dirichlet allocation; ML, Machine Learning; VADER, Valence Aware Dictionary and sEntiment Reasoner.
References
- 1. WHO Coronavirus (COVID-19).(2021) Dashboard. Who.int. Available from: https://covid19.who.int/ . (Accessed April 20, 2021). [Google Scholar]
- 2. Canada.(2021) WHO Coronavirus Disease (COVID-19) Dashboard with Vaccination Data. Who.int. Available at: https://covid19.who.int/region/amro/country/ca . (Accessed April 20, 2021). [Google Scholar]
- 3. Abd-Alrazaq A, Alhuwail D, Househ M, Hamdi M, Shah Z. Top Concerns of Tweeters during the COVID-19 Pandemic: Infoveillance Study. J Med Internet Res (2020) 22(4):e19016. 10.2196/19016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Boon-Itt S, Skunkan Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill (2020) 6(4):e21978. 10.2196/21978 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Chandrasekaran R, Mehta V, Valkunde T, Moustakas E. Topics, Trends, and Sentiments of Tweets about the COVID-19 Pandemic: Temporal Infoveillance Study. J Med Internet Res (2020) 22(10):e22624. 10.2196/22624 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Valdez D, Ten Thij M, Bathina K, Rutter LA, Bollen J. Social media Insights into US Mental Health during the COVID-19 Pandemic: Longitudinal Analysis of Twitter Data. J Med Internet Res (2020) 22(12):e21418. 10.2196/21418 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Blei DM, Andrew YN, Michael IJ. Latent Dirichlet Allocation. J machine Learn Res (2003) 3:993–1022. 10.5555/944919.944937 [DOI] [Google Scholar]
- 8. Hutto C, Gilbert E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social media Text. ICWSM (2014) 8(1):216–25. Available at: https://ojs.aaai.org/index.php/ICWSM/article/view/14550 . [Google Scholar]
- 9. Purnat TD, Wilson H, Nguyen T, Briand S. EARS - A WHO Platform for AI-Supported Real-Time Online Social Listening of COVID-19 Conversations. Stud Health Technol Inform (2021) 281:1009–10. 10.3233/SHTI210330 [DOI] [PubMed] [Google Scholar]
- 10. Li C, Chen LJ, Chen X, Zhang M, Pang CP, Chen H. Retrospective Analysis of the Possibility of Predicting the COVID-19 Outbreak from Internet Searches and Social media Data, China, 2020. Euro Surveill [Internet (2020) 25(10). 10.2807/1560-7917.ES.2020.25.10.2000199 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Qin L, Sun Q, Wang Y, Wu K-F, Chen M, Shia B-C, et al. Prediction of Number of Cases of 2019 Novel Coronavirus (COVID-19) Using Social media Search index. Ijerph (2020) 17(7):2365. 10.3390/ijerph17072365 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Shen C, Chen A, Luo C, Zhang J, Feng B, Liao W. Using Reports of Symptoms and Diagnoses on Social media to Predict COVID-19 Case Counts in mainland China: Observational Infoveillance Study. J Med Internet Res (2020) 22(5):e19421. 10.2196/19421 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Li J, Xu Q, Cuomo R, Purushothaman V, Mackey T. Data Mining and Content Analysis of the Chinese Social media Platform Weibo during the Early COVID-19 Outbreak: Retrospective Observational Infoveillance Study. JMIR Public Health Surveill (2020) 6(2):e18700. 10.2196/18700 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. China: number of social media users 2017-2025.(2021) Statista.com. Available at: https://www.statista.com/statistics/277586/number-of-social-network-users-in-china/ . (Accessed July 24, 2021).
- 15. Younis J, Freitag H, Ruthberg JS, Romanes JP, Nielsen C, Mehta N. Social media as an Early Proxy for Social Distancing Indicated by the COVID-19 Reproduction Number: Observational Study. JMIR Public Health Surveill (2020) 6(4):e21340. 10.2196/21340 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Xu P, Dredze M, Broniatowski DA. The Twitter Social Mobility Index: Measuring Social Distancing Practices with Geolocated Tweets. J Med Internet Res (2020) 22(12):e21499. 10.2196/21499 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Bisanzio D, Kraemer MUG, Brewer T, Brownstein JS, Reithinger R. Geolocated Twitter Social media Data to Describe the Geographic Spread of SARS-CoV-2. J Trav Med [Internet (2020) 27(5). 10.1093/jtm/taaa120 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Bisanzio D, Kraemer MUG, Bogoch , Brewer T, Brownstein JS, Reithinger R. Use of Twitter Social media Activity as a Proxy for Human Mobility to Predict the Spatiotemporal Spread of COVID-19 at Global Scale. Geospat Health (2020) 15(1):19–24. 10.4081/gh.2020.882 [DOI] [PubMed] [Google Scholar]
- 19. Jang H, Rempel E, Roth D, Carenini G, Janjua NZ. Tracking COVID-19 Discourse on Twitter in North America: Infodemiology Study Using Topic Modeling and Aspect-Based Sentiment Analysis. J Med Internet Res (2021) 23(2):e25431. 10.2196/25431 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Zhao X, Knobel P. Face Mask Wearing during the COVID-19 Pandemic: Comparing Perceptions in China and Three European Countries. Transl Behav Med (2021) 11(6):1199–204. 10.1093/tbm/ibab043 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Chandra R, Krishna A. COVID-19 Sentiment Analysis via Deep Learning during the Rise of Novel Cases. PLoS ONE (2021) 16(8):e0255615. 10.1371/journal.pone.0255615 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Imran AS, Daudpota SM, Kastrati Z, Batra R. Cross-Cultural Polarity and Emotion Detection Using Sentiment Analysis and Deep Learning on COVID-19 Related Tweets. IEEE Access, 8. (2020). p. 181074–90. 10.1109/ACCESS.2020.3027350 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Das S, Kolya AK. Predicting the Pandemic: Sentiment Evaluation and Predictive Analysis from Large-Scale Tweets on Covid-19 by Deep Convolutional Neural Network. Evol Intel (2021) 1–22. 10.1007/s12065-021-00598-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Shorten C, Khoshgoftaar TM, Furht B. Deep Learning Applications for COVID-19. J Big Data (2021) 8(1):18. 10.1186/s40537-020-00392-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Twitter. Twitter Research for Academics and Marketers. Twitter; (2021). Available at: https://developer.twitter.com/en/use-cases/do-research . (Accessed May 3, 2021). [Google Scholar]
- 26. Slavik CE, Buttle C, Sturrock SL, Darlington JC, Yiannakoulias N. Examining Tweet Content and Engagement of Canadian Public Health Agencies and Decision Makers during COVID-19: Mixed Methods Analysis. J Med Internet Res (2021) 23(3):e24883. 10.2196/24883 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Chum A, Nielsen A, Bellows Z, Farrell E, Durette P-N, Banda JM, et al. Changes in Public Response Associated with Various COVID-19 Restrictions in Ontario, Canada: Observational Infoveillance Study Using Social media Time Series Data. J Med Internet Res (2021) 23(8):e28716. 10.2196/28716 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Krippendorff K. Content Analysis: An Introduction to its Methodology. 4th Edn. Thousand Oaks, CA: SAGE Publications; (2018). [Google Scholar]
- 29. Governor Abbott Lifts Mask Mandate.(2021) Opens Texas 100 Percent. Texas.Gov. Available at: https://gov.texas.gov/news/post/governor-abbott-lifts-mask-mandate-opens-texas-100-percent . (Acceesed May 4, 2021). [Google Scholar]
- 30. Chandrasekaran R, Mehta V, Valkunde T, Moustakas E. Topics, Trends, and Sentiments of Tweets about the COVID-19 Pandemic: Temporal Infoveillance Study. J Med Internet Res (2020) 22(10):e22624. 10.2196/22624 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Lwin MO, Lu J, Sheldenkar A, Schulz PJ, Shin W, Gupta R, et al. Global Sentiments Surrounding the COVID-19 Pandemic on Twitter: Analysis of Twitter Trends. JMIR Public Health Surveill (2020) 6(2):e19447. 10.2196/19447 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Garcia K, Berton L. Topic Detection and Sentiment Analysis in Twitter Content Related to COVID-19 from Brazil and the USA. Appl Soft Comput (2021) 101(107057):107057. 10.1016/j.asoc.2020.107057 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Huang B, Carley KM. A Large-Scale Empirical Study of Geotagging Behavior on Twitter. In: Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. New York, NY: ACM; (2019). 10.1145/3341161.3342870 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.